
- Apple iPhone Air - almacsutka
- Google Pixel 10 Pro XL – tíz kicsi Pixel
- Honor 400 Pro - Gép a képben
- Android alkalmazások - szoftver kibeszélő topik
- Poco F7
- iPhone topik
- Samsung Galaxy A56 - megbízható középszerűség
- Apple iPhone 17 - alap
- Így teljesít a Nubia Z80 Ultrában az új Snapdragon
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
Új hozzászólás Aktív témák
-

dezz
nagyúr
Sőt, a táblázat alapján a kétszerezés is csak akkor igaz, skalár FP esetén, ha egyszerre akarunk 2 FMUL-t vagy 2 FADD-ot. 1 FMUL + 1 FADD esetén, úgy tűnik, nincs változás. SSEx esetén szintén nem látok változást. És itt a változás hiánya fele peak/magot jelent... Ez valahogy nem áll össze.
-

P.H.
senior tag
Azért ráerőszakolás, mert
- ha (Intel-nél) egy magon vagy (AMD-nél) egy modulon egy szál fut, az kihasználhatja a teljes rendelkezésre álló mozgásteret
- ha egy-egy szál legalább átlagosan 1.0 FP-műveletet képes indítani órajelenként, már akkor is kihasználja két szál mind a Bulldozer, mind a Sandy Brige FPU-ja által nyújtott lehetőségeket, az X6-ét viszont még messze nem, ott így is lassabb lesz, mint "lehetne".
- 1.0 felett már akár akadályozhatják egymást, így szálanként akár lassabbak lehetnek egy X6-on futó szálhoz képest, de itt 4 modulos Bulldozer esetén is 8 szálról beszélünk, ahogy 4 magos Sandy Bridge-nél is.A K8-hoz képes egyrészt kétszeres a 64->128 bit szélesítés miatt, további kétszeres az FMA-képességgel; 2 FMA utasítás 2-2 FADD+FMUL-nak felel meg. Persze ez kissé marketingízű

Mégsem olvastad el a teljes szöveget:
"In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data."
Összhangban van a kettő; (lebegőpontos) fmul-fadd-fmac csak két egységen van jelölve. -
P.H.
senior tag
Nem igazán értem, mire gondolsz, a számok valósak.
- a Sandy Bridge egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 2 256 bites műveletet (16 FLOP) képes végrehajtani, azaz ráerőszakolva a gondolatmenetedet, szálanként 4 vagy 8 FLOP jut.
- a Bulldozer egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 1 256 bites műveletet (ugyancsak 8 FLOP) képes végrehajtani, azaz a gondolatmenettel szálanként 4 FLOP jut.
Nekem 128 bites végrehajtás mellett ez azonosnak tűnik, nem "fele akkora peak" értéknek, AVX esetén a a Sandy Bridge 2x erősebb. Érdekes, nem érdekes, ez van. Ezenkívül 100 más dolog határozza meg azt, hogy mennyire lehet megközelíteni az elméleti maximumot.
Például K8 és K10.5 egyaránt 2 FLOP/órajel tempóval tudja végrehajtani az x87-es kódokat, mégis ennyi különbség van köztük ugyanannál a kódnál: c1 oszlop az IPC (1.6 vs 2.1), a soronkénti c2/c0 hányados megadja az órajelenként végrehajtott átlagos x87-műveleteket: 0.8 vs 1.05; (itt az alsó a program).Nem azt írták, hogy magonként négyszerezik a számítási kapacitást a K8-hoz képest, hanem FPU-nként.
Abból a teljes szövegből lehet tudni, amit #120-ba bemásoltam az Opt. Guide-ból, illetve innen (234. oldal):
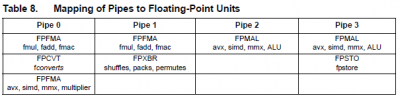
-
P.H.
senior tag
Nem csak a teoretikus műveletvégzési sebességtől lehet gyorsabb(?), mint az X6, ez csak pár számot tartalmazó táblázat meg egy-egy ábra, amelyekből nem látszik, hogy pl. sokkal okosabban osztja/oszthatja el az végrehajtó egységek között a műveleteket (lásd pl. itt a 147. oldalt; nem nagy dolognak látszik, de pl. egy ilyen felezi vagy 2/3-olja az IPC-t K10-en is, ha nincsenek ennek figyelembevételével kézzel rendezve az asm-utasítások).
Az FPU-ban 4 execution port van, kettőre legfeljebb 128 bites FP-műveletek, kettőre pedig legfeljebb 128 bites integer-műveletek mehetnek -, órajelenként 1-1-1-1. Egy 256 bites AVX-utasítás 2 db 128 bites műveletre fordul le és így kerül be az FPU-ba. Az AMD-slide szerint 128 bites SSE, 128 bites AVX és 256 bites AVX esetén azonos a végrehajtási sebesség. Ez úgy alkot logikus egységet, ha egy-egy FLEX FP 2x 128 bit (8 SP vagy 4 DP FLOP) műveletre képes órajelenként. Ezt mondják az Opt. Guide-ban, a slide-on és az AMD-blogban (itt is a táblázatban).
Ha valóban ilyen jól sikerült nekik továbbfejleszteni pár "egyszerű" lépéssel az FPU-t, annak örülni kell; de nem kell beleképzelni további pár superior, még eltitkolt képességet; FLOP/órajelben ennyi van. Mostmár inkább az lesz érdekes, hogy mennyi lesz az órajel hozzá (akár a következő 1-2 generáción belül).






Új hozzászólás Aktív témák

- Battlefield 6
- AliExpress tapasztalatok
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Kalacskepu: Elrontott Radeon X1950 Pro megjavítása
- Projektor topic
- AMD Navi Radeon™ RX 9xxx sorozat
- Elektromos autók - motorok
- Ventilátorok - Ház, CPU (borda, radiátor), VGA
- SSD kibeszélő
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- További aktív témák...

- AMD Ryzen 5 5600X Wraith Stealth dobozos - Aqua garancia 2026.03.07-ig (AM4)
- AMD Ryzen 5 7500F - Új, 3 év garancia - Eladó!
- Eladó AMD Ryzen 7 3700X CPU Bequiet Pure rock 2 hűtővel.
- BESZÁMÍTÁS! AMD Ryzen 9 3900X 12 mag 24 szál processzor garanciával hibátlan működéssel
- Intel Core i9-9900K 8-Core 3.6GHz (16M Cache, up to 5.00 GHz) Processzor!
- Designer 4K Monitor - BenQ PD-3200-U
- LG 32SQ700S-W - 32" VA Smart - 3840x2160 4K UHD - 62Hz 5ms - WebOS - Wifi + BT - USB-C - Hangszórók
- OnePlus 13 Gyors teljesítmény és modern dizájn Midnight Ocean 16/512 GB
- Telefon felvásárlás!! Samsung Galaxy S23/Samsung Galaxy S23+/Samsung Galaxy S23 Ultra
- BESZÁMÍTÁS! MSI B450 R7 1800X 16GB DDR4 512GB SSD RTX 2060 Super 8GB Rampage SHIVA Corsair 550W
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest