- Amazfit Active 2 NFC - jó kör
- Azonnali mobilos kérdések órája
- Google Pixel 8a - kis telefon kis késéssel
- iPhone topik
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Fotók, videók mobillal
- Google Pixel topik
- One mobilszolgáltatások
- Android alkalmazások - szoftver kibeszélő topik
- Milyen okostelefont vegyek?
Új hozzászólás Aktív témák
-

thon73
tag
válasz
 eastsider
#2114
üzenetére
eastsider
#2114
üzenetére
Na, akkor jókora bug-ot kell keresni

Két-táblás content-provider 8-8 szöveges, többmezős adattal: 44 Kilo(!)B; Alkalmazás 1,09 MB
Feltölthetem próbaként bármekkorára, de már ebből is látszik, h. nagyságrendi különbség van.
Van egy olyan progi, h. SQLite Debugger, azzal meg tudod nézni, h. mi a pálya az adatbázis-fileban. ((Több ilyen van, lehet, h. van még jobb is. Ja, root kell, de úgy tudom, az van.))Bocs, megnéztem a linket is: az első az az. Szerintem a bindView megértéséhez nem kell feltétlenül "képes" alapból kiindulni, de persze lehet, csak az nagyon összetett a megértéshez. Na, ez szép magyar! De a lényeg mégiscsak ez.
-
thon73
tag
válasz
eastsider
#2112
üzenetére
Ööö. Nézz körül az SO-n egy egyszerűbb példáért, mert neked NEM ez fog kelleni. Ez BaseAdapter-t bővít, a tiednek CursorAdapter alap kell!!!
A "deprecated" cuccból hiányozni fog az utolsó paraméter, de ahhoz küldj listát, és akkor lehet látni, h. hol a bibi.
A képfeldolgozó programok ált. cachelik a thumbnail-eket, (úgy láttam), különben lassú. De ebben nincs tapasztalatom. Elvileg a méretnek sem lenne szabad nagynak lennie, hiszen csak szöveget tárolsz. Hol nézted? Alkalmazásinfo méretben? -
thon73
tag
válasz
eastsider
#2108
üzenetére
Loaderben most eléggé otthon vagyok...

De szerintem Neked nem a Loader rész fog kelleni. Az adapter nem is tud a loader-ről, a loader csak betolja az adatokat az adapterbe.
Szerintem custom CursorAdapter-re lesz szükséged, amiben a bindView() metódust kell átírnod (lehet h. a newView.t is, ill. biztos). A bindView paraméterként tartalmazza a Cursor-t, ezt felhasználva tudod a képet megjeleníteni.
A Loader tehát csak át fogja adni a kikeresett Cursor-t (Még URL-t tartalmaz) az adapter-nek, és az adaptert kell úgy módosítani, hogy az URL-t bármilyen módon is, de feldolgozza.((Ez egyébként pont ugyanaz, mint, amit WonderCSabo írt; csak az a BaseAdapter alapú adapterekre vonatkozik, ott a getView-t, itt a bindView-t kell változtatni. Kicsit más a technika, de az elv ugyanaz: egy listaelem megjelenítését az adapter végzi az adatok alapján.))
-
#2103
thon73
tag
WonderCSabo
#2101
thon73
tag
válasz
 WonderCSabo
#2101
üzenetére
WonderCSabo
#2101
üzenetére
Aha. Ez ugyan nem sqlite, csak sima Loader, de a hiba pont ugyanott van!
Aki Loader-t akar csinálni annak ITT egy jó előadás; de a lényeg az első hozzászólásban van:
"Important: I no longer recommend to use a Loader for "one-shot" actions because it's complicated and has a few side-effects."
No ezen én is elgondolkodtam...
Ettől függetlenül az ea. nagyon jó, és csomó buktatót (pl. a Loader mindig kétszer tüzel...) felsorol; de speciel a filteres gond (vagyis hogy a filter a még fel nem töltött adapterből szed ki adatot, aztán a felülírja vele a már betöltötteket) nem szerepel benne.
Még küzdök vele egy kicsit...Aprópopo: Hogy a betöltés alatt egy karika forogjon, azt meg lehet valami egymondatos gyári utasítással oldani, vagy azzal is nekem kell játszani?
-
#2100
thon73
tag
WonderCSabo
#2096
thon73
tag
válasz
WonderCSabo
#2096
üzenetére
Az entries értékét leellenőriztem, az mindig megfelelő.
Egy kicsit előrébb jutottam - néha ugyanis feldobja a listát, néha nem - és azt találtam, hogy elindítja a filtert, mégpedig mindenképp. A filter viszont kiveszi a még üres (null) értéket az adatokból, majd PÁRHUZAMOSAN fut a performFiltering és a Loader. A Loader előbb végez, és onLoadFinished-ben beállítja az adatokat. Majd jön a Filter (ami még az üres adatokat szűrte!), és átállítja az egész történetet üresre, hiszen -szerinte - nincsenek is adatok.
Erre nem is gondoltam, mert 1. ekkor még elvileg nem is létezik a filter. 2. ha a filter-szöveg üres, akkor nem is szűr. Csakhogy ilyenkor is beállítja a teljes adatmennyiséget - ami szerinte: üres.Namost. Hogyan bogozom ezt ki?
Az onCreateView-ben állítom be a filtert, így:filter = (EditText) view.findViewById(R.id.filter);
filter.addTextChangedListener(new TextWatcher()
{
@Override
public void onTextChanged(CharSequence s, int start, int before, int count)
{
((MainListAdapter)getListAdapter()).getFilter().filter(s);
}Ezt nem tudom nagyon máshova tenni, mert csak egyszer indíthatom el.
Tegyek be egy flag-et az adapterbe, ami figyeli, hogy vannak-e már beállított adatok??
Vagy ne engedjem meg, hogy az adatok értéke null legyen? Hanem az üres adatot egy üres (de létező) ArrayList jelentse?
Vagy mit érdemes ilyenkor csinálni?((Az ArrayAdapter is alternatíva lenne, de annak majd minden részét módosítottam volna, ezért használtam BaseAdapter alapot. Sztem. a probléma ettől független. ))
Be is bizonyítottam, hogy ez a probléma, itt:
protected void publishResults(CharSequence constraint, FilterResults filterResults)
{
------------------>if (filterResults.values != null)
{
filteredEntries = (List<SampleEntry>) filterResults.values;
notifyDataSetChanged();
}
}No, így működik. Órákat játszottam vele, de erre nem gondoltam volna...
Most már csak arra kell rájönnöm, hogy a.) mi a nyavaja indítja a filtert b.) ezt a tákolt ellenőrzést hogyan tudom szépen megcsinálni... -
thon73
tag
Sziasztok! Elakadtam egy BaseAdapter bővítésnél. Az adapter egy ArrayList-et használ, amit egy setData() metódus állít be:
public void setData( List<SampleEntry> entries )
{
this.originalEntries = entries;
this.filteredEntries = entries;
notifyDataSetChanged();
}A setData()-t egy ListFragment-ben hívom meg, egy Loader részeként:
public void onLoadFinished(Loader<List<SampleEntry>> loader, List<SampleEntry> data)
{
((MainListAdapter)getListAdapter()).setData(data);
}Az első végrehajtáskor ez tökéletesen működik. Ha elfordítom a készüléket, akkor is lefutnak a fenti metódusok, de - a notifyDataSetChanged() - hívás ellenére NEM jelenik meg semmi.
Ha ekkor frissítem a listát (pl. még egy elemet hozzáadok), akkor az EGÉSZ lista megjelenik, vagyis az összes elemet tartalmazza.
Ha az elemet (próbaként) a setData() részben adom hozzá, akkor sem jelenik meg a lista.Rengeteget olvastam a notifyDataSetChanged()-ről, de nem jutottam eredményre. Az a gyanúm, hogy nincs még ListView, amikor az első setData() lefut, ezért nem tud még mit frissíteni.
Hogyan tudnám ezt megoldani??
-
#2061
thon73
tag
WonderCSabo
#2058
thon73
tag
válasz
WonderCSabo
#2058
üzenetére
Köszönöm a sok ötletet és útmutatót!

Lehet, hogy egy esős délutánt már illene azzal töltenem, hogy végigolvasom a Java-t, nem mindig csak azt, ami éppen kell.Én még nem látom át teljes mélységében, hogy melyik megoldás a jobb/ideálisabb, de azt már látom, hogy a probléma bármelyikkel megoldható. A nyitás/zárást én speciel eddig is minden kiírt blokk köré raktam, nem hiszem, hogy jelentős gyorsulás érhető el egy hosszútávon nyitott file-lal. Viszont egy esetleges adatvesztés jobban zavarna, ha pl. zárás és flush nélkül lépek ki véletlenül a programból.
Annyit viszont már átláttam, hogy ez a worker-thread file-kezelés tud elég csapdás lenni... na ezek a kész megoldások ebben biztosan segítenek.
-
#2046
thon73
tag
WonderCSabo
#2045
thon73
tag
válasz
WonderCSabo
#2045
üzenetére
Ja, nem erre használnék Loopert, attól függetlenül tűnt fel. Looperrel egy lineáris file írást akartam kitenni, hogy a számítások meg az írás külön szálon fusson. És csak küldözgetné a háttérszálra, ami kész van és ki kell írni...
Olymódon semmi gond, hogy le tudom állítani, csak nem is gondoltam rá idáig. Ha életben hagyom, akkor nem fog újabb és újabb szálakat indítani minden egyes Activity újraindítás? Vagy nem érdekes, mert eltakarítja, amelyikre nincs élő hivatkozás?A cikkekért köszönet, megint csak megvilágosodott egy-két dolog. Minél többet ismerek meg az androidból, annál nagyobb a rálátásom a saját tudatlanságomra...
-
#2044
thon73
tag
WonderCSabo
#2040
thon73
tag
válasz
WonderCSabo
#2040
üzenetére
Bocs, átmenetileg net-mentes lettem...
Tehát, ha az elindított thread-ek tovább futhatnak, akkor azokat is illik leállítani onPause-ban? Ami meg hosszan kell azt indítsam service-ként? Eddig nem használtam Looper-t (vagy legalábbis nem tudtam róla), ez meg most elbizonytalanított...
-
thon73
tag
Aha. Pont erre jutottam, hogy az app sokkal ellenállóbb, mint az activity.
Azt hittem pedig, hogy amikor memóriára van szükség, akkor nem csak az Activity-t, hanem a teljes App-ot leállítja. (A kilövés az világos, az FC is logikus, de arra nem gondoltam)Csakhogy ez újabb gondolatokat is ébreszt bennem: Ha az app megmarad, akkor a teljes process megmarad, nem? Akkor viszont az elindított thread-ek sem fognak megállni? Vagy hogyan van ez? Én azt gondoltam, hogy a BACK-kel (v. pl. finish-sel) való kilépéskor, ill. ha elfogy a hely, akkor ez leáll - de ezek szerint tévedtem.
-
thon73
tag
Meg tudja valaki mondani, hogy elméletben meddig él az Application példány?
Globális változókat tettem Application szintre, és véletlenül vettem észre, hogy ezek a - hiába indítottam el ezeregy programot - nem szűnnek meg soha. (Mondjuk, újratalapítésig pl.)
Erre lehet számítani, vagy az Application osztály is eltűnik egyszercsak, és újra létrehozásra kerül egy következő indításkor?
-
thon73
tag
válasz
eastsider
#2020
üzenetére
Aha. Két malomban őrlünk. Háromban.
Tehát: a program elkészítésének a folyamatára értem, hogy először egy vagy két, de független táblával próbálkozz, az is elég izgalmat ad. Csak ha ez már jól működik, akkor próbáld beletenni a join-t táblát. Egyszerre kivitelezni az egészet annyi hibalehetőséget ad az első próbáig, hogy nagyon nehéz kilábalni belőle. Szerintem jobb, ha egy egyszerűbb része biztonságosan működik, és utána lépsz tovább.
A végső elrendezéshez:
Két megközelítés létezik (sztem.): én egyesével viszem be az adatokat. Vagyis: EGY kép/könyv/adat felvételekor választom ki hozzá a megfelelő kapcsolt adatot (tekercs/író stb.)
Te sztem. KÖTEGELT felvitelt szeretnél: kiválasztod a tekercset, aztán hozzárendelsz - gondolom egy hatalmas poolból - egy csomó képet. Ez is járható út.A lényeg nem változik:
Egyszerre egy rekordot tudsz létrehozni. Annak a mezőit kell kitöltened. A TEKERCSEK mező értékét kiválaszthatod a létrehozáskor (egyszeres módszer), vagy már tudod előre, és ezt az ismert tekercs _id-t teszed az összes létrehozandó rekordba (kötegelt mód).Mind a két módszernek megvan a létjogosultsága. Pl. van 3000 képem, kijelölök 250-t, és egyszerre (kötegben) hozzárendelem egy tekercshez. Ennek ellenére nem fogod tudni megkerülni az egyszeres módszert sem, két okból: 1. a képek más adatokat is tartalmaznak ISO, hely stb. Ezt honnan veszik? Minden tekercsen egyforma? Akkor uis a tekercs táblába tartozik. EXIF adatot importál? Az egy külön funkció, és kézzel is meg kell tudnod változtatni. 2. mi van, ha egy képet rossz helyre raktál?
Sztem. is hasznos, sőt a legfontosabb egy program felépítését megbeszélni; kételyem csak abban van, hogy mennyire érdekes ez másoknak, akik itt esetleg rövid android praktikákat akarnak megtudni. De éppen át is vonulhatunk valami semleges területre, ha untatjuk az itt olvasókat. Én speciel hasznosnak tartanám, ha nálamnál tapasztaltabbak is hozzátennék a tudásukat; azt azért átérzem, hogy ez a projekt mennyire fontos neked.
Amúgy én azt tenném, hogy egyszerűen, magyarul és képekkel leírnám, hogy mit is akarok, hogy tegyen a program, végiglogikáznám, aztán ahhoz alkotnám meg a hátteret.
-
thon73
tag
válasz
eastsider
#2018
üzenetére
Bocs, de valahol teljesen elvesztettem a fonalat... Hogyhogy nem tartozik adat egy id-hez, amit viszont ismersz?
Szerintem (de nyugodtan szóljon bele adatbázis-tudós is):
Van a könyvek/képek tábla (ami kezdetben üres), és van az írók/tekercsek tábla, ami szintén üres.
Azt kell megoldanod, hogy fel tudj vinni egy KÉPET, ami hivatkozik egy tekercsre. Mivel ezt nem az _id alapján, hanem listából választod ki, nem tudsz "üres" _id-t hozzárendelni (az ugyanis meg sem jelenik a listában); legfeljebb azt tudod jelezni, hogy NINCS hozzárendelve tekercs (már ha ez megengedett)
És persze kell egy "űrlap", ahol a tekercseket viszed fel.Én a helyedben először gyártanék egy felületet csak a képek táblához. Aztán ugyanezt kibővíteném egy független tekercsek táblával. Amikor ez kész, akkor megpróbálnám kiegészíteni azzal, hogy a képek listájában megjelennek a tekercsek, ill. a képek űrlapján is ki lehessen választani egy tekercset. Közben adni fogja magát, hogy miként kényelmes elrendezni, listákkal, tabokkal, fragmentekkel...
Mindenkitől bocs, hogy ennyit dumálok, de pont ugyanezen vergődtem végig, és pontosan tudom, hogy nem egyszerű. Mindenesetre fentebb már megosztottam a kódot, ahol én tartok; szerintem azért is érdemes kipróbálni (mármint a kész programot használni), mert gyorsan kiderül, hogy hol vannak azok a részek, ahol megbicsaklik az egész felület. Eredetileg én sem gondoltam egy csomó mindenre, ez csak a fejlesztés során fog kiderülni...
-
thon73
tag
válasz
eastsider
#2016
üzenetére
Na, igen. Ez pont így működik, ha fel van töltve az adatbázis. De hogy töltöd fel? Először uis. üres.
A képeket ugyanígy oldottam (volna) meg, jelenleg csak a hivatkozásoknál tartok - vagyis bármilyen file-t tudok tárolni, akár képet is.
((Mondjuk én lehet, h. tárolnék egy másolatot a képről, vagy egy thumbnail-t; külön helyen)) -
thon73
tag
válasz
eastsider
#2014
üzenetére
A tabos elképzelés ott halt meg, hogy valójában ezek a listák egymásba lesznek öltve. Vegyünk egy idióta példát:
beírsz egy könyvet: Egri Csillagok
kiválasztod az írót: Gárdonyi Géza
de közben megnézed a többi könyvét: szűkített lista, benne Tüskevár
Jé, ezt nem is ő írta, kiválasztod az írót: Írók listája
Jé, nincs benne Fekete István
Író hozzáadása: Fekete István...
És így tovább a végtelenségig.Én csináltam egy ListFragmentet, és egy EditFragmentet. Most jön a következő probléma: ezek a különböző táblák esetében 90%-ban egyformák lesznek. Tehát csináltam egy General... Fragment-szettet, és ebből származtattam le az egyes tábláknak megfelelő tényleges Fragmenteket.
Akkor jött a következő probléma: ezek a spéci, egymásra hivatkozó mezők igazából új változótípusnak felelnek meg, ezért alkottam belőlük új változókat.
Hopp: és a végeredmény egy felxibilis rendszer, akárhány táblával, könnyen változtatható felépítéssel... viszont egy igen kövér, és sokrétű kóddal. És a legnagyobb vicc, hogy engem tulképp csak az export/import funkcionalitás érdekelt
Az a baj, hogy az sqlite nagyon jó. Az android nagyon jó. A kettőt összekötő híd viszont kompletten hiányzik. Mármint a UserInterface oldala, mert amúgy a program adatainak tárolására elég könnyen használható.
De ez csak a magánvéleményem.
És azért teszem itt közzé, mert a fentebb közzétett programhoz tartozik. -
thon73
tag
válasz
eastsider
#2012
üzenetére
Én ezt egy cseppet átgondolnám.
Csak a saját elgondolásomat tudom közreadni. A tekercs/kép párosnál nekem az író/könyv jobban kézreáll, de ez tetszőlegesen behelyettesíthető...
Tehát:
Van az ÍRÓK tábla (vagy TEKERCS), ami nem hivatkozik senkire.
Van a KÖNYVEK tábla (vagy KÉPEK), ami hivatkozik EGYETLEN ÍRÓRA (vagy EGYETLEN TEKERCSRE)Ha ez utóbbit listában akarod megjeleníteni, akkor JOIN táblát érdemes használni, hogy lásd a könyv íróját vagy a kép tekercsét is egyúttal. Technikailag javaslom, hogy kiválasztásnál mindig egy új, részleteket mutató Fragmentet hozz létre. Ezt a Backstackra rakhatod, és akkor könnyű visszaugrani a listához. Egy másik elem kiválasztása nem ennek a Fragment-példánynak a mezőit változtatja, hanem létrehoz egy újat.
((Nehéz lesz megoldani egyébként az ÍRÓ (TEKERCS) kiválasztását innen - de nem lehetelen, csak dolgozni kell vele.)) A másik buktató a fragmentek egymás melletti/feletti megjelenítése, de az sem lehetetlen.Amikor viszont az ÍRÓK/TEKERCSEK listában vagy, akkor lehet, hogy szeretnéd megnézni, hogy mely könyveket írta/képeket tartalmazza. Na, ebben az esetben kell a KÖNYVEK/KÉPEK listát úgy megjeleníteni, hogy szűkítjük a listát a megfelelő íróra/tekercsre.
Hozzáteszem, hogy úgy tapasztaltam, majdnem minden megoldható az sqlite szintjén is, vagy a program szintjén is. Ha univerzáslis megoldásra van szükség, akkor szerintem az sqlite kihasználása gyorsabb, áttekinthetőbb, biztonságosabb; míg speciális esetekben (pl. statikus adathalmaz, speciális - ékezetes - keresések) érdemes/szükséges kódot írni, ami néha!! gyorsabb lehet.
Amúgy én pont ezen küzdöttem végig magam, nem minden pontja volt egyszerű, hibátlan és magától értetődő, de már egész jól működik. Szívesen segítek.
-
thon73
tag
A broadcast-okkal megy is szépen, a példaprogramokban is broadcast-ok szerepelnek, csak éppen a rendszer által indítottak.
Lehet, hogy nekem is broadcastolni kellene az activity-ben, ha valami változik? Hm. Ez egy megfontolandó ötlet, köszi.Amúgy a Loader-ekkel én is csak ismerkedés szintjén "játszom". Van egy file-ban tárolt adathalmaz, aminek a beolvasása kb. 4-5 sec. Ezt akartam beletenni Loader-be. Ez - a felhasználó oldaláról - statikus adathalmaz, tehát nincs mit figyelni. Az én (tesztelő) oldalamról van lehetőség a változtatásra, de akkor újramenti a teljes megváltoztatott adatbázist (mert módosításkor az összefüggő adatok miatt a nagyrésze megváltozik). Ettől függetlenül arra voltam kíváncsi, hogy ha én változtatok a külső adatokon az Activity-ben (bocsánat -ból), akkor hogyan értesülhet erről a Loader.
A fenti (mostmár két) megoldáson kívül még egy érdekes osztályt találtam: a FileObserver-t. De az még bonyolultabbnak tűnt.Ami még gondnak tűnik nekem: végső soron a Loader-rel is be kell olvasnom mindent, ahhoz, hogy a lista eleje megjelenjen. Ez amúgy logikus (mert nem biztos, hogy a lista eleje töltődik be először), de a várakozási idő ugyanúgy megvan (csak pörög az óra...)
-
thon73
tag
Ilyen nehezet kérdeztem, vagy mindenki békésen szunnyad az ebéd(ek) után?
Saját fejem törésével erre jutottam: Van itten egy olyan, hogy a LoaderManager-től le tudom kérdezni az aktív Loader-eket. Az Activity induláskor megnézi, hogy van-e Loader, s ha igen, akkor beregisztrálja magát (Uis. ilyenkor valaki már létrehozta a Loadert, pontosabban az előző megvalósulásunk hozta létre.) Záráskor szintúgy megnézi, csak éppen kiregisztrálja magát, - kiregisztrálTATja magát a megtalált Loader-rel az obszerválandók közül. Néha elgondolkodom, hogy télleg az Android Way a legegyenesebb-e??

Ha valaki látott már egyszerűbbet, akkor ne habozzon elmesélni...
Teljesen más: Tudja valaki mi az a Samsung File-Stor Gadget? A nem létező UMS kapcsolatom SGSII 4.1.2 alatt ezzel mégis létezik. Ha tudnám, mi ez, rátenném a tabletre is... A szívemhez közel áll a Mass-Storage gyorsasága, és a proxy szerver sem zavarja...
-
thon73
tag
Sziasztok!
Egy érdekes problémával küszködök. AsyncTaskLoader-t készítettem, ami működik is. DE! A háttérben álló adatok az Activity-n keresztül változtathatóak meg, tehát az AsyncTaskLoader-nek valahogy az Activity-t kellene figyelnie, hogy mikor következik be változás.
A gond akkor kezdődik, amikor elfordítom a készüléket, uis. ilyenkor egy új Activity keletkezik (és ettől a ponttól már ezt kellene figyelni, és a régit elengedni), ugyanakkor (ha jól értem a működést) az AsyncTaskLoader túlél, legfeljebb újraindul.
Hogyan illik ezt elegánsan megcsinálni?
Egy leegyszerűsített példában csak egy gombnyomással akarom szimulálni az adatváltozást. Az Observer az AsyncTaskLoader lenne, az Observable pedig az Activity (vagy a Button, de az előbbi egyszerűbb). Na de akkor hogyan tudná az Observable oldal magát kikapcsolni, meg aztán az új Activity-t visszakapcsolni?
Meg tudja ezt valaki mondani? Vagy valami más ötlet esetleg? -
thon73
tag
Először is mindenkinek köszönöm a GIT-es útmutatókat; kezdem átlátni, hogy mit is kell csinálni. Kis trouble, hogy itt proxy mögött vagyok, de sebaj, majd otthon linux alól. Mellékesen jegyzem meg, hogy az AIDE tableten (használja vki?) elvileg a menüsorból tudja az egészet, ezért gondoltam hogy könnyebb lesz. ((Igaz, még azt sem próbáltam, csak láttam)) Köszönöm!
to Sianis:
Szerintem az a hiba, hogy a BackStack NEM a fragmentet, hanem az oda vezető utat tárolja. A->B azt jelenti, hogy az A-B replace kerül a stackra. Amikor ezt C-ről hívod, akkor - elvileg - a B->A replace-t végzi el újra. Nagy a gyanúm, hogy a lejátszás már ott elakad, hogy nincs meg a B fragment. Replace-t én ugyan ritkán használtam, de ha kettébontod remove-ra és add-ra, akkor talán könnyebb felderíteni a hibát.
Én azt gondolom, hogy az add(B) részt felesleges a Stackra tenni, csak a remove(A)-t tedd rá! Ha ezt a tranzakciót játszod vissza, akkor - elvileg - meg kell jelennie A-nak. Elvileg. És szerintem. De nem tudtam kipróbálni.
((Bocs, még annyi, hogy természetesen a remove(B) és remove(C)-re is szükség van a megfelelő helyen, csak nem a visszapörgetésben.)) -
thon73
tag
Részben a fenti okok miatt (idő és hozzáértés hiánya) én is közzéteszek egy feladatot, hátha érdekel valakit:
Hatszögletű billentyűzet
Az ötlet egy régi palmOS programon, a myKbd-n alapul, de az elrendezés a honlapíró sajtja. Ilyen kellene Androidra, esetleg további ficsörökkel. (Ha valaki megtanulja, iszonyatosan gyorsan lehet vele írni.)
Én ugyan csak közvetítő vagyok, de természetesen a segítséget javadalmazással gondoltam. Érdeklődőket pü-ben várom.
Ha ez nem ide való, csapjatok nyakon nyugodtan, csak mondjátok meg, hol lehet ilyesmi felől érdeklődni! Köszi! -
thon73
tag
válasz
eastsider
#1975
üzenetére
Elküldöm nyilvánosan, mást is érdekelhet:
[link]Ez ugyanaz a program, mint az Enumber nyilvántartó, de könyveket tart számon. Van a Books adatbázis, amelyik hivatkozik az Authors adatbázisra.
Elnézést kell kérjek azoktól, akik megnézik:
- én csak hobbiprogramozó vagyok, másrészt a program csak gyakorlásból készült. Magam is találtam hibákat benne. A program egyébként működik, de javítása folyamatban. Ha bárki javítási javaslattal él, örömmel veszem.
- már javasoltátok, hogy töltsem fel a Github-ra. Előbb-utóbb fel lesz, de nem jöttem rá Eclipse alól hogyan kell. Csak AIDE alatt találtam meg, de az most nincs (új telo rom, ugye). Köszönöm, ha valaki segít benne!
- természetesen "AS IS", tényleg csak meg akartam ismerni, hogyan működik...U.i.: Valaki találkozott már olyannal, hogy WinXP alatt a file-ok egy részének mérete konkrétan 0 lesz? Driveteszt ok, Kaspersky ok. De a forrást elő kellett ássam egy korábbi mentésből, mert ez is érintett volt. Hm. Legalább azt tudnám, hogy hogyan kerülhetem el legközelebb...
-
thon73
tag
válasz
eastsider
#1971
üzenetére
Én tudok mutatni olyat, amiben kettő van, és nem száll el

Ha kapcsoltak a táblák, akkor le sem tudod máshogy kérdezni (mármint külön ContentProviderrel). Több info kellene ahhoz, hogy válaszolni tudjak, de egy működő example-t (jó összetett ugyan) tudok küldeni.
Nekem a fő gond az volt, hogy mikor lehet teljes névvel, ill. mikor lehet csak rövid névvel hivatkozni az egyes mezőkre.
LEFT OUTER JOIN-nal kötöttem össze a két táblát.
A projection-ben a teljes (tabla.mezo) mezőnevet használtam, a from-ban csak a mezo-t. Ez akkor gond, ha mindkét táblában ugyanaz a mező neve (pl. maga az _id). Ilyenkor át lehet "nevezni" a mezőt, de erre nem volt szükségem.
Nem tudom, hol lesz a hiba, de emlékeim szerint ez sokáig nem tisztult le nekem, és folytonosan elszállt. Az sqlite-nak átküldött szövegeket érdemes átnézni, abból gyakran kiderül a turpisság. -
#1961
thon73
tag
WonderCSabo
#1960
thon73
tag
válasz
WonderCSabo
#1960
üzenetére
Pont ez az, ami a videon .50 körül van: drag&drop. Annyi a különbség, hogy itt az elemet hosszú nyomással, ott meg egy, az elején álló jellel fogjuk meg. Ez persze lényegtelen.
A listaelem kibontás is nagyon tetszik, (bár olyat szöveggel - lényegesen kevésbé animált módon - már csináltam.)
Köszönöm ezt is!Igaziból egy "todo" részt szeretnék csinálni az adatbáziskezelő segítségével, és ezzel könnyen be tudom állítani a manuális sorrendet. Meg persze lehet rendezni is mindenféle módon - de ez nagyon hiányzott.

-
thon73
tag
Köszi mindkettőtöknek! Elmélyedek benne.
A rommal az a baj, hogy csak egy stock rom átírás, de utánanézek, van-e forrása. Ez a rész speciel idegennek tűnik benne, azért is írtam ide a pontos elérését.
Ha nincs támogatás, az nem baj, majd támogatom magamat De legalább nem kell az egészet nulláról kitalálni.
Köszönöm! -
thon73
tag
Régóta szeretnék egy olyan listView-t, amiben az elemeket kedvem szerint (húzogatással) átrendezhetem.
Egy sikeres telefon újraélesztés után NeatROM 4.1.2-t tettem fel, ahol a rendszermenüben szerepel ez. Kijelző/Notification Panel/Toggle button order (a két nyelv keveréséből gondolom, hogy ez nem szabványos alkatrész). Nehézségek árán ugyan, de mozgás közben csináltam egy felvételt:
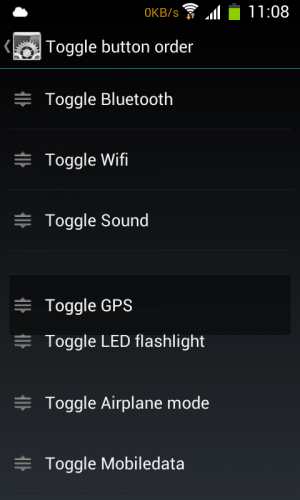
Ha listaelemek előtti ikont megfogom, akkor fel-le lehet húzni az elemet, és ha elhagyja a mellette lévő listaelem felezővonalát, akkor az a húzott elem "alatt" vagy inkább "mögött" átugrik az üres helyre. Na, ez így elmondva igen szegényes, de elég kézenfekvően működik. És sok-sok elemmel (vagyis görgetés közben is működik.
Nem tudja valaki véletlenül, hogy ezt a funkciót hol tudom elérni, vagy van-e valahol ilyen kód, ami ezt megcsinálja? Amivel én próbálkoztam, az sokkal szegényesebb volt - gyakorlatilag arra jutottam, hogy a teljes listView-t újra kellene írni. Egy ilyen kód sok melótól megmentene... Hálás köszönet előre is!
-
thon73
tag
válasz
eastsider
#1881
üzenetére
Régen is ui threaden töltődött, aztán mégis használtuk a progikat...
Ráadásul, úgyis meg kell várni amíg betöltődik, mer ugye épp a listát akarod megnézni.
A saját tapasztalatom az, hogy érdemes Content Providert csinálni. Kicsit korlátozott, amit az adatbázissal csinálhatsz, de jobban átlátható a kód, könnyebben belepasszol abba, amit az Android szeretne.Én ugyan nem vagyok nagy guru, de szívesen belenézek a debugba; több szem többet lát...
-
thon73
tag
válasz
eastsider
#1879
üzenetére
Én megcsináltam mindkettőt. Ha CursorLoader-t szeretnél használni, akkor kell hozzá ContentProvider is - úgy tudom. Egyiket se nagyon nehéz elkészíteni, de az utóbbi meglehetősen hosszú. A kész Loader csak pár sor viszont. Saját Loader csak akkor kell - szerintem - ha nem sqlite a forrás, hanem valami elvarázsolt dolog.
Loader nélkül már nem kedveli a rendszer - vagyis deprecated, de működik.
Pár hozzászólással ezelőtt feltettem egy E-number kezelő kódot, abban mindkettőre szerepel példa. -
thon73
tag
Kedves Adatbázis Guruk!
Csinált már valaki olyat, hogy NEM a beépített szöveges keresésekkel keresett android sqlite adatbázisban? A lehetőségeket (keresésre külön oszlop pl.) olvastam itt-ott a neten, ezt pl ki is próbáltam. De saját tapasztalata (amit esetleg meg is osztana) van valakinek? Ahol esetleg nem kéne duplázni az adatokat.
(((az ANDROID sqlite lényeges, mert C forráskódban láttam erre beépített lehetőséget is, de tudtommal itt nincs)))Ha valaki zsákutcába futott ezzel, és elmondja, annak is örülnék; legalább arra már nem próbálkozom.
Köszönöm!
-
#1819
thon73
tag
WonderCSabo
#1816
thon73
tag
válasz
WonderCSabo
#1816
üzenetére
Csak együttérezni tudok.

A Support Fragmenttel én is tapasztaltam anomáliákat 2.3.x és 4-x alatt nem egyformán működött. A másik falba ütközésem a nested megvalósítással történt, így utólag valószínű pont emiatt. (Nem megfelelően állt fel a layout, különösen újraindításnál.) Én feladtam a nested variánst, azóta mindent szigorúan az Activity vezérel (szinte csak erre tartom )
De elismerésem, hogy ezt így kibogoztad!!! -
#1815
thon73
tag
WonderCSabo
#1814
thon73
tag
válasz
WonderCSabo
#1814
üzenetére
Nem is rajzolnak a fragmentek, csak különböző paramézersorokat kérnek be, amiből összeáll a végén egy rajz. De azt nem is látom, csak a végére gyártja le, és mutatja meg az egyik fragment. De ez nem lényeges.
Az onResumeFragments azért kell, mert az onResume részig még nem álltak össze a Fragmentek, már amit a rendszer állít vissza.
Pont ez teszi nehézzé, hogy nincs olyan pont, ami még biztosan le[ut, de a Fragmentek már üzemkészek. Viazont kezdem átlátni, hogy két irányt kell elkészíteni. Az első elkészítéskor az onActivityCreate érheti el a másik Fragmentet ˙Activityn át), később viszont ekkor még nem látja az Activity a másik Fragmentet, tehát nekem kell explicite az OnResumeFragmentsben meghívnom egy adatokat beállító külön fragment metódust.
Ez a megoldás nem túl szép, szerintem a staticus mező tisztább! Köszi a segítséget, a beszélgetés nélkül még törtem volna rajta a fejem egy darabig. -
#1813
thon73
tag
WonderCSabo
#1812
thon73
tag
válasz
WonderCSabo
#1812
üzenetére
Az, hogy lényeges különbség van a retained Fragment ELSŐ LÉTREHOZÁSA, és az összes többi VISSZAÁLLÍTÁS között.
Vagyis:
A Fragmentet először az Activity.onResumeFragments részben fogom megtalálni. Ha nincs meg, akkor itt kell először is létrehozni.
Ha nem volt meg, akkor a létrehozás után még semmilyen élitciklus nem fut le (majd csak az onResumeFragments UTÁN)
Ha viszont megvolt, akkor eddigre minden lefutott, beleértve a Fragment.onResume metódusát is.A konkrét próbálkozásban egy ListFragmentet készítettem, amelyik az adatait ebből a megőrzött globális adatállományból veszi (a végső megoldás mindig egy kicsit összetettebb persze). Ez azt jelenti, hogy valahol meg kell mondjam az adapternek, hogy hol vannak az adatai.
Az első létrehozáskor (persze ilyenkor az adatállomány még üres, de majdan ide fog bekerülni) nem lesz gond, hiszen mire a ListFragment életciklus részei lefutotnak, ott van az Activityből elérhető módon a másik, adatokat tartalmazó Fragment.
Minden további indításkor azonban mindkét Fragment végigfut az onResume-ig, mielőtt én egyáltalán látnám az adatokat tartalmazó Fragmentet az Activity.onResumeFragments részében! Vagyis nekem kellene kiadni egy pl. MyListFragment.onVariableReady() utasítást, ami betölti az adapterbe az immáron elérhető adatokat.
Ez a megoldás viszont az első indításkor nem lesz jó, hiszen még adapter sincs sehol!
Hozzáteszem: ez a ListFragment dolog valójában csak egy próba. Nekem egy sok részletből álló rajzot kellene elkészítenem, aminek az egyes részeit tudom egy-egy Fragmenttel megalkotni. Az alapadatokat természetesen mentem, de minden apró számítást nem akartam. Ettől a speciális problémától elvonatkoztatva a kérdés általános érvényű: hová tegyem a Fragment megőrzendő adatait, ha magát a konkrét Fragmentet nem akarom megőrizni ((mert pl. változik a gép fordításával))?
A static field egyébként jó ötlet, csak úgy emlékszem, valamiért (újra el kellene olvasni) kerülendőnek javasolta a hivatalos doksi. De ezt elő kéne ásni, lehet, hogy rosszul emlékszem...
((Bocs, ha kicsit bonyolult, már játszom vele egy ideje. Szívesen küldök kódot, de a sallangok, és próbálkozások miatt előbb ki kellene fésülnöm. Bár kivételesen a szöveg talán többet mond.))
-
#1811
thon73
tag
WonderCSabo
#1810
thon73
tag
válasz
WonderCSabo
#1810
üzenetére
Miért ajánlgatja a doksi a retained Fragmentet, ha ilyen nehéz megoldani az elérését másik Fragmentből!?
A static field-es osztályt hogyan mentem meg biztonságosan? Átviszem az onSaveInstanceState-ben?
Menteni nem akartam, akár nagy is lehet a mérete. Ezek csak olyan "melléktermék" adatok, amik megkönnyítik, hogy nem kell mindent újraszámolni, ha egy másik Fragment nyílik meg, vagy ha újraindul az Activity. De a static field szimpatikus. Az végső soron az Activity-hez kapcsolható, semmi dolga a Fragmentekkel. Így csak az Activity-ig kell "visszanyúlnom" az adatokért.
-
thon73
tag
Egyszerűsítem a kérdést:
Hová tegyem azokat az (akár nagyméretű) globális adatokat, amiket több fragmentből el akarok érni, de szeretném megtartani őket a konfigurációs változások alatt is?
((Egy ötletem van: Application szintre. Megpróbáltam a retained fragmentet, de sehogyse megy.)) -
thon73
tag
Néhány globális változót egy "retained fragment"-be helyeztem. Létezik olyan pont, amikortól a többi fragment (természetesen az activity-n keresztül) elérheti ezeket a változókat?
Uis. a változók csak az activity onResumeFragments részére térnek vissza (itt tudom újra megtalálni a megtartott fragmentjüket). Ugyanakkor eddigre az összes többi, nem megtartott Fragment is feláll, és az Fragmentek onResume része is lefut.
Van még valamilyen pont az onResume UTÁN, ahol MÁR tudnék kommunikálni a többi fragmenttel (konkrétan a megtartottal), de MÉG nem indult el a Fragment a felhasználó szempontjából?
Előre is köszönöm!
((Átmenetileg úgy oldottam meg, hogy az Activty "értesíti" a Fragmenteket, hogy a változók rendelkezésre állnak. De nem hiszem el, hogy ez lenne a real android way...)) -
thon73
tag
A kérdés több, mint jogos, de a válasz egyszerű: megígértem, hogy még a hétvégén elkészítem, és így egyszerűbb volt feltölteni. (Így is késtem vele egy napot
 ) ((Igaz, az nem mentesít, hogy az AIDE, amit tableten használok, alapból ismeri a GitHubot)) Ha megfelelő géphez kerülök, akkor felkerül oda, ill. blogcikket is szerettem volna/szeretnék írni erről, mert én rengeteget tanultam belőle - többek között itt kapott infókból is. Az eredeti ötlet többet tud, a kapcsolt táblákat (kereszthivatkozásokat) is kezeli.
) ((Igaz, az nem mentesít, hogy az AIDE, amit tableten használok, alapból ismeri a GitHubot)) Ha megfelelő géphez kerülök, akkor felkerül oda, ill. blogcikket is szerettem volna/szeretnék írni erről, mert én rengeteget tanultam belőle - többek között itt kapott infókból is. Az eredeti ötlet többet tud, a kapcsolt táblákat (kereszthivatkozásokat) is kezeli. -
thon73
tag
válasz
 lac14548
#1714
üzenetére
lac14548
#1714
üzenetére
Az E-számokat tároló adatbázis kísérleti programja (és kódja) ITT TÖLTHETŐ LE Telepíthető adb a /bin mappában.
A program az alfa változat alfája. Egy nagyobb történetből lett "lebutítva". Teljesen működőképes (én használom), de nincs széles körben tesztelve, szóval AS IS (olyan amilyen). Ez azt is jelenti, hogy nem tökéletesen kész, de különben soha nem érnék idáig vele.
Mivel a kérdés itt merült fel, itt is osztom meg, de a megosztás célja elsősorban a tanulás. Ha bárkit érdekelnek részletek, talál hibákat stb. itt/püben/egyéb módon is szívesen fogadom.
Egy-két apróság:
Ez egy egyszerű sqlite alapú adatbázis, id-n kívül 3 szöveges mezővel. A negyedik mező tartalmazza a "normalizált", vagyis ékezetek nélkül kereshető kódot. Az adatbázist lista, ill. az egyes elemeket szerkeszthető módon is megjeleníti. A lista az E-számokra rendezett, szűrhető (minden mezőre, ékezet, kis-nagy betű nem érdekes), és (most még) unique bejegyzések nincsenek kikötve.
Gyakorlatilag loggol (igencsak bőven) egy {sdcard}/enumberdb mappába (a syslogon kívül), de elmétileg ez összeakadhat (ld. előző kérdéseim a threadekkel kapcsolatban) dolgozom rajta.
Az érdekessége (talán) a saját (egyszerű) file kezelővel bíró csv szerű export/import funkció, az adatok ezzel is bővíthetőek, ill. archiválhatóak. Vigyázat! importnál beilleszti a meglévő adatok közé a rekordokat!! (KI van kapcsolva az unique védelem, ugye.)
Külcsín, működés (pl ékezet, kereshető mezők) könnyen, igény szerint módosíthatóak. Persze a nyelv is.
Jó próbálgatást! Ötleteket, kritikákat szívesen veszek - már ami a kóddal kapcsolatos. Tudom, ez nem a Google Play, nem is ilyetén céllal került ide ez a kód. -
thon73
tag
Aha. Ezt nem olvastam, csak a doksit. Akkor tényleg nem véletlenül írják, hogy Android alatt ez nem használható.
Megnéztem a "hivatalos" Log-ot is, de az teljesen használhatatlan (nekem), mert alacsony szintű hívással az op-rendszer logját írja, amit viszont én nem tudok kiolvasni. (Ill. csak PC kapcsolatban, meg rootolt készüléken)
Még nem tudok teljes mélységben válaszolni, de próbálkoztam, olvasgattam, és érdekes eredményeket kaptam.
1. A külön file-író thread azért is nagyon jó ötlet, mert akkor ez nem is lassítja pl. az UI thread-et. Az elkészítéstől egy kicsit megriadtam, de nekiláttam. ITT találtam egy hasonló elgondolást, ebből annyi látszik, hogy ez nem lesz olyan egyszerű.2. A Channel thread-safe egy programon belül. Hm. ezt nem tudtam, pedig a doksi is egyértelműen ezt írja.
3. ITT azt az okosságot írják, hogy Channelen kívül NEM lehet többször (tehát több threadból) írásra megnyitni egy file-t. (Ez szerintem nem igaz, én írtam file-t egyszerre több nyitott úton keresztül, igaz egy thread-en.)
4. Ez a legérdekesebb: leteszteltem. Csináltam több párhuzamos thread-et, mindegyik ugyanazt csinálja: megnyitja/írja/bezárja ugyanazt a file-t, mégpedig OutputStreamWriter(FileOutputStream) úton. (Igaz, ez pufferelt, de a puffer többszörösét írtam ki, kb 2 Mbyteot, 4 threadról.)
Nem létezik, hogy soha ne ütközzenek. Mégis, az összes kiírás tökéletes! Tettem elé time-stamp-et, sokszor egyforma, mégsincs hiba!!
Vagyis: Minden elmélet ellenére gyakorlatilag lehet egyszerre több threadról írni ugyanazt a file-t. Most akkor ez hogyan lehet? Mégis "thread-safe" lenne az alacsony szintű írás androidon?? Lehet, h. itt működik, más java környezetben meg nem??
-
thon73
tag
Még egy utolsó kérdést hadd tegyek fel:
A file írás nem mindig történik meg a záráskor sem (Ezt RandomAccessFile esetén tapasztaltam, még a program bezárása után is hozzányúlt, igaz, csak a metaadatokhoz).
Nem biztonságosabb a FileLock használata az esetemben? Vagy ugyanazt az eredményt érem el, mint a synchronized védelemmel? -
thon73
tag
Vicces, most derült ki mennyire topa vagyok a multithread-del, mégis megosztom egy volt ötletem. Én scrolloztatni akartam a képet, amíg a delikvens hosszan nyom egy pontot. A longpress nem jó, mert az csak egy dolgot csinál meg utána, aztán megint vár. Sztem. neked ugyanez kell fordítva: Ha érintés történik, akkor megszakítod a thread-et.
Egy két kódrészlet:TouchThread touchThread;
@Override
public boolean onTouchEvent(MotionEvent event)
{
...
case MotionEvent.ACTION_DOWN:
touchDirection = 1;
touchThread = new TouchThread();
touchThread.start();
break;
case MotionEvent.ACTION_UP:
if (touchThread != null)
touchThread.interrupt();
break;
}
...
}
private class TouchThread extends Thread
{
@Override
public void run()
{
// Csak vár, hogy hosszú nyomás legyen
for (int cnt=0; cnt<3; cnt++)
{
sleep(100);
if (isInterrupted())
{
touchThread = null;
return;
}
}
// Innentől történik a gyorsuló görgetés
int pause = 150;
while(true)
{
for (int cnt=0; cnt<15; cnt++)
{
sleep(pause);
if (isInterrupted())
{
touchThread = null;
return;
}
// Itt kérjük meg a görgetést az UI száltól !!!!!!
touchThreadHandler.sendEmptyMessage(0);
}
if (pause > 85)
pause -= 30;
}
}
// A görgetést a Handler fogja elvégezni
private Handler touchThreadHandler = new Handler()
{
@Override
public void handleMessage(Message msg)
{
if (touchDirection >= 0)
rollForwardLine();
else
rollBackwardLine();
touchState = 0;
invalidate();
}
}
}Ezt elég régen írtam, aztán megszakadt a dolog. Egyébként nem csak az időzítést tudja, hanem egyre gyorsul is a görgetés, amíg nyomod a képet.
Bocs, hogy a kód összetöredezett, amíg kiszemezgettem, de sztem a lényeg érthető. Mint kiderült, nem vagyok (még) teljesen otthon a thread-ekben; (ha valaki hibát talál, és szól, köszönöm); de a kód prímán működik. -
thon73
tag
Aha! Köszönöm. 1. pont alapján a kódot javítottam.
2. Eddig multithreadet (a rendszer által kínált lehetőségeken kívül) csak időzítési feladatokra használtam. Viszont - a log szigorításával - szükségem lett volna egy "saját" log-ra, amit akkor is használhatok, ha tableten dolgozom. A program nagyon egyszerű, egy file-ba írja az üzeneteket. ((Az esetleges összeomlás miatt a metódus nyitja-írja-zárja a file-t (flush is lehetne helyette, de az idő nem volt lényeges szempont)). Ilyen üzenet bármelyik thread-ről érkezhet, ezért szeretnénk biztos lenni abban, hogy működik.
Két megoldást találtam a figyelmeztetésed után:
private final Object lock = new Object();
private static String addTextToFileLog( File logFile, String text )
{
synchronized( lock )
{
OutputStreamWriter logStream = new OutputStreamWriter( new FileOutputStream(logFile, true));
logStream.append( text );
logStream.flush();
logStream.close();
}
}illetve:
private static synchronized String addTextToFileLog( File logFile, String text )
{
OutputStreamWriter logStream = new OutputStreamWriter( new FileOutputStream(logFile, true) );
logStream.append( text );
logStream.flush();
logStream.close();
}(A hibaellenőrzést az egyszerűség kedvéért töröltem.)
Van előnye egyik vagy másik megközelítésnek? Egyáltalán jó ez így, vagy valamit elnéztem?
Ha még abban tudnék egy kis segítséget kapni, hogy ezt hogyan tesztelhetem a szimpla próbálkozáson kívül, azt is megköszönném! -
thon73
tag
Bocsánat, ha nagyon alapot kérdezek:
Az android forráskódban mindig synchronized( mLock ) kifejezés szerepel. Miért nem a védett tartalomra (mondjuk egy array-listre) szinkronizál, miért kell egy külön objektumot erre létrehoznia? (Azt értem, hogy ez miként működik, csak azt nem, hogy ez így miért jobb?)
Én ugyanis eddig mindig a védett tartalmat írtam be.A másik hasonló kérdésem: ha ugyanazt a file-t külön szálakon is írom, de minden szál külön nyitja meg (tehát nem közös leírót használnak), akkor ugye nem kell a szálakkal és a szinkronizálással törődnöm, a rendszer sorba rakja a kiírt adatokat? (Mindig csak egy sornyi append van, tehát a program oldaláról nem feltétlenül kellene külön lock-olnom a file-t)
Gyakorlatilag működik a program, csak azt nem tudom bizonyítani, hogy elvileg is mindig működőképes lesz. Köszönöm!
-
thon73
tag
válasz
 pittbaba
#1716
üzenetére
pittbaba
#1716
üzenetére
Lehet, h. hülyeség, amit gondolok, de a "kilövés" az egész Application process-t érinti. A handler azon belül van, - elvileg - az is megszűnik. Arra kellene rájönni, hogy miért lő ki a rendszer egy előtérben lévő Applicationt? B lehetőség: Ha esetleg nem az application process indítaná a handler-t? Pl. service - bár ezzel nincs tapasztalatom.
-
thon73
tag
válasz
lac14548
#1714
üzenetére
Engem se fogott meg
 Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Azért írtam ide, mert úgy gondoltam, ide küldöm - hátha más is érdeklődik. -
thon73
tag
válasz
 TheProb
#1693
üzenetére
TheProb
#1693
üzenetére
Mi akadálya van előtte elolvasni egy java könyvet is?
A saját tapasztalatom az volt, hogy C alapok mellett elég volt két rövid jegyzetet elolvasni, és utána a Java-val együtt az Androidot elkezdeni. Nem akarok keveset mondani, de a Java-val nem volt semmi komoly gondom 2-3 hónap után. Az Android 2 év után is produkál számomra átláthatatlan kérdéseket. Bár bizonyára én sem vagyok kellő módon képzett... -
thon73
tag
válasz
lac14548
#1692
üzenetére
Akkor jó, ezt alapból tudja. A megnevezéseket kell átírni, meg bevinni egyszer az adatokat.
((Amúgy egyáltalán nem (volt) egyszerű feladat. Pontosabban egyszerű, de nem rövid feladat. Android alatt van egy príma sqlite adatbáziskezelő, de nincs összekötve a felszínnel (mármint a képernyővel), tehát meg kell írni a listázós/űrlapos részeket is.))Küldd el, kérlek, pontosan milyen mezők kellenek! A megnevezéseket uis. a kódban tudom megváltoztatni. És milyen "végtermék" kellene? Forrás-project eclipse alá? Vagy csak a kész progi?
Egyébként van kész, és szabadon beállítható adatbáziskezelő a marketen: pl. Memento Database. Ez a feladat azzal is tökéletesen elvégezhető.
A saját programnak mások az előnyei: speciális részek is beépíthetőek (pl. ékezetes keresés, összekötés naptárral) stb. A kívánt feladatot egyébként ebben is könnyen meg tudom csinálni.
-
thon73
tag
válasz
lac14548
#1686
üzenetére
Speciel nekem van egy szótár (egyfajta saját adatbázis alapján) és egy sqlite adatbázist használó keretprogramom is.
Egy ilyet összerakni tényleg nem rövid idő és nem is kevés munka. De a fentiek nagyjából készek. A szótár amúgy is érdekel, ha az átalakítás nem olyan vészes, akkor abban tudok segíteni. Kis java/android tudás azért a megértéséhez sem hátrány. -
-
thon73
tag
Visszatérek egy korábbi beszélgetéshez, mert ígértem, hogy számot adok az eredményeimről (ezt egy rövid részben már megtettem). Bocs, egy kicsit hosszabb lesz, aki nem érdeklődik, ugorjon nyugodtan!

Másrészt kicsit Java topicba kívánkozik, de mivel a mérések célja az Android felderítése volt, (no meg itt kezdtünk bele), inkább itt folytattam.A probléma: indexelt utf-8 kódolású fileban ugrálni (seek) ide-oda, és rövid részeket beolvasni. Az első ötlet a Reader, a második ötlet a puffer használata volt. Mindkettő jó, de az alap osztályokkal nem megvalósítható.
fis = new FileInputStream( file ); // byte alapú beolvasás
isr = new InputStreamReader( fis, "UTF-8" ); // már karakteralapú, dekódolt és pufferelt (fix puffer)
br = new BufferedReader( isr ); // readLine is van, és még nagyobbra állítható pufferfis.getChannel().position(pos) segítségével seek megvalósítható. DE! Amíg van a pufferban elem, azt használja. A puffer nem törölhető, az available() sem implementált, amivel skippelni lehetne. Egy megoldást láttam: minden seek után újranyitni a file-t. További hátrány: a puffert teljes egészében dekódolja, ha kell, ha nem.
Megoldás: puffereléssel és utf8 dekódolással bővített Reader osztály (én valójában a RandomAccessFile-t használok a háttérben, de FileInputStream ugyanúgy jó. A "kimenet" azonban Reader lesz.) Ez már másnak is eszébe jutott ITT, én ezt az ötletet fejleszettem tovább.
A tesztben hátulról előre 100 byte-onként végzek lineRead()-et egy 3,8 megás, rövid sorokat tartalmazó szöveges file-ban. Az eredmények megdöbbentőek (sajnos eléggé szórnak) A nem-pufferelt (egyébként azonos osztály) 20000 ms körül teljesített. Ugyanez puffereléssel: 600-900 ms
Kimértem a különböző pufferméreteket is (ez a szórás miatt nehezebben meghatározható). DE! Az jól látszik, hogy 500 byte puffer alatt rosszabb a teljesítmény (800-1000 ms); 500-2000 byte között a legjobb (700-750 ms), 2000 felett pedig konstansan romlik (800-900 ms).
Ez utóbbi eredmények között lényegi különbség (szerintem) nincs, vagyis nincs értelme sokat változtatni a 8192 standard pufferméreten. (((A régi szép időkben ismert szektornyi "raw" readhez amúgy sem enged oda a rendszer)))
A pufferelt/nem pufferelt közötti különbséget sokkal kisebbnek gondoltam. Érdekes, hogy ennek ellenére nincs pufferelésre (gyári) lehetőség RandomAccessFile esetén. 20x különbség nagyon sok.Ha esetleg már valaki küzdött ezzel, és megosztaná a véleményét, nagyon örülnék.
-
thon73
tag
Elkészültem az első mérésekkel. A szórás ugyan nem változott, de a pufferelt és nem pufferelt beolvasás között több nagyságrendi különbség van. Még file-ban való ugrálás és rövid stringek esetén is, és még utf-8 átalakítással együtt is nyer a pufferelt változat.
Én legalábbis nem gondoltam volna, hogy ekkora különbség van... -
thon73
tag
Csak egy apró kérdés: gondoltam kimérem az sd kártya műveletek idejét.
A programciklus végtelenül egyszerű: egymásba ágyazott BufferedReader/InputStreamReader/FileInputStream olvas hátrafelé (getChannel/position() beállításával) egy kb 7 megás file-t, mindig ugyanazt. Kiírás (képre, logra) nincs, csak mérés SystemClock.elpsedRealTime()-mal. A program UI szálon van, végig előtérben.De miért van az, hogy ugyanaz a program, ugyanazt csinálja, ugyanazon a file-on - és mégis valami irgalmatlanul szór? Ennek nem kellene egy közel konstans értéknek lennie?
(Pontosabban: az irgalmatlanul az közel 1000 ms) -
#1609
thon73
tag
WonderCSabo
#1608
thon73
tag
válasz
WonderCSabo
#1608
üzenetére
Abszolút off, de nagyon kíváncsi vagyok!
Bevallom, én EGY egész évig bütyköltem az androidon, mire az első komoly programot biztonságosan el tudtam készíteni. (Igaz, munka és család mellett, kicsit hobbiból csináltam, viszont komoly C hátterem volt, és az objektumokkal sem most találkoztam először.)
Mondjuk, most tartok ott, hogy a Karma által felsorot elemek egy részét én is felsoroltam volna, a másik részében meg tudom, honnan kell elindulni, de még soha nem használtam.
Viszont a sokadik emberke kérdezi meg, hogy itt van egy ilyen meg olyan program, segítsetek, hogyan dobjam össze egy esős (havas) délutánon! Androidot(Eclipset stb.) ugyan még nem is láttam közelről.
Most komolyan: én rontottam el valamit, és negatív az iq-m? Ez tényleg így megy?
Mert akkor LÉGYSZI LÉGYSZI LÉGYSZI nekem is árulja el valaki, hogy a túróba kell ezt a vacakot felprogramozni!? Nekem valahogy mindig hibaüzenetek jönnek, és a legtöbbször nem is egy e betűt hagytam le az utasítás végéről...Bocs, nem akartam gunyoros lenni, de engem ez télleg nagyon érdekel!
Ja, és ami nem OFF: Meg lehet tanulni Java-t is (azt még magyarul is), Androidot is (ahhoz azért angol tudás kell), internetes útmutatókból is. Nekem ugyan nem hirtelen, de sikerült. Amikkel kezdtem, azt ITT leírtam. Ez is egy forrás, elég alapszintű, van sok más is, néhányat az oldalon is felsoroltam.
-
thon73
tag
Megint egy Java/Android problémába futottam bele.

Sqlite adatbázist használok több táblával. A táblák kezelése igényel egy csomó String konstanst, amiket eddig ténylegesen String konstansként is tároltam, táblánként. Ez eddig működik.
A több tábla miatt szerettem volna a "közös" részeket kiemelni: pl. a contentType() az minden táblában ContentResolver.CURSOR_DIR_BASE_TYPE + "/" + contentSubType() érték lesz, természetesen a contentSubType() táblánként különböző.
Ezért fogtam a konstansokat, és áttettem őket metódusokba, melyek nem tesznek mást, mint visszaadnak egy String értéket (ehhez más metódusok meghívása is szükséges lehet, de végső soron ezek konstansok lesznek). Emiatt static-ként jelöltem meg ezeket.
DE! A szülő osztályban (ami az általános tábla azonosítókat kezelné) a static-abstract összeférhetetlenség miatt nem tudok abstract metódusokat alkalmazni! (amik az egyes táblábakat kényszerítenék a saját, egyedi azonosítóik megadására)Vagyis a gond gyökere: sqlite adatbázisnál nincs a tábláknak megfelelő osztálypéldány, csupán az adatbázishoz/táblához tartozó konstansok vannak (amit a Java nagyon nem szeret). Nem találtam ideális megoldást, eddig minden táblához van egy osztály, ami csak a konstansokat tartalmazza.
Ti hogyan szervezitek az adatbázistáblák konstansait egységes rendszerbe?
-
thon73
tag
Igen, a mérés bennem is felmerült. Nem voltam biztos abban, hogy nincs egy konkrét elméleti adat - pl. az említett méretek, ezért kérdeztem. A mérés nagy hátránya, hogy könnyen lehet, h. ez az érték gépfüggő. Mellesleg - megjegyzem - puffer nélkül is észrevehetetlenül gyors, gyanítom, hogy pufferrel is az lesz. Tényleg igaz: nem kell talán minden lépést kimérni, azér' van a négy processzor...
Hm. Nekem a Java és az Android teljesen új volt, C-ben programoztam előtte (ráfordított időt tekintve: hobbiszinten). Talán furcsa, de - ennek ellenére - a natív rész akkor még nagyon távolinak tűnt, egyszerűbb volt Java-ra átteni, és még akkor sokat javítottam (pontosabban bővítettem) az algoritmuson. Az eredetit amúgy se lehetett volna átteni, a PalmOS nagyon máshogy "gondolkodott". A sebességgel most nincs gondom, a teljes szöveges keresést jó lenne natívan megcsinálni, de az eddig nem volt szükséges.
A program elkészülte után Attila megkért arra, hogy legyen bővíthető a szótár. Emiatt elég mélyen beleástam magam az sqlite-ba, most lett egy komplett front-end, ami kapcsolt táblákat is kezel. (Ez nem baj, mert egy ilyen nyilvántartó program amúgy is kellett volna, de eredetileg a szótár miatt csináltam.) Arra rájöttem, hogy ilyen speciális megoldásoknál az sqlite "kicsit" korlátozott. Az idő rövidsége miatt viszont a blog folytatására nem maradt időm, így aztán se az sqlite front-end, se a szótár doksija nem került (még) se fel, se megírásra. Szóval hiányos a "doksi", igyekszem pótolni (mert nekem is segítség), de ha bárki egy picit is érdeklődik, a kódot/adatot szívesen megosztom addig is.
-
thon73
tag
Igen, ez egy szótár, pontosabban szótár keretprogram. ITT elkezdtem irogatni egy-két dolgot, csak nem volt időm még befejezni. Viszont a program működik, sőt V.Attila is ezt használja. (csak az ő verziója fapadosan bővíthető) (((Vannak más szóanyagok is, de legalitásuk kétséges.)))
Ha röviden akarok arra válaszolni, hogy miért kell még egy szótár: mert elég könnyűnek tűnt megcsinálni, olyan functionalitást tartalmaz, amit máshol nem találtam, és úgy tudom beállítani, hogy a kezem alá dolgozzon. ((Aki szótárazott hosszú szöveget képernyőn, az tudja miről beszélek.))
"Az indexet desktopon kéne megcsinálni" - ez teljesen igaz, az androidos indexelés kísérlet volt, pont azt felmérni, hogy mennyi időbe telik. Aztán így maradt. Megjegyzem, ez egy külön app, amit csak én használok, nekem viszont fontos volt (utazás alatti fejlesztés miatt), hogy desktoptól független legyen.
A "háromféle" módból kettőről fent már írtam, de kell még egy. Nézzünk két bejegyzést: "adatbázis" és "adat-bázis".
(1) Ha ki akarod keresni, nem biztos, hogy lesz ékezetes billentyűd stb., tehát mindkettoben kell egy "ADATBAZIS"-t tartalmazó mező.
(2) Ha sorba akarod rendezni, akkor kell az ékezet, de a két bejegyzés megfelelő mezője egyforma lesz: "ADATBÁZIS", vagyis eltűnik a kötőjel.
(3) Kell az eredeti, átalakítatlan szó is, többek között azért, mert Attila szópárokat ír be, én viszont szeretném az azonos szavakat egyetlen bejegyzésba sűríteni, és ekkor az "adatbázis" és az "adat-bázis" két külön szóként szerepel.Ehhez sqlite-ban (mivel csak a standard sorbarakó lehetőségeket használhatom (((Megj: az UNICODE NEM alkalmas szótáras sorrend kialakítására, mert az pl. németben és magyarban más lesz, bár ettől még használható)))), szóval, három mezőben kell tárolnom ugyanazt a szót. Egyébként pont a kipróbálás végett készítettem egy sqlite keretet is. (A keret közel kész, de teljes anyaggal még nem töltöttem fel.)
Bocs, nem akartam ennyire eltérni a témától, bár szívesen és örömmel megvitatom az egész szótár-projektet. Eddig úgyis csak a saját elgondolásaimra támaszkodhattam, ill. most már a tapasztalatra is, mert két platformon is jól működik. ((Na jó, az egyik halott...))Sőt, ha van itt profi fejlesztő, én én annak is örülnék, ha valaki az ötleteimet megvalósítja; a költségen felül ráadásnak az ötlet is az övé lehet. De az egész onnan indult, hogy (még a Palm OS időkben) nem vállalta senki, hogy ilyesmiket fejlesszen...
P.S: ha valaki egyébként tudja az eredeti kérdésre a választ: vagyis milyen értéket érdemes BufferReader-ben puffernek megadni rövid beolvasásoknál, azt továbbra is köszönöm!
-
#1569
thon73
tag
WonderCSabo
#1568
thon73
tag
válasz
WonderCSabo
#1568
üzenetére
Nem az SQL önmagában, hanem a konkrét megvalósításban. Az adatbázis (most) statikus, nincs törlés, nincs beillesztés, (ha lenne, itt már nyerne az SQL), csak olvasás van. A statikus adatbázist be kellene olvasni teljes egészében (egyébként már ez elég lassú, közel 300.000 elemről beszélünk (Ja igen, és már most van 8 ilyen adatbázisom)). A legnagyobb probléma azonban az, hogy sqlite-ban (legalábbis android alatt) az összehasonlító metódust nem tudom én, kódból elkészíteni (más nyelvekben van erre lehetőség). Emiatt minden egyes bejegyzésre (rekordra) le kell generálni a mezőket pl. ékezet nélkül. Nem akarok részletekbe menni, de nekem háromféle összehasonlítás kell, amit most kód végez. Sqliteban ehhez minden rekordban 3 mező kellene, praktikusan mindegyik ugyanazzal az adattal, amit mindhárom mezőben más írásmóddal írok. Ezek egyébként izgalmas kérdések, mert azt boncolgatják, lehet-e ilyen volumenű feladatra telefont használni.
Namármost a vicc az, hogy lehet; legalábbis nekem prímán működik. A sebessége is kiváló, hiszen max. 20 keresésből megtalálja a kívánt elemet. Ez azt jelenti, hogy írom a keresőszót, és folyamatában, minden betű után keres. Ugyanakkor - mivel nem elég gondosan oldottam (még!) meg - csak az indexadatok olvasása 4 másodperc (ez lassú, ha elfordításkor ennyit kell várni), az indexelés meg 45 perc (SGSII-n), de ugye azt egyszer csinálom meg egy életben (elvileg).
Úgy gondoltam, ha már ezt kijavítom (a 4 mp-et mármint), akkor az itt javasolt beolvasást is átírom, csak éppen elakadtam a puffer-méret kérdésnél. (No igen, az is egy válasz, hogy 8192, nem olyan sok az...
)A "szívásról" annyit, hogy az első verzió PalmOS alatt született, ahol még kevesebb adatbázis-támogatás volt. Sőt! legfeljebb 64K elemet tudott kezelni, tehát több "táblába" kellett rendeznem az adatokat. Na az szívás volt, 3 hétig törtem a fejem az algoritmusokon. Viszont ezt átteni Android (és Java) alá csak egy délután volt. Most ott tartok, hogy az Android alatt néhány dolgon lehetne gyorsítani és egyszerűsíteni...
-
#1567
thon73
tag
WonderCSabo
#1566
thon73
tag
válasz
WonderCSabo
#1566
üzenetére
A file indexelve van, és az indexek sorba rendezve. De a szabadszavas keresésnél meg kell nézzem, hogy melyik indexnél kezdődik ugyanígy a bejegyzés. Ezzel egyébként nincs is gond, a rendezettség miatt rohadt gyorsan kikeresi a megfelelő bejegyzést.
Eredetileg RandomAccessFile segítségével oldottam meg az egész beolvasást, mivel az könnyen pozícionálható (csak nem pufferelt beolvasást csinál.) Itt javasoltátok, hogy a szabványos read... metódusokat használjam,, mert az is pozícionálható, egyúttal pufferelhető is. (((Hozzáteszem, a RAF ráadásul elég érdekesen (halasztottan) működik, ami egy kicsit megnehezítette, hogy a file véletlen módosulását az időpont ellenőrzésével figyeljem...)))
Szóval ezt a read dolgot építeném be, mert több szempontból is jobbnak tűnik. A BufferedReader wrapper osztályban meg lehet adni a puffer méretét (gyárilag 8192). Azt nem látom át, hogy nekem ilyen rövid beolvasásokkal van-e értelme a BufferedReader-t használni, és ha igen (mert gondolom, csak egy egységnyit tud fizikailag beolvasni a rendszer), akkor van-e értelme a 8192-t lecsökkenteni? És tovább: ha igen, mekkorára?
Bocs, ha előbb félreérthető voltam, nem az egész file-t akarom pufferolni, csak az előolvasást. Ill. nem akarom, csak lehet, h. célszerűbb. (((Beolvasások: ListView-ban egymás utáni rekordok, darabonként kb. 30-300 karakter, de talán egy sincs 1000 felett. Keresésnél: 10-20 db 1-5 karakter hosszú beolvasás különböző helyekről, majd a megtalált rekord a fenti módon.)))
Amit eddig a doksikban olvastam, az elég általánosan fogalmaz, és nem is magyarázza el a miérteket.
[Ja, és még egy: sqlite-tal is kipróbáltam, de ekkora méret több sebből vérzik, jobb lett a saját adatbázis] -
thon73
tag
Sziasztok! A keresőrutin egy nagy (7-15 Mb) fileban ide-oda ugrál, és minden alkalommal kb. 1-5 byte-ot olvas be. Amikor megtalálja a megfelelő részt (ez kb 10-20 beolvasás), akkor beolvas max. 1000 karaktert egyetlen helyről.
Érdemes-e puffert használni, ha érdemes, akkor mekkorát? Van az androidon valami hardveres/op rendszer által meghatározott minimális puffer méret? Köszi! -
thon73
tag
És akkor a "mögötte lévő", vagyis utoljára indított Activity látszik?
Első körben kiebrudalatam a teljes DialogFragment-et. Egyszerű dialogusokkal átlátható a kód teljesen, majd meglátjuk hogy kell (kell-e egyáltalán) visszatenni. Végülis, amíg elforgatás nincs, addig minden oké...
((Egy picit más: mi a nyavajának tűnik el az EditText tartalma a DialogFragment-ben elforgatáskor? Dinamikusan adtam hozzá, itt is kéne vhogy ID-t adni neki, hogy menteni tudja?))
Bocs, közben bővült a válaszod... Megpróbálom második körben így átalakítani.
Eredetileg azt hittem, ez valami triviális kérdés, amivel csak én nem találkoztam. De ezek szerint ez nem is olyan egyszerű...
-
thon73
tag
Persze, csak az a vicc, hogy épp ezt a négy funkciót akartam egy közös Activity-be rakni, amit most visszatennék négy másikba...
(((Eredetileg maga a FileSelectActivity végezte el az import/export funkciót, mert csak arra kellett a file kiválasztása. De most ugyanezt a file-kiválasztót szeretném másra is használni (háttérben álló külső file becsatolása egy adatbázis-rekordba), és ezért "kiszerveztem". Így viszont már két emeleten lépnek be az Activity-k, egy harmadikon pedig a DialogFragment.))) Izgalmas lesz tesztelni... -
thon73
tag
Megpróbálom. Végiggondolva a lehetőségeket, mindig a visszatérésnél van a gondom. Az Activity ugyanis az onActivityResult-ba tér vissza (ami a MainActivity-ben van), ill. a DialogFragment is az Activity-t kapja meg, tehát oda mehet vissza.
Namármost: Vagy szétosztom mindkét helyen a négy további osztály irányába az eredményeket (pl. a rquestCode alapján)
Vagy mégis egyszerűbb (csak áttekinthetetlenebb), ha az egyes eseményeket itt (vagyis a visszatérési metódusokban) kezelem le.
Hm. Emellett még meg kell tartani egy csomó paramétert, ami ugye vagy egy "utazó" Uri, de valószínűbb, hogy kellene csinálnom egypár változót (pl. egy retained Fragmentben), és a kérdések során ezek kerülnek egymás után feltöltésre. Amikor az utolsó kérdés is teljesült, akkor ezen változók alapján tudom végrehajtani a feladatot (pl. az import-ot). A változók talán azért előnyösebbek, mert segítenek, ha egy lépéssel vissza kell lépni. ((Mert pl. a FileSelector-nak meg kell kapni a "címsort" is, vagyis, miért válasszunk ki egy file-t.))
Lehet, h. kicsit zavaros, bocs. De bennem valahogy talán kezd körvonalazódni. Köszönöm a segítséget! Kicsit még kezdő vagyok ebben a szervezésben, túlnőtt rajtam a program (önmagában már működő 31 class, 4 funkcióval, és ez tenne rendet közöttük), de majd belerázódom... -
thon73
tag
Köszönöm! Akkor nekiállok bogozgatni...
Ezek szerint minden egyes lépés más és más, egymástól távol eső kódba kerül, ráadásul közöttük még az egész hóbelevanc újra is indulhat.
Végső soron akkor ezek között a részek között a file Uri-t kell körbe-körbe küldözgetnem. Abból le tudom vágni a nevet, a path-ot, az external drive-ot is (mármint ez utóbbit akkor, ha nem kell).
((Hogy teljes legyen a boldogságom, a MainActivity már most is négy "beszélgetős" funkciót tartalmaz, és közülük az import a legegyszerűbb...))Kicsit égnek áll a nem létező hajam, de majd kifésülöm (legalább a kódot)
Köszönöm! -
thon73
tag
Egy kicsit elakadtam, tudna valaki utat mutatni? Egy file importja során a program a következő "elvi" úton fut végig:
- MainActivity: Import gomb -> meghívja a FileSelectorActivity-t
- FileSelectorActivity: kiválasztjuk a file-t
- MainActivity: onActivityResult() -> meghívja MainDialogFragment-et
- MainDialogFragment: importálhatjuk az adatokat?
- MainActivity: positiveAnswerFromDialog -> meghívja az importálásért felelős Activity-tEz így egyszerűnek tűnik, de több helyen is vérzik:
1. Ha a dialogus "importálhatunk?" kérdésére nemmel válaszolunk, akkor vissza kéne jutni a FileSelectorActivity-ba (ráadásul az elhagyott könyvtárba!), hogy tovább válogassunk. Itt akkor újra ugyanúgy meg kell hívnom a FileSelectorActivity-t, mint az Import gombnál?
2. A dialogus csak a file nevére kérdez rá. A file adatai (Uri vagy File) hogyan "utaznak át" az onActivityResult részből (ahol megkapjuk őket) a positiveAnswerFromDialog részbe (ahol a dialogus visszatér)? Hozzak létre egy osztályváltozót a MainActivity-ben, vagy küldjem körbe az adatokat a dialoguson keresztül?
Hogyan érdemes egy ilyen összetett (többlépcsős) kommunikációt szépen megszervezni? Előre is köszönöm!
-
#1506
thon73
tag
WonderCSabo
#1502
thon73
tag
válasz
WonderCSabo
#1502
üzenetére
Keress ra Jess Anders two way gridview! En meg nem probaltam, de szerintem ez pont az, amit keresel! ((bocs, kulfoldon vagyok, nem tudom a pontos cimet eloasni)) Ha megvan, beszamolnal, h. jo-e?
Udv es BUEK mindenkinek!
-
#1497
thon73
tag
SektorFlop
#1493
thon73
tag
válasz
 SektorFlop
#1493
üzenetére
SektorFlop
#1493
üzenetére
Köszi SektorFlop! Én már feladtam, pedig klassz lenne

Feladat a következő: van egy listfragment balról, bármelyik elemét tappintva annak részletei megjelennek egy - nevezzük így - editfragmentben jobbról. Az editfragment mintegy "kiúszik" az elemből, majd "visszaúszik" a listába. A nehézséget az jelenti, hogy az editfragment eltűnése UTÁN a listfragment a teljes képszélességet foglalja el.
Ameddig eljutottam: A két fragment egy linearlayoutban volt. Az editfragment lassabban tűnt el, mint a helyéül szolgáló frame, így az animáció nem látszott.
Az a gyanúm, hogy átfedő fragmentekkel kellene dolgoznom (framelayout) és a programból beállítani a szélességeket. Igaz, hogy a listfragment így is azonnal elfoglalná a teljes szélességet, de legalább látszana az átfedő editfragment animációja. Ehhez a történethez viszont elég sok elvarázsolt számítás kellene - különösen, ha hozzávesszük, hogy más az elrendezés fekvő és álló módban.
((Extraként még jobb lenne, ha az activity-k is így animálnának, csak teljes képernyőben. De ez már egyszerűbb ügy lesz.))
Minden jó ötletet köszönök! -
thon73
tag
Köszi, ez a "középutas" ötlet kiváló.
Eredetileg AlertDialog-ot használtam (és igen, elég), csak:
- elfordítás nem megoldott, amit úgy oldottam meg, hogy DestroyView (ha jól emlékszem) magasságában bezártam a dialogust. (na jó, ez apró hiba, minek állandóan forgatni a gépet!
- tetszett az ötlet, hogy a terjedelmes kódból kikerülnek a dialogusok, bár (mivel a dialogushívás az activity törzsön keresztül történik) ki-be kell ugrálni az egyes programrészek között.Ettől függetlenül, egy sima confirmation dialog esetén lehet, hogy tényleg célszerűbb az AlertDialog.
-
#1484
thon73
tag
WonderCSabo
#1483
thon73
tag
válasz
WonderCSabo
#1483
üzenetére
Megerősíteni egy-egy akciót. Van egymás mellett egy list, és a lista egyik elemét mutató űrlap. Az űrlap törlésekor rákérdez, cancel-nél rákérdez, ha a listából másik elemet választok, de az űrlap már szerkesztés alatt van, rákérdez. Ha nem töröéhető az űrlap (foreign key constraint miatt), akkor figyelmeztet. Aztán van egy file választó rész, ott még több figyelmeztetés van.
Amit nem értek: minden eseménynél a dialógus megfelelő gombja szerint megyek ugye tovább. De vannak nagyon hasonló dialógusok (are you sure pl.), ott mindegyik akciónak külön dialógust (file-t) készítek? Egyáltalán érdemes minden fragmentet külön fileba tenni, vagy egy nagy file készítse el a sok fragmetet? Szóval nem látom, milyen szerkezet a legelőnyösebb; viszont minden tutorial csak egyetlen dialogusról ír. -
thon73
tag
Ezt (az animációs kérdést) még nem tudtam megoldani, addig is kihagytam az animációt.
Lenne viszont egy egyszerűbb kérdésem: nagy mennyiségű (6-8 db) DialogFragment-et használok/nék. Mi erre a jó megközelítés, hogyan érdemes ennyit beépíteni a programba (egyetlen activity, két fragmenttel)? Van erre egy jó tutorial?
((Pontosítom: A DialogFragment-ek - önmagukban - prímán működnek, a kérdés nem A dialogus létrehozására, hanem SOK dialogus ésszerű kezelésére vonatkozik.))
Köszönöm! -
thon73
tag
Hát, úgy látszik, mindig csak én akadok el... Vérszemet kaptam a stílusokon, és - gondoltam - a fragmentekbe is beteszek egy kis animációt.
Egymás mellett van két fragment: egy listFrag (list_frame frame layoutban) és egy editFrag (edit_frame-ban). Ez a layout, ami programból kapja meg a fragmenteket:<LinearLayout
android:id="@+id/landscape"
android:orientation="horizontal" ...>
<FrameLayout
android:id="@+id/list_frame"
android:layout_weight="2" .../>
<FrameLayout
android:id="@+id/edit_frame"
android:layout_weight="3" .../>editFrag itt animálva belép (csak lényegi rész!):
fragmentTransaction.setCustomAnimations(android.R.anim.slide_in_left , android.R.anim.slide_out_right, android.R.anim.slide_in_left, android.R.anim.slide_out_right);
fragmentTransaction.add(R.id.edit_frame, editFrag, "EDIT");
fragmentTransaction.addToBackStack("LIBDB");és itt animálva eltűnik:
fragmentManager.popBackStackImmediate();
A gond az, hogy edit_FRAME akkor is "tartja a helyét", ha editFRAG eltűnik, emiatt a listFRAG (és Frame) nem szélesedik ki a teljes képszélességre.
Ezért hozzátettem még egy sort:findViewById(R.id.edit_frame).setVisibility(View.GONE);
Volilá! A ListFrag most a teljes képszélességet elfoglalja! (Persze, editFrag létrehozásakor a Frame-t is visszakapcsolom.)
Csakhogy, ezzel eltűnt az animáció, mert a setVisibility előbb végrehajtásra került.Meg lehet szerintetek ezt valahogy együtt oldani? Tehát: editFrag animálva elosonjon, és a listFrag EZT KÖVETŐEN (vagy ezzel együtt) kitöltse a teljes helyet??
Előre is köszönöm! -
#1477
thon73
tag
WonderCSabo
#1476
thon73
tag
válasz
WonderCSabo
#1476
üzenetére
Kiváló és egyszerű. Köszi! Ez jó lesz
-
#1475
thon73
tag
WonderCSabo
#1474
thon73
tag
válasz
WonderCSabo
#1474
üzenetére
Igaz, style nélkül, de ezt csináltam meg. A gond csak annyi, hogy rengeteg ilyen customview van, ezért akartam betenni alapértelmezettenk ezt a style-t, vagy az attributumokat. Még keresek tovább; ezt biztos vhogy. meg lehet csinálni...
Kieg: a rengeteg, az rengeteg ugyanolyan. Összesen csak két custom view típust csináltam, csak sok példányuk van szana-szét.
-
#1473
thon73
tag
WonderCSabo
#1472
thon73
tag
válasz
WonderCSabo
#1472
üzenetére
Köszi, sikerült színes részeredményeket elérni, és ezzel rövidtávon meg is elégszem. De alapos külső segítséget (na jó, kritikát) kaptam a család tízéves stylistjától is :-)
Még egy kérdés, amivel nem jutok dűlőre: Van egy custom view, ami egy TextView-ból származik. Annak a formázását hogyan tudom a témához hozzáadni? Konkrétan ugyanolyan külsőt szeretnék, mint az EditText, csak más színekkel. Egy ilyesmit (a viewben) készítettem, de nem sikerül a témába szerelni.
-
#1471
thon73
tag
WonderCSabo
#1470
thon73
tag
válasz
WonderCSabo
#1470
üzenetére
Az elejét olvastam, de megriasztott a két utolsó gigantikus méretű file... Ezek szerint ne kézzel álljak neki, hanem fogjak egy ilyen programot (mint pl. a holos cucc), ami legyártja a nekem tetsző színben az egészet. No, nekiállok játszani, ((eddig a külsőségekkel még nem nagyon foglalkoztam.))
Köszönöm! -
thon73
tag
Meg tudnátok mondani, hogy ha új, saját témát (konkrétan színvilágot) szeretnék a programomnak, akkor honnan érdemes elindulni? A hogyan az megy, csak nem tudom, hol találok olyan összefoglalót, hogy mi mindenre kell figyelemmel lenni, milyen attributumokat kell feltétlen definiálni stb.
-
#1463
thon73
tag
WonderCSabo
#1462
thon73
tag
válasz
WonderCSabo
#1462
üzenetére
A teljes táblát egy ListView jeleníti meg, ott a join-nal összekötött táblákat egyszerűen lekérdezem, és a mezőket a megf. TextView-kba teszem. Ez gond nélkül megy.
Az egyes elemeket azonban egy űrlap jeleníti meg, ahol az egyes elemek önmagukban is megváltoztathatóak. Pl. egy könyv írójának itt az írók közül kiválaszthatok valaki mást, mielőtt magát az adatbázis-sort módosítom. A kódot egyébként megírtam, és működik is, de a linkelt adatbázisok űrlapjának kódja emiatt többször hosszabb, mint az egyetlen adatbázisra hivatkozók. A végleges megvalósításban ráadásul több ilyen "linkelt" elemet is kellene kezelnem, ezért gondoltam, hogy ezt a kódot valahogy leválasztom, akár View-ba, akár speciális új változótípus-szerű osztályba.
A félelmem pont az amire WonderCSabo rámutatott; hogy ezt túlságosan belekötöm a Fragmentbe, akkor vagy az nem tud békésen eltűnni újraindítás után, vagy a lekérdezést nem tudom megfelelően elvégezni. Pláne, ha több TextView-t kell egy id-hez kötni.
Hosszas keresés után most találtam egy megoldást (vagy legalábbis annak tűnik): ITT Megpróbálom így átkonvertálni. Meg valószínűleg lassan elolvasok egy komolyabb könyvet a software design patterns témában...
-
thon73
tag
Kicsit szégyenlem, hogy mindig én kérdezek; valószínű egy picit nagyobb fába vágtam a szekercét, mint gondoltam...
Van két adatbázis-táblám. Db1 egyik mezője (egy long id érték) hivatkozik Db2 egy elemére. Amikor Db1 űrlapját jelenítem meg, akkor természetesen nem a long érték, hanem a Db2-ben hivatkozott elem szöveges részei kerülnek kiírásra. Ez szerencsére eddig elég jól működik.A kérdésem a következő: létre tudnék-e hozni olyan custom TextView-t vagy akár speciális osztályt, amelyik KÖVETI a hivatkozás megváltozását. Vagyis, ha a long id megváltozik, akkor frissíti a hozzá tartozó szöveges értékeket is (kikeresi az új értéket az adatbázisból). ÉS mindezt valahogy úgy, hogy a Fragment (amiben az űrlap elhelyezkedik) újraindításait is átvészelje.
Bocsánat, ha homályos egy kicsit a kérdésem. Bevallom, nekem is. Ezt a funkciót most a Fragment-en belül elhelyezkedő kódrészek valósítják meg, csak szeretném ezt a kódot egy kicsit elhatárolni a Fragmenttől. Pl. ha több hasonló hivatkozó értékem van, akkor is tudjam használni. Van valakinek valami ügyes ötlete? Előre is köszönöm!
-
-
#1456
thon73
tag
WonderCSabo
#1455
thon73
tag
válasz
WonderCSabo
#1455
üzenetére
Igen, így képzeltem el, de egyetlen részt nem értek: "és a custom view alá berakja a saját űrlapját." Ezt hogy csinálom meg? ((Xml-ben meg is van, de nem akartam, hogy minden layout-nak hivatkoznia kelljen a közös layout-ra (meg akkor az ősfragment működése is komplikálódik.) )) Programkódból ez hogyan oldható meg? addView-vel?
-
#1454
thon73
tag
WonderCSabo
#1453
thon73
tag
válasz
WonderCSabo
#1453
üzenetére
Kipróbáltam a lehetőségeket. Végső soron a setArguments() nagyon hasonló lehetőséget ad egy Builder/Fleunt interfészhez. A hátránya, hogy a paramétereket Bundle-ban kell átadnom; előnye, hogy nem kell a mentéssel/visszatöltéssel foglalkozni, a paraméterek újraindítás után is hozzáférhetőek. A Builder/Fleunt talán könnyebben beállítható a hívó oldalon.
Lenne egy másik kérdésem is: még mindig a template alapján elkészített leszármazottak problematikájával vagyok elfoglalva - ezúttal a layout oldalán. A Fragmentek egy-egy adatbázis táblából származó elemet jelenítenek meg. A layoutban sok a közös, pl. Add, Update, Delete stb. gombok; de az űrlap szerű rész minden táblánál egyedi.
Úgy gondoltam, hogy létrehozok egy "alap" layoutot egy ViewStub-bal, amit az egyes Fragmentek programból lecserélnek a nekik megfelelő űrlap-layoutra.
Ahogy olvasgattam, egy ilyen megoldástól több helyen óvtak, merthogy nagyon rontja a performance-ot. (Én nem tudom elképzelni.) Van más lehetőség programból al-layout létrehozására? ((Mind az alap, mind az űrlap layout elég összetett.)) -
#1452
thon73
tag
WonderCSabo
#1451
thon73
tag
válasz
WonderCSabo
#1451
üzenetére
Köszi! No, ez eszembe se jutott. Csak, hogy jól értem-e:
Mivel a paraméterek között van kötelező, meg opcionális, az lenne tehát a legjobb, ha készítek egy Builder-t az első létrehozáshoz. Az összes szükséges paramétert ebben megadom a Fragment első létrehozásánál; majd az előbbi módszerrel mentem és visszatöltöm az összes - immáron belső - paramétert az újraindításnál.
Ez egyúttal azt is jelenti, hogy nem kell leszármazottakat készítenem, egyetlen osztály - többféle paraméterezéssel - megcsinálja az összes tábla listázását.
((Hm. Én csak egy könnyen bővíthető programot szerettem volna, de ez a módszer hatalmas előrelépés egy szabadon (programkód változtatás nélkül) megadható adatbázisszerkezetet használó kezelő irányában )) -
#1450
thon73
tag
WonderCSabo
#1442
thon73
tag
válasz
WonderCSabo
#1442
üzenetére
Kedves WonderCSabo! (ill. kedves mindenki!)
Még egy utolsót szeretnék kérdezni, mielőtt végképp feladom a küzdelemet...
Az előző megoldások tökéletesek, ki is próbáltam őket, - csak éppen (List)Fragment-nél nem működnek. Ott ugyanis úgy kell elkészítenem a kódot, hogy ÜRES Konstruktorral újra elkészíthető legyen a Fragment.
Problémám a következő: Teljesen egyforma ListView-k (és ListFragmentek) jelenítik meg egy adatbázis különböző tábláit. Az eltérés néhány (6-7) paraméterben van: LoaderId, projection, from, to, content_uri stb.; maga a kód mindig azonos.Mi lenne a legjobb módszer arra, hogy egyetlen ListFragment osztály tartalmazza a kódot, és minden táblához ebből - más paraméterezéssel - egy külön ListFragmentet készítsen? Tényleges paraméterezés nem használható, az üres konstruktor miatt. Két ötletet kínlódtam ki: vagy abstract metódusokkal kényszerítem ki a "paraméterek" átadását a leszármazottakban, vagy az argument Bundle-be teszem bele egy-egy konkrét ListView-ban a paramétereket.
Nem létezik, hogy ne lenne erre valami pofonegyszerű megoldás, csak sehogy nem találom.

Előre is köszönet minden hasznos ötletért! -
#1443
thon73
tag
WonderCSabo
#1442
thon73
tag
válasz
WonderCSabo
#1442
üzenetére
Akkor csak a tanulság kedvéért. Vigyázat mindenki csukja be a szemét, hibás kód következik!
public ABSTRACT class A extends ListFragment {
public STATIC ListFragment newInstance() {
return new ??getClass??();
}
}
public class B extends A {
}
public class C extends A {
}Az ötlet az volt, hogy B.newInstance() létrehoz egy B példányt, melyet ListFragment-ként visszaad, míg C.newInstance() létrehoz egy C példányt, melyet szintén ListFragmentként ad vissza.
Ha a tényleges példány csak az abstract, mint minta alapján jönne létre, akkor a kérdőjeles rész mindig a példány osztálya lenne. De persze ez nem működik, legalábbis a static metódusban nincs ilyen hivatkozás. Nem staticban egyébként a this így működik, mentségemre legyen mondva.Utólag látom, hogy az egész hibás ötlet volt. (Tegyük még hozzá: newInstance minden esetben egy hosszabb Bundle-t hoz létre, ezért merült fel az ötlet.)
(((Azt már tényleg csak ezer zárójelben teszem hozzá, hogy a leszármazott osztály nevét meg lehet szerezni, és lehet ilyet körülményesen mégis gyártani, de a javasolt megoldás sokkal átláthatóbb, és kényelmesebb.)))
Remélem senkit nem bosszantottam azzal, hogy csupán a tanulság kedvéért helytelen kódot szemeteltem a fórumba.
Én nagyon sokat tanultam a javaslataidból, hála és köszönet! -
#1441
thon73
tag
WonderCSabo
#1440
thon73
tag
válasz
WonderCSabo
#1440
üzenetére
Na, én pont ebbe a hibába estem bele mielõtt kérdeztem.
Illetve estem volna, ha az Eclipse engedi... -
#1439
thon73
tag
WonderCSabo
#1438
thon73
tag
válasz
WonderCSabo
#1438
üzenetére
Igen, én is így csináltam végül, köszönöm a segítséget. ((Sőt, a nagyon kevés különbözőséget mutató osztályokból készítettem egy Factory-t (ha jól értelmeztem a leírásokat); hiszen ott csak "belső" különbségek vannak, kivülről (pl. az activity felől) mindegyik csak egy típusos ListFragment.))
Hadd legyek mégis az ördög ügyvédje. Ha az osztály absztrakt, akkor csak a leszármazottakon keresztül valósulhat meg, nem? Akkor sem tudhat a gyerekeiről? Pontosabban csak absztrakt metódusokon keresztül írhatja elő, hogy mit csináljon meg a leszármazott? Teszem azt, szükségem lenne egy állandóra (pl. a LOADER_ID-re, amelyik minden leszármazottban egyedi). Vagy a leszármazott osztály nevére/példányára, mint az előbbi példában (amit egyébként tanácsodra elvetettem). Annak alapján, amit olvastam, a kérdés költői, mert úgy tűnik, nem tudhat. Csak épp nekem ez nem tűnik logikusnak. De elfogadom, hogy így van, és bocs, hogy tudatlanságból kötözködöm.
Az útmutatást pedig tényleg nagyon köszönöm, mert most nem csak működik a kód, de "szép" is.
-
#1437
thon73
tag
WonderCSabo
#1435
thon73
tag
válasz
WonderCSabo
#1435
üzenetére
Köszönöm a segítséget, és a sok olvasnivalót! Megint sokat tanultam, és legalább látom, hogy jó irányban kezdtem tapogatózni.
Helyesebb lett volna talán a teljes problémát leírni (és ez absz. android): Egy összetett adatbázisban több, egymásra hivatkozó tábla van. Class A,B,C... mindegyike egy egy táblához tartozó ListFragmentet jelent. ((És van egy hasonló, "űrlap" szerű csoport is táblánként.)) A ListFragment legtöbb része (Loader, Filter, kommunikáció az activityvel) azonos, de a táblára vonatkozó részek, egy-egy menüpont azért különbözik. Ezért gondoltam egy "közös" template szülő absztract osztályra.
Az Activity csak a Fragmentek kezelését végzi, az ő szempontjából elég annyi, hogy ez egy Fragment, a részletek (leszármazások) nem érdekesek.
Nos, ezért gondoltam arra, hogy a newInstance is közös lehetne - csak épp itt nem látom, hogy melyik al-osztályból kellene példányt készíteni.
Amit olvastam, annak alapján a newInstance mindig az al-osztályba kerül, így én is ezt a megoldást fogom követni. Elfér ott az a három sor...To SektorFlop:Örülök, ha működik! Az idő meg úgyis körbe-körbe visszajön - nekem is rengetegen/rengeteget segítettek! Üdv!
-
thon73
tag
Van két-három nagyon hasonló osztályom, legyenek Class A, Class B és Class C. Mindegyikben van egy-egy newInstance() metódus, a korábban javasolt Static Factory Method szerint. (Az útmutatásért ismét köszönet és hála
)Arra gondoltam, hogy az azonos részeket kiemelem egy közös "szülő-szintű" abstract osztályba, melynek neve Class Template. Így a három osztály csak egész kevés kódot fog tartalmazni (csak amennyi különböző bennük), és rendre Class A extends Template... stb. módon hivatkoznak a Template osztályra.
A kérdésem a következő: Létre lehet-e hozni a static newInstance() metódust is az abstract Template osztályban úgy, hogy az egyes leszármazott osztályok (Class A, B és C) örököljék, de az ezeken a leszármazott osztályokon meghívott newInstance() a saját osztály példányát adja vissza?
Vagyis:
abstract class Template {
static ???? newInstance() {
return ????;
}
}
class A extends Template {
}után az A.newInstance() az A osztály egy példányát adja vissza??
Eddig annyit gugliztam ki, hogy ez az Abstract Factory Pattern-be tartozik, de a konkrét kérdéssel kapcsolatban csupa ellentmondást találtam.
Nagyon hálás lennék, ha valaki ezt röviden el tudná magyarázni! Köszönöm!SektorFlop! Most működik?
-
#1425
thon73
tag
SektorFlop
#1424
thon73
tag
válasz
SektorFlop
#1424
üzenetére
Az a lényeg szempontjából mindegy. Az első példa sem list-tel operál.
Szívfájdítóul: én se vagyok otthon, viszont most éjjel is majd 30 fok van, ráadásul a tengerre néz az ablak... de hogy nekem se legyen olyan jó, holnap nyakig öltönyben előadás![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#1413
thon73
tag
SektorFlop
#1412
thon73
tag
válasz
SektorFlop
#1412
üzenetére
Írtam egy kis programot hozzá. EZT vettem alapul. És ITT a bővített program zip formában.
A teljes arraylist-et az outputFragment kezeli. Amikor az inputFragment-en beírsz, az értéket elküldi az Activity-nek, az Activity pedig továbbküldi az outputFragment-nek. Ez utóbbi írja be a list-be, és frissíti a listát.
A Te esetedben nem az activity, hanem a db hordozza az adatot. De az array-t szerintem a listfragmentnek kéne kezelnie (vagy az activity-nek).
A lényeg: MINDENKÉPPEN jeleznie kell az inputFragmentnek a ListFragment irányába, hogy új elem érkezett!! Ezt nem fogja (szerintem) beépített on... metódus megtenni, neked kell megcsinálni. VAGY: a LOader osztály már megcsinálja "magától".A példa globális adapter változót használ, de a getListAdapter() is jó, csak a típusát módosítani kell (uis. nincs benne notifyDataSetChanged)
public void refreshOutput( String data )
{
// 1. érdekes: ez is működik
// lista.add( data );
// 2. adapter írja be - azonnal kiírja
// adapter.add( data );
// 3. invalidateviews - azonnal működik
// lista.add( data );
// getListView().invalidateViews();
// 4. notify
lista.add( data );
adapter.notifyDataSetChanged();
}A fenti kódban váltogasd a kommenteket, de szerintem nem ez a baj, hanem a ListFragment nem kap értesítést. ((Hogy az 1. példa miért működik, azt nem tudom, annak nem lenne szabad.
))Ja, igen. A forgatás (újraindítás) törli a listánkat, de most nem is ez volt a feladat. Neked meg a db úgyis megmarad.
Remélem segítettem
-
#1411
thon73
tag
SektorFlop
#1410
thon73
tag
válasz
SektorFlop
#1410
üzenetére
Amikor megnyomod a gombot, akkor a db.newCostRow(c); betölti az adatokat egy adatbázisba. Két sorral később a cm.setCostItem(); "visszatölti" az adatokat az ArrayList-be?
Hogy fér hozzá a Fragment1 a cm listához?
Itt történik a megjelenítendő lista feltöltése?
Mert ha igen, akkor a bibi valahol a két Fragment kezelésében lesz. Ha itt lecserélted a komplett listát, akkor itt kellene értesítened az Adaptert vagy a ListView-t, hogy változott a helyzet. De a Fragment - elvileg - közvetlenül nem férhet hozzá egy másik Fragment adataihoz (különösen nem a ListView-hoz).
Ha a Fragment1 változtatja az adatokat, akkor neki "üzennie" kéne az Activity-n keresztül, hogy Fragment2 frissítse a listát. Vagy. Fragment1 csak bekéri és átadja az adatokat, majd üzen Fragment2-nek (aki a listát is tartalmazza), hogy a bekért adatokkal frissítse az ArrayList-et is, és a listát is.
De lehet, hogy csak bennem nem állt össze, bocs. -
thon73
tag
Bocsánat a pongyola fogalmazásért! Igazad van, a "cursor oldallal" csak azt akartam kifejezni, hogy az eredmény oldalán. Azóta kipróbáltam, az android-tól független sqlite "csonkolja" az oszlopneveket.
A legtöbb nehézségem egyébként abból fakadt, hogy megtanultam valamit sqlite-ban, működött is; de nem tudtam átfogalmazni az android/java által elgondolt módra. Mindegy, most már egyre jobban kitapasztalom... -
thon73
tag
Köszönöm mindenkinek! A lényegi kérdés pont az, amit hunfatal tett fel (Cursor oldal), a SektorFlop által feltett (query oldal) sem triviális, de ott működtek a teljes nevek.
Az elméleti kérdés érdeklődőknek továbbra is fennáll
: miért dob exception-t, ha a Cursor oszlopaira teljes névvel akarok hivatkozni ((azt a választ, hogy azért mert nem teljes névvel azonosítja az oszlopokat, már tudom, de: miért van így??)) ÉS ha exception-t dob (a log-ban piros sorok), akkor hogyan mehet tovább? Na de ez csupán filozófia.A konkrét kérdést így próbáltam ki:
String[] projection = new String[] {
BooksTable.FULL_ID,
AuthorsTable.FULL_NAME + " AS N ",
BooksTable.FULL_TITLE + " AS T " };
CursorLoader cursorLoader = new CursorLoader(getActivity(),
BooksTable.CONTENT_URI,
projection,
BooksTable.FULL_SEARCH + " like ? ",
new String[] { "%"+filterString+"%" },
AuthorsTable.FULL_NAME + " COLLATE LOCALIZED ");ahol:
case BooksTable.DIRID:
// Set the table
queryBuilder.setTables( BooksTable.TABLENAME +
" LEFT OUTER JOIN " + AuthorsTable.TABLENAME +
" ON " + BooksTable.FULL_AUTHOR_ID + "=" + AuthorsTable.FULL_ID );A FULL_ jelenti a teljes azonosítót table.column formátumban. Ellenőrzés log-ban:
"Cursor cols: " + Arrays.toString( data.getColumnNames()
Eredménye:
Cursor cols: [_id, N, T ]Vagyis: az AS a cursor oldalon is működik! Arra persze figyelni kell, hogy egy _id oszlop maradjon! Én egyébként ezt megkerülve minden oszlopnak más nevet adtam előtte, ill. a két _id-t (csak ellenőrzésre kellett) oszlopszám alapján kérdeztem le. De ez a módszer sokkal jobb ((és ezt a problémát nem találtam még sehol a neten, biztos mindenki rögvest tudta...))
SektorFlop! Az nagyon jó hír, biztosan fogok még kérdezni ezret. Egy egyszerű adatbáziskezelőt készítgetek, próbaként könyvek/szerzők stb. feljegyzésével, de a végső cél egy beteg-adat kezelő alkalmazás.
Egy átfogó kérdésem rögtön lenne: nagy szükségem van export/import funkcióra. Kapcsolt adatbázisoknál van-e erre valami elegáns v. beépített módszer? Magamtól úgy terveztem megoldani, hogy exportnál a hivatkozott elem részeit is kiírom, importnál pedig megkeresem, van-e ilyen elem, és úgy hivatkozok rá, vagy ha nincs - létrehozom. A nem kapcsolt táblák már jönnek-mennek!((Ha esetleg valaki még meg tudná mondani, hogyan lehet a LogCat-ot vágólapra másolni az Eclipse-ben, akkor kissé könnyebben tudnám ide másolni a releváns részeket. A mentés/keresés/megnyitás/másolás egy kissé macerás...))
-
thon73
tag
Néhány próbálkozás után tapasztalati úton megválaszoltam magamnak: JOIN táblák esetén:
- A lejérdezés (qurey) minden formája (tehát értelemszerűen ContentProvider, Loader stb-be épített is) EGYEDI oszlopnevet kíván (tehát helyes a TELJES nevet megadni "table.column" formában). Logikus, hiszen különben nem tudja különválasztani az azonos nevűeket.
- Most jön a csavar: A Cursor NEM fogadja el a TELJES nevet, hanem az oszlopot CSAK a rövid, táblán belüli oszlopnévvel azonosítja. Ez nem akadályozza meg, hogy pl. két "_id" oszlop legyen. Ilyenkor persze név alapján nem lehet lekérdezni.((Hát egy újabb órát vakargattam a fejem, mire rájöttem, hogyan tudom kiszedni a két _id-t
 ))
)) -
thon73
tag
Készített már valaki SQLite JOIN paranccsal összekapcsolt táblákból CursorLoader-t és List-et? Egész messzire jutottam (végül is van lista), de nem teljesen tiszta, hogy mikor kell teljes (table.column) és rövid (column) formában megadott adatbázis-oszlop neveket használnom.
Konkrétan az adapter hibát dob, ha teljes (table.column) nevet adok meg: requesting column name with table name -- ... java.lang.Exception. (A cursorLoader meg akkor, ha rövidet...)
DE!
A program vígan továbbfut, mintha mi sem történt volna.
ÉS:
Ha nem használhatok teljes nevet, akkor hogyan tudok lekérdezni a két külön táblában lévő azonos nevű elemet (pl. _id) ?Ha valaki tapasztalt tudna ilyen irányban segíteni, szívesen küldök kódot is.















 ) ((Igaz, az nem mentesít, hogy az AIDE, amit tableten használok, alapból ismeri a GitHubot)) Ha megfelelő géphez kerülök, akkor felkerül oda, ill. blogcikket is szerettem volna/szeretnék írni erről, mert én rengeteget tanultam belőle - többek között itt kapott infókból is. Az eredeti ötlet többet tud, a kapcsolt táblákat (kereszthivatkozásokat) is kezeli.
) ((Igaz, az nem mentesít, hogy az AIDE, amit tableten használok, alapból ismeri a GitHubot)) Ha megfelelő géphez kerülök, akkor felkerül oda, ill. blogcikket is szerettem volna/szeretnék írni erről, mert én rengeteget tanultam belőle - többek között itt kapott infókból is. Az eredeti ötlet többet tud, a kapcsolt táblákat (kereszthivatkozásokat) is kezeli.

 Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!






![;]](http://cdn.rios.hu/dl/s/v1.gif)
 ))
))Új hozzászólás Aktív témák
Hirdetés

- Intel Core i7 6700K / GTX 1660TI / 16GB DDR4 RAM / 500 GB SSD konfig eladó
- Samsung Galaxy S23 128GB, Kártyafüggetlen, 1 Év Garanciával
- Samsung Galaxy A53 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- Megkímélt állapotú Xbox Series X 1TB eladó. Kitisztítva és újrapasztázva!
- Gamer PC - i5 13400F, GTX 1080ti és 16gb DDR5
- 130+131+132+133 - Lenovo Legion Pro 7 (16IRX9H) - Intel Core i9-14900HX, RTX 4080
- Azonnali készpénzes GAMER / üzleti notebook felvásárlás személyesen / csomagküldéssel korrekt áron
- Telefon felvásárlás!! Xiaomi Redmi 9, Xiaomi Redmi 9AT, Xiaomi Redmi 10, Xiaomi Redmi 10 2022
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- Telefon felvásárlás!! iPhone 12 Mini/iPhone 12/iPhone 12 Pro/iPhone 12 Pro Max
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest