- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Google Pixel topik
- Honor Magic7 Pro - kifinomult, költséges képalkotás
- Megjelent a Poco F7, eurós ára is van már
- Samsung Galaxy Watch6 Classic - tekerd!
- Realme 9 Pro+ - szükséges plusz?
- iPhone topik
- Poco F6 5G - Turbó Rudi
- Honor Magic5 Pro - kamerák bűvöletében
- Hammer 6 LTE - ne butáskodj!
Új hozzászólás Aktív témák
-

freeapro
senior tag
válasz
 5leteseN
#2072
üzenetére
5leteseN
#2072
üzenetére
A deepseek 70b nem biztos, hogy megér ennyi felhajtást.
Gondolkodtam egy 3090 + 3060 kombón, de a mostani alaplapomban nincs elég hely a PCIe csatlakozók között. (A régi AM4-es alaplapomba bezzeg elfért volna. Épp hirdetem, ha valakit érdekel)Egyébként miért kell 4db 22GB-os VGA?
-

consono
nagyúr
válasz
5leteseN
#2030
üzenetére
Nyilván nem a titkos céges doksikat töltöd fel ide, hanem amit tanulsz például. Azt meg már úgy is felhasználták, nem értem a problémát. A NotebookLM egy tényleg jól használható tanulási/kutatási segédeszköz.
Azt meg csak halkan jegyzem meg, hogy igazán ma már csak azt tudod eldönteni, hogy kivel osztod meg a személyes adataida, azt nem nagyon, hogy megosztod e...
-
-

DarkByte
addikt
válasz
5leteseN
#1919
üzenetére
A temperature-re tekints úgy, mint egy plusz véletlen tényező, aminek a hatására minden kiadott token-nél a legvalószínűbb következő token közül mennyire a nem top1-et fogja választani. Ettől lesz választékosabb úgy mond a kimenet, így tud variánsokat adni.
Kódolásra lefordítva: egy adott kódolási problémát is sokféleképpen meg lehet oldani, ha leveszed a temperature-t, mindig egy valamit fog kiírni (feltéve hogy az input prompt, context és seed ugyanaz marad), cserébe ha ez egy rossz megoldás, nem tudod onnan kimozdítani tisztán csak újragenerálással, hanem hozzá kell nyúlni a többi dolog valamelyikéhez.
A temperature = 0 akkor jó ha a 100% reprodukálhatóságra mész, akárhányszor futtatsz le valamit (feltéve hogy persze közben a model, a videókártya driver, a videókártya, a numerikus számítást végző kód könyvtárak, és egyéb függőségek amelyek kihatnak a számításokra nem változnak).
-

5leteseN
senior tag
válasz
5leteseN
#1891
üzenetére
Most vettem észre, hogy a csatolt képen csak egy 3090 van, tehát annál a konfignál nincs mit összeadni.
Mintha írtad is volna, hogy egy korábbi állapot volt a két VGA-s összeállítás.Most már nem tudod ezt a két-VGA-s esetet megnézni az LLM betöltődéssel(hogy az összevont méretű VRAM műxik-e)?
-

Mp3Pintyo
HÁZIGAZDA
-

tothd1989
tag
válasz
5leteseN
#1841
üzenetére
Lefuttatam a benchmarkot, hogy tudjak némi használható adattal is szolgálni.
FastSD Benchmark - PyTorch--------------------------------------------------------------------------------Device - CPU,Intel(R) Core(TM) i7-14700KFStable Diffusion Model - stabilityai/sd-turboImage Size - 512x512Inference Steps - 1Benchmark Passes - 3Average Latency - 4.134 secAverage Latency(TAESD* enabled) - 1.472 sec--------------------------------------------------------------------------------*TAESD - Tiny AutoEncoder for Stable DiffusionFastSD Benchmark - OpenVINO--------------------------------------------------------------------------------Device - CPU,Intel(R) Core(TM) i7-14700KFStable Diffusion Model - rupeshs/sd-turbo-openvinoImage Size - 512x512Inference Steps - 1Benchmark Passes - 3Average Latency - 3.468 secAverage Latency(TAESD* enabled) - 1.154 sec--------------------------------------------------------------------------------*TAESD - Tiny AutoEncoder for Stable Diffusion -
tothd1989
tag
válasz
5leteseN
#1826
üzenetére
Huhh, köszi a leírást (örvendetes, hogy, itt nem divat a ménemóvasolvissza').
Ha nem lettem volna teljesen egyértelmű (elő szokott fordulni), a k80-ra azért gondoltam, mert kis pénzért a sok vram + cuda csábító volt, és ha nem válik be - nem fáj, mert nem áldoztam sokat rá.
Nagyon referenciáim nincsenek mihez, vagy mivel mérjek - én csak a nyers tulajdonságokat látom...
Kb ahhoz viszonyítok mindent, hogy a 3070TI-m mennyire gyorsan számol, mert más AI ready kártyám nincs (a 6600xt-t nem tudtam rábírni, mert szerintem ott valami gubancot okoz, hogy egy virtualizált környezetben van, meg eleve szarok a radeon driverek).
P40: ezzel az a bajom, hogy ennyiért vagy minimálisan többért már egy rtx 3080-at be lehet szerezni amit könnyebb eladni ha esetleg cserélek.
VISZONT, mivel a 3080 csak éppen hogy a 3070 TI felett van, így nyilván nem veszek magánemberként olyan kártyát CSAK AI-ra, ami jobb mint ami abban a gépben van amin játszom (főleg úgy, hogy amúgy már egy ideje kinőttem a kártyát, mert nagyon kevés 4k 144fps-re). -
5leteseN
senior tag
válasz
5leteseN
#1826
üzenetére
A 3090 vs. P40 Yt-videó alól egy hozzászólás (gép fordítással):
@FromDesertTown 1 nappal ezelőtt :
" K80 cards are interesting old monsters - only $50 for a 24GB GPU (used). Sure, it's so old that it only supports up to CUDA 11.4 v4, so you're out of luck trying to run most models, and the technical specs are very lackluster other than the high VRAM, but it's sure to tempt some folks!""A K80 kártyák érdekes régi szörnyek - mindössze 50 dollár egy 24 GB-os GPU-ért (használt). Persze, olyan régi, hogy csak a CUDA 11.4 v4-ig támogatja, így nincs szerencséje a legtöbb modell futtatásával, és a műszaki specifikációk nagyon halványak a magas VRAM-on kívül, de néhány embert biztosan csábít!"

-
tothd1989
tag
válasz
5leteseN
#1823
üzenetére
A hűtés nem hiszem, hogy probléma lenne, a blogomban leírt amd gépbe raknám, ami egy nzxt h7 flowban lakik. abban mindennek is van hely. tápcsatit írtam, hogy kell,
bár nem tudom nem e lehet esetleg direktbe a cpu konnektort beletolni, mert a tápon van még cpu output. nwm, túlterhelné azt a szálat a tápon, bár 1000w-os, de ügye pci-en van a nagyobb teljesítmény. a 24gb-ot néztem, hogy 2x12 (mivel gyakorlatilag két kártya van egyetlen nyákon), nem tudom megmondom öszintén, hogy kezeli. szeretnék valami kártyát csak AI-ra, de a legközelibb elérhető opció a 3060 vagy a 1080 (20-as szériában nem nagyon láttam olyat aminek több mint 8gb vramja van), ezért gondolkodtam el rajta. -
5leteseN
senior tag
válasz
5leteseN
#1803
üzenetére
Az előzőekhez tartozik a Thunderbolt-5 10GBps-os valósnak becsült sebességéhez képest, hogy a jelenleg többségi használatú alaplapokban a DDR4-ek 35-60GBps közötti sebességűek, kétcsatornás üzemmódban(tipikus-általános, megfizethető-kategóriás asztali-PC).
A DDR5-ösök ezt tudják duplázni 50-120GBp közé.
A Ph-Fórumos DDR5-legjobbra(házi-rekordra) én kb 150GBps-ra emlékszem, V.I.P-RAM-mal, vízhűtéssel, tuning-alaplappal, és természetesen ezek árával +a saját tesztelő-beállító munka.
A Thunderbolt-5 esetén az ezzel összehasonlítható érték ugye az azonos mértékegységbe konvertált 10GBps, és a x4-5-6-ős összeaddó érték az almás kütyük esetében(az első TH-5 100%, a többi x0,7 kb).Így összehasonlítható értékekkel kerek a "történet".
-

S_x96x_S
addikt
válasz
5leteseN
#1793
üzenetére
> Gyanítom, hogy a szűk keresztmetszet a két almás-kütyü közötti sávszélesség lesz!
több Thunderbolt 5 -ös kapcsolattal nem olyan vészes. ( Thunderbolt Bridge )
itt egy USB4 mesh network -ös leírás, a TB5 az dupla annyit tud ;
https://fangpenlin.com/posts/2024/01/14/high-speed-usb4-mesh-network/---
Az M3 Ultrának 6 db TB5 - ös kapcsolata van
Az M4 Max-osnak 4 db TB5
És mindegyiken van még tartaléknak egy "10 gigabites Ethernet-port" -
S_x96x_S
addikt
válasz
5leteseN
#1780
üzenetére
> Például: egy 10GB-os LLM mekkora VRAM-ot igényel összesen?
attól függ.
pl.
https://huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
pl. egy Qsen2.5-14B-Instruct - Q4_K_S -el 8192 Context -el
ami -->
7.88 GB model size ( + 2.16 GB Context Size ) = 10.04GB Total Size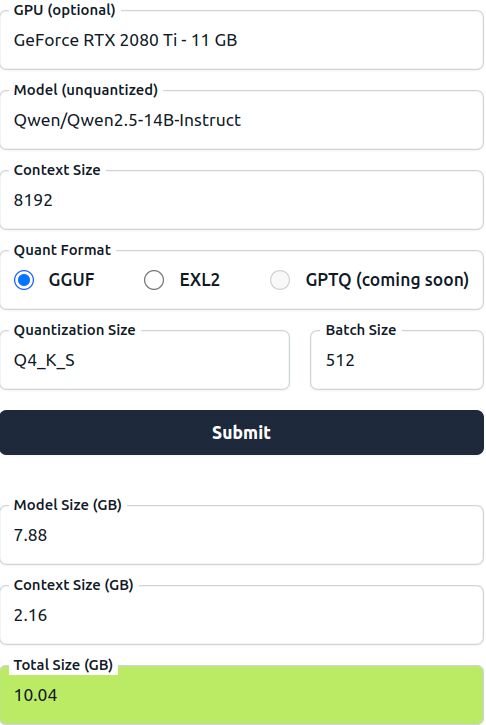
-
S_x96x_S
addikt
válasz
5leteseN
#1724
üzenetére
Az üzlet a 96GB -ra bővített RTX 4090 -ben van.
arra kéne rástartolni.
https://x.com/minotauronlucy/status/1893823097158979836a sima 48GB -ra bővített RTX4090 - már alap.
https://www.bilibili.com/video/BV1c9rHYrEdx/ -
5leteseN
senior tag
válasz
5leteseN
#1710
üzenetére
Minden rosszban van valami jó: Kb. negyedáron megcsíptem egy "majdnem-3090"-et!


Ha valaki bomba-(fél-)áron szeretne RTX 3090 tudást(AI-MI-re) akkor jelenleg ez az egyik jó választás(a nem túl sokból)
![;]](//cdn.rios.hu/dl/s/v1.gif)
Összehasonlítás a korábbi kedvencemmel(RTX 4070Ti 16GB VRAM) és a szinte Etalon-nal(RTX 3090 24GB VRAM): ITT
ITT pedig, ha durván adod elő(gondolkodom rajta ):
3090 vs. 2x2080Ti 22GB !
Figyelem: Ez utóbbi teszt "csak" játék összehasonlítás, SLI-s 2080Ti-kel, nem AI-MI teljesítményeket vet össze! A játék teljesítmény (még) nem vehető át 1-az-1-be AI-MI-k esetére, mert a jelenlegi AI-MI-k (még csak !! ) egy VGA-t tudnak használni!
Szerintem(is) kb fél-, más-fél-év múlva jönnek ki ezek a- AI-MI szoftver megoldások. Én készülök!
Én készülök! -
DarkByte
addikt
válasz
5leteseN
#1663
üzenetére
Ezen se nagyon remegnék amíg az USA védő tarfiát vet ki a kínai cuccokra, illetve alapból is idegenkedik/tiltja a kínai fejlesztéseket. (csak ETF-en keresztül tartok Nvidia-t, sok minden mással vegyesben; illetve régi hír, azóta visszakúszott az Nvidia árfolyam, rájöttek az emberek, hogy attól hogy a Deepseek olcsón tanítható volt, az igény AI futtatására nem csökkenni fog hanem növekedni, amihez ugyanúgy kell rengeteg vas)
A tanítása a Deepseek-nek amúgy "öregecske" H100-akon ment valahogy mégis
Az Nvidia nem csak AI fronton van jelen, a tudományos világ már ezen jelenség előtt is a CUDA-t preferálta párhuzamos számításra (okkal lett ennek hátán az az AI alapja úgymond). Olyan nagy kipukkanás akkor se lenne ha hirtelen mindenki ráunna erre az egészre.
-
DarkByte
addikt
válasz
5leteseN
#1653
üzenetére
Nem akarom elvenni a reményed, de attól tartok azok a kártyák már túl régiek ehhez, hiába van rajtuk relatíve sok VRAM
 Egy GTX1080 teljesítmény szintjén is épp hogy vannak, és azon is már malmozós volt nekem pár előző generációs modell (pl. SDXL). Nem beszélve hogy alapból hátrányból indulnak amiatt hogy nem CUDA képesek. Illetve elég régi architektúra, egy idős a Pascal-al. Az Nvidia CUDA szempontból most nyugdíjazta a Pascal-t, már nem jönnek rá új CUDA feature-ök driver-ből. AMD oldalt ahol eleve hátrányból indul az egész, és tkp. most növesztik ki az egész AI GPU stack-et, gyanúsan nem fognak az ilyen régi kártyák támogatására túl sokat fordítani, ha fordítani fognak egyáltalán.
Egy GTX1080 teljesítmény szintjén is épp hogy vannak, és azon is már malmozós volt nekem pár előző generációs modell (pl. SDXL). Nem beszélve hogy alapból hátrányból indulnak amiatt hogy nem CUDA képesek. Illetve elég régi architektúra, egy idős a Pascal-al. Az Nvidia CUDA szempontból most nyugdíjazta a Pascal-t, már nem jönnek rá új CUDA feature-ök driver-ből. AMD oldalt ahol eleve hátrányból indul az egész, és tkp. most növesztik ki az egész AI GPU stack-et, gyanúsan nem fognak az ilyen régi kártyák támogatására túl sokat fordítani, ha fordítani fognak egyáltalán.
Talán OpenCL-en keresztül korlátozottan meg tudod őket hajtani valamennyire.tothd1989: világos, tisztában vagyok vele. De azért ez a végtelenségig nem lesz így. Én jelenleg most mintha azt látnám az Intel esélyesebb hogy képes lesz érdemleges szoftveres körítést adni ehhez. Nem túl mélyen ástam bele maga, de azért utána keresgéltem, és az IPEX-en át már egész sok minden megoldható. Pl. Deepseek Qwen alapú modellt annyira nem volt őrületesen bonyolult beüzemelni a B280-on Ollama-val. Nyilván továbbra sem lesz olyan kulcsrakész mint a CUDA-val elindítani bármit, de egy fokkal jobb a helyzet mint AMD-éknél.
-
tothd1989
tag
válasz
5leteseN
#1645
üzenetére
Moseras képe tökéletesen deklarálja a kérdésed. Használható, ugyanakkor nem a legjobb a TOPS/kwh mutatója. Én is matekolok magamban, hogy megérné-eé esetleg beruházni 2-3db-ra, mintha kicsit megindult volna lefelé árban a 20-as széria, de talán majd akkor ha sikerül behúzni egy 5080-at és végre eltudom küldeni nyugdíjba a mostani vga-t.
Más, tettem ma egy próbát, felraktam a virtualizált gépre az LM Studiót próbaképp. Az tiszta sor, hogy a QEMU procit nem ismeri fel, de a 6600XT át van adva ennek a gépnek és nem találja meg. Nem kellene neki támogatni ezt a kártyát? -
5leteseN
senior tag
válasz
5leteseN
#1644
üzenetére
A kérdésem: A 2080-nak felépítéséből adódóan van alapvető hátránya az AI-MI szoftverek Windows-os futtatásánál a 3090, 4000-es, 5000-es sorozathoz képest, ami miatt hosszú távú hobbi alkalmazásra nem ajánlott?
..vagy csak a teljesítményhez képest fajlagosan egyre magasabb fogyasztás a hátránya a modernebb nV-s GPU?-khoz képest
-
tothd1989
tag
válasz
5leteseN
#1639
üzenetére
A szerver bulit egyelőre elengedtem, amíg nem tudok egy fix feladatot adni nekik, amire nem elég az r9, mert fűtetlen műhelyben vannak, a lakásban meg a rossebb se akarja hallgatni a zúgásukat (még az r9nek is van némi alaphangja, mivel a két nvme meghajtó mellett kapott helyet 3db hdd is, illetve levegővel van hűtve, 2 vga (a 6600xt mellett egy gt740) van benne, szóval kell hűteni). Illetve a 360e pár hónapja táppénzen van, valami nyűgje lett a táppal, csere után is lekapcsol pár perc után.
-

Zizi123
senior tag
válasz
5leteseN
#1611
üzenetére
Ez senkit nem érdekel sajnos. Se a költsége, se a fenntartása, se az üzemeltetése se semmi. A lényeg, hogy a pénz el legyen verve.
Persze megy a sírás folyamatosan, hogy nincs pénz.Mai új ötlet:
20mFt-ért SolidWorks workstation WTF?????
1TB RAM !!!! A létező legelvetemültebb konfiguráló cég sem rakott még bele 128GB-nál többet. Jellemzően 32GB, vagy max 64GB RAM-ot javasolnak.
De nem értem meg, hogy csak ezen tudnak dolgozni????
-
Zizi123
senior tag
válasz
5leteseN
#1609
üzenetére
A DeepSeek 671B Q4 404GB
Eddig is volt kisebb pl. LLama 3.1 ami benchmark %-ban, tudásában alig marad el a V3 -tól.
De az nekünk már nem jó, mert elavult, az R1 az igazi...Mondjuk azt nem teljesen értettem amikor magyarázták, hogy miért is kell nekünk a Reasoning amikor dokumentumokban akarunk kerestetni konkrét adatokat. Miért is kell az érvelés.
Amikor mondtam nekik, hogy akkor kb az kell nekünk mint a NotebookLM, csak lokálisan, és a DeepSeek LLM-el, akkor azt mondták, hogy "Igen, feldolgozott dokumentum halmazon célzott rövid kérdések (nem RAG hanem a teljes dokumentumon értelmezett kérdés). -
Zizi123
senior tag
válasz
5leteseN
#1590
üzenetére
Hááát igen, ezek a nagy kérdések.
Én is azt tapasztaltam, és olvastam, hogy a dual CPU közel sem 2x sebesség, arról nem beszélve, hogy drágább is maga a rendszer. Már a CPU is, de utána az alaplap a ház, valószínűleg a táp is...
A kérdés, hogy nekem szükségem van-e rá.
Mert ha 1db 64 mag 128 szálas CPU kiszolgálja bőven, akkor nem szórakozok 2x32 maggal drágábban. -

repvez
addikt
válasz
5leteseN
#1346
üzenetére
közelében jársz a dolgoknak, de egyelöre én megelégednék olyannal ami egyszerü .
Mert nem érzem most sem egy megugorhatatlan dolognak, azt, hogy ha megadok egy paramétert akkro azt elvileg már tudja, hogy milyen képlettel kellene kiszámolni és kap egy eredményt ez eddig nem egy bonyi dolog. a következő lépésnek se kéne, hogy ezt az eredményt pontosan fel is ahsználja, hogy egy tervrajzot vagy egy olyan ábrát adjon vissza amin valoban csak annyi elem vagy akkora méretnek látszik amit a képlet alapján számolt.
Vagy például ha van egy PCB-d és megadod a paramétereit, hogy mekkor a befoglalo mérete és azt kéred, hoyg készitsen hozzá egy dobozt, akkor az a dobz akkora méretü legyen, hogy beleférjen amit beletennél. Mert most is volt hogy kértem töle, ,hogy egy esp nyákhoz hogyan kell mondjuk egy servót bekötni és szovegben jot irt ,de mikor azt kértem, hoyg ezt képen is mutassa meg akkor csak egy nyákra hasonlito valamit adott amin összevissza voltak a csipek és a vezetékelés is mindenfele ment , hogy messziről ugy látszodott mintha valoban egy kapcsolás lenne, de ha közelebbről megnézted akkor láttad, hogy köze sincs a valosághoz. tehát valahogy a szöveges válaszban adottakat kéne átultetni a képi kijelzéshez is, hogy egyezzen a két eredmény. -
S_x96x_S
addikt
válasz
5leteseN
#1069
üzenetére
> amiben három-VGA-s, 2011-3-as alaplapot adnak ...
> E5-2666v3 CPU-val
> (bőven elég lesz 5 évig az AI/MI-s VG-ak alá),
A CPU-nak: max 40 PCIe 3.0 sávja van. Vagyis modern GPU-t nem tudsz kihajtani vele.
és egy modern SSD-vel se tudod etetni a GPU-t.
Öt év ráadásul nagy idő. -

gabranek
senior tag
válasz
5leteseN
#1047
üzenetére
Azért durva, hogy van benne nsfw szűrő...Ráadásul mindjárt dupla is, mert a promptot is szűri, de ha ennek ellenére át is slisszan az ellenőrzésen, 90%, hogy elhomályosítja a képet
Nekem sajnos a juggernautXL modelt használva crashel a program. A PCM és turbo modelleknél pedig az ajánlott érték fölé emelve a lépésszámot (6+) nagyon leromlik a végeredmény.
A sebességével viszont semmi problémám, még quality módban is max 5-6 mp egy kép generálása. Foocusban a 4 lépéses lightning módban ha 20 mp környékén megkaptam a képet, már nagyon örültem. És ott azért a quality vagy speed opcióval összehasonlítva nagyon is érezhető volt a minőségromlás. De azokkal 5-6 perc volt egy kép.#Mp3Pintyo: egy bemutatót szívesen fogadnék az advenced mód lehetőségeiről, mert pl. az upscaling működésére eddig nem sikerült rájönnöm
-
5leteseN
senior tag
válasz
5leteseN
#1032
üzenetére
Miután feltöltöttem új X99-es "barátom" DDR3-as RAM helyeit, gondoltam, megnézem, mi a helyzet a Piacon, és "leültem"!

Ezért: 128GB RAM(4x32GB) 60€ körül DDR3-ból és 70€ körül DDR4-ből. Ráadásul az eBay-es rápillantás után nem győzöm elzavarni őket(Kösz, nem kérek árleszállításost sem, stb...), mert még mindig van egy csomó RAM-om a polcon.
Úgy hogy lazán megéri X99-re alapozott alap-rendszert összerakni(ha valakinek nincs erre a célra korábbi PC-je), mert harmad áron kijön, mint az asztali elemekből összerakott új Ryzen+DDR5 rendszer, annál ugyan 20-30%-kal kisebb CPU-RAM sebességgel, DE cserébe 2-3-szeres RAM-mérettel!
A RAM-ok esetében nem is biztos a sebesség-lemaradás, mert a szokásos Ryzen-ek csak 2-csatornás módban dolgoznak a gyorsabb DDR5-ös RAM-okkal, míg az ebben az üzemmódban nem sokkal lassabb DDR4-ek a szerverprocesszorokkal négy-csatornás üzemmódban "tolják", ősszességében tehát gyorsabbak!
Ott van még (a rövidesen learatható bónuszként) a több VGA-s üzemmód lehetősége is az X99-es platform mellett.Érdekességként:
- kínai X99-es alaplap 8xRAM, 3xVGA: 70€ körül
- Ryzen 3600X szintű CPU: 20-30€
- 128GB DDR4 RAM: 70€
- Bónusz: 2-3(-4+ +20-40€-ért) VGA használat lehetősége!!!
- kétCPU-s alaplap ártöbblete: 30-40+ €.Az nem szabad elfelejteni, hogy VGA-k 5-10(akár-15)-ször hatékonyabbak(RTX 3090), tehát egy dupla-CPU-s (csak-CPU-val dolgozó) AI-PC kb egy gyenge nVidia VGA tudását közelíti, 3-szoros fogyasztással!
A CPU-s rendszer előnye viszont, hogy a csillagászati árú(3090, és 4000-es nV-sorozat) tagjai is csak 16-24GB VRAM-mal rendelkeznek, tehát például egy 40GB-os Flux ugyan úgy CPU-rendszer-RAM összeállítást fog használni(ha van elég a drága asztali RAM-ból) kb dupla sebességgel, mint egy csak CPU+RAM-os X99-es PC.Minden jónak tűnő hír ellenére: Csak CPU-val tartósan nem éri meg AI területen ismerkedni, de (szerintem ! ) jó, és sokkal megfizethetőbb kiegészítője egy X99-es (sok-RAM-os, +sok-VGA-s) gép, mint egy ide(AI) nem optimális jelenlegi (tipikus)új asztali-PC!
Ha már a Flux.1 Image Generator szóba került: ITT lehet online próbálgatni, e-mail-es regisztrálás után.
"Nem rossz, nem rossz..."
-

#79563158
törölt tag
válasz
5leteseN
#1028
üzenetére
Szerintem pont a lényeget nem érted. Nem csak akkor jelent problémát a backdoorozott gép, amikor valamit futtatsz rajta, hanem attól a pillanattól fogva, amikor rácsatlakoztattad a hálózatra. Ha volt rajta backdoor és rácsatlakoztattad, akkor már sanszos, hogy hiába húzod ki, mert nullánál nagyobb az esélye, hogy mire kihúzod már pivotoltak egy másik eszközödre.
Hogy miért nem hiszek benne, hogy megtalálnák a backdoort:
A Stuxnet évekig maradt rejtve, a Juniper backdoor szintén, a SolarWinds hónapokig. Ezek mind szuperbiztonságos hálózatokon mentek úgy, hogy olyan cybersecurity szakemberek vizsgálták a hálózatot akiknek ez a munkájuk. Ahhoz, hogy egy random kínai dzsunka alaplap BIOS-ában megtaláljanak egy backdoort kell egy spektrumon lévö unatkozó cybersecurity szakember, aki hétvégén a CoD vagy párja helyett inkább reverse engineerkedéssel szeretné mulatni az idöt. Nem mondom, hogy nincs ilyen, de én nem mernék rá nagyobb tétben fogadni, hogy tényleg megtalálná bárki. Ezt 10+ év szakmai cybersecurity tapasztalata alapján mondom, nem csak lelkes hobbiistaként.De ez itt tényleg off. Ha neked ez belefér használd egészséggel, csak nem szeretném, hogy mások a kockázatok ismerete nélkül ugyanezt csinálják.
-
#79563158
törölt tag
válasz
5leteseN
#1019
üzenetére
Nem tartom valószínünek, hogy backdoor lenne benne (mondjuk azt sem, hogy a szakmai berkek megtalálnák a backdoort), de ha van benne, akkor nem csak akkor jelent problémát amikor érzékeny feladatokon dolgozol, hanem amikor hálózatra van kötve. Ha a belsö hálózatodon van egy backdoorozott gép, akkor gyakorlatilag a teljes hálózatod úgy kell kezelni, mintha direktben internetre lenne kötve, mivel a fertözött hostról bármilyen eszközödet tudják támadni.
Én nem feltétlenül mernék ilyet használni szigorú hálózati szegmentáció nélkül, még akkor se ha van lokális IPS/IDS/tüzfal, mindig minden eszköz azonnal patchelve és hardenelve van, nincs gyenge jelszó, stb. De ugye mindenkinek más a kockázat éhsége.
-

scream
veterán
válasz
5leteseN
#1019
üzenetére
Szeretem magam abba a hitbe ringatni, hogy a nagyobb nevű alaplapgyártóknál nem a beragadt raktárkészletek kikukázása utáni legózás eredményéhez, Pistajóska által tákolt fw-t szállítanak - így legalább, ha van rajta backdoor, valamilyen "rendezett" körülmények közötti backdoor kerül rá - ahol talán vigyáznak arra, hogy tőlük kifelé már ne kerüljön az adat.
-
-
válasz
5leteseN
#1007
üzenetére
Tetszik az elképzelés nekem is. A chatgpt "szerű" AI-hoz milyen vas kellene? vga vagy cpu? rengeteg ram? Az lenne a cél, h én feltanítom amivel akarom: bash, python skript írás, full linux ismeretek, hasonló dologgal és segítene fejleszteni. Ezt a chatgpt is tudja de jobb lenne ha otthon maradnánk az adatok

-
#1011
Komplikato
veterán
5leteseN
#1007
Komplikato
veterán
-
DarkByte
addikt
válasz
5leteseN
#1007
üzenetére
A több VGA használat tutira jön.
Pl. a Flux kapcsán is meg lehetne csinálni, hogy a T5 és a VAE rész is másik kártyán menjen, és akkor ezek a fázisok párhuzamosan tudnának menni, illetve egy-egy kártyába összesen kevesebb mindent kellene betölteni. (illetve a T5 részt nem a CPU-n kellene futtatni mint most, sokkal gyorsabb lenne, csak a 24GB-s kártyákkal egyszerűen nincs neki hely)
Jelenleg pl. ComfyUI ezt nem támogatja. Nem tudom megmondani a workflow egyes elemei melyik kártyára töltődjenek be.
De ami késik az nem siet..---
Apropó, a héten jön a ComfyUI-ba az Execution model inversion, ami rádob még egy lapáttal a workflow lehetőségekre, kvázi adva egy metaprogramozási lehetőséget. for ciklusok, változók, node-ok dinamikusan hozhatnak létre további node-okat.
Megint kinyit egy új dimenziótItt van pár demó workflow hogy mire lesz ez jó: [link]
Bár szerintem egyik sem igazán mutatja meg jól.Nekem pl. van egy több emberes InstantID workflow-m ami egy kép img2img párján azonos pozícióra azonos fejeket visz át. Azt jelentősen leegyszerűsítené például
-
DarkByte
addikt
válasz
5leteseN
#1002
üzenetére
Elvileg lett most egy nf4 (4bit kvantált?) flux dev modell is, ami megy 6/8GB-os kártyákkal Forge-on keresztül.
Viszont ComfyUI támogatása nincs, és comfyanonymous azt írja, hogy nem tervezi egyelőre támogatni, mert saját próbái szerint jóval rosszabb minőségű képet produkál mint a teljes modell.
-
-
consono
nagyúr
válasz
5leteseN
#957
üzenetére
Szerintem az AMD évekkel ezelőtt lemaradt a szoftveres körítéssel és most ennek issza meg a levét. Mindenki a CUDA-t használta, mert AMD oldalon nem volt ilyen. MEg az van, hogy amíg az NVidia elkezdett az ML/AI gyorsítással foglalkozni és ezzel bankot robbantott, az AMD inkább a szuperszámítógépek felé nyitott...
-
gabranek
senior tag
válasz
5leteseN
#952
üzenetére
Szia!
RX 6750 XT/12Gb. Asrock B460M Steel Legend, i5-10400F, 2 x 16Gb 3000Mhz ram, M2 NVME vinyó.
Az AMD-s indító .bat-al indítom, a defaultal el sem indult.
Picit utána gugliztam és elég sokan panaszkodnak, hogy AMD kártyával lassú a generálás...sokaknál meg semmi gond nincs vele Ezek szerint eléggé random a dolog. -

freddirty
senior tag
válasz
5leteseN
#932
üzenetére
LLM-es összehasonlításom nincs, de a tomshardware stable diffusion benchmarkot csinált tavaly:
https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarksDe itt van belőle a lényeg:
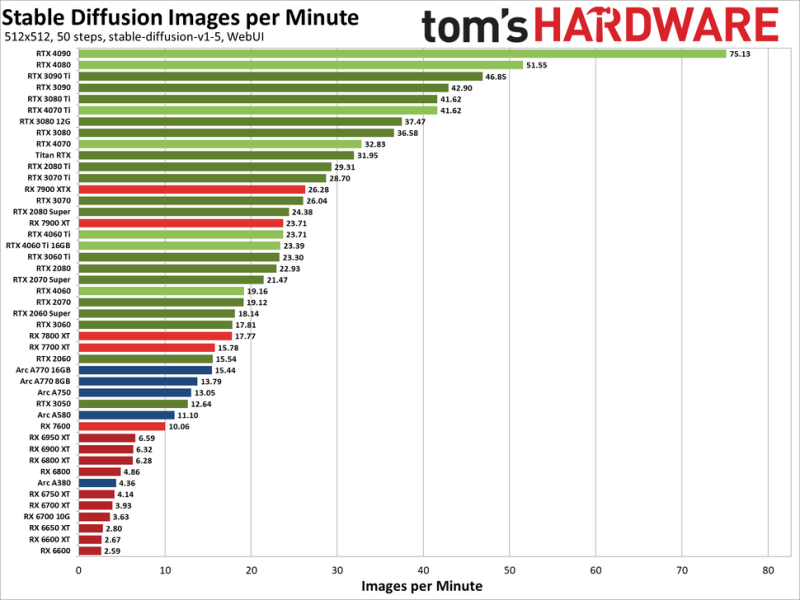
Az a baj LLM-nél. hogy a 24Gb is kevés egy 70b modell betöltéséhez. Ahhoz kellene két 3090 (48GB VRAM) és 64GB RAM. De ha csak hobbizik az ember akkor nem biztos hogy egy ilyen power hungry gépet építene csak azért hogy beférjen az a 70b modell.
Részemről 4060 16gb van az egyik gépemben és 3060 12gb a másikban. Kb. azonosak sebességben. (A 4060 újabb ugyan de szűkebb a vram sávszélessége) -
DarkByte
addikt
válasz
5leteseN
#905
üzenetére
Nem igazán létezik ilyen összehasonlítás. Teljesen más a CPU-k és GPU-k architektúrája.
Plusz a magszám különbség is tetemes. Abban a szerver prociban van 28 mag, még egy pl. Nvidia RTX 4090-ben ~16 ezer CUDA core van, ami direkt matrix műveletekre van kihegyezve.
llama.cpp-s LLM szervereket (pl. Ollama is ezt integrálja) relatíve korrekt sebességgel lehet futtanti nagy nyelvi modellt procin, arra jó lehet, bár ott sem fogod a GPU-t utolérni. Viszont könnyebb >32GB rendszer memóriát tenni alá, ami előnye.
Stable Diffusion egyenesen kínszenvedés CPU-n, azt el lehet felejteni.
-
consono
nagyúr
válasz
5leteseN
#880
üzenetére
Hányadik évében vagyunk az emberi civilizációnk? A mesterséges intelligencia új szakterulet, alig 60-70 éves. Nem értem azt amit a fejlődés lassúságáról, meg az elköltött pénzről írsz... Mennyibe került eljutni a holdra? Mennyibe került kifejleszteni az atomerőművet? Mennyi idő alatt jutottunk el a könyvnyomtatásig? Szerintem baromi gyors a fejlődés, csak az ingerküszöb is megváltozott. Meg hát be kellene látni, hogy nem lesz AGI desktopon...
-

moseras
tag
válasz
5leteseN
#867
üzenetére
ollama run gemma2:9b-instruct-q8_0
>>> Éva a 32 éves nő, 9 hónap után szült egészséges gyermeket, akkor a hasonló korú barátnője várhatóan hány hónap terhe
... sség után fog szülni?A terhesség általában 9 hónapig tart.
Ezért, ha Éva 9 hónap után szült, a hasonló korú barátnője is várhatóan **9 hónap** után fog szülni.
Fontos megjegyezni, hogy ez csak egy átlagos időtartam. A terhesség hossza minden nőnél eltérő lehet. -
-
consono
nagyúr
válasz
5leteseN
#867
üzenetére
Ez szerintem sokkal inkább amiatt van, hogy nem "prinme"-olod a kérdés feltététele előtt rendesen. Szerintem ha előtte felvezeted, hogy "Szeretném, hogy gondolkozz, logikusan, lépésről lépésre, és mondd el a következtetéseidet, ahoyg haladsz. A válaszadáshoz tudnod kell, hogy az emberek 9 hónap terhesség után születnek meg". Érdemes lehet megnézni, hogy egy ilyen felvezetés után mit válaszol. A ChatGPT-nél ez tökéletesen működik:
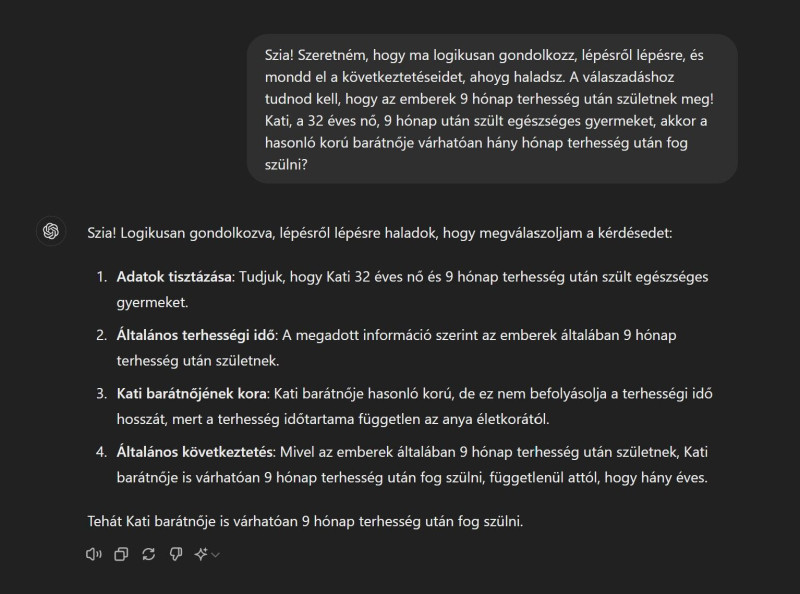
Szóval az nem teljesen igaz, hogy nem tudnak következtetéseket levonni az LLM-ek...
-
repvez
addikt
válasz
5leteseN
#626
üzenetére
igen pont ezért keresem, hogy melyek lennének azok a szoftverek amik megfelelnének a célnak, de egyelöre nem találtam .
A modellek elkészitése tiszta sor, vagy blender és 3dsmax vagy fusion 360. az ami nincs meg , hogy ezt hogy birjam rá , hogy AI által megtanuljon dolgokat virtuálisan ami után a kész termék is muködni tud.DE még olyan sem ami normális mind mappingra lehetne használni, a legtöbben csak ugymond elöre felé lehet haladni tehát csak szulö gyerek leágazásokat lehet irni, de nem lehet kombinálni öket, interakciot köztük szintén nem.
ugy értem, hogy ha beirok egy számot az egyik részhez akkor azt egy másikkal összeadjam vagy bármilyen matematikai összefuggést csináljak vele.
és a legtöbb manuális, tehát nem rendezi egycsoportba a hasonlo részeket. Aki esetleg emlékszik az IWIW féle ismertségi hálora , hogy szépen kiadta automatikusan azokat a csoportokat, hoyg kit honnan ismerhetek anélkül, hogy én manuálisan rendeztem volna egy csokorba öket.
programozoi tudás hijján meg szintén reménytelen, hogy megoldodjon , az AI-val probálkozok csinálni programot , de a legeszerübb részt se tudja hibátlanul megoldani, vagy a karakter szám limit miatt, vagy amiatt, mert amit elsöre jol csinál egy korrekcio után elrontja. -
Mp3Pintyo
HÁZIGAZDA
válasz
5leteseN
#615
üzenetére
8B: 8 milliárd paraméteres
Q[Szám]: Ez a kvantálás bitmélységét jelzi. Például a "Q5" 5 bites kvantálást jelent. Minél alacsonyabb a szám, annál jobban tömörített a modell, ami gyorsabb következtetési időt, de potenciálisan alacsonyabb pontosságot eredményezhet.
K: Ez az alkalmazott kvantálási módszer egy adott típusát jelöli. Ez az elnevezési konvenció része, de a The Bloke modelljeivel összefüggésben nem határoz meg további részleteket.
S, M, L: Ezek a betűk a kvantálási módszer különböző változataira utalnak. Az "S" például jelentheti a "small"-t vagy egy olyan változatot, amely kevesebb memóriát használ, míg az "M" jelentheti a "medium"-t vagy a méret és a pontosság közötti egyensúlyt, az "L" pedig a "large"-t vagy egy olyan változatot, amely nagyobb méret árán nagyobb pontosságra törekszik. -
DarkByte
addikt
válasz
5leteseN
#570
üzenetére
Mondjuk szinte biztos vagyok benne hogy még bőven akad inkompatibilitás, de ha olyan Proton szerűen fejlődésnek indul most hogy open source lett, azzal csak mindenki nyer. 1-2 GPU generáció múlva vissza is nézek majd erre hol tartunk. Amint egy ComfyUI-t tudok hasonló sebességgel és minden add-on-al használni mint Nvidia-n, már érdekelni fog


















![;]](http://cdn.rios.hu/dl/s/v1.gif)
 Én készülök!
Én készülök!





 :
:
























Új hozzászólás Aktív témák
Hirdetés
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- exHWSW - Értünk mindenhez IS
- Házimozi belépő szinten
- Kertészet, mezőgazdaság topik
- Milyen légkondit a lakásba?
- Nintendo Switch 2
- Google Pixel topik
- sziku69: Fűzzük össze a szavakat :)
- Formula-1
- Honor Magic7 Pro - kifinomult, költséges képalkotás
- További aktív témák...

- Easun iSolar SMW 11kW Twin Hibrid inverter // Dupla MPPT // BMS // WiFi
- GAMER PC : RYZEN 7 5700G/// 32 GB DDR4 /// RX 6700 XT 12 GB /// 512 GB NVME
- GAMER MSI LAPTOP : 15,6" 144 HZ /// i5 12450H /// 16GB DDR4/// RTX 4050 6GB/// 1TB NVME
- Manfrotto 055 magnézium fotó-videófej Q5 gyorskioldóval
- Sony ECM-W2BT
- Bomba ár! HP ProBook 450 G7 - i5-10GEN I 16GB I 256SSD I HDMI I 15,6" FHD I Cam I W11 I Gar
- AKCIÓ! Csere-Beszámítás! Manli RTX 3070Ti 8GB GDDR6X Videokártya!
- Honor 9X Lite 128GB, Kártyafüggetlen, 1 Év Garanciával
- Újszerű Asus ExpertBook B1 B1500 - 15.6" FullHD IPS - i5-1235U - 16GB - 512GB SSD - Win11 - Garancia
- BESZÁMÍTÁS! MSI B550 7 5800X 16GB DDR4 512GB SSD RTX 3070 8GB Rampage SHIVA Enermax 750W
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged