-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 Jack@l
#52317
üzenetére
Jack@l
#52317
üzenetére
Pedig az AMD oda teszi. Nem véletlen, hogy az AMD-féle SAM az AGESA 1.1.0.0-t követeli. Abba a mikrokódba van beépítve a szolgáltatás.
Ennek az AMD szerint két előnye van. Egyrészt már így bootol be az OS, tehát nem kell az átméretezéssel törődni az OS-en belül, másrészt olyan programspecifikus optimalizálásokra is lehetőséget ad, amelyek a szimpla resizable BAR mellett nehezen kivitelezhetők.
#52329 morgyi : A resizable BAR igazából minden PCI Express 3.0-s GPU-n menne. Ez egy PCI-SIG által specifikált képesség. Leginkább azért nem izgultak ennyire rá eddig, mert a WDDM 2-vel rohadt nehezen kezelhető.
-
-

Simid
senior tag
válasz
Jack@l
#52260
üzenetére
Most akkor ki van használva minden vagy sávszél limit miatt DXR alatt is csak malmozik a cuda magok jelentős része?

Hát ezért vártam itt tegnap óta tűkön ülve, hogy újra leereszkedj hozzánk halandókhoz és megmondd a frankót?

-
-
#52199
 Malibutomi
nagyúr
Jack@l
#52198
Malibutomi
nagyúr
Jack@l
#52198
-
#52196
Malibutomi
nagyúr
Jack@l
#52192
Malibutomi
nagyúr
válasz
Jack@l
#52192
üzenetére
Jah, latszik hogy az AMD most kulon vette a gamer es a compute kartyakat, szoval ez nem meglepo.
Szvsz az Nvidia rosszabb volt, amig az AMD hozott kihasznalatlan nagy compute teljesitmeny...most az Nvidia kartyaknak van szep nagy es jatekokban kihasznalatlan szamitasi teljesitmenyuk.
-
-
#52133
Malibutomi
nagyúr
Jack@l
#52132
Malibutomi
nagyúr
válasz
Jack@l
#52132
üzenetére
Es erkeznek be a szallitmanyok ujra par napos atfutassal.

Ahol neztem ott pl 12-re irtak a kovetkezo szallitmany varhato erkezest.
Akkor vissza az egyes pontra miert is jo ezert szurkolni mar elore? Persze koltoi kerdes sokaknak csip a pelus a gondolatra is hogy az AMD-nek barmi kicsit is jobban sikerulhet akar veletlenul is mint az NV-nek.
-

Mumee
őstag
válasz
Jack@l
#51769
üzenetére
Értem a gondot ezzel, de ezeket minden gyártó kozmetikázza, tök fölösleges fennakadni rajta.
Erre vannak a független tesztek.
Arról is volt leak, hogy az AMD drivere most nagyon stabilnak tűnik minden tekintetben, te meg bedobod hogy artifactol, bugos és társai.Eleve nem is értem, hogy most hirtelen hogy jött ez a bugol és artifactol a driver neked.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#51765
üzenetére
A Metro Exodus pont ilyen.

#51767 Locutus : Nem az effekten múlik a Radeonok sebessége, hanem a BVH gyorsítóstruktúrán. Ha azt nagyrészt bele tudja erőszakolni a 128 MB cache-be, akkor nyert ugye van a rendszernek. Ezt úgy lehet egyébként megfektetni, hogy a BVH legalább 9 szintű lesz, de ehhez nagyon durva geometriai részletesség kell, és annyival hatékonyabb bárminél az RDNA2 a kis háromszögekkel dolgozó geometria feldolgozásában, hogy akkor meg máshol kerül előnybe.
-
-
-

arn
félisten
válasz
Jack@l
#51705
üzenetére
A jelenlegi jatekokban talan tobbet fog szamitani, hogy mekkora az rt sulya, mint hogy mivel szamoljak. Ezekben a hybrid rt renderekben az elozo generacios kartyak rt kepessegeihez igazitottak, azt pedig megugorja a legkisebb bignavi is.
Hogy lattunk “pure” rt rendert az turinggal es ampererel, ehhez kepest alig skalazodott a regi jatekokban, igy az amdnel sem az rt kepessegek lesznek fontosak, hanem a raszteresek, amiben meg jonak tunik. Igy mar nem varnek nagy elterest rt tesztekben sem, szamomra erdekesebb lesz, itt hogy teljesit.
-
arn
félisten
válasz
Jack@l
#51705
üzenetére
Szvsz csak a megnovelt rt szamolasi kapacitas kozotti kulonbseg latszik, nincs hatekonysag kezeles kulonbseg, az ampere 1.0ban is ennyivel gyorsabb lenne, mint a turing. Kivancsi leszek hogy aranylik ehhez az amd, elvileg lassabbnak kellene lennie mint a 3080, de a 2080ti es a 3070 viszonyabol ugy tunik nem csak ez a szuk keresztmetszet, amugy a 3070 nem ennyivel lenne gyorsabb.
aktualisan ki a 3dmark szponzor?

Ps: de komolyan ennyire futotta a tesztben, hogy a kamera megy korbe? Es ezert penzt kernek. Hu de messze kerultunk a regi allleejtos 3dmark scenektol. -
Mumee
őstag
válasz
Jack@l
#51691
üzenetére
Csak a legutóbbi eltolásig még úgy volt, hogy hamarabb lesz game, mint Navi. Így logikusan megjelenéskor nem lett volna, ami tud RT-t AMD oldalon.
Tehát hivatalosan csak azt mondhatták, hogy megjelenéskor még nem lesz RT AMD kártyán.Azóta frissítették, hogy tolták 3 hetet?
-

Chiller
őstag
válasz
Jack@l
#51685
üzenetére
Talán csak egyszerűen nem írhatták bele eddig, mert NDA volt...
Majd frissítik, ha ráérnek. Valószínűsítem, hogy csont nélkül fog menni AMD-n is egyből. (ha kész lesz az RT driver megjelenésre)
Vagy hogy gondoltad, minden eddig már megjelent RT játékra külön kell majd AMD patch?
@Callisto: simán lehetséges ez is, igen.
-

Raggie
őstag
válasz
Jack@l
#51279
üzenetére
Csak amelyik hozzászólásra válaszolva írtad ezt, az pont nem a króm demóról szólt, hanem ebben a leakben szereplő szintetikus RT tesztben mutatott teljesítményről.
Azért fontos kérdés ez, mert még egyelőre az várt a forgatókönyv, hogy az 1.0-s RTX programokban nem lesznek olyan jók az AMD kártyák de az 1.1 bejövetelével már igen. Az utóbbiban akár optimalizálástól függően túl is szárnyalhatják az Nvidia kártyákat RTX teljesítményben.
De ha már most az 1.1-es tesztprogramban 30%-os lemaradást mérnek akkor az nem túl sok jót sejtet.Szerk: ezért is próbáltam rákérdezni erre.
-
-

do3om
addikt
válasz
Jack@l
#50313
üzenetére
Szerintem amikorra kijön a következő DX még mindíg a bbi11 lesz a használt.
Be kell vallani végre elbaszott egy DX ez. Nem tudom hol a hiba de valahogy nem jött be a fejleszőknek hogy több munkát igényel ugyan az.
Van itt aki többet szeret dolgozni miközben az eredmény egy régebbi dolgátol semmivel sem lesz jobb? Se lehet nem jól tudom, talán m8krolagokkal kapcsolatban minta ajánlott lenne a 12ő.
5 éves vagy mennyi régebben már rég kint volr a következő, és nézhettük az összehasonlítást, mert volt mit. -
-
#50292
 Robi BALBOA
őstag
Jack@l
#50290
Robi BALBOA
őstag
Jack@l
#50290
Robi BALBOA
őstag
válasz
Jack@l
#50290
üzenetére
Abban a demóban igen jól ment a Vega56, persze ezt csak azért mutatták be, hogy Hw-es RT nélkül is lehet normálisan futtatni RT-t.
(#50291) Televan: Az fix, meg vannak vadulva az emberek, hogy vehessenek új karit.
Én is ki akarom váltani a 1080Ti SLI-t egy(vagy két![;]](//cdn.rios.hu/dl/s/v1.gif) ) karival, de az fix, hogy nem adok 400-500k-t egy 10gb-os kariért, de még 300k-t sem.
) karival, de az fix, hogy nem adok 400-500k-t egy 10gb-os kariért, de még 300k-t sem.Fontos nyílván, szerintem ilyen oda-vissza téma lesz, egyik gaméban egyik a másikban másik kari lesz jó, csak nehogy ezzel is elkezdjen trükközni az Nv mint a tesszelációval, mondjuk ott vissza nyalt a fagyi, mert míg az AMD karik driverből tudták állítani a (a játékban direkt 128x-osra vett) tesszeláció mértékét, értelmes szintekre 8-16-32.....-osra, addig ilyen az Nv-nél nem volt.
-
#49617
 KillerKollar
őstag
Jack@l
#49614
KillerKollar
őstag
Jack@l
#49614
KillerKollar
őstag
válasz
Jack@l
#49614
üzenetére
Egy 700$-os aktuális flagship kártyánál elvárható a max grafika szerintem. Nem azért vettem, hogy mediumon játszogassak.
(#49615)EXA
2080 Ti-m volt, minden generációban cserélem a kártyámat, ezért mondtam, hogy addig, amíg nem jön a következő generáció, addig a 10GB tuti elég lesz, aki hosszabb időre veszi, annak már nem biztos.
Én eddig mindig Ti class kártyát vettem, de a 3090 dupla áron 10-15% extra teljesítményért pofátlan volt nekem, a 24GB memória meg fölösleges, mire kelleni fog már le is cseréltem a kártyát, azért meg nem fizetek érte dupla árat, amikor úgyis elbuknám ha eladom. -
#49613
KillerKollar
őstag
Jack@l
#49601
KillerKollar
őstag
válasz
Jack@l
#49601
üzenetére
De nem mindenki fogja megvenni a legújabb kártyákat. Rengeteg ember fog még 1-2 évig 2070/2080-asokat használni 8GB memóriával, az alap 3070 is csak 8GB-os és ha a 20GB-os 3080 200-300$-al drágább lesz akkor lehet, hogy az sem lesz olyan népszerű mint a 10GB-os.
Addig amíg ez a generáció a legfrissebb addig nem hinném, hogy a fejlesztők hagynák, hogy elfogyjon a 10GB memória, főleg tripla A-s címeknél, ahol azért van egy komoly fejlesztőcsapat, 1-2 összetákolt optimalizálatlan indie címnél lehet, hogy nincs arra kapacitás, hogy erre odafigyeljenek de túlnyomó részt kétlem, hogy a közeljövőben ez probléma lenne.
Ha igen, akkor mindenki veheti meg az 1000$-os csúcskártyát, akinek meg "csak" egy 3060/3070 8GB kártyára tellik az mehet a búsba...
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#49601
üzenetére
Az új generációs konzolokon eleve finomszemcsés adatmenedzsment van, míg PC-n egyelőre szabványosan csak durva szemcsézettségű érhető el. Ez azért nagy hátrány, mert ha egy játéknak mondjuk kell egy textúrából 4 kB-nyi adat, akkor azt a konzol 4 kB-os lap szintjén be tudja tölteni, míg PC-n be kell tölteni az egész textúrát, ami több megabájt is lehet. Hiába kell neked belőle csak 4 kB-nyi adat, nem tudod csak azt beolvastatni. Ezek azért elég nagy különbségek. Emiatt nem is érdemes a memóriákat összehasonlítani, mert konzolon a memóriahasználat nem pazarló, míg PC-n erősen pazarló sajnos.
-
Chiller
őstag
válasz
Jack@l
#49507
üzenetére
Csak indítsd el a Supreme Commandert és rájössz hogy még mindig így van.
szerk: World in Conflictban is rosszabb a kép. TDU1-ben is. NFS MW (2005)-ben is.
Sajnos már nem sok játékkal játszom, és főleg régebbiekkel (mint látszik). Így nem tudom manapság mi a helyzet. Az új Deus Exekben pld. nem láttam különbséget.
-

hokuszpk
nagyúr
válasz
Jack@l
#49507
üzenetére
"ember meg nem mondja szemre melyik-melyik. "
ebben nemlennek annyira biztos, anno volt, hogy egy vajtfulu ismerosomnek nem 1x , hanem 2x sebesseggel masoltam le egy audiocd -t de nem mondtam el ezt neki , viszont masnap visszahozta, hogy az 1x masolatot még elviseli, de ez annal is roszabbul szól, masoljam le meg1x...
ha nemvelem tortenik, ensemhiszem el... -
Abu85
HÁZIGAZDA
válasz
Jack@l
#49362
üzenetére
A mikropoligonokkal eleve az a probléma, hogy a quadrasteres mai VGA-k négyes pixelblokkolra raszterizálnak. Vagyis ha mondjuk egy poligon egy pixelnyi kiterjedésű, akkor előfordulhat, hogy 12 pixelre kell raszterizálni, amiből 11 pixelnyi munka teljesen felesleges, mert csak egy pixelt fed le a poligon. Ettől meg kell csinálni, csak azonnal megy a kukába az eredmény. Az új módszerrel a hardver detektálja, hogy egy poligon túl kicsi, és kevesebb pixelnyi munkát csinál.
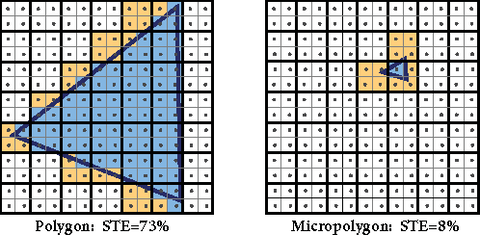
A fenti képen látható maga probléma. Minél kevesebb az a sárga rész, annál jobb a rendszer, mert a sárga részek kiszámolt, de nem használt adatok.Ez valószínűleg nagyon fontos a konzoloknak, hiszen egészen durva adatmennyiséggel tudnak dolgozni a gyorsítótárazás miatt. Viszont a hardvert is fel kell készíteni rá, hogy kvázi minden pixelre, lényegében pixelnyi nagyságú poligonok jutnak. A hagyományos quadrasteres módon összeomlana a fill rate. A raszterizálással elvégzett munka ~90%-a felesleges lenne. Ha azonban van egy alternatív, mikropoligon pipeline, akkor a felesleges munka csak 10-20% körül lesz, miközben az eredmény ugyanaz.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#49078
üzenetére
Az inline raytracingnél sugárkövetés az állapotot hozzátársítva hozza létre a sugarakat, majd arra megcsinálja a lekérdezést. Ez ugye végigköveti a sugarat a meghatározott távolságig a BVH-n keresztül, majd visszatér az eredménnyel. Ezt azért vezették be, mert a mai hardverekben nincs koherenciamotor, tehát effektíve a komplex sugárkövetés eleve annyira megterhelő, hogy hiányzik a sávszélesség hozzá. Minden másodlagos sugár már egy lassú véletlenszerű memóriaelérést eredményez, tehát az aktuális komplexitási szinten csak a hardver felesleges szopatása adatmozgással, illetve elszeparált dinamikus shader indítással vesződni. Ahol ennek előnye lenne, mert van előnye, az legalább tízszer gyorsabb hardvereket igényel, hogy megvalósítható legyen real-time.
Mire elérünk arra a szintre, hogy a dinamikus shadereknek előnye van, addig a sugárkövetés annyira elterjed, hogy megéri sok tranzisztort ellőni rá, tehát nagy sávszélt raknak a lapkák mellé, teletömik őket cache-sel, és egy koherenciamotort is beléjük tömnek, hogy a másodlagos sugarak is koherensek legyenek. Ez nem a következő generációban fog megvalósulni, mert ezeknek a tranzisztorköltsége nagy, tehát jelenleg nem éri meg pár játékbeli effektért feláldozni egy GPU általános teljesítményét. Így viszont az a kritikus tényező, hogy az API szintjén is kellően kedvező legyen a sugárkövetési megoldás, ami ezeknek a szerencsétlen, nem éppen réjtrészingre kigyúrt hardvereknek tud segíteni.A réjtrészing aktuálisan rendkívül gyenge megítélése pont annak köszönhető, hogy hardverben sem erre megy még a fókusz, illetve még a DXR 1.0 is szopat a dinamikus shaderekkel, illetve az adatmozgással.
-

Jacek
veterán
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#48650
üzenetére
HBCC jól van. Erre a technológiára épülnek a konzolok.
Valószínűleg PC-n is lesz majd egyszer SFS, ahogy az Xbox Series X/S-en, de nem tudni, hogy mikor. Nem kizárt amúgy, hogy az AMD bedobja az SSG API-ját, de egyelőre kételkedem, ez a megoldás tényleg szabványosan kellene.(#48649) TESCO-Zsömle: Nem sokat ér, mert mindig bólogató fejet válaszol ilyenekre.

-
#48629
 TESCO-Zsömle
titán
Jack@l
#48626
TESCO-Zsömle
titán
Jack@l
#48626
TESCO-Zsömle
titán
válasz
Jack@l
#48626
üzenetére
Nem érdekel, ha nem lesz kártya, nem buszjegyre kell.
Egy dolog az alacsony ellátottság (bányász-bumm), megint más előre, szánt szándékkal irreálisan alacsony árat mondani, hogy felverjék az érdeklődést, aztán úgy intézni, hogy végül csak ne annyi legyen.
Szegény usereket sajnálom, akiket annyira felhájpoltak, hogy pár hete szaré-hogyé adták el a 2080-at, Super-t, Ti-t, most meg nincs mit tenni a gépbe és fizethetnek ugyanannyit, mint az előzőért... -
#48617
 Petykemano
veterán
Jack@l
#48616
Petykemano
veterán
Jack@l
#48616
Petykemano
veterán
válasz
Jack@l
#48616
üzenetére
fogalmam sincs, hogy honnan van az a táblázat, de remek hamisítvány.
Elméletben a Game/oo Cache kompenzálja az alacsonyabb memória adatátviteli sebességet
Furcsa és egyben egyedi, hogy ebben a táblázatban másfélszerezték a SP/CU számot az eddigiekhez képest. Eddig ugyanis a 40CU 2560 Stream processzort jelentett, itt meg 3840-et. Ez mondjuk megmagyarázná, hogy miképp érheti el a 2080Ti szintjét a 40CU(Pár poszttal feljebb meg egy olyan blokk diagram volt, amin 160CU volt.)
Vajon ezt hogy jöhetne ki?
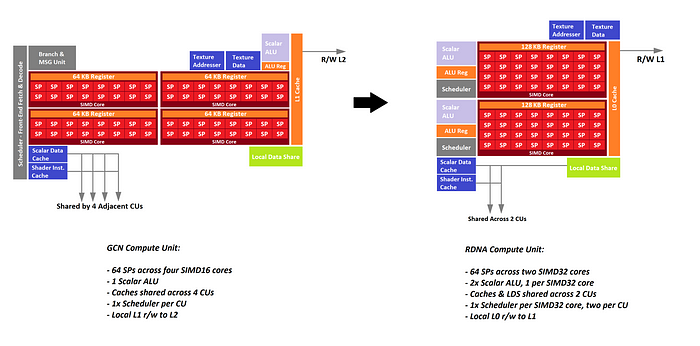
[link]egy CU-ban 3db SIMD32 lehetne?
Vagy variable width SIMD units lehetne?(Persze csak lehetne, mert a táblázat nyilvánvalóan fake.)
-
#48419
TESCO-Zsömle
titán
Jack@l
#48418
TESCO-Zsömle
titán
válasz
Jack@l
#48418
üzenetére
Szerintem se. A Titánok ismárve, hogy a 0-ás végű compute csipet kapják, amik játékra annyira nem jók, de bennük van egy csomó nyalánkság, amikhez a gaming vonalon már nem lehet hozzájutni.
Plusz amit itt talán morgyi (nem emlékszem) vetett fel, hogy 3090-ként, új titának titulálva lenyeli a nép az 1500$-os cetlit, de ha ugyanezt 3080 Ti/Super néven hozzák, akkor ott lett volna hőbörgés... -
kisfurko
senior tag
válasz
Jack@l
#48250
üzenetére
Szerintem mindegy, hogy árnyékot, vagy akármit számolsz. Persze, abban lehet valami, hogy ha a blendinget, stencilt használod, akkor a nagyobb RBE (ROP) terhelés a megnövekedett késleltetéssel negatívan hathat a teljesítményre (mint az R600-nál).
Én úgy képzelem el, hogy a vezérlök elött lesz egy naaagy cache, amiben összefut minden shader engine és a másik chipet összekötö interface (infinity akármi). Ami kérés a másik chipböl jön, az ugyanúgy vár a DRAM controllerre, mint a lokális shader engine-ek. Vagyis direkten már semmi sem fogja elérni a memóriát, minden az L3 (L4?) cache-en keresztül fog menni. Hogy ehhez mit szólnak majd az RBE-k, nem tudom, mert régen próbálták már az RBE-t leválasztani a DRAM controllerröl (R600), de az nem jött be nekik. Hátha most ügyesebbek, vagy a mai workloadok jobban elviselik. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#48256
üzenetére
Az AMD nem futtat olyan próbateszteket, amik a netre vannak kötve.
A partnerek pedig nem tudnak majd tesztet futtatni, mert nincs meg a kulcsuk a meghajtóhoz. Még ha egyet meg is szereznek, az egy egész percig él, és szükségük van a másikra, hogy ne vágja le a működést TDR-rel a meghajtó egy perc után. Ez többlépcsős hitelesítés, mint ahogy a Steam működik. Nem véletlenül nem szivárognak az eredmények, majd ha lesz offline meghajtó, akkor várható, hogy jön valami adat.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#48253
üzenetére
Nem érted az AotS működését. Az csak azért fut normálisan DX11 mellett, mert minden gyártó megkerül egy rakás API limitációt. Van egy profil írva rá, amivel bizonyos ellenőrzéseket nem hajt végre a meghajtó, mert nem lesz belőle probléma az alkalmazás alatt. Ha ez hiányzik, akkor ezeket az ellenőrzéseket végre kell hajtani, tehát alapvetően képtelenség, hogy egy GPU 2000 pontnál többet összekaparjon, ugyanis maga a CPU lelimitálja. Én sok dolgot el tudok képzelni egy új architektúráról, de azt nem, hogy megoldja ezeket a gondokat, ahhoz ugyanis legalább ezerszer gyorsabbnak kellene lennie.
A tesztdriverekből pedig hiányoznak a profilok.
Én már láttam ilyet, mivel amikor megérkezik az éves nagy meghajtófrissítés, akkor az csak úgy fog működni, hogy csatlakoznom kell az AMD szerveréhez egy külön alkalmazással. Ekkor összeköti a gépemet a szerverrel az app, és lehúz onnan egy hitelesítőkulcsot, ami feloldja a meghajtónak a működését. Ez a kulcs percenként frissül, amikor direkt kihúztam a kábelt a netből legutóbb, akkor nem működött tovább a meghajtó, szimpla TDR-rel lelőtte magát. Ilyen biztonsági intézkedés van már egy ideje, hogy valós tesztek friss meghajtókról, friss hardverekről ne jelenhessenek meg idő előtt.
Ezért nincsenek idő előtti teszteredmények a friss meghajtókról, illetve ma már a hardverekről sem annyira. Van a hitelesítőalkalmazásban egy telemetria, ami ellenőrzi, hogy ki mit futtat a működés ideje alatt, tehát jegyzi, hogy melyik gépen született az adott eredmény, ami kiszivárog.
Ugyanígy működik egyébként a Radeon Software developer módba kapcsolása is, azzal a különbséggel, hogy az nem igényel valós idejű hitelesítést, egyszer összekötöd a szerverrel, és működik a fejlesztői mód amíg újra nem indítod az OS-t.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#48251
üzenetére
Ebben a tesztben egy profil nélküli D3D11 driver nem lehet gyorsabb 2000 pontnál. Ha 6000-et el tud érni, akkor az AMD feltalálta a spanyol viaszt, de valószínűbb, hogy kamu, mert nincs valós hardveres lehetőség a CPU limitációin túllépni.
Profilt pedig a tesztdriverek nem biztosítanak, hogy ne lehessen a teljesítményét belőni a hardvernek. Az AotS esetében a megfelelő profil kétszeresére növeli a teljesítményt a profil nélküli működéshez képet. -
kisfurko
senior tag
válasz
Jack@l
#48232
üzenetére
Már nagyon régóta felosztják a képernyöt négyzetekre, és azok kerülnek a work groupokba. Amikor bejött az elágazás a shader programokban, akkor volt is ebböl gond, hogy le kellett futtatni a csoportot így is, és úgy is (talán Ati x1800, x1900, és Nvidia 6800 idejében).
A memóriát se egy vezérlön keresztül érik el, hanem 4-6-8 van, crossbarral. Már egy GPU-s megoldásnál is osztoznak a vezérlökön a GPC-k, SE-k. A késleltetés biztos nöni fog, de azt cache-el lehet ellensúlyozni, valamint a GPU-k nem annyira érzékenyek rá, mint a CPU-k. Azért a Ryzeneken is látszik, hogy nem olyan durva, ha másik processzortól jön az adat. Ha van elég sávszélesség a processzorok között, kellöen gyors a busz, akkor azért müködhet, még ha nem is 100-os hatékonysággal. Majd meglátjuk, minden a busz sebességén és késleltetésén múlik. -
#48229
Petykemano
veterán
Jack@l
#48214
Petykemano
veterán
válasz
Jack@l
#48214
üzenetére
Igazából a képernyő már most is fel van osztva szeletekre. A vegával.debütált valami dynamic workgroup distributor.
Ezeket a szeleteket különböző Shader Engine -ek Compute Engine-ek végezték.Egy Compute Enginehez kötődik egy L2$ szelet. Ha a compute enginek között kommunikáció szükséges, akkor az most is csak ramon keresztül történhet.
Tehát ha egy-egy shader Engine-t választasz le.chipletbe, azzal lényegében nem okoztál nagy késleltetés növekedést.
A nagy kérdés a lapka közepén található parancsprocesszor, geometriai processzor. És hardveres ütemezőkkel kapcsolatban van. Itt nem egyértelmű, hogy milyen cacheből dolgozik és az sem, hogy mi van, ha ezekből kettő van.
Így tudnám elképzelni a dolgot, hogy az L2$ mögé beraktak még egy L3$-t és az egyaránt kiszolgálja az L2$-t is és IF-t is. És akkor két lapkán egymás felé fordítják az IF-fel a lapkákat és az köti össze a command és geometry processzort és a L3$-t is.
-
#48220
 Alogonomus
őstag
Jack@l
#48214
Alogonomus
őstag
Jack@l
#48214
Alogonomus
őstag
válasz
Jack@l
#48214
üzenetére
"512 bitesként és 16 gbn-osként fogják hirdetni, ami nagyon nem lesz igaz. Mert két memvezérlő lesz 8-8 gb-al bekötve. Ha írni kell és mindkét kártya használja a "közös" memóriát, tükrözni kell az adatokat és csak 256 bittel lehetséges. Olvasáskor így meglehet az 512 bit, feltéve ha mindkét mag egyszerre dolgozik."
Még ha nem is tudná ezt szinte mindig az AMD driverből kezelni, akkor is sokkal ritkábban jelentene korlátozást, mint az Nvidia látszólagosan megduplázott CUDA magok kihasználhatósága.
Az Ampere kártyák hardveres korlátja szoftveresen aligha oldható meg, így csak speciálisan megírt grafikus motor esetén tudnák kihasználni a kártya potenciálját, bár akkor pedig valószínűleg vagy a fogyasztásuk szállna el még jobban, vagy thermal throttling miatt a működési frekvencia esne vissza jelentősen. Bányászáshoz például tényleg jobbak lehetnek az Ampere kártyák, mint az RDNA2 kártyák, mert bányászáshoz írhatnak speciális algoritmust a kártya speciális duplázott magjaihoz. Valószínűleg fordult a világ, és most az Nvidia lesz a miner kártya, az AMD pedig gamer kártya. -

poci76
aktív tag
válasz
Jack@l
#48214
üzenetére
Két chipről lehetett eddig olvasni: a 21-es "big navi"-ról és a 22-es kistesóról. Ha jön a két chipes videokártya, akkor nekem az lenne a logikus, hogy az AMD olyat akar dobni, mint anno a Threadripperrel, azaz teljesen titokban tartotta a két chipes megoldás lehetőségét, és kivárta, hogy az Nvidia lépjen. Ebből nekem az következne, hogy ha a 6800-as big navi a 3800 RTX közelében lesz önmagában, 16 GB 256 bites RAM-mal, akkor jön mellé a 6900-as két 21-es chippel, 32 GB RAM-mal. Ennél kellően visszavennék az órajelet, és válogatott chipek mennének rá, minél alacsonyabb tápfesszel, ahogy Threadrippernél, hogy mondjuk 350 W-ba beleférjen a kártya. Egy ilyen kombó a 3900 RTX-et is jócskán felülmúlhatná, persze baromi drágán. Meglenne a presztizskártya, amiből ugyan nem kel el túl sok, de mivel nem kell hozzá külön chipet gyártani, még akár közvetlen nyereséget is hozhatna.
-

And01
aktív tag
válasz
Jack@l
#48214
üzenetére
Ez nem jó/rossz kérdés hanem felkészülés egy
jövőbeli technológiai limitációra.
Szerintem messze jobb lesz mint gondolod (egységes mem címtér)
Bár késleltetésre lehet nem lesz jó hatással. (Time will tell)
Mint mindennek, ennek is lesz/lehet gyenge pontja.
A legjobb működő példa erre designre az első generációs epic cpu
De itt a fejlettebb IF link segíthet hogy jobb legyen a kommunikáció. -
And01
aktív tag
válasz
Jack@l
#48206
üzenetére
Bonyolultnak és lomhának talán még a gcn archot lehetett volna nevezni,
de ezen már túl léptek egy ideje.
A chiplet alapú cuccok pedig a jövő, mindhárom cég számára.
Az új euv alapú gyártástechnológiákon a levilágitható lapkaterület
fele duv megoldásnak, tehát a maximális lapkaméret is fele lesz a
a jelenlegi maximumnak, a jelenlegi 6-8xx mm2 lapkákat el lehet felejteni. -
#48207
 szmörlock007
aktív tag
Jack@l
#48206
szmörlock007
aktív tag
Jack@l
#48206
szmörlock007
aktív tag
válasz
Jack@l
#48206
üzenetére
Miért? Intel is elég durván a chiplet irányban mozog a gpuk esetében. Megjegyzem jobb ha tőlem tudod, hogy az nvidia is

A Hopperre is számtalan utalás jött már egy esetleges modulos dizájnra. De akkor ugye ha véletlen nvidia is elhozza valamikor a chiplet dizájnt (akár hoppernél, akár később) akkor azt is ennyire lefogod szólni előtte? -
#47921
Alogonomus
őstag
Jack@l
#47920
-

sutyi^
senior tag
válasz
Jack@l
#47647
üzenetére
Elvileg 20Tflops / 300W volt target nagy NAVI-val.
Az annyit tesz hogy 50%-al jobb perf/W mutató volt a cél egy 225W-os refkartyához képest. Elvileg Abu infoja szerint ezt sikerült megugrani 22TFlops / 280W-al. Az annyit tesz hogy ~17,8%-al sikerült jobbat alkotni mint a target. Hogy ez javarészt még architektúrábol vagy fejlettebb 7nm-es gyártási technológiából jött össze azt csak AMD tudja.
Ennek értelmében van legalább egy kártya ami egy 2080Ti-re 45-50%-ot kéne dobjon elméletben.





























![;]](http://cdn.rios.hu/dl/s/v1.gif) ) karival, de az fix, hogy nem adok 400-500k-t egy 10gb-os kariért, de még 300k-t sem.
) karival, de az fix, hogy nem adok 400-500k-t egy 10gb-os kariért, de még 300k-t sem.























Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- Csere-Beszámítás! Ryzen 9 9950X Processzor!
- Bomba ár! Lenovo X1 Yoga 2nd - i7-7G I 8GB I 256SSD I 14" WQHD I HDMI I W11 I CAM I Garancia!
- MacBook felvásárlás!! Macbook, Macbook Air, Macbook Pro
- Apple iPhone 13 Pro , 128GB , Kártyafüggetlen
- Apple iPhone 14 Pro Max / 256 GB / 88% akkumulátor / 1év Garanciával / Gyári Független
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged