Hirdetés
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Megtartotta Európában a 7500 mAh-t az Oppo
- Bemutatkozott a Poco X7 és X7 Pro
- 8000 mAh-s aksi a Kínában most bemutatott Honor 500-akban
- Vivo X300 Pro – messzebbre lát, mint ameddig bírja
- Samsung Galaxy S24 - nos, Exynos
- Xiaomi 15T Pro - a téma nincs lezárva
- Windows 10 Mobile (Windows Phone) szakmai topik
- EarFun Air Pro 4+ – érdemi plusz
Új hozzászólás Aktív témák
-
#133
 P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
válasz
 hugo chávez
#132
üzenetére
hugo chávez
#132
üzenetére
Abból az alapfeltevésből kell kiindulni, hogy a konkurencia a termékéről nem állíthatnak valótlanságot (házon belül azt mondanak, amit akarnak, ezért került X6 a táblázatba, nem Magny Cours, ezesetben a 48 helyén 96 szerepelne
 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).Azzal a két sorral arra utalnak, hogy az Intel-nél 1 FADD- és 1 FMUL-jellegű 128 bites utasítás indítható órajelenként a két specializált végrehajtó egység miatt, X6-nál szintúgy, az AMD 2 FMAC portja viszont általános, a fentiek bármilyen kombinációját kezeli órajelenként. Ennek kézzelfogható jelentősége főleg 2 szál párhuzamos futtatása esetén van, kevésbé "tartja fel" egymást a két thread.
-
#123
 dezz
nagyúr
hugo chávez
#119
dezz
nagyúr
hugo chávez
#119
dezz
nagyúr
válasz
hugo chávez
#119
üzenetére
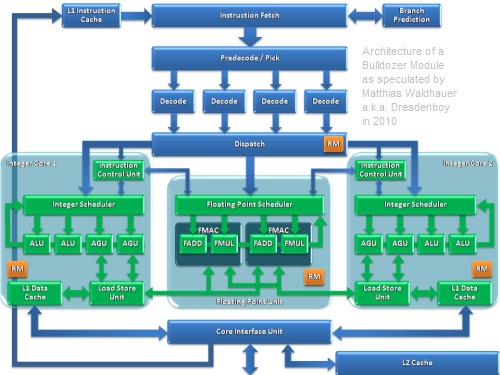
128-bit FMAC = 128 bit FMUL + 128 bit FADD
ps. én nem programozom PC-n, ez leginkább P.H. asztala.
(#120) P.H.: "Azt hiszem, lényegretörő és egyértelmű."
Nem tudom, én számomra nem derült ki a szövegből egyértelműen, hogy mehet-e 2x128 bit FMUL + 2x128 bit FADD. De a gyakorlat azt mutatja (lást teszteredmények), hogy mehet, mert hogy nem lassabb, mint a 6-magos K10, hanem gyorsabb.
És ha így van, akkor nem tudom, miért nem tud 2x256 bit AVX-et.
-
#121
 Abu85
HÁZIGAZDA
hugo chávez
#119
Abu85
HÁZIGAZDA
hugo chávez
#119
Abu85
HÁZIGAZDA
válasz
hugo chávez
#119
üzenetére
Nem feltétlen szükséges. Elérhető lenne C++-ból, csak fordító kell. Az AVX GPU-s támogatáson azonban nem éri meg gondolkodni. Pont a viszonylag kevés támogatott utasítás miatt fogyasztanak kevesebbet a GPU-k egységnyi számítási kapacitás mellett. Az AVX támogatásával ugyan nőne a lehetőségek tárháza, de kevesebb lenne a nyers számítási kapacitás, mert a chipdizájn bonyolódna és a fogyasztás drasztikusan nőne.
-
#120
P.H.
senior tag
hugo chávez
#119
P.H.
senior tag
válasz
hugo chávez
#119
üzenetére
"Nekem nem igazán világos ez, egy 128 bites egységen hogy "megy át" egy ciklus alatt 4x32 bit FMUL és 4x32 bit FADD? Az nem lehet, hogy FADD, vagy FMUL esetén 4, FMAC esetén pedig csak 2 FMUL és 2 FADD művelet van ciklusonként?"
Sehogy, 1 execution portra órajelenként 1 műveletet lehet indítani (ez a port mint kifejezés lényege), és itt most 128 bites portokról van szó.
Az Optimization Guide ide vonatkozó része (ez teljesen újra lett írva a korábbi verziókhoz képest
)The AMD Family 15h processor floating point unit (FPU) was designed to provide four times the raw FADD and FMUL bandwidth as the original AMD Opteron and Athlon 64 processors. It achieves this by means of two 128-bit fused multiply-accumulate (FMAC) units which are supported by a 128-bit high-bandwidth load-store system. The FPU is a coprocessor model that is shared between the two cores of one AMD Family 15h compute unit. As such it contains its own scheduler, register files and renamers and does not share them with the integer units. This decoupling provides optimal performance of both the integer units and the FPU. In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data. A crossbar (XBAR) unit is integrated into FPU pipe 1 to execute the permute instruction along with shifts, packs/unpacks and shuffles. There is an FPU load-store unit which supports up to two 128-bit loads and one 128-bit store per cycle.
FPU Features Summary and Specifications:
• The FPU can receive up to four ops per cycle. These ops can only be from one thread, but the thread may change every cycle. Likewise the FPU is four wide, capable of issue, execution and completion of four ops each cycle. Once received by the FPU, ops from multiple threads can be executed.
• Within the FPU, up to two loads per cycle can be accepted, possibly from different threads.
• There are four logical pipes: two FMAC and two packed integer. For example, two 128-bit FMAC and two 128-bit integer ALU ops can be issued and executed per cycle.
• Two 128-bit FMAC units. Each FMAC supports four single precision or two double-precision ops.
• FADDs and FMULs are implemented within the FMAC’s.
• x87 FADDs and FMULs are also handled by the FMAC.
• Each FMAC contains a variable latency divide/square root machine.
• Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together.Azt hiszem, lényegretörő és egyértelmű.
-
#114
dezz
nagyúr
hugo chávez
#106
dezz
nagyúr
válasz
hugo chávez
#106
üzenetére
Ezt írják: "Two 128-bit FMAC units, one for each core"
FMAC = FMUL + FADD. Ennyi volt eddig is egy magban a K10-nél.
Ez magonként 4db FMUL és 4db FADD művelet ciklusonként.
8 FLOP/ciklus x 8 mag = 64 FLOP/ciklus...
A kis képeken talán egy FMA-t vettek egy FLOP-nak. (Mintha GPU-knál lenne ez szokás.) -
#113
dezz
nagyúr
hugo chávez
#103
dezz
nagyúr
válasz
hugo chávez
#103
üzenetére
Ugye nem gondoljátok komolyan, hogy a Bulldozer egy magra vetítve fele annyi FP számolóegységgel rendelkezik, mint a K10? Nem hinném, hogy így lenne...
Attól, hogy a 128-bites egységeket (FMUL és FADD) össze lehet vonni kétmagonként (2xFMUL + 2xFADD), illetve be lehet fogni őket FMA-ra, még nem lesz belőlük fele annyi...
Ami az SSEx vs. AVX-et illeti: akármilyen befolyásos is az Intel, egyik napról a másikra akkor sem fogják átírni az összes létező szoftvert AVX-re, és ha át is írnak valamit, az SSx verziót nem fogják eltüntetni a Föld színéről...
Később meg a Bulldozerből is jön elvileg a magonként 256-bites FP egységekkel rendelkező változat (hogy ez vajon az "enhanced" lesz-e már, vagy csak a "next-gen."...).
-
#111
 hohoo
senior tag
hugo chávez
#110
hohoo
senior tag
hugo chávez
#110
hohoo
senior tag
válasz
hugo chávez
#110
üzenetére
Nem keverem. AVX támogatású gpu egységek nélkül opencl (vagy stream vagy mi az az alap api) kell(mert ki akar gpu gépi kóddal szórakozni?). Ha tudja avx-re használni akkor viszont nem kell feltétlenül.
-
#107
hohoo
senior tag
hugo chávez
#106
hohoo
senior tag
válasz
hugo chávez
#106
üzenetére
http://www.google.com/search?hl=hu&safe=off&client=opera&hs=QYb&rls=hu&channel=suggest&q=flex+fp+flops&btnG=Keres%C3%A9s&aq=f&aqi=&aql=&oq=
mindenhol máshol meg 8 mag 4 modult írnak...
Ha úgy lenne ahogy mondod mi értelme lenne? annál a phenom 2 is jobb lenne 128 bites műveletekkel.
-
#105
hohoo
senior tag
hugo chávez
#103
hohoo
senior tag
válasz
hugo chávez
#103
üzenetére
A fura az, hogy ezt a 64 gflopsot mindenhol 4 modulra, vagyis 8 magos bullra írják...
nem 8 modulos 16 magosra.Csak te szerinted 16 magos az a 64

-
#102
 Kotomicuki
senior tag
hugo chávez
#98
Kotomicuki
senior tag
hugo chávez
#98
Kotomicuki
senior tag
válasz
hugo chávez
#98
üzenetére
De ez várható is volt, ha már "megfelezték" az FPU-kat - emlékeim szerint, de majd kijavítotok, ha tévedek, amikor sikeresebb volt az AMD a CPU-k terén, mint az iNtel, akkor az FPU rész is minimum egálban volt a kékekkel.
Innentől tényleg az lesz a mérvadó, hogy melyik cég tudja megnyerni a szoftverfejlesztőket az igazának. Ebben pénzügyileg és eladott CPU darabszám szerint sem áll a zászló a zöldeknek - gondolom a kékek most sem fogják meghazudtolni önmagukat: a piaci és gazdasági erőfölénnyel való visszaélés, ha szükséges, ha nem, elő fog kerülni a tarsolyból.
Hacsak nem fog bele egy átfogó szoftver-fejleszt(tet)ésbe (Bull+HD7000 - ha a TSMC is majd úgy "akarja") az AMD, akkor a Bull. sem váltja majd be a hozzáfűzött reményeket.

(Gondolom, hogy egyből jelennének meg az ellenfél által (le)fizetett fejlesztők, Bull.-on akadozó szoftverei, amit minden, hardverrel foglalkozó site-nak kutya kötelessége volna naponta szajkózni. Ezért még a kék-(másik)zöld ellentét barátsággá szelídülését sem tartom kizártnak, erre az időre. Tehát az "itt a hardver, kezdjetek vele vmit, önállóan" már nem járható út!)A platformosodásnak is megvannak, sőt, még csak itt jönnek elő, a maga hátulütői: ha nem tudják elfogadtatni a sajátot a fejlesztőkkel - nekik is 2-3 felé fejleszteni, mert mindenkié más... -, vásárlókkal - a marketing bullshit kit, hogyan tud átvágni... - , akkor nagyobbat buknak vele, mintha csak külön-külön, a piacvezető által diktált, éppen aktuális trendhez simulnának hozzá a termékeikkel - a piacvezető mindig is akkora profittal dolgozik, hogy lenne életterük mellette, ahogy eddig is volt.

(A gyárt(at)ás terén fennálló, és ennek a szinte soha le nem küzdhető hátránynak is szerepe van az AMD gyengélkedésében - egyáltalán, az a tény, hogy önállóan nem tud semmilyen termékét sem legyártani (profitkiesés a bérgyártók miatt), onnantól vesztett helyzetben van - , örök 2.-nak maradásában.)[Lehet, hogy akkor járnának a legjobban, ha egy teljesen "más", eddigi ellenfeleiktől mentes piacot teremtenének, ahol egyedül ők diktálhatják a feltételeket (vhogy úgy, ahogy az nV is megpattant a PC-s üzletágból, de azt nem föladva): egy alaplapos, teljesen ráintegrált alkatrészakkel készülő PC, semmi külön kártya, max. külső csatlakoztatási lehetőség a többi piaci résztvevő felé, (EP)ROM-ba égetett Op.renszerrel, stb. ~kb. a modern C64, de időtálló teljesítménnyel, előrelátóan megszerkesztett szoftver- (pl. Open CL) és Op.rendszerkörnyezettel - esetleg almás vagy IBM-s (SUN-os, stb.) együttműködésben/támogatással. Kezdetben a M$ op.rendszerének a hardvert nem kellő mértékben való kihasználására építkezve, ezzel valós teljesítménybeli fölényt elérve...]
-
#101
 Zeratul
addikt
hugo chávez
#98
Zeratul
addikt
hugo chávez
#98
Zeratul
addikt
válasz
hugo chávez
#98
üzenetére
64 FLOPS mióta duplája a 64 FLOPS nak? 128 bites kód esetén az SB csak felét tudja a Bullnak.
-
#100
P.H.
senior tag
hugo chávez
#98
P.H.
senior tag
válasz
hugo chávez
#98
üzenetére
Ha ennyire kisarkítva nézed, akkor 256 bites AVX esetén igen, ennyi. De nem minden fekete-fehér. Ahogy linkelted is:
"When Intel introduced SSE2 in the P4, each 128-bit instruction was cracked into two 64-bit uops, and the throughput did not substantially improve. This created a chicken and egg problem: Intel wanted developers to use SSE2 (since the P4 was not designed to execute x87 particularly fast), but developers do not want to rewrite or recompile code for a marginal gain.Sandy Bridge can sustain a full 16 single precision FLOP/cycle or 8 double precision FLOP/cycle – double the capabilities of Nehalem. This guarantees that software which uses AVX will actually see a substantial performance advantage on Sandy Bridge and should spur faster adoption. Intel seems to have learned from the lessons of SSE2 and hopefully, the uptake for AVX amongst the software community will be far swifter."
Adott mindkét oldalon egy-egy 128 bites FPU, külön FADD és FMUL futtató egységekkel: el kellett dönteni, hogy az igen nagy mennyiségű plusz tranzisztort (és az általuk igényelt plusz fogyasztást) mibe fektetik:
- az AMD a 128 bites végrehajtásra és a meglevő programokra helyezte a hangsúlyt: két majdnem azonos képességű FADD+FMUL végrehajtót tettek az FPU-ba, pontosan úgy, ahogy eddig a K7-K10 családban 3 majdnem azonos ALU+AGU van; így teljesen mindegy, hogy a programban milyen az FADD- és FMUL-jellegű utasítások aránya (eddig nagyon nem volt az). Ezt megfejelték azzal, hogy a register-to-register értékmásolás (amik nagy része az AVX alatt feleslegessé válik, de SSEx alatt elég sok van, mivel egy-egy művelet felülírja az egyik paraméterét) 0 órajelet igényel, a registerfile megoldja saját hatáskörben (órajelenként 4-et, ha minden igaz).
Az AVX-es programokat nem túl hatékonyan hajtja végre, de az SSEx-alapúak végrehajtását eléggé felgyorsítja.- az Intel maradt az 1 FADD + 1 FMUL futtatóegység felépítésnél, ezt látták 256 bites végrehajtókkal, felhasználva hozzá a meglevő integer adatutat is, illetve hozzáadva egy kis energiatakarékosságot (innen):
Floating point warm-up effect
The latencies and throughputs of floating point vector operations is varying according to the processor load. The ideal latency is 3 clock cycles for a floating point vector addition and 5 clock cycles for a vector multiplication regardless of the vector size. The ideal throughput is one vector addition and one vector multiplication per clock cycle. These ideal numbers are obtained only after a warm-up period of several hundred floating point instructions.
The processor is in a cold state when it has not seen any floating point instructions for a while. The latency for 256-bit vector additions and multiplications is initially two clocks longer than the ideal number, then one clock longer, and after several hundred floating point instructions the processor goes to the warm state where latencies are 3 and 5 clocks respectively. The throughput is half the ideal value for 256-bit vector operations in the cold state. 128-bit vector operations are less affected by this warm-up effect. The latency of 128-bit vector additions and multiplications is at most one clock cycle longer than the ideal value, and the throughput is not reduced in the cold state.
The cold state does not affect division, move, shuffle, Boolean and other vector instructions.
There is no official explanation for this warm-up effect yet, but my guess is that the processor can turn off some of the most expensive execution resources to save power, and turn on these resources only when the load is heavy. Another possible explanation is that half the execution resources are initially allocated to the other thread running in the same core.
Mindkettő kihozza a maximumot a 32 nm-es lehetőségekből, mivel mindkettő szinte megduplázza az FPU fizikai méretét. Az AMD annyival van könnyebb helyzetben, hogy mivel a korábbi - K8-alapú - FPU-kat arra tervezte, hogy minden 128 bites utasítás 2x 64 bitesre fordítódik és hajtódik végre, így amikor 128 bitesre bővítette azt, akkor az FPU "kiürült", azonos végrehajtási sebességhez feleannyi belső uop-műveletet kap. Ezt most kitömik a 2. szállal.
-
#99
 Oliverda
félisten
hugo chávez
#98
Oliverda
félisten
hugo chávez
#98
Oliverda
félisten
válasz
hugo chávez
#98
üzenetére
Már csak alkalmazás kellene ami egyáltalán használja az AVX-et.
-
#96
P.H.
senior tag
hugo chávez
#93
P.H.
senior tag
válasz
hugo chávez
#93
üzenetére
Erről az ábráról van szó.
Nincs újabb, 4 magos Sandy Bridge-dzsel és 8 modulos Bulldozerrel számoltak, így jönnek ki az értékek: felszorozták az FPU-darabszámmal a névleges teljesítményt, mivel X6-hoz 48-at írnak, ami ott 8 FLOPS/mag=FPU, a K10 órajelenként 2 4xSP bites műveletet tud. A Bulldozer szintúgy, tehát a 64 FLOPS-hoz 8 Bulldozer-FPU kell. Így nézve kijön, hogy azonos magszám (4) mellett a Sandy Bridge 256 bites műveleteknél 2x akkora teljesítményt hoz, mint 128 biten, a 8 modulos (mindkét esetben 2 művelet/órajel), 16 magos Bulldozer pedig konstant 64 FLOPS-ot.
Hogy miért így hasonlított össze az AMD, azt ők tudják...
-
#94
Abu85
HÁZIGAZDA
hugo chávez
#93
Abu85
HÁZIGAZDA
válasz
hugo chávez
#93
üzenetére

Ez a legutolsó Flex FP összefoglaló. Szokás szerint apró betűs rész nélkül.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#91
Abu85
HÁZIGAZDA
hugo chávez
#90
Abu85
HÁZIGAZDA
válasz
hugo chávez
#90
üzenetére
Akkor az IB lehet, hogy bővít, majd meglátjuk.
A Bulldozer az FMUL+FADD-nál nem tiszta, hogy hogyan működik. Az AMD FLOP/ciklus paramétereit nézve, csupán annyi derül ki, hogy a modul FLOP/ciklus teljesítménye megegyezik az SB mag FLOP/ciklus teljesítményével. Persze a trükk mindig az apró betűs részben van elrejtve.


 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).










![;]](http://cdn.rios.hu/dl/s/v1.gif)
Új hozzászólás Aktív témák

- Pánik a memóriapiacon
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Milyen notebookot vegyek?
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Kettő együtt: Radeon RX 9070 és 9070 XT tesztje
- Megtartotta Európában a 7500 mAh-t az Oppo
- BMW topik
- Gaming notebook topik
- Autóápolás, karbantartás, fényezés
- EAFC 26
- További aktív témák...

- BESZÁMÍTÁS! ASRock B550M R7 5700X 32GB DDR4 1TB SSD RTX 4070 Super 12GB GameMax Aero Mini ECO 650W
- Samsung Galaxy S23 Ultra 5G 512GB, Kártyafüggetlen, 1 Év Garanciával
- Jabra Speak2 75 MS Teams USB-bluetooth hangszóró
- Apple iPhone 13 128GB, Kártyafüggetlen, 1 Év Garanciával
- Telefon felvásárlás!! Apple Watch Series 6/Apple Watch Series 7/Apple Watch Series 8
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest