Hirdetés
- Telekom mobilszolgáltatások
- Xiaomi 15T Pro - a téma nincs lezárva
- Samsung Galaxy S26 Ultra - fontossági sorrend
- Samsung Galaxy A57 - kecses test, lusta lélek
- Hivatalos a OnePlus Watch 4
- Távozik az Apple vezérigazgatója
- Fittyet hány a pesti napfényre a Honor 600
- Poco X8 Pro Max - nem kell ide sem bank, sem akkubank
- Betáblázta magát az Oppo
- Milyen okostelefont vegyek?
Új hozzászólás Aktív témák
-

lanszelot
addikt
válasz
 martonx
#6019
üzenetére
martonx
#6019
üzenetére
Köszönöm szépen.
Valamit nem jó; értek, mert eddig jutottam, de nem jó:
//Create another table - Main table for shared ID -This table share ID with supplier_groups
$sql = "CREATE TABLE IF NOT EXISTS suppliers (
supplier_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
supplier_name TEXT NOT NULL,
group_id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
FOREIGN KEY (group_id)
REFERENCES supplier_groups (group_id))";
try {
$connection->exec($sql);
echo "Table suppliers created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
//Create another table - Secondary table with shared ID - This table got ID from suppliers table
$sql = "CREATE TABLE IF NOT EXISTS supplier_groups (
group_id integer PRIMARY KEY,
group_name text NOT NULL)";
try {
$connection->exec($sql);
echo "Table supplier_groups created successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
}
// Create (Insert) Data. SQL query to insert data into the "suppliers" table
$sql = "INSERT INTO suppliers (supplier_name) VALUES ('Obi van Kenobi')";
$sql2 = "INSERT INTO supplier_groups (group_name) VALUES ('jedi')";
try {
$connection->exec($sql);
$connection->exec($sql2);
echo "Data inserted successfully";
} catch (PDOException $e) {
echo "Error: " . $e->getMessage();
} -
lanszelot
addikt
válasz
martonx
#6017
üzenetére
Köszönöm szépen a választ.
Oda írtam a példát. Az id pont úgy van ahogy írtad.
És azt is tudom hogy constraint és /vagy foreign key -t kell használom, de nem tudom hogyan.
Azért írtam le a kódot, hogy lehessen látni, hogy mit szeretnék.
Természetesen azid FROM usres(id)sort kellene javítani,
constraint és /vagy foreign használataval,
Csak nem tudom hogy.
Bárhogy próbáltam, sehogy se volt jó.Sqlite pdo php -val használom.
-

bambano
titán
válasz
martonx
#6004
üzenetére
Én úgy értettem abból, amit írt, hogy össze akarja kötni az azonos időben különböző mérőkkel mért értékeket, és ezt nem lehet időbélyeg alapján, mert az mindig változik.
Tehát ha valamiféle egységben (gazdasági egység, megrendelő, számlázási egység) több mérő van, tudni akarja az egy időpontban mért értékeket. Találgatás: például nálam 5 hőmennyiség mérő van, ha simán leszeded a mért értékeket, különbözik az időpont, de bizonyos célokra tudni kell, hogy amikor az egyik mért valamit, pontosan akkor mit mért a másik. -

fjanni
tag
válasz
martonx
#6000
üzenetére
Nem ugyanarra van, minden tábla más mérési pont adatát tárolja, valamelyik gáz fogyasztás és van amelyik villamos energia fogyasztás adatot tárol, és olyan is van ahol villamos teljesítmény adatot tárolnak adott timestamp-hez kötve.
Ha sikerülne elérni hogy újrafejlesszék akkor annak milyennek kellene lennie?
Jelenleg ilyen egy tábla, a tábla neve MP001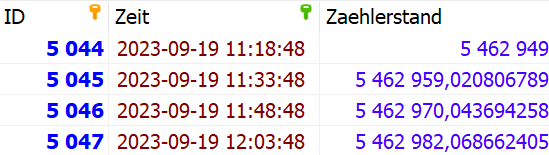
Egy másik tábla pedig: MP002
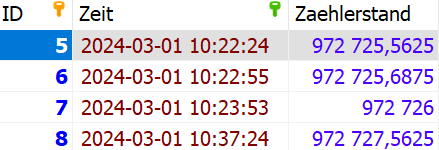
Látható hogy szinte minden táblában más az időbélyeg adat, van ahol rövid időn belül sok adat lett letárolva stb.
Ehelyett mi a jó megoldás?
Az hogy egy táblába írok úgy hogy minden adatnak van egy mérési pont azonosítója?
ID / MP_code / Zeit / Zaehlerstand - itt ügyelni kell arra hogy az időbélyeg adatok egy beírásnál megegyezzenek.
vagy
egy rekordba legyen írva az össze adat egy dátum mellé?
ID / Zeit / MP001 / MP002 / MP003 .... ahány mérési pont van?Ha elfogadják az új formátumok akkor pedig átkonvertáljuk a régi adatokat is ebbe az új formátumba.
-

Louro
őstag
válasz
martonx
#6000
üzenetére
Uh, ilyen nálunk is van az egyik területen. Kb. 3-4 hetente felhívom a figyelmüket, hogy rendezzék már az adataikat. Ugyanarra a témára, naponta hoznak létre táblákat és van, hogy 1-2 rekord van csak benne. Mondtam nekik, hogy +1 oszlop, ami a napot jelöli, sokkal ideálisabb lenne. Ehelyett már 300+ táblájuk van csak egy célra és nekik így jó. Szerencsére csak két ilyen fafejű kolléga van. Persze panaszkodni tudnak, hogy ha az SSMS-ben lenyitják a táblák listáját, akkor van, hogy megnyekken a rendszer.
És nem egy DWH területről beszélünk. Kb. 100 táblában elférnének, de ehelyett 5000+ táblájuk van. Nekem fizikailag fáj, ha velük kell foglalkoznom. Hiába jelzem, hogy ha unique indexet akarnak trigger miatt, akkor ne 4 adatból rakják össze, amik ráadásul eltérő adattípusúak, hanem csináljanak egy dedikált unique mezőt és arra lehet indexálni.
De hát mi csak csóró üzemeltetők vagyunk és ők a détaendzsinírek.
-

Gergello
addikt
válasz
martonx
#5661
üzenetére
Ez az 1 keresés van az egész oldalon, egy nem túl bonyolult query, szerintem én is normálisan megírtam. Miért rontsam le a Google-essel ? Megjelenítésbe nem is tudom, hogyan illeszthető.
Fizetősöket meg se néztem. Ott láttam, hogy egy konkurencia használja a findologic-ot.
-
válasz
martonx
#5526
üzenetére
Van egy selectem, amin kb így néz ki
Select *
From
Adattabla at
Where
at.azonosito = '1234'
Order by created_date asc
Fetch first 1 rows only;Van egy temp táblám, amibe egy oszlop van csak amiben van 1000 azonosító, és ezt szeretném az 1234 helyére beilleszteni, lefuttatni, és az 1000 eredményt egyben látni. Remélem így érthetőbb voltam :)
-

Magnat
veterán
válasz
martonx
#5513
üzenetére
Selectnél működik:
SET @row_number = 1;
SELECT
(@row_number:=@row_number + 1) AS num,`cust_partnerkod`
FROM cikktorzs_customer WHERE `cust_partnerkod`= 200000De update-nál nem, ugyanarra az értékre updateli az összes érintett sort:
SET @row_number = 1
UPDATE cikktorzs_customer c_c, (SELECT (@row_number:=@row_number + 1) AS num, cust_partnerkod AS i_c_p FROM cikktorzs_customer LIMIT 1 ) i_c_c SET `cust_partnerkod` = cust_partnerkod + @row_number WHERE cust_partnerkod = 200000 -

wmarci
senior tag
válasz
martonx
#5443
üzenetére
Sziasztok!
Adott egy SQL adatbazisban egy tabla, ahol az elso oszlop az ID (INT), illetve van meg 10 masik oszlop varos nevekkel, a cella ertekek itt 1-100ig terjedo random szamok (km).
1. Hogyan tudok egy bizonyos ID-ra ugy raszurni, hogy az 5 legnagyobb erteku oszlop (legtobb km) ASC sorrendben legyen. (Horizontal sorting?)
2.Kivalasztani azt a recordot a tablabol, amelyik a legtobb cellat tartalmazza, aminel >= 50 az ertek?Huh, remelem ertheto, ahogy megfogalmaztam ezt.
Koszi a segitseget elore is!
-

Taci
addikt
válasz
martonx
#5432
üzenetére
Nem saját link egyik sem, mind kifelé mutat, és 5 percenként jön pár 20-50-100 új.
Pl.:<a href="https://mobilarena.hu/tema/sql-kerdes/friss.html"target="_blank" rel="noopener noreferrer">SQL kérdések</a>Azt, hogy melyikre hányszor kattintanak, csak saját kódon belül tudom mérni. (Vagy nem tudom jól használni a Google toolját.
 )
)De akárhogy is, ott is ugyanaz lenne a helyzet a végén (Google adatbázisa), ott is van egy számláló egy rekordhoz, amit emelni kell.
Simán csak egy update?UPDATE clicks SET clicks_counter = clicks_counter + 1 WHERE link_id = 123Vagy van ennek jobb módja is? Mert nem tudom, mennyire "jó" ha folyamatosan update van a táblán (még ha erre is van kitalálva).
-
Taci
addikt
válasz
martonx
#5416
üzenetére
Utánanéztem, lehet-e natív eszközökkel inkrementális backupokat készíteni, és ezt a linket találtam: incremental-backup-using-mysqldump
MySQL, InnoDB, incremental backupAkinek van tapasztalata ebben a témakörben, kérem, segítsen megérteni, mi és hogyan működik, mert egyszerűen nem áll össze.
Hosszú lesz, szóval csak ha van egy fölös 5 percetek így karácsony előtt, csak akkor álljatok neki.A fenti linken azt írják, kell előbb egy teljes backup, aztán ahhoz képest készül majd a "különbözet" (inkrementális backup).
Követtem a leírást, a példát, el is készülnek a fájlok, de nagyon sok kérdőjel van bennem. Próbáltam végig követni, mi és miért történik, de nem értem. Összeírtam magamnak időpontokkal, hogy mikor-mi történt a rendszerben:16:59
- összes létező log fájl (mysql-bin.0000xx) törlése (teszt szerver, csak hogy tiszta lappal induljak)
17:00
- full backup"mysqldump" . " --skip-extended-insert --complete-insert--single-transaction --skip-lock-tables --flush-logs --master-data=2--user=" . $username . " --password=" . $password . " " . $dbname ." > " . $backup_folder . $backup_filename_sql;
- létrejött: backup-20211222-1700.sql (65 MB, benne minden adat)
- létrejött: mysql-bin.000001 (1 kB)
17:02
- szerver leállítása
17:03
- szerver indítása (csak hogy lássam, mi történik ilyenkor a mysql-bin fájlokkal)
- létrejött: mysql-bin.000002 (1 kB)
- módosult: mysql-bin.000001 (nagyobb lett - 769 kB)
- kérdés: Mi íródott bele, és miért ekkor?
17:04
- módosult: mysql-bin.000002 (nagyobb lett - 770 kB)
- kérdés: Mi íródott bele, és miért ekkor?
17:10
- Adatok folyamatosan kerülnek az adatbázisba, de a 01 és 02 fájlok nem változnak.
17:20
- A 01 és 02 fájlok továbbra sem módosultak.
- kérdés: A 01, 02 stb. fájlokban a saját szkriptjeim tartalmát látom. Miért?
- kérdés: ib_logfile0, ib_logfile1 stb. Ezek milyen fájlok? 262.144 kB méretűek...
17:21
- módosult: mysql-bin.000002 (nagyobb lett - 7.212 kB)
- kérdés: Miért? Mi került bele, és miért pont most?
- kérdés: 7 MB-os fájl 20 perc után? Az előző 3 hónap teljes adatbázisa 65 MB körül van... Akkor ez mi?
22:25
- semmi változás, pedig folyamatosan kerültek be új rekordok az elmúlt 4 órában
22:27
- incremental backup"mysqladmin" . " --user=" . $username ." --password=" . $password . " flush-logs";
- létrejött: mysql-bin.000003 (1 kB)
- módosult: mysql-bin.000002 (nagyobb lett - 106.819 kB)
- kérdés: 107 MB? 4 órányi adat után? 65 MB a full backup 3 hónap után...
22.39
- módosult: ib_logfile0 és ib_logfile1, de a méretük az előzőekhez képest nem változott (262.144 kB), csak a fájl időbélyegzője.
- kérdés: Ezek milyen fájlok? Mi változott bennük, ha a méretük változatlan maradt?
- módosult: az ibdata1 fájl is friss időbélyegzős lett
22.41
- módosult: ib_logfile0, ib_logfile1 és ibdata1 időbélyegzője
Úgy látszik, ez a 3 fájl szinkronban frissül (legalábbis az időbélyegzők).A full backup-hoz találtam még egy "--delete-master-logs" kapcsolót is, de az csak talán egy 1 kB körüli fájlt csinált, amiben nem volt érdemi adat, szóval azt nem is használtam.
Szóval amiket nem értek:
- 20 perc után csinált egy 7 MB-os differenciál fájlt. De az előző 3 hónap összes rekordja elfér 65 MB-ban. Akkor mi kerül 7 MB-ba 20 perc után?
- Akármelyik fájlba nézek bele (mysql-bin.0000xx), a saját szkriptjeim "tartalmát" látom. Nagyon fura. Semmilyen adat a rekordokból, csak a szkriptjeim sorai...
- A link alatt ezt írja: And we only need to save mysql-bin.000002, because it contains all changes we done after our full backup. Ebből én azt értettem (amit írt is), hogy a mysql-bin.0000xx fájlok tartalmazzák a full backup óta történt változásokat, így a fő backup mellé ezeket kell majd lementeni. De akkor a rekordokat kellene tartalmaznia, nem a szkriptjeim "kivonatát"...Valami nálam csúszik nagyon félre? Nem értem ezt az egészet.
Úgy indultam neki, hogy full backup - töltés felhőbeli tárhelyre. Aztán inkrementális backup, kis fájlok, mennek szintén felhőbe. Aztán majd valamikor (csak példa, mondjuk hetente) újra 1 full backup, és a hét hátralévő részében inkrementális, kis fájlok.
De egyrészt ezek az inkrementális fájlok hatalmas fájlok (ahhoz képest, hogy max pár 100 rekordot tartalmaznak elvileg), másrészt, a tartalmukat sem értem.Rosszul hívom meg a full- és inkrementális backupolást? Rossz fájlokat vizsgálok?
Mit rontok el?Hátha valakinek van tapasztalata a témában. Már csak az utolsó lépés (backup) hiányzik ahhoz, hogy költözhessek (szolgáltatóhoz), de ez egyelőre nagyon nem áll össze.
Köszönöm előre is, ha két bejgli közt (vagy akár csak pezső után majd) van időtök ránézni.
-
Taci
addikt
válasz
martonx
#5414
üzenetére
Ez a 2 példa jó, köszönöm.
Viszont ugye ha esetleg programhiba rontotta el az adatokat, az nem jelenti, hogy csökkenni fog az adatbázis mérete. Tehát a vizsgálatom nem helyes (a régi fájlok törlésére vonatkozólag), legalábbis nem elég. Bár ezt az esetet (programhiba) úgyis csak utólag lehet észrevenni.Nem felhőben vagyok, és 5 percenként pár 100 rekord van mentve, így muszáj vagyok sűrűn backupolni. Legalább egy 2-3 órás periódusban gondolkodom. Aztán azért lenne fontos a megfelelő vizsgálat (arról, hogy nem-e egy sérült adatbázis-állaptot mentek le), mert arra gondoltam (és úgy csináltam meg), hogy másnap a legelső backupnál törli az előző napi backupokat, kivéve a legutolsót. Így a végén minden napról lesz egy valid mentésem.
De ez még sok kérdőjeles koncepció, bár minden eleme készen van már és működik, csak ahogy írtam is, arra alapoztam, hogy ha nagyobb a lementett adatbázis az előzőnél, akkor valid is. És ez így nem biztos.
-

nyugis21
csendes tag
válasz
martonx
#5373
üzenetére
Az esemény az, ami megtörtént, a feladat az, ami elintézésre vár, el kell őket különíteni, ráadásul egészen más kapcsolatokra van szükség, lásd lentebb.
A példát csak hirtelen írtam, de nyilván minden az, amit meg kell tenni a közeljövőben.
Azt még nem tudom, mi lesz, ha a feladat meghiúsul, majd kiderül, ezért kellene végre eljutnom odáig, hogy legyen egy minimálisan működő séma és elkezdhessem tesztelni.A táblák közötti kapcsolatot továbbra se látom tisztán, az eseménynél egy eseményhez kell több személy, a résztvevők, míg a feladatnál egy személyhez több feladat kell, pont az ellenkezője.
Nem jövök rá, hogyan lehet az egészet kezelni, ebben kérek segítséget.
-
nyugis21
csendes tag
válasz
martonx
#5364
üzenetére
Kérlek nézd el nekem, hogy utoljára valamikor 2010 táján Access-eztem, és nem is hiányzik.
Ezt nem értem, megsértődtél, mert gratuláltam, hogy találtál egy extra megoldást, amit eddig mások nem vettek észre, hogy táblán belül is lehet kapcsolat?
Ezen miért sértődtél meg?Egy dolgot kell megoldanod, hogy amikor egy újabb eseményt felviszel a formon, akkor ki tudj (de ne legyen muszáj) választani egy szülő eseményt, pl. az előzőleg felvittet. Így tudod logikailag megoldani, hogy a jövőbeli események kapcsolódnak az őket kiváltó eseményhez, azaz a tábla önmagához kapcsolódik.
Sejtettem, hogy nem accessel van a gond, ezek szerint nem is az adatbevitellel, hanem még a táblák egymáshoz kapcsolásával.
5295-nél tartunk, eddig jutottam, ezek szerint ez így nem jó?
Itt egy példa, mondjuk a mostaniak alapján:
1. esemény:
találkozó X.20 21-23 között, résztvevők: nyugis, martonx, ispy
leírás: access adatbeviteli form probléma megbeszélése
feladatok:
nyugis - acces-ben adatbeviteli formok végigpróbálása
ispy - acces és vba kapcsolati videok listájának kigyűjtéseVagyis a következő két esemény az lesz, hogy
nyugis mondjuk X.21 9-13 között végigteszteli az access formokat, mikor milyen hibák jönnek elő
majd a harmadik esemény az lesz, hogy ispy mondjuk X.22 14-22 között webes keresgéléssel listát csinál.Ezek az események még nem léteznek, még csak feladatok, de el van döntve, hogy ezek lesznek a következők, amik az 1-es esemény, a találkozó következményei.
Vagyis nekem előre kell beírnom, hogy mi(k) lesz(nek) a következő lépés(ek) és majd akkor lesznek véglegesítve (kezdő-vég dátum, résztvevők, leírás) amikor megvalósult.
Akkor a 5295 táblák közötti kapcsolat így nem jó?
Ispy:
Mi a trükköd, hogy te tudsz kétszer is írni egymás után?Kössz, de nyugdíjas fejjel nem akarok nekiülni programozni, az egyetlen életcélom most ezt a megoldást megvalósítani, legkésőbb a karácsonyi ünnepekig, ez a nagy projektem.

-
Taci
addikt
válasz
martonx
#5335
üzenetére
Na nagy nehezen csak tudtam lockolni a táblát (phpMyAdminból nem volt olyan egyszerű), adtam hozzá egy 30 másodperces sleep-et.
Abban a 30 mp-ben valóban nem volt hozzáférés a táblához, ez viszont a weboldal felőli oldalon abban mutatkozott meg, hogy új adatot nem tudott behúzni. De ami cache-elve volt, azt szépen hozta újra, mintha semmi se történt volna.Viszont így bár lehet, hogy maga az UPDATE processz hamar lefutna (sőt, igazából folyamatosan azt nézem, hogy futtatom, és közben privát böngészésben nézem, hogy ne cache-ből szedjen adatokat, de így is gond nélkül betölt mindent) inkább napi 1x futtatom csak (az UPDATE-et használó karbantartó szkriptet), azt is valami hajnali órában, így biztosan nem fog "bad user experience"-t okozni.
Köszönöm ismételten a segítséget!
Amúgy jó lenne, ha valahogy ezt a rengeteg segítséget meg tudnám hálálni. Nem szeretek csak kérni, úgy vagyok rendben magammal, ha viszonozni is tudom.
-

nyunyu
félisten
válasz
martonx
#5335
üzenetére
2) pontban egyáltalán nem vagyok biztos.
Mostani banki GDPR projektemen kb. harmadannyian vagyunk, mint kéne, Üzlet meg csodálkozik, hogy miért tart annyi ideig a projekt, miért nem lesz idén se kész.
Csak hát a többi projektről elszállingózó emberek pótlása nagyobb prioritású.
Plusz közben szórakoztatják a fejlesztőcsapatot olyan derült égből vis majorokkal is, mint pl. moratórium, ami tavaly+idén totálisan megborította a futó IT projektek ütemezését, határidejeit, mert plusz ember az nincs a kormány ad hoc ötleteléseinek záros határidőre lefejlesztésére.
Előzőleg meg telconak dolgoztam, az se volt sokkal különb.

-
Taci
addikt
válasz
martonx
#5333
üzenetére
Na kipróbáltam, futott az update(-elő szkript) kb. fél percig, addig mint az őrült kattintgattam a weblapon (ezzel select lekérdezéseket generálva), és nem volt megakadás sehol sem.
Próbáltam direktben lockolni is a táblát (LOCK TABLE cikkek WRITE), de egyrészt ez alatt is ment minden, másrészt a SHOW OPEN TABLES által visszaadott adatokban azt láttam, hogy nincs is lockolva. (Szóval lehet, ez nem is volt jó teszt ehhez.)
Úgy csináltam anno meg amúgy (a kategóriás karbantartó szkriptet), hogy 100 rekordonként tol egy commit-ot. Nem tudom, ebben a kontextusban ennek köze van-e bármihez.
Annyit találtam még (SQL oldalon), hogy talán lehet csak az érintett mezőket lockolni:
SELECT ... FROM your_table WHERE domainname = ... FOR UPDATE
Ezzel van tapasztalatotok? Jó lehet ide?Az indexeket létrehoztam az érintett mezőkre. Viszont ott észre vettem egy "érdekességet":
Azt mondta az egyik mezőnél (utf8mb4), hogy Warning: #1071 Specified key was too long; max key length is 767 bytes. Ennek utána olvastam, és értem is az okát.A kérdésem az lenne ezzel kapcsolatban, hogy amikor ránézek az indexre, ezt látom:
varchar(255)-ből varchar(191) lett. (ugye 767 / 4).
Ez azt jelenti, ha az eredeti sztring 255 karakter hosszú, indexelve ebből csak az első 191 lesz? Vagy ez pontosan hogyan "manifesztálódik"?"bár szemlátomást, ő magával is ezt teszi
"
Ott a pont. Bár hidd el, nem szánt szándékkal teszem. 
-
nyunyu
félisten
válasz
martonx
#5329
üzenetére
csomó lehetőséged van tehermentesítened az adatbázist, anélkül, hogy belegörcsölnél az SQL minden mélységébe. Pl. cachelés
Hibernate cachelésétől ments meg Uram minket.
Olyan szinten telibeszarja a DBk többfelhasználós jellegét, hogy öröm nézni.
Addig konzisztens csak önmagával, amíg rajta kívül nincs senki más, aki módosíthatja ugyanazt az adatbázist!Ha a háttérben megupdatelsz egy rekordot, azt a Hibernate nem szokta észrevenni, és a felette lévő alkalmazásban módosul a becachelt verzió, akkor szemrebbenés nélkül hülyeséggel írja felül a már megváltozott rekordot.
Nesze neked tranzakciók függetlensége.
-
Taci
addikt
válasz
martonx
#5329
üzenetére
Persze, amint gép elé kerülök, lock-olom a táblát, és megnézem, mi történik web oldalon. Ezt még sosem néztem meg.
Az milyen megoldás lenne amúgy, hogy amíg fut az update, addig a select egy erre beállított view-t használna? Vagy így a lock-olt táblára támaszkodó view sem "érhető el"?
(Az indexet mindenképp megcsinálom - ha esetleg nem lenne. Csak ez most eszembe jutott.)
-
nyugis21
csendes tag
válasz
martonx
#5292
üzenetére
Pedig csak egy mondat volt.
1. Csak éppen értelmezhetetlen, mert az Acces nem enged két kapcsolatot két tábla között, lásd lentebb.
2. Nekem már papírom van róla, hogy nem vagyok aktív, felesleges emlékeztetned rá.
A tények:
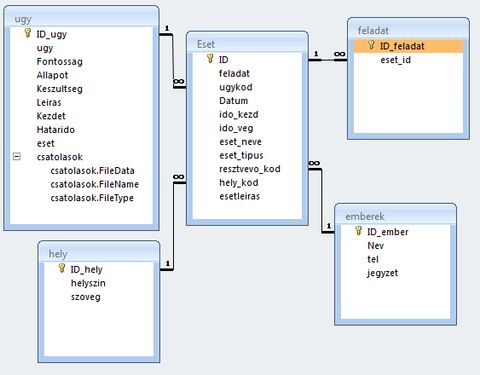
Láthatod, hogy ott van az új feladat tábla, de vagy ezt a kapcsolatot hozom létre, ami a képen látható, vagy a másikat, az Eset táblából a feladat-ot kötöm össze a Feladat tábla ID_feladat-tal.A kettő egyszerre nem megy, ezért nem értem, amit írtál.
-
nyugis21
csendes tag
válasz
martonx
#5284
üzenetére
OK,megpróbálok gyorsan áttekintést adni, de most estem vissza, megint ezernyi dolgot varrtak a nyakamba, hogy "neked úgyis mindenre van időd."

Nos, a táblákkal elakadtam, igen, amiket írtam, az megvan, és talán első lépésben annál nem kell több adat, ha igen, talán egyszerű lesz hozzáírni.
Elolvastam pár leírást, és volt egy nagyon jó javaslat, hogy mindent a legvégső lekérdezés alapján kell megtervezni, de itt elakadtam, mert többféle módon kell majd látni az adatokat.
Tehát az alapsor adott, dátum és idő, ha egyszeri dologról van szó (levél, telefon) és idősáv, ha esemény (pl. hosszú beszélgetés) kell.
Azaz itt már bejön egy kódmező, ahova az esemény formáját lehet kiválasztani.
Azután az adott esemény valamilyen ügyhöz tartozik, valamint vannak résztvevő személyek (aki levelet írt, vagy aki(kk)el beszéltem, utóbbi esetben van helyszín is.Azután jön a nagy dilemmám, hogy a kapcsolatokat hogyan tegyem bele, mert a fentiekből következik, hogy egy ügyhöz sok esemény kapcsolódik, de az egyszer dátum szerinti sorrendben van, másodszor van bizonyos események között logikai kapcsolat van (pl. megbeszélés után van több feladat, levelet írni, telefonálni, vagy következő megbeszélésre iratot beszerezni), és emellett bejön még a határidő és feltétel, hogy a következő megbeszélés csak akkor lehetséges, ha azok teljesültek.
Ezért talán az "ügy" és az "események" között kell egy újabb kódmező, ami azt jelzi, hogy teljesültek a feltételek, és tovább lehet lépni.
A végső megjelenítés történhet az adott ügy szerint, hogy mikor és mi történt, kik vettek rész és hol voltak az események - itt megint bejön a dilemma, hogy időbeli vagy logikai sorrend legyen.
Valamint kell olyan megjelenítés is, hogy adott személlyel milyen ügyeim voltak, ami sokkal bonyolultabb lesz, hiszen az adott személyről van szó, de az ügy listájában ott lesz, hogy az adott személy az ügynek csak bizonyos eseményeiben vett részt.
Nost így ennyi van a fejemben, két napja nem voltam pc előtt, majd talán holnap tudok egy képernyőképet feltenni, hogy a három táblával eddig mire jutottam.
-
nyugis21
csendes tag
válasz
martonx
#5282
üzenetére
Értelemszerűen csak az adatbevitelre vonatkozott.
sztanozs
Dehogynem, a lekérdezéseknél az adatokat csak megjeleníti, átírásuk nem lehetséges, vagy csak előre tervezetten.Még mindig várom a választ a kérdésemre, hogy hogyan lehetséges-e a táblák átmásolása különböző adatbázisok között, mert láttam, hogy a sokféle különböző minta adatbáziban lényegében ugyan azok a táblák voltak alapként.
(furcsa, hogy csak egy választ engedélyez a fórum, akkor így írom, hátha így elfogadja.)
-
-
nyunyu
félisten
válasz
martonx
#5241
üzenetére
ElasticSearchtől azóta kapok sikítófrászt, mióta kedvenc adóhatóságunk olyat szeretett volna az adószámla egyenlegek tárolására + napi újraszámolására, mert az menő, passzol a mikroszerviz architektúrába, és jól skálázható. (meg ingyenes(?) a licensze, tehát többet lehetett volna a projektből khm. megtartani)
Szerencsére főnökömnek sikerült megértetnie velük, hogy nagy mennyiségű, jól struktúrált adat kezelésére rendes RDBMS való, meg arra találnak hozzáértő szakembereket is, sok tapasztalattal.
Aztán a projekt végén, amikor csak a mi modulunk készült el határidőre (emiatt nem kellett meneszteni a projektért felelős álomtitkárt, meg az illetékes vezérőrnagyokat a sóhivatalból), akkor jól le lettünk szúrva, hogy de hát az architektúra szerint semmi SQL nem lehet a kódban, hol van az ElasticSearch, így nem veszik át.
Közben a projektmenedzseri divatlapokban olvasott menő három-négybetűs buzzwordökből összeollózott szent architektúrát szolgaian követő többi fejlesztőcsapat 2 év alatt 2 év késést hozott össze
-
Taci
addikt
válasz
martonx
#5131
üzenetére
Már fontolóra vettem, ha másért nem is, hogy lássam, ott is ugyanez-e a sebesség. Plusz ugye a Weblap készítés topikban szolgáltatóválasztásnál az Azure-t ajánlottad.
Egyelőre nem köt semmi a MySQL-hez, csupán pár lekérdezésem van, aminek jól (gyorsan) kellene működnie (az itt tárgyalt a legfontosabb), ezekben meg annyira nem lehet semmi specifikus, vagy ha igen, akkor van alternatívája.
Teszek egy próbát vele. -
nyunyu
félisten
válasz
martonx
#5131
üzenetére
Kérdés, hogy azokból a free megoldások (Oracle XE, SQL Server Express) mennyire használhatóak az ő céljaira, hiszen pár magra meg pár GB RAMra vannak korlátozva, és az adatbázis lehetséges mérete is korlátozott, ez többmillió soros táblákhoz kevés lehet.
Oracle XE:
- 2 szál
- 2GB RAM
- 12GB tárterület
- 3 DB (séma?)SQL Server Express:
- 4 mag
- 1GB RAM
- 1MB puffer
- 10GB tárterületMindenesetre egy próbát megérnek, hogy melyik hogyan hasít a gépeden.
Más kérdés, hogy a MariaDBs szintaxist, adattípusokat biztosan át kell majd írni PL/SQL-re vagy T-SQL-re.
Amennyire múltkor nézegettem a MariaDBt, szintaxisa inkább az Oracle szintaxisához áll közelebb.Nem tudom, hogy hoztad létre az ID mezőket a táblákban, ha autoincrementesek, akkor egyszerűbb lehet az SQL Server Expresst használni, mivel Oracle még mindig szekvenciákat használ, amit neked kell manuálisan
kezelni.PostgreSQL-t nem vágom.
-
Taci
addikt
válasz
martonx
#5100
üzenetére
Próbáltam azt is, kicseréltem a *-ot 2 mezőre, de csak minimálisat gyorsult, annyit, amennyivel kevesebb adatot kellett visszaadnia. (Jelen lekérdezésnél 18mp helyett 17mp.)
Próbáltam azt is, hogy a most fent lévő xampp lite mellé felraktam a legfrissebb xampp-ot is, feltöltöttem adatokkal - és ugyanez a helyzet. Szóval nem a rendszer valamilyen hibája.
Annyit vettem észre "változást", hogy a "Copying To Tmp Table On Disk" helyett most a "Sending Data" veszi el a sok időt. De a végeredmény ugyanolyan lassú.
@bambano: Distinct-et nem használok, mert a join-olás miatt 1-1 bejegyzéshez az eredeti táblában (itt item) több kategória is tartozik, azok így több külön rekordba kerültek, és mivel így van több unique rekord ugyanahhoz az item_id-hoz, így sajnos nekem nem jó. (Mivel pont hogy az item_id-ra akartam volna használni a distinct-et.)
-----
Gondoltam, megnézem már, hogy a lekérdezés melyik része lassítja le az egészet amúgy.
Így néznek ki:Where, Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idShowing rows 0 - 24 (901830 total, Query took 0.0165 seconds.)
Egy kérdés itt:
Amúgy az miért van, hogy habár azt írja ki, hogy 0.01 mp-ig tartott a lekérdezés, mégis, a lekérdezés indítása után kb. 5-7 mp-cel jelenítette csak meg ezt az eredményt?
A lekérdezés gyors, de mégis csiga lassan adja vissza az eredményt?
Most akkor a szememnek higgyek vagy az adatoknak?------
Group By, Order By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)Showing rows 0 - 24 (768981 total, Query took 0.0351 seconds.)
------Group By nélkül:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)ORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 0.0420 seconds.)
------Minden benne:
SELECT i.item_id, i.item_dateFROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Showing rows 0 - 3 (4 total, Query took 2.5095 seconds.)
------Szóval Group By (vagy Distinct) nélkül gyors a lekérdezés (bár mintha erre is lett volna cáfolat korábban, már nem tudom, annyi tesztet csináltam, már kavarodnak az eredmények).
Közben átmentem a másik (lokál) szerverre, és ott meg ugyanez a lekérdezés már az Order By-jal is belassul... Tök jó, hogy mindig változó eredményt kap, segít megtalálni a hibát...Még annyi ötletem van, hogy választok egy szolgáltatót, és reménykedem benne, hogy csak az én lokál telepítéseimen szerencsétlenkedik a kód (és én), és éles szerveren rendben lesz.
Egy kérdés:
Ha egyszer tényleg jó lenne a lekérdezés (mármint Group By vagy Distinct nélkül), hogyan tudnám "pótolni" azok funkcióját?Mert tegyük fel, ezeket a rekordokat adta vissza most eredményül:
item_id | category_id | item_date11 | 32 | 21111 | 27 | 21111 | 13 | 21135 | 7 | 165De így a 11-es item_id 3-szor szerepel, nekem pedig az kell, csak 1-szer legyen, akármi is van.
A Distinct nem jó, mert a különböző category_id-k miatt egyedi minden rekord, tehát szerepelni fog mind ugyanúgy külön.
A Group By nem jó, mert szörnyen lelassítja.Milyen megoldás jöhet még szóba?
-
Taci
addikt
válasz
martonx
#5094
üzenetére
Sajnos semmin nem változtatott, ~300e rekordnál a lekérdezésed ~13 mp alatt dob csak eredményt.
Viszont a Profiling szerint a legtöbb időt a "Copying To Tmp Table On Disk" viszi el.
És amit korábban linkeltem magyarázat szerint rendesen indexelt tábláknál ez a lépés nem is kellene, hogy ott legyen:
"But generally speaking, the indexed sort would probably be chosen, if for no other reason, because it does not need to accumulate the entire result set in temporary storage before sorting and thus uses much less temporary storage."Szóval ebből gondolom, hogy talán az indexeléssel lehet baja. Csak azt nem találom, mi. Egy (a lekérdezésnél használatlan) mezőn kívül mind indexelve van. A rajzolást már elkezdtem, hátha a végére jutok valahol.
-
Taci
addikt
válasz
martonx
#5092
üzenetére
Köszönöm, hogy ránéztél.
Nem Select *-ot fogok használni, viszont itt nincs annyi mező, hogy a query-t bonyolítsam vele, így az olvashatóság kedvéért ehhez a példához elégnek találtam.
A Group By-nak tényleg nem jártam alaposabban utána még - főleg azért nem, mert ahogy írtad is az okát, működött, így nem gondoltam, hogy baj van vele. Mindenképp alaposan utána járok most már, már amikor tegnap a hibát láttam, akkor felírtam a teendők közé.
Megfogadom a tábla- és mezőneves tanácsodat.
Nem item a tábla neve ("rendes" neve van), de a fenti (egyszerűsítő) törekvés miatt ebbe a példába elégnek találtam.
Sajnos igen, ez a db fiddle-teszt nem elég arra, hogy itt és ennyi adattal kiütközzön a hiba úgy, mint sok adattal nálam.
De köszönöm szépen az ötletet is, és hogy ránéztél.
-
Taci
addikt
válasz
martonx
#5083
üzenetére
Sikerült feltöltenem, bár nem túl sok adattal: db-fiddle
(Fel akartam tölteni ~300e rekorddal, de nem hagyta, így nem akartam az időt húzni, hogy megtaláljam, hol a határ.)Eredetileg ezt a lekérdezést írtam bele (Group By-jal és Distinct nélkül):
SELECT *FROM items AS iJOIN items_categories AS icON i.item_id = ic.item_idJOIN categories AS cON c.category_id = ic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDi.item_id NOT IN (117,132,145,209,211)GROUP BY i.item_idORDER BY i.item_date DESC LIMIT 4Viszont erre ezt a hibát dobta:
Query Error: Error: ER_WRONG_FIELD_WITH_GROUP: Expression #3 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.ic.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by -
nyunyu
félisten
válasz
martonx
#5083
üzenetére
Korábban írta, hogy MariaDBt használ, azt meg nem támogatja az SQLFiddle.
Múltkor próbáltam felrakni a gépemre a MariaDBt, de már az is gondot okozott, hogy találjak Win7 x64-en elinduló verziót, asszem a 10.3.30-ig kellett visszamennem.
Utána meg szívtam a mellécsomagolt HeidiSQL IDEvel *, aminek a működése eléggé az agyamra ment, meg az Oracle hibaüzeneteinél is semmitmondóbb hibaüzenetektől ** is a falra másztam, amikor valami szintaktikai hiba volt, vagy éppen Oracle kompatibilis módban lévő MariaDBnek nem tetszett a kód.
Kb. fél nap google után inkább feladtam, hogy az Oracle alatt hibátlanul működő példámat átírjam MariaDBre.
*: Rég dolgoztam ennyire használhatatlan IDEvel, szerintem még az SQL Server 2000-ét is alulmúlja. (2005-től jött helyette a Visual Studio stílusú SQL Server Management Studio)
**: pl. a lemaradt egy vessző hibaüzenet végére odamásol sortörések nélkül 5 sor kódot, amiből minden látszik, kivéve az, hogy melyik sor végéről maradt le.

Ennyire hülye még az Oracle SQL Developer se szokott lenni, pedig az sem a szívem csücske. -
Taci
addikt
válasz
martonx
#5067
üzenetére
Megvan a "bűnös": az ORDER BY.
SELECT DISTINCT *FROM feeds AS fJOIN feed_item_categories AS ficON f.feed_id = fic.feed_idJOIN categories AS cON c.category_id = fic.category_idWHEREc.category_id NOT IN (1,3,13,7,20)ANDf.feed_id NOT IN (101,456,3566,32345,56432,223444,344456)ORDER BY f.feed_date DESC LIMIT 4Ha benne van: Showing rows 0 - 3 (4 total, Query took 19.2113 seconds.)
Ha nincs benne: Showing rows 0 - 3 (4 total, Query took 0.0541 seconds.)Pedig indexelt a feed_date.
Amikor explain-nel megkérdezem, mi történik, ezt mondja:
table: f
type: index
possible_keys: PRIMARY
key: feed_date
rows: 298917
Extra: Using where; Using index; Using temporary; Using f...A "régi" lekérdezést miért nem lassítja be az ORDER BY?
SELECT * FROM feedsWHERE(feed_category NOT LIKE '%cat1%'OR feed_category NOT LIKE '%cat2%'OR feed_category NOT LIKE '%cat3%'OR feed_category NOT LIKE '%cat4%')ORDER BY feed_date DESC LIMIT 4(Nem pont ugyanazt csinálja, mint a felső, csak azért másoltam be, hogy meglegyen, melyik a "régi".)
0.3591 seconds
Egyértelműen látszik, mennyivel gyorsabb a JOIN-os megoldás, de az a baj, hogy, hogy kell az ORDER BY - vagy legalábbis az lenne a fontos, hogy a leszűkített (WHERE) rekordlista teljes tartalmát időrendileg csökkenő sorrendben kell visszaadnom, négyesével.
Ezért csináltam úgy már eredetileg is, hogy megvan a feltételek alkalmazása (WHERE), aztán a találati lista rendezése (ORDER BY), aztán az első 4 listázása.
Aztán következő lekérdezésnél ugyanígy, csak a már korábban kilistázott elemek kizárása (id NOT IN...).Tudnátok tanácsot adni, kérlek?
-
-

#68216320
törölt tag
válasz
martonx
#5023
üzenetére
Sorry, nem válasz akart lenni.
Sziasztok.
Kicsit off a téma, de nem teljesen.
Tudtok olyan free web api url-t, ami az EB meccsek eredményeit folyamatosan visszaadja mondjuk json vagy valami hasonló formátumban? Szeretnék egy parser-t csinálni rá, hogy saját db-ben tudjam használni ezeket. -

kw3v865
senior tag
válasz
martonx
#5015
üzenetére
Akkor is kell az index a temp táblára, ha csak 15 rekordot tartalmaz? Ennél nem nagyon lehet benne több sor. Igazából nem látok most észrevehető javulást ezzel a temp táblás cache-eléssel. Nem erre számítottam, de ez van. Ennél a függvénynél minden egyes ms sokat számít. Ha már 1 ms-sel meg tudnám javítani a futásidejét, az is eredmény lenne. Valószínűleg a minimum 9 olyan select miatt nem lehet gyorsabb, amelyek táblát is használnak, azokon már nem tudok gyorsítani.
Explain analyse-szel sajnos nem tudom kideríteni mely része a lassú a függvénynek, tehát egyelőre csak tippelgetni tudok min lehetne még optimalizálni. Talán azt próbálom még meg, hogy ami nem feltétenül szükséges, azt kiteszem a C#-ba, és az eredményt paraméterként adom meg ennek a függvénynel. Bár ezek nem túl összettt műveletek.
-
Taci
addikt
válasz
martonx
#4980
üzenetére
Amúgy azért őket választottam, mert habár saját HTML (és CSS, JS, PHP, SQL) kódot írtam, nem tudom, hogyan "védhetném" meg az oldalamat a különböző féle (általános) támadások ellen. Ezért eleve abból indultam ki, hogy WordPress-re van millió kiegészítő, van pár (elvileg) nagyon jó, ami a biztonságért felel (pl. Wordfence), így némi kompromisszummal, de tudom a 2 világot (saját kódok szabadsága + WordPress biztonsága) kombinálni.
Régebben amikor WP-t tanultam, akkor ajánlották és használtam a Wordfence plugint, azokból a reportokból láttam, hogy mennyi mindent megfogott. Fogalmam sincs, hogyan kell/lehet egy weblapot/tárhelyet másképp megvédeni, és védeni pedig sajnos van mitől, nem a backup-ok visszaállításával szeretném az időmet majd tölteni.
Na de ez teljesen más téma (security), amihez még annyira sem értek, mint az SQL-hez (és az sem sok... ), szóval muszáj vagyok már kész megoldásokat és rendszereket használni, mert erre tényleg nincs már időm/energiám 0-ról megtanulni (mert elég nagy témakör, ha jól sejtem.) -
-
Taci
addikt
válasz
martonx
#4971
üzenetére
Igen, igazatok van, nem rinyálok, nekiülök és megcsinálom. Köszönöm, hogy elolvastátok azt a hosszú bejegyzést, és köszönöm az iránymutatást.
@nyunyu: Köszönöm szépen, hogy ilyen részletesen leírtad ezt a processzt. De nem akarom megtartani a táblák jelenlegi tartalmát, naponta töröltem eddig a tesztek miatt.
majd még csak ezután fog kezdődni a kálváriád, amikor ki fog derülni, hogy MariaDB-t nem támogatnak
Így gondolom, ez sem fontos, mert a (remélhetőleg) végleges adatbázist tartalommal majd ott kezdem el felépíteni és feltölteni. -

Micsurin
nagyúr
válasz
martonx
#4794
üzenetére
Opre szerver + 2 klienses és szolgáltatásos beadandó ami páros munka lett volna egyedül toltam le mert beleszart a társam, tanárt nem láttam a félévben mindent demonstrátor tart van olyan tárgyunk (digitális rendszerek, ALU és alap tervezési feladatok) 2x tartottak konzit amúgy egy fél hiányos fél katyvasz pdf halmazból OMB módszerrel tanulj.
Nem véletlen kértem segítséget és hagytam a végére dolgot nem épp lustaságból. Szeptember 1 óta ~200 km-ert mentem motorral, mikor ügyintézni kellett beszaladnom a TO-ra vagy a városba, egy út oda és vissza ~40km.
Nem jött be...!
![;]](//cdn.rios.hu/dl/s/v1.gif) Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
-
Micsurin
nagyúr
válasz
martonx
#4767
üzenetére
De várj már a having az azért lenne, hogy az Új és a Használt gépek esetében is csak azokat vegye figyelembe a csoportosítás után az átlaghoz amik ára 5m alatti.
Ha ott átlagolok az kicsit felrúgna mindent.

Vagy én értem nagyon félre? Adatb-hez mindig is szobanövény voltam mert nem is érdekelt különösebben.Igen így kevésbé hányok a féléves beadandómtól.
-
nyunyu
félisten
válasz
martonx
#4736
üzenetére
Bármely programnyelvbe beletartoznak a deklaratív nyelvek is, ahova az SQL is tartozik.
Deklaratív programozási paradigmánál az elemi adatokat/tényeket és a köztük lévő kapcsolatokat definiálod, majd ezek elemeire kérdezel rá ("szűrsz"), gép meg majd valahogyan megoldja.
Programozási nyelvek másik, nagyobb csoportja az imperatív nyelvek csoportja, ahol az egymás után következő elemi utasításokat/lépéseket rágod a gép szájába.Programozó részéről ezek két különböző megközelítést, gondolkozásmódot igényelnek.
(Ezért nem értem, mi a francnak erőltetik pl. a lambda-függvényeket a modern imperatív programnyelvekben. Hacsak nem az a cél, hogy elméleti matematikusok svájci bicskaként tudják használni a Java 8-at?) -
bambano
titán
válasz
martonx
#4606
üzenetére
egyetértek, nincs mit magyarázni, a postgresql legalább annyit vagy többet tud, mint ez a pandas. mondjuk ez így csak a statisztikai funkciókra igaz, mert ha melléteszed például a geometriai funkcióit is, akkor a python a fasorban sincs a postgresql-hez képest.
az utóbbi időben az a vélemény alakult ki bennem a postgresql-ről, hogy a legjobb, ha hagyod az adatbáziskezelőt dolgozni.
-
Louro
őstag
válasz
martonx
#4596
üzenetére
Köszönöm. Nekem is ez a legizgalmasabb a jelenlegi munkámban, bár többnyire SQL-ben oldom meg. Persze a vizualizáció Excel-ben történik - sajnos.
Esetleg tudsz mondani egy példát, hogy mi az, amit SQL-ben nem lehet vagy rosszabbul, mint Python-ban? De érzem, hogy pont a vizualizáció lesz a kulcs
-
-
#68216320
törölt tag
válasz
martonx
#4540
üzenetére
Természetesen, otthon használatra megy, tanulásra - hobby célokra. Vagyis kb. zéró terhelés, max 1-2 user egyidejű kiszolgálása lesz. Eddig max 3000-es táblám volt a legnagyobb (retro számítógép program kategorizálásnál). De ez sem jellemző.
Szóval tényleg nem kell sok. Viszont most felhőbe menne majd cucc és jelenleg 1GB RAM-ot bérelek, szeretném, ha ennyi is maradnaDesktop gépen (win10) sikerült még az 5.7-est leszorítanom alapjáratban 30MB körüli értékre. [kép]
A 8-ast is megpróbálom valamennyire visszavenni (win10 / linux), de majd kiderül hogy sikerült. -
nyunyu
félisten
válasz
martonx
#4538
üzenetére
Egyébként MySql-nek (meg amúgy bármelyik SQL-nek) tök jól lehet paraméterezni a memória foglalását.
A teljesítmény rovására.
Nézz meg egy ingyenes, egy procimag+1GB RAMra limitált MS SQL licenszet, meg a rendes verzióját.
DB tipikusan olyan alkalmazási terület, ahol a több RAM mindig jobb.
Persze ha van három táblád, 10-10 sorral, akkor az 1GB is elég lehet, de párezer soros táblák joinolgatásánál már észreveszed a különbséget.
-
Louro
őstag
válasz
martonx
#4496
üzenetére
Én a DBA-ra nem haragszok, mert lehet rá számítani, csak sajnos más feladatokat is ellát. (Munkaszervezésbeli hiba az IT részlegen (szerintem).)
Én egy kicsit IT vénával megáldottüzleti elemző vagyok. Nem csak megírom a SELECT-et, hanem a teljesítményre és az olvashatóságra is igyekszek figyelni. De amúgy értem amire utalsz.
@nyunyu (4497): Elvileg a 2008->2012 átállás már jóvá lett hagyva és jönne az UAT, de se neki nincs erre ideje, se nálunk, mert persze ez nem fontos a fejeseknek. Tesztelés nélkül biztos nem engedném. Az nagyon amatőr lenne. A jelenlegi helyzetben meg a VPN döcög. Amúgyis nehezebben halad a munka
-
kw3v865
senior tag
válasz
martonx
#4458
üzenetére
Átgondoltam és kicsit máshogy közelítem meg a kérdést: adott egy tábla, melynek van egy ID mezője. Ehhez nem akarok hozzányúlni (később még szükség lehet rá). Azonban, szeretnék egy másik ID-t, ami természetesen szintén egyedi kell, hogy legyen. Erre azért van szükség, mert jelenleg nem a számomra megfelelő sorrendben vannak az adatok. Azaz, lényegében azt szeretném, hogy ORDER BY "ClassID", "Valami" ASC. Ez alapján legyen kiosztva az új ID, növekvő sorrendben.
Szerinted ezt hogyan lehetne megvalósítani a legegyszerűbben? Új táblát nem akarok, a már meglévővel kell dolgoznom.
Index-eléssel vajon megoldható? https://www.postgresql.org/docs/10/indexes-ordering.html
Ezáltal lenne egy indexem, de én egy új mezőt is akarok.
Ha megvan az index, majd csinálok egy CLUSTER-ezést: https://www.postgresql.org/docs/10/sql-cluster.html
Végül csak simán hozzáadok egy új serial mezőt, az jó megoldás lehet? -

Male
nagyúr
válasz
martonx
#4333
üzenetére
Közben meglett a válasz: Igen. Azt hittem, hogy itt is van limit, mint a PHP esetén, hogy pl 60s után annyi, nem fut tovább... de nem, az SQL lekérés 20 perce futott, és mivel állandóan újat is küldtek, így persze belefutott az össz. limitbe, és vége lett mindennek.
Végül kiküldték mi volt az utolsó három SQL lekérés, ami beragadt, aminél kiakadt... és így megtaláltam, mert már látványra is vacak volt, de localon lepróbálva az adatbázis másolaton is iszonyat ideig futott (kb 20 perc után kilőttem).
Csak véletlen egybeesés volt a tárhely váltással, hogy most jelentkezett, máshogy használták (egy olyan módon, amit eleve beépíteni sem akartam, mert mondtam, hogy ebből teljesítmény gond lesz, de kikövetelték... de nem használták, és közben az évek során annyira megnőtt az adatok mennyisége, hogy nem pár másodperces lefutás lett, hanem fél órás, mire elkezdték így használni). Végül elcsesztem rá fél napot, de sikerült optimalizálni a lekérést, és így leszorítani 0.4 másodpercre (Jó, amikor írtam 4 éve az eredetit, akkor kevesebbet is tudtam, ma már elve nem úgy írnám meg.) -
kezdosql
tag
válasz
martonx
#4246
üzenetére
A nekem címzett kérdésed félre ment, talán ezt a kérdést az sqlite fejlesztőinek kellene feltenned, nem én készítem az sqlite-ot
A lekezelo valaszaidbol ugy tunt, teljesen profi vagy, gondoltam meg tudod mondani, milyen fuggvenyekkel vagy hokusz-pokusszal mukodik a dolog, mert a datum kezeles egy alapveto igeny.
... arra valóban az annyit ócsárolt MS Access a legalkalmasabb.
Sokadszorra irom le, hogy olyan megoldas kell, ahol a user nem fer hozza az adatokhoz.
Milyen verziókkal vannak a gondok?
Az allando es teljesen hektikus frissitesekkel.
Egy pelda, egyik kis cegnel drupalt hasznalnak, a drupalhoz erto admin havi par oraban van fizetve.
Biztonsagi res vagy mas dolog miatt frissitenie kellett a mysql-t, amihez a drupalt is frissiteni kellett, majd kiderult, hogy nemelyik modul, amit hasznaltak, az uj verziokkal meg nem mukodik, igy ket hetig szenvedett a zadmin elvtars, amig talalt olyan mysql es drupal verziot, amivel minden modul ismet mukodott, hogy vegre ismet mukodjon a weboldal.
Amikor a fonokseg kerdezte, hogy miert volt ket hetig problemajuk az ugyfeleknek a webbel es ezt elmondta, kozoltek vele, hogy ez azt bizonyitja, hogy o csinalta az egeszet, csak azert, hogy ket heti fizetest kicsikarjon toluk, de errol ne is almodjon.Na, pont ilyet lehet kikerulni az altalad is emlitett C#-os vagy mas progik leforditasaval, attol kezdve ott az exe, adott a kornyezet, es teszi a dolgat tartosan.
-
kezdosql
tag
válasz
martonx
#4237
üzenetére
Perszehogynem, rajtad kivul mindenki eszrevette, hogy lemaradt egy karakter, talan igy lehet a bolhabol elefantot csinalni.
A crossplatform is lenyegtelen mellekszal, a verziokkal vannak a gondok.
Hasonlokeppen a grafikus opcio is lenyegtelen, a lenyeg az, hogy sqlite-ban nem tudsz menut csinalni, amibol lehet valasztani. Kell egy masik programnyelv hozza.
Amugy a neked szolo kerdest is elegansan figyelmen kivul hagytad, pedig tenyleg erdekel,
 hogy sqlite-ban miert kell a datumot szovegkent tarolni, es milyen konverziokkal lehet datumok kozott muveleteket vegezni?
hogy sqlite-ban miert kell a datumot szovegkent tarolni, es milyen konverziokkal lehet datumok kozott muveleteket vegezni? -
kezdosql
tag
válasz
martonx
#4227
üzenetére
Pont nem igy van, mert hatranyos helyzetukent ms-buzik tanitottak es a hasznalhatatlan access-t vertek belem, mint sql-t, es a mai napig nem tudok megszabadulni attol a hulye es hazug szemlelettol.:-(((
Amugy pont most irtam, megirnad, sqlite-ban a datum kezeles miert problemas es hogyan lehet megoldani, milyen konverziok es trukkok kellenek hozza?
-

Ispy
nagyúr
válasz
martonx
#4220
üzenetére
Ezt írta a végén:
"Ha lenne egy egyszeru alkalmazas, ami csak annyit tud, hogy negy adat tetszoleges kombinaciojara lehet vele keresni, sot szurni a megjelenitendo adatokat, meglenne a boldogsag."
Ebből nekem az jön le, hogy nincsen kész program, igaz közben minden mást is írt, elég zavaros, de ez alapján nincsen mit csomagolni, szvsz.
-
Louro
őstag
válasz
martonx
#4200
üzenetére
Gondolom nálatok is egy interjún, egy szimpla SELECT feladat láttán, ha azt kérné a jelentkező, hogy szóban elmondhatja e, hogy hogyan oldaná meg, ti is elkerekedett szemekkel kérnétek, hogy mondja. (Egy adatelemző ne beszéljen, kódoljon és értelmezzen
)Előző munkahelyemen Oracle volt és ott a temptáblát a többsége simán CREATE TABLE-DROP megoldással kezelte. (Mondjuk én CTE-párti vagyok, de sok kifinomult megoldás van a szemét elkerülésére.)
-
kezdosql
tag
válasz
martonx
#4107
üzenetére
A helyedben belatnam, hogy nem programrol, hanem tablakrol es kapcsolatokrol beszelunk, es mivel en vizualis tipus vagyok, rajzolgatok.
Raadasul eleg a megnevezes, es nem kell szorakozni a tipusokkal, amirol egyreszt fogalmam sincs, hogy adott verzioju mssql mi a nyavalyat kovetel meg es milyen formaban es milyen hossz kell neki - mind lenyegtelen, az ID, a szoveg es a datum mezo a lenyeg, azok meg egyertelmuen kiderulnek a megnevezesekbol.Amugy eleg erthetoen beirtam a semat, konnyen lehet latni a kapcsolatokat, de majd pontositom, hogy ti is megertsetek.
Nekem egy oldalon kell latnom a tablakat, kozottuk a kapcsolatokat, az akarhanyszaz soros create parancssorbol nehez kihamozni, mi hol van es mivel fugg ossze.
Ha az sql-hez ertes azt jelenti, hogy tobb szaz create.. parancssort beirsz es a vegen raboksz valamire, hogy ezt innen veszem, akkor valoban nem ertek sql-hez, nekem le kell rajzolnom a tablakat es memorizalnom kell, hogy melyik tablaban miket kapcsolok ossze. A hosszu lista nekem nem mond semmit, amig nem rajzoltam le a sok kis (nagyobb) teglalapot.

Most sajnos komolyabb gondokkal kel foglalkoznom, de hamarosan jovok a listaval.


















 )
)













![;]](http://cdn.rios.hu/dl/s/v1.gif) Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.
Ösztöndíj megtartására gyúrok, leakarom cserélni a Delkevic dobot egy teljes GPR rendszerre, dob + leömlők + sport kati.








 hogy sqlite-ban miert kell a datumot szovegkent tarolni, es milyen konverziokkal lehet datumok kozott muveleteket vegezni?
hogy sqlite-ban miert kell a datumot szovegkent tarolni, es milyen konverziokkal lehet datumok kozott muveleteket vegezni?Új hozzászólás Aktív témák
Hirdetés
- HiFi műszaki szemmel - sztereó hangrendszerek
- f(x)=exp(x): A laposföld elmebaj: Vissza a jövőbe!
- Autós topik
- MasterDeeJay: Asus B150-Plus D3 coffeetime mod! (DDR3)
- Milyen RAM-ot vegyek?
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- D1Rect: Nagy "hülyétkapokazapróktól" topik
- Graphics: Telefonvásárlási kálváriám....avagy clickbait cím: Horror a hardveraprón
- Telekom mobilszolgáltatások
- Proxmox VE
- További aktív témák...

- Thrustmaster TMX Force Feedback Kormány szett 3 hónap Garancia Beszámítás Házhozszállítás
- Nothing Phone (1) / 8/128GB / Kártyafüggetlen / 12Hó Garancia
- Új! AKRacing Premium Master gamer szék
- Lenovo L13 G2 Core i5 1135G7 Intel Iris XE 8Gb Ram 256Gb NVMe SSD Boltból Garanciával Számlával
- Eladó Vivo Y19S 6/128GB fehér / 12 hónap jótállás
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest