- Samsung Galaxy S23 Ultra - non plus ultra
- Honor Magic V2 - origami
- Mobil flották
- Fotók, videók mobillal
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Milyen okostelefont vegyek?
- Apple Watch Ultra - első nekifutás
- iPhone topik
- Android alkalmazások - szoftver kibeszélő topik
-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

#82819712
törölt tag
válasz
 lezso6
#41633
üzenetére
lezso6
#41633
üzenetére
Szeretem mikor példákkal beszélgettek itt mert az széleskörben érthető
PH Popular Hardver
csak aztán óvatosan a kompkkal kényes téma ez most még a végén Clark Ádám kell a futószalagba is.
Igen a sebesség egyértelműen hiányzott a kompokból.
lehet a dual Cu-ra is kellett volna mondanod egy példát egy építkezésen pakoló két munkással akik az ablakon adják be a cserepet (cache) és emiatt nem kell két munkásnak fel le szaladgálni a lépcsőn dupla ideig.
Így talán azt a vitát is megúsztuk volna és "a DCU az más" ennyi."így utólag belegondolva lehet az AMD tévedett a 64 szállal kapcsolatban, legalábbis grafika terén, mert ugye compute-ban meg igencsak jó."
Nem tévedett csupán közös tervezés...
Eddig is beszélte a reddit népe hogy a Rdna játék arhtektúra és szétválik a computesúlyos GCN-től.
és nocsak a MAC 4 Vegával (2*2) azaz GCN-el erősít (sok ember meghökkenésére) a compute force-os területen.Amire nem harapott rá fura módon senki mint téma az a RNDA2 fix funkciós működése
"2020-21 will pack some fixed-function hardware for certain real-time ray-tracing effects."![Akit meg érdekel ilyesmi az [L:https://youtu.be/Ph94nbfB_zM]IDE[/L] megy megnézni. Majd ha megmutatja valaki hogy kell videót beágyazni PHra az szóljon ;) [L:/dl/upc/2019-06/794156_leak.jpg](IMG:/dl/upc/2019-06/794156_leak.thumb.jpg)(/IMG)[/L]](https://www.techpowerup.com/img/um7Y9TjdI33zqHNy.jpg "Akit meg érdekel ilyesmi az [L:https://youtu.be/Ph94nbfB_zM]IDE[/L] megy megnézni. Majd ha megmutatja valaki hogy kell videót beágyazni PHra az szóljon ;) [L:/dl/upc/2019-06/794156_leak.jpg](IMG:/dl/upc/2019-06/794156_leak.thumb.jpg)(/IMG)[/L]")
-
#41631
 Petykemano
veterán
lezso6
#41629
Petykemano
veterán
lezso6
#41629
Petykemano
veterán
válasz
lezso6
#41629
üzenetére
Engedd meg, hogy lefordítsam egy számomra autentikusabb példára. Mindamellett, hogy persze érthető és most hallgattam meg Steve Burke és David KAnter beszélgetését, ami szintén tisztított a képen.
Hasznos volt a magyarázatod, de nem haragszol, úgy vélem, pont az maradt ki, amire rákérdeztem:
- miért kamion = Wave64 (ami ha jól értem egy 64 darabos adatcsomagot jelent)
- miért olyan áteresztőképességű utakat használunk, ami az RDNA-ban már kétszeres?Utak helyett folyóval illusztrálnám, amin kompok viszik át az autókat.
Az autók az adatok.GCN:
- 4db 16 férőhelyes komp (4x SIMD16)
- maximum 64 autó átvitelére lehet egyszerre jegyet váltani.RDNA:
- 2db 32 férőhelyes komp (2x SIMD32)
- lehet 64, de már akár csak 32 autó átvitelére is jegyet váltani.Az a szabály, hogy akik együtt váltanak jegyet, azok kénytelenek mind ugyanazon a kompon menni. Hiába tűnik úgy, hogy a 64 autó átszállítására a 4db 16 férőhelyes komp ideális. Valójában 64 autó átszállítására a GCN esetében 1 kompnak 4x kell fordulnia, akkor is, ha egyébként a másik 3 komp sajnálatos módon nem csinál semmit. És sajnálatos módon akik már átjutottak a túloldalra, nem távozhatnak, amíg mind a 64-en biztonságosan át nem értek.
A GCN maximális kihasználtságához 4 csoportra lenne szükség, akik együtt váltanak jegyet.
Az RDNA abban segít, hogy ha 64-en állnak össze és váltanak jegyet, akkor azok még mindig csak egy komppal utazhatnak, de a 32 férőhelyes kompnak elég csak kétszer fordulnia. Míg ha történetesen 32 autós áll össze, akkor akár egy fuvarral átérhet az egész csoport a túloldalra és mehet dolgára.
Tehát a kérdés:
- Miért szabály az, hogy 64-en válthatnak csak egyszerre jegyet? Ha tudjuk, hogy a kompunk 16 férőhelyes és egy csoportot csak egy komp tud szállítani, akkor miért nem 16 engedjük, hogy 16 fős csoportokban váltsák meg a jegyet?
- Vagy ha tudjuk, hogy 64-es csoportokban jönnek/jöhetnek csak a kocsik, akkor miért szarakodunk 16 férhelyes kompokkal, miért nem dolgozunk 64 férőhelyesekkel?
Lehet olyan, hogy több nem 64 fős csoport akar átutazni? Abban az esetben pont hasznos, ha több kisebb komp van.Szóval ha tudjuk, hogy egy Wave64 csak egy SIMD csoporton tud tudni, akkor miért nem Wave16-ok vannak? A wave64 mindig 64 adatot jelent, vagy csak maximum 64-et? Miben jelentene hátrányt ha 16 hosszú lenne a max?
-
#41628
Petykemano
veterán
lezso6
#41627
Petykemano
veterán
válasz
lezso6
#41627
üzenetére
Ez alapján tökre illik rá, hogy a gpu nem késleltetésérzékeny. Csak közben de.
De had értsem meg én is, hogy ha van egy wave64, ami a max 16 széles feldolgozótömbön 4 órajelciklus alatt tud lefutni csak és a 4x16-os CU-n 4 wavefrontnak kellene folyamatosan futnia a maximális kihasználtsághoz.
Akkor miért kell 64 hosszú (?) Wavefrontot futtatni? Ez minek a hülye ötlete volt?
Vagy miért kell 16-os tömbökre bontani a CU-kat, miért nem 64, amit szükség esetén Lehetne bontani 2/4 felé? -

Abu85
HÁZIGAZDA
válasz
lezso6
#41624
üzenetére
Ez még mindig túlegyszerűsített. Tehát a GCN-nél egy SIMD16 10 wave-et képes futtatni és egy wave lefuttatásához négy ciklus kell. De nem azért kell ennyi, mert 3 ciklusig pihizik, hanem azért, mert egy wave 64 lane széles, tehát egy wave-ből egy ciklusban csak 16 lane-t futtat. Most itt megjegyezném, hogy a Polaris esetében már 8 wave-re lett csökkentve az IB mérete, de ez igazából nem túl lényeges, 6 wave fölött elég jól le lehet fedni a memóriaelérést. Ha most minden klappol a GCN-ben, akkor a peak érték VALU szintjén 1 lane/clock.
És a munkakiosztás is számít, a GCN úgy működik, hogy megvan az adott erőforrásigénye a feladatnak, és arra futtat x wave-et. Tegyük fel, hogy ötöt. Ilyenkor az új wave-ek adagolása úgy történik, hogy mindegyik SIMD16 kap egy új wave-et, és ezek közül maximum egy lehet vertex shader wave, mert azok tipikusan eszik a regisztert és a cache-t. A compute egy picit bonyolultabb, mert ott az LDS is bejön a képbe, mint limit. De ugye asznkron compute-ban tudod mixelni a grafikai és a compute munkákat, csak legyen elég erőforrásod, hogy legalább 4 wave fusson per SIMD16. De persze van egyébként kiterjesztés is, ami a wave_limit, mert sokszor a cache-hit többet ér, mint a memóriaelérés átfedése. Nagyjából hasonlóan működik az összes többi modern GPU, az arányoknál van különbség, de ugyanúgy lehet egy kódnál fontosabb a cache-hit, mint a throughput, ugyanúgy limit lesz az LDS és a regiszter mindenhol, leginkább az LDS, stb. Ez az, amit értettek azon, hogy a mai architektúrákat könnyű megtanulni, de nehéz olyan kódot írni, ami igazán jól kihasználja a multiprocesszorok képességeit. Ha sok wave fut az is lehet baj, ha kevés, az is, aztán milyen feladatokat érdemes egymás mellett futtatni, hogy legyen elég regiszter+LDS ahhoz, hogy elég wave futhasson, stb.A Navi ezeken annyit változtatott, hogy a multiprocesszor olyan robusztus, hogy lényegében egy "just works" típusú rendszer lett. Tele van cache-sel, képes a saját működését a munkafolyamathoz igazítani, az ütemezés a cache tartalmához igazodik. Ha a késleltetésből származik elő, akkor úgy működik, ha a throughputból, akkor úgy. Tehát lényegében írsz egy kódot, és minden olyan optimalizálás, amit ma azért csinálsz, hogy igazodj a hardverek limitjeihez, a munkacsoportok mérete ne hasson rosszul a vektorregiszter lokalitására, ne legyenek rossz hatékonysággal használva az I-cache-ek (ez explicit API-val kiemelten fontos), a wave-ek tényleg megfelelően legyenek kiosztva, azok a Navinál igazából már nem kritikusak. Lehet ezekre optimalizálni, de arányaiban nagyon gyorsan megvan az az optimális kihasználtság, amiért a GCN-en, illetve a Turingon sokat küzdesz, ráadásul sokszor eltérő optimalizálási stratégiával.
Érdemes megnézni, hogy a Navi mennyire teker olyan kódokban, amit tipikusan Turingra írtak. Például a BF5 egyes shaderei, ahol kifejezetten arra optimalizál a motor, hogy az L1 gyorsítótár aktívan használva legyen, mivel a vektorregiszterek újrahasznosítási lehetősége tipikusan rövid. A Navinak ez pont csemege, mert négyszer nagyobb L1 gyorsítótára van, mint a többi hardvernek, illetve még van egy extra alacsony késleltetésű L0 gyorsítótár is a két SIMD-re. Mindegy, hogy a shadert Turingra optimalizálták, hardverből le van kezelve az a probléma, amire a DICE optimalizált.
Ennek egyébként akkor lesz nagy hátránya, ha elkényelmesedik a piac, mert oké, hogy a Navira gyorsan megvan a sebesség (konzolon fut, a PC-s meg majd vesz gyorsabbat mentalitás), de például a GCN, a Turing, és lényegében az összes régebbi GPU nagyon is igényli ezeket az optimalizálásokat. És nyilván ezek azért még maradnak egy darabig, nem is kevés ideig. Tehát nem szabad átesni itt a ló túloldalára.
-

.Ishi.
aktív tag
válasz
lezso6
#41618
üzenetére
Ez jogos, az AMD nem ígérget semmit, figyel arra, hogy hivatalosan mit kommunikálnak. (Bár azért Koduri is nyomta a hype-ot olyan mondatokkal a Vega idejében, hogy "várjátok meg a gaming drivereket" és hasonlók.)
Viszont egy kompetens marketing csapat tudja kezelni ezt is, mert nem "szokásos hype" alakult ki, hanem a "1080 teljesítmény 250 dodóért" vagy "RX 590 teljesítmény 75W TDP-ből." Marketingből szerintem valamennyire lehetne kezelni az ilyen durva wishful thinking helyzetet. (Vagy nem kezelik, mert látják, hogy a Navi pl. túl drága lesz a 200 dolcsi alatti szegmensbe vagy valami. De akkor is, valamilyen kommunikáció jobb, mint a semmilyen.)
-
Abu85
HÁZIGAZDA
válasz
lezso6
#41616
üzenetére
Nem teljesen. A NOC és az NTC nem csak erre vonatkozik. Nyilván a része rendre a Wave32 és a Wave64, de például a Wave32 nem sokat ér akkor, ha nem tudod elfedni a memóriaelérés késleltetését. Ez tehát önmagában nem működik, kell hozzá egy másik képesség, ami részben szoftveres, de a lényege a gyorsítótár tartalmát figyelembe vevő ütemezés. És emiatt van az, hogy egyetlen korábbi SIMT GPU-nál sem éri el az 1-et az egy munkaelemre levetített IPC. Az, hogy a Navi erre képes legyen, durván ki van tömve cache-sel. Összesen 336 kB-nyi cache-ről beszélünk itt per multiprocesszor. Ezzel szemben a GCN-ben van 80 kB, a Turingban van 96 kB. Persze a multiprocesszor az eléggé laza megfogalmazás, hiszen ezt lehet egyszerűre és bitang komplexre is tervezni, de ha per-ALU-ra vetíted le ezt, akkor a Navi esetében 2,625 kB/ALU, míg a GCN és a Turing esetében ez az érték rendre 1,25 és 1,5. Gyakorlatilag a cache-rendszer az oka annak, amiért olyan magas IPC-t lehet elérni munkaelemekre levetítve. Emiatt nem csak a Wave32-ről van szó, mert az igazából nem ér semmit egy ilyen cache-rendszer nélkül. A GCN-en is lehetne Wave32-t csinálni, vagy a Turingon is Wave16-ot (ők warpnak hívják, de igazából mindegy), de szart sem érne, mert csak szopatnád az architektúrádat azzal, hogy nem lesz elég wave elfedni a memóriaelérést. Gyakorlatilag rosszabbul járnál a Wave64 és a Wave32 módokhoz képest. Nem is kínálja fel a GCN és a Turing a felezés lehetőségét. A hardver csak drámait lassulna tőle.
-
#41589
Petykemano
veterán
lezso6
#41586
Petykemano
veterán
válasz
lezso6
#41586
üzenetére
Voltak, akik végeztek ad-hoc számításokat, hogy mennyibe kerülhet a navi kártya.
$100 lapka
$80-90 GDDR6
$60-70 PCB, hűtés, egyébsumma $250 lehet, de lehet, hogy felül van lőve így is.
Ez válasz arra, hogy miért nem polaris. De egyben azt is jelenti, hogy a $380 árral van meg a 45%-os margó, ami efelett kel el, az grátisz.Ehhez képest mennyi lehet 2 HBM2 stackel szerelt Vega? Nyilván $50-ral olcsóbb a lapka, de a HBM2 ennyivel drágább is lenne?
A $250-300-os vega 56-ok már önköltségi áron mennének? -
#41581
Petykemano
veterán
lezso6
#41577
Petykemano
veterán
válasz
lezso6
#41577
üzenetére
Annyira nem új node. Meg hát élvileg volt egy respin. (Reméljük nem a sorozatgyártott szemetet adják most el) De biztos kell még tapasztalatot gyűjteni.
Ámít nem értek, hogy a Vega 20 is itt készül, ami 40%-kal nagyobb is. Ha az kijön 4 hbm-mel $699-ből, akkor ezen mi kerül $4-500-ba.
-
-

Tyrel
őstag
válasz
lezso6
#41575
üzenetére
De mindig csak a saját előző fejlesztéseikhez képest lépnek előre, az nVidiától közben egyre jobban elmaradnak... Eleinte csak 300W fogyasztásokkal tudtak versenyezni a felsőbb kategóriákban, most meg már meg se próbálják, egyre nagyobb a távolság.
Persze ez nem lenne gond ha nagyon költséghatékony kártyákat csinálnának, fillérekért, hiszen akkor legalább a ruppótlan piacokat uralhatnák, pl. balkán, ázsia nagyja, oroszország, ilyenek, onnan is lehet jó bevétel... de ez se megy, nevetséges árcédulákkal jönnek ki a cuccaik.
A Vega messze túl drága volt, hivatalosan nem is csökkent eleget az ára csak próbálnak tőle szabadulni a gyártók is meg nagykerek is, azért lehet néha úgy-ahogy elfogadható áron hozzájutni, de már azt is erősen beárnyékolja a 2060.
A VII-t inkább hagyjuk is, túl sokat fogyaszt, messze túl drága, nincs custom, és nem kínál semmit a konkurenciával szemben, kivéve persze több VRAM-ot ami nem kell semminek.
Aztán itt ez a Navi is, a jelenlegi RTX szériával szemben is igen erősen megkérdőjelezhető már az árazása, ha meg még jön ez a SUPER is, akkor meg végképp piacképtelen lesz.Komolyan ilyen rettenetesen pozícionált termékekkel és ilyen nevetséges árazással mi a jó francot akarnak???

Pedig amúgy pl. egy 5700 XT önmagában valószínűleg nem lenne rossz kártya, de alapból sokkal kevesebb AMD rajongó van mint nVidia, rosszabb a hírűk, népszerűtlenek, és akkor erre még jön az, hogy a SUPER megjelenésével olcsóbban kapsz legalább ugyan olyan jó (vagy inkább jobb) kártyát a másik oldalról... innentől kezdve meg kb. a reviewer-ek meg az a 12 rajongó fognak Navi-t venni.

Ha ennyire nem megy inkább hagyják a francba az egészet, meg közben adjanak hálát amiért a konzolok hardvereiben az nVidia nem verseng velük, különben azt is elbuknák pillanatok alatt.
-
#41576
Petykemano
veterán
lezso6
#41567
Petykemano
veterán
válasz
lezso6
#41567
üzenetére
Van egy fószer, aki azt hangoztatja, hogy a 7nm (N7, de elvileg Samsung is) nem igazán jó abban, hogy viszonylag nagy lapkát (gpu) magas órajelre tudjon pörgetni.
A zen2-höz és socokhoz képest a naviX lapka még mindig óriási.Egyébként Szerintem a 5700 -> 5700xt skálázódása kifejezetten jó: ~10% frekvencia és 10% cu (~20% tflops) beáldozásával ~20%-kal alacsonyabb a TBP.
Ezzel együtt persze lehet, hogy a vágott lapka minősége annnyival rosszabb is és valójában mindkettő a maga kategóriájában túl van húzva.
-
válasz
lezso6
#41569
üzenetére
Azt nem értem, hogy miért nem csinálnak nagyobb GPU-t több végrehajtóval és alacsonyabb feszültséggel, órajellel. Tiszta golyósok. A vezetés egyszerűen idióta. Azt képzelhették, hogy egy évvel ezelőtt kijönnek, és ahhoz tervezték a GPU méretet? Csak hát szokás szerint addig csúsztak vele, hogy mire kijött, már tök elb.szott koncepció lett, mert húzni kell az égbe. És ez megy már 7 éve folyamatosan. Ha egyszer lenne annyi esze a boardnak, hogy figyelembe vennék, hogy úgyis csúsznak egy évet, és 30%-kal több magot terveznének a modellekbe, akkor maradhatnának az elképzelt fogyi keretben, egyből versenyképesek lennének és az AIB gyártóknak sem kéne harakirit elkövetni, mikor meglátják a TBP értéket.
-

sutyi^
senior tag
válasz
lezso6
#41567
üzenetére
Szokás szerint megint közel teljesen ki van facsarva, amit lehet órajelek tekintetében és azért ilyen a fogyasztás.
Ha mindkét kártya alacsonyabb órajelekkel jönne, akkor ugyan csak GTX 1660 Ti / RTX 2060-al versenyeznének, de sokkal barátságosabbak lennének a fogyasztási mutatók + még lenne benne órajel tartalék.
-
válasz
lezso6
#41560
üzenetére
A naviról tényleg nem tudunk sokat, a super viszont faék egyszerűen számolható. De navinál elfogadtam az amd saját méréseit, pedig kétkedve kellett volna fogadnom, elfogadom a kritikát. Átlagban jó eséllyel még a 2060S sem lesz meg, ha a szokásos 5-10%-os nagyotmondást kivonom az egyenletből.
A kérdés inkább a Super sorozat árazása lesz, nem a teljesítménye. Túl optimistának látom azt, hogy az árakat kategóriánként egy az egyben viszik tovább.
-

Raymond
titán
-
Raymond
titán
válasz
lezso6
#41498
üzenetére
Nem koteketni, a tablazatnak nem volt ertelme. Itt a hozzaszolas amire valaszoltam:
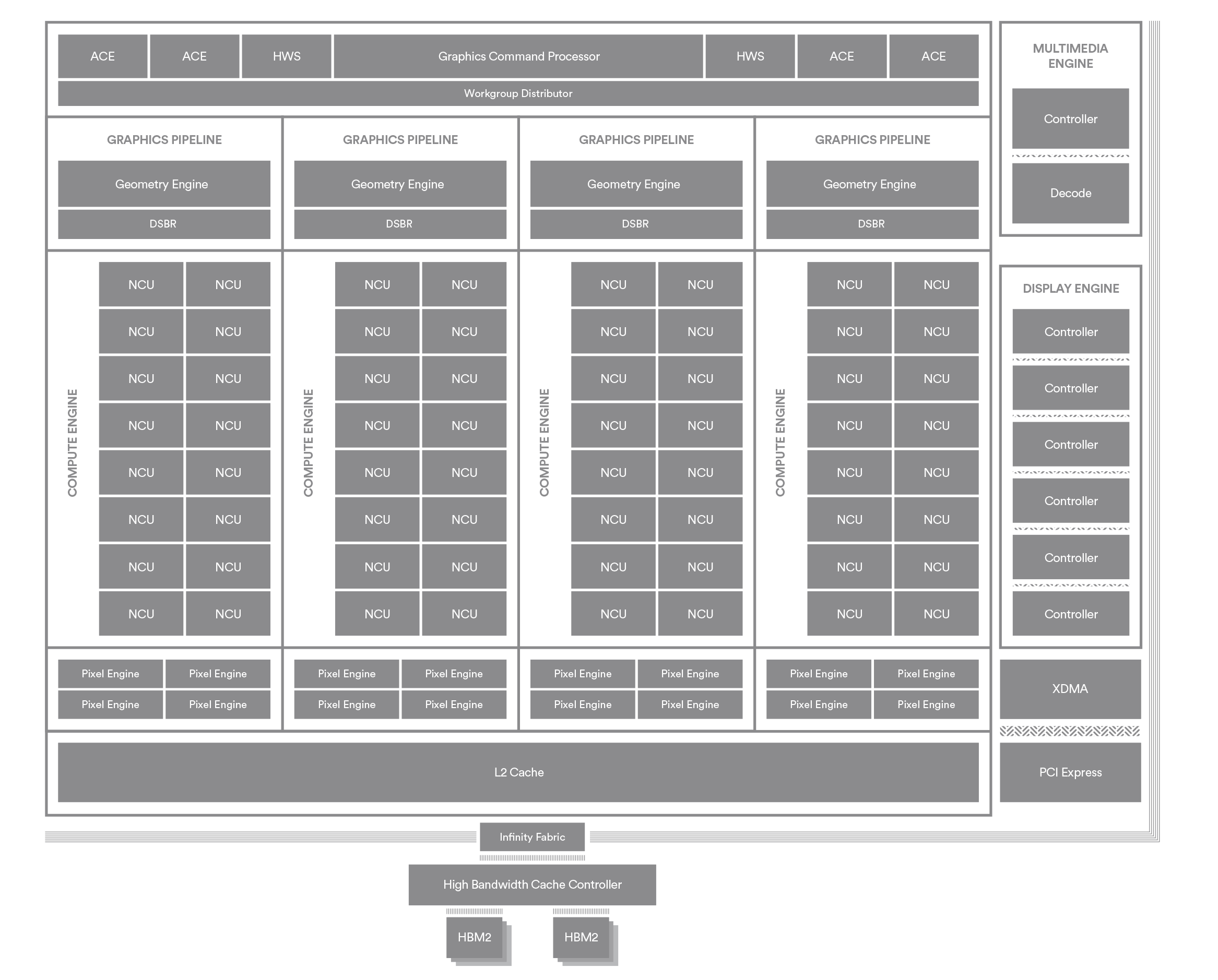
Nem hiztak meg a CU-k ahogy a tablazatodban szerepelt, maradt a 64 ALU csak nem 4x16 hanem 2x32 felosztaban. Attol hogy aztan odairtad hogy DCU attol meg a CU-k nem hiztak amilyenre irtad es meg mindig 40 van beloluk. A 20 amirol irogatsz az a Work Processor ami 2 CU-bol all. Navi:
Navi = 4x Compute Engine
1x CE = 10 Work Processor
1 WP = 2 CU
1CU = 64 ALUA diak vilagosak, nincs mit felreerteni, de ugy latszik neked sikerult. Meg valamilyen oknal fogva kotni az ebet a karohoz is.
-
#41499
Petykemano
veterán
lezso6
#41491
Petykemano
veterán
válasz
lezso6
#41491
üzenetére
Vajon hogy skálázódik?
-A dual compute unit valószínűleg nem, tehát nem lesz triple compute unit.
-Egy prím unithoz tartozhat 5-nél.több DCU? - valószínűleg igen, csak az eddigi GCN-es tapaaztalatok azt mutatják, hogy egy ilyen egységben (shader unit), 10-nél több CU nem volt megfelelően kihasználható. De vajon ez változott?
- egy SE-ben 2 "shader unit" van. Lehetne több? Azzal valószíneg az ütemező (ace, hws, wgd) terhelődne túl. (Felfételezvén, hogy az ütemezés a shader enginek számával skálázódik, különben semmi értelme nincs annak, hogy egy shader engineben 2 shader unit van)
- 2.SE-nél lehet több?Nekem úgy tűnik ez az architektúra.legalja. nem.mondanám még tahitinek se, mert ott ugyan csak két se volt, de tele volt tömve cuval.
Ha minden szinten skálázható, akkor
4x4x8x2 CU érhető el. Itt persze már minden szinten szűk keresztmetszetek léphetnek fel.
Ez persze csak feltételezés részemről. De ha így van, akkor tényleg navi=scalabilityMár csak az a kérdés, hogy ebből a 2×2×5(×2) felépítésből hogy tiltanak le 4CU-t? (Ami 2 DCU)
-
Raymond
titán
válasz
lezso6
#41490
üzenetére
Nem, nem azert irjak hogy 40 mert ugy lehet a GCN-hez hasonlitani hanem azert mert 40. Amit a 10. oldalon latsz ott nem egy GCN-t hasonlit egy fel DCU-hoz hanem 1:1 az arany. A fenti RDNA abra azert van ugy hogy a ket CU kozti shared cache-eket lasd.
(#41489) meteoreső
Mielott belemerulnenk - ugye vilagos hogy az a vastagitott mondat engem igazol?
-
Raymond
titán
válasz
lezso6
#41482
üzenetére
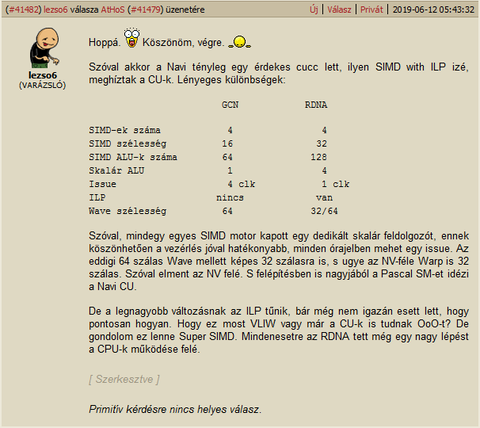
Valamit elneztel/elszamoltal, igy nez ki valojaban ha a te tablazatod hasznalom:
GCN RDNA
SIMD-ek száma 4 2
SIMD szélesség 16 32
SIMD ALU-k száma 64 64
Skalár ALU 1 2
Issue 4 clk 1 clk
ILP nincs van
Wave szélesség 64 32/64Ott van a 11. oldalon. Az ALU-k szama nem duplazodott, csak az a 64 nem 4x16 hanem 2x32 felosztasban mukodik. A skalar ALU (SFU) is csak 2 es nem 4.
-
#41340
Petykemano
veterán
lezso6
#41339
Petykemano
veterán
válasz
lezso6
#41339
üzenetére
Ön nyert
nyereményét itt veheti át -
válasz
lezso6
#39301
üzenetére
Szerintem Szimplán azért mert drágább a HBM2 mint a GDDR6. Volta is HBM ramos, szerintem ez nem tapasztalati kérdés. RTX karikon is pont dupla annyi ram lenne ha nem 9-11$ között lenne egy stack ezt gondolom hisz tavaly még arról volt szó, hogy az új széria duplázni fogja a Vramot a Pascal hoz képest.
-
#39302
 Komplikato
veterán
lezso6
#39301
Komplikato
veterán
lezso6
#39301
Komplikato
veterán
válasz
lezso6
#39301
üzenetére
OFF: Néztem ma egy ellemző teszt videót, ami arról szólt, hogy az RTX kártyák egy részén, amin Micron GDDR6 van miért is ugrál össze vissza a vram sebessége, amitől az atomdrága kártyákon be, beszaggatnak a játékok és tesztek. Hogy a halálban juthat át ilyesmi a tesztsoron egyáltalán?
-

Oliverda
titán
válasz
lezso6
#39299
üzenetére
Miért nem HBM került a Turing GPU-k mellé? Annyira hülyék lennének az NV-nél, hogy nem ismerik az általános iskolai matekot?
Na meg valaki Lisa Sunak is szólhatna, hogy itt az ideje HBM-et pakolni az összes termékre.
Q24: Are you glad to see HBM2 on your AMD products? Is it still too expensive for the mid-range?
LS: It is a great technology, it really is. I think right now as you know there’s a real tightness in memory supply around the world, but put that aside (and by the way as that’s true for G5, that’s true for DDR4, that’s true for HBM) I think HBM is a great technology. I think over time we’ll see it become more cost effective, but it is still certainly on the higher side in terms of cost.
Ilyen tájékoztlan elnök-vezérigazgatóval nem csoda, hogy itt tart a cég.

-
#39153
Petykemano
veterán
lezso6
#39151
Petykemano
veterán
válasz
lezso6
#39151
üzenetére
Jólvan, én csak feldobtam. Csak fura, hogy a szabadalmak (a kutatás, gondolkodás, fejlesztés) abba az irányba megy, amiben már most is patent, míg a gyenge körítés, ami hatékonytalanná és így sok esetben sikertelenné teszi, marad, illetve hát reszelgetik.
Meg hát ha ennyire patent a compute és nem arról ban szó, hogy a compute kapacitás elméleti maximumának a a nem elég magas kihasználtságát nem a rossz ütemezés, nem kellően finom granularitás okozza, hanem malmoznak a CU-k, akkor miért nem kapcsolják le?
Na de most csak kötözködtem, abu az, aki szerint a geometria és főleg a rop meg a sávszél elég, több CU kell.Amúgy abuval.mi van, sabbaticalon van, vagy átment ő is az intelhez?
-
válasz
lezso6
#39142
üzenetére
Igen meg tudnák oldani.A probléma az amit írtál is, hogy egy GPU nak lássa az egészet a rendszer. Erre kínál megoldást az MCM -GPU és ugye jobb hatásfokú lehet mint a jelenlegi monolith tervezet AMD nél. ráadásul nem kell , hogy tükör legyen a két réteg, hanem akár különböző dizájn és akár eltérő RAM is kerülhet fel. Egyébként nvidia bemutatta a Volta alapú MCM -t már, kísérleti fázisban. Azért van tapasztalatuk a Tegra- Parker SOC ból , még ha nem a desktop x86 vonalon.
Elég nagyot ugorhatna így a Raytracing/ DirectML, és egyébb AI támogatott grafikai elemek is, ha mindkét cég lépne ebben a vonalban. -
válasz
lezso6
#39137
üzenetére
vagy erre gondolhatnak, [link] épp erről beszéltünk a Radeon 7 hír alatt. Ilyen dizájnól építeni többet egy fedél alá akár külön feladatokra ráhangolva( RT) eltérő ramokkal is akár.
Úgy gondolom valóban probléma lehetett a Navival tervezés szintjén és nem képes megfelelő sebességre, gondolom ezért van 1080 körülre beharangozva olcsón ( bukóval? ). Jó ötletnek tartom ezt a dolgot, emlékeztet a CPU részleg lépésére. Mondjuk Nvidia azért nem alszik, az biztos, mint Intel tette. -
#45185024
törölt tag
válasz
lezso6
#39039
üzenetére
Amikor azt monda konkrétan ugye Lisa hogy az AMD a saját útját járja arra gondol hogy nem kell a Fix funkciós Tensor magos csoda ahhoz hogy Te RT-t használj.
Egy versenyképes termékhez egy 200 e körüli legalább 60 FPSsel járó termék kellene. Ami nincs.
Tegnap néztem ezt a Metro Exodust ahogy a gameplayba megy a pasi 5 percig a posztapokaliptikus porsivatagba és végig azon járt a fejem a refleksön itt ? Pocsolya szimulátor itt ?
Kávézgatnak ott egymással a Tensor magok majd, esetleg megbeszélik a tegnapi meccs állását. VII meg végig pörgi. Emiatt gondolom hogy az Intel is az AMD módszerét fogja használni sőt a végén maga az NV is.
A tegnapi cikkből idéznék:
"az AMD Radeon VII teljesítményét egy „DLSS-szerű” hatás elérésére lehet használni, de olyan megközelítést használva, amely a Radeon hardveren fog működni. "
Minden VS nélkül szerinem elbagatelizálják az emberek az 1 TB/s sávszélességet és a 16GB HBM-et.
Olyan terméket kell kihozni ami jó árérték arány mellett folyamatosan kihasznált.
A lehetőségekben kell körülnézni
Microsoft Azure AI ->> CES DEMO -

Cathulhu
addikt
válasz
lezso6
#39039
üzenetére
Nem feltetlen baj az ha szigoruan DL-t nezunk. A GPUk nagy elonye leginkabb a tanitas es szvsz hulye az aki FP16-on tanit, dedukciora meg van a GPU-nal hatekonyabb hardver. Viszont ha DL es jatekot nezunk (mint pl a DLSS), akkor a geforceokon jatek alatt gyakorlatilag malmoznak a tensor core-ok, amiket igy legalabb munkara lehet fogni, anelkul, hogy ez befolyasolna az FPS-t. Mig egy Radeonon ugyanazoknak az egysegeknek kellene a dedukciot is vegezni, mint magat a renderelest, igy hacsak nem utemezik kurvajol a feladatokat, akkor bizony az FPS rovasara fog menni. Bar ha tenyleg ROP vagy egyeb bottleneck van a vegan, akkor marad boven folos kapacitas DLSS-re is.
-
válasz
lezso6
#38985
üzenetére
hw.fr-en is csak a pixel throughputból következtetnek a raszterizációra, szóval attól tartok, nincs ilyen mérés. Ha kevesebb a raszter, mint a ROP, azt még körbe lehet lövöldözni olyan adattípusokkal, amik kettő vagy több ciklust igényelnek a ROP-on. A több rasztert nem is tudom, ki lehet-e egyáltalán mérni.
-
válasz
lezso6
#38982
üzenetére
Én biztos vagyok benne, hogy elég jól kiszámíthatóan nőne - +15-20%-ig tuti, utána valóban kérdésesebb.
Nem tudom, van-e bármi akadálya, hogy egy SE-ben megduplázzák a raszter szélességét. Amúgy a Polaris-os 8 pix / clk info honnan van? Nem tudom, mekkora a rasztermotorok helyigénye, de könnyen lehet, hogy nem szarakodtak, és minden chipben ugyanaz a 16 széles cucc van.
-
válasz
lezso6
#38956
üzenetére
A GPU-knál messze nem ennyire karcos a szűk keresztmetszet téma, ezért nem lehet kijelenteni, hogy a ROP a limit. Igen, ha rátolnál 30% ROP-ot (és sávszélt, mert abban nincs különbség), akkor gyorsabb lenne további 10-15%-kal - de ha rátolnál 30% SM-et, az is hozna +15% körül.
Ugye a Vega (meg a Polaris, meg a Fury) esetében annyiban más a helyzet, hogy a harvestelt chip alig lassabb a teljesnél, ott már lehet mondani, hogy van valami durva szűk keresztmetszet. NVIDIA oldalon ezt eddig sehol nem láttam. -
válasz
lezso6
#38951
üzenetére
Igen, most nézem, hogy a CB tesztben valóban nem FE 2070 van (gondolom, ezért erősebb a TPU-s mérés), viszont látszanak az in-game órajelek. Ha jól látom, az összevetésben 8% órajel-differenciával számoltál - valójában a CB tesztben ennyi az órajelek különbsége, tehát a felsorolt kapacitás-különbségek 29% különbséget hoznak, nem 20%-ot. A raszter nem ér sokat a ROP nélkül, a többiből meg egész jól összeáll a 2080 előnye. Az amúgy lehet, hogy a 2080 kicsit ROP-limites, de nem durván.
Hogy a Radeonnál miért kevés a ROP? Azért, mert ha műszakilag nézzük a kategóriákat, és nem fogyasztói szemmel, akkor a Vega 64-nek az 1080 Ti-vel kellene versenyezni, nem az 1080-nal. TFlops terén ott is van. Pixel terén - nagyon nincs. Sajnos arról nincs még csak közelítő adat sem, hogy mennyivel esik az effektív ROP throughput NVIDIA oldalon a felezett blending miatt, de vélelmezem, hogy nem lehet drámaian sok, mert akkor arra találtak volna valami orvosságot.
(#38954) Yutani: szerintem ennél bonyolultabb kérdés ez. Nekem nem maga az uarch tűnik a fő problémának (legalábbis nem az ALU rész, ahol az univerzalitás lecsapódik), hanem egyrészt az órajel, másrészt az SE-k száma körüli rejtély.
-
válasz
lezso6
#38925
üzenetére
Aha, más teszteket nézünk, meg egyéb differenciák is vannak
 Sorban:
Sorban:
- 2080-nál a boost clock minden bizonnyal úgy, hogy cherry picked változatok mentek egyes reviewereknek, vagy szimplán szerencséjük volt. Nézd meg a computerbase tesztjét, ott vannak az órajelek monitorozva.
- A 70 és a 80 közötti különbséget is a cb tesztben néztem, az FE változatok között - ott 29%. Lehet, a TPU gyengébb 2080-ast vagy erősebb 2070-est használt, sajnos ők nem monitorozzák az órajeleket.
- A felezett blending nem változott a Maxwellel - check (meg amúgy a linkelt cikk sem ír ilyesmit). Annyi pontosítás, hogy INT8 format esetén teljes sebességű a blending, de tudtommal ez a formátum már nem túl domináns.
- A 37% gondolom úgy jött ki, hogy az ALU/TEX előnyt felszoroztad az órajel-differenciával. Viszont ez így nagyon szélsőséges, átlagos játékmix mellett az ALU/TEX előny azonos backend mellett a GFlops differencia 50-60%-ánál többet nem hoz. Ld. pl. 1080 és 1070.Szóval nekem túl sok furcsaság nincs a számokban - a Turing architektúrás előrelépése meglepő, de a duplázott SM-infrastruktúra biztosan sokat ér. Abban meg igazad van, hogy fogalmunk sincs, mit jelent ez számszerűen - én az egyszerűség kedvéért úgy tekintem, hogy ez meg az L1 cache felel az előrelépés nagy részéért.
-
válasz
lezso6
#38919
üzenetére
Én nem azt látom
A 2070 és a 2080 között 22-25% különbséget számoltam, ha a GPC-ket nem veszem figyelembe, ehhez képest közel 30% van. Azért az nem zéró.
A felezett blending nem a 2070-nél van, hanem az összes NVIDIA chipnél a Fermi óta.
Az órajeleket a tesztekben mértek szerint néztem, computerbase-en. Az 1080 Ti 1600 körül vagy alatt muzsikál átlagosan, a 2080 meg 1860 környékén. Mire gondolsz pontosan kiegyensúlyozatlanság alatt?
A VS topikban nehéz lenne erről eszmét cserélni, mert az nem olvasom
-
válasz
lezso6
#38896
üzenetére
Az ördög mindig a részletekben rejtőzködik.
A geometria szerepe nehéz kérdés, igazából a franc tudja, mennyit számít a 2070 és a 2080 között, de a többi matek alapján néhány %-nál aligha többet - ezért is kételkedem egyébként abban, hogy a GCN-ben ez a rész komoly limit lehet.
A 2070 nem igazán limites raszterben, a 48 raszter + 64 ROP elég jó kombináció a felezett blending miatt. Ezzel szemben a 2080-ban a 96 raszter pont annyi, mint halottnak a csók.
A 2080 gyakorlati órajele 15-20%-kal magasabb, mint az 1080 Ti-é, ezért órajelre normálva 74-77 ROP áll szemben 88-cal, ami csak 15-20% különbség; memória terén szűk 10%-kal gyengébb a 2080. Ezt kompenzálja a Volta idejében felturbózott L1 cache, ami ennek a különbségnek akár jelentős részét eltüntetheti. És akkor a 2080-ban ott van a "csodafegyver", a duplázott (vagy igazából a szerver-vonalról lehozott) SM-infrastruktúra - az biztosan sokat hoz. -

HSM
félisten
válasz
lezso6
#38896
üzenetére
Nézd meg a memória sávszélességét... Ott van a nyakán, plusz az RTX-en elvileg még fejlettebb tömörítés van a memória felé. Én itt keresném a titok nyitját. Plusz az architekturális fejlesztések, a Turing elég nagyot lépett előre ezen a téren.
Én az origi Vega10-nél is itt gyanítottam az egyik legnagyobb szűk keresztmetszetet, hogy elfogy a sávszél (ők nm takarékoskodnak vele olyan jól alapból). Ezt megerősíteni látszik, hogy mennyivel jobban megy a Vega "VII".
-
Cathulhu
addikt
válasz
lezso6
#38853
üzenetére
Koszi, bar sajnos felet sem ertem, de elhiszem

Compute is eleg felemas amugy, nehol ragyog a vega, nehol kohog.
A Texture Read Bandwidth tesztben meg egyszeruen elhasal, HBM2 ide vagy oda.
[link]A VII-re most +62%-ot mondd az AMD luxmarkban, ahol pedig kifejezetten eros mar a 64 is.
-
válasz
lezso6
#38769
üzenetére
Nézőpont kérdése, szerintem attól frontend, hogy a renderelési folyamat elejét csinálja. A raszter inkább a közepe.
A TU106 esetében van értelme a több ROP-nak egy bizonyos határig, mert ha nem csak sima color fillt csinál a ROP, hanem blendinget, akkor 2 clk egy művelet. Franc tudja, mik az arányok, de biztosan nem 100% a fill.(#38768) Raymond: persze, mert az 56 memória-órajele alacsonyabb. Azonos órajelen nézd meg.
-
válasz
lezso6
#38764
üzenetére
Műszakilag, vagy a renderelési folyamat tekintetében?
Előbbiben tudtommal igen, utóbbiban nem.(#38763) Yutani: nehéz szétválasztani a ROP és a sávszélesség hatását. Ha a megduplázott backendhez dupla raszter is járna, az sztem 30-40% extra teljesítményt simán hozna azonos órajel mellett is. Így a raszterizálók lesznek teljesen csúcsra hajtva - amennyi tartalék volt eddig bennük, annyival előrébb van a chip. Túl sok olyan workload nincs a jelenlegi motorokban, amihez több pixelművelet kell, mint raszter - míg az NVIDIA esetében a felezett blending miatt van értelme a több ROP-nak, itt még az sem játszik.
(#38765) Raymond: szerintem a -4CU hatása átlagos teljesítmény tekintetében kerekítési hiba - nézd meg a 64-es órajelre húzott Vega56 teszteket.
-
#38760
Petykemano
veterán
lezso6
#38759
Petykemano
veterán
válasz
lezso6
#38759
üzenetére
Hát eza 128 ROP elég érdekes.
Kezdenek megdőlni az elméletek, hogy mi a szűk keresztmetszet.
Eddig azt gondoltuk, hogy a vega 64-nek kevés a ROP és/vagy a sávszélesség. Most már van kvázi tile-based rendering (dsbr), van szupersok ROP és elképesztő sávszélesség. Én nem mondom, hogy nem látszik a teljesítményen, mert a 20%kal magasabb frekvenciát meghaladó mértékben nőtt a teljesítmény (25-35%), de hát azért mégsincs az az érzésem, hogy sikerült átvágni a gordiuszi csomót. Ráadásul mindezt úgy sikerült, hogy plusz erőforrást dobott rá az AMD - bruteforce -, míg látszólag az Nvidia okosba'Most már nem csak tfopsban van fölényben az AMD, hanem ROP számban és sávszélességben is. (Utóbbi persze rayfield-tracingnél jjól jöhet).
Mi van még? Már csak a geometria maradt a sok korábbi találgatásból, ami magyarázná, hogy a Radevon Vega VII miért marad el továbbra is a vele közel azonos erőt képviselő 2080Ti-től.
Kiváncsi vagyok, a naviban már javításra kerülő NGG funkció is hoz-e az órajelen felül 10-20%-ot, mint ahogy az emelt ropszám és sávszélesség tette.
-

arn
félisten
válasz
lezso6
#38051
üzenetére
Fene tudja, hogy mit varialnak az architekturaval. De kenytelenek lesznek viritani, mert az rtx2060 rt szempontjabol nagyobb megvagas lesz a memsavszelesseg miatt, viszont az azt nem hasznalo jatekoknal messze nem lesz akkora a szakadek a 2070hez kepest - szvsz erre keszulnek.
Hatekonysagban csak behozni fogjak az nvt, ami kisebb csikszelessegen nem nagy kunszt... addig lesznek versenykepesek, amig az nv nem lep. En jobban orulnek hatekonysagra kihegyezett dboknak, mint szennehuzottaknak - Az nv okosan oldja meg, rairja a 2080gtxre, hogy 215w, aztan a custom kartyak nagy resze meg masfelszer annyit fogyaszt.
-
-
#37872
 huskydog17
addikt
lezso6
#37865
huskydog17
addikt
lezso6
#37865
huskydog17
addikt
válasz
lezso6
#37865
üzenetére
"Kutyát nem érdekel a PhysX már"
Ennél messzebb nem is állhatnál a valóságtól. Inkább nézz utána, mert jelenleg ez a legelterjedtebb.
Yany kolléga már részletezte. UE4 és Unity 4&5 motorok Physx-t használnak alapértelmezetten.Nézd meg hány játék készült/készül ezekkel a motorokkal és utána gondold át újra amit írtál.
-
#37870
huskydog17
addikt
lezso6
#37865
huskydog17
addikt
válasz
lezso6
#37865
üzenetére
Ja nem fejlesztik, mégis jön 20-án a 4.0 verzió.
-
#37867
 FollowTheORI
nagyúr
lezso6
#37865
FollowTheORI
nagyúr
lezso6
#37865
-
Cathulhu
addikt
válasz
lezso6
#37859
üzenetére
AMD-nek mar van bevett toolja, a HIP, amibol CUDAbol tudo szabvany kodot generalni, arra meg rahuzza a sajat ROCm stackjet, ha meg open source, akkor csak lebranchel belole, aztan idovel ker egy PR-t, bar azt nem tudom az nVidia engedni fogja-e.
Tensorflownal 1.3-nal kezdtek el pl, 1.12 ota resze a hivatalos releasenek. Azota mukodik is rendesen a GPU gyorsitas vegre -
#37860
FollowTheORI
nagyúr
lezso6
#37859
válasz
lezso6
#37859
üzenetére
Nem lehet CUDA ha tényleg megy AMD GPU-n is...
De azis lehet az egész át van már portolva CPU-ra.Más kérdés hogy valóban a kutya sem fogja már használni valószínűleg.
Nagy kár érte, mert ha azonnal ilyesmi lett volna, akkor bőven jobb játékok lennének ma már ilyen téren.
Érdekes egyébként amit mondassz... nem tudom meg lehetne e valahogy hekkelni a régi kódbázisú játékokat az újra.
Van pár amin lehetne javítani.
Node sebaj... majd a remasterek.![;]](//cdn.rios.hu/dl/s/v1.gif)
-

-FreaK-
veterán
válasz
lezso6
#37707
üzenetére
Én pont a dubstep miatt nézem őket!
Viccet félre téve, szerintem nincs különbség az információ kinyerés szempontjából a videós és az írott teszt között, mert videónál is csak oda tekerek ahol a grafikonok kezdődnek és onnan nézem, ha nem érdekel a többi. A jobb csatornáknál (GN pl.)meg van ugyan úgy írott teszt is, ha valaki azt preferálja.
Adott esetben viszont többlet információt is tartalmazhat egy videó, mint pl. amikor a példánál maradva a Gamer's Nexus pl. részletesen kivesézi az adott grafikonokat. Van, hogy számomra az az informatívabb, a száraz, írott tartalom ellenében. -
#37576
Petykemano
veterán
lezso6
#37575
Petykemano
veterán
válasz
lezso6
#37575
üzenetére
Semmit nem vesztettünk.
De úgy igazán semmit nem is nyertünk."The Radeon R9 290X, codename "Hawaii XT", was released on October 24, 2013 and features 2816 Stream Processors, 176 TMUs, 64 ROPs, 512-bit wide buses, 44 CUs (compute units) and 8 ACE units. The R9 290X had a launch price of $549. "
290: Oct 2013 : $399
290X: Oct 2013 : $549
390: June 2015 : $329
390X: June 2015 : $42920 hónap elteltével 5%-kal magasabb frekvencia 20%-kal olcsóbban
480: June 2016 : $199 (4 GB) $239 (8 GB)
580: April 18, 2017: $199 (4 GB) $229 (8 GB)
590: November 15, 2018: $27929 hónap elteltével 15%-kal magasabb frekvencia 20%-kal drágábban
-
#37453
Petykemano
veterán
lezso6
#37451
Petykemano
veterán
válasz
lezso6
#37451
üzenetére
Külön AI lapka nem lesz, ez ütött szöget.a fejembe miután olvastam Pinky fejtegetését, hogy a Rome olyan, mint egy gpu, Amiben a CCX-ek a SE-k.
A gondolat nem egyedülálló :
"Az, hogy ezt a struktúrát fel lehetne használni gpuknál, nem egyedi gondolat. Sőt, kicsit a 4 Shader engine már eleve ez. De mennyivel jobb lenne minden shader enginet külön gyártani és IF-fel össszekapcsonil? Akár külön célra. Akár válogatva."
Már felvetődött korábbanUgyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Miért ne lehetne olyan Sye design, ami olyan okos, mint a vega20, meg olyan, amiből az okosságot kivágják?
Miért ne lehetne egyik külön gyártott SE-ban 16CU, a másikban 11?Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
-
#37452
 szmörlock007
aktív tag
lezso6
#37451
szmörlock007
aktív tag
lezso6
#37451
szmörlock007
aktív tag
válasz
lezso6
#37451
üzenetére
Mondjuk ez a másik, hogy a kövi körben szerintem elég nagy esély van rá, hogy lesz olyan APU amihez hbm-et tesznek. Ugyanis kövi körben még marad a ddr4 ami már a vegát is visszafogja. Na most 7nm-en az apu igp része, ami a navira épül majd nyilván jóval több feldolgozót fog tartalmazni, de ddr4-el szinte alig gyorsulna.
"Külön AI lapka nem hiszem, hogy lesz. Az AMD mindig mindent a CU-k SIMD-jeibe épített be."
Igen, ez csak egy kósza gondolat volt. -
#37450
szmörlock007
aktív tag
lezso6
#37449
szmörlock007
aktív tag
-
#37447
szmörlock007
aktív tag
lezso6
#37445
szmörlock007
aktív tag
válasz
lezso6
#37445
üzenetére
+1
Arra is kíváncsi vagyok, hogy még a 2016-os capsaicin dián a navi mellett két dolog szerepelt: next gen memory, valamint scalability. Na most a next gen memory nyilván a hmb3 lesz, de a scalabilityre kíváncsi vagyok. Korábban volt még arról szó lehet azt jelenti mint az epycnél, hogy több kisebb lapkát tesznek egybe. De az is lehet, hogy valami uacrh-os fejlesztés. Majd kiderül a ces-en remélhetőleg
-
#37442
szmörlock007
aktív tag
lezso6
#37441
szmörlock007
aktív tag
válasz
lezso6
#37441
üzenetére
Hmm, köszi az összefoglalót meg a linket. Jónak tűnik. Igaz, szerintem a játéknál nem vagy nem csak a kihasználtság a probléma. A vega 64 12-13 tflopsal az 1080ti felett de legalább egy szinten kéne lennie. Viszont ha megnézzük a compute oldalról, az mi 60 fp 32-őt használó alkalmazásokban a hasonló teljesítményre képes v100 szintjén volt a méréseknél. Tehát csak játékoknál jön elő az, hogy az nvidia azonos tflops-al rendelkező kártyái jobban mennek. Ergo szerintem máshol van a probléma, pl vega64 csak 64 rop-al rendelkezik míg 1080ti 96 stb..... Ilyenekre gondolok.
-
#37438
Petykemano
veterán
lezso6
#37437
Petykemano
veterán
válasz
lezso6
#37437
üzenetére
Ezt nem én mondtam, hanem a wikipedia
Szerintem inkább ne kérjük,.hogy Abu mondja el, hogy ez mér lesz jó, mert ő túlságosan el van ragadtatva ettől és ennek megfelelően túl sokat is remél tőle. Sajnos tényleg semmi nem hozott a pulbikum szemében értelmezhető előnyt azok közül, amikért Abu sejtelmesen rajongott.
-
Abu85
HÁZIGAZDA
válasz
lezso6
#37379
üzenetére
Az nem. Az SRAM ECC, az lényegében egy end-to-end ECC. De ez önmagában nem elég a RAS-hoz. Ott külön szervizelhetőségi paraméterezhetőség van a rendszerben, hogy a megfeleljen a RAS-funkcionalitásnak, ami végeredményben lehetővé teszi, hogy a szerver 24/7 működjön. Ez azért nem volt eddig benne a GPU-kban, mert marha bonyolult, viszont így megnyíltak a GPU-k is a feladatkritikus rendszereknél.
-
#45185024
törölt tag
válasz
lezso6
#37362
üzenetére
Jó hát nem játékra erősítették ez látszik az előrelépéseken is.

Nem 1.25 performancet vártunk a 7nm-től. De szervereknél más a fontosabb
Viszont az 1800-as órajelet akkor is említsük meg mert ez később fontos lehet.
Lisa interjú az előadás után.


























![;]](http://cdn.rios.hu/dl/s/v1.gif)


















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- Samsung Galaxy Xcover 5 64GB, Kártyafüggetlen, 1 Év Garanciával
- Új, verhetetlen alaplap sok extrával!
- BESZÁMÍTÁS!Gigabyte B650M R7 7800X3D 64GB DDR5 1TB SSD RTX 3080Ti 12GB Corsair 4000D Airflow TG 750W
- Samsung Galaxy S22 Ultra 512GB, Kártyafüggetlen, 1 Év Garanciával
- Honor 200 Pro 512GB, Kártyafüggetlen, 1 Év Garanciával
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest