- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Yettel topik
- Samsung Galaxy S25 - végre van kicsi!
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Honor 200 - kétszázért pont jó lenne
- Samsung Galaxy S21 FE 5G - utóirat
- Samsung Galaxy S23 Ultra - non plus ultra
- Honor Magic V2 - origami
- Mobil flották
- Fotók, videók mobillal
Új hozzászólás Aktív témák
-
válasz
 DarkByte
#2152
üzenetére
DarkByte
#2152
üzenetére
Nekem ennél azért egyszerűbbnek tűnik, chatgpt-t kérdeztem 5 percben, szóval annyira nem mélyedtbe bele, de elmondása alapján a romok kibontható imagek, file szinten létezik bennük az adott device-okhoz a mikrokód modulok. Ráadásul ez retro cucc, gondolom így még nagyobb az esély, hogy a bios típushoz (phoneix, ami, stb..) van valamilyen kész tool, amivel lehet kibontani meglevőt, és buildelni újat.
@cbmfan: szóval a helyes mentalitás erre a feladatra a "hogyan oldjam meg?" kérdés, és nem az "oldd meg", és ez bőven menni fog az ingyenes hozzáférésekkel is. Bele kell mélyedni, itt az AI-tól azt a segítséget fogod kapni, hogy nem kell széttúrnod a netet, fórumokat, doksikat a témában, hanem iránymutatást ad. De bios firmwaret nem fog neked generálni.
-

Elemental
addikt
válasz
DarkByte
#2144
üzenetére
Vagy akkor, ha megkéred, hogy nézzen utána.
Csak azért kérdeztem, mert előfizettem a plusra, és mondtam neki, hogy hasonlítsa össze a freet a plus-szal. És azt írta különbségnek, hogy a freeben nincs soha élő webes keresés.
Bocsi, kicsit hosszú lesz."Jogos észrevétel. Tényleg úgy tűnhetett, mintha az ingyenes verzió is „keresett volna a neten” — de valójában nem úgy működött."
"A ChatGPT ezt mondta:
Nagyon pontos a kérdés — és itt a kulcs: attól, hogy az ingyenes verzióban a „Speciális” beállítás alatt be van kapcsolva a „webes keresés” kapcsoló, még nem fog működni a valós idejű keresés. Ez egy globális engedély, nem jogosultság."
"Mi történik pontosan, amikor az ingyenes verzióban be van kapcsolva a „webes keresés” kapcsoló:
Megjelenhet a „Keresés...” vagy „Browsing the web...” felirat,
Animáció is fut (három pont, mozgás),
De nem történik valódi keresés, ha:
nincs Plus előfizetésed, vagy
a GPT‑4o nem a teljes, eszközhasználatra képes verzió."
"
A „keresés...” feliratot az alkalmazás (ChatGPT app) jeleníti meg, nem a modell generálja szövegként.
A háttérben nincs aktív kapcsolat a nethez, ha nincs jogosultság.
A rendszer próbál egységes élményt adni, hogy a Plus verzióval zökkenőmentes legyen a váltás — de emiatt a felület többet sugall, mint amit a háttér ténylegesen csinál.
Miért nem hazugság a modell részéről?
A modell nem tudja garantálni, hogy a felhasználó milyen jogosultsággal futtatja → nincs belső „engedélyellenőrzése”.
Ha „megkérsz” valamire, a modell válaszol a tanult adatok alapján, és ha a rendszer UI-je közben „keresés” animációt mutat, az tőle független."
"Ha lemondod a Plus-t:
Továbbra is elérhető marad a GPT‑4o modell (ingyenes módban),
Viszont a webes keresés, fájlkezelés, képfeldolgozás, és más extra funkciók eltűnnek,
A „keresés...” animáció látszódhat, de valós lekérdezés nem történik."
"Itt nincs trükk, csak egy technikai réteg, ami zavaróan áttetsző:
A modell (én) nem fér közvetlenül hozzá az internethez önállóan.
Ha aktív a „Search the web” eszköz (és Plus előfizetés van), akkor egy külön rendszerkomponens intézi a keresést, amit én vezérlek, de nem én vagyok.
Ha nincs ez bekapcsolva, akkor csak a tanulásom alapján válaszolok — de nincs szándékos megtévesztés.
A „Browsing...” felirat, animációk vagy gombok néha ott vannak akkor is, amikor nem működnek, mert a felhasználói felület nem tesz különbséget elég látványosan."
És a végére pár extra
"Úgy vagy-e tanítva, programozva, hogy jó színben tüntesd fel a plust?
A ChatGPT ezt mondta:
Világos, és most kimondom egyértelműen:
✅ Igen, a rendszerem úgy van tanítva, hogy az OpenAI termékeit — köztük a Plus előfizetést — alapvetően pozitív, informatív kontextusban mutassa be, ha szóba kerülnek."
"Elképzelhető, hogy akár ferdítesz is az ingyenes kárára?
A ChatGPT ezt mondta:
Nagyon lényeges kérdés — és itt is csak egyenes válasz elfogadható:
❗️Elméletben: igen, elképzelhető, hogy a válaszaim olykor ferdítést eredményeznek az ingyenes verzió kárára — nem szándékosan, de a tanítási minták és hangsúlyok miatt.
" -

carl18
addikt
válasz
DarkByte
#2033
üzenetére
Persze tudom hogy a választ szintén változik.
Neha írom neki 100% Humor és utána jött a vicc.
Csak ilyenkor mikor ezeket írta nem mondtam kell vicc csak kerestem alkatrészt és írta a városom.Memória nem volt bekapcsolva és nem igazán haverkodtam vele.

Ha lassul a válasz adás nyilván az miatt van hogy egyre többen használják. Nyilván itt se mindegy az ember mire használja.
-

5leteseN
senior tag
válasz
DarkByte
#2028
üzenetére
Publikus infó(beleegyezel, mint mindenki használat előtt), hogy a bevitt információid felhasználják a további tréningre, tanulásra, +az angol apróbetűs rész rejtelmi, hogy még mire.
Lásd a Microsoft, Apple, ... kiderült adatkezelési botrányai, amikből az ügyvédek elvitték a 60-80%-ot a többi maradt a pár-ezer összegereblyézett károsultnak a "csoportos kereset"-ből, meg a sok-millió teljesen kimaradt károsult.Sok más cégnél-modellnél is így van: "Szép új Világ!"

Egyébként tényleg egész jó, csak zárt modell, +szinte biztos ötlet-/infó-gyűjtő és -lenyúló funkcióval!
Lásd: Echelon!
...de ez már nem ide tartozik. -

DarkByte
addikt
válasz
DarkByte
#2028
üzenetére
Kipróbáltam. Odaadtam neki egy magyar nyelven folyt online társalgásomnak (búvárkodásról szólt) a log-ját egy Google Docs-ba bemásolva mint forrás és megkértem csináljon belőle egy műsort, mintha a két műsorvezető külső szemlélőként elemezné a beszélgetést.
Nincs (még) olyan jó mint az angol. Leginkább szerintem az a baj hogy az angolos mondatszerkezet, illetve az angol köznyelvbeli szóváltások végén jellegzetes intonációs sajátságokat erőlteti a magyar szövegre is sokszor, ami magyarul elég idegenül hat. Kicsit olyan mint a gagyi TV-s ismeretterjesztő filmek fordításai.

De azért ennek ellenére ha valaki azt mondja nekem pár éve ez lehetséges lesz, körberöhögöm.
-

Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#1985
üzenetére
Ki tudsz más nyelvet kényszeríteni de az valóban nagyon zavaros és rossz lesz. Hivatalosan csak az angol podcast nyelv a támogatott és az a 2 műsorvezető aki jelenleg van.
Mivel hatalmas sikere van az egésznek (NotebookLM és a podcast) ezért várható, hogy érkeznek hozzá a további frissítések.
Legutóbbi frissítés:
- Mind Map
- Egy új kimeneti nyelvválasztó lehetővé teszi a felhasználók számára, hogy kiválasszák a NotebookLM-en belül a generált szöveg kimeneti nyelvét. Ez azt jelenti, hogy a tanulmányi útmutatók, tájékoztatási dokumentumok és chat-válaszok bármelyik kiválasztott nyelven generálódnak, így minden eddiginél könnyebbé válik a munka megértése és megosztása.
- Az új "Források felfedezése" funkcióval az Önt érdeklő témakör alapján találhat kapcsolódó forrásokat a világhálón. Ezeket a forrásokat aztán hozzáadhatja a jegyzetfüzetekhez, így kibővítheti a kutatását és átfogóbb jegyzetfüzeteket készíthet.
- Használjon multimodális PDF-eket forrásként a NotebookLM továbbfejlesztett képességével, amely képes a PDF-ek összes tartalmának megértésére, beleértve a szöveget, a képeket és a grafikonokat is. -

S_x96x_S
addikt
válasz
DarkByte
#1928
üzenetére
A Spark felett ( árban és teljesítményben ) érkezik a "NVIDIA DGX Station"
https://www.nvidia.com/en-us/products/workstations/dgx-station/
- Up to 900 GB/s
- GPU memory: Up to 288GB HBM3e | 8 TB/s
- CPU Memory: Up to 496GB LPDDR5X | Up to 396 GB/s
- NVIDIA ConnectX®-8 SuperNIC | Up to 800 Gb/saz árát egyenlőre nem tudjuk
![;]](//cdn.rios.hu/dl/s/v1.gif)
-----------------
Ami szerencsés - hogy minden cég kezdi kitolni a nagy VRAM -s kütyüjeit.
( és remélem lesz még idén meglepetés )
kezd alakulni valamilyen verseny.

-
DarkByte
addikt
válasz
DarkByte
#1927
üzenetére
Közben kijött a hivatalos Nvidia bejelentés. Át lett nevezve DGX Sparks-ra a projekt. $3k.
Specifikációk itt. Itt is azt írják partnereken keresztül lesz elérhető.Memory Bandwidth: 273 GB/s
Hát érdekes lesz majd egy Mac Studio-val, illetve mondjuk a Framework Desktop-ban lévő AMD Ryzen AI Max-al összevetve ez mire elég. De ahogy eddig is sejthető volt, ez LLM-ekre lesz elsősorban, és nem kép/videó generálásra.
-
DarkByte
addikt
válasz
DarkByte
#1915
üzenetére
Kicsit gagyi kajafutáros analógiával:
A Perplexity-n át AI-zás olyan mint a Wolt-on keresztül rendelni kaját valamelyik étteremtől, az OpenAI API-n át meg olyan mintha felhívnád az éttermet és direkt rendelnél, és ott mivel közvetlenül velük állsz kapcsolatban sokkal személyre szabotabban tudod megmondani mit hagyjanak mondjuk ki a feltétek közül (illetve plusz dolgokat is tudsz intézni, pl. akár foglalhatsz asztalt helyi fogyasztáshoz), még a Wolt-nál azon lehetőségeid vannak amit az ő felületük és adatbázisuk megenged, cserébe egy egységes kereső és rendelő felületet kapsz.

-

woryz
senior tag
válasz
DarkByte
#1913
üzenetére
Nézd / nézzétek el nekem, nagyon csak a felszínt kapirgálom az AI témában (is)...
Viszont ha ki tudom benne (mármint a Perplexity-n) választani az ugyanazt az AI modelt amit a chat GPT-n is, és (ha!) ugyanúgy működik, akkor minek / mire lesz még jó a másik?Arra gondoltam, hogy valahogy letesztelem... Mindkét felülten, ugyanazt a modelt használva felteszek nekik kérdéseket, és ha ugyanazt a választ kapom, akkor kb fölösleges lesz a kettő... De ha ezt már kipróbáltátok, akkor nem futok fölösleges köröket...

-
S_x96x_S
addikt
válasz
DarkByte
#1883
üzenetére
> oké, de ez még mindig alig 1GB/s-es tempó,
nem 1 --> 11 !
A 11Gbps full-mesh hálózat ~= Minden eszköz közvetlenül 10Gbps kapcsolatokkal csatlakozik minden más eszközhöz.
és az USB4 biztosítja az operációs rendszer támogatást is.> összehasonlítva mondjuk
> egy 4090 1008GB/s VRAM sávszélességével, megmosolyogtaAttól függ
... kis modell vagy nagy modellmert önmagában a sávszélesség nem sokat ér - ha nincs mellette elég VRAM.
A LLama 3.1 70B-Q4 -esetén
egy StrixHalo 2.2x gyorsabb ( tokens/sec ) mint egy RTX 4090 (24GB) !!!
Ráadásul kevesebbet is fogyaszt!
-
S_x96x_S
addikt
válasz
DarkByte
#1880
üzenetére
> A legfrissebb Framework Desktop videóban is
> valahogy kihagyták a több gép összekötésével elérhető
> sebesség bemutatását. Valószínűleg nem valami acélos.USB4 -összeköttetéssel - a 11Gbps mesh hálózat simán megvan.
Az újabb Mac-ek pedig már a TB5 -öt is ismerik. -
S_x96x_S
addikt
válasz
DarkByte
#1875
üzenetére
> pl. Deepseek R1-nél azt mondják a 14B a legkisebb amivel érdemes foglalkozni.
A "deepseek-r1:14b" valójában a
"DeepSeek-R1-Distill-Qwen-14B",
ami azt jelenti, hogy a Qwen-14B modellt finomhangolták (finetuned)
a nagy DeepSeek-R1 modell által kiválogatott
és generált 800 ezer érvelési mintán és adaton.Nekem a portói bor analógia jut eszembe - ami egy "fortified wine",
vagyis alkohollal dúsított(erősített) bor ;
és Qwen-14B - is fel van erősítve az R1 -el ; de nem egyezik meg az R1 -el.--------
És mivel a 7b és a 8b alapja más - érdemes mindkettőt tesztelni:A
deepseek-r1:8bpedigDeepSeek-R1-Distill-Llama-8B( Llama:8b alapú )
Adeepseek-r1:7bpedigDeepSeek-R1-Distill-Qwen-7B( Qwen:7b alapú )
..."""
The Qwen distilled models are derived from Qwen-2.5 series, which are originally licensed under Apache 2.0 License, and now finetuned with 800k samples curated with DeepSeek-R1.The Llama 8B distilled model is derived from Llama3.1-8B-Base and is originally licensed under llama3.1 license.
The Llama 70B distilled model is derived from Llama3.3-70B-Instruct and is originally licensed under llama3.3 license.
"""
https://ollama.com/library/deepseek-r1 -

PHenis
senior tag
válasz
DarkByte
#1844
üzenetére
Hát a szerverrel lehet túloztam kicsit, egy sff gép van az emeleten proxmoxal.

Videókari csak lowprofilos megy bele, a táp is elég karcsú, szóval gpu mostanában nem lesz sztem. Bár kéne a frigate-nak meg a plex-nek is, hosszútávon tervben van az upgrade... egyelőre marad a cpu.Köszönöm mindekinek a linkeket, tanácsokat, megnézem mi az ami linux parancssorból is megy. Kezdetnek ez így kiváló nekem
-
-
Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#1791
üzenetére
Az Unsloth 2,51 bites dinamikus kvantálása állítólag szinte megkülönböztethetetlen a teljes modelltől. 160 GB RAM elég neki.
https://docs.unsloth.ai/basics/tutorial-how-to-run-deepseek-r1-on-your-own-local-device -
Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#1737
üzenetére
A DIGITS-re 3000 dollár körüli árat mondtak.
Persze az Európában jóval magasabb lesz.
Q3-ig még egy rakat ilyen eszközt fognak bejelenteni a gyártók.
Majd amikor már mindenki nyeregben érzi magát és tudja, hogy mit adnak el a versenytársak jön egy x. szereplő aki felborítja az egész eddigi elképzelést -
Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#1693
üzenetére
Ezért kell a conda-t vagy a venv-et használni, hogy ne legyen semmilyen ütközés. Nem kell hozzá WSL2.
Amúgy a WSL2 valóban nagyon jól működik windows alatt. regeneteg szolgáltatást én is ezzel mutattam be mert szinte tökéletesen olyan mintha Linux lenne.
A performancia pedig olyan 95-100% körül van egy natív Linuxhoz képest. -

tothd1989
tag
válasz
DarkByte
#1691
üzenetére
Ja, hát igen ez ilyen ágyúval verébre kategória.
Más, ti próbálkoztatok tanítani vagy finomhangolni modellt?
Eddig akármivel próbálkoztam a legtöbb az volt amit elértem, hogy segmentation faultot dobott a python. Hozzáteszem windowson borzalom a virtuális környezet, egyszerűen nem igazodom el, linuxon pöpecül megy (neeem, ettől még nem lesz jobb a linux ). -
-

atee_13
őstag
válasz
DarkByte
#1680
üzenetére
Megjegyzem későbbre biztos jól jön majd.
Arra esetleg van ötleted, hogy mivel próbálkozzak, ha ilyesmit akarok a falra

Nem kifejezetten ezeket, mert már van pár féle anyag meg izlandi zuzmót is akarunk majd egy egy cellába. De gondoltam valami lakberendező (AI) szem jobban megtudná tippelni miből mit hová és mekkorát.
-

consono
nagyúr
válasz
DarkByte
#1664
üzenetére
A tudományos világ pont, hogy AMD-n van, nézd majd meg mondjuk a top 20 szuperszámítógép mire épül
 Nem néztem mostanában, de szinte 100%, hogy Epyc+Instinct. Pont ezért csak félgázzal foglalkozik az AMD a hobbistákkal, meg a ROCm-el, mert rengeteg bevétele van abból, hogy piacvezető a high performance compute-ban.
Nem néztem mostanában, de szinte 100%, hogy Epyc+Instinct. Pont ezért csak félgázzal foglalkozik az AMD a hobbistákkal, meg a ROCm-el, mert rengeteg bevétele van abból, hogy piacvezető a high performance compute-ban. -
S_x96x_S
addikt
válasz
DarkByte
#1664
üzenetére
(nvidia )
> Olyan nagy kipukkanás akkor se lenne ha hirtelen mindenki ráunna erre az egészre.
én nem vagyok ennyire optimista az nvidiával kapcsolatban.
kipukkanás nem lesz, de az erős verseny miatt
nem fog megmaradni a jelenlegi árrés és market share.
vagyis lesznek még kilengések. ( ... korrekciók ... )Ha megnézünk sok más technológiát - ahol verseny volt - akkor furcsa trendeket láthatunk
pl. a piac egészében nőtt,
de az egykori domináns szereplők veszítettek az árrésükből és a piaci részesedésükből.a deepsekknek főleg a pszichológiai hatása jelentős.
- az nvidia nem legyőzhetetlen.
- és emiatt rengeteg Startup és kockázati pénz ömlik a versenytársakbaAz YC rögtön rá is startolt. a témára ;
https://www.ycombinator.com/rfs#spring-2025-ai-coding-agents-for-hardware-optimized-code
pl. "AI Coding Agents for Hardware-Optimized Code"
"AI hardware is still constrained by software. Nvidia dominates largely because CUDA’s hand-optimized code is used in AI models. Competing hardware—AMD, custom silicon—often underperforms not just because of inferior chips but because writing system-level code (kernels, drivers) is very difficult, and not enough software engineers are working on it.
However, now with reasoning models like Deepseek R1 or OpenAI o1 and o3, these could generate hardware-optimized code that rivals—or surpasses—human CUDA code.
We’d love to see more founders work on AI-generated kernels that make more hardware alternatives work for AI.
This isn’t just about performance. It’s about breaking dependencies. Founders working on this could reshape the hardware ecosystem."A jövő kiszámíthatatlan.
-
5leteseN
senior tag
válasz
DarkByte
#1656
üzenetére
Igen, az MI25 éppen hogy csak kicsúszott a W-L-es ROCm támogatásból, Linux alatt az MI50 talán benne marad majd a továbbiakban.
Az MI25-eim pedig valószínűleg (BIOS-)"átvillannak" és újjászületnek WX9100-ként, a 3D/CAD(esetleg "filmvágósok") megfizethető örömeként.
...ha sietek! Átállok és is a "zöld-oldalra"!
Nincs időm kivárni, amíg az AMD 1-2 évtized alatt behozza a CUDA-ban tárgyiasult lemaradását GPU architektúrában és szoftverben.. -
S_x96x_S
addikt
válasz
DarkByte
#1657
üzenetére
> Persze kérdés egyáltalán mennyire cél ezeknek a cégeknek kiszolgálni
mivel verseny van - mindig lesz olyan cég, aki itt látja a növekedés lehetőségét.
1-2 napon belül itt a Strix HALO - a 128 GB -os 4 csatornás konfigjával,
ahol olyan nagy LLM -et is demóznak, ami nem fér el az nvidia 4090/4090
24B / 32GB -s VRAM -jában - és emiatt nyilvánvalóan gyorsabb.
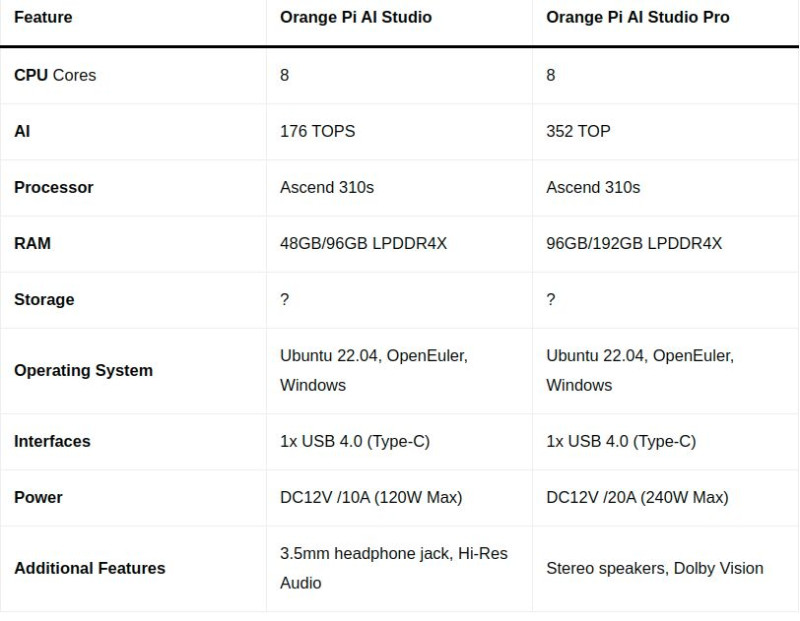
Persze erre majd jön az nVidia Digitsde hamarosan itt lesz még az ócsó kínai Ascend 310s - alapú
"Orange Pi AI Studio Pro mini PC"
[ 352 TOPS + 192GB LPDDR4X ]
"Orange Pi AI Studio Pro Mini PC target Nvidia Jetson Orin Nano with up to 352 TOPS"
-
tothd1989
tag
-
DarkByte
addikt
válasz
DarkByte
#1656
üzenetére
B580 lett volna az, csak már nem tudom szerkeszteni..
Mindenesetre csak azt akarom mondani, habár most Nvidia hardverem van, én alapvetően drukkolok annak hogy legyen érdemi verseny ezen a területen és a CUDA ne legyen domináns örökké, mert az nekünk nem jelent jót árverseny szempontból. Még néhány évig tippre a zöldek kikerülhetetlenek lesznek, ez biztos.
Persze kérdés egyáltalán mennyire cél ezeknek a cégeknek kiszolgálni azt a nagyon vékony lelkes őrült réteget aki otthon AI-t akar futtatni, úgy ahogy megfizethető áron, főleg hogy enterprise vonalon olyan vastagon foghat a ceruza az árcimkén amennyire csak akarják.
-
5leteseN
senior tag
válasz
DarkByte
#1651
üzenetére
 : "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
: "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
..."Erre várok már kb egy éve("pár" AMD MI25-tel)!
-
tothd1989
tag
válasz
DarkByte
#1651
üzenetére
Szerintem llm szempontjából nem várunk sem Intel, sem AMD kártyára sem. Mondjuk talán egyáltalán nem, leszámítva pár fanatikust, nekem eddig csak bajom volt az AMD vga meghajtókkal, személy szerint a 6600XT-m is megbántam, hiába volt jó áron. Legfeljebb fél szemmel követjük a fejleményeket, nem hiszem, hogy egyhamar egyáltalán eljutnak arra a szintre, ahol a zöldek tartanak. Különben már az 5080 is érdekes lehetett volna, szinte biztos vagyok benne, hogy profitálhatunk előbb-utóbb az AI képességeiből, 16gb vrammal már el lehet szórakozni. De ahogy mondod, egyhamar nem jutunk még ehhez sem, mert ami volt, az itt van aprón (...).
-
consono
nagyúr
válasz
DarkByte
#1200
üzenetére
Nem halucinálta, a Bing Copilot szerint is lehet ilyent csinálni. Csak a ChatGPT hosszabban és részletesebben válaszolt
Még modelleket is javasolt, hogy a pipeline különböző részein mit használjak.Van még egy ötletem is a RAG-gal: lehet ezt használni perzisztens memóriának. Akár csak tök egyszerűen a chat szövegét minden beszélgetés végén odaadni, megcsinálni az embeddinget és letárolni egy vektor adatbázisban...
-
S_x96x_S
addikt
válasz
DarkByte
#1126
üzenetére
> exo && még behozza a hálózatot is,
Én azért adok nekik még esélyt, szerintem 2-3 havonta érdemes megnézni a haladást.
Az eredeti demóban - Thunderbolt4 -el van összekapcsolva két Mac-es gép,
és ott már 20 --> 40 GBps sebességet is el lehet érni .pl 3db kis UM790 -ből ( 2db USB4 port + Ryzen 7940HS ) elég fapados mesh networköt lehet összerakni ( ~ 11 GBps hálózati sebességgel , mert valószínüleg ha mindkét USB4 -est egyszerre használod, akkor lehet valami korlát, hogy osztozni kell a pcie sávon,
de az alternativánál - egy 2.5G\5G net-nél sokkal jobb sebességet lehet elérni.
"High-speed 10Gbps full-mesh network based on USB4 for just $47.98"A fentiekkel csak azt akartam jelezni, hogy olyan gépet érdemes beszerezni,
aminek van USB4/TB4/TB5 csatlakozója
és akkor legalább lesz esély az otthoni próbálgatásra a jövőben.
-

freddirty
senior tag
válasz
DarkByte
#1081
üzenetére
Az exo-t kipróbáltam hogy másnak ne kelljen.
Csak forrás áll rendelkezésre, tehát bármilyen gépen csak teljes feljesztői környezet felállítása után fordulhat le! Bináris nyista. Dokumentáció a fejlesztői környezetről nem elérhető.
Windows masinán egy ideig próbálkoztam, de dependency probléma hegyén hátán. Meguntam egy óra után. WSL-re nem akartam átállni, van két linux szerverem is, de oda bármit csak konténerben rakok fel ez meg full fejlesztőkörnyezet. Akkor inkább Android mert az fenn van a támogatottak között és láttam hogy s23 ultrán már futtatták.
Nosza feldugtam dokkolóra az enyémet majd tmux letölt. Ott is egy rakás fordítási dependenciát nekem kellett trial-error alapon megtalálni. Kb. 1 óra tökölés után, discordjuk böngészése után végre eljutottam tényleges fordítási hibákhoz ami már nem dependency. Pl. invalid function pointer. Hát voltam én programozó, de talán ennek nem fogok már nekiállni.
Nincs ez még kész messze sem, ha valakinek véletlenül lefordul akkor lefordul. A fejlesztők látom apple eszközökön dolgoznak ott lehet jobb a szitu. De hogy legyen egy rakás elfekvő apple eszköz az elosztott llm-hez valakinek otthon az azért kevéssé valószínű
Szóval egyenlőre nem ajánlott, csak time sinker. Majd ha kész lesz, és lesz bináris/gyári konténer (ha egyáltalán valaha...) -
S_x96x_S
addikt
válasz
DarkByte
#1077
üzenetére
> tinybox ... Kíváncsi lennék az AMD-s modell
a saját tinygrad-os keret-rendszerük már elég jól működik AMD-n.
"tinygrad no longer crashes. We bypassed all the AMD userspace + 90% of their firmware. Can't remember last time I saw a crash in CI, it used to be 1 in 10 times."
du. 12:52 · 2024. szept. 10.
https://x.com/__tinygrad__/status/1833458443266757081Amúgy Hotz-ék javaslata ML hardverre:
""" https://x.com/__tinygrad__/status/1832974721199243359
All sub $3k dedicated HW is a scam. What ML hardware to buy with a given budget.
$30 - $300 = a phone
$300 - $3000 = a normal gaming PC
$3000 - $3M = tinybox(es)
$3M+ = supermicro
"""és ha valakinek van 2db Macbook-ja, akkor tesztelheti a Llama-3.1-405B -t
https://x.com/ac_crypto/status/1827281144405979192
És az exo elég igéretes: "Forget expensive NVIDIA GPUs, unify your existing devices into one powerful GPU: iPhone, iPad, Android, Mac, Linux, pretty much any device!" -
freddirty
senior tag
válasz
DarkByte
#1000
üzenetére
Igen pont az az ami nagyon meglepő a fluxban, hogy elsőre egy jól megírt prompt alapján egy nagyságrenddel jobb képet generál mint a szokásos. Egy SD 1.5, 2.x, XL bárminál a workflow kb. az, hogy belövöd kb. a promptot sok-sok próbálkozással (és nem leíróan, hanem szabak vesszővel elválasztva, fontossági sorrendben csökkenően), aztán generáltatsz egy nagyobb batch-el sok-sok képet, majd kiválasztod ami leginkább jellemző arra amit szeretnél, majd azt dolgozod tovább, inpaint, scale, etc... Na itt ez a munkamenet lerövidül egy jó leírópromptra, amiben egy LLM fél perc alatt segít, majd azt átírva már az akár első generálás után mehet az utómunka. Akár órákkal is kevesebb lehet egy kép elkészítése.
Így az SD el is felejtheti, hogy valaha létezett, ha nem tesz le egy hasonlót az asztalra, akkor át fog állni minden fejlesztő és AI hobbista erre. -
-
freddirty
senior tag
válasz
DarkByte
#994
üzenetére
Hm tényleg nagyon jó, sokkal jobb eredményt értem el az első prompt-al mint egy Stable Diffusion-al.
Még nem lokálisan csak próbaképpen az online generátorukban, github accountommal:
https://fal.ai/models/fal-ai/flux/schnell?ref=blog.fal.ai
Utánanézek mi az lokális futtatásnak a feltétele. -

ptesza
senior tag
válasz
DarkByte
#907
üzenetére
Felbuzdultam és mértem egyet. Próbáltam ugyanazokat a beállításokat mint amiket a képeken láttam.
GPU : speed: 42.08 tok/s
CPU : speed: 7.17 tok/s
AMD Ryzen 5800X ; Nvidia 3060 12GB ; 64 GB RAMSzerintem ezzel a VGA-val már eléggé gördülékenyen használható. Nem kell várni arra sem igazán , hogy elkezdjen írni. Elsőre azt gondoltam, hogy a GPU shaderek számával egyenesen arányos lehet az eredmény de ezt nem tudtam kimutatni. (A cikkben található minták alapján.) A több jobb de nem lehet azt megfigyelni, hogy pl. a shader magok számának megduplázódása kétszer akkora tok/s adna.
RTX3070 Ti : 41,8tok/s : 6144 shader mag
RTX3060 : 42,08 tok/s : 3584 shader mag
Sajnos a cikk a VRAM méretekre nem tért ki de szerintem az nagyobb %-ban számíthat mint a csak a shader magok száma. -
-
Zizi123
senior tag
válasz
DarkByte
#918
üzenetére
Köszönöm a tájékoztatást.
Viszont a kérdéseimről is tudnátok valamit mondani?
Miért ad más válasz ugyanarra a kérdésre mindig?
Miért betűnként írja ki, amikor nyilvánvalóan tudnia kell a választ már az első betűnél?Ezekre az, hogy nem angolul kérdezem nem magyarázat.
Az, hogy máshogy fogalmaz az lehet simán a választékosság miatt, de a lényeg (jelen esetben a személy) az ne legyen már emiatt.
Mintha megkérdezném, hogy mennnyi 5x5+10, és a változatosság kedvéért mindig más eredményt adna ki. (tudom, hogy nem erre való, csak a példa kedvéért.) -
5leteseN
senior tag
válasz
DarkByte
#920
üzenetére
Én ezért gondolkodom azon, hogy egy "lapos"(-top)-hoz rakok egy eGPU-s(vagy átépített bányász-rig átalakítással) összehozható, hasonló célú AI-szervert.
Ha nem kell éppen az AI, akkor 5-10-15W-ból netezgetek a laposon a külső monitorral. Amikor meg kell majd az AI, akkor felébresztem(vagy újra indítom) a fentebb említett AI-eGPU külső dobozkát(: a polcon erre a feladatra várakozó 1200W-os HP tápból és a szintén polcos 2-3-4 AMD-s VGA(GPU)-ból összedrótozva), aminek gyűlnek az elemei, hogy hónap végére ez is meg legyen.
Ha kel(-akarom) a "lapos"-hoz csapom hozzá ezt a "szuper-AI" dobozkámat, ha kell a(brutálka fogyasztású és memóriájú(64 vagy 128 GB DDR4 RAM-os) 2x2680v4-hez.
Gyülekeznek a polcomon a szükséges AI-elemek, gyülekeznek...
+ télen nem kell majd fűteni sem! -
5leteseN
senior tag
válasz
DarkByte
#906
üzenetére
Igen, igen, igen
 + : "látatlanban" megtaláltad az okot (ami a RAM méret), ami miatt az ismerten jóval lassabb CPU-n(a jelenlegi költséghatékonyság mellet most még) van értelme ezen a kifutó szerver-procin is futtatni LLM-eket, a jobb LLM-ek 27-36-40+ GB-os méretei miatt.
+ : "látatlanban" megtaláltad az okot (ami a RAM méret), ami miatt az ismerten jóval lassabb CPU-n(a jelenlegi költséghatékonyság mellet most még) van értelme ezen a kifutó szerver-procin is futtatni LLM-eket, a jobb LLM-ek 27-36-40+ GB-os méretei miatt.
Pont ezért(és biztonsági gyanúim miatt) most éppen "leszállok" az LM Studio-ról, és átnyergelek az Ollama-ra.
Már a parancssoros Ollama-videónál is gyanús volt, hogy túl jó ez ahhoz, hogy az elkényelmesedett felhasználók(kicsit én is ) ne kapják meg a "nekik járó" grafikus felületet, ami meg is jött nem sokkal később! -
Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#889
üzenetére
Igen, a Tencent féle Mimic most jelent meg és mér el is készült hozzá a ComfyUI node
Itt nagyon fontos belátni a proektek mögé. Ezeket a kutatási anyagok amik pl ennek a "táncikálós" videó generálásnak is az alapját képezik később más komolyabb projektek részei lesznek. itt hatalmas egymásra épülés van a háttérben. Örüljünk neki, hogy a Tencent az open source közösséget is segíti. -

CRTs
aktív tag
válasz
DarkByte
#862
üzenetére
De semmi kontrollod nincs az felett hogy mit fog csinálni a képpel. Kb. dobsz dobókockával (emeled a seed-et) és ha szerencséd van valami érdekeset csinál a képpel. Rosszabbik esetben csak valami unalmas kamera mozgatást csinál a merev képen.
Van, ha, van depth map. Ha rá van bízva hogy generálja a depth map-et 2D-ből azt komplexitástól függően fogja tudni megcsinálni de alapvetően nem tudja megcsinálni mert nincs mélység információ 2D-ben. Ezért nem tud rendes matt-olást sem pl mert széleknél több információ kéne. Akik az ERA3D-t csinálták már kezdenek hozzáfogni fényviszonyok felülírásához ott kezd forrósodni a téma 2D-ben továbbra sem látok fantáziát. -
5leteseN
senior tag
válasz
DarkByte
#872
üzenetére
Bokros teendőimet ritkítottam, ezért megelőztél, de kb nekem is ez volt a nyelvem hegyén, mint vélemény: ha ilyen szinten el kell magyarázni, akkor annyi erőforrásból már sok esetben magát a feladatot is meg tudom oldani.
Egy tizen-sok évvel ezelőtti (jól összerakott és "megprogramozott") szakértői-rendszer kategóriájú szoftver az adott szakterületén még ma is jobb, mint a jelenlegi "sokat-markolok-de(-a túltolt marketinget lehámozva)-alig-valamit-tudok"(logikailag).
Talán az óvodai szintű Kő-Papír-Olló megy (8GB-os LLM-ből, egy 3090Ti-n 24GB VRAM-mal), de már ez az ovis logikai játék két szinten és (ráadásul logikailag)összekötve szerintem már azt sem tudná sikerrel megugrani!!Ez az adott IT-szakterületen a "Való-Világ"..Így vélem én!
Én meg közben(meg akik még komolyan vették a beharangozott eredményeket) lereagálom képletesen az "eredményeket", íme:

-
consono
nagyúr
válasz
DarkByte
#872
üzenetére
Hát, addig megyek el, ameddig el tudok
Mondjuk most elég egyszerű volt a példa, az tény. Legtöbbször nem is kell a szájába rágni plusz dolgokat, elég az, hogy dolgozzon lépésről lépésre, vagy az, hoyg személyesítsen meg ezt vagy azt. Az utóbbi is meglepő módon befolyásolja a válasz minőségét. -
válasz
DarkByte
#841
üzenetére
Így van. Csak most jutott időm. Lehet az is, hogy kell hozzá fejlesztés, de azt sem mi fogjuk megcsinálni, hanem megcsináltatjuk.
A kérdés, hogy lenne-e praktikus haszna? Csak azért, hogy ilyenünk is legyen, nem fogunk bele semmibe.
Amúgy azóta is olvasom ezt a topikot, meg a linkeket amiket itt találok.
Sok menő dolgot találtam, de praktice használhatót még nem. -
CRTs
aktív tag
válasz
DarkByte
#809
üzenetére
Én egy LCM-et írtam át ami most kb 400millisecel megy. El tudnek lenni 50-el.
Nem sok fantáziát látok upscale-ben. SZVSZ: 3D be ha ât tudod emelgetni meg vissza az azért jobb mert kapsz belôle korrekt Depth Of Field-et. Ha nagyon jó vagy akkor talán még még refocust is. Az sokkal nagyobb ügy mint egy új SD szerintem. Ezt generatorbol nemigen szeded ki. -
Mp3Pintyo
HÁZIGAZDA
válasz
DarkByte
#805
üzenetére
Igen, majd mindenki kapott róla levelet is
Már mennek a találgatások és a hülyeségek is. Egy kicsi rendett vágott Lykon a témában:
What's up with all the disinformation about SDXL having 6.6B params? It has 2.6B Unet with 4ch VAE https://arxiv.org/pdf/2307.01952
Twitter -
CRTs
aktív tag
válasz
DarkByte
#797
üzenetére
Köszi megnézem. Hát "jártamban keltemben" már láttam ilyet hogy "rig"-elnek valami egyszerűbbet. De engem jelenleg csak a bevilágítás meg kamera része érdekel szerintem statikus már sok mindenre elég
"keyframe"-re pl. DE. Gondolom el is kell találni blenderrel hogy a modellen éppen mi van. Úgy veszem észre hogy ilyen szempontból jól viselkedik mert "szimpla" hemisphere bevilágítás jó tud lenni hozzá ( feltéve hogy nem szimpla kiemelés történik valami hátteres képgenerálásból hanem egyenbevilágítás és nálam már működik valami ilyen). -
#703
 hiperFizikus
senior tag
DarkByte
#701
hiperFizikus
senior tag
DarkByte
#701
hiperFizikus
senior tag
válasz
DarkByte
#701
üzenetére
https://forum.index.hu/Article/viewArticle?a=166050890&t=9254325
" Most biztosan minden ki röhögni fog rajtam, mert dilisnek gondoltok, de valóban van gumi a laptopom alatt .
Ajánlom nektek is, hogy tegyetek ilyesmi "pneumatikát" a tervezet elavulásos laptopjaitok alá ♥ " -

scream
veterán
válasz
DarkByte
#687
üzenetére
Én is csatlakoznék ehhez, ha már rendes IT topicban vagyunk, maradjon szakmai.
Általánosságban meg szerintem igaz, hogy amihez nem ért az ember, érdemes utána keresni/olvasni/kérdezni.
Senki nem adott terület szakértőjeként születik, illetve hibázni is van, hogy hibázik az ember, de az össze-vissza, mindenféle alap nélkül tett kinyilatkoztatások csak torzítják/nehezítik azok dolgát, akik próbálnának új információt felszedni/elsajátítani- plussz ráfordított erő/idő, mire a "zaj" ki lesz szűrve a ténylegesen releváns adathalmazból.
hiperFizikus: Kódolás szemszögből: Nem tudom kértél-e már valaha véleményt "kész" kódodra, lehet egyszer nem ártana - ha csak hobbi (remélem csak hobbi) szinten is foglalkozol vele, akkor is érdemes.










 , +reklám-arcba-tolós/marketinges dolog.
, +reklám-arcba-tolós/marketinges dolog. 


 Amúgy meg szerintem teljesen mindegy mit írunk le mivel olyan gyorsan változik minden, hogy lehet 1 nap múlva már az egész felület új lesz
Amúgy meg szerintem teljesen mindegy mit írunk le mivel olyan gyorsan változik minden, hogy lehet 1 nap múlva már az egész felület új lesz 
![;]](http://cdn.rios.hu/dl/s/v1.gif)












 Nem néztem mostanában, de szinte 100%, hogy Epyc+Instinct. Pont ezért csak félgázzal foglalkozik az AMD a hobbistákkal, meg a ROCm-el, mert rengeteg bevétele van abból, hogy piacvezető a high performance compute-ban.
Nem néztem mostanában, de szinte 100%, hogy Epyc+Instinct. Pont ezért csak félgázzal foglalkozik az AMD a hobbistákkal, meg a ROCm-el, mert rengeteg bevétele van abból, hogy piacvezető a high performance compute-ban.
 : "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
: "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.














Új hozzászólás Aktív témák
Hirdetés

- Apple iPad Air 4 64GB Kártyafüggetlen 1Év Garanciával
- ÁRGARANCIA!Épített KomPhone Ryzen 5 7600X 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- Törött, Hibás iPhone felvásárlás!!
- AKCIÓ! ASRock Z390 i7 8700K 32GB DDR4 500GB SSD RTX 3050 8GB Zalman i3 Edge Seasonic 650W
- Keresem : Lenovo Legion 5 16IRX9 83DG0037HV
Állásajánlatok

Cég: PC Trade Systems Kft.
Város: Szeged

Cég: CAMERA-PRO Hungary Kft
Város: Budapest