
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)
- Feltalálta a Google a keresőmotort
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- iPhone topik
- Huawei Watch Fit 5 Pro - jó forma
- Kreatív előzetesen az Xperia 1 VIII
- Magisk
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Szívós, szép és kitartó az új OnePlus óra
- Google Pixel topik
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
Új hozzászólás Aktív témák
-
 epicdev
junior tag
epicdev
junior tag
Nem sql kérdés, Libreocce calc probléma, de talán valakinek van rá ötlete.

Két lista van, egyszerűek, megnevezés, kategória és leírás
Az első az általános lista, a másikban az a nagyon kevés van, ami az általános lista két vagy több eleméből jött létre és új definíciót eredményezett.
Úgy kellene megjeleníteni ezeket, hogy az alapelemeket is lehessen látni.
egyszerű példa:
alaplistában:
víz - kategória, leírás
gőz - kategória, leírásmásik listában:
vízgőz - kategória, leírás
(és ide kellene valahogy linkelni a fenti kettőt, hogy lehessen látni a forrásokat is)bonyolultabb probléma:
(egy egészen más listában)
pár tucatnyi elem vanEgy másik listában minden új tételben csak a fenti elemek némelyike fordulhat elő bennük, és valahogyan hivatkozni kell rájuk.
példa:
alaplista
A
B
C
Daz új lista
AB
ACA
BAC
DBBACBmindegyiknél azokra az elemekre is kell hivatkozás, amik előfordulnak bennük
remélem, érthető
-
 velizare
nagyúr
velizare
nagyúr
Először is nagyon szépen köszönöm a segítséget mindenkinek

Látod, te is php-val oldottad meg.
 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed bambano: ha csak azt írod le, hogy rossz séma, rossz séma, abból nem fogom tudni hol rontottam és hogyan kellene.

pch: sajnos abból egy szót se értek. Nekem az még túl bonyolult

nem is baj, ha nem érted a triggert, kapudrog.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
 lanszelot
addikt
lanszelot
addikt
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();Először is nagyon szépen köszönöm a segítséget mindenkinek
Látod, te is php-val oldottad meg.
megválaszoltad saját kérdésed bambano: ha csak azt írod le, hogy rossz séma, rossz séma, abból nem fogom tudni hol rontottam és hogyan kellene.
pch: sajnos abból egy szót se értek. Nekem az még túl bonyolult
-
 bambano
titán
bambano
titán
felvettél egy group_id mezőt, ami a hagyományos módszere az 1 : N kapcsolat tárolásának relációs algebrában.
És ezt mondta korábban: "Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet." -
 sztanozs
veterán
sztanozs
veterán
-
bambano
titán
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();te most itt hagyományosan berögzülten gondolkodsz?

-
sztanozs
veterán
Sehogy nem oldja meg, mert rossz az adatbázis sémája és nem akarja elhinni. De ez nem probléma, most a matematika ellen fogad, és megvárjuk, amíg megoldja.

A te megoldásod is rossz, mert ha az insert into suppliers utasításban egy oszlopot adsz meg, akkor a valuesben nem lehet két kérdőjel.
ahh, persze, kimaradt a group id. nem volt kedvem felhuzni egy php pdo-val, hogy kiprobaljam... amugy meg tenyleg teljesen rossz a sema, es persze a tablak letrehozasanak a sorrendje is szamit.
vsz most jol es kicsit egyszerubben//Create groups table - First table with shared ID - This table provides ID for suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
UNIQUE(id, group_name))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create suppliers table - Main table with shared ID - This table gets ID from supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
group_id INTEGER NOT NULL,
FOREIGN KEY (group_id) REFERENCES supplier_groups (id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO supplier_groups (group_name) VALUES (:name);
SELECT id FROM supplier_groups WHERE group_name = :name)";
$sql2 = "INSERT INTO suppliers (supplier_name, group_id) VALUES (:name, :id)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['name' => 'jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql2);
$statement->exec(['name' => 'Obi van Kenobi', 'id' => $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage(); -
bambano
titán
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
UNIQUE(id, supplier_name))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO suppliers (group_name) VALUES (?)"
$sql2 = "SELECT id FROM group_name WHERE group_name = ?)";
$sql3 = "INSERT INTO suppliers (supplier_name) VALUES (?, ?)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['jedi']);
$statement = $connection->prepare($sql2);
$statement->exec(['jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql3);
$statement->exec(['Obi van Kenobi', $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}Sehogy nem oldja meg, mert rossz az adatbázis sémája és nem akarja elhinni. De ez nem probléma, most a matematika ellen fogad, és megvárjuk, amíg megoldja.
A te megoldásod is rossz, mert ha az insert into suppliers utasításban egy oszlopot adsz meg, akkor a valuesben nem lehet két kérdőjel.
-
sztanozs
veterán
Köszönöm szépen a választ.
Nekem nem működik. Lehet én csinalok valamit rosszul ezért belinkelem a kódodt, és a hibát.
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT)";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}Hiba: "Error: SQLSTATE[23000]: Integrity constraint violation: 19 NOT NULL constraint failed: suppliers.group_id"
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT,
UNIQUE(id, supplier_name))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql1 = "INSERT OR IGNORE INTO suppliers (group_name) VALUES (?)"
$sql2 = "SELECT id FROM group_name WHERE group_name = ?)";
$sql3 = "INSERT INTO suppliers (supplier_name) VALUES (?, ?)";
try {
$statement = $connection->prepare($sql1);
$statement->exec(['jedi']);
$statement = $connection->prepare($sql2);
$statement->exec(['jedi']);
$gid = $statement->fetchColumn();
$statement = $connection->prepare($sql3);
$statement->exec(['Obi van Kenobi', $gid]);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
} -
sztanozs
veterán
Rég óta próbálom az sqlite pdo php -t , de sehol sincs semmi róla.
Borzasztó nehéz bármit is találni. Mind hiányos, és felületes.
Vagy pont az ellenkezője. Egyik se jó egy kezdőnek.
Én is biztos vagyok, hogy a kód nem tökéletes, de működik.
Senki sem segít, így örülök ha működik.
Amit akarok az php-val simán meg lehet oldani.
Amiért akarom, mert hülyeségnek tartom, hogy azért hozzak létre plusz egy oszlopot minden táblába, plusz még egy táblát, hogy össze kössem a táblákat, mikor sokkal egyszerűbben meg lehet csinálni.
Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet.
Akkor marad a php.Erdekelne, hogy hogyan oldod meg ezt phpban...
-
 pch
senior tag
pch
senior tag
Rég óta próbálom az sqlite pdo php -t , de sehol sincs semmi róla.
Borzasztó nehéz bármit is találni. Mind hiányos, és felületes.
Vagy pont az ellenkezője. Egyik se jó egy kezdőnek.
Én is biztos vagyok, hogy a kód nem tökéletes, de működik.
Senki sem segít, így örülök ha működik.
Amit akarok az php-val simán meg lehet oldani.
Amiért akarom, mert hülyeségnek tartom, hogy azért hozzak létre plusz egy oszlopot minden táblába, plusz még egy táblát, hogy össze kössem a táblákat, mikor sokkal egyszerűbben meg lehet csinálni.
Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet.
Akkor marad a php.trigger amit keresel.
triggerrel oldható meg, hogy insert esetén a kapott iD-t egy másik táblába beírjuk.
https://sqlite.org/lang_createtrigger.html -
lanszelot
addikt
Szerintem el kellene olvasnod pár alap irodalmat az adatbázis tervezésről, különös tekintettel a normálformákra, az 1 : N és az M : N kapcsolatok ábrázolására.
Mert amit akarsz, az NINCS. Ha pedig úgy akarod tárolni az adatot, amit abból a php kódrészletből ki lehet olvasni, akkor az úgy téves.Rég óta próbálom az sqlite pdo php -t , de sehol sincs semmi róla.
Borzasztó nehéz bármit is találni. Mind hiányos, és felületes.
Vagy pont az ellenkezője. Egyik se jó egy kezdőnek.
Én is biztos vagyok, hogy a kód nem tökéletes, de működik.
Senki sem segít, így örülök ha működik.
Amit akarok az php-val simán meg lehet oldani.
Amiért akarom, mert hülyeségnek tartom, hogy azért hozzak létre plusz egy oszlopot minden táblába, plusz még egy táblát, hogy össze kössem a táblákat, mikor sokkal egyszerűbben meg lehet csinálni.
Lehet pont azért látom meg a hibát a rendszerben, mert még nem rögzült belém, hogy ezt így kell, mert csak így lehet.
Akkor marad a php. -
bambano
titán
Szerintem el kellene olvasnod pár alap irodalmat az adatbázis tervezésről, különös tekintettel a normálformákra, az 1 : N és az M : N kapcsolatok ábrázolására.
Mert amit akarsz, az NINCS. Ha pedig úgy akarod tárolni az adatot, amit abból a php kódrészletből ki lehet olvasni, akkor az úgy téves. -
lanszelot
addikt
Hello,
Hogy kell létrehozni táblát úgy, hogy az id-je egy másik tábla id-je legyen? (Utolsó előtti sor.)CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id FROM users(id),
address TEXT)Lehet, hogy rosszul írtam le mit szeretnék.
Leírnám, hátha érthetőbb:
Van egy adatbázis, amiben több TABLE van.
Azt szeretném, ha adatot viszek be, akkor automatikusan generálódjon egy id, ami midegyikbe automatikusan bele kerül. -
lanszelot
addikt
De, pont ugyanazt kell csinalni... Es az ordernel itt is meg kell adni a users.id-t.
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id INTEGER,
address TEXT,
FOREIGN KEY (id) REFERENCES users (id))Köszönöm szépen a választ.
Nekem nem működik. Lehet én csinalok valamit rosszul ezért belinkelem a kódodt, és a hibát.
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
email TEXT)";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
id INTEGER,
group_name TEXT NOT NULL,
FOREIGN KEY (id) REFERENCES suppliers (id))";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}Hiba: "Error: SQLSTATE[23000]: Integrity constraint violation: 19 NOT NULL constraint failed: suppliers.group_id"
-
sztanozs
veterán
De, pont ugyanazt kell csinalni... Es az ordernel itt is meg kell adni a users.id-t.
CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id INTEGER,
address TEXT,
FOREIGN KEY (id) REFERENCES users (id)) -
lanszelot
addikt
-
bambano
titán
Honnan találná ki az adatbáziskezelő, hogy melyik group id-t kell beleírnia? Azt te fogod megadni, nincs más megoldás.
-
sztanozs
veterán
ha azt irsz bele amit akarsz, akkor nincs ertelme a ket tablanak meg a foreign key-nek...
foreign key ugy mukodhet, hogy a user kivalasztja egy listabol az erteket (dropdown box), nem pedig szabad szoveges. -
lanszelot
addikt
hogy lehetne autoincrement primary key, amikor foreign key is egyben?
Ebben a sorrendben kell letrehozni es feltolteni a tablakat:CREATE TABLE IF NOT EXISTS supplier_groups (
... group_id integer AUTOINCREMENT PRIMARY KEY,
... group_name text NOT NULL)
CREATE TABLE IF NOT EXISTS suppliers (
... supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
... supplier_name TEXT NOT NULL,
... group_id INTEGER NOT NULL,
... FOREIGN KEY (group_id)
... REFERENCES supplier_groups (group_id))
INSERT INTO supplier_groups (group_name) VALUES ('Jedi')
INSERT INTO suppliers (supplier_name, group_id) VALUES ('Obi van Kenobi',1)Köszönöm szépen a választ.
Ez így nem jó, mert a group_id -t nekem kell megadni.
Pont az a lényeg, hogy automatikusan átadja, ne nekem kelljen php -van bele íratni.
Így hülyeségeket hoz létre. Foreign key-nek semmi értelme, azt írok be amit akarok. -
sztanozs
veterán
Köszönöm szépen.
Valamit nem jó; értek, mert eddig jutottam, de nem jó:
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
group_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
FOREIGN KEY (group_id)
REFERENCES supplier_groups (group_id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
group_id integer PRIMARY KEY,
group_name text NOT NULL)";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}hogy lehetne autoincrement primary key, amikor foreign key is egyben?
Ebben a sorrendben kell letrehozni es feltolteni a tablakat:CREATE TABLE IF NOT EXISTS supplier_groups (
... group_id integer AUTOINCREMENT PRIMARY KEY,
... group_name text NOT NULL)
CREATE TABLE IF NOT EXISTS suppliers (
... supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
... supplier_name TEXT NOT NULL,
... group_id INTEGER NOT NULL,
... FOREIGN KEY (group_id)
... REFERENCES supplier_groups (group_id))
INSERT INTO supplier_groups (group_name) VALUES ('Jedi')
INSERT INTO suppliers (supplier_name, group_id) VALUES ('Obi van Kenobi',1) -
lanszelot
addikt
Köszönöm szépen.
Valamit nem jó; értek, mert eddig jutottam, de nem jó:
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
group_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
FOREIGN KEY (group_id)
REFERENCES supplier_groups (group_id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
group_id integer PRIMARY KEY,
group_name text NOT NULL)";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
} -
 martonx
veterán
martonx
veterán
Köszönöm szépen a választ.
Oda írtam a példát. Az id pont úgy van ahogy írtad.
És azt is tudom hogy constraint és /vagy foreign key -t kell használom, de nem tudom hogyan.
Azért írtam le a kódot, hogy lehessen látni, hogy mit szeretnék.
Természetesen azid FROM usres(id)sort kellene javítani,
constraint és /vagy foreign használataval,
Csak nem tudom hogy.
Bárhogy próbáltam, sehogy se volt jó.Sqlite pdo php -val használom.
Google legelső találatát javaslom megnézni a nagyon meglepő: sqlite foreign key keresésre.
Ha ez alapján még mindig nem megy, és nem világos, akkor ugyan nem használok sqlite-ot, de gyere vissza kérdezni, és segítünk. -
lanszelot
addikt
Köszönöm szépen a választ.
Oda írtam a példát. Az id pont úgy van ahogy írtad.
És azt is tudom hogy constraint és /vagy foreign key -t kell használom, de nem tudom hogyan.
Azért írtam le a kódot, hogy lehessen látni, hogy mit szeretnék.
Természetesen azid FROM usres(id)sort kellene javítani,
constraint és /vagy foreign használataval,
Csak nem tudom hogy.
Bárhogy próbáltam, sehogy se volt jó.Sqlite pdo php -val használom.
-
martonx
veterán
Hello,
Hogy kell létrehozni táblát úgy, hogy az id-je egy másik tábla id-je legyen? (Utolsó előtti sor.)CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id FROM users(id),
address TEXT)Szerintem foreign Key-re gondolsz. Egyáltalán milyen SQL-ről beszélünk?
Az Order tábládba legyen id (int autoincrement mondjuk), userId, ami legyen Foreign Key a User táblára és az address mező.
-
lanszelot
addikt
Pl valamilyen sql-t, de ezt mondjuk a topik címe determinálja
Nem tudom mennyi bejegyzés van, de pár millió rekordot jó szervezés meg kulcsolás esetén kb bármilyen vason meg lehet oldani bármilyen sql szerverrel .. meg persze kell hozzá vmi frontend, jellemzően browseres megoldás a legelterjedtebb (ekkor persze kell webszerver, de az is van ingyé), de még excelben is meg lehet csinálni (ami a háttérben beszélget az sql szerverrel).Lehet pl MariaDB (azaz MySql), Transact (MS) Sql-nek is van ingyenes verziója olyan limitációkkal amit jó eséllyel nem fogtok elérni, meg még jó hosszan lehetne sorolni.
Hello,
Hogy kell létrehozni táblát úgy, hogy az id-je egy másik tábla id-je legyen? (Utolsó előtti sor.)CREATE TABLE IF NOT EXISTS users (
id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
username TEXT NOT NULL,
email TEXT)
CREATE TABLE IF NOT EXISTS order (
id FROM users(id),
address TEXT) -
 Magnat
veterán
Magnat
veterán
Lexikon keszitesre milyen ingyenes es biztonsagos megoldast javasoltok?
pelda:
cimszo: fekete
def1: szin
jelentes: ide jonnek a szinnel kapcsolatos leirasok
kulcsszo: szindef2: lopott aru
jelentes: ide jonnek a peldak, leirasok
kulcsszo: szlengstb. stb.
Jelenleg a 0. fazisban vagyunk, mert a kezdetekben az adatgyujtok allandoan modositottak vagy (veletlenul) toroltek korabbi beirasokat, mert szovegfajlba irtak.
Most ott tartunk, hogy cimszo es jelentes es kudo neve szerint kuldik nekem hetente a gyujteseket, osszesitem oket ABC szerint egy Libreoffice Calc fajlba kiegeszitve a kuldes datumaval.
Majd egy okos csapat eldonti, hogy a kulonbozo jelentesek hanyfele kategoriaba tartoznak es milyen kulcsszavak tartozik hozza
A problema ugyanugy fennall, mert az okosok osszevonnak dolgokat, ezert a bekuldok ujra bekuldenek olyan dolgokat, amiket korabban az okosok mar kilottek vagy modositottak.
Olyan megoldas kellene, hogy a bekuldok lathassak, hogy korabban miket fogadott el az okos csapat, de ne tudjanak belepiszkalni.
Pl valamilyen sql-t, de ezt mondjuk a topik címe determinálja
Nem tudom mennyi bejegyzés van, de pár millió rekordot jó szervezés meg kulcsolás esetén kb bármilyen vason meg lehet oldani bármilyen sql szerverrel .. meg persze kell hozzá vmi frontend, jellemzően browseres megoldás a legelterjedtebb (ekkor persze kell webszerver, de az is van ingyé), de még excelben is meg lehet csinálni (ami a háttérben beszélget az sql szerverrel).Lehet pl MariaDB (azaz MySql), Transact (MS) Sql-nek is van ingyenes verziója olyan limitációkkal amit jó eséllyel nem fogtok elérni, meg még jó hosszan lehetne sorolni.
-
 shipfolt
kezdő
shipfolt
kezdő
Lexikon keszitesre milyen ingyenes es biztonsagos megoldast javasoltok?
pelda:
cimszo: fekete
def1: szin
jelentes: ide jonnek a szinnel kapcsolatos leirasok
kulcsszo: szindef2: lopott aru
jelentes: ide jonnek a peldak, leirasok
kulcsszo: szlengstb. stb.
Jelenleg a 0. fazisban vagyunk, mert a kezdetekben az adatgyujtok allandoan modositottak vagy (veletlenul) toroltek korabbi beirasokat, mert szovegfajlba irtak.
Most ott tartunk, hogy cimszo es jelentes es kudo neve szerint kuldik nekem hetente a gyujteseket, osszesitem oket ABC szerint egy Libreoffice Calc fajlba kiegeszitve a kuldes datumaval.
Majd egy okos csapat eldonti, hogy a kulonbozo jelentesek hanyfele kategoriaba tartoznak es milyen kulcsszavak tartozik hozza
A problema ugyanugy fennall, mert az okosok osszevonnak dolgokat, ezert a bekuldok ujra bekuldenek olyan dolgokat, amiket korabban az okosok mar kilottek vagy modositottak.
Olyan megoldas kellene, hogy a bekuldok lathassak, hogy korabban miket fogadott el az okos csapat, de ne tudjanak belepiszkalni.
-
bambano
titán
Értem a 3 tábla felépítését és ez a megoldás jónak tűnik. Megoldja azt hogy eltérő időbélyegekkel hogyan lehet összefűzni adatokat.
Az adat összefűzés azért kell mert ipari üzemről van szó ahol gázmérők regisztrálják a fogyasztást főmérők/almérők/mellérendelt mérők struktúrában. Minden időpontban meg kell tudni mondani pl. hogy az almérőkőn mért fogyasztás összege megegyezik-e a főmérőével. De ugyanígy az elektromos mérőknél pl. hogy a napelem általt termelt energia / a hálózatról vásárolt energia / visszatermelés hogyan viszonyul egymáshoz és pl. mennyi az üzem tényleges fogyasztása stb. és mindezeket összesítve órára/napra/hétre hónapra stb. Tehát különböző mérőpontoknál szerzett adatokkal műveleteket kell végezni, ezt pedig csak úgy lehet hogy összerendelem azokat.
Ez azonban egy jelentős struktúra váltás és egy német cégnél ezt nehéz átvinni, de megpróbálom.
Viszont nekem addig is kell egy megoldás és a korábban említett View jó lehet erre. Fogom a tábla adatokat, először is konvertálom az időt a legközelebbi negyed órás időre (00/15/30/45min) beleteszem a mérési pont azonosítóját (MPxxx) is az adat mellé és unionnal összefűzöm őket. Aztán ezt a view-t használom a Grafana Query-kben.Ha fafejség ellen kell harcolni, arra a nézettábla megoldás.
Itt az az érdekes helyzet van, hogy a nézettábla két irányból is alkalmazható:
1. van egy pocsék tárolási struktúrád, és abból akarsz jó nézetet generálni.
2. csinálsz egy rendes tárolási struktúrát és abból generálsz pocsék nézetet.Én azt javaslom, hogy minél előbb át kell térni a rendes megoldásra, vagyis 2.
Tehát megcsinálod a 3 táblát, elkezded abba tölteni az adatokat, akár visszamenőleg is, és ráhúzol annyi nézetet, amennyi az aktuális helyzetben kell. Ráadásul nézetet ráhúzni és eldobni sokkal egyszerűbb, mint alaptáblát módosítani. Megcsinálod, hogy azok a programok, amik a rossz struktúrát használják, használják a nézettáblákat, amiket meg ezután módosítotok, már az új megoldást használják.
szerk: ha minden szenzor egy tábla rendszerben tárolod az adatokat és egy nézettáblába hozod össze a sok táblát, akkor ott problémás lehet, hogy egy új szenzor hozzáadásakor megcsinálod a szenzor saját tábláját, és amikor a nézettáblát módosítod, akkor le kell bontani a korábbi nézettáblát és feltenni az újat. Ha pedig minden szenzor egy tábla rendszer van, akkor az új nézettábla létrehozása nem befolyásolja a többi működését.
Itt kerül elő az alapkérdés, hogy milyen a kapcsolat a fafejűekkel, hogy nekik mi mindenről van döntési joguk és mi mindent kell tudniuk. Én csendben átírnám, oszt jónapot.
-
 fjanni
tag
fjanni
tag
Értem a 3 tábla felépítését és ez a megoldás jónak tűnik. Megoldja azt hogy eltérő időbélyegekkel hogyan lehet összefűzni adatokat.
Az adat összefűzés azért kell mert ipari üzemről van szó ahol gázmérők regisztrálják a fogyasztást főmérők/almérők/mellérendelt mérők struktúrában. Minden időpontban meg kell tudni mondani pl. hogy az almérőkőn mért fogyasztás összege megegyezik-e a főmérőével. De ugyanígy az elektromos mérőknél pl. hogy a napelem általt termelt energia / a hálózatról vásárolt energia / visszatermelés hogyan viszonyul egymáshoz és pl. mennyi az üzem tényleges fogyasztása stb. és mindezeket összesítve órára/napra/hétre hónapra stb. Tehát különböző mérőpontoknál szerzett adatokkal műveleteket kell végezni, ezt pedig csak úgy lehet hogy összerendelem azokat.
Ez azonban egy jelentős struktúra váltás és egy német cégnél ezt nehéz átvinni, de megpróbálom.
Viszont nekem addig is kell egy megoldás és a korábban említett View jó lehet erre. Fogom a tábla adatokat, először is konvertálom az időt a legközelebbi negyed órás időre (00/15/30/45min) beleteszem a mérési pont azonosítóját (MPxxx) is az adat mellé és unionnal összefűzöm őket. Aztán ezt a view-t használom a Grafana Query-kben. -
 Jim74
nagyúr
Jim74
nagyúr
"Valóban a mérő azonosító karaktereiben lehet betű is.": majd valami agyhalott kitalálja, hogy legyen benne ékezetes betű, pl. tulaj neve vagy címe rövidítve, esetleg bugos utf8 konverter az adatbáziskezelőben (mint ma a debianban...
) és akkor lefekszik az egész....Egyébként a számmal is az a gond, hogyha nem tudod a határait, nem biztos, hogy találsz hozzá természetes adattípust. Akkor eltárolod stringként, és vége. Vagy jöhet olyan történet is, mint egyszeri lakcímnél, hogy beépítenek egy telket, és hirtelen a természetes szám házszámból lesz egy /b.
Soha nem tudhatod, hogy egy architect miket képes elbarkácsolni
Kollégám mondása: az ügyintézői találékonyság határtalan.

-
bambano
titán
"Valóban a mérő azonosító karaktereiben lehet betű is.": majd valami agyhalott kitalálja, hogy legyen benne ékezetes betű, pl. tulaj neve vagy címe rövidítve, esetleg bugos utf8 konverter az adatbáziskezelőben (mint ma a debianban...
) és akkor lefekszik az egész....Egyébként a számmal is az a gond, hogyha nem tudod a határait, nem biztos, hogy találsz hozzá természetes adattípust. Akkor eltárolod stringként, és vége. Vagy jöhet olyan történet is, mint egyszeri lakcímnél, hogy beépítenek egy telket, és hirtelen a természetes szám házszámból lesz egy /b.
Soha nem tudhatod, hogy egy architect miket képes elbarkácsolni
-
Jim74
nagyúr
Én is közüzemi cég szerűséget találgatok...
Szerintem a mérőket ki kell venni, mert stringek között keresni rosszabb, mint egész számok között, másrészt nem tudni, melyik mérő neve milyen hosszú.Archiváláson valóban érdemes gondolkodni, de a kötelező megőrzési idő, szerintem, elég nagy ahhoz, hogy archiválástól függetlenül meg lehet borítani a lekérdezéseket. Ha a jelentési teljesítmény nem jó, akkor nem jól tervezték meg az adatbázist.
Egyébként a nagy tábla a biztonsági mentéseket borítja meg leghamarabb...
Valóban a mérő azonosító karaktereiben lehet betű is. Áramban vagyok otthon, ott eddig csak számmal találkoztam, de simán bejöhet olyan gyártó, aki betűt is elkezd alkalmazni az azonosítóban.
A többi hasznos infót is köszönöm
. -
bambano
titán
Nekem az a gyanúm, hogy valami olyan feladatról lehet szó, mint egy közüzemi cégnél, hogy jönnek a mérőkről az adatok és két adott időpont között ki kell számolni az adott időszakban elfogyasztott (mért) mennyiséget.
Szerintem ehhez elegendő egy tábla (feltéve, ha a mérőkről nem szükséges további információ, pl. telepítési hely, lokáció, hitelesítési év, ilyesmi).
Viszont az adatok mennyiségétől függően már most érdemes elgondolkodni az időközönkénti archiváláson, mert egy ilyen tábla elképesztő nagyra tud "hízni", ami az esetleges riportolási performanciát megboríthatja.
Én nem vagyok data enginieer, csak egy mezei riportingos, ezért az irományomat ilyen kritikus szemmel nézd kérlek.Én is közüzemi cég szerűséget találgatok...
Szerintem a mérőket ki kell venni, mert stringek között keresni rosszabb, mint egész számok között, másrészt nem tudni, melyik mérő neve milyen hosszú.Archiváláson valóban érdemes gondolkodni, de a kötelező megőrzési idő, szerintem, elég nagy ahhoz, hogy archiválástól függetlenül meg lehet borítani a lekérdezéseket. Ha a jelentési teljesítmény nem jó, akkor nem jól tervezték meg az adatbázist.
Egyébként a nagy tábla a biztonsági mentéseket borítja meg leghamarabb...
-
Jim74
nagyúr
Én úgy értettem abból, amit írt, hogy össze akarja kötni az azonos időben különböző mérőkkel mért értékeket, és ezt nem lehet időbélyeg alapján, mert az mindig változik.
Tehát ha valamiféle egységben (gazdasági egység, megrendelő, számlázási egység) több mérő van, tudni akarja az egy időpontban mért értékeket. Találgatás: például nálam 5 hőmennyiség mérő van, ha simán leszeded a mért értékeket, különbözik az időpont, de bizonyos célokra tudni kell, hogy amikor az egyik mért valamit, pontosan akkor mit mért a másik.Nekem az a gyanúm, hogy valami olyan feladatról lehet szó, mint egy közüzemi cégnél, hogy jönnek a mérőkről az adatok és két adott időpont között ki kell számolni az adott időszakban elfogyasztott (mért) mennyiséget.
Szerintem ehhez elegendő egy tábla (feltéve, ha a mérőkről nem szükséges további információ, pl. telepítési hely, lokáció, hitelesítési év, ilyesmi).
Viszont az adatok mennyiségétől függően már most érdemes elgondolkodni az időközönkénti archiváláson, mert egy ilyen tábla elképesztő nagyra tud "hízni", ami az esetleges riportolási performanciát megboríthatja.
Én nem vagyok data enginieer, csak egy mezei riportingos, ezért az irományomat ilyen kritikus szemmel nézd kérlek. -
bambano
titán
Én úgy értettem abból, amit írt, hogy össze akarja kötni az azonos időben különböző mérőkkel mért értékeket, és ezt nem lehet időbélyeg alapján, mert az mindig változik.
Tehát ha valamiféle egységben (gazdasági egység, megrendelő, számlázási egység) több mérő van, tudni akarja az egy időpontban mért értékeket. Találgatás: például nálam 5 hőmennyiség mérő van, ha simán leszeded a mért értékeket, különbözik az időpont, de bizonyos célokra tudni kell, hogy amikor az egyik mért valamit, pontosan akkor mit mért a másik. -
fjanni
tag
Nem ugyanarra van, minden tábla más mérési pont adatát tárolja, valamelyik gáz fogyasztás és van amelyik villamos energia fogyasztás adatot tárol, és olyan is van ahol villamos teljesítmény adatot tárolnak adott timestamp-hez kötve.
Ha sikerülne elérni hogy újrafejlesszék akkor annak milyennek kellene lennie?
Jelenleg ilyen egy tábla, a tábla neve MP001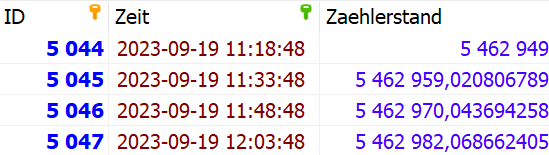
Egy másik tábla pedig: MP002
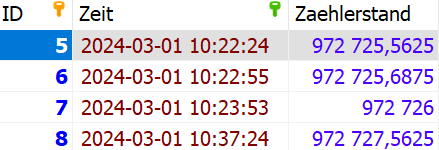
Látható hogy szinte minden táblában más az időbélyeg adat, van ahol rövid időn belül sok adat lett letárolva stb.
Ehelyett mi a jó megoldás?
Az hogy egy táblába írok úgy hogy minden adatnak van egy mérési pont azonosítója?
ID / MP_code / Zeit / Zaehlerstand - itt ügyelni kell arra hogy az időbélyeg adatok egy beírásnál megegyezzenek.
vagy
egy rekordba legyen írva az össze adat egy dátum mellé?
ID / Zeit / MP001 / MP002 / MP003 .... ahány mérési pont van?Ha elfogadják az új formátumok akkor pedig átkonvertáljuk a régi adatokat is ebbe az új formátumba.
-
 Louro
őstag
Louro
őstag
Uh, ilyen nálunk is van az egyik területen. Kb. 3-4 hetente felhívom a figyelmüket, hogy rendezzék már az adataikat. Ugyanarra a témára, naponta hoznak létre táblákat és van, hogy 1-2 rekord van csak benne. Mondtam nekik, hogy +1 oszlop, ami a napot jelöli, sokkal ideálisabb lenne. Ehelyett már 300+ táblájuk van csak egy célra és nekik így jó. Szerencsére csak két ilyen fafejű kolléga van. Persze panaszkodni tudnak, hogy ha az SSMS-ben lenyitják a táblák listáját, akkor van, hogy megnyekken a rendszer.
És nem egy DWH területről beszélünk. Kb. 100 táblában elférnének, de ehelyett 5000+ táblájuk van. Nekem fizikailag fáj, ha velük kell foglalkoznom. Hiába jelzem, hogy ha unique indexet akarnak trigger miatt, akkor ne 4 adatból rakják össze, amik ráadásul eltérő adattípusúak, hanem csináljanak egy dedikált unique mezőt és arra lehet indexálni.
De hát mi csak csóró üzemeltetők vagyunk és ők a détaendzsinírek.
-
martonx
veterán
Jelenleg van kb. 200 tábla, ez talán felmehet max. 500-ra, tehát nem olyan sok tábláról beszélünk.
Negyed óránként történik a szenzorokbol kiolvasás, ez lehet gáz fogyasztás számláló, vagy villamos energia számláló állás, tehát rekord sem lesz olyan sok.
Van még egy olyan gond is hogy nem ugyanabban az időben olvasnak ki minden szenzort, tehát nem 00/15/30/45 a datetime-ban a min értéke. Ez olyan gondot okoz hogy simán nem lehet join-al kapcsolni az adatokat ha pl. számolni akarok velük, hanem külön külön át kell előbb konvertálni a fent említett 15 perces osztásra és utána mehet a Join.
A fentebb javasolt View megoldás jó lehetne olyan szempontból is, hogy abban ezt az átalakítást már meg lehetne tenni, így a View-ből indított Query-k már egyszerűbbek lehetnek. Ezt úgy tenném meg hogy a legközelebbi 15 perces egész értékre tenném át a View-ban az adatot, de ügyelni kellene arra is hogy ha több olvasás is történt akkor is csak egyet használjon fel. Az új mérési pont belépésekor pedig elég lenne azt csak a View-be felvenni.
Értem azt hogy egy táblában kellene lenni az összes szenzor adatnak és minden adatnak legyen egy szenzor azonosítója pl. "MP001". De azt hogyan javasoljátok megtenni? Tehát lineárisan, azaz Union-al egymáshoz fűzni őket, vagy mátrix szerűen, egy rekordba összefűzni az összes adatot ami egy időponthoz tartozik? Ez utóbbi esetben Join-al az átkonvertált negyed órás adatokat lehetne felhasználni. Ez utóbbi a felhasználás szempontjából (műveletek végzése, Grafana diagramban megjelenítés) talán jobb lenne, de mivel a szenzor azonosítók lennének a mezőnevek, előre kellene definiálni az összes lehetséges MP mezőt hogy egy új MP esetén ne kelljen adatstruktúrát változtatni. Ez nem túl elegáns megoldás.
A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?
Egyedi ID mezőt hogyan tudok ez esetben mellé tenni?Az említett Triggeres módszert nem ismerem, az mennyiben lenne más/jobb?
500 tábla nem sok pont ugyanarra??? Elmebeteg mennyiség. Sürgősen tervezzétek át, fejlesszétek újra.
-
Jim74
nagyúr
-
bambano
titán
Hasonló témához periférikusan közöm van. Egy táblába jönnek különböző mérők adatait és az időben egymást követő, de azonos mérő azonosítóhoz tartozó adatok egy növekvő sorszámmal vannak ellátva hasonlóan, ahogy Bambano is írta.
Ha egy lokáción lecerélik a mérőt, akkor az új mérő azonosítóval újra indul a sorszámozás. Nálunk csak dátum pontosságal jönnek az adatok, de így is kezelhetetlen lenne az egész, ha mérőnként lenne egy-egy tábla.
Nem én találtam ki, hogy így legyen, én csak felhasználója vagyok az adatoknak.NEM ezt írtam.
-
Jim74
nagyúr
Jelenleg van kb. 200 tábla, ez talán felmehet max. 500-ra, tehát nem olyan sok tábláról beszélünk.
Negyed óránként történik a szenzorokbol kiolvasás, ez lehet gáz fogyasztás számláló, vagy villamos energia számláló állás, tehát rekord sem lesz olyan sok.
Van még egy olyan gond is hogy nem ugyanabban az időben olvasnak ki minden szenzort, tehát nem 00/15/30/45 a datetime-ban a min értéke. Ez olyan gondot okoz hogy simán nem lehet join-al kapcsolni az adatokat ha pl. számolni akarok velük, hanem külön külön át kell előbb konvertálni a fent említett 15 perces osztásra és utána mehet a Join.
A fentebb javasolt View megoldás jó lehetne olyan szempontból is, hogy abban ezt az átalakítást már meg lehetne tenni, így a View-ből indított Query-k már egyszerűbbek lehetnek. Ezt úgy tenném meg hogy a legközelebbi 15 perces egész értékre tenném át a View-ban az adatot, de ügyelni kellene arra is hogy ha több olvasás is történt akkor is csak egyet használjon fel. Az új mérési pont belépésekor pedig elég lenne azt csak a View-be felvenni.
Értem azt hogy egy táblában kellene lenni az összes szenzor adatnak és minden adatnak legyen egy szenzor azonosítója pl. "MP001". De azt hogyan javasoljátok megtenni? Tehát lineárisan, azaz Union-al egymáshoz fűzni őket, vagy mátrix szerűen, egy rekordba összefűzni az összes adatot ami egy időponthoz tartozik? Ez utóbbi esetben Join-al az átkonvertált negyed órás adatokat lehetne felhasználni. Ez utóbbi a felhasználás szempontjából (műveletek végzése, Grafana diagramban megjelenítés) talán jobb lenne, de mivel a szenzor azonosítók lennének a mezőnevek, előre kellene definiálni az összes lehetséges MP mezőt hogy egy új MP esetén ne kelljen adatstruktúrát változtatni. Ez nem túl elegáns megoldás.
A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?
Egyedi ID mezőt hogyan tudok ez esetben mellé tenni?Az említett Triggeres módszert nem ismerem, az mennyiben lenne más/jobb?
Hasonló témához periférikusan közöm van. Egy táblába jönnek különböző mérők adatait és az időben egymást követő, de azonos mérő azonosítóhoz tartozó adatok egy növekvő sorszámmal vannak ellátva hasonlóan, ahogy Bambano is írta.
Ha egy lokáción lecerélik a mérőt, akkor az új mérő azonosítóval újra indul a sorszámozás. Nálunk csak dátum pontosságal jönnek az adatok, de így is kezelhetetlen lenne az egész, ha mérőnként lenne egy-egy tábla.
Nem én találtam ki, hogy így legyen, én csak felhasználója vagyok az adatoknak. -
bambano
titán
Jelenleg van kb. 200 tábla, ez talán felmehet max. 500-ra, tehát nem olyan sok tábláról beszélünk.
Negyed óránként történik a szenzorokbol kiolvasás, ez lehet gáz fogyasztás számláló, vagy villamos energia számláló állás, tehát rekord sem lesz olyan sok.
Van még egy olyan gond is hogy nem ugyanabban az időben olvasnak ki minden szenzort, tehát nem 00/15/30/45 a datetime-ban a min értéke. Ez olyan gondot okoz hogy simán nem lehet join-al kapcsolni az adatokat ha pl. számolni akarok velük, hanem külön külön át kell előbb konvertálni a fent említett 15 perces osztásra és utána mehet a Join.
A fentebb javasolt View megoldás jó lehetne olyan szempontból is, hogy abban ezt az átalakítást már meg lehetne tenni, így a View-ből indított Query-k már egyszerűbbek lehetnek. Ezt úgy tenném meg hogy a legközelebbi 15 perces egész értékre tenném át a View-ban az adatot, de ügyelni kellene arra is hogy ha több olvasás is történt akkor is csak egyet használjon fel. Az új mérési pont belépésekor pedig elég lenne azt csak a View-be felvenni.
Értem azt hogy egy táblában kellene lenni az összes szenzor adatnak és minden adatnak legyen egy szenzor azonosítója pl. "MP001". De azt hogyan javasoljátok megtenni? Tehát lineárisan, azaz Union-al egymáshoz fűzni őket, vagy mátrix szerűen, egy rekordba összefűzni az összes adatot ami egy időponthoz tartozik? Ez utóbbi esetben Join-al az átkonvertált negyed órás adatokat lehetne felhasználni. Ez utóbbi a felhasználás szempontjából (műveletek végzése, Grafana diagramban megjelenítés) talán jobb lenne, de mivel a szenzor azonosítók lennének a mezőnevek, előre kellene definiálni az összes lehetséges MP mezőt hogy egy új MP esetén ne kelljen adatstruktúrát változtatni. Ez nem túl elegáns megoldás.
A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?
Egyedi ID mezőt hogyan tudok ez esetben mellé tenni?Az említett Triggeres módszert nem ismerem, az mennyiben lenne más/jobb?
Ha össze akarod kapcsolni a méréseket, akkor azt kell csinálni, hogy a mérés konkrét dátuma mellett egy azonosító sorszámot is leraksz a táblába, és azzal joinolsz, nem a dátummal. Persze lehetne olyat is, hogy az a program, ami a mérést végzi, lekér egy dátumot, amikor indul, és utána az összes mérési adatot azzal a dátummal teszi le.
Azt látom abból, amit leírtál, hogy nagyon erősen javasolt lenne nulláról újraterveztetni az egészet egy szakértővel. Az, hogy 500 darab azonos tábla legyen egy adatbázisban, az abszolút nonszensz.
"A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?": a view, magyarul nézettábla *NEM LÉTEZIK*. Az egy definíció, ami leírja, hogy a tárolási sémából hogyan kell előállítani a nézettáblát. A lekérdezéskor számolódik ki. A magától frissül kérdés értelmetlen. Azt az adatot tartalmazza, amit megadsz neki, hogy tartalmazzon.
-
fjanni
tag
Nem ismerem a MariaDB lehetőségeit de én ezt úgy oldanám meg, hogy van egy function, amiben egy olyan kurzor van, ami a felolvasandó táblákon megy végig, a belseje pedig végrehajtja a lekérdezést a paraméterként kapott táblán, és egy record típusú OUT változóban gyűjti a dolgokat összegezve, alternatív megoldás, hogy egy külső táblába insertája a gyűjtött adatokatl. Ezt Postresben és Oracle-ben dinamikus query-nek hívják.
De ennek a megoldásnak elég komoly limitáció vannak és nagyon nem mindegy, hogy mennyi rekordon akarsz dolgozni. Mennyi recordot vársz eredménynek.
Ha jól olvasom, szenzorok adatait akarod összegezni, amire sokkal egyszerűbb és tartósabb megoldás a többek által javasolt triggeres módszer.
Arra is oda kell figyelni, hogy az adatbázisban ha elszaporodnak a táblák, az tud tárolási és működési kockázat lenni. Nem tudom hány szenzorról beszélünk, de mondjuk százezres nagyságrendnél az általad elképzelt bármelyik működés használhatatlan lesz.Jelenleg van kb. 200 tábla, ez talán felmehet max. 500-ra, tehát nem olyan sok tábláról beszélünk.
Negyed óránként történik a szenzorokbol kiolvasás, ez lehet gáz fogyasztás számláló, vagy villamos energia számláló állás, tehát rekord sem lesz olyan sok.
Van még egy olyan gond is hogy nem ugyanabban az időben olvasnak ki minden szenzort, tehát nem 00/15/30/45 a datetime-ban a min értéke. Ez olyan gondot okoz hogy simán nem lehet join-al kapcsolni az adatokat ha pl. számolni akarok velük, hanem külön külön át kell előbb konvertálni a fent említett 15 perces osztásra és utána mehet a Join.
A fentebb javasolt View megoldás jó lehetne olyan szempontból is, hogy abban ezt az átalakítást már meg lehetne tenni, így a View-ből indított Query-k már egyszerűbbek lehetnek. Ezt úgy tenném meg hogy a legközelebbi 15 perces egész értékre tenném át a View-ban az adatot, de ügyelni kellene arra is hogy ha több olvasás is történt akkor is csak egyet használjon fel. Az új mérési pont belépésekor pedig elég lenne azt csak a View-be felvenni.
Értem azt hogy egy táblában kellene lenni az összes szenzor adatnak és minden adatnak legyen egy szenzor azonosítója pl. "MP001". De azt hogyan javasoljátok megtenni? Tehát lineárisan, azaz Union-al egymáshoz fűzni őket, vagy mátrix szerűen, egy rekordba összefűzni az összes adatot ami egy időponthoz tartozik? Ez utóbbi esetben Join-al az átkonvertált negyed órás adatokat lehetne felhasználni. Ez utóbbi a felhasználás szempontjából (műveletek végzése, Grafana diagramban megjelenítés) talán jobb lenne, de mivel a szenzor azonosítók lennének a mezőnevek, előre kellene definiálni az összes lehetséges MP mezőt hogy egy új MP esetén ne kelljen adatstruktúrát változtatni. Ez nem túl elegáns megoldás.
A View egyébként mindig a tartalmazza az összes adatot, azaz magától frissül?
Egyedi ID mezőt hogyan tudok ez esetben mellé tenni?Az említett Triggeres módszert nem ismerem, az mennyiben lenne más/jobb?
-
 rum-cajsz
őstag
rum-cajsz
őstag
Sziasztok, segítségeteket szeretném kérni.
Hogyan lehet egy SQL lekérdezést úgy elkészíteni hogy a magja csak egyszer szerepeljen, de a From-ban szereplő tábla 6 féle lehet és ezek mindegyikére le kell futnia, úgy hogy az eredmények Union-al legyenek összefűzve.
A magban is van két From, melyeket Join-al fűzök össze (tábla párok).
Azaz van egy lekérdezésem amely két tábla adatait összesíti Join-al (ez működik is, változókban van a tábla pár neve), és ezt szeretném összesen 6 tábla párra automatikusan lefuttatni, az eredményeket pedig Unionnal összefűzni.
Hogyan lehet ezt SQL-ben (MariaDB) megtenni?Nem ismerem a MariaDB lehetőségeit de én ezt úgy oldanám meg, hogy van egy function, amiben egy olyan kurzor van, ami a felolvasandó táblákon megy végig, a belseje pedig végrehajtja a lekérdezést a paraméterként kapott táblán, és egy record típusú OUT változóban gyűjti a dolgokat összegezve, alternatív megoldás, hogy egy külső táblába insertája a gyűjtött adatokatl. Ezt Postresben és Oracle-ben dinamikus query-nek hívják.
De ennek a megoldásnak elég komoly limitáció vannak és nagyon nem mindegy, hogy mennyi rekordon akarsz dolgozni. Mennyi recordot vársz eredménynek.
Ha jól olvasom, szenzorok adatait akarod összegezni, amire sokkal egyszerűbb és tartósabb megoldás a többek által javasolt triggeres módszer.
Arra is oda kell figyelni, hogy az adatbázisban ha elszaporodnak a táblák, az tud tárolási és működési kockázat lenni. Nem tudom hány szenzorról beszélünk, de mondjuk százezres nagyságrendnél az általad elképzelt bármelyik működés használhatatlan lesz. -
Magnat
veterán
Akkor kell írni egy tárolt eljárást, ami a szenzorokból érkező adatokat kiegészíti egy szenzor azonosítóval és egy táblába insert-álja bizonyos időközőnként az összes szenzor adatait. A duplikált betöltés érdekében a datetime, counter, sensorid mezők összevonásával képeztek egy egyedi azonosítót, amire vizsgáltok betöltéskor, hogy ugyannak a szenzornak ugyanazon adata ne töltősldhessen be többször.
Ha új szenzor kerül a rendszerbe, akkor csak ezen töltő eljárást kell kiegészíteni az új szenzor táblájával és id-jával.
Így egy táblában lesz historikusan az összes szenzor adata és csak a töltést kell időzíteni automatikus futásra.Akkor már inkább triggerekkel, insertre insertálni a közös táblába is, törlésre (ha van) törlést csinálni a közösre is és akkor mindig szinkronban lesz ... vagy egyszerűen írni egy view-t, ami megcsinálja az union-t és akkor abban lehet keresgélni.
-
Jim74
nagyúr
Ezt biztosan nem csinálnám, mert ebből orbitális katyvasz lesz a végén.
Ha mindenáron ilyen elhibázott adatszerkezetet kell csinálni, akkor valami szabályrendszert csinálnék (fogalmam sincs, hogy a mariadb vagy a mysql tud-e ilyet, a postgresql tud), hogy ha insert történik az egyedi táblába, akkor párhuzamosan legyen egy insert az összesített táblába is. Ekkor normális adatbáziskezelő egy tranzakción belül elvégzi a két insertet és van rá reális esély, hogy nem szalad szét a két tábla.Továbbra is erőltetném azt az alapelvet, hogy adatbáziskezelésnél a redundancia rossz, menekülünk tőle, mint ördög a tömjénfüsttől.
Akkor én valamit félreértettem a feladatnál.
-
bambano
titán
Akkor kell írni egy tárolt eljárást, ami a szenzorokból érkező adatokat kiegészíti egy szenzor azonosítóval és egy táblába insert-álja bizonyos időközőnként az összes szenzor adatait. A duplikált betöltés érdekében a datetime, counter, sensorid mezők összevonásával képeztek egy egyedi azonosítót, amire vizsgáltok betöltéskor, hogy ugyannak a szenzornak ugyanazon adata ne töltősldhessen be többször.
Ha új szenzor kerül a rendszerbe, akkor csak ezen töltő eljárást kell kiegészíteni az új szenzor táblájával és id-jával.
Így egy táblában lesz historikusan az összes szenzor adata és csak a töltést kell időzíteni automatikus futásra.Ezt biztosan nem csinálnám, mert ebből orbitális katyvasz lesz a végén.
Ha mindenáron ilyen elhibázott adatszerkezetet kell csinálni, akkor valami szabályrendszert csinálnék (fogalmam sincs, hogy a mariadb vagy a mysql tud-e ilyet, a postgresql tud), hogy ha insert történik az egyedi táblába, akkor párhuzamosan legyen egy insert az összesített táblába is. Ekkor normális adatbáziskezelő egy tranzakción belül elvégzi a két insertet és van rá reális esély, hogy nem szalad szét a két tábla.Továbbra is erőltetném azt az alapelvet, hogy adatbáziskezelésnél a redundancia rossz, menekülünk tőle, mint ördög a tömjénfüsttől.
-
Jim74
nagyúr
Akkor kell írni egy tárolt eljárást, ami a szenzorokból érkező adatokat kiegészíti egy szenzor azonosítóval és egy táblába insert-álja bizonyos időközőnként az összes szenzor adatait. A duplikált betöltés érdekében a datetime, counter, sensorid mezők összevonásával képeztek egy egyedi azonosítót, amire vizsgáltok betöltéskor, hogy ugyannak a szenzornak ugyanazon adata ne töltősldhessen be többször.
Ha új szenzor kerül a rendszerbe, akkor csak ezen töltő eljárást kell kiegészíteni az új szenzor táblájával és id-jával.
Így egy táblában lesz historikusan az összes szenzor adata és csak a töltést kell időzíteni automatikus futásra. -
bambano
titán
Szerintem érdemes az ilyet jó tanács hatására minél előbb meglépni, mintsem összeboruljon és kényszerből időlimit alatt átfaragni.
YMMV. -
martonx
veterán
Hogy ez mekkora butaság volt, de már mindegy.

-
fjanni
tag
Mert szenzorokkal gyűjtünk mérési pontokról adatokat (kb. 200-nál tartunk és folyamatosan bővül) és annak idején úgy lett felépítve az adatstruktúra hogy minden szenzor adata külön táblába megy és minden táblának ugyanaz a szintaktikája (datetime, counter). Ezen nem tudok változtatni.
-
bambano
titán
Sziasztok, segítségeteket szeretném kérni.
Hogyan lehet egy SQL lekérdezést úgy elkészíteni hogy a magja csak egyszer szerepeljen, de a From-ban szereplő tábla 6 féle lehet és ezek mindegyikére le kell futnia, úgy hogy az eredmények Union-al legyenek összefűzve.
A magban is van két From, melyeket Join-al fűzök össze (tábla párok).
Azaz van egy lekérdezésem amely két tábla adatait összesíti Join-al (ez működik is, változókban van a tábla pár neve), és ezt szeretném összesen 6 tábla párra automatikusan lefuttatni, az eredményeket pedig Unionnal összefűzni.
Hogyan lehet ezt SQL-ben (MariaDB) megtenni?Ezzel nekem az lenne a kérdésem, hogyha hat táblád van, ami egyforma és uniont csinálsz belőle, akkor miért nem egy táblában van minden adat?
-
fjanni
tag
Én is valami hasonlóban gondolkodtam.
Mivel ciklust hagyományos értelemben nem lehet kezelni az SQL-ben tudtommal, ezért egy eljárás használata jó megoldás lehet.
Az eljárás törzsébe teszem a mag lekérdezést, CALL -al definiálom a tábla párokat és mindegyiket meghívom. Ha lesz új táblapár akkor azt egyszerűen utánaírom.Tehát valahogy így:
DELIMITER//
CREATE or REPLACE PROCEDURE cyle_sum(IN kiln1 VARCHAR(50), IN kiln2 VARCHAR(50))BEGIN
WITH
Q1 AS (
törzs lekérdezés
FROM adatbázisnév.$kiln1
),
Q2 AS (
törzs lekérdezés
FROM adatbázisnév.$kiln2
)
SELECT *
FROM Q1
JOIN Q2 ....
ENDCALL cycle_sum(tablename1,tablename2)
UNION
CALL cycle_sum(tablename3,tablename4)Ebben több dolog van amiben bizonytalan vagyok:
- lehet-e így hivatkozni a változónévre a magban lévő FROM-ban
- ha össze akarok fűzni eredményeket akkor azt az UNION-al így kell-e megtennem
ez így lefut-e a Grafana-ban -
fjanni
tag
Sziasztok, segítségeteket szeretném kérni.
Hogyan lehet egy SQL lekérdezést úgy elkészíteni hogy a magja csak egyszer szerepeljen, de a From-ban szereplő tábla 6 féle lehet és ezek mindegyikére le kell futnia, úgy hogy az eredmények Union-al legyenek összefűzve.
A magban is van két From, melyeket Join-al fűzök össze (tábla párok).
Azaz van egy lekérdezésem amely két tábla adatait összesíti Join-al (ez működik is, változókban van a tábla pár neve), és ezt szeretném összesen 6 tábla párra automatikusan lefuttatni, az eredményeket pedig Unionnal összefűzni.
Hogyan lehet ezt SQL-ben (MariaDB) megtenni? -
bambano
titán
Sziasztok!
Egy PostgreSQL-es kérdésem lenne, amin már régóta agyalok, mi lenne a megfelelő megoldás.
- Adott egy - nem túl bonyolult - függvény, ami egy táblából dolgozik a lekérdezéshez és nagyon gyakran, 0,5 másodpercenként meg van hívva, tehát nagyon fontos, hogy igen gyors legyen (ez meg is valósul, tényleg nagyon gyors).
- Ennek a táblának a tartalma dinamikusan változik, 20 másodpercenként frissül és alapvetően elég kevés rekordot tartalmaz pont azért, hogy gyors legyen.
- A kérdés az, hogy milyen megoldással frissüljön ennek a táblának a tartalma úgy, hogy ne akadályozza a függvény futását, amely ezt a táblát használja.
- 1. megoldás: a frissítés abból áll, hogy először TRUNCATE-elem a táblátTRUNCATE TABLE tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
- 2. megoldás:DELETE FROM tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;Ezt a két lépést úgy akarom megoldani, hogy egy blokkban fusson le, tehát egy függvénybe teszem bele.
Fontos kérdés, hogy mi van, ha éppen akkor hívódik meg a függvényem, ami a táblát használja, amikor éppen a frissítő függvény (truncate/delete, majd insert) fut?
Előállhat olyan helyzet, hogy épp üres táblát használ a függvényem?Egyrészt lehet tranzakcióval szeparálni.
Másrészt csinálhatsz verziózott adatokat.
Hozzáadsz egy verzió mezőt, minden adatbetöltésnél egy új verziószámot írsz bele, és a tranzakció végén inkrementálod az aktuális verzió mezőt.Tudomásom szerint a postgresnek nincs in-memory táblája, ramdiszkre lehet tablespace-t rakni.
Vagy erre a táblára használhatsz másik adatbáziskezelőt, ami erre van optimalizálva.
-
Magnat
veterán
-
martonx
veterán
Jaja, csak ötleteltem, ha már ennyire gyorsan változó adatokról van szó. Az egész rendszer ismerete nélkül, nekem látatlanban ez az egész inkább architekturális hibának tűnik, mintsem megoldandó problémának.
-
Magnat
veterán
-
martonx
veterán
Sziasztok!
Egy PostgreSQL-es kérdésem lenne, amin már régóta agyalok, mi lenne a megfelelő megoldás.
- Adott egy - nem túl bonyolult - függvény, ami egy táblából dolgozik a lekérdezéshez és nagyon gyakran, 0,5 másodpercenként meg van hívva, tehát nagyon fontos, hogy igen gyors legyen (ez meg is valósul, tényleg nagyon gyors).
- Ennek a táblának a tartalma dinamikusan változik, 20 másodpercenként frissül és alapvetően elég kevés rekordot tartalmaz pont azért, hogy gyors legyen.
- A kérdés az, hogy milyen megoldással frissüljön ennek a táblának a tartalma úgy, hogy ne akadályozza a függvény futását, amely ezt a táblát használja.
- 1. megoldás: a frissítés abból áll, hogy először TRUNCATE-elem a táblátTRUNCATE TABLE tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
- 2. megoldás:DELETE FROM tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;Ezt a két lépést úgy akarom megoldani, hogy egy blokkban fusson le, tehát egy függvénybe teszem bele.
Fontos kérdés, hogy mi van, ha éppen akkor hívódik meg a függvényem, ami a táblát használja, amikor éppen a frissítő függvény (truncate/delete, majd insert) fut?
Előállhat olyan helyzet, hogy épp üres táblát használ a függvényem?inmemory tábla esetleg? Egyébként biztos SQL szinten kellene ezeket a gyorsan változó adatokat kezelni?
-
Magnat
veterán
Szia,
nem ismerem a PostgreSQL-t, de igent tippelnék, sőt, mivel az insert elvileg row exclusive lockol (tehát nem a teljes táblát) az is lehet, h a rekordok fele már be lesz szúrva amikor a fv lefut, a többi meg még nem ...
BEGIN;
TRUNCATE TABLE tábla;
LOCK TABLE tábla IN EXCLUSIVE MODE;
INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
COMMIT;Én vhogy így csinálnám, nyilván ha a fv éppen akkor fut rá amikor ez történik, akkor egy picit várni fog. (Már ha fontos, h üres táblára vagy az insert közepén ne fusson le)
Illetve a truncate elvileg gyorsabb mint a delete, szóval amiatt is így használnám.
Sorry, a lock table a truncate elé kerül:
BEGIN;
LOCK TABLE tábla IN EXCLUSIVE MODE;
TRUNCATE TABLE tábla;
INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
COMMIT; -
Magnat
veterán
Sziasztok!
Egy PostgreSQL-es kérdésem lenne, amin már régóta agyalok, mi lenne a megfelelő megoldás.
- Adott egy - nem túl bonyolult - függvény, ami egy táblából dolgozik a lekérdezéshez és nagyon gyakran, 0,5 másodpercenként meg van hívva, tehát nagyon fontos, hogy igen gyors legyen (ez meg is valósul, tényleg nagyon gyors).
- Ennek a táblának a tartalma dinamikusan változik, 20 másodpercenként frissül és alapvetően elég kevés rekordot tartalmaz pont azért, hogy gyors legyen.
- A kérdés az, hogy milyen megoldással frissüljön ennek a táblának a tartalma úgy, hogy ne akadályozza a függvény futását, amely ezt a táblát használja.
- 1. megoldás: a frissítés abból áll, hogy először TRUNCATE-elem a táblátTRUNCATE TABLE tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
- 2. megoldás:DELETE FROM tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;Ezt a két lépést úgy akarom megoldani, hogy egy blokkban fusson le, tehát egy függvénybe teszem bele.
Fontos kérdés, hogy mi van, ha éppen akkor hívódik meg a függvényem, ami a táblát használja, amikor éppen a frissítő függvény (truncate/delete, majd insert) fut?
Előállhat olyan helyzet, hogy épp üres táblát használ a függvényem?Szia,
nem ismerem a PostgreSQL-t, de igent tippelnék, sőt, mivel az insert elvileg row exclusive lockol (tehát nem a teljes táblát) az is lehet, h a rekordok fele már be lesz szúrva amikor a fv lefut, a többi meg még nem ...
BEGIN;
TRUNCATE TABLE tábla;
LOCK TABLE tábla IN EXCLUSIVE MODE;
INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
COMMIT;Én vhogy így csinálnám, nyilván ha a fv éppen akkor fut rá amikor ez történik, akkor egy picit várni fog. (Már ha fontos, h üres táblára vagy az insert közepén ne fusson le)
Illetve a truncate elvileg gyorsabb mint a delete, szóval amiatt is így használnám.
-
 kw3v865
senior tag
kw3v865
senior tag
Sziasztok!
Egy PostgreSQL-es kérdésem lenne, amin már régóta agyalok, mi lenne a megfelelő megoldás.
- Adott egy - nem túl bonyolult - függvény, ami egy táblából dolgozik a lekérdezéshez és nagyon gyakran, 0,5 másodpercenként meg van hívva, tehát nagyon fontos, hogy igen gyors legyen (ez meg is valósul, tényleg nagyon gyors).
- Ennek a táblának a tartalma dinamikusan változik, 20 másodpercenként frissül és alapvetően elég kevés rekordot tartalmaz pont azért, hogy gyors legyen.
- A kérdés az, hogy milyen megoldással frissüljön ennek a táblának a tartalma úgy, hogy ne akadályozza a függvény futását, amely ezt a táblát használja.
- 1. megoldás: a frissítés abból áll, hogy először TRUNCATE-elem a táblátTRUNCATE TABLE tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;
- 2. megoldás:DELETE FROM tábla;
majd INSERT-álom a sorokat:INSERT INTO tábla SELECT * FROM másik_tábla WHERE feltétel;Ezt a két lépést úgy akarom megoldani, hogy egy blokkban fusson le, tehát egy függvénybe teszem bele.
Fontos kérdés, hogy mi van, ha éppen akkor hívódik meg a függvényem, ami a táblát használja, amikor éppen a frissítő függvény (truncate/delete, majd insert) fut?
Előállhat olyan helyzet, hogy épp üres táblát használ a függvényem? -
Magnat
veterán
Tanulási vagy munkacél? Utóbbira a licensz lehet probléma.
Előbbire:
- nagyon alapokra az sqlzoo.net oldalon az alap sql-t elég jól meg lehet tanulni.
- ha már kicsit komolyabb tanulás a cél, akkor a Microsoftnak az sql server management studio elérhető. Van hozzá egy egész jó példa adatbázis is, amit adventureworks néven találsz meg. (Telepítés kicsit ijesztő lehet.)
- ha youtuberek is beleférnek ide, akkor Pinal Dave és Bert Wagner egész jó videókat készítettek már.Transact (MS) Sql Server Express üzleti felhasználásra is free.
-
martonx
veterán
-
Louro
őstag
Tanulási vagy munkacél? Utóbbira a licensz lehet probléma.
Előbbire:
- nagyon alapokra az sqlzoo.net oldalon az alap sql-t elég jól meg lehet tanulni.
- ha már kicsit komolyabb tanulás a cél, akkor a Microsoftnak az sql server management studio elérhető. Van hozzá egy egész jó példa adatbázis is, amit adventureworks néven találsz meg. (Telepítés kicsit ijesztő lehet.)
- ha youtuberek is beleférnek ide, akkor Pinal Dave és Bert Wagner egész jó videókat készítettek már. -
shipfolt
kezdő
Akkor Libreoffice Base se jo?
Mit tudok hasznalni, amit egyszeru telepiteni es hasznalni egy PC-n offline modban es amihez nem kell tucatnyi mas minden, mint mysql-hez?
-
sztanozs
veterán
Ja, hogy azt o akkor irta, amikor SQL-nek meg hire-hamva se volt.
Jol sejtettem, hogy hogy nem SQL-lel, hanem adatkezelessel van problemam
sztanozs:
Nekem azt tanitottak, hogy SQL-ben tablak osszekapcsolasa reven lehet urlapok letrehozasa reven adatokat kezelni. (Access)Most utana olvasva lattam, hogy van egy kozvetlen modszer is, amikor SQL-ben futtathato programokat kell irni, es feltetelek reven nagyon egyszeruen lehet adatokat modositani.
Ezt veszelyesnek tartom, mert barmikor barmilyen adatot felul lehet irni, nem is marad nyoma, hogy ki es mikor csinalta, mert a program csak addig el, amig az illeto begepeli es lefuttatja, nincs elmentve, mint egy urlap.Szerintem aki neked Access-t tanitott "adatbazis" cimen, annak nem volt fogalma arrol, hogy az Access kb annyira adatbazis-kezelo, mint ahogy egy kockas fuzet Excel workbook...
-
bambano
titán
Ja, hogy azt o akkor irta, amikor SQL-nek meg hire-hamva se volt.
Jol sejtettem, hogy hogy nem SQL-lel, hanem adatkezelessel van problemamsztanozs:
Nekem azt tanitottak, hogy SQL-ben tablak osszekapcsolasa reven lehet urlapok letrehozasa reven adatokat kezelni. (Access)Most utana olvasva lattam, hogy van egy kozvetlen modszer is, amikor SQL-ben futtathato programokat kell irni, es feltetelek reven nagyon egyszeruen lehet adatokat modositani.
Ezt veszelyesnek tartom, mert barmikor barmilyen adatot felul lehet irni, nem is marad nyoma, hogy ki es mikor csinalta, mert a program csak addig el, amig az illeto begepeli es lefuttatja, nincs elmentve, mint egy urlap.Nem adatkezeléssel, hanem algoritmus hiányosságokkal van bajod. Igen, azt a könyvet akkor írta, amikor az első sql alapú adatbáziskezelés már két éves volt.
-
shipfolt
kezdő
Ja, hogy azt o akkor irta, amikor SQL-nek meg hire-hamva se volt.
Jol sejtettem, hogy hogy nem SQL-lel, hanem adatkezelessel van problemamsztanozs:
Nekem azt tanitottak, hogy SQL-ben tablak osszekapcsolasa reven lehet urlapok letrehozasa reven adatokat kezelni. (Access)Most utana olvasva lattam, hogy van egy kozvetlen modszer is, amikor SQL-ben futtathato programokat kell irni, es feltetelek reven nagyon egyszeruen lehet adatokat modositani.
Ezt veszelyesnek tartom, mert barmikor barmilyen adatot felul lehet irni, nem is marad nyoma, hogy ki es mikor csinalta, mert a program csak addig el, amig az illeto begepeli es lefuttatja, nincs elmentve, mint egy urlap. -
sztanozs
veterán
Bambanonek kudos, hogy leirta, de szvsz faszerkezet - illetve rekurziv struktura - SQL megvalositasa nem akkora raketatudomany, mint aminek latszik. Legfeljebb csak nem talakoztal meg vele...
-
shipfolt
kezdő
ID
Elozo_id
megnevezés
leiras
hatarido
lezart?nem kell két különböző sort egy rekordba rakni. a rekord szerkezet az adatod szerkezetével kell megegyezzen.
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Amikor le akarod zárni a feladatot, akkor meg kell nézni, hogy az a feladat, amelyik az elozo_id-ben van, le van-e zárva.
Szerintem trigger erre felesleges.
Bombano!
Olyan megoldast irtal, amit egyetlen konyvben sem talaltam.
Nem akarsz konyvet - vagy blogot - irni "Ami a SQL tankonyvekbol kimaradt" cimmel?
-
pch
senior tag
Wow, beinditottam a forumot.

Koszonom a javaslatokat, harom problemam van ezekkel.
Az elso, hogy meg erosen kezdo vagyok, a triggerekrol kosza hirek erejeig hallottam.
(Az adatbazis kiepitesenel lecovekeltem, mert furcsasagokat lattam kulonbozo konyvekben, de ezt most hagyjuk.)A masodik az "elmelet es gyakorlat" utkozese:
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Ez a gyakorlatban nem igy mukodik, hanem harom lepesben megy:
Eloszor belapatolod a feladatokat hevenyeszett hataridokkel,
majd jon a felulvizsgalat, hogy mennyi feladat van es mennyi ido,
majd jonnek a kivalasztasok, hogy miket lehet gyorsan megoldani, vagy melyek valoban fontosak, vagy melyiknel van rovid hatarido, ezeket elore veszik.
Csak ekkor jon a felulvizsgalat, hogy milyen kapcsolatok vannak kulonbozo szempontok alapjan, es ha ez a fontos, akkor ehhez mely masik szukseges vagy megoldhato, tehat a prioritasok erosen valtoznak hangulatok vagy kotelezettsegek valtozasa miatt.
A harmadik, amivel bajban vagyok az az, hogy ezt a megoldast a gyakorlatban hogyan tudom megoldani?
Beiraskor egyszeru, az "elozo ID" mezo uresen marad (lehet null feltetel kell ra)
De, amikor be kell allitani, akkor valahogy ra kell keresni minimum az "ID + megnevezes" mezokre, es nem latok arra lehetoseget, hogy ugyanabban a tablaban keressek, aminek az egyik rekordjat megnyitottam szerkesztesre.Ezt hogyan lehet megoldani?
Ha fontos, akkor Access 2007-en kezdtem tanulgatni, mert annal konnyu a tablakat beallitani es a kozottuk levo kapcsolatokat vizualisan megjeleniteni, nemreg kezdtem a Libreoffice Base-t hasznalni.
Én az alábbit csinálnám:
ID: auto increment
Feladat: varchar(255)
Leírás: text
Határidő: date
Kész: enum('n';'i')
Sor: int(10)
Függ: int(10) NULLBeírod a feladatot. Ha rendezni kell akkor a sor mondja meg hol van (tizessével szoktam számolni, de ha fel kell cserélni 2 sort akkor ugye update és kész)
A függ-be ha van érték akkor az az adott ID-jű feladattól függ, ha nincs akkor nincs függése.
A függésre nézz olyan példát ahol egy menü van táblázatba. Na ez is olyan Főmenű + almenű. Csak itt ugye feladat lezárása előtt le kell kérdezni, hogy a függő feladat (aminek ugye tudjuk az ID-jét) kész-e. Ha igen mehet a feladat rögzítése benne a függő ID-vel. -
Magnat
veterán
Wow, beinditottam a forumot.
Koszonom a javaslatokat, harom problemam van ezekkel.
Az elso, hogy meg erosen kezdo vagyok, a triggerekrol kosza hirek erejeig hallottam.
(Az adatbazis kiepitesenel lecovekeltem, mert furcsasagokat lattam kulonbozo konyvekben, de ezt most hagyjuk.)A masodik az "elmelet es gyakorlat" utkozese:
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Ez a gyakorlatban nem igy mukodik, hanem harom lepesben megy:
Eloszor belapatolod a feladatokat hevenyeszett hataridokkel,
majd jon a felulvizsgalat, hogy mennyi feladat van es mennyi ido,
majd jonnek a kivalasztasok, hogy miket lehet gyorsan megoldani, vagy melyek valoban fontosak, vagy melyiknel van rovid hatarido, ezeket elore veszik.
Csak ekkor jon a felulvizsgalat, hogy milyen kapcsolatok vannak kulonbozo szempontok alapjan, es ha ez a fontos, akkor ehhez mely masik szukseges vagy megoldhato, tehat a prioritasok erosen valtoznak hangulatok vagy kotelezettsegek valtozasa miatt.
A harmadik, amivel bajban vagyok az az, hogy ezt a megoldast a gyakorlatban hogyan tudom megoldani?
Beiraskor egyszeru, az "elozo ID" mezo uresen marad (lehet null feltetel kell ra)
De, amikor be kell allitani, akkor valahogy ra kell keresni minimum az "ID + megnevezes" mezokre, es nem latok arra lehetoseget, hogy ugyanabban a tablaban keressek, aminek az egyik rekordjat megnyitottam szerkesztesre.Ezt hogyan lehet megoldani?
Ha fontos, akkor Access 2007-en kezdtem tanulgatni, mert annal konnyu a tablakat beallitani es a kozottuk levo kapcsolatokat vizualisan megjeleniteni, nemreg kezdtem a Libreoffice Base-t hasznalni.
Szia,
"De, amikor be kell allitani, akkor valahogy ra kell keresni minimum az "ID + megnevezes" mezokre, es nem latok arra lehetoseget, hogy ugyanabban a tablaban keressek, aminek az egyik rekordjat megnyitottam szerkesztesre." - no offense, de ez nem igazán sql kérdés, ez már annak az eszköznek a funkcionalitásának a függvénye, amiben a megoldást fejleszted. Sql kliens-szerver kontextusban egyébként sincs olyan, h valamit megnyitottál szerkesztésre, mármint létezik rekord és tábla lock is összetett tranzakcióknál, de ez amit leírtál a valóságban sztem tipikusan úgy néz ki, h kiadsz egy selectet bizonyos filterrel, amivel listázod a feladatokat, aztán amikor az egyiknek ki akarod jelölni a szülőjét, akkor adott kritérium szerint kiadsz egy másik selectet ez esetben ugyanarra a táblára valamilyen más szűréssel, aztán ha kiválasztotta a user, h melyik lesz a szülője, akkor kiadsz egy update-ot a megfelelő rekordra és beírod a kiválasztott szülő rekord id-ját a megfelelő mezőbe.
Ezen 3 művelet közben nem lesz megnyitva szerkesztésre az adott rekord (ideális megközelítésben legalábbis semmiképpen), hanem az sql szerver közben teszi a dolgát és amikor kiadod az update-ot a megfelelő rekordra, akkor megfogja és megcsinálja.
Triggerelést én is elengedném ezzel a problémával kapcsolatosan. -
shipfolt
kezdő
ID
Elozo_id
megnevezés
leiras
hatarido
lezart?nem kell két különböző sort egy rekordba rakni. a rekord szerkezet az adatod szerkezetével kell megegyezzen.
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Amikor le akarod zárni a feladatot, akkor meg kell nézni, hogy az a feladat, amelyik az elozo_id-ben van, le van-e zárva.
Szerintem trigger erre felesleges.
Wow, beinditottam a forumot.
Koszonom a javaslatokat, harom problemam van ezekkel.
Az elso, hogy meg erosen kezdo vagyok, a triggerekrol kosza hirek erejeig hallottam.
(Az adatbazis kiepitesenel lecovekeltem, mert furcsasagokat lattam kulonbozo konyvekben, de ezt most hagyjuk.)A masodik az "elmelet es gyakorlat" utkozese:
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Ez a gyakorlatban nem igy mukodik, hanem harom lepesben megy:
Eloszor belapatolod a feladatokat hevenyeszett hataridokkel,
majd jon a felulvizsgalat, hogy mennyi feladat van es mennyi ido,
majd jonnek a kivalasztasok, hogy miket lehet gyorsan megoldani, vagy melyek valoban fontosak, vagy melyiknel van rovid hatarido, ezeket elore veszik.
Csak ekkor jon a felulvizsgalat, hogy milyen kapcsolatok vannak kulonbozo szempontok alapjan, es ha ez a fontos, akkor ehhez mely masik szukseges vagy megoldhato, tehat a prioritasok erosen valtoznak hangulatok vagy kotelezettsegek valtozasa miatt.
A harmadik, amivel bajban vagyok az az, hogy ezt a megoldast a gyakorlatban hogyan tudom megoldani?
Beiraskor egyszeru, az "elozo ID" mezo uresen marad (lehet null feltetel kell ra)
De, amikor be kell allitani, akkor valahogy ra kell keresni minimum az "ID + megnevezes" mezokre, es nem latok arra lehetoseget, hogy ugyanabban a tablaban keressek, aminek az egyik rekordjat megnyitottam szerkesztesre.Ezt hogyan lehet megoldani?
Ha fontos, akkor Access 2007-en kezdtem tanulgatni, mert annal konnyu a tablakat beallitani es a kozottuk levo kapcsolatokat vizualisan megjeleniteni, nemreg kezdtem a Libreoffice Base-t hasznalni.
-
bambano
titán
ID
Elozo_id
megnevezés
leiras
hatarido
lezart?nem kell két különböző sort egy rekordba rakni. a rekord szerkezet az adatod szerkezetével kell megegyezzen.
Ha elkezded bontani a feladatot, berakod a fő feladatot a táblázatba, megjegyzed az id-jét, és amikor a fő feladat alfeladatait rakod bele, akkor az elozo_id mezőbe beleírod a megjegyzett id-t.
Amikor le akarod zárni a feladatot, akkor meg kell nézni, hogy az a feladat, amelyik az elozo_id-ben van, le van-e zárva.
Szerintem trigger erre felesleges.
-
Louro
őstag
Én úgynevezett triggerben gondolkodnék elsőre.
bambano iránya tényleg jó, hidd el. Legyen egy új oszlopod, aminek a neve Esemény. Az egyszerűség kedvéért számokkal érdemes jelölni, de ha kicsi a tábla és van dögivel hely és kakaó, akkor szövegesen is beírhatod.
Szóval ez úgy nézne ki, hogy tegyük fel az első eseményed: létrehozás. Azaz itt létrehozod a feladatot (ID). Második esemény lehet mondjuk a feladatkiosztás. Itt legyen az a feltétel, hogy ha a Hatarido kitöltésre kerül.
CREATE TRIGGER séma.triggerNeve
ON séma.táblaNeve
AFTER UPDATE AS
BEGIN
SET NOCOUNT ON;
IF UPDATE (Hatarido)
BEGIN
UPDATE séma.táblaNeve
SET Esemeny = 'Feladatkiosztás'
FROM séma.táblaNeve S
INNER JOIN Inserted I
ON S.ID = I.ID
END
ENDMásik gondolatom a feladatot sokadszor olvasva, hogy azt akarod, hogy van a táblád és ha másik táblában rögzítenek Eseményt, akkor az a tábládon hajtson végre valamit. Igazából itt is triggert látom a legjobbnak. Csak akkor annyiban módosul a fenti script, hogy a 2. sorban, a tábla neve a másik táblára mutasson és a belső update-nél is az ON-nál érdemes figyelni a kötésre. Az Inserted-et úgy képzeld el, mint egy átmeneti tábla, amiben a 2. sorban hivatkozott tábla adott rekordja van (, amire elsül a trigger). Ilyenkor a legfrissebb adatokat tartalmazza. Ennek párja a "deleted", ami a frissítés előtti állapotot tárolja. Akadnak helyzetek, amikor vagy ez vagy az kell. De többnyire inkább a friss kell. Ha nem jegyzed meg, akkor általánosságban inkább használd az Inserted átmeneti táblát.
Szóval úgy érzem triggereket fogsz gyártani
(Max jönnek az okosabbak és mutatnak jobb megoldást. Munka után, agymosottan ezt tudtam segíteni.)Extra javaslat: Ha 4-5 lépés van a folyamatban, akkor érdemes eltárolni az időpontot és a felhasználót. Ha több, akkor lehet egy táblát csinálnék, hogy tároljuk el a lépést, időpontot és a nevet. Később jól jöhet.
-
shipfolt
kezdő
Ezt nem ertem
Megmutatnad egy peldaban nekem?feladat tabla:
==========
ID
Megnevezes
Leiras
Hatarido
-------
+ ID_elozo ????Ket kulonbozo sort, rekordot kell egy rekordba tenni?
Utana pedig feltetelkent kell kezelni sql utasitasban?
-
bambano
titán
Hatha megse halott a lista es van egy alvo adatbazis guru a kornyeken...
Hogyan lehet relacios adatbazisban "esemeny-lancokat" letrehozni?
Van pl. egy egyszeru "feladat" tabla, (ID, Megnevezes, Leiras, Hatarido) egy ideje szepen tudom kezelni SQL-bol, konnyu letrehozni, modositani es torolni a kulonbozo tennivalokat.
DE hogyan lehet olyan feladatot letrehozni, ami csak egy masik feladat befejezese utan lesz megoldhato?
Biztosra veszem, hogy kell egy masik tabla, amiben jelezni kell, hogy melyik legyen az elso, es melyik a kovetkezo.
DE mindket rekord ugyanabban a "feladat" tablaban van, es akarhany konyvet, leirast neztem vegig, ilyen peldat sehol se lattam.
Nem kell másik tábla, a táblába beleraksz egy mezőt, amibe beleírod annak a feladatnak az azonosítóját, aminek be kell fejeződnie ez előtt a feladat előtt.
Gyakorlatilag egy fa gráfot kell tárolni a szülőre mutató azonosítóval.
-
shipfolt
kezdő
Hatha megse halott a lista es van egy alvo adatbazis guru a kornyeken...
Hogyan lehet relacios adatbazisban "esemeny-lancokat" letrehozni?
Van pl. egy egyszeru "feladat" tabla, (ID, Megnevezes, Leiras, Hatarido) egy ideje szepen tudom kezelni SQL-bol, konnyu letrehozni, modositani es torolni a kulonbozo tennivalokat.
DE hogyan lehet olyan feladatot letrehozni, ami csak egy masik feladat befejezese utan lesz megoldhato?
Biztosra veszem, hogy kell egy masik tabla, amiben jelezni kell, hogy melyik legyen az elso, es melyik a kovetkezo.
DE mindket rekord ugyanabban a "feladat" tablaban van, es akarhany konyvet, leirast neztem vegig, ilyen peldat sehol se lattam.
-
 Panhard
tag
Panhard
tag
Sziasztok! Csak érdekesség képpen írom, már megoldódott a probléma: Egy laptopon fut a xampp webszerver és adatbázis. Egyik napról a másikra nem volt hozzáférésem az adatbázishoz. phpmyadminal sem, és HeidiSQL-el sem tudtam bejelentkezni root felhasználóval sem. A my.ini-be beírtam a "skip-grant-tables" paramétert, így már le tudtam menteni az adatbázist, de csak az xampp újratelepítés után lett újra használható. Ismeri valaki ezt a problémát? Van rá valami orvosság?
-
Louro
őstag
Sziasztok!
T-SQL, SQL Server 2016
Tegnap óta rágódok egy feladaton, hogy miképp lenne a leghatékonyabb megcsinálni. Lehet megmosolyogtató, de vannak buktató.
A végcél:
A nehézséget az okozza - , hogy elsősorban, hogy fafejű főnökök vannak, így kötött a forma -, hogy az oszlopnevek dátumok. Ezzel nem is lenne igazából bajom.
A. verzió:
Agyaltam rajta, hogy ennek a transzponáltját csináljam-e meg. Mondhatni egy SELECT és sok-sok aggregált függvénnyel könnyen előállnak az adatok egy lépésben. De van a riportban 3 sor, amiben ragaszkodnak a % jelhez. Ha ezt az aggregáltba beteszem, akkor az unpivot során, amikor a végleges formára hoznám, nem tudja feldolgozni, mert eltérő az adattípus.
A/1. verzió: amikor az aggregált számokat előállítom, mindent szöveggé alakítom és tudok unpivot-tal élni.
A/2. verzió: A speciális jelet kihagyom, majd a végleges nézetre hozáskor soronként végigiterálva megkeresem azt a 3 sort és betoldom a százalékjellel.B. verzió:
Ettől tartok, hogy überciki, de aztán lehet mégsem. Létrehozom a végleges formához a táblát. Mindig létrehozok egy új oszlopot a kívánt névvel és annyi update-et írok, amennyi sorom van. Így a speciális karakterek is könnyen kezelhetőek és módosítás/bővítés is talán átláthatóbb.Utálom a túlbonyolított, átláthatatlan kódokat. Ha kell, áldozok a performancia oltárán, mert nem több száz milliós táblákkal kell dolgozni szerencsére.
Bevallom az A/1. verzió most ugrott be, mikor elkezdtem írni. Ez tűnne a legideálisabbnak, mert az aggregált függvényekben ott lesz az üzleti logika ( SUM(CASE WHEN...)) ).
Esetleg valakinek valami javaslata?
Lemaradt, hogy az A/1 azért nem ad aggódásra okot, mert a végeredményt persze levél törzsébe kell kiküldeni. Szóval bármi lehet az adattípus.
-
Louro
őstag
Sziasztok!
T-SQL, SQL Server 2016
Tegnap óta rágódok egy feladaton, hogy miképp lenne a leghatékonyabb megcsinálni. Lehet megmosolyogtató, de vannak buktató.
A végcél:A nehézséget az okozza - , hogy elsősorban, hogy fafejű főnökök vannak, így kötött a forma -, hogy az oszlopnevek dátumok. Ezzel nem is lenne igazából bajom.
A. verzió:
Agyaltam rajta, hogy ennek a transzponáltját csináljam-e meg. Mondhatni egy SELECT és sok-sok aggregált függvénnyel könnyen előállnak az adatok egy lépésben. De van a riportban 3 sor, amiben ragaszkodnak a % jelhez. Ha ezt az aggregáltba beteszem, akkor az unpivot során, amikor a végleges formára hoznám, nem tudja feldolgozni, mert eltérő az adattípus.
A/1. verzió: amikor az aggregált számokat előállítom, mindent szöveggé alakítom és tudok unpivot-tal élni.
A/2. verzió: A speciális jelet kihagyom, majd a végleges nézetre hozáskor soronként végigiterálva megkeresem azt a 3 sort és betoldom a százalékjellel.B. verzió:
Ettől tartok, hogy überciki, de aztán lehet mégsem. Létrehozom a végleges formához a táblát. Mindig létrehozok egy új oszlopot a kívánt névvel és annyi update-et írok, amennyi sorom van. Így a speciális karakterek is könnyen kezelhetőek és módosítás/bővítés is talán átláthatóbb.Utálom a túlbonyolított, átláthatatlan kódokat. Ha kell, áldozok a performancia oltárán, mert nem több száz milliós táblákkal kell dolgozni szerencsére.
Bevallom az A/1. verzió most ugrott be, mikor elkezdtem írni. Ez tűnne a legideálisabbnak, mert az aggregált függvényekben ott lesz az üzleti logika ( SUM(CASE WHEN...)) ).
Esetleg valakinek valami javaslata?
-
Louro
őstag
-
pch
senior tag
Erre nem lenne célszerűbb írni egy before insert (Oracle) vagy instead of triggert (MS SQL) * ami azt csinálja, hogy ha már van fej_id, tetel_id, ar, kedv értékekkel sorod, akkor annak mennyiségét, értékét megnöveli az újonnan beszúrandó mennyiséggel, mennyiség*árral?
Ha meg nincs, akkor beszúrja az új sort?Mondjuk a táblákra aggatott triggerek nem szokták növelni a DB logika átláthatóságát
*: pontos szintaxisuk nekem sincs meg fejben.
Nem. Külön kell rögzíteni minden tételt, hiába ugyanaz (látszólag) és gombra kellene az azonosokat összerakni.
-
bambano
titán
Erre nem lenne célszerűbb írni egy before insert (Oracle) vagy instead of triggert (MS SQL) * ami azt csinálja, hogy ha már van fej_id, tetel_id, ar, kedv értékekkel sorod, akkor annak mennyiségét, értékét megnöveli az újonnan beszúrandó mennyiséggel, mennyiség*árral?
Ha meg nincs, akkor beszúrja az új sort?Mondjuk a táblákra aggatott triggerek nem szokták növelni a DB logika átláthatóságát
*: pontos szintaxisuk nekem sincs meg fejben.
alapadatok tábláját módosítani, az nekem nagyon büdös.
szerintem nem sql lekérdezéssel van itt baj, hanem a komplett algoritmus hibás. -
 nyunyu
félisten
nyunyu
félisten
Üdv!
Van egy tábla benne tételek.
Legyen rendelés a neve ( tetel_id, fej_id, menny, ar, kedv)
Szeretném őket groupolni és az összesítő szerint updatelni.
Azaz:
SELECT tetel_id, fej_jd, sum(menny), ar, kedv FROM rendeles WHERE fej_id=? GROUP BY tetel_id, ar, kedv
Ez a lekérdezés ugye pont ezt csinálja, hogyha azonos az ár és a kedvezmény összevonja a cikkeket.
Hogy tudom megcsinálni, hogy ennek a lekérdezés eredményét visszarakja a rendeles táblába, felülírva azt.
Gondoltam temp táblára, majd abba insert a fenti select majd delete a fej_id szerint majd megint instert és törölni a temp-ből utána.
De ez legalább 3 lekérés.
Van-e ennél jobb módszer?Köszi
Erre nem lenne célszerűbb írni egy before insert (Oracle) vagy instead of triggert (MS SQL) * ami azt csinálja, hogy ha már van fej_id, tetel_id, ar, kedv értékekkel sorod, akkor annak mennyiségét, értékét megnöveli az újonnan beszúrandó mennyiséggel, mennyiség*árral?
Ha meg nincs, akkor beszúrja az új sort?Mondjuk a táblákra aggatott triggerek nem szokták növelni a DB logika átláthatóságát
*: pontos szintaxisuk nekem sincs meg fejben.
-
Louro
őstag
Üdv!
Van egy tábla benne tételek.
Legyen rendelés a neve ( tetel_id, fej_id, menny, ar, kedv)
Szeretném őket groupolni és az összesítő szerint updatelni.
Azaz:
SELECT tetel_id, fej_jd, sum(menny), ar, kedv FROM rendeles WHERE fej_id=? GROUP BY tetel_id, ar, kedv
Ez a lekérdezés ugye pont ezt csinálja, hogyha azonos az ár és a kedvezmény összevonja a cikkeket.
Hogy tudom megcsinálni, hogy ennek a lekérdezés eredményét visszarakja a rendeles táblába, felülírva azt.
Gondoltam temp táblára, majd abba insert a fenti select majd delete a fej_id szerint majd megint instert és törölni a temp-ből utána.
De ez legalább 3 lekérés.
Van-e ennél jobb módszer?Köszi
Mivel egyszeri eset és nem rendszeres, igazából mindegy, hogy hány lépésben oldod meg. De, ha automatizálni kellene, akkor is temptáblákkal oldanám meg, hogy átlátható és könnyen értelmezhető legyen.
-
pch
senior tag
Üdv!
Van egy tábla benne tételek.
Legyen rendelés a neve ( tetel_id, fej_id, menny, ar, kedv)
Szeretném őket groupolni és az összesítő szerint updatelni.
Azaz:
SELECT tetel_id, fej_jd, sum(menny), ar, kedv FROM rendeles WHERE fej_id=? GROUP BY tetel_id, ar, kedv
Ez a lekérdezés ugye pont ezt csinálja, hogyha azonos az ár és a kedvezmény összevonja a cikkeket.
Hogy tudom megcsinálni, hogy ennek a lekérdezés eredményét visszarakja a rendeles táblába, felülírva azt.
Gondoltam temp táblára, majd abba insert a fenti select majd delete a fej_id szerint majd megint instert és törölni a temp-ből utána.
De ez legalább 3 lekérés.
Van-e ennél jobb módszer?Köszi
temporary táblával megoldva...
-
pch
senior tag
Üdv!
Van egy tábla benne tételek.
Legyen rendelés a neve ( tetel_id, fej_id, menny, ar, kedv)
Szeretném őket groupolni és az összesítő szerint updatelni.
Azaz:
SELECT tetel_id, fej_jd, sum(menny), ar, kedv FROM rendeles WHERE fej_id=? GROUP BY tetel_id, ar, kedv
Ez a lekérdezés ugye pont ezt csinálja, hogyha azonos az ár és a kedvezmény összevonja a cikkeket.
Hogy tudom megcsinálni, hogy ennek a lekérdezés eredményét visszarakja a rendeles táblába, felülírva azt.
Gondoltam temp táblára, majd abba insert a fenti select majd delete a fej_id szerint majd megint instert és törölni a temp-ből utána.
De ez legalább 3 lekérés.
Van-e ennél jobb módszer?Köszi
-
 Petya25
őstag
Petya25
őstag
-
Louro
őstag
Az a bajom, hogy ez egy eleve hiányosan érkező lista, és csak az érték nélküli mezőkbe kellene generálnom egyedi tartalmat. Ez a mező sajnos a fogadó táblában kulcs mező, üresen nem mehet be.
Esetleg szét tudom választani a listát töltött nem töltött ágra és az üres ágra identity-t tenni a betöltés előtt. Köszi.Akkor az alábbi nem lehet megoldás?
update [táblanév]
set [mező]= newid()
where [mező] is nullEz alfanumerikus. De az is jó, amit írtál, hogy ketté szedni az ETL folyamatot.
-
Petya25
őstag
Én eleve úgy szoktam mezőt létrehozni, hogy
create table [táblanév](
id bigint identity(1,1)
)Bár utólag is megoldható:
alter table [táblanév]
add id bigint identity(1,1)Ekkor 1-essel kezd és mindig eggyel növeli a mező értékét. Ha keletkezik egy új rekord, akkor megkapja a következő futószámot.
Remélem ez jó. A randommal az a bajom, hogy fontos-e az egyediség. Ha igen, akkor azt figyelni, hogy ki lett-e osztva az adott sorszám....De, ha nagyon beteg azonosító is jó, akkor:
alter table [táblanév]
add id varchar(1000)update [táblanév]
set id = newid()Ez elég random. A rand() függvénnyel meg generáltatsz egy véletlenszámot és azt írja be a mezőbe. Nem rekordonként generál egy számot. Ezért kaptad mindenhol ugyanazt.
Az a bajom, hogy ez egy eleve hiányosan érkező lista, és csak az érték nélküli mezőkbe kellene generálnom egyedi tartalmat. Ez a mező sajnos a fogadó táblában kulcs mező, üresen nem mehet be.
Esetleg szét tudom választani a listát töltött nem töltött ágra és az üres ágra identity-t tenni a betöltés előtt. Köszi. -
Louro
őstag
Én eleve úgy szoktam mezőt létrehozni, hogy
create table [táblanév](
id bigint identity(1,1)
)Bár utólag is megoldható:
alter table [táblanév]
add id bigint identity(1,1)Ekkor 1-essel kezd és mindig eggyel növeli a mező értékét. Ha keletkezik egy új rekord, akkor megkapja a következő futószámot.
Remélem ez jó. A randommal az a bajom, hogy fontos-e az egyediség. Ha igen, akkor azt figyelni, hogy ki lett-e osztva az adott sorszám....De, ha nagyon beteg azonosító is jó, akkor:
alter table [táblanév]
add id varchar(1000)update [táblanév]
set id = newid()Ez elég random. A rand() függvénnyel meg generáltatsz egy véletlenszámot és azt írja be a mezőbe. Nem rekordonként generál egy számot. Ezért kaptad mindenhol ugyanazt.
-
Petya25
őstag
MS SQL-ben egyedi kulcsot generálnék egy mezőbe, de így minden mezőbe ugyanaz kerül
Valami tipp?update tábla set mező = RAND()
-
Petya25
őstag
Köszönöm szuper, nem jöttem rá eddig, de így megtaláltam.
-
Louro
őstag
Valakinek lenne ötlete, hogy egy régi Visual Studio Toolbox-ait, hogy lehetne bekapcsolni egy újabb verzióban?
Nem gondolnám, hogy az új nem kezeli a régieket, ezekkel olvastam be fájlokat illetve exportáltam kifele tartalmat.
Hiányzik a Control flow és a Data flow amit használnék az adat be-ki töltésekhez.
köszönöm
Uh, remélem meg lett idő közben. De ha mégsem. A középső részben, ahol vannak a node-ok. Annak a jobb felső sarkában van két ikon. Variables és Toolbox. Ha minden igaz, ezt keresed.
Engem is bosszantott, amikor volt verzióváltás. -
 Taoharcos
aktív tag
Taoharcos
aktív tag
Nem vagyok benne teljesen biztos, hogy saját user tábláról van szó, vagy a mysql saját user táblájáról.
SHA1-ből nem tudsz csinálni SHA256-t, sőt általánosságban hashből nem nagyon tudsz csinálni egy másik hasht, ugyanis hash gyártáshoz szükség van a kiinduló plaintext szövegre.
Azt lehet csinálni, hogy belépéskor, ha stimmel a jelszó, azaz egyezik a régi hash-sel, akkor le lehet gyártani az újat, a régit meg lehet törölni.
A mysql saját user táblájáról van szó.
-
 nevemfel
senior tag
nevemfel
senior tag
Nem vagyok benne teljesen biztos, hogy saját user tábláról van szó, vagy a mysql saját user táblájáról.
SHA1-ből nem tudsz csinálni SHA256-t, sőt általánosságban hashből nem nagyon tudsz csinálni egy másik hasht, ugyanis hash gyártáshoz szükség van a kiinduló plaintext szövegre.
Azt lehet csinálni, hogy belépéskor, ha stimmel a jelszó, azaz egyezik a régi hash-sel, akkor le lehet gyártani az újat, a régit meg lehet törölni.
-
Taoharcos
aktív tag
Sziasztok!
Mysql adatbázisról kérdeznék. A mysql user jelszava alapártelmezetten SHA1-el van titkosítva. Valaki állította már át SHA256-ra? -
Petya25
őstag
Valakinek lenne ötlete, hogy egy régi Visual Studio Toolbox-ait, hogy lehetne bekapcsolni egy újabb verzióban?
Nem gondolnám, hogy az új nem kezeli a régieket, ezekkel olvastam be fájlokat illetve exportáltam kifele tartalmat.
Hiányzik a Control flow és a Data flow amit használnék az adat be-ki töltésekhez.
köszönöm -
 Jim Tonic
nagyúr
Jim Tonic
nagyúr
Hello,
Semmit se tudok az sql-ről.
Több kérdésem lenne:
Nekem php-hez kellene.
Gépemen van php, apache.
Sqlite-ot ajánlották, de semmit se találok hozzá. (Video tutorial)
Amit találok mindegyik terminalban turkálnak.
Azt írták nem kell terminálba turkálni, php alapból tudja, ha ini -ben beállítom.
Így azt se tudom hogy telepítsem.
Hogy induljak el.Ezért mysql-t raktam fel. De ezzel se tudom mit kell csinálni, hogy php-val használjam. Ezzel se találtam semmi tutorial-t php hoz . Csak ilyen nagyon alap dolgok.
Amit szeretnék: páromnak weboldal ahova beírja a receptjeit.
Gombbal hozzá adja egyesével a hozzávalókat.
Tehát lenne a database receptek, tables pl kokusz kocka, és ebbe kellene bele a hozzávalók, és az elkészítés, hozzávalókba kell a tészta, krém, öntet, díszítés. És ezekbe a vaj, tojas, tej stb.
Ezt meg lehet így csinálni? Mert sehol se találtam több mélységer.
Igazából semmit se találok amire nekem szükségem lenne.Nagyon alap tutorialokat végig néztem többet is. Hogy készítek, törlök, módosítok. Illetve ezt [link] végig olvastam. De ezekből nekem nem jött le, hogyan tudnám megoldani ami nekem kell.
Generáltasd le Copilottal.
-
pch
senior tag
Hello,
Semmit se tudok az sql-ről.
Több kérdésem lenne:
Nekem php-hez kellene.
Gépemen van php, apache.
Sqlite-ot ajánlották, de semmit se találok hozzá. (Video tutorial)
Amit találok mindegyik terminalban turkálnak.
Azt írták nem kell terminálba turkálni, php alapból tudja, ha ini -ben beállítom.
Így azt se tudom hogy telepítsem.
Hogy induljak el.Ezért mysql-t raktam fel. De ezzel se tudom mit kell csinálni, hogy php-val használjam. Ezzel se találtam semmi tutorial-t php hoz . Csak ilyen nagyon alap dolgok.
Amit szeretnék: páromnak weboldal ahova beírja a receptjeit.
Gombbal hozzá adja egyesével a hozzávalókat.
Tehát lenne a database receptek, tables pl kokusz kocka, és ebbe kellene bele a hozzávalók, és az elkészítés, hozzávalókba kell a tészta, krém, öntet, díszítés. És ezekbe a vaj, tojas, tej stb.
Ezt meg lehet így csinálni? Mert sehol se találtam több mélységer.
Igazából semmit se találok amire nekem szükségem lenne.Nagyon alap tutorialokat végig néztem többet is. Hogy készítek, törlök, módosítok. Illetve ezt [link] végig olvastam. De ezekből nekem nem jött le, hogyan tudnám megoldani ami nekem kell.
Írj rám, mert már megsajnáltalak
-
lanszelot
addikt
Hello,
Semmit se tudok az sql-ről.
Több kérdésem lenne:
Nekem php-hez kellene.
Gépemen van php, apache.
Sqlite-ot ajánlották, de semmit se találok hozzá. (Video tutorial)
Amit találok mindegyik terminalban turkálnak.
Azt írták nem kell terminálba turkálni, php alapból tudja, ha ini -ben beállítom.
Így azt se tudom hogy telepítsem.
Hogy induljak el.Ezért mysql-t raktam fel. De ezzel se tudom mit kell csinálni, hogy php-val használjam. Ezzel se találtam semmi tutorial-t php hoz . Csak ilyen nagyon alap dolgok.
Amit szeretnék: páromnak weboldal ahova beírja a receptjeit.
Gombbal hozzá adja egyesével a hozzávalókat.
Tehát lenne a database receptek, tables pl kokusz kocka, és ebbe kellene bele a hozzávalók, és az elkészítés, hozzávalókba kell a tészta, krém, öntet, díszítés. És ezekbe a vaj, tojas, tej stb.
Ezt meg lehet így csinálni? Mert sehol se találtam több mélységer.
Igazából semmit se találok amire nekem szükségem lenne.Nagyon alap tutorialokat végig néztem többet is. Hogy készítek, törlök, módosítok. Illetve ezt [link] végig olvastam. De ezekből nekem nem jött le, hogyan tudnám megoldani ami nekem kell.
-
 cattus
addikt
cattus
addikt
Szerkesztési idő lejárt.
Ha az ügyfélnek két azonos időbélyegű előfizetése van, akkor a row_number() -es megoldás véletlenszerűen vagy az egyiket vagy a másik státuszát fogja visszaadni, így csak 1 sor fog hozzá tartozni.
Míg a másik két opció mindkét legfrissebb előfizetés státuszát visszaadja, azokkal egy ügyfélhez 2 sort fogsz kapni.(Ha a row_number()-t rank()-ra cseréled, akkor az is mindkettőt vissza fogja adni.)
Köszi a részletes választ, egy időben egy userhez csak egy előfizetés tartozik, így az első is szuperül működik.
-
nyunyu
félisten
Mármint sokkal egyszerűbb, mint ügyfelenként meghatározni az utolsó előfizetési dátumot, és az ahhoz tartozó rekordot visszakeresni az előfizetés táblában, hogy utána joinolhassam az előfizetőhöz:
select u.*, s.status
from users u
left join (
select *
from subscription
where (customer_id, createdate) in (
select customer_id, max(createdate)
from subscription
group by customer_id) s
on s.customer_id = u.customer_id;(Tényleg, Oraclen kívül van más olyan DB is, ami támogatja a sokoszlopos IN / NOT IN műveleteket?
Ha jól rémlik, ez a szintaxis nincs szabványosítva)Valószínűleg ablakozós max() függvénnyel is lehetne írni, és akkor nem kellene a group by köré írt külső query:
select u.*, s.status
from users u
left join (
select *
from subscription
where createdate = max(createdate) over (partition by customer_id)
) s
on s.customer_id = u.customer_id;Talán így a legrövidebb a kód.
Szerkesztési idő lejárt.
Ha az ügyfélnek két azonos időbélyegű előfizetése van, akkor a row_number() -es megoldás véletlenszerűen vagy az egyiket vagy a másik státuszát fogja visszaadni, így csak 1 sor fog hozzá tartozni.
Míg a másik két opció mindkét legfrissebb előfizetés státuszát visszaadja, azokkal egy ügyfélhez 2 sort fogsz kapni.(Ha a row_number()-t rank()-ra cseréled, akkor az is mindkettőt vissza fogja adni.)
-
nyunyu
félisten
select u.*, s.status
from users u
left join (
select x.*,
row_number() over (partition by customer_id order by created desc) rn
from subscription x
) s
on s.customer_id = u.customer_id
and s.rn = 1;Beszámozod a subscription táblát ügyfelenkénti létrehozási dátum szerint csökkenőbe, aztán ebből joinolod az első rekordot az usershez.
(Nem szeretek alquerykben group by-jal bohóckodni, mert úgy sokkal hosszabb+bonyolultabb+olvashatatlanabb lenne a kód.)
Mármint sokkal egyszerűbb, mint ügyfelenként meghatározni az utolsó előfizetési dátumot, és az ahhoz tartozó rekordot visszakeresni az előfizetés táblában, hogy utána joinolhassam az előfizetőhöz:
select u.*, s.status
from users u
left join (
select *
from subscription
where (customer_id, createdate) in (
select customer_id, max(createdate)
from subscription
group by customer_id) s
on s.customer_id = u.customer_id;(Tényleg, Oraclen kívül van más olyan DB is, ami támogatja a sokoszlopos IN / NOT IN műveleteket?
Ha jól rémlik, ez a szintaxis nincs szabványosítva)Valószínűleg ablakozós max() függvénnyel is lehetne írni, és akkor nem kellene a group by köré írt külső query:
select u.*, s.status
from users u
left join (
select *
from subscription
where createdate = max(createdate) over (partition by customer_id)
) s
on s.customer_id = u.customer_id;Talán így a legrövidebb a kód.
-
nyunyu
félisten
Hali,
Az alábbi problémával szembesültem amit egyelőre nem sikerült megoldani. Postgres alatt adott két tábla, Users (id, customer_id) és Subscriptions (customer, status, created). Egy userhez nulla vagy több subscription is tartozhat (customer - customer_id kapcsolat). Az lenne a célom, hogy minden userhez lekérjem a legfrissebb subscription statuszát (created alapján, ha nincs, akkor null). Mi lenne erre a legegyszerűbb megoldás?
select u.*, s.status
from users u
left join (
select x.*,
row_number() over (partition by customer_id order by created desc) rn
from subscription x
) s
on s.customer_id = u.customer_id
and s.rn = 1;Beszámozod a subscription táblát ügyfelenkénti létrehozási dátum szerint csökkenőbe, aztán ebből joinolod az első rekordot az usershez.
(Nem szeretek alquerykben group by-jal bohóckodni, mert úgy sokkal hosszabb+bonyolultabb+olvashatatlanabb lenne a kód.)
-
cattus
addikt
Hali,
Az alábbi problémával szembesültem amit egyelőre nem sikerült megoldani. Postgres alatt adott két tábla, Users (id, customer_id) és Subscriptions (customer, status, created). Egy userhez nulla vagy több subscription is tartozhat (customer - customer_id kapcsolat). Az lenne a célom, hogy minden userhez lekérjem a legfrissebb subscription statuszát (created alapján, ha nincs, akkor null). Mi lenne erre a legegyszerűbb megoldás?
-
nyunyu
félisten
Alaposan le volt tesztelve a query, csak arra nem számítottam, hogy a tesztek után 2 héttel élesítéskor lesznek olyan igénylések, amik a különböző rendszereink közötti útvesztőben ideiglenesen hibás állapotban lesznek.
Tesztek idején még nem is léteztek!!! -
 tm5
tag
tm5
tag
Az a bajom, hogy túlzottan alulnézetből látom az adatokat, és nem mindig ismer(het)em a keletkezésük, elromlásuk pontos körülményeit a különböző rendszerek közti adatszinkronizációk útvesztőjében, viszont nekem kéne helyrekalapálni a félreálló biteket.
Bár elnézve azt,hogy ~3500 GDPR érett igénylést akartam javítani, de belekerült 10 friss is a szórásba, az csak 0.3% hibaarány, bőven elviselhető kerekítési hiba
UPDATE/DELETE végrehajtása előtt nem szoktál egy
--UPDATE/DELETESELECT * FROMés a query többi része
lekérdezést futtatni? Nekem néhányszor mentett már életet. -
nyunyu
félisten
Az a bajom, hogy túlzottan alulnézetből látom az adatokat, és nem mindig ismer(het)em a keletkezésük, elromlásuk pontos körülményeit a különböző rendszerek közti adatszinkronizációk útvesztőjében, viszont nekem kéne helyrekalapálni a félreálló biteket.
Bár elnézve azt,hogy ~3500 GDPR érett igénylést akartam javítani, de belekerült 10 friss is a szórásba, az csak 0.3% hibaarány, bőven elviselhető kerekítési hiba
-
bambano
titán
Ehh,
and t.torlesi_datum is not nullhelyettand t.torlesi_datum > h.letrehozasi_datumkellett volna, és akkor biztosan nem nyírom ki a rossz ideiglenes számlaszámon létrejött friss igényléseket.
(Véglegeset 1 munkanappal később kaptak volna a számlavezető rendszertől, ami biztosan különböző lett volna a korábbiaktól.)Asszem felírhatom a kéménybe korommal, hogy ez az n+1-edik módszer, ahogy a rendszerünk képes elkefélni az adatokat.
szóval az adatbáziskezelő megint az utasításaid szerint működött?
-
nyunyu
félisten
Adott egy ilyen query
update hiteligenylesek
set torolt = 1
where (foszamla, alszamla) in
(select foszamla, alszamla
from hiteligenylesek h
left join torolt_igenylesek t
on t.foszamla = h.foszamla
and t.alszamla = h.alszamla
left join aktiv_igenylesek a
on a.foszamla = h.foszamla
and a.alszamla = h.alszamla
where h.torolt = 0
and t.torlesi_datum is not null
and a.foszamla is null);
Hiteligenylesek táblában vannak a hitelek adatai, torolt_igenylesek és aktiv_igénylesek táblákba be lett importálva a számlavezető rendszer már törölt és aktív állománya január végéig. (torlesi_datum <= január 31)Ehhez képest az Oracle valahogy teret váltott, és a február 29-én létrejött igényléseket is töröltre állította, pedig az azonosítóik sem a torolt_igenylesek, sem az aktiv_igenylesek táblában nem szerepelnek

(torolt flagjük meg nyilvánvalóan 0, hiszen a query futtatása előtti napokban jöttek létre.)Még mindig nem értem, a nincs találat hogyan felel meg az is not null feltételnek.
Ehh,
and t.torlesi_datum is not nullhelyettand t.torlesi_datum > h.letrehozasi_datumkellett volna, és akkor biztosan nem nyírom ki a rossz ideiglenes számlaszámon létrejött friss igényléseket.
(Véglegeset 1 munkanappal később kaptak volna a számlavezető rendszertől, ami biztosan különböző lett volna a korábbiaktól.)Asszem felírhatom a kéménybe korommal, hogy ez az n+1-edik módszer, ahogy a rendszerünk képes elkefélni az adatokat.
-
nyunyu
félisten
De kéne.
Eredeti DBben nem ugyanúgy hívják a hiteligenylesek meg a másik rendszerből származó táblákban a számlaszámos mezőket, így nem akadt fenn azon az Oracle, hogy elfelejtettem táblaaliast írni a select oszlopai elé, mivel egyértelmű volt, hogy melyik táblából jön.
Csak itt a szemléltetés kedvéért olvashatóbbá egyszerűsítettem a kódot, és nem követtetem a DBnk örökölt hülyeségeit, hogy minden táblában másképp hívják ugyanazokat a mezőket, aszerint, hogy ki mikor/hogyan specifikálta.
Pl. createdate vs create_date még az egyszerűbbik eset...
-
bambano
titán
Adott egy ilyen query
update hiteligenylesek
set torolt = 1
where (foszamla, alszamla) in
(select foszamla, alszamla
from hiteligenylesek h
left join torolt_igenylesek t
on t.foszamla = h.foszamla
and t.alszamla = h.alszamla
left join aktiv_igenylesek a
on a.foszamla = h.foszamla
and a.alszamla = h.alszamla
where h.torolt = 0
and t.torlesi_datum is not null
and a.foszamla is null);
Hiteligenylesek táblában vannak a hitelek adatai, torolt_igenylesek és aktiv_igénylesek táblákba be lett importálva a számlavezető rendszer már törölt és aktív állománya január végéig. (torlesi_datum <= január 31)Ehhez képest az Oracle valahogy teret váltott, és a február 29-én létrejött igényléseket is töröltre állította, pedig az azonosítóik sem a torolt_igenylesek, sem az aktiv_igenylesek táblában nem szerepelnek
(torolt flagjük meg nyilvánvalóan 0, hiszen a query futtatása előtti napokban jöttek létre.)Még mindig nem értem, a nincs találat hogyan felel meg az is not null feltételnek.
nem kellene hisztiznie, hogy a select foszamla,alszamla részben a főszámla és az alszámla melyik táblából van?
-
nyunyu
félisten
Adott egy ilyen query
update hiteligenylesek
set torolt = 1
where (foszamla, alszamla) in
(select foszamla, alszamla
from hiteligenylesek h
left join torolt_igenylesek t
on t.foszamla = h.foszamla
and t.alszamla = h.alszamla
left join aktiv_igenylesek a
on a.foszamla = h.foszamla
and a.alszamla = h.alszamla
where h.torolt = 0
and t.torlesi_datum is not null
and a.foszamla is null);
Hiteligenylesek táblában vannak a hitelek adatai, torolt_igenylesek és aktiv_igénylesek táblákba be lett importálva a számlavezető rendszer már törölt és aktív állománya január végéig. (torlesi_datum <= január 31)Ehhez képest az Oracle valahogy teret váltott, és a február 29-én létrejött igényléseket is töröltre állította, pedig az azonosítóik sem a torolt_igenylesek, sem az aktiv_igenylesek táblában nem szerepelnek
(torolt flagjük meg nyilvánvalóan 0, hiszen a query futtatása előtti napokban jöttek létre.)Még mindig nem értem, a nincs találat hogyan felel meg az is not null feltételnek.
-
 F1DO
senior tag
F1DO
senior tag
Nem lehet, hogy az Excel ODBC drivere kavar be?
Nálam Oracle SQL Developerrel is az a helyzet, hogy ha jobb klikk, save as-szel rákattintok az eredményhalmazra, és excel van kiválasztva, akkor egyszerűen megáll, amint eléri a fájlméret a 3MB-t.
Múltkor 3-4 napig vertem szemmel egy 17 ezer soros excelt, mire rájöttem, hogy igazából 25 ezer sort kellett volna átnéznem
Azóta csak csv-be mentek.
Most hogy mondod..
Lehet hogy itt lesz a kutya elásva, vagy valahol itt. Ugyanis vagy 2 hete befrissítettem az MS SQL Enterp. Managert és kiakadt az excel importálásakor (itt visszafele volt a művelet) valamilyen "Microsoft.ACE.OLEDB.16.0 szolgáltató nincs bejegyezve a helyi gépen" hibaüzenettel visszadobta az importálást. Akkor valahogy - már nem emlékszem pontosan - 'bebikáztam' egy kiegészítő driver telepítéssel, de nem teljesen tiszta a dolog, olyan értelmezésben hogy nem volt időm bogarászni mi is a megoldás pontosan és mit csinál, melóban pörgés van ugye, örülsz ha tudsz tovább haladni. (Az importálás excelből MS SQL-be megoldódott és az elmúlt vagy 15 évben - azóta csinálom ezt - nem volt ilyesmire példa, hogy az SQL-ből az EXcelbe nem viszi át az összes rekordot - avagy nem futottam bele ilyesmibe!!!!!)Korábban nem volt ilyen probléma, a copy with headers átvitte az összes eredmény sort.
-
 DeFranco
nagyúr
DeFranco
nagyúr
Nem lehet, hogy az Excel ODBC drivere kavar be?
Nálam Oracle SQL Developerrel is az a helyzet, hogy ha jobb klikk, save as-szel rákattintok az eredményhalmazra, és excel van kiválasztva, akkor egyszerűen megáll, amint eléri a fájlméret a 3MB-t.
Múltkor 3-4 napig vertem szemmel egy 17 ezer soros excelt, mire rájöttem, hogy igazából 25 ezer sort kellett volna átnéznem
Azóta csak csv-be mentek.
Érdekes, nálam nincs ilyen probléma a developerben, igaz én "export"-ot használok, nem tudom, hogy a "save as" alatt ezt értetted-e.
-
nyunyu
félisten
Sziasztok!
Van egy jelenség ami előtt értetlenül állok. Nem tisztán SQL kérdés, de a forrás onnan származik.
MS SQL Management studio-ban futtatok egy sima select query-t.
Lejön az eredmény, az eredmény ablakban ahol a rekordok vannak bal felső sarokra rákattintok - kijelölődik az egész táblázat.
Majd jobb egér gomb katt-ra elöjövő menüből a - Copy with Headers-re kattintok.
Nyitok egy új üres excel táblázatot és bemásolnám de nem viszi át az összes sort!
Pl az eredmény rekordok száma 1245 a 'Paste' után az excel munkalapon meg 968 sor van.
Ez hogy lehet? Min megy félre a beillesztés?HA mondjuk Save results As.. ra kattintok és .csv-ben exportálom az eredményt akkor átmegy minden rekord, csak ilyenkor a fejléc marad le.
Dolgozom excellel, makrózok is benne stb. Észrevettem már hogy ha A oszlopban nincs érték akkor bizonyos műveleteknél hajlamos figyelmen kívül hagyni azt az egész sort, hiába van adat mondjuk B oszloptól. De most ez sem áll fenn, minden A oszlopban van értelmes adat.
Nem lehet, hogy az Excel ODBC drivere kavar be?
Nálam Oracle SQL Developerrel is az a helyzet, hogy ha jobb klikk, save as-szel rákattintok az eredményhalmazra, és excel van kiválasztva, akkor egyszerűen megáll, amint eléri a fájlméret a 3MB-t.
Múltkor 3-4 napig vertem szemmel egy 17 ezer soros excelt, mire rájöttem, hogy igazából 25 ezer sort kellett volna átnéznem
Azóta csak csv-be mentek.
-
 Dolby
senior tag
Dolby
senior tag
Sziasztok!
Van egy jelenség ami előtt értetlenül állok. Nem tisztán SQL kérdés, de a forrás onnan származik.
MS SQL Management studio-ban futtatok egy sima select query-t.
Lejön az eredmény, az eredmény ablakban ahol a rekordok vannak bal felső sarokra rákattintok - kijelölődik az egész táblázat.
Majd jobb egér gomb katt-ra elöjövő menüből a - Copy with Headers-re kattintok.
Nyitok egy új üres excel táblázatot és bemásolnám de nem viszi át az összes sort!
Pl az eredmény rekordok száma 1245 a 'Paste' után az excel munkalapon meg 968 sor van.
Ez hogy lehet? Min megy félre a beillesztés?HA mondjuk Save results As.. ra kattintok és .csv-ben exportálom az eredményt akkor átmegy minden rekord, csak ilyenkor a fejléc marad le.
Dolgozom excellel, makrózok is benne stb. Észrevettem már hogy ha A oszlopban nincs érték akkor bizonyos műveleteknél hajlamos figyelmen kívül hagyni azt az egész sort, hiába van adat mondjuk B oszloptól. De most ez sem áll fenn, minden A oszlopban van értelmes adat.
Nem az a helyzet, hogy csak az aktuálisan látszó rekordokat másolja? Szokott lenni gomb amivel a query összes eredményét meg lehet jeleníteni, utána másolj. (Ha még aktuális esetleg)
-
pch
senior tag
Sziasztok!
Van egy jelenség ami előtt értetlenül állok. Nem tisztán SQL kérdés, de a forrás onnan származik.
MS SQL Management studio-ban futtatok egy sima select query-t.
Lejön az eredmény, az eredmény ablakban ahol a rekordok vannak bal felső sarokra rákattintok - kijelölődik az egész táblázat.
Majd jobb egér gomb katt-ra elöjövő menüből a - Copy with Headers-re kattintok.
Nyitok egy új üres excel táblázatot és bemásolnám de nem viszi át az összes sort!
Pl az eredmény rekordok száma 1245 a 'Paste' után az excel munkalapon meg 968 sor van.
Ez hogy lehet? Min megy félre a beillesztés?HA mondjuk Save results As.. ra kattintok és .csv-ben exportálom az eredményt akkor átmegy minden rekord, csak ilyenkor a fejléc marad le.
Dolgozom excellel, makrózok is benne stb. Észrevettem már hogy ha A oszlopban nincs érték akkor bizonyos műveleteknél hajlamos figyelmen kívül hagyni azt az egész sort, hiába van adat mondjuk B oszloptól. De most ez sem áll fenn, minden A oszlopban van értelmes adat.
Rakj fel egy libreoffice-t.
-
F1DO
senior tag
Sziasztok!
Van egy jelenség ami előtt értetlenül állok. Nem tisztán SQL kérdés, de a forrás onnan származik.
MS SQL Management studio-ban futtatok egy sima select query-t.
Lejön az eredmény, az eredmény ablakban ahol a rekordok vannak bal felső sarokra rákattintok - kijelölődik az egész táblázat.
Majd jobb egér gomb katt-ra elöjövő menüből a - Copy with Headers-re kattintok.
Nyitok egy új üres excel táblázatot és bemásolnám de nem viszi át az összes sort!
Pl az eredmény rekordok száma 1245 a 'Paste' után az excel munkalapon meg 968 sor van.
Ez hogy lehet? Min megy félre a beillesztés?HA mondjuk Save results As.. ra kattintok és .csv-ben exportálom az eredményt akkor átmegy minden rekord, csak ilyenkor a fejléc marad le.
Dolgozom excellel, makrózok is benne stb. Észrevettem már hogy ha A oszlopban nincs érték akkor bizonyos műveleteknél hajlamos figyelmen kívül hagyni azt az egész sort, hiába van adat mondjuk B oszloptól. De most ez sem áll fenn, minden A oszlopban van értelmes adat.
-
Tothg86
aktív tag
-
bambano
titán
Sziasztok!
Egy kis segítséget szeretnék kérni. Nemrég kezdtem Hibernate-el dolgozni, és kissé elakadtam, szeretnék egy kis segítséget.
Van egy munkahelyi tábla, amiben nincsen auto increment ID, nincs semmilyen primary key sem. Szembesültem azzal (ha jól értem), hogy a hibernate megköveteli az egyértelmű azonosítást. Mivel nincs a táblában ID, ezért egy darab azonosítót nem tudok hozzárendelni. Olvastam, hogy van lehetőség összetett kulcs hozzárendélésére az EmbeddedID annotation-nel.
Jól értem? Egy netes példában az volt, hogy egy külön osztályt hozok létre a kulcsnak, és itt jelölöm, hogy @Embeddable. De ez már beleszámít a mappingbe?
Köszi, ha tudtok segíteni ebbenez ugyan nem hibernate topic, de ha nincs egyértelmű kulcs, akkor legyen.
-
nyunyu
félisten
Nem. De rájöttem, mit rontottam el.
Amikor alapból felveszem a mezőt akkor reklamál, hogy tegyem be valami agrregálásba vagy groupba is. A MIN ezt megoldja. De ha benn hagyom akkor továbbra is 2 sorban jeleníti meg.
Szóval jó volt elsőre is, csak ki kellett volna törölnöm a Group by-ból a mezőt.Ha valami(ke)t aggregálni szeretnél, akkor a group by-nál fel kell sorolnod minden olyan mezőt, ami a selectnél fel van sorolva és NEM számított mező.
Aggregálandó mezőket viszont nem szabad beírni a group by-hoz.Persze lehetne ablakozó függvényekkel bonyolítani a történetet, hogy ne kelljen group by, de úgy kétszer olyan hosszú lenne a kód, és nehezebb megérteni, mit csinál
select id, kezdes
from (
select id, kezdes, row_number() over (partition by id order by kezdes asc) rn
from tabla)
where rn = 1; -
 Lokids
addikt
Lokids
addikt
Nem. De rájöttem, mit rontottam el.
Amikor alapból felveszem a mezőt akkor reklamál, hogy tegyem be valami agrregálásba vagy groupba is. A MIN ezt megoldja. De ha benn hagyom akkor továbbra is 2 sorban jeleníti meg.
Szóval jó volt elsőre is, csak ki kellett volna törölnöm a Group by-ból a mezőt. -
nyunyu
félisten
-
Lokids
addikt
-
 coco2
őstag
coco2
őstag
"A számítógépet logikus dolgokra lehet programozni. Előre nem ismerhető szeszélyek meghatározására nem alkalmas.": próbáljunk meg az sql témakörben maradni.
Az algoritmus abszolút egyszerű: van egy tábla az adatbázisban, ahova a főnök beírja azokat a napokat, amikor valamiért nem az alapértelmezett nyitvatartás van. Ezt törvény szerint 60 nappal előre kell megoldani, tehát nem mindig írják bele egy évre előre. A szabály annyi, hogy ha ebben a táblában van az adott dátumra rendkívüli nyitvatartás bejegyezve, akkor az nem munkanap. Minek bonyolítsam. Amikor naptár szerint hétfő-péntek munkanap és nincs rekord arra a dátumra, az munkanap.
Ha 60 nappal előre mindig meg kell adni, mi lesz munkanap, és mi nem, amin utólag nem változtathatnak, és határidőt soha sem kell 60 napra előre számolni, akkor létezik logikus megoldás. Hanem azt korábban nem írtad, és nekem nincsen ismeretem a kérdéses környezet ügyintézésében. Mint ahogy abban sem, létezik-e 60 napon túli határidő? Ha igen, megint csak baj van.
-
nyunyu
félisten
-
Lokids
addikt
Sziasztok!
Hogyan tudom megcsinálni azt, hogy 1 sorban jelenjen meg az alábbi a korábbi dátummal.
ID Kezdés
1 2020.01.01
1 2020.02.01Akkor csak ez jelenjen meg:
1 2020.01.01 -
Tothg86
aktív tag
Sziasztok!
Egy kis segítséget szeretnék kérni. Nemrég kezdtem Hibernate-el dolgozni, és kissé elakadtam, szeretnék egy kis segítséget.
Van egy munkahelyi tábla, amiben nincsen auto increment ID, nincs semmilyen primary key sem. Szembesültem azzal (ha jól értem), hogy a hibernate megköveteli az egyértelmű azonosítást. Mivel nincs a táblában ID, ezért egy darab azonosítót nem tudok hozzárendelni. Olvastam, hogy van lehetőség összetett kulcs hozzárendélésére az EmbeddedID annotation-nel.
Jól értem? Egy netes példában az volt, hogy egy külön osztályt hozok létre a kulcsnak, és itt jelölöm, hogy @Embeddable. De ez már beleszámít a mappingbe?
Köszi, ha tudtok segíteni ebben -
bambano
titán
egyébként a PostgreSQL úgy alakult ki anno, hogy az Ingresből fejlesztették tovább, Postgres néven. Amikor a korábbi lekérdező nyelvét lecserélték szabvány sql-re, akkor átnevezték a projektet Postgresql-re és maradt a rövid neve postgres.
A Postgre az nem hivatalos neve.
-
bambano
titán
Oracleben gyorsan összedobva:
with munkanap as (
select a.*
from (
select to_date('2023-12-31','yyyy-mm-dd') + rownum as actdate, to_char(to_date('2022-12-31','yyyy-mm-dd') + rownum, 'd') as dateid
from (
select rownum r
from dual
connect by rownum <= 5000)
) a
left join days d
on d.actdate = a.actdate
and d.dateid = 0
where a.dateid in (1,2,3,4,5)
and d.actdate is null)
select actdate
from (
select m.*, row_number() over (order by actdate asc) rn
from munkanap m
where m.actdate > to_date('2024-12-20','yyyy-mm-dd')) x
where rn = 15;Ahogy néztem reggel, Postgre szintaxissal sokkal egyszerűbb lenne a munkanap CTE.
én is megcsináltam, még éjjel
with naptar as (
select napok,
(case when date_part('dow',napok) between 1 and 5 then 1 else 0 end)::integer
*
(case when calendar.date is null then 1 else 0 end)::integer as isworkday
from
generate_series(now()::date,now()::date+'60 days'::interval,'1 day'::interval) as napok
left outer join
calendar on napok=calendar.date)
select napok::date,-1+sum(isworkday) over (order by napok) as workdays
from naptar where isworkday=1;kb. ennyi az alap, ebből lehet közvetlen lekérdezést csinálni vagy window funkcióval és rownumberrel, vagy én csináltam belőle egy view-t és abból közvetlenül lehet selectelni.
egy rakás lehetséges optimalizáció még van benne, például a két case helyett lehetne egyet, stb.





 megválaszoltad saját kérdésed
megválaszoltad saját kérdésed 

![;]](http://cdn.rios.hu/dl/s/v1.gif)

























































Új hozzászólás Aktív témák
-
Fórumok
Mobilarena - mobil fórumok
Okostelefonok Mobiltelefonok Okosórák Autó+mobil Üzlet és Szolgáltatások Mobilalkalmazások Tartozékok, egyebek Mobilarena blogokPROHARDVER! - hardver fórumok
Notebookok TV & Audió Digitális fényképezés Alaplapok, chipsetek, memóriák Processzorok, tuning Hűtés, házak, tápok, modding Videokártyák Monitorok Adattárolás Multimédia, életmód, 3D nyomtatás Tabletek, E-bookok Nyomtatók, szkennerek PC, mini PC, barebone, szerver Beviteli eszközök Egyéb hardverek PROHARDVER! BlogokIT café - infotech fórumok
Infotech Hálózat, szolgáltatók OS, alkalmazások SzoftverfejlesztésGAMEPOD - játék fórumok
PC játékok Konzol játékok MobiljátékokLOGOUT - lépj ki, lépj be!
LOGOUT reakciók Monologoszféra FototrendFÁRADT GŐZ - közösségi tér szinte bármiről
Tudomány, oktatás Sport, életmód, utazás, egészség Kultúra, művészet, média Gazdaság, jog Technika, hobbi, otthon Társadalom, közélet Egyéb Lokál PROHARDVER! interaktív
- Fórumok
- Szoftverfejlesztés
- SQL kérdések
- (kiemelt téma)

- sziku69: Szólánc.
- Feltalálta a Google a keresőmotort
- Milyen légkondit a lakásba?
- sziku69: Fűzzük össze a szavakat :)
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Motorolaj, hajtóműolaj, hűtőfolyadék, adalékok és szűrők topikja
- VGA kibeszélő offtopik
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Házimozi belépő szinten
- További aktív témák...

- ASUS RX 9070 XT 16GB GDDR6 PRIME OC - Új, 2 év gari - Eladó!
- Fujitsu LIFEBOOK E459 I3-8130U 8 GB 256 GB NVMe 15,6" FullHD laptop
- HP ProBook 450 G8 I3-1115g4 8 GB 256 GB NVMe 15,6" FullHD IPS laptop
- Lenovo Thinkpad T14 G2 Ryzen 3 5450u/16GB/256 GB SSD/14"FHD gyári gar
- HP Elite x2 G4 I5-8265U/8 GB RAM/256 SSD/3k IPS TOUCH 2in1 laptop és tablet
- iPhone 13 128GB 89% (1év Garancia)
- Apple MacBook Pro 14 M4 2024 24GB/512GB SSD újszerű állapotú 100% akku 40 ciklus
- Lenovo ThinkPad L14 Gen 2 Ryzen 5 pro 5650U, 16GB RAM, 256-512GB SSD, jó akku, számla, gar
- BESZÁMÍTÁS! Sapphire B650M R5 7500X3D 32GB DDR5 500GB SSD RTX 5070 Ti 16GB Zalman I3 NEO Black 850W
- Samsung Galaxy A57 5G - Gray - 8/256GB - BONTATLAN - TELJESEN ÚJ - Jótállás:2028.04.23-ig
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest