- Android alkalmazások - szoftver kibeszélő topik
- Okosóra és okoskiegészítő topik
- Samsung Galaxy S25 - végre van kicsi!
- Videón a Z Flip7 méretes külső kijelzője
- Magisk
- És egy Tecno Pova 7 Ultra 5G is felbukkant
- Milyen okostelefont vegyek?
- Honor 200 Pro - mobilportré
- Mobil flották
- Redmi Note 10S - egy a sok közül
Új hozzászólás Aktív témák
-

sztanozs
veterán
Igen, az in_array sinám végigiterál, amíg meg nem találja, míg a másik változat (key_exists) esetében azt a tulajdonságot abuzáljuk, hogy a kulcsok hash-elve vannak tárolva és sokkal gyorsabban kereshetők, mint maga az adat.
Mivel nincs rendes Set megoldás (illetve a DS/Set nincs alapból telepítve), így a tömb asszociatív kulcs keresés megoldását lehet abuzálni, hogy sebességben sikert érjünk el.
Ezzel a módszerrel tárolhajuk az összefüggéseket két irányból is:<?php
$kategoriak = array(
'szorakozas' => ['elozetes', 'film', 'sorozat', 'hbo', 'mozi'],
'kultura' => ['mozi', 'szinhaz', 'múzeum', 'koncert', 'film'],
'masszázs' => ['eufória']
);
$kulcsok = [];
foreach($kategoriak as $kat => $v) {
foreach($v as $kulcs) {
if (key_exists($kulcs, $kulcsok)) {
$kulcsok[$kulcs][] = $kat;
} else {
$kulcsok[$kulcs] = array($kat);
}
}
}
var_dump($kulcsok); -

Taci
addikt
válasz
 sztanozs
#20893
üzenetére
sztanozs
#20893
üzenetére
#20894: Ah, az azért már nem elhanyagolható sebességbeli különbség...
 Csak jó lenne tudni ki is használni.
Csak jó lenne tudni ki is használni. 
A Pythonba nem kezdenék bele, bőven elég ez is, köszönöm. Látod, ezzel sem haladok épp villámtempóban.
A tömbbe a kulcsszavakat kézzel írom bele. Jönnek külső forrásból a bejegyzések, hozzájuk az általuk megadott kulcsszavak, tagek, kategóriák, én pedig azokat rendezgetem magamnak a saját kategóriáimba. (Enélkül nagyon össze-vissza lenne minden, átláthatatlanul.)
Ezen a táblázatos tároláson el kell gondolkodnom, ki kell próbálnom. És igazán nem is értem.
Most simán csak in_array()-jel nézem meg, hogy az adott kulcsszó benne van-e valamelyik kategóriához tartozó kulcsszavai között. De ehhez ugye végig kell mennem a külső forrásból megadott kulcsszavakon (foreach), aztán a kategóriákhoz beállított kulcsszavakon is (foreach).
Ha táblázat van tömb helyett, az én tapasztalatommal kapásból feltöltenék egy tömböt a táblázat adaival, és foreach-et használék, hogy bejárjam. De sejtésem szerint nem ez az ajánlásod lényege.

(A linkeket átnézem alaposan, amint odaérek. Köszönöm.)
Upd.: És azt is, amit most küldtél, még csak most látom, a hozzászólás elküldése után. Köszönöm szépen ismét a segítségedet és a türelmedet!
-
sztanozs
veterán
válasz
sztanozs
#20895
üzenetére
és egy némileg lassabb implementáció PHP-ben:
<?php
$A = [];
$B = [];
foreach (range('A', 'Z') as $a){
foreach (range('A', 'Z') as $b){
foreach (range('A', 'Z') as $c){
$A[] = $a.$b.$c;
$B[$a.$b.$c] = 0;
}
}
}
echo count($A).'<BR>';
echo count($B).'<BR>';
$time_start = microtime(true);
for($i=0; $i<10000; $i++){
in_array('ZZZ', $A);
}
$time_end = microtime(true);
$execution_time = ($time_end - $time_start);
echo $execution_time.'<BR>';
$time_start = microtime(true);
for($i=0; $i<10000; $i++){
key_exists('ZZZ', $B);
}
$time_end = microtime(true);
$execution_time = ($time_end - $time_start);
echo $execution_time.'<BR>';
?>A különbség 1 sec vs 0.5 milisec.
-
sztanozs
veterán
Különbség a full list scan (foreach) és hashset között:
>>> # 456.976 elem listában
>>> A = ['AAAA', ..., 'ZZZZ']
>>> # 456.976 elem hasset-ben
>>> B = set('AAAA', ..., 'ZZZZ')
>>> # 2000 elem egy listában ami random négy karakter (~85% találati valószínűséggel)
>>> C = ['@ABC', ..., 'XYZ@']
>>> # keresés eredmények másodpercben
>>> timeit.timeit("[c in A for c in C]",number=1,globals=globals())
10.154
>>> timeit.timeit("[c in B for c in B]",number=1,globals=globals())
0.000786
Azaz míg 2000 elem megkeresése végigiterálva a félmilliós listában 10 másodpercig tart, addig ugyanannyi idő alatt 20.000.000 (húszmillió) elemet le lehet ellenőrizni egy félmilliós adattartalmú hashset-ben. -
sztanozs
veterán
Ezért is kell a kulcsszavakat és a kategóriákat táblázatban tárolni.
Ha táblázatban tárolod indexelve, akkor nem full table search lesz (azaz nem három egymásba ágyazott foreach), hanem Hash/B-Tree search, ami sokkal jobb.
De még két hashset/dictionary is jóval gyorsabb lenne, mint két lista.
https://www.php.net/manual/en/book.ds.php
http://docs.php.net/manual/en/class.splobjectstorage.php -

biker
nagyúr
Én a leírásból valami nagyon rekurzív megoldást látok.
amit írsz, az szerintem a klasszikus cimkézés, ahol egy rekordhoz a cimkék el vannak tárolva, és abban fulltext search a barátod, match against....
Ha nem akarod nagyon rekurzívvá tenni, akkor a cimkék is táblában
CimkeTabla id, cimke
Rekordok id, nev, akarmi, cimkek
és a cimkékben id-k felsorolva. De a fulltext search jól dolgozik indexelt táblákkal. -
Taci
addikt
válasz
sztanozs
#20888
üzenetére
Mindenek előtt köszönöm, hogy kódot is írtál!

Viszont talán nem egy dologról beszélünk. (simán benne van, ti látjátok a jó utat, én meg továbbra is vakon vagyok)
SQL-lel nem lehet (jelen pillanatban) ezt megcsinálni, mert a kulcsszavak nem táblázatban vannak, hanem simán egy tömbben.
De amúgy ha a kulcsszavak táblázatban lennének, akkor sem lenne gyorsabb szerintem, sőt, hiszen azért csak gyorsabb egy kész tömbön végigmenni, mint előtte a tömb elemeit SQL-ből lekérni.Mutatok egy éles példát:
Külső forrásból ez a sztring érkezik:
$rekord_kulcsszavak = "Kultúra,előzetes,eufória,filmtv,hbo,második évad,rév marcell,sam levinson,sorozat,zendaya";Ezt szétbontom tömbbe, elemenként.
Ezeket az elemeket egyesével megnézem, milyen kategóriákhoz tartoznak (a kategóriákhoz tartozó kulcsszavak alapján), és azokat írom be a KUlcsokKAtegóriák táblába:
- Kultúra --> kultura
- előzetes --> szorakozas
- eufória --> nincs ilyen kulcsszó
- filmtv --> nincs ilyen kulcsszó
- hbo --> szorakozas, már benne van a kategóriában, skip
- második évad --> nincs ilyen kulcsszó
- rév marcell --> nincs ilyen kulcsszó
- sam levinson --> nincs ilyen kulcsszó
- sorozat --> szorakozas, már benne van a kategóriában, skip
- zendaya --> nincs ilyen kulcsszóTehát a rekordhoz a kultura és a szorakozas kategóriák kerülnek mentésre.
@biker: Amikor bekerül egy rekord a fő táblába, az az infó is mentve van vele, hogy milyen verziójú kategória tömb alapján lett kategóriákba besorolva. Így amikor ez a szkript elindul, elsőnek csak azt ellenőrzi, melyik rekordnál van más (régebbi) verzió. Így csak azokat a rekordokat nézi át, amik régi verzióval készültek. Nincs felesleges művelet.
Viszont ha aztán frissítenem kell a kategóriákhoz tartozó kulcsszavakat, akkor muszáj vagyok emelni a verziószámot is, mert nem tudhatom, melyik rekord fog új/más kategóriá(k)ba kerülni.A fenti példánál maradva:
Mondjuk azokkal a kulcsszavakkal az 1.0-s verzióban a következő kategóriákba kerülne a rekord: kultura, szorakozas, és mondjuk az "eufória" miatt a masszazs kategóriába (csak egy példa).
Aztán ezt észreveszem, hogy hopp, az "eufória" kulcsszó nem jó a masszazs kategóriába, úgyhogy kiszedem onnan.
Ekkor ha nem emelek verziót (1.0 marad), akkor az a rekord skippelve lesz, így marad a masszazs kategóriában, hibásan.
De verziót emelek (1.1 lesz), így újra ellenőrzive lesz, és kikerül a rossz kategóriából. De ennek sajnos az az ára, hogy verzióemelésnél mindet újra át kell nézetnem, mert nem tudhatom, melyik fog változni, addig, amíg nem ellenőrzöm újra. Viszont a következő változtatásig ez a szkript skippelni fogja az összeset már, mert 1.1-re át lett írva mind. -
biker
nagyúr
Elég furának tartom, hogy "ész nélkül" kapcsolatokat állítunk fel, miért nem akkor keresünk kapcsolatokat amikor kell? Ha ez valami kereső, ami kategóriák közt keres, akkor főleg.
"ész nélkül" értsd nem akkor amikor kell, nem úgy ahogy kell, és nem csak azon a rekordokon amin kell -
sztanozs
veterán
Ezt simán meg lehet csinálni SQL alapon mindenféle plusz kalkuláció nélkül is. Kellenek a következők:
- KATEGORIA tábla (ID, MEGNEVEZES)
- KULCSSZO tábla (ID, KULCS)
- M:N kötőtábla a Kulcsok és Kategóriák között (KUKA - KAT_ID, KULCS_ID)
- REKORDOK tábla (ID, ... mindenféle mezők ... )
- M:N kötőtábla a rekordok és kulcsok között (REKU - REKORD_ID, KULCS_ID)
Ezekkel simán SQL alapon lehet kimutatni a kategóriákat, mindenféle külön szenvedés nélkül:SELECT
R.*,
GROUP_CONCAT(KAT.MEGNEVEZES)
FROM REKORDOK AS R
JOIN REKU ON R.ID=REKU.REKORD_ID
JOIN KUKA ON REKU.KULCS_ID = KUKA.KULCS_ID
JOIN KATEGORIA AS KAT ON KUKA.KAT_ID = KAT.IDKb fejből, de lehet, hogy kell egy nested select:
SELECT
R.*
RK.KATEGORIAK
FROM REKORDOK JOIN
(SELECT
R.ID,
GROUP_CONCAT(KAT.MEGNEVEZES) AS KATEGORIAK
FROM REKORDOK AS R
JOIN REKU ON R.ID=REKU.REKORD_ID
JOIN KUKA ON REKU.KULCS_ID = KUKA.KULCS_ID
JOIN KATEGORIA AS KAT ON KUKA.KAT_ID = KAT.ID
GROUP BY R.ID) AS RKAT ON R.ID = RKAT.ID -
Taci
addikt
válasz
sztanozs
#20883
üzenetére
Már csak rákérdezek, mert ezt a feladatot nem látom máshogy (könnyebben, főleg gyorsabban) megoldhatónak:
Adott 40 kategória. Minden kategóriában vannak kulcsszavak, van, amiben csak 20, van amiben 240, van amiben 600.
Minden rekordhoz tartoznak szintén kulcsszavak, egy, vagy akár több is.A szkript ezeket a rekordokhoz tartozó kulcsszavakat vizsgálja végig a kategóriák kulcsszavain, az összesen, és ha valamelyikben egyezés van, azt a kategóriát bejegyzi neki.
Így alakul ki a végére, hogy az adott rekord milyen kategóriákba kerül.
Aztán ezek a kategóriás kulcsszavak változhatnak, bekerül pár, kikerül pár, és ez alapján a rekordokat is módosítani kell.A 90 mp jelenleg arra elegendő, hogy ezeket az ellenőrzéseket és bejegyzéseket megcsinálja kb. átlag 1200 elemhez.
Lefuttattam 3 mp-cel, 32-re volt ideje.Ezen akárhogy nézem, gyorsítani csak úgy tudnék, ha vagy kategóriákat törölnék, vagy kulcsszavakat. Egyiket sem akarom, sőt, kulcsszavakból egészen biztosan még több lesz.
Ez amúgy csak pár egymásba ágyazott
foreach, semmi több:-- foreach - a kategóriák listájából a kategóriák neveire
---- foreach - a kategóriák neveihez tartozó tömb elemeire, amik a kategóriák kulcsszavai
------ foreach - a rekordokhoz tartozó kulcsszavakraEzután már csak a megfelelő rekordot hozza létre, módosítja vagy törli.
Ebben a kontextusban, ezekkel a számokkal is olyan szörnyűnek hangzik? Csak mert 0 viszonyítási alapom van, nem látnám, hogy bárhol "pazarolnék", nem tudom, hogyan lehetne ezen gyorsítani.
-

pelyib
tag
Crontab tud tol-igot kezelni, tehat beallitod h x idotartamban hivja meg a skripted, nem kell tobb bejegyzes.
A scriptet meg ugy modositanam, h az elmenti az utolso feldolgozott elem IDjat vagy barmit amivel a kovetkezo futasnal meg tudja talalni a kovetkezot feldolgozando elemet.
Tehat az elso indulasnal 0rol indul, feldolgoz Y dbot majd leall, crontab inditja ujra, megnezi hogy mi volt az utolso es onnan folytatja. -
Taci
addikt
válasz
sztanozs
#20883
üzenetére
*Naprendszeren kívül - nagyban gondolkodom.
Ezért is írtam, hogy ez a része nem lényeges most. Nyilván átnézem újra, mindent logolva, mi tart mégis ennyi ideig.
Előbb futtat egy lekérdezést, ahol csak a rekordhoz tartozó verziószámot ellenőrzi. Ha nem a legfrissebb (amit egy tömbből ellenőriz a legelején), akkor ezekből visszaad egy listát (id-k).
Aztán ezen a nem legfrissebb verziójú rekordokon végig futtat pár ellenőrzést, sztringekből, és JOIN-olt táblákból dolgozik, aminek a végén kap egy eredményt, és attól függően kell a JOIN-olt táblákban update-elni, törölni vagy hozzáadni (vagy mindet).Ez legutóbb 6 percig tartott 8150 rekordnál.
Ahogy a részletes logot nézem, azt látom, hogy van olyan rekord, ahol akár 4 mp-be is kerül a processz, máshol meg 1 mp-en belül megvan 2-3.
Én is szívom a fogam, mert azért tényleg nem DNS-t vizsgál a szkript... De ezt úgyis átnézem, mert ez így sok.
Lehet, itt az én gépem (tesztkörnyezet - XAMPP) teljesítménye a szűk keresztmetszet, és szolgáltatónál repülni fog.De ettől függetlenül...
...csak annak az elvére szeretnék ráérezni, hogyan lehet vajon ezt megcsinálni, ha mindenképp kezelnem kellene ezt a helyzetet (szkript futása nem fér 90 mp-be bele).
Ma reggel az jutott eszembe, hogy vajon ha a Cron job meghívja a szkriptet, aztán azt 85 mp-nél commit-olom, majd meghívatom vele rekurzívan saját magát addig, amíg végig nem megy minden elemen, akkor vajon a 2. hívás (és a többi) még a Cron job-hoz tartozik?
Ezt fogom majd kipróbálni. -
Taci
addikt
A szolgáltató 90 mp-ben maximalizálja a Cron Job-ok futási idejét.
Viszont van 1 szkriptem, aminek az összes elemen végig kell mennie néha, számolni, átírni stb. (ez a része most nem lényeges). És ez már most, 20e elem környékén sem fér bele a 90 mp-be. (duplájába se)Hogyan tudom ezt megoldani? Az oké, hogy mondjuk 85 mp-nél azt mondom, na most egy commit, aztán vége. De aztán valahogy triggerelnem kellene újra ezt a szkriptet, hogy folytassa, ahol az előbb abbahagyta. Viszont ilyenkor már a cron job le lesz állítva.
Nem állíthatok be 10-20-30 cron jobot, hátha mindre szükség van, hogy végig menjen az összes elemen.Hogyan lehet ezt megoldani?
Hátha van valalmilyen ötletetek. -

maestro87
őstag
Sziasztok!
Van ötletetek, hogy API lekérdezésnél miért kapok mindig "access-token was expired" hibaüzenetet?
Google táblázatba szeretnék API-val adatokat felvinni, de csak az access token megszerzéséig tudok eljutni. Mit csinálhatok rosszul? Nem vágom ezt a témát, de kellenének az adatok. Esetleg ha valaki privátban tudna segíteni azt megköszönném.
Azért itt kérdezem, mert talán itt van a legtöbb szakértő a témában. -

#45252096
törölt tag
válasz
sztanozs
#20879
üzenetére
OOO tenyleg, de hulye vagyok, koszonom az eszrevetelt. Verebre agyuval
Az eredmenyfrissitest ugy gondoltam (befejezodottre allitast), hogy azt valami kulson apin keresztul kerdeznem le. Es ehhez ugye kell scheduler, ami minden nap tobbszor is megnezi, hogy van-e mar eredmeny, vagy esetleg elmaradt-e valami miatt a meccs. Lehet eleg lenne naponta ketszer, nem szukseges azonnali eredmeny.
Es mondjuk ejjel frissitenem a ranglistat, az alapjan, kinek hogy sikerult a tippelgetes. -
sztanozs
veterán
válasz
 #45252096
#20878
üzenetére
#45252096
#20878
üzenetére
Nem kell ehhez job szerintem, csak az adott mezőt nem kell tárolni, hanem kalkulálni - pontosabban az elkezdődött az az, ha a lekérdezés dátuma és ideje a kezdés dátuma és ideje után van. A befejeződött-et lehet kézzel állítani, mert adott meccseknél nem lehet tudni, mennyi a hosszabbítás, illetve adott esetben idő előtt is befejeződhet a meccs.
-
#45252096
törölt tag
Sziasztok,
lenne egy laraveles kerdesem.
Csinalok egy nb1es tippelos oldalt. REST apin keresztul lehet lekerni a heti meccseket.
Jelenlegi fordulot (mig nem talalok egy olyan oldalt, ahol le tudnam kerdezni a heti meccseket REST apin) manualisan vittem be az adatbazisba. Egy meccsre mindig csak meccs kezdeseig lehet fogadni. Jelenleg egy meccsnek 3 allapota van: elkezdodott, nem kezdodott el es vege.
Azt szeretnem elerni, hogy ha egy meccs elkezdodik, akkor ne lehessen ra tippet kuldeni, tehat mondjuk ha szombaton 3kor kezdodik egy Fradi meccs, akkor haromkor mar ne lehessen ra fogadni, tehat REST apin keresztul ne jelenjen meg mar az adott meccs.
Tehat szeretnek egy olyan hatterfolyamatot, ami ha eszleli, hogy egy meccs abban masodpercben elkezdodott, akkor allitsa at statuszat.
Laravel doksiban lattam, hogy vannak jobok meg task scheduler. Sok gondolkozas nelkul azt mondanam, hogy masodpercenkent lekerdeznem az adatbazist, hogy van-e olyan meccs amit mondjuk epp elkezdodik, ha igen inditson egy jobot, ami megvaltoztatja a statuszat.
Ezenkivul szeretnek kesobb olyan hatterfolyamatokat: minden nap ejjel lekeri az adott heti meccseket es ha van valtozas akkor felulirja (mondjuk elmarad vagy megvaltozott az idopont) illetve egy olyan is jo lenne, ami minden oraban megnezi, hogy vege van-e mar a meccsnek. Persze csak ha majd talalok olyan oldalt, ahonnan letudnam kerni a magyar meccseket.
Azt szeretnem kerdezni, hogy a fenti elgondolas mennyire jo ? Szeretnek egy teljesen automatizalt weboldalt -
Taci
addikt
Van esetleg bevált módszeretek / keretrendszeretek SQL adatbázis (táblák) biztonsági mentésére (php-alapon, hogy cron jobként futtathassam)? Elsősorban MS OneDrive-ra szeretném bizonyos rendszerességgel a kiválasztott táblák backupjait kimenteni, de ahogy olvastam, abba az irányba talán nincs annyira kiforrott megoldás, mint Google Drive-ra. De ott is van elég tárhelyem, szóval az is jó lenne.
Tudtok valami bevált megoldást ajánlani?
-
Taci
addikt
Ezzel a kódolásos dologgal valami nincs rendben nálam, kérnék egy kis segítséget.
Adott egy saját függvény, hogy szépen logoltatni tudjak. A lényegi része:
error_log($message_to_log, 3, $log_file_custom_path);
(vagy jobb lenne simán csak file_put_contents használatával a fájlba írogatni?)A .log fájlok, ahova mennek az adatok UTF-8 kódolással vannak elmentve.
De pár napja azt vettem észre, hogy egyszer csak fogja, és többet nem UTF-8-as kódolású a fájl, hanem átállítja a már tartalommal bőven feltöltött fájlt is ANSI-ra, és minden magyar ékezetes szöveg "szétesik".
Azok is, amiket előtte láttam, hogy rendben, utf8-asként, normálisan kódolva szerepeltek.
(Pl. tegnap még azt volt benne utf8-asként, hogy Találat kategóriára, ma meg már Találat kategĂłriára...)Adatbázis oldalon és kapcsolódásnál is minden szépen be van állítva (pl. $conn->set_charset("utf8mb4"); ).
Gondolom, ezért is kerül rendben minden az adatbázisba, még akkor is, ha a logban a "szétesett" verzió szerepel.Az ini_get('default_charset') azt mondja, UTF-8.
Gondolom, így a php.ini-ben nincs dolgom.Hogyan lehet ezt megoldani? Máshol nincs jele szerencsére ennek az UTF8-->ANSI váltásnak, csak a logban, de ez is zavaró, mert keresek bennük. (Plusz nem tudom, máshova bekavar-e.)
Szívesen vennék valamilyen hasznos tanácsot, hogy mit kell még beállítani, vagy hogy hogyan kaphatom el, mi csinálja ezt az utf8-->ansi cserét.
Köszönöm. -
Taci
addikt
UTF-8-ban van minden, és direkt úgy csináltam meg, hogy amit nem abban kapok, először azt is átalakítom azzá. Amúgy azóta minden más linknél jól működik (normálisan adták meg, normál ékezetekkel -amiben épp van-, szóval az egy egyszeri "valaminek" tűnik csak), plusz módosítottam is a függvényen:
1. FILTER_VALIDATE_URL-rel teszt. Ha false, akkor
2. a header-ös ellenőrzéses teszt (200 OK). Ha ezen is megbukna, akkor kuka.Plusz így átgondolva ha még 3. lépésnek bevonnám az ékezetes betűk ellenőrzését, (hogy ha az van benne, akkor jóhiszeműen átengedem, mert biztos csak amiatt nem volt jó az első 2 teszt), akkor igazából ha a link annyi lenne csak, hogy "é", azt is átengedné.
Szóval jó ez így, nem is ér további energiaráfordítást.
Köszi azért, hogy írtál.
-
Taci
addikt
Kérnék egy kis segítséget.
Olyan szinten vért izzadtam ezzel...
$str1 = "Névtelen";$str2 = "Névtelen";$pattern = "/á|é|í|ó|ö|ő|ú|ü|ű/i";echo preg_match($pattern, $str1) . "<br>";echo preg_match($pattern, $str2) . "<br>";Az output pedig ez:
01Az elsőt (str1) én gépeltem be, a másodikat egy link címéből másoltam ki ( [link] ).
Aztán kb. fél óra idegőrlő próbálgatás után (kb. annyi kellett, hogy a link részeit külön-külön megnézve megtaláljam, mi nem stimmel) megnéztem a link forrását, ahol azt láttam, hogy aNévtelenaz ott valójábanNe%CC%81vtelen.Ezt találtam róla:
e%CC%81 (U+0065 U+0301): Combining character e + ́Még a Notepad++ is furcsán "kezeli", mert amikor kijelölném (normál é betűnek látszik), akkor elsőre csak a feléig jelöli, aztán következő lépésben (Shift + jobbra) a másik felét.
Ide be tudom most csak azt a karaktert másolni: é
És fura módon ha a sima é-re keresek, ezt is találatnak dobja. De amikor egyet visszatörlök: e lesz.Találtam egy ilyen patternt, ami "beugrik" mindenre:
/\p{L}+/u
Viszont én kifejezetten azt szeretném, hogy csak akkor adjon találatot, hogy magyar ékezetes betűk vannak benne.Amihez használnám:
Linkeket ellenőrzök vele.if (filter_var($link, FILTER_VALIDATE_URL, FILTER_NULL_ON_FAILURE))
Ez hibásnak dobja, ha ékezetes karakter van a linkben (works as designed), ezért egy újabb lépcsőben ellenőrzöm, hogy a magyar ékezetes betűk vannak-e benne, és ha igen, akkor tovább engedem.Na ez eddig működött, most ezzel a "fura ékezetes megoldással" már nem.
Hirtelen ötlettől vezérelve megnéztem a header-jét, és bár böngészőben 200-as státuszú, a get_headers által visszaadva HTTP/1.1 404 Not Found.
Hogyan lehetne ezt megoldani?
Egy másik linkben © karaktert fogott meg a szkriptem... hát legyen az ő bajuk, aki így enged ki egy linket. Bár ennél speciel 200-as a státusz a headerben, de hát akkor is.
-
Taci
addikt
Köszönöm a választ mindenkinek, átnézek mindent! Még biztos lesz kérdésem ezzel kapcsolatban, de most nekiülök alaposan átnézni a témakört, mert elsőre nem gondoltam, hogy ennyit kell majd ezzel (is) foglalkozni. De ahogy látom, ez a .htaccess-es dolog azért csúnyán félre is tud menni - viszont nagyon hasznos is tud lenni, szóval jobb, ha ebbe is belerázódom.
@Mr. Y:
Meg tudnád mutatni a .htaccess-ed tartalmát (akár csak az ide vonatkozó részt)? Persze csak a publikus részeket, szenzitív infók nélkül.
mobal adott már egy jó példát erre (köszönöm), szeretnék még esetleg egy másikat is látni, összehasonlítani. -
Háromféle megoldást tudok erre.
Az elsőt írták is, mindenhová egy index.html/php és az átirányít, vagy a tárhelykiszolgáló beállításai között a fő index fájl elérését megadod, mint error page. Ugyanis ebben az esetben, ha olyan url-t probálnak megnyitni a weboldaladon, amihez nem tartozik index fájl, automatikusan átugrik. Ilyen az én weboldalam is, mindkettő megoldást alkalmazom és onnan ugyan nem látsz be a háttérbe.
Harmadik lehetőség pedig, hogy aktiválsz egy lezárást. Ebben az esetben ezt fogja visszakapni a kíváncsiskodó: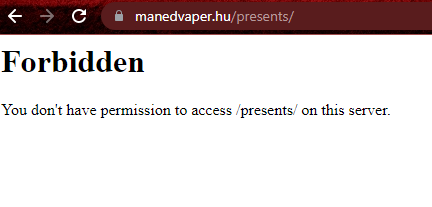
-

pmonitor
aktív tag
Lehet, hogy nagyon amatőr, de én úgy oldottam meg, hogy amelyik mappához nem szeretném, hogy hozzáférjenek(mármint hogy kilistázzák), abba mindbe tettem egy index.php-t. Mondjuk nálam nincsenek olyan hú de kényes adatok. Max. a letöltéseknél tudja valaki megkerülni vele azt, hogy a letöltés számához hozzáadja, ha letöltenek valamit. Tehát ha az én webhelyem ki is listázná, akkor sem lenne katasztrófa. Egyébként meg néha úgyis lejönnek érdekes file-ok is, hogy a böngészőbe Ctrl+S -> Weboldal - teljes mentése. Pl. ezt lementve lejön 3.65 Mb.
-
pelyib
tag
2 dolgot emelnek ki ebben a temaban:
- front controller pattern -> PHP-nak egy belepesi pontja van, ez pedig az web/index.php, ebbol kovetkezik, h a docroot a web/ folder, ide csak azt rakod ami publikusan el lehet erni
- tipikusan ilyesmi konyvtarstrukturad kene, h legyen [pelda]:/app_root//config <- konfiguracios fajlok/bin <- ide kerul ami a teminalbol futtatsz/src <- ide rakod a sajat kodod/web <- a korabban mar emlitett index.php lakohelye -
Taci
addikt
index.html van - bár gondolom ez esetben mindegy. (Azt még meg kell keresnem, hogyan kell átirányítanom - amúgy is, mert almappában vannak a fájlok, és amúgy is azt szeretném, hogy ha www.weblap.hu/index.html-t írja be, kiírva a címsorban akkor is www.weblap.hu legyen stb. De ezeket megkeresem.)
Eddig ezeket találtam:
Options -Indexes- így már nem lehet listázni a mappákat.RewriteCond %{HTTP_REFERER} !^weblap_linkje [NC]RewriteRule \.(gif|jpg|jpeg|png|webp|ico|
php|js|css|xml|log|txt|html)$ - [F,L]
- Ezzel pedig a fájlokhoz való direkt hozzáférés van tiltva, csak a weblapon keresztül lehet őket elérni. (ide talán a html nem kell, mert bár a lapon keresztül megnyitja ezeket a belső linkeket is, külön beírva már nem)Még valamit érdemes ide felvennem, figyelnem valamire?
-
Taci
addikt
Amikor pár hete azt kerestem, hogyan kell/lehet védeni egy PHP-alapú weboldalt, többek között szerepelt a "hide files from the browser". Több helyen is feltűnt, de igazán jó leírást még nem sikerült találnom róla.
Ez amúgy azt jelenti, hogy ezt megelőzzük?

Ami biztos, hogy a weblaphoz szükséges fájlok ne legyenek a gyökérkönyvtárban.
Plusz a .htaccess fájllal is van teendő - bár ez nem egyértelmű, hogy mit-hogyan. Ahogy láttam, a fő cél ezzel az, hogy a .php fájlokhoz hozzáférést letiltsa.Tudnátok esetleg egy megfelelő linket, jól összeszedett, alapos cikket mutatni, amit átolvashatok, hogy a jó irányba tereljen, ha lehet, példákkal kiegészítve, hogy értsem, mit-miért?
Köszönöm.
-
pelyib
tag
"1) require_once" egyertelmuen
Amugy ha nem akarod magad szivatni akkor composer es rabizod a tobbit.
Ha jol ertem amugy akkor azt irod le, h van egy A.php B.php es C.php. A es B is behuzza a C-t.
Ha A-t vagy B-t inditod akkor kapod a hibat? Ebben az esetben csak korbe neznek.
Ha legalabb PHP 7.0-t hasznalsz, akkor wrappold be az appodat egy try-catchel es debug backtracetry {
require your_file.php
} catch (Throwable $throwable) {
var_export($throwable);
} -
pmonitor
aktív tag
válasz
sztanozs
#20857
üzenetére
>nem a php2/php3 korában vagyunk, hogy ezt meg lehetne csinálni.
Akkor megnyugodtam.
A contact form javítva. Köszi, hogy szóltál. Na, ilyenre gondoltam, hogy vki. esetleg figyelmeztetne vmilyen hiányosságra a .txt-vel kapcsolatban(pl. vmi. beállítási problémára). A webprogramozásban nem vagyok otthon. Magyarul: örülök, hogy össze raktam vhogy az oldalt.
szerk.: egyébként a contact oldalon kinn van az e-mail címem is.
-
pmonitor
aktív tag
válasz
sztanozs
#20855
üzenetére
A webhelyszolgáltatómnak nem tudom az álláspontját, de valszeg. nem. Mondjuk nem úgy gondoltam az engedélyt, hogy feltörik a webhely szolgáltatómat, vagy az én jelszavamat. Mert azt tudom, hogy a dróton el lehet kapni. Végül is így mindenhez hozzá lehet férni. Csak konkrétan ehhez az egy file-hoz másik szerverről. Amiről szó volt.
Ez ellen lehet, hogy a szolgáltatóm sem tiltakozna. -
Taci
addikt
Jó pár cron job-om ugyanazt a php fájlt használja (jelenleg require-rel). Függvényt ugye nem lehet újra deklarálni, ezért hogy ne legyen PHP Fatal error: Cannot redeclare fuggvenynev(), néztem, mi lenne a legjobb megoldás.
1) require_once
2) require és if (!function_exists('fuggvenynev'))A leírás szerint egyértelmű, hogy a
require_oncepont erre van kitalálva:
The require_once expression is identical to require except PHP will check if the file has already been included, and if so, not include (require) it again.De inkább rákérdezek, hogy tényleg ez-e a jó megoldás.
Csak mert ez olyan fura nekem. Én úgy értelmeztem (lehet, rosszul), hogy a require(_once) az kvázi olyan, mintha a behúzott fájl tartalma a behúzott helyre lenne másolva.
De mint ilyen, nem lenne szabad hogy látszódjon másik fájl futásából. Tehát ha én 10szer húzom be ugyanazt a fájlt 10 különböző kódba, és ezek egyszerre futnak, ezek nem kéne hogy "lássák egymást", így a "Cannot redeclare" hiba sem állhatna fent.
Viszont mégis adott, így gondolom, talán memóriában tárolásról lehet szó, és ott ellenőrzi, hogy az adott függvény deklarálva van-e. (De akkor pedig az csak addig él, amíg az eredetileg hívó szkript fut. Ha befejezte a futását, akkor törlődik a memóriából. Mi van akkor, ha közben egy másik szkript épp használná valamelyik függvényt az első require_once-ból, de mivel az a másodiknak már nem engedte a require-et, viszont időközben kilépett, mi történik ekkor? Logikus az lenne, ha látja, hogy volt másik require_once, amit elutasított, de az azt hívó még fut, addig a memóriában tartja neki.)Kusza ez nekem, ezért kérnék tanácsot, hogy végülis melyik a jobb, az 1) vagy a 2)?
Köszi.








 Csak jó lenne tudni ki is használni.
Csak jó lenne tudni ki is használni. 




















Új hozzászólás Aktív témák
Hirdetés
- HiFi műszaki szemmel - sztereó hangrendszerek
- Kerékpárosok, bringások ide!
- Filmvilág
- WoW avagy World of Warcraft -=MMORPG=-
- Tarr Kft. kábeltv, internet, telefon
- One otthoni szolgáltatások (TV, internet, telefon)
- Android alkalmazások - szoftver kibeszélő topik
- Okosóra és okoskiegészítő topik
- Samsung Galaxy S25 - végre van kicsi!
- Autós topik
- További aktív témák...

- Csere-Beszámítás! Asus Számítógép PC Játékra! R5 1600X / GTX 1080 8GB / 32GB DDR4 / 256SSD + 2TB HDD
- Bomba ár! Dell Latitude 5310 - i5-10GEN I 16GB I 256SSD I HDMI I 13,3" FHD I Cam I W11 I Garancia!
- Eredeti Windows 10 / 11 Pro aktiválókulcs AZONNALI SZÁLLÍTÁSSAL!
- Csere-Beszámítás! MSI Gaming X RTX 4060Ti 16GB GDRR6 Videokártya!
- BESZÁMÍTÁS! ASRock B250 i5 6600 16GB DDR4 256 SSD 500GB HDD GTX 1050 2GB Zalman Z1 Njoy 550W
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest