Hirdetés
- Samsung Galaxy A17 5G – megint 16
- Poco F8 Ultra – forrónaci
- Samsung Galaxy Watch5 Pro - kerek, de nem tekerek
- Örömkönnyek és üres kezek a TriFold startjánál
- Milyen robotporszívót vegyek karácsonyra? (2025)
- Töltő már van a Galaxy S26 Ultrához
- Milyen okostelefont vegyek?
- Bekerül az Apple Pay és Google Pay a Budapest GO alkalmazásba
- Samsung Galaxy Watch8 - Classic - Ultra 2025
- Vivo X300 - kicsiben jobban megéri
Új hozzászólás Aktív témák
-
#133
 P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
hugo chávez
#132
P.H.
senior tag
válasz
 hugo chávez
#132
üzenetére
hugo chávez
#132
üzenetére
Abból az alapfeltevésből kell kiindulni, hogy a konkurencia a termékéről nem állíthatnak valótlanságot (házon belül azt mondanak, amit akarnak, ezért került X6 a táblázatba, nem Magny Cours, ezesetben a 48 helyén 96 szerepelne
 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).Azzal a két sorral arra utalnak, hogy az Intel-nél 1 FADD- és 1 FMUL-jellegű 128 bites utasítás indítható órajelenként a két specializált végrehajtó egység miatt, X6-nál szintúgy, az AMD 2 FMAC portja viszont általános, a fentiek bármilyen kombinációját kezeli órajelenként. Ennek kézzelfogható jelentősége főleg 2 szál párhuzamos futtatása esetén van, kevésbé "tartja fel" egymást a két thread.
-
P.H.
senior tag
Azért ráerőszakolás, mert
- ha (Intel-nél) egy magon vagy (AMD-nél) egy modulon egy szál fut, az kihasználhatja a teljes rendelkezésre álló mozgásteret
- ha egy-egy szál legalább átlagosan 1.0 FP-műveletet képes indítani órajelenként, már akkor is kihasználja két szál mind a Bulldozer, mind a Sandy Brige FPU-ja által nyújtott lehetőségeket, az X6-ét viszont még messze nem, ott így is lassabb lesz, mint "lehetne".
- 1.0 felett már akár akadályozhatják egymást, így szálanként akár lassabbak lehetnek egy X6-on futó szálhoz képest, de itt 4 modulos Bulldozer esetén is 8 szálról beszélünk, ahogy 4 magos Sandy Bridge-nél is.A K8-hoz képes egyrészt kétszeres a 64->128 bit szélesítés miatt, további kétszeres az FMA-képességgel; 2 FMA utasítás 2-2 FADD+FMUL-nak felel meg. Persze ez kissé marketingízű
Mégsem olvastad el a teljes szöveget:
"In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data."
Összhangban van a kettő; (lebegőpontos) fmul-fadd-fmac csak két egységen van jelölve. -
P.H.
senior tag
Nem igazán értem, mire gondolsz, a számok valósak.
- a Sandy Bridge egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 2 256 bites műveletet (16 FLOP) képes végrehajtani, azaz ráerőszakolva a gondolatmenetedet, szálanként 4 vagy 8 FLOP jut.
- a Bulldozer egy FPU-val futtat 2 szálat, egy FPU órajelenként 2 128 bites (8 FLOP) vagy 1 256 bites műveletet (ugyancsak 8 FLOP) képes végrehajtani, azaz a gondolatmenettel szálanként 4 FLOP jut.
Nekem 128 bites végrehajtás mellett ez azonosnak tűnik, nem "fele akkora peak" értéknek, AVX esetén a a Sandy Bridge 2x erősebb. Érdekes, nem érdekes, ez van. Ezenkívül 100 más dolog határozza meg azt, hogy mennyire lehet megközelíteni az elméleti maximumot.
Például K8 és K10.5 egyaránt 2 FLOP/órajel tempóval tudja végrehajtani az x87-es kódokat, mégis ennyi különbség van köztük ugyanannál a kódnál: c1 oszlop az IPC (1.6 vs 2.1), a soronkénti c2/c0 hányados megadja az órajelenként végrehajtott átlagos x87-műveleteket: 0.8 vs 1.05; (itt az alsó a program).Nem azt írták, hogy magonként négyszerezik a számítási kapacitást a K8-hoz képest, hanem FPU-nként.
Abból a teljes szövegből lehet tudni, amit #120-ba bemásoltam az Opt. Guide-ból, illetve innen (234. oldal):
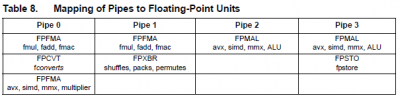
-
P.H.
senior tag
Nem csak a teoretikus műveletvégzési sebességtől lehet gyorsabb(?), mint az X6, ez csak pár számot tartalmazó táblázat meg egy-egy ábra, amelyekből nem látszik, hogy pl. sokkal okosabban osztja/oszthatja el az végrehajtó egységek között a műveleteket (lásd pl. itt a 147. oldalt; nem nagy dolognak látszik, de pl. egy ilyen felezi vagy 2/3-olja az IPC-t K10-en is, ha nincsenek ennek figyelembevételével kézzel rendezve az asm-utasítások).
Az FPU-ban 4 execution port van, kettőre legfeljebb 128 bites FP-műveletek, kettőre pedig legfeljebb 128 bites integer-műveletek mehetnek -, órajelenként 1-1-1-1. Egy 256 bites AVX-utasítás 2 db 128 bites műveletre fordul le és így kerül be az FPU-ba. Az AMD-slide szerint 128 bites SSE, 128 bites AVX és 256 bites AVX esetén azonos a végrehajtási sebesség. Ez úgy alkot logikus egységet, ha egy-egy FLEX FP 2x 128 bit (8 SP vagy 4 DP FLOP) műveletre képes órajelenként. Ezt mondják az Opt. Guide-ban, a slide-on és az AMD-blogban (itt is a táblázatban).
Ha valóban ilyen jól sikerült nekik továbbfejleszteni pár "egyszerű" lépéssel az FPU-t, annak örülni kell; de nem kell beleképzelni további pár superior, még eltitkolt képességet; FLOP/órajelben ennyi van. Mostmár inkább az lesz érdekes, hogy mennyi lesz az órajel hozzá (akár a következő 1-2 generáción belül).
-
#120
P.H.
senior tag
hugo chávez
#119
P.H.
senior tag
válasz
hugo chávez
#119
üzenetére
"Nekem nem igazán világos ez, egy 128 bites egységen hogy "megy át" egy ciklus alatt 4x32 bit FMUL és 4x32 bit FADD? Az nem lehet, hogy FADD, vagy FMUL esetén 4, FMAC esetén pedig csak 2 FMUL és 2 FADD művelet van ciklusonként?"
Sehogy, 1 execution portra órajelenként 1 műveletet lehet indítani (ez a port mint kifejezés lényege), és itt most 128 bites portokról van szó.
Az Optimization Guide ide vonatkozó része (ez teljesen újra lett írva a korábbi verziókhoz képest
)The AMD Family 15h processor floating point unit (FPU) was designed to provide four times the raw FADD and FMUL bandwidth as the original AMD Opteron and Athlon 64 processors. It achieves this by means of two 128-bit fused multiply-accumulate (FMAC) units which are supported by a 128-bit high-bandwidth load-store system. The FPU is a coprocessor model that is shared between the two cores of one AMD Family 15h compute unit. As such it contains its own scheduler, register files and renamers and does not share them with the integer units. This decoupling provides optimal performance of both the integer units and the FPU. In addition to the two FMACs, the FPU also contains two 128-bit integer units which perform arithmetic and logical operations on AVX, MMX and SSE packed integer data.
A 128-bit integer multiply accumulate (IMAC) unit is incorporated into FPU pipe 0. The IMAC performs integer fused multiply and accumulate, and similar arithmetic operations on AVX, MMX and SSE data. A crossbar (XBAR) unit is integrated into FPU pipe 1 to execute the permute instruction along with shifts, packs/unpacks and shuffles. There is an FPU load-store unit which supports up to two 128-bit loads and one 128-bit store per cycle.
FPU Features Summary and Specifications:
• The FPU can receive up to four ops per cycle. These ops can only be from one thread, but the thread may change every cycle. Likewise the FPU is four wide, capable of issue, execution and completion of four ops each cycle. Once received by the FPU, ops from multiple threads can be executed.
• Within the FPU, up to two loads per cycle can be accepted, possibly from different threads.
• There are four logical pipes: two FMAC and two packed integer. For example, two 128-bit FMAC and two 128-bit integer ALU ops can be issued and executed per cycle.
• Two 128-bit FMAC units. Each FMAC supports four single precision or two double-precision ops.
• FADDs and FMULs are implemented within the FMAC’s.
• x87 FADDs and FMULs are also handled by the FMAC.
• Each FMAC contains a variable latency divide/square root machine.
• Only 1 256-bit operation can issue per cycle, however an extra cycle can be incurred as in the case of a FastPath Double if both micro ops cannot issue together.Azt hiszem, lényegretörő és egyértelmű.
-
P.H.
senior tag
Nem kellett hozzá apró betűs rész.
Vették a jelenlegi generáció legnagyobbját (X6) és összehasonlították következő generáció bevezetéskori legnagyobbjával (8 modul); hogy teljes legyen a táblázat, hozzávették az Intel legerősebb AVX-képes CPU-ját is. Az pedig 4 magos - még most is. -
#100
P.H.
senior tag
hugo chávez
#98
P.H.
senior tag
válasz
hugo chávez
#98
üzenetére
Ha ennyire kisarkítva nézed, akkor 256 bites AVX esetén igen, ennyi. De nem minden fekete-fehér. Ahogy linkelted is:
"When Intel introduced SSE2 in the P4, each 128-bit instruction was cracked into two 64-bit uops, and the throughput did not substantially improve. This created a chicken and egg problem: Intel wanted developers to use SSE2 (since the P4 was not designed to execute x87 particularly fast), but developers do not want to rewrite or recompile code for a marginal gain.Sandy Bridge can sustain a full 16 single precision FLOP/cycle or 8 double precision FLOP/cycle – double the capabilities of Nehalem. This guarantees that software which uses AVX will actually see a substantial performance advantage on Sandy Bridge and should spur faster adoption. Intel seems to have learned from the lessons of SSE2 and hopefully, the uptake for AVX amongst the software community will be far swifter."
Adott mindkét oldalon egy-egy 128 bites FPU, külön FADD és FMUL futtató egységekkel: el kellett dönteni, hogy az igen nagy mennyiségű plusz tranzisztort (és az általuk igényelt plusz fogyasztást) mibe fektetik:
- az AMD a 128 bites végrehajtásra és a meglevő programokra helyezte a hangsúlyt: két majdnem azonos képességű FADD+FMUL végrehajtót tettek az FPU-ba, pontosan úgy, ahogy eddig a K7-K10 családban 3 majdnem azonos ALU+AGU van; így teljesen mindegy, hogy a programban milyen az FADD- és FMUL-jellegű utasítások aránya (eddig nagyon nem volt az). Ezt megfejelték azzal, hogy a register-to-register értékmásolás (amik nagy része az AVX alatt feleslegessé válik, de SSEx alatt elég sok van, mivel egy-egy művelet felülírja az egyik paraméterét) 0 órajelet igényel, a registerfile megoldja saját hatáskörben (órajelenként 4-et, ha minden igaz).
Az AVX-es programokat nem túl hatékonyan hajtja végre, de az SSEx-alapúak végrehajtását eléggé felgyorsítja.- az Intel maradt az 1 FADD + 1 FMUL futtatóegység felépítésnél, ezt látták 256 bites végrehajtókkal, felhasználva hozzá a meglevő integer adatutat is, illetve hozzáadva egy kis energiatakarékosságot (innen):
Floating point warm-up effect
The latencies and throughputs of floating point vector operations is varying according to the processor load. The ideal latency is 3 clock cycles for a floating point vector addition and 5 clock cycles for a vector multiplication regardless of the vector size. The ideal throughput is one vector addition and one vector multiplication per clock cycle. These ideal numbers are obtained only after a warm-up period of several hundred floating point instructions.
The processor is in a cold state when it has not seen any floating point instructions for a while. The latency for 256-bit vector additions and multiplications is initially two clocks longer than the ideal number, then one clock longer, and after several hundred floating point instructions the processor goes to the warm state where latencies are 3 and 5 clocks respectively. The throughput is half the ideal value for 256-bit vector operations in the cold state. 128-bit vector operations are less affected by this warm-up effect. The latency of 128-bit vector additions and multiplications is at most one clock cycle longer than the ideal value, and the throughput is not reduced in the cold state.
The cold state does not affect division, move, shuffle, Boolean and other vector instructions.
There is no official explanation for this warm-up effect yet, but my guess is that the processor can turn off some of the most expensive execution resources to save power, and turn on these resources only when the load is heavy. Another possible explanation is that half the execution resources are initially allocated to the other thread running in the same core.
Mindkettő kihozza a maximumot a 32 nm-es lehetőségekből, mivel mindkettő szinte megduplázza az FPU fizikai méretét. Az AMD annyival van könnyebb helyzetben, hogy mivel a korábbi - K8-alapú - FPU-kat arra tervezte, hogy minden 128 bites utasítás 2x 64 bitesre fordítódik és hajtódik végre, így amikor 128 bitesre bővítette azt, akkor az FPU "kiürült", azonos végrehajtási sebességhez feleannyi belső uop-műveletet kap. Ezt most kitömik a 2. szállal.
-
#96
P.H.
senior tag
hugo chávez
#93
P.H.
senior tag
válasz
hugo chávez
#93
üzenetére
Erről az ábráról van szó.
Nincs újabb, 4 magos Sandy Bridge-dzsel és 8 modulos Bulldozerrel számoltak, így jönnek ki az értékek: felszorozták az FPU-darabszámmal a névleges teljesítményt, mivel X6-hoz 48-at írnak, ami ott 8 FLOPS/mag=FPU, a K10 órajelenként 2 4xSP bites műveletet tud. A Bulldozer szintúgy, tehát a 64 FLOPS-hoz 8 Bulldozer-FPU kell. Így nézve kijön, hogy azonos magszám (4) mellett a Sandy Bridge 256 bites műveleteknél 2x akkora teljesítményt hoz, mint 128 biten, a 8 modulos (mindkét esetben 2 művelet/órajel), 16 magos Bulldozer pedig konstant 64 FLOPS-ot.
Hogy miért így hasonlított össze az AMD, azt ők tudják...


 ; de nyilván nem szerencsés itt sem nagyon kozmetikázni).
; de nyilván nem szerencsés itt sem nagyon kozmetikázni).


Új hozzászólás Aktív témák

- urandom0: Száműztem az AI-t az életemből
- GL.iNet Flint 2 (GL-MT6000) router
- Samsung Galaxy A17 5G – megint 16
- Az SK Hynix elárulta, hogy meddig nem lesz elég memória
- Call of Duty: Black Ops 6
- Anime filmek és sorozatok
- Polgári repülőgép-szimulátorok
- A Retro Games feltámaszt egy legendát
- Mibe tegyem a megtakarításaimat?
- Poco F8 Ultra – forrónaci
- További aktív témák...

- Sanyo akkutöltő + 2 használható akku
- GYÖNYÖRŰ iPhone 14 128GB Midnight -1 ÉV GARANCIA - Kártyafüggetlen, MS3971, 94% Akkumulátor
- Boyoye digitális beltéri HD tv antenna / 12 hó jótállás
- Gamer PC-Számítógép! Csere-Beszámítás! R7 2700X / GTX 1080Ti / 16GB DDR4 / 512 SSD!
- 188 - Lenovo LOQ (15IRX10) - Intel Core i5-13450HX, RTX 5060
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest