- Samsung Galaxy S23 Ultra - non plus ultra
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Garmin Instinct – küldetés teljesítve
- Google Pixel topik
- Nem minden Nothing Phone (3) születik egyenlőnek
- Samsung Galaxy Watch4 és Watch4 Classic - próbawearzió
- Telekom mobilszolgáltatások
- Honor 400 - és mégis mozog a kép
- iOS alkalmazások
- Netfone
-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
#22856
 Cathulhu
addikt
Balala2007
#22851
Cathulhu
addikt
Balala2007
#22851
Cathulhu
addikt
válasz
 Balala2007
#22851
üzenetére
Balala2007
#22851
üzenetére
Úgy tűnik marad a 2 hardver szál / mag egy ideig. Viszont az összevont cache valószínű elég IPC növekedést fog hozni, hogy egy generációra elég legyen, őszintén furcsállottam már Zen2-nél is, hogy I/O die és CCD ide vagy oda, a CCX felosztotáshoz nem nyúltak
-
#22852
 paprobert
őstag
Balala2007
#22851
paprobert
őstag
Balala2007
#22851
paprobert
őstag
válasz
Balala2007
#22851
üzenetére
Desktop szinten nem kell ezentúl kényszerűen a chiplet egyik felén futtatni bizonyos szoftvereket, nem lesz inter-cache penalty.
Egyben ez nominálisan nem, de indirekten cache növekedést is jelent.Jól hangzik.
-
#22562
 Floyd80
addikt
Balala2007
#22552
Floyd80
addikt
Balala2007
#22552
Floyd80
addikt
válasz
Balala2007
#22552
üzenetére
Itt van németül is ugyanez:
-
#22558
 joysefke
veterán
Balala2007
#22557
joysefke
veterán
Balala2007
#22557
joysefke
veterán
válasz
Balala2007
#22557
üzenetére
Ezt a spanyol oldalt seggbe szvsz fogják rúgni...
-
#22554
joysefke
veterán
Balala2007
#22552
joysefke
veterán
válasz
Balala2007
#22552
üzenetére
Ezek már a végleges teljesítmény adatok? Az X470 lappal elég gyenge memóriaértékeket produkált a proci.
Kaptatok tesztpéldányt? Tudod a memória késleltetéseket kommentálni?
-
#22553
 DraXoN
addikt
Balala2007
#22552
DraXoN
addikt
Balala2007
#22552
DraXoN
addikt
válasz
Balala2007
#22552
üzenetére
nem 3600X, sima 3600
azért az durva, hogy cinebenchben hozza a leggyengébb 6magos, a 8magos 1700X pontszámát (és más alkalmazásokban is ez kitűnik)...
-
#22256
 Petykemano
veterán
Balala2007
#22254
Petykemano
veterán
Balala2007
#22254
Petykemano
veterán
válasz
Balala2007
#22254
üzenetére
AdoredTV lázálmain túl csak ez van: der8auer
-
#22255
 Raymond
titán
Balala2007
#22254
Raymond
titán
Balala2007
#22254
Raymond
titán
válasz
Balala2007
#22254
üzenetére
A mostani 8 magos 2700X orajeleibol indulok ki, azt a 4.3Ghz-re a +15%-ot csak kisajtoljak 7nm-en es akkor ott lesznek ahol az i7-9700K es i7-9900 uldogel.
-
#22253
Raymond
titán
Balala2007
#22252
Raymond
titán
válasz
Balala2007
#22252
üzenetére
Mondjuk az eleg is, az IPC ott lesz ahol a mostani Intel felhozatal van es ahogy kineznek a dolgok az orajelek is ott lesznek, azt a 15%-ot csak kikaparjak valahogy 7nm-en.
-
#22250
Raymond
titán
Balala2007
#22244
Raymond
titán
válasz
Balala2007
#22244
üzenetére
"felzarkozas a Skylake-hez"
Na de ez azt jelenti hogy felzarkozas a Kaby Lake es Coffee Lake, ergo a mostani sorozathoz is. A Skylake-hez kepest on nem volt valtozas az orajel novelsen es a +50% core es velejaro bizsu novelesen.
-
#22249
Petykemano
veterán
Balala2007
#22247
Petykemano
veterán
válasz
Balala2007
#22247
üzenetére
Jó, de abban a topikban se mondta senki, hogy a zen2-ben jönne AVX512 és/vagy SMT4
-
#22246
Petykemano
veterán
Balala2007
#22244
Petykemano
veterán
válasz
Balala2007
#22244
üzenetére
Hangzatos lecsapás, de had kérdezzem már meg, hogy ki és mikor állította, hogy a Zen2-ben lesz AVX512 és/vagy 4xHTT?
-
#22245
joysefke
veterán
Balala2007
#22244
joysefke
veterán
válasz
Balala2007
#22244
üzenetére
Fogtok kapni eng samplet?
-
#21774
 awexco
őstag
Balala2007
#21770
awexco
őstag
Balala2007
#21770
awexco
őstag
válasz
Balala2007
#21770
üzenetére
Mi az a Cori ?
-
#21773
 Simid
senior tag
Balala2007
#21770
Simid
senior tag
Balala2007
#21770
Simid
senior tag
válasz
Balala2007
#21770
üzenetére
"The DOE presented a slide outlining the Milan processors. But, in a case study of how easily slides can be misinterpreted if you aren't there for the presentation, the speaker specifically stated that the "64 cores" listing refers to AMD's Rome processors, and not the Milan chips. For now, the DOE isn't at liberty to disclose the core counts for the Milan CPUs."
Ez igaz a többi specre is a cikk szerint.
Link -
#21772
 S_x96x_S
addikt
Balala2007
#21770
S_x96x_S
addikt
Balala2007
#21770
S_x96x_S
addikt
válasz
Balala2007
#21770
üzenetére
>Zen3-ban se lesz AVX512:
Ez egybevág a Chiphell -es leakkel , ami szerint :
Zen 3: SMT4
Zen 4: AVX512 -
#21771
Petykemano
veterán
Balala2007
#21770
Petykemano
veterán
válasz
Balala2007
#21770
üzenetére
A zen3 talán csak finomítás (zen2+)?
Ticktock
+DDR5
Eddig úgy volt, h a szerverprocesszorok validálása hosszadalmas és költséges. A ddr5 érthető, de a CPU hogyhogy frissül 1 év után? Az epyc előzőleg nem kapta meg a finomítást. -
#21684
S_x96x_S
addikt
Balala2007
#21682
S_x96x_S
addikt
válasz
Balala2007
#21682
üzenetére
> Zen2 ujdonsagok a New Horizonts-bol:
hivatalos slide: https://www.slideshare.net/AMD/amd-next-horizon-122143522
-
#21683
 füles_
őstag
Balala2007
#21682
füles_
őstag
Balala2007
#21682
füles_
őstag
válasz
Balala2007
#21682
üzenetére
AdoredTV informacio megint igaznak bizonyultak. Epyc2: 14nm-es I/O die es korulotte 7nm-es compute die-ok.
-
#21651
 Oliverda
titán
Balala2007
#19987
Oliverda
titán
Balala2007
#19987
Oliverda
titán
válasz
Balala2007
#19987
üzenetére
Másfél év késéssel más is rájött:[link]
-
#21556
S_x96x_S
addikt
Balala2007
#21551
S_x96x_S
addikt
válasz
Balala2007
#21551
üzenetére
>Elszabadult egy ThreadRipper 2990X (PR 32c/64t)
ne örüljünk túl korán ...
lehet, hogy FAKE az egész ( photoshop )
https://twitter.com/PaulyAlcorn/status/1009146859695300608
https://twitter.com/IanCutress/status/1009179446287446017 -
#21554
Petykemano
veterán
Balala2007
#21551
Petykemano
veterán
válasz
Balala2007
#21551
üzenetére
Létezik, hogy ez már most (illetve ez is) B2 stepping?
-
#21552
joysefke
veterán
Balala2007
#21551
joysefke
veterán
válasz
Balala2007
#21551
üzenetére
ez all core 4.1- 4.2 GHz vagy ez csupán a turbóra vonatkozik?
-
#21519
 lezso6
HÁZIGAZDA
Balala2007
#21518
lezso6
HÁZIGAZDA
Balala2007
#21518
válasz
Balala2007
#21518
üzenetére
Jó sokat megtudtunk.

-
#20900
 apatyas
Korrektor
Balala2007
#20890
apatyas
Korrektor
Balala2007
#20890
apatyas
Korrektor
válasz
Balala2007
#20890
üzenetére
A 12 ciklusosnak mennyi a teljesítményelőnye? Jól látszik?
-
#20836
joysefke
veterán
Balala2007
#20835
joysefke
veterán
válasz
Balala2007
#20835
üzenetére
Köszi!
ezek szerint félreértettem.
Eddig azt hittem, hogy a Meltdown semmilyen fenyegetést nem jelent AMD rendszeren, a Spectre pedig csak elméleti szinten (near zero risk) jelent fenyegetést, aminek a kihasználhatósága (AMD rendszeren) kérdőjeles.
-

Balala2007
tag
válasz
Balala2007
#20489
üzenetére
Reszletesebb TechReport HP Envy x360 15z (Ryzen2500U) review
-
#20490
 zsolt320i
senior tag
Balala2007
#20489
zsolt320i
senior tag
Balala2007
#20489
zsolt320i
senior tag
válasz
Balala2007
#20489
üzenetére
Végre, egy AMD "Lapos" ami versenyképes a teljesítmény terén, fogyasztásban viszont valami gikszer van.
Ezt mi okozhatja? -
#20398
 Németh Péter
őstag
Balala2007
#20396
Németh Péter
őstag
Balala2007
#20396
válasz
Balala2007
#20396
üzenetére
AMD to launch 12nm Ryzen in February 2018, says mobo makers
Februárban startolnak az 12nm-es Ryzenek? Hmmm, új chipset is kell...
Their corresponding chipsets, the 400 series, will also become available in March 2018 with X470- or B450-based motherboards to be the first to hit the store shelves.
-
#20397
solfilo
veterán
Balala2007
#20396
válasz
Balala2007
#20396
üzenetére
Ha ez igaz, akkor idén nem jön a mobil Raven sem.
Érdekes, hogy a Ryzen 5 Pro Mobile alig gyorsabb IGP-ben az A12-nél a slide szerint, pedig 11NCU vs 8CU. Bár ha Ryzen 5 (és nem 7), lehet ebben nincs 11.
(/IMG)")
-

Sipike19
tag
válasz
Balala2007
#20124
üzenetére
Valóban, csak már kifutottam a szerkesztési időből, egyébként az akart lenni.
-
#20122
 Yutani
nagyúr
Balala2007
#20120
Yutani
nagyúr
Balala2007
#20120
válasz
Balala2007
#20120
üzenetére
256GB memória 1333 MHz-en?
(#20123) stratova: Még az is lehet.

-
Sipike19
tag
válasz
Balala2007
#20120
üzenetére
Régen órajel duplázás évenként, meg fele annyi tranyó két évenként.
Most dupla annyi mag/év lesz....
Kellett az AMD ébredése ehez
-
#19988
 Bici
félisten
Balala2007
#19987
Bici
félisten
Balala2007
#19987
válasz
Balala2007
#19987
üzenetére
Nem lehet, hogy valami bug miatt tiltották le?
-
Balala2007
tag
válasz
Balala2007
#17216
üzenetére
Vegleges, hogy az FMA4 kimarad a Zenbol. Gyozott az eredeti SSE5 koncepcio.
....eees akkor egy utolso utani csavar: benne van az FMA4 a piaci 800F11-ekben, de nem jelenti a CPUID (Ez egy 1800X-bol van):
FMA4 :VFMADDPS ymm,ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD132PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD213PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00c
FMA3 :VFMADD231PS ymm,ymm,ymm L: 1.39ns= 5.0c T: 0.28ns= 1.00cEbben az a jo, hogy ha egy kod lekerdezi, hogy mehet-e a FMA4, akkor nemleges valaszt kap, de check nelkul ra lehet eroltetni, cserebe viszont akar mar a kovetkezo steppingbol repulhet minden kulon ertesites nelkul.
-
#19936
 shabbarulez
őstag
Balala2007
#19935
shabbarulez
őstag
Balala2007
#19935
shabbarulez
őstag
válasz
Balala2007
#19935
üzenetére
Én semmi jelentősebb különbséget nem látok a korábbi sávszélesség értékekhez képest. Továbbra is ugyanazt az anomáliát látni, mint amit hó elején egyszer már leírtam Fierynek lásd: [link] Továbbra is nehezen hihető hogy fele olyan széles adatbuszon ugyanakkora vagy kétszer akkora sávszélességet ér el az AMD L2/L3 cache esetén. Ez kvázi 2x-4x-es hatékonyság különbség, ami nagyon szemet szúr és nehezen racionalizálható.
-
#19811
mzso
veterán
Balala2007
#19801
mzso
veterán
válasz
Balala2007
#19801
üzenetére
Ehhh... Akkor Raven Ridge csak jövőre jön valamikor...
-
#19805
Oliverda
titán
Balala2007
#19801
Oliverda
titán
válasz
Balala2007
#19801
üzenetére
Remélhetőleg sikerül legalább ~10 százalékot emelni az IPC-n, illetve minimum duplázni a CCX-ek közötti sávszélességet.
golya87: Kb 3 évig nem lesz új foglalat.
-
#19803
 golya87
őstag
Balala2007
#19801
golya87
őstag
Balala2007
#19801
golya87
őstag
válasz
Balala2007
#19801
üzenetére
Tudható arról valami korábbi ígéret, hogy a Zen2,3... új foglalatba jön-e?
Extra nehéz kérdés: szerver fronton is várható ez a foglalathűség? -
#19802
Remus389
veterán
Balala2007
#19801
Remus389
veterán
válasz
Balala2007
#19801
üzenetére
Üssék a vasat, amíg meleg.
-
#19730
Oliverda
titán
Balala2007
#19718
Oliverda
titán
válasz
Balala2007
#19718
üzenetére
A Shadow Taghez kapcsolódóan:
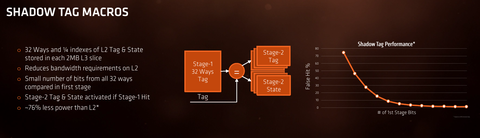
-
#19727
Raymond
titán
Balala2007
#19726
Raymond
titán
válasz
Balala2007
#19726
üzenetére
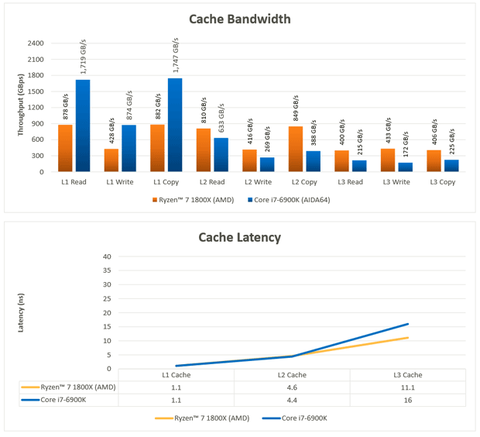
+Fiery
Ezek 8 magra felskalazva 2048GB, 1024GB es 512GB olvasast adnak, realis eredmenyek (i7-6900K) olyan 2048GB, 700-800GB es 350-400GB korul vannak ami OK. Ezzel szemben az AMD-s 6900K eredmenyek joval elmaradnak:
-
Balala2007
tag
válasz
Balala2007
#19704
üzenetére
A 128 bites lebegőpontos összeadás a szorzás időigénye 4 órajel
(V)ADDPS/PD: 3 lat
(V)MULPS: 3 lat
(V)MULPD: 4 lat
FMA: 5 lataz Intel-processzorok regiszterfájljának képessége, hogy önállóan felismerje és végrehajtó egység közreműködése nélkül lekezelje a regiszternullázó utasításokat, szintén kívánatos funkció
Ebbol a temabol leheto a legtobbet hozza a Ryzen, az osszes (P)XOR/ANDN/PCMPEQ/(P)SUB a maximumon mukodik benne.
-
#19671
Oliverda
titán
Balala2007
#19353
Oliverda
titán
válasz
Balala2007
#19353
üzenetére
- az L2 késleltetésre az a 12 így jött ki: The L2 cache size is 512 Kbytes with a variable load-to-use latency of no less than 12 cycles.
no less than 12 cycles, azaz sosem kevesebb, mint 12 órajel, tehát ez így kvázi akármennyi lehet, csak kevesebb nem
- az L3 latency pedig: The L3 has an average load-to-use latency of 35 cycles.
average, azaz átlagos; úgymint a 4 szelet késleltetése nem ugyanannyi, és ha az algoritmus az, hogy x cím y szeletbe kerül, x+1 cím pedig más szeletbe fog (a címet hash-eli), akkor szerencsés teszt mérhet ennél kevesebbet, szerencsétlen pedig akár mindig többet is
Az NB-órajel miért nem jön föl sehol a RAM- és L3-késleltetéshez? A Zen NB-órajele mennyi? Nem kevesebb, mint 1300 MHz? Nem lenne meglepő, és ugye az L3 azon az órajelen megy, legalábbis a Phenom óta ez van/volt.
-
#19380
Petykemano
veterán
Balala2007
#19377
Petykemano
veterán
válasz
Balala2007
#19377
üzenetére
Ha felezni, negyedelni lehet, az megmagyarázza, hogy a 6 magos miért 16 és nem 12. Jól is van így, talán 1-2%-ot számít.
De 4 magosból miért nincs 16 megás? Legalább a top sku, azért az 1-2%-ért vs 8 mega.Ha van 6 magos (legalább 3-3 felosztásban, ha más kombinációban nem is), akkor 4 magost is lehetne 2-2 felosztásban készíteni. Ha az egyik ccx-et le kell tiltani, érthető a 8 mega. De 2-2 esetén indokolja valami, hogy nem tud 16 mega lenni a l3 úgy, mint 3-3 esetén? Vagy ez csak termék szegmentációs döntés?
-
#19356
Simid
senior tag
Balala2007
#19353
Simid
senior tag
válasz
Balala2007
#19353
üzenetére
Ezt nem nagyon értem...
Akkor ezek szerint az A0 steppinggel még ezeket az eredményeket mérték, de a rovarirtás után rosszabb lett a késleltetés és ezt pár napja még maguk sem tudták
Mondjuk úgy néz ki nincs nagy baj a teljesítménnyel.
Ryzen 6 core 3.3/3.7Ghz CPU-Z benchmark
(0.374V-on, újabb 'mellékterméke' a bugtalanításnak![;]](//cdn.rios.hu/dl/s/v1.gif) )
) -
Balala2007
tag
válasz
Balala2007
#18388
üzenetére
Ez volt a terv L2/L3-ra, de a közelében sincsenek, amikkel minket megkerestek...
-
#19122
max-pain
senior tag
Balala2007
#19116
max-pain
senior tag
válasz
Balala2007
#19116
üzenetére
Egyreszt mert ugytunik bizonyos esetekben megsem hoz erdemi teljesitmeny novekedest (lasd a PCSX2 emulator GSdx plug-in-ja eseteben a keszitok szerint csak software renderer eseteben van teljesitmeny novekedes AVX2 eseteben (amit alig hasznal valaki), minden mas esetben marad az SSE4.1), masreszt pedig nincs ugy nyomva mint az SSE2 volt az Intel reszerol (a P4 eseteben nem is csoda, hogy igy nyomtak, valamint nem is volt tiltva az alacsonyabb kategoriakban sem (Celeron)). Ahhoz kepest az AVX2 nincs nagyon tolva, sok chip vagy egyaltalan nem tamogatja (Atom szeria) vagy le van benne tiltva (Haswell, Skylake es Kaby Lake alapu Pentium procik). A gepcserek lelassultak, stb, stb, stb...
-
#19120
lezso6
HÁZIGAZDA
Balala2007
#19112
válasz
Balala2007
#19112
üzenetére
Utánaolvastam, valóban.

-
#18959
 Fiery
veterán
Balala2007
#18958
Fiery
veterán
Balala2007
#18958
Fiery
veterán
válasz
Balala2007
#18958
üzenetére
A 15DD valoban a Raven Ridge iGPU-janak PCI device ID-je, viszont a 9874 a Carrizo/Bristol Ridge iGPU ID-je.
-
#18945
 velizare
nagyúr
Balala2007
#18940
velizare
nagyúr
Balala2007
#18940
válasz
Balala2007
#18940
üzenetére

-
#18944
 JColee
őstag
Balala2007
#18940
JColee
őstag
Balala2007
#18940
JColee
őstag
válasz
Balala2007
#18940
üzenetére
Gondolom kikerül majd realworldtech-re is. -
#18943
Petykemano
veterán
Balala2007
#18940
Petykemano
veterán
válasz
Balala2007
#18940
üzenetére
Hírbeharangozták, hogy "tegnap" volt valami ISSCC előadás. Erről van már friss info? Ez a David Kanter cikk felfedése nem az, ugye?
-
#18830
 Ragnar_
addikt
Balala2007
#18828
Ragnar_
addikt
Balala2007
#18828
Ragnar_
addikt
válasz
Balala2007
#18828
üzenetére
Hát a 6c/12t-nél szerintem lehet számítani egy lightos 500$-os árra kb. Annyi előnye lehet egy AMD confignak, hogyha tartja a tokozás időtállóságát, mint AM3 esetében akkor mehet majd az upgrade következő genből lapcsere nélkül.. Van erre már valami infó ? DDR4 biztos marad néhány évig még..
-

Panzika
tag
válasz
Balala2007
#18567
üzenetére
Játékokban igen lesz neki lemaradása, de ugyan ez elmondható a 6900K-ról is, mert a 6700k is elpaskolja játékokban. Ezek a procik már inkább munkára valók. Játékra inkább a 4-6 magos SR lesz jó erősebb egyszálas teljesítménnyel. Én a 4 vagy 6 magos SR-re meg a 1070 szintű Vegára fenem a fogam. Megint lesz egy erős full AMD-s masinám

-
#18568
 lee56
őstag
Balala2007
#18567
lee56
őstag
Balala2007
#18567
lee56
őstag
válasz
Balala2007
#18567
üzenetére
"illetve forditva nezve boven van meg fejlesztesi lehetoseg a Zen leszarmazottaihoz.."
..Amik jönni is fognak szépen menetrendszerűen évente egyesével, ha lehet hitelt adni a Papermasteres interjúknak. Lesz miért dolgozniuk legalább.
Apropó memória-bechmarkokról tudsz valamit Ryzen esetében? Ebben volt szinte egyik legnagyobb lemaradás intelhez képest talán.
-
#18554
lee56
őstag
Balala2007
#18550
lee56
őstag
válasz
Balala2007
#18550
üzenetére
Ebben vajon most bele kell érteni a Zen+olást, vagy az akkor csak a négy év után jön el? Mert eddigi slide-okban már 2018-19-re lehetett látni zen+-okat, akármit is jelentsen.
Elég fura kijelentés ez így, mit fognak akkor csinálni időközben : Hátradőlnek és nézik intel fejlesztéseit, elmúlt 5+ évben ez azért annyira nem vált be?! -
#18552
 Z_A_P
addikt
Balala2007
#18550
Z_A_P
addikt
Balala2007
#18550
Z_A_P
addikt
válasz
Balala2007
#18550
üzenetére
Zen is going to be tock, tock, tock

-
#18519
Petykemano
veterán
Balala2007
#18516
Petykemano
veterán
válasz
Balala2007
#18516
üzenetére
The Stilt az AT fórumról azt írta erről, hogy
- az lapka, amelyikben egy CCX-ben 2 mag is hibás automatikusan 4 magos lesz, mert nem lehet aszimmetrikus/eltérő a két CCX L3 cache-e
- ha CCX-enként 1-1 mag hibás, akkor lehet 6 magos.(Kérdés, hogy a 4 magos úgy, hogy 2-2 mag tiltódik le CCX-enként a szimmetria miatt, vagy úgy, hogy 1 CCX)
Mindemellett értékelem a hozzászólásod, és köszönöm. Nem tudom, kinek van igaza. Lehet, hogy neked. De ha tényleg ilyen kötöttségeket építettek be, az azért kár.
(#18517) Yutani
Pedig egyébként kisebb magszámú CPUk esetén szép húzás lehetne, ha az L3 méretéhez nem nyúlnának. 1-2%-ot lehet, hogy számítana az IPC-ben. egy 4 magos proci esetén a magonként 2x akkora L3$. -
#18517
Yutani
nagyúr
Balala2007
#18516
válasz
Balala2007
#18516
üzenetére
Az AMD az FX-nél megoldott a core és L2$ letiltását úgy, hogy nem kellett az L3$-hez nyúlnia, az minden FX-ben maradt az eredeti méretű. Természetesen a Zen egy teljesen más design, de nem lehet, hogy itt is meg tudják oldani az FX-nél is alkalmazott letiltási lehetőséget?
A linkelt kép csak egy blokkdiagram, de abból én azt mondanám laikusként, hogy amennyire szimmetrikus és ahogy kinéz, lekapcsolni a magot csak az L3$-sel együtt lehet. Sőt, az is lehet, hogy mindjárt a fél komplexet le kell kapcsolni, ha az egyik mag hibás, így (The Stilt után szabadon) mindkét CCX-ben le kell tiltani 2-2 magot, hogy megkapjuk a 4 magos Zent.
-
#18504
lezso6
HÁZIGAZDA
Balala2007
#18503
válasz
Balala2007
#18503
üzenetére
Ez nagyon jó jel, ha legalább 3.6-os alapórajellel ki tudják adni. Ezért érdemes várni. -
#18391
 Thrawn
félisten
Balala2007
#18390
Thrawn
félisten
Balala2007
#18390
Thrawn
félisten
válasz
Balala2007
#18390
üzenetére
Bár mindig ilyen offolásokat lehetne itt olvasni
-
#18389
Oliverda
titán
Balala2007
#18388
Oliverda
titán
válasz
Balala2007
#18388
üzenetére
Az SKL/KBL miért lassabb ennyivel, mint a HSW/BDW?
-
#18186
 Laja333
őstag
Balala2007
#18184
Laja333
őstag
Balala2007
#18184
Laja333
őstag
válasz
Balala2007
#18184
üzenetére
Persze. Első blikkre nekem az ugrott be erről a cikkről, hogy az ilyen új, bevezetésre szánt feature-nél jól is jönnek az ilyen független vélemények. Szerintem is inkább építő jellegű, mint fordítva.
-
#18180
Laja333
őstag
Balala2007
#18178
Laja333
őstag
válasz
Balala2007
#18178
üzenetére
A kommentek a legjobbak.
-
#17831
Yutani
nagyúr
Balala2007
#17828
válasz
Balala2007
#17828
üzenetére
Nem tudom, mennyire hiteles egy olyan többszálú renderer benchmark, ahol egy FX-4100 megelőz egy FX-8120 CPU-t. Vagy ez másképp működik, mint pl. a Cinebench?
-
#17829
 kleinguru
addikt
Balala2007
#17828
kleinguru
addikt
Balala2007
#17828
válasz
Balala2007
#17828
üzenetére
8350-em harmada, negyede ~

Jó lesz ez végre
Ui.: már ha van bármi valóságalapja, illetve 600 dollár alatt lesz a magyar ára
-
#17680
lezso6
HÁZIGAZDA
Balala2007
#17678
válasz
Balala2007
#17678
üzenetére
És a Keccak? Jó tudom, sokat akarok.
-
#17667
Yutani
nagyúr
Balala2007
#17665
válasz
Balala2007
#17665
üzenetére
Jogos, mindkettőtöknek igaza van.
-
Balala2007
tag
válasz
Balala2007
#16714
üzenetére
Van mar valami hasonlo Zen temaban?
Most mar van.
-
#17663
Yutani
nagyúr
Balala2007
#17662
válasz
Balala2007
#17662
üzenetére
Azonos pontszámú single thread eredmények:
FX-8320 3500 MHz
Phenom X3 8550 2200 MHz
Athlon 64 FX-55 2600 MHzUgyanehhez a Zen mintának 1440 MHz kellett.
-
Balala2007
tag
válasz
Balala2007
#16712
üzenetére
Az elso Zen-specifikus publikus doksi:
Secure Encrypted Virtualization Key
Management Technical Preview -
#17438
 Goose-T
veterán
Balala2007
#17437
Goose-T
veterán
Balala2007
#17437
Goose-T
veterán
válasz
Balala2007
#17437
üzenetére
Közben lett angol nyelvű hír is belőle. Érdekes, hogy ennyivel előrébb jártak a németek.
-
#17414
Petykemano
veterán
Balala2007
#17406
Petykemano
veterán
válasz
Balala2007
#17406
üzenetére
Keller szavai: we know how to.build high frequency processors
Ez is a bulldozerből jön. (Mármint a know how)
-
#17408
Oliverda
titán
Balala2007
#17406
Oliverda
titán
válasz
Balala2007
#17406
üzenetére
Nekem is a macskák ugrottak be róla először, de ez nem is meglepő, Keller már két éve hintelt róla.
Olyan szempontból állhat a scratch, hogy hasonló mix még nem volt nekik, nem tudom, hogy tervezés szempontjából ezért mennyire kellett nulláról indulniuk, de a Jaguar elég jó alapot jelenthetett, Keller erre is utalt korábban.
"1 applikaciot mar tudok, ami megzavarodik tole..."
Melyik és hogyan?
-
Balala2007
tag
válasz
Balala2007
#16807
üzenetére
5 szintu topologia
1 applikaciot mar tudok, ami megzavarodik tole...
-
#17217
Oliverda
titán
Balala2007
#17216
Oliverda
titán
válasz
Balala2007
#17216
üzenetére
Arra van tipped, hogy itt az egyes tesztekben miért lassabb a Kaverinál a Carrizo? Főleg Linux alatt feltűnő a dolog, lehet valami szoftveres probléma áll a háttérben.
"Vegleges, hogy az FMA4 kimarad a Zenbol. Gyozott az eredeti SSE5 koncepcio."
Nem meglepő. Jelenleg semmi értelme egyedi megoldásokkal próbálkozni, azt kell támogatni ami az Intelekben van (vagy lesz).
-
#16810
 hugo chávez
aktív tag
Balala2007
#16808
hugo chávez
aktív tag
Balala2007
#16808
hugo chávez
aktív tag
válasz
Balala2007
#16808
üzenetére
"FLOPS-ban konkretan a fele lesz a Skylake-nek per core."
Ez ugye csak az AVX-512-re érvényes? Vagyis ott, ahol az 512 bites vektorműveletek mehetnek? Tehát pl. 256 bites AVX-ben már kb. egál?
-
#16809
 derive
senior tag
Balala2007
#16808
derive
senior tag
Balala2007
#16808
derive
senior tag
válasz
Balala2007
#16808
üzenetére
Amire a Skylake Xeonok kijonnek, mar a Zenbol is Zen+ lesz.
Haat nem hiszem, hogy az Intel gyarilag magonkent finomhangolja a turbot, en inkabb a fix megoldasban hiszek. A magasabb rendu huzalozasban lehetnek olyan kulonbsegek, ami miatt par mag magasabb orajelet erhet el (pl vastagabb/surubb interconnectek es tapvezetekek). Esetleg direkt ugy valogatja ki, a magokat, hogy ne legyen ket kazan egymas mellett vagy ne kelljen masik maggal osztozni a cachen. -
#16720
 F34R
nagyúr
Balala2007
#16719
F34R
nagyúr
Balala2007
#16719
F34R
nagyúr
válasz
Balala2007
#16719
üzenetére
Amint lesz a megjelenezhez kozelebbi info akkor egeszen biztos hogy Phoronixon vagy hackernews-n megjelenik a hozza kapcsolodo bejegyzes is.
-
#16718
F34R
nagyúr
Balala2007
#16714
F34R
nagyúr
válasz
Balala2007
#16714
üzenetére
A friss linux kernelek fel lesznek ra keszitve, majd microcode-t kell frissiteni es akkor megy vele minden utasitaskeszlet is.
-
#16715
 And01
aktív tag
Balala2007
#16714
And01
aktív tag
Balala2007
#16714
And01
aktív tag
válasz
Balala2007
#16714
üzenetére
A forrás valamiféle tesztelő lehet,
de érdemi adatot nem írt,
meg nem is tartom valószínűnek hogy az nda lejárta elött túl sok lényeges
info kerülne ki! A polaris teljesitményéről sem tudunk semmit,
pedig a megjelenése a küszöbön van!
Itt még írnak pár dolgot [link] (szerintem hihető) de persze garancia semmire nincs! -
#16713
Bici
félisten
Balala2007
#16712
válasz
Balala2007
#16712
üzenetére
A linux kernelben benne is lesz hamarosan a szükséges támogatás: [link]
-
#16661
Oliverda
titán
Balala2007
#16658
Oliverda
titán
válasz
Balala2007
#16658
üzenetére
A fejlesszünk a (bizonytalan) jövő igényeinek néhányszor már nem jött be, talán a jelennek való megfelelés nagyobb sikert hoz.
Az AVX és az FMA pedig nem fog hiányozni, ahol ez igazán fontos (pl. HPC) oda az AMD GPU-val próbál betörni.
-
#16659
Fiery
veterán
Balala2007
#16658
Fiery
veterán
válasz
Balala2007
#16658
üzenetére

-
#16653
Petykemano
veterán
Balala2007
#16652
Petykemano
veterán
válasz
Balala2007
#16652
üzenetére
Pont erre voltam kiváncsi, hogy miért 4+2-nél húzták meg a határt, amikor bulldozernél 2+2 volt.
De érteni vélem.Azt olvastam pl a VISC témában, hogy az IPC sok esetben attól is függ, hogy mennyire lehet feladatot párhuzamosítani. Ez az Instruction Level Parallelism, ami már most is eléggé csúcsra van járatva. feltételezem, hogy az OoO végrehajtás pont azt szolgálja, hogy a CPU amennyire lehet, minél ügyesebben átrendezze a műveleteket, hogy minél magasabb ILP-t tudjon elérni. A csúcsra járatás tekintetében a 4 ALU, amennyivel az HSW és a SKL is rendelkezik, nem véletlen és nem véletlenül nem több.
Tulajdonképpen a bulldozer 1 magja akkor képes volt extrém esetben kvázi 4 ALU szélesként funkcionálni, ezért is lehetett, hogy az integer teljesítmény core2core nem is maradt el annyira. Viszont összetett, vagy FPU intenzív terhelés alatt "összeomlott".A Zen esetén a 4 ALU továbbra is biztosítja a megfelelő integer feldolgozó szélességet, sőt úgy, hogy ezek inkább ALU-k, mint AGU-k, talán még erősebb, stabilabb teljesítményt is adhatnak (persze ez még mindig függ attól, hogy a többi rész tudja-e etetni), de mivel van 2 dedikált AGU, ezért összetett terhelés esetén, tehát amikor az FPU is enni kér, nem feleződik le a integer számítási kapacitás: részben mert van 2 AGU, sőt, maguk az ALU-k is tudhatnak saját maguknak alapvető agu jellegű műveleteket elvégezni.
A rendelkezésre álló erőforrások kihasználtságát az SMT növelheti, hiszen ha két külön szálat futtat a mag, akkor kevesebbet kell bűvészkedni az utasítások párhuzamosíthatóságán.Azt mondd el még nekem, hogy mi a helyzet a FPU képességekkel.
Próbáltam keresni gyorsan a neten, és azt meg is találtam, hogy egy bulldozer modul 2 128 bites FMAC egységet tartalmaz, ami tulajdonképpen 1-1 add + multiply egység, ha jól sejtem gyárilag összeolvasztott egysége.
Ezzel szemben a Zennél 2 FMUL és 2 FADD egység van, ami a leírás szerint egyenként 3ciklus késleltetéssel végeznek műveletet, és össze tudnak állni FMAC-ké 5 ciklus késleltetéssel műveletet végzendő.
Itt már is kérdezném, hogy fenti azt jelenti, hogy azért választották-e vajon a különálló FMUL és FADD egységeket, mert a bulldozer esetén a 2 FMAC különálló FADD és FMUL műveleteket is csak ugyanazzal a késleltetéssel tudott végrehajtani, mint FMAC műveleteket és persze ezekből is csak egyszerre kettőt?Itt ami kérdés számomra, hogy vajon egy bulldozer mag, pontosabban amikor egy szál futott egy bulldozer modulon, akkor vajon mindkét FMAC egységet tudta-e használni és csak több szál esetén volt osztozkodás? Vagy egy szál a modulban 128 bites utasítás esetén érintetlenül hagyta a másik FMAC egységet és csak akkor használta, ha 256bites utasítást kellett végrehajtania?
Ez azért érdekes kérdés, mert ha előbbi, vagyis a modulon futó 1 szál teljes mértékben tudta hasznosítani a modul FPU-ját, akkor a Zen, amely magonként kap majd egy "ilyet", 1 szálas FPU teljesítményben milyen előrelépést tud majd felmutatni?
Ellenben ha utóbbi, hogy a bulldozerben 1 szál jellemzően csak az FPU felét használta, akkor a The Stilt által mondott "1 zen mag = 0.73XV modul" komoly előrelépést jelent. -
#16648
Petykemano
veterán
Balala2007
#16647
Petykemano
veterán
válasz
Balala2007
#16647
üzenetére
Valóban 4 ciklus. Ijedtem félrevezetőt írtam. Ciklus.
Haswellnek is annyi. Csak emlékből: Jaguarnak 2, így ez is arra utalhat, hogy legalább intel szintű magas frekvenciájúra szeretnék a zent.Igen, AGLU-nak becézik, nem tudom, hogy mi a jelentősége, hatása, hogy az AGU-k egy része ALU funkciókat is ellát. Vagy hogy ez így miért jó. Viszont ha már itt tartunk, mesélj már, hogy miért elég a Zennek 4 ALU + 2 AGU ?
-
#16416
 leviske
veterán
Balala2007
#16403
leviske
veterán
Balala2007
#16403
leviske
veterán
válasz
Balala2007
#16403
üzenetére
Miután ezek FP4-es variánsok, innentől tényleg elég esélyes sajnos, hogy magával az AM4-el van gond.
-
#16407
Petykemano
veterán
Balala2007
#16403
Petykemano
veterán
válasz
Balala2007
#16403
üzenetére
@Balala2007
Ezzel kapcsolatban én eddig semmi kézzelfoghatót, érdemlegeset nem olvastam. Kapott hideget, meleget is: több évtizedes tapasztalat, recently ARM, volt köze a néhai K7-hez is, stb, ugyanakkor semmilyen sikertermék nem fűződik a nevéhez az utóbbi időben.
Lehet, hogy csak csupán Jim Keller megüresedett széek miatt van ennek a hírnek hírértéke. De Zaidi nem kifejezetten oda érkezik. -
#16405
 ldave
félisten
Balala2007
#16403
ldave
félisten
Balala2007
#16403
ldave
félisten
válasz
Balala2007
#16403
üzenetére
Kíváncsiságból megnéztem gyorsan a mostani laptopom hogy szerepel ebben a tesztben (ami egy ivy-s gép, 2013-ból) az itt legjobb pontszámhoz képest: [link]
-
#16404
derive
senior tag
Balala2007
#16403
derive
senior tag
válasz
Balala2007
#16403
üzenetére
Haat ezek szerint az erosebbek befogjak a 6100Ut...
-
#15829
apatyas
Korrektor
Balala2007
#15828
apatyas
Korrektor
válasz
Balala2007
#15828
üzenetére
És egy normál programban ezek az utasítások benne vannak, vagy Intelre van fordítva és észre sem veszi? Az AGU-ra vonatkozóan. A többi dolog talán magától érvényre jut.
-
#15418
Oliverda
titán
Balala2007
#15413
Oliverda
titán
válasz
Balala2007
#15413
üzenetére
Tekintve, hogy mennyire bejöttek eddig a nem konzervatív dizájnok, érthető, sőt kézenfekvő az irány.
Az AVX-512 pedig nem valószínű, hogy komolyan hiányozna még egy darabig.
-
#15277
Oliverda
titán
Balala2007
#15275
Oliverda
titán
válasz
Balala2007
#15275
üzenetére
Amiért visszament (Zen, K12) azt már elvileg be kellett fejeznie. Kíváncsi vagyok hol köt ki.
On September 18th, 2015, Keller departed from AMD to pursue other opportunities, ending his three-year employment (and longest-spanning employment to date) at AMD
-
#15276
 UnSkilleD
senior tag
Balala2007
#15275
UnSkilleD
senior tag
Balala2007
#15275
UnSkilleD
senior tag
válasz
Balala2007
#15275
üzenetére
ez nem jó hír...
-
#15008
Petykemano
veterán
Balala2007
#15007
Petykemano
veterán
válasz
Balala2007
#15007
üzenetére
Ahogy a wccf-en felröppent, úgy le is lőtték
Bár több okom van azt hinni, hogy ezek a szivárgások nem igazak, de ha mégis, az eléggé lapos.
A bristol ridge alig különbözik felépítésében a carrizotól, sehol egy utalás az apukba beépítendő HBM-ről, amivel azok grafikai teljesítményét tolnák ki felvéve a versenyt az intel érkező megoldásaival, sehol egy említés 8+12/16 magos apu (a 200W-os HPC piacra szánt pletyke asztali deriváltja), asztali CPU vonalon semmi előrelépés 2016Q3-ig, pedig ha már a excavator+ magokból desktop aput építenek, egy frissítést ez is megérne idén
De legalább szerepel rajta a Stoney Ridge.
-
#14846
Oliverda
titán
Balala2007
#14828
Oliverda
titán
válasz
Balala2007
#14828
üzenetére
-
#14845
Oliverda
titán
Balala2007
#14841
Oliverda
titán
válasz
Balala2007
#14841
üzenetére
Nem rémlik, hogy az AMD valaha is alkalmazott volna inkluzív cache-t. Nálam ez is csak azt támasztja alá, hogy a Zen több ponton fog hasonlítani a Nehalem-Haswell vonalra.
"The L2 cache acts as a buffer to the L3 cache so you don’t have all of the cores banging on the L3 cache, requiring tons of bandwidth.
The L3 cache is shared by all cores and in the initial Core i7 processors will be 8MB large, although its size will vary depending on the number of cores. Multi-threaded applications that are being worked on by all cores will enjoy the large, shared L3 cache.
Intel defended its reasoning for using an inclusive cache architecture with Nehalem, something it has always done in the past. Nehalem’s L3 cache is inclusive in that it contains all data stored in the L1 and L2 caches as well. The benefit is that if the CPU looks for data in L3 and doesn’t find it, it knows that the data doesn’t exist in any core’s L1 or L2 caches - thereby saving core snoop traffic, which not only improves performance but reduces power consumption as well.
An inclusive cache also prevents core snoop traffic from getting out of hand as you increase the number of cores, something that Nehalem has to worry about given its aspirations of extending beyond 4 cores. " - [link]
Olyan ötletet is hallottam már, hogy az inkluzív dizájnra most elsősorban a TSX miatt van szükség.
-
#14844
 TESCO-Zsömle
titán
Balala2007
#14841
TESCO-Zsömle
titán
Balala2007
#14841
TESCO-Zsömle
titán
válasz
Balala2007
#14841
üzenetére
Úgy látom a szerkesztés-gombot is be kellett áldozni...
-
#14811
Yutani
nagyúr
Balala2007
#14808
válasz
Balala2007
#14808
üzenetére
Ha mindaz bejön, amit a blokkdiagram mutat és a fenti cikk fejteget, akkor valami jó dolog van készülőben!
Kérdés: A blokkdiagramban nem látszik CMT-re utalás. Ez jelent valamit?































![;]](http://cdn.rios.hu/dl/s/v1.gif) )
)






















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Xbox Series X|S
- Samsung Galaxy S23 Ultra - non plus ultra
- Luck Dragon: Asszociációs játék. :)
- Path of Exile (ARPG)
- Formula-1
- Sütés, főzés és konyhai praktikák
- Medence topik
- Samsung Galaxy Felhasználók OFF topicja
- Kerékpárosok, bringások ide!
- HiFi műszaki szemmel - sztereó hangrendszerek
- További aktív témák...

- Samsung Galaxy Z Fold5 , 12/256 GB , Kártyafüggetlen
- Apple iPhone 13 128GB, Kártyafüggetlen, 1 Év Garanciával
- PlayStation Plus Premium 24 hónapos előfizetés , egyenesen a Sony-tól!
- Konzol felvásárlás!! Nintendo Switch
- ÁRGARANCIA!Épített KomPhone i5 10600KF 16/32/64GB RAM RX 7600 8GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged