Hirdetés
- iPhone topik
- Google Pixel topik
- Bemutatkozott a Poco X7 és X7 Pro
- Xiaomi 14 - párátlanul jó lehetne
- Xiaomi 13T és 13T Pro - nincs tétlenkedés
- Samsung Galaxy Watch5 Pro - kerek, de nem tekerek
- Milyen okostelefont vegyek?
- Samsung Galaxy S24 - nos, Exynos
- Karácsonyi telefonajánló 2025
- Samsung Galaxy S25 - végre van kicsi!
Új hozzászólás Aktív témák
-
#144
 stratova
veterán
SteaMMouse
#143
stratova
veterán
SteaMMouse
#143
stratova
veterán
válasz
 SteaMMouse
#143
üzenetére
SteaMMouse
#143
üzenetére
Szerencsés egybeesés, hogy ez éppen az a terület ahol már FX-8320 is veri Phenom II 1100T-t mind, teljesítmény mind fogyasztás/teljesítmény terén alapon és húzva is.
-
#143
 SteaMMouse
csendes tag
stratova
#142
SteaMMouse
csendes tag
stratova
#142
SteaMMouse
csendes tag
válasz
 stratova
#142
üzenetére
stratova
#142
üzenetére
Huhh ez szép terjedelmes válasz volt! A linkekért pedig külön nagy köszönet.

Ami azt illeti a váltásra azért kerül sor, mert 3D modellezéssel foglalkozom (3DS MAX, Adobe AE 3D animálás, apróságok). Ezek pedig már bizonyítottan keresztbe megették a gépem (azóta próbálok újítgatni, most készülök procit javítani, utána pedig a későbbiekben, ha nagyobb projektekhez is érek még RAMot is). Minden esetre köszi a tippet&tanácsot. Eddig sajnos nem igazán forgolódtam FX körben, denagyonlassan gatyába rázom magam. Köszi mégegyszer!
-
#142
stratova
veterán
SteaMMouse
#141
stratova
veterán
válasz
SteaMMouse
#141
üzenetére
20-ért már olyan léghűtést kapnál, hogy az FX földig hajol. De szerintem FX-8320 + Scythe Ashura. Sőt megkérdezheted a témájában, itt is. A szűk keresztmetszet esetleg az alaplapod lehet még a 4 +1-es VRM miatt, de esélyesen gyári FX-8350 órajelre egy FX-8320 is belőhető benne. Gondolom a 4.0 GHz-es 965-öt egy erősebb táp szolgálta, ha amúgy az a proci szépen muzsikál csak komoly multi esetén váltanám le FX-re mert c2c jobb a Phenom II egy szálon. Ha az FX vagy az OFF klubtagok között árulja valaki a portékáját, annak az előélete gyakran visszakövethető. Ha nem feszelték agyon, használtan érdekesebb lehet.
-
#141
SteaMMouse
csendes tag
SteaMMouse
csendes tag
Csak így még egy kérdés.
FX8320 vagy 8350? Tudom nem olyan kifejezetten apró órajel különbségről beszélünk, de megéri-e egy jóvalta olcsóbb 8320 megvásárlása és túlórajelezése vagy inkább fektessek bele jóvalta többet és akkor már egy 8350 jobb választás lenn? Tudom a túlórajelezés nem mindig a legjobb választás. De azért 20 000 Ft ide vagy oda (legalacsonyabb különbség is 14 000) azért igenis számít. -
#140
SteaMMouse
csendes tag
Rypejakten
#139
SteaMMouse
csendes tag
válasz
 Rypejakten
#139
üzenetére
Rypejakten
#139
üzenetére
Köszönöm szépen a tanácsod!
-
#139
 Rypejakten
addikt
SteaMMouse
#138
Rypejakten
addikt
SteaMMouse
#138
Rypejakten
addikt
válasz
SteaMMouse
#138
üzenetére
abszolút nem éri meg, akkor már inkább Vishera alapú FX8320-at vegyél.
-
#138
SteaMMouse
csendes tag
SteaMMouse
csendes tag
Nem tudom mennyi aktuális a dolog így 2 évvel később, de mennyire jó/rossz döntés beruházni egy 8150-re?

-
#135
 Kotomicuki
senior tag
Kotomicuki
senior tag
Kotomicuki
senior tag
Mindig tanul az ember, köszönöm a "vitát" a benne résztvevőknek!
Számomra ebből az szűrődött le, hogy az AMD még sem adja fel és megpróbál felnőni a feladathoz:
Ha már nem tudja a CPU-erőben befogni ellenfelét, akkor megduplázza a végrehajtó egységek számát - ez az nV ellen nagyjából bevált, "képösszerakó"-GPU szinten. Míg az FPU-t kicsit univerzálisabbá téve javítja annak teljesítményét.
Gondolom, majd ha kijön mindkét újdonság (Bull., HD 7k), és az ezen kettős közös erejét kihasználó programok (Catalyst szinten ez már megvalósítható lenne, vagy feltétlenül "külsős" támogatást igényelne? - Ha az első eset (jól!) megvalósítható lenne... ), akkor nagyot billen(het) a mérleg, eddig nem túl kedvezően álló nyelve az AMD felé - csak valóban jöjjenek azok a programok.
), akkor nagyot billen(het) a mérleg, eddig nem túl kedvezően álló nyelve az AMD felé - csak valóban jöjjenek azok a programok.
(Szegény, iNtel által megvásárolt, programfejlesztők: a 128 bites AVX-t sem tudták még rendesen alkalmazni/kihasználni, erre a 256 bitest kell majd mostantól erőltetniük... - kár, hogy nem építőjellegű okokból!)Vajh, hol tarthatnánk már, ha egymást erősítené (amivel - ezek szerint hamisan - érvelnek a jelenleg fennálló rendszer mellett) és nem egymást gátolná (sajnos, ez most a valóság - ha egy csoport monopolhelyzetbe kerül...) a konkurenciaharc - nem csak az informatikában...
-
#134
hugo chávez
aktív tag
P.H.
#133
hugo chávez
aktív tag
"Azzal a két sorral arra utalnak, hogy az Intel-nél 1 FADD- és 1 FMUL-jellegű 128 bites utasítás indítható órajelenként a két specializált végrehajtó egység miatt, X6-nál szintúgy, az AMD 2 FMAC portja viszont általános, a fentiek bármilyen kombinációját kezeli órajelenként."
Rendben, ez így logikusnak tűnik, de akkor az AMD-nek ezt kellett volna odaírnia, nem azt, hogy a Sandy FPU-i nem képesek egy ciklus alatt két 128 bites AVX műveletre, mert ez nem igaz. Azt, hogy leírnak egy kritériumot, a többit meg hozzágondolják (mármint, hogy nem csak 1 FADD és 1 FMUL, hanem vagy 2 FADD, vagy 2 FMUL végrehajtására is képes legyen ciklusonként) és utána a hozzágondolt extra kritériumnak nem megfelelőnek nyilvánítják a konkurencia termékét, inkább nem akarom minősíteni.
 (Ilyen húzásra inkább az Intel-től számítana az ember...
(Ilyen húzásra inkább az Intel-től számítana az ember...  )
) -
#133
 P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
válasz
 hugo chávez
#132
üzenetére
hugo chávez
#132
üzenetére
Abból az alapfeltevésből kell kiindulni, hogy a konkurencia a termékéről nem állíthatnak valótlanságot (házon belül azt mondanak, amit akarnak, ezért került X6 a táblázatba, nem Magny Cours, ezesetben a 48 helyén 96 szerepelne
 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).Azzal a két sorral arra utalnak, hogy az Intel-nél 1 FADD- és 1 FMUL-jellegű 128 bites utasítás indítható órajelenként a két specializált végrehajtó egység miatt, X6-nál szintúgy, az AMD 2 FMAC portja viszont általános, a fentiek bármilyen kombinációját kezeli órajelenként. Ennek kézzelfogható jelentősége főleg 2 szál párhuzamos futtatása esetén van, kevésbé "tartja fel" egymást a két thread.
-
#132
hugo chávez
aktív tag
P.H.
#129
hugo chávez
aktív tag
Még valamit nem értek: azon a slide-on, amit te és Abu mutattatok, az van, hogy a Sandy FPU-ja nem tud 2 128 bites AVX utasítást végrehajtani egy ciklus alatt (miért ne tudna?), de a "FLOPs/cycle (128-bit AVX)" részhez már 32 (ami ugye FPU-nként 2x128 bit) van írva. Akkor ez hogy van?
Én néztem volna be valamit, vagy az AMD anyaga még annál is nagyobb bullshit, mint ahogy eddig gondoltam? -

dezz
nagyúr
Sőt, a táblázat alapján a kétszerezés is csak akkor igaz, skalár FP esetén, ha egyszerre akarunk 2 FMUL-t vagy 2 FADD-ot. 1 FMUL + 1 FADD esetén, úgy tűnik, nincs változás. SSEx esetén szintén nem látok változást. És itt a változás hiánya fele peak/magot jelent... Ez valahogy nem áll össze.
-
P.H.
senior tag
Azért ráerőszakolás, mert
- ha (Intel-nél) egy magon vagy (AMD-nél) egy modulon egy szál fut, az kihasználhatja a teljes rendelkezésre álló mozgásteret
- ha egy-egy szál legalább átlagosan 1.0 FP-műveletet képes indítani órajelenként, már akkor is kihasználja két szál mind a Bulldozer, mind a Sandy Brige FPU-ja által nyújtott lehetőségeket, az X6-ét viszont még messze nem, ott így is lassabb lesz, mint "lehetne".
- 1.0 felett már akár akadályozhatják egymást, így szálanként akár lassabbak lehetnek egy X6-on futó szálhoz képest, de itt 4 modulos Bulldozer esetén is 8 szálról beszélünk, ahogy 4 magos Sandy Bridge-nél is.A K8-hoz képes egyrészt kétszeres a 64->128 bit szélesítés miatt, további kétszeres az FMA-képességgel; 2 FMA utasítás 2-2 FADD+FMUL-nak felel meg. Persze ez kissé marketingízű
Mégsem olvastad el a teljes szöveget:
"In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data."
Összhangban van a kettő; (lebegőpontos) fmul-fadd-fmac csak két egységen van jelölve. -
dezz
nagyúr
A #115-ösben linkelt eredmények valóságosságára gondoltam.
Rosszul fogalmaztam, a fele akkora peaket az X6-hoz képest értettem, per mag.
Tudom, hogy sokminden beleszól. Az a kérdés, hogy ezzel a fele/mag, összességében tehát 2/3-os peakkel lehet-e ennyivel gyorsabb a gyakorlatban az X6-nál (nem csak kivételes esetben).
Mem tudom, miért ráerőszakolás /mag vagy /szál alapon hasonlítani.
Itt FPU-nként sincs négyszerezés... Kétszerezés van, de 2-magonként 1 FPU.
Három pipe-nál látok ott AVX-et. Vagy az egy sorban lévők mehetnek egyszerre?
-
P.H.
senior tag
Nem igazán értem, mire gondolsz, a számok valósak.
- a Sandy Bridge egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 2 256 bites műveletet (16 FLOP) képes végrehajtani, azaz ráerőszakolva a gondolatmenetedet, szálanként 4 vagy 8 FLOP jut.
- a Bulldozer egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 1 256 bites műveletet (ugyancsak 8 FLOP) képes végrehajtani, azaz a gondolatmenettel szálanként 4 FLOP jut.
Nekem 128 bites végrehajtás mellett ez azonosnak tűnik, nem "fele akkora peak" értéknek, AVX esetén a a Sandy Bridge 2x erősebb. Érdekes, nem érdekes, ez van. Ezenkívül 100 más dolog határozza meg azt, hogy mennyire lehet megközelíteni az elméleti maximumot.
Például K8 és K10.5 egyaránt 2 FLOP/órajel tempóval tudja végrehajtani az x87-es kódokat, mégis ennyi különbség van köztük ugyanannál a kódnál: c1 oszlop az IPC (1.6 vs 2.1), a soronkénti c2/c0 hányados megadja az órajelenként végrehajtott átlagos x87-műveleteket: 0.8 vs 1.05; (itt az alsó a program).Nem azt írták, hogy magonként négyszerezik a számítási kapacitást a K8-hoz képest, hanem FPU-nként.
Abból a teljes szövegből lehet tudni, amit #120-ba bemásoltam az Opt. Guide-ból, illetve innen (234. oldal):
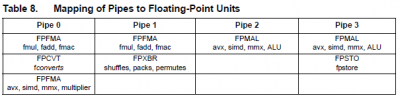
-
dezz
nagyúr
Oké, de ha valósak a tesztek, akkor nem csak az X6-nál gyorsabb, hanem a SandyB-nél is. Elképzelhetőnek tartod ezt fele akkora peak értékkel?
Vagy tegyük fel, nem valósak azok a számok. A Bulldozer nagyjából fele olyan gyors lesz (hasonló órajelen), mint a SandyB 256-bites AVX-ben -- és csak 128-bites SSEx/AVX-ben lesznek kb. egálban? Érdekes lesz/lenne...
Ha helyes az a 48-as szám a slide-on az X6-nál, akkor 1-1 magra és azonos frekire vetítve K10-hez képest is a fele lesz a peak 128-bites SSEx-ben és sima FP-ben. Ehhez képest ezt írják:
"The AMD Family 15h processor floating point unit (FPU) was designed to provide four times the raw FADD and FMUL bandwidth as the original AMD Opteron and Athlon 64 processors."
"kettőre legfeljebb 128 bites FP-műveletek, kettőre pedig legfeljebb 128 bites integer-műveletek mehetnek"
Ezt honnan lehet tudni?
-
P.H.
senior tag
Nem csak a teoretikus műveletvégzési sebességtől lehet gyorsabb(?), mint az X6, ez csak pár számot tartalmazó táblázat meg egy-egy ábra, amelyekből nem látszik, hogy pl. sokkal okosabban osztja/oszthatja el az végrehajtó egységek között a műveleteket (lásd pl. itt a 147. oldalt; nem nagy dolognak látszik, de pl. egy ilyen felezi vagy 2/3-olja az IPC-t K10-en is, ha nincsenek ennek figyelembevételével kézzel rendezve az asm-utasítások).
Az FPU-ban 4 execution port van, kettőre legfeljebb 128 bites FP-műveletek, kettőre pedig legfeljebb 128 bites integer-műveletek mehetnek -, órajelenként 1-1-1-1. Egy 256 bites AVX-utasítás 2 db 128 bites műveletre fordul le és így kerül be az FPU-ba. Az AMD-slide szerint 128 bites SSE, 128 bites AVX és 256 bites AVX esetén azonos a végrehajtási sebesség. Ez úgy alkot logikus egységet, ha egy-egy FLEX FP 2x 128 bit (8 SP vagy 4 DP FLOP) műveletre képes órajelenként. Ezt mondják az Opt. Guide-ban, a slide-on és az AMD-blogban (itt is a táblázatban).
Ha valóban ilyen jól sikerült nekik továbbfejleszteni pár "egyszerű" lépéssel az FPU-t, annak örülni kell; de nem kell beleképzelni további pár superior, még eltitkolt képességet; FLOP/órajelben ennyi van. Mostmár inkább az lesz érdekes, hogy mennyi lesz az órajel hozzá (akár a következő 1-2 generáción belül).
-
#123
dezz
nagyúr
hugo chávez
#119
dezz
nagyúr
válasz
hugo chávez
#119
üzenetére
128-bit FMAC = 128 bit FMUL + 128 bit FADD
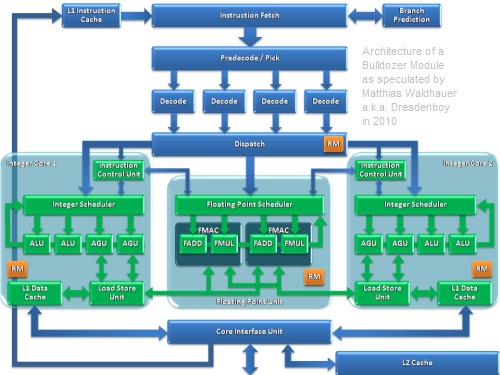
ps. én nem programozom PC-n, ez leginkább P.H. asztala.
(#120) P.H.: "Azt hiszem, lényegretörő és egyértelmű."
Nem tudom, én számomra nem derült ki a szövegből egyértelműen, hogy mehet-e 2x128 bit FMUL + 2x128 bit FADD. De a gyakorlat azt mutatja (lást teszteredmények), hogy mehet, mert hogy nem lassabb, mint a 6-magos K10, hanem gyorsabb.
És ha így van, akkor nem tudom, miért nem tud 2x256 bit AVX-et.
-
#122
hugo chávez
aktív tag
P.H.
#120
hugo chávez
aktív tag
Igen, így már teljesen egyértelmű, köszi
(#121) Abu85:
"Az AVX GPU-s támogatáson azonban nem éri meg gondolkodni."
Na igen, dedikált GPU-nál nem érné meg, de én nem tartom lehetetlennek, hogy az Intel meg fogja lépni a jövőbeni (Haswell-t követő) APU/HPU-inál, mert, feltételezem, hogy így sokkal jobban együtt tudnának működni a "CPU" és a "GPU" magok.
-
#121
 Abu85
HÁZIGAZDA
hugo chávez
#119
Abu85
HÁZIGAZDA
hugo chávez
#119
Abu85
HÁZIGAZDA
válasz
hugo chávez
#119
üzenetére
Nem feltétlen szükséges. Elérhető lenne C++-ból, csak fordító kell. Az AVX GPU-s támogatáson azonban nem éri meg gondolkodni. Pont a viszonylag kevés támogatott utasítás miatt fogyasztanak kevesebbet a GPU-k egységnyi számítási kapacitás mellett. Az AVX támogatásával ugyan nőne a lehetőségek tárháza, de kevesebb lenne a nyers számítási kapacitás, mert a chipdizájn bonyolódna és a fogyasztás drasztikusan nőne.
-
#120
P.H.
senior tag
hugo chávez
#119
P.H.
senior tag
válasz
hugo chávez
#119
üzenetére
"Nekem nem igazán világos ez, egy 128 bites egységen hogy "megy át" egy ciklus alatt 4x32 bit FMUL és 4x32 bit FADD? Az nem lehet, hogy FADD, vagy FMUL esetén 4, FMAC esetén pedig csak 2 FMUL és 2 FADD művelet van ciklusonként?"
Sehogy, 1 execution portra órajelenként 1 műveletet lehet indítani (ez a port mint kifejezés lényege), és itt most 128 bites portokról van szó.
Az Optimization Guide ide vonatkozó része (ez teljesen újra lett írva a korábbi verziókhoz képest
)The AMD Family 15h processor floating point unit (FPU) was designed to provide four times the raw FADD and FMUL bandwidth as the original AMD Opteron and Athlon 64 processors. It achieves this by means of two 128-bit fused multiply-accumulate (FMAC) units which are supported by a 128-bit high-bandwidth load-store system. The FPU is a coprocessor model that is shared between the two cores of one AMD Family 15h compute unit. As such it contains its own scheduler, register files and renamers and does not share them with the integer units. This decoupling provides optimal performance of both the integer units and the FPU. In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data. A crossbar (XBAR) unit is integrated into FPU pipe 1 to execute the permute instruction along with shifts, packs/unpacks and shuffles. There is an FPU load-store unit which supports up to two 128-bit loads and one 128-bit store per cycle.
FPU Features Summary and Specifications:
• The FPU can receive up to four ops per cycle. These ops can only be from one thread, but the thread may change every cycle. Likewise the FPU is four wide, capable of issue, execution and completion of four ops each cycle. Once received by the FPU, ops from multiple threads can be executed.
• Within the FPU, up to two loads per cycle can be accepted, possibly from different threads.
• There are four logical pipes: two FMAC and two packed integer. For example, two 128-bit FMAC and two 128-bit integer ALU ops can be issued and executed per cycle.
• Two 128-bit FMAC units. Each FMAC supports four single precision or two double-precision ops.
• FADDs and FMULs are implemented within the FMAC’s.
• x87 FADDs and FMULs are also handled by the FMAC.
• Each FMAC contains a variable latency divide/square root machine.
• Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together.Azt hiszem, lényegretörő és egyértelmű.
-
#119
hugo chávez
aktív tag
hohoo
#111
hugo chávez
aktív tag
Szerintem attól, hogy egy GPU/IGP SIMD egységei támogatják az AVX-et, még ugyanúgy vagy kell egy OpenCL-hez hasonló API/Framework, vagy, ha nem akarnak használni API-t, akkor valami alacsony szintű, hardverközeli nyelven kell szenvedni, de erről szerintem inkább dezz tudna nyilatkozni, mert a programozás nem az én asztalom. Ráadásul pl. az OpenCL nagy előnye, hogy egy OpenCL-re írt progi gyakorlatilag mindenen képes lehet futni, amihez van OpenCL driver, tehát CPU-n, GPU-n, IGP-n, vagy, heterogén módon, akár ezeken egyszerre is.
(#114) dezz:
"Ez magonként 4db FMUL és 4db FADD művelet ciklusonként."
Nekem nem igazán világos ez, egy 128 bites egységen hogy "megy át" egy ciklus alatt 4x32 bit FMUL és 4x32 bit FADD? Az nem lehet, hogy FADD, vagy FMUL esetén 4, FMAC esetén pedig csak 2 FMUL és 2 FADD művelet van ciklusonként?
-
#114
dezz
nagyúr
hugo chávez
#106
dezz
nagyúr
válasz
hugo chávez
#106
üzenetére
Ezt írják: "Two 128-bit FMAC units, one for each core"
FMAC = FMUL + FADD. Ennyi volt eddig is egy magban a K10-nél.
Ez magonként 4db FMUL és 4db FADD művelet ciklusonként.
8 FLOP/ciklus x 8 mag = 64 FLOP/ciklus...
A kis képeken talán egy FMA-t vettek egy FLOP-nak. (Mintha GPU-knál lenne ez szokás.) -
#113
dezz
nagyúr
hugo chávez
#103
dezz
nagyúr
válasz
hugo chávez
#103
üzenetére
Ugye nem gondoljátok komolyan, hogy a Bulldozer egy magra vetítve fele annyi FP számolóegységgel rendelkezik, mint a K10? Nem hinném, hogy így lenne...
Attól, hogy a 128-bites egységeket (FMUL és FADD) össze lehet vonni kétmagonként (2xFMUL + 2xFADD), illetve be lehet fogni őket FMA-ra, még nem lesz belőlük fele annyi...
Ami az SSEx vs. AVX-et illeti: akármilyen befolyásos is az Intel, egyik napról a másikra akkor sem fogják átírni az összes létező szoftvert AVX-re, és ha át is írnak valamit, az SSx verziót nem fogják eltüntetni a Föld színéről...
Később meg a Bulldozerből is jön elvileg a magonként 256-bites FP egységekkel rendelkező változat (hogy ez vajon az "enhanced" lesz-e már, vagy csak a "next-gen."...).
-
P.H.
senior tag
Nem kellett hozzá apró betűs rész.
Vették a jelenlegi generáció legnagyobbját (X6) és összehasonlították következő generáció bevezetéskori legnagyobbjával (8 modul); hogy teljes legyen a táblázat, hozzávették az Intel legerősebb AVX-képes CPU-ját is. Az pedig 4 magos - még most is. -
#111
 hohoo
senior tag
hugo chávez
#110
hohoo
senior tag
hugo chávez
#110
hohoo
senior tag
válasz
hugo chávez
#110
üzenetére
Nem keverem. AVX támogatású gpu egységek nélkül opencl (vagy stream vagy mi az az alap api) kell(mert ki akar gpu gépi kóddal szórakozni?). Ha tudja avx-re használni akkor viszont nem kell feltétlenül.
-
#110
hugo chávez
aktív tag
hohoo
#108
hugo chávez
aktív tag
"Ez akkor lenne jó, ha a gpu-n lehetne futtatni avx-es dolgokat majd a trinity-ben."
Nos, szerintem az Intel pont ezt akarja a jövőben, vagyis AVX utasításkészletet támogató SIMD egységekkel akarja felváltani a jelenlegi IGP-iben lévő vektormagokat.
"Viszont ha azon nem lehet, akkor opencl-re kell alapozni avx helyett később amd-nél, ami meg rizikós, mert ehhez az amd-nek úgy meg kéne venni a fejlesztőket mint ahogy az intel teszi."
Itt úgy érzem, hogy némiképp kevered a dolgokat, mert az AVX egy SIMD utasításkészlet, az OpenCL pedig egy API. Amúgy az OpenCL-nek már van AVX támogatása.
-
#109
hugo chávez
aktív tag
hohoo
#107
hugo chávez
aktív tag
Nézd, erre nem tudok mit mondani, a Sandy-nél ugye egy mag két 256 bites műveletet tud egyszerre ciklusonként, egy FADD-et és egy FMUL-t :"Sandy Bridge can sustain a full 16 single precision FLOP/cycle" és "Sandy Bridge can execute a 256-bit FP multiply, a 256-bit FP add and a 256-bit shuffle every cycle" [link], a Bull Flex FP-jéről (amiből modulonként egy van) pedig azt írják, hogy egy 256 bites (feltételezem, hogy vagy FADD, vagy FMUL) műveletet tud ciklusonként: "The beauty of the Flex FP is that it is a single 256-bit FPU that is shared by two integer cores. With each cycle, either core can operate on 256 bits of parallel data via two 128-bit instructions or one 256-bit instruction" [link] szóval ebből az következik, hogy a 64 FLOPs/ciklus a 16 magos (8 modulos és 8 Flex FP-s) Interlagos-ra vonatkozik.
-
hohoo
senior tag
De olyat is látok, hogy egy 4 magos sb-ben 8 db avx képes egység van, ami tényleg egyenlő lenne a 16 magos 8 modulos bulléval, mert abban is annyi van.
Ha ez így van akkor avx-ben fele akkora teljesítményű lesz egy azonos árkategóriájú bull mint egy sb. Viszont integerben gyorsabb lesz 2x. Nyilván az amd mérnökök nem hülyék, és kiszámolták hogy mennyire van kihasználja az integer rész és az fpu, és azért alkották ilyenre. Ha jól tudom általában a feltételes utasítások fogják meg a procikat, ami meg integeren fut, így tehát logikus, hogy integerből több kell mint fp-ből. (ezért nem szeretik a feltételes utasításokat a gpu-k)
VAGY rendesen úgy tervezték a bullt hogy már számításba vették a gpu-val egybeforrasztást, és mivel a gpu sokkal jobb lebegőpontos műveletekben, egy idő után már nem is nagyon kell ilyen egység a cpu részbe.
Ez akkor lenne jó, ha a gpu-n lehetne futtatni avx-es dolgokat majd a trinity-ben.
Viszont ha azon nem lehet, akkor opencl-re kell alapozni avx helyett később amd-nél, ami meg rizikós, mert ehhez az amd-nek úgy meg kéne venni a fejlesztőket mint ahogy az intel teszi. -
#107
hohoo
senior tag
hugo chávez
#106
hohoo
senior tag
válasz
hugo chávez
#106
üzenetére
http://www.google.com/search?hl=hu&safe=off&client=opera&hs=QYb&rls=hu&channel=suggest&q=flex+fp+flops&btnG=Keres%C3%A9s&aq=f&aqi=&aql=&oq=
mindenhol máshol meg 8 mag 4 modult írnak...
Ha úgy lenne ahogy mondod mi értelme lenne? annál a phenom 2 is jobb lenne 128 bites műveletekkel.
-
#106
hugo chávez
aktív tag
hohoo
#105
hugo chávez
aktív tag
Ha nekem nem hiszel, akkor nézd meg itt alaposan a "Standard 128-bit mode" és a "Shared AVX mode" című képeket, vagy kérdezd meg Abut, vagy P.H.-t, hogy mi következik a jelenleg ismert adatokból.
Ja és az nem 64 GFLOPS, hanem 64 "darab" 32 bites, vagy másképpen 8 "darab" 256 bites lebegőpontos művelet/órajel

-
#105
hohoo
senior tag
hugo chávez
#103
hohoo
senior tag
válasz
hugo chávez
#103
üzenetére
A fura az, hogy ezt a 64 gflopsot mindenhol 4 modulra, vagyis 8 magos bullra írják...
nem 8 modulos 16 magosra.Csak te szerinted 16 magos az a 64

-
#104
hohoo
senior tag
dízelracer
#95
hohoo
senior tag
válasz
 dízelracer
#95
üzenetére
dízelracer
#95
üzenetére
Te tényleg ennyire éjsötét vagy? Vagy szórakozol?
-
#103
hugo chávez
aktív tag
Oliverda
#99
hugo chávez
aktív tag
Hát, tény, hogy jelenleg nem sok ilyen van, de azért lehet találni egy párat, pl az x264 is támogatja: [link]
(#100) P.H.:
Na igen, kissé "külön úton" járnak, majd meglátjuk, hogy melyik lesz a jobb, de az a baj, hogy a Bull még mindig nincs kint, hogy valós alkalmazásokban össze lehetne mérni a Sandy-kkel és azt sem lehet biztosan tudni, hogy mikor jön.
Azon meg nem csodálkozok, hogy az Intel ráfeküdt az AVX-re, mert nekik ez lehet az igazi belépő a heterogén érába, szerintem a Haswell-ben, vagy az utána jövő generációban a jelenleg a Sandy-ben lévő IGP szerepét át fogják venni az AVX képes, a későbbiekben akár 1024 bites SIMD egységek.(#101) Zeratul:
Pont ez volt a problémám Abu slide-jával, hogy nem gyengén félrevezető marketinganyag, de segítek neked értelmezni
![;]](//cdn.rios.hu/dl/s/v1.gif) , ott egy 16 magos Interlagos-t hasonlítottak egy 4 magos Sandy-hez, úgy, hogy ezt az "apró" tényt nem írták oda, tehát, ha egy 8 magos asztali Bulldozer-re (Zambezi) vagy kíváncsi, akkor oszd el a Flex FP oszlopban lévő számokat kettővel.
, ott egy 16 magos Interlagos-t hasonlítottak egy 4 magos Sandy-hez, úgy, hogy ezt az "apró" tényt nem írták oda, tehát, ha egy 8 magos asztali Bulldozer-re (Zambezi) vagy kíváncsi, akkor oszd el a Flex FP oszlopban lévő számokat kettővel.(#102) Kotomicuki:
"De ez várható is volt, ha már "megfelezték" az FPU-kat"
Várható volt, de azért reménykedtem, meg persze arról is szó volt, hogy jóval 4 GHz felett lesz az alapórajele, de most úgy néz ki, hogy ez sem fog összejönni

-
#102
Kotomicuki
senior tag
hugo chávez
#98
Kotomicuki
senior tag
válasz
hugo chávez
#98
üzenetére
De ez várható is volt, ha már "megfelezték" az FPU-kat - emlékeim szerint, de majd kijavítotok, ha tévedek, amikor sikeresebb volt az AMD a CPU-k terén, mint az iNtel, akkor az FPU rész is minimum egálban volt a kékekkel.
Innentől tényleg az lesz a mérvadó, hogy melyik cég tudja megnyerni a szoftverfejlesztőket az igazának. Ebben pénzügyileg és eladott CPU darabszám szerint sem áll a zászló a zöldeknek - gondolom a kékek most sem fogják meghazudtolni önmagukat: a piaci és gazdasági erőfölénnyel való visszaélés, ha szükséges, ha nem, elő fog kerülni a tarsolyból.Hacsak nem fog bele egy átfogó szoftver-fejleszt(tet)ésbe (Bull+HD7000 - ha a TSMC is majd úgy "akarja") az AMD, akkor a Bull. sem váltja majd be a hozzáfűzött reményeket.

(Gondolom, hogy egyből jelennének meg az ellenfél által (le)fizetett fejlesztők, Bull.-on akadozó szoftverei, amit minden, hardverrel foglalkozó site-nak kutya kötelessége volna naponta szajkózni. Ezért még a kék-(másik)zöld ellentét barátsággá szelídülését sem tartom kizártnak, erre az időre. Tehát az "itt a hardver, kezdjetek vele vmit, önállóan" már nem járható út!)A platformosodásnak is megvannak, sőt, még csak itt jönnek elő, a maga hátulütői: ha nem tudják elfogadtatni a sajátot a fejlesztőkkel - nekik is 2-3 felé fejleszteni, mert mindenkié más... -, vásárlókkal - a marketing bullshit kit, hogyan tud átvágni... - , akkor nagyobbat buknak vele, mintha csak külön-külön, a piacvezető által diktált, éppen aktuális trendhez simulnának hozzá a termékeikkel - a piacvezető mindig is akkora profittal dolgozik, hogy lenne életterük mellette, ahogy eddig is volt.
(A gyárt(at)ás terén fennálló, és ennek a szinte soha le nem küzdhető hátránynak is szerepe van az AMD gyengélkedésében - egyáltalán, az a tény, hogy önállóan nem tud semmilyen termékét sem legyártani (profitkiesés a bérgyártók miatt), onnantól vesztett helyzetben van - , örök 2.-nak maradásában.)[Lehet, hogy akkor járnának a legjobban, ha egy teljesen "más", eddigi ellenfeleiktől mentes piacot teremtenének, ahol egyedül ők diktálhatják a feltételeket (vhogy úgy, ahogy az nV is megpattant a PC-s üzletágból, de azt nem föladva): egy alaplapos, teljesen ráintegrált alkatrészakkel készülő PC, semmi külön kártya, max. külső csatlakoztatási lehetőség a többi piaci résztvevő felé, (EP)ROM-ba égetett Op.renszerrel, stb. ~kb. a modern C64, de időtálló teljesítménnyel, előrelátóan megszerkesztett szoftver- (pl. Open CL) és Op.rendszerkörnyezettel - esetleg almás vagy IBM-s (SUN-os, stb.) együttműködésben/támogatással. Kezdetben a M$ op.rendszerének a hardvert nem kellő mértékben való kihasználására építkezve, ezzel valós teljesítménybeli fölényt elérve...]
-
#101
 Zeratul
addikt
hugo chávez
#98
Zeratul
addikt
hugo chávez
#98
Zeratul
addikt
válasz
hugo chávez
#98
üzenetére
64 FLOPS mióta duplája a 64 FLOPS nak? 128 bites kód esetén az SB csak felét tudja a Bullnak.
-
#100
P.H.
senior tag
hugo chávez
#98
P.H.
senior tag
válasz
hugo chávez
#98
üzenetére
Ha ennyire kisarkítva nézed, akkor 256 bites AVX esetén igen, ennyi. De nem minden fekete-fehér. Ahogy linkelted is:
"When Intel introduced SSE2 in the P4, each 128-bit instruction was cracked into two 64-bit uops, and the throughput did not substantially improve. This created a chicken and egg problem: Intel wanted developers to use SSE2 (since the P4 was not designed to execute x87 particularly fast), but developers do not want to rewrite or recompile code for a marginal gain.Sandy Bridge can sustain a full 16 single precision FLOP/cycle or 8 double precision FLOP/cycle – double the capabilities of Nehalem. This guarantees that software which uses AVX will actually see a substantial performance advantage on Sandy Bridge and should spur faster adoption. Intel seems to have learned from the lessons of SSE2 and hopefully, the uptake for AVX amongst the software community will be far swifter."
Adott mindkét oldalon egy-egy 128 bites FPU, külön FADD és FMUL futtató egységekkel: el kellett dönteni, hogy az igen nagy mennyiségű plusz tranzisztort (és az általuk igényelt plusz fogyasztást) mibe fektetik:
- az AMD a 128 bites végrehajtásra és a meglevő programokra helyezte a hangsúlyt: két majdnem azonos képességű FADD+FMUL végrehajtót tettek az FPU-ba, pontosan úgy, ahogy eddig a K7-K10 családban 3 majdnem azonos ALU+AGU van; így teljesen mindegy, hogy a programban milyen az FADD- és FMUL-jellegű utasítások aránya (eddig nagyon nem volt az). Ezt megfejelték azzal, hogy a register-to-register értékmásolás (amik nagy része az AVX alatt feleslegessé válik, de SSEx alatt elég sok van, mivel egy-egy művelet felülírja az egyik paraméterét) 0 órajelet igényel, a registerfile megoldja saját hatáskörben (órajelenként 4-et, ha minden igaz).
Az AVX-es programokat nem túl hatékonyan hajtja végre, de az SSEx-alapúak végrehajtását eléggé felgyorsítja.- az Intel maradt az 1 FADD + 1 FMUL futtatóegység felépítésnél, ezt látták 256 bites végrehajtókkal, felhasználva hozzá a meglevő integer adatutat is, illetve hozzáadva egy kis energiatakarékosságot (innen):
Floating point warm-up effect
The latencies and throughputs of floating point vector operations is varying according to the processor load. The ideal latency is 3 clock cycles for a floating point vector addition and 5 clock cycles for a vector multiplication regardless of the vector size. The ideal throughput is one vector addition and one vector multiplication per clock cycle. These ideal numbers are obtained only after a warm-up period of several hundred floating point instructions.
The processor is in a cold state when it has not seen any floating point instructions for a while. The latency for 256-bit vector additions and multiplications is initially two clocks longer than the ideal number, then one clock longer, and after several hundred floating point instructions the processor goes to the warm state where latencies are 3 and 5 clocks respectively. The throughput is half the ideal value for 256-bit vector operations in the cold state. 128-bit vector operations are less affected by this warm-up effect. The latency of 128-bit vector additions and multiplications is at most one clock cycle longer than the ideal value, and the throughput is not reduced in the cold state.
The cold state does not affect division, move, shuffle, Boolean and other vector instructions.
There is no official explanation for this warm-up effect yet, but my guess is that the processor can turn off some of the most expensive execution resources to save power, and turn on these resources only when the load is heavy. Another possible explanation is that half the execution resources are initially allocated to the other thread running in the same core.
Mindkettő kihozza a maximumot a 32 nm-es lehetőségekből, mivel mindkettő szinte megduplázza az FPU fizikai méretét. Az AMD annyival van könnyebb helyzetben, hogy mivel a korábbi - K8-alapú - FPU-kat arra tervezte, hogy minden 128 bites utasítás 2x 64 bitesre fordítódik és hajtódik végre, így amikor 128 bitesre bővítette azt, akkor az FPU "kiürült", azonos végrehajtási sebességhez feleannyi belső uop-műveletet kap. Ezt most kitömik a 2. szállal.
-
#99
 Oliverda
félisten
hugo chávez
#98
Oliverda
félisten
hugo chávez
#98
Oliverda
félisten
válasz
hugo chávez
#98
üzenetére
Már csak alkalmazás kellene ami egyáltalán használja az AVX-et.
-
#98
hugo chávez
aktív tag
Abu85
#94
hugo chávez
aktív tag
Már elkezdtem írni a nem túl pozitív
véleményemet a slide-ról, de látom, hogy P.H. megelőzött, mindegy, azért köszi (#96) P.H.:
Hát akkor ennyi, azonos FPU órajelen, 256 bites AVX kód esetén a 4 magos Sandy dupla akkora peak teljesítményre képes, mint egy 8 magos (4 modulos) Bulldozer

-
#97
 nuke7
veterán
antikomcsi
#89
nuke7
veterán
antikomcsi
#89
nuke7
veterán
válasz
 antikomcsi
#89
üzenetére
antikomcsi
#89
üzenetére
-
#96
P.H.
senior tag
hugo chávez
#93
P.H.
senior tag
válasz
hugo chávez
#93
üzenetére
Erről az ábráról van szó.
Nincs újabb, 4 magos Sandy Bridge-dzsel és 8 modulos Bulldozerrel számoltak, így jönnek ki az értékek: felszorozták az FPU-darabszámmal a névleges teljesítményt, mivel X6-hoz 48-at írnak, ami ott 8 FLOPS/mag=FPU, a K10 órajelenként 2 4xSP bites műveletet tud. A Bulldozer szintúgy, tehát a 64 FLOPS-hoz 8 Bulldozer-FPU kell. Így nézve kijön, hogy azonos magszám (4) mellett a Sandy Bridge 256 bites műveleteknél 2x akkora teljesítményt hoz, mint 128 biten, a 8 modulos (mindkét esetben 2 művelet/órajel), 16 magos Bulldozer pedig konstant 64 FLOPS-ot.
Hogy miért így hasonlított össze az AMD, azt ők tudják...
-
#94
Abu85
HÁZIGAZDA
hugo chávez
#93
Abu85
HÁZIGAZDA
válasz
hugo chávez
#93
üzenetére

Ez a legutolsó Flex FP összefoglaló. Szokás szerint apró betűs rész nélkül.
-
#93
hugo chávez
aktív tag
Abu85
#91
hugo chávez
aktív tag
Neked van valami frissebb, vagy részletesebb anyagod a modulonkénti FLOP/ciklus-ról?
Mert az Oliverda által írt cikkben a slide-okon az van, hogy a 16 magos (2x4 modulos?) Interlagos 64 FLOP/ciklust tud akkor is, ha a két 128 bites FMAC-en két 128 bites utasítás hajtódik végre és akkor is ha egy 256 bites, tehát az a kérdés, hogy itt a FLOP alatt 32 (SP), vagy 64 (DP) bitet értenek-e? Mert, ha 32 bites, akkor azonos FPU órajelen egy 4 magos Sandy ugyanannyi (64) FLOP/ciklust tud, mint egy 16 magos Interlagos, ami nem túl jó előjel a 8 magos Zambezi lebegőpontos teljesítményére nézve. Jó, az FMA valószínűleg valamennyit fog dobni a tényleges sebességen, de ennek mértéke jelenleg nem ismert, szóval akár egészen kicsi is lehet. -
#92
hohoo
senior tag
dízelracer
#79
hohoo
senior tag
válasz
dízelracer
#79
üzenetére
Aha tehát rosszabb lesz mint a phenom2? okos megállapítás

-
#91
Abu85
HÁZIGAZDA
hugo chávez
#90
Abu85
HÁZIGAZDA
válasz
hugo chávez
#90
üzenetére
Akkor az IB lehet, hogy bővít, majd meglátjuk.
A Bulldozer az FMUL+FADD-nál nem tiszta, hogy hogyan működik. Az AMD FLOP/ciklus paramétereit nézve, csupán annyi derül ki, hogy a modul FLOP/ciklus teljesítménye megegyezik az SB mag FLOP/ciklus teljesítményével. Persze a trükk mindig az apró betűs részben van elrejtve.
-
#90
hugo chávez
aktív tag
Abu85
#82
hugo chávez
aktív tag
"Maga az AVX utasításkészlet ugyanaz az SB-ben és ugyanaz lesz az IB-ben..."
Lehet, hogy az IB-ben bővítenek az AVX utasításkészleten, mert vannak erre utaló jelek:
"These build upon the instructions coming in Intel® microarchitecture code name Ivy Bridge, including the digital random number generator, half-float (float16) accelerators, and extend the Intel® Advanced Vector extensions (Intel® AVX) that launched in 2011." [link]
és
"Q: Is there a version of Intel Compiler available that supports Intel AVX?
A: Yes, the current Intel Compiler supports the Intel AVX instructions. This version also includes support for SSE4, AES and PCLMULQDQ instructions. To use the post-32nm new instructions for the processor codenamed Ivybridge, it is required that you use Intel(R) Parallel Composer 2011 Update 2 or Intel(R) Composer XE 2011 Update 2. The compiler version is 12.0.2.x." [link]persze biztosat csak akkor lehet tudni, ha az Intel kiad egy hivatalos közleményt.
"A 256 bites utasítás esetében nem lesz különbség, egy-egy utasítás lehetséges a Bulldozer modulban és az SB/IB magban. Mindezt órajelenként persze."
A Sandy magonként egy 256 bites FADD-ot és egy 256 bites FMUL-t tud egyszerre ciklusonként, mint azt fLeSs, P.H. és David Kanter is írta, a Bull pedig nekem úgy tűnik, hogy modulonként csak vagy egy 256 bites FADD-ot, vagy egy 256 bites FMUL-t tud ciklusonként. Mondjuk, Oliverda azt írta a cikkében, hogy a Bull modulokban lesz két 128 bites SIMD Integer egység is és nekem az jött le, hogy ezek az FMAC-ekhez hasonlóan szintén képesek lesznek "összevonva" 256 bites műveletekre. Ezzel szemben az Intelnél a 256 bites integer műveleteket majd csak a Haswell fogja tudni az AVX2 utasításkészlettel.
-
#89
 antikomcsi
veterán
antikomcsi
veterán
antikomcsi
veterán
Szerintem be is fejezhetjük az offolást, úgysincs értelme annak, amit csinálunk.
Üdv, Nektek!
-
#88
Zeratul
addikt
antikomcsi
#86
Zeratul
addikt
válasz
antikomcsi
#86
üzenetére
Emlékeim szerint viszont ez a királyság nagyon rövid volt, hisz a 9800GX2 nem tűrte az ellentmondást senkitől.
Csak amíg a 3800x2-n nyeresége volt az AMDnek addig a 9800GX2 a gyártási költségeket se fedezte. A 4800x2 ellen már nem is volt ellenszere az nVidiának, a legutóbbi dupla GPUs próbálkozása meg inkább szánalmas lett mint sikeres.
-
#87
 Remus389
veterán
antikomcsi
#86
Remus389
veterán
antikomcsi
#86
Remus389
veterán
válasz
antikomcsi
#86
üzenetére
a 3800-as szeria akkor is siker volt, megha mersekeltebb siker, de siker
szegeny nvidianak is lejjebb kellett vinnie a viszonylag dragan gyarthato 8800gt arat es ki kellett hozni az egychipes 3850/70-esek ellen a 9600gt-t, mert megirigyelte az amd sikereit a kozepkategoriaban(ahol a legtobb karesz fogy).
egyszoval a 3800-asok is sikeresek voltak a maguk arszegmenseben
-
#86
antikomcsi
veterán
Remus389
#83
antikomcsi
veterán
Úgy látom az eltelt idő megszépítette az emlékeidet.
A 3850/70 akkor fogyott volna még jobban, ha nem ég a nép 8800GT lázban. Nem sok lehetőségük volt labdába rúgni.
A korona meg presztízs kérdés, nincs sok jelentősége számunkra, az mindig vándorol egyik fejről a másikra.
A 3870X2 valóban legyűrte a nála legalább másfél évvel idősebb 8800GTX-et, tulajdonképpen itt lépett rá az AMD a másik ösvényre. Egy gpu-val nem tudott lépést tartani, ezért inkább úgy döntöttek, hogy a csúcson 2 db. egyszerűbb, olcsóbb tervezési és gyártási költségű lapkát küld harcba egy nyákon.
Emlékeim szerint viszont ez a királyság nagyon rövid volt, hisz a 9800GX2 nem tűrte az ellentmondást senkitől.
(#85) R.Zoli
Ha az egyik cégnek részvényese lehetnék, én mégis inkább az nv-nél állnék sorba osztalék fizetéskor, ha fényesen áll, ha nem.
(#84) nuke7
6600GT - 7600GT - 8800GTS 320/640 - 8800GT 512 - GTX260 - GTX460
Igen, ezek mind valóban sz@rok voltak, senki nem akart ilyet. -
#85
 R.Zoli
őstag
antikomcsi
#80
R.Zoli
őstag
antikomcsi
#80
R.Zoli
őstag
válasz
antikomcsi
#80
üzenetére
Azért NV tényleg nem áll fényesen. Leggyorsabb VGA címet is elég régóta nem uralták folyamatosan, die size/performance arányban is gyengék, illetve mobil platformban is veri őket az AMD, pedig a mobil a legdinamikusabban fejlődő ág és akkor a fusion-ről nem is beszéltem... A legjobb példa az MXM modulos high-end mobil chipek ahol is a 6990M 75 wattos keretből átlagban 15%-kal elveri az NV zászlósát... Egyébként meg a HPC piacon az NV nem egyeduralkodó, azért használtak már Radeonokat is etéren, tény ,hogy van előnye de még ez is könnyen romba dőlhet a 7000-es széria megjelenésével,mert az sokkal fejlettebbnek ígérkezik amit az NV évek múlva tervez majd.
-
nuke7
veterán
igen, erre gondoltam, csak már késő volt, hogy rendesen fogalmazzak
(#80) antikomcsi: egyet kell, hogy értsek az előttem szóló remusz-szal, ugyanis rendre a 3870x2 és 4870x2 állva hagyta a nvidia játékos kártyáit...
és most mondthatod azt, hogy az nvidia előrébb jár, mert ők a hpc piacon is jelen vannak, de ha nem bírtak normális játékos kártyát összehozni jó áron 2-3 "generácio" alatt, akkor most ki van előrébb? - nem lehet, hogy az amd csak tényleg egy másik piacra koncentrált, ahol át is vette a vezetést..?
- nem lehet, hogy az amd csak tényleg egy másik piacra koncentrált, ahol át is vette a vezetést..? -
#83
Remus389
veterán
antikomcsi
#80
Remus389
veterán
válasz
antikomcsi
#80
üzenetére
tévedsz mert a 3800-as széria igen komoly siker volt, és a koronát is elhódították az nvidiától a 3870X2 személyében, és a 3850/70-es karik szép számmal fogytak
a 4800-as pedig nemcsak komoly siker volt, hanem kb szenzációs
-
Abu85
HÁZIGAZDA
Ezt nem teljesen értem, szerintem valamit félreértettél ezzel kapcsolatban. Maga az AVX utasításkészlet ugyanaz az SB-ben és ugyanaz lesz az IB-ben, mint a Bulldozerre épülő AMD processzorokban. Ami különbség lesz az AVX kezelésben, hogy egy Bulldozer modul két 128 bites AVX utasítást is megcsinál, míg a Sandy Bridge és az Ivy Bridge mag egyre képes. A 256 bites utasítás esetében nem lesz különbség, egy-egy utasítás lehetséges a Bulldozer modulban és az SB/IB magban. Mindezt órajelenként persze.
A Bulldozer az FMA4 támogatásban és az XOP utasításkészletben tart előrébb. Ebből az FMA4 a lényeges. Az Intel az FMA3-at vezeti be a Haswellben, amire az AMD válaszol egy kompatibilis FMA3-mal a NG Bulldozerben, miközben a programozhatóság rugalmasságát szem előtt tartva megőrzik az FMA4-et is. -
#81
 RyanGiggs
őstag
dízelracer
#79
RyanGiggs
őstag
dízelracer
#79
RyanGiggs
őstag
válasz
dízelracer
#79
üzenetére
"...2x annyi maggal"... és több fogyasztással. (szerintem)
Már nagyon kíváncsi vagyok erre a Bull-ra...lehet végül i5-2500K-t veszek?! -
#80
antikomcsi
veterán
nuke7
#75
antikomcsi
veterán
Itt most nem csúcs kategóriás dolgokról volt szó, vagy gpu felépítésről tranzisztorról-tranzisztorra. Csupán fejlesztésről. Az nv ebben előrébb jár, és már betette arra a piacra a lábát, ahova az AMD eddig nem tudta.
Viszont ha minden jól megy a 7000-es széria, vagy annak néhány tagja már alkalmas lesz a gpu-t olyan számítási feladatokra befogni amire eddig nem lehetett. És mivel az nv már most gennyesre kereste magát e téren, ez szerintem lemaradásnak fogható fel.
Erről lenne szó, nem az odapörkölésről.
Amúgy meg a 2900XT az egyenesen bukta volt, a 3000-es sorozat nem tudta felvenni a versenyt rendesen, a 4000-es sorozat már jobb volt, rögtön ennek kellett volna jönni a 3000-esek helyett, ezek is nagyjából annyival voltak olcsóbbak, mint amennyivel lassabbak voltak a konkurenciánál. Ami jól sikerült marketingileg az az 5000-es kártyák dx11-es hájpolásának meglovagolása, de sajnos túl sok hasznot az sem hozott kezdetben az ismert problémák miatt.
-
#79
dízelracer
őstag
dízelracer
őstag
Tartok tőle, hogy ez bizony kevés lesz a Sandy Bridge i5/i7 ellen vagy maximum azonos teljesítményt nyújt majd 2x annyi maggal.
-
#75
nuke7
veterán
antikomcsi
#74
nuke7
veterán
válasz
antikomcsi
#74
üzenetére
hát pedig én azokról beszéltem, mert azok a csucskategoriás dolgok, már megbocsáss...
és az amd - a szerinted toldozott - foldozott 2900xt gpu-val - eléggé odapörkölt a csúcs nvidia kártyáknak, ezt te is úgy értelmezed, ahogy akarod... -
Zeratul
addikt
Rosszul. AMD féle CMT esetén a feladatütemező két különálló integer egységre küldi a feladatot míg intelnél közösek a integer végrehajtó egységek. FPU intelnél tud 2 128bites műveletet egyszerre viszont nem tudja összevonni egy 256bitesnek, Bull 2 128bites egyszerre vagy 1 256bites művelet.
-
#71
Abu85
HÁZIGAZDA
antikomcsi
#57
Abu85
HÁZIGAZDA
válasz
antikomcsi
#57
üzenetére
Teljesen rossz az elemzésed. Az ATI az R600-at szándékosan úgy tervezte, hogy 5-6 generációig bírja. Ezt leírtam már a 2900XT megjelenésekor, hogy a base architektúra legalább 4-5 évig változatlan marad. Ez kb. így is lett. Módosítások persze voltak, amik a hatékonyságot növelték, de ez várható, ugyanarra felépítésre nem lehet építeni éveken keresztül. Tulajdonképpen két nagyobb lépcső volt. Az egyik az R700-zal, amikor a SIMD-ek felépítése megváltozott, és a másik a Cayman, amikor a VLIW szuperskalár processzor 5 utasról 4-re csökkent. Ez a Compute teljesítményt szorgalmazta hatékonyabbá tenni.
Az új HD 7000-es Core architektúra nyomokban sem hasonlít a GF100-hoz. Ha valamivel hasonlóságot lehet vonni az a Larrabee, de azzal is csak nagyon felületesen. Az alapokban csak abból érdemes kiindulni, hogy a GF100 streamalapú skalár rendszer, míg a Larrabee és a Radeon Core vektoros feldolgozókat használ. Az NV az Echelon projekt alapján valamelyik váltásnál szintén áttér a vektoros processzorokra, de nem tudni pontosan, hogy mikor. Legkésőbb szerintem a Maxwellnél meg lesz lépve, de akár a Kepler esetében is bekövetkezhet.
Szintén adalék, hogy az AMD nem dobja el a VLIW rendszert, mivel a Core egy Compute architektúra, így eléggé nyilvánvaló, hogy nem skálázható olyan jól, mint a régi VLIW. Nem nehéz erre példát találni. Nézd meg a Barts és a GF116, illetve a Turks és a GF118 teljesítményét. Majd nézd meg az egymással versenyző lapkák méretét. Rögtön látod, hogy miért kritikus probléma egy Compute architektúra rossz skálázhatósága. A grafikára tervezett architektúrák a játékokban, közel azonos, vagy kisebb méretben ripityára verik a Compute irányú rendszereket.
A Brazos diák a teljesítmény szerint rangsorolják a rendszert az Intel platformjaihoz. Ez a szokásos marketing része a dolognak. Ár szerint az Atom az ellenfél. Ezt az árlistákon is ellenőrizni tudod.
A másik szempont a platform dizájnja. Ez dönti el, hogy a kiválasztott rendszer egyáltalán befér-e az adott gépbe. Minél kisebb valami (kevesebb tű, kisebb kiterjedés) annál jobb. Kis méretben több hely marad például az aksinak, ami fontos egy mobil terméknél.
Brazos platformdizájn:
Fő lapka (Ontario/Zacate): BGA-413-as tokozás, 19x19 mm-es
Vezérlőhíd (Hudson-1): FC BGA-605-ös tokozás 23x23 mm-es
Pine Trail platfromdizájn:
Fő lapka (Pineview): FC BGA-559-es tokozás, 22x22 mm-es
Vezérlőhíd (NM10): BGA-360-as tokozás 17x17 mm-es
2011-es ULV Pentium/Celeron platfromdizájn:
Fő lapka (Arrandale): PGA-988-as tokozás, 37,5x37,5 mm-es
Vezérlőhíd (HM55): FCBGA-951-es tokozás 27x27 mm-es
Ebből tökéletesen látható, hogy a dizájn szempontjából a legkisebb gépek a Brazosból és a Pine Trail platformból építhetők. Egy ULV dizájnnak minimum 1,5x akkora az alaplapi helyigénye, következésképpen, drágább lesz a NYÁK, ráadásul sokkal bonyolultabb mindkét lapka tokozása, ami drágább routingot, és több nyomtatott áramköri lapot igényel, mint a másik két platform. -
korcsi
veterán
Egy modulban van független integer egység és egy megosztható 256 bites lebegőpontos, tehát integer és 128 bites lebegőpontos műveletekre vetítve 2 teljes értékű magnak fogható fel, egyedül AVX-es utasításoknál kell osztozni a lebegőpontos egységen.
"Tehát az intel HT-je lett fizikailag felturbózva integrálva a processzorba"
Amúgy az Intel HT-ja is processzorba van integrálva -
Abu85
HÁZIGAZDA
Ottoka ezt szokás szerint megint teljesen félreérted. Meg lett erősítve hivatalosan, hogy a Computexes időskála él.
Ha azt az NVIDIA megerősítette volna, hogy nem igaz, akkor beleírtam volna a hírbe. Mivel nem válaszoltak a mailre, így nem tudtam semmi hivatalosat beleírni a hírbe.
Ugyanez történt most is az adatokra. A táblázatra az AMD nem reagált érdemben semmit, így a DH adata él a hírben.
-
Abu85
HÁZIGAZDA
Nem biztos, hogy jó stratégia lehozni az asztali piacra egy 2000 tűs foglalatot. Szerintem az Intel jobban járna egy 1300-1400 tűssel. Egyszerűen kétlem, hogy 2000 tű körül lesz valaminek piaca, egy iylen foglalat olyan bonyolult routingot és rengeteg rétegből álló NYÁK-ot követel, hogy értékelhető nyereség mellett egy alaplap ára nem lehet 500 dollár alatt. Nem véletlen, hogy ilyen foglalatot eddig csak a szerverekben láttuk. Az AMD is megtehetné, hogy lehozza a Socket G34-et, de mondták, hogy 600 dolláros alaplapoknak az asztali piacon szerintük nincs értelme. Az Intel szerint a fejlesztési tervből ítélve van, majd meglátjuk, hogy valójában lesz-e.
Én úgy gondolom, hogy aki ilyen árkategóriában gondolkodik, az mérnöki számításokhoz illő személyi szuperszámítógépet akar, ekkor már a jobb stabilitást és támogatást biztosító Xeon konfiguráció felé érdemes indulni. Opteront valószínűleg nem fognak vásárolni, mert a személyi szuperszámítógépek piacát az AMD túl kicsinek tartja. A legutóbbi felmérés szerint nem érte el a teljes asztali piac 0,5%-át sem. Éppen ezért nem is készítettnek megfelelő alaplapot ide. -
Abu85
HÁZIGAZDA
Én a táblázatot vettem át forrásnak. Erről kérdeztem meg az AMD-t, hogy kommentálja. Azt írták, hogy várjam meg a megjelenést és kiderül, hogy igaz-e. A megjelenésről az AMD újfent leírta, hogy jelenleg is az az időskála él, amit a Computexen bemutattak, vagyis június 1-jétől számítva 60-90 nap. Ez akárhogy is számolom augusztust jelent. Tekintve, hogy ez az AMD-től származik, ez a hivatalos infó. Egy hivatalos adat mindig erősebb a pletykánál, konkrétan üti azt. A pletyka csak akkor kerül felhasználásra, ha annak nincs hivatalos megerősítése. A hírben a táblázat fel is lett használva, de le van írva, hogy nincs megerősítve az egész. Komolyan nem látom át, hogy ezzel mi a probléma.
-
#66
 thboxx
aktív tag
antikomcsi
#62
thboxx
aktív tag
antikomcsi
#62
thboxx
aktív tag
válasz
antikomcsi
#62
üzenetére
Úgy emlékszem egy régebbi cikkben, mikor még csak hallani lehetett, hogy majd valamikor lesz egy bulldozer, olyasmit olvastam, hogy egy modul 2 külön szálat képes kezelni, legyen az különböző, vagy egyforma számítás. Tehát az intel HT-je lett fizikailag felturbózva integrálva a processzorba, ami ugye így jobb mint az intel HT-je. Vagy lehet rosszul emlékszem?
-
nuke7
veterán
"A775 pl még mindíg versenyben van kb 2006 óta..." - kis ferdítéssel
(#60) Dragbajnok :
nem, úgylátszik antikomcsi meg Te nem tudod, hogy én miről beszélek... techreport:
"GeForce GTX 200 cards haven't quite reached Radeon HD 5800 levels of scarceness, though. Newegg still stocks more than two dozen GTX 200 cards, including over a dozen GTX 260s. That said, prices seem a wee bit higher than in the past, with only three of those cards selling for $170 or less."xbitlabs:
"However, it was a true Pyrrhic victory: GeForce GTX 295 turned out extremely complex in design and expensive to manufacture. Remember that it used two PCBs, one per GPU, that were tied together into a high-tech “sandwich” with a cooler inside. This cooler is also result of a compromise. Yes, formally, Nvidia took over the leadership, but in reality GeForce GTX 295 didn’t become very popular neither among the manufacturers, nor among consumers, and even turned out unprofitable for Nvidia. Its high production cost was one of the factors that determined such outcome, because a graphics accelerator with complex design like that couldn’t be cheap. As a result, the new solution was pretty hard to find in retail, and even if you did find it, then its price could be way higher than the recommended one. Moreover, the investment was not worth the performance advantage in games over Radeon HD 4870 X2. Another indication of the crisis is the fact that EVGA GeForce GTX 295+ remained the only such graphics solution that we managed to get into our lab."aki nem érti, azt sajnálom, ne mondja akkor, hogy én nézzek meg több forrást...
direkt szószerintit akartam idézni...
az tény, hogy asztali cpu-ban az amd nem tud/akar a csúcsra törni, ez nyilvánvalóan profit kérdés.
nem hoz nekik valsz. annyit a presztízs amennyibe egy ilyen kifejlesztése + gyártása kerülne.
nem így a vga piacon - mondjuk ott megengedhették maguknak, hogy lenyomják az nvidiát párszor, ezért nem is értem, hogy mi az, hogy toldozták foltozták a 2900xt-t...szóval igazából nem értem, hogy miért húzza le valaki az amd-t mert nem minden téren egyeduralkodó
-
#63
 zoltanz
nagyúr
antikomcsi
#62
zoltanz
nagyúr
antikomcsi
#62
zoltanz
nagyúr
válasz
antikomcsi
#62
üzenetére
Persze engem is ez érdekelne igazán.
-
#62
antikomcsi
veterán
zoltanz
#61
antikomcsi
veterán
Mivel a modulon belül az egy-egy integer mag, az egy-egy szál, így ha eszközkezelőben megnyitod, természetesen 8 magot fogsz látni.
Inkább az a kérdés, ha olyan alkalmazást használsz, ami főként csak az egyik féle integer magnak fekszik igazán, akkor mi lesz?
Azt hiszem a pontos válasszal meg kell várjuk a tényleges megjelenés utáni teszteket.
-
-
#60
 Dragbajnok
tag
antikomcsi
#57
Dragbajnok
tag
antikomcsi
#57
Dragbajnok
tag
válasz
antikomcsi
#57
üzenetére
"Tudod Te mire gondolok. Míg az AMD toldozta-foltozta a 2900XT-ben megismert chipet, addig az nv 3 teljesen új gpu generációt fejlesztett. Az AMD sajnos ezt nem tudta megtenni 65-55 nanométeren, mert brutálisan nagy lapkái lettek volna. És csak most fog tudni a 7000-es sorozattal arra az útra lépni, amire az nv a GF100 sorozattal betette a lábát. A célpiac nagy része így telítődik, mire lesz válaszuk. Ez sajnos jókora lemaradás."
Ez Abu szájából úgy hangzott az elmúlt időszakban hogy az AMD a játékokra koncentrál a gpu tervezésénél az NV pedig a hpc piacra.Eddig nem is lenne baj,de mikor olyanokat irogatott az új NV arhitektúráról hogy alkalmatlan a játékos piacra az azért elég erős volt.(Mondhatni tipikus Abu.)
"Ez a veszteséges értékesítés, meg, hogy egy nv chip brutálisan drága, míg egy R szériás radeon 2 fillér volt, azért nem egészen így van. Jobban teszed, ha az információt több helyről szerzed be."Hát igen ez is csak Abu torzítása és mára itt a PH-n sikerült elérnie hogy a nagytöbség azt hiszi hogy az NV óriási veszteséget termel és a csőd szélén áll és külömben is rohadékok.És ha valaki mutat nekik egy kimutatást a két cég bevételeirő akkor szinte képtelenek elhinni hogy az NV több profitot termel mint az AMD.Mert Abu aztmondta meg Abu ezt nem így látja meg ő különben is mindenkinél jobban tudja.És aki nem ezt állítja az buzi.És most ugyan ez az oltogatás megy az AMD apu-ival kapcsolatban is.(Ami szerintem is nagyon jó és ígéretes dolognak ígérkezei)Csak megint ez a túl hypeolás.
-

Darmol
senior tag
Hehh, már előre csorgatom a nyálam a tesztek után
, bár pénzem sajnos nem lesz rá.
Persze az Intel csúcsokat valszeg úgysem tudja megdönteni, de nem is azért veszem az AMD-t.
Egyébként (#47)-t nem értem. Mire gondolsz azzal h "jókora lemaradás"?
Az Intel procik nyilván nagyobb teljesítményűek, sőt mostanában még összességében is jobbak sok szempontból mint az AMD-k, de az utóbbi felhasználóbarát politikáját az Intel sosem tudta még megközelíteni sem.
A procik is olyanok mint a cégek. Az egyik izomból nyomul, a másik meg minden mással amivel valamennyire kompenzálni tud. Ezért is vagyok kíváncsi, milyen tényleges újításokkal rukkolt most elő az AMD.
A grafikus procikat, hagyjuk mert off.
-
#57
antikomcsi
veterán
nuke7
#51
antikomcsi
veterán
Tudod Te mire gondolok. Míg az AMD toldozta-foltozta a 2900XT-ben megismert chipet, addig az nv 3 teljesen új gpu generációt fejlesztett. Az AMD sajnos ezt nem tudta megtenni 65-55 nanométeren, mert brutálisan nagy lapkái lettek volna. És csak most fog tudni a 7000-es sorozattal arra az útra lépni, amire az nv a GF100 sorozattal betette a lábát. A célpiac nagy része így telítődik, mire lesz válaszuk. Ez sajnos jókora lemaradás.
Meg lehet magyarázni ezt is, ha jól esik, még el is lehet hinni, de a tények attól még nem változnak.
Ez a veszteséges értékesítés, meg, hogy egy nv chip brutálisan drága, míg egy R szériás radeon 2 fillér volt, azért nem egészen így van. Jobban teszed, ha az információt több helyről szerzed be.
A procit meg szerintem nem Ő akarja versenyeztetni, hanem a generációs lépések szerint úgy gondolja, hogy a megjelenő FX-eknek azok lennének az ellenlábasai.
És van egy olyan érzésem, ha hozná azt a teljesítményt akkor az is lenne kikiáltva ellenfélnek. Így meg nézünk egy hasonló teljesítményűt, és megnevezzük azt közvetlen ellenfélnek.
Nézd meg a brazosos diákat. Az E széria a pentium ellen volt ábrázolva, a C a celeron ellen, és az atom alul kullogott. Megjelenés után, ezt valahogy mindenki elfelejtette, és az atomot állítja be a brazos párjának, pedig nem ez volt beígérve.
-

Mozsa
tag
Ezen én is meglepedőtem (na jó abszolút nem) hogy az októberben megjelenő bull pletykáról nem írtál. Mondjuk piros címmel.
De hát miért is nem? Mert nem lett megerősítve hivatalosan, mondanád.
De az nvidia megerősítette a crytek-es sztorit? Gondolom nem, arról még is tudtál írkálni.
-

Zso2
őstag
válasz
 Televan74
#48
üzenetére
Televan74
#48
üzenetére
Ezt a tokozási mánia mindíg előjön, mondj már egy tokozást az Inteltől,amivel nincs el ugyanannyi ideíg teljesítményben az user. Esetek 99%-ban új lapot vesz az ember , mikor a régi gépét lecseréli, sőtt itt a Ph-n akik a legjobban hangoztatják ezt a mizériát , 1 éven belül több alaplap megfordul náluk. A775 pl még mindíg versenyben van kb 2006 óta...
-
#51
nuke7
veterán
antikomcsi
#47
nuke7
veterán
válasz
antikomcsi
#47
üzenetére
már nem azért, de elég jól bejött nekik ez a stratégia, míg az nvidia elég sokat küszködött - ha mostmár nem is annyira para.
de voltak nekik "isten" hatalmas chipes vga-k, amiket be kellett szüntetni mert csak veszteségesen tudták értékesíteni az amd miat...
nemgond, hogy szerinted az nem más, mint jókora lemaradás. Sajnos.(#45) Zso2: 49-es hsz? egyébként meg ha azzal a sandy-vel akarod versenyeztetni az amd-t, nyugodtan vedd meg a 16 magos opteront, a hozzávalókkal együtt, ahogy más írta is előttem...
-

Davos44
csendes tag
Én is úgy tudom, hogy az első "wave" a procikból augusztusban jön, a kövik meg októberben. Még az AMD is mondta anno hivatalosan, hogy több részletben bocsájtják piacra a procikat. Októberiek valszeg kicsit nagyobb órajellel esetleg TDP-vel rendelkeznek. Bár ez a része spekuláció. (Bár a TDP-t valószínűnek tartom, pl 955BE-ből is volt 95W és 125W verzió)
-
#47
antikomcsi
veterán
nuke7
#44
antikomcsi
veterán
Ez most kb. pont úgy hangzik, mint amikor azt hallgattuk, hogy az AMD soha nem fog nagy chipeket gyártani a vga kártyákra, mert Ők más utat járnak. Aztán most láthatjuk mi lesz a helyzet.
Igazából az óriásnak vélt előnyről kiderült, hogy az nem más, mint jókora lemaradás. Sajnos.
Nehogy ez legyen cpu fronton is.
-
Zso2
őstag
válasz
Televan74
#43
üzenetére
vaz, akkor ne érje utol... . Ezt amúgy komolyan kérdezted?
(#44) nuke7: nincs Abu magyarázta olyannal, ami nekem nem válasz.. ..ha Intel megcsinálja, AMD miért nem? Éppen ez feltételezi a lemaradását.. nem tudnak high-end kategóriát csinálni ami versenyképes az Intelével, ezért is tudja az Intel drágábban adni a cpu-it, amire persze morgás tárgya örökké. -
smkb
őstag
A google translatével lefordítod és október az, csak fura mód, mik nincsenek a török nem az október szót használja az októberre, hanem "Ekim" és jól fordítja a google, mert az bizony októbert jelent magyarul...
"Bulldozer FX işlemcilerinin 60-90 gün içerisinde çıkacağını açıklayan AMD cephesinde oluşan son tablo lansman için Ekim
" ami nyersben :" Bulldozer FX processors will come within 60-90 days of the last table in front of launch, AMD announced for October"Viszont, te mit használtál forrásnak, ha nem az eredeti donanimhaber hírt? Egy már "elég szar a török-angol fordítás" -t??
-
Abu85
HÁZIGAZDA
Oda van leírva. Konkrétan mondták, hogy nem szeretnék kommentálni. Azt mondták, hogy várjuk ki a megjelenést, és akkor minden kiderül.
Ha egy pletykára egy hivatalos forrásból származó ellentmondás jön, akkor melyik legyen az erősebb?A DonanimHaber egyébként nem mondott októbert, legalábbis nem általánosan: [link] - elég szar a török-angol fordítás, de azt lehetett tényleg kivenni, hogy a TBD-s procik októberben érkeznek.
Hát, hogy mi a mókás, azt nem szeretném kommentálni. Sokszor az a bajod, hogy a pletyka le van írva, most meg az, hogy nem. Talán szelektíven szereted ezeket olvasni?
-
smkb
őstag
"Le van írva, hogy konkrétan megkérdeztük az AMD-t, hogy most mi van. Visszaírták, hogy a Computexen közölt megjelenési terv él. Ennil hivatalosab adat nincs."
Aha, de a hír többi tartalmára van hivatalos adat nem ?
Azokra mit is mondott az AMD?"Az AMD-t megkerestük a DonanimHaber táblázatával kapcsolatban, de ahogy arra számítani lehetett rá nem szerették volna kommentálni az adatokat."
Jaaa..., hogy csak szelektíven pletykálkodunk, ami pletyka tetszik, lehozzuk, amelyik része nem, azt nem
Mókás.... -
Abu85
HÁZIGAZDA
Nem lehet a Sandy Bridge-E az ellenfele, mert a Zambezi 942 lábas, míg a Sandy Bridge-E 2011 lábas processzor. Az AMD lehozhatja a Socket G34-et, ami 1900 lábas, de mondták, hogy nem lenne 600 dollár alatt alaplap, így feleslegesnek látnak még egy foglalatot bevetni az asztali piacon. Akinek ilyen extrém igényei vannak, hogy személyi szuperszámítógépet akar építeni, azok megvehetik a 16 magos Opteront.
-
#36
RyanGiggs
őstag
antikomcsi
#30
RyanGiggs
őstag
válasz
antikomcsi
#30
üzenetére
ááá, azért annyira nem gondolom erősnek a Bull-t!!
Pedig nem lenne rossz!!(#35) Abu :
Az alsókategóriás Bulldozer 4 vagy 2 magos az is csak értelmezés kérdése?!
Tehát akkor valójában?? -
-
Zso2
őstag
Szerintem elvileg a Bullnak az ellenfele a Sandy Bridge E . Csak igen a majd 1 generáció teljesítménykülönbség ezt hozta ki a dologból..és az árak ennek megfelelően alakulnak, szóval valszeg mindenki belövi teljesítmény arányosan a cpu-it.
A nyakamat rá ,hogy a Bull nem lesz teljesítmény/ár bajnok, mert nagyon erős ebben a Sandy, ennél jobbat nem hiszem,hogy tudnak. -
#32
Abu85
HÁZIGAZDA
antikomcsi
#30
Abu85
HÁZIGAZDA
válasz
antikomcsi
#30
üzenetére
Azoknak nem állít konkurenciát az AMD. Nem fognak még egy foglalatot bevezetni. A szerverbe szánt G34-et lehozhatnák, de nem lenne 600 dollár alatt alaplap, hiszen majdnem 2000 tűs a foglalatról van szó.
-
#28
RyanGiggs
őstag
antikomcsi
#27
RyanGiggs
őstag
válasz
antikomcsi
#27
üzenetére
Én is azt írtam fentebb tippnek!! Hisz a mostani i5/i7=SB!
És ha így van, akkor gondolom az ára is 40-50k között lesz az FX-8asoknak!
Mert ha drágább lesz, akkor aki fejleszteni akar az vesz inkább
45k-ért egy i5-2500K-t, amit 4Ghz fölé is lazán lehet tuningolni. -
RyanGiggs
őstag
Értem.
Tehát akkor az FX-4xxx-esek "valós" 4magosak....FX-8xxx-esek "valós" 8magosak!
Akkor úgy is lehetne értlemezni hogy az FX-4xxx-esek a "régi' i5-ösök
ellen lép harcba, az FX-6xxx-esek a "régi" i7-esek ellen van,és az
FX-8xxx-esek meg az új Sandy Bridge ellen jönnek!
Igaz még pontos adatok nincsenek és tesztek sincsenek...de ez lehet?! -
Puma K
nagyúr
Hmmm...
1. Magok száma: OK!
2. Maximális fogyasztás: OK!
3. Órajelek: ?Nekem valahogy nem szimpatikus az általam megemlített 3. pont miatt. De így látatlanban konkrét véleményem nincs, miszerint jó-e vagy sem. Majd ha megjelennek a tesztek róluk, majd akkor.
Amúgy ez az AMD válasza az Intel jelenlegi SB procijaira? Tehát az 1 generációs különbség az Intel javára még fennáll?
-
#23
antikomcsi
veterán
RyanGiggs
#21
-
#16
bel6
tag
Depression
#1
bel6
tag
válasz
 Depression
#1
üzenetére
Depression
#1
üzenetére
A hátán hordja a magjait a sok kis apró lábával
-
#14
 lee56
őstag
Depression
#1
lee56
őstag
Depression
#1
lee56
őstag
válasz
Depression
#1
üzenetére
Hát magos, mit nem lehet ezen érteni?
-

zörbi
csendes tag
Az ipon szerint ismét halaszották, ezúttal októberre. Vártam is hogy lehozza-e a hírt a PH. Mondjuk én a Llano-t várom már, hogy megjelenjenek az asztali verziók. Ez a 125W nekem túl sok, volt anno P4-esem
Volt hogy apám rámparancsolt hogy kapcsoljam ki a gépet mert nem tud aludni. -
#1
 Depression
veterán
Depression
veterán
Depression
veterán
A nyitószövegben hát magos proci szerepel.












 ), akkor nagyot billen(het) a mérleg, eddig nem túl kedvezően álló nyelve az AMD felé - csak valóban jöjjenek azok a programok.
), akkor nagyot billen(het) a mérleg, eddig nem túl kedvezően álló nyelve az AMD felé - csak valóban jöjjenek azok a programok.
 (Ilyen húzásra inkább az Intel-től számítana az ember...
(Ilyen húzásra inkább az Intel-től számítana az ember...  )
)

 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).














![;]](http://cdn.rios.hu/dl/s/v1.gif) , ott egy 16 magos Interlagos-t hasonlítottak egy 4 magos Sandy-hez, úgy, hogy ezt az "apró" tényt nem írták oda, tehát, ha egy 8 magos asztali Bulldozer-re (Zambezi) vagy kíváncsi, akkor oszd el a Flex FP oszlopban lévő számokat kettővel.
, ott egy 16 magos Interlagos-t hasonlítottak egy 4 magos Sandy-hez, úgy, hogy ezt az "apró" tényt nem írták oda, tehát, ha egy 8 magos asztali Bulldozer-re (Zambezi) vagy kíváncsi, akkor oszd el a Flex FP oszlopban lévő számokat kettővel.
















 Azért valami halványan rémlett.
Azért valami halványan rémlett. 










 Hm, derek...
Hm, derek... 



























Új hozzászólás Aktív témák


- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max
- Azonnali készpénzes félkonfig / félgép felvásárlás személyesen / csomagküldéssel korrekt áron
- ÚJ HP ProBook 445 G11 - 14" WUXGA - Ryzen 5 7535U - 16GB - 256GB - MAGYAR - 2+ év garancia
- HIBÁTLAN iPhone 13 128GB Starlight -1 ÉV GARANCIA - Kártyafüggetlen, MS3432
- Samsung Galaxy S23 FE / 8/128GB / Kártyafüggetlen / 12Hó Garancia
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi