- Minden készen áll a Galaxy Unpackedre
- Apple iPhone 16 Pro - rutinvizsga
- Samsung Galaxy Watch6 Classic - tekerd!
- Samsung Galaxy S21 FE 5G - utóirat
- Samsung Galaxy Watch5 Pro - kerek, de nem tekerek
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Samsung Galaxy S21 és S21+ - húszra akartak lapot húzni
- Samsung Galaxy A36 5G - a középső testvér
- Eltűnhet a Dinamikus Sziget
- Xiaomi 13 - felnőni nehéz
Új hozzászólás Aktív témák
-
#2059
 MasterDeeJay
veterán
Zizi123
#2058
MasterDeeJay
veterán
Zizi123
#2058
-

S_x96x_S
addikt
válasz
 Zizi123
#1966
üzenetére
Zizi123
#1966
üzenetére
> Már nem is a Quasar Alpha a király ,
Attól függ, hogy mire.
a Gemini 2.5 Pro Exp - mindenképpen érdemes tesztelni,
főleg akkor, hogyha [ jó * olcsó ] modell szükséges." Gemini 2.5 Pro Experimental is the best model in the world. "https://www.thealgorithmicbridge.com/p/google-is-winning-on-every-ai-front
-
S_x96x_S
addikt
válasz
Zizi123
#1965
üzenetére
> Ezt kitudnám váltani a OpenRouter-rel, vagy T3 Chat-el, hogy olcsóbban jöjjön ki?
a "T3 Chat" - a 8$ korlátlan árával elég furcsa;
mivel nem definiálják a "korlátlan" chat definícióját; emiatt lehet benne pár csapda.
( és jobb esetben csak throttling-al büntetik a túlhasználatot ; vagy más gyengébb modellre irányítanak át )
Úgyhogy céges szinten - én biztosan nem preferálnám.
Ráadásul nem látok API-s elérést se ;
Se GDPR betartást.
---
Az OpenRouter - ben több fantázia van,
de az OpenAI -is modellek ugyanolyan API árban vannak;
vagyis - csak ettől - nem várnék költségcsökkentést.
Viszont elérhető sok más modell is - és rugalmasabb lehet a modellek közötti váltás.
és könnyebb lehet a tesztelés is.
De ha ki tudjátok használni az olcsóbb OpenAI -"Batch API price" -t
akkor viszont az OpenAI - olcsóbb lehet - mert mintha az OpenRouter nem támogatná ezt.
( legalábbis az áraknál nem tüntetik fel külön )
Az OpenRouter - sok modelljével és sok szolgáltatójával ( Ázsia, Kína) - viszont meg is vághatjátok magatokat; főleg - hogyha ügyfél neveket és adatokat is tartalmazhatnak a chat szövegek. Mert mindig be kell kalkulálni, hogy valamelyik szolgáltató elmenti az adatokat - ami ki is szivároghat.
Egy Európai GDPR-es szolgáltatóval még védekezhetsz;
egy nagy USA szolgáltató határeset, hogyha nem GDPR kompatibilis;
de egy Kínai/Ázsiai - pedig nehezen védhető jogilag,
hogyha valamilyen pereskedésre, kártérítésre kerül sor.
( persze a jogi dolgok és a következmények elsősorban az ügyvezető és a tulajdonosok problémája - mivel őket büntetik meg. )
------Az OpenAI - legalább GDPR kompatibilis.
https://openai.com/security-and-privacy/
"OpenAI supports our customers’ compliance with privacy laws, including the GDPR and CCPA, and offers a Data Processing Addendum for customers. Our API, ChatGPT Enterprise, ChatGPT Team, and ChatGPT Edu products are covered in our SOC 2 Type 2 report and have been evaluated by an independent third-party auditor to confirm that our controls align with industry standards for security and confidentiality. Visit our security portal to learn more about our security controls and compliance activities." -
S_x96x_S
addikt
válasz
Zizi123
#1830
üzenetére
> a memória sávszélesség a legfontosabb
> a nagy LLM-ek használata közben, akkor ez eleve kizárja azt, hogy világverő legyen.Elnézést valószínüleg - félreérthető voltam.

azt irtam, hogy
"Max 4 chiplet lehet egyben és kétféle memóriát használ mindegyik chiplet:"
vagyis egy chiplet adatát adtam meg:
- gyors: 32 - 64 GB -os [ 273 Gb/s] LPDDR5X -es ( hasonló mint a Strix Halo ) ]
- és egy lassú So-DIMM -es DDR5 ~ 90Gb/s - sebességgeset.amit fel kell szorozni 4x - a 4 chipletes verzióhoz.
- max memória : 2.304 GB ( 256 GB LPDDR5X + 8x DDR5 DIMMs )
- és max sávszél - 1.45 TB/sLásd slide :


persze mire a Zeus megjelenik +2 év múlva, akkora
a [ Strix Halo / nVidia Digits ] utódja is kaphat nagyobb bővíthető memóriát ; -
S_x96x_S
addikt
válasz
Zizi123
#1828
üzenetére
(Bolt graphic )
> Mivel bővíthető egyébként, milyen memóriával?Sima laptop [ SO-DIMM DDR5 ] -el.
Max 4 chiplet lehet egyben és kétféle memóriát használ mindegyik chiplet:
- gyors: 32 - 64 GB -os [ 273 Gb/s] LPDDR5X -es ( hasonló mint a Strix Halo ) ]
- és egy lassú So-DIMM -es DDR5 ~ 90Gb/s - sebességgeset.a két típusú memóriát mintha együtt használná
és így 273+90 = 363 Gb/s sebességet adnak meg
a slide-okon - 1 chipletre. ( slide 36. )https://bolt.graphics/wp-content/uploads/2025/03/Bolt-Zeus-Announcement-External.pdf
> mire piacra kerülne lesznek sokkal jobbak, és így el sem kezdik gyártani...
IP Licenszet árulnának mint az ARM;
vagyis tervet - amit az ügyfél cutomizálhat. -

DarkByte
addikt
válasz
Zizi123
#1812
üzenetére
Mert erre is meg kell tanítania valakinek.
Amire alapból tanítva van hogy adjon egy következő token-t neked statisztikai alapon. Akkor is ha az baromság. Ezért hallucinál, mert nincs más választása alap esetben. Álmodik neked egy szöveget, Karpathy így is hívja a nyers LLM-et: internetes dokumentum szimulátor.Ahhoz hogy azt tudja mondani "nem tudom" be kell "drótozni" utólagos finomhangolással az "agyának" azon részeit ami akkor aktiválódik amikor bizonytalan a megoldásban. De ahhoz előbb ezeket meg kell találni, hogy tanító példákat lehessen rá neki írni, ami már önmagában nem egyszerű.
A ChatGPT pl. már csinál ilyet, plusz az előfeldolgozója sokszor rájön hogy az alap LLM képtelen arra amit kérsz és elkezd inkább külső eszközöket használni. De, figyelembe véve hogy a probléma halmaz az "emberiség tudása" azért van pár variáció.

De tényleg, nézzétek meg a Karpathy videót. Rengeteg dolgot helyre tesz. Igen hosszú, de lehet több szakaszban.
Nem árt megérteni hogy az LLM tudása egy veszteséges tömörítése az internet egészének. Nem emlékszik mindenre kristály tisztán. Azokat a dolgokat amelyek nagyon sokszor vannak említve a tanuló adatbázisában (vagy mesterségesen priorizálva voltak, pl. egy Wikipedia szócikk) tisztábban "emlékszik" mint amelyeket csak nagyon keveset láttot. Utóbbiaknál sokkal nagyobb az esélye hogy kitalál neked valamit.
Minő érdekes, mi is pont így működünk. Ha valami tudást keveset vagy elvétve használtál, az homályos
-
S_x96x_S
addikt
válasz
Zizi123
#1795
üzenetére
> Azért vicces, hogy 1 tenyérben elfér,
Ez nem a pici Mac Mini ( ami tenyérbe mászó )
A Mac Studió már nem fér el egy tenyérben.
és majd itt ( https://github.com/ggml-org/llama.cpp/discussions/4167 ) is lesz valami benchmark.

az r/LocalLLaMA -s csoportban már tárgyalják is ...
https://www.reddit.com/r/LocalLLaMA/comments/1j43us5/apple_releases_new_mac_studio_with_m4_max_and_m3/ -
-

5leteseN
senior tag
válasz
Zizi123
#1612
üzenetére
Én a cég részére történő (kb felesleges ? : lehet, hogy már van egy előre meghozott döntés, szóval ezen)keresés közben összeszednék a helyedben annyi infót a lehetséges költséghatékony hw/sw megoldásokról amennyit lehet! Ha ezt némi otthoni érdeklődéssel, "munkával" kiegészíted, akkor jól megbecsülhetően a kb 1, azaz egy hét intenzív és célirányos munkáddal (a Net-en) nagyon-nagyon jól eladható, friss-naprakész tudásod lesz!
Ebből a tudásból meg akár jobb állásod, saját céged?
![;]](//cdn.rios.hu/dl/s/v1.gif)
...de: ahogy látod!

-
5leteseN
senior tag
válasz
Zizi123
#1610
üzenetére
Én is azt javasolnám, hogy(ha vannak ilyen variációk), akkor a tervezett 2-3-4 hardvert futtatnám szolgáltatónál, és ezt megmutatnám döntés előtt!
És én nem terveznék a 600GB-os LLM-mel: Mp3pintyó videója mutatta, hogy a legnagyobb teljesített a leggyengébben.

Szerintem heteken belül kijon egy felezett és jobb teljesítményű modell.
Egy LLM-hez összerakott, rugalmatlan, nehezen bővíthető és változtatható "vas" a legnagyobb bukta egy ilyen gyors fejlődés alatt álló területen!
A jó megoldás egy kisebb LLM, +szakterületes-RAG/-LoRA kiegészítés a megoldás.
Ehhez sejthető feladathoz a Watt-égető CPU-s megoldások durva pénzkidobás. Vásárláskor is, üzemeltetéskor is.
Az azonos fejlettségi szintű, azonos-elégséges memóriás rendszerek összevetésében a GPU-s megoldások 6-20-szoros teljesítményt tudnak, kb 50-100% Watt-ból.Több szempontos gyors összevetés.
-
5leteseN
senior tag
válasz
Zizi123
#1603
üzenetére
Én a helyedben(ha lennék) egy olyan "átlagos", AMD-CPU-s szervert raknék össze, ami sok-csatornás DDR5 RAM-ot használ, és minél több VGA-ja van a későbbi (több-VGA-s
) fejleszthetőség lehetőségét megteremtve.
Ha egy CPU-val nem elég=>megfizethető összegű CPU "miatt" maradt és a +1 "átlagos" szerver CPU-val lesz egy immár duál rendszered, aminél, ha jól vetted a RAM-okat, akkor nem kell további, csak átcsoportosítasz!
Ha ez sem elég, akkor én vennék a már 250$ körüli-"filléres" TESLA P40-eket, amiket egymással össze lehet kötni: 24GB/db!
A számítási teljesítményük grafikás AI-MI-hez már nem elég, de linkeltem ide a forrást, ahol "azt dobta a Gép" az egyik értelmes elemzőnek, hogy szöveges LLM-ekhez belépő szintre elég!
Az Egy P40! ...a 24GB-tal!
Neked meg lesz egy szervered legkevesebb 4 VGA hellyel!
...és(szerintem) a 3-4 TESLA P40, az összegzett 3-4x24GB-jával szöveges LLM-hez már bőven elég, és szerintem a 3-4x250W-ból bőven leveri a keretedből megfizethető csak dupla-Th-tripper-es rendszereket is.
kb ezért, még mindig: A rendszer-RAM-ok (GPU-VRAM-okhoz képest)viszonylagosan lassú sebessége miatt az átlagos AMD-CPU-kat sem fogja a lehetséges maximumra kihajtani.
Az elavultnak tűnő P40-ekkel épített rendszer szerintem bőven veri a csúcs-AMD-s duál szervert is, és a CPU-ár különbözetből bőven ki is jön a P4q "farm"!
A "belépős" P40-ekhez: Szerintem fél-egy éven belül legrosszabb esetben féláron eladható, és 2-3-4 szintén összeköthető nVidia-s 4000-es RTX-re lehet váltani, kb bőven megtripázva a GPU számítási szintet, alig kevesebb RAM-okból(24GB helyett "csak" 16GB-ok/darab=>4x16GB=64GB).
Így szerintem jól skálázható egyre feljebb a rendszer, lesz pénz a következő szinthez, és teljesen költséghatékony kb minden szintnél!
A magam egyéni-hobbi szintjén én is ilyet tervezek-csinálok!
-
-

Mp3Pintyo
HÁZIGAZDA
válasz
Zizi123
#1589
üzenetére
Ha nagyobb projekt akkor nem értem a CPU-t.
Egyszerűen használhatatlanul lassú egy GPU-hoz képest.
a 2b modellek persze elérnek valamekkora sebességet de akkor is nincs értelme.
Főleg ha az egy reasoning modell, ott aztán tényleg előjön a sebesség különbség.
Mac Mx-et nem lehet a projekter használni? mert az is sokkal gyorsabb mint egy CPU. -
S_x96x_S
addikt
válasz
Zizi123
#1588
üzenetére
> DeepSeek 761B Q8 (720GB) vagy Q4 (404GB) futtatása lenne a feladat.
jó feladat .
Mivel mindenképpen lesz tanulópénz
és ha ezt limitálni szeretnéd,
akkor felhőben
( ahol lehet bérelni 1TB -os memóriás CPU -t is 1-2 órát kifizeve )
érdemes demózni a megrendelőnek, hogy mi várható,
főleg akkor - hogyha több párhuzamos kérés is vanÉn például Adatbázis + LLM integrálással ( is ) foglalkozom / érdekel / tanulom / etc.
és sok mindent újra kellett gondolnom.
Feltételezem, hogy a következő lépés nálatok is
a céges dokumentumokra valamilyen RAG ráültetése.Vagyis mielőtt összeraksz egy konfigot - teszteld felhőben
és akkor a megrendelőt nem éri meglepetés.------------
ha alapos akarsz lenni,
akkor pár napot rá kell szánni, hogy át-túrod a
https://www.reddit.com/r/LocalLLaMA/ -tami azt jelenti, hogy az idei összes poszt címét átolvasod.
( vagy csak rákeresel a :
cpu + deepseek / Xeon + deepseek / Epyc + Deepseek / -re ; stb ..)$6,000 computer to run Deepseek R1 670B Q8 locally at 6-8 tokens/sec
DeepSeek R1 671B over 2 tok/sec *without* GPU on local gaming rig!
Epyc Turin (9355P) + 256 GB / 5600 mhz - Some CPU Inference Numbers
etc.
persze SSD-vel is kísérleteznek sokan
Running Deepseek R1 IQ2XXS (200GB) from SSD actually worksvagy hybrid megoldással is.
"My DeepSeek R1 671B @ Home plan: CPU+GPU hybrid, 4xGen5 NVMe offload"--------------
A legelterjedtebb megoldások:- több - 2-4 db : M2 Ultra 192GB -al
( de 128 GB M4 MAX .. ) és TB 4 / 5 -el összekapcsolva.- bármi amit az https://github.com/exo-explore/exo ; https://github.com/zml/zml
támogat - vagyis több szerver , gpu - összekapcsolása egy mesh hálózatba.Sok új hardver is várható,
- NVidia Digits : A GTC konf ( March 17–21, 2025. ) után több infó is
várható és valószínűleg a Deepseek 671B -vel is lesz demózva,
most még csak annyit tudunk - hogy májustól + $3000 USD -tól és össze is lehet kapcsolni.
"Each Project Digits system comes equipped with 128GB of unified, coherent memory — by comparison, a good laptop might have 16GB or 32GB of RAM — and up to 4TB of NVMe storage. For even more demanding applications, two Project Digits systems can be linked together to handle models with up to 405 billion parameters (Meta’s best model, Llama 3.1, has 405 billion parameters).- AMD Strix HaLO mini -pc -k ( 128GB 4 csatornás RAM ) - összekapcsolva.
HP Z2 Mini G1a is a workstation-class mini PC with AMD Strix Halo and up to 96GB graphics memory
Szerintem az nVidia Digits -nél olcsóbb lehet.- "Orange Pi AI Studio Pro mini PC with 408GB/s bandwidth"
https://www.androidpimp.com/embedded/orange-pi-ai-studio-pro/
( Ascend 310s ; 352 TOP ; 96GB/192GB LPDDR4X ) mivel kínai proci - olcsó lesz - de egy magyar cég nem biztos, hogy kínai SDK -ban ... megbízik. )----
Ha CPU -s szervert állítasz össze, akkor legyen jövőálló.
-és ki lehessen tömni olcsó 32GB -os Radeon RT -vel
ami hybrid megoldás esetén sokat tud gyorsítani.
Vagyis nem árt sok - PCIe Gen5 - sáv a GPU -CPU kommunikációhozés AVX-512 -is hasznos lehet:
"Ollama will now use AVX-512 instructions where available for additional CPU acceleration"Az Intel AMX ( CPU utasításkészlet ) sötét ló ,
ígéretes - de nem sok Open Source-os sw támogatja.
"Why NuPIC on Intel® Xeon® Processors Makes CPUs Ideal for AI Inference
Numenta and Intel are opening a new chapter in this narrative, making it possible to deploy LLMs at scale on CPUs in a cost-effective manner.
Here are a few reasons why.
Performance: 17x Faster Than NVIDIA* A100 Tensor Core GPUs"
https://www.intel.com/content/www/us/en/developer/articles/technical/usher-in-a-new-era-of-accelerated-ai-on-cpus.html-------------
-
5leteseN
senior tag
válasz
Zizi123
#1591
üzenetére
... és arról sem szabad elfeledkezned, hogy a két CPU dupla RAM-sebességet tesz lehetővé!
Ez pedig nagyon kell a CPU-knak AZ AI-MI-ben. Ezért tippeltem azt, hogy a két gyengébb CPU az összességében kb dupla memória teljesítménnyel (szerintem) jobb AI-MI teljesítményt hoz, mint az egy(de feleslegesen erősebb)CPU, mert a felezett adatmozgatások miatt nem tudja kihasználni az emiatt felesleges számítási kapacitását.
A RAM-sebesség többet számít, mint a CPU számítási teljesítmény!Nem pontosak az idézett számok, de íme egy VGA RAM(DDR5, DDR6. ...) sebesség és teljesítmény táblázat:

Én az E5-2680 V4-es XEON-ból 4-csatornásan, 2.400MHz-en, alig tudok kifacsarni egy kicsit 41.000 MBps RAM-teljesítmény, ami a fenti táblázathoz átváltva és felkerekítve is csak 42GBps!
Két csatornával a fele a memória teljesítmény és mint írtam, 30-50-??kal kevesebb volt a CPU-s AI-MI teljesítmény!A fenti XEON CPU-m az INTEL laborban tud max 77BGps-ot.
A már elég lepukkant, és MI-re csak belépő szinten alkalmaz RADEON VEGA 56(=>64) VGA-m(jobb alsó sarok: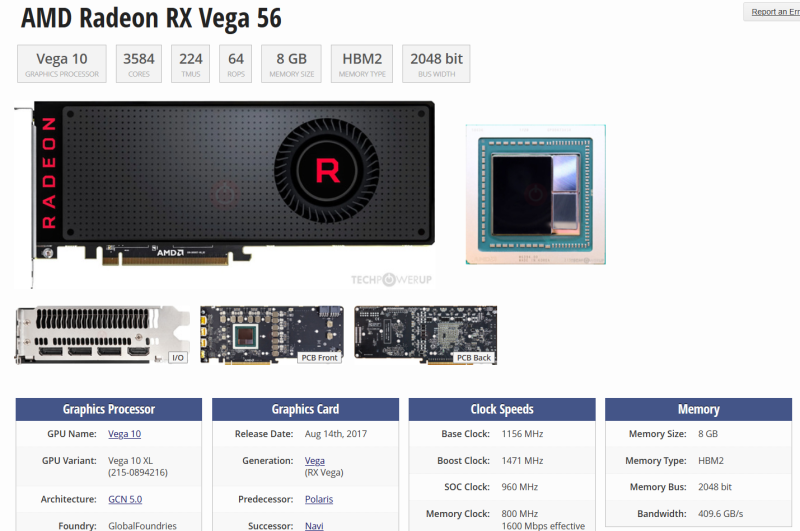
...tud kb 410GBps-ot! Opszi...
A RAM-Témában most írta az egyik tag, hogy a csúcs Ryen-je a csúcs DDR5 RAM-okkal tud 2-csatornásan 150GBps-ot."Jó" feladatot kaptál!

-
5leteseN
senior tag
válasz
Zizi123
#1588
üzenetére
Pont az AI-MI-re nem tudom a választ az 1-CPU kontra 2-CPU kérdésben, de CAD-CAM feladatoknál 1-2 éve az E5-26xx-sorozatoknál tartósan, átlagban a duál processzoros munkaállomás csak 1,4-1,7-es teljesítményt tudott az azonos, de csak 1-CPU-s összeállításhoz képest.
Ez itt most más terület, mert az adatmozgatás is nagyon sokat számít, és dupla CPU dupla memória-sebességet jelent. Nem CPU-k számítása főleg a szűk keresztmetszet az AI-MI-ben(ha jól látom), hanem jóval ennek a számolási szűk keresztmetszetnek a belépése előtt már a RAM-ok miatt satu-fék van.Ezeket az infókat összeadva Én egy "nem-csúcs-processzoros, két-CPU-s" rendszert raknák össze, a lehetséges leggyorsabb RAM-okkal, lehetséges legtöbb memória-csatornás üzemmódot használva.
A neten nézelődve, és korábbi ismereteimet összerakva dobja ezt a "Gép"! Érdekelne majd egy teszt!
Jut eszembe a végére: E5-2680V4 XEON, 64GB DDR4 RAM/4-csatornás üzemmódban a Geekbench 6. az AI teszt alatt 5.200 körüli pontot hozott!
Ugyanez a gép, de csak 32GB RAM/2-csatornás üzemmódban alig több, mint 4000 pontot.
Ez saját mérés volt, nem egy "hallottam, vkitől, aki hallotta..." infó!Azt viszont nem tudom, (mert erre nem mértem akkor), hogy a különbséget befolyásolta-e, hogy az egyik esetben 64GB volt az azonos MHz-es RAM(de 4-csatornán), míg a másik esetben csak 32GB(két csatornán).
"Sorry!"

-
Mp3Pintyo
HÁZIGAZDA
válasz
Zizi123
#1581
üzenetére
Iszonyatosan lassú tud lenni egy rendes GPU-hoz képest.
Válaszd meg nagyon jól a modellt amit használni akarsz. Ahogy csökkented a paraméterszámot úgy növekszik a sebesség is általában.
Az egyes modellek között is vannak sebesség különbségek azonos paraméterszám esetén.
Próbáld ki az LM Studio-t. Ott nagyon jól tudod finomhangolni a hardveredre a modell működését.Amúgy egy méretesebb modell Nvidia 3090-es videókártya esetén 40token/sec.
-
S_x96x_S
addikt
válasz
Zizi123
#1581
üzenetére
(LLM + CPU)
attól függ. Pl. egy extrém nagy modell ha nem fér bele a GPU - memóriájába
akkor lassabb lehet, mint egy 8 csatornás szerver 1 TB RAM -al.--------
1.) CPU -nál is a rendszermemória sávszélessége a döntő.
Vagyis egy 4, 8 netalán 12 mem csatornás szerveren sokkal gyorsabb.
valamint ha van avx2, avx512 - az is hasznos tud lenni. ( legalábbis majd az új ollama verzió hatékonyabban tud futni )2.) A Mixture of expert modelleknek kisebb a hw igénye.
3.) Simán el lehet kezdeni a próbálkozást bármilyen gépen.
csak az elején kis modellekkel kell kezdeni
és folyamatosan lehet növelni.én CPU-val az https://ollama.com/ -t használom ( linux )
de biztos van sok más alternativa.Például egy 4.7GB méretű - nem magyar nyelvre optimalizált modell
kb 4 token/s - on fut az egyik lassú 8250u procis laptopomon."""
$ ollama list qwen2.5:7b
NAME ID SIZE MODIFIED
qwen2.5:7b 845dbda0ea48 4.7 GB 3 weeks ago$ ollama run qwen2.5:7b --verbose
>>> kérek 3 magyar mesehős nevet ( és csak a nevet ) !
Kolos Kiss
Pihenő Pista
Balogh Béla
total duration: 11.26544795s
load duration: 46.268931ms
prompt eval count: 50 token(s)
prompt eval duration: 5.426s
prompt eval rate: 9.21 tokens/s
eval count: 19 token(s)
eval duration: 4.825s
eval rate: 3.94 tokens/s
""" -
S_x96x_S
addikt
válasz
Zizi123
#1417
üzenetére
> a MacBook pro-t témának, hanem S_x96x_S.
elnézést;
a MacBook Pro -t
- az "M4 Pro" vs. "M4 Max" szemléltetésére
- és az eltérő memória sávszélesség miatt hoztam fel.
és egy MacBook Pro -n ( kimaxolva 128GB-ra )
már elég sok mindent lehet futtatni.
és ha valaki komolyan foglalkozni fog ezzel a jövőben - akkor ideális lehet.--------
amúgy az "NVIDIA GeForce RTX 4060 Ti 16GB" - ( 288.0 GB/s ) bandwidth-je
elég szegényes egy desktop gpu-hoz mérten;
hasonló kategória mint az M4 PRO -é. ( ami 273 GB/sec )-------
Engem amúgy "a tényleg nagy" modellek futtatása érdekel.
remélem a jövő héten megjelennek az EXO-s tesztek és akkor kevésbé kell találgatni. -
-

Zizi123
senior tag
válasz
Zizi123
#1417
üzenetére
Akkor ez azt jelenti, hogy otthon "amatőr" szinten el lehet "játszadozni" a MacMini M4 Pro 64Gb-al (1mFt+ -ért) (5,69token), csak nem lesz gyors. Vagy ugyanezt a feladatot megtudod oldani 4db NVIDIA GeForce RTX 4060 Ti 16GB-el sokkal olcsóbban és gyorsabb 4-5x. (mondjuk ha az áram ingyé van, vagy van napelemed (és ingyé van))
Mondjuk amit nem teljesen értek, hogy ami szükséges:
1db 48Gb-os kártya
2db 24Gb-os kártya
4db 12GB-os kártya
4db (????) 16GB-os kártya (miért nem elég a 3?) -

consono
nagyúr
válasz
Zizi123
#1414
üzenetére
De miért MacBook Pro-t? Itt mi otthoni körülményekről beszéltünk, meg Mac Miniről, annak van ár, meg teljesítmény előnye a hasonló mini PC-khez képest. 300 eFt-ért nem nagyon tudsz olyan teljesítményt kihozni, mint az alap M4-es Mini. Max használtan, de az is nehéz, ha egy 12 GB-s 3060 80-90-100 pénz... És otthon igen is fontos a fogyasztás, legalább is nekem az, mert én fizetem a számlát

-
-
S_x96x_S
addikt
válasz
Zizi123
#1410
üzenetére
> Értem, csak senki nem beszélt eddig notebookról.
Az M4 lényegében egy low-power processzor.
rakják tablet-be :
- "M4-es csippel jön az új iPad Pro, ami az Apple eddigi legvékonyabb terméke"
és mac-mini -be is, és notebook-ba is.Az apple amióta kirugta az Intelt-t és átváltott a saját tervezésű chipjeire
egyáltalán nem követi a PC-s tervezési irányzatokat
és teljesen egyedi chipeket készít - széles memóriabusszal.
- 128 bites
- 256 bites
- 384 bites
- 512 bites
https://prohardver.hu/hir/kimaxolta_apple_m4_pro_max_soc.htmlA PC-nél
"Dual-channel-enabled memory controllers in a PC system architecture use two 64-bit data channels." vagyis 2x64 = 128 bit
https://en.wikipedia.org/wiki/Multi-channel_memory_architecture
A szerverek viszont 8, 12, csatornás memóriát használnak;> Pl az Intel i5-14500 CPU-ban mennyi memória controller van?
kétcsatornás DDR5 memória ;
2x64 = 128 bit ; vagyis annyi tudhat mint az alap M4
és kevesebbet mint az "M4 Pro"> Én eddig azt hittem, hogy maga a memória modulnak ,
> a rajta levő chipnek van 1 sebessége. De akkor ezek szerint nem.
Memória-sávszélesség ~~ mint az autópálya sávok.
több sáv - nagyobb átbocsátóképesség; ( ~ memory bandwith ) -
S_x96x_S
addikt
válasz
Zizi123
#1408
üzenetére
> Ez így igaz, ahogy az Apple sem tudja összehozni szerintem.
a titok nyitja, hogy több memória vezérlőt használ az Apple M4
https://en.wikipedia.org/wiki/Apple_M4M4: : LPDDR5X-7500 8x = 120 GB/sec Total Bandwidth (Unified)
M4 PRO : LPDDR5X 8533 16x = 273 GB/sec"
M4 MAX 10c : LPDDR5X 8533 24x = 410 GB/sec"
M4 MAX 12c : LPDDR5X 8533 32x = 546 GB/sec"> Nem túl sportszerű mobil GPU-val hasonlítgatni a MacMini-t
az "M4 MAX" csak a MacBook Pro -ban van, ami Notebook;
vagyis a Notebook-oos GPU-al fair összehasonlítani. -
S_x96x_S
addikt
válasz
Zizi123
#1390
üzenetére
> Hát nem tudom, de a 8GB RAM, nem tűnik túl acélosnak az alapmodellben.
Az M4 alapmodell már 16GB RAM - 300e Ft-ért
10 magos CPU
10 magos GPU
16 GB egyesített memória
256 GB‑os SSD‑tároló Lábjegyzet ¹
16 magos Neural Engine
Előoldal: két USB-C port, fejhallgató-csatlakozó
Hátoldal: három Thunderbolt 4 port, HDMI‑port, gigabites Ethernet-port
299 990 Ft> De ha akkor meg már 700e-ért olyan PC-t lehet kapni ami agyonveri a Macmini-t...
sok mindenben igen, de sok mindenben meg nem.
A gyors egyesített memória sebessége eléggé fontos,
és egy M4 PRO-s 273GB/s of memory bandwidth -et lehetetlen
összehozni 2 csatornás DDR5-ből.és 999.999 Ft egy 64GB ( 273GB/s bw ) egyesített memóriás M4 PRO,
ami már a használható közeli ..
( összehasonlításul egy nvidia RTX 4070M ( mobil ) -nak 256.0 GB/s - a mem bandwith-je ) és ött nem tudsz még 48GB-os modelleket futtatni. -
S_x96x_S
addikt
válasz
Zizi123
#1250
üzenetére
> Van vagy 1000 könyvem, van-e olyan ingyenes AI,
A könyv gerincén lévő feliratot kellene értelmezni,
( pl. több 4K-s fotóval a teljes könyvespolcról ; könyves szekrényről )
vagy a könyvek egyedi címlapját - ( ~ 1000 db Képet) ?
pl.
Az Anthropic Sonett 3.5 -el valószínüleg lehet olyan python programot generálni,
ami valamelyik képfelismerős - lokálisan telepített ollama modell-t meghívja
és a címet és az írót kiszedi a képről
és egy nagy csv-be lementi.
A csv-t pedig már könnyű beimportálni egy excel-be és rendezni manuálisan. -
Mp3Pintyo
HÁZIGAZDA
válasz
Zizi123
#1217
üzenetére
A releases résszel ne foglalkozz.
Utolsó frissítések: https://github.com/comfyanonymous/ComfyUI/commits/master/
Frissítés: git pull
Nézd meg a commitokat. most is frissült 10 órája.
Ma is tett ki az egyik fejlesztő tweetet, hogy mik változtak a felületen. Lett nagyon jó billentyűparancs kezelő. -
-
Mp3Pintyo
HÁZIGAZDA
válasz
Zizi123
#1113
üzenetére
8GByte-os GPU esetén teljesen esélytelen használod egy ekkora CLIP modellt mint a T5.
Ha a Flux.1 modellhez töltötted le ott akkor a minimális méretűre quantált verzó kell alapmodellnek és a CLIP modell sem ez ha jól emlékszem.
S3-hoz is ezt használják de azon a GPU-n egy örökkévalóság lenne képet generálni ezzel a két modellel.Tölts le egy SDXL vagy egy 1.5-ös modellt a Civitai oldalról. Ezeket nyugodtan tudod használni a saját gépeden és kellően gyorsak is lesznek (a modellekben található a CLIP és nem különálló). Az mp3pintyo youtube csatornán rengeteg trükkről találsz videót amivel tudod gyorsítani a generálás folyamatát.
-
DarkByte
addikt
Mert fogalma sincs mit kérdezel, és hallucinál mindig oda valami oda illeszthető nevet.
Ez nem újdonság, az összes LLM így működik. Olyat sose fog mondani magától hogy "bocs, de nem tudom".Az LLM továbbra is: egy nagyon komplex autocomplete. Az eddig kiírt token-ek alapján a modellben kódolt statisztikai alapon (+ a temperature beállítás miatt némi véletlenszerűséggel) eldőlő következő legvalószínűbb token-t (szótöredék) határozza meg minden egyes inference lépésben.
Amikor úgy tűnik jól tudja amit kérdezel az azért van mert rengetegszer látta ezt a valamit és az "égett be" neki az agytekervényébe. Ha valami niche dolgot kérdezel ott óriási a szórás és valami véletlenszerű dolog lesz a kimenet.
Az LLM nem tudástár. Nem ez a célja.
Ha tényekben akarod gyökeredztetni, kell neki kiegészítő segítség. Web search lehetősége, RAG, vagy valamilyen eszköz használat biztosítása. Ha azoktól megkapja az infót, azt nagyon szépen újra fogalmazza úgy hogy a kérdésedre válaszoljon. -
Mp3Pintyo
HÁZIGAZDA
Nem erre van. Dark Byte is jól mondta. Minimális magyar tartalommal tanították be. Meg kell tanulni használni. A nagy nyelvi modell nem egy internetes kereső. Arra vagy használj egy keresőt vagy egy keresőt nagy nyelvi modellel kiegészítve pl Perplexity-t. Az keres a neten és a kapott információt már fel tudja dolgozni az LLM sokkal fogyaszthatóbb formába
















![;]](http://cdn.rios.hu/dl/s/v1.gif)












Új hozzászólás Aktív témák
Hirdetés
- Motorolaj, hajtóműolaj, hűtőfolyadék, adalékok és szűrők topikja
- PROHARDVER! feedback: bugok, problémák, ötletek
- AMD Radeon™ RX 470 / 480 és RX 570 / 580 / 590
- Beszántaná a marketingért felelős részlegét az Intel
- Mielőbb díjat rakatnának a görögök az olcsó csomagokra az EU-ban
- Kínai és egyéb olcsó órák topikja
- Motoros topic
- PlayStation 5
- Minden készen áll a Galaxy Unpackedre
- VR topik
- További aktív témák...

- GARIS! Lian Li HydroShift !!!! LCD !!!! 360TL (RGB)
- Nitro ANV15-51 15.6" FHD IPS i5-13420H RTX 4050 16GB 512GB NVMe magyar vbill ujjlolv gar
- KFA2 RTX 3060 12GB GDDR6 1-CLICK OC Eladó!
- ZOTAC RTX 3060 12GB GDDR6 GAMING Eladó!
- DELL LATITUDE 7400, 14" FHD IPS, i7-8665U CPU, 16GB DDR4, 256GB SSD, W11, 27% áfás számla, 1 év gara
- ÁRGARANCIA! Épített KomPhone i5 13400F 32/64GB RAM RX 7700 XT 12GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! ASRock B250 i5 6600 16GB DDR4 256 SSD 500GB HDD GTX 1050 2GB Zalman Z1 Njoy 550W
- Geforce GTX 1050, 1050 Ti, 1060, 1650, 1660 - GT 1030 - Low profile is (LP)
- LG 27GR95UM - 27" MiniLED - UHD 4K - 160Hz 1ms - NVIDIA G-Sync - FreeSync Premium PRO - HDR 1000
- iKing.Hu - Xiaomi 14 Ultra - Ultra White - Használt, karcmentes
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged