- iPhone topik
- QWERTY billentyűzet és másodlagos kijelző is lesz a Titan 2-ben
- Yettel topik
- Minden a BlackBerry telefonokról és rendszerről
- Nem növel telepméretet a Galaxy S26 Ultra
- Apple Watch Sport - ez is csak egy okosóra
- Ezek a OnePlus 12 és 12R európai árai
- Milyen okostelefont vegyek?
- Redmi Note 12 Pro - nem tolták túl
- Kézbe fogták az ultravékony Z Fold7-et
Új hozzászólás Aktív témák
-
#2971
 thon73
tag
WonderCSabo
#2970
thon73
tag
WonderCSabo
#2970
thon73
tag
válasz
 WonderCSabo
#2970
üzenetére
WonderCSabo
#2970
üzenetére

Éppen pont ez az, amire gondoltam!! (csak nem tudtam, hogy erre gondolok; meg csak a master/develop szálat fundáltam ki)
Nem állítom, hogy minden git utasítást fejből tudnék, ami ilyen klassz elrendezést csinál - pláne nem az Android Studio alatt -, de ezt már majd kikeresgélem.
Sejtettem, hogy ezt tudnia kell egy ilyen rendszernek. Hála és köszönet!
-
#2968
thon73
tag
WonderCSabo
#2967
thon73
tag
válasz
WonderCSabo
#2967
üzenetére
Köszönöm, kipróbálom a válaszokat - vagyis a rengeteg commitot és a brancheket is.
Egyébként dolgozik valamelyikőtök két (vagy több) gépen? Mármint h, saját tapasztalattal ez milyen?
-
thon73
tag
Köszönöm! Ez jó ötlet. És akkor az egyes brancheket kell csak átnéznem, ha a "nagy" változtatásokra vagyok kíváncsi.
Egyébként a "master" szál commit-jait a legvégén ki tudom törölni? Vagy csak amíg nem töltöttek le belőle (hiszen én magam fogom letölteni mindig a másik gépen)? Vagy akkor az "oldal"-branchok sem tudnak hoova kötődni? Vagy ez hülyeség, és úgy kell hagyni, ahogy van?
Bocs, de tényleg csak az alaplépéseket ismerem a gitből, az AS meg absz. erre támaszkodik. Ami amúgy egyáltalán nem baj, mert minden segédeszköz nélkül a kék égen közlekedik az anyag... -
thon73
tag
Bocs, ha nagyon alap és off a kérdésem; viszont ha valaki megvilágítaná, azt nagyon megköszönném.
KÉT Android Studio között szeretném a projektet átmozgatni. (Praktikusan hol az otthoni, hol a munkahelyi gépen dolgozom. Amúgy Eclipse alatt ez simán ment másolással, itt nem.) Addig jutottam, hogy erre a GitHub a legjobb, az alaplépések meg is vannak.
A kérdésem az, hogy miként tudom megtenni, hogy ne keletkezzen millióegy commit? Én csak a főbb lépcsőket szeretném a GitHub-on tartani. Ha mondjuk délelőtt van egy fél órám, este egy másik fél, akkor ezt a kétszer tíz sort pl. nem.
Vagy esetleg van valami egyéb kézenfekvő módszer erre, ami elkerülte a figyelmemet?
Köszönöm! -
#2848
thon73
tag
WonderCSabo
#2847
thon73
tag
válasz
WonderCSabo
#2847
üzenetére
Szóval Oracle JDK 8?
A korábbi gépen fent volt (Eclipse mellett), de egy idő után nem jött a frissítés, és az internetbanking panaszkodott. Azóta OpenJDK volt; de akkor visszatérek.
Köszi!Amúgy "gondom" nekem sincs vele, inkább csak ismeretlen, csak igen komoly erőigénye van. Win7 és Ubuntu 14.04 alatt is használom, a std. virtuális gép egyikben sem talált elég memóriát (hiába 4Gb már kevés...). A saját tabletemmel mondjuk gond nélkül kommunikált.
Még egyet áruljatok el, légy szíves! Minden betű széle kissé lila (Ubuntu alatt), akármit állítok. A rendszerbeállítások hatástalannak tűnnek, ha a Settings-ben kapcsolom ki az antialias-t, akkor meg borzalmasak lesznek a betűk. Csak nekem káprázik a szemem?
-
-
thon73
tag
Nekem is lenne egy-két apró kérdésem Android Studio fanokhoz (lusta voltam, eddig csak épp kipróbáltam, most viszont már nincs is más...RIP Eclipse...)
1. Ubuntu 14.04 alatt 4 Gb aktív memória mellett memóriahiányról panaszkodik (csak a virtuálisgép kezelő). A /tmp könyvtár mondjuk ram-ban van, mert ssd használok. Ezzel van valakinek tapasztalata? Dobjam ki a tmp-t a ssd-re? Vegyek még négy Gb-ot? Volt aki már találkozott ilyennel?
2. Csaknem olvashatatlan az editor rész. Ugyanakkor azt írja, hogy a font megváltoztatása nem javasolt. Ezzel van valakinek tapasztalata? Esetleg egy javaslata valami jó fontra? Hátha nem kell végigprógálgatnom az összeset. (jó, tudom: ízlések és pofonok, de akkor is)
Előre is köszönöm! -
thon73
tag
Ha még nem kezdtél semmi komolyba, nekem van egy-két ötletem...
![;]](//cdn.rios.hu/dl/s/v1.gif)
- atomik billentyűzet (magyar párja a kinesa)
- könyvolvasó szótározórésszel, és a kiírt szavakat ki is kérdezi (önbevallásos módon).
- még jobb, ha az olvasó-rész egyúttal szerkesztő is (ld. a régi WordSmith PalmOS alól)
- még jobb, ha a szerkesztő nem (csak) a formátumokkal, hanem a színekkel is kombinál - ez kis képernyőn előnyösebb (ld. ugyanaza a progi)
- még jobb, ha legalább minimális makrólehetőségekkel is bír
- további - akár univerzálisan használható - makrószöveg kezelő (szintén volt PalmOS alatt, de nem emlékszem a nevére). Ez nem makrónyelv, csak előre beírt szövegeket enged fa-struktúra szerűen pillanatok alatt előkeresni.
- további ötlet szövegszerkesztésre - diktafonnal egybeépített szövegszerkesztő. Még olyan programot sem találtam, ahol rendesen lehetne a felvett audiorészben pozícionálni, nem ám olyat, ami egyszerre vesz fel, és egyszerre enged írni - a kettőt összehangolva. ((Fontos megjegyzés: tablet+Bt keyboard pont olyan gyors, mint a nagygép; a fenti kinesa mellett láttam a 200 feletti sebességet, én is 100 körül írok - tehát lehet szöveget írni tableten, sőt telefonon is.))
- más téma: adatbázis kezelő (leginkább egy front-end), DE ami össze van kötve a naptárral és a címtárral (vagy egyebekkel is). Ilyen sincs egy se.
- futás (sport) közben egy mérés mellett kitartásra is buzdító szöveges (svox) szoftver. Pl: "kitartás, már csak 200 m a hegy teteje!"
- folyadék fogyasztást (kalória stb. akár) "mérő" program. Ezt szaknyelven úgy is hívják (ha a másik oldalt is méri a delikvens): vizelet ürítési napló.Ha ez mind kész,még van egy-két ötletem.
A projektek 0-80%-os készültségi fokban részben meg is vannak; érdeklődés esetén szívesen közkincsé teszem. És ha valaki elkészíti, elsőként fogom letölteni a fizetős változatot!
-
thon73
tag
Bocs a késői válaszért...
Teljes mértékben egyetértek, én is így szoktam megadni.
De most kivételesen egy xml-szerű, human-readable leíró fájlból érkeznek az adatok, többek között a színek is. A számok (tehát a színkódok is) long pontossággal kerülnek feldolgozásra.
Amúgy eddig a részig prímán működik
-
thon73
tag
Többek között ez bizonytalanított el: saturatedCast
Tehát vannak olyan algoritmusok, ahol az előjelbit "elveszik".De a válaszok alapján primitív típusokkal nyugodtan dolgozhatok. Köszönöm!
((tovább olvasva rájöttem, hogy a primitivek közötti levágást konverziónak, ezt meg castnak nevezi az irodalom)) -
thon73
tag
Hát ez az. De az int ugye signed int. Ezért nem mindegy, hogy a long->int veszteséges átalakításnál mi történik. Ha csak eldobja a felső két byte-ot, akkor minden ok. Ha azonban az átalakítás Integer.MAX_VALUE és MIN_VALUE között történik, akkor az algoritmustól függően a színek (kevésbé átlátszó) felét elveszíthetem.
Eddig úgy tűnik, hogy a primitív típusoknál az előbbi történik. Abban nem voltam biztos, hogy ez mennyire biztosan van így.
-
thon73
tag
válasz
 Superhun
#2761
üzenetére
Superhun
#2761
üzenetére
Tehát minden esetben csak levágja a long felső két byte-ját, és az alsó kettő lesz az int, mintha nem is lennének negatív számok (mármint a longban). Vagyis pl. a -2L az nem -2 lesz int-ben, ha megfordítjuk a kérdést.
Köszi, ez nagyon fontos, mert így 5 betűvel - (int) - megoldottam az egész átalakítás kérdést. A legtöbb helyen (pl. sqlite) az Androidban uis. long szerepel. És a Color-ban ehhez nincs semmi segítség; bár a fentiek alapján nem is kell.
Köszönöm! -
thon73
tag
Egy apróságot meg tudnátok nekem erősíteni?
Egy color értéket szeretnék int-be tenni, ami ugye unsigned. Viszont long értékként kapom meg.long colorInLong = 0xFFFFFFFF;
int color = (int) colorInLong;Ez a konverzió minden esetben jó lesz? Vagy miként illik ezt elvégezni? (A long valid color értéket tartalmaz.) Köszi!
-
thon73
tag
Sőt, továbbmegyek. Valószínűleg inkább egy Loader-re lenne szükségem, ami a Service inicializálását elvégzi. Találtam egy ilyet Can you use a LoaderManager from a Service?
Van ezzel valakinek tapasztalata? Akár az AsyncTask, akár a Loader nagy segítség lenne... Jelenleg van egy 4-5 mp-es előkészítési idő, amit a rendszer már nem enged meg. ((De csak egyetlen egyszer, amikor a service-t először elindítom.)) Köszönöm! -
thon73
tag
Készítettem egy InputMethodService-t. DE az inicializálás (ami csak akkor történik meg, amikor ezt a billentyűzetet kiválasztjuk) rel. hosszú idő.
Hogyan lehet egy ilyen service-ből időigényes feladatot végrehajtani? AsyncTask-kal? Az indítható service alól? Előre is köszönöm! -
thon73
tag
Sziasztok!
PreferenceActivity-n belül csinált már valaki olyan Preference-t, ami 'int' értéket ment el? Maga a Preference forráskód minden típusra (intre floatra stb.) tartalmaz egy-egy metódust, de bevitelre csak az EditTextPreference osztályt találtam, ami csak String-et tárol.
Köszönöm, ha van egy link vagy útmutató! -
thon73
tag
Viszont működik

Ez nem a 4-8 bites konverzió. Ez a "függvény" azt a 16 (4 biten) 32 (5 biten) vagy 64 (6 biten) alapszínt választja ki, ami a setPixel()-nak átadva, majd a getPixel-től visszakérve önmaga marad. Ez uis. csak ezekre a színekre igaz, az összes többi szín ezek valamelyikére fog alakulni (lévén több színt ekkora helyen nem lehet ábrázolni.)
Ha valahogy meg tudnám szerezni rgb_565 formátumban a színadatokat, akkor erre semmi szükség nem lenne. -
thon73
tag
Úgy tűnik, mindig túlságosan elvarázsolt problémákkal találkozom...

Hátha mégis valaki beleütközik ugyanebbe, megválaszolom magamnak.
Megdöbbentő módon az Android valójában csak kétféle módon tudja a bitmap színeket kezelni: ARGB_8888 és RGB_565 kódolással. (Létezik, de nem javasolt az ARGB_4444. Létezik, de nem működik a getPixel() metódussal az ALPHA_8)
(((Nekem még nem okozott problémát, de a megjelenítés ált. RGB_565-tel történik, vagyis valahol az ARGB_8888 mindig átalakításra kerül.)))Egy "térképet" szerettem volna megrajzolni (ezért nem jó egy tömb) 512 különböző színnel. A szinek nem lényegesek, az viszont igen, hogy pont azt a színt "vegyem ki", amit a képbe belerajzoltam. A korlátozott hely miatt arra gondoltam, hogy valamelyik helytakarékosabb kódolást fogom választani.
Ez viszont egyáltalán nem egyszerű, mert a getPixel által visszaadott alapszínek(R,G,B) mindig 256 árnyalat terjedelműek lesznek - nem pedig a kódolással azonosak. Továbbra sem találtam metódust a "raw" színérték megszerzésére.ARGB_8888 alatt persze minden tökéletesen működik, hiszen itt minden alapszín 256 árnyalattal kódolt. Ehhez azonban dupla hely kell...
ARGB_4444 alatt az alapszinek 4 bit terjedelműek, vagyis 16 árnyalatuk van. Ha azonos színt akarunk visszaszerezni, akkor a szinek 4 bites értékét dupláznunk kell: 2->22 8->88 c->cc (hexában). Az ilyen, hexában azonos számjegyekkel bíró színeket megadva (pont 16 van) ugyanazt a színértéket kapjuk a getPixellel, mint amivel rajzoltunk.
Persze, semmi nem elég, nekem az RGB_565 kódolású rajzból kellett azonos színeket kiszednem. A source kód a dithering miatt elég elvarázsolt, nehéz kideríteni, hogy pontosan hogyan kódol, ill. sokkal összetettebben kódol, mint amire ehhez a feladathoz szükség van. Matematikailag a következő összefüggést találtam:
5 bites szinek - R és B, 32 árnyalat: setPixel( árnyalat * 8 + 5 ) beállítás után a getPixel() / 8 visszaadja az eredeti árnyalatot.
6 bites szín - G, 64 árnyalat: setPixel( árnyalat * 4 + 2 ) beállítás után a getPixel() / 4 szintén az eredeti árnyalatot adja vissza. ((Megjegyzem, az első 32 árnyalatra az előző összefüggés is működik))Bocs, ha valakit untattam ezzel, de nekem hosszas fejtörést okozott, hogy megtaláljam azokat a színeket, amiket beállítva ugyanazt az értéket kapom vissza. Megjegyzem, hogy több különböző alapszín árnyalatot ezek a kódolások nem is tudnak tárolni, az összes többi "bemeneti" szín ezen árnyalatok valamelyikére redukálódik.
Még annyit tennék hozzá, hogy amennyi info-t találtam, az Android ebben is elég egyedi. Vannak 565-888 színkódolás átalakítások, de mintha az android egyiket sem követné, hanem valami saját algoritmusa lenne.
-
thon73
tag
Ha készítek egy RGB_565 kódolású bitmap-et, akkor van lehetőségem a "nyers", 16 bites color információ kinyerésére/beállítására? (mondjuk egy ponton) Vagy hogyan módosul a setPixel/getPixel color értéke (ami elvileg ARGB_8888)? Az R-G-B byte-ok utols 5 (ill. G esetén 6) bitje kerül felhasználásra? Vagy arányosan tömöríti a színeket?
Sehol nem találtam erre útmutatást, és amit kipróbáltam, abban sem értem, hogy mi történik. Hogyan lehet az ARGB_8888 és az RGB_565 értéket egymásba konvertálni? (Tegyük fel, hogy az "elveszett" színek nem számítanak, csak az átkonvertálhatóak)
Előre is hálásan köszönöm!
-
thon73
tag
Van valakinek tapasztalata a View onMeasure() metódusában?
<FrameLayout android:id="@android:id/inputArea"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:visibility="gone">
</FrameLayout>Ebbe a FrameLayout-ba helyezek egy custom View-t, aminek semmilyen Layout paramétert nem adok meg. Ilyenkor - gondolom a Frame Layout miatt - teljes képernyőszélesség:MeasureSpec.EXACTLY és teljes képernyőmagasság:MeasureSpec.AT_MOST értékekeket kapok az onMeasure paramétereiként.
Hiába írom be a kép létrehozásánál pl. ezt:
boardView = new BoardView( this );
boardView.setLayoutParams( new ViewGroup.LayoutParams( 200, 200 ) );NEM 200x200-as kérést, hanem az előbbi értékeket kapom. (Akkor is, ha ViewGroup helyett FrameLayout-ot adok meg, hiszen az csak leszármazottja.)
Ezzel szemben, ha készítek egy res/layout xml-t, és ugyanezt a custom View-t abból (inflate-tel) készítem el, akkor figyelembe veszi a View-hez beírt layout paramétereket.
Két kérdésem van:
- Mit rontok el a programkódnál megadott paramétereknél, ami miatt nem veszi azokat figyelembe?
- Mikor vehetem biztosra, hogy a megkapott mérési értékek a teljes képernyő méretét fogják tartalmazni - már amennyiben semmilyen layout paramétert nem adok meg? (Az oké, hogy AT_MOST, meg EXACTLY jelzőkkel)Amúgy a kép arányaihoz akarom passzintani a View-t, ami rendben is működik - ha a második kérdésre "mindig" a válasz. A másik részt meg csak simán nem értem - eredetileg ezzel akartam volna biztosítani a második kérdést...
-
thon73
tag
Ha esetleg van valakinek tapasztalata ilyesmivel - a doksi több helyen is ezt írja a send...KeyEvent() metódusoknál:
"Note that it's discouraged to send such key events in normal operation; this is mainly for use with TYPE_NULL type text fields, or for non-rich input methods. A reasonably capable software input method should use the commitText(CharSequence, int) family of methods to send text to an application, rather than sending key events."
Ebben az esetben hogyan tudok olyasmiket visszaküldeni mint pl. fel-le nyilak? Mert a közvetlen környezetemet még csak-csak elszerkesztgetem, bár egy backspace, delete, jobbra-balra megoldása sem túl egyszerű.A másik teljesen független kérdésem, hogy egy custom View szeretné megváltoztatni a saját méretét (vagyis onMeasure-ben EXACTLY esetén más értéket adna vissza), akkor milyen utasítást kell kiadnom? requestLayout? invalidate? Köszönöm!
-
thon73
tag
 Pontosan. Miután kicsontoztam a softkeyboard példaprogramot, már nem is volt annyira bonyolult, mint amennyire tartottam tőle! A lényegi részek megvannak, remélem a többivel sem akadok el. Még kell rajta filozofálni egy kicsit, mert 3 inches képernyőn azért nem a tökély
Pontosan. Miután kicsontoztam a softkeyboard példaprogramot, már nem is volt annyira bonyolult, mint amennyire tartottam tőle! A lényegi részek megvannak, remélem a többivel sem akadok el. Még kell rajta filozofálni egy kicsit, mert 3 inches képernyőn azért nem a tökély  De tableten note-stylussal meg ujjal is nagyon jó.
De tableten note-stylussal meg ujjal is nagyon jó. -
thon73
tag
Hm. Ez egy soft-keyboard lesz, a bitmap a layout, vagy nevezhetjük háttérnek is. Az onDraw semmi mást nem tesz, csak kirakja ezt a bitmapet, meg egy karikát ahol a user ujja van. Esetleg nyomvonalat. Nem hiszem, hogy nyernék a worker-threaddel, mert a képet ígyis, úgyis újra ki kellene raknia. Ezért hagytam ezt a megoldást. Mindenesetre elég jól megy, de lehet h. még lehetne optimalizálni...
-
thon73
tag
Azt hiszem megoldottam, bár lehet, h. nem ez a legoptimálisabb. A grafikában nem vagyok otthon. (A nem ide tartozó részek hiányoznak a kódból.)
private Bitmap skin;
private Bitmap skinscaled;
private void init()
{
skin = BitmapFactory.decodeResource(getResources(),
R.drawable.portrait);
}
protected void onSizeChanged (int w, int h, int oldw, int oldh)
{
skinscaled = Bitmap.createScaledBitmap( skin, w, h, false);
}
protected void onDraw(Canvas canvas)
{
canvas.drawBitmap( skinscaled, 0f, 0f, null);
}Egy további kérdés még felmerült bennem: az onDraw-ban megkapott canvas-szal csak az onDraw-ban rajzolhatok (invalidate után mindent újra), vagy máshol is rajzolhatok rá, olyat, amit nem kell letörölni a következő rajz előtt? (Az ujj húzásának az útját mutatja; felemelésig)
-
thon73
tag
Bocsánat, még egy kérdés az optimalizálásról.
Van egy - mondjuk 1200x800 pixeles képem, amit az onDraw helyez bele a Viewbe így:
canvas.drawBitmap(skin, null, dst, null);
(Rect dst értékét az onSizeChanged-ben szedem össze, gyakorlatilag a View mérete, a bitmap dekódolása, közelítő átméretezése meg a konstruktorokban van.)Kérdés:
Mivel rajzolok a bitmap felszínén (egy pont követi az ujjamat), ez a drawBitmap() minden alkalommal lefut. És minden alkalommal ismételten átméretezi a bitmap-et. (Hol 798, hol 356 stb a View mérete, pl. ahogy forgatom a készüléket.)Ezt kell-e v. lehet-e optimalizálni? Az inSampleSize segítségével már megközelítőleg ekkora képet csináltam, de nem pontosan ekkorát. Vagy ez nem akkora terhelés? Végül is elég gyorsan fut...
-
thon73
tag
Meg tudnátok mondani, hol találok "matrix transformation" témában egyszerű magyarázatot?
Arra lenne szükségem, hogy egy nagyméretű bitmap-et (lehet a resource-k között) átalakítsak éppen akkorára, mint amekkora a custom View. Mivel az onDraw (egyebek mellett) ezt folyamatosan újra megjeleníti - gondolom - célszerű lenne egy éppen megfelelő méretet tárolni belőle átmenetileg.
Addig jutottam, hogy ezt a matrix segítségével lehet megtenni, de sem a hogyant, sem a miértet nem értem.
-
thon73
tag
Kérdésem:
A ListView-nál azt írja a tudomány, hogy Loader töltse be a háttérszálon, és Filter szűrje, szintén háttérszálon.
Ha szeretnék beletenni egy sort-ot (mégpedig úgy, hogy menet közben a sort feltételt a felhasználó megváltoztathassa), akkor azt hova érdemes/kell tenni?Ha a Loader-be teszem, akkor az egész lassú betöltést megismétli, amikor csak a sorrendet akarom módosítani.
Ha a Filterbe teszem, akkor minden szűrés elején egy csomó ideig sorrendbe rak.
Ha csak az adapterbe teszem, akkor meg nem a háttérszálon történik. ((Ez önmagában nem baj, de lehet, hogy lassúbb, mint a filter))
Van erre nézve valakinek tapasztalata?
Készítsek egy külön asynctaskot? (Egyetlen sorért!?) Egy második Filter osztályt, ami rendez és nem szűr? Broadcastal kérjem meg a LOader-t, hogy ne töltsön csak rendezzen? Nekem egyik sem szimpatikus.
Előre is köszI! -
thon73
tag
Bocs, csak most csatlakoztam bele a történetbe.
Én ugyanezzel a problémával szembesültem, azzal kiegészítve, hogy nem csak az ékezetek, hanem néhány írásjel átalakítására is szükségem volt. Végül úgy oldottam meg, hogy készítettem egy kb 300 elemű tömböt. Az indexet az unicode kód adta, az elem értéke pedig visszaadta, hogy milyen ékezettelen karakternek kell ezt tekinteni. A tömb mérete felett csak nagyon elvarázsolt karakterek vannak (vagyis az európai nyelvekben nem használatosak), így ott mindig az "ugord át" jelet adta vissza.
((Nagyon zárójelben jegyzem meg, hogy ezt továbbgondolva ezzel az egy táblázattal sikerült a lényeges nyelveken rendezni a kifejezéseket, ill. keresni is ékezetlenített módon.))
Persze ez is csak egy módszer a sok közül, de gyors, tömör és hasznos volt. Nem a végleges változat, de ITT megtaláltam, amit írtam róla korábban.A targettel kapcsolatban annyit fűznék hozzá (bár fentebb elhangzott), hogy ebbe a hibába én is beleestem, mert 2.36 alá írtam a programokat, és a régi sdk-val fordítottam.
Valóban az a követendő, hogy a leges-legújabb sdk legyen fent, és ez szerepeljen a project.properties-ben is. (És amivel szintén voltak hm. gondjaim: a support library-t is illik ezzel együtt frissíteni a projektben). A minimalis és a target (a manifestben) ettől függetlenül bármire beállítható. (Én is többnyire API8/API10 kombóra fordítok, de (((elvileg))) a legutoljára letöltött sdk-val.) -
thon73
tag
Bocsánat, hogy a sok magas szintű fejlesztés mellett egy nagyon kezdő kérdéssel állok elő.

A multithread-ek világában próbálok elmélyedni. Tudna valaki egy olyan kódot/linket adni, ahol specifikusan Android-on a happens-before eseményt tudnám tanulmányozni; vagyis amivel el tudom érni, hogy a thread-ek biztosan megkeveredjenek?
Specifikusan egy olyan ötlet kellene, hogy a thread a saját cache-ében tárolja el a globális változómat, és nemigen tudom, hogyan lehetne ezt kikényszeríteni.
Nem a helyes megoldásra van szükségem (arról rengeteg okos ötlet van), hanem magát a hibajelenséget szeretném látni.
Előre is köszönöm! -
thon73
tag
Thx. Mindkettőtöknek!
Shared prefsre én is gondoltam, de eredetileg függetleníteni akartam a context-től. Végül is nem gond; úgy oldottam meg, hogy a könyvtár alapból beállított adatokkal már működik; ha meg változtatni akarok rajta futás közben, akkor ahhoz kell context is.
Amúgy ha a process eltűnik, akkor az Application is eltűnik, nem? Vagyis mindent újra kell indítani. Vagyis ideális alternatíva lenne globális adatok elhelyezésére (speciel most nekem nem erre kell, csak belső adatok tárolására voltam kíváncsi). Ennek ellenére azt olvastam, hogy nem ajánlott elrendezés, mert nehéz tesztelni...
És csak a teljesség kedvéért: ha csinálok egy singletont, ami valójában egy példány, csak saját magára való hivatkozást tárol, akkor az hogy létezik, hogy az Activity-vel együtt eltűnik? (És nem az Applicationnel. Vagyis memória kevés, háttérben Activity bezár, Application marad, de a singleton is eltűnik.) Ezt egyébként több helyen olvastam, és már én is tapasztaltam. Annak nem kéne a process végéig megmaradni?? Vagy az önhivatkozás máshogy számítana?? Ennek a kérdésnek ugyan már semmi köze az eredeti problémához, csak érdekel...
-
thon73
tag
Van egy static metódusokat tartalmazó osztályom. Ez az osztály néhány belső adatot szintén static osztályváltozókban tárol. Amit a konfigurációs változások és singletonok kapcsán olvastam, kissé elbizonytalnított.
- A program újraindításakor (konfigurációs változás miatt) vajon megmaradnak-e ezek az adatok(gondolom ez a helyzet), vagy új osztály (új adatokkal keletkezik?) Hogyan lehet kikényszeríteni, hogy az osztály újrainicializálja az adatait?
- Van-e arra esély, hogy a program újraindítás nélkül (pl. ha csak háttérbe kerül) egyszer csak bezárja ezt az osztályt, aztán újraindítja újrainicializált adatokkal?
Nekem az kellene, hogy minden indítás üres adatokat eredményezzen, viszont azok a program újraindulásáig megmaradjanak. És a hab a tortán: lehetőleg NE legyen köze az Activity-hez, context-hez. (Uis. egy független részben szerepelnek a metódushívások.) Vajon ez megoldható?
-
thon73
tag
válasz
 eastsider
#2168
üzenetére
eastsider
#2168
üzenetére
Bocs, de nem egyszerűbb felrakni újra ez egész csomagot? Ez az "egyetemen beállított, hazavitt" dolog szerintem tartalmaz egy-két buktatót. Az eredeti csomag letöltve/felrakva teljesen üzemkész; (a JavaJDK-t, meg a drivert amúgy sem az kezeli.) Csak úgy kérdezem.
Bocs eastsider, nem frissítettem,mielőtt válaszoltam, de a lényeg: az jó megoldás amit írsz!
-
thon73
tag
válasz
eastsider
#2162
üzenetére
Sztem. az s az egy String. Ha egy objektomra vagy kíváncsi egy listában, akkor az egészben keresd! Most épp egy substring-et keresel!
Sztem. az egészet ráadásul arraylistté is kell alakítani, ahhoz, hogy működjön:
Arrays.asList(aperture_array).indexOf( aperture ); - feltéve, h. aperture egy string. -
#2160
thon73
tag
WonderCSabo
#2159
thon73
tag
válasz
WonderCSabo
#2159
üzenetére
 Ja, akkor mégiscsak én értettem félre. Nem csoda, hogy nem sikerült megkeverni a gépet... Viszont akkor jól fog működni amit írtam!
Ja, akkor mégiscsak én értettem félre. Nem csoda, hogy nem sikerült megkeverni a gépet... Viszont akkor jól fog működni amit írtam! (((Ezt az egyszerű log-ot csak úgy hirtelen készítettem, amikor a még-nem-rootolt tab nem volt hajlandó kiírni a rám vonatkozó system log-ot (AIDE-t használtam külföldön, net nemigen volt). És a feladatát tökéletesen el is látta. Később univerzálissá - pontosabban thread-safe-é akartam tenni, csak megzavart, amiket olvastam: eredetileg is thread-safe volt
)))(((Most meg van egy nagy adathalmazom, amit a program szépen feldolgoz. Arra gondoltam, hogy nem fogom minden csip-csup hibáért leállítani az egész folyamatot, hanem szépen log-olja a hibákat, és csak a végén mondja meg, volt-e hibás (nem importálható) adat. Erre viszont pont kéznél volt ez - a logtól független - secunder log. Egyébként ez tök jól működik, abban nem voltam biztos, hogy minden körülmény között fogja-e ezt produkálni...)))
Hálás köszönet, nem rongálom tovább a kiírást...
-
thon73
tag
Tapasztalt guruktól szeretnék segítséget kérni!
Korábban azt mondtátok, (és ezzel a doksi is, meg még én is egyetértünk), hogy egy KÖZÖS file írása több file-ból és több thread-ból veszélyes, mert a kiírt tartalom összekeveredik.Tesztelés szempontjából megpróbáltam ezt elérni, (mármint, hogy a program rossz legyen, és keveredjenek az adatok), és LEHETETLEN! Minden ellenőrzést kivettem, és már nem is Channel-en keresztül próbálkozom (ami elvileg thread safe). Két, teljesen más package nevű program van, mindkettő több szálat futtat. Az adatok mindkét program minden száljáról megérkeznek.
//Nyitás közös
OutputStreamWriter stream = null;
File file = new File( Environment.getExternalStorageDirectory(), "ThreadCheck.log");
stream = new OutputStreamWriter( new FileOutputStream(file, true) );
//Több ilyen thread van:
new Thread(new Runnable() {
public void run() {
try {
for (int n = 1; n < 8000; n++) {
stream.append( "Egyes" );
}
}
catch (Exception e) {
Log.e("THREAD", e.toString());
}
}
} ).start();A kész file az "Egyes", "Kettes" stb. szavakat egyben, épen tartalmazza.
Én értettem félre valamit, vagy ez egy Android tulajdonság, amiben meg lehet bízni?
Vagy hogyan tudom a programot "elrontani", és honnan tudhatom meg az ellenkezőjét: hogy minden körülmény között jól fog működni?Előre is köszönöm!
(((Egy "log" szerű programrészre lenne szükségem: több file, esetleg több thread is ír ugyanabba a file-ba üzeneteket. Az üzenetek sorrendje stb. nem lényeges, csak az, hogy egy üzenet egyben maradjon. Ez ugye megvalósul, csak abban nem vagyok biztos, hogy ez így biztonságosan jó-e.)))
-
#2153
thon73
tag
kemkriszt98
#2144
thon73
tag
válasz
 kemkriszt98
#2144
üzenetére
kemkriszt98
#2144
üzenetére
MIt jelent, hogy "teljesen rossz helyen"? Rossz kezdőponton v. csak rossz irányban/méretben? Én első körben leellenőrizném az összes értéket log-ban, aztán kiderül...
-
thon73
tag
Ha számolni kell, akkor még jobb - durván - számtani sorként tárolni ezeket (Durván: mindig feleződik, de csak kb.) Kis nehézséget jelent a köztes értékek tárolása, mert pl. létezett 1/100 és 1/50 is; nekem pl. a Momettán az volt (1956-ban gyártott készülékről beszélünk)
Mindenesetre az egész érték jelentheti a sorban elfoglalt helyet, azzal (amennyire emlékszem) számolni is lehet. Egy emelés megfelel egy blendének, ugye? Egyúttal megadja a String-Resource érték indexét is.
Bocs, hogy belekontárkodom, de a dolgozat szempontjából nem lenne egy jó ötlet összehasonlítani a kül. tárolási módok előnyeit és hátrányait? Ez uis. egy komoly számítástechnikai kérdés, a többi viszont csak technológia. Pontosabban, hogy mennyire tudsz elevezni az Android hibái és korlátai között. -
thon73
tag
válasz
eastsider
#2133
üzenetére
Én egészként. Mondjuk első két byte egész mp, másik két byte törtrész nevezője, és még mindig van négy byte. Vagy + = egész, - = törtrész, és akkor egy bit jelzi a formát. Vagy: egy byte típus (óra, perc, mp, tört), többi az érték. Vagy memóriapazarló módon: egy mező: érték, másik mező: típus.
De én az elsőket választanám, és csinálnék hozzá egy osztályt. -
thon73
tag
válasz
eastsider
#2128
üzenetére
Elvileg már vannak nested-fragment-ek, de support library-val nekem nem ment. Amikor elfordítottam a készüléket pontosan ellenkező sorrendben jelentek meg a Fragmentek - az utolsó dialog volt legalul. ((Ez egyébként bug-ok között szerepel, akkor meg is találtam. Nem tudom, hogy későbbi változatokban javították-e, ott sokan panaszkodtak, hogy nem.))
Én minden eredményt visszaadnék az Activity szintjére és onnan nyitnék meg - akár a még megtartott Dialog tetején - egy új fragmentet. Kicsit játszani kell az adatok ide-oda utaztatásával, de legalább tökéletesen működik.
A másik lehetőség, hogy az egyszerűbb dialogusoknál nem használsz fragmentet. Sztem. annak az egyetlen előnye, hogy újraindításnál megmarad, ez meg nem. -
thon73
tag
No, úgy tűnik, sikeresen beletenyereltem valamibe, ami messze meghaladja a tudományom. Ami megnyugtat: nem csak az enyémet. Tanulás céljából ajánlom a következő cikket: [link]; szerencse h. az említett professzor volt olyan kedves, és a pórnépnak is csinált biztonságos osztályokat...
Kibogoztam az ArrayAdapter source-kódját is. A konstruktorban megadhatjuk a felhasználni kívánt ArrayList-et, melyet = jellel tárol a belső változóban.
Ezt követően a Filter() rész pont azt csinálja, amit én: lock-olja a belső változó hozzáférését, és végigolvassa a tömböt (pontosabban átmásolja egy másikba). Ez azonban NEM szinkronizált cselekedet, uis. időközben egy másik programrész (akár UI szálon,mert a Filter worker-szálon van!) módosíthatja az eredeti tömböt. Vagy összeomlik, vagy exception-t kapunk. A saját változatomban (belassítottam a filtert) sikerült is a hibát produkálni.
Ált. persze nem lesz hiba, egyszerűen azért, mert a Filter (ha egyáltalán használjuk), sokkal gyorsabban lefut, semmint változna közben a tömb. De ha a Filter lassul - akkor máris előjöhet a hiba, még a legegyszerűbb listában is. Az én problémám nyilván szélsőséges (túl nagy a lista), és valójában a filtert nem is akartam használni (pont a lassúsága miatt), de a logikai hiba az akkor is logikai hiba.
Elvi megoldást úgy találtam a magam számára, hogy készítek egy ArrayList leszármazottat, amit a Loader fel tud tölteni, távolról változtatható - de csak akkor, ha a Filter nem állítja le a működését. Pl. úgy, hogy a filter teljesen más metódussal vesz ki elemeket; ha a tömb változik, akkor ez a lehetőség lezárul, úgyis megváltozott a szűrni kívánt anyag.
Gondoltam, megosztom a gondolataimat, hátha mást is érdekel ez a kérdés. De, mint fent írtam, ez kicsit több, mint amit biztonságosan átlátok, így aztán ha hülyeséget gondolk, kérlek, javítsatok!

-
thon73
tag
Egy kis olvasás után jobban meg tudom fogalmazni a kérdésem:
A BaseAdapter legnagyobb része UI szálon fut, tehát használhat a program többi részével közösen egy olyan ArrayList-et, amit a többi rész is csak UI szálon módosít.
A BaseAdapter egyúttal Filterable is lett, vagyis tartalmaz egy Filter.performFiltering metódust, ami viszont egy Worker thread-en dolgozik, ÉS olvassa a fenti ArrayList adatokat.
Én úgy látom, hogy csak a Filter.performFiltering területén kell védenem ezt a közös ArrayList-et a módosítástól.
Mi lenne erre a leghatékonyabb módszer? ((Vehetünk két helyzetet is: kis méretű és extra nagy méretű listák, ahol a filtering is sokáig tarthat))
Vagy valamit teljesen rosszul értek?Természetesen az osztálynevek a felmenőket jelentik, mindegyikből van saját.
-
thon73
tag
Bocs, van egy elég kezdő kérdésem, de nem nagyon értem...
Egy BaseAdapter alapú Adapter külső adatokra hivatkozik. Amit private-ként tárol, azok nem maguk aza adatok, hanem csak egy mutató a távoli adatokra. (ListArray mérete kb. 200 ezer elem)
Ha valaki megváltoztatja az adatokat (mármint a tömb marad, csak hozzáad v. elvesz), akkor a notifyDatasetChanged()-del tájékoztat arról, hogy újra kell rajzolni a ListView-t. Eddig nincs is talán gond.
DE!
Ha a háttérben elindul a Filter, akkor az a távoli adatokból végez egy leválogatást. Hogyan tudom megakadályozni, hogy a leválogatás közben kívülről megváltozzanak az adatok?
Jól sejtem, hogy a synchronized( lock ) ((ahol lock egy sima private osztály-objekt)) csak a saját osztály által elkövetett változtatásoktól véd?Vagy hogyan illik ezt megcsinálni? A gyári ArrayAdapter csinál egy komplett másolatot az összes adatról, mielőtt elkezdené leválogatni. Ez nem túl idő- és munkaigényes?
Vagy mi a jó út erre? Előre is köszönöm!
-
thon73
tag
válasz
eastsider
#2116
üzenetére
Jah, pont ezt. De akkor rendben is vagy: 68 Kb.
Valószínűleg valahol tárolja a képeket. Lehet h. már várnak az eltakarításra, gondolom azt is beleszámolja. Azt kell végiggondolnod, hogy a betöltött képekkel mit csinálsz? Ha mindig újratöltöd, akkor a lista minden soránál tölteni meg számolni fog.
Jelenleg a Loader semmit se csinál a képekkel, csak a szöveget tölti be. Az adapter tölt képet.
Az elvileg megoldható, hogy a loader betöltse a képet, de nem javasolnám, mert macera.
Inkább azt kéne megoldani, hogy az adapter egy hátsó szálon töltse a képet. Pl.: Adapternek szüksége van egy képre, akkor azt a hátsó szál lekicsinyíti, és menti egy cache-be. Ha ott megvan, akkor persze adapter csak beolvassa. Hogy miként lehet a konkrét listaelemet frissíteni, ha kész a töltés, azt még nem látom át. De ez csak egy hirtelen ötlet volt - mindenesetre valahogy szét kell választani a csigalassú részeket, meg eldönteni a memória vs. idő kérdést. Alighanem ehhez most papír meg ceruza kell inkább, s csak aztán a kódírás... ha szabad javasolnom. -
thon73
tag
válasz
eastsider
#2114
üzenetére
Na, akkor jókora bug-ot kell keresni
Két-táblás content-provider 8-8 szöveges, többmezős adattal: 44 Kilo(!)B; Alkalmazás 1,09 MB
Feltölthetem próbaként bármekkorára, de már ebből is látszik, h. nagyságrendi különbség van.
Van egy olyan progi, h. SQLite Debugger, azzal meg tudod nézni, h. mi a pálya az adatbázis-fileban. ((Több ilyen van, lehet, h. van még jobb is. Ja, root kell, de úgy tudom, az van.))Bocs, megnéztem a linket is: az első az az. Szerintem a bindView megértéséhez nem kell feltétlenül "képes" alapból kiindulni, de persze lehet, csak az nagyon összetett a megértéshez. Na, ez szép magyar! De a lényeg mégiscsak ez.
-
thon73
tag
válasz
eastsider
#2112
üzenetére
Ööö. Nézz körül az SO-n egy egyszerűbb példáért, mert neked NEM ez fog kelleni. Ez BaseAdapter-t bővít, a tiednek CursorAdapter alap kell!!!
A "deprecated" cuccból hiányozni fog az utolsó paraméter, de ahhoz küldj listát, és akkor lehet látni, h. hol a bibi.
A képfeldolgozó programok ált. cachelik a thumbnail-eket, (úgy láttam), különben lassú. De ebben nincs tapasztalatom. Elvileg a méretnek sem lenne szabad nagynak lennie, hiszen csak szöveget tárolsz. Hol nézted? Alkalmazásinfo méretben? -
thon73
tag
válasz
eastsider
#2108
üzenetére
Loaderben most eléggé otthon vagyok...

De szerintem Neked nem a Loader rész fog kelleni. Az adapter nem is tud a loader-ről, a loader csak betolja az adatokat az adapterbe.
Szerintem custom CursorAdapter-re lesz szükséged, amiben a bindView() metódust kell átírnod (lehet h. a newView.t is, ill. biztos). A bindView paraméterként tartalmazza a Cursor-t, ezt felhasználva tudod a képet megjeleníteni.
A Loader tehát csak át fogja adni a kikeresett Cursor-t (Még URL-t tartalmaz) az adapter-nek, és az adaptert kell úgy módosítani, hogy az URL-t bármilyen módon is, de feldolgozza.((Ez egyébként pont ugyanaz, mint, amit WonderCSabo írt; csak az a BaseAdapter alapú adapterekre vonatkozik, ott a getView-t, itt a bindView-t kell változtatni. Kicsit más a technika, de az elv ugyanaz: egy listaelem megjelenítését az adapter végzi az adatok alapján.))
-
#2103
thon73
tag
WonderCSabo
#2101
thon73
tag
válasz
WonderCSabo
#2101
üzenetére
Aha. Ez ugyan nem sqlite, csak sima Loader, de a hiba pont ugyanott van!
Aki Loader-t akar csinálni annak ITT egy jó előadás; de a lényeg az első hozzászólásban van:
"Important: I no longer recommend to use a Loader for "one-shot" actions because it's complicated and has a few side-effects."
No ezen én is elgondolkodtam...
Ettől függetlenül az ea. nagyon jó, és csomó buktatót (pl. a Loader mindig kétszer tüzel...) felsorol; de speciel a filteres gond (vagyis hogy a filter a még fel nem töltött adapterből szed ki adatot, aztán a felülírja vele a már betöltötteket) nem szerepel benne.
Még küzdök vele egy kicsit...Aprópopo: Hogy a betöltés alatt egy karika forogjon, azt meg lehet valami egymondatos gyári utasítással oldani, vagy azzal is nekem kell játszani?
-
#2100
thon73
tag
WonderCSabo
#2096
thon73
tag
válasz
WonderCSabo
#2096
üzenetére
Az entries értékét leellenőriztem, az mindig megfelelő.
Egy kicsit előrébb jutottam - néha ugyanis feldobja a listát, néha nem - és azt találtam, hogy elindítja a filtert, mégpedig mindenképp. A filter viszont kiveszi a még üres (null) értéket az adatokból, majd PÁRHUZAMOSAN fut a performFiltering és a Loader. A Loader előbb végez, és onLoadFinished-ben beállítja az adatokat. Majd jön a Filter (ami még az üres adatokat szűrte!), és átállítja az egész történetet üresre, hiszen -szerinte - nincsenek is adatok.
Erre nem is gondoltam, mert 1. ekkor még elvileg nem is létezik a filter. 2. ha a filter-szöveg üres, akkor nem is szűr. Csakhogy ilyenkor is beállítja a teljes adatmennyiséget - ami szerinte: üres.Namost. Hogyan bogozom ezt ki?
Az onCreateView-ben állítom be a filtert, így:filter = (EditText) view.findViewById(R.id.filter);
filter.addTextChangedListener(new TextWatcher()
{
@Override
public void onTextChanged(CharSequence s, int start, int before, int count)
{
((MainListAdapter)getListAdapter()).getFilter().filter(s);
}Ezt nem tudom nagyon máshova tenni, mert csak egyszer indíthatom el.
Tegyek be egy flag-et az adapterbe, ami figyeli, hogy vannak-e már beállított adatok??
Vagy ne engedjem meg, hogy az adatok értéke null legyen? Hanem az üres adatot egy üres (de létező) ArrayList jelentse?
Vagy mit érdemes ilyenkor csinálni?((Az ArrayAdapter is alternatíva lenne, de annak majd minden részét módosítottam volna, ezért használtam BaseAdapter alapot. Sztem. a probléma ettől független. ))
Be is bizonyítottam, hogy ez a probléma, itt:
protected void publishResults(CharSequence constraint, FilterResults filterResults)
{
------------------>if (filterResults.values != null)
{
filteredEntries = (List<SampleEntry>) filterResults.values;
notifyDataSetChanged();
}
}No, így működik. Órákat játszottam vele, de erre nem gondoltam volna...
Most már csak arra kell rájönnöm, hogy a.) mi a nyavaja indítja a filtert b.) ezt a tákolt ellenőrzést hogyan tudom szépen megcsinálni... -
thon73
tag
Sziasztok! Elakadtam egy BaseAdapter bővítésnél. Az adapter egy ArrayList-et használ, amit egy setData() metódus állít be:
public void setData( List<SampleEntry> entries )
{
this.originalEntries = entries;
this.filteredEntries = entries;
notifyDataSetChanged();
}A setData()-t egy ListFragment-ben hívom meg, egy Loader részeként:
public void onLoadFinished(Loader<List<SampleEntry>> loader, List<SampleEntry> data)
{
((MainListAdapter)getListAdapter()).setData(data);
}Az első végrehajtáskor ez tökéletesen működik. Ha elfordítom a készüléket, akkor is lefutnak a fenti metódusok, de - a notifyDataSetChanged() - hívás ellenére NEM jelenik meg semmi.
Ha ekkor frissítem a listát (pl. még egy elemet hozzáadok), akkor az EGÉSZ lista megjelenik, vagyis az összes elemet tartalmazza.
Ha az elemet (próbaként) a setData() részben adom hozzá, akkor sem jelenik meg a lista.Rengeteget olvastam a notifyDataSetChanged()-ről, de nem jutottam eredményre. Az a gyanúm, hogy nincs még ListView, amikor az első setData() lefut, ezért nem tud még mit frissíteni.
Hogyan tudnám ezt megoldani??
-
#2061
thon73
tag
WonderCSabo
#2058
thon73
tag
válasz
WonderCSabo
#2058
üzenetére
Köszönöm a sok ötletet és útmutatót!
Lehet, hogy egy esős délutánt már illene azzal töltenem, hogy végigolvasom a Java-t, nem mindig csak azt, ami éppen kell.Én még nem látom át teljes mélységében, hogy melyik megoldás a jobb/ideálisabb, de azt már látom, hogy a probléma bármelyikkel megoldható. A nyitás/zárást én speciel eddig is minden kiírt blokk köré raktam, nem hiszem, hogy jelentős gyorsulás érhető el egy hosszútávon nyitott file-lal. Viszont egy esetleges adatvesztés jobban zavarna, ha pl. zárás és flush nélkül lépek ki véletlenül a programból.
Annyit viszont már átláttam, hogy ez a worker-thread file-kezelés tud elég csapdás lenni... na ezek a kész megoldások ebben biztosan segítenek.
-
#2046
thon73
tag
WonderCSabo
#2045
thon73
tag
válasz
WonderCSabo
#2045
üzenetére
Ja, nem erre használnék Loopert, attól függetlenül tűnt fel. Looperrel egy lineáris file írást akartam kitenni, hogy a számítások meg az írás külön szálon fusson. És csak küldözgetné a háttérszálra, ami kész van és ki kell írni...
Olymódon semmi gond, hogy le tudom állítani, csak nem is gondoltam rá idáig. Ha életben hagyom, akkor nem fog újabb és újabb szálakat indítani minden egyes Activity újraindítás? Vagy nem érdekes, mert eltakarítja, amelyikre nincs élő hivatkozás?A cikkekért köszönet, megint csak megvilágosodott egy-két dolog. Minél többet ismerek meg az androidból, annál nagyobb a rálátásom a saját tudatlanságomra...
-
#2044
thon73
tag
WonderCSabo
#2040
thon73
tag
válasz
WonderCSabo
#2040
üzenetére
Bocs, átmenetileg net-mentes lettem...
Tehát, ha az elindított thread-ek tovább futhatnak, akkor azokat is illik leállítani onPause-ban? Ami meg hosszan kell azt indítsam service-ként? Eddig nem használtam Looper-t (vagy legalábbis nem tudtam róla), ez meg most elbizonytalanított...
-
thon73
tag
Aha. Pont erre jutottam, hogy az app sokkal ellenállóbb, mint az activity.
Azt hittem pedig, hogy amikor memóriára van szükség, akkor nem csak az Activity-t, hanem a teljes App-ot leállítja. (A kilövés az világos, az FC is logikus, de arra nem gondoltam)Csakhogy ez újabb gondolatokat is ébreszt bennem: Ha az app megmarad, akkor a teljes process megmarad, nem? Akkor viszont az elindított thread-ek sem fognak megállni? Vagy hogyan van ez? Én azt gondoltam, hogy a BACK-kel (v. pl. finish-sel) való kilépéskor, ill. ha elfogy a hely, akkor ez leáll - de ezek szerint tévedtem.
-
thon73
tag
Meg tudja valaki mondani, hogy elméletben meddig él az Application példány?
Globális változókat tettem Application szintre, és véletlenül vettem észre, hogy ezek a - hiába indítottam el ezeregy programot - nem szűnnek meg soha. (Mondjuk, újratalapítésig pl.)
Erre lehet számítani, vagy az Application osztály is eltűnik egyszercsak, és újra létrehozásra kerül egy következő indításkor?
-
thon73
tag
válasz
eastsider
#2020
üzenetére
Aha. Két malomban őrlünk. Háromban.
Tehát: a program elkészítésének a folyamatára értem, hogy először egy vagy két, de független táblával próbálkozz, az is elég izgalmat ad. Csak ha ez már jól működik, akkor próbáld beletenni a join-t táblát. Egyszerre kivitelezni az egészet annyi hibalehetőséget ad az első próbáig, hogy nagyon nehéz kilábalni belőle. Szerintem jobb, ha egy egyszerűbb része biztonságosan működik, és utána lépsz tovább.
A végső elrendezéshez:
Két megközelítés létezik (sztem.): én egyesével viszem be az adatokat. Vagyis: EGY kép/könyv/adat felvételekor választom ki hozzá a megfelelő kapcsolt adatot (tekercs/író stb.)
Te sztem. KÖTEGELT felvitelt szeretnél: kiválasztod a tekercset, aztán hozzárendelsz - gondolom egy hatalmas poolból - egy csomó képet. Ez is járható út.A lényeg nem változik:
Egyszerre egy rekordot tudsz létrehozni. Annak a mezőit kell kitöltened. A TEKERCSEK mező értékét kiválaszthatod a létrehozáskor (egyszeres módszer), vagy már tudod előre, és ezt az ismert tekercs _id-t teszed az összes létrehozandó rekordba (kötegelt mód).Mind a két módszernek megvan a létjogosultsága. Pl. van 3000 képem, kijelölök 250-t, és egyszerre (kötegben) hozzárendelem egy tekercshez. Ennek ellenére nem fogod tudni megkerülni az egyszeres módszert sem, két okból: 1. a képek más adatokat is tartalmaznak ISO, hely stb. Ezt honnan veszik? Minden tekercsen egyforma? Akkor uis a tekercs táblába tartozik. EXIF adatot importál? Az egy külön funkció, és kézzel is meg kell tudnod változtatni. 2. mi van, ha egy képet rossz helyre raktál?
Sztem. is hasznos, sőt a legfontosabb egy program felépítését megbeszélni; kételyem csak abban van, hogy mennyire érdekes ez másoknak, akik itt esetleg rövid android praktikákat akarnak megtudni. De éppen át is vonulhatunk valami semleges területre, ha untatjuk az itt olvasókat. Én speciel hasznosnak tartanám, ha nálamnál tapasztaltabbak is hozzátennék a tudásukat; azt azért átérzem, hogy ez a projekt mennyire fontos neked.
Amúgy én azt tenném, hogy egyszerűen, magyarul és képekkel leírnám, hogy mit is akarok, hogy tegyen a program, végiglogikáznám, aztán ahhoz alkotnám meg a hátteret.
-
thon73
tag
válasz
eastsider
#2018
üzenetére
Bocs, de valahol teljesen elvesztettem a fonalat... Hogyhogy nem tartozik adat egy id-hez, amit viszont ismersz?
Szerintem (de nyugodtan szóljon bele adatbázis-tudós is):
Van a könyvek/képek tábla (ami kezdetben üres), és van az írók/tekercsek tábla, ami szintén üres.
Azt kell megoldanod, hogy fel tudj vinni egy KÉPET, ami hivatkozik egy tekercsre. Mivel ezt nem az _id alapján, hanem listából választod ki, nem tudsz "üres" _id-t hozzárendelni (az ugyanis meg sem jelenik a listában); legfeljebb azt tudod jelezni, hogy NINCS hozzárendelve tekercs (már ha ez megengedett)
És persze kell egy "űrlap", ahol a tekercseket viszed fel.Én a helyedben először gyártanék egy felületet csak a képek táblához. Aztán ugyanezt kibővíteném egy független tekercsek táblával. Amikor ez kész, akkor megpróbálnám kiegészíteni azzal, hogy a képek listájában megjelennek a tekercsek, ill. a képek űrlapján is ki lehessen választani egy tekercset. Közben adni fogja magát, hogy miként kényelmes elrendezni, listákkal, tabokkal, fragmentekkel...
Mindenkitől bocs, hogy ennyit dumálok, de pont ugyanezen vergődtem végig, és pontosan tudom, hogy nem egyszerű. Mindenesetre fentebb már megosztottam a kódot, ahol én tartok; szerintem azért is érdemes kipróbálni (mármint a kész programot használni), mert gyorsan kiderül, hogy hol vannak azok a részek, ahol megbicsaklik az egész felület. Eredetileg én sem gondoltam egy csomó mindenre, ez csak a fejlesztés során fog kiderülni...
-
thon73
tag
válasz
eastsider
#2016
üzenetére
Na, igen. Ez pont így működik, ha fel van töltve az adatbázis. De hogy töltöd fel? Először uis. üres.
A képeket ugyanígy oldottam (volna) meg, jelenleg csak a hivatkozásoknál tartok - vagyis bármilyen file-t tudok tárolni, akár képet is.
((Mondjuk én lehet, h. tárolnék egy másolatot a képről, vagy egy thumbnail-t; külön helyen)) -
thon73
tag
válasz
eastsider
#2014
üzenetére
A tabos elképzelés ott halt meg, hogy valójában ezek a listák egymásba lesznek öltve. Vegyünk egy idióta példát:
beírsz egy könyvet: Egri Csillagok
kiválasztod az írót: Gárdonyi Géza
de közben megnézed a többi könyvét: szűkített lista, benne Tüskevár
Jé, ezt nem is ő írta, kiválasztod az írót: Írók listája
Jé, nincs benne Fekete István
Író hozzáadása: Fekete István...
És így tovább a végtelenségig.Én csináltam egy ListFragmentet, és egy EditFragmentet. Most jön a következő probléma: ezek a különböző táblák esetében 90%-ban egyformák lesznek. Tehát csináltam egy General... Fragment-szettet, és ebből származtattam le az egyes tábláknak megfelelő tényleges Fragmenteket.
Akkor jött a következő probléma: ezek a spéci, egymásra hivatkozó mezők igazából új változótípusnak felelnek meg, ezért alkottam belőlük új változókat.
Hopp: és a végeredmény egy felxibilis rendszer, akárhány táblával, könnyen változtatható felépítéssel... viszont egy igen kövér, és sokrétű kóddal. És a legnagyobb vicc, hogy engem tulképp csak az export/import funkcionalitás érdekeltAz a baj, hogy az sqlite nagyon jó. Az android nagyon jó. A kettőt összekötő híd viszont kompletten hiányzik. Mármint a UserInterface oldala, mert amúgy a program adatainak tárolására elég könnyen használható.
De ez csak a magánvéleményem.
És azért teszem itt közzé, mert a fentebb közzétett programhoz tartozik. -
thon73
tag
válasz
eastsider
#2012
üzenetére
Én ezt egy cseppet átgondolnám.
Csak a saját elgondolásomat tudom közreadni. A tekercs/kép párosnál nekem az író/könyv jobban kézreáll, de ez tetszőlegesen behelyettesíthető...
Tehát:
Van az ÍRÓK tábla (vagy TEKERCS), ami nem hivatkozik senkire.
Van a KÖNYVEK tábla (vagy KÉPEK), ami hivatkozik EGYETLEN ÍRÓRA (vagy EGYETLEN TEKERCSRE)Ha ez utóbbit listában akarod megjeleníteni, akkor JOIN táblát érdemes használni, hogy lásd a könyv íróját vagy a kép tekercsét is egyúttal. Technikailag javaslom, hogy kiválasztásnál mindig egy új, részleteket mutató Fragmentet hozz létre. Ezt a Backstackra rakhatod, és akkor könnyű visszaugrani a listához. Egy másik elem kiválasztása nem ennek a Fragment-példánynak a mezőit változtatja, hanem létrehoz egy újat.
((Nehéz lesz megoldani egyébként az ÍRÓ (TEKERCS) kiválasztását innen - de nem lehetelen, csak dolgozni kell vele.)) A másik buktató a fragmentek egymás melletti/feletti megjelenítése, de az sem lehetetlen.Amikor viszont az ÍRÓK/TEKERCSEK listában vagy, akkor lehet, hogy szeretnéd megnézni, hogy mely könyveket írta/képeket tartalmazza. Na, ebben az esetben kell a KÖNYVEK/KÉPEK listát úgy megjeleníteni, hogy szűkítjük a listát a megfelelő íróra/tekercsre.
Hozzáteszem, hogy úgy tapasztaltam, majdnem minden megoldható az sqlite szintjén is, vagy a program szintjén is. Ha univerzáslis megoldásra van szükség, akkor szerintem az sqlite kihasználása gyorsabb, áttekinthetőbb, biztonságosabb; míg speciális esetekben (pl. statikus adathalmaz, speciális - ékezetes - keresések) érdemes/szükséges kódot írni, ami néha!! gyorsabb lehet.
Amúgy én pont ezen küzdöttem végig magam, nem minden pontja volt egyszerű, hibátlan és magától értetődő, de már egész jól működik. Szívesen segítek.
-
thon73
tag
A broadcast-okkal megy is szépen, a példaprogramokban is broadcast-ok szerepelnek, csak éppen a rendszer által indítottak.
Lehet, hogy nekem is broadcastolni kellene az activity-ben, ha valami változik? Hm. Ez egy megfontolandó ötlet, köszi.Amúgy a Loader-ekkel én is csak ismerkedés szintjén "játszom". Van egy file-ban tárolt adathalmaz, aminek a beolvasása kb. 4-5 sec. Ezt akartam beletenni Loader-be. Ez - a felhasználó oldaláról - statikus adathalmaz, tehát nincs mit figyelni. Az én (tesztelő) oldalamról van lehetőség a változtatásra, de akkor újramenti a teljes megváltoztatott adatbázist (mert módosításkor az összefüggő adatok miatt a nagyrésze megváltozik). Ettől függetlenül arra voltam kíváncsi, hogy ha én változtatok a külső adatokon az Activity-ben (bocsánat -ból), akkor hogyan értesülhet erről a Loader.
A fenti (mostmár két) megoldáson kívül még egy érdekes osztályt találtam: a FileObserver-t. De az még bonyolultabbnak tűnt.Ami még gondnak tűnik nekem: végső soron a Loader-rel is be kell olvasnom mindent, ahhoz, hogy a lista eleje megjelenjen. Ez amúgy logikus (mert nem biztos, hogy a lista eleje töltődik be először), de a várakozási idő ugyanúgy megvan (csak pörög az óra...)
-
thon73
tag
Ilyen nehezet kérdeztem, vagy mindenki békésen szunnyad az ebéd(ek) után?
Saját fejem törésével erre jutottam: Van itten egy olyan, hogy a LoaderManager-től le tudom kérdezni az aktív Loader-eket. Az Activity induláskor megnézi, hogy van-e Loader, s ha igen, akkor beregisztrálja magát (Uis. ilyenkor valaki már létrehozta a Loadert, pontosabban az előző megvalósulásunk hozta létre.) Záráskor szintúgy megnézi, csak éppen kiregisztrálja magát, - kiregisztrálTATja magát a megtalált Loader-rel az obszerválandók közül. Néha elgondolkodom, hogy télleg az Android Way a legegyenesebb-e??
Ha valaki látott már egyszerűbbet, akkor ne habozzon elmesélni...
Teljesen más: Tudja valaki mi az a Samsung File-Stor Gadget? A nem létező UMS kapcsolatom SGSII 4.1.2 alatt ezzel mégis létezik. Ha tudnám, mi ez, rátenném a tabletre is... A szívemhez közel áll a Mass-Storage gyorsasága, és a proxy szerver sem zavarja...
-
thon73
tag
Sziasztok!
Egy érdekes problémával küszködök. AsyncTaskLoader-t készítettem, ami működik is. DE! A háttérben álló adatok az Activity-n keresztül változtathatóak meg, tehát az AsyncTaskLoader-nek valahogy az Activity-t kellene figyelnie, hogy mikor következik be változás.
A gond akkor kezdődik, amikor elfordítom a készüléket, uis. ilyenkor egy új Activity keletkezik (és ettől a ponttól már ezt kellene figyelni, és a régit elengedni), ugyanakkor (ha jól értem a működést) az AsyncTaskLoader túlél, legfeljebb újraindul.
Hogyan illik ezt elegánsan megcsinálni?
Egy leegyszerűsített példában csak egy gombnyomással akarom szimulálni az adatváltozást. Az Observer az AsyncTaskLoader lenne, az Observable pedig az Activity (vagy a Button, de az előbbi egyszerűbb). Na de akkor hogyan tudná az Observable oldal magát kikapcsolni, meg aztán az új Activity-t visszakapcsolni?
Meg tudja ezt valaki mondani? Vagy valami más ötlet esetleg? -
thon73
tag
Először is mindenkinek köszönöm a GIT-es útmutatókat; kezdem átlátni, hogy mit is kell csinálni. Kis trouble, hogy itt proxy mögött vagyok, de sebaj, majd otthon linux alól. Mellékesen jegyzem meg, hogy az AIDE tableten (használja vki?) elvileg a menüsorból tudja az egészet, ezért gondoltam hogy könnyebb lesz. ((Igaz, még azt sem próbáltam, csak láttam)) Köszönöm!
to Sianis:
Szerintem az a hiba, hogy a BackStack NEM a fragmentet, hanem az oda vezető utat tárolja. A->B azt jelenti, hogy az A-B replace kerül a stackra. Amikor ezt C-ről hívod, akkor - elvileg - a B->A replace-t végzi el újra. Nagy a gyanúm, hogy a lejátszás már ott elakad, hogy nincs meg a B fragment. Replace-t én ugyan ritkán használtam, de ha kettébontod remove-ra és add-ra, akkor talán könnyebb felderíteni a hibát.
Én azt gondolom, hogy az add(B) részt felesleges a Stackra tenni, csak a remove(A)-t tedd rá! Ha ezt a tranzakciót játszod vissza, akkor - elvileg - meg kell jelennie A-nak. Elvileg. És szerintem. De nem tudtam kipróbálni.
((Bocs, még annyi, hogy természetesen a remove(B) és remove(C)-re is szükség van a megfelelő helyen, csak nem a visszapörgetésben.)) -
thon73
tag
Részben a fenti okok miatt (idő és hozzáértés hiánya) én is közzéteszek egy feladatot, hátha érdekel valakit:
Hatszögletű billentyűzet
Az ötlet egy régi palmOS programon, a myKbd-n alapul, de az elrendezés a honlapíró sajtja. Ilyen kellene Androidra, esetleg további ficsörökkel. (Ha valaki megtanulja, iszonyatosan gyorsan lehet vele írni.)
Én ugyan csak közvetítő vagyok, de természetesen a segítséget javadalmazással gondoltam. Érdeklődőket pü-ben várom.
Ha ez nem ide való, csapjatok nyakon nyugodtan, csak mondjátok meg, hol lehet ilyesmi felől érdeklődni! Köszi! -
thon73
tag
válasz
eastsider
#1975
üzenetére
Elküldöm nyilvánosan, mást is érdekelhet:
[link]Ez ugyanaz a program, mint az Enumber nyilvántartó, de könyveket tart számon. Van a Books adatbázis, amelyik hivatkozik az Authors adatbázisra.
Elnézést kell kérjek azoktól, akik megnézik:
- én csak hobbiprogramozó vagyok, másrészt a program csak gyakorlásból készült. Magam is találtam hibákat benne. A program egyébként működik, de javítása folyamatban. Ha bárki javítási javaslattal él, örömmel veszem.
- már javasoltátok, hogy töltsem fel a Github-ra. Előbb-utóbb fel lesz, de nem jöttem rá Eclipse alól hogyan kell. Csak AIDE alatt találtam meg, de az most nincs (új telo rom, ugye). Köszönöm, ha valaki segít benne!
- természetesen "AS IS", tényleg csak meg akartam ismerni, hogyan működik...U.i.: Valaki találkozott már olyannal, hogy WinXP alatt a file-ok egy részének mérete konkrétan 0 lesz? Driveteszt ok, Kaspersky ok. De a forrást elő kellett ássam egy korábbi mentésből, mert ez is érintett volt. Hm. Legalább azt tudnám, hogy hogyan kerülhetem el legközelebb...
-
thon73
tag
válasz
eastsider
#1971
üzenetére
Én tudok mutatni olyat, amiben kettő van, és nem száll el
Ha kapcsoltak a táblák, akkor le sem tudod máshogy kérdezni (mármint külön ContentProviderrel). Több info kellene ahhoz, hogy válaszolni tudjak, de egy működő example-t (jó összetett ugyan) tudok küldeni.
Nekem a fő gond az volt, hogy mikor lehet teljes névvel, ill. mikor lehet csak rövid névvel hivatkozni az egyes mezőkre.
LEFT OUTER JOIN-nal kötöttem össze a két táblát.
A projection-ben a teljes (tabla.mezo) mezőnevet használtam, a from-ban csak a mezo-t. Ez akkor gond, ha mindkét táblában ugyanaz a mező neve (pl. maga az _id). Ilyenkor át lehet "nevezni" a mezőt, de erre nem volt szükségem.
Nem tudom, hol lesz a hiba, de emlékeim szerint ez sokáig nem tisztult le nekem, és folytonosan elszállt. Az sqlite-nak átküldött szövegeket érdemes átnézni, abból gyakran kiderül a turpisság. -
#1961
thon73
tag
WonderCSabo
#1960
thon73
tag
válasz
WonderCSabo
#1960
üzenetére
Pont ez az, ami a videon .50 körül van: drag&drop. Annyi a különbség, hogy itt az elemet hosszú nyomással, ott meg egy, az elején álló jellel fogjuk meg. Ez persze lényegtelen.
A listaelem kibontás is nagyon tetszik, (bár olyat szöveggel - lényegesen kevésbé animált módon - már csináltam.)
Köszönöm ezt is!Igaziból egy "todo" részt szeretnék csinálni az adatbáziskezelő segítségével, és ezzel könnyen be tudom állítani a manuális sorrendet. Meg persze lehet rendezni is mindenféle módon - de ez nagyon hiányzott.
-
thon73
tag
Köszi mindkettőtöknek! Elmélyedek benne.
A rommal az a baj, hogy csak egy stock rom átírás, de utánanézek, van-e forrása. Ez a rész speciel idegennek tűnik benne, azért is írtam ide a pontos elérését.
Ha nincs támogatás, az nem baj, majd támogatom magamat De legalább nem kell az egészet nulláról kitalálni.
Köszönöm! -
thon73
tag
Régóta szeretnék egy olyan listView-t, amiben az elemeket kedvem szerint (húzogatással) átrendezhetem.
Egy sikeres telefon újraélesztés után NeatROM 4.1.2-t tettem fel, ahol a rendszermenüben szerepel ez. Kijelző/Notification Panel/Toggle button order (a két nyelv keveréséből gondolom, hogy ez nem szabványos alkatrész). Nehézségek árán ugyan, de mozgás közben csináltam egy felvételt:
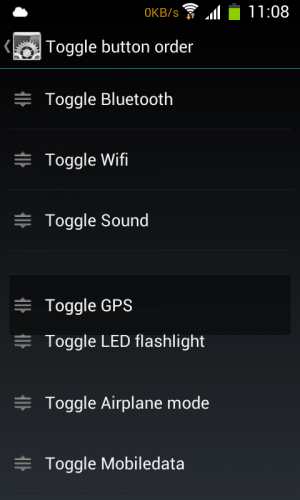
Ha listaelemek előtti ikont megfogom, akkor fel-le lehet húzni az elemet, és ha elhagyja a mellette lévő listaelem felezővonalát, akkor az a húzott elem "alatt" vagy inkább "mögött" átugrik az üres helyre. Na, ez így elmondva igen szegényes, de elég kézenfekvően működik. És sok-sok elemmel (vagyis görgetés közben is működik.
Nem tudja valaki véletlenül, hogy ezt a funkciót hol tudom elérni, vagy van-e valahol ilyen kód, ami ezt megcsinálja? Amivel én próbálkoztam, az sokkal szegényesebb volt - gyakorlatilag arra jutottam, hogy a teljes listView-t újra kellene írni. Egy ilyen kód sok melótól megmentene... Hálás köszönet előre is!
-
thon73
tag
válasz
eastsider
#1881
üzenetére
Régen is ui threaden töltődött, aztán mégis használtuk a progikat...
Ráadásul, úgyis meg kell várni amíg betöltődik, mer ugye épp a listát akarod megnézni.
A saját tapasztalatom az, hogy érdemes Content Providert csinálni. Kicsit korlátozott, amit az adatbázissal csinálhatsz, de jobban átlátható a kód, könnyebben belepasszol abba, amit az Android szeretne.Én ugyan nem vagyok nagy guru, de szívesen belenézek a debugba; több szem többet lát...
-
thon73
tag
válasz
eastsider
#1879
üzenetére
Én megcsináltam mindkettőt. Ha CursorLoader-t szeretnél használni, akkor kell hozzá ContentProvider is - úgy tudom. Egyiket se nagyon nehéz elkészíteni, de az utóbbi meglehetősen hosszú. A kész Loader csak pár sor viszont. Saját Loader csak akkor kell - szerintem - ha nem sqlite a forrás, hanem valami elvarázsolt dolog.
Loader nélkül már nem kedveli a rendszer - vagyis deprecated, de működik.
Pár hozzászólással ezelőtt feltettem egy E-number kezelő kódot, abban mindkettőre szerepel példa. -
thon73
tag
Kedves Adatbázis Guruk!
Csinált már valaki olyat, hogy NEM a beépített szöveges keresésekkel keresett android sqlite adatbázisban? A lehetőségeket (keresésre külön oszlop pl.) olvastam itt-ott a neten, ezt pl ki is próbáltam. De saját tapasztalata (amit esetleg meg is osztana) van valakinek? Ahol esetleg nem kéne duplázni az adatokat.
(((az ANDROID sqlite lényeges, mert C forráskódban láttam erre beépített lehetőséget is, de tudtommal itt nincs)))Ha valaki zsákutcába futott ezzel, és elmondja, annak is örülnék; legalább arra már nem próbálkozom.
Köszönöm!
-
#1819
thon73
tag
WonderCSabo
#1816
thon73
tag
válasz
WonderCSabo
#1816
üzenetére
Csak együttérezni tudok.
A Support Fragmenttel én is tapasztaltam anomáliákat 2.3.x és 4-x alatt nem egyformán működött. A másik falba ütközésem a nested megvalósítással történt, így utólag valószínű pont emiatt. (Nem megfelelően állt fel a layout, különösen újraindításnál.) Én feladtam a nested variánst, azóta mindent szigorúan az Activity vezérel (szinte csak erre tartom )
De elismerésem, hogy ezt így kibogoztad!!! -
#1815
thon73
tag
WonderCSabo
#1814
thon73
tag
válasz
WonderCSabo
#1814
üzenetére
Nem is rajzolnak a fragmentek, csak különböző paramézersorokat kérnek be, amiből összeáll a végén egy rajz. De azt nem is látom, csak a végére gyártja le, és mutatja meg az egyik fragment. De ez nem lényeges.
Az onResumeFragments azért kell, mert az onResume részig még nem álltak össze a Fragmentek, már amit a rendszer állít vissza.
Pont ez teszi nehézzé, hogy nincs olyan pont, ami még biztosan le[ut, de a Fragmentek már üzemkészek. Viazont kezdem átlátni, hogy két irányt kell elkészíteni. Az első elkészítéskor az onActivityCreate érheti el a másik Fragmentet ˙Activityn át), később viszont ekkor még nem látja az Activity a másik Fragmentet, tehát nekem kell explicite az OnResumeFragmentsben meghívnom egy adatokat beállító külön fragment metódust.
Ez a megoldás nem túl szép, szerintem a staticus mező tisztább! Köszi a segítséget, a beszélgetés nélkül még törtem volna rajta a fejem egy darabig. -
#1813
thon73
tag
WonderCSabo
#1812
thon73
tag
válasz
WonderCSabo
#1812
üzenetére
Az, hogy lényeges különbség van a retained Fragment ELSŐ LÉTREHOZÁSA, és az összes többi VISSZAÁLLÍTÁS között.
Vagyis:
A Fragmentet először az Activity.onResumeFragments részben fogom megtalálni. Ha nincs meg, akkor itt kell először is létrehozni.
Ha nem volt meg, akkor a létrehozás után még semmilyen élitciklus nem fut le (majd csak az onResumeFragments UTÁN)
Ha viszont megvolt, akkor eddigre minden lefutott, beleértve a Fragment.onResume metódusát is.A konkrét próbálkozásban egy ListFragmentet készítettem, amelyik az adatait ebből a megőrzött globális adatállományból veszi (a végső megoldás mindig egy kicsit összetettebb persze). Ez azt jelenti, hogy valahol meg kell mondjam az adapternek, hogy hol vannak az adatai.
Az első létrehozáskor (persze ilyenkor az adatállomány még üres, de majdan ide fog bekerülni) nem lesz gond, hiszen mire a ListFragment életciklus részei lefutotnak, ott van az Activityből elérhető módon a másik, adatokat tartalmazó Fragment.
Minden további indításkor azonban mindkét Fragment végigfut az onResume-ig, mielőtt én egyáltalán látnám az adatokat tartalmazó Fragmentet az Activity.onResumeFragments részében! Vagyis nekem kellene kiadni egy pl. MyListFragment.onVariableReady() utasítást, ami betölti az adapterbe az immáron elérhető adatokat.
Ez a megoldás viszont az első indításkor nem lesz jó, hiszen még adapter sincs sehol!
Hozzáteszem: ez a ListFragment dolog valójában csak egy próba. Nekem egy sok részletből álló rajzot kellene elkészítenem, aminek az egyes részeit tudom egy-egy Fragmenttel megalkotni. Az alapadatokat természetesen mentem, de minden apró számítást nem akartam. Ettől a speciális problémától elvonatkoztatva a kérdés általános érvényű: hová tegyem a Fragment megőrzendő adatait, ha magát a konkrét Fragmentet nem akarom megőrizni ((mert pl. változik a gép fordításával))?
A static field egyébként jó ötlet, csak úgy emlékszem, valamiért (újra el kellene olvasni) kerülendőnek javasolta a hivatalos doksi. De ezt elő kéne ásni, lehet, hogy rosszul emlékszem...
((Bocs, ha kicsit bonyolult, már játszom vele egy ideje. Szívesen küldök kódot, de a sallangok, és próbálkozások miatt előbb ki kellene fésülnöm. Bár kivételesen a szöveg talán többet mond.))
-
#1811
thon73
tag
WonderCSabo
#1810
thon73
tag
válasz
WonderCSabo
#1810
üzenetére
Miért ajánlgatja a doksi a retained Fragmentet, ha ilyen nehéz megoldani az elérését másik Fragmentből!?
A static field-es osztályt hogyan mentem meg biztonságosan? Átviszem az onSaveInstanceState-ben?
Menteni nem akartam, akár nagy is lehet a mérete. Ezek csak olyan "melléktermék" adatok, amik megkönnyítik, hogy nem kell mindent újraszámolni, ha egy másik Fragment nyílik meg, vagy ha újraindul az Activity. De a static field szimpatikus. Az végső soron az Activity-hez kapcsolható, semmi dolga a Fragmentekkel. Így csak az Activity-ig kell "visszanyúlnom" az adatokért.
-
thon73
tag
Egyszerűsítem a kérdést:
Hová tegyem azokat az (akár nagyméretű) globális adatokat, amiket több fragmentből el akarok érni, de szeretném megtartani őket a konfigurációs változások alatt is?
((Egy ötletem van: Application szintre. Megpróbáltam a retained fragmentet, de sehogyse megy.)) -
thon73
tag
Néhány globális változót egy "retained fragment"-be helyeztem. Létezik olyan pont, amikortól a többi fragment (természetesen az activity-n keresztül) elérheti ezeket a változókat?
Uis. a változók csak az activity onResumeFragments részére térnek vissza (itt tudom újra megtalálni a megtartott fragmentjüket). Ugyanakkor eddigre az összes többi, nem megtartott Fragment is feláll, és az Fragmentek onResume része is lefut.
Van még valamilyen pont az onResume UTÁN, ahol MÁR tudnék kommunikálni a többi fragmenttel (konkrétan a megtartottal), de MÉG nem indult el a Fragment a felhasználó szempontjából?
Előre is köszönöm!
((Átmenetileg úgy oldottam meg, hogy az Activty "értesíti" a Fragmenteket, hogy a változók rendelkezésre állnak. De nem hiszem el, hogy ez lenne a real android way...)) -
thon73
tag
A kérdés több, mint jogos, de a válasz egyszerű: megígértem, hogy még a hétvégén elkészítem, és így egyszerűbb volt feltölteni. (Így is késtem vele egy napot
) ((Igaz, az nem mentesít, hogy az AIDE, amit tableten használok, alapból ismeri a GitHubot)) Ha megfelelő géphez kerülök, akkor felkerül oda, ill. blogcikket is szerettem volna/szeretnék írni erről, mert én rengeteget tanultam belőle - többek között itt kapott infókból is. Az eredeti ötlet többet tud, a kapcsolt táblákat (kereszthivatkozásokat) is kezeli. -
thon73
tag
válasz
 lac14548
#1714
üzenetére
lac14548
#1714
üzenetére
Az E-számokat tároló adatbázis kísérleti programja (és kódja) ITT TÖLTHETŐ LE Telepíthető adb a /bin mappában.
A program az alfa változat alfája. Egy nagyobb történetből lett "lebutítva". Teljesen működőképes (én használom), de nincs széles körben tesztelve, szóval AS IS (olyan amilyen). Ez azt is jelenti, hogy nem tökéletesen kész, de különben soha nem érnék idáig vele.
Mivel a kérdés itt merült fel, itt is osztom meg, de a megosztás célja elsősorban a tanulás. Ha bárkit érdekelnek részletek, talál hibákat stb. itt/püben/egyéb módon is szívesen fogadom.
Egy-két apróság:
Ez egy egyszerű sqlite alapú adatbázis, id-n kívül 3 szöveges mezővel. A negyedik mező tartalmazza a "normalizált", vagyis ékezetek nélkül kereshető kódot. Az adatbázist lista, ill. az egyes elemeket szerkeszthető módon is megjeleníti. A lista az E-számokra rendezett, szűrhető (minden mezőre, ékezet, kis-nagy betű nem érdekes), és (most még) unique bejegyzések nincsenek kikötve.
Gyakorlatilag loggol (igencsak bőven) egy {sdcard}/enumberdb mappába (a syslogon kívül), de elmétileg ez összeakadhat (ld. előző kérdéseim a threadekkel kapcsolatban) dolgozom rajta.
Az érdekessége (talán) a saját (egyszerű) file kezelővel bíró csv szerű export/import funkció, az adatok ezzel is bővíthetőek, ill. archiválhatóak. Vigyázat! importnál beilleszti a meglévő adatok közé a rekordokat!! (KI van kapcsolva az unique védelem, ugye.)
Külcsín, működés (pl ékezet, kereshető mezők) könnyen, igény szerint módosíthatóak. Persze a nyelv is.
Jó próbálgatást! Ötleteket, kritikákat szívesen veszek - már ami a kóddal kapcsolatos. Tudom, ez nem a Google Play, nem is ilyetén céllal került ide ez a kód. -
thon73
tag
Aha. Ezt nem olvastam, csak a doksit. Akkor tényleg nem véletlenül írják, hogy Android alatt ez nem használható.
Megnéztem a "hivatalos" Log-ot is, de az teljesen használhatatlan (nekem), mert alacsony szintű hívással az op-rendszer logját írja, amit viszont én nem tudok kiolvasni. (Ill. csak PC kapcsolatban, meg rootolt készüléken)
Még nem tudok teljes mélységben válaszolni, de próbálkoztam, olvasgattam, és érdekes eredményeket kaptam.
1. A külön file-író thread azért is nagyon jó ötlet, mert akkor ez nem is lassítja pl. az UI thread-et. Az elkészítéstől egy kicsit megriadtam, de nekiláttam. ITT találtam egy hasonló elgondolást, ebből annyi látszik, hogy ez nem lesz olyan egyszerű.2. A Channel thread-safe egy programon belül. Hm. ezt nem tudtam, pedig a doksi is egyértelműen ezt írja.
3. ITT azt az okosságot írják, hogy Channelen kívül NEM lehet többször (tehát több threadból) írásra megnyitni egy file-t. (Ez szerintem nem igaz, én írtam file-t egyszerre több nyitott úton keresztül, igaz egy thread-en.)
4. Ez a legérdekesebb: leteszteltem. Csináltam több párhuzamos thread-et, mindegyik ugyanazt csinálja: megnyitja/írja/bezárja ugyanazt a file-t, mégpedig OutputStreamWriter(FileOutputStream) úton. (Igaz, ez pufferelt, de a puffer többszörösét írtam ki, kb 2 Mbyteot, 4 threadról.)
Nem létezik, hogy soha ne ütközzenek. Mégis, az összes kiírás tökéletes! Tettem elé time-stamp-et, sokszor egyforma, mégsincs hiba!!
Vagyis: Minden elmélet ellenére gyakorlatilag lehet egyszerre több threadról írni ugyanazt a file-t. Most akkor ez hogyan lehet? Mégis "thread-safe" lenne az alacsony szintű írás androidon?? Lehet, h. itt működik, más java környezetben meg nem??
-
thon73
tag
Még egy utolsó kérdést hadd tegyek fel:
A file írás nem mindig történik meg a záráskor sem (Ezt RandomAccessFile esetén tapasztaltam, még a program bezárása után is hozzányúlt, igaz, csak a metaadatokhoz).
Nem biztonságosabb a FileLock használata az esetemben? Vagy ugyanazt az eredményt érem el, mint a synchronized védelemmel? -
thon73
tag
Vicces, most derült ki mennyire topa vagyok a multithread-del, mégis megosztom egy volt ötletem. Én scrolloztatni akartam a képet, amíg a delikvens hosszan nyom egy pontot. A longpress nem jó, mert az csak egy dolgot csinál meg utána, aztán megint vár. Sztem. neked ugyanez kell fordítva: Ha érintés történik, akkor megszakítod a thread-et.
Egy két kódrészlet:TouchThread touchThread;
@Override
public boolean onTouchEvent(MotionEvent event)
{
...
case MotionEvent.ACTION_DOWN:
touchDirection = 1;
touchThread = new TouchThread();
touchThread.start();
break;
case MotionEvent.ACTION_UP:
if (touchThread != null)
touchThread.interrupt();
break;
}
...
}
private class TouchThread extends Thread
{
@Override
public void run()
{
// Csak vár, hogy hosszú nyomás legyen
for (int cnt=0; cnt<3; cnt++)
{
sleep(100);
if (isInterrupted())
{
touchThread = null;
return;
}
}
// Innentől történik a gyorsuló görgetés
int pause = 150;
while(true)
{
for (int cnt=0; cnt<15; cnt++)
{
sleep(pause);
if (isInterrupted())
{
touchThread = null;
return;
}
// Itt kérjük meg a görgetést az UI száltól !!!!!!
touchThreadHandler.sendEmptyMessage(0);
}
if (pause > 85)
pause -= 30;
}
}
// A görgetést a Handler fogja elvégezni
private Handler touchThreadHandler = new Handler()
{
@Override
public void handleMessage(Message msg)
{
if (touchDirection >= 0)
rollForwardLine();
else
rollBackwardLine();
touchState = 0;
invalidate();
}
}
}Ezt elég régen írtam, aztán megszakadt a dolog. Egyébként nem csak az időzítést tudja, hanem egyre gyorsul is a görgetés, amíg nyomod a képet.
Bocs, hogy a kód összetöredezett, amíg kiszemezgettem, de sztem a lényeg érthető. Mint kiderült, nem vagyok (még) teljesen otthon a thread-ekben; (ha valaki hibát talál, és szól, köszönöm); de a kód prímán működik. -
thon73
tag
Aha! Köszönöm. 1. pont alapján a kódot javítottam.
2. Eddig multithreadet (a rendszer által kínált lehetőségeken kívül) csak időzítési feladatokra használtam. Viszont - a log szigorításával - szükségem lett volna egy "saját" log-ra, amit akkor is használhatok, ha tableten dolgozom. A program nagyon egyszerű, egy file-ba írja az üzeneteket. ((Az esetleges összeomlás miatt a metódus nyitja-írja-zárja a file-t (flush is lehetne helyette, de az idő nem volt lényeges szempont)). Ilyen üzenet bármelyik thread-ről érkezhet, ezért szeretnénk biztos lenni abban, hogy működik.
Két megoldást találtam a figyelmeztetésed után:
private final Object lock = new Object();
private static String addTextToFileLog( File logFile, String text )
{
synchronized( lock )
{
OutputStreamWriter logStream = new OutputStreamWriter( new FileOutputStream(logFile, true));
logStream.append( text );
logStream.flush();
logStream.close();
}
}illetve:
private static synchronized String addTextToFileLog( File logFile, String text )
{
OutputStreamWriter logStream = new OutputStreamWriter( new FileOutputStream(logFile, true) );
logStream.append( text );
logStream.flush();
logStream.close();
}(A hibaellenőrzést az egyszerűség kedvéért töröltem.)
Van előnye egyik vagy másik megközelítésnek? Egyáltalán jó ez így, vagy valamit elnéztem?
Ha még abban tudnék egy kis segítséget kapni, hogy ezt hogyan tesztelhetem a szimpla próbálkozáson kívül, azt is megköszönném! -
thon73
tag
Bocsánat, ha nagyon alapot kérdezek:
Az android forráskódban mindig synchronized( mLock ) kifejezés szerepel. Miért nem a védett tartalomra (mondjuk egy array-listre) szinkronizál, miért kell egy külön objektumot erre létrehoznia? (Azt értem, hogy ez miként működik, csak azt nem, hogy ez így miért jobb?)
Én ugyanis eddig mindig a védett tartalmat írtam be.A másik hasonló kérdésem: ha ugyanazt a file-t külön szálakon is írom, de minden szál külön nyitja meg (tehát nem közös leírót használnak), akkor ugye nem kell a szálakkal és a szinkronizálással törődnöm, a rendszer sorba rakja a kiírt adatokat? (Mindig csak egy sornyi append van, tehát a program oldaláról nem feltétlenül kellene külön lock-olnom a file-t)
Gyakorlatilag működik a program, csak azt nem tudom bizonyítani, hogy elvileg is mindig működőképes lesz. Köszönöm!
-
thon73
tag
válasz
 pittbaba
#1716
üzenetére
pittbaba
#1716
üzenetére
Lehet, h. hülyeség, amit gondolok, de a "kilövés" az egész Application process-t érinti. A handler azon belül van, - elvileg - az is megszűnik. Arra kellene rájönni, hogy miért lő ki a rendszer egy előtérben lévő Applicationt? B lehetőség: Ha esetleg nem az application process indítaná a handler-t? Pl. service - bár ezzel nincs tapasztalatom.
-
thon73
tag
válasz
lac14548
#1714
üzenetére
Engem se fogott meg
 Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Azért írtam ide, mert úgy gondoltam, ide küldöm - hátha más is érdeklődik. -
thon73
tag
válasz
 TheProb
#1693
üzenetére
TheProb
#1693
üzenetére
Mi akadálya van előtte elolvasni egy java könyvet is?
A saját tapasztalatom az volt, hogy C alapok mellett elég volt két rövid jegyzetet elolvasni, és utána a Java-val együtt az Androidot elkezdeni. Nem akarok keveset mondani, de a Java-val nem volt semmi komoly gondom 2-3 hónap után. Az Android 2 év után is produkál számomra átláthatatlan kérdéseket. Bár bizonyára én sem vagyok kellő módon képzett...








![;]](http://cdn.rios.hu/dl/s/v1.gif)







 De tableten note-stylussal meg ujjal is nagyon jó.
De tableten note-stylussal meg ujjal is nagyon jó. Köszönöm! Ez lényegesen egyszerűbb!
Köszönöm! Ez lényegesen egyszerűbb!










 Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Ezért csináltam sajátot. A program kész, csak átírom a mezőket. Kis türelmet mégis kérek (munkahely, egyebek), de sztem. hétvégén küldöm. Az ékezetekkel nem értek egyet, mert uis. pl. én is ékezet-mentes bill.zetet használok. Egyébként egy kódtábla átírásával gyakorlatilag bármilyen keresési megfeleltetés beállítható, úgyhogy kipróbálhatjuk az ékezetes keresést is. Üdv!
Új hozzászólás Aktív témák
Hirdetés
- Acer Wave 7 Mesh: Hetediziglen
- Nintendo Switch 2
- Azonnali alaplapos kérdések órája
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- Formula-1
- Xbox Series X|S
- Azonnali informatikai kérdések órája
- Milyen egeret válasszak?
- Debrecen és környéke adok-veszek-beszélgetek
- Háztartási gépek
- További aktív témák...

- G.SKILL 32GB Trident Z5 DDR5 6400MHz CL32 KIT F5-6400J3239G16GX2-TZ5S
- ZBook Power 15 G10 15.6" FHD IPS i7-13700H RTX A1000 32GB 512GB NVMe gar
- Nitro AN515-44 15.6" FHD IPS Ryzen 5 4600H GTX 1650 16GB 512GB NVMe gar
- MacBook Pro 14 M2 MAX 4(!)TB SSD 32GB RAM HUN
- Gamer PC - i5 12400f, RTX 3080 és 16gb DDR5 + GARANCIA
- Huawei Nova Y70 128GB, Kártyafüggetlen, 1 Év Garanciával
- Huawei Nova Y90 128GB, Kártyafüggetlen, 1 Év Garanciával
- AKCIÓ! ASUS ROG Zephyrus GA403UV Gamer notebook - R9 8945HS 16GB RAM 1TB SSD RTX 4060 8GB WIN11
- AKCIÓ! Apple iPad Pro 11 2024 1TB WiFi + Cellular tablet garanciával hibátlan működéssel
- Telefon felvásárlás!! iPhone 16/iPhone 16 Plus/iPhone 16 Pro/iPhone 16 Pro Max
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest