Hirdetés
- Yettel topik
- Mobil flották
- Apple Watch Sport - ez is csak egy okosóra
- Luna Ring 2.0 - így van értelme
- Itt a Galaxy S26 széria: az Ultra fejlődött, a másik kettő alig
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Poco F5 - pokolian jó ajánlat
- Szívós, szép és kitartó az új OnePlus óra
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Xiaomi 17 - még mindig tart
-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-
válasz
 apatyas
#23108
üzenetére
apatyas
#23108
üzenetére
Olvastam valahol, hogy az APU-k támogatása elég sok helyet igényel a BIOS chipen, de ez max. régebben lehetett valamennyire elfogadható érv szerintem, illetve ugye egy új BIOS-t nem kötelező feltenni, vagyis ha ott a régi is, miért nem lehet csinálni egy olyan újat, ami az új CPU-kat és APU-kat támogatja csak azoknak, akik újra váltanának?!
Szóval szerintem trehányság, munkakerülés (nagy falat, és nem igen hoz profitot), illetve tán alaplapgyártói sóhajtozásokra hallgatás. De csak tippelgetek. -
-
#22264
 Petykemano
veterán
apatyas
#22260
Petykemano
veterán
apatyas
#22260
Petykemano
veterán
válasz
apatyas
#22260
üzenetére
from full sse (128) to avx2+fma (256)
ez alapján a cb r20-ban nagyobb lehet a difi majd a zen+ és zen2 között.
-

DraXoN
addikt
válasz
apatyas
#21795
üzenetére
am3+ cpukat és chipseteket meddig akarják még gyártani? intel már az akkori vele egyidős termékét már kb. majdnem el is felejtette, hogy létezett
![;]](//cdn.rios.hu/dl/s/v1.gif)
elvileg valahol ázsiában van még rájuk igény (oem-eknél) ... én ezt hallottam itt fórumokon utoljára.. de annak i majd 1 éve...
nyilván olcsón lehet gyártani és eladni (mert van rá gyártósor kapacitás, ami nélküle üres(ebb) lenne..)... egyébként biztos nem gyártanák már... -
DraXoN
addikt
válasz
apatyas
#21736
üzenetére
Valóban érdekes, hogy most az "egy lépést vissza" tűnik a jó lépésnek egy "optimális" késleltetés elérésére a cpu magok között, (így nem az egyik a másikon át küld adatot). De mivel tokozáson belül marad még lehet gyors emiatt... attól függ milyen rövid az útvonal a cpu és memória között (minden út közbeni elágazás növelheti pár ns-al az elérési időt)..
A zen1 nél láthat volt, hogy a "biztosra" játszottak, itt már merészebb elképzelések is jönnek, és előjön az is, hogy miért is "csoda" a IF, és miért is kellett AMDnek.
Sokan fújoltak zen1 esetén, hogy IF "csoda" nem nagy szám, mert azzal is csak épp beérte intelt, de azt megtudta volna tenni IF nélkül is, de utána megint sok idő kellett volna egy "új" drasztikus változáshoz.. de így, hogy minden külön fejleszthető lesz, kaphat új lapkát (amit egyszerűbb tervezni mert kevesebb a komponens), vagy akár új vezérlőt (csak ddr5, pcie4 miatt, azonos cpu lapkával), és nem kell totálisan teljes chipdesignt tervezni minden alkalommal, a felépítés alapján variálható is (egy másik vezérlő több IF sáv és a magokat csak mellépakolják), brutális összegeket és időt lehet spórolni vele, már a korábbi lapkán belüli ccx alkalmazással is lehetett nyerni (pl APU esetén hogy az egyik ccx cpu helyére gpu-t raktak), de az akkor se teljesen legó volt, mert a szilíciumlapkát át kellett tervezni és a komponenseket helyezni (bár akkor is sokat gyorsított az elkészülésén).
De ha a gyümölcse az IF-nek beérik, akkor amit most látunk, hogy jön, még mindig csak "sejteti" a valódi képességeket. Pl. új apu generációnál lehet csinálni, hogy tényleg csak 8 magos és kidobják a chipről az egyik CPU-t, de cserébe beraknak helyére egy gpu magot, esetleg HMB memóriával... és könnyen tudnak variálni több sebességi tartományba is az APUk között (ha van értelme), így lehet rajta akár Vega M szintű chip, vagy akár valami alap Vega 10 szerű.. (bár nem hiszem, hogy az aktuális felhozatalból kerülne mellé valami) -

hokuszpk
nagyúr
válasz
apatyas
#21168
üzenetére
nekem egy 2850XX jelolesu samplet kuldott tesztre az AMD. 3 ccxes a kicsike, ezzel a megoldassal magasan tarthato az orajel, nem szall el a fogyasztas, es 12 magot lehet hajtani.
Sajnos csak akkor kerul forgalomba, ha az Intel uj nyolcmagosai nagyon elhuznak, vagyis ez a B terv.
De tobbet nemmondhatok, igy is tulsokat szivarogtattam, kezeljétek bizalmasan az infot. -
#21169
Petykemano
veterán
apatyas
#21168
Petykemano
veterán
válasz
apatyas
#21168
üzenetére
Nem akartam károgni, de egy ideje már várom, hogy az intel fejlesztései beérjenek. Nem véletlen, hogy a core archigektúrát nem fejlesztik olyan nagyon. Ma fogják bejelenteni, hogy még idén megjelenik az x86-os utasításkészletet emulálni képes 1000x gyorsabb (Single Thread!!!) Kiskereskedelmi forgalomban is elérhető Kvantum számítógép.
Hát mit mondjak? RIP AMD
Bolond, aki ezekután még Várja a ryzen 2-t... -

Balala2007
tag
válasz
apatyas
#20900
üzenetére
A 12 ciklusosnak mennyi a teljesítményelőnye? Jól látszik?
Persze, a 17->12 clk L2-hit csokkentes ugyanigy -5clk-kal huzza le a L2-miss/L3 hit szamokat is Nezd meg a velemenyeket a Pinnacle Ridge-rol, sokaknak tetszik a novekedes. A pontos aranyokat nehez megbecsulni, mert a hivatalos memClk is novekszik 2933MHz-re, de a PR javulasa nemigen szarmazhat masbol.
-
#20679
 TESCO-Zsömle
titán
apatyas
#20676
TESCO-Zsömle
titán
apatyas
#20676
TESCO-Zsömle
titán
válasz
apatyas
#20676
üzenetére
Az első egy növekedési görbe, ami azt mutatja, hogy mennyivel a piaci átlag fölé klőnek. Mivel -relatíve- le vannak maradva, ezt én nem nevezném extrának.
A második meg PpW görbe a saját és a konkurencia (Intel) gyártástechnológiái okozta különbség csökkentéséről.
De lehet, hogy én vagyok a helikopter és neked van igazad a grafikonok értelmezhetetlensége kapcsán...
sz: Ami engem illet, én annyit tudtam meg, hogy a Zen2 2019-2020 környékén jön, ami számomra tökéletesen megfelelő életciklus a Ryzen 1700-asnak. Ha mákom van, még lapot se kell cserélnem, mert elég lesz egy UEFI update.
-
#20604
 Németh Péter
őstag
apatyas
#20603
Németh Péter
őstag
apatyas
#20603
-
#20561
Petykemano
veterán
apatyas
#20557
Petykemano
veterán
válasz
apatyas
#20557
üzenetére
2.Amit most írtál, azzal teljes mértékben egyetértek. Szerintem sem lenne sok értelme egy duplázott TDP-jű ryzent (AM4) hozni, még akkor se, ha esetleg ezzel pár százalékos előnyre tennének szert.
Amit én mondtam: a Threadripper elsősorban a magok száma miatt kétszer nagyobb TDP-vel már létező termék. Elképzelhetőnek tartom, hogy ha a a Threadrippert alkotó Zeppelin lapkák nem LPP/HDL node-on, hanem HP/HPL node-on készültek volna (vagy készülnének), akkor a Ryzen 1800X és a kétszer magasabb TDP-jű TR 1950X max XFR órajele között valamivel nagyobb lenne a differencia a jelenlegi 100MHz-nél. Ezzel az elgondolással koherens a fake slide.
-
#20555
Petykemano
veterán
apatyas
#20551
Petykemano
veterán
válasz
apatyas
#20551
üzenetére
1. A 180w egyértelműen a dupla lapka miatt van. Itt ami nem biztos az az, hogy a 4.2GHz xfr a 180w tdpnek, és/vagy a B2 steppingnek köszönhető-e.
2. Arról beszéltem, hogy a TR kialakítás dupla tdpje HP node esetén valószínűleg a jelenlegi 100MHZ-es max xfr különbségtől (ryzen vs tr) nagyobbat.tehet lehetővé. Erre a jelenségre hoztam példának az ismerten HP nodeon készült piledrivert.
Te milyen kirakattermékről beszélsz, aminek nem látod értelmét? -

Bucsi13
tag
válasz
apatyas
#20513
üzenetére
Lehet olvastam valahol, lehet csak képzelem szóval off
De úgy rémlik, hogy a Cortanának fenntartott részegységeket maga a proci mint low-power hangfelismerő egység jelzi a rendszernek, nem a win osztja így le, szóval pingvin is csak 10 CU-t lát.
Ha nem beszélek hülyeséget
-

stratova
veterán
válasz
apatyas
#20146
üzenetére
Attól tartok ezzel a nómenklatúrával ez még Bristol Ridge, aminek lassan egy éve kisker piacon kellene lennie. Raven Ridge szvsz Summit Ridge-dzsel bevezetett elnevezést követi (lásd R5 2500U <- std mobile, az asztali APU pl R5 2500G lehet) és a doboz-dizájnt is ehhez igazítanám AMD helyében.
-
#19637
Petykemano
veterán
apatyas
#19635
Petykemano
veterán
válasz
apatyas
#19635
üzenetére
Azért kérdezem, mert ha lehet durva mennyiségi kedvezményeket adni, akkor moat biztosan kapnak.
Odamegy az amd. Erre oemek azt mondják, hát vennénk egyet kettőt, de hát látod a te cuccaid alig fogynak, többet nem merünk. Így ugyan másfélszer annyiért Adod mint az Intel a milliós példányszámú megrenseléseket, és így drágábban is leszünk kénytelenek adni, de hát legalább van belőle.Nem ez szokott lenni?
-

Fiery
veterán
válasz
apatyas
#19110
üzenetére
Baromira leegyszerusitve a temat: a mai processzorokban talalhato 128 bites (pontosabban 128 bit szeles) lebegopontos egyseg nem 1 db 128 bites lebegopontos szamot tarol, hanem 2 db 64 bitest (FP64) vagy 4 db 32 bitest (FP32). Ugyanigy a 256 bit szeles regiszterek sem 1 db 256 bites szamot tarolnak, hanem 4 db 64 bitest vagy 8 db 32 bitest.
Az AMD-t mi anno par eve kerdeztuk, hogy tervezik-e a 128 bites lebegopontos abrazolast (FP128 vagy quad-precision) a GPU-iknal vagy FPU-iknal, de mondtak, hogy a juzerek 99%-anak a dupla pontossag (FP64) sem lenyeges. A maradek 1%-nak az 1%-anak kellene csupan FP128, tehat a megcelozhato piac borzalmasan kicsi, es igy nem eri meg veluk foglalkozni. Akinek az kell, az megy FPGA-ra vagy emulalja az FP128-at FP64-gyel (nyilvan nem tul nagy tempoval).
-
#18851
Petykemano
veterán
apatyas
#18850
Petykemano
veterán
válasz
apatyas
#18850
üzenetére
Nekem nincs jósgömböm, az AdoredTV készítőjének van.
De Ragnar_-tól is elkérheted. Szerinte - hogy idézzem - 6/12 $500 lesz, aminek semmi értelme, mert $400-ért már most is lehet kapni.
Vagy aki lehetetlenül pesszimista jóslatokat fogalmaz meg, attól nem kell elkérni a jósgosítványt?De igazad van, amíg ki nem derül, az egésznek semmi értelme. (Vagy úgy tűnik visszatértünk a startvonalhoz: a nekünk kedves, szimpatikus véleményeket érdemesnek tartjuk a megfontolásra, vitára, a nekünk nem szimpatikus, vagy szerintünk túlzó, vagy szerintünk alaptalan vélemény megfogalmazója meg húzzon innen a fenébe hülyeséget terjeszteni.)
-
#18596
Petykemano
veterán
apatyas
#18592
Petykemano
veterán
válasz
apatyas
#18592
üzenetére
Én a választ nem tudom, csak próbálok logikusan gondolkodni.
Ha a Phenom2-nél meg tudták oldani, hogy a magokat külön-külön kapcsolják le, akkor ez példaként állhat.
Elhangzott, CCX-ben minden mag átlagban ugyanolyan késleltetéssel fér hozzá minden L3 területhez, vagyis a L3 nincs exkluzívan felpartícionálva. Bízom benne, hogy CCX-enkénti magok számának szinkronitásának kötöttsége, azért áll fenn, mert 1 mag letiltásával az L3 cache nem tiltódik le, hanem CCX-enként a 3(vagy 2) magnak továbbra is rendelkezésére fog állni a 8MB L3. Abban látok logikát, megmagyarázható, hogy úgy nem tudna jól műküdni, hogy a hibás CCX-ben csak 4-6, a hibátlanban másikban meg 8MB az L3 van.4-6 magos konstrukcióban a magasabb 1 magra jutó L3$ pár százalékkal emelheti az IPC-t.
Elképzelhető, hogy szegmentálásra is felhasználható lenne ha csak a drágább 4-6 magosok kapnák meg, akkor nem csak frekvenciában lehetnének jobbak, hanem némileg IPC-ben is.Én ezt nem tudom, csak remélek egy ilyen flexibilis működést.
Ez a pár százalék - mind frekvenciban, mind IPC tekintetében - különösen a 4 magos verzióknál lehet fontos. a 4.5Ghz-es Kaby Lake-kel biztos meglesz az összehasonlítása a 4 magos verziónak.
-
Fiery
veterán
válasz
apatyas
#17590
üzenetére
Nem tudom, hogy mennyire lesz jo a Summit Ridge. 3 GHz-en nagyon jo lesz, de 3 GHz keves a mai vilagban. Azt pedig nem tudom en sem, es talan me'g az AMD sem jelen pillanatban, hogy a piaci launch idejere meddig sikerul feltornaszni az orajelet a megcelzott TDP kereten belul maradva.
-

joczo1337
tag
válasz
apatyas
#17348
üzenetére
Hmm,most nezem...en eszre sem vettem ugy megorultem neki
Talan a flagship modellekben megis benne lesz,es az alacsonyab kategoriabol marad ki.
Tobb info sajnos nincs,mint kiderult az ismeros is csak kapta valahonnan...pedig az elso gondolatom rogton az volt,hogy benchmark.AZONNAL
-
Fiery
veterán
válasz
apatyas
#17211
üzenetére
Egyelore semmi biztosat nem lehet tudni arrol, hogy a 24 magos verzio hogyan fog "keletkezni". Mindket megoldas lehetseges, hiszen elmeletben siman le lehet tiltani egy core complex magjait is, egyesevel; es nyilvan L3 cache szeleteket is lehet tiltani, akarcsak az Intel processzorok eseteben. Az pedig, hogy most nincs me'g szo 6 magos Summit Ridge-rol, az a jovore nezve nem sokat jelent. Barmikor be lehet dobni, ha a piacon igeny mutatkozik egy ilyen modellre. Egy jol mukodo "nagy" termekbol mindig konnyebb kisebbet, egyszerubbet, olcsobbat "varazsolni", mint felskalazni egy butabbat, egyszerubbet. Az AMD -- ahogy irtam is mar fentebb -- nagyjabol a konzol biznisz elnyerese ota egyebkent is nagyon raallt a LEGO megoldasokra, azaz szinte szabadon tudja varialni az x86 magok mennyiseget a kulonfele uncore-okkal, integralt FCH-kkal es kulonfele meretu iGPU-kkal. Minden piacon levo es hamarosan erkezo termekuk ennek a LEGO modellnek felel meg, ebbe pedig a le/fel skalazas is benne van, legalabbis papiron.
-

lee56
őstag
válasz
apatyas
#17037
üzenetére
Oké mert hát "future is fusion" végülis, nemigaz? 10 éves lesz lassan ez a szállóige, de mégis hol tart a HSA? GPGPU-zás úgy általában? Szoftverek? IGPU-t grafikán kívül (van hogy még arra se - dual graphic magic - amikor lassabb lesz az eredmény ha "besegít a IGP) bármi másra használni tudó appok/játékok? Ahham. De adjunk neki úgy még 5-10 évet és azt mondom megérte, jó irány, csak kicsit korán léptek talán rá erre az ösvényre. Persze valakinek ki kell taposni az utat, de AMD nem arról híres hogy a rendkívül innovatív termékeiből meggazdagodott volna, sajnos.
Amúgymeg, ez nem magyarázat arra, miért álltak le közben AM3+ vonallal. Főleg hogy a HSA-zásból 2 éve még ennyi se látszódott mint ma, és ez se valami sok..
De ha olvastad Fiery hozzászólásait is a témában, akkor nem lehet nagyon új neked amit írtam, ugyanis ő lelkes követője a HSA-nak, talán még alapítványi részesedést is szerzett, ezért van hogy nagyon elismerően szokott nyilatkozni róla, generálja a hype-ot (negatív reklám is reklám végül is ugye).

-

Panzika
tag
válasz
apatyas
#16973
üzenetére
Bocsi mar latom

(#16974) lee56: ezert irtam hogy pletyka
A pletykakat meg tudjuk hogyan kell kezelni(#16976) Z10N: akkor tevedtem nem zen hanem Carizzo
De lehet hogy a SR-ben is benne lesz az NB meg az SB
De gondolom ez a 24 savos pci-e csak a prototipuson van. Remelem a veglegesben tobb savos lesz
-
válasz
apatyas
#16006
üzenetére
Ja, hogy úgy. De hogy lehet így számolni?
 Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.
Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.  Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.
Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.szerk: a HT meg a CMT közötti különbség amúgy tiszta. Egyébként nekem is tök az maradt meg, hogy a HT +60% körülit dob, nem tudom miért, gondolom valami vérpista szájából.


(#16008) Oliverda: Ja, hát baromság is lett volna az intel részéről, ha a P4 óta, csak most jöttek volna rá, hogy az OS ütemezőt is okosítani kéne a HT megfelelő kihasználásához.
-
-

dergander
addikt
-

Valdez
őstag
válasz
apatyas
#15331
üzenetére
Hát ha nem 15wattra limitálná a hp a szerencsétlen 8700 és 8800p-t, akkor talán értelmes eredmények is születnének, ne mondja nekem senki, hogy egy laptopba 15w fölé ne lehessen menni, az intelnek is vannak 28 és 47w tdp-s mobil cuccai, a carrizo meg alapesetben 35w. 14nm-en ez még jobb lenne.
-
Fiery
veterán
válasz
apatyas
#14866
üzenetére
En 2 lehetoseget latok magam elott, amivel igazolni lehetne ugymond a slide-ok hitelesseget. Az elso ugy nezne ki, hogy az AMD jobban halad a Zennel, mint mondjuk 1 eve azt vartak, es 2016 elejen jonnek a szerver+HEDT Zen termekek, es 2016 vegen jonnek a mainstream desktop+mobil termekek. A masik lehetoseg, hogy direkt tulontul optimistan vazoljak fel a roadmapet, hogy ezzel meg tudjak gyozni a befektetoket, hogy ne hatraljanak ki a ceg mogul.
-
stratova
veterán
válasz
apatyas
#14355
üzenetére
Vagy ha már magát a 4 modulos lapkát nem fejlesztik, kicsit finomíthatnák a kalibrálást (p-state: fid, vid) amíg piacon tartják.
PSCheck fogyasztás és eredmények: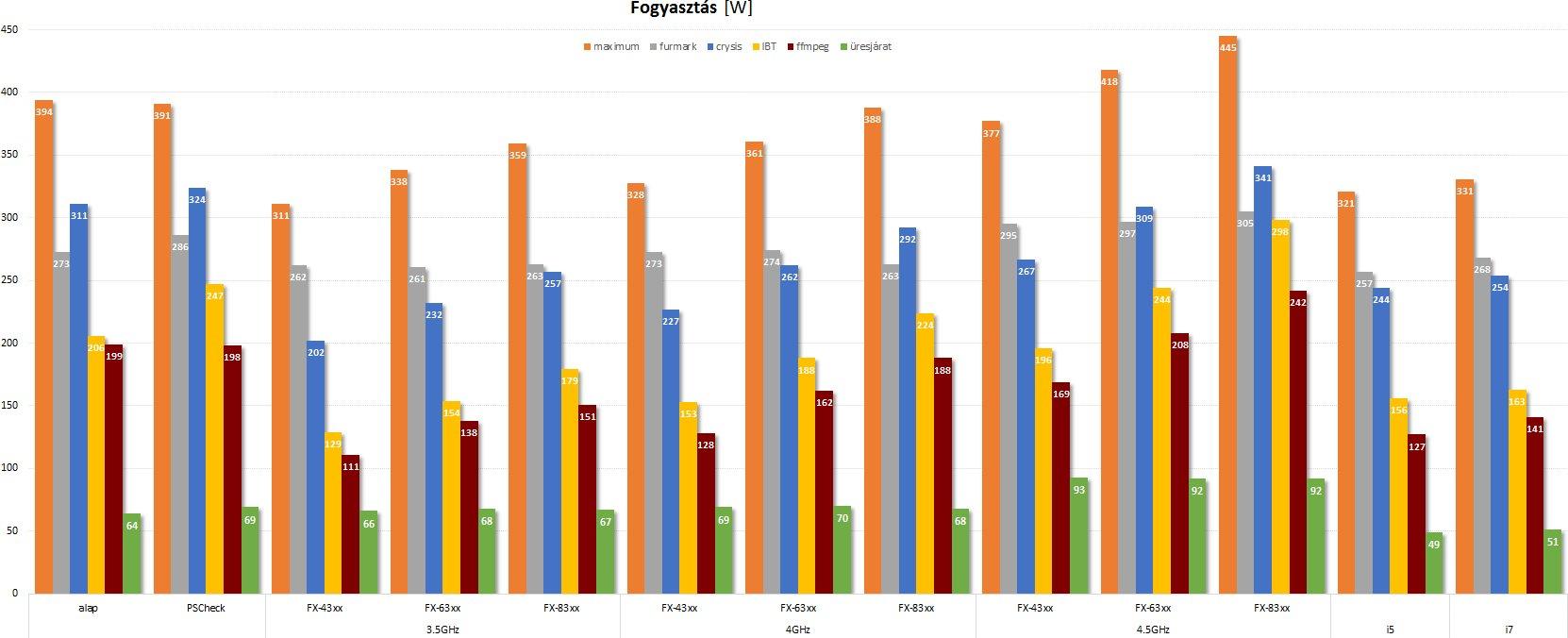
Egyébként a Jaguar vonalon mennek tovább: Jaguar (Kabini) -> Puma (Beema) -> Puma+ (?)


-
stratova
veterán
válasz
apatyas
#14097
üzenetére
Ez egy érdekes kérdés.
Nvidia:
(olcsó)
GM108, GM107 -> 28 nm(nagy teljesítményű/drága)
GM206, GM204, GM200 -> 20 nmAzt nem mondom, hogy 28 nm-en megette a fene, de legalább olyan fejlődést kellene felmutatni CPU/GPU részről is az APU-nak mint amit Nvidia azonos csíkszélességen összehozott Maxwellel, Keplerhez képest.
Lehet hogy AMD a Radeonnak tartogatja a TSMC 20 nm gyártókapacitást (ha már lefoglalták a részüket).
Vagy az új APU is csak GloFo-nál készül és csúszik a 20 nm felfuttatása. Bár komolyabb tőkeinjekciót kap:
Abu Dhabi's Advanced Technology Investment Co (ATIC) plans to invest up to $10 billion over the next two years in GlobalFoundries' upstate New York semiconductor factory, its chief executive said on Friday.Bár a TSMC befektetése legalább beérni látszik:
GlobalFoundries competes against leading contract chipmaker Taiwan Semiconductor Manufacturing Co, or TMSC, which is also investing heavily in technology to maker smaller integrated circuits.








 )
)

![;]](http://cdn.rios.hu/dl/s/v1.gif)








 azzal a kiegészítéssel, hogy sokat adjanak ki és el.
azzal a kiegészítéssel, hogy sokat adjanak ki és el. 












 Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.
Ez alapján ha a HT +0%-ot hoz, akkor is 50% a "skálázódás" mértéke, ezzel a elcseszett módszerrel a 0%-os HT "skálázódás" csak úgy érhető el, ha lefagy a rendszer.  Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.
Én meg már néztem, hogy akkor az OS-ok ütemezőjét kéne frissíteni a bullhoz hasonlóan, hogy jó legyen a HT-s teljesítmény, azaz minden szál lehetőleg külön magon menjen.






Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.


- INTEL Core i7-13700F 3.40GHz LGA-1700 (30M Cache, up to 5.20 GHz) OEM CPU!
- Intel Core I9 12900KF - 16mag/24szál - Új, bontatlan, 1 év gari - Eladó!
- Intel Core I5 14500 - 14mag/20szál - Új, bontatlan - Gari 2027.03.11. -ig - Eladó!
- Intel Core I3 9100f
- BESZÁMÍTÁS! Intel Core i9 14900K 24 mag 32 szál processzor garanciával hibátlan működéssel
- ÁRGARANCIA!Épített KomPhone Ryzen 7 7800X3D 32/64GB RAM RTX 5090 32GB GAMER PC termékbeszámítással
- Telefon felvásárlás!! Samsung Galaxy A22/Samsung Galaxy A23/Samsung Galaxy A25/Samsung Galaxy A05s
- Samsung Odyssey G7 S28BG702EP IPS Monitor! 3840x2160 / 144Hz / 1ms / FreeSync / G-Sync
- HP Victus Gaming Laptop RTX 4070 / i7-13700H 16GB DDR5 1TB SSD Garancia
- Nemzetközi csomagküldés olcsón EU akár 2800 Ft-tól CsomagExpress
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest