
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)
- Huawei Watch Fit 3 - zöldalma
- Huawei Watch Fit 5 Pro - jó forma
- Feltalálta a Google a keresőmotort
- Yettel topik
- Xiaomi 14 - párátlanul jó lehetne
- Samsung Galaxy S25 - végre van kicsi!
- Honor 200 Pro - mobilportré
- Poco F8 Ultra – forrónaci
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Magisk
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 Ablakos
addikt
Ablakos
addikt
Ha futtatod, akkor is illik megadni a függőségeit a classpath-on, különben nem tudja használni.
java -cp ".:/src/java/CSV/opencsv-5.12.0.jar" AddressExample
A . az aktuális könyvtár, a : pedig a linuxos separator, amikor több elemet sorolunk fel.A classpath eclipse-ben is bekonfigolható valahogy. Jobb klikk a projektre, properties, és akkor ott valamelyik tabon be lehet tallózni a jar fájlt, amit akarsz, hogy lásson a projekted fordításkor meg futtatáskor. Asszem.
Ez a megoldás. Ráadásul ApacheCommonLang függőség is van futtatáskor, de az adott instrukciód alapján már fut is a Móricka programom.
 (Szénné olvastam a netet, de ezt a separátort nem vettem sehol észre.) Mindenhol a függőségkezelést erőltetik, de szeretném kézzel-lábbal összekínlódni az alkotást.
(Szénné olvastam a netet, de ezt a separátort nem vettem sehol észre.) Mindenhol a függőségkezelést erőltetik, de szeretném kézzel-lábbal összekínlódni az alkotást.Köszi mindenkinek a segítséget.
-
Ablakos
addikt
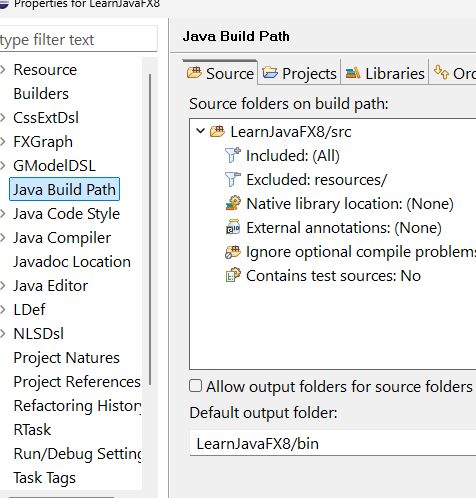
Valószínűleg azért találja meg a második megoldásod, mert ott explicite kikötöd neki, hogy az src-ben keresse a fájlt, és ugyanezen okból hiszem azt, hogy az az
Excluded: resources/lesz a ludas.Ugyanis ezzel azt mondod az ecplise compilerének, hogy a resources mappát hagyja figyelmen kívül, ne tegye át a bin alá, és amikor futtatod, valószínűleg a kódod a bin-ben keresi a fájlt. Töröld azt az exclusiont, ellenőrizd, hogy átkerültek-e a fájlok a bin-be a fordítás során, és hogy működik-e immáron az első megoldás. Remélem igen, mert ha nem, akkor hülyeséget beszélek.

Igen, ez volt a megoldás. Eddig nem nyitottam le source folder fát. Nem tudtam, hogy ilyen szűrők vannak itt.
Köszönöm!!!
-
Ablakos
addikt
Csak érdekes, hogy ez a kód az idézett URL-es kódom helyett már nem dobja a null kivételt.
String fxmlDocPath = "file:src/resources/fxml/sayhello.fxml";URI uri = new URI(fxmlDocPath);URL fxmlURL = uri.toURL();De visszatérve az eredeti minta részletre a BuildPath
-
Ablakos
addikt
Végig szöszöltem az OCP idevonatkozó részét, és most fedeztem fel, hogy átléptem a
"If the catch or finally block throws an exception, no suppressions
happen" elég fontos szabályt. Ezen értetlenkedtem.
-
Ablakos
addikt
Még egy kis kiegészítés a comparator implementációhoz.
Ha nagyon nagy számokkal dolozunk, akkor nem szerencsés a kivonásos módszer használata, pl. ap1.getLiteracyRate() - p2.getLiteracyRate(). Ugyanis ha egy nagyon negatív számból kivonunk egy nagyon pozitív számot, akkor az eredmény túlcsordulhat és átcsap az ellenkező előjelbe, ami nyilván elrontja az egész sorrendezést.
Érdemes inkább a relációs operátorokat (<, >) használni a kivonás helyett.(Most nincs lehőségem kipróbálni, ezért kérdezek.
)Ebben az esetben az intermediate egy int eredményt vár, hogy sortolja a stream-et. A kacsacsőr boolean-t ad vissza. Vagy ezt az igaz/hamis értéket még vizsgálni kell operátorral? Így kell érteni?
-
Ablakos
addikt
A
partreferenciája nem szűnik meg, ha arra gondoltál. A belepakolt Stringeket a clear ugyan eltávolítja a listából, de apartél és virul. Egy referencia akkor szűnik meg, amikor semmilyen más élő objektum nem hivatkozik rá (mert mondjuk az utolsó hivatkozást is felülcsapod valami más referenciával).
Na meg a vezérlés kifutott a scope-jából is, ami a part esetén a metódus kapcsos zárójelei között található. (Ha a while ciklus kapcsos zárójelei közé tennéd a part deklarációt, akkor az lenne az ő scope-ja és minden körben új példány készülne belőle, de azt most nem akarod.)A csoda a
listRecipes.add(new Recipe(part));soron történik, apartreferenciáját megjegyzi a recipe ojjektum is - immáron nem csak apartváltozó fog arra hivatkozni -, az ő referenciáját pedig beledobjuk alistRecipeslistába, így az már nem vész el addig, amíg alistRecipeslétezik.Tehát a clear helyett bátran csinálhatsz egy új lista objektumot a
partváltozódnak, sőt illene is, ha nem akarod piszkálni a régi lista tartalmát, ami már alistRecipesbugyraiban pihen.Köszönöm, teljesen világos. Tehát a part.clear() helyett egy part = new ArrayList<>() a megoldás.
(Sajnos az elmélet és a gyakorlat még nincs szinkronban nálam. Tudom, hogy referenciával megy az objektum másolás, de én foxi módra eltökéltem hogy átmásolódik az egyik lista tartalma a másikba.)
Tudom, hogy referenciával megy az objektum másolás, de én foxi módra eltökéltem hogy átmásolódik az egyik lista tartalma a másikba.) -
Ablakos
addikt
A
containsteljeskörűen működik. Ha belenézel azObjectosztályba (ami minden osztály őse), láthatod, hogy azequalsmetódus referenciák egyenlőségét vizsgálja - lévén más információja nincs az osztályról. Azt csinálja, mint amit az == operátor.Tehát az
equalsés egyben acontainsalapértelmezett működése az, hogy csak akkor tekint két objektumot egyenlőnek / a lista egy tagjának, ha az az objektum ugyanaz az objektum, mondjuk úgy, hogy ugyanazon a memóriacímen található adathalmaz.Abban a pillanatban, hogy kiadod a
newutasítást, a jvm egy vadonatúj objektumot fog gyártani neked. Még ha ugyanazt a szöveget adod is meg neki a könyv címe paraméterben, még ha ugyanaz az évszám, még ha látszólag ugyanúgy is néz ki az az objektum, mint egy másik, a referenciájuk eltér, hiszen anewutasítással ezt kérted a jvm-től, egy új objektumot.A referencia alapú összehasonlítás időnként hasznos dolog, de a modelljeinkben többnyire nem ez a legjobb megoldás. Ezért készítünk az objektumainknak saját
equalst, amikor azokat egymással össze akarjuk hasonlítani, és azt várjuk el tőle, hogy egyenlőnek tekintsen két könyv objektumot, ahol a cím és az évszám egyenlő. Ezt sajnos meg kell írnod, mert a jáva túl buta, hogy kitalálja a programozó gondolatait, elvárásait.
(És készítünk nekik saját hashcode implementációt is, amikor azokat mondjuk HashSet-ben kívánjuk gyűjtögetni, vagy HashMap kulcsaként akarjuk felhasználni.)Tehát a
Book b1 = new Book("a", 1);és aBook b2 = new Book("a", 1);eltérő referenciával bír, az alapértelmezettequalsszerint ők különböző objektumok. Míg aBook b3 = b1;ugyanazzal a referenciával bír, mint a b1 objektumod, az alapértelmezettequalsszerint ők ugyanazok az objektumok.Értem és köszönöm a magyarázatot.
-
Ablakos
addikt
Egy félrenyelésnél is nemzetiségi útra megy az étel és az óvodában, iskolában is kisebbségi kereket kell vetni. Jobb ha megbarátkozunk ezzel.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
 floatr
veterán
floatr
veterán
-
 skoda12
aktív tag
skoda12
aktív tag
Részvétem. Mindig nehéz azokkal, akik csak a pénzért csinálják.
Azt mondjuk nem értem, hogy ki másnak kellett volna megtalálni a PR-ben elrejtett dolgokat. Aki hozzáfér a PR-hez, az megtalálhatja. Mondjuk ha csak 1 ember rivjúzik a csapatban, akkor kézenfekvő, hogy ki fogja megtalálni a hibákat.Az volt a problémájuk, hogy a PR-be már eleve nem kellett volna kimennie a problémák egy részének, hanem a devnek kellett volna valamilyen szinten átnéznie a saját kódját mielőtt kiküldi reviewra. Senior devtől kevesebb ilyen jellegű problémát vártak.
-
skoda12
aktív tag
Ezek szerint akkor olyan dolgokba kötöttél bele, amibe felesleges lett volna?
Ha nem, akkor most hagyod elrothadni a kódot?
Mindezt azért, mert a csapatod tagjai nem alkalmazzák a közösen elfogadott kódolási irányelveket. (Gondolom, közösen fogadtátok el. Sőt gondolom, időnként felül is vizsgáljátok azokat.)
És azért is, mert páran nem elég érettek a felnőtt viselkedésre? Akik a tévedésekre való rámutatást nem fejlődési lehetőségnek, hanem személyes sértésnek veszik.Mindezekből következően saját magad és voltaképp még a crybaby csapattársaidat is megszívatod az egyre jobban degradálódó kóminőséggel. Megéri? Azon csapattársaid, akik jó minőséget állíta(ná)nak elő, őket is a gányolás keserédes mezejére száműzöd ezzel. Nem?
Amúgy abszolút egytértek a mondandód első felével, én sem vagyok büszke az 5 éve írt kódomra, hát még az 1997-ben írtakra.
 Viszont ez azt is jelenti, hogy ma már sokkal jobbat tudok alkotni, és holnap mégjobbat fogok tudni. A sun is biztosan jobbat írna ma, mint, amit most látunk belőle.
Viszont ez azt is jelenti, hogy ma már sokkal jobbat tudok alkotni, és holnap mégjobbat fogok tudni. A sun is biztosan jobbat írna ma, mint, amit most látunk belőle.Nem gondolom, hogy felesleges kötekedés lett volna részemről. Volt ott minden, közösen elfogadott irányelvekkel való szembemenetel újra és újra, túlbonyolított kód (többszáz sor, ami pár tíz sorra redukálható), unorthodox megoldások pl hashmapből key alapján for looppal érték visszakeresése, funkcionális hibák, nem azt implementálták, amit a ticket kért vagy 5 requirementből csak 4-et sikerült implementálni, stb.
De most ez nyilván rosszul jön le, mert az látszik, hogy egy embernek több másikkal volt konfliktusa és a többségnek általában igaza van. Azért utólag 1 emberről megtudtam, hogy amikor lekérték arról a projektről, akkor több más ok mellett az is elhangzott fentről, hogy rendszeresen túl sok olyan dolgot találtam a PR-jeiben, amit nem nekem kellett volna megtalálni.
-
 mobal
nagyúr
mobal
nagyúr
Voltam olyan projekten, ahol már már megszállottságig fajult az új dolgok megtanulása. Hetente cseréltük le a félig magunkévá tett libeket valami fancy újra, és integráltuk bele az alkalmazásba újra és újra és újra, mindig volt valami hot topic. Brr. Na de ez a másik véglet. Talán nem kell mondanom, az alkalmazás elkészülte folyamatosan csúszott. Talás sose készült el, már nem vagyok ott, hogy ezt megtapasztalhattam volna.
Nekem annyit adott az a projekt, hogy megtanultam a világ túl gyorsan változik, hogy minden újat meg akarjak tanulni - nem is lehet - és elveszi az időt az értelmes dolgokban való elmélyüléstől. Persze megértem, hogy másokat meg csak az újdonság érdekel, és nem zavarja őket az a sok zaj a fejükben, aminek a felére holnap már senki sem emlékszik amúgy, mert csak hype volt körülötte. Azt meg végképp nem tudom hova tenni, ha valakit az alapján ítélünk meg (el?), hogy mavent vagy gradlet használ, neadjisten antot. Ha neki ettől jobb, váljon egészségére.
Vagy menjen és vezesse le a feszkót maven irtással, addig sem zavarja a terméken dolgozó népeket. 
Amúgy utálom az xml-t, és szeretem a mavent. Há!
"ha valakit az alapján ítélünk meg (el?), hogy mavent vagy gradlet használ"
Én nem ítélek meg senkit ez alapján. Le is írtam az elején, hogy nem akarok ebből most keresztes háborút, és továbbá azt is, hogy fiatal vagyok xml-ek irogatásához. Amit leírtál szerintem szélsőséges, fontosnak tartom, hogy hozzuk be az új dologokat de nem kell a ló másik oldalára esni.
-
floatr
veterán
Úristen, ez már ennyi ideje így működik?
Értem én, hogy kényelmes, de azért na, hát mióta nem antipattern a repository megnyitása a nagyvilágnak?! Legalább egy bekapcsoló annotációt el tudtam volna képzelni ehhez a remek fícsörhöz.
Minden esetre nagyon köszi a linket, ma is okosabb lettem.Eleve a data-rest csomag kérdéses. Nem erőltetném, pláne ha összetettebb az adatmodell
-
Drizzt
nagyúr
What kind of sorcery is this?
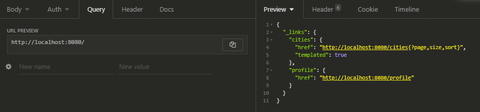
Spring boot 2.4.0, data-jpa és data-rest függőségekkel. Jó, van még egy h2 db, meg egy actuator, de az nem számít. Semmi konfiguráció, sem extra függőség, nem értem.
Szóval csináltam egy hót egyszerű spring boot appot, tettem bele egy City nevű jpa entity-t, meg hozzá egy töküres JpaRepository-t. Zéró REST végpont mutat bárminemű City-vel kapcsolatos dologra, mégis, amikor megkérdezem a root végpontot, akkor ezt a fenti izét nyomja az arcomba.
Az összes végpont, amit csináltam egy "/hello", és a hello world-ön kívül semmit sem csinál.Már átnéztem a spring doksi teljes hateoas szócikkét, de egy falat megjegyzés sincs arról, hogy a spring kitalált nevű végpontokat szór fel nekem az alkalmazásomra csak úgy, expozálva ezáltal az app belső dolgait, konkrétan az entitások neveit. Egyrészt ez felháborító, hogy kérdés nélkül ilyet csinál, másrészt ti találkoztatok ezzel? Miatököm csinálja, és hogyan lehet kikapcsolni?
Ez a Spring Data Rest default viselkedese. Convention over configuration, mint megannyi mas helyen a spring bootban.
Megfeleloen uj Spring verziokkal o lesz a baratod: [stackoverflow: set exposed repositories to annotated only. ] -
 togvau
senior tag
togvau
senior tag
Én például onnan tudom, hogy valamikor régen olvastam a hibernate dokumentációjában. Szerintem elég közismert dolog... legalábbis a dokumentációba belelapozó emberek között. Én úgy vagyok vele, hogy ha igényes munkát akarok végezni, akkor érdemes megismerni a használt frameworkot kicsit közelebbről is. Így amikor fikázom, talán kisebb eséllyel teszem magamat nevetségessé.
szerk.: A jelenség a transient módosítótól teljesen független.
Én arra se emlékszem amit múlt héten olvastam, főleg ha nem találkozok rendszeresen az ott olvasott dologgal. Sajnos nem fér el a sok számot, kis-nagybetűt, és most már speciális karaktert is kötelezően tartalmazó jelszavak, meg az évszak divatjainak megfelelő frameworkok felesleges infoi mellé.
Annyira nem közismert, hiszen akkor a google-n rögtön kidobott volna rá ilyen megoldást, még is, erre a hibára csak a rossz importos válaszú dolgokat dobta fel.
Igényes munkát nem akarok végezni, hiszen egy igénytelen ürülékrakást kell úgy ahogy használhatóvá tákolni, hiszen újraírásra (amivel igényessé lehetne tenni) nincs pénzMi a nevetséges abban, hogy egy hiányosságot fikázok? Ez egy marhaság. Default mindkettőt néznie kéne. De legalább is specifikus errorban jelezni, hogy máshogy kéne.
-
togvau
senior tag
Kicsomagolod, castolod a belét, becsomagolod. Mondjuk, amit az Optional.map() csinál, ha már az Optional a példa.
disclaimer: Remélem azt nem kell mondanom, hogy ha a kalapács nyelével akarod beverni a szöget, akkor ne csodálkozz, ha körülményes. Ha mondanom kell, akkor egy java software design témájú könyv elolvasása szerintem hasznos lenne. Valami a nagyoktól: Josh Bloch, Bob Martin, Kent Beck, Fowler, ...
Ja igen, zavarbaejtően sok állítmány és szleng került a mondataidba, nem vagyok benne biztos, hogy jól értem a problémát, de van egy olyan érzésem, hogy máshogyan illene struktúrálni azt a kódot.
nem tűnt fel, hogy egy idióta által fejlesztett rakás ürüléket próbálok vállalható állapotba hozni? Úgyhogy a design BS-el nem tudok mit kezdeni.
-
 Csaby25
őstag
Csaby25
őstag
Én ezzel úgy vagyok, hogy mivel a technológiák úgyis jönnek-mennek, nettó időpazarlásnak érzem bármilyen céleszköz megtanulását.
A java gyermekkorában csak az awt eszközkészlet állt rendelkezésre, hogy az ember desktop guit gyártson jávában, de elég lowlevel volt, platformonként eltért a végeredmény. Aztán évek múltán ráhúzták a swinget, amivel már egészen egységes látványt lehetett rajzolni és elég sokáig életben is maradt ez az eszköz. Bár az awt ismeretek jól jöttek, de azért kellett új kocepciókat újratanulni. Majd néhány (sok) évvel ezelőtt valamilyen megfontolásból - feltételezem, modernizálási célzattal -, készítettek egy másik eszközt desktop gui rajzoláshoz, elnevezték javafx-nek, és ugyanazzal a lendülettel deprecated is lett a swing. Nyilván teljesen más koncepciók mentén készült, így megint kellett rengeteget tanulni. Nem mintha ítélkeznék e fölött, mert egyikhez sem volt túl sok közöm. Aztán néhány (már nem olyan sok) évvel ezelőtt azt mondták, hogy oké, most már a javafx-et sem támogatjuk, halott világ a desktop gui világa, a web a jövő.
És ez csak egy példa a sok közül, egyszerűen nem lehet mindent is életben tartani, így végső soron azok lesznek a túlélők, akik általános megoldást tudnak nyújtani számtalan problémára... vagy ha képesek a készítőik végtelen ideig fenntartani a hype-ot az eszközük körül, esetleg végtelen pénzzel megtámogatva nem jelent nekik gondot a támogatás finanszírozása.A lényeg, amit ki akartam hozni mindebből, hogy desktop gui építésre való eszközzel nem igazán lehet webappot csinálni. Webapp ismeretekkel viszont bármit készíthetek, ami elfut egy böngészőben, és azt a böngészőt akár egy desktopon is lehet üzemeltetni. Van overhead, igen, nem optimális megoldás, igen. Fejlesztőként viszont nekem fontosabb, hogy milyen gyorsan avul el a tudásom. Szívesen tanulok meg egzotikumokat is, ha az feltétlenül szükséges egy munka elvégzéséhez. Már csak azért is, mert adhat egy másfajta nézőpontot, amit a mainstream-től sose kapnék meg. De attól még nem feltétlenül szívatom magam olyan felesleges dolgok megtanulásával, amelyekre néhány éven belül várhatóan csak egy szűk rétegnek lesz igénye.
Annak a megítélését pedig, hogy a desktop mennyire halott és a javafx mennyire felesleges, másra bízom, mert nem áll szándékomban a saját jövőképemet / ízlésemet másra erőltetni. Mindenki döntse el maga, miben látja a jövőt. A zsákutcákat úgy általában én elkerülném. Pláne akkor, ha az embernek erősen korlátozott a rendelkezésre álló ideje. Még egy ok, hogy fókuszáltan, a lehető legrövidebb idő alatt a lehető legszéleskörűbb ismeretetet szedje fel.
Aki meg szeret kockáztatni, az kinézhet magának egy ritka egzotikumot, arra építve, hogy senki sem tanulja, mert mindenki utálja, igény viszont van rá (elavult banki mainframe-en futó szoftverek megvannak?), és majd jó zsíros fizetést lehet elkérni a melóért. Annyira egyénfüggő, hogy mi a jó választás, ki mit szeret.
--- szerk.: Az android / ios ugyanez az általános vs céleszköz téma pepitában. Egy androidon is van böngésző, ergo egy webapp azon is működik, és zéró android ismeret felszedése kell hozzá.
Lehet, hogy félreértettél, én nem kimondottan JavaFX-t akarok tanulni, de mivelhogy a legtöbb Java kezdőtanfolyam tartalmazza, ezért gondoltam nem hagyom ki és szánok rá egy kis időt. Láttam, hogy már régi de úgy tudom ez a legújabb GUI Java-ra.
-
 mateo91
tag
mateo91
tag
"Most azt csináltam hogy ezt az eclipse mappát töröltem."
Persze, miért ne, pótalkatrész!
Azt nem tudom, hogy eclipse mappa nélkül hogyan tud működni, mivel az adja a felhasználói felület vázát (ezekszerint mégsem), de örülök, hogy sikerült működésre bírni.eeepc: Az ilyen kompakt cuccokkal óvatosan kell bánni, mert a vas okozhat kompatibilitási problémákat. Nem is olyan régen volt egy NASom, szerettem volna jávát telepíteni rá, amikor is kiderült, hogy ARM proci van benne és max csak valami kiherélt, butított jávát támogat. Az Intel procival szerelt változatot kellett volna vennem, mert azon nagyobb eséllyel működnek a PC-re készült programok.
A másik lazábban kapcsolódó sztori, hogy egy huszonvalahány éves PC-re sem sikerült már bármit telepítenem, sőt egyre kevesebb dolgot, mert annak a procija ugyan intel, de nem támogatja pl. az SSE utasításkészletet, és úgy tűnik az egy rendkívül fontos dolog. Szóval csak azt akarom mondani, hogy kockázatos PC-re írt szoftvert használni egy nem "igazi" PC-n, mert nem biztos, hogy működni fog.amd procis, amúgy eskü erre is gondoltam, nem e hardveres probléma.
1gb rammal volt nekem is de bővítettem 4gbra,nincs gond. -
 axioma
veterán
axioma
veterán
"Most azt csináltam hogy ezt az eclipse mappát töröltem."
Persze, miért ne, pótalkatrész!
Azt nem tudom, hogy eclipse mappa nélkül hogyan tud működni, mivel az adja a felhasználói felület vázát (ezekszerint mégsem), de örülök, hogy sikerült működésre bírni.eeepc: Az ilyen kompakt cuccokkal óvatosan kell bánni, mert a vas okozhat kompatibilitási problémákat. Nem is olyan régen volt egy NASom, szerettem volna jávát telepíteni rá, amikor is kiderült, hogy ARM proci van benne és max csak valami kiherélt, butított jávát támogat. Az Intel procival szerelt változatot kellett volna vennem, mert azon nagyobb eséllyel működnek a PC-re készült programok.
A másik lazábban kapcsolódó sztori, hogy egy huszonvalahány éves PC-re sem sikerült már bármit telepítenem, sőt egyre kevesebb dolgot, mert annak a procija ugyan intel, de nem támogatja pl. az SSE utasításkészletet, és úgy tűnik az egy rendkívül fontos dolog. Szóval csak azt akarom mondani, hogy kockázatos PC-re írt szoftvert használni egy nem "igazi" PC-n, mert nem biztos, hogy működni fog.eeepc-m volt, sima windows intel minden, de valami 1GB ram-mal
-
 Superhun
addikt
Superhun
addikt
-
togvau
senior tag
ott ahol 1-1 van, ott onetoone is van.
Kipróbáltam viszont egy ilyet, hogy végül is 1 lekérdezésben legyen minden ami épp kell
@Query("SELECT u.id, p, (SELECT ph.id FROM Photo ph WHERE ph.user.id = ?1) FROM UserProperties p LEFT JOIN FETCH p.user u WHERE u.id=?1")public Triplet<Long, UserProperties, List<Long>> stb...erre: jdbcSQLDataException: Scalar subquery contains more than one row; SQL statement
És ez igaz is, pont azért van ott long list. Akkor miért sír? -
togvau
senior tag
nem. Az ugyan azt írja 20x, ahogy szokta, hogy nem talál megfelelő osztályt a szerializáláshoz (mert nincs is olyan félig összeszedett entity), de amúgy a json serializációig minden rendben, előtte kiíratom a visszaadott objektumot, onnan is látom, hogy spamet rak bele.
Nagyon furán működik ez a spring data.pl van 2 entity, 1-1 kapcsolattal. Kellene nekem a "gyerek" összes infoja, a szülő id-ja alapján.
@Query("SELECT p FROM UserProperties p INNER JOIN User u ON u.userProperties = p.id WHERE u.id=?1")@Query("SELECT u.userProperties FROM User u WHERE u.id=?1")
2 queryt eredményez mindkettő, ahol összejoinolja ahogy az első queryben van, majd még egy query ahol a User-t lekérdezi ugyan olyan where-el... tehát 2x megcsinálja ugyan azt. Akár lazy, akár eager a kapcsolat. Akkor is megcsinálja, a user repository findbyid-t nyomok.Ok hogy id alapján történik minden, ami szinte ingyen van, de na... Tényleg csak natív queryvel lehet beleverni, hogy egy queryvel megcsinálja ezt? Vagy a spring show sql nem azt írja ki ami tényleg történik? Vagy el van cseszve a H2 driver?
-
Csaby25
őstag
Azért mindennek van határa!
A stream api és a lambdák nem azért léteznek, hogy másképp is lehessen for ciklust írni.Azért használunk steam apit, mert komplexebb műveleteket is egységbe zár, kis túlzással atomi műveletként tudunk rá tekinteni. Más szóval nincs mellékhatása, ezért szeretjük. Nyilván, ha valaki nem jól használja, akkor lehet mellékhatása, és néhány esetben a fordító meg is fogja ezeket a hibákat, ahogy az látható. Sajnos más esetekben nem fogja meg. Ez szintén látható a legutolsó kinyilatkoztatásból.
Mellékhatásnak tekintünk minden olyan változást a futó program állapotában, ami a monadon (az az egység amin pl. a stream műveleteket alkalmazod) kívül történik. Ezt most jó hülyén fogalmaztam meg, remélem érthető. Tehát az, hogy például a foreach-en (mapen, filteren, stbn) belül egy akármilyen azon kívül eső változó értékét buzeráljuk, az mellékhatás. A lambda nem nyúlhat a saját scope-ján kívül. Elméletben. Gyakorlatban persze meg lehet tenni, csak igénytelen kódot eredményez. Mellékhatásokkal. Értelmét veszti az egész koncepció. Nem véletlenül ragaszkodik a fordító is ahhoz, hogy final dolgok legyenek a lambdában behivatkozva. Final, tehát nem változtatható. Egyszer értéket kap és úgy marad. Ha neked nem így struktúrált a kódod, akkor nem a lambda a jó megoldás. Vagy átstruktúrálod úgy, hogy jó legyen, ez már egyéni preferencia kérdése.
Légyszives ismerkedjetek meg a monad fogalmával, mielőtt ilyen gusztustalan bűnöket követtek el.
Addig meg légyszi maradjatok a for ciklusnál. Az tökéletesen fog működni. Mert annak nem célja a mellékhatások kiküszöbölése. Bár nem néztem át tüzetesen a problémás kódot, de a hiba környékén lévő szándék számomra azt mutatja, hogy ott a for ciklus a gyors megoldás.Köszi, asszem...

-
 Taoharcos
aktív tag
Taoharcos
aktív tag
Azért mindennek van határa!
A stream api és a lambdák nem azért léteznek, hogy másképp is lehessen for ciklust írni.Azért használunk steam apit, mert komplexebb műveleteket is egységbe zár, kis túlzással atomi műveletként tudunk rá tekinteni. Más szóval nincs mellékhatása, ezért szeretjük. Nyilván, ha valaki nem jól használja, akkor lehet mellékhatása, és néhány esetben a fordító meg is fogja ezeket a hibákat, ahogy az látható. Sajnos más esetekben nem fogja meg. Ez szintén látható a legutolsó kinyilatkoztatásból.
Mellékhatásnak tekintünk minden olyan változást a futó program állapotában, ami a monadon (az az egység amin pl. a stream műveleteket alkalmazod) kívül történik. Ezt most jó hülyén fogalmaztam meg, remélem érthető. Tehát az, hogy például a foreach-en (mapen, filteren, stbn) belül egy akármilyen azon kívül eső változó értékét buzeráljuk, az mellékhatás. A lambda nem nyúlhat a saját scope-ján kívül. Elméletben. Gyakorlatban persze meg lehet tenni, csak igénytelen kódot eredményez. Mellékhatásokkal. Értelmét veszti az egész koncepció. Nem véletlenül ragaszkodik a fordító is ahhoz, hogy final dolgok legyenek a lambdában behivatkozva. Final, tehát nem változtatható. Egyszer értéket kap és úgy marad. Ha neked nem így struktúrált a kódod, akkor nem a lambda a jó megoldás. Vagy átstruktúrálod úgy, hogy jó legyen, ez már egyéni preferencia kérdése.
Légyszives ismerkedjetek meg a monad fogalmával, mielőtt ilyen gusztustalan bűnöket követtek el.
Addig meg légyszi maradjatok a for ciklusnál. Az tökéletesen fog működni. Mert annak nem célja a mellékhatások kiküszöbölése. Bár nem néztem át tüzetesen a problémás kódot, de a hiba környékén lévő szándék számomra azt mutatja, hogy ott a for ciklus a gyors megoldás.Mondtam, hogy nem túl szép.

Egyébként teljesen igazad van. -
 p76
senior tag
p76
senior tag
-
 ReSeTer
senior tag
ReSeTer
senior tag
Néhány egyszerű példa:
String[] valami = { "ez", "az", "amaz" };System.out.println(valami[0]); // ezString az = valami[1]; // azSystem.out.println(valami[2]); // amaz
Egy lépésben építettem egy 3 fiókos szekrényt és mindegyik fiókba tettem 1-1 szót. Ezekre a fiókokra a szögletes zárójelben lévő számmal tudok hivatkozni és tudom felhasználni a bennük tárolt szavakat, például értékül adhatom egy másik változónak, vagy kiírhatom konzolra, stbstb. Vedd észre, hogy nullától számozódik. Próbáld ki más számokkal is.String[] masValami = new String[4];masValami[0] = "ez";masValami[1] = "az";masValami[2] = null;
Itt az első lépésben csak létrehoztam egy 4 fiókos szekrényt, de üresen. Ezt követően tettem valamit az első (0) és második (1) fiókjába. A harmadik fiókba (2) explicite null-t tettem, a negyedik fiókhoz (3) nem nyúltam, de annak az értéke is null. Egy üres fiókban null van.String[] megintMas;megintMas = new String[]{ "ezt", "csak", "ilyen", "terjengősen", "lehet" };megintMas[1] = "CSAK";
Itt először csak jelzem, hogy lesz egy fiókos szekrényem, de nem tudom, mekkora. A második sorban jönnek létre a fiókok (5 db), amiket fel is töltök. Az utolsó sorban pedig a második fiókban (1) lévő szöveget lecserélem arra, hogy "CSAK".
Játsz vele, kombináld, nézd meg, hogy mi működik és mi nem. Sok sikert.Ja igen, nem csak Stringgel működik, hanem más típusokkal is:
int[] szamok = { 4, 2, 3, 9 };szamok[0] = 8;int ketto = szamok[1];Ok, érthetőnek tűnik.
Kösz a válaszokat! -
p76
senior tag
"Good Comments
Some comments are necessary or beneficial. We’ll look at a few that I consider worthy of the bits they consume. Keep in mind, however, that the only truly good comment is the comment you found a way not to write."Robert.C.Martin: Clean Code
-
 Mr K
őstag
Mr K
őstag
-
Mr K
őstag
SajatClass sajat = new SajatClass();try {sajat.futtat();} finally {sajat.ment();}
Ha kivétel történik a futtás során, a mentés akkor is megtörténik. Ez inkább javallott, mint a finalize() funkció használata. Vagy akár a sima metódus szekvencia. Mondjuk ha hiba esetén mégsem szeretnél menteni, akkor felejtsd el, amit írtam, arra tényleg jó a szekvencia.Neked nem kell kézzel semmit sem takarítani, a garbage collector majd teszi a dolgát, nincs destruktor. De ezt már írták.
A finalize általában nem fog működni:
public class T {
static void p(String msg) { System.out.print(msg); }
public static void main(String[] args) {
p("started"); T t = new T(); t = null; p(" finished");
}
private T() { p(" constructed"); }
@Override protected void finalize() { p(" finalized"); }
}
(Kimenet: started constructed finished)Ha a teszt JVM-emen beszúrok egy GC-t, akkor javul a helyzet:
p("started"); T t = new T(); t = null; System.gc(); p(" finished");
(Kimenet: started constructed finished finalized)De azon túl, hogy egy normális programot nyilván nem lehet telehinteni GC hívásokkal, az egész viselkedés még a garbage collector implementációjától is függ, szóval a finalize egyáltalán nem megoldás a problémára.
-
 Keem1
veterán
Keem1
veterán
Java konfigurációk esetén nekem először a properties fájl ugrik be, faék egyszerűségű textfile kulcs-érték párokkal. Lásd mondjuk: [link]
Ennek "modernebb", spórolósabb változata a yaml, de ha neked az ini tetszik, biztos az is jó. Mondjuk ha nem kötött, hogy csak ini lehet, én ezért nem hoznék be egy libet, hogy néhány konfig cuccot tároljak.Nincs az a metódus, ami megfut, ha azt mondod a programnak, hogy kill.
Persze ha normál terminálásra gondolsz, akkor izé... nem értem a kérdést.
A main metódus a be és kilépési pont. Megírod a kezecskéddel, hogy milyen esemény hatására terminálódjon a programod, és előtte azt mentesz, amit akarsz.Esetleg a jvm shutdown hook-ra gondoltál? Lehet haszna, de nézz utána, hogy mikor hogyan működik, mert egy egyszerű programnál én nem biztos, hogy szórakoznék vele.
---
Trubad Úr. Én szívesen megcsinálom neked. 1M HUF lesz.

Nem-nem, egyáltalán nem ragaszkodom az ini-hez (elsőre platformfüggetlenként ez ugrott be), ezt a properties-t is meg fogom nézni (
). Alapvetően ilyenre a registry-t használnám alapesetben, de ugye mint írtam, linuxon is futtatni kéne a cuccost.Szerintem az lesz, hogy:
main(){kezdő();.... // tényleges metódusokvégző();}Alternatíva:
main(){SajatClass sajat = new SajatClass();sajat.Futtat();}
Ahol a külső osztály destruktorába tenném esetleg, vagy valami finalize.Nem bonyolítom túl. Abból akartam kiindulni, hogy hátha lehetne a main-t tartalmazó osztálynak egy destruktort írni, ami felszabadít mindent, és egyúttal a konfig adatokat is fájlba írja. De ahogy olvastam, ilyen nincs. Ugye, nincs?
-
mobal
nagyúr
Értelek, egy 20 éves tapasztalattal rendelkező jelentkezőnél valóban béna dolog a kódminőség felől érdeklődni, tiszta sor. Ezer ennél relevánsabb kérdést is feltehetnének. Ugyan korrigálhatnám a neked feltett kérdésemet úgy, hogy mit válaszolnál a kérdésre akkor, ha junior lennél egy junior pozira, de érzem, hogy a válaszod ugyanaz lenne.
Nekem nincs ennyi év a hátam mögött, de úgy vélem 20 éves múlttal sem feltétlenül sértődnék meg egy ilyen kérdésen, szerintem ha ez érdekli az interjúztatót a legjobban, akkor szíve joga rákérdezni. Nyilván annak is tudatában van a HR (ha meg nincs akkor így járt), hogy egy ilyen kérdés feltevése milyen színben tünteti fel őket. Szerencsére az állásinterjún a felvételizőnek is van lehetősége arról beszélgetni, amiről konkrétan ő szeretne, és én jelöltként is ugyanúgy elvárom a felvételiztetőtől, hogy készséggel válaszoljon a kérdésemre, mint fordított helyzetben. Nem kellemes, amikor megítélik az embert a feltett kérdése alapján. De legalább hamar kiderül, hogy nincs meg az összhang, próbaidő sem kell ennek a megállapításához.
Talán azért ez a véleménykülönbség, mert sokat szívtam legacy kóddal, és sokkal jobban megérint a kódminőség (hiánya), mint másokat. És mivel eddig szinte minden kollégámmal jól kijöttem, annyira nem szokott érdekelni, mennyire jól tudok velük együtt dolgozni... eddig mindig sikerült jól együtt dolgoznunk. Esetedben meg talán máshol vannak a hangsúlyos pontok.
Ez az oka annak is hogy ráugrottam a hozzászólásodra, mert mérhetetlenül sajnálatosnak tartom, hogy a menedzserek mellett sok fejlesztő is tesz a minőségre (szinte lényegtelen összetevőnek tartják), és nem látják, hogy ezzel a saját vagy sorstársaik életét teszik pokollá hosszú távon. Azt hiszem a válaszaimmal igazából csak keresem a megerősítést, hogy valóban az a jó irány, ha a határidőt, a rövid távú sikereket tartja az ember szem előtt. Egyelőre nem sikerült meggyőznöm vagy meggyőzetnem magam, de igyekszem.----
PeachMan:
Hogy ON is legyek, nálam a model az entitás réteget jelenti - vagy perzisztens réteget, ahogy te fogalmazol. POJOk, amelyek már jávául íródtak, de közvetlenül a DB-be mentjük őket és DB-ből töltjük fel őket. Az ORM akítvan használja őket, lévén ők képezik az O-t az ORM-ben.
A DTO (Data Transfer Object) pedig adatok továbbításáért felel a komponensek között, ez jellemzően magasabb rétegekben jelenik meg (ha a perzisztens réteg van alul és a view felül).Hogy mennyire szép elfelejteni a DTO-kat és mindenhol csak a modelt használni, nos, szerintem ez komplexitás kérdése. Egy szép világban nem lenne szükség DTO-ra, mert minek lekopizni valamit pusztán azért, hogy 2 service beszélgetni tudjon egymással. De van egy rakás oka, amiért mégis van létjogosultsága.
Lehet technológiai oka, mondjuk az ORM meg tud zavarodni, ha egy entitásban több collection is van, DTO-k bevezetése jó workaround tud lenni. Te is említetted, hogy a view-nak nincs szüksége minden mezőre, ez is egy valid ok. Főleg akkor, ha nemcsak nincs szüksége, hanem egyenesen tilos egy view-nak látnia minden adatot. Lehet ok a sebesség optimalizálás. Ha egy view-nak csak 1-2 mező kell egy 20 oszlopos táblából, nagyon nem mindegy, hogy mind a 20 mezőt áttolod-e egy microservice-ből a másikba, vagy csak a szükségeseket. Egy DTO-t létre lehet hozni azzal a 2 szükséges mezővel és azt passzolgatni. Az sem mindegy, hogy egy entitásban a kapcsolódó táblák adatai is feltöltésre kerülnek vagy sem, és erre a view-nak szüksége van-e vagy sem. Van, hogy az ORM-et megkerülve jpql vagy akár natív sql végrehajtásával kell felszívni bizonyos adatokat, mert annyira tetü lassú lenne máskülönben, hogy a user megunja az életét. Ez már egy optimalizációs indok lehet, és nem is a fejlesztés legelején kell erről gondolkodni, hanem a végén, de akkor marha nehéz lesz átállni DTO-ra, ha eddig végig az entitásokat passzolgattuk a komponensek között.
Gondolom vannak érvek a model használata mellett is, de most nem jut eszembe ilyen, és biztosan jön valaki, aki arról is tud mesélni. Ja igen, az ORM is nyújthat megoldásokat az általam fentebb felvetett indokokra, csak nem ismerem annyira mélyen őket, hogy mindegyikre tudnék mondani valami dögös annotációt.
DTO-t használni nekem könnyebbség. Nagyobb rugalmasságot ad. Ha változik a model, nem feltétlenül kell a service rétegen keresztülverni a változásokat pl.20 éves múlttal is szerintem ugyan olyan fontos a kódminőség kérdése.
-
axioma
veterán
Értelek, egy 20 éves tapasztalattal rendelkező jelentkezőnél valóban béna dolog a kódminőség felől érdeklődni, tiszta sor. Ezer ennél relevánsabb kérdést is feltehetnének. Ugyan korrigálhatnám a neked feltett kérdésemet úgy, hogy mit válaszolnál a kérdésre akkor, ha junior lennél egy junior pozira, de érzem, hogy a válaszod ugyanaz lenne.
Nekem nincs ennyi év a hátam mögött, de úgy vélem 20 éves múlttal sem feltétlenül sértődnék meg egy ilyen kérdésen, szerintem ha ez érdekli az interjúztatót a legjobban, akkor szíve joga rákérdezni. Nyilván annak is tudatában van a HR (ha meg nincs akkor így járt), hogy egy ilyen kérdés feltevése milyen színben tünteti fel őket. Szerencsére az állásinterjún a felvételizőnek is van lehetősége arról beszélgetni, amiről konkrétan ő szeretne, és én jelöltként is ugyanúgy elvárom a felvételiztetőtől, hogy készséggel válaszoljon a kérdésemre, mint fordított helyzetben. Nem kellemes, amikor megítélik az embert a feltett kérdése alapján. De legalább hamar kiderül, hogy nincs meg az összhang, próbaidő sem kell ennek a megállapításához.
Talán azért ez a véleménykülönbség, mert sokat szívtam legacy kóddal, és sokkal jobban megérint a kódminőség (hiánya), mint másokat. És mivel eddig szinte minden kollégámmal jól kijöttem, annyira nem szokott érdekelni, mennyire jól tudok velük együtt dolgozni... eddig mindig sikerült jól együtt dolgoznunk. Esetedben meg talán máshol vannak a hangsúlyos pontok.
Ez az oka annak is hogy ráugrottam a hozzászólásodra, mert mérhetetlenül sajnálatosnak tartom, hogy a menedzserek mellett sok fejlesztő is tesz a minőségre (szinte lényegtelen összetevőnek tartják), és nem látják, hogy ezzel a saját vagy sorstársaik életét teszik pokollá hosszú távon. Azt hiszem a válaszaimmal igazából csak keresem a megerősítést, hogy valóban az a jó irány, ha a határidőt, a rövid távú sikereket tartja az ember szem előtt. Egyelőre nem sikerült meggyőznöm vagy meggyőzetnem magam, de igyekszem.----
PeachMan:
Hogy ON is legyek, nálam a model az entitás réteget jelenti - vagy perzisztens réteget, ahogy te fogalmazol. POJOk, amelyek már jávául íródtak, de közvetlenül a DB-be mentjük őket és DB-ből töltjük fel őket. Az ORM akítvan használja őket, lévén ők képezik az O-t az ORM-ben.
A DTO (Data Transfer Object) pedig adatok továbbításáért felel a komponensek között, ez jellemzően magasabb rétegekben jelenik meg (ha a perzisztens réteg van alul és a view felül).Hogy mennyire szép elfelejteni a DTO-kat és mindenhol csak a modelt használni, nos, szerintem ez komplexitás kérdése. Egy szép világban nem lenne szükség DTO-ra, mert minek lekopizni valamit pusztán azért, hogy 2 service beszélgetni tudjon egymással. De van egy rakás oka, amiért mégis van létjogosultsága.
Lehet technológiai oka, mondjuk az ORM meg tud zavarodni, ha egy entitásban több collection is van, DTO-k bevezetése jó workaround tud lenni. Te is említetted, hogy a view-nak nincs szüksége minden mezőre, ez is egy valid ok. Főleg akkor, ha nemcsak nincs szüksége, hanem egyenesen tilos egy view-nak látnia minden adatot. Lehet ok a sebesség optimalizálás. Ha egy view-nak csak 1-2 mező kell egy 20 oszlopos táblából, nagyon nem mindegy, hogy mind a 20 mezőt áttolod-e egy microservice-ből a másikba, vagy csak a szükségeseket. Egy DTO-t létre lehet hozni azzal a 2 szükséges mezővel és azt passzolgatni. Az sem mindegy, hogy egy entitásban a kapcsolódó táblák adatai is feltöltésre kerülnek vagy sem, és erre a view-nak szüksége van-e vagy sem. Van, hogy az ORM-et megkerülve jpql vagy akár natív sql végrehajtásával kell felszívni bizonyos adatokat, mert annyira tetü lassú lenne máskülönben, hogy a user megunja az életét. Ez már egy optimalizációs indok lehet, és nem is a fejlesztés legelején kell erről gondolkodni, hanem a végén, de akkor marha nehéz lesz átállni DTO-ra, ha eddig végig az entitásokat passzolgattuk a komponensek között.
Gondolom vannak érvek a model használata mellett is, de most nem jut eszembe ilyen, és biztosan jön valaki, aki arról is tud mesélni. Ja igen, az ORM is nyújthat megoldásokat az általam fentebb felvetett indokokra, csak nem ismerem annyira mélyen őket, hogy mindegyikre tudnék mondani valami dögös annotációt.
DTO-t használni nekem könnyebbség. Nagyobb rugalmasságot ad. Ha változik a model, nem feltétlenül kell a service rétegen keresztülverni a változásokat pl.Egy kicsit a kodminoseghez. Ez is olyan, hogy at lehet esni boven a lo tuloldalara. Lassan mar hulyenek nezes esete forog fent, amikor rankeroltetik a 16-os complexity-t (vayg mennyire van allitva), nem beszelve az abbol adodo extra feladatokrol (a complexity miatt letrehozott kulon fuggvenynek vajon kell-e ujra parameter-ellenorzest csinalnia, es a unit test-jenek kell-e olyan eseteket is lefednie, ami az egyetlen hivasi helyen nem fordulhat elo?). Szoval en egyetertek az elvekkel altalaban, de nagyon durva amikor valaki nem azt nezi hogy milyen egy masik - az adott feladattal megbizhato! ha valami komplex cucc kozepe, akkor nem egy most esett ki a bootcamp-bol - fejleszto megerti-e, hanem hogy a szintetikus pontozassal mibe tud belekotni.
Nyilvan ez nem jelenti azt, hogy nincs szarul megirt kod. Csak hogy neha annyira de annyira tullihegik... en 20+ ev multtal pont nem tudnam felsorolni a solid betuszo feloldasat, ettol fuggetlenul azert lehet megis annak megfeleloen dolgozni. Kicsit olyan mint a torvenyek betartasa: egyreszt a torveny a tarsadalmi normak osszegyujtese, megfogalmazasa; masreszt meg senki nem tudja beteve a BTK-t, megis tud esetekrol zsigerbol jo ertekelest adni. A solid is nem csak ugy kinott es tanitjak, hanem a "termeszetesen" kialakult best practice-nek egy szaraz, es megis gumiszabaly osszefoglaloja. Kb. arra jo hogy indokolni tudd, hogy a masiknak (vagy plane kezdonek) az elkepzelese miert nem jo, de nem ugy adsz ki tervet a kezedbol hogy elotte gyorsan leellenorzod, hogy vajon stimmel-e minden betu.
Szerintem. YMMV. -
 #68216320
törölt tag
#68216320
törölt tag
Értelek, egy 20 éves tapasztalattal rendelkező jelentkezőnél valóban béna dolog a kódminőség felől érdeklődni, tiszta sor. Ezer ennél relevánsabb kérdést is feltehetnének. Ugyan korrigálhatnám a neked feltett kérdésemet úgy, hogy mit válaszolnál a kérdésre akkor, ha junior lennél egy junior pozira, de érzem, hogy a válaszod ugyanaz lenne.
Nekem nincs ennyi év a hátam mögött, de úgy vélem 20 éves múlttal sem feltétlenül sértődnék meg egy ilyen kérdésen, szerintem ha ez érdekli az interjúztatót a legjobban, akkor szíve joga rákérdezni. Nyilván annak is tudatában van a HR (ha meg nincs akkor így járt), hogy egy ilyen kérdés feltevése milyen színben tünteti fel őket. Szerencsére az állásinterjún a felvételizőnek is van lehetősége arról beszélgetni, amiről konkrétan ő szeretne, és én jelöltként is ugyanúgy elvárom a felvételiztetőtől, hogy készséggel válaszoljon a kérdésemre, mint fordított helyzetben. Nem kellemes, amikor megítélik az embert a feltett kérdése alapján. De legalább hamar kiderül, hogy nincs meg az összhang, próbaidő sem kell ennek a megállapításához.
Talán azért ez a véleménykülönbség, mert sokat szívtam legacy kóddal, és sokkal jobban megérint a kódminőség (hiánya), mint másokat. És mivel eddig szinte minden kollégámmal jól kijöttem, annyira nem szokott érdekelni, mennyire jól tudok velük együtt dolgozni... eddig mindig sikerült jól együtt dolgoznunk. Esetedben meg talán máshol vannak a hangsúlyos pontok.
Ez az oka annak is hogy ráugrottam a hozzászólásodra, mert mérhetetlenül sajnálatosnak tartom, hogy a menedzserek mellett sok fejlesztő is tesz a minőségre (szinte lényegtelen összetevőnek tartják), és nem látják, hogy ezzel a saját vagy sorstársaik életét teszik pokollá hosszú távon. Azt hiszem a válaszaimmal igazából csak keresem a megerősítést, hogy valóban az a jó irány, ha a határidőt, a rövid távú sikereket tartja az ember szem előtt. Egyelőre nem sikerült meggyőznöm vagy meggyőzetnem magam, de igyekszem.----
PeachMan:
Hogy ON is legyek, nálam a model az entitás réteget jelenti - vagy perzisztens réteget, ahogy te fogalmazol. POJOk, amelyek már jávául íródtak, de közvetlenül a DB-be mentjük őket és DB-ből töltjük fel őket. Az ORM akítvan használja őket, lévén ők képezik az O-t az ORM-ben.
A DTO (Data Transfer Object) pedig adatok továbbításáért felel a komponensek között, ez jellemzően magasabb rétegekben jelenik meg (ha a perzisztens réteg van alul és a view felül).Hogy mennyire szép elfelejteni a DTO-kat és mindenhol csak a modelt használni, nos, szerintem ez komplexitás kérdése. Egy szép világban nem lenne szükség DTO-ra, mert minek lekopizni valamit pusztán azért, hogy 2 service beszélgetni tudjon egymással. De van egy rakás oka, amiért mégis van létjogosultsága.
Lehet technológiai oka, mondjuk az ORM meg tud zavarodni, ha egy entitásban több collection is van, DTO-k bevezetése jó workaround tud lenni. Te is említetted, hogy a view-nak nincs szüksége minden mezőre, ez is egy valid ok. Főleg akkor, ha nemcsak nincs szüksége, hanem egyenesen tilos egy view-nak látnia minden adatot. Lehet ok a sebesség optimalizálás. Ha egy view-nak csak 1-2 mező kell egy 20 oszlopos táblából, nagyon nem mindegy, hogy mind a 20 mezőt áttolod-e egy microservice-ből a másikba, vagy csak a szükségeseket. Egy DTO-t létre lehet hozni azzal a 2 szükséges mezővel és azt passzolgatni. Az sem mindegy, hogy egy entitásban a kapcsolódó táblák adatai is feltöltésre kerülnek vagy sem, és erre a view-nak szüksége van-e vagy sem. Van, hogy az ORM-et megkerülve jpql vagy akár natív sql végrehajtásával kell felszívni bizonyos adatokat, mert annyira tetü lassú lenne máskülönben, hogy a user megunja az életét. Ez már egy optimalizációs indok lehet, és nem is a fejlesztés legelején kell erről gondolkodni, hanem a végén, de akkor marha nehéz lesz átállni DTO-ra, ha eddig végig az entitásokat passzolgattuk a komponensek között.
Gondolom vannak érvek a model használata mellett is, de most nem jut eszembe ilyen, és biztosan jön valaki, aki arról is tud mesélni. Ja igen, az ORM is nyújthat megoldásokat az általam fentebb felvetett indokokra, csak nem ismerem annyira mélyen őket, hogy mindegyikre tudnék mondani valami dögös annotációt.
DTO-t használni nekem könnyebbség. Nagyobb rugalmasságot ad. Ha változik a model, nem feltétlenül kell a service rétegen keresztülverni a változásokat pl.Köszi a választ. Otthon részletesen újra átolvasom.
-
 M_AND_Ms
veterán
M_AND_Ms
veterán
Hmm. Azt hiszem, te többet láttál bele a kérésbe, mint én.
Ha neked tennék fel a kérdést egy interjún, hogy szerinted milyen egy jó, minőségi java osztály implementációja, akkor mit válaszolnál?---
A felhozott példákat én egy lehelletnyit túlzónak tartom, a vas rácsszerkezetét inkább hasonlítanám mondjuk a gépi kódhoz, mintsem a kódminőség megítéléséhez. Az meg igazán örvendetes lenne, ha az IT iparban is olyan képzésük lenne az embereknek, mint orvosi fronton, mentoring, sokéves rezidenskedés, stb. Én se kérdezném meg tőle az adagolást, mert feltételezném, hogy pontosan tudja. Na meg a beteg halálozások száma is jó indikátora a hozzáértésnek."Hmm. Azt hiszem, te többet láttál bele a kérésbe, mint én."
Ez igaz....én csak a vaskalapos, merev és felesleges kérdéseket nem szeretem...
"Ha neked tennék fel a kérdést egy interjún, hogy szerinted milyen egy jó, minőségi java osztály implementációja, akkor mit válaszolnál?"
Megkérdezném a kérdést feltevőt, hogy valóban, ezt az interjúra szánt 10 percet akarja arra felhasználni, hogy megtárgyaljuk, mitől lesz szép egy java kód? Vagy inkább ténylegesen ki akarja deríteni fogok-e tudni hatékonyan együtt dolgozni abban a csapatban, vagy annak az élén ahova épp embert keresnek. Mert pl én azért vagyok épp ott, hogy megtudjam ezt (a java kódkonferenciára ki se öltöztem volna).
Hála égnek, ilyen interjún nem voltam soha, és nem is voltam kényszerhelyzetben, hogy bele kellet volna mennem ilyenbe...Eddig mindig egy kötetlen, informális beszélgetésbe csöppentem, ahol a szűk szakmai dolgokról nem volt szó. Alapértelmezett volt, hogy ha kovácsnak jelentkezem és ők kovácsot keresnek, akkor nem kérdés, hogy mindketten tudjuk, milyen a felpattanó szikrába belenézni (ha ez nem így volna, úgyis kiderülne, egy héten belül)
20 éves tapasztalattal a hátam mögött pedig az a véleményem, hogy egy IT projekt legutolsó, szinte lényegtelen része, hogy mennyire szépen, mennyire jó minőségben (sic) vannak implementálva a java osztályok. (nyilván számít a kód milyensége, de nem ezen fogunk elbukni... mielőtt valaki visszadobná a labdát)
"A felhozott példákat én egy lehelletnyit túlzónak tartom"
A példák, mindig valami túloznak... -
M_AND_Ms
veterán
"Konkrétan a hozzászólás melyik részét tartod bullshitnek és miért"
Azt, amit kérnek, hogy felmondjon a jelentkező a hr-esnek, mint a leckét az iskolában. Ez számomra a tudás hibás és teljesen felesleges visszakérdezése: fejből tudni és visszamondani az elméleti anyagot, még "ha álmodból keltenek is fel. " Az ilyen tudás megszerzése jön a "magolásból", és nem a gyakorlatból, vagy a rátermettségből. Ez alapján tuti nem a megfelelő és alkalmas embert fogják felvenni.
A tapasztalatom (20 aktív IT, + 10 év egyéb terület) az, hogy az elméleteket halmozó emberek aszok, akik a megbeszéléséken a szót viszik, az elveket hangoztatják és az időt rabolják, de a tényleges munkát már képtelenek elvégezni.
Az ilyen szintű elméleti alaptéziseket nem kell hangoztatni, hanem azoknak megfelelően kell dolgozni. Egy kovács se tudja fejből elsorolni, hogy mi a helyes kalapálás alapelmélete és hogy milyen rácsszerkezetű a vas...egy kovács alkalmazásakor se kell ilyeneket kérdezni ... Vagy egy anesztes orvosnál se kérdeznek az állásinterjún olyat, hogy miből, mennyit adagol a lumbális érzéstelenítésnél és azt milyen szempontok alapján dönti el. -
#68216320
törölt tag
Csak annyit tudok a prjektedről, amennyit most leírtál róla, így lehet, hogy valamit félreértek.
1. Én most microservice bűvkörökben élek és a selfcontained alkalmazás a kedvenc, vagyis semmit sem vágok, cserébe viszont pici a cucc, és nincs benne ui. Természetesen a komponensek közti kommunikációt megvalósító DTO-kat, külön, közös projektbe teszem, hogy mindegyik komponens ugyanazt lássa.
Ha látod értelmét a vágásnak (mert mondjuk több egymástól eltérő modul is használná), akkor vágj. Ha nincs értelme, akkor ne vágj. A legrosszabb, amit tehetsz, hogy túl korán vágsz és később szívsz, hogy hát lehet, nem is ott kellett volna, ajaj.
A több UI, több modul felállás szimpi.2. A tesztet. Nincs hibátlan osztály. A tesztet. Leginkább párhuzamosan. TDD. Mondtam már, hogy a tesztet?
Amúgy meg a te dolgod, ahogy jobban esik. Főleg, ha a teszttel kezded.3. Ha valami nem komplex, én nem frameworközök, mert csak megköti a kezet, lassít, bonyolít. Amúgy passzolom a kérdést, nem tartom magam frontend gurunak. Persze lehet az, hogy mondjuk valaki csak az angulart ismeri és semmi mást, neki érezhetően könnyebb dolga lesz abban megcsinálni, mint szenvedni egy fura jsp-vel.
4. Ne származz le.
Oké, hogy a nyelv megengedi, de attól még nem jó.
Én nem osztom azt a nézetet, hogy ami úgy néz ki mint egy kacsa és olyan hangot ad ki, mint egy kacsa, az egy kacsa. [link]
Az egy másik osztály.
Ha mégis van némi közük egymáshoz, akkor még a composition-t tudom elképzelni, vagyis az osztály egy tagja lesz a meglévő cucc, és az osztályod csak az értelmes mezőket engedi ki az apiján.Köszönöm a válaszokat
1. Akkor lehet annál maradok, hogy minden marad egy projectben. Igazából pont azért kérdeztem, mert jelenleg tényleg nem indokolja semmi, hogy szétszedjem. Csak valahol láttam egy ilyen project-et és gondoltam, hátha ... de akkor nem csinálom egyelőre.
2. Akkor hogy is? A tesztet?
3. Az igazság az, hogy nem ismerek egy framewörköt sem. Tudom, kellene csak próbáltam elodázni. De nagyon úgy tűnik, hogy nincs mese... Angular? Meglesem.
4. Nem túl komplex. Anno úgy olvastam még, hogy ilyenkor ezt kell tenni. Persze tényleg megoldás a 2 külön osztály. Vagy gondoltam, hogy barkácsdolom picit:
- átnevezném az eredeti osztályt
- absztrakt lenne az eredeti osztály
- kivenném az eredeti osztályból azokat a tulajdonságokat, amik nem közösek
- leszármaznék 2 osztállyal belőle. az 1. kapná az eredeti nevet és megkapná a saját tulajdonságát. a 2. kapna egy új nevet és a saját tulajdonságaitÍgy az eredeti néven meglenne az osztályom az eredeti member-ökkel és lenne egy új az új member-ökkel de csak azokkal amik neki kellenek.
Persze lehet marhaság amit akarok, sajnos kuka vagyok még a programozáshoz.Vagy túlkombináltam valamit megint
-
floatr
veterán
Oh, az első kérdést nem olvastam, az már tényleg nem lenne egyszerű.
Ilyesmire gondoltál?
Persze ha a pánikkeltés a cél, akkor biztosan cifrázható tovább. String[] arrayOfStrings = { "alma", "körte", "banán", "cseresznye", "áfonya" };
String longest = Arrays.stream(arrayOfStrings)
.collect(Collectors.maxBy(Comparator.comparing(String::length)))
.orElse(null);
(a kedvedért több sorba törtem )A reduce nekem valamiért testhezállóbb volt, talán azért is, mert ritkán használok spéci collectorokat. Hirtelen nem is tudnám most rövidebben leírni collectorral, és ezt már én is túlzásnak érzem. Ízlés dolga. A for ciklus a tuti, azt mindenki érti és villámgyors.
Ebbe most futottam bele teljesen véletlenül
@Getter@AllArgsConstructorpublic class MinMax {Optional<String> min, max;public static MinMax of(String[] arrayOfString) {var length = comparing(String::length);return stream(arrayOfString).collect(teeing(minBy(length),maxBy(length),MinMax::new));}} -
floatr
veterán
Oh, az első kérdést nem olvastam, az már tényleg nem lenne egyszerű.
Ilyesmire gondoltál?
Persze ha a pánikkeltés a cél, akkor biztosan cifrázható tovább. String[] arrayOfStrings = { "alma", "körte", "banán", "cseresznye", "áfonya" };
String longest = Arrays.stream(arrayOfStrings)
.collect(Collectors.maxBy(Comparator.comparing(String::length)))
.orElse(null);
(a kedvedért több sorba törtem )A reduce nekem valamiért testhezállóbb volt, talán azért is, mert ritkán használok spéci collectorokat. Hirtelen nem is tudnám most rövidebben leírni collectorral, és ezt már én is túlzásnak érzem. Ízlés dolga. A for ciklus a tuti, azt mindenki érti és villámgyors.
Alakul...
A végén szét lehet szerelni komponensekre, és lehet hozzá majd YAML konfigot írniA reduce a legegyszerűbb, de akkor hadd húzzak lapot 19-re
Arrays.sort(arrayOfStrings, Comparator.comparing(String::length));
String shortest = arrayOfStrings[0];
String longest = arrayOfStrings[arrayOfStrings.length - 1]; -
 Sirpi
senior tag
Sirpi
senior tag
Oh, az első kérdést nem olvastam, az már tényleg nem lenne egyszerű.
Ilyesmire gondoltál?
Persze ha a pánikkeltés a cél, akkor biztosan cifrázható tovább. String[] arrayOfStrings = { "alma", "körte", "banán", "cseresznye", "áfonya" };
String longest = Arrays.stream(arrayOfStrings)
.collect(Collectors.maxBy(Comparator.comparing(String::length)))
.orElse(null);
(a kedvedért több sorba törtem )A reduce nekem valamiért testhezállóbb volt, talán azért is, mert ritkán használok spéci collectorokat. Hirtelen nem is tudnám most rövidebben leírni collectorral, és ezt már én is túlzásnak érzem. Ízlés dolga. A for ciklus a tuti, azt mindenki érti és villámgyors.
Én így írnám, felesleges a reduce meg a collect is:
String[] arrayOfStrings = { "alma", "körte", "banán", "cseresznye", "áfonya" };
String longest = Arrays.stream(arrayOfStrings)
.max(Comparator.comparingInt(String::length))
.orElse(null); -
floatr
veterán
Egy adott fajta kód vagy stílus azok számára nehezen olvasható, akik nem szoktak hozzá. Kezdőként én is nehezen dekódoltam, hogy mi van. Aztán megszoktam és már nem nehéz.
A fenti kód nyúlfarknyi. Ebbe belemagyrázni azt, hogy ez azért nem jó, mert lehet nem nyúlfarknyit is írni, hát, jó, de a fenti kód továbbra is nyúlfarknyi marad, minden más csak a kivetített félelmeid. Vagy valaki más félelmei, nem célom személyeskedni.
A lambda nem egy kalapács, hogy mindenre IS használható, ahogy egyébként semmi sem az, nincs ultimate weapon minden problémára. Természetes, hogy a 200 soros förmedvényt nem egy lambda blokkban kódolja le az ember, hanem elgondolkozik, hogy miért lett ez 200 sor, aztán egyszerűsít, absztrahál, és kitalál egy a probléma megoldására optimálisnak tűnő módszert, stílust, eszközt, stb. Ami nem KELL, hogy egyáltalán tartalmazzon lambdát végül.A lambda (meg lényegében a stream api) azért jó, mert egységet képez, egy komplexebb folyamatot is atomi egységbe zár, nincs mellékhatása, ergo "bugmentes". Ha matekosabb beállítottságúnak érzed magad, olvass kicsit a monad-ról. Ha kevésbé matekosnak, akkor inkább ne, nehogy eret vágj magadon.
Nyilván ezt is el lehet cseszni, ha mondjuk egy a lambdán kívül létrehozott listát piszkálunk a lambda belsejében, annak már lesz mellékhatása, de az nem is a lambda hibája.Én személy szerint azért nem szeretem a stream apit, mert lassú. Egy forEach lassabb egy for ciklusnál, és ez engem időnként zavar.
Nehéz debugolni? A régi eclipse valóban elég körülményesen működött, a closure környezetének csak egy részét látta. Hogy most jól működik-e, nem tudom. Mint mondtam, nem illik 200 soros lambda törzseket produkálni, és akkor nem kell debugolni sem. Problem solved. Érthető, hogy a határidő szűkössége miatt folyamatosan megy a
gányolás... khm... képződik tech dept, de akkor is a fejlesztő felelőssége marad, hogy jól olvasható kódot produkáljon a végén. Ha valaki elég igénytelen arra, hogy egy egyszerű lambda kifejezést túlbonyolítva ott hagy, refakt nélkül, oké, de nem az eszközt kellene ilyenkor hibáztatni az olvashatatlan és debugolhatatlan kód miatt. Gondolom.
Egyébként meg a 200 soros blokk metódusba szervezésével és egy jól irányzott method ref beillesztésével máris nagyot léptünk előre a tisztánlátás útján. Az már más kérdés, hogy sok esetben ez csak a probléma elfedésére jó és nélkülözi az igazi optimalizálást.Az olvashatóságot egyébként tengernyi más dolog is befolyásolja, csak hogy a legkézenfekvőbbet említsem, a nevek. Ha semmitmondó változó és metódus neveket használ a fejlesztő, akkor az olvasó arra kényszerül, hogy belenézzen a metódusba. Ha kifejező neveket használ, akkor erre nincs szükség. Innentől kezdve meg már teljesen mindegy, hogy igazi metódusokat, vagy névtelen metódusokat használunk a megoldásban. De akkor sem illik túlbonyolítani egy lambda kifejezést.
--------
@floatr: Sajnos nem értem a kérdést, kifejtenéd? A reduce egy darab string optional-t ad vissza, azon nem tudok már sokmindent gyűjtögetni.Szokás enterprise körökben túltolni a legegyszerűbb dolgokat is. Ha reduce helyett egy collectort használtál volna, no meg persze factory-kat, akkor lehetne kelteni kisebbfajta pánikot a juniorok között
Amúgy az első kérdésére csak egy reduce nem fog megoldást adni, vagy két streamet használsz, vagy egy collectorral párban gyűjtöd a min/max értékeket. De akkor meg minek...
Amúgy szerintem nincsen különösebb baj a streamekkel, amíg olvashatóan és ésszerűen van szervezve. A hármas operátort sokan nem szeretik, mert rontja az olvashatóságot. Én egyedül azt a gányolást utálom, amikor mindent be akarnak szuszakolni egy sorba. Na meg az enterprisify kódot
-
#68216320
törölt tag
Ez mennyire BestPactice? Én még úgy tanultam, hogy próbáljuk kerülni a lambda-t, mert a forráskód nehezebben olvasható majd. Nem "nyúlfarknyi" példákra, gondolok, hanem nagyobb osztályokra például. Persze most nem azt mondom, hogy 1-1 forEach vagy hasonló nem kerülhet bele csak például nálam egy-egy komplexebb sor átláthatósága debug esetén nehezebb/lassabb.
Persze tény, hogy elegánsabbVagy ez teljesen rendben van és marhaságot tanultam?
-
floatr
veterán
-
axioma
veterán

Bar kezdonek nem biztos hogy igy kezdenem, de igen, engem is zavar hogy a null-ra kulon kell a kezdes miatt vizsgalni (bar lehetne az elso elem a min/max, de akkor meg nem elegans onmagaval ujranezni). Amikor me'g csak indexszel lehetett vegigmenni, ez fel se merult. -
floatr
veterán
Létezik most a piacon olyan cloud szolgáltató, ami ingyen tud biztosítani egy minimál szolgáltatást?
Gondolok itt olyasmire, hogy mondjuk futtatnék egy java backendet, valamilyen frontendet (jsf, angular, tökmindegy), és legyen mögötte egy akármilyen DB pár MB tartalommal. A frontendre mondjuk havi 1-2000 request eshet be, és szinte zéró processzoridőt vagy memóriát használna. Egy jegyzettömb szintű alkalmazást képzelj el.
Nézegettem az aws-t, de ott a 12 hónapos akció lezárultával mintha esszenciális komponensek válnának fizetőssé. A lambda és a dynamodb marad free, de jól gondolom, hogy ezekkel a frontend már nem lesz elérhető?
A Google AppEngine még a másik kiszemeltem, de basszus, kívülről képtelen vagyok eldönteni, hogy ezzel most meg lehet oldani a free időszak lejárta után is vagy sem.
Akinek van tapasztalata a fenti, vagy akár más cloud szolgáltatók terén, mutasson irányt, melyikkel nem fogok csalódni? Köszi. -
mobal
nagyúr
Létezik most a piacon olyan cloud szolgáltató, ami ingyen tud biztosítani egy minimál szolgáltatást?
Gondolok itt olyasmire, hogy mondjuk futtatnék egy java backendet, valamilyen frontendet (jsf, angular, tökmindegy), és legyen mögötte egy akármilyen DB pár MB tartalommal. A frontendre mondjuk havi 1-2000 request eshet be, és szinte zéró processzoridőt vagy memóriát használna. Egy jegyzettömb szintű alkalmazást képzelj el.
Nézegettem az aws-t, de ott a 12 hónapos akció lezárultával mintha esszenciális komponensek válnának fizetőssé. A lambda és a dynamodb marad free, de jól gondolom, hogy ezekkel a frontend már nem lesz elérhető?
A Google AppEngine még a másik kiszemeltem, de basszus, kívülről képtelen vagyok eldönteni, hogy ezzel most meg lehet oldani a free időszak lejárta után is vagy sem.
Akinek van tapasztalata a fenti, vagy akár más cloud szolgáltatók terén, mutasson irányt, melyikkel nem fogok csalódni? Köszi.Heroku? Esetleg egy olcsó Digitalocean?
-
#68216320
törölt tag
Nem igazán így néz ki. A sequence csak egy futósorszám. Tehát tényleg csak egy szám van benne... az éppen aktuális érték. Ha elkéred tőle az értéket, automatikusan növeli magát eggyel (vagy neked kell növelned kézzel... kinézem ezt a mysql-ből). Ha mindenképpen táblaként akarod elképzelni, akkor van egy oszlopa, neve mondjuk legyen value, és van egy sora, abban az érték pedig 6, mert mondjuk a 6 volt az utoljára kiosztott id.
Lásd az oldal alján.Szóval találkoztam már pár helyen ilyen megoldással... bár az oracle volt, nem mysql, de a concept ugyanaz, globálisan egyedi id. Nyilván nem kötelező minden táblán ezt használni, táblák egy csoportján is lehet, meg létrehozhatsz több sequence-t, más-más csoportoknak... ahogy a domain megköveteli.
Bár a hozzászólások alapján úgy látom, ebből 1 fő tábla lesz.
Drizzt, bambano, Szmeby: Köszönöm szépen a válaszokat, kiegészítéseket, íránymutatást. Ha megengeditek csak azért, hogy pontosabban megértsem a mikor-mit-miért összefüggéseket, felvázolnék másik helyzetet, amire szintén keresnék optimális megoldást. Csak fantázia, mint az előző, de a tapasztalatot majd vinném egy real projectbe.
Legyen mondjuk egy ingatlanközvetítőnk ahol a kiindulópont egy abstract ingatlan class. (tulajdonos_id, ugyintezo_id, telepules_id, cim, ar, alapterulet)
Ebből származna le:
1. lakas class (szobaszam, felszobaszam)
2. haz class (szobaszam, telek meret, mellekepuletek_osszterulet, terasz, kozmuvesites)
3. irodaUzlethelyiseg class (helyisegek_szama, utcafrontrol_megozelitheto, kirakat)
Nem pontos, de a lényeg, hogy egy ős osztály és mondjuk 3 leszármazott osztály. Jelen esetben nagyon nem bővülhetne, talán még garázs és zártkert, de gondolom tényleg fix számú a lehetőség, ami ide sorolható.
Ami szükséges volna, az egyedi id, azaz, ha valaki azt mondja a 725-ös ingatlan adatait kéri, akkor abból egyértelmű legyen, hogy milyen/melyik ingatlan. Azaz esetünkben a 3 tábla osztozna egy id sequence-en.
Lenne mondjuk egy galéria tábla is, amiben a képfájlok url-jét/sorrendjét tárolnánk mondjuk webes megjelenítéshez. Ide tehát kellene, hogy kerüljön egy "ingatlan_id" majd a saját id mellé.
Ebben az esetben hogy nézne ki a táblaszerkezet? Teljesen megegyezne az object szerkezettel?
-
#68216320
törölt tag
"Viszont ekkor az autoincrement id a mysql-ben csak egy táblára lesz érvényes, azaz lenne 1-es id-val tv és mosógép is."
Nem kötelező a táblákra bízni az id generálást, autoincrement használata helyett csinálhatsz az adatbázisban egy sequence-et (vagy sequence table-t? nem tudom, mysqlnél milyen eszközök állnak rendelkezésre), és az entitásaid abból szedhetik majd a next id-t.
Érdekem megoldás amit felvázolsz. Szoktak ilyen megoldást alkalmazni? Igazából azt nem tudom mennyire kell ragaszkodnom a táblaszerkezetben az osztályok szerkezetéhez? Nyilván ORM esetében feltétlenül, bár hallok olyanokat, hogy nem túl célszerű a használata. Ha jól értem akkor az alábbi módon nézne ki, igaz?
+----+-------+ +----------------------+ +----------------------+
| sequence | | TBL1 | | TBL2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| id | table | | id | field1 | field2 | | id | field1 | field2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| 1 | TBL1 | | 1 | ... | ... | | 3 | ... | ... |
| 2 | TBL1 | | 2 | ... | ... | | 4 | ... | ... |
| 3 | TBL2 | +----+--------+--------+ +----+--------+--------+
| 4 | TBL2 |
+----+-------+Ahol a sequence tábla id auto_increment, a tbl1, tbl2 id pedig unique.
Drizzt: Megnéztem a linket, köszönöm. Van egyébként valami javasolt/preferált megoldás a 3 közül vagy teljesen szabadon választhatok közülük. Esetemben a mindent egy táblába a null/notnull miatt nem volna célszerű. A teljesen különálló táblák és a közös tábla-saját típusos tábla megoldások között dilemmázok. Mivel alapvetően a lekérdezések lesznek töbségben és sejthetőleg típusra szűkítve főként, a külön-külön önálló tábla megoldást érzem picit jobb megoldásnak. De bizonytalan vagyok
-
Drizzt
nagyúr
Pedig részben de, komoly volt.
Fiatal, frameworkökön nevelkedett fejlesztő, aki még sosem érzett ingerenciát arra, hogy jobban beleássa magát a java nyelvbe, és eddig a munkája során sem szembesült olyan problémával, amihez szüksége lett volna ilyen tudásra... és a nyolcas számrendszer csak egy bugyuta példa volt, nyilván vannak a jávának ennél kevésbe szembeötlőbb furcsaságai. Szóval sem igénye, sem kényszere nem volt még rá, ellenben tudja mi az a solid és mellesleg bármit összedob neked springben fél óra alatt. Nyilván nem ő fog a csapatból beágyazott kódot írni, de bizonyos szinten mindenki csak rétegtudással bír. Van, aki meg a GC lelkét ismeri kívül belül, de szenved a jsf-fel. Ezért nehéz megmondani valakiről, hogy milyen is a tudásszintje, ha nem konkretizálod az igényeket. Főleg, hogy nem is igazán a tudás számít, hanem a szorgalom (szerintem). Annyira változik a világ, hogy többet ér az adaptív mint az okos.Ezzel én is egyetértek, de sajnos állásinterjún kitalálni, hogy ki esik ebbe a kategóriába, elég nehéz feladat. Meg magadról átadni állásinterjún, hogy erre képes vagy, az is hasonlóan nehéz lehet.
De én is ismerek olyat, aki 5 év Java tapasztalattal azt hiszi, hogy a Java nem működik jól, mert két Integer objektum ==-vel összehasonlítva false, pedig ugyanaz az érték van benne... -
 VTom
veterán
VTom
veterán
Szia Balázs,
sokféle nézőpontból meg lehet közelíteni a tudásszintet és annak méregetését, esetleg tudnád konkretizálni? Ha nem, akkor parancsolj, itt egy rakás, ami felméri, mennyire vagy járatos a jáva (sötét) lelkivilágában.
Nekem még nem volt igényem a tudásszintem méregetésére, szóval nagyon nem is tudnék mást mondani. Esetleg annyit, hogy járj el állásinterjúkra, a cégek majd felmérik a tudásszinted. Mert attól, hogy valaki kívül-belül érti a jávát, még nem feltétlenül lesz értékes a munkaerőpiacon... ha mondjuk nem látott még springet vagy ee-t. Ellenben magas tudású fejlesztők vakargatják a fejüket olyanon - ha először találkoznak vele -, hogy a System.out.println(013) miért 11-et ír ki a konzolra.
Szóval nehéz a tudásszint meghatározása, mondhatni szubjektív.Ellenben magas tudású fejlesztők vakargatják a fejüket olyanon - ha először találkoznak vele -, hogy a System.out.println(013) miért 11-et ír ki a konzolra.
Azért ez nem volt komoly, ugye?
-
Csaby25
őstag
-
MrSealRD
veterán
-
 Sokimm
senior tag
Sokimm
senior tag
Hogyan lehet vizsgálni, ha egy Objektum példánya létrejött (van, létezik)?
if (myObject != null) {
System.out.println("myObject objektumom létezik, hivogathatom a metódusait");
} else {
System.out.println("myObject objektumom nem létezik, ha ráhívok egy metódusára, NullPointerException a jutalmam");
}vagy
if (myObject instanceof String) {
System.out.println("myObject objektumom létezik, sőt azt is tudom róla, hogy String típusú, így bátran Stringgé castolhatom");
}Ha eleve String típusú a myObject változód, akkor felesleges instanceof-olni.
Pl.:String myObject = "kiskutya";
A bal oldalon jelölve vagyon, hogy ez legalább egy String, és mivel a java erősen típusos nyelv, compile error figyelmeztetne, ha valamit elcsesztél volna.Object myObject = "kiskutya";
Ebben az esetben nem lehetsz teljesen biztos benne, hogy ez egy String (annak ellenére, hogy erről a nyilvánvaló példáról ordít, hogy az), de ha szeretnéd String-ként kezelni, akkor castolnod kell mielőtt meghívod rajta a String osztély metódusait ((String)myObject).isEmpty(); Ha pedig ezt biztonságban szeretnéd elvégezni, akkor a castolás előtt érdemes csekkolni egy instanceof-fal, hogy valóban String van-e benne.
A null nem String, a null nem is Object, a null semmi. Az instanceof mindig false-szal fog visszatérni egy null referenciára, mert a semmiről nem lehet eldönteni annak típusát.És ha létrejött a példány, akkor még lehet null tartalmű, amire hogyan kérdeznétek rá? (azon túl, hogy kiteszed egy lokális változóba, ahogy az előbb írtad (ha nincs más, marad ez a módszer, csak elég bénácskának néz ki a kezdő szememnek))
Ha létrejött a példány, nem lehet null.Kiteheted lokális változóba, ha úgy kényelmes:
String product = info.getProductString();
if (product != null && product.equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}De nem kötelező, használhatod a gettert is újra meg újra:
if (info.getProductString() != null && info.getProductString().equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}De akár meg is mókolhatod a lekérdezéskor, hogy kiküszöböld az API hülyeségeit:
String product = info.getProductString() == null ? "" : info.getProductString(); // ez egy ternáris operátor, egyfajta kompakt if: ha a getter null, akkor üres stringet használ helyette, különben meg a getter által visszaadott nemnull értéket
if (product.equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}A java könyvek, vagy pl. az oracle tutorial relatíve korán elmagyarázza a java objektumok, referenciák, nullitás témakörét, érdemes rászánni azt a kis időt.
Köszönöm, köszönöm, így már megy (nem sok időm van programozni, de már megy ez a része, hála nektek!)
Köszönet mindenkinek!Új problémába futottam, remélem erre is lenne pár szavatok:
Nem tudok string-ből short-ot csinálni.public static void main(String[] args) throws IOException {
String product_ID = "0x068E";
Controller StringToShort= new Controller();
StringToShort.ASD(product_ID);
}public static void ASD(String product_ID_String) throws IOException {
short ProductID_short = 0;
try {
ProductID_short = Short.parseShort(product_ID_String);
} catch (NumberFormatException e) {
System.err.println("The string is not properly formatted!");
}
}Mért nem tudom short-á varázsolni a string tartalmat?
-
 Aethelstone
addikt
Aethelstone
addikt
Hogyan lehet vizsgálni, ha egy Objektum példánya létrejött (van, létezik)?
if (myObject != null) {
System.out.println("myObject objektumom létezik, hivogathatom a metódusait");
} else {
System.out.println("myObject objektumom nem létezik, ha ráhívok egy metódusára, NullPointerException a jutalmam");
}vagy
if (myObject instanceof String) {
System.out.println("myObject objektumom létezik, sőt azt is tudom róla, hogy String típusú, így bátran Stringgé castolhatom");
}Ha eleve String típusú a myObject változód, akkor felesleges instanceof-olni.
Pl.:String myObject = "kiskutya";
A bal oldalon jelölve vagyon, hogy ez legalább egy String, és mivel a java erősen típusos nyelv, compile error figyelmeztetne, ha valamit elcsesztél volna.Object myObject = "kiskutya";
Ebben az esetben nem lehetsz teljesen biztos benne, hogy ez egy String (annak ellenére, hogy erről a nyilvánvaló példáról ordít, hogy az), de ha szeretnéd String-ként kezelni, akkor castolnod kell mielőtt meghívod rajta a String osztély metódusait ((String)myObject).isEmpty(); Ha pedig ezt biztonságban szeretnéd elvégezni, akkor a castolás előtt érdemes csekkolni egy instanceof-fal, hogy valóban String van-e benne.
A null nem String, a null nem is Object, a null semmi. Az instanceof mindig false-szal fog visszatérni egy null referenciára, mert a semmiről nem lehet eldönteni annak típusát.És ha létrejött a példány, akkor még lehet null tartalmű, amire hogyan kérdeznétek rá? (azon túl, hogy kiteszed egy lokális változóba, ahogy az előbb írtad (ha nincs más, marad ez a módszer, csak elég bénácskának néz ki a kezdő szememnek))
Ha létrejött a példány, nem lehet null.Kiteheted lokális változóba, ha úgy kényelmes:
String product = info.getProductString();
if (product != null && product.equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}De nem kötelező, használhatod a gettert is újra meg újra:
if (info.getProductString() != null && info.getProductString().equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}De akár meg is mókolhatod a lekérdezéskor, hogy kiküszöböld az API hülyeségeit:
String product = info.getProductString() == null ? "" : info.getProductString(); // ez egy ternáris operátor, egyfajta kompakt if: ha a getter null, akkor üres stringet használ helyette, különben meg a getter által visszaadott nemnull értéket
if (product.equals("CM STORM INFERNO GAMING MOUSE")) {
System.out.println("match!!!");
}A java könyvek, vagy pl. az oracle tutorial relatíve korán elmagyarázza a java objektumok, referenciák, nullitás témakörét, érdemes rászánni azt a kis időt.
Annyit tennék hozzá, hogy "CM..".equals(obj.getAkarmi());
-
 bambano
titán
bambano
titán
Szia,
linux, windows, micsoda? Amikor azt mondod, hogy letöltötted a javat, akkor jre-t vagy jdk-t töltöttél le? Tök jó, hogy eddig eljutottál, már nem sok van hátra. Ha letöltötted, telepítsd is fel.
A jdk_home nekem egy környezeti változónak tűnik a neve alapján (bár azok nagybetűsek szoktak lenni és nekem JAVA_HOME rémlik), ha az, vedd fel. A jdk1.8.0_171 érzésem szerint nem egy fájl, hanem egy könyvtár, és ott találod, ahova azt a bizonyos javat feltelepítetted. Keress rá. Az elérési utat kell megadni a környezeti változóban.
Bár nem használom, de a Netbeans ugyebár egy fejlesztőeszköz, ami megkönnyíti a java programok írását, és mint olyan, szüksége van a jdk-ra, amivel a kódot lefordíthatja. Tudnia kell, hogy hol találja. Ha csak sima szövegszerkesztőben írnál programot, akkor neked is szükséged lenne a jdk-ra, amivel a java osztályaidat bájtkódra fordíthatod. Nem a Netbeanstől lesz java programod, hanem a jdk-tól, a NB csak egy segédeszköz.A suliban nem mondja el a tanár, hogy hogyan készül a java program? Miért nem? A tanárt kérdezted már a problémádról? Miért nem segített?
Én, amikor kérdést teszek fel, igyekszem nem pongyolán fogalmazni, mert tudom, hogy ha én nem veszem a fáradságot arra, hogy minél jobban megértessem a problémám másokkal, más se veszi a fáradságot, hogy dekódolja a mondandóm.
Amúgy:
https://www3.ntu.edu.sg/home/ehchua/programming/howto/JDK_Howto.htmlha találgatnom kellene, azt találgatnám, hogy letöltött egy jdk-t, azzal felrakta a netbeanst.
a netbeans belevarrja a konfigba, hogy hol van a jdk. viszont amikor upgradelte a jávát, akkor a régit levette, az új meg máshol van, pláne, ha a verziószám benne van az elérési útban. -
 Orionk
senior tag
Orionk
senior tag
A célod, hogy (jó) java fejlesztő legyél, vagy hogy átmenj egy interjún?
Ha már tudod rá a választ, akkor itt van pár hasznos link, hogy megismerd a java nyelv furcsaságait:
java puzzlers
java tutorials
ocp mock tests
Légy kíváncsi és gyakorolj sokat, nem jelenthet problémát egy interjú, ha értesz hozzá.Egyébként google: java interview questions.
köszi.
Természetesen jó akarok lenni és ahhoz türelmesen tanulok, de nagyon szeretnék már dolgozni is.A Java Puzzlers feladatokhoz van-e valami leírás ami elmagyarázza, hogy miért úgy fut a kód, ahogy?
-
#74220800
törölt tag
Hali,
mondjuk én első körben nem egyből egy random mátrixszal indítanék, hanem egy kicsit ellenőrzöttebb körülmények között tesztelném a cuccot. Pl. egy ilyennel:
1 1 1 1 1
1 2 2 2 1
1 2 3 2 1
1 2 2 2 1
1 1 1 1 1És akkor debug módban szépen lépkedve kiderítheted, hogy az a baj, hogy először mindig felfelé próbálkozol kijutni, majd ha nem megy, akkor lefelé. Csakhogy a próbálkozásod előtt nem csekkolod, hogy egyáltalán érdemes-e (<x). Mindenképp megpróbálod, így visszajutunk egy korábbi állapotba, ahonnan nem sikerült felfelé kijutni, így azt megpróbálni sem lenne érdemes, de ő csakazértis újra felfelé próbál. Nem tud, ezért megint lefelé indul el. A lefele ágban először újra felfelé indulna, és... gondolom érted, hogy ez a végtelenségig tart, ide-oda pingpongozik a két sor egymással.
Egy ilyen térképpel például szépen működik a progi, mert mindig csak felfelé kell másznia:
1 1 1 1 1
1 2 2 2 1
1 3 3 3 1
1 4 4 4 1
1 5 5 5 1Rekurzív hívásnál nagyon fontos a sorrend, amint tudod, terminálni kell a folyamatot. Érdemes először ellenőrizni, hogy a szomszédos szám valóban jó irány-e, és csak akkor ráhívni rekurzívan, ha tényleg van esély a kijutásra.
----
Apró adalék, hogy egy kis emlékezet bevezetésével, drasztikusan gyorsítható a program. Ugyanis ha számon tartod (pl. egy kimeneti mátrixban), hogy adott cellából sikerült-e korábban kijutni, akkor nem kell újra és újra végigjátszani a teljes útvonal bejárást.Thx mint mindig.
Megcseréltem az If-eknél a sorrendet és most működik....
if (row == arr.length -1 || row == 0 || column == arr[row].length -1 || column == 0)
return true;
else if (arr[row-1][column] < x && flows(row-1,column, arr))
return true;
else if (arr[row+1][column] < x && flows(row+1,column, arr))
return true;
else if (arr[row][column-1] < x && flows(row,column-1, arr))
return true;
else
return (arr[row][column+1] < x && flows(row,column+1, arr));Deeee, ezt megint nem teljesen értem. Ok gondolom ha az első értek hamis, akkor eleve be sem kéri a 2. elemet. De miért nem megy úgy, ha előszór a rekurzív képletet hívom meg, ha hamis, akkor lep tovább a következö if-re?
-
#74220800
törölt tag
Remek... letelt az időkorlát. -.-
Szóval azt még elfelejtettem, hogy ha Set-re váltasz, akkor a Point.equals mellett a Point.hashcode-ot is implementálnod kell. Az IDE elvégzi helyetted, de a lényeg:
A HashSet úgy működik, hogy a beletolt objektumra először hashcode-ot számol, ez csak egy szám. Ehhez a hashcode-hoz létrehoz egy izét, nevezzük vödörnek, és ebbe a vödörbe dobja bele az objektumodat.
Ha egy újabbat adnál hozzá, akkor arra is hashcode-ot számol, és csak az adott hashcode-hoz tartozó vödörrel foglalkozik, végigmászik a vödör tartalmán, az equals-szal csekkolja, hogy benne van-e már, és ha talált, akkor nem teszi bele újra.
Ha a hashcode számítást elcseszed, akkor előfordulhat olyan, hogy van 2 objektumod, ami az equals szerint azonos, de a hashcode szerint nem. Mindkettő bele fog kerülni a Set-be (!!), mert a másik az eltérő hashcode miatt másik vödörbe kerül. Ilyet sose csinálj.
Vagy például megváltozik az objektumod állapota (mondjuk most nem, mert minden final, de máskor, mással, másnál igen), és a megváltozott állapot miatt megváltozhat a hashcode is. Na az az objektumod, ha benne volt egy set-ben, akkor ott is marad, sose találod meg. Vicces dolgok ezek.
Gondolhatnád, hogy akkor legyen a hashcode mindig 1, abból baj nem lehet. Jó gondolat, de lassú lesz, épp azért szegmentálunk sok kis vödörre relatíve kis számításigényű megoldásokkal, hogy csak egy kis vödör tartalmán kelljen végigsuhanni, gyorsan el lehet dönteni, hogy valami benne van-e abban a Set-ben avagy sem.@ disy68 és Szemby köszi!
Most működik, de azért nem minden kristálytiszta.
Meg egyszer pls itt mit is csinálunk?
public boolean equals(Object obj{
PolyLine other= (PolyLine) obj;
return points.equals(other.points);
}főleg ezt nem értem: other.points
Objectet becastoljuk PolyLine-ra, majd azt visszacastoljuk Arreylistre, aztán az equals ekkor a beépített metódus a két arraylist miatt?
-
 Szmeby
tag
Szmeby
tag
Ezért ne kövesd el te azt a hibát, amit a java megalkotói, hogy túl általános típust használsz.
Jó, tudom, csak kompatibilitás, de akkoris.Szóval a probléma a PolyLine.equals-ban van. Mivel a szignatúrája szerint Objectet vár, az ember bármit beadhat. És hidd el, be is fog. Amin aztán az egész cucc megfekszik (pl. ClassCastException-nel), ha nem figyelsz. Rosszabb esetben - mint most is - működik tovább hibásan.
Javaslom, minden equals metódusodban ellenőrizni a bejövő paraméter típusát. Ha nem jó típus, akkor false, ha jó típus, akkor pedig tessék castolni, és aztán hasonlítgatni. Könnyebben kibukik, hogy a beadott PolyLine nem is ArrayList, amivel hasonlítani akarod.
Egyébként az equals, hashcode metódusokat egy IDE szépen ki is generálja neked, van rá menüpont.Szóval listát a listával:
public boolean equals(Object obj){
if (obj == this) {
return true;
}
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
PolyLine other = (PolyLine) obj;
return points.equals(other.points);
}Ha nem kellenek az ismétlődések, miért nem egy rendezett Setet használsz erre a célra? LinkedHashSet, vagy valami ilyesmi. Ő magától megcsinálja.
Pár megjegyzés:
- Osztályon belül felesleges gettereket használnod, simán lehet hivatkozni a field-ekre, pl.:return Math.sqrt(Math.pow(this.x - other.x, 2) + Math.pow(this.y - other.y, 2));- Ha az objektum állapota nem változhat, akkor érdemes a field-eket final-ra állítani, így még véletlenül sem fogod tudni tönkretenni az objektumaidat. Továbbá egy ilyen tipikus value object esetén én még a getterek elhagyását is megkockáztatnám, valahogy így:
public class Point{
public final int x;
public final int y;
public Point(int x, int y){
this.x = x;
this.y= y;
}
public boolean equals(Object other){
// ...
}
public double getDistance(Point other){
// ...
}
public String toString(){
// ...
}
}- Ne félj interfészt használni, ahol lehet, könnyebben cserélgetheted majd mögötte az implementációt. Ha nem akarod cserélgetni, akkor sem árt, mert idővel rááll a kezed, és nem kell folyton törnöd az APIt egy kis módosítás miatt.
Erre gondolok:private ArrayList<Point> points = new ArrayList<Point>();
// helyett
private List<Point> points = new ArrayList<Point>();
// esetleg (attól függ, milyen funkcionalitást vársz el tőle, legyen-e rendezett, stb)
private Collection<Point> points = new ArrayList<Point>();- Ciklusban Stringeket konkatenálni + jellel nem szép dolog, brutálisan pazarló. Minden egyes konkatenáció egy újabb és egy újabb Stringet hoz létre, amit aztán a következő körben el is dob, mert csak átmenetileg volt rá szükség. StringBuilder javallott és annak append metódusa. Vaaagy használod a listák toString metódusát, mert van.
Remek... letelt az időkorlát. -.-
Szóval azt még elfelejtettem, hogy ha Set-re váltasz, akkor a Point.equals mellett a Point.hashcode-ot is implementálnod kell. Az IDE elvégzi helyetted, de a lényeg:
A HashSet úgy működik, hogy a beletolt objektumra először hashcode-ot számol, ez csak egy szám. Ehhez a hashcode-hoz létrehoz egy izét, nevezzük vödörnek, és ebbe a vödörbe dobja bele az objektumodat.
Ha egy újabbat adnál hozzá, akkor arra is hashcode-ot számol, és csak az adott hashcode-hoz tartozó vödörrel foglalkozik, végigmászik a vödör tartalmán, az equals-szal csekkolja, hogy benne van-e már, és ha talált, akkor nem teszi bele újra.
Ha a hashcode számítást elcseszed, akkor előfordulhat olyan, hogy van 2 objektumod, ami az equals szerint azonos, de a hashcode szerint nem. Mindkettő bele fog kerülni a Set-be (!!), mert a másik az eltérő hashcode miatt másik vödörbe kerül. Ilyet sose csinálj.
Vagy például megváltozik az objektumod állapota (mondjuk most nem, mert minden final, de máskor, mással, másnál igen), és a megváltozott állapot miatt megváltozhat a hashcode is. Na az az objektumod, ha benne volt egy set-ben, akkor ott is marad, sose találod meg. Vicces dolgok ezek.
Gondolhatnád, hogy akkor legyen a hashcode mindig 1, abból baj nem lehet. Jó gondolat, de lassú lesz, épp azért szegmentálunk sok kis vödörre relatíve kis számításigényű megoldásokkal, hogy csak egy kis vödör tartalmán kelljen végigsuhanni, gyorsan el lehet dönteni, hogy valami benne van-e abban a Set-ben avagy sem. -
 cigam
titán
cigam
titán
Ha mindenáron le akarod szűkíteni a kört az alapvető dolgokra, Java esetén vedd például az OCA (Oracle Certified Associate) vizsga anyagát. Az Oracle oldalán is egészen jó tutorial van, és önszorgalomból még mélyebbre áshatsz a java elcseszett bugyraiban.
Apró kiegészítés, hogy ehhez azért programozni is tudni kell, tehát az OCA tananyag nem tartalmazza azokat az általános technikákat, hogy mi fán terem az iteráció, a szelekció, ahogy az alapvető algoritmusokat, adatszerkezeteket sem tárgyalja (rendezések, fák, stb).Nagyon alap dolgokat magyaráz, viszont a Java rengeteg irritálóan logikátlan működésére is rávilágít. Már ha igazán beleásod magad. Az OCP egy szinttel tovább lép, de igazából csak még több alap osztály működéséről regél. Véleményem szerint talán túl is tolja ezt, az IDÉk világában nagyon nem érdemes fejből vágni a StringBuilder összes metódusát. Mert minek. Ott a forrás, megnézem, fél másodperc, és ennyi.
De ha nagyon bele akarod ásni magad, hát kezdd a java.lang.* package osztályaival, aztán jöhet a java.util.*, java.util.concurrent.*, stbstb. De totál felesleges.A programozás reál tárgy, nem kell semmit beseggelni, mint a történészeknek. Az összefüggéseket kell ismerned. Nem az a lényeg, hogy fejből vágod, mennyi 4*5, hanem az, hogy ki tudod számolni. Vagy pl. nem kell ismerned, hogy az int -2147483648-tól 2147483647-ig tud számokat ábrázolni, hanem tudod, hogy a byte 8, a short 16, az int 32 biten tárolja az adatokat, amiben egyenlő arányban van negatív és pozitív, a nullát pozitívnak számítva. Kis matek és kijönnek a számok.
Nincs rajz. A szakmánk annyira gyorsan változik, hogy a rajz is folyamatosan változna, emberenként totál eltérő. Arról nem is beszélve, hogy az emberiség nagyon kis százaléka rendelkezik olyan memóriával, ami hiánytalanul visszaadna neked egy korrekt rajzot.
Akik ebből élnek, az általuk használt dolgokat már annyiszor guglizták ki, hogy megjegyezték. Ha idővel kevesebbet használják az adott dolgot, lassan elfelejtik, kikopik, megfeljebb újra rákeresnek, ha újra előjön. Ettől függetlenül nem hátrány, ha mesterien használod a keresőt, mert szükséged lesz rá. Ez így on-demand működik. Képtelenség mindent megtanulni. Az adott projekt dönti el, hogy mit kell használnod. Nekem például totál leépült a java.io tudásom, pedig rendkívül hasznos cuccok vannak benne... viszont évek óta a közelébe sem néztem. Elfelejtem, ennyi. Majd újra előjön, ha használnom kell. Ott a forrás, a javadoc, tutorialok, stackoverflow, google ...És igen, jó ha előre felkészülsz, hogy specializálódni fogsz, nem feltétlenül egy dologra, de fogsz. Mint mondtam, a világ összes ideje sem elég arra, hogy minden területen naprakész legyél.
Ha csak azt nézzük, hogy a youtubera másodpercenként több órányi anyag kerül fel, ugyanilyen rémisztő a helyzet az új programnyelvek, frameworkök, technológiák területén is. Teljesen felesleges megtanulni valamit, amit nem használsz, időt energiát és pénzt pazarolsz vele. Főleg, hogy az összes szinte ugyanaz más köntösben. Kitalálnak egy új nyelvet, ami egy másik hibáit hivatott javítani, cserébe viszont más hibákat hoz be. A hiba alatt inkább a kényelmetlen, körülményes használatot értem. Egyik nap trendi, megismered, megtanulod, másnap már egy másik nyelv a favorit. Unaloműzésnek tökéletes, arra, hogy szélesítsd a látókörödet, kiváló, találkozhatsz érdekes, hovatovább hasznos megoldásokkal, de pusztán azért, hogy majd egyszer talán lesz haszna és használni is fogod, elárulom: nem lesz.Majd a projekt eldönti, hogy mit lesz a jó választás. Adott problémához kell keresned megoldást, és nem a megoldásokat bemagolni. Egyik nap kiderül, hogy Scalaban mennyivel hatékonyabb megoldani xy-t, és lényegében dobhatod a kukába mindazt a java tudást, amit csak azért szedtél fel, mert hátha jó lesz valamire. Ez persze erős sarkítás, de a magolással töltött időt hasznosabban is eltölthetted volna.
Szóval ha megvannak a programozás alapok, akkor már csak egy megoldandó problémát kell keresned / csinálnod, majd arra prezentálni egy jó megoldást, alaposan körüljárva a témát, kisakkozva, hogy mi miért úgy van, ahogy. Meg hogy hogyan lehetne rajta még többet javítani, teszemazt lecserélve az ArrayListet LinkedListre, vajon mennyivel javul vagy romlik a performancia, stb. Bátran használd a keresőt, idővel majd úgyis megtanulod a gyakran használt dolgokat.
Aztán talán felébred benned az igény az igényes kód előállítására is, megismerkedsz a tervezési mintákkal, Bob bácsi clean code irányelveivel, úgy gondolom ezek sokkal időtállóbbak, mint egy 86-ik framework ismerete.
Köszi, hogy ilyen részletesen leírtad!
-
cigam
titán
Köszi az útmutatást!
Sajna nem látok ilyen beállítást:
Bár látszólag a "Run Maven Build" hozzá van társítva az X (+M?)-hez, de akkor sem éled fel, ha kiveszem.
-
 MeghaL0L
addikt
MeghaL0L
addikt
Ööö, a jávának van az a faramuci tulajdonsága, hogy package-ekbe rendezhetőek az osztályok. Ez azért jó, mert így ugyanolyan nevű osztályok akár több helyen (más package-ben) is szerepelhetnek.
Ezért adjuk meg a package-et a fájl elején, és szívunk az importokkal, hogy a jó osztályt elő tudjuk varázsolni.Namármost az import ugyan kényelmesen elfedi előlünk az osztályok igazi nevét (fully qualified name), de érdemes tudni, hogy titokban ő odateszi.
Mondjuk, ha visszafejted a classodat, akkor asszem úgy írja ki:javap Elso.classA java CLI parancs után pedig az osztály nevét kell írni (nem a fájlnevet), tehát a fully qualified name-re van szükség, ami a package-et is tartalmazza. Különben szerencsétlen java nem fogja megtalálni. Valahogy így:
java elso.ElsoJa és persze a java parancsot a project root-ból kell indítani, tehát abból a könyvtárból, ahonnan a package-ben lévő könyvtárakon a java végig tud szambázni.
Működnie kell... vagy közben más lett a hibaüzenet.Köszönöm szépen mindenkinek, sikerült!
-
 Ursache
senior tag
Ursache
senior tag
Tedd azt.
1 sor mindig jobb, mint 5. Főleg, ha ilyen boolean marhulásból áll. Az egyik kedvenc "egysorosom":boolean isOk(String param) {
boolean ok;
if ("OK".equals(param)) {
ok = true;
} else {
ok = false;
}
return ok;
}Egyébként, ha még szeretnéd cizellálni, adhatsz valami szép, értelmes nevet annak a logikai kifejezésnek, valahogy így:
...
myObject.setOnePropertyValue(isConstant1Checked());
...
}
private boolean isConstant1Checked() {
return myVariable.equalsIgnoreCase(CONSTANT1) && checked;
}Bár a kontextus ismerete nélkül lehet, hogy nem így kell, vagy nem is lehet, csak arra akartam rávilágítani, hogy a bonyolult logikai kifejezéseket érdemes olvasható formába önteni. Akinek pedig nagyon furdalja az oldalát a kíváncsiság, hogy vajon mit is jelent az isConstant1Checked(), mert számára nem nyilvánvaló, majd belenéz abba az egysoros metódusba, esetleg még ad neki valami kifejezőbb nevet.
Egyébként ez már túlzás is lehet... csináld érzéssel, az a lényeg.
Ahogy szebb, olvashatóbb, nincsenek kőbe vésett szabályok. Akár maradhat úgy is, amilyenre átírtad. Örülök, hogy segíthettem.---------------------------
#8354 MPeter87:
Ha már kifogytál a könyvekből meg az oktatóvideókból, keress magadnak feladatot és készítsd el. Van-e olyan igényed, problémád, amit lehetne automatizálni, amit egy szoftver megoldana? Akár a hobbiddal kapcsolatban, vagy akár amit el tudnál adni másoknak, mert szükségük lehet rá, vagy csak készíts egy 826-ik jegyzettömb, vagy naptár, esetleg rss olvasó alkalmazást. Csatlakozhatsz akár opensource fejlesztésekhez is, nézelődj pl. a githubon, keress olyan projektet, amiben látsz fantáziát, vagy csak ihletet ad egy saját projekthez. Persze az a legjobb, ha fizetnek is érte, csak akkor nem biztos, hogy olyan terméken dolgozhatsz, amit szeretsz is.Egyébként - ha van már rutinod - az előbb említett clean code tanulmányozása sem ördögtől való gondolat, mert szerintem az Angster könyben lévő példakódokban nem kevés code smell lehet. Már nem emlékszem, csak a hasonló oktatókönyvekkel szerzett tapasztalat mondatja ezt velem. Merem ajánlani Josh Bloch Effective Java könyvét (az angol változatot... hacsak nem szereted az interface-t felületnek hívni, mert akkor a magyar is megteszi), vagy uncle Bob (Robert C. Martin) Clean Code könyvét, videóit. Meg ha már a Martinoknál tartunk (
), Martin Fowler, és Kent Beck is egész jó könyveket írt a refactoringról meg a TDD-ről. De blogokat, cikkeket is találsz elvétve, pl. http://blog.cleancoder.com/, vagy http://martinfowler.com/" 1 sor mindig jobb, mint 5."
en mas kodjanak a debuggolasa kozben nagyon nem szeretnek ilyennel talalkozni.
-
MrSealRD
veterán
Tedd azt.
1 sor mindig jobb, mint 5. Főleg, ha ilyen boolean marhulásból áll. Az egyik kedvenc "egysorosom":boolean isOk(String param) {
boolean ok;
if ("OK".equals(param)) {
ok = true;
} else {
ok = false;
}
return ok;
}Egyébként, ha még szeretnéd cizellálni, adhatsz valami szép, értelmes nevet annak a logikai kifejezésnek, valahogy így:
...
myObject.setOnePropertyValue(isConstant1Checked());
...
}
private boolean isConstant1Checked() {
return myVariable.equalsIgnoreCase(CONSTANT1) && checked;
}Bár a kontextus ismerete nélkül lehet, hogy nem így kell, vagy nem is lehet, csak arra akartam rávilágítani, hogy a bonyolult logikai kifejezéseket érdemes olvasható formába önteni. Akinek pedig nagyon furdalja az oldalát a kíváncsiság, hogy vajon mit is jelent az isConstant1Checked(), mert számára nem nyilvánvaló, majd belenéz abba az egysoros metódusba, esetleg még ad neki valami kifejezőbb nevet.
Egyébként ez már túlzás is lehet... csináld érzéssel, az a lényeg.
Ahogy szebb, olvashatóbb, nincsenek kőbe vésett szabályok. Akár maradhat úgy is, amilyenre átírtad. Örülök, hogy segíthettem.---------------------------
#8354 MPeter87:
Ha már kifogytál a könyvekből meg az oktatóvideókból, keress magadnak feladatot és készítsd el. Van-e olyan igényed, problémád, amit lehetne automatizálni, amit egy szoftver megoldana? Akár a hobbiddal kapcsolatban, vagy akár amit el tudnál adni másoknak, mert szükségük lehet rá, vagy csak készíts egy 826-ik jegyzettömb, vagy naptár, esetleg rss olvasó alkalmazást. Csatlakozhatsz akár opensource fejlesztésekhez is, nézelődj pl. a githubon, keress olyan projektet, amiben látsz fantáziát, vagy csak ihletet ad egy saját projekthez. Persze az a legjobb, ha fizetnek is érte, csak akkor nem biztos, hogy olyan terméken dolgozhatsz, amit szeretsz is.Egyébként - ha van már rutinod - az előbb említett clean code tanulmányozása sem ördögtől való gondolat, mert szerintem az Angster könyben lévő példakódokban nem kevés code smell lehet. Már nem emlékszem, csak a hasonló oktatókönyvekkel szerzett tapasztalat mondatja ezt velem. Merem ajánlani Josh Bloch Effective Java könyvét (az angol változatot... hacsak nem szereted az interface-t felületnek hívni, mert akkor a magyar is megteszi), vagy uncle Bob (Robert C. Martin) Clean Code könyvét, videóit. Meg ha már a Martinoknál tartunk (
), Martin Fowler, és Kent Beck is egész jó könyveket írt a refactoringról meg a TDD-ről. De blogokat, cikkeket is találsz elvétve, pl. http://blog.cleancoder.com/, vagy http://martinfowler.com/Amúgy pont Robert C. Martin Clean Code könyvéből táplálkozom jelenleg főként... Néha azért túlzásnak érzem amit elsőre ír... Aztán belátom, hogy annyira nem is hülyeség.

-
 tboy93
nagyúr
tboy93
nagyúr
Ahogyan jólesik. Nemigazán épülnek egymásra. Javahoz itt van még néhány ha nagyon unatkoznál:
Uncle Bob - Clean Code (videók)
Unlce Bob - Clean Coder (Inkább könnyű olvasmány, mint szakkönyv... magyarul túlélőkönyv programozóknak néven fut, ha jól tudom.)
Martin Fowler - Refactoring
De pl. Kent Becktől is vannak egész jó könyvek...Koszonom szepen!
-
floatr
veterán
Igazán nincs mit. Haszontalan tanácsot bárkinek szívesen adok.
Há! Itt azt állítják, hogy alapesetben a session.close() is nyomja a flush-t. Pedig le mertem volna fogadni, hogy nem tesz ilyet. Nagyon rég Hibernate-eztem.
Amúgy ez kicsit meglepő, de ember legyen a talpán, aki egy ilyen apidoc-ból kideríti, mi a szitu: "The Session is sometimes flushed before query execution in order to ensure that queries never return stale state." Nesze semmi, fogd meg jól.
Most én se tudom sajnos kipróbálni, de egyre kevésbé valószínű, hogy exception lenne a vége.Bár csak hibernate-es projektjeink vannak, de ezt most próba nélkül én sem vágom. Jártam már vele úgy, hogy mentette a változásokat, meg úgy is, hogy nem.
(#8132) M_AND_Ms
A hibernate session egészen más állat. Nem szabad azt gondolni, hogy egy ORM művelet egyből DB művelettel is jár. Max a stateless session és a natív query az, ami garantáltan egyből elvégzi a feladatát DB-ben is. -
Aethelstone
addikt
Igazán nincs mit. Haszontalan tanácsot bárkinek szívesen adok.
Há! Itt azt állítják, hogy alapesetben a session.close() is nyomja a flush-t. Pedig le mertem volna fogadni, hogy nem tesz ilyet. Nagyon rég Hibernate-eztem.
Amúgy ez kicsit meglepő, de ember legyen a talpán, aki egy ilyen apidoc-ból kideríti, mi a szitu: "The Session is sometimes flushed before query execution in order to ensure that queries never return stale state." Nesze semmi, fogd meg jól.
Most én se tudom sajnos kipróbálni, de egyre kevésbé valószínű, hogy exception lenne a vége.Ez szerintem attól is függ, hogy éppen van-e aktív tranzakció. A tranzakció a commit-tel lesz sikeres, ergó ebben az esetben kell visszaírni a változásokat. Ha csak simán nyomunk egy close-t a Session-ra, akkor ugye teljesen attól függ(sometimes), hogy éppen van-e valami tranzakció. Mert egy close a commit nélkül eredménytelen elvileg...
A fax se tudja. DB függő is lehet, illetve JDBC implementáció......
-
MrSealRD
veterán
Hát igen, más meglepő dolog nemigen történhet. Esetleg egy exception.
A close nem flush-ol, szóval detached-be mennek az objektumaid.
De miért is tennél ilyet? Előtte kommitálj, és nem lesz baj.A kommentes dolgot pedig teljesen jól látod. Azért van version control, hogy ne kelljen kommentel teleszemetelni a kódot. Én személy szerint ezeket a marker kommenteket sem bírom, szinte soha nincs rájuk szükség, de mint minden, ez is ízlés kérdése.
Igen ez a másik lehetőség. Az exception. Most nem tudtam öszedobni egy DB-t meg entitásokat, meg valid kódot, hogy kipróbáljam. De az exception-re lennék kíváncsi. Elszáll, vagy simán lefut és detached?
Wá, köszi. Ez eszembe sem jutott. Vannak élethelyzetek amikor fura nem életszerű kérdésekkel zaklatják az ember lelki békéjét. De mivel ilyen helyzet nem megy ki a kezem közül, ezért nem tudom rá a választ.
-
Aethelstone
addikt
Bocs, hogy én is felhozom, csak szeretnék rávilágítani a különbségre.
Az, hogy mindkét esetben láncban hívogatjuk a metódusokat, csak egy aspektusa a problémának. Valaki korábban említette, hogy pusztán a metódusok láncban hívása az un. "Law of Demeter" megsértése. Én ugyan nem nevezném törvénynek, de nem tényleg ajánlanám. Annak ellenére, hogy nekem is sokszor rááll a kezem.
Viszont a builder pattern ettől gyökeresen különbözik, és ezért "veszélytelen". Leginkább abban tér el, hogy a Builder mindig ugyanazon az objektumon dolgozik, a metódusok ugyanazzal a típussal térnek vissza. Egy nem builder esetén viszont ez korántsincs így, a hívó nem ismeri, nem ismerheti azt az osztályt, amit egy metódushívás visszaad, amit pedig annak a metódusa adna vissza, azt mégúgyse, és így tovább. Persze lehet szeretni, meg használni, legrosszabb esetben megtanulod a magad kárán.
Ez igaz, de sok esetben nincs veszélye. Tipikus példa a konténer(DTO) jellegű osztályok.
Ha egymásba vannak ágyazva és engem csak egy érték érdekel, mondjukmyDTO.getSzamlak().getTetelek(0).getValue();
Itt ugye lehetne, hogy a getTetelek(0) esetén egy Tetel objektumot kvázi kiemelek és a getValue() metódust ezen hívogatom a jövőben, amennyiben többször is szükségem van az értékére. Vagy a fent írt sort idézgetem annyiszor, amennyiszer szükségem van rá.
Teljesítmény szempontjából semmiféle hátránya nincs, ha nem emelem ki, viszont megspórolok egy plusz objektumhivatkozást. Nyilván ha egy metódust drága hívogatni, akkor kiemelem, de pusztán annyit próbálok én is már ezer+1 hozzászóláson keresztül magyarázni, hogy a láncban hívás alapvetően lehet jó is. Feladatfüggő.
Nyilván ha nem tudom, hogy pontosan mit csinál a lánc, akkor tartózkodom a használatától, de ismétlem önmagam, a láncolt hívások alapvetően nem az ördögtől valóak és csak azért, mert nemteccik, nem kell elvetni a használatát.Law of Demeter, ha nem akarja egy objektum, hogy ilyen módon hívogassam a metódusait, akkor szervezze már úgy, hogy ne férjek hozzá, ha meg nem szervezi úgy és public, akkor miért ne használjam?
Ennyi. Zárom.
-
 Atlantisz48
őstag
Atlantisz48
őstag
Ha komolyabban szeretnél foglalkozni a dologgal, telepíts egy IDE-t magadnak (IntelliJ Idea, Eclipse, Netbeans, akármi), sok szenvedéstől kímél meg, ha ebben írod a programod.
Ugyanis fordítási hibád van, és ezek azonnal jelzik neked. Időnként még használható javítást is tudnak prezentálni. Bár az üzenet egyértelmű: a Thread.sleep() metódus ellenőrzött kivételt dob, amivel neked kezdened kell valamit.
Vagy elkapod, és "kezeled":try {
while (idozito < 5){
System.out.print("*");
Thread.sleep(500);
idozito = idozito + 1;
}
} catch (InterruptedException e) {
// a te esetedben ilyen amúgyse fog történni, de kezelni kötelező
System.err.println("Bajci van! Valami kilőtte alólam a szálat.");
e.printStackTrace();
}Vagy továbbpasszolod a kivételt a hívónak a stacken eggyel feljebb, vagyis a ciklust tartalmazó metódusod végére a paraméterek után odabiggyeszted a throws InterruptedException szavakat. Ilyenkor viszont a hívóban kell kezelned a problémát... vagy onnan is továbbküldöd... teheted ezt egészen addig, amíg el nem éred a main metódust, de ha az sem kezeli, akkor a programod a kivételdobás pillanatában rövid úton le fog állni (mivel a kivételt senki sem kezelte le).
Kis szösszenet az InterruptedExcpetion-ről.
Köszönöm a részletes magyarázást,
Netbeans-ben sikerült működésre bírni. -
 emvy
félisten
emvy
félisten
Valóban, kis ész is kell a programozáshoz.
Legalábbis ha egy Optionallal találkozok, akkor nem hívom rá a get()-et izomból, hanem előtte tesztelem / szűröm / orElse..., hiszen bizonyára okkal lett Optional.
Sokkal többet ér, mint egy getApplication().getServiceProvider().getService()
.call(something.prepare().getValue()); trainwreck közepén felugró NPE.Inkább úgy fogalmaznék, az erkölcsi kényszer adott, a fejlesztő legfeljebb nem él vele. A saját belátására van bízva, mihez kezd. Míg egy null-t úgy be lehet nézni, mint a huzat.
Ennyi erővel a sima ref típusokon is ellenőrizhetnél
. Azt akarom mondani, hogy a garancia az mindig jobb.. -
emvy
félisten
Az Optional sajnos elég gyenge megoldás, mert nem kényszerít rá, hogy ellenőrizd
-
mobal
nagyúr
Ha egy taskot küldesz be, akkor ezt szépen időzítve hajtja végre.
Közelítsük meg empirikus úton:
service.scheduleWithFixedDelay(task, 500, 1000, TimeUnit.MILLISECONDS);Szerintem első körben töröld azt az i++; sort a ciklusod közepéből, csak zavar.
Majd vedd le a max értékét 1-re, hogy lásd, mit csinál az executor 1 taskkal.
Fél másodpercet vár, majd 1 másodpercenként meglöki ugyanazt a taskot.Ha a max értékét felhúzzuk 2-re, akkor egyértelművé válik, mi történik. A két task azonnal bekerül az executorba, mindkettő vár fél másodpercet, majd egymás mellett elindulnak. És persze az executor mindkettőt 1 másodpercenként meglöki újra, továbbra is egymás mellett futnak, hiszen ugyanakkor, ugyanolyan időzítéssel készültek el.
Ha a pool méretét nem a procik száma alapján határozod meg, hanem lehúzod 1-re, majd a max értékét felnyomod 10-re, akkor is úgy tűnik, mintha egyszerre hajtódnának végre. Valójában csak 1 szálon teszik egymás után, de a task nem csinál semmit, így villámgyorsan megtörténik, az időzítésük ugyanaz, tehát továbbra is egymáshoz nagyon közeli időpontban fognak megfutni.
Megteheted azt, hogy
service.scheduleWithFixedDelay(task, i * 200, max * 200, TimeUnit.MILLISECONDS);, de lehet erre szofisztikáltabb megoldás is. Mivel ez esetben ismerned kell azt, hogy összesen hány taszkot bízol a service-re, ami nem feltétlenül ismert az első taszk indításakor.
Nem vagyok otthon ebben a szálkésleltetésben, de csak van rá valami megoldás. A többi metódusát már nézted? 3rd-party library-ket?Jobban belegondolva, nem biztos, hogy ez ennyire egyértelmű, mert a magok száma borítja a dolgot. Egy egymagos gépen evidens. De egy 4 magos gépen, 4 szálon futtatva mit vársz tőle? 4 szál párhuzamosan futtat 1-1 taskot, majd x idő múlva indulna újabb 4 task? Mi van, ha a 4-ből 1 túl hosszú, és jönne a következő kör? Olyankor csak 3 új szál induljon? Vagy egy se, és 1 kör kimarad? Ha minden egyes taskot x idővel eltolva indítanál, akkor mi értelme több szálat használni? Sőt extrém hosszú taskoknál ugyanúgy előjöhet a fentihez hasonló probléma. Vagy olyankor nem kell várni, azonnal induljon a következő task, amíg van szabad szál?
Legrosszabb esetben csinálhatsz egy custom executorService implementációt.
Ezen gondolkoztam a mai nap. Lényegében adatokat töltök le, de muszáj 50 ms szünettel dolgoznom mert flood ként érzékeli a gép és letilt. Emiatt most már úgy gondolom, hogy nem jó megoldás.
-
 szcsaba1994
tag
szcsaba1994
tag
A szabály az szabály. Sőt, lambdát is tilos írni, hátha véletlenül classra fordul.
Amúgy nem tudom, engem szerencsére nem érint. Csak sajnálom azt, akit igen. Remélem nem megy el tőle a kedve, amíg munkát nem talál. Akkor végre tanulhat is valami hasznosat.
Bocsánat a kirohanásomért, de nehezen viselem, ha oktatás címszó alatt rossz szokásokra nevelnek.Ha az automatikus kiértékelő rendszer (teszt?) az oka, akkor az a hibás és meg kell javítani. A teszt arra való, hogy a public APIn keresztül ellenőrizze a cuccot, se több, se kevesebb. Hogy én azt belül hogyan oldom meg, hány osztályt hozok létre mögötte és azok hogyan viselkednek, ahhoz senkinek semmi köze.
szcsaba1994: Ez a Tabla osztály konkrétan micsoda? Úgy érzem, hogy ez a Node... legalábbis ahogyan használni szeretnéd. A minimax elindul egy Node-on (Tablan?) és rekurzívan egyre mélyebbre haladva bejárja a gyerekeit, akik szintén Node-ok. Vagy a Tabla csak valami payload?
Amúgy igen, a gyerekek és az érték mindenképpen kell a számításhoz. Meg az az infó, ami alaján eldöntöd, hogy az aktuális Node min vagy max. A szülőt én feleslegesnek tartom, de nem ismerem a feladatot, szóval lehet, hogy kell.
Valami ilyesmi:
class Node {
private List<Node> children;
private int heuristicValue;
private boolean isMax; // például, de más módon is el lehetne dönteni hogy min vagy max
...
}A táblában van a 8*8-as mező, meg vannak valósítva a legfontosabb metódusok (lépés lehetséges-e, üres-e, milyen típus van az adott mezőn)
Inverse Chess-t kell megvalósítani -
 Lortech
addikt
Lortech
addikt
Azt értem, hogy nem szabad, de azt nem, hogy miért nem?
Mi az oka annak, hogy a fejlesztő nem struktúrálhatja a kódját úgy, ahogy az szerinte használható és átlátható?
Remélem nem az, hogy a prof könnyebben kinyomtathassa az 1 db fájl tartalmát.Egy normális világban / OO nyelvben egy kicsit is komplexebb megoldást nem egy osztály valósít meg. És akkor csodálkozunk, hogy az egyetemről érkezők olyan minőségű kódot produkálnak, amilyet. (Én is ilyet produkáltam, és utólag visszanézve nem vagyok rá büszke.)
Szerencsétlenek nem hogy nem látnak mást, még a kreatívabb kisebbséget is megkötik az idióta szabályaikkal.Lortech: A nested class is egy újabb osztály. Bár nem erről szólt a feladat, de ha úgy tartja kedvem, 826 osztályt is tehetek egy fájlba, csak éppen rettentő gusztustalan lesz.
Persze ebben az esetben én is inner classra szavazok, nagyon ide kívánkozik. Inkább, mint az egymásba ágyazott konténerek végeláthatatlan sora. Vagy akkor szívassuk meg a tanárt, és az olvashatatlanságig bonyolítsuk túl, legyen neki is pár kellemes órája, amíg kitalálja, mit csinál.Jó, akkor anonymous vagy local class se lehet? Pl. nem implementálhatsz egy Comparatort inline. Miért? Hogyan?
Persze, a nested class is class, ha de ha pl. egy beadandó automatikus kiértékelő rendszer valamilyen mesterséges korláta az, hogy "1 db osztályt" használhatsz, akkor lehet opció.
Egyébként nyilván ökörség bármi ilyen megkötés. -
skoda12
aktív tag
Azt értem, hogy nem szabad, de azt nem, hogy miért nem?
Mi az oka annak, hogy a fejlesztő nem struktúrálhatja a kódját úgy, ahogy az szerinte használható és átlátható?
Remélem nem az, hogy a prof könnyebben kinyomtathassa az 1 db fájl tartalmát.Egy normális világban / OO nyelvben egy kicsit is komplexebb megoldást nem egy osztály valósít meg. És akkor csodálkozunk, hogy az egyetemről érkezők olyan minőségű kódot produkálnak, amilyet. (Én is ilyet produkáltam, és utólag visszanézve nem vagyok rá büszke.)
Szerencsétlenek nem hogy nem látnak mást, még a kreatívabb kisebbséget is megkötik az idióta szabályaikkal.Lortech: A nested class is egy újabb osztály. Bár nem erről szólt a feladat, de ha úgy tartja kedvem, 826 osztályt is tehetek egy fájlba, csak éppen rettentő gusztustalan lesz.
Persze ebben az esetben én is inner classra szavazok, nagyon ide kívánkozik. Inkább, mint az egymásba ágyazott konténerek végeláthatatlan sora. Vagy akkor szívassuk meg a tanárt, és az olvashatatlanságig bonyolítsuk túl, legyen neki is pár kellemes órája, amíg kitalálja, mit csinál.Volt több ilyen tárgyam is, ahol meg volt határozva keményen, hogy csak a tanár libjeit lehetett használni. Oop prog tárgyhoz írt prof valami horror libet millió template paraméterrel ellátva, aminek kb az volt a lényege, hogy nem lehetett ciklust írni, mert hogy akkor az nem OO. Az volt a terv, hogy a diák majd funktorokat ad át a lib osztályainak.
Bementem vizsgára, 30 sorban megoldottam a feladatot, majd megbuktattak egy for ciklus miatt. Ez ilyen, túl kell élni ezeket a tárgyakat.
-
 Sk8erPeter
nagyúr
Sk8erPeter
nagyúr
"Ja, pont akkora őrültség, mint aki a magyar mondataiban nem használ ékezetet.
"
Hehe, hát igen. (#7687) bambano:
"teljes őrültségnek tartom, ha valaki kétféle klavi kiosztást használ..."
Meg ez is jó.(#7683) emvy:
"Teljes orultsegnek tartom, ha valaki HU layouttal kodol"
Jaj, de szeretem az ilyeneket. Mi az a komoly hátrány, ami származik abból, ha valaki átállítja például a toggle comment hotkey-jét az IDE-ben? (Csak egy példa arra, ami mondjuk HU layouttal nem szokott tipikusan működni, de na bumm, körülbelül fél perc átállítani.) Mi az, ami miatt probléma lenne, hogy valaki HU layoutot használ, amikor világéletében ezt szokta meg, mert mondjuk nem élt hosszabb távon külföldön, ami miatt feltétlenül át kellett volna magát állítania más kiosztásra?
Ez nagyjából olyan, mintha beszólok, hogy milyen gyökérség ékezetek nélkül írni, mert amúgy tök idegesítő egy magyar nyelvű fórumon, annak ellenére, hogy nyilván az itt tevékenykedők többsége folyamatosan tudja olvasni az ilyen szöveget is, mivel nem egy túl komoly agyi munka, de akkor is zavaró (másnak nem biztos, nekem például igen, és tudom, "így jártam"). Ha magyar fórumra írsz, miért nem állítod át a layoutot (vagy magadat) magyarra?(#7702): Egy ilyen tényleg nem lehet rossz, de mondjuk itt fura picit, hogy ennyire magasra van emelve, így az ember csuklójának tartása gépeléskor kicsit "megtörik", és nem folyamatos az emelés.
-
 alfa20
senior tag
alfa20
senior tag
Szia!
Hehe, Eclipse telepítés után első dolgom lekapcsolgatni a key bindingokat.
Window -> Preferences -> General -> Keys:
Majd a szűrőbe bepötyögöd, hogy Ctrl+Alt+B
Kijelölöd a problémás összerendelést, és Unbind gomb. Vagy beállíthatsz valami neked tetsző kombót is.Csekkold a többi Ctrl+Alt+ kombót is, valószínűleg nem ez lesz az egyetlen.
Köszönöm! -
floatr
veterán
A szmájliból talán sejthető, hogy nem gondoltam komolyan, amit írtam.
A visibility modifier-es kérdést viszont helyénvalónak érzem. Aki "életvitelszerűen" használja a javat, annak gondolkozás nélkül megy. A csak elméletet ismerőnek pedig csak egy újabb kézzel megfoghatatlan bemagolható valami.
Szerintem a kérdés inkább a gyakorlottságot akarta felderíteni. Ha az ember írogat magának programokat, és legalább egy értelmes könyvet olvasott már (pl. Effective Java - Bloch, Clean Code - Martin, Refactoring - Fowler, stb), ennek mennie kell, és ehhez nem kell munkatapasztalat.
Értettem persze, számomra az egész fejben fejlesztős tudás az, ami kétséges értékű. Láttam már sokféle juniort meg elvileg tapsztaltabbat is, aki kente-vágta a kvízkérdésekre a választ, de a problémákat nem tudta megoldani, inkább csak generálni
-
floatr
veterán
-
MrSealRD
veterán
2. What about this?
Tudtommal csak az awt tud ikont pakolni a system tray-re. Hogy buborékra képes-e, azt passzolom. Majd meséld el.Nem rossz. Az külön tetszik, hogy javafx. Egy másik funkcióra pont alkalmas is lesz.
A fenti témához viszont egy fixen a taskbarra ülő "valami"-t szeretnék használni. Két szerepe lenne. Az egyik, hogy mutatja a %-ot, a másik, hogy innen elérhető az alkalmazás fő ablaka.
-
 norbert1998
nagyúr
norbert1998
nagyúr
Bakker, hogy erre nem jöttem rá

Mondjuk azóta nem nagyon foglalkoztam vele, haladtam tovább, ott már teljes sikerrel. Már csak a beolvasás rossz, azt meg a tanár mondta, hogy megcsekkolja.Köszi
-
norbert1998
nagyúr
Szia!
Az ember maximum 7 dolgot tud egyszerre fejben tartani. A program komplexitása messze meghaladja ezt a számot. Vagyis az időd nagy részét arra pazarlod, hogy a fejedből kieső információt folyamatosan töltöd vissza, miközben ettől függetlenül hibát is keresel. Ne csodálkozz, ha nem megy. Senkinek sem menne.
Az oktatás célja új tudásanyag átadása, és nem a szívatás. Ha tömbök használatát kell gyakorolni, akkor gyakoroljátok, de ezt nem egy átláthatatlan programon kell csinálni, mert az már nem a tömbök használata lesz. Ezzel csak arra akarok célozni, hogy bizonyos komplexitás elérésekor meg KELL tanulni a kód kisebb egységekre bontásának módjait. Különben az energia egyre nagyobb részét fogja felemészteni az, hogy próbálod megérteni, mi történik, és egyre kevesebb figyelem jut a tényleges gyakorlásra.
A nehezebb mód az, hogy tovább görcsölsz rajta, és majd egyszer sikerül rátalálni az egyik hibára. Sajnos hátra van még a többi hiba is. Mindig van egy újabb hiba.
Ezen valamelyest javíthatsz, ha elkezded debugolni: teszel egy breakpoint-ot a problémás rész elé, és debug módban indítod a programot. Majd szépen lassan, soronként egyesével lépkedve, a változók értékeit folyamatosan ellenőrizve megnézed, mit is a csinál a gép.A könnyebb (és melósabb) mód, ha legalább megtanulsz metódust készíteni.
Első lépés:
public class Beadando {
public static void main(String[] args) {
new Beadando.doit();
}
// ez egy példány szintű metódus, nincs visszatérési értéke, nincs paramétere
public void doit() {
// a main helyett ide kerül minden
}
}A static main metódus a program belépési pontja, ugyan a Beadando osztályban van (mert valahova tenni kell), de nem sok köze van hozzá. Ami a main-ben történik, hogy az osztályból készül egy példány, és azonnal ráhívsz annak egy példány szintű (nem static) metódusára. Én doit-nek neveztem, te úgy nevezed, ahogy akarod. Minden más marad a régiben.
A következő lépés lehetne mondjuk a Beadando által gyakran használt változókat kiemelni, field-et csinálni belőle. Ha nem lenne egy Beadando példányod, ezt nem tehetnéd meg ilyen szépen. Pl. én kiemelném az adatot tartalmazó tömböket, sőt a színeket tartalmazó konstansokat is:
public class Beadando {
private static final String RESET = "\u001B[0m";
private static final String RED = "\u001B[31m";
private static final String BLUE = "\u001B[34m";
private static final String CYAN = "\u001B[36m";
private int n=500;
private String [] nev =new String [n];
private String [] gazdnev =new String [n];
private String [] tomeg =new String [n];
private String [] kor =new String [n];
public static void main(String[] args) {
new Beadando().doit();
}
public void doit() {
// ide kerül minden
}
}
Értelemszerűen ezeket már nem kell belül létrehoznod, elég hivatkozni rájuk. Javaban a konstans static és final módosítóval is rendelkezik, a példány szintű field-eknek nem kell static-nak lenniük. Nem is ajánlott.new Beadando()
Ez készít egy példányt az osztályból. Mivel az osztálynak még nincs látható(!) konstruktora, az alapértelmezett konstruktor (aminek nincs paramétere) használható a példányosításkor.A tömb mérete nem túl szép ott a field-ek között, lehetne akár konstruktor argumentum. A konstruktor tekinthető egy spéci metódusak is, máshogy is néz ki. Ő csak egyszer hajtódik végre, a példány létrehozásakor. A tömböket is elég ilyenkor lefoglalni:
public class Beadando {
private static final String RESET = "\u001B[0m";
private static final String RED = "\u001B[31m";
private static final String BLUE = "\u001B[34m";
private static final String CYAN = "\u001B[36m";
private String [] nev;
private String [] gazdnev;
private String [] tomeg;
private String [] kor;
private int n;
public static void main(String[] args) {
// new Beadando(500).doit();
// vagy akár így is lehet példányosítani és ráhívni az egyik metódusára:
Beadando beadando = new Beadando(500);
beadando.doit();
}
// ez a konstruktor, van egy int argumentuma, ebben lesz majd az 500
public Beadando(int n) {
this.nev =new String [n];
this.gazdnev =new String [n];
this.tomeg =new String [n];
this.kor =new String [n];
this.n = n; // ha esetleg még valahol hivatkoznál az n-re, a this.n-nel ezt megteheted
}
public void doit() {
// ide kerül minden
}
}A field-ekre a this. prefix-szel hivatkozhatsz, de elhagyható, ha a neve nem ütközik más változó nevével.
Első blikkre egész szépen kiszervezhetők metódusokba a case blokkokban lévő cuccok. Kezdd a belül lévő legkisebbekkel. Kommentekkel még el is nevezted őket, szinte adja magát.
Pl. ebből:
// ...
public void doit() {
// ... a doit elején lévő cuccok
case 3 : { //főmenü 1-es menüpont->2-es menüpont
String kereses=extra.Console.readLine("Milyen korút keressünk?");
db=0;
i=0;
while(kor[i++]!=null){
}
for (int g=0;g<i;g++){
if (kereses.equals(kor [g])){
torvalogatas[db]=g;
db++;
}
}
break;
}
// ... a doit végén lévő cuccok
}
}Ez lesz:
// ...
public void doit() {
// ... a doit elején lévő cuccok
case 3 : { //főmenü 1-es menüpont->2-es menüpont
db = keresKorra(torvalogatas);
break;
}
// ... a doit végén lévő cuccok
}
// ez egy új metódus, az osztályon belül, de a doit metóduson kívül
private int keresKorra(int[] torvalogatas)
String kereses=extra.Console.readLine("Milyen korút keressünk?");
int db=0; // Figyelem! Ez a db, nem a metóduson kívül található db.
int i=0; // Ahogy ennek az i-nek sincs semmi köze a külső i-hez. Ezek csak itt belül léteznek.
while(kor[i++]!=null){
}
for (int g=0;g<i;g++){
if (kereses.equals(kor [g])){
torvalogatas[db]=g;
db++;
}
}
return db; // Itt a metódus futása megszakad és visszatér a return mögött található változó értékével.
}
}A metódusokat tetszőleges sorba rendezheted, azokat, amelyek hasonló dolgot csinálnak, egységesítheted. Amelyek pedig ugyanazt csinálják, több helyen újra felhasználhatod, eltérő paramétereket adva neki.
private int keresKorra(int[] torvalogatas)
Az első elem egy láthatóságot szabályozó módosító, a private csak az osztályon belül látható, a public bárhol, a többi most nem érdekes, jelen esetben teljesen mindegy, melyiket használod.
A következő a metódus visszatérési értékének típusa. Sajnos max. csak 1 db visszatérési értéke lehet egy metódusnak, ez most egy int (a metódus törzsében található return utasítással adod majd vissza a tényleges értéket). Ha a metódus nem kell, hogy visszaadjon értéket, akkor a típus a void lesz (a return pedig elhagyható).
Aztán jön a metódus neve, tetszőleges, bár a szokásos névkonvenciók rá is vonatkoznak, kezdődjön kisbetűvel, és az ékezetes betűket inkább hanyagold.
A zárójelek között pedig vesszővel elválasztva felsorolod a metódus paramétereit (típusa és a metóduson belül használt neve).
Ha a metódusban kivételt is dobunk és azt nem kapjuk el, akkor a ) után szerepel a throws kulcsszó és a kivételek vesszővel elválasztva, pl.: void metodusNeve(String param1, int param2) throws IOException { }. A fordító majd úgyis reklamál, ha ilyet kell csinálnod.A return a metódusban bárhova tehető, de ha a vezérlés elér hozzá, - akár egy ciklus kellős közepén is vagy - a metódus futása megszakad és visszatér az adott változó aktuális értékével. Ez alól csak a finally blokk kivétel, mert az abban lévő cucc a metódus elhagyása előtt még gyorsan megfut.
A metódus felhívása így történik:
db = keresKorra(torvalogatas);
Metódus neve, és zárójelben vesszővel elválasztva felsorolod az átadni kívánt paramétereket. Ha a metódus valamilyen értékkel is visszatér (nem void), akkor azt az értéket el is tárolhatod egy változóban, most a db változóba tettük egy sima értékadás keretében. Persze ha kint nincs szükséged a visszaadott értékre, nem kell azt mindenáron változóba tenni, az értékadás elhagyható.A metódus törzse egy külön világ, itt csak a field-eket és a beadott paramétereket látod, ezekkel dolgozhatsz.
A paraméterek érték szerint adódnak át. Ez primitív típusoknál (int, char, boolean, stb.) egyértelmű, az érték átadásra kerül, de a metódusban bármit is csinálsz vele, az a metóduson kívül nem fog érvényre jutni. Immutable típusoknál (pl. String) sincs veszély, mert azok úgy lettek megalkotva, hogy bármit is csinálsz vele, magán az objektum állapotán nem változtat, inkább új objektumot hoz létre.
Viszont van minden más (pl. a fentebb említett Dog osztály, vagy éppen a tömbök), amelyek akár több értéket is képviselhetnek. Ezért aztán csak azok memóriacíme kerül értékként átadásra, így ha ezek tartalmát módosítod a metóduson belül, a módosításod a metóduson kívül is érvényre jut. Hiszen a metóduson kívül létező tömb és a metódusnak átadott tömb címe ugyanaz, ugyanazt a memóriaterületet piszkálod.
És itt jutottunk el ahhoz a csúnya megoldáshoz, amit alkalmaztam: átadtam a torvalogatas tömböt a metódusnak, pedig az csak ír bele. Nem szép dolog metóduson belül a paramétereket változtatni, normális esetben csak olvasni szabadna, de ez például egy módszer arra, hogy a metódus több dolgot is változtasson (mivel csak egy visszatérési értéke lehet, és azt a db-re elpazaroltuk).
Persze a több visszatérési értékre van más megoldás is, pl. minden visszaadandó cuccot becsomagolni egy objektumba, de egyelőre szerintem ennyi is elég.Kellemes refaktorálást. Miközben bontod szét a kódot, valószínűleg a mostani hiba okát is meg fogod találni. Ha lehet, említsd meg a tanárnak, hogy az ezersoros programod kezd átláthatatlanná válni, meséljen már az osztályokról, példányokról és metódusokról.
Ami pedig az érettségit illeti: Egy problémát meg lehet oldani jól és hatékonyan, de meg lehet oldani gányolással is. Nem kell ismerni az osztályokat, a metódusokat, de még a for ciklust sem hozzá. Csak éppen évekkel tovább tart a megoldás, és lehet hogy kapsz rá egy kettest. És egy bizonyos méret felett az ember már nem a megoldással foglalkozik, hanem a kapálózással, hogy a víz felszínén tudjon maradni. Kizárt, hogy érettségin ne kelljen ezeket az alap dolgokat használni. De tedd fel magadnak a kérdést: Könnyű érettségit akarsz? Jó munkahelyet magas fizuval? Ha igen, és a tömböket már unalomig gyakoroltad, akkor érdemes továbblépni a List-re. Annyi hasznos dolog van még a nyelvben, sose jutsz a végére.
Bár lehet, hogy feleslegesen pötyögtem... csapd fel a tankönyvet a metódusnál és hajrá.
Persze a legjobb az lenne, ha az osztályok és metódusok után egy elegáns mozdulattal telepítené mindenki a junit-ot, és TDD-ben gyakorolnátok tovább. Mennyivel könnyebb lenne az immáron jól struktúrált kódon megtalálni a hibákat. És a refaktorálás is veszélytelenebb lenne. Szép álom.
Szia!
Valójában 3-400 soros programot kellene írni. Az első része az volt, hogy alkossunk egy feladat specifikációt, ami alapján elkészül a program. Extra dolgokat tudhat, viszont kevesebbet nem. Nos, kicsit nagyon elvetettem a sulykot a feladatspecifikacional. Így most tulajdonképpen iszom a levét.Jézus, mennyit írtál!
 köszönöm szépen
köszönöm szépen
Sajnos ez nekem még mindig nagyon magasÉs tankonyvunk sincs. Semmit nem írt ki az oktatási minisztérium. Egy füzetbe jegyzetelunk és kész.
WonderCSabo: ha format left vagy right-tal kiiratod, akkor sincs elcsúszva a felső sor?
-
floatr
veterán
-
#39560925
törölt tag
Az alapvető probléma az, hogy két helyen kell ugyanazt karbantartani. Amíg csak néhány entitásról van szó, oké, de amikor elkezd növekedni a számuk, és elkezdenek ezek változni is, akkor születnek újabb bogárkák.
Mert például valaki elfelejtette átvezetni a módosítását a másik osztályba, elfelejtődik, és később jönnek a hibák.
Röviden: a duplikált kód rossz.Ez persze nem jelenti azt, ne lehetnél vele boldog, csak érdemes jobb megoldás után kutatni.
Láttam olyan helyet, ahol ennek a menedzselésére bevezették a kódgenerálást. Ott aztán már durva állapotok vannak, ha az ember ilyesmire kényszerül. Egy xtend leíróban legózhatod össze a java forráskódot töredékekből, ezzel többféle forrást is generálhatsz, amit majd a compiler fordít, stbstb. Így xtend-ben kell egyszer megírni a cuccot és az akár 20 féle DTO-t is kigenerál neked. Vagy amennyit akarsz. Tiszta káosz. Cserébe viszont az xtend nehezebben olvasható. Vagy lehet, hogy csak szokni kell. Szerencsére nem sokáig kellett gyönyörködnöm benne.
Alvás helyett gondolkodtam floatr hozzászólásán. Biztos, hogy JSON serialization-ről beszélt. Ha a kapcsolatokra teszek @JsonIgnore-t, akkor amikor csak alap információk kellenek az entitásokról, jól fog működni parszolás. Amikor pedig egy nagy objektumot küldenék, pl Movie, és benne minden kapcsolódó adattal, akkor ilyen esetekre definiálnék wrapper osztályt, és benne lenne minden szükséges adat egy mezőként.
Pl:
public class MovieWrapper {
private MoviesEntity movie;
private ArrayList<ActorsEntity> actors;
private ArrayList<WritersEntity> writers;
// többi kapcsolat
...
// getterek, setterek
}Ezt az objektumot gyönyörűen meg tudom konstruálni a business logic layerben, amikor még van hibernate sessionöm, és így nincs konverzió, kódduplikáció, csak 1 kis extra karbantartás.
Kérdés: Jackson tudni fogja ezt parszolni? Most nem tudom kipróbálni, mert már aludni akarok, és mobilról írtam.
-
emvy
félisten
Az alapvető probléma az, hogy két helyen kell ugyanazt karbantartani. Amíg csak néhány entitásról van szó, oké, de amikor elkezd növekedni a számuk, és elkezdenek ezek változni is, akkor születnek újabb bogárkák.
Mert például valaki elfelejtette átvezetni a módosítását a másik osztályba, elfelejtődik, és később jönnek a hibák.
Röviden: a duplikált kód rossz.Ez persze nem jelenti azt, ne lehetnél vele boldog, csak érdemes jobb megoldás után kutatni.
Láttam olyan helyet, ahol ennek a menedzselésére bevezették a kódgenerálást. Ott aztán már durva állapotok vannak, ha az ember ilyesmire kényszerül. Egy xtend leíróban legózhatod össze a java forráskódot töredékekből, ezzel többféle forrást is generálhatsz, amit majd a compiler fordít, stbstb. Így xtend-ben kell egyszer megírni a cuccot és az akár 20 féle DTO-t is kigenerál neked. Vagy amennyit akarsz. Tiszta káosz. Cserébe viszont az xtend nehezebben olvasható. Vagy lehet, hogy csak szokni kell. Szerencsére nem sokáig kellett gyönyörködnöm benne.
> Láttam olyan helyet, ahol ennek a menedzselésére bevezették a kódgenerálást. Ott aztán már durva állapotok vannak, ha az ember ilyesmire kényszerül. Egy xtend leíróban legózhatod össze a java forráskódot töredékekből, ezzel többféle forrást is generálhatsz
Jaja, kozben meg egy sor mellett elmagyarazzak neked, hogy a tobbszoros orokles egyebkent rossz, mert ize. Pl. a tobbszoros orokles hianya valami, ami _allandoan_ problema (nekem). A masik meg az, h nem lehet rendesen monkey patchelni, de az kisebb problema. Kodgeneralast mi akkor csinaltunk, amikor .Net-ben meg Javaban is el kellett erni ugyanazok az entitasokat -- ott tenyleg az volt a legegyszerubb, hogy mittudomen, XML-ben leirod, h hogy nez ki az ojjektum, aztan kesz.
-
#39560925
törölt tag
Jobban belegondolva a google is szereti halmozni a rest hívásokat. Jó, persze mögötte ott egy bazinagy elosztott rendszer.
Pl. gmail:
Listás nézetben csak az első x db mail látszik (sender, subject és esetleg a body eleje). Nem fogja lehúzni az összes email összes tartalmát. Sőt egy conversationbe belépve sem tölt le mindent, csak az elsőt meg az utolsót. Ha akarod olvasni a többit majd kattintasz és lehúzza azokat is.
Ez soksok apró hívás, mindig csak a legszükségesebbet letöltve. Így fenn tudja tartani a látszatot, hogy ő milyen gyors. Szóval lehet ezt hatékonyan csinálni, csak meg kell találni az egyensúlyt.Megjegyzem, a konvertálgatást csak utolsó mentsvárként javasoltam.
De ezzel a konvertálással most nagyon egyszerűen tudok küldeni azt amit akarok.
-
#39560925
törölt tag
Ha más lehetőség nincs a copy-paste mindig segít.
MovieEntity a JPA-nak, MovieRepresentation a JSON parsernek, és a kettő közé egy finom konverter, ami egyikből másikat csinál. A két eszköz nem fog egymásnak bekavarni, a konverterben meg célzottan meg tudod adni, miből mikor mit csináljon.Ahh, ez lesz a megoldás.
Akkor ezzel zárom a napot, holnap folytköv. Köszi a segítséget mindenkinek! -
#39560925
törölt tag
Kicsit későn lövöm el a hsz-t, feltartottak. Talán ad ötletet.
--------
Szerintem fixen belőtt annotációkkal nem fog menni, mivel nem egyértelmű, hogy melyik fetch módot kell alkalmazni.
Alap, hogy minden lazy. Mivel csak a REST hívás beérkezésekor tudod eldönteni, hogy adott esetben melyik kapcsolatot kell eager fetchelni, nincs mese, runtime ott helyben kell megmondanod neki.Erre sokféle módszer létezik, hogy melyik szép, azt nem tudom.
1. Ha a user a filmre kíváncsi, előkeresed a filmet, majd ráhívsz a getActors() metódusra (ez úgy tudom meglöki a proxy-t és ha sessionben vagy, akkor feltölti az actorokkal is).
2. Talán named query használatával (movie és actor joinnal) ez a bohóckodás egyszerűbbé tehető.
3. Rémlik valami olyasmi, hogy JPA/Hibernate alatt runtime felülbírálható a fetch mód. De itt is áll, hogy minden lazy és szükség esetén adott hívásnál döntöd el, hogy mit nyomatsz eagerrel. Mintha valamiféle fetch profilt kellene ehhez létrehozni (ezzel jól megannotálva az entitást), és az entitás lekérésekor elég csak a profilra hivatkozni.
4. ...
Sajnos nagyon régen Hibernate-eztem, nem biztos, hogy ezek a legjobb megoldások, vagy hogy egyáltalán működnek.
A hibernate doksit nézted már?Többnyire gúglit nézek, aztán onnan mindenfelé vezetnek utaim, többek között a hibernate doksihoz is.
Nekem az 1-es megoldás tetszik a legjobban, és ha nem jön be, akkor megnézem a többivel. A gond lehet, hogy valójában nem is itt van, hanem a JSON parserrel, de ez még kiderül, mindenesetre most nőtt annyival a tudásom, hogy jó ideig ellegyek vele.
Egyébként több helyen is olvastam, hogy a hibernatenek tudnia kéne kezelni eager fetchelés közben az ilyen ciklikus, 2 irányú many-to-many kapcsolatokat, de úgy látszik a gyakorlatban még sincs így.
(#7191) emvy: Hmm, logikusan tűnik.
-
Ursache
senior tag
Hát, hajrá, hajrá.
Én első körben kideríteném, mi az a Newton-módszer. Ilyesmikre a wikipedia jó kiindulópont szokott lenni.
Aztán átültetném ezt egy olyan nyelvbe, amiben változóknak lehet értéket adni, meg mindenféle vezérlési szerkezetekkel lehet ezeket piszkálni.
A szemfülesebbek 2 kattintásból is találnak hozzá pszeudokódot.
Persze megérteni azt is meg kell, de jóval egyszerűbbé válik átültetni az egészet javaba. És végülis erről szól az alkalmazott matek, nem?
Egy munkahelyen ennél azért jóval húzósabb feladatokat kell majd csinálni, és sokszor nemigen akad olyan, aki megmondja a tutit.A gyengébbek persze matlabozhatnak is, de egy java fórumon ilyet csak nem mondok. Én amúgy javaban csinálnám, mert a matlabhoz még annyira sem értek.
Amúgy elég sok az átfedés a feladatok között... szabad csapatban dolgozni?
A gyengebbek javazhatnak is, az igazi hc arcok assembly-ben irjak...
-
 WonderCSabo
félisten
WonderCSabo
félisten
Hát, hajrá, hajrá.
Én első körben kideríteném, mi az a Newton-módszer. Ilyesmikre a wikipedia jó kiindulópont szokott lenni.
Aztán átültetném ezt egy olyan nyelvbe, amiben változóknak lehet értéket adni, meg mindenféle vezérlési szerkezetekkel lehet ezeket piszkálni.
A szemfülesebbek 2 kattintásból is találnak hozzá pszeudokódot.
Persze megérteni azt is meg kell, de jóval egyszerűbbé válik átültetni az egészet javaba. És végülis erről szól az alkalmazott matek, nem?
Egy munkahelyen ennél azért jóval húzósabb feladatokat kell majd csinálni, és sokszor nemigen akad olyan, aki megmondja a tutit.A gyengébbek persze matlabozhatnak is, de egy java fórumon ilyet csak nem mondok. Én amúgy javaban csinálnám, mert a matlabhoz még annyira sem értek.
Amúgy elég sok az átfedés a feladatok között... szabad csapatban dolgozni?
Newton-módszer pár hsz-el feljebb linkelve van.
Persze Google segítségével is két kattintás, ahogy mondod a pszeudokód is. -
 RexpecT
addikt
RexpecT
addikt
DateTime now = new DateTime();
DateTime tomorrow = now.plusDays(1);
if (tomorrow.isAfter(now)) {
doIt();
}java.util.Date típusra ide-oda tud konvertálni is, ha szükséged van rá.
Vagy ha nem bírod a 3rd party librarykat, akkor java8 LocalDateTime?
LocalDateTime.from(new Date().toInstant()).plusDays(1);
Rengeteget szívhatsz a másodpercek babrálásával. Az, hogy 1 óra 3600 másodperc, pont annyira igaz, mint hogy egy év 365 nap... vagy mint fentebb, hogy 1 nap 24 óra. Általában igaz, kivéve a kivételek esetén.
A daylight-savig csak egy a sok hülyeség közül. Vannak szökőévek, elcsalt másodpercek, időzónák, saját elcseszett DLS megoldásokkal, borzalom.
Javaslom a jodát, hasznos kis eszköz.axioma & Aethelstone & Szmeby köszi a válaszokat!
-
 geckowize
őstag
geckowize
őstag
Na igen. Ha kényszeríted, nem adja meg magát.
Bezzeg így:
byte x = 3;
byte y = 5;
byte a = (byte) maxObject.max(x,y);
System.out.println(a);Az oké, hogy a paraméterek mind elférnek a double által lefoglalt területen, viszont így kénytelen vagy double típust visszaadni. A double értéket viszont csak double típusú változóba tudsz beletölteni hiánytalanul.
Ha lefelé castolod (pl. byte-ra), akkor információ veszhet el.
Egy nagy vödörből nem tudod az összes vizet áttölteni egy kis vödörbe. Viszont ha a nagy vödörben eleve kevés víz van, és ezt tudod is, akkor az áttöltés veszteség nélkül megoldható. Bocs a hülye metaforáért.Bár gányolásnak tartom, de ennél a példánál (két szám maximumát adja vissza) nincs túl nagy veszély. A programozó józanságára van bízva, hogy ha byte-okat ad be, akkor byte-ot biztonságosan visszakaphat. Ha az egyik int lenne, de az érték nem változna, még az is oké. Viszont ha az int értéke pl. 300, akkor gáz van, mert az nem fér bele a byte-ba.
De még 2 byte paraméternél is lehet gond, ha nem maximumot ad vissza a metódus, hanem az összegüket. Bár ez double esetén is gond, ha elegendően nagy számokkal dolgozol.
Amúgy azért nem szeretem ezt, mert figyelmetlenségből is könnyű rontani, ami egy nagy alkalmazásnál aranyos bugokat szül.Köszi, így már működik, és a magyarázatod is érthető volt.
-
Szmeby
tag
Hm. Nem rémlik, hogy ezt próbáltam volna. Köszi a tippet, holnap teszek egy próbát.
Én a másik irányba mozdultam el, hozzáadtam a resteasy cuccait is system classként. Sajnos akkor máshol ütötte fel a fejét a ClassCastException. Végül sikerült elérnem, hogy már el sem indult a cucc.
Vagy azt a custom classloader okozta, már nem emélkszem.Úgy néz ki, sikerül megpatkolni. A jetty által system class-ként alapértelmezetten beállított cuccokat kicsaptam.
webapp.setSystemClasses(new String[0]);
Így minden class a webappok saját classloaderével töltődik be, még a RuntimeDelegate singletonból is készül 1-1 példány a webappokban. A PermGen szépen megugrott ennek hatására.
Kicsit pazarló, és talán drasztikus lépés, de úgy tűnik most működik. Még kicsit játszok vele.Az kavart meg, hogy a RuntimeDelegate javaxos package-ben volt, míg a resteasy-s leszármazottai org.jboss... package-ben voltak. Kiderült, hogy a RuntimeDelegate IS a resteasy része. Abban a hitben voltam a package alapján, hogy ez valami jdk-s cucc. És mivel a default jetty beállítások miatt ez a system classloaderrel töltődött be, meg sem fordult a fejemben, hogy ez a resteasy libből jön.
-
Lortech
addikt
"Amúgy hol vannak a resteasy lib-ek? WEB-INF/lib-ben van mindkét war-ban ugyanaz a verzió?"
Igen, mindkér war WEB-INF/lib könytárában vannak a jarok. Ugyanaz a verzió, bár szerintem ez már nem sokat számít."Én a "-verbose:class" -t is megnézném, hátha valami összefüggés kiolvasható belőle."
Jaja, tegnap már mentem vele egy kört, de elég nagyok ezek a warok, hogy az eclipse console 2 war esetén is kifusson a maxra húzott pufferből.Köszönöm mindenkinek a tippeket, még szenvedek vele egy kicsit.
Legrosszabb esetben majd futnak külön jettyben.Érdekességképpen:
Thread.currentThread().getContextClassLoader()
/* WebAppClassLoader=webapp2 */
org.jboss.resteasy.specimpl.ResteasyUriBuilder.class.getClassLoader()
/* WebAppClassLoader=webapp2 */
javax.ws.rs.core.UriBuilder.fromUri(absoluteUri).getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */
javax.ws.rs.core.UriBuilder.class.getClassLoader()
/* sun.misc.Launcher$AppClassLoader@74f2ff9b */
javax.ws.rs.ext.RuntimeDelegate.class.getClassLoader()
/* sun.misc.Launcher$AppClassLoader@74f2ff9b */
javax.ws.rs.ext.RuntimeDelegate.getInstance().getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */org.jboss.resteasy.core.ThreadLocalResteasyProviderFactory (ami egy RuntimeDelegate) rendelkezik egy "org.jboss.resteasy.spi.ResteasyProviderFactory defaultFactory" field-del (ami szintén egy RuntimeDelegate). Bár threadlocal az osztály neve, de azt a funkcióját épp nem használja semmire, hanem a defaultFactory-val dolgozik, amihez a webapp1 anno már készített egy példányt. Ezen a példányon keresztül gyűrűzik be a rossz classloader a másik webapp-ba.
Az UriBuilder mélyén minden a webapp1 classloaderével készült.
org.jboss.resteasy.specimpl.ResteasyUriBuilder.class.getClassLoader()
/* WebAppClassLoader=webapp1 */
new org.jboss.resteasy.specimpl.ResteasyUriBuilder().getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */Feltételezem, úgy lenne ez szép, ha a közös libek közös classloaderrel töltődnének be (külön webapp-ban?), csak hát erős a gyanúm, hogy a sok war libjei más-más közös részhalmazzal rendelkeznek.
Vaaagy, kicsomagolom a warokat egy helyre, és minden fusson a system classloaderrel.
Ez már nagyon hekkes lenne. -
Aethelstone
addikt
"Amúgy hol vannak a resteasy lib-ek? WEB-INF/lib-ben van mindkét war-ban ugyanaz a verzió?"
Igen, mindkér war WEB-INF/lib könytárában vannak a jarok. Ugyanaz a verzió, bár szerintem ez már nem sokat számít."Én a "-verbose:class" -t is megnézném, hátha valami összefüggés kiolvasható belőle."
Jaja, tegnap már mentem vele egy kört, de elég nagyok ezek a warok, hogy az eclipse console 2 war esetén is kifusson a maxra húzott pufferből.Köszönöm mindenkinek a tippeket, még szenvedek vele egy kicsit.
Legrosszabb esetben majd futnak külön jettyben.Érdekességképpen:
Thread.currentThread().getContextClassLoader()
/* WebAppClassLoader=webapp2 */
org.jboss.resteasy.specimpl.ResteasyUriBuilder.class.getClassLoader()
/* WebAppClassLoader=webapp2 */
javax.ws.rs.core.UriBuilder.fromUri(absoluteUri).getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */
javax.ws.rs.core.UriBuilder.class.getClassLoader()
/* sun.misc.Launcher$AppClassLoader@74f2ff9b */
javax.ws.rs.ext.RuntimeDelegate.class.getClassLoader()
/* sun.misc.Launcher$AppClassLoader@74f2ff9b */
javax.ws.rs.ext.RuntimeDelegate.getInstance().getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */org.jboss.resteasy.core.ThreadLocalResteasyProviderFactory (ami egy RuntimeDelegate) rendelkezik egy "org.jboss.resteasy.spi.ResteasyProviderFactory defaultFactory" field-del (ami szintén egy RuntimeDelegate). Bár threadlocal az osztály neve, de azt a funkcióját épp nem használja semmire, hanem a defaultFactory-val dolgozik, amihez a webapp1 anno már készített egy példányt. Ezen a példányon keresztül gyűrűzik be a rossz classloader a másik webapp-ba.
Az UriBuilder mélyén minden a webapp1 classloaderével készült.
org.jboss.resteasy.specimpl.ResteasyUriBuilder.class.getClassLoader()
/* WebAppClassLoader=webapp1 */
new org.jboss.resteasy.specimpl.ResteasyUriBuilder().getClass().getClassLoader()
/* WebAppClassLoader=webapp1 */Feltételezem, úgy lenne ez szép, ha a közös libek közös classloaderrel töltődnének be (külön webapp-ban?), csak hát erős a gyanúm, hogy a sok war libjei más-más közös részhalmazzal rendelkeznek.
Vaaagy, kicsomagolom a warokat egy helyre, és minden fusson a system classloaderrel.
Ez már nagyon hekkes lenne.Vagy a két WAR tartalmát egybe rakod
-
Lortech
addikt
Szoktatok több wart közös jvm-ben futtatni?
Én most egy embedded jettyvel küzdök. Adott néhány war, egy jettyben, de külön contextHandlerben. Látszik, hogy mindegyik war kap saját classloadert, még jó is lenne, ha ezek nem akadnának össze úton útfélen.
A probléma gyökere, hogy a resteasy egy uri feloldásakor a javax.ws.rs.core.UriBuilder-t használja (pontosabban annak egy resteasy-féle leszármazottját), az pedig a (szintén resteasy-féle) javax.ws.rs.ext.RuntimeDelegate kvázi-singletonhoz. Itt borul a bili, mivel a webapp1 már létrehozta ezt a singletont a saját classloaderével. Lazy init, hurrá!
public UriBuilder createUriBuilder() {
return new ResteasyUriBuilder();
}Érdekes, hogy amikor ráhívunk ennek a példánynak a createUriBuilder() metódusára, akkor az a webapp1 classloaderével betöltött objektumot gyártja le, függetlenül attól, hogy a metódus hívásakor a webapp2 környezetében járunk, a currentThread contextClassLoadere is a webapp2 classloaderére mutat.
Nem volt még alkalmam megismerkedni a classloaderek világával, valakinek van ebben tapasztalata? Hogyan is kellene - illene - több wart futtatni 1 embedded jetty alól?
Meg egyáltalán... nem a thread contextclassloaderét kellene használnia egy objektum legyártásakor? Vagy ilyenkor a legyártást végző osztály classloaderét örökli az új objektum? Ezekszerint az utóbbi.És persze a problémát az okozza, hogy a visszakapott UriBuilder objektumot ez a szerencsétlen castolná önmagára... vagyis majdnem, hiszen az cast során már képes a webapp2 által betöltött típust használni.
Eredmény: ClassCastExceptionNincs általános válasz, normálisan nem kéne ilyen probléma legyen két war között. A frameworköknek és konténereknek kéne megoldani, hogy ilyen ne legyen, mégis gyakran előfordulnak ehhez hasonló érdekességek.
A RuntimeDelegate lehet speciális, mivel javax-es package-ben van, és elképzelhető, hogy ezt a jetty a system classloaderrel tölti. Valami közös szülő classloadernek lennie kéne a két alkalmazás között, ami okozza a problémát, másként érvényesülne az, hogy a szóban forgó osztályok a war-ok WEB-INF/lib WEB-INF/classes-eiből töltenek, mivel ez prioritást élvez, és a két "különböző" verzió nem akadna össze.Meg egyáltalán... nem a thread contextclassloaderét kellene használnia egy objektum legyártásakor? Vagy ilyenkor a legyártást végző osztály classloaderét örökli az új objektum? Ezekszerint az utóbbi.
Utóbbi. A createUriBuilder működhetne úgy is, hogy a thread context classloaderrel tölt be egy implementációt, de a bemásolt kód nem ezt teszi (az se biztos, hogy ez a sor indukálja a class betöltését).
Amúgy hol vannak a resteasy lib-ek? WEB-INF/lib-ben van mindkét war-ban ugyanaz a verzió?
Én a "-verbose:class" -t is megnézném, hátha valami összefüggés kiolvasható belőle. -
floatr
veterán
Szoktatok több wart közös jvm-ben futtatni?
Én most egy embedded jettyvel küzdök. Adott néhány war, egy jettyben, de külön contextHandlerben. Látszik, hogy mindegyik war kap saját classloadert, még jó is lenne, ha ezek nem akadnának össze úton útfélen.
A probléma gyökere, hogy a resteasy egy uri feloldásakor a javax.ws.rs.core.UriBuilder-t használja (pontosabban annak egy resteasy-féle leszármazottját), az pedig a (szintén resteasy-féle) javax.ws.rs.ext.RuntimeDelegate kvázi-singletonhoz. Itt borul a bili, mivel a webapp1 már létrehozta ezt a singletont a saját classloaderével. Lazy init, hurrá!
public UriBuilder createUriBuilder() {
return new ResteasyUriBuilder();
}Érdekes, hogy amikor ráhívunk ennek a példánynak a createUriBuilder() metódusára, akkor az a webapp1 classloaderével betöltött objektumot gyártja le, függetlenül attól, hogy a metódus hívásakor a webapp2 környezetében járunk, a currentThread contextClassLoadere is a webapp2 classloaderére mutat.
Nem volt még alkalmam megismerkedni a classloaderek világával, valakinek van ebben tapasztalata? Hogyan is kellene - illene - több wart futtatni 1 embedded jetty alól?
Meg egyáltalán... nem a thread contextclassloaderét kellene használnia egy objektum legyártásakor? Vagy ilyenkor a legyártást végző osztály classloaderét örökli az új objektum? Ezekszerint az utóbbi.És persze a problémát az okozza, hogy a visszakapott UriBuilder objektumot ez a szerencsétlen castolná önmagára... vagyis majdnem, hiszen az cast során már képes a webapp2 által betöltött típust használni.
Eredmény: ClassCastExceptionJBoss tud olyant, hogy egy közös war-ba lehet telepíteni a közösen használt libeket. Mondjuk az sem sokkal jobb megoldás, de kicsit furcsállom ezt a classloader összeakadást. Most nézem, hogy maven plugin is van arra, hogy egy konkrét war-ból kimásolja a libeket az újba jettyhez.
Én mondjuk tutira kitesztelném ezt a dolgot egy saját jarba forgatott singletonnal, ami logol mindent, ami az életciklusával kapcsolatos.
-
 jetarko
csendes tag
jetarko
csendes tag
A magam részéről feleslegesnek tartom ennyire túlbonyolítani a dolgot. Ha statikus szövegről van szó, akkor annak a pártján vagyok, hogy tároljuk property fájlban, nyelvenként külön-külön:
messages_hu_HU.properties
messages_en_US.properties
stb...
Egy új nyelv bevezetése pofonegyszerű... persze ehhez matatni kell a fájlrendszeren.Amennyiben vannak olyan szövegek, amelyek gyakran változnak, akkor azok lehetnek adatbázisban (akár in-memory db, akár ennek rendszeres backup-jával). Igazából attól függ, hogy mi a célja, mire használod a szövegeket, mennyire érzékeny adatok ezek, stb.
Azzal, hogy két helyen tárolod a cuccokat, magadra vetted ezek szinkronban tartásának terhét. Ha ez az igény, akkor nincs mit tenni. Gondoltál a teljesítmény problémákra is, csinálsz hozzá pár komponens tesztet, ezeket akár egy CI rendszerben, akár időnként kézzel megfuttatod, és nincs vele teendő. Legfeljebb majd később átírod, a szoftver úgyis mindig fejlődik.
Sosincs jó megoldás, mindig a körülményektől, a felhasználási módtól függ. Mindig kell kompromisszumokat kötni, de ha már ezt teszem, igyekszem úgy, hogy a lehető legegyszerűbb maradjon a végeredmény. Csak ezt tudom tanácsolni neked is.Én is túlbonyolításnak érzem, de hát kísérletezek
A csak db-be tárolással az a gondom, hogy ha MVC-ben vagyok, akkor a modelhez mindig adjam hozzá azt a szöveget ami ott megjelenik ez sok-sok model.add sor is lehet vagy nem tudom, hogy lehetne máshogyan.Az új nyelv futásidőben való hozzáadás az én megoldásomnál bonyolult, mert entitáson keresztül kezelem a db-t és ha új nyelvet akarok, akkor bővítenem kéne az entitásomat és erről fogalmam nincs, hogy lehetne futásidőben, vagy teljesen máshogyan kéne felépítenem az entitás rendszert, tuti lehetne trükközni, de még nem jöttem rá.
-
jetarko
csendes tag
"A másik mód az lenne, hogy db-ben tárolok minden token és értéket..."
Ismerek olyan rendszert, ahol adatbázisban tárolják az üziket. Megvan az előnye és a hátránya, ahogy a property fájlnak is. Megjegyzem, ott nem a Properties osztályt használják erre, hanem van rá egy egyedi megoldás.Én a magam részéről a property fájlt favorizálom, mert nem látom azt az üzleti esetet, hogy ezeknek az üzeneteknek futásidőben változniuk kéne. Van egy programod, támogat 30 különböző nyelvet. Az jó esetben 30 property fájl, csókolom.
Ha adatbázisban lenne, akkor tuti készítenél hozzá valamit, amivel menet közben szerkeszteni is lehet. Az 30 db textarea. Ilyenkor történik az, hogy "ó, csak a magyar/angol nyelvűt írom át, a többi nem érdekes". És elszabadul a pokol.
Vagy pl. hogyan tervezed kiírni a "Nincs adatbázis kapcsolat" hibaüzit, ha azt adatbázisban tárolod?
Jó, persze a kivételeket bele lehet tolni a kódba, vagy property-be...Természetesen lehet olyan szöveg, ami gyakran változik, annak valóban nem property fájlban a helye, de a labelek, hibaüzik, stb. szerintem nem ilyenek.
Na megcsináltam.
Fejlesztés közben a tokeneket tárolom 1db properties fájlban, lehet 10 nyelv, akkor is csak egyben tárolom.
Írtam egy fv-t, ami a property fájl alapján a tokeneket felveszi db-be, ha van értéke a fájlban, akkor az értéket beszúrja, ha nincs akkor az értékhez a token kerül be maga.
A másik fv az adott nyelvhez tartozó property fájlt módosítja a db tartalma alapján. Ha ezt meghívom, akkor vagy 1db token értékét cseréli az adott nyelv property fájlban, vagy a db-ben tárolt összes értéket kiírja a fájlba.
A db-be kerüljenek tokeneket csak akkor kell lefuttatni ha új token kerül a property-be, ekkor az új token bekerül db-be. Innentől csak a 2. fv dolgozik.
Erre írtam egy felületet, ami onblur műveletre ajaxosan frissíti az adott property fájlban és db-ben szereplő értéket is.
A cacheSeconds 1-re van állítva. Jelenleg 100 tokennel nagyon gyorsan változtatva a frontenden az értékeket remekül működik, a context újratöltéstől semmi memória nem növekszik.
Ugye ez által futás közben bármikor beletudok nyúlni a token értékekbe, de a rendszer mégis a property fájlok alapján dolgozik, amihez gondolom valami gyors fa van építve, nem kell szarakodnom folyamatos db basztatás, cachelés dolgokkal.
Azt még nem találtam ki, hogy ezzel a megoldással futás közben új nyelvet, hogy tudok hozzácsapni, de majd még agyalok rajta.
A hibája ennek amit jelenleg látok, hogy a property fájl frissítéskor a fájl egésze újraírodik, ez ha nagyon sok token van lehet sokáig tartana. Ezt letesztelem hamarosan mennyi idő lehet 1milla tokent fájlba írni. A másik pedig az lehet, ha sok ember nagyon gyorsan sok tokent módosít egyszerre, de hát ezt nem tudom egymagam leszimulálni
A db réteg fölöslegesnek tűnik és majdnem, hogy az is, de ha cserélem a war-t a tomcatemben és közben egyik token értékét átírtam, akkor a régi propertiekkel felül csapom a jelenlegit és elveszett a módosítás, ha nem szedem le előtte a property fájlt.
Vélemény? -
 glutamin
őstag
glutamin
őstag
Pont ellenkezőleg, ott akad el először. Az a root cause.
Mikor hiba történik az pl. kivételt (exception) generál, ez megszakítja az adott blokk végrehajtását, a kivétel elkezd visszafelé vándorolni a stack-en. Teszi ezt addig a pontig, amíg azt egy catch ág el nem kapja. Normális esetben a catch blokk csinál is valamit, vagy feloldja a hibát és minden megy tovább onnantól a maga medrében, vagy pl. tovább dobja azt akár egy másik kivételbe csomagolva. Az ilyen elkapom-továbbdobom megoldások eredményezik a "caused by" blokkokat a stacktrace-en. Mire a felhasználó/fejlesztő találkozik a hibával, a kiváltó oka sokszor el is tűnik a felszínen. Ezért érdemes először alul keresni az igazi okot.
Itt ragadnám meg az alkalmat, hogy megjegyezzem, ne csináljatok üres catch blokkokat, mert ott elveszik a hiba, és később nehéz lesz megtalálni.Na sikerült. Még mindig vannak hibaüzenetek, de a tutorial szerint ez most nem érdekes. Valszeg a hibernate.cfg.xml fájlban volt hiba. Kommentezést kiszedtem. Projektben a JAVA környezetet átkapcsoltam 1.7-ről 1.6-ra. Utána már csatlakozott. Akkor még egy adatbázisjelszó javítás volt és most itt tartok:
SLF4J: Failed to load class "org.slf4j.impl.StaticLoggerBinder".
SLF4J: Defaulting to no-operation (NOP) logger implementation
SLF4J: See http://www.slf4j.org/codes.html#StaticLoggerBinder for further details.
Hibernate: insert into UserDetails (userName, userId) values (?, ?)Hétvégén nekifekszem és végigzongorázom az alap SQL műveleteket, aztán lassan megnézem mi az a Maven


 (Szénné olvastam a netet, de ezt a separátort nem vettem sehol észre.) Mindenhol a függőségkezelést erőltetik, de szeretném kézzel-lábbal összekínlódni az alkotást.
(Szénné olvastam a netet, de ezt a separátort nem vettem sehol észre.) Mindenhol a függőségkezelést erőltetik, de szeretném kézzel-lábbal összekínlódni az alkotást.



 Tudom, hogy referenciával megy az objektum másolás, de én foxi módra eltökéltem hogy átmásolódik az egyik lista tartalma a másikba.)
Tudom, hogy referenciával megy az objektum másolás, de én foxi módra eltökéltem hogy átmásolódik az egyik lista tartalma a másikba.)![;]](http://cdn.rios.hu/dl/s/v1.gif)











































 köszönöm szépen
köszönöm szépen 




Új hozzászólás Aktív témák
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)

A topicot kiemeltem. Valaki nem akar egy nyitó hsz-t írni?:))
- MasterDeeJay: Low budget (50.000 forint) light gémer gép összerakása
- Samsung Galaxy Felhasználók OFF topicja
- Kerékpárosok, bringások ide!
- Építő/felújító topik
- Büszke apukák és anyukák topikja
- AliExpress tapasztalatok
- Huawei Watch Fit 3 - zöldalma
- Debian GNU/Linux
- Trollok komolyan
- Először kombinálja a Full HD-t az 1000 Hz-cel egy monitor
- További aktív témák...

- Lenovo ThinkPad L13 Gen 3 i5-1245U 16GB 512GB FHD+ IPS 1 év teljeskörű garancia
- BESZÁMÍTÁS! Akár Részletfizetés 0% THM ÚJ AMD RYZEN AM5 processzorok 3 év garanciával 27% áfaval
- GAMER PC! i5-13500 / RTX 3070 Ti / 16GB DDR / 512GB NVMe / 650w!
- Geforce GTX 1050, 1050 Ti, 1060, 1650, 1660 / GT 1030 - Low profile is (LP)
- Új AKRACING CORE EX gamer szék dobozában, BONTATLAN!
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest