Új hozzászólás Aktív témák
-

nyunyu
félisten
Szerkesztési idő lejárt.

Ha az ügyfélnek két azonos időbélyegű előfizetése van, akkor a row_number() -es megoldás véletlenszerűen vagy az egyiket vagy a másik státuszát fogja visszaadni, így csak 1 sor fog hozzá tartozni.
Míg a másik két opció mindkét legfrissebb előfizetés státuszát visszaadja, azokkal egy ügyfélhez 2 sort fogsz kapni.(Ha a row_number()-t rank()-ra cseréled, akkor az is mindkettőt vissza fogja adni.)
-
nyunyu
félisten
Mármint sokkal egyszerűbb, mint ügyfelenként meghatározni az utolsó előfizetési dátumot, és az ahhoz tartozó rekordot visszakeresni az előfizetés táblában, hogy utána joinolhassam az előfizetőhöz:
select u.*, s.status
from users u
left join (
select *
from subscription
where (customer_id, createdate) in (
select customer_id, max(createdate)
from subscription
group by customer_id) s
on s.customer_id = u.customer_id;(Tényleg, Oraclen kívül van más olyan DB is, ami támogatja a sokoszlopos IN / NOT IN műveleteket?
Ha jól rémlik, ez a szintaxis nincs szabványosítva)Valószínűleg ablakozós max() függvénnyel is lehetne írni, és akkor nem kellene a group by köré írt külső query:
select u.*, s.status
from users u
left join (
select *
from subscription
where createdate = max(createdate) over (partition by customer_id)
) s
on s.customer_id = u.customer_id;Talán így a legrövidebb a kód.
-
nyunyu
félisten
Ehh,
and t.torlesi_datum is not nullhelyettand t.torlesi_datum > h.letrehozasi_datumkellett volna, és akkor biztosan nem nyírom ki a rossz ideiglenes számlaszámon létrejött friss igényléseket.
(Véglegeset 1 munkanappal később kaptak volna a számlavezető rendszertől, ami biztosan különböző lett volna a korábbiaktól.)Asszem felírhatom a kéménybe korommal, hogy ez az n+1-edik módszer, ahogy a rendszerünk képes elkefélni az adatokat.
-
Most hogy mondod..
Lehet hogy itt lesz a kutya elásva, vagy valahol itt. Ugyanis vagy 2 hete befrissítettem az MS SQL Enterp. Managert és kiakadt az excel importálásakor (itt visszafele volt a művelet) valamilyen "Microsoft.ACE.OLEDB.16.0 szolgáltató nincs bejegyezve a helyi gépen" hibaüzenettel visszadobta az importálást. Akkor valahogy - már nem emlékszem pontosan - 'bebikáztam' egy kiegészítő driver telepítéssel, de nem teljesen tiszta a dolog, olyan értelmezésben hogy nem volt időm bogarászni mi is a megoldás pontosan és mit csinál, melóban pörgés van ugye, örülsz ha tudsz tovább haladni. (Az importálás excelből MS SQL-be megoldódott és az elmúlt vagy 15 évben - azóta csinálom ezt - nem volt ilyesmire példa, hogy az SQL-ből az EXcelbe nem viszi át az összes rekordot - avagy nem futottam bele ilyesmibe!!!!!)Korábban nem volt ilyen probléma, a copy with headers átvitte az összes eredmény sort.
-

Lokids
addikt
Nem. De rájöttem, mit rontottam el.
Amikor alapból felveszem a mezőt akkor reklamál, hogy tegyem be valami agrregálásba vagy groupba is. A MIN ezt megoldja. De ha benn hagyom akkor továbbra is 2 sorban jeleníti meg.
Szóval jó volt elsőre is, csak ki kellett volna törölnöm a Group by-ból a mezőt. -

bambano
titán
én is megcsináltam, még éjjel

with naptar as (
select napok,
(case when date_part('dow',napok) between 1 and 5 then 1 else 0 end)::integer
*
(case when calendar.date is null then 1 else 0 end)::integer as isworkday
from
generate_series(now()::date,now()::date+'60 days'::interval,'1 day'::interval) as napok
left outer join
calendar on napok=calendar.date)
select napok::date,-1+sum(isworkday) over (order by napok) as workdays
from naptar where isworkday=1;kb. ennyi az alap, ebből lehet közvetlen lekérdezést csinálni vagy window funkcióval és rownumberrel, vagy én csináltam belőle egy view-t és abból közvetlenül lehet selectelni.
egy rakás lehetséges optimalizáció még van benne, például a két case helyett lehetne egyet, stb.
-

coco2
őstag
Aludtam rá egyet, és leesett, hogy tényleg ostoba vagyok

Felesleges annyit előre gyorsítani. Van lekérdezési rekord limit. Elég csak a munkanapokat egyesével bejegyezni a hr oldal alapján, aztán X1 dátumtól kezdve kérni X2 (vagy X2+1) rekordot, és a legutolsóból kivenni a dátumot. És arra még azt se mondhatja senki, hogy kinézetre csúnya.
@bambano
>Szerk: nem csak az a nap marad ki, amit a hr portálon közölnek. Az is kimarad, ami helyi okokból nem munkanap vagy nem teljesértékű munkanap. Pl. egy rakás cégnél karácsony és szilveszter között takarékon vannak.
A számítógépet logikus dolgokra lehet programozni. Előre nem ismerhető szeszélyek meghatározására nem alkalmas.
-
bambano
titán
akkor fejlesztenetek kell
szerintem ez sem jó.
például idén dec. 20-án ki akarok adni egy 15 napos határidőt, kijön január 4, szombat, lépek tovább, január 6. hétfő az első munkanap.
Csak közben volt egy 6 napos karácsony meg egy szilveszter, és ez így pont 4 munkanap lesz. -

tm5
tag
Nem nagyon használom én se, csak van néhány kollégám akik rá vannak függve.
És igen ha ilyen kell akkor én is a MERGE-öt szoktam. Csak akkor amikor ez a kérdés felpattant pont egy ilyen csináltunk a melóban.Ha már veszélyesen élés akkor, hadd említsem az Updateable viewk tömkelegét INSTEAD OF triggerekkel. A fél ház (WS backend) ezen lóg.
-

fjanni
tag
Kösz a segítséget, de ez nekem egy kicsit bonyolult, egyszerűbb megoldás nincsen?
Tulajdonképpen nem kell új tábla, csak egy Select ami a táblában lévő adatok mellé kiszámolja az utolsó két oszlopot. Az első három oszlop van a táblában.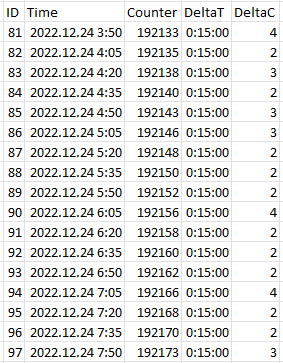
Ha a deltaT és deltaC megvan akkor már Group by-al tudok periódusokra összegezni, csak azt nem tudom kiszámolni hogy mennyi a növekmény.
-
nyunyu
félisten
Sebtében összetákolt Oracle példa:
create table gazora (idobelyeg timestamp, allas number);
insert into gazora (idobelyeg, allas)
values (systimestamp, 70);
insert into gazora (idobelyeg, allas)
values (systimestamp-1, 65);
with oraallas as (
select idobelyeg,
allas,
row_number() over (order by idobelyeg desc) rn
from gazora
)
select akt.idobelyeg aktualis_ido,
akt.allas aktualis_allas,
elozo.idobelyeg elozo_ido,
elozo.allas elozo_allas,
akt.idobelyeg - elozo.idobelyeg eltelt_ido,
extract(day from (akt.idobelyeg - elozo.idobelyeg)*24*60*60)/60 eltelt_ido_perc,
akt.allas - elozo.allas allas_valtozas,
(akt.allas - elozo.allas)/extract(day from (akt.idobelyeg - elozo.idobelyeg)*24*60*60)/60 atlag_fogyasztas
from oraallas akt
join oraallas elozo
on elozo.rn = akt.rn + 1
where akt.rn = 1;CTE-ben megfordítottam a számozás irányát, hogy fixen rn=1 legyen a legutolsó rekord, eggyel nagyobb az eggyel régebbi.
join feltételben lévő on elozo.rn = akt.rn + 1 feltétellel tudsz játszani, hogy hány méréssel korábbi rekordhoz képest akarsz eltérést, átlagot számolni.(interval adattípus miatti típuskonverzióért elnézést, nem lehet értelmesen percre váltani.)
-
Köszi
 és Apollo17hu Neked is.
és Apollo17hu Neked is.
Igen ilyen oszlopok vannak. Az a baj, hogy egy meneten belül a fogadások száma eltérő lehet, így nem tudom, hogy hányszor kellene joinolnom, vagy hány extra mezőt kellene képeznem.
Valamilyen windowed function kéne, ami egy kumulatív sum--ot, vagy sorszámozást képezne egy menet belül, ha az egymást követő fogadások nyerőek, de nullát venne fel, amikor jön egy vesztes fogadás és a következő nyerő fogadásnál egyről indul.
Ciklust nem szeretnék írni rá, csak worst case, mert nem igazán hatékony szerintem SQL-ben.
Végső cél, hogy meg tudjam mondani, hogy melyik volt a leghosszabb nyerő szériájú menet. -
-
nyunyu
félisten
Nálunk úgy van megoldva az Oracle alatt megváltozott szerződések továbbítása, hogy rá van téve egy-egy insert meg update trigger a szerződések táblába, ami kiírja egy temp táblába a módosult rekord rowid-ját.
Aztán van egy eljárás, ami a temp táblába kiírt azonosítójú rekordokból felépít egy material viewt a szerződés+kapcsolódó ügyféladatok aktuális tartalmával, majd törli a tempet, ezzel azt érjük el, hogy a matviewban csak az utolsó szinkronizáció óta megváltozott rekordok tartalma lesz meg.
Amikor az SQL Servert használó dokumentumkezelő rendszernek olyanja van, a DBConnectoron keresztül meghívja ezt az eljárást, aztán a matviewban látható aktuális adatokkal megupdateli a saját tábláit.
Nyilván ha két szinkronizáció között többször változik egy rekord (pl. frissül az ügyfél címe, aztán az igazolványszáma), akkor többször fog bekerülni az azonosítója a tempbe, de a belőle épített matviewban már csak egyszer fog szerepelni, a legfrissebb adattartalommal.
-

syC
addikt
Sajnos az nem jó, mert olyan intenzitással jönnek az adatok hogy másodpercenként kb 100x változik a tábla. Végül megoldottam temporary table-lel, favágó módon: Kiszedem az egyik gépből az adatokat, majd a másik gépen felépítek belőle egy temporary table-t, amivel már tudok joinolgatni. Szerencse, hogy a szolgáltatás, amihez kell, nem fix periodikus futású, hanem prompt. De mindenesetre köszönöm az előző tippet.
-

Pürrhosz
csendes tag
Ezek valójában 1-1 relációk, nem kell N-M-re átalakítani.
Vannak az A rekordok amik kétfélék lehetnek(b és c), az A-ban vannak azok a tulajdonságok amik a B-nek és a C-nek is közös tulajdonságai.
Tehát egy B vagy egy C az pontosan egyféle A-hoz van hozzárendelve.
Most lenne egy D tábla ami ugyancsak használná a B és C rekordokat. Itt is egy B sor vagy egy C sor pontosan egyféle D-hez kapcsolódna(vagy A-hoz).
pl. vannak az emberek(ez az A)
B - hím tulajdonságok
C - nőstény tulajdonságok
D - ez lenne most az állatok, ami szintén használná a B és C táblákat. -
-
-

Petya25
őstag
Már rájöttem a dologra.
Az ékezetet nem kezeli, megzavarta...Ez lett a megoldás:
DECLARE @cols AS NVARCHAR(MAX),
@query AS NVARCHAR(MAX)SET @cols = STUFF((SELECT distinct ',' + QUOTENAME(c.datum)
FROM tabla c order by 1
FOR XML PATH(''), TYPE
).value('.', 'NVARCHAR(MAX)')
,1,1,'')set @query = 'SELECT hely, ' + @cols + ' from
(
select datum, ertek, hely from tabla
) x
pivot
(
max(ertek)
for datum in (' + @cols + ')
) p 'execute (@query)
-
-
nyunyu
félisten
Ahogy nézegetem, nem Oracle környezetekben eléggé kihívás a regexp_substr-nek megfelelő funkcionalitás, általában nincs olyan függvény, ami csak a mintának megfelelő részstringet adja vissza.
Pl. MS SQL Servereken lehet bohóckodni a
substr(information, patindex('%[0-9]{13}%', information), 13)-mal.Meg a számjegy osztályra hivatkozást szögletes zárójelbe kell csomagolni: [[:digit:]], ehelyett egyszerűbb/rövidebb a 0-9 karaktereket matchelni, ahogy írtátok a [0-9]-cel.
-
nyunyu
félisten
Ja, CTAS nem csak tábla másolásra jó.
Pl. van egy giga lekérdezésed, ami sok táblából lapátol össze adatot, akkor a konkrét végeredményt is el tudod úgy menteni, hogy a SELECT elé írod, hogy
CREATE TABLE <táblanév> ASItt persze figyelni kell arra, hogy az eredeti lekérdezésben minden mezőnév egyedi legyen.
Meg arra is figyelni kell, hogy az eredményhalmazban szereplő leghosszabb string alapján határozza meg a számított VARCHAR() mezők hosszát, így ha a létrehozott táblába akarsz később insertálni, akkor nem biztos, hogy bele fog férni ugyanannak a lekérdezésnek az eredménye, ha mondjuk egy oszlopba két stringet fűzöl össze, aztán később hosszabb stringek lesznek a forrás táblákban... -

pch
senior tag
Ez nem azt az eredményt adja.
Mégegyszer: A kuldes_id és a szamla_id a tételeknél van. Egy rendeléshez több tétel is kapcsolódik. Ha a tételnél a kuldes_id-be 0 van akkor ugye azzal még kell foglalkozni. De van olyan eset is ahol mondjuk 10 tételnek már van kuldes_id-je ami nem 0 de egynek nincs.
Akkor azzal még van teendő.
-

Panhard
tag
Igazából az lenne a feladat, hogy egy webcímben GET kérés paramétereként adom meg a kezdő és a záró dátumot. Valahogy így:
http://weboldal.hu?id1=2022-07-10&id2=2022-07-20
De a lényege az lenne, hogy akinek megadom ezt a linket, az ne tudjon másik dátumra lekérdezni. Én a weboldalon legenerálok egy md5-ben lévő dátumot. Esetleg teszek még más karaktereket is mellé, hogy véletlenül se tudjon legenerálni másik dátumra kódot. (ha esetleg rájönne, hogy csak egy dátum van az md5-ben) Ezt elküldöm a felhasználónak. Ezért kellene valahogy így kódolni a paramétereket:http://weboldal.hu?id1=ea88fe6807b44f248329a85debee3c58
Ez így egy dátumra való lekérdezéssel működik is, mert ott az adatbázisban minden sor dátumát át tudom alakítani md5-re és utána csak össze kell hasonlítani a webcímben kapott md5 értékkel. De nekem két dátum között található összes sort kellene lekérdeznem, amit így nem lehet.
Vagy esetleg van másmilyen bevált megoldás arra, hogy a GET kérés paraméterében lévő értékek manipulálásával ne tudjon mást lekérdezni a felhasználó? -
-

Magnat
veterán
"Sok fejfájástól megment, ha több tábla joinja alapján kell updatelni egy táblát..." - de ez egy tábla ...
"Egyébként már az updateedet sem értem, miért kéne többször lefutnia az alselectnek, ha egyre limitáltad a visszaadható eredmény számát?" - azért, mert egy rekordhoz egyszer kell lefusson, de az első update után változik az adatnézet, ha akkor újra kiértékelődik a belső select, akkor már az eggyel növelt értékű rekordot kellene (mármint a logikám szerint) megtalálnia.
-
-
#5449
 Prog-Szerv
csendes tag
nyunyu
#5447
Prog-Szerv
csendes tag
nyunyu
#5447
Prog-Szerv
csendes tag
Kicsit agyaltam rajta, így az van amit említettél is, sajnos ez kiszelektálja azokat a projekteket is amikben van 0 hour érték is és annál nagyobb is:
SELECT COUNT(DISTINCT project_id) FROM join_project_task JOIN project ON project.id = join_project_task.project_id WHERE project.elements > 0 AND join_project_task.hours > 0Ez úgy tűnik működik, csak azokat szelektálja amikben csak 0 hour értékű task van:
SELECT COUNT(DISTINCT project_id) FROM join_project_task JOIN project ON project.id = join_project_task.project_id WHERE project.elements > 0 AND join_project_task.hours = 0Próbáltam beépíteni a not in operátort de erre 0 értéket kapok vissza:
SELECT COUNT(DISTINCT project_id) FROM join_project_task JOIN project ON project.id = join_project_task.project_id WHERE project.elements > 0 AND project.id NOT IN (SELECT project_id FROM join_project_task WHERE hours = 0) -
#5448
Prog-Szerv
csendes tag
nyunyu
#5447
Prog-Szerv
csendes tag
Kezdem kapizsgálni....az a baj hogy nekem nem a task táblában tárolódik az hour -ra vonatkozó adat és mivel ez egy elég masszív program nem szeretném ezt a részét átalakítani, mert akkor egy csomó másik helyen módosítanom kellene a kódot
Szóval az hour a "join_project_task" táblán belül van. Leegyszerűsítve csak arra ami nekünk most itt kell:
"project" tábla tartalma: id
"task" tábla tartalma: id, name
"join_project_task" tartalma: project_id, task_id, hoursAz hours értéke változhat, nem fix, tehát előfordulhat hogy például egy szerelés 4 óra de lehet hogy csak 2, ezért van így tárolva. Ez olyasmi mint egy digitális jelenléti ív, tehát változhat hogy 1-1 feladat mennyi idő alatt készül el, utólag kerül beírásra.
-
-
-
nyunyu
félisten
Sosem szerettem az ősrégi szintaxist, mert nem bírtam megjegyezni, hogy az Oracle a feltétel melyik oldalán várja a (+)-t a left illetve right joinnál.
select t1.*, t2.*
from tabla1 t1, tabla2 t2
where t1.id = t2.id (+);Aha, amelyik oldal nem kötelező / lehet null, oda kell tenni a (+)-t.
Vagyis a fenti példa egy left join.Arra meg egyáltalán nem emlékszem, hogy Teradatában volt-e ilyen left/right szintaxis.
Csak annyi rémlik, hogy update közben is tudott implicit joinolni, amit rajta kívül egyik DB motor sem ismert:update tabla1
set valami = tabla2.valami
where id = tabla2.idSzabvány SQL mindenesetre jóval olvashatóbb, mint ezek az elfajzott példák.

-

Szigii
csendes tag
Köszi a segítséget, ki is jött egy eredmény
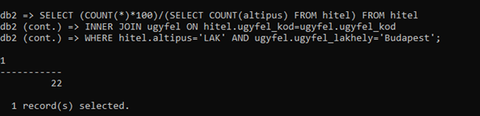
Viszont itt a hitel.altipusnál a teljes összeggel kell osztani nem csak a a 'LAK' típusokra, nem?
Azért gondolom így, mivel megkapjuk a 755db ügyfelet, akiknek lakáshitelük van és budapesti lakosúak
Ezt szorozzuk 100al és osztjuk az összes létező hitel típussal (ami ebben a feladatban 3333, amiből a 'LAK' 1972db), amire ki jön a 22%
Bocsi, ha egy kicsit bonyolultan írtam le a gondolatmenetem.
-

martonx
veterán
Nem csak Hibernate létezik ORM-ként, és nem csak ORM szinten lehet cachelni
Maximális respect a DB tudásodnak, de nem kell mindig mindent DB szinten megoldani.Ez itt nagyon off topic, de minek görcsöltetitek, és csuklóztatjátok szegény kezdő kollégát (bár szemlátomást, ő magával is ezt teszi
) olyan problémák, olyan technológiai szintű mélységében, amikkel egyrészt jó eséllyel a való életben találkozni se fog (vagy végül elég lesz egy hiányzó indexet feltennie), másrészt, ha nem is DB szinten, hanem kód szinten de, tök simán kezelni lehet. -
Taci
addikt
Ez nagyon hasznos információ, köszönöm!
Tehát ilyenkor sorbanállás van? Tehát egy sima Select is sorban áll, és a (honlapot használó) user nem kap vissza addig adatot, amíg az update nem végez?
Akkor csak lenne még kérdésem:
Melyik a jobb megoldás ezt a helyzetet kezelni?
- Egy index a cikk_id-ra (ezt kapja vissza a kategóriakarbantartó szkript),
- vagy mégiscsak egy külön tábla ennek a mezőnek?Nem fér bele semennyi várakozás, sorbanállás, hogy a user megkapja a tartalmat (a honlap a kért adatokkal betöltődjön). Most oké, még pár 10ezer rekordnál a karbantartó szrkipt hamar végez, de később ez csak lassulni fog.
Tényleg nagyon köszönöm ezt az információt!
-
Taci
addikt
De most kiderült, hogy ezekről szó sincs, hanem a kategoria_verzio az ellenőrző szkriptednek egy flag, hogy az adott cikket már ne kelljen vizsgálnia?
Igen, pontosan.
Akkor marad úgy, ahogy eredetileg volt felépítve. Csak pár héttel/hónappal ezelőttről emlékszem, hogy valaki írta itt, hogy az úgy nem jó, ha ez a két mező, amit folyamatosan frissítve lesz így vagy úgy (kategória verziója, illetve cikkhez tartozó kategóriák írott nevei, vesszővel elválasztva - amikre "rá tudok nézni"), a többi adat mellett van, ugyanabban a táblában.
Sajnos már nem találok rá arra a válaszra. De ezért tettem fel a nyitó kérdést, hogy maradhat-e így, ahogy most van (amit most Te is megerősítettél), vagy esetleg rakjam külön táblába.Köszönöm szépen még egyszer a sok segítséget!
-
nyunyu
félisten
Oracle alatt lehet még használni egy rakat aggregáló függvényeknél az over (partition by valami) záradékot, akkor dinamikusan csoportosítja a rekordokat, és nem kell a lekérdezés végére a kemény group by:
create view cikkek_vw as
select c.id cikk_id,
c.cim cim,
c.create_date datum,
c.creator cikk_iro,
listagg(ck.kategoria_id, ', ') within group (order by ck.kategoria_id) over (partition by c.id) kategoria_id,
listagg(k.nev, ', ') within group (order by ck.kategoria_id) over (partition by c.id) kategoria_nev
from cikkek c
join cikk_kategoria ck
on c.id = ck.cikk_id
join kategoriak k
on ck.kategoria_id = k.id;De pl. az előbb linkelt MS SQL doksiban explicite leírják, hogy náluk kötelező a group by a string ragasztó függvényhez.
-
Taci
addikt
Köszönöm szépen, ezzel így már szépen alakul.
Viszont még lenne benne csavar:
3 tábla van (példád alapján írom):
- 1.: cikkek (c.cim, c.create_date stb.)
- 2.: kategoria (k.id, k.nev)
- 3.: cikkek_kategoriak (ck.cikk_id, ck.kategoria_id): Mivel egy cikk több kategóriában is lehet, ezért javaslatotokra ezt külön szedtem ebbe a táblába, így minden rekord 1-1 kapcsolat a cikk és a kategória között. Ha egy cikkhez 3 kategória tartozik, akkor 3 rekord van hozzá.Amit írtál, az szépen visszaadja a kért adatokat, de csak a kategóriák id-ját, és ha egy cikkhez több kategória van, akkor annyi rekordot ad vissza.
Pl.: ha a cikk_id = 5 -höz van kategória 3, 15 és 22, akkor így adja most vissza:cikk_id ... kategoria_id5 35 155 22Viszont úgy szeretném, hogy cikkenként csak egy rekordot adjon vissza, és a kategoria_id-khoz tartozó szringeket (neveket) sorolja fel, vesszővel elválasztva.
Tehát ha a 3-as kategória a "belfold", a 15-ös a "kulfold", a 22-es pedig a "sport", akkor ezt adja vissza:cikk_id ... kategoria_nevek5 belfold,kulfold,sportEddig arra jutottam, hogy:
create view cikkek_vw asselect c.id cikk_id,c.cim cim,c.create_date datum,c.creator cikk_iro,ck.kategoria_id cikk_kategoria_id,k.nev kategoria_nevfrom cikkek cjoin cikk_kategoria ckon c.id = ck.cikk_idJOIN kategoriak AS kON ck.kategoria_id = k.id;(Lehet, ide most nem a legpontosabban írtam át, de a lényege ez, és nálam a valós kód szépen hozza.)
Tehát ez kiírja több rekordban, ha egy cikkhez több kategória is van, viszont így már odaírja a kategória nevét is, nem csak az id-ját.
cikk_id ... kategoria_id kategoria_nev5 3 belfold5 15 kulfold5 22 sportValahogy meg lehet csinálni, hogy 1 cikk csak egyszer szerepeljen (ezt a distinct vagy a group by megoldja), és hogy a különböző kategóriák vesszővel elválasztva egy új mezőben legyenek az adott egy darab cikk rekordjában?
Mert ez így valóban egy az egyben az lenne, mint a mostani külön tábla tartalma.@Ispy: Már megvolt, a sokadik is, már a ló túloldalon vagyok lassan...
-
Taci
addikt
Izgalmasan hangzik.
Bár élvezetes valószínűleg akkor lehetett (volna), ha nem tegnapelőttre kérik a megoldást. De azért ez az eredmény biztosan nagyon jó érzéssel tölthetett el. SQL-ben már nem volt több nyitott kérdés a listámban, csak ez a kettő, ezért tettem fel így a végén. Közben még JS- és PHP-oldalon van teendőm (a tesztek során ami hibát találtam, összeírtam, azokat javítom, és tesztelem újra).
Nagyon szeretném már elindítani az oldalt. Eredetileg nyár elején akartam, viszont ott vettem észre, hogy az SQL-oldalt nagyon rosszul raktam össze. Most már (a Ti segítségeteknek hála ) az a rész úgy néz ki, rendben lesz.
De ha már ennyit "késtem", nem kapkodom, próbálok átgondolni mindent, előre is tervezni. Inkább induljak később, de minél kevesebb probléma legyen a későbbiekben - főleg ha azokat még most "elkaphatom". (De azért kategorizáltam a To-do lista elemeit is, van, ami azonnal megoldandó (mert rosszul működik, rossz eredményt ad stb.), de van amit v1.1-ként jelöltem csak, hogy majd indulás után ráér bőven.) -
Taci
addikt
Köszönöm a magyarázatot, így már világos.
@martonx: Neked is.
Amúgy csinálom, folyamatosan. Azért jött fel ez a legutóbbi két kérdés, mert anno amikor nagyon-nagyon elakadtam, akkor találtam egy srácot, aki órabérben ránézett az egészre, ő tett jó pár javaslatot és kommentet, és ezeket én feljegyeztem (a to-do listámba). Vele azóta sajnos nem tudtam beszélni, a kérdések pedig ott voltak nyitott pontként, és most, hogy végre a keresés részét is rendbe raktam (és a hozzá kapcsolódó pontok kikerültek így a listából), utamba került ez a két kérdés is, ezért kértem tanácsot velük kapcsolatban. Mert ha olyan dolgok lettek volna, amikkel előre számolnom kell (és a kódokat hozzájuk igazítanom), akkor még indulás előtt történjen.
Köszönöm a türelmeteket és a segítségeteket. -
-
#5237
 Apollo17hu
őstag
nyunyu
#5236
Apollo17hu
őstag
nyunyu
#5236
Apollo17hu
őstag
Hat, azt nem tudom, hogy mi hogyan irodhatott, de abban nagyon igazad van, hogyha az ember nem gyakorlott benne, akkor elegge necces a hasznalata. Egy kivalasztott peldara meg nehany masodperc alatt lefutott a kodom, de szazmillios rekordszamom van, ugyhogy inkabb elengedem a rekurziv temat. Igazabol csak egy szep megoldast kerestem, mert mas modon kozel 100%-os pontossaggal meg tudom hatarozni az ertekeket - es szerencsere ez most eleg.
-

Sokimm
senior tag
A gyerekekkel való példa csak példa, az adatok "értelmezéséhez" kellett, bár lehet elég bénán fogalmaztam, ettől függetlenül siekrült a művelet, köszönöm a segítséget (mindenkinek!).
(hogy válaszoljak is: Azért kell a 2 táblából egy 3.at csinálni, hogy merge-öljem az összes adatot egybe, de "logika" alapján. Az első 2 tábla majd megy a levesbe, a 3. lesz használva csak a jövőben)
Ezért nem elég csak egy lekérdezés, fontos a friss táblába mozgás.
Most viszont a WHERE résszel szenvedek (megint szerintem szintaktika), mert mindig kér kezdő paramétert SQL futtatásakor.
Most nem írok béna példát, csak a szintaktikát kérném segítsetek megérteni.
(Nem tudom mikor használunk gyémánt operátort, vagy [...] ilyet, meg a sima zárójeleit se értem a Microfos-nak. )
)
A hibám az, hogy a WHERE végén lévő Zenetagozatosok.NEV mindig kér kezdő paramétert SQL futtatásakor, nem képes a két tábla azonos oszlopát összehasonlítani automatán.UPDATE ...
SET ...
WHERE (((ÖsszesGyerekTabla.NEV)=([Zenetagozatosok].[NEV])));







![;]](http://cdn.rios.hu/dl/s/v1.gif)

































 )
)Új hozzászólás Aktív témák
Hirdetés
- A fociról könnyedén, egy baráti társaságban
- Project Motor Racing-Straight4 Studios
- Teljes verziós játékok letöltése ingyen
- One otthoni szolgáltatások (TV, internet, telefon)
- Óvodások homokozója
- Medence topik
- Nyíregyháza és környéke adok-veszek-beszélgetek
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Ubiquiti hálózati eszközök
- További aktív témák...

- Easun iSolar SMW 11kW Twin Hibrid inverter // Dupla MPPT // BMS // WiFi
- GAMER PC : RYZEN 7 5700G/// 32 GB DDR4 /// RX 6700 XT 12 GB /// 512 GB NVME
- GAMER MSI LAPTOP : 15,6" 144 HZ /// i5 12450H /// 16GB DDR4/// RTX 4050 6GB/// 1TB NVME
- Manfrotto 055 magnézium fotó-videófej Q5 gyorskioldóval
- Sony ECM-W2BT
- ÁRGARANCIA!Épített KomPhone i7 14700KF 32/64GB RAM RTX 5070Ti 16GB GAMER PC termékbeszámítással
- LG 27CN650N-6A - Felhő Monitor - 1920x1080 FHD - 75Hz 5ms - USB Type-C - Quad Core - BT + WiFi
- DDR5 16GB 8GB 32GB 4800MHz 5600MHz RAM Több db
- Magyarország piacvezető szoftver webáruháza
- IKEA Format lámpák eladóak (Egyben kedvezménnyel vihető!)
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged