- Google Pixel topik
- Amazfit Active 2 NFC - jó kör
- Samsung Galaxy S22 Ultra - na, kinél van toll?
- Mobil flották
- Apple iPhone 16 Pro - rutinvizsga
- Megvan a Pura 80 nemzetközi startja
- Garmin Forerunner 970 - fogd a pénzt, és fuss!
- A Samsung gyártja az első 2 nm-es Qualcomm lapkát?
- Megjelent a Poco F7, eurós ára is van már
- Okosóra és okoskiegészítő topik
Új hozzászólás Aktív témák
-
-
#1578
 freddirty
senior tag
aprokaroka87
#1576
freddirty
senior tag
aprokaroka87
#1576
freddirty
senior tag
válasz
 aprokaroka87
#1576
üzenetére
aprokaroka87
#1576
üzenetére
Akkor az már eléggé pöpec AI. A legtöbb mindenféle hülyeséget hord össze a földbe döngölve így a megbízhatóságát. Nagyjából itt van ma a határa az AI-nak az alkalmazások nagy részénél. Ha kérdezek és a válasz nem 100%-osan jó akkor inkább nem is kérdezek. Mondjuk egy programrészletet a válaszban ki tudok javítani a használat során (mert időt spórol nekem az ai nem szakértelmet), de ha egzakt 100%os válaszokat akarok mert a tudásom nem elegendő akkor ma még nem megoldás az AI.
-
freddirty
senior tag
@Mp3Pintyo: Láttam a videóidban hogy postgres vector adatbázist használsz RAG-hoz.
Idáig az anythingllm és webui RAG funkcióit próbálgattam és egyszerűbb inputokkal hasonlóan működnek mint mondjuk a Te Rejtős példád az n8n használatával.
De komolyabb doksiknál már megfekszik az AI, halucinál, kevés valóságtartalommal, hülye válaszokkal jön vissza. /több száz oldalas IT specifikációk/
Megpróbálnám az n8n-el is, hátha. Nálam picit más az IT környezet, homelab szerver amin a konténerek/szolgáltatások futnak, az egyetlen lokális a desktopomon az ollama mert ugye a videokártya a gaming gépben van
Na de a kérdés, hogy milyen postgres szerver kell a RAG-hoz n8n mögé? Van egy rakat konténer amit rá tudok tenni a szerverre, kböző verziók, official/non official image-ek. -
-
freddirty
senior tag
válasz
 DarkByte
#1081
üzenetére
DarkByte
#1081
üzenetére
Az exo-t kipróbáltam hogy másnak ne kelljen.
Csak forrás áll rendelkezésre, tehát bármilyen gépen csak teljes feljesztői környezet felállítása után fordulhat le! Bináris nyista. Dokumentáció a fejlesztői környezetről nem elérhető.
Windows masinán egy ideig próbálkoztam, de dependency probléma hegyén hátán. Meguntam egy óra után. WSL-re nem akartam átállni, van két linux szerverem is, de oda bármit csak konténerben rakok fel ez meg full fejlesztőkörnyezet. Akkor inkább Android mert az fenn van a támogatottak között és láttam hogy s23 ultrán már futtatták.
Nosza feldugtam dokkolóra az enyémet majd tmux letölt. Ott is egy rakás fordítási dependenciát nekem kellett trial-error alapon megtalálni. Kb. 1 óra tökölés után, discordjuk böngészése után végre eljutottam tényleges fordítási hibákhoz ami már nem dependency. Pl. invalid function pointer. Hát voltam én programozó, de talán ennek nem fogok már nekiállni.
Nincs ez még kész messze sem, ha valakinek véletlenül lefordul akkor lefordul. A fejlesztők látom apple eszközökön dolgoznak ott lehet jobb a szitu. De hogy legyen egy rakás elfekvő apple eszköz az elosztott llm-hez valakinek otthon az azért kevéssé valószínű
Szóval egyenlőre nem ajánlott, csak time sinker. Majd ha kész lesz, és lesz bináris/gyári konténer (ha egyáltalán valaha...) -
freddirty
senior tag
válasz
DarkByte
#1000
üzenetére
Igen pont az az ami nagyon meglepő a fluxban, hogy elsőre egy jól megírt prompt alapján egy nagyságrenddel jobb képet generál mint a szokásos. Egy SD 1.5, 2.x, XL bárminál a workflow kb. az, hogy belövöd kb. a promptot sok-sok próbálkozással (és nem leíróan, hanem szabak vesszővel elválasztva, fontossági sorrendben csökkenően), aztán generáltatsz egy nagyobb batch-el sok-sok képet, majd kiválasztod ami leginkább jellemző arra amit szeretnél, majd azt dolgozod tovább, inpaint, scale, etc... Na itt ez a munkamenet lerövidül egy jó leírópromptra, amiben egy LLM fél perc alatt segít, majd azt átírva már az akár első generálás után mehet az utómunka. Akár órákkal is kevesebb lehet egy kép elkészítése.
Így az SD el is felejtheti, hogy valaha létezett, ha nem tesz le egy hasonlót az asztalra, akkor át fog állni minden fejlesztő és AI hobbista erre. -
freddirty
senior tag
válasz
DarkByte
#994
üzenetére
Hm tényleg nagyon jó, sokkal jobb eredményt értem el az első prompt-al mint egy Stable Diffusion-al.
Még nem lokálisan csak próbaképpen az online generátorukban, github accountommal:
https://fal.ai/models/fal-ai/flux/schnell?ref=blog.fal.ai
Utánanézek mi az lokális futtatásnak a feltétele. -
freddirty
senior tag
A 3090 tényleg jó kártya, ha valaki nagyon komolyan akar otthon local AI-al foglalkozni akkor vesz kettőt használtan, és az már elég sok mindenre elég.
De azért megvannak a kockázatai. A 3090-en a vramok a kártya hátoldalára fértek már fel csak, ergo nem hűti a CPU hűtő blokk. Thermal padok kötik össze a backplate-el és hát az nem sokat ér. 90-100 fokon mennek. Játék közben nem annyira gáz, de ha bányászva volt vele akkor ott 100 fokon pörgött a vram 7/24-ben. Ergo eléggé kérdéses mikor adja fel a kártya végleg. Meg persze használt kártyánál kérdéses az még, hogy hogy volt beszerelve, meg volt-e támasztva, lógott-e, mert a böszme kártyák hajlamosak elrepedni a csatlakozó végénél. Szóval használt kártyánál azért van rizikó, ki kell fogni olyat ami tényleg nem volt f**sá bányászva (de nyilván egy eladó sem fogja a igazat mondani hisz nem érdeke).
A 40-es széria nem annyira bányászott már, de ott meg az áramfelvétel a probléma, 4090-esek power csatlakozói előbb utóbb mind elégnek.
Szóval ha kell a vram és komolyan benne van vki a local ai-ban akkor 3090/4090 max ha elég akkor mehet javításra, vagy lecserélésre. Hobbira meg egy 3060 vagy 4060 bőven elég.
De kíváncsi leszek milyen lesz az nvidia 50xx széria. Lesz-e normális 256 bites 16gb+ 5060-as kártya? -
freddirty
senior tag
válasz
 5leteseN
#932
üzenetére
5leteseN
#932
üzenetére
LLM-es összehasonlításom nincs, de a tomshardware stable diffusion benchmarkot csinált tavaly:
https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarksDe itt van belőle a lényeg:
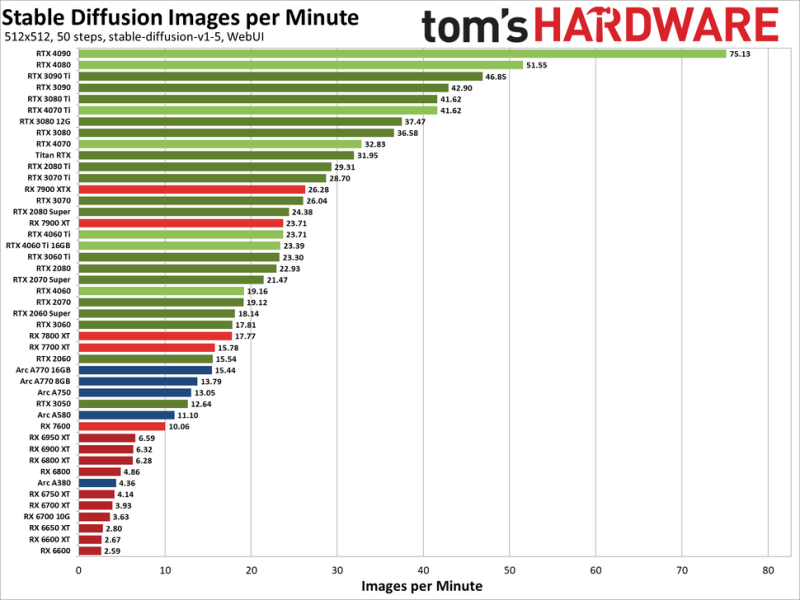
Az a baj LLM-nél. hogy a 24Gb is kevés egy 70b modell betöltéséhez. Ahhoz kellene két 3090 (48GB VRAM) és 64GB RAM. De ha csak hobbizik az ember akkor nem biztos hogy egy ilyen power hungry gépet építene csak azért hogy beférjen az a 70b modell.
Részemről 4060 16gb van az egyik gépemben és 3060 12gb a másikban. Kb. azonosak sebességben. (A 4060 újabb ugyan de szűkebb a vram sávszélessége) -
freddirty
senior tag
Én tennék egy próbá a helyedben local AI megoldással, megetetnék próbából pár doksit és kérdeznék az llmtől jól körülírva az igényemet. Ebből kiderül mennyire jó lenne ez neked. Kellene hozzá egy pc 16-32gb ram, videokártya mondjuk 8-12gb vrammal. Ollama windows-ra van, llama3 jó lesz llmnek, frontendnek RAG doksi adatbázissal meg elég kész megoldást ad egy anythingllm konténerben. Kell némi IT tudás azért.
Nekem vegyesek a tapasztalataim, valamikor jó válaszokat kapok valamikor nem. Van olyan doksi amit képtelen jól megérteni bárhogy is próbálkozom darabolni áírni, valamit igen. Szerintem elég niche technológia. Mindig oda jutok végső következtetésnek mint az utóbbi években sokszor az AI területén, hogy jó-jó de valahogy mindig még messze van az a megoldás amit elvárnánk vs. ahogy most működik. A legjobb szó rá még mindig a weak AI. -
freddirty
senior tag
na pont arra lennék kíváncsi, hogy vagyunk-e már ott, hogy egy adott speciből képes-e már az AI használható kódot generálni, amihez annyira már nem kell hozzányúlni hogy minden egyes sort át kellene néznem mert annak nincs értelme.
De ezek szerint akkor szerrinted nem.
És igen pont az olyan problémákra lenne ez jó ami, csak egyszer használatos vagy akár ideig óráig aztán ha változik/cserélődik a speci akkor úgyis neki kell esni a megoldásnak újra.
Nyilván business crritical szolgáltatásokban, meg ahol a biztonság fontos, nincs keresnivalója ilyen alacsony minőségű kódnak, de sok problémára viszont jó megoldást nyújthat, és nagyságrendekkel csökkenthetné a ráfordított (felesleges) időt.
Na mindegy akkor elengedem megint egy időre a dolgot, de remélem sikerül még fejlődnie a világnak ebbe az irányba is. -
freddirty
senior tag
Aki AI-al segített kódolásban jártas, az meg tudná mondani, hogy jár-e már a technológia ott, hogy mondjuk specifikáció alapján leszállít az AI egy szar minőségű kódot/library-t amit már csak javítani és tovább fejleszteni kell?
Csak azért kérdezem, mert régen voltam már fejlesztő (90-es évek, 2000-es évek eleje) és nem sok időm/kedvem van manapság soksok órát rádobni 1-2 feladatra, főleg ha annak a nagy része mondjuk "favágás".
Pl. ha van egy custom (nem json, nem standard, stb...) file vagy protokol leírásom többszáz mezővel, akkor le tud-e szállítani egy parsert hozzá. Nyilván technikailag meg tudnám írni hobbiból de ez pure favágás nézni a specit és számolgatni a mezőget, javítgatni ha elcsúsztam vhol a számításban stb...Biztos nem tolnám el ilyenre a szabadidőmet. Erre pont jó lenne egy AI által generált akármi, amit aztán át lehetne szervezni más funkciókba/library-kbe. Mondjuk pythonban, azt még az én öreg fejem is felfogja -
#675
freddirty
senior tag
hiperFizikus
#672
freddirty
senior tag
válasz
 hiperFizikus
#672
üzenetére
hiperFizikus
#672
üzenetére
a szokásos AI képzelgés, megfelelési kényszer stb...
Én a lokális AI-al játszogatok mostanában, abban látok végre fantáziát. Pl. le lehet venni a "kreativitását" paraméterrel és meg lehet adni neki egy körítést, hogy hogy viselkedjen. Pl én bankkártya elfogadás/kibocsátás környékén dolgozom 20+ éve, és ha megadom neki hogy akkor most ő egy payment expert ilyen olyan protokolokban jártas (MC/Visa stb.. ), majd egy RAG adatbázisban mellétolok pár hivatalos MC doksit, plus leveszem a kreativitást 0.1-re, akkor szépen lehet kérdezni tőle, hogy akkor szerinte ebben vagy abban a mezőben az intefészen milyen adatoknak kell lenni ilyen olyan szituban. Szóval végre hasznos munkára lehet fogni és nem egyszerű beszélgetésekre jó csak. De hasonlóan hasznossá tudtam tenni amikor a mai elszabott keresők már nem tudtak értelmest választ adni. Pl. kerestem lokálisan futtatható website editor/publisher megoldást ami nem wordpress. A kböző keresők idiótábbnál idiótább válaszokat adtak vissza nyilván egy csomó hirdetéstől befolyásolva. A local AI alacsony kreativitással egyből kiköpött négy tökéletes alternatívát. Szóval nem véletlenül parázik a google, hogy a keresői no1. poziját úgy ahogy van elveszti. -
freddirty
senior tag
Igen alapvetően érdekes a kérdés, de inkább filozófiai. Jelenleg oda jutott a tudomány a weak AI-al, hogy lemodellezte ahogy az agy tárol adatokat. De ettől függetlenül az agy még sokkal bonyolultabb működésű és nem is biztos hogy szükség volna egy teljes modellre. De még a letárolt nyelvi modell "visszahvása" is másképp működik, pl. az agyunk annál gyorsabban tud dönteni minél több input áll rendelkezésére, ez egy jelenlegi llm-nél pont fordítva van minél több input van annál több erőforrást(CPU/GPU) fog megenni.
Szertintem jelenleg elég parttalan ez a vita, jobb arra koncentrálni, hogy a jelenlegi weak AI-t hogyan lehet hasznosítani a legjobban.













Új hozzászólás Aktív témák
Hirdetés

- Xiaomi 15 Ultra 512GB, Kártyafüggetlen, 1 Év Garanciával
- Samsung Odyssey OLED G8! 32"/4k/240hz/0,03ms/10BIT/Freesync-G-sync/HDMI 2.1/Smart Monitor
- Új 512GB WD SN5000S Gen4 x4/ Steam Deck ready/ garancia/ ingyen fox
- i7 8700/ RX6500/ 32GB DDR4/ 512GB m.2/ garancia/ ingyen foxpost
- ASUS TUF Gaming A17 FA707NV - 17.3"FHD 144Hz - Ryzen 7 7735HS - 16GB - 1,5TB - RTX 4060 - Garancia
- Bomba ár! Fujitsu LifeBook E754 - i5-4GEN I 8GB I 256SSD I 15,6" HD I HDMI I W10 I Garancia!
- ÁRGARANCIA! Épített KomPhone i9 14900KF 64GB RAM RTX 5080 16GB GAMER PC termékbeszámítással
- LG 48GQ900-B - 48" OLED - 4K 3840x2160 - 138Hz & 0.1ms - G-Sync - FreeSync - HDMI 2.1
- Asus Rog Strix G16
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7600X 16/32/64GB RAM RTX 4060Ti 8GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest