
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)
- Rég várt frissítést kap az Android tárcsázója
- Poco F8 Ultra – forrónaci
- iPhone topik
- Xiaomi 17 Ultra - jó az optikája
- Apple Watch
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Nagy bemutatóra készül az Oppo
- Szaporodik és sokasodik a One UI 8.5
- Huawei Watch Fit 5 Pro - jó forma
- Okosóra és okoskiegészítő topik
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 floatr
veterán
floatr
veterán
-
 Zsoxx
őstag
Zsoxx
őstag
Nos, a telefonban van scanner, de nem tudom hogyan lehetne okosítani. Azon kívül, hogy megmutatja a dekódolt szöveget és link esetén megnyit egy browsert semmi egyebet nem láttam még benne alapból. Aztán hogy éppen ezen a telefonon valahogy talán össze lehet mégis barkácsolni, hogy custom url-t hívjon, de esetleg egy másikon nem ezért szerintem jobb egy külön app erre.
Az említett leltározó program remek, de idő közben újabb igény merült fel, így magam kell írjak egy egyszerű appot. Szerencsére sok forrást találni a már említett ZXing libre alapozva, ezek lesznek a kiindulási alapok.
ZXing embedded lesz természetesen, hogy ne kelljen külső app a használathoz.
Kotlin-nak nem állok most neki, egyelőre JAVA alapon fogom elkészíteni.
Szóval a kiinduló kérdés itt el is dőlt. -
 sztanozs
veterán
sztanozs
veterán
-
sztanozs
veterán
Nem tudok Android appot készíteni sajnos. Szóval valami free megoldás volna jó erre. A rest már rendben lenne spring-ben, még tokenezgetni sem kellene, mert teljesen lokális hálón lenne a dolog. Szóval nem volna bonyesz.
Viszont az android oldal teljesen off nekem.
Esetleg az olvasóra volna ötleted?Ennél olcsóbban nem programozza neked le senki: [link]
-
 mobal
nagyúr
mobal
nagyúr
Készítesz egy vonalkód olvasó alkalmazást és egy rest apin elküldöd a spring boot alapú alkalmazásodnak a kódot?
-
 disy68
aktív tag
disy68
aktív tag
Belefutottam egy hibába és egyelőre nem sikerül megoldanom. Szeretném a segítségeteket kérni.
Van egy terminal/commandline futtatható "jar" fájlom, ami pár paramétert kapva teszi a dolgát.
Ebben használok egy "config.properties" fájlt. Alaphelyzetben az "src/main/resources/config.properties" path-on van, innét Eclipse-ből indítva szépen el is éri, működik, ahogy kell.
Azt szeretném elérni, hogy odamásolhassam a futtatható JAR mellé és úgy is tudjam használni bármikor. Na, ez nem megy és nem tudom hogyan kellene megoldani. A futtatható jar külön paramétert nem kaphat erre, automatikusan kellene maga mellett megkeresnie.Jelenleg ilyen a betöltő:
public static Properties loadProperties(String propertiesFilename) {Properties prop = new Properties();try (InputStream stream = ClassLoader.getSystemResourceAsStream(propertiesFilename)) {if (stream == null) {throw new FileNotFoundException();}prop.load(stream);} catch (IOException e) {e.printStackTrace();}return prop;}CodeSource codeSource = YourMainClass.class.getProtectionDomain().getCodeSource();File jarFile = new File(codeSource.getLocation().toURI().getPath());String jarDir = jarFile.getParentFile().getPath();A fentivel megvan a jar path-ja, hozzácsapod az elvárt fájlnevet és azt próbálod beolvasni, ha nincs ilyen fájl, akkor mehet fallback-nek a resource beolvasás. Esetleg a jar mappájában keresel bármilyen .properties fájlt és mindegyiket beolvasod, de ez már részletkérdés.
-
floatr
veterán
Maradtam a pom.xml-nél. Kényelmes, ha minden ilyesmit látok egy helyen.
Más:
Hogyaza... frissítettem az STS-t és valami gond van az Eclipse-el.
Ezt a hibaüzenetet kapom: [kép]
Azt hittem a desktop gépemen van valami gond, megcsináltam a laptopon is, de ugyanez lett a vége. Ilyenkor most mivan?Ebben nem tudok segíteni. Pont az ilyenek miatt hagytam a fenébe az eclipse-re épített extra verziókat.
-
floatr
veterán
Ha kézzel csinálsz egy manifestet, az is teljesen jó, és akkor nem kell maven extra hozzá. Most hirtelen nem is tudom, melyik a praktikusabb, mert az XML sokkal terjengősebb, mint a manifest maga.
-
floatr
veterán
Sziasztok.
Teljesen elfelejtettem, hogyan lehetne megcsinálni, hogy egy "jar" fájl konzolban hívásakor automatikusan induljon egy package/osztályban lévő "main" metód?Például így fut: java -cp Hello.jar hu.valami.Hello
De így szeretném: java Hello.jarA pom.xml-be kell valami build megjegyzés vagy hogyan lehetne megcsinálni?
Update:
Közben STS-ben csináltam egy "Export/Java/Runnable JAR file" megoldást, de ezzel bepakolta a jövő hetet is a jar-ba.Manifest file-t generálsz main class definícióval [link]
-
floatr
veterán
Nem tudom mennyire sikerült leírnom a feladatot. A lényeg, hogy idegen szerveren futtatva a programomat védeni kellene bizonyos adatokat, amik ott helyben vannak tárolva. Konfig adatok esetén fájlban vannak ezek, egyéb adatok esetén mondjuk sql-ben.
Ha valaki ránéz a szerveren ezekre az adatokra akkor simán kiolvasva őket használhatatlanok legyenek csak a program futása közben tudja használni ezeket. Vagyis valami kulccsal titkosítani kellene. De hogy hol lenne mondjuk tárolva ez a kulcs, na azt nem tudom. Tehát valami elvi megoldás kellene, hogy hogyan lehetne ezt felépíteni.Van olyan kulcs amit az adott szerver tulajdonosa (cég) ismer és azt használná a program titkosításra. (ez a jelen feladat)
És lenne olyan is, amit csak én ismerek és az valahogy fixen a programban lenne, azzal tudná a program az általam biztosított adatokat írni/olvasni. (ez egy következő feladat)
Docker secret is lehet
-
 #68216320
törölt tag
#68216320
törölt tag
De ha bekérem a kulcsot, akkor mindjárt kérhetném az adott jelszót is. Persze több jelszó esetén már kellemesebb a kulcsot megadni és azzal decrypt-álni a többit.
Viszont az alap probléma adott még. A user meg akarja változtatni a property-t kézzel, akkor hogyan tudja beírni a property-be kézzel a titkosított jelszót.
Vagyis példaként:
Egy e-mail küldő konfig fájlban lenne az smtp-host, user, pass, port. Ezeket a user kézzel állítja be a saját adatai alapján. De ugye a pass-t nem adhatja meg csak plain, mert nem biztonságos. Az email küldőt pedig egyéb osztályok hívják, szóval nincs külön indítás ahol megadhatnám a key-t, kiegészítő modul lenne.Mi van olyankor ha úgy csinálnám, hogy a program (ami hívja majd az email osztályt) minden híváskor átadja a használt key-t (mondjuk nem tudom még az honnét jönne létre). Ezzel tudja ugye decrypt-álni a jelszót az email osztály. Viszont lenne egy ellenörzés, hogy amikor plain text a konfig fájlban a jelszó (modjuk éppen szerkesztette az előbb a user), akkor először encrypt-álja és ezután az általános módon beolvassa, decrypt és használja.
Valami hasonló módon csinálja linuxon a transmission-daemon is a config fájlban.
De továbbgondolva a dolgot általános is lehetne a kérdés. Bizonyos esetekben jó lenne SQL-ben tárolt adatoknál is pár olyan értéket titkosítva tárolnom, amit a programom tud írni-olvasni, de ha a user ránéz (akinél fut a programom) ő az sql-ből nem tudja kiolvasni. Ezek olyan dolgok lennének, amikot kénytelen vagyok adni a programmal, de saját, védett adatok lennének viszont kellenek a program működéséhez és alkalmanként távolról frissíteném-bővíteném ezeket.
Nem tudom mennyire sikerült leírnom a feladatot. A lényeg, hogy idegen szerveren futtatva a programomat védeni kellene bizonyos adatokat, amik ott helyben vannak tárolva. Konfig adatok esetén fájlban vannak ezek, egyéb adatok esetén mondjuk sql-ben.
Ha valaki ránéz a szerveren ezekre az adatokra akkor simán kiolvasva őket használhatatlanok legyenek csak a program futása közben tudja használni ezeket. Vagyis valami kulccsal titkosítani kellene. De hogy hol lenne mondjuk tárolva ez a kulcs, na azt nem tudom. Tehát valami elvi megoldás kellene, hogy hogyan lehetne ezt felépíteni.Van olyan kulcs amit az adott szerver tulajdonosa (cég) ismer és azt használná a program titkosításra. (ez a jelen feladat)
És lenne olyan is, amit csak én ismerek és az valahogy fixen a programban lenne, azzal tudná a program az általam biztosított adatokat írni/olvasni. (ez egy következő feladat)
-
 bambano
titán
bambano
titán
-
Drizzt
nagyúr
Jasypt, Spring cloud config. Ami az erdekes a kerdeskorben, hogy az encryption keyt hol tudod eltarolni es beszerezni az alkalmazas altal, de mas user altal nem.
-
sztanozs
veterán
-
sztanozs
veterán
-
floatr
veterán
-
 Mr K
őstag
Mr K
őstag
Milyen megoldással lehetne egy külső program konzolba írt tartalmát parse-olni?
Van egy linux-os programom, ami bizonyos szenzorok adatait az alábbihoz hasonló módon adja vissza a konzolba kiírva:
... (néhány sor sima text elötte)group1.data1.value1: 123456group1.data1.value2: valamiszoveggroup1.data1.value3: 123.01group1.data2.value1: valamiszoveggroup1.data2.value2: 123456group2.data1.value1: 123456group2.data1.value2: 123456group2.data2.value1: 123456group3.data1.value1: 123456...A lényeg, hogy minden tag új sorban van, a variable neve pontokkal van, a value lehet string, int, float.
Szeretném bizonyos időközönként (30 másodpercenként) lefuttatni ezt a külsős exe programot és a visszakapott értékeket db-ben tárolni.
Mivel volna érdemes nekikezdeni?
Az exe futtatásban, a visszakapott értékek parsolásában kellene segítség.
Db kezelés nem gond.Az exe futtatása megoldható a
Runtime.getRuntime().exec(...)hívással. Visszakapsz egy processz-t, aminek a lefutásátwaitFor()-ral megvárod. Itt van rá egy kis példa program, ami már demonstrálja azt is, hogy hogyan lehet az exe outputját (stdout) megszerezni. (Alternatíva, hogy az exe egy fájlba írja az outputját, amit futás után normál módon fájlként felolvasol.)A parsolásra régebben még azt mondtam volna, hogy kell írni egy parsert, de manapság ez nem divat... Ha tényleg ennyire rögzített a szerkezet, akkor a sorban szereplő négy komponens (csoport, adatnév, értéknév, érték) előbányászható egy reguláris kifejezéssel is, pl. ezzel:
^([^.]+)\.([^.]+)\.([^.]+): *(.*?) *$Az outputot soronként célszerű feldolgozni, az elején vagy ki kell hagyni fix számú sort, vagy egyszerűen ki kell hagyni azokat, amire nem illeszkedik a regex:
Pattern pattern = Pattern.compile(<a fenti regex>);
while (<van sor>) {
Matcher m = pattern.matcher(<a sor tartalma>);
if (m.find()) {
String sensorGroup = m.group(1);
// ...
String sensorValue = m.group(4);
// DB mentés
}
}Alternatív szervezés: linux-ban oldod meg, amit lehet. A java program nem hajt végre exec-et, helyette a standard input-ot olvassa, és dolgozza fel. Hívni meg valahogy így:
>sensor.exe <opciók> | java -jar sensorprocessor.jarÉs az egészet lehet futtatni pl. cron-ból. (Hátránya, hogy a JVM indítás kissé erőforrásigényes, 30 másodpercenként meg pláne.)
Megjegyzések: (1) fejből írtam, a kódot tekintsük pszeudokódnak, (2) a regex pattern-ben a
\-eket duplikálni kell a Java string konstansban.Szerk: A korábbi válaszokat nem láttam, pár dolog így ismétlés, bocs.
-
bambano
titán
Van pár szempont ami miatt a sheel-ből nem volna jó dolgoznom.
- Egyrészt szeretném a beérkezett értékeket validálni mielőtt tárolom. Persze ezt is lehet bash-el, de java kényelmesebb volna.
- A szerveren mindenképp van java, mert van egy API, amivel pedig le lehet majd kérdezni ezeket. Tehát a függőségek mindenképp megvanak már
- Szeretném magát az sql részt nem látható módon használni, tehát nem volna jó, ha az insert into mondjuk script-ben lenne
- Lenne windows-os gép is, ami szenzor adatot kap, ott akkor új megoldás kellene a parse-oláshoz (persze ott is megoldható)Amit mondasz, az mondjuk tökéletes megoldás lehetne arra az esetre, amikor az rpi-ket kell használnom majd. Ott problémás lenne a java.
Azon gondolkodom, hogy esetleg tényleg a megoldás az lenne, hogy egy API-t csinálni java-ban, amit a kliensek hivogatnak és a már parse-olt adatokat azon keresztül tolnák befelé. Merthogy a szerveren amúgy is van tomcat. Aztán ott validálnám és ha oké tárolnám (mysql, influx, miegyéb) Ha nem oké majd a response jelzi a kliensnek.
Ekkor a kliens lehet mondjuk a mostani gép linux-al és akkor a sed szétszedné az adatokat (és mondjuk curl hívná az api-t). Ez járható lenne a későbbi rpi kliensek esetén is. A win-es megoldást nem tudom még, hogy ott miként lehetne szétkapni az adatokat és hívni az api-t, de gondolom ott sincs nagy csavar a dologban.Ez mennyire lenne járható út?
"Egyrészt szeretném a beérkezett értékeket validálni mielőtt tárolom.": egyrészt lehet shellben, awk-ban, bármiben validálni. de validálhatod az adatbázisban is. már ha a mysql alkalmas erre, sose próbáltam. postgresql alkalmas.
"esetleg tényleg a megoldás az lenne, hogy egy API-t csinálni java-ban, amit a kliensek hivogatnak és a már parse-olt adatokat azon keresztül tolnák befelé.": van ilyen api, a mysql hálózati apija, minek akarnál még egy újabb apit kitalálni?lyalyly curl... most eltekintve attól, hogy tök értelmetlen http-n csinálni ilyet, a curl-ben túl sok hiba van ahhoz, hogy komoly rendszeren használd.
ha mindenáron kell a wines kliens, akkor winre van sed, bash, mysql kliens, és ugyanaz, mint linuxon. hogy powershellben mekkora meló leprogramozni, nem tudom. de mivel úgysem tudod ugyanazt a szenzorprogramot futtatni, ezért a rendszer mindenképpen különbözni fog.de ha már itt tartunk: miért nem rakod bele a mysql klienst a szenzorokat kezelő programba?
persze elfelejtettem az alapvető kérdést feltenni: dolgozni akarsz vagy megoldani a problémát?
-
floatr
veterán
Van pár szempont ami miatt a sheel-ből nem volna jó dolgoznom.
- Egyrészt szeretném a beérkezett értékeket validálni mielőtt tárolom. Persze ezt is lehet bash-el, de java kényelmesebb volna.
- A szerveren mindenképp van java, mert van egy API, amivel pedig le lehet majd kérdezni ezeket. Tehát a függőségek mindenképp megvanak már
- Szeretném magát az sql részt nem látható módon használni, tehát nem volna jó, ha az insert into mondjuk script-ben lenne
- Lenne windows-os gép is, ami szenzor adatot kap, ott akkor új megoldás kellene a parse-oláshoz (persze ott is megoldható)Amit mondasz, az mondjuk tökéletes megoldás lehetne arra az esetre, amikor az rpi-ket kell használnom majd. Ott problémás lenne a java.
Azon gondolkodom, hogy esetleg tényleg a megoldás az lenne, hogy egy API-t csinálni java-ban, amit a kliensek hivogatnak és a már parse-olt adatokat azon keresztül tolnák befelé. Merthogy a szerveren amúgy is van tomcat. Aztán ott validálnám és ha oké tárolnám (mysql, influx, miegyéb) Ha nem oké majd a response jelzi a kliensnek.
Ekkor a kliens lehet mondjuk a mostani gép linux-al és akkor a sed szétszedné az adatokat (és mondjuk curl hívná az api-t). Ez járható lenne a későbbi rpi kliensek esetén is. A win-es megoldást nem tudom még, hogy ott miként lehetne szétkapni az adatokat és hívni az api-t, de gondolom ott sincs nagy csavar a dologban.Ez mennyire lenne járható út?
Ez a formátum YAML-ként is értelmezhető, így egy YAML parser be tudja olvasni, és akkor nem egy igénytelenül gányolt shell-ninja szutyokkal oldod meg, amit 1 év múlva a saját szerzője sem tud már támogatni.
De van rá lényegében kész megoldás is: ELK stack. Azt pont ilyenekre találták ki. Logstash illesztőkön keresztül Elastic-ba tolja a szenzorok adatait, amit később Kibanával meg tudsz jeleníteni. Ezt a shelles babrálást meg felejtsd el
-
bambano
titán
a véleményedtől függetlenül súlyos hiba java vm-et meg java-s programot indítani ott, ahol egy sed vagy awk program tökéletesen elegendő. attól, hogy van java a gépeden, még nem kell minden esetben használni.
a mysql-nek van parancssori kliense, az tökéletes arra, hogy betöltsd az adatokat az adatbázisba."jó lenne java exec megoldással a kimenetet elkapni és parse-olni.": azt sem értem, ehhez minek java exec. feltalálták a csővezetéket, tessék szabvány bemenetet olvasni és parsolni, ha mindenáron java-ban akarod.
bocs, de úgy gondoltam, hogy nem központi probléma megoldani, hogy egy linuxon futó program kimenete hogy kerül egy windowson futó programba. te írtad, hogy linuxon futó program szenzor adatokat gyűjt. miért akarnák windowson adatbázisba rakni?
hagyd a fenébe a java-t, shell szkript topicban vagy linux kezdő topicban megmondják a jó megoldást. szenzor program kiolvassa a mért értékeket, kiküldi szabvány kimenetre, azt sed-del, awk-val vagy shell szkripttel átalakítod szabvány sql insert utasítássá, azt bele küldöd a mysql kliensbe és kész. ennyi. nem java, meg legyen kéznél jdbc driver, meg vm meg a fene se tudja még mi minden függőség.
-
bambano
titán
Milyen megoldással lehetne egy külső program konzolba írt tartalmát parse-olni?
Van egy linux-os programom, ami bizonyos szenzorok adatait az alábbihoz hasonló módon adja vissza a konzolba kiírva:
... (néhány sor sima text elötte)group1.data1.value1: 123456group1.data1.value2: valamiszoveggroup1.data1.value3: 123.01group1.data2.value1: valamiszoveggroup1.data2.value2: 123456group2.data1.value1: 123456group2.data1.value2: 123456group2.data2.value1: 123456group3.data1.value1: 123456...A lényeg, hogy minden tag új sorban van, a variable neve pontokkal van, a value lehet string, int, float.
Szeretném bizonyos időközönként (30 másodpercenként) lefuttatni ezt a külsős exe programot és a visszakapott értékeket db-ben tárolni.
Mivel volna érdemes nekikezdeni?
Az exe futtatásban, a visszakapott értékek parsolásában kellene segítség.
Db kezelés nem gond.A magam részéről mindenképpen szívlapáttal csapnám fejbe, aki erre a problémára java programot ír.
bash shell + sed.szerk: letenni fájlba, linuxon, lyalylyly
-
Drizzt
nagyúr
Milyen megoldással lehetne egy külső program konzolba írt tartalmát parse-olni?
Van egy linux-os programom, ami bizonyos szenzorok adatait az alábbihoz hasonló módon adja vissza a konzolba kiírva:
... (néhány sor sima text elötte)group1.data1.value1: 123456group1.data1.value2: valamiszoveggroup1.data1.value3: 123.01group1.data2.value1: valamiszoveggroup1.data2.value2: 123456group2.data1.value1: 123456group2.data1.value2: 123456group2.data2.value1: 123456group3.data1.value1: 123456...A lényeg, hogy minden tag új sorban van, a variable neve pontokkal van, a value lehet string, int, float.
Szeretném bizonyos időközönként (30 másodpercenként) lefuttatni ezt a külsős exe programot és a visszakapott értékeket db-ben tárolni.
Mivel volna érdemes nekikezdeni?
Az exe futtatásban, a visszakapott értékek parsolásában kellene segítség.
Db kezelés nem gond.A Linuxos program időzített futtatására használj cront, vagy egyszerűen írj egy bash scriptet, ami tight loopban vár. A kimenetet meg simán irányítsd bele egy fájlba. A Java programban ugyanezt a fájlt nyisd meg ugyanilyen időközönként. Aztán dolgozd fel, s írd ki adatbázisba. Amúgy ahogy az adatod jellegét nézem, kb. egy time series database-ben lenne a legjobb őket tárolni. Erre jó pl. Influxdb. Aztán csinálhatsz rá mindenféle fancy ábrát Grafanával.
Parse-olni ezt egyébként elég egyszerű, soronként végigolvasod, majd line.split("."), a három elemű tömböt meg felhasználod ahogy akarod..
Más: Mi a legjobb, legmélyebb Spring video course amivel találkoztatok? Kéne nekem egy masszívabb. Ha csak fizetős van, az se gond. De örülnék, ha legalább 20 óra körüli lenne és nagyon a részletekbe menő.
-
 axioma
veterán
axioma
veterán
Köszönöm a válaszokat

1. Akkor lehet annál maradok, hogy minden marad egy projectben. Igazából pont azért kérdeztem, mert jelenleg tényleg nem indokolja semmi, hogy szétszedjem. Csak valahol láttam egy ilyen project-et és gondoltam, hátha ... de akkor nem csinálom egyelőre.
2. Akkor hogy is? A tesztet?

3. Az igazság az, hogy nem ismerek egy framewörköt sem. Tudom, kellene csak próbáltam elodázni. De nagyon úgy tűnik, hogy nincs mese... Angular? Meglesem.
4. Nem túl komplex. Anno úgy olvastam még, hogy ilyenkor ezt kell tenni. Persze tényleg megoldás a 2 külön osztály. Vagy gondoltam, hogy barkácsdolom picit:
- átnevezném az eredeti osztályt
- absztrakt lenne az eredeti osztály
- kivenném az eredeti osztályból azokat a tulajdonságokat, amik nem közösek
- leszármaznék 2 osztállyal belőle. az 1. kapná az eredeti nevet és megkapná a saját tulajdonságát. a 2. kapna egy új nevet és a saját tulajdonságaitÍgy az eredeti néven meglenne az osztályom az eredeti member-ökkel és lenne egy új az új member-ökkel de csak azokkal amik neki kellenek.
Persze lehet marhaság amit akarok, sajnos kuka vagyok még a programozáshoz.Vagy túlkombináltam valamit megint
Biztos kozos ososztaly kell neked, nem lenne jobb a kozos interface? Mar persze ha arrol van szo hogy azert szeretned oket valahogy kozositeni, mert kesobb egyforman kezelned a kettot (az egyforma tulajdonsagokkal). Ha most sehol nem kezeled egyutt, akkor meg siman ket osztaly, az nem akadalyozza hogy kesobb kozos interface is legyen, ha valos indok lesz ra.
-
 Szmeby
tag
Szmeby
tag
Egy saját hobby project kapcsán merült fel pár kérdés, amiben szeretném a közösség véleményét kérni.
1. Maven build-et használok. Mikor szokás parent-child project-et csinálni?
Most van egy parent pom.xml-em, amiben jelenleg két child pom.xml van. Perzisztens réteg és üzleti réteg, de harmadikként menne majd a WebUI még ide (esetleg más UI ha lesz)2. Mit szoktatok előbb elkészíteni? Az osztályt vagy a unit tesztet? Mert ugye ha a tesztet írom előbb, kevesebb esélye van szerintem, hogy bizonyos elemek tesztelése kimarad. Tudom mit akarok csinálni, mik lesznek a funkciói, mik lesznek a paraméterei és ez alapján mik lesznek a buktatók. Ez alapján meg tudnám csinálni az osztályt ami hibátlanul elvégzi a feladatokat. Vagy célszerűbb sorban? Osztály aztán hozzá a teszt?
3. Servlet-WebUI elkészítéshez mit ajánlotok? Nem lenne komplex a feladat, HTML/CSS/JS ismeretem van. Framework vagy inkább valami saját JSP?
Csak annyit tudok a prjektedről, amennyit most leírtál róla, így lehet, hogy valamit félreértek.
1. Én most microservice bűvkörökben élek és a selfcontained alkalmazás a kedvenc, vagyis semmit sem vágok, cserébe viszont pici a cucc, és nincs benne ui. Természetesen a komponensek közti kommunikációt megvalósító DTO-kat, külön, közös projektbe teszem, hogy mindegyik komponens ugyanazt lássa.
Ha látod értelmét a vágásnak (mert mondjuk több egymástól eltérő modul is használná), akkor vágj. Ha nincs értelme, akkor ne vágj. A legrosszabb, amit tehetsz, hogy túl korán vágsz és később szívsz, hogy hát lehet, nem is ott kellett volna, ajaj.
A több UI, több modul felállás szimpi.2. A tesztet. Nincs hibátlan osztály. A tesztet. Leginkább párhuzamosan. TDD. Mondtam már, hogy a tesztet?
Amúgy meg a te dolgod, ahogy jobban esik. Főleg, ha a teszttel kezded.3. Ha valami nem komplex, én nem frameworközök, mert csak megköti a kezet, lassít, bonyolít. Amúgy passzolom a kérdést, nem tartom magam frontend gurunak. Persze lehet az, hogy mondjuk valaki csak az angulart ismeri és semmi mást, neki érezhetően könnyebb dolga lesz abban megcsinálni, mint szenvedni egy fura jsp-vel.
4. Ne származz le.
Oké, hogy a nyelv megengedi, de attól még nem jó.
Én nem osztom azt a nézetet, hogy ami úgy néz ki mint egy kacsa és olyan hangot ad ki, mint egy kacsa, az egy kacsa. [link]
Az egy másik osztály.
Ha mégis van némi közük egymáshoz, akkor még a composition-t tudom elképzelni, vagyis az osztály egy tagja lesz a meglévő cucc, és az osztályod csak az értelmes mezőket engedi ki az apiján. -
#68216320
törölt tag
Egy saját hobby project kapcsán merült fel pár kérdés, amiben szeretném a közösség véleményét kérni.
1. Maven build-et használok. Mikor szokás parent-child project-et csinálni?
Most van egy parent pom.xml-em, amiben jelenleg két child pom.xml van. Perzisztens réteg és üzleti réteg, de harmadikként menne majd a WebUI még ide (esetleg más UI ha lesz)2. Mit szoktatok előbb elkészíteni? Az osztályt vagy a unit tesztet? Mert ugye ha a tesztet írom előbb, kevesebb esélye van szerintem, hogy bizonyos elemek tesztelése kimarad. Tudom mit akarok csinálni, mik lesznek a funkciói, mik lesznek a paraméterei és ez alapján mik lesznek a buktatók. Ez alapján meg tudnám csinálni az osztályt ami hibátlanul elvégzi a feladatokat. Vagy célszerűbb sorban? Osztály aztán hozzá a teszt?
3. Servlet-WebUI elkészítéshez mit ajánlotok? Nem lenne komplex a feladat, HTML/CSS/JS ismeretem van. Framework vagy inkább valami saját JSP?
4. Ha van egy már meglévő model amiből leszármaznék, mert mert az új model tartalmaz még pár tulajdonságot, de van olyan is amit a parent igen, de a child nem, akkor azt hogyan szokás megoldani? Obj esetén mondjuk lehet NULL, de például int vagy boolean esetében mit csinálok vele? Ha adok értéket akkor azt hihetem, hogy az valós.
-
Szmeby
tag
Ez mennyire BestPactice? Én még úgy tanultam, hogy próbáljuk kerülni a lambda-t, mert a forráskód nehezebben olvasható majd. Nem "nyúlfarknyi" példákra, gondolok, hanem nagyobb osztályokra például. Persze most nem azt mondom, hogy 1-1 forEach vagy hasonló nem kerülhet bele csak például nálam egy-egy komplexebb sor átláthatósága debug esetén nehezebb/lassabb.
Persze tény, hogy elegánsabbVagy ez teljesen rendben van és marhaságot tanultam?
Egy adott fajta kód vagy stílus azok számára nehezen olvasható, akik nem szoktak hozzá. Kezdőként én is nehezen dekódoltam, hogy mi van. Aztán megszoktam és már nem nehéz.
A fenti kód nyúlfarknyi. Ebbe belemagyrázni azt, hogy ez azért nem jó, mert lehet nem nyúlfarknyit is írni, hát, jó, de a fenti kód továbbra is nyúlfarknyi marad, minden más csak a kivetített félelmeid. Vagy valaki más félelmei, nem célom személyeskedni.
A lambda nem egy kalapács, hogy mindenre IS használható, ahogy egyébként semmi sem az, nincs ultimate weapon minden problémára. Természetes, hogy a 200 soros förmedvényt nem egy lambda blokkban kódolja le az ember, hanem elgondolkozik, hogy miért lett ez 200 sor, aztán egyszerűsít, absztrahál, és kitalál egy a probléma megoldására optimálisnak tűnő módszert, stílust, eszközt, stb. Ami nem KELL, hogy egyáltalán tartalmazzon lambdát végül.A lambda (meg lényegében a stream api) azért jó, mert egységet képez, egy komplexebb folyamatot is atomi egységbe zár, nincs mellékhatása, ergo "bugmentes". Ha matekosabb beállítottságúnak érzed magad, olvass kicsit a monad-ról. Ha kevésbé matekosnak, akkor inkább ne, nehogy eret vágj magadon.
Nyilván ezt is el lehet cseszni, ha mondjuk egy a lambdán kívül létrehozott listát piszkálunk a lambda belsejében, annak már lesz mellékhatása, de az nem is a lambda hibája.Én személy szerint azért nem szeretem a stream apit, mert lassú. Egy forEach lassabb egy for ciklusnál, és ez engem időnként zavar.
Nehéz debugolni? A régi eclipse valóban elég körülményesen működött, a closure környezetének csak egy részét látta. Hogy most jól működik-e, nem tudom. Mint mondtam, nem illik 200 soros lambda törzseket produkálni, és akkor nem kell debugolni sem. Problem solved. Érthető, hogy a határidő szűkössége miatt folyamatosan megy a
gányolás... khm... képződik tech dept, de akkor is a fejlesztő felelőssége marad, hogy jól olvasható kódot produkáljon a végén. Ha valaki elég igénytelen arra, hogy egy egyszerű lambda kifejezést túlbonyolítva ott hagy, refakt nélkül, oké, de nem az eszközt kellene ilyenkor hibáztatni az olvashatatlan és debugolhatatlan kód miatt. Gondolom.
Egyébként meg a 200 soros blokk metódusba szervezésével és egy jól irányzott method ref beillesztésével máris nagyot léptünk előre a tisztánlátás útján. Az már más kérdés, hogy sok esetben ez csak a probléma elfedésére jó és nélkülözi az igazi optimalizálást.Az olvashatóságot egyébként tengernyi más dolog is befolyásolja, csak hogy a legkézenfekvőbbet említsem, a nevek. Ha semmitmondó változó és metódus neveket használ a fejlesztő, akkor az olvasó arra kényszerül, hogy belenézzen a metódusba. Ha kifejező neveket használ, akkor erre nincs szükség. Innentől kezdve meg már teljesen mindegy, hogy igazi metódusokat, vagy névtelen metódusokat használunk a megoldásban. De akkor sem illik túlbonyolítani egy lambda kifejezést.
--------
@floatr: Sajnos nem értem a kérdést, kifejtenéd? A reduce egy darab string optional-t ad vissza, azon nem tudok már sokmindent gyűjtögetni. -
 Lortech
addikt
Lortech
addikt
Ez mennyire BestPactice? Én még úgy tanultam, hogy próbáljuk kerülni a lambda-t, mert a forráskód nehezebben olvasható majd. Nem "nyúlfarknyi" példákra, gondolok, hanem nagyobb osztályokra például. Persze most nem azt mondom, hogy 1-1 forEach vagy hasonló nem kerülhet bele csak például nálam egy-egy komplexebb sor átláthatósága debug esetén nehezebb/lassabb.
Persze tény, hogy elegánsabbVagy ez teljesen rendben van és marhaságot tanultam?
A best practice az olvasható kód.
Ez persze bizonyos mértékig szubjektív.
Az olvashatóság lambda esetében még inkább az, erősen függ attól, hogy ki az olvasó. Ki mihez van szokva, kinek már állt rá jobban az agya. Már csak azért is, mert a lambda nem volt mindig alap nyelvi elem, és máig rengeteg kódbázis van, ami nem ilyen szemléletben íródott. Ha a csapat, aki a kódot írja és karbantartja, lambdát preferálja, akkor menjen a lambda, de azért ne ész nélkül.
Az adott problémától függ, hogy lambdával olvashatóbb lesz-e a kód, esetleg hatékonyabb vagy elegánsabb. -
axioma
veterán
Ez mennyire BestPactice? Én még úgy tanultam, hogy próbáljuk kerülni a lambda-t, mert a forráskód nehezebben olvasható majd. Nem "nyúlfarknyi" példákra, gondolok, hanem nagyobb osztályokra például. Persze most nem azt mondom, hogy 1-1 forEach vagy hasonló nem kerülhet bele csak például nálam egy-egy komplexebb sor átláthatósága debug esetén nehezebb/lassabb.
Persze tény, hogy elegánsabbVagy ez teljesen rendben van és marhaságot tanultam?
Engem meg code review-n (prod.code) direkt felszolitottak, hogy lambda-sitsak. Szerintem attol fugg, hogy hol mi a szokas, en egyebkent nem tartom olvashatatlanabbnak (csak az adott esetben kovettem a korabbi kodstilust). Szerintem nem art megszokni, peldaul a sonarlint ezt nem veszi elagazasnak es extra bonyolitaspontnak ha jol remlik
-
Lortech
addikt
Odáig megvagyok, hogy megvan a dinamikusan összerakott kép egy BufferedImage-ben.
Ezt eddig fájlba tároltam csak le ImageIO.write()-al.
Viszont, ahogy említettem a browsernek ezt most stream-ként adnám át. Ha jól értem akkor monjuk egy response.setContentType("image/jpeg") és a ServletOutputStream megoldja a dolgot?Valami ilyesmi ugrik be nagy vonalakban a leírtak alapján:
BufferedImage generatedImage = imageGenerator(...);response.setContentType("image/jpeg");ServletOutputStream streamOut = response.getOutputStream();ImageIO.write(generatedImage, "jpg", streamOut);out.close();Ez így valamennyire jó irány?
Jonak nez ki.
Annyi megjegyzes, hogy ImageIO es a beepitett javas kepfeldolgozo megoldasok nagyon eroforraspazarloak mind memoria, mind cpu szempontjabol, es a vegeredmeny minosege sem feltetlenul a legjobb, szoval ha komoly megoldas kell, akkor erdemes ezeket kikerulni es valami nativ celeszkozt hasznalni (Pl convert (imagemagick) parancs linuxon), majd a vegeredmenyt direktben kiirni az outputstreamre. -
Lortech
addikt
Milyen megoldással lehetne egy servlet-ben megoldani azt, hogy amikor képet jelenítek meg egy weboldalon, akkor ne a kép nevét használjam az url-ben, hanem egy servlet url-t és az egy kép stream-et adjon vissza header-el?
Tehát ne ez legyen:
<div><img src="valami.hu/valami_kep_neve.jpg"></div>Hanem ez:
<div><img src="valami.hu/kepstream/123456"></div>Azaz dinamikusan generálódna le egy adott kép minden request-re és nem akarom szerver oldalon tárolni.
Anno PHP-ban az elv az volt, hogy elküldtem egy header-t és azután raw-ként az image adatait.
Itt valami hasonló dolog lenne? Header+stream?Kissé összemosódik a kép "nevének" (fájlnév / uri ? ) és magának a képnek a dinamikussága.
Nem világos az sem, hogy jön ide a header. Mindegy, kezdjük el és hátha kiderül, mire gondoltál./kepstream-re mappelsz egy servletet web.xml-ben vagy annotációval, request.getPathInfo-ból kiparse-olod a /kepstream utáni részt, megvan a path paramétered, amivel a képet azonosítod szerver oldalon.
Aztán a httpservletresponse outputstreamedre azt írsz dinamikusan, amit csak akarsz, akár on-the-fly generált képet, akár fájlból beolvasottat.
Plusz content-disposition, content-type headert nem árt kitölteni a céljaidnak megfelelően. -
 Aethelstone
addikt
Aethelstone
addikt
-
mobal
nagyúr
Elnézést, hogy ennyire felhúztam magam a dolgon. Valóban sürgős lett volna vagy legalábbis mihamarabb szerettem volna a témával foglalkozni, de másképp alakult és ezért csak ma néztem rá. Tehát jól érzékelted. A guglizással igazad van, de a címszavak nem ugrottak be ezért nem vezettek akkor eredményre a találatok.
A segítséget köszönöm, megnéztem a linket is és kerestem a címszavakra is. Pontosan ilyesmire lenne szükségem. Át is nézem mihamarabb a talált oldalakat.mobal: Tőled is elnézést szeretnék kérni, a sértettség és a tanácstalanság beszélt belőlem. Máskor próbálok mérsékeltebb lenni.
Ha van erre lehetőség és nektek is megfelel javasolnám a problémás hozzászólások törlését, mivel egyáltalán nem vág a témába és 10 év múlva nem akarom újraolvasni.
Töröltem. Legközelebb erre jobban figyeljünk oda, és most ezt engedjük el.
-
Aethelstone
addikt
Segítséget szeretnék kérni a következőben.
Egy olyan osztályt szeretnék csinálni, amivel be tudok tölteni egy képet, majd erre a képre kisebb képeket tudok rámásolni átlátszó háttérrel (pl. PNG) a megadott koordinátákra.
Aztán ezt az új bitmap-et vagy letárolnám képfájlként (png, jpeg) vagy stream-ként vissza is adhatnám megfelelő kép fejléccel. Ergo egy servletbe dinamikusan beépíthető lenne.Egyelőre nincs ötletem milyen címszavakkal volna értelme kutakodnom info után.
Adnátok megfelelő címszavakat kereséshez?https://stackoverflow.com/questions/14241944/overlay-images-in-java
Overlay images. Kb. ezek lennének a kulcsszavak.
-
disy68
aktív tag
Szerintem érdemes ismerni mindkettőt, de a maven-t mindenképp. Kezdőként elég az egyik is. A Gradle rugalmasabb, a néhanapján felmerülő cache problémákat szopás kiszűrni. A maven kevésbé rugalmas - pluginekkel persze lehet bármit - de régi motoros, szerintem minden problémára van megoldás (plugin) hozzá. Gradle esetében találkoztam olyannal, ami nincs vagy csak részben volt meg a maven-es megoldáshoz képest.
-
mobal
nagyúr
-
Zsoxx
őstag
Jelenleg egy ilyen Udemy-s anyagom van. Ez megfelelő lehet szerinted? Nekem jónak tűnik a content alapján.
Illetve találtam a YT-on magyar nyelvű anyagot is. A San Franciscoból jöttem csatornán Spring Boot ismeretek címmel.
A magyar nyelvűvel kezdeném, mert az angol lassabban megy kicsit sajnos (még). Gondolom nem gond, ha két külön helyről jön infó. Átfogóbb képet kapok. Igazából nem rohanok sehova csak veszett módon érdekel a Java és most lett egy kis időm.
Eddig PHP vonalon dolgoztam, kevéske OOP-vel sajnos a régi projectek miatt, mindenféle framework nélkül. A JAVA mellett állt rá az agyam is az OOP szemléletre. De ez egy másik történet ...
SFJ úgy tűnik leállt, már vagy fél éve nincs új videójuk. Bár a Spring Boot kurzus teljes, de a Dockert félbehagyták.
-
Drizzt
nagyúr
Nagyon köszönöm az infokat.
Olvasok a témában. Sokat kell pótolnom, helyretennem. De ez van, meglesz majd.A Spring Boot használata például akkor erősen javasolt, ugye?
Igazság szerint azért akartam eredetileg csak tiszta JavaSE kódot, hogy az alapokkal tisztában legyek. Lássam azokat a feladatokat/megoldásokat amiket egy framework elfed.
Esetemben nem maga a project elkészítése, hanem a Java gyakorlása a cél.A terv első lépésként egy fapados user/account résszel egy webes view-al megszerkesztett crud-ot tudó felület. Valami termék készlet manager. Mondjuk a fentebb említett "car" készlet kezelése.
Csak amolyan tanulásként.Szerintem a legérdemesebb beszerezni valamelyik beginner Udemys Spring traininget. Általában nagyon szájbarágósak és a végletekig praktikusak. Ha szerencséd van, olyan helyed dolgozol, hogy van ingyen access. Ha nem, akkor érdemes kinézni valamelyik akciósat és rákölteni vagy 10-20 eurót. Szerintem ezerszer könnyebb megérteni egy ilyenből, mint könyvekből, vagy írott tutorialokból.
-
disy68
aktív tag
Nagyon köszönöm az infokat.
Olvasok a témában. Sokat kell pótolnom, helyretennem. De ez van, meglesz majd.A Spring Boot használata például akkor erősen javasolt, ugye?
Igazság szerint azért akartam eredetileg csak tiszta JavaSE kódot, hogy az alapokkal tisztában legyek. Lássam azokat a feladatokat/megoldásokat amiket egy framework elfed.
Esetemben nem maga a project elkészítése, hanem a Java gyakorlása a cél.A terv első lépésként egy fapados user/account résszel egy webes view-al megszerkesztett crud-ot tudó felület. Valami termék készlet manager. Mondjuk a fentebb említett "car" készlet kezelése.
Csak amolyan tanulásként.Amiért javaslom egy valamilyen dependency injection framework használatát - szigorúan constructor injection-nel - mert ad egy szemléletet, amit jó megszokni. Ez volna az inversion of control.
-
disy68
aktív tag
Megkeveredtem a DAO és DTO fogalmak között.
Tehát valami ilyesmi lenne?
View <- (Model) -> Service <- (DTO) -> PersistenceAzaz arra irányulna az újabb kérdésem, hogy a DTO, amit mondjuk megkapok adatbázisból és van benne ID, nem juthat el a view rétegbe igaz? Hanem a kontroller mintegy mapper-ként új objektumot (POJO) hoz létre, de szintén a DTO-ból kapott ID-t használva és azt adja a View-nak?
DTO: data transfer object
ez lehet bármilyen két komponens közötti kommunikációban szereplőDAO: data access object
ez egy olyan objektum, amin keresztül adatokat érünk el/tudunk manipulálni, általában adatbázissal a túloldalon - az objektum elrejti a DB részleteketrepository:
a DAO-hoz hasonló pattern, inkább domain centrikusabb, az adat objektumokat entity-nek hívjuk ebben az esetben
A rétegek szervezése/szeparálása fontos dolog, nehéz elsőre ráérezni, fog kelleni hozzá némi tapasztalat. Annyit szerintem mindenképp jegyezz meg most, hogy nincs semmi kőbe vésve. Vannak ajánlások, de mindig az adott problémához keressük a megoldást, nem pedig valami "best practice-t" erőszakolunk rá mindenre.Amennyiben egy egyszerű crud a cél, akkor nem is feltétlen szükséges külön entity/dto/pojo-kat készíteni a különböző rétegekhez, mert fölöslegesen kéne transzformálgatni mindent többször is.
Ha a crud-nál tovább lépünk vagy más jellegű a probléma, akkor hasznos lehet különválasztani a rétegeket jobban.Amúgy olvass még kicsit utána funkcionális programozásnak, immutability-nek - java 8 óta java-ban is van hozzá támogatás - szerintem árnyalja majd a képet.
A Spring JavaEE vs sima java témakörben pedig én javaslom a keretrendszer használatát, ha máshoz nem is, de a dependency injection miatt mindenképpen.
-
mobal
nagyúr
-
mobal
nagyúr
Rendben. Köszi
Nem tudom, olyat lehet kérni itt a csoportban, hogy mondjuk csinálok egy nagyon alap project-et amit feltolok mondjuk a napokban gitlab-ra és megkérlek benneteket, hogy átfussátok? Tényleg alap CRUD dolgok, sima konzolos view-al.
Szoktak ilyet kérni? Vagy ezt nem illik?
Szeretném, ha helyesen rögzülnének bennem a pattern-ek.
Aztán javítgatom, mintegy példaként a későbbiekre.Szerintem ha bedobod ide lesz olyan aki ránéz
. GitHub? -
mobal
nagyúr
Megkeveredtem a DAO és DTO fogalmak között.
Tehát valami ilyesmi lenne?
View <- (Model) -> Service <- (DTO) -> PersistenceAzaz arra irányulna az újabb kérdésem, hogy a DTO, amit mondjuk megkapok adatbázisból és van benne ID, nem juthat el a view rétegbe igaz? Hanem a kontroller mintegy mapper-ként új objektumot (POJO) hoz létre, de szintén a DTO-ból kapott ID-t használva és azt adja a View-nak?
Ne bonyolítsd túl, a dto csak egy pojo ami tartalmazza a post adatokat példul - ha már az én példámnál vagyunk.
-
#68216320
törölt tag
Springet még hagyom, sima JDBC-t használok majd és alap funkciókat.
Viszont megkeveredtem, azt hittem DAO-t kizárólag perzisztens rétegben használunk.
Azt hiszem kellene keresnem valami megfelelő MVC alapú alap funkcionalitású (FW nélküli) kódrészletet, hogy a helyére kerüljenek a dolgok.Elnézést a bugyuta kérdésekért.
 vissza a padba...
vissza a padba...Még egy gyors kérdés, akkor elvben valahogy így nézne ki?
View <- (Model) -> Service <- (DAO) -> Persistence
Megkeveredtem a DAO és DTO fogalmak között.
Tehát valami ilyesmi lenne?
View <- (Model) -> Service <- (DTO) -> PersistenceAzaz arra irányulna az újabb kérdésem, hogy a DTO, amit mondjuk megkapok adatbázisból és van benne ID, nem juthat el a view rétegbe igaz? Hanem a kontroller mintegy mapper-ként új objektumot (POJO) hoz létre, de szintén a DTO-ból kapott ID-t használva és azt adja a View-nak?
-
mobal
nagyúr
Öööö... úgy kellene? Akkor megkeveredtem.
Nálam ott full SQL adatok vannak. Többek között az ID is.(#10482) floatr:
Most még nem használok keretrendszert, előbb megpróbálom teljesen átlátni a dolgot. (Ezután gondoltam Spring komponensekkel lecserélni amit lehet, aztán menne az egész JavaEE vonalra)
Nálam a terv az lenne, hogy maga a perzisztens réteg egy külön maven modulban van és kifelé interfészként van jelen. Emiatt én úgy gondoltam, hogy a DAO csak ebben a modulban létezik, vissza már modelt ad a szerviz rétegnek. A cél az lenne esetemben, hogy egy mozdulattal a perzisztens réteg modult lecserélve akár más tárolást lehessen használni. Már, ha ez nem hibás koncepció részemről.
A service réteg szintén külön maven modul. Arra gondoltam, hogy ő pedig csak model-t lát, számára a DAO nem létezik.Én amikor Springben csinálok egy API-t a következőket követem, a Controller kap egy kvázi DTO-t (sima POJO ami semmire nem jó csak adatokat szállítani) amit validálok majd adott esetben elmenetem tehát model készül belőle.
Amúgy meg modelekkel dolgozom repository-n keresztül.
Ahogy a kolléga is írta feljebb.
mobal,
-
floatr
veterán
Én anno úgy tanultam, hogy a model-ben kizárólag "nyers" adatok szerepelhetnek. De akkor persze lehet, hogy rosszul emlékszem. Megkoptak az emlékeim sajnos a hosszú kihagyás után.
És akkor az ID hogy nézzen ki? Legyen mondjuk csak getter hozzá, setter nem és a konstruktorban adjak mondjuk az ID-nak értéket kizárólag?
Ha a service rétegben van egy addCar akkor ugye ott még nincs ID-m. Tehát kellene egy ID nélküli konstruktor. Ha DAO-ból jön vissza adat, akkor ott már van ID, tehát kell egy olyan konstruktor is.
Ez így biztonságos? Nem szeretném, ha kivülről lehetne az ID-t variálni. Vagy rossz a gondolatmenet?A népszerűbb keretrendszerek azt a felállást támogatják, hogy Model + Repository/Dao + Service. Az ID kezelését egy alp perzisztencia motor is megoldja, és a Repository/Dao dolga a Model és adatbázis közti kapcsolat funkcionalitásának megteremtése.
Ezzel szemben van a domain driven design, ami az adatokat hordozó objektumnak adja a funkcionális részt is. -
mobal
nagyúr
Én anno úgy tanultam, hogy a model-ben kizárólag "nyers" adatok szerepelhetnek. De akkor persze lehet, hogy rosszul emlékszem. Megkoptak az emlékeim sajnos a hosszú kihagyás után.
És akkor az ID hogy nézzen ki? Legyen mondjuk csak getter hozzá, setter nem és a konstruktorban adjak mondjuk az ID-nak értéket kizárólag?
Ha a service rétegben van egy addCar akkor ugye ott még nincs ID-m. Tehát kellene egy ID nélküli konstruktor. Ha DAO-ból jön vissza adat, akkor ott már van ID, tehát kell egy olyan konstruktor is.
Ez így biztonságos? Nem szeretném, ha kivülről lehetne az ID-t variálni. Vagy rossz a gondolatmenet?Nyers adatok a DTO-ban szerepelnek nem?
-
 Sirpi
senior tag
Sirpi
senior tag
Egy elméleti, amolyan programozás technikai kérdés merült fel bennem.
Sajnos nagyon alap, de elbizonytalanodtam, a segítségeteket kérném.Tételezzük fel hogy autók adatait szeretném egy felületen feldolgozni, majd egyszerű CRUD műveletekkel adatbázisban használni.
Van egy "Car" model, ami ugye tartalmazza az autó adatait. Ezt a service rétegben dolgozom fel. Ha letárolom akkor átkerül a perzisztens rétegbe, ahol egy "CarDAO" lesz. Ebben van már adatbázisban található ID is, mert update/delete művelethez kelleni fog.
A problémám az, hogy mondjuk update/delete esetén, amikor amikor a "service" rétegben meghívom a perzisztens réteg updateCar/deleteCar funkcióit, akkor át kell adnom neki egy ID-t, hogy melyikkel dolgozzon. Ergo a "service" rétegben is tudnom kell az ID-t. Vagyis egy listázásnál mondjuk, amiből mondjuk egy kattintás a felületen a megfelelő sorban az update/delete, mintha a CarDAO objektumot adnám neki vissza. Ami esetemben "CarDAO" == "Car"+ID
Hogyan kellene ezt szépen megoldani, hogy a service réteg ne DAO-t kapjon, hanem Model-t?A modelben is szerepeljen az ID field, és amikor pl. listából kiválasztasz egy elemet, akkor tudsz ID alapján módosítani/törölni.
-
Drizzt
nagyúr
Felmerült bennem egy kérdés egy saját project-et illetően.
Ha mondjuk egy project-et kezdek, aminek van több különálló komponense, akkor azokat érdemes külön-külön maven project-ben csinálni?
Például: Ha mondjuk egy blog-ot veszünk alapul, annak van több különálló komponense.
- kliens rész (blog olvasása)
- writer rész (blog írása)
- admin (blog-ok karbantartása)
- user account / user rights
- képkezelő komponens
- stb.Csak példa volt. De arra gondolok, hogy ilyenkor egy maven project legyen az egész, vagy mondjuk érdemes egy 'blog' parrent project-et csinálni és abba megcsinálni egyesével a komponenseket? Gondolom ha külön lenne jobban lehetne karbantartani, nem?
Vagy túlbonyolítom a helyzetet és elég, ha külön-külön package-be mennek?Ha külön vannak, akkor mindenképpen nyered:
- Az egyes komponensek fordítása jóval gyorsabb lesz.
- Kisebbek, célszerűen jobban értelmezhetők lesznek a komponensek.
Hátrány:
- A verziószámokkal komoly kavarodást lehet összehozni. Bár ha követi az ember a semver szabályait, akkor igazából nem kéne, de én azt tapasztalom, hogy mégis nagyon nehéz eldönteniük embereknek, hogy mikor melyik verziószámot kellene léptetniük.Extrémebb eset, ha kiszervezed teljesen független alkalmazásokba a modulokat, amik különféle API-kal kommunikálnak. Előny:
- Lehet skálázni csak azt a komponenst, amit kell.
- Lehet heterogén az architektúra.
Hátrány:
- Amint valami kimegy a hálózatra, fel kell arra készülni, hogy a kommunikációval bajok lesznek. Timeout-ok, elveszett üzenetek, duplikált üzenetek.Még lehet message bus architektúrát is alkalmazni. Ez olyan, mint az utóbbi, de az üzenetek tárolása, küldése, etc. nem a saját alkalmazásod feladata, hanem egy message bus-é. Mint pl.: a Kafka, vagy JMS.
-
mobal
nagyúr
Rendben, köszönöm a bíztatást, meglesem a tutorial-t
Ja még egy dolog, ami most merült fel bennem. Utánnajárok majd a témának, de érdekelne, hogy Spring konfigurációkban annotációkat vagy XML-t szoktál inkább használni? Nekem tetszenek az annotációk. Ha esetleg valaki xml-el konfigurál akkor könnyebben felhasználható a kód a keretrendszeren kívül? Vagy mi az előnye/hátránya személyes tapasztalatod alapján?
(#10415) Drizzt: Értem amit mondasz és megfontolandó. Bár esetemben nem maga a project elkészítése lett volna a cél, az csak egy eszköz lenne a tanulásra, hogy mégse 100 darab "Hello world" szintű nyúlfarknyi kód legyen.
De kicsit körbejárom a dolgot akkor még1x.És köszi mindkettőtöknek a válaszokat. Nagyon felpörögtem a témára...
xml-t még bottal se piszkálnám. Annotáció, vagy Java. Spring Boot amugy nagyon sokmindent megcsinál alapból, továbbá a változó értékeit én properites fájlból szoktam állítani, ennek köszönhetően környezetnek megfelelő értékeid lehetnek.
-
mobal
nagyúr
Köszönöm az info-kat.
Volt már saját project-em Java-ban, a felsorolt fogalmakkal is tisztában vagyok. Én a maven-t ismerem és használtam, illetve perzisztens rétegben MySQL-t és mintapéldáknál (lustaságból) a Derby-t. Az MVC sem probléma, próbálok interfészeket használni és szép kódot írni. ORM-et még nem használtam Java-ban, kizárólag PHP vonalon a Laravel-ben találkoztam vele. Szóval az új lesz. SOLID alapelvek rendben, értem és próbálom helyesen alkalmazni őket, DI-re is törekszem, bár néha ott még bakizom.
Marad akkor az a felállás, hogy megcsinálom a tervemet Spring nélkül, refaktor amíg rendben lesz és ezután ugyanazt elkezdem a Spring-et és megpróbálom majd azzal megcsinálni.
Én azért azt javaslom, hogy a tutorialt nézd meg és annak a fényében döntsd el, hogy keretrendszer segítségével vagy nélkül kezded el.
Hamar bele lehet jönni szerintem

-
mobal
nagyúr
Alapvető fogalmakkal kell tisztáznod először és utána szerintem mehetne a Spring.
Amire szükséged lesz (így hirtelen fejből, nem teljes lista):
- Singleton
- MVC
- Repository
- DI
- Annotációk
- Hibernate (ORM)
- SQL
- ... és még sok dologEgy kiindulási alap: [link], továbbá célszerű Gradle vagy Maven tool-al is megismerkedned (én személy szerint a Gradle-t ajánlom).
-
Drizzt
nagyúr
Szerintem határozottan nem érdemes nulláról SE-vel elkezdeni megírni. Hiszen éppen ez lenne a Spring, meg az EE lényege: ne kelljen feltalálni a spanyolviaszt, s lehessen a business logic-ra fókuszálni.
Szerintem érdemes mindkettőhöz amúgy valamilyen maven archetype-ból kiindulni. Vannak pl.: egyszerű REST + EJB + JPA skeletonok, azokat már elég jól testre lehet szabni és kibővíteni, mégis faék egyszerűek.
-
mobal
nagyúr
Tudnátok linkelni elsősorban magyar (picit még lassan megy az angol) nyelvű doksit Spring, egészen pontosan Spring Boot kezdeti elsajátításához?
Kitaláltam gyakorlásnak egy hobby project-et (web view, mysql a crud műveletekhez) ahol az MVC-t szeretném begyakorolni. A szokásos JDBC/SQL Query használata helyett szeretnék JPA-t kipróbálni, még sohasem használtam.
Illetve nem tudom mi annak a technikának a neve, amikor először a Unit teszteket írják meg, de azzal a megoldással próbálkoznék majd.A Spring számomra még ismeretlen terület, ezért kellene pár kezdeti info hozzá magyarul. Aztán úgy gondolnám, ha van egy kis alap és nem a tanulási görbe legalján vagyok akkor már a még nem megfelelő angolommal már mennének az idegennyelvű doksik is. (legalább fejlődik az angolom is)
A Spring Tool Suite (Eclipse) IDE-t használnám. Megfelelő választás lehet a projecthez? Látom vannak kiegészítők VS Code és Atom IDE-hez is.
Spring az egy elég nagy falat, elég sok technikát / technológiát foglal magában.
-
#68216320
törölt tag
Tudnátok linkelni elsősorban magyar (picit még lassan megy az angol) nyelvű doksit Spring, egészen pontosan Spring Boot kezdeti elsajátításához?
Kitaláltam gyakorlásnak egy hobby project-et (web view, mysql a crud műveletekhez) ahol az MVC-t szeretném begyakorolni. A szokásos JDBC/SQL Query használata helyett szeretnék JPA-t kipróbálni, még sohasem használtam.
Illetve nem tudom mi annak a technikának a neve, amikor először a Unit teszteket írják meg, de azzal a megoldással próbálkoznék majd.A Spring számomra még ismeretlen terület, ezért kellene pár kezdeti info hozzá magyarul. Aztán úgy gondolnám, ha van egy kis alap és nem a tanulási görbe legalján vagyok akkor már a még nem megfelelő angolommal már mennének az idegennyelvű doksik is. (legalább fejlődik az angolom is)
A Spring Tool Suite (Eclipse) IDE-t használnám. Megfelelő választás lehet a projecthez? Látom vannak kiegészítők VS Code és Atom IDE-hez is.
Közben az merült fel bennem, hogy a Spring megértéséhez közelebb vinne-e az a módszer, ha ugyanazt a project-et először sima JavaSE-vel oldanám meg. Jdbc, Servlet, stb.
Ezután teljesen ugyanazt csinálnám meg Spring-el (esetleg jóval későbben JavaEE-vel talán)
Így talán az elméleti és megvalósítási különbségek egyértelműbbek lennének.Főleg mondom ezt az alapján, hogy 2 év kihagyás után az akkori friss Java tudásomból mostanra megkophattak jelenleg még előre nem látható részek.
Vagy ne törődjek vele és ugorjak neki csak a Spring-nek? -
#68216320
törölt tag
Érdekem megoldás amit felvázolsz. Szoktak ilyen megoldást alkalmazni? Igazából azt nem tudom mennyire kell ragaszkodnom a táblaszerkezetben az osztályok szerkezetéhez? Nyilván ORM esetében feltétlenül, bár hallok olyanokat, hogy nem túl célszerű a használata. Ha jól értem akkor az alábbi módon nézne ki, igaz?
+----+-------+ +----------------------+ +----------------------+
| sequence | | TBL1 | | TBL2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| id | table | | id | field1 | field2 | | id | field1 | field2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| 1 | TBL1 | | 1 | ... | ... | | 3 | ... | ... |
| 2 | TBL1 | | 2 | ... | ... | | 4 | ... | ... |
| 3 | TBL2 | +----+--------+--------+ +----+--------+--------+
| 4 | TBL2 |
+----+-------+Ahol a sequence tábla id auto_increment, a tbl1, tbl2 id pedig unique.
Drizzt: Megnéztem a linket, köszönöm. Van egyébként valami javasolt/preferált megoldás a 3 közül vagy teljesen szabadon választhatok közülük. Esetemben a mindent egy táblába a null/notnull miatt nem volna célszerű. A teljesen különálló táblák és a közös tábla-saját típusos tábla megoldások között dilemmázok. Mivel alapvetően a lekérdezések lesznek töbségben és sejthetőleg típusra szűkítve főként, a külön-külön önálló tábla megoldást érzem picit jobb megoldásnak. De bizonytalan vagyok
Ehh, most esett csak le, hogy ezzel a megoldással gyakorlatilag ugyanazt csinálnám, mintha az ős-leszármazott osztályokat modellezném csak teljesen értelmetlen módon, mert akkor legalább az ősben benne lennének a közös értékek. Szóval ez így nagyon nem jó
-
Szmeby
tag
Érdekem megoldás amit felvázolsz. Szoktak ilyen megoldást alkalmazni? Igazából azt nem tudom mennyire kell ragaszkodnom a táblaszerkezetben az osztályok szerkezetéhez? Nyilván ORM esetében feltétlenül, bár hallok olyanokat, hogy nem túl célszerű a használata. Ha jól értem akkor az alábbi módon nézne ki, igaz?
+----+-------+ +----------------------+ +----------------------+
| sequence | | TBL1 | | TBL2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| id | table | | id | field1 | field2 | | id | field1 | field2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| 1 | TBL1 | | 1 | ... | ... | | 3 | ... | ... |
| 2 | TBL1 | | 2 | ... | ... | | 4 | ... | ... |
| 3 | TBL2 | +----+--------+--------+ +----+--------+--------+
| 4 | TBL2 |
+----+-------+Ahol a sequence tábla id auto_increment, a tbl1, tbl2 id pedig unique.
Drizzt: Megnéztem a linket, köszönöm. Van egyébként valami javasolt/preferált megoldás a 3 közül vagy teljesen szabadon választhatok közülük. Esetemben a mindent egy táblába a null/notnull miatt nem volna célszerű. A teljesen különálló táblák és a közös tábla-saját típusos tábla megoldások között dilemmázok. Mivel alapvetően a lekérdezések lesznek töbségben és sejthetőleg típusra szűkítve főként, a külön-külön önálló tábla megoldást érzem picit jobb megoldásnak. De bizonytalan vagyok
Nem igazán így néz ki. A sequence csak egy futósorszám. Tehát tényleg csak egy szám van benne... az éppen aktuális érték. Ha elkéred tőle az értéket, automatikusan növeli magát eggyel (vagy neked kell növelned kézzel... kinézem ezt a mysql-ből). Ha mindenképpen táblaként akarod elképzelni, akkor van egy oszlopa, neve mondjuk legyen value, és van egy sora, abban az érték pedig 6, mert mondjuk a 6 volt az utoljára kiosztott id.
Lásd az oldal alján.Szóval találkoztam már pár helyen ilyen megoldással... bár az oracle volt, nem mysql, de a concept ugyanaz, globálisan egyedi id. Nyilván nem kötelező minden táblán ezt használni, táblák egy csoportján is lehet, meg létrehozhatsz több sequence-t, más-más csoportoknak... ahogy a domain megköveteli.
Bár a hozzászólások alapján úgy látom, ebből 1 fő tábla lesz.
-
bambano
titán
Fix számú, jelen esetben 3 fajta termék kategória van. Nem is várható bővülés, max jóval később talán 1-2 legfejjebb. Ez a 3 fajta termékkategória összesen 5 mezőben egyezik és minden egyébben különbözik. Ebben az esetben sem volna kényelmes inkább 3db külön-külön tábla? A lekérdezések gyorsabbak és egyszerűbbek lennének.
"Nem is várható bővülés": híres utolsó mondatok

a lekérdezés sebessége egyrészt nem számít akkor, amikor elméletben vizsgálsz egy logikai struktúra->tárolási struktúra leképezést, másrészt nem is tudhatod előre, mi a gyorsabb, harmadrészt oldja meg a hardver
szerintem a kód mindenféle részén folyton azt mókolni, hogy most melyik táblát kell joinolni, hova mit írsz, az nagyobb teher, mint berakni egy táblába, indexelni, a többit oldja meg az adatbáziskezelő meg a beszerzési osztály rambevásárló felelőse.
-
Drizzt
nagyúr
Fix számú, jelen esetben 3 fajta termék kategória van. Nem is várható bővülés, max jóval később talán 1-2 legfejjebb. Ez a 3 fajta termékkategória összesen 5 mezőben egyezik és minden egyébben különbözik. Ebben az esetben sem volna kényelmes inkább 3db külön-külön tábla? A lekérdezések gyorsabbak és egyszerűbbek lennének.
Még egy aspektust akarok felvetni. Milyen táblákhoz kapcsolódik a termék még? Ha van olyan, ami termék ID-t használ, akkor innentől kezdve abban a táblában ha akarsz foreign key-t használni, akkor kénytelen leszel 3 különféle oszlopot felvenni. (Utóbbit mondjuk úgy is ki lehet küszöbölni, ha minden 1:1, 1:n kapcsolatot is kapcsolótáblával valósítasz meg, mintha n:n lenne, mert ilyenkor a foreign key a kapcsolótáblába kerül át.)
Másik dolog amit fontolj meg, hogy érdemes lehet Flywayt, vagy Liquibase-et használni, ami jelentősen meg tudja könnyíteni az életed, ha később mégis kell változtatni az adattáblák struktúráján, s ilyenkor a meglevő rendszerek update-elése automata kell, hogy legyen.
-
bambano
titán
Felmerült bennem egy kérdés egy adatmodell-database leképezését illetően. Csak elméleti a dolog, a megvalósítás technikája érdekelne igazából.
Tételezzük fel, hogy van egy "Termekek" absztrakt osztályom. Itt található id, nev, gyarto, stb.
Ebből leszármaznak a Televíziók, Mosogepek osztályok. Ezekben már különböző adatok találhatóak. Például a Televiziok esetében kijelzoMeret, hdmiSzama, stb - Mosogepek esetében energiaOsztaly, centrifugaSebesseg, stb.Az volna a kérdésem, hogy adatbázisban ezt szintén így kellene megcsinálni? Azaz "termekek" táblát létrehozni, amiben id, nev, gyarto mezők lennének és mondjuk egy termek_tipus mező? Aztán lenne egy "televiziok" tábla amiben lenne egy termek_id és jönnének a kijelzoMeret, hdmiSzama mezők? Aztán a "mosogepek" tábla hasonló megoldással?
Vagy érdemesebb volna csak két táblát (televiziok, mosogepek) csinálni, részben azonos mezőkkel? Viszont ekkor az autoincrement id a mysql-ben csak egy táblára lesz érvényes, azaz lenne 1-es id-val tv és mosógép is.Mi ilyen esetben az elfogadott megoldás?
szerintem meg egy táblát kell csinálni a terméknek, azon mezőkkel, amelyek biztosan mindegyik terméknél előfordulhatnak, meg egy táblát a változó tulajdonságoknak, és abba belerakni az adott termék tulajdonságait. esetleg egy harmadikat tulajdonságtípusnak.
A harmadikba beleraknád, hogy milyen tulajdonságok fordulnak elő (pl. kijelzőméret, hdmi száma), a másodikba meg hogy termek_id,tulajdonsag_id, ertek.
-
 RexpecT
addikt
RexpecT
addikt
Érdekem megoldás amit felvázolsz. Szoktak ilyen megoldást alkalmazni? Igazából azt nem tudom mennyire kell ragaszkodnom a táblaszerkezetben az osztályok szerkezetéhez? Nyilván ORM esetében feltétlenül, bár hallok olyanokat, hogy nem túl célszerű a használata. Ha jól értem akkor az alábbi módon nézne ki, igaz?
+----+-------+ +----------------------+ +----------------------+
| sequence | | TBL1 | | TBL2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| id | table | | id | field1 | field2 | | id | field1 | field2 |
+----+-------+ +----+--------+--------+ +----+--------+--------+
| 1 | TBL1 | | 1 | ... | ... | | 3 | ... | ... |
| 2 | TBL1 | | 2 | ... | ... | | 4 | ... | ... |
| 3 | TBL2 | +----+--------+--------+ +----+--------+--------+
| 4 | TBL2 |
+----+-------+Ahol a sequence tábla id auto_increment, a tbl1, tbl2 id pedig unique.
Drizzt: Megnéztem a linket, köszönöm. Van egyébként valami javasolt/preferált megoldás a 3 közül vagy teljesen szabadon választhatok közülük. Esetemben a mindent egy táblába a null/notnull miatt nem volna célszerű. A teljesen különálló táblák és a közös tábla-saját típusos tábla megoldások között dilemmázok. Mivel alapvetően a lekérdezések lesznek töbségben és sejthetőleg típusra szűkítve főként, a külön-külön önálló tábla megoldást érzem picit jobb megoldásnak. De bizonytalan vagyok
Valószínűleg én is két táblába raknám, hogy ne kelljen joinolgatni. Egyébként miért baj, hogy ugyanazzal az id-val van rekord két táblában is?
Egyébként meg lehet mondani, hogy mettől kezdje az id-t osztani:id INT UNSIGNED NOT NULL AUTO_INCREMENT = 100, -
Szmeby
tag
Felmerült bennem egy kérdés egy adatmodell-database leképezését illetően. Csak elméleti a dolog, a megvalósítás technikája érdekelne igazából.
Tételezzük fel, hogy van egy "Termekek" absztrakt osztályom. Itt található id, nev, gyarto, stb.
Ebből leszármaznak a Televíziók, Mosogepek osztályok. Ezekben már különböző adatok találhatóak. Például a Televiziok esetében kijelzoMeret, hdmiSzama, stb - Mosogepek esetében energiaOsztaly, centrifugaSebesseg, stb.Az volna a kérdésem, hogy adatbázisban ezt szintén így kellene megcsinálni? Azaz "termekek" táblát létrehozni, amiben id, nev, gyarto mezők lennének és mondjuk egy termek_tipus mező? Aztán lenne egy "televiziok" tábla amiben lenne egy termek_id és jönnének a kijelzoMeret, hdmiSzama mezők? Aztán a "mosogepek" tábla hasonló megoldással?
Vagy érdemesebb volna csak két táblát (televiziok, mosogepek) csinálni, részben azonos mezőkkel? Viszont ekkor az autoincrement id a mysql-ben csak egy táblára lesz érvényes, azaz lenne 1-es id-val tv és mosógép is.Mi ilyen esetben az elfogadott megoldás?
"Viszont ekkor az autoincrement id a mysql-ben csak egy táblára lesz érvényes, azaz lenne 1-es id-val tv és mosógép is."
Nem kötelező a táblákra bízni az id generálást, autoincrement használata helyett csinálhatsz az adatbázisban egy sequence-et (vagy sequence table-t? nem tudom, mysqlnél milyen eszközök állnak rendelkezésre), és az entitásaid abból szedhetik majd a next id-t.
-
Drizzt
nagyúr
Felmerült bennem egy kérdés egy adatmodell-database leképezését illetően. Csak elméleti a dolog, a megvalósítás technikája érdekelne igazából.
Tételezzük fel, hogy van egy "Termekek" absztrakt osztályom. Itt található id, nev, gyarto, stb.
Ebből leszármaznak a Televíziók, Mosogepek osztályok. Ezekben már különböző adatok találhatóak. Például a Televiziok esetében kijelzoMeret, hdmiSzama, stb - Mosogepek esetében energiaOsztaly, centrifugaSebesseg, stb.Az volna a kérdésem, hogy adatbázisban ezt szintén így kellene megcsinálni? Azaz "termekek" táblát létrehozni, amiben id, nev, gyarto mezők lennének és mondjuk egy termek_tipus mező? Aztán lenne egy "televiziok" tábla amiben lenne egy termek_id és jönnének a kijelzoMeret, hdmiSzama mezők? Aztán a "mosogepek" tábla hasonló megoldással?
Vagy érdemesebb volna csak két táblát (televiziok, mosogepek) csinálni, részben azonos mezőkkel? Viszont ekkor az autoincrement id a mysql-ben csak egy táblára lesz érvényes, azaz lenne 1-es id-val tv és mosógép is.Mi ilyen esetben az elfogadott megoldás?
Teljesen nem olvastam vegig az alabbi linket, de szerintem minden kerdesedre valaszt kapsz belole. A valasz: attol fugg. 3 fo megoldas van: egy tabla az osszes termektipussal. Ezzel lehet a leggyorsabban lekerdezni termektipusokat ativelo modon, de constrainteket not null constrainteket nem tudsz megadni, ha az altipusok egy reszenel kellene, de legalabb egy altipusnal nem. Aztan lehet mindegyik tioust sajat tablaba rakni. Ekkor az osszes tipus lekerdezesehez tobb tablat kell lekerdezni. Aztan van a kozos tabla a kozos mezoknek, majd egyedi altipus mezoknek kulon tablak, amik visszareferalnak a kozos tulajdonsagokat tartalmazo tablara. Itt joinnal lehet lekerdezni az osszes altipus osszes elemet egyszerre. [link]
-
RexpecT
addikt
Kis segítséget kérnék. Van egy model-em, amiben 2db dátum+idő-t (datetime?) kellene tárolnom. Értékeket egyenként venne fel, azaz az évszámot külön adom neki, hónapot, stb. Aztán ezt a model menne majd a DAO-nak aki MySQL DateTime formában tárolja.
Az volna a kérdésem, hogy mi volna megfelelő? A Date object? Vagy van valami speciálisabb, amivel kényelmesen setter-ekkel vagy egy string-ből be tudok adni mondjuk egy "2019-02-01 11:59:59" dátumot?Update: Ez mennyire lehet jó megoldás?
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date date = sdf.parse("2019-01-01 00:00:00");Java 8 és felette érdemesebb a LocalDateTime-ot használni.
-
Lortech
addikt
Urak. Hogyan tudom megcsinálni, hogy a maven által elkészített jar fájlban az App class (ez az egy main() van benne) hívódjon meg automatikusan, amikor a java -jar usermanager.jar parancssort beírja valaki?
Ez a jelenlegi pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.etcetc.usermanager</groupId>
<artifactId>user-manager</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>user-manager</name>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
<finalName>usermanager</finalName>
</build>
</project>[link]
szerk: 2.2-t szoktam egyszerű esetben preferálni. -
Lortech
addikt
Tudnátok segíteni, hogy a .classpath fájlt miért nem zárja ki a .gitignore?
Az alábbi jelenleg a .gitignore tartalma# Java
*.class
*.jar
*.war
*.ear
# Eclipse
.project
.classpath
.settings
# Idea
.idea
*.iml
*.iws
*.ipr
# OS
Thumbs.db
.DS_Store
# Gradle
.gradle
!gradle-wrapper.jar
# Maven
target
# Build
out
build
bin
# Other
*.log
*.swp
*.bakAz szokott lenni az oka, hogy mar trackelve van a fajl, ilyenkor a gitignore hatastalan.
-
 mbalazs7
csendes tag
mbalazs7
csendes tag
-
 Rickeffe
aktív tag
Rickeffe
aktív tag
Nincs response request nélkül
Igen, tudom. Pont ez okozza a problémát. A swing-es gui-ban ugye így van megcsinálva (ugyebár ott sima ügy) és megszokták.
Az ajax esetében esetleg valami megoldással azt volna csak gondolom első lépésben megkérdezni, hogy volt-e változás. Már csak a felesleges kommunikáció minimalizálása érdekében. Ha volt akkor kellene gondolom a táblázat adatait frissítenem.Ha fw akkor milyen framework volna megfelelő?
A pollingot akartam javasolni de az nem minimalizál
-
RexpecT
addikt
Sziasztok, egy kis segítségre volna szükségem egy probléma megoldását illetően.
Szükséges volna egy WEB-es felületen egy SQL tábla adatait táblázatosan megjelenítenem.
A problémát az okozza, hogy amolyan "observer"-es megoldással, ha az SQL tábla adatait egy másik felhasználó megváltoztatja akkor automatikusan ennek az én webfelületemen is frissülnie kellene.
Milyen megoldással/technológiával lehetne megoldanom, hogy az observer-em ilyenkor request nélkül egy response-t csináljon a servlet-es webfelületen?Update: A dolog még csak tervezési fázisban van, teljes szabadság van az adott technológia kiválasztásában. Egyetlen megközés, hogy Tomcat alatt fusson.
Kis guglizással szerintem ezt keresed: Server-Sent Events (SSE)
-
sztanozs
veterán
Sziasztok, egy kis segítségre volna szükségem egy probléma megoldását illetően.
Szükséges volna egy WEB-es felületen egy SQL tábla adatait táblázatosan megjelenítenem.
A problémát az okozza, hogy amolyan "observer"-es megoldással, ha az SQL tábla adatait egy másik felhasználó megváltoztatja akkor automatikusan ennek az én webfelületemen is frissülnie kellene.
Milyen megoldással/technológiával lehetne megoldanom, hogy az observer-em ilyenkor request nélkül egy response-t csináljon a servlet-es webfelületen?Update: A dolog még csak tervezési fázisban van, teljes szabadság van az adott technológia kiválasztásában. Egyetlen megközés, hogy Tomcat alatt fusson.
Nincs response request nélkül. Ezt valami aktív technológiával lehet megoldani (vagy valami frameworkkel, vagy sima webservice + időzített ajax lekérés)
-
 Regirck
senior tag
Regirck
senior tag
Nem biztos, hogy jól értem, de esetleg valami ilyesmi?
private static double keplet(double num) {
return num/2+4;
}
public static void main(String[] args) {
double num = 16;
int count = 10;
for (int i = 0; i < count; i++) {
num = keplet(num);
}
System.out.println("Result: " + num);
}Count értelemszerűen annyi, ahányszor számolni akarsz. Num a kezdeti érték.
Hálás köszönet!

-
 Taoharcos
aktív tag
Taoharcos
aktív tag
A swing is elvesztegetett idő, egy munkaadó se kiváncsi erre. Inkább valami mást tanulj, Vaadinon kivűl még ott van a GWT, Struts, de a JSF vagy JSP is hasznosabb, vagy JPA, Hibernate, Eclipselink, Spring, Junit, Mockolás, TDD, SQL stb.
Ha már könyvből tanulsz "az agyhullám java" sokkal hasznosabb, aktuálisabb és érthetőbb. Ráadásul a Youtube-on sok jó java oktató videó van, angolul rengeteg, de még magyarul is sok. -
floatr
veterán
Szerintem kár erre vesztegetni az idődet. Az új irány: REST és microservices
Vagy android -
Aethelstone
addikt
-
Taoharcos
aktív tag
Az a gond, hogy a forráskódot és a class-t felhasználnák majd osx es linux rendszereken is. Uft8 kellene. Igazából már csak a bevitelt kellene valahogy megoldani. Gondolom az UTF8 ékezetek 2bytes tárolása okoz gondot, de egyelőre nem tudom pontosan mi a gond csak tippelek.
Kipróbáltad ahogy leírtam és neked is ezt az eredményt adja?(#9142) disy68:
Nálam a fentebb leírt UTF-8 beállításaimmal fordítva/futtatva az INPUT_MESSAGE helyesen jelenik meg, de ékezetet beírva a
out.println(String.format("key: '%s'", scanerObj.next().charAt(0)));sornál ugyanazt a hibát adja, mint amit már mutattam.Vagy egy kis plusz kóddal eldöntöd milyen oprendszeren fut a program (System.getProperty("os.name")), és annak megfelelő karakter kódolást használod.
Találtam egy oldalt, ami szépen leírja, de nem próbáltam ki a kódot. -
Taoharcos
aktív tag
Az a gond, hogy a forráskódot és a class-t felhasználnák majd osx es linux rendszereken is. Uft8 kellene. Igazából már csak a bevitelt kellene valahogy megoldani. Gondolom az UTF8 ékezetek 2bytes tárolása okoz gondot, de egyelőre nem tudom pontosan mi a gond csak tippelek.
Kipróbáltad ahogy leírtam és neked is ezt az eredményt adja?(#9142) disy68:
Nálam a fentebb leírt UTF-8 beállításaimmal fordítva/futtatva az INPUT_MESSAGE helyesen jelenik meg, de ékezetet beírva a
out.println(String.format("key: '%s'", scanerObj.next().charAt(0)));sornál ugyanazt a hibát adja, mint amit már mutattam.Igen.
De ha UTF-8 helyett cp1250 van akkor jó. -
Taoharcos
aktív tag
Help!
Van egy mintaprogramom, ami konzolból vár a felhasználótól karaktereket és ír ki szöveget.
OSX-en szépen fut az UTF-8-al, de Win alatt helytelenül jeleníti meg az ékezeteket, mivel az UTF8 2Byte-ot kiírja.
Ha chcp 65001-vel átváltom Win alatt a command line kódolását, akkor a kijelzés jó lesz, de bevitelnél meg sem jelennek az ékezetes karakterek.Hogyan lehetne ezt rendesen használni?
Mindenképpen UTF-8 kell? Nem jó a cp1250?
-
disy68
aktív tag
Helló, jó kis probléma
Hirtelen olyat találtam, hogy:
import java.io.PrintStream;
import java.io.UnsupportedEncodingException;
import java.util.Scanner;
public class Main {
private static final String UTF_8 = "UTF-8";
private static final String INPUT_MESSAGE = "Írj be egy betűt: ";
public static void main(String[] args) throws UnsupportedEncodingException {
try (Scanner scanerObj = new Scanner(System.in, UTF_8);
PrintStream out = new PrintStream(System.out, true, UTF_8)) {
while (true) {
out.print(INPUT_MESSAGE);
out.println(String.format("key: '%s'", scanerObj.next().charAt(0)));
}
}
}
}Ezzel helyesen kezeli a scanner által utf-8-nak beolvasott betűket, viszont az INPUT_MESSAGE-et nem. Amit találtam még, hogy indítani a -Dfile.encoding=IBM437 (nálam ez az alapértelmezett kódlap chcp parancs megmondja) paraméterrel, bár ezzel nem kísérletezgettem szóval nem tudom működne-e helyesen.
-
#68216320
törölt tag
Jelenleg ott tart a dolog, hogy jó a szöveg megjelenítése, ha a fordító és a VM is UTF8-al van indítva.
Viszont ékezetes bevitelnél hibát kapok: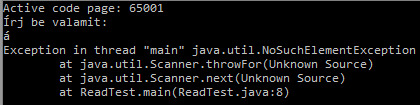
OS X-en nincs vele gond.
import java.util.*;
class ReadTest {
public static void main ( String[] arguments ) {
System.out.println("Írj be valamit: ");
char key;
Scanner scanerObj = new Scanner(System.in,"UTF-8");
key = scanerObj.next().charAt(0);
System.out.println("key: ' " + key + "'");
}
}Fordító:
javac -encoding UTF-8 %Name%.javaVM:
chcp 65001 (utf8-ra váltja a konzolt)
Java -Dfile.encoding=UTF-8 %Name%Még mindig nem sikerült megoldani. Szóval ha valakinek van ötlete ...
-
Aethelstone
addikt
Help!
Van egy mintaprogramom, ami konzolból vár a felhasználótól karaktereket és ír ki szöveget.
OSX-en szépen fut az UTF-8-al, de Win alatt helytelenül jeleníti meg az ékezeteket, mivel az UTF8 2Byte-ot kiírja.
Ha chcp 65001-vel átváltom Win alatt a command line kódolását, akkor a kijelzés jó lesz, de bevitelnél meg sem jelennek az ékezetes karakterek.Hogyan lehetne ezt rendesen használni?
Dobj már ide valami kódot....egyébként meg.....
-
Aethelstone
addikt
-
#68216320
törölt tag

















 vissza a padba...
vissza a padba...









Új hozzászólás Aktív témák
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Nyomtatók, szkennerek Tabletek, E-bookok PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- Java programozás
- (kiemelt téma)

A topicot kiemeltem. Valaki nem akar egy nyitó hsz-t írni?:))
- Mibe tegyem a megtakarításaimat?
- Tőzsde és gazdaság
- Revolut
- World of Tanks - MMO
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Milyen ÚJ notebookot vegyek?
- Milyen TV-t vegyek?
- HiFi műszaki szemmel - sztereó hangrendszerek
- Autós topik
- Speciális kiadású AMD-s alaplapot villantott az ASUS a 20 éves ROG-jubileumra
- További aktív témák...

- 24 magos AMD Threadripper alapú munkára kiváló félgép, 128GB RAM-mal
- HP ZBook Fury 15 G7 i7-10850H 32GB 512GB SSD Quadro T2000 4GB FHD HUN bill, szép állapotban eladó
- Eladó MacBook Pro 16,1 2019 CTO
- új 0 km es garanciás lenovo loq rtx 5050 8gb
- Eladó teljesen újszerű karcmentes Samsung Galaxy Watch Ultra
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest