- Android alkalmazások - szoftver kibeszélő topik
- iPhone topik
- Xiaomi 15 - kicsi telefon nagy energiával
- Samsung Galaxy S22 és S22+ - a kis vagány meg a bátyja
- Átlépi végre az iPhone az 5000 mAh-t?
- Fejlődik az okosóra piac, csak visszafelé
- Hat év támogatást csomagolt fém házba a OnePlus Nord 4
- Netfone
- iOS alkalmazások
- QWERTY billentyűzet és másodlagos kijelző is lesz a Titan 2-ben
-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

Balala2007
tag
válasz
 Raymond
#22253
üzenetére
Raymond
#22253
üzenetére
IPC: megfeleloen EU korlatos esetekben kijohet a 4x256b vs 3x256b EU-k elonye is, csak kerdes, hogy mennyi ehhez szukseges AVX kod van.
az orajelek is ott lesznek
Ezt honnan lehet biztosan tudni? Eddig a csak a szokasos jocskan a celfreq alatti peldanyokrol volt szo, es mas magas freq-t 7nm-en meg nem gyartottak tudtommal. Nem veletlenul a nagy magszamu EPYC-kel akartak kezdeni, ahol nem csucs sebesseggel is tarolni lehetne. -

S_x96x_S
addikt
válasz
Raymond
#22203
üzenetére
> Sim Lim Square!? Hahahahahahahahaha
> Tudod hogy mi az? Tobbszintu bvasarlokozpont ami csak elektronikara specializalodik.Egyrészt
- Ronda árlista ( totálisan egyetértek )
- egy ici-pici bolt ( igaz ami igaz )
És ennek ellenére - mégis ők leakelték ki az INTEL 9x00- es árakat. most meg a Ryzen 3000-es árakat.
( persze attól hogy az INTELES infó bejött nekik nem következik, hogy a Ryzen 3x -ban is biztos igazuk van, de nem is zárható ki )totál ronda:
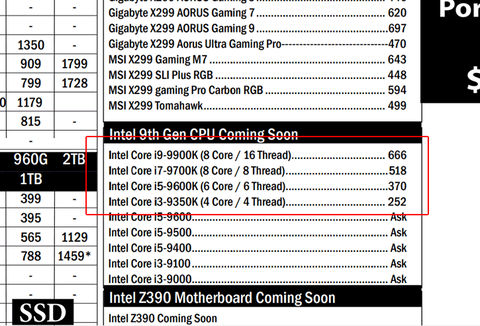
https://www.guru3d.com/news-story/intel-core-9x00-processor-prices-listed-at-singapore-distributor.html>Az a doksi/kep eleg volt arra hogy lassa az ember hogy kamu,
jó neked, hogy egy ronda árlistából el tudod dönteni, hogy komoly-e a cég és az infó vagy sem.
nekem ez sajnos még nem megy.
hagyd meg nekem - hogy majd a valóság ábrándítson ki - amikor bejelentik a hivatalos árakat és modelleket. -
S_x96x_S
addikt
válasz
Raymond
#22190
üzenetére
>Arra hogy a kepet valaki amator modon gyartotta egy aktualis Ryzen/TR-eket tartalmazo tablazatbol.
 Azt speciel én screenshotoltam 2sec alatt - az eredit pdf-ből ,
Azt speciel én screenshotoltam 2sec alatt - az eredit pdf-ből ,
én nem vesződtem semmiféle photoshoppal, az eredeti is ilyen béna volt.
lásd:
https://prohardver.hu/tema/amd_cpu-k_jovoje_amit_tudni_velunk/hsz_790-790.html> Ez az arlista egy maximalisan amator takolmany, eleg szomoru hogy egyaltalan diskura folyik rola.
>1) Az Athlon 200ge hibasan van irva, helyesen 200GEjelezd a bizgram-nak.
a legtöbb probléma még mindig megvan.
az "Athlon 200ge" engem is zavart de túltettem magamat rajta.
friss lista: https://www.bizgram.com/pricelists/001%20Bizgram%20Daily%20DIY%20Pricelist.pdfEgyébként a BizGram híresen rondán Leak-el. Az Intel Core 9x00 -es leak-jük is hasonlóan ronda.
semmit nem fejlődtek. Teljesen jogosak a kritikáid. Attól még hogy igaz volt - totál ronda.
https://www.guru3d.com/news-story/intel-core-9x00-processor-prices-listed-at-singapore-distributor.html
Egy rendes "fake" - igényes - foglalkoznak vele, szépen néz ki ... de ez ...
max csak akkor bocsánatos "bün" - ha mégis igaz. -

stratova
veterán
válasz
Raymond
#19785
üzenetére
Ezt nem vitatta senki. Bár van "asztali" BGA-s. Azért a notebook piacot se hagyjuk ki
igaz a Intel Skull Canyon NUC6i7KYK kb házon belüli "ilyet is tudunk" móka, P580-as Xeon 1535M v5-ös Dell Precision 15 és 17 elvileg kapható, ahogy Zbook 17 is.Szóval nálam még nyitott kérdés, hová szánja Intel az esetleges AMD IGP-t.
-

HavocS
senior tag
válasz
Raymond
#19590
üzenetére
Nekem stratégiailag kicsit gyanús. Ha én lennék az AMD, és tényleg nem tudnám miért produkál a zsírúj hype hardverem ilyen eredményeket, azonnal küldenék egy tesztpéldányt, hogy még a release-re elkészülhessen az AIDA64 bugfix és mindenki méricskélhesse boldogan.
Erről viszont szó sincs.
Szóval nekem kicsit büdös a dolog hogy rájöttek hogy HW gubanc van, és jobb az nekik, ha a megjelenéskor inkább CPU-Z-vel, Cinebench-csel meg Winrarral méricskél majd mindenki...
Aztán ne legyen igazam. -
-

Vitka675
tag
válasz
Raymond
#19534
üzenetére
A 4c8t tekintetében ezen a vonalon gondolkodom én is. Korábban tőlem sokkal okosabbak kifejtették, hogy ok, hogy Vulcan meg DX12 stb, de a játékok még csak most kezdenek el kacsintgatni a 4+ szál felé. Ha nagyjából megmarad az MSRP, és az 1400X kapható lesz a 6600k árában, esetleg alatta, egy felső-középkategóriás gamer gépbe kitűnő választás. Kezdenek lassan sokasodni a magok és szálak, de a régi jól bevált recept még mindig érvényes, miszerint a játékok a magas órajelet és a nagy méretű cache-t kedvelik. A listából ennek a legmagasabbak az órajelei, meglátjuk meddig megy fel, írtak már 4,3-4,5öt levegőn. i5höz képest pedig a +2mb cache kellemes.
Ha nem is eszi meg a 6700K-t, de 6600K alternatívaként kb abban az árban SMT-vel iszonyat jó alternatíva lesz. Mivel nem használnék ki 12 szálat, valszínű érkezik az 1400X.
-

Omli85
őstag
válasz
Raymond
#19536
üzenetére
Most ha a múltat/jelent nézzük egy jóval olcsóbb 8320 vagy 8320E is tudta a jóval drágább 8350 vagy ép 9xxx modellek órajelét teljesítményét. Persze egyértelmű nem hasonlíthatjuk a két szériát egymáshoz mert ég és föld. De bízok benne ha már szorzózár nélküli minden modell, hogy nem lesznek egyéb buktatók aminek okán a szorzózár feloldása végül is felesleges...vagy épp a TDP korlát fog meg ha úgy van... Ha nem lesz szabad a vásár OC téren mint eddig akkor kicsit azért szomorú leszek és szerintem nem csak én
. -
Omli85
őstag
válasz
Raymond
#19534
üzenetére
Szerintem ott egyértelműen az alacsony órajel miatt van az alacsony tdp, kellett egy kis tdp-s 8/16-os modell is a palettába.
Ugyan nem lesz benne szuper automata OC de hát veterán AMD-s emberkéknek manual OC meg se kottyan. És azért a pénzért könnyen lehet, hogy egy nagyon durva ár/teljesítmény kombó lehet az eredmény. Remélhetőleg elboldogul minimum az 1700X órajeleivel de van egy olyan érzésem, hogy talán fognak azok többet is menni.
Hamarosan meglátjuk
-

Simid
senior tag
válasz
Raymond
#19366
üzenetére
Azért gyanús, hogy itt már az XFR is aktív volt (és miért ne lenne ha ezek már production sample-k). Akkor viszont mondjuk egy 4.2Ghz egyszálas XFR-rel számolva már inkább 'csak' Broadwell szint. Az reálisabbnak tűnik.
Na meg az sem mindegy, hogy ez a teszt mennyire tükrözi a valós alkalmazásokban nyújtott teljesítményt. Szép és jó, ha itt jól szerepel, de pl az FX8350 is jobban teljesít multi thread pontszámban mint a 4770K (azonos órajelen), aztán a valóságban nem sok ilyen esetet látsz.
-

Ragnar_
addikt
válasz
Raymond
#19349
üzenetére
Jaja, ha célkitűzés volt a latency csökkentése akkor azt nagy valószínűséggel súlyponti elemként kezelték a fejlesztés folyamán, és nem valószínű, hogy ha gond lett volna vele akkor az a csak már bugjavított steppingen derül ki. Totál laikusként, mint lehetőség bennem az is felmerülne, hogy lehet, hogy a bugfix rontott a latencyn (persze ha köze nincs a kettőnek egymáshoz, akkor nyilván nem..
 )
) -
válasz
Raymond
#19342
üzenetére
Mivel meglepődtek, hogy nagy a késleltetés, az azt jelenti, nem ilyennek akarták. Azt nem tudom, hogy a CONS uarch azért lett-e olyan, mert azt úgy tervezték, de aztán verzióról verzióra javítottak az L1-L2 cache késleltetésen.
Persze mindez csak laikus vélemény, majd Fiery megmondja, mi a helyzet.

-
HavocS
senior tag
válasz
Raymond
#19287
üzenetére
Na közben rájöttem hogy hülyeséget mondtam, Hyper 103 van, csak sokat vaciláltam a kettő között és nem is emlékeztem hogy végül ezt vettem
Viszont azt nem látom a listában, meh.szerk: ééés közben már találtam egy PH cikket ahol pont írja hogy a 103 sehogysem kompatibilis. RIP.
Mondjuk kíváncsi leszek a gyáriak milyenek lesznek, remélem adnak legalább olyan minőségűt mint az intel ad, az FX-ekhez csomagoltak katasztrofálisak, tényleg szigorúan csak alapórajelre jók.
-

Sipike19
tag
válasz
Raymond
#19039
üzenetére
Ja meg úgy, hogy a Ryzen 3400MHz-en ment.
Így aztán ez nem ad hiteles képet 3400Mhz-en turbó nélkül a 6800K, és a 6850K szintje között mozog, ez derül ki belőle, és az, hogy valóban nagy a diferencia különböző feladatokban.
De egy bekapcsolt turbóval, magasabb órajelen, akár a 6900K szintjét is megütheti, kisebb TDP keretből, és alacsonyabb áron, szintén olcsóbb alaplapokkal, és XFR-el akár még fölötte is végezhet.
És még csak azt sem tudjuk, hogy mennyit lehet tuningolni rajta, bár egyes hírek szerint, és Simid által linkelt oldalon feltüntetett órajel alapján, jobban húzható lesz a 6900K-nál, valószínűleg jól működik a gyártástechnológia.Ja, és a RAM órajelek sem azonosan voltak beállítva a teszt során.
-

dezz
nagyúr
válasz
Raymond
#7201
üzenetére
Miket nem mondasz...
2010Q4 volt az első negyedév több éve, amikor önerőből is nyereséges volt a vállalat. A másik 3 negyedévben is a GF kezdeti veszteségeiben való osztozás fordította negatívba a mérleget. (Az utolsó negyedévben onnan is bevétel jött már.) A bevétel, Cost of Revenue és Gross Profit meg inkább stagnált. [link]De ha még úgy is lett volna, ahogy írod, nem lenne ésszerű azt extrapolálni a jövőre nézve, teljesen új mikroarchitektúrák bevezetése közepette.
-
dezz
nagyúr
válasz
Raymond
#7192
üzenetére
Az árrés megspórolása, a fejlesztések saját érdekek szerinti irányítasa...
Bár ehhez az ATIC-nek is lenne néhány keresetlen szava...
Mindenesetre, rövid távon inkább csak akkor lenne ehhez kedve a Dellnek, ha tényleg nagyon jól sikerült a Bulldozer. Viszont ezzel kapcsolatban némi aggodalommal tölt el a csokikon szereplő alacsony órajel. -
dezz
nagyúr
válasz
Raymond
#5816
üzenetére
Ehhez annyit tennék még hozzá, hogy 65nm-en legendásan sz@r volt a natív 4-magos kihozatal (az Intel ugye be sem vállalta), és ha megfeledkeztünk volna róla, ott volt az a TLB-s bug is. A Shanghai az AMD kifejezett örömére mentes az ilyen (jelentős) bugoktól, és minden bizonnyal jóval kisebb kihívás a gyártása is. A volumen attól függ, mennyire járatta be az AMD a 45nm-es gyártást. Nem ma kezdték az átállást és a rampingot, így valószínűleg mára (relatíve) szép számmal ontják a gépsorok...
Szóval lehet fogadásokat kötni kinek-kinek szájíze szerint, de biztosra menni, meg lehülyézni a másikat a választása miatt nem igazán indokolt.
-

Oliverda
titán
válasz
Raymond
#5814
üzenetére
Parancsolj: [link]
Arról pedig továbbra sincs halvány lila gőzöd sem hogy hány darab van a newegg-en meg gyanítom arról sincs hogy a newegg maga mekkora. Csak a süket, üres és néha kamu "objektív" dumát nyomod bele a semmibe.
A többire kár válaszolni, mert már egyrészt 15ször elmondtam, másrészt utána ugyanazokat leírnád újból mint legalábbis aki nem tud olvasni vagy szellemileg rokkant lenne. Persze lehet hogy csak a hülyét játszod vagy tényleg az vagy, nem tudom. Valójában mindegy, egyik sem vet rád túl jó fényt szerintem.
-
Oliverda
titán
válasz
Raymond
#5811
üzenetére
Szerintem összekeversz dezz-zel.
Másrészt nem igazán értem hogy hogyan jön ide most a 3GHz-es 65nm-es Phenom (nyilván kevered a 9950-el). Ja...hogy biztos B3-as aminek semmivel sem lett jobb a skálázhatósága mert csak és kizárólag a TLB hibát javították. Így már értem...
"Egyebkent azt valahogy "elfelejted" hogy az eredeti Phenom-bol is volt a Newegg-en par darab a megjelenes utan."
Igen, csak hogy ez nem Phenom. A Barcelona premierje és a newegg-en való megjelenése között nem egy hét telt el hanem jóval több (kb. 4). Másrészt elárulom hogy ha valami már elérhető a newegg-en, akkor az bárki számára akár 1 nap alatt beszerezhetővé válik bármelyik államban is lakjon az USA-ban. Tehát ezt ott nyugodtan nevezhetjük már széleskörben elérhető terméknek. Bár gondolom már kismilliószor vásároltál tőlük és pontosan tudod hogy hogyan is működnek, és nyilván azt is látod hogy miből pontosan hány darab van náluk éppen raktáron.
Persze ha te azt várod hogy a sarki csehó csaposa majd a Krušovice mellé is Opteron 2384-et dob neked alátétnek akkor javaslom fantáziálgass még egy kicsit a szakadt bibliád felett.
-
Oliverda
titán
válasz
Raymond
#5747
üzenetére
Tudom hogy miket "éreztél" a közelmúltban aminek aztán pont az ellenkezője igazolódott be, majd általában jöttél az ócska hites szövegeddel. Szóval ha esetleg vallási identitászavarral küszködsz, vagy nem tudod elfogadni hogy a néhol kissé felületes tájékozottságodnak köszönhetően te is össze tudsz hordani hülyeségeket, akkor talán érdemes lenne felkeresni egy segítőt.
-
Oliverda
titán
válasz
Raymond
#5743
üzenetére
Remélem hogy nem veszed nagyon zokon ha azt mondom hogy nem bízok túlságosan az AMD-vel kapcsolatos megérzéseidben (
). Bő 4 hónap alatt sikerült stepping váltás nélkül leszorítani a 140W-os 9950 fogyasztását a 125W-os kategóriába (1.30V->1.25V), úgy hogy a 65nm-re nem mondanám hogy túlságosan fekszik nekik mint gyártástechnológia. Valószínűleg mostmár a 65nm-es K10-zel kapcsolatos kutatásokat is leépítik, és még az eddiginél is nagyobb hangsúlyt helyeznek a 45nm-es kutatásra és fejlesztésre.140W-os Opteron pedig szerintem sosem lesz.
mod: légbőlkapott hír
-
Oliverda
titán
válasz
Raymond
#5741
üzenetére
Szándékosan nem hoztam szóba a Xeon-okat, utólag ki is akartam törölni őket a hozzászólásból csak már letelt a mod idő. A Barcelona vs. Shanghai viszonyát próbáltam összevetni. Ugyanis szerintem elég valószínű hogy azokat ugyanabban az alaplapban és RAM modulok mellett használták.
Gondolom azt te is látod (vagy inkább nem látod) hogy semmiféle infó nincs arról hogy milyen egyéb alkatrészeket használtak fel a "teszthez", illetve hogy milyen energiatakarékossági beállíátsok mellett mértek. Majd ha lesz alaposabb teszt több infóval akkor visszatérhetünk a témára.
-
dezz
nagyúr
válasz
Raymond
#5707
üzenetére
Természetesen nem erre utaltam, hanem az #5703-asban (amire te válaszoltál) idézet idézésre. (Már ami annak első mondatát illeti, mert a konfidenciáról szóló rész nem szerepel a transcriptben.) Csak hogy konkrétan szerepeljen, hogy mit és hogyan mondott a 2009-es dátummal kapcsolatban.
Majd ebből következett a vélhetőennel kezdődő válaszom a számodra.
Hakuoro: Jól hangzik!
-
dezz
nagyúr
válasz
Raymond
#5704
üzenetére
Nos, a kérdés-felelet így hangzott [link]:
[i]"Doug Freedman - American Technology Research:
Can you also talk a little bit about where you stand on the development of the new cores, the Bulldozer and Bobcat that were talked about at the last technical analyst day?Derrick R. Meyer:
The Bulldozer core is in development in 45-nanometer technology and we’ll be sampling that in 2009."[/i]Vélhetően nem hobbiból csinálják...
Csak valószínűleg még maguk sem tudják, hogy fog sikerülni az új core, és utóbbitól fog függeni, hogy alakulnak a továbbiak. Azt is el tudom képzelni, hogy mind az új, mind a régi maggal megtervezik az új procikat (moduláris tervezés!), aztán majd kiderül, melyik megy sorozatgyártásba... -
dezz
nagyúr
válasz
Raymond
#5701
üzenetére
Ez a rész azért érdekes:
"As recently as April, AMD President and COO Dirk Meyer was telling financial analysts that samples of Bulldozer were still on the schedule for 2009. But he neglected to mention how AMD intends to use it, because AMD isn't confident enough in its plans for the Bulldozer cores to share them with the public, Allen said." -
Oliverda
titán
válasz
Raymond
#5676
üzenetére
Ray, tudom mit magyarázol már sokadjára, ezért nem is reagáltam a hsz első felére.
A késés pedig most úgy fest hogy elmarad. Bármennyire is sajálod majd esetleg ezt.
"Ha valami csoda folytan a Deneb 20%-al gyorsabb lesz ugyanazon az orajelen mint a mostani kinalat akkor is csak epphogy beeri a Penryn-t azt sem mindenhol."
Meg ahol gyorsabb lesz.
-
#5293
 csatahajós
senior tag
Raymond
#5291
csatahajós
senior tag
Raymond
#5291
csatahajós
senior tag
válasz
Raymond
#5291
üzenetére
Updatelték a linket Raymond postjában. SZóval ha a 4.0Ghz nem is hangzik valósnak, a Phenom FX létezésére elég meggyőzőek a logok meg a táblázat, persze lehet ilyet photoshoppolni is nem mondom.
Amúgy az Athlon X2 6500+ nem véletlen 3.3Ghz-es? Van eről hivatlaos info? (akárhogy is, nem semmi hogy a már csonttá rágott K8ból még kihoztak egy még gyorsabbat ... én már a 6000+ -ról is azt hittem hogy na ez aztán tényleg az utolsó...
Meg kérdés pl hogy a 6500+ Brisbane vagy Windsor-e? Mert ha ez is még 90nm-es (amit nem nagyon hiszek) akkor ez maga a csoda kb.
-
Oliverda
titán
válasz
Raymond
#5143
üzenetére
Ettől olyan sokkal nem lettem okosabb na de mindegy.
Ha jól tudom így viszont lassabb lesz a keresés benne tehát nőhet a késleltetése. Feljebb kellene srófolni az L3 órajelét. Főleg ha már DDR3 lesz mellette mivel a jelenlegi K10es procikban a sávszélesség sem valami túl rózsás L3 fronton. -
-

#95904256
törölt tag
válasz
Raymond
#5125
üzenetére
Hm, nem tudtam hogy imádják a C2 tulajok a SuperPI-t, illetve az FSB-s összefüggéssel sem vagyok tisztában. ;)
Viszont azt nagyjából tudom mit is csinál a SuperPI. A Gauss-Legendre algoritmus segítségével interpolálja PI számjegyeit, vagyis minden egyes közelítésnél az előző ( vagy kiindulási ) eredményeket használja fel. Ez persze önmagában nem magyarázza a stream jellegű feldolgozást. Ehhez még azt is tudni kell hogy olyan sokjegyű számokat ábrázol a memóriában a program ( bináris formában ), amelyek jóval túlmutatnak a lebegőpontos egység pontosságán. Az ilyen számokat meg csak úgy lehet feldolgozni ha a program egy-egy számcsoportot dolgoz fel egyszerre ( ami befér pl. az FPU-ba ) majd a részeredményeket görgeti magaelőtt. Vagyis szekvenciálisan dolgozza fel az adatokat.
szerk.: Megjegyzem, egyetlen algoritmus kivételével nincs olyan eljárás amivel PI számjegyeit úgy lehetne megkapni hogy ne kelljen tárolni és dolgozni az előző számjegyekkel. De ennek a kivételes algoritmusnak is nő a memóriaigénye a kiszámolandó számjegy pozíciójával összefüggően.
-

Rive
veterán
válasz
Raymond
#5122
üzenetére
Volt is már ilyen balhér egyszer, Itanium alapokon. Az egyik SPEC2k teszt hirtelen hatalmas javulást mutatott az előző procc-eresztéshez képest, elég sokan kétségbevonták a teszt hitelességét. Csak épp az adott teszt futás közben úgy öt megányi adatot buherált össze-vissza, a procc meg az adott generációval ugrott talán kettőről hat mega L2-re.
-
-
#5109
Sandormaster
aktív tag
Raymond
#5108
Sandormaster
aktív tag
válasz
Raymond
#5108
üzenetére
Éreztem sajnos hogy így eltolódik
De ahogy nézem "kisebb" X2-es is el lehet érni jó megahertzeket, most látom VaniliásRönk adatlapján se rossz az az eredmény az 5000+ -tól
Amúgy szerintetek nem gáz hogy az AMD ilyen eltolódásban van az intellhez képest
Remélem felhasználó barát árakkal és a rajongói táborral még feljöhetnek Bár tartok tőle hogy ha a 45nm nem hozza a kellő eredményeket akkor ez a késleltetéses spirál tovább fokozódik -

Cagm^c
tag
válasz
Raymond
#4817
üzenetére
Ha a magyar árak nem lesznek magasak, akkor jól fogunk járni. A 9850BE simán 50.000Ft alatt rajtolhat. Ha a tuning is rendben, akkor az 5000+BE után ez lehet AMD vonalon a következő "slágercikk" a tunereknek.
Nekem úgy tűnik, hogy éledezik az AMD. Sikerült hozni az útitervet. Sőt! Talán még gyorsítottak is rajta. Ez mindenképpen egy pirospont. Inkább ígérjenek kevesebbet, de azt tartsák is be. Nem úgy mint tavaj ilyenkor a 3GHz-s Phenommal.
Ennek fényében simán elképzelhető, hogy év végére már hazánkban is megvásárolhatóak lesznek a 45nm-esek. -
Oliverda
titán
válasz
Raymond
#4716
üzenetére
Ez konkrétan a te agyszüleményed. Jelen állás szerint a B2 stepping 2.3GHz-ig jutott hivatalosan, ezzel szemben a B3 2.6GHz-et fog tudni. A TLB fixen kívül tényleg semmi sem változik.
Na jó nem vitatkozok tovább, nem szeretném hogy Dezz vs. Raymond szintig süllyedjen a dolog.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
-

dokar
addikt
válasz
Raymond
#4709
üzenetére
sztem hitre alapozza

de amúgy komolyra fordítva a szót, az újabb revíziók általában egyre precízebb gyártást hoznak maguk után. nézd meg pl a 65nm-es K8 AM2 procik a kezdetben milyen órajeleken mentek és most mennyin tudnak.de abban egyetértek, hogy ez a B3 semmi megváltást nem hoz, csak eloltja az alapjában véve sem égő tüzet

-

P.H.
senior tag
válasz
Raymond
#4663
üzenetére
Értem. Nagyon eltérőt mást ebben a felbontásban sem lehet találni a magokon belül, csak két másik dolgot:
- megfordították az L2 cache-eket
- a Northbridge látható része némileg eltér a korábbitólfLeSs #4664: Ezt hogy érted?
A képen csak azt akartam mutatni, hogy láthatóan a 128-bit SSE-t úgy érték el, hogy a korábbi 64 bites végrehajtókat megduplázták fizikailag (a K8-as képet innen fordítottam be 90 fokkal, és kicsinyítettem.






 Azt speciel én screenshotoltam 2sec alatt - az eredit pdf-ből ,
Azt speciel én screenshotoltam 2sec alatt - az eredit pdf-ből ,










 )
)



























![;]](http://cdn.rios.hu/dl/s/v1.gif)

Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Milyen processzort vegyek?
- Mibe tegyem a megtakarításaimat?
- Milyen TV-t vegyek?
- AMD Navi Radeon™ RX 6xxx sorozat
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- One otthoni szolgáltatások (TV, internet, telefon)
- BestBuy topik
- Android alkalmazások - szoftver kibeszélő topik
- Milyen videókártyát?
- iPhone topik
- További aktív témák...

- Apple iPhone 13 128GB / Kártyafüggetlen 1ÉV GARANCIÁVAL
- BESZÁMÍTÁS! MSI B450M R5 5500 32GB DDR4 512GB SSD RTX 3060 12GB Rampage SHIVA Chieftec 600W
- HATALMAS AKCIÓK / MICROSOFT WINDOWS 10,11 / OFFICE 16,19,21,24 / VÍRUS,VPN VÉDELEM / SZÁMLA / 0-24
- Eladó ÚJ, BONTATLAN Samsung Galaxy A05s 4/64GB ezüst / 12 hónap jótállással!
- Országosan a legjobb BANKMENTES részletfizetési konstrukció! Lenovo ThinkPad L16 Gen 1 Prémium
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest