- iPhone topik
- Keretmentesít a Galaxy S25 FE
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- One mobilszolgáltatások
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Xiaomi Watch 2 Pro - oké, Google, itt vagyunk mi is
- Samsung Galaxy S20 és S20+ duplateszt
- Magyarországon is kapható a Moto G85 5G
- Samsung Galaxy A56 - megbízható középszerűség
Új hozzászólás Aktív témák
-
#42988
 Busterftw
nagyúr
Petykemano
#42987
Busterftw
nagyúr
Petykemano
#42987
Busterftw
nagyúr
válasz
 Petykemano
#42987
üzenetére
Petykemano
#42987
üzenetére
A wfttech-es leakben volt szo agressziv arazasrol, top modell 499 dollarert.
De szerintem ez kizart. Bar msrp lehet 499 dollar, a piaci ar meg....
-
#42906
 Pug
veterán
Petykemano
#42903
Pug
veterán
Petykemano
#42903
válasz
Petykemano
#42903
üzenetére
Egyszeruen perpill bizonyos chip-ek eseten mi a Q2-es igenyek felet nem tudjuk kiszolgalni, top customerek eseten, ugy hogy ez csak discrete semiconductor piac, akkor szerinted az IC piacon mi lehet....
-
#42905
 Kolbi_30
őstag
Petykemano
#42903
Kolbi_30
őstag
Petykemano
#42903
Kolbi_30
őstag
válasz
Petykemano
#42903
üzenetére
Mindent elvisznek nem tudnak eleget gyartatni. Ez van.
-
#42885
 awexco
őstag
Petykemano
#42881
awexco
őstag
Petykemano
#42881
awexco
őstag
válasz
Petykemano
#42881
üzenetére
Cpu frontról jöhetett egy kis know how . Ill anno az Amd megvásárolt valami céget ami a cache skálázásával foglalkozott .
-
#42864
 szmörlock007
aktív tag
Petykemano
#42862
szmörlock007
aktív tag
Petykemano
#42862
szmörlock007
aktív tag
válasz
Petykemano
#42862
üzenetére
Ha Kína megpróbálja annektálni tajvant akkor pontosan tudják, hogy a csendes óceáni amerikai hadiflotta (akinek a tábornoka épp a napokban kért további forrást tajvan miatt) is beköszön a csatába

Arról nem is szólva, hogy India és Japán a térségben egyértelműen tajvan és az usa mellé állna a jelek szerint.... -
#42863
 wjbhbdux
veterán
Petykemano
#42862
wjbhbdux
veterán
Petykemano
#42862
wjbhbdux
veterán
válasz
Petykemano
#42862
üzenetére
Ne fesd az ördögöt a falra, inkább úgy gondolj rá, mint nálunk amikor simicska húsüzeméből vetted a csirkemellett most meg mészároséból, nagy különbség nem lesz a végfelhasználónak csak más nyer ott rajta. sőr lehet olcsóbb is lesz mert akkor már tajvanban is a muszlim rabszolgák gyártják majd a videokártyákat fizetett munkások helyett.
-
#42855
 Valdez
őstag
Petykemano
#42844
Valdez
őstag
Petykemano
#42844
Valdez
őstag
válasz
Petykemano
#42844
üzenetére
Hong Kong diplomáciai úton került vissza Kínához, ez mind le volt előre papírozva. Tajvan esete teljesen más.
[link] -
#42854
Busterftw
nagyúr
Petykemano
#42853
Busterftw
nagyúr
válasz
Petykemano
#42853
üzenetére
-
#42850
 Yutani
nagyúr
Petykemano
#42849
Yutani
nagyúr
Petykemano
#42849
válasz
Petykemano
#42849
üzenetére
Á, van London is az USA-ban, nagyon átverősek. Na meg Venice is. Jó kis A64.

-
#42846
 paprobert
őstag
Petykemano
#42844
paprobert
őstag
Petykemano
#42844
paprobert
őstag
válasz
Petykemano
#42844
üzenetére
Ha a máltai üzemre mint az európai chipgyártás fontos részére gondoltál, akkor
 . Átverős a neve, az valójában USA keleti part.
. Átverős a neve, az valójában USA keleti part. -
#42845
 b.
félisten
Petykemano
#42843
b.
félisten
Petykemano
#42843
válasz
Petykemano
#42843
üzenetére
Szerintem Nvidia ha kell vesz/ rendel magának gyártókapacitást mint az Intel. bevételük alapján azt kizártnak tartom, hogy ne tudna annyit fizetni, mint az AMD, hisz magasan felette vannak még mindig, csak valószínűleg AMD nek megéri ennyit fizetni érte, nekik meg nem, inkább így fogalmaznék. Jelenleg az 5 nm-re egyformán ( kis volumennel)vannak benevezve, ( szerintem ez lesz a CPU/ GPU amit emlegetnek,Ada Lovelace új GPU ami lehetséges, hogy mobil SOC alapú, 5 nm).
múlt heti hír , hogy tárgyalnak plusz kapacitásról 7 nm-n TSMC vel.
Ami probléma szerintem itt, hogy elszámolták magukat a Samsunggal,( ha ez igaz, vannak kétségeim)de ha megnézed a teszteredményeket és a mostani helyzetet lehet mégsem, inkább okosan csinálták.Eza CPU dizájn szerintem más lesz ..
-
#42841
 killbull
aktív tag
Petykemano
#42840
killbull
aktív tag
Petykemano
#42840
killbull
aktív tag
válasz
Petykemano
#42840
üzenetére
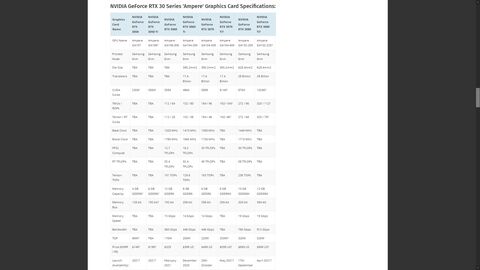 Nem szentírás de nagyjából!
Nem szentírás de nagyjából! -
#42839
killbull
aktív tag
Petykemano
#42838
killbull
aktív tag
válasz
Petykemano
#42838
üzenetére
Nem!
Arra pl hogy régen vettem R7 260X et és GTX 750Ti al sokkal jobban jártam volna pl akkor. Most nézd meg az RTX 3050 et 90 Watton ami jönni fog, RX 590 szinten van, AMD belépő kategória azt hiszem az RX 6500 vagy RX 6500XT lesz, már a felette lévő RX 6600 is egy kiherélt PCIe 4 x8, az RTX 3050 meg x16.
Egyszerű a válasz!
-
#42836
killbull
aktív tag
Petykemano
#42833
killbull
aktív tag
válasz
Petykemano
#42833
üzenetére
A valóság meg az hogy azonos árkategóriába szinte biztos hogy Nvidia +10 fps.
Vagy nézzük meg azt hogy a mostani AMD driver WHQL ugyan az mint az előtte lévő optimal.
Ugyan úgy becrashelhet a géped hogy csak reset gombal tudod életre kelteni, ilyen nem megengedett Nvidianál.Ne vedd oltásnak, 15+ éve AMD s vagyok és az évek alatt se érdekelt hogy ha Nvidiám lett volna több fps em lett volna, de mostanában annyi crashem volt a géppel AMD driver miatt hogy már hajítom ki a fél millás gépet az ablakon kategória volt. Most se merek frissíteni mert nem fagy és van új driver. Ha jól tudom AMD átírja Nvidia meg eleve nem enged meg ilyet hogy egy gép lefagyjon.
Erre gondolok pl, figyeld hogy ki van idegileg a srác, ezt én is végigjártam: [link]
-
#42835
 FLATRONW
őstag
Petykemano
#42833
FLATRONW
őstag
Petykemano
#42833
FLATRONW
őstag
válasz
Petykemano
#42833
üzenetére
Én inkább úgy mondanám, hogy aki pl. egy r5 2600x-el rendelkezik és ilyen beállítások mellett akar játszani, annak nem éri meg új generációs AMD és NV felsőkategóriás kártyát venni.
Ugyanúgy az 5700xt/5600xt szintjén van a 6900xt. -
#42834
 Televan74
nagyúr
Petykemano
#42833
Televan74
nagyúr
Petykemano
#42833
Televan74
nagyúr
válasz
Petykemano
#42833
üzenetére
Vagy a sok felhasználó elmegy Intel venni a Nvidia mellé.
![;]](//cdn.rios.hu/dl/s/v1.gif) Én is erősen gondolkozom rajta!
Én is erősen gondolkozom rajta! 
-
#42831
Yutani
nagyúr
Petykemano
#42830
válasz
Petykemano
#42830
üzenetére
Durva, hogy a Ryzen 5 1400 medium beállításnál jobb FPS-t produkál egy 5600XT-vel, mint RTX 3080-nal 1080p-n.
Természetesen ez olyan együttállás, ami nem életszerű, azaz Ryzen 5 1400 kategóriájú CPU mellé senki nem rak RTX 3080-at, hogy 1080p mediumban játsszon. Ez mind csak a teszt kedvéért vizsgált körülmény, hogy láthatóvá váljon egy bizonyos bottleneck. Tehát senki ne úgy vegye, hogy szar az NV, ez csak egy extrém teszt.
-
#42828
Yutani
nagyúr
Petykemano
#42827
válasz
Petykemano
#42827
üzenetére
Tulajdonképpen hard fork lesz, lesz egy új ETH hálózat, de mellette megy tovább a régi is.
-
#42827
 Petykemano
veterán
Petykemano
#42754
Petykemano
veterán
Petykemano
#42754
Petykemano
veterán
válasz
Petykemano
#42754
üzenetére
Itt is egy cikk az ETH2-ről
[link]Csak azért hozom be, mert azt mondják, hogy a váltás nodeonként megy végbe és azért érdemes váltani, mert olcsóbb lesz a tranzakciós díj. Az ETH1 és ETH2 hálózat pedig nem lesz átjárható.
Ez azért érdekes, mert ugye az előző cikkben azt írták, hogy az ETH2 megszünteti, vagy enyhít a bányászhatóságot. Tehát ETH1 hálózatban maradni a bányászoknak lesz érdeke, az ETH2-re váltani pedig azoknak,.akik amúgy pénzügyi eszközként használnák.
Gondolom ez azt is jelenti, hogy kétféle currency is lesz ezáltal. Ha úgy lesz, hogy a bányászok maradnak az ETH1 hálózatban bányászni, megtehetik, de talán van rá esély, hogy esik az árfolyama, mert mindenki, aki befektetésként tekint rá, az alacsonyabb tranzakciós költségben érdekelt. De lehet a vége egy teljes kettéválás is.
Mindenesetre a példa azt mutatja - remélhetőleg -, létezhet kriptovaluta hatalmas gpu kapacitás , vagy legalábbis a rendszerhasználat szempontjából csak előállító bányászat nélkül.
-
#42824
b.
félisten
Petykemano
#42823
válasz
Petykemano
#42823
üzenetére
Szerintem egy igazán dekstop gamer PC-nek nem alternatíva még mindig minőségben prémium előfizetőként sem. Arra megért nekem 10-15 K-t hogy ha rendezvényeken vagyok , vagy üzleti megbeszélések, este felmegyek a szálloda szobába a kis laposommal aztán játszogatok, de igazából egy több éves használt VGA-t sem tudna nekem kiváltani.
pl egy GTx 1070 vagy GTx 980 -/vega56-64 még mindig mérföldekkel reszponzívabb élményt ad mint a Cloud gamning, aki ilyen kártyával legalább rendelkezik annak nem biztos, hogy annyira érdemes váltani, max ha elromlik neki.
tehát aki hardcore gamer Pc-n annak ez még mindig nem elég jó. Most ezt ki kell bírni, nem szabad fejleszteni, de szerintem ez az átkényszerülés a Cloud oldalára még nem opció, a konzolokat már inkább adom, hogy arra többen váltanak.
persze hosszú távon ha így marad akkor igen, de még korai szerintem erről beszélni.Szerinte Nvidia mosta Stadia haldokolására apellál elsősorban.
-
#42822
b.
félisten
Petykemano
#42821
válasz
Petykemano
#42821
üzenetére
Hát mivel náluk nem kell újra megvenned a játékot hogy játszhass, így is jónak mondható a 99 $ / év.
2-3 havonta akciózknak, pl karácsonykor 23$ volt fél év és 39 $ egy év. Gondolom ezt szokásukat most is megtartják. -
#42755
Petykemano
veterán
Petykemano
#42754
Petykemano
veterán
válasz
Petykemano
#42754
üzenetére
Egy összefüggésen elgondolkodtam.
Talán lehet valami alapja tényleg a JPR konklúziójának, legalábbis nincs egyedül ezzel a véleménnyel.Az Nvidia az új kártyák esetén - ebből volt nagy botrány - csak az ETH bányászkapacitást korlátozza. Azt tudjuk, hogy az Nvidia célja elsősorban nem az, hogy a gamerek számára olcsóbban elérhetővé tegye a portékáját, hanem az, hogy a bányászok ne ezt vegyék. A hátsó szándék ezzel az, hogy a saját jövőbeli piacát és keresletét megóvja a bányából visszaömlő használt gpuktól.
Ez egybevág azzal, amit a JPR jósol az ETH1 => ETH2 átmenet kapcsán, vagyis az nvidia is arra készül, hogy a főleg ETH1-re irányuló gpu bányászat emiatt be fog omlani. ÉS ennek eszkalálódó hatásaitól akarja magát még most megóvni.
-
#42753
 Devid_81
félisten
Petykemano
#42752
Devid_81
félisten
Petykemano
#42752
Devid_81
félisten
válasz
Petykemano
#42752
üzenetére
Allitolag errol a bizonyos 2.0-as verzios frissitesrol mar regota beszelnek
Mondjuk en annyira kovetem csak a banyat, hogy kb elsapadva nezem a VGA arakat, bar ameddig a mostani VGA-m el addig biztos nem fejlesztek egyik oldalon sem, igy felolem lehet barmennyi barmelyik VGA.Viszont ha tenyleg atternek ezek is olyanra, hogy a VGA-k nem lesznek jok akkor az azert majd elindit egy vagany hasznaltpiacos Ampere VGA lavinat
-
#42751
 solfilo
veterán
Petykemano
#42746
solfilo
veterán
Petykemano
#42746
válasz
Petykemano
#42746
üzenetére
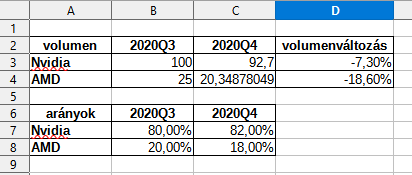
Ideteszem a dGPU részesedét, hátha valaki nem kattint.

Most nézem, van egy ilyen: "Overall GPU shipments increased by 20.5% from last quarter, AMD shipments increased 6.4%, Intel’s shipments rose 33.2%, and Nvidia’s shipments decreased by -7.3%.", akkor elég sokat eshetett az AMD szállítása is, hisz szűkült a részesedése dGPU piacon.
számolgattam, AMD volumene 18,6%-ot esett egy negyedév alatt, durva.
-
#42747
 huskydog17
addikt
Petykemano
#42746
huskydog17
addikt
Petykemano
#42746
huskydog17
addikt
válasz
Petykemano
#42746
üzenetére
Tovább nyílt az olló az AMD és nVIDIA között a dGPU piacon, ez nem lep meg sajnos. Egy év alatt az AMD 27-ről 18%-ra esett, ami jó nagy zuhanás, két új architektúrával (RDNA1-2) sem tudtak piacot szerezni. Ez nem túl biztató. A jelenlegi helyzet sem kedvező ennek megfordítására, márpedig ha nem történik egy kisebb csoda, akkor egy év múlva akár 10% alá is csökkenhet a részesedésük.
-
#42716
 Locutus
veterán
Petykemano
#42715
Locutus
veterán
Petykemano
#42715
Locutus
veterán
válasz
Petykemano
#42715
üzenetére
Van esetleg jobb ötleted, hogy mit tehetnének?
-
#42660
Devid_81
félisten
Petykemano
#42659
Devid_81
félisten
válasz
Petykemano
#42659
üzenetére
Teljesen jo lepes az nVidiatol.
Szerintem meg GTX 480-asuk is van valahol a raktarbanHa igy haladunk megint varhatod hogy a HD 4770 beessen 25k ala
AMD-nek a Vega VII/7-et kellene ujra gyartani, sott abbol kaphatnank akar full fat die verziot is, az csak ugy f0sna ki magabol a coint
-
#42626
 #09256960
törölt tag
Petykemano
#42625
#09256960
törölt tag
Petykemano
#42625
#09256960
törölt tag
válasz
Petykemano
#42625
üzenetére
Láttam már ház hirdetést is hogy lehet bitcoinnal fizetni
Azt a 3000 nm2-est csak össze kellene valahogy bányászgatni -
#42598
huskydog17
addikt
Petykemano
#42591
huskydog17
addikt
válasz
Petykemano
#42591
üzenetére
A kártyák nagy része főleg a 3060Ti változatok bányákban kötnek ki, mert a azon van a legnagyobb haszon a bányászoknak, a board partnerek pedig így masszív pénzeket spórolnak, azaz pont hogy jóval nagyobb a nyereségük. Valszeg azért kapnak keveset, mert az NV a GDDR6 chipekre vár, ugyanis a board partnereknek a GPU-t a VRAM-mal együtt szállítják csomagban (az AMD is így csinálja). Ahogy már mondták a többiek, várjuk meg a hamarosan megjelenő pénzügyi jelentéseket.
Az EVGA csak a 3060Ti változatból ők havi 2000-et, a többi Ampere-ből talán jóval többet (feltételezem), aztán valószínűleg ők is sokat adnak és közvetlenül bányászoknak, így jóval többet keresnek rajta, mintha kereskedési láncba szállítanák a kártyákat. A kereskedelmi lánca küldött példányokat pedig csillagászati áron is megveszik, így persze, hogy nem mennek csődbe.
Van egy olyan megérzésem, hogy az NV-nél rekord bevétel és nyereség lesz Q4-ben (az AMD-nél is). -
#42594
b.
félisten
Petykemano
#42591
válasz
Petykemano
#42591
üzenetére
Ahhoz hosszabb idő kell,de meglátjuk. Nem nagy cég amúgy.
-
#42593
 Raymond
titán
Petykemano
#42591
Raymond
titán
Petykemano
#42591
Raymond
titán
válasz
Petykemano
#42591
üzenetére
Nemsokara kiderul mi van, most jonnek a Q4-es eredmenyek mindenkitol (az NV-t kiveve, az majd egy honappal kesobb).
-
#42592
paprobert
őstag
Petykemano
#42591
paprobert
őstag
válasz
Petykemano
#42591
üzenetére
A jó kérdéseket tetted fel.
-
#42463
 Piszmaty76
aktív tag
Petykemano
#42461
Piszmaty76
aktív tag
Petykemano
#42461
Piszmaty76
aktív tag
válasz
Petykemano
#42461
üzenetére
Kb. másfél órája vagyunk túl egy földrengésen (Székesfehérvár). Legalább 2 percig fogtam a tévém biztos ami biztos (brutális hastáncot nyomott), szóval még nincs vége a 2020-nak, még bármi beleférhet. Egy kicsit azért vicces, hogy Horvátországban van 6,4-es földrengés és én Fehérváron a 10. emeleten fogom a tévém, mintha az életem múlna rajta...

-
#42402
Piszmaty76
aktív tag
Petykemano
#42400
Piszmaty76
aktív tag
válasz
Petykemano
#42400
üzenetére
Lisának is van bőrkabátja?
-
#42401
solfilo
veterán
Petykemano
#42400
válasz
Petykemano
#42400
üzenetére

-
#42316
paprobert
őstag
Petykemano
#42312
paprobert
őstag
válasz
Petykemano
#42312
üzenetére
A gyorsított feladatok nem most lettek feltalálva. Sebességet nyersz, de tud törni a használhatóság.
Mobilon azért lett kritikus, mert néhány wattos power limit van. Szervereknél nincs ekkora nyomás. Ott a flexibilitás és a szoftverezhetőség többet ér, van is rá keret.
Az univerzális hardver és a hardveresen gyorsított megoldások ciklikusan váltják egymást a feladat megoldhatóságának függvényében. Eleinte csak CPU-n létezik a feladat -> dedikált hardver a sebességért -> idővel vissza univerzális hardverre, mert olyan apróvá vált a feladat hogy nem éri meg a dedikált egység.
A specifikus hardverek szuper dolgok -ha működnek-, de univerzális sebességre is mindig szükség lesz.
Az erős host processzor mellett a gyorsítókártyák cserélgetése nem véletlenül egy működő modell. Ha ebből kiveszed az erős host processzort, csak gyengébb eredményt kapsz.
-
#42222
Devid_81
félisten
Petykemano
#42218
Devid_81
félisten
válasz
Petykemano
#42218
üzenetére
-
#42027
awexco
őstag
Petykemano
#42025
awexco
őstag
válasz
Petykemano
#42025
üzenetére
Alapvetően mindent én se értek , de gyanítom , h nincsenek hasonló termékeik ergó nincs átfedés . Viszont ami meg van az kiegészíti egymást faxán .
Ha komplett platformban gondolkoznak akkor valszeg 1-2 végletekig butított termék lecsorog majd desktopra , vagy kifejlesztenek ... Pl AMD procis notiban , alaplapon Intel hálózati vezérló ...
Erről mondjuk az ugrott be , h AMD nem tud olcsó gagyi chipsetet magának fejleszteni ?
Vagy mért az Asus csinálja neki ? Nem jobb lenne házon belül ? Bár lehet egy komplett deal része . -
#42018
 Laja333
őstag
Petykemano
#42004
Laja333
őstag
Petykemano
#42004
Laja333
őstag
válasz
Petykemano
#42004
üzenetére
Ez elég kemény... Kevés lesz az NV-nél, ha a lépést akarja tartani.
Szórja a pénzt és még csak meg sem látszik.
AMD fele annyit költ fejlesztésre, mint csak az NV de még így is elkaszálja Intellel együtt.
Mi lenne itt ha ők is annyit költenének R&D-re...
-
#42007
awexco
őstag
Petykemano
#42004
awexco
őstag
válasz
Petykemano
#42004
üzenetére
Azt kezdtem nézni , h Xilinx-el együtt AMD fejlesztési büdzsével , alkalmazottak / fejlesztők stb. Kb hamarosan kb egy súlyba lesz . És sokan azzal dobálóznak , h az nvidia mennyivel nagyobb cég nagyobb fejlesztési költségvetés stb ...
Azért kemény dió lesz összefésülni Xilinxet és AMD -t
De gyanítom , h mivel van miből keményen megtolják a fejlesztéseket. Hogy mi ebből mit fogunk látni mint földi halandók az más kérdés ... -
#41912
 Raggie
őstag
Petykemano
#41911
Raggie
őstag
Petykemano
#41911
Raggie
őstag
válasz
Petykemano
#41911
üzenetére
ROFL, zseniális!

-
#41787
b.
félisten
Petykemano
#41786
válasz
Petykemano
#41786
üzenetére
nincs rá szükség
-
#41785
Raymond
titán
Petykemano
#41782
Raymond
titán
válasz
Petykemano
#41782
üzenetére
Miert? A 20GB az 20 x 8Gbit, ahhoz nem kellenek 16Gbit GDDR6X chip-ek ugyanugy ahogy a 24GB-os 3090-hez se kellenek (24 x 8Gbit).
-
#41784
b.
félisten
Petykemano
#41782
válasz
Petykemano
#41782
üzenetére
-
#41766
szmörlock007
aktív tag
Petykemano
#41763
szmörlock007
aktív tag
válasz
Petykemano
#41763
üzenetére
Szerintem a 21 év végén jövő Cdna2 lesz az első igazi komoly húzóerő az Amd-nél, a Cdna1 szerintem ilyen bemelegítő lesz, hogy megvessék a lábukat a piacon (főleg szoftveresen). A Cdna2-re fog épülni a 2 exascale gép is ha jól tudom (illetve az egyik biztos, a másik custom Gpu, gondolom a Cdna2-höz adnak hozzá pár extrát), az szoftveresen nagy lökés lesz a platformnak.
-
#41764
b.
félisten
Petykemano
#41763
válasz
Petykemano
#41763
üzenetére
nagyon sok ilyen rojekt lesz még, szinte mindenhonnan ezt hallani, hogy mennyire ráfekszenek erre, biztos jut mindkét cégnek bőven.
-
#41740
b.
félisten
Petykemano
#41738
válasz
Petykemano
#41738
üzenetére
Én pont azt gondolom, hogy AMD vagy Intel.
Ha mos lenne amúgy kész ARM rendszere nvidiának valószínűleg az övék lenne.
Vannak tök jó cikkek erről. Úgy gondlom amúgy ha ez a projekt kicsúszik Intel kezéből egy lavinát indít el, és erre vár Nvidia és AMD is.
Ahogy írja Abu jelenleg Nvdiának csak az IBM lenne, de az messze van szükséges teljesítménytől.Intel és Nv kombó esetleg...
3 lehetőséget látok.1,Ha AMD időben kész lesz a Frontierrel, még akkor lehet esélyük arra ,hogy ezta projektet is megoldják, elöbb mint Intel. Ha az USA bevállalja a blamát és leváltja teljesen ebben a beruházásban Intelt. A tervek szerint 500 millió dollárból lehetne meg pluszban ez a váltás, amit szerintem még bevállalnának ha csak ezen múlna.
2, Várnak Intelre és csúszik a projekt, de álítólag örjöngenek már a megrendelők és jönnek a hírek, egyre többen elhagyták Intelt a megbízott mérnökcsapatból,.
Nagy érvágás volt hogy az egyik legfontosabb emberkéjük ebben a projektben és teamben felállt és átment a Micronhoz.3, Van olyan vészforgatókönyv, hogy megkérik Nvidiát tervezze át az A100 -at az Intelhez és biztosítsa a két cég a megfelelő koherens összekötetéshez szükséges hátteret. van az a pénz ...
Eza legmerészebb ötlet,de van olyan vélemény is , hogy ez azért lenne , mert nem akarják hogy ezt a projektet is AMD valósítsa meg , mert nem bíznak bennük teljesen valamint nem szeretnék, hogy egy cég kezében összpontosuljon az összes fontosabb rendszerük.
Addison Snell ezt szeretné, ebben bízna ,de egyre jobban derülnek ki a dolgok, hogy az One APi még sem olyan mint ahogy a kékek előadták...Érdekes játék lesz az biztos de a leglogikusabb az lenne ha várnának még vagy AMD lenne teljesen, aka Frontier. Jelenleg egyre kevésésbé bíznak az Intelben hogy ha sikerül is a Ponte, az valóban hozza azt a teljesítményt amit ígérnek és úgy néz ki addigra AMD és Nv is szintet lép ráadásul.
-
#41715
 Abu85
HÁZIGAZDA
Petykemano
#41701
Abu85
HÁZIGAZDA
Petykemano
#41701
Abu85
HÁZIGAZDA
válasz
Petykemano
#41701
üzenetére
A fogyasztást a mai hardvereknél eleve a fogyasztási limit befolyásolja. Ha befogásra kerülnek a nem használt részegységek, attól a fogyasztási limit nem változik, maximum nem x MHz-es tartományban lesz az órajel, hanem x-200 MHz-esben.
-
#41698
 FollowTheORI
nagyúr
Petykemano
#41697
FollowTheORI
nagyúr
Petykemano
#41697
válasz
Petykemano
#41697
üzenetére
Ebbe nincsennek benne az új technológiák, tehát oké valami gyorsult vagy nem ennyit vagy annyit, de mennyivel látsz szebb dolgot cserébe?
Pl a 3090 vs 2080Ti-be tuti nincs benne az RT + DLSS, vagy az hogy 4K-ban mennyivel erősebb átlagosan.
-
#41693
 HSM
félisten
Petykemano
#41686
HSM
félisten
Petykemano
#41686
HSM
félisten
válasz
Petykemano
#41686
üzenetére
Pedig az izgalmas dolgok 0,95V alatt kezdődnek azokkal a GPU-kkal, amit meg sem néztek. Szerintem brutális, amit tud, nálam 0,85V-on stabil 1100Mhz-en.
[link]
Az egy egészen más dolog (termékpozicionálás), hogy gyárilag nagyon messze a csip perf/watt optimumától lett megállapítva az órajel. -
#41691
Abu85
HÁZIGAZDA
Petykemano
#41690
Abu85
HÁZIGAZDA
válasz
Petykemano
#41690
üzenetére
Az 580-on és az 590-en eltérő lapkák vannak. Előbbin Polaris 20, utóbbin Polaris 30. A Polaris 30 nem is 14 nm-es node-on készül. Természetes, hogy két teljesen különböző lapka ebben eltér.
-
#41687
Abu85
HÁZIGAZDA
Petykemano
#41686
Abu85
HÁZIGAZDA
válasz
Petykemano
#41686
üzenetére
Minden VGA-t alul tudsz feszelni, csak kérdés, hogy az az alulfeszelt eredmény átmegy-e a GPU-ra írt terhelésszimuláción. Nem véletlen van az a feszültség oda állítva, ahova. Ha egy GPU-t nagyjából 40-50%-osan terhelő játék lenne a mérce, akkor persze lehetnek alacsonyabb feszültséget alkalmazni, csak bajban lenne a termék, ha szembejön mondjuk a Strange Brigade, ami azért 60-70%-osan is leterheli a GPU-kat.
-
#41685
Abu85
HÁZIGAZDA
Petykemano
#41684
Abu85
HÁZIGAZDA
válasz
Petykemano
#41684
üzenetére
Mert 16 nm-en jött be FinFET, és elsőre marhára jól kezelhető volt. A gondok 10 nm-en kezdődtek vele. Majd a GAAFET is kezelhető lesz 3/2 nm-et. Aztán 1 nm-en már lehetnek vele problémák.
Az AMD is nagyon jól eltalálta a 14 nm-t. Ha nem találták volna el jól, akkor a Vega 20 jobban elhúzott volna már elsőre.
Ebben érzem, hogy mindenki a bérgyártót akarja belelátni, de nem sok közük van ehhez. Tapasztalat, tapasztalat, tapasztalat. Ez a három dolog kell a modern node-okhoz.
-
#41682
Abu85
HÁZIGAZDA
Petykemano
#41681
Abu85
HÁZIGAZDA
válasz
Petykemano
#41681
üzenetére
Ha megnézed az A100-at, ami a TSMC-nél készül, az se hatékonyabb ám. Sőt, FP32 számítási kapacitásban alatta van a GA102-nek, miközben fogyasztásban felette. A probléma nem igazán a gyártástechnológia, hanem az, hogy az NV akkor a 12 nm-t ismerte, mert a 16 nm half-node-ja volt, míg most a 7 és 8 nm-t nem ismerik, nem is vihették át a dizájnkönyvtáraikat rá, most van velük először dolguk. Ez nem igazán a bérgyártó mondjuk úgy felelőssége, a FinFET tényleg nehezen kezelhető alacsony csíkszélességen, és ki kell azt tapasztalni.
Ugyanezt rá lehetne húzni a Vega 20-ra is, ami 7 nm-en jött. Annál is hasonló lett volna a grafikon a Vega 10-hez viszonyítva. Aztán látod, hogy hova jutottak a Renoirral.
-
#41680
Yutani
nagyúr
Petykemano
#41678
válasz
Petykemano
#41678
üzenetére
Zseniális!
-
#41679
b.
félisten
Petykemano
#41678
válasz
Petykemano
#41678
üzenetére
Jól tolod
-
#41677
b.
félisten
Petykemano
#41676
válasz
Petykemano
#41676
üzenetére
hát akkor lassan gyertek át az Nvidia találgatósba mi meg átballagunk az AMD -s be .
Én akkor kezdeném.
Nincs semmi baj a driverekkel, user error.
-
#41670
Abu85
HÁZIGAZDA
Petykemano
#41669
Abu85
HÁZIGAZDA
válasz
Petykemano
#41669
üzenetére
Persze. A mostani helyzetnek már lőttek. Mire megoldják rég a második 5 nm-es lapkáját hozza az AMD, és akkor ugyanott lesznek, mint ma. Ezt a problémát át kell ugraniuk. Nem is azt mondom, hogy a TSMC-nél, mert náluk azért nagy a licit az 5 nm-re. Mehetnek a Samsunghoz is. Csak legyenek ott a kezdésnél, mert akkor a második körben nem kerülnek hátrányba.
Jövőre az AMD csak szerverbe hozza a Zen 4-et. Amikor ebből lesz desktop, akkor bőven lesz új verzió, ha kell. Bele van tehát már tervezve, hogy a Zen 4-nek esetleg problémái lesznek 5 nm-en. Ha nem, akkor az még jobb, nem kell az új revízió.
-
#41668
Abu85
HÁZIGAZDA
Petykemano
#41667
Abu85
HÁZIGAZDA
válasz
Petykemano
#41667
üzenetére
Eleve az NV-nek már rég váltania kellett volna. Szóval a 7-8 nm már a késői váltással elúszott. Innen már előre kellene tekinteni az 5 nm-re.
Az AMD eleve a szerverrel megy először 5 nm-re. Kis Zen 4 chiplet, amit majd rádobnak az EPYC-ekre. Ebből baj nem lehet. A probléma a későbbi lapkáknál jöhet elő, de akkorra lesz tapasztalat.
Amíg a Windows nem bizonyítja, hogy képes jól kezelni az eltérő teljesítményű magokat, addig az AMD biztosan távol marad ettől. Az Intel azért megy erre, mert nincs más választása, de a Zen magok nem csak gyorsak, hanem keveset is fogyasztanak, ezért tudnak 64 magot belerakni akkora fogyasztásba, ahova az Intel csak feleennyit. -
#41665
Abu85
HÁZIGAZDA
Petykemano
#41658
Abu85
HÁZIGAZDA
válasz
Petykemano
#41658
üzenetére
Többször írtam már, hogy a FinFET közeledik a végéhez. Mi volt az AMD-nek az első 7 nm-es lapkája? A Vega 20. Nem volt valami jó a fogyasztásban, de utána mindegyik javult, és most a Renoir már igen nagy órajelen is keveset fogyaszt. A kettő közötti különbség a tapasztalat.
Az NV-re is ugyanazok a fizikai törvények vonatkoznak, így elsőre nekik sem sikerült jól a FinFET egy modern node-on. Ez van. Hozni kell jövőre egy másikat 8 nm-re, és az jobb lesz, majd egy harmadikat, és az már igen jó lesz, közel az elméleti maximumokhoz.Amíg a GAAFET nincs itt, addig elsőre nagy mázli kell, hogy összejöjjön egy lapka egy új node-on. Ez nem igazán a Samsung és a TSMC hibája, hanem az adott node-ra vonatkozó tapasztalat hiánya.
-
#41659
 Ragnar_
addikt
Petykemano
#41658
Ragnar_
addikt
Petykemano
#41658
Ragnar_
addikt
válasz
Petykemano
#41658
üzenetére
"Ezért tolja ezúttal a 4K szekeret az nvidia, miközben kevés a 4k user."
Meg lehet, hogy azért is, mert van olyan engine, ahol 1080p-ben a 3080 CPU limites egy húzott 10700k-val is.. (Alig megy jobban, mint 1440p-ben)
-
#41655
Laja333
őstag
Petykemano
#41654
Laja333
őstag
válasz
Petykemano
#41654
üzenetére
Nem, ez úgy néz ki, hogy a Cola oldalára rá van nyomtatva az ajánlott fogyasztói ár, amit vagy betart az üzlet, vagy nem.
-
#41653
b.
félisten
Petykemano
#41651
válasz
Petykemano
#41651
üzenetére
igen jelenleg az Fe a legolcsóbb.de gyakorlatilag ez egy kamu MSRP, mert nem lehet venni elég FE-t állítólag, erről szől a fentebb említett kommentben lévő cik. Aztán mi az igazság majd kiderül.
-
#41652
#25237004
törölt tag
Petykemano
#41651
#25237004
törölt tag
válasz
Petykemano
#41651
üzenetére
Ajánlom a 41639-es kommentet ebben a topicban.
-
#41650
b.
félisten
Petykemano
#41649
válasz
Petykemano
#41649
üzenetére
Most a legolcsóbb lett a legjobb hűtéssel talán nincs 100 $ felár.,de nincs elég készlet belőle. Az AIB kártyák meg nem MSRP áron mennek. Azaz a meghírdetett MSRP ár így, hogy nincs FE elég ,egy marketing érték, a valós árak 720-750 € tól indulnak de a jobb modellek 800 +.
-
#41640
b.
félisten
Petykemano
#41638
válasz
Petykemano
#41638
üzenetére
attól hogy ők megtehetik, megteheti ezt Intel is ha csak Licenszelnek.
De így ARM alapon nem lesz minden nyitott,a szerver és HPC vonal és Nvidia saját fejlesztései i az így kialakított speciális magok és architektúrák vagy akár alaplapok nem lesznek nyitottak. Az hogy lesznek bizonyos dizájnok, amik licenszelhetők az nem jelenti azt hogy mindent ki kell adnia Nvidiának és az így összeálítot gyorsítók biztos nem lesznek nyíitottak se az összeköttetés amit ahhoz fognak használni.
Ez még minimum 3 év szerintem, de inkább több amúgy a véleményem szerint. -
#41637
b.
félisten
Petykemano
#41633
válasz
Petykemano
#41633
üzenetére
tegnap a másik cikk alatt már leírtam de ide is beteszem beidézem, hogy szerintem nvidiát a cloud gaming és maga a Mobil piaci bevétel másod-harmad sorban érdekli csak :
"
Hogy őszinte legyek és lehet hogy ez most oltári nagy szamárságnak tűnik, de én azt gondolom Nvidának az ARM mint olyan és a nyílt licenszeik a mobil szegmens stb egy pozitív hozadéka a valódi terveiknek ,mellékvágány csak. nem érdekli annyira , mint sokan gondljuk szerintem. ( persze igen, csak nem elsődlegesen)
A valódi céljuk szerintem egyébként az, amit írsz, csak nem egészen úgy .
Ez is csak egy vélemény ahogy én gondolom:
Egy komplett ökoszisztémát kialakítani szerver és exascale vonalon kizárolagos( és így ahogy írod a másik két versenytárs elött zárt ) rendszerben.
AMD és Intel az X86-64 vonalon építkezik és hülye lenne késöbb beengedni Nv-t pusziért és Nv is hülye lenne tőlük függni, hogy bejuthasson egy egy zsíros exascale/ A.I. projektbe.
Magyarul lesz egy külön rendszere ,amiben olyat tud kínálni, amibe a másik két fél nem tud bejutni, az ARM alapú szerverekbe és porjektekbe amihez Nv kialakít egy rendszert és ez fordítva is igaz , onnentól felejtős lesz az, hogy X86 rendszerekbe ő bejuthasson az AMD / Intel mellé. Ez a mostani nyílt , szabadon licenszelhető rendszerben nem lenne megvalósítható.
Intel mellé még addig igen, míg Intel nem dobja piacra a saját gyorsítóit.
Mit eredményez ez?
Azt hogy egyik cég sem lazíthat mostantól. Nvidának úgy kell fejlesztenie mind a CPU és mind a GPU vonalát hogy az előnyősebb / gyorsabb legyen az AMD és Intel X86 konfigurációinál.
Intel nagyon gyorsan kénytelen lesz olyan GPu-t / gyorsítót fejlszteni ami ütőépes lehet AMD és Nvidia termékeivel, ha nem, akkor gyakorlatilag végük, mert Nvidia nem fog adni nekik gyorsítót a CPU-k mellé és AMD sem.
Magyarul a nagy összeborulás az AMD vel és így az Nvidia kizárása hamarosan visszájára sül el Intelnek, ha nem lép SOS mind GPu, mind CPu fronton, mert a versenytársak elötte járnak már GPU vonalon évekkel és CPu fronton is AMD, de ARM sincs elmaradva.
AMD x86 vonalon kénytelen Intelt szemelött tartani, tehát így az helyett hogy 3 szereplős lenne az x86 piac 2+1 szereplős és elkülönült lesz egy vonal. Szerintem ez egy nagyon okos húzás Nvidiától, mert elszakad a két licensztulajdonsotól, mert bármit lép azt x86 részen kell ellensúlyozni a másik két gyártónak, és ez fordítva is igaz,de neki nincs konkurenciája a saját architektúráján egyelőre és nem fogja beengedni se AMD-t se Intelt bizonyos fejlesztésekbe, vagy biztosít nekik licenszet és cserébe kér X86-64 et.( ezt amúgy kétlem)
Szóval egyszerre kockázatos és szeniális dolog ez, de egy olyan piacot céloznak meg vele(a szerver piac 90 % része még mindíg Intel) ami lassan el kezd felosztódni,2-3 éven belül Intel elveszti a dominanciáját és ez egy akkora pénz, ami onnan lehullik, amekkora simán ellensúlyozza ezt a rizikot, ha bejön.
Ez mellett az ARM mobil fejlesztései lehetnek nyitottak és fent vázolt forgatókönyvet pár bizonyos rendszerre ami saját fejlesztés lesz ,fogja Nv bevezetni azt gondolom."Továbbra is azt gondlom, hogy egy taktikai húzás volt, hogy komplett renszert kínáljanak, ne kelljen függniük a másik két cég x86-64 licenszétől és közben tőlük elzárt rendszert építsen ki, amiben a másik két cég nem tud belenxyúlni és résztvenni benne. Ezt ha nyít forráskódon probálja meg nem tudná végrehajtani.
Intel került így a legnagyobb szarba amúgy, mert most kell az a Xe gyorsító, jobban mint bármikor... -
#41634
Abu85
HÁZIGAZDA
Petykemano
#41633
Abu85
HÁZIGAZDA
válasz
Petykemano
#41633
üzenetére
Ha a cloud gaming számítana, akkor az NV ennyi pénzt olyan világszintű hálózati infrastruktúra fejlesztésébe ölt volna, mint amilyen van a Google-nek és a Microsoftnak. És itt nem a szerver telepítése a lényeg, hanem az, hogy rakjál mögé egy szolgáltatást. Például a Google keresőt, mert attól, hogy kiépíted a szervert, még nem fog állandóan működni. A Google azért van előnyben, mert nekik ott a szervereket igénylő keresője, és a szabad kapacitásukat elhasználják cloud gamingre.
Na most egy szolgáltató nem fog csak azért szervereket kiépíteni, hogy legyenek, mert akkor nem működnek. Muszáj valami szolgáltatás rájuk, mert a cloud gaming időszakos, tehát amíg nem játszanak elég sokan a peremhálózaton, addig a szerver minden percben egyre több veszteséget termek. És itt mindegy, hogy ARM procit adnak-e ingyen, akkor sem fogják megépíteni, ha azt a tetemes veszteséget le kell nyelniük.
A TSMC nem veri fel az árakat. Van kapacitás, kiírják licitre, és aki többet fizet, az viszi. Ez sosem fog változni, mert a TSMC-nek elemi érdeke, hogy a gyárai teljes kapacitással működjenek.
-
#41597
Yutani
nagyúr
Petykemano
#41596
válasz
Petykemano
#41596
üzenetére
Szerintem összefügghet azzal, amit Abu mondott a GDDR6X elérhetőségéről. Egyelőre inkább több kártyát adnak ki kevesebb memóriával, de ha kijön az AMD a nagyobb memóriás GDDR6 kártyákkal és a termelés is felfutott a Micronnál, akkor jöhetnek a dupla memóriás Empír kártyák.
-
#41595
Yutani
nagyúr
Petykemano
#41594
válasz
Petykemano
#41594
üzenetére
Hát ha jön egy 16GB Navi21 a 3080 köré és egy 12GB-os a 3070 köré, akkor az NV-nek is hoznia kell nagyobb memóriás kártyákat. Gondolom nem csak a magyar NV vásárlók keveslik a 8 és 10GB memóriát 4k-ra.
-
#41593
Yutani
nagyúr
Petykemano
#41588
válasz
Petykemano
#41588
üzenetére
Mi az oka? Ki akarják csinálni teljesen az AMD-t.
-
#41590
 Malibutomi
nagyúr
Petykemano
#41588
Malibutomi
nagyúr
Petykemano
#41588
Malibutomi
nagyúr
válasz
Petykemano
#41588
üzenetére
Sok a rossz chip ami csak vagottnak jo?
-
#41589
wjbhbdux
veterán
Petykemano
#41588
wjbhbdux
veterán
válasz
Petykemano
#41588
üzenetére
az előző generációban (16+20) 13 kártyájuk volt, ehhez képest ez még sehol nincs
-
#41557
Abu85
HÁZIGAZDA
Petykemano
#41554
Abu85
HÁZIGAZDA
válasz
Petykemano
#41554
üzenetére
Úgy lehet, ahogy régen az AMD is ott volt tranzisztorsűrűségben az Intel nyakán, hiába volt 28 nm az AMD, és 14 nm az Intel. A Carrizo ugye 12,7 Mtr/mm2 volt, míg a Broadwell LCC 13 Mtr/mm2.
A legfőbb különbséget a dizájnkönyvtár adja. Ezt egy csomó mindenre rá tudod tervezni, és ugyan az áramkörök egyes elemei eléggé fixek, tehát a cache-ek esetében azért nem fogsz sokat hozni egy máshogy optimalizált dizájnkönyvtárral, az ALU-k, a buszok, illetve a vezérlést biztosító részegységek tekintetében azért nagyon is lehet a magas tranzisztorsűrűségre optimalizálni.
Van tehát egy viszonylag nagy tartomány, amit alapvetően lehet célozni a tranzisztorsűrűség tekintetében. Minél nagyobb ez az érték, annál rosszabb lesz az órajel skálázhatósága, illetve annál rosszabb a fogyasztási karakterisztika, de ha ezek nem zavarnak, akkor egy korábbi generációs node-dal megközelítőleg el lehet érni egy újabb generációs node tranzisztorsűrűségét. Az NV ez bevállalta, viszont nem tudnak egyszerűen 2 GHz fölé menni órajeleben, ahogy az AMD olyan egyszerűen teszi a PS5-nél az RDNA2-vel, vagy fixen 1,825 GHz-re sem képesek, ami az XSX paramétere. Az Ampere fail-safe órajele csupán 800 MHz, nagyjából a fele az XSX ilyen paraméterének. ilyen minden architektúrában van a power virusok miatt, ha esetleg a terhelés olyan extrém lenne, akkor a GPU nem fagy le, hanem visszavált egy nagyon alacsony órajelre, kb. soha nem következik be, de ha mégis, akkor ott van egy mód, hogy ne fagyjon a hardver, ugye AVFS nélkül a Microsoftnak ezt az alapszintű órajelet kell alkalmaznia az Xboxnál. A PC-s RDNA2 fail-safe-je 1,79 GHz lesz, picit kisebb, mint a boxé.
Az AMD a saját GPU-ira egy ideje már nem density optimized, hanem performance optimized dizájnkönyvtárat használ. Még az APU-k is úgy vannak megcsinálva, hogy van egy mixed dizájnkönyvtár, ami a CPU-ra density, míg a GPU-ra performance szinten dolgozik. Ezért van olyan veszettül megküldve a Renoir Vegájának órajele.
Ez ilyen balansz játék tehát. Ha nagyon szükséged van a tranyóra, akkor be lehet áldozni a fogyasztást és az órajelet. Ha annyira nincs, akkor érdemes valami ideális egyensúlyt találni. Ha magas órajelre és jó fogyasztási karakterisztikára van szükséged, akkor be lehet áldozni a tranyósűrűséget értük.
-
#41556
paprobert
őstag
Petykemano
#41554
paprobert
őstag
válasz
Petykemano
#41554
üzenetére
Úgy tűnik, hogy az Nvidia is megtalálta a sűrűség-optimalizált dizájnkönyvtárat.
Magyarázná az órajeleket.
-
#41382
b.
félisten
Petykemano
#41381
válasz
Petykemano
#41381
üzenetére
ne már ez komoly?
és újra megismétli magát a történelem.
Ez azért két dolgot nagyon szépen előrevetíthet és bocsánat hogy megint áthajlóan ugyan de nvidia lehetőségekkel gondolkozok.1, Az AMD az IF segítségével saját gyorsítóival és CPU -val így még nagyobb konkurencia lesz az Intelnek, ez már kifejezetten aggályos rájuk és egyébként az egész piacra nézve. Ha ezt meglépi AMD / már pedig meglépi/ akkor igazából konkurenciát a CCIX integrálásáig( ha lesz ilyen és így szinte biztosra vehető, hogy AMD nem fogja erőltetni ) egyik gyártó sem tud megfelelő teljesítményt felállítani a pirosak ellen szerver fronton.
hosszabb távon ez azt jelentheti még ha kicsit futurisztikus is amit leírok :
.- hogy Intel kénytelen lesz megadni az Nvdiának az NV link támogatást , ha nem akarja hogy kigolyózzák.( Így kérdés hogy nvidiának kelleni fog e Intel.támogatása, ha ővék lesz/ lenne az ARM)
- Még is csak kelleni foga piacnak az ARM - Nvidia páros hogy több szereplős maradjon ez a szegmens .
- ezek hosszú távú folyamatok, az elkövetkező pár évben AMD teljese átfordíthatja a szerverpiacot magának mivel kész interfésszel megfelelő gyorsítóval és CPU val rendelkezik a piacon már ennek az évnek a végére. -
#41312
 gejala
őstag
Petykemano
#41311
gejala
őstag
Petykemano
#41311
gejala
őstag
válasz
Petykemano
#41311
üzenetére
És akkor arról még nem is beszéltünk, hogy attól még, ha NV sokat is fogyaszt majd, AMD még nem biztos, hogy keveset fog. A 7000-es széria óta nem adtak ki olyat, aminek relatíve alacsony lett volna a fogyasztása (mondjuk ilyen Pascal szinten), ellenben mindig túlhúznak mindent +5 fps nyereségért..
AMD a középkategóriába is képes 150-200W kártyákat hozni, felsőben meg alapból bőven 200W fölött járnak. 5700XT is annyit fogyaszt, mint a 2080, pedig jobb gyártástech RT magok nélkül. -
#41271
solfilo
veterán
Petykemano
#41270
válasz
Petykemano
#41270
üzenetére
köszi a találatot
-
#41234
Yutani
nagyúr
Petykemano
#41233
válasz
Petykemano
#41233
üzenetére
Szerintem CoreTeks ebből vette az ábrákat. Mindjárt nem fura.
Egyébként a múltban is használtak teáskannát 3D modellezés bemutatókon, legalábbis így emlékszem.
-
#41233
Petykemano
veterán
Petykemano
#41228
Petykemano
veterán
válasz
Petykemano
#41228
üzenetére
Robust, Efficient Multiprocessor-Coprocessor Interface - Nvidia
(src)Különös, hogy visszaköszön a teáskanna
-
#41229
Yutani
nagyúr
Petykemano
#41228
válasz
Petykemano
#41228
üzenetére
Elég érdekes. Várom a vs videót.
-
#41220
paprobert
őstag
Petykemano
#41219
paprobert
őstag
válasz
Petykemano
#41219
üzenetére
10GB piszok kevés lesz egy high end next-gen kártyához... csalódott lennék ha ez igaz lenne.
-
#41201
 gV
őstag
Petykemano
#41200
gV
őstag
Petykemano
#41200
gV
őstag
válasz
Petykemano
#41200
üzenetére
közel sincs annyi cache benne:
GA100: L1 24576KB + L2 40960KB = 65536KB
Matisse: L1 768KB + L2 4096KB + L3 32768KB = 37632KB
sőt szerintem az L2 49152KB a chipen csak mivel nem megy a teljes 6144bit mem sem csak 5120bit ezért az L2 is le van tiltva akárcsak a 1080Ti-nél -
#41199
Abu85
HÁZIGAZDA
Petykemano
#41198
Abu85
HÁZIGAZDA
válasz
Petykemano
#41198
üzenetére
Azért 13 MB-ot nem neveznék kevésnek. És akkor még a CPU/GPU L1-eket nem is számoltam.
A Navi 10-ben például 4 MB L2 van. -
#41197
Abu85
HÁZIGAZDA
Petykemano
#41195
Abu85
HÁZIGAZDA
válasz
Petykemano
#41195
üzenetére
A cache-ből. A gyorsítótárakat miatt lesz nagy a tr/mm2.
-
#41126
b.
félisten
Petykemano
#41125
válasz
Petykemano
#41125
üzenetére
Egyetértek nem fogják mainstreambe a legdrágább gyártástechonógiát behozni,de a non EUV nem nevezhető szerintem ma már annak a TSMC nél ,valamint úgy gondolom elég zsíros falat Nvidia ahhoz, hogy csak úgy elengedjek a Samsunghoz őket... Erre szokták azt mondani van az a pénz és meg az is lehet hogy TSMC adott olyan lehetőséget/ ajánlatot a zöldeknek hogy a 7 nm esetleg a Geforce vonalra is bejöhet De szerintem felesleges lenne egyenlőre, ha csak nem tartanak valamelyik konkurenciától vagy az is lehet hogy jól sikerült az érkező navi széria és mégiscsak kell pénzt áldoznia a bőrjakósnak erre...
Igen valószínűleg azt jelenti hogy le kellene mondaniuk feleslegesen haszonról,de az utóbbi 1 évben úgy látom Nvidia felfogása és hozzáállása erősen megváltozott, egyre több minden jön tőlük fejlesztés gyanánt és nyitottabbak lettek szabványok/ támogatások terén, és dolgoznak a jövőjükön...Nem követik el az Intel hibáját.
Én azt gondolom látva az Intel chiplet rendszerét és azt hogy Nvidia is erre tervez a Hopper-rel az a cég aki most ebbe nem lép be az nagyon lemarad.
Elméletileg az MCM egy akkor ugrást hozhat hogy a mostani legerősebb rendszerek is lenullázódhatnak( idézőjelben persze) értelmes skálázódás esetén.
Biztos vagyok benne hogy AMD is kénytelen ezt minél előbb abszolválni és fogják is. Arra kellene rábeszélnie Pepének Lisa-t, hogy ne elsőnek hozzák ki ,mert belebuknak megint abba hogy az ő kárukon tanul a többi szereplő ezt hagyjuk meg Kodurinak és az Intelnek.....Azt gondolom CDNA nem lesz még az,mert Amperevel megy ringbe, CDNA 2 pedig az lesz, mert Hopper ellen csak úgy lesz esélyes szereplő... -
#41123
b.
félisten
Petykemano
#41121
válasz
Petykemano
#41121
üzenetére
és ennyit arról ami Cifu és Abu között téma volt, hogy Nvidia mit tud megvenni gyártókapacitásban és csíkszélben ha akar és mi mit ér meg nekik. Kíváncsi leszek nagyon.
Nem tartom kizártnak egy MCM bejelentését hamarosan a zöldeknél 5 nm-n...
mert ne már hogy az áruló Koduri fogja itt a mellét verni a kékeknél. Majd mi megmutatjuk. (ezért szeretem Nvidiát amúgy, ha ez igaz lesz amit írtam. ) -
#41091
b.
félisten
Petykemano
#41090
válasz
Petykemano
#41090
üzenetére
Ezt hogy érted ?
-
#41063
b.
félisten
Petykemano
#41062
válasz
Petykemano
#41062
üzenetére
Kíváncsi leszek.
64 TOPS INT8 ban kb a Tesla V100, igaz ez erre kihegyezett gyorsító. -
#40941
Pug
veterán
Petykemano
#40939
válasz
Petykemano
#40939
üzenetére
Akkor magyarán ez nem "GPU piaci penetráció",.... de semmi baj
Adsz valaminek egy fals elnevezést és ugyan abban a sorban le is írod, hogy miért nem valid az elnevezés... esetleg politkusnak készülsz?
-
#40913
Pug
veterán
Petykemano
#40898
válasz
Petykemano
#40898
üzenetére
Mondjuk lehet én vagyok balfék, de a Corona-hoz tartozó disease csoportot nem találtam a setting-ek között...
Szerk, nem szóltam, a GPU section arra van dedikálva... csak az meg nálam nem indul el

-
#40899
Locutus
veterán
Petykemano
#40898
Locutus
veterán
válasz
Petykemano
#40898
üzenetére
Ennek az eredményeihez amúgy hogyan és mennyire férnek hozzá vajon USA-n kívüli laborok és cégek, hogy kezdjenek vele valamit? A weboldal infóiból ítélve nekem eléggé US-onlynak tűnik a dolog, az összes támogató, és labor is ottani.
-
#40838
b.
félisten
Petykemano
#40837
válasz
Petykemano
#40837
üzenetére
Hát igen, ez egy takarékosabb megoldás.
-
#40780
 Cifu
félisten
Petykemano
#40779
Cifu
félisten
Petykemano
#40779
válasz
Petykemano
#40779
üzenetére
Qualcomm, Intel, nVidia...
-
#40694
 _drk
addikt
Petykemano
#40693
_drk
addikt
Petykemano
#40693
_drk
addikt
válasz
Petykemano
#40693
üzenetére
Még egyelőre felesleges feltenni a kérdést, mert nem működik!
Mihelyst működik, egyértelmű lesz a válasz.
Ha már csak egy szolgáltatást kell fizetni, minek fizetnél hardvert?
Mondjuk a Stadia megoldás az nagyon burzsuly, nem élet képes hogy kétszer fizetsz, és ezt még bármikor lelőhetik...
Másik oldalról a gamer notik sose érték meg, az játékra nagyon feláras.
De kezdetben ezek az üzleti notik nagyon jó célcsoport. -
#40692
_drk
addikt
Petykemano
#40687
_drk
addikt
válasz
Petykemano
#40687
üzenetére
Szerintem a notisok a legnagyobb a célcsoportja a streamingnek. Rengeteg van a piacon ami teljesen alkalmatlan játékra, a tulajnak esze ágában sincs lecserélni mert az i5ös boldogan viszi az Excelt és chrome-ot.
És hát ügye csak játékra kiadni annyit?
Azt ne felejtsük el hogy ez csak 5 dollár mondjuk. Havi kiadásban simán kivitelezhető.
A 2-300 ezer forint viszont elég húzós egyszeri kiadásra, hiába 3 évre szól, és minden van amit akarsz.
Hc gamernek sose lesz jó, de Casual szintre tökéletes. -
#40691
Cifu
félisten
Petykemano
#40690
válasz
Petykemano
#40690
üzenetére
Tudom, hogy az Activision-Blizzard most vonta vissza magát a GFN-ről, de azt gondolnám, hogy a cloud gaming szolgáltatók meg fogják tudni oldani. Mármint úgy értem, hogy még a legnagyobb kiadóknak is szüksége van online terjesztési módra. Ez lehet a Steam, vagy a gog, vagy az Epyc saját game store-ja.
Meg is válaszoltad a kérdésedet. Tehát én azt sejtem, hogy nem fogod tudni megoldani egy 5$-os előfizetéssel azt, hogy bármilyen játékot játsszál, mert az exkluzív címek utáni vadászat lesz a vásárlókat begyűjtő kampány lényege.
Ahogy nem tudsz egy mozi/sorozat stream szolgáltatóval az összes sorozatot és mozifilmet élvezni, úgy esélyesen egyetlen cloud gaming szolgáltatással se fogod tudni játszani az összes játékot. Kell majd a GFN mellé Google Stadia, Amazon, PSN, stb...
-
#40689
 Ribi
nagyúr
Petykemano
#40687
Ribi
nagyúr
Petykemano
#40687
Ribi
nagyúr
válasz
Petykemano
#40687
üzenetére
3 éven át 5$ az kb 60k, a vga is kb ennyibe kerül. És akkor nem kell Cifu által írt dolgokkal foglalkoznod. Illetve amikor a legtöbb embernek még a szerver lag is sok, akkor milyen játékélményre lehet számítani magánál a játéknál? Volt pár demo és a "nem tökéletes minden" esetén játszhatatlan volt az egész.
-
#40688
Cifu
félisten
Petykemano
#40687
válasz
Petykemano
#40687
üzenetére
Milyen érvet lehet felhozni?
1.: Bármilyen meglévő játékkal játszhatsz (pl. Armed Assault 3-at nem játszhatok GFN-en, ahogy Red Dead Redemption 2-őt sem).
2.: Bárhol is vagy, függetlenül az internet minőségétől játszhatsz (laptopot gamingre értelmesen az vesz, aki utazik rendszeresen).
3.: Lehetőség van a moddingra, addonokra. -
#40650
b.
félisten
Petykemano
#40649
válasz
Petykemano
#40649
üzenetére
Valószínűleg megkörnyékeznek több platformot. Akár Xbox is szóba jöhet a Shield mellett, valamint helyi szolgáltatókkal akarnak szerződéseket kötni, pl lehetséges , hogy hamarosan Telekomnál is akár elérhetővé válik.
Ennél jobban a hétköznapi emberekhez nem tudnák eljuttatni a felső kategóriás PC játékot. Hasonló üzleti modellt látnak benne szerintem ,mint a mobil játék piac, ahol olyan emberek millióit érik el, akik amúgy soha nem költenének videokártyára, így ez akár még jobb befektetés is lehet mint a PC gamerek jelenlegi köre.
Persze ez csak terv, de a Stadia drága, nem mindenhol elérhető,direkt marketing kell, hogy az emberke ezt megvegye,bizonyos csoportokra hat, mondjuk úgy kockákra akik nem akarnak PC fejlesztésre költeni, rendelkeznek saját játékokkal és elérhetően gyorsa kiszolgálás.
Míg mondjuk ha egy egyszerű emberkét a Telekom vagy a Digi saját felületről saját gyors és közeli elérésű peremhálózatártól ,mint egy videotéka, odateszi az teljesen más.
Ráadásul Nvidiánál hozzácsapod a saját steam fiókodat plusz kapod ingyen a játékokat, még arra sem kell költened.Lényegesen jobb üzleti modell mint a Stadia vagy Ps Now, mert nem igényel saját kiépítésű kiszolgálóhálózatot, nem igényel hardveres kötöttséget, hanem a szolgáltatók saját rendszerét használja.. Szerintem zseniális húzás lehet , de nagy munkát és marketinget igényel.













 . Átverős a neve, az valójában USA keleti part.
. Átverős a neve, az valójában USA keleti part.




![;]](http://cdn.rios.hu/dl/s/v1.gif) Én is erősen gondolkozom rajta!
Én is erősen gondolkozom rajta! 



























Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Megbízhatatlan oldalakat ahol nem mérnek (pl gamegpu) ne linkeljetek.
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- iPhone topik
- Nyíregyháza és környéke adok-veszek-beszélgetek
- Milyen légkondit a lakásba?
- Kompakt vízhűtés
- Nintendo Switch 2
- Felirat égetés filmre !!
- EA Sports WRC '23
- Lakáshitel, lakásvásárlás
- Mielőbb díjat rakatnának a görögök az olcsó csomagokra az EU-ban
- További aktív témák...

- SzoftverPremium.hu
- Samsung Galaxy A22 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- Bomba ár! Dell Latitude 3550 - i5-5GEN I 4GB I 500GB I 15,6" HD I HDMI I Cam I W10 I Garancia!
- BESZÁMÍTÁS! ASUS TUF Z390-PRO GAMING alaplap garanciával hibátlan működéssel
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5700X 16/32/64GB RAM RTX 4060Ti 8GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest