-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
válasz
 #95904256
#9933
üzenetére
#95904256
#9933
üzenetére
Azért fejleszti az Intel az FMA-t, mert nagy előny, nem kell kivégezni senkit. Az AMD azért van FMA-ban előrébb, mert az ATI-tól elég komoly szakemberek érkeztek, és ezért van hamarabb FMA-juk.
De amúgy, én még mindig azt mondom, hogy abban az up to 56x-ben csúnyán benne van az Intel OpenCL drivere. Sokszor a harmadát tudja sebességben, mint az AMD drivere. Ez saját mérés, és a processzor ugyanaz (Core 2 Quad 9550). Itt a szoftveres részleget kellene gatyába rázni, de amúgy az AMD sem állt jobban, amikor elkezdte ezt az OpenCL-t, csak annyi az előny, hogy három évvel hamarabb láttak neki az alapoknak. Ez szoftverben számottevő különbség. -

Jack@l
veterán
válasz
#95904256
#9924
üzenetére
Nem, a lényeg, hogy az opencl programok kb 10x-20x lassabban futnak cpu-n mint gpu-n, intelen meg még lassabb kicsit.
Pont az a probléma a diával, hogy nincs ott az platform, amihez elsősorban kitalálták, Opencl-t az ATI szeretné minél jobban elterjeszteni a régebbi kiforrottabb CUDA ellenfeleként. -
Abu85
HÁZIGAZDA
válasz
#95904256
#9924
üzenetére
Nem, itt az AMD megmutatta, hogy az OpenCL-t használó Mandelbrot FMA4-re fordított verziója mennyivel gyorsabban fut az FMA4 és az XOP mellett a Bulldozer architektúrán mint a Sandy Bridge-en, amiből hiányzik az FMA4 és az XOP. A GPU-nak ehhez semmi köze. Azt persze valószínűnek tartom, hogy az AMD a Sandy Bridge-hez az Intel OpenCL driverét használták a sajátjuk helyett, ami sebességben kapásból hátrány az Intelnek.
Egyébként a konkurencia is ki tudja használni a GPU-t. Az OpenCL képes arra, hogy más gyártó termékein futtasson egyszerre egy programot. Kell hozzá egy OpenCL CPU és egy GPU driver. Persze a szoftver szempontjából nem árt, ha az a két driver nem haklis egymásra, de ez nem sebességben szokott kiütközni, hanem fagyásban. Manapság szerencsére egyre ritkább, de bekövetkezhet. Jobb együttműködés kell a gyártóktól, de a konkurens termék kvalifikálása senkinek sem az érdeke.

-
Abu85
HÁZIGAZDA
válasz
#95904256
#9909
üzenetére
Szerintem a Mandelbrot set szimplán újra van fordítva, hogy kezelje az XOP-t és az FMA4-et. A HPC piacon kiemelten fontos lehet, de a desktopon nem hiszem. Ami probléma még, hogy az Intelnél az OCL driver egy híg fos. Persze ez nem meglepő, alig pár hónapja fejlesztenek OCL-t, míg az AMD lassan három éve. Nem hiszem, hogy a különbségekben csak a hardver játszik szerepet, az AMD az OpenCL támogatásában meglépet a konkurenciától. Már az NV is lemarad mögöttük, mondjuk ők valószínűleg szándékosan, hogy a CUDA stratégia előnyben legyen.
-
Abu85
HÁZIGAZDA
válasz
#95904256
#9861
üzenetére
Azt nem tudni pontosan. A tesztekből ez az előny két esetben mutatható ki. A Dirt 3 és a Metro 2033 esetében a rajzolási parancsok száma magas. 60 fps-re 5000-7000 van kiadva. Függetlenül attól, hogy több szálra van-e optimalizálva vagy sem, ez a szituáció a Bulldozernek tetszik. Ez abból adódhat, hogy a rajzolási parancsok feldolgozása nem nagy számítási kapacitást, hanem inkább jó throughput képességet igényel. Igazából számolni annyira nem is kell ezen a szinten, hanem csak tovább kell adni egy parancsot a VGA-nak. Tekintve, hogy az API-kon keresztül a játékok ezen a ponton komoly terhelést kapnak, így ez a futtatása szempontjából kritikus tulajdonság. Ezek tipikusan azok a területek, hogy ha javítasz rajtuk akár egy picit is, akkor az már jól hat a teljes program futtatására, hiszen a teljesítmény főleg ettől függ. Sokat persze nem lehet javítani, ami abból is látszik, hogy az előny nem több 2-3%-nál VGA-limit mellett. Én úgy gondolom, hogy a dizájn kialakításánál van valami trükk, amitől az architektúra valamivel gyorsabban lehetővé teszi a rajzolási parancsok kiadását.
A másik amit láttam az a Lost Planet. Az egy kakukktojás lesz szvsz, mert a Hyper-Threading technológiát nem szereti a motor. Inkább lassít, mint gyorsít alatta. Ezt az AMD ezért használhatta fel. Valószínű, hogy HT nélküli procival már nem lenne előnyben az FX.Minimum biztos nő (erre az AMD is kitért egy slide-ban), de általában ez is VGA-limites dolog, tehát max grafika mellett nagy ugrásra nem kell számítani. A processzor szerepe a játékokban nagyon specifikus. Szinte lényegtelen egy bizonyos szint felett. Most az, hogy az AMD ezt a skálázódást reklámozza jó dolog, de látod, hogy 2-3%-nál nem vagy beljebb. Továbbra is az lesz, hogy az egyes programok számára lesz egy olyan határ a procinál, aminél tovább egyszerűen nem skálázódnak. Rendszerint ez 200 dollár körüli termék szokott lenni.
Ami ezen változtathat az az OpenCL/DirectCompute bevetése az általános számításoknál. Azon sokat lehet nyerni, de ott is csak akkor, ha beveted a Bulldozer új utasításait, vagy a proci melletti IGP-ket felhasználód számításra. -
-

dezz
nagyúr
válasz
#95904256
#9785
üzenetére
Nagyon ritka, hogy 3 független utasítás jöjjön egymás után... Összetettebb számításoknál eleve 1.0 alatt szokott lenni az IPC. Többet számít a front-end, pl. elágazásbecslés.
(#9784) atti_2010: Állítólag a glofo-s kapcsolatokért is ő volt a felelős, és az elnökség szerint nem tudta igazán szervezetté tenni a gyártást, illetve elég hathatósan érvényesíteni az AMD érdekeit.
(#9787) Abu85: Miért e jelző?

(#9789) P.H.: Ki lehet, ki lehet, de az átlagos kód 1.0 körüli IPC-vel fut, ugyebár...
-
-

Zeratul
addikt
válasz
#95904256
#9772
üzenetére
Bull FPU vagy dupla mennyiségű műveletet hajt végre a modul 1 futtatási szálához rendelve vagy szétválasztva mindkét szálon azonos mennyiséget. Az FPU throughputja meg duplája a K10nek, szóval nem látom miért lenne lassabb a K10nél. Jó van látencia de arra van feladatütemező hogy lehetőleg max througputon fusson a végrehajtóegység. Integernél meg az AMD szerint a K10 3 utas VE je csak 1.75 művelet végzett ezért a 2 utasra csökkentés nem jár drasztikus teljesítmény csökkenéssel (persze szintetikus benchmarkok alatt más a helyzet)
-

Oliverda
titán
válasz
#95904256
#9578
üzenetére
A skálázhatóságot folyamatosan próbálják javítani még az adott steppingen belül is. Jó példa erre, hogy a Deneb C3 3400 MHz-en kezdett 140 wattal most pedig 3700 MHz-nél tart 125 wattal miközben a stepping nem változott.
Thoroughbred "A" (130nm) ---> Thoroughbred "B" (130nm)
ClawHammer "C0" (130nm) ---> ClawHammer "CG" (130nm)
Winchester "D0" (90nm) ---> Venice/San Diego "E3-E6" (90nm)
Windsor "F2" (90nm) ---> Windsor "F3" (90nm)
Brisbane "G1" (65nm) ---> Brisbane "G2" (65nm)
Agena "B2" (65nm) ---> Agena "B3" (65nm)
Deneb "C2" (45nm) ---> Deneb "C3" (45nm)
Amikor a betű is változik akkor valami nagyobb módosítás történik. Ilyen utoljára a Winchester->Venice váltáskor volt emlékeim szerint. Akkor SSE3 támogatást kapott az utóbbi az előbbihez képest, és akkor még a kódnév is változott. Más nagyobb horderejű változtatás most nem rémlik ebben az esetben.
mod: a Thoroughbred esetében meg azt hiszem, hogy a B stepping kapott még egy fémréteget, illetve a lapka területe is nőtt kissé.
-
Oliverda
titán
válasz
#95904256
#9564
üzenetére
A szeptember 19. sosem volt hivatalosan bejelentett dátum. Sőt egészen pontosan napra pontosan meghatározott publikus dátumból eddig nem volt egy darab sem. Az egész az ebben a hírben látható videóból indult ki. Mondjuk ez alapján akár november 19. is lehetne a nap.

-
válasz
#95904256
#8883
üzenetére
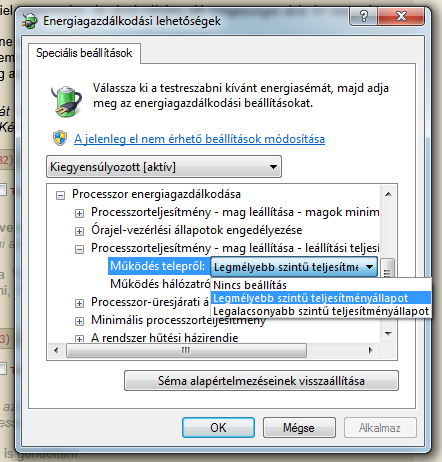
Így kell aktiválni. A szandimnál bepróbálkoztam vele, de nagyon nincs érezhető hatása, sőt, mintha többet is fogyasztana ezzel. Gondolom azért, mert nem tudja külön vezérleni / lekapcsolni a magokat. Na de majd a bull.
-

P.H.
senior tag
válasz
#95904256
#8736
üzenetére
2 évvel ezelőtt is másról beszéltek az azóta sem implementált FMA megvalósításukkal kapcsolatban, mint ami most várható
Náluk attól függ még (jelen pillanatban is, és még pár hónapig), hogy mit lesz szükséges megvalósítani a konkurencia ellen: az utasításkódolás adott (VEX) és a fejlesztés mindenképp szükséges belül. Az FMA3-hoz ugyanúgy 3 bemenet kell, mint az FMA4-hez, és minden jel arra mutat, hogy jelenlegi generációban nem rendelkeznek az ehhez szükséges belső felépítéssel.
-
P.H.
senior tag
válasz
#95904256
#8731
üzenetére
A Haswell-lel kapcsolatban nem lennék biztos a dologban, annak a microarch-váltásnak arról kell szólnia, hogy a belső RISC uop-ok tudjanak kezelni 2-nél több bemeneti register-értéket (FP) illetve 1 EFLAGS-mezőt + legalább 2 register-értéket (INT) bemenetként.
A 2 register vagy 1 register + 1 EFLAGS bemenetre vonatkozó uop-megkötést úgy tűnik, még mindig hordozza a legújabb generációjuk is (eléggé régóta, talán P6 óta), belül: +1 közvetlen érték mint bement lehet emellett, kimenet lehet 3., átnevezett register.(Ennél többet ellenük nem nagyon lehet felhozni a Sandy Bridge ellen amúgy
)Ezt mindenképp meg kell lépniük a Haswell-nél, pont az FMA-jellegű dolgok miatt: a többi ilyen utasításnál a hátráltató hatást, azaz hogy 1-nél több uop-ra fordulnak, sikeresen elrejtették a kisebb (Nehalem) - nagyobb (Sandy Bridge) uop-cache-ekkel. Ezzel viszont egyidejűleg felgyorsítják az ADC/SBB, CMOVcc vagy akár a BLEND-utasításokat is.
-

Remus389
veterán
válasz
#95904256
#8584
üzenetére
igen ott van a Via is, ők is vagy 100-an vannak, összehoznak egy olcsó netbookba való CPU-t, aztán eladnak belőle néhányat
de teljesen más egy Atom szintű CPU-t összehozni nagyjából meglévő technológiákkal, aminek az ár/érték illetve a teljesítmény/fogyasztása jó, és teljesen más egy olyan milliárd feletti tranzisztorszámú CPU-t(nagyteljesítményűt) összehozni ami az élvonalba kerül, és az Intel aktuális nagyágyújával versenyképes(milliárdok: komoly K+F, okos szakemberek megfizetése/elcsábítása, saját gyár előnye ott is K+F)
egy olyan F1-es autót is lényegesem nehezebb összehozni ami versenyképes a Mclarennel vagy a Ferkókkal, mint néhány embernek meglévő technológiával összetákolni egy igen gyors autót, csak mondjuk 3 mp-el lassabb, tehát semmit se ér F1-ben, pont azt a 3 mp különbség milliárdokba kerülhet(K+F)
itt is így látom, az a néhány % különbség döntő, ez ezt csak komoly kutatás+fejlesztéssel, komoly agyelszívással érhető el, jó fizetésekkel, amihez az Intelnél megvan a tőke, ráadásul saját gyár is tehát össze tudják hangolni jobban a procival
nem is tudom valamikor olvastam hogy az egyik negyedévben(vagy évben) az Intel kábé 10.000.000.000, vagyis tiz milliárd profittal zárt, míg az AMD -300 millióval
ennek tükrében azért kisebbfajta csoda lenne ha a Bull technikailag megverné az Intelt
azért ha egy cég ennyi pénzt tud ölni egy projectbe másik meg nemtudom tizedannyit, kisebbfajta csoda lenne ha az AMD "nyerne" a csúcscpuk csatáját
szerintem már ők is rájöttek erre, ezért inkább ár/értékkel operálnak, sok embert vonz hogy négymagos gép meg fusion, és mondjuk 100 dolcsival olcsóbb ugyanolyan lapi, tehát ebben látják a jövőt
ráadásul a desktop szegmens is zsugorodik, oda is sokan Intelt vesznek, tehát a Bull nem is olyan nagy üzlet
nehéz szülés az biztos, ez is, most Október, Októberben majd Karácsony, Karácsonykor majd Április, na és onnan még bő két hónap és megszületik talán, és talán csalódás lesz
![;]](//cdn.rios.hu/dl/s/v1.gif) eddig is ez volt
eddig is ez volt -
Remus389
veterán
válasz
#95904256
#8581
üzenetére
hehe, hát persze hogy nem kicsi
 , nem ezt mondom(szerintem te vagy az értetlen, és te nem fogod fel)
, nem ezt mondom(szerintem te vagy az értetlen, és te nem fogod fel)csak a góliát ellenfeleihez képest kicsi, illetve a magára vállalt sokféle projekthez kicsi
van fogalmad mekkora projekt kifejleszteni egy processzor architektúrát? És nem is egyet hanem ott van még a fusion változatok(több! Brazos, Lliano, Trinity-t is elkezdték biztos jó régen) és a videokártya(kell felső, közepes stb) részleg is, meg a chipsetek
a mennyiség akár a minőség rovására is mehet, vagy késésekhez vezet, erre kicsi az AMD, főleg a tőkéje, meg az embere
az hogy kicsi mint mondtam, relatív
Tökmindegy +1
ehhez képest meg lehet nézni az Intelt, nem hinném hogy sokkal több lenne a projektje erre viszont nemtudom akár százszor annyi pénze van és 8x annyi embere
nekik jön az Ivy Bridge és annak herélt változatai van még SSD project is, aztán slussz(legalábbis így hirtelen), és erre van 8x annyi ember és sokkal több zsé, meg gyárak meg minden
-
Remus389
veterán
válasz
#95904256
#8579
üzenetére
hát viszont profitban több mint tízszer nagyobb, pénzmennyiségben
vagy nem is tudom melyik cégnek kell komoly pénzeket fordítani az adósság kezelésre, emellett folyamatosan csökken a bevételük is, embereket is rúgnak ki, és közbe több nagy projektjük van
elég kényelmetlen helyzet
a legfontosabbat a tőkét, okosan kihagytad az "érveid" közül(már megszoktam hogy itt a vitázók úgy tekerik-ferdítik a dolgokat nehogy igazam legyen
)tehát az intel jóval komolyabb cég, legalábbis a tőkét nézve, ahhoz képest nem sokkal több a projektje, és nem is nagyon szoktak csúszni(ritkán, mondjuk legutóbb volt egy baki az SB esetében, de az hiba volt az más, nem késés)
valahogy azt érezni hogy túlvállalták magukat az AMD-nél és emiatt késnek, miért nem lehet ezzel egyetérteni hisz relatív kis cég, kis profittal, relatív kevés alkalmazottal(nem a sarki zöldségezhez kell mérni
vagy a MOL-hoz, hanem a nagy IT cégekhez), ennyi -
Remus389
veterán
válasz
#95904256
#8577
üzenetére
igen, minden relatív
a sarki zöldségesnél pedig összehasonlíthatatlanul nagyobb
de a sarki zöldséges nem tervez párhuzamosan több, akár 1 milliárd tranzisztor feletti nagyteljesítményű processort, és ezek továbbfejlesztéseit
ehhez meg kevés lehet a 11000 alkalmazott, aminek legalább fele nem is mérnök
ehhez képest az Intel több mint 10x nagyobb
érezni azért hogy az erejüket ez meghaladhatja
ráadásul már folyik a épp most megszült projekt továbbfejlesztése is, tehát nagyon sok helyen akar helytállni az AMD és nekem úgy tűnik erőlködnek nagyon, bizonyíték erre hogy mindennel csak csúsznak, föl kéne venni még 2x ennyi szakembert, de arra nincs pénz
-
-
-
válasz
#95904256
#6722
üzenetére
Igen, ahogy mondod. Tény az, hogy nem sikerült az előzőleg megálmodott órajelekig eljutni a Netbursttel, és ennek gátja a szivárgási áram miatti magas fogyasztás és melegedés, ha jól tudom.
Azért vontam párhuzamot a Bulldozer és a Pentium 4 között, mert láttatni akartam azt, hogy mi lesz akkor, ha az előre eltervezett órajeleket nem lehet hozni az architektúrával.
Persze a P4 is ment szépen, és épp elég volt lépést tartania vele az AMD-nek, de az Intel tudott váltani. Ha a Bulldozer nem jön be nekik úgy, ahogy eltervezték, nehezen hiszem, hogy előrántanak egy, a C2D/Athlon64 viszonylathoz hasonlóan jó teljesítményű processzort. De akkor meg mi lesz?
-

zsolt320i
senior tag
válasz
#95904256
#6712
üzenetére
nekem más a véleményem, igaz én termelési rendszerekkel foglalkozom, és azt látom hogy egy dolgot ugyanannyi idő megcsinálni jól mint rosszul.
szóval elhiszem hogy sokat kell dolgozni rajta meg sokba kerül, de az a nem mind egy hogyan és mire használjuk az erőforrást.
elolvasom még egyszer amit Oli bemásolt mert rengeteg érdekes infó tartalmaz, kell emésszem egy kicsit -
zsolt320i
senior tag
válasz
#95904256
#6707
üzenetére
ez kezd érdekelni.... (nem akarok vélemény háborút, csak pusztán érdeklődés és véleményem fejtem ki)
1. ha fejlesztek nem mindegy hogy milyet fejlesztek, ugyanannyi időbe és munkába kerül egy jót is kifejleszteni meg egy "szart is", szal közel a zs is amit bele kell ölni ugyanaz
2. biztos hogy növekedne, a "core" mérete nagyobb az amd magjánál? -
Oliverda
titán
válasz
#95904256
#6707
üzenetére
Meg láthatólag nem arra mennek már egy ideje, hogy az Intel architektúráit másolgassák mert azzal mindig csak mögöttük lennének egy lépéssel. Az eddigiek alapján ehhez a teljesen új architektúrához (CMT) magas órajelek kellene a megfelelő számítási teljesítményhez. Na meg persze ahhoz hogy még gazdaságosan lehessen gyártani de ezt le is írtad.
zsolt320i: Sandy Bridge-ből nem lesz 5GHz-es mert azt az architektúrát nem úgy tervezték, hogy ezt bírja.
"szted miért lesz c2c-ben gyengébb a nulldózer?"
Mert úgy lett megtervezve, hogy azonos órajelen gyengébb lesz. Lapozz vissza pár oldalt vagy esetleg olvasd el ezt a topikot. Ott részletesen van taglalva.
-
Oliverda
titán
válasz
#95904256
#6586
üzenetére
Nincsmit.
Amúgy az SMT (állítólag) sosem volt téma:
When Intel announced Hyper Threading, AMD wasn't (publicly) paying any attention at all to TLP as a means to increase overall performance. But now that AMD is much more interested and more public about their TLP direction, we wondered if there was any room for SMT a la Hyper Threading in future AMD processors, potentially working within multi-core designs.
Fred's response to this question was thankfully straightforward; he isn't a fan of Intel's Hyper Threading in the sense that the entire pipeline is shared between multiple threads. In Fred's words, "it's a misuse of resources." However, Weber did mention that there's interest in sharing parts of multiple cores, such as two cores sharing a FPU to improve efficiency and reduce design complexity. But things like sharing simple units just didn't make sense in Weber's world, and given the architecture with which he's working, we tend to agree.
A megvalósításhoz szükséges plusz szilíciumról meg ezt állítják:
"If you were to pull one core from each module, you would remove ~5% of silicon from the total die."
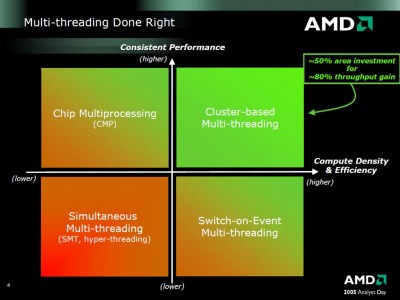
Valamint optimális esetben állítólag 80%-ot is hozhat a megoldás. Még mielőtt valaki megkérdezi hogy ez hogyan jött ki, nem tudom mert nem én számoltam. A HT esetében ugyanez 20%.
-
Oliverda
titán
válasz
#95904256
#6584
üzenetére
Egyelőre kb ennyi a hivatalos belőle:


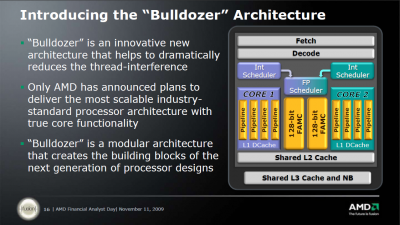
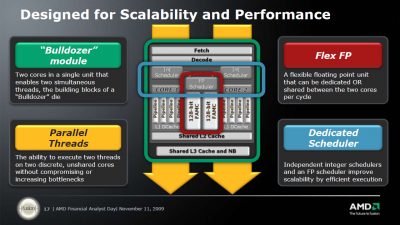
Ami nem hivatalos:
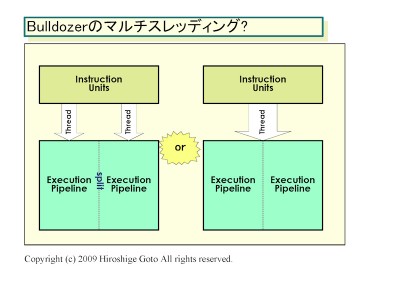


A CMT-ről:

(ez nagyítható)
Tehát itt épp arról van szó hogy a CMT hatékonyabb, azaz jobb terület/teljesítmény mutatója, valamint nincs meg az a hátránya mint a HT-nek, hogy bizonyos alkalmazások nem hogy gyorsulnának de még inkább belassulnak a hatására. [link]
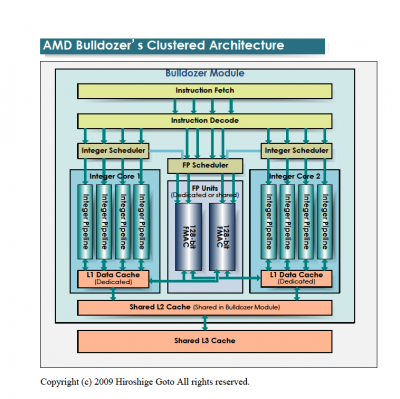
A Bulldozer-nél a "core" részegység mint olyan megszűnik létezni és "module" lesz helyette. Amit feljebb látsz az egy darab modul. Egy ilyet két magnak fog látni az OS. Az L1 I-Cache, az L2 és az FPU megosztott lesz a modulon belül, de terheléstől függően dinamikusan használhatóak lesznek ezen részegységek erőforrásai. Tehát pl. egy egy szálat terhelő alkalmazásnál a teljes FPU sávszélesség használható lesz. A modulok egy nagyobb megosztott L3-mal lesznek összekötve. A legnagyobb egy lapkás verzió elvileg 4 modult fog tartalmazni (32nm-en).
Ez sem hivatalos:

-

Bluegene
addikt
válasz
#95904256
#6371
üzenetére
az Atom nem továbbfejlesztés, tehát nem egy meglévő architektúrát pofoztak tovább, vagy nem egy meglévő pl Core2-es processort butítottak, hanem alapjaiból, teljesen új felépítésű, úgy mint a netburst pl vagy a K7
A K10 -> K10.5 több újdonságot tartalmaz ez tuti nem igaz, nagyon hasonló a phenom1 és 2, most viccelsz?[link]
egy továbbfejlesztés (K10->K10.5) és új fejlesztés (Atom, P4, Bulldozer) között érzed a különbséget?
-
Bluegene
addikt
válasz
#95904256
#6368
üzenetére
a #6345-ben belinkeltem egy cikket és onnan veszem
tetszik nem tetszik az Intel Atom vadi új fejlesztés
K5 [Kryptonite 5]: 1996, K6: 1997, K6-2: 1997, K6-III: 1998
K7: 1999, K7.5: 2001
K8: 2003, K9: 2005, K10: 2007, K10.5: 2008P5 [Pentium]: 1993, P55C [Pentium MMX]: 1996
P6 [Pentium Pro]: 1995, P6B [Pentium II]: 1997, P6C [Pentium III]: 1999, P6D [Pentium M]: 2003, P6E [Core]: 2005, Core 2 ["P6F"]: 2006, Nehalem ["P6G"]: 2008
NetBurst: 2000, NetBurst HT: 2003, NetBurst AMD64 [Prescott 2M]: 2004
P7 [Itanium]: 2001
Atom: 2008jó persze lehet ezzel vitatkozni, én úgy tudom a K8 nagyon hasonló a K10-hez felépítésben, de a K7 volt az őse, amihez szintén hasonlított csak volt IMC-je
egyszóval a 2003-ban megjelent K8-ra építenek ma is, csak annak továbbfejlesztett négymagos változata, de alapjaiban ua., még egyszálas teljesítménye is igen közel vanmost a Bulldozer más lesz, és majd ezt fogják továbbfejleszteni majd éveken át, szal az első Bulldozer olyan lesz mint a Q6600 sokat zabál, de gyors lesz, és évekig kiszolgál
, egyszóval megéri az árát
Oliverda: mennyit olvassak vissza? 200 hsz-t? vagy 500-zat? -
#5343
 csatahajós
senior tag
#95904256
#5342
csatahajós
senior tag
#95904256
#5342
csatahajós
senior tag
válasz
#95904256
#5342
üzenetére
Hmmm a HD534 akkor ezek szerint 3,4 Ghz-et takarna?
bízakodó vagy, de úgy legyen!Különben a "HD" szerintem pont kizárt, nehogy a kedves userek összekevrjék a GPU-t a CPU val és fordítva
Különben mi a véleményetek a Kuma-ról illetve a később várható L3 nélküli Propus meg Regor-ról (tudom a Kuma-nak van L3-ja de csak két magra oszlik)?
Ugyan árban nem versenyképes de érdekes alternatíva azért az Agena-nak a Kuma ha az egyszálas, inkább játékokban és hétköznapibb alkalmazásokban mérhető teljesítményt nézzük. -
#5339
csatahajós
senior tag
#95904256
#5333
csatahajós
senior tag
válasz
#95904256
#5333
üzenetére
"Bár ha mégegyszer odaengedik a tűzhöz a nevezéktanos emberüket akkor lehet hogy Pulsar X4 2000++ lesz..."
MEGALOL

Az fix h ráférne egy pár hét kreatív-szabi
Oliverda: és akkor lesz AMD vonalon is X9650
(csak a Q hiányzik) ? Egyébként valószínűleg ez lesz, hogy vagy a Phenom név mögött vagy a szám előtt után lesz egy-két plusz karakter.Mondjuk én azt se bánom ha kisgizikének hívják csak üssön és ne legyen túl drága.
-
Oliverda
titán
-
-
#5263
shabbarulez
őstag
#95904256
#5260
shabbarulez
őstag
válasz
#95904256
#5260
üzenetére
Szerintem leginkább a gyárak életciklusát nem lehet felgyorsítani, ott van a szűk keresztmetszet. A gyárak kialakítása egyre drágul, ezt a még tovább rövidülő életcilkus mellett egyre nehezebb lenne retábilisan fenntartani. Ott van pl az AMD egyik drezdai gyára amit épp most állítanak át és e miatt kiesik a termelésből közel egy évig. Ez komoly bevétel kieséssel jár és e mellett az átállás jelentős költségeit is rá kell költeni. Később amikor ez a gyár termelni kezd, ki kell tudnia gazdálkodni ezeket a többlet költségeket és ha erre egyre rövidebb idő áll rendelkezésére, a gazdaságosság egyre kevésbé valószínű. A másik lehetőség gyorsított tempóban gyárakat építeni, de ezt megint nehéz tőkével bírni és a rövidülő életciklus alatt a megtérülés is egyre kétségesebb. Az egyetlen jó megoldás egy generáció átugrása, kérdés ennek mennyire lenne realítása. A 22nm bevezetése egyébként körülményes és drága lesz, hisz a nagy félvezető gyártók nagy valószínűséggel ennél a gyártástechnológiánál fognak 450mm-es ostyákra átállni.
-
#5261
 VaniliásRönk
nagyúr
#95904256
#5260
VaniliásRönk
nagyúr
#95904256
#5260
VaniliásRönk
nagyúr
válasz
#95904256
#5260
üzenetére
Szerintem az a probléma, hogy hónapokba telik mire a waferből chip lesz, max. párhuzamosítással lehetne gyorsítani a dolgon, de gondolom szükség van a korábbi eredményekre, hogy tudják merre kell továbblépni.
Meg ugye nem az a cél, hogy minél előbb gyártani tudjanak, hanem hogy minél előbb gazdaságosan tudjanak gyártani, nem csak megoldást, hanem gazdaságos és tömegtermelésben is működőképes megoldást kell találni.
Persze mindez csak rettentően laikus elmélkedés. -

Andre1234
aktív tag
válasz
#95904256
#5247
üzenetére
csak az ad168 videomátrix nem hajlandó pcmcia-s kártyával kommunikálni, ezért a kollegák sokasága szerzi be a régi laptopokat szervízre.áruvédelmi kapuk még csak-csak működnek.(de úgy néz ki ,hogy találtunk vmi usb átalakítót ami egyenlőre működik ezért is néztem ki eee pc-t)
milyen 486 ill pentium kellene?van nekem kirakva a polcra keretbe amd486 dx4 100mhz-es proci és egy p1 mmx 133 asszem, és egy körbesarkazott duron ami már elvillant.
-
#5069
shabbarulez
őstag
#95904256
#5067
shabbarulez
őstag
válasz
#95904256
#5067
üzenetére
Nem olyan új dolog az. Elméletileg az AMD már tavaly májusban kiadott egy ilyen 1Ghz-re down clockokt K8-ast, bár annak 9W TDP-t írtak. [link]
Kérdés miben fog eltérni ez az új variás ami idén én végére várható. Mit kalapálnak még rajta, ehhez a 1.5 évvel korábbi változathoz képest. Gondolom elsősorban az idle fogyasztást akarják jelentősen csökkenteni, mert különben aksi időtartamban nehéz lenne versenyre kelniük.
-
#4999
 dangerzone
addikt
#95904256
#4998
dangerzone
addikt
#95904256
#4998
dangerzone
addikt
válasz
#95904256
#4998
üzenetére
.....ha már a nevét kikerested, akkor jobban megnézhetted volna azt is, hogy 2 hetente van egy új hozzászólás....és valószínűleg nem lett volna értelme odaírnom....na hát ez van. AKI MEG ESETLEG TUDNA VMI ÉRTELMESET IS HOZZÁSZÓLNI AZ ANYÁZÁS HELYETT, ANNAK MEGKÖSZÖNNÉM ! ;)
-
-

Balala2007
tag
válasz
#95904256
#4951
üzenetére
Előbb kipróbáltam ezt a cache-miss dolgot egy Phenom-on és egy Wolfdale-en is. Mindkettő képes volt arra hogy amíg a cache-miss miatt bejön a RAM-ból a dolog addig több száz utasítást ( add, xor, inc, fld, fstp, ... ) végrehajtsanak, így a több száz utasítással és azok nélkül is ugyanannyi volt a futásidő.
En is kiprobaltam egy Phenomon, es nekem az jott ki, hogy a reordering az csak ROB-nyi uop kozott mukodik. Az ellenkezoje meglepett volna, hiszen a retirement is in-order minden esetben.
#define BUFFER_SIZE 16 * 1024 * 1024
#define STRIDE 1024
#define READS 10000000
__declspec(naked) void __fastcall Walk(DWORD *raddr, DWORD repeat) {
__asm {
startWalk:
mov ecx, [ecx]
dec edx
jnz startWalk
ret
}
}
__declspec(naked) void __fastcall Walk2(DWORD *raddr, DWORD repeat) {
__asm {
startWalk2:
mov ecx, [ecx]
nop
....
nop
dec edx
jnz startWalk2
ret
}
}
void _tmain(int argc, _TCHAR* argv[])
{
double start, end;
DWORD *buff = NULL;
buff = (DWORD *)VirtualAlloc(NULL, BUFFER_SIZE, MEM_COMMIT, PAGE_READWRITE);
int index = 0;
for (index = 0; index < (BUFFER_SIZE / sizeof(DWORD)) - (STRIDE / sizeof(DWORD)); index += STRIDE / sizeof(DWORD))
buff[index] = (DWORD)&buff[index + STRIDE / sizeof(DWORD)];
buff[index] = (DWORD)&buff[0];
Walk(buff, READS);
start = (double)__rdtsc();
Walk(buff, READS);
end = (double)__rdtsc();
printf("Clocks:%f\n", (end - start) / (double)(READS));
start = (double)__rdtsc();
Walk2(buff, READS);
end = (double)__rdtsc();
printf("Clocks:%f\n", (end - start) / (double)(READS));
return;
}Ez a szokasos lancolt listas memoriaolvasgatast csinalja 2 verzioban. A masodiknal a futasido megegyezik az elsovel (nalam 145 clock-ra jon ki 1024byte-os stride-dal), amig csak 66db nop-ot szurok be. Ez stimmel is, mert 66 nop + 3 uop + 1 fetch bubble az 72 uop. A 67. nop utan erdekes modon elkezd lassulni, pedig a 145 clock alatt meg boven lenne ideje nop-okat apritani, de hat nem tud az in-order retirement miatt.
-

Rive
veterán
válasz
#95904256
#4951
üzenetére
Előbb kipróbáltam ezt a cache-miss dolgot egy Phenom-on és egy Wolfdale-en is. Mindkettő képes volt arra hogy amíg a cache-miss miatt bejön a RAM-ból a dolog addig több száz utasítást ( add, xor, inc, fld, fstp, ... ) végrehajtsanak, így a több száz utasítással és azok nélkül is ugyanannyi volt a futásidő.
Jól értem, tulajdonképpen egy stall-nyi szünetet töltöttél fel független utasításokkal? Ez szép, de gyakorlatban hány utasításnyi hosszra szoktak elhúzódni az alapblokkok? 3-5? 10? Meg hány utasítás forog egyszerre feldolgozás alatt? Tipikusan néhány tucat? A SUN-féle megoldás azért új, mert ennél jóval nagyobb távokról is szó lehet, a dolog nincs a VÁ hosszához kötve.Majd kerestem egy UltraSparc T1 leírást, amiből kiderült hogy ez a processzor in-order végrehajtással rendelkezik, de képes arra hogy pl. egy cache-miss-nél egy másik szálon (scout-thread) tovább futtassa a további utasításokat. Kvázi out-of-order végrehajtást csinál úgy hogy befog egy másik egységet a feladatra.
Ha jól értem, a T1 (vagy csak a T2? Ebben nem vagyok biztos, nem igazán másztam bele a csalkádfába) igazából nem másik egységet, hanem inkább csak másik (in szitu tükrözött) kontextust fog be a dologra... -
Rive
veterán
válasz
#95904256
#4946
üzenetére
Az Intel/AMD-féle spekulatív végrehajtás néhány tucat utasítás mélységű, és az ugrás-előrejelzésel együtt ugye arra szolgál, hogy a feltételes utasítások dekódolásától a tényleges kiértékelhetőségig tartó, tipikusan néhány tucatnyi utasítás végrehajtása megkezdődhessen és jó eséllyel megfelelő véget érjen.
A Niagara cucca viszont a memóriahasználatot próbálja előrejelezni: a max. néhány ezer utasításnyi távolban szükségessé váló memóriaterületeket tölti előre.
A két megközelítés annyira eltérő, hogy én a Niagara megoldásának hatékonyságára még tippelni se merek, annyira idegen nekem.
-

zlutor
aktív tag
válasz
#95904256
#4935
üzenetére
Te vagy a processzor lelekbuvar, biztosan nem tevedsz...

De majd fLeSs megmondja...En csak annyit akartam mondani, hogy az Inteles HT megoldas nem futtat gyorsabban egyszalas progit attol, hogy ugy tunik, mintha ket proci lenne. Ami ugye raadasul nem is ketto, csak 1,x...)
Na, mindegy...

-
-
P.H.
senior tag
válasz
#95904256
#4931
üzenetére
- SZVSZ a találati arány általában messze 80-90% felett van jó ideje, a prefetch-megoldások a döntőbbek inkább, adat-megközelítésben ezek sokkal kisebb találati aránnyal rendelkezhetnek.
- Nem értem pontosan, mire gondolsz itt, a függőségek esetén. (ok, INC nincs, ECX >= 8
). A VIA és az AMD esetén jól lehet látni, milyen módon oldják meg a portok közti elosztást (~FIFO, alap -> szabályok); az Intel-nek sincs sokkal több órajelbeli (= több lépcsőjű) ideje ezt a leosztást megoldani a közös ROB/RS-sel, tehát nagyon bonyolult nem lehet (csak nem utasítássorrendbeli egyszerű "balról jobbra"?)- VIA: "Pl. duplapontos szorzással 3 órajel alatt végez, viszont csak 2 órajelenként indítható. Az osztás viszont az első órajeltől kezdve átlapolt! Ilyet sem az AMD sem az Intel nem tud..." Pedig pont neki nem kellene tudnia ilyeneket, ismerve azt, hogy hova szánja...
Ígéretesen hangzik, de ezzel én megvárnám pl. a részletes latency/throughtput értékeket tartalmazó dokumentációt. -
zlutor
aktív tag
válasz
#95904256
#4923
üzenetére
Haat, ebben azert nem vagyok biztos...
A HT valami olyasmi - amennyire en tudom - hogy bizonyos dolgok meg vannak duplazva a prociban, igy ha tobb(!) szalat kell futtatni, akkor esetleg(!) gyorsabb. Ha meg olyat hasznal jellemzoen, amibol nincs ketto, akkor nem gyorsabb...
De magam is irtam olyan ellenpeldat: sok szalon futo, de szalankent erosen rekurziv progit, ami semmit - de tenyleg semmit - nem profitalt a HT-bol. Egy szalon futott X ideig (50% load a task managerben), ket szalon is X ideig futott, de a task manager szerint 100% volt a load... Az X2-esemen nem volt gond, ott ket szalon ~ feleannyi ido alatt vegzett...
Az mar cska hab volt a tortan, hogy a Core2-k sem igazan szerettek...
Szoval, ha az AMD megcsinalja, hogy virtualisan egy magnak latszon a sok valodi mag, akkor megerdemelnek egy HATALMAS
-t... Meg ugy is, ha ez csak valamifele fordito progi oldali tamogatassal, mert az brutalis teljesitmenyt adhatna... Persze, az lenne az igazi, ha vegre jol skalazodo alkalmazasok keszulnenek... -
P.H.
senior tag
válasz
#95904256
#4927
üzenetére
Feltételezve, hogy a "szerk:" részt nekem szántad:
Nem könnyű radikálisan új felépítést alkotni ("az aktuális K7-K8-K10 nagyon is jó"? volt erre egy hsz-em tavaly: "Az, hogy az AMD miért nem tudja járatni ezt az alapvető felépítést az annak „megfelelő” órajelen (szerintem egy olyan 4 GHz-ig kellene dual-core K10-nek skálázódni, hogy megoldódjanak rövidtávon az AMD problémái), ezt pontosan nem tudjuk, de lehetséges, hogy ennek okát nem a szűk értelemben vett magokon belül kell keresni." De jelen pillanatban én nem tudom, hol kellene keresni az okot.)
- branch-prediction eljárások (és amekkora megbízhatósággal rendelkeznek) nem hiszem, hogy manapság fontosabbak lennének a megfelelő prefetch-algoritmusoknál.
- OoO hatékonysága: ezen a téren SZVSZ az AMD teljesen jó úton jár, lásd pl. a VIA Isaiah-t, ahol ugyancsak egy-egy port-hoz külön ütemező (RS) járul. (Te írtad anno, hogy az Intel érzékenyebb az utasítássorrendre, mint az AMD.) De az AMD-féle egyszerű pack-stages átrendezésnek sincs tovább jövője, látszik, hogy a többiek kifinomultabb algorimusokat alkalmaznak.
- lebegőpontos végrehajtás: persze, minél gyorsabb, annál jobb. Jó kérdés, hogy min múlnak a tervezési szempontok: a VIA össze tudott hozni 2 clock-os összeadást, az Intel 3 clock-ost, az AMD 4-est. Abszolút nem tükrözik a számok az erőviszonyokat, a szükségleteket és az anyagi hátteret.
-
P.H.
senior tag
válasz
#95904256
#4923
üzenetére
Ezek csak találgatásoknak tűnnek megalapozott információk helyett, én azon gondolkodok inkább, hogy a találgatások között miért volt fontos kiemelni azt, hogy "- Not VLIW, still OoO superscalar architecture"
De ha meg akarnám magyarázni a dolgot, erre és erre indulnék el (amit eddig Hans de Vries legnagyobb tévedésének tartottam, máig nem tudom hova tenni).
-
P.H.
senior tag
válasz
#95904256
#4899
üzenetére
Ha valóban ekkora (órajelekben mérhető) hatása van a késleltetésre önmagában az asszociativitásnak (és most csak maradjunk a Merom-családon belül, ott igazán érdekes a kérdés, főleg visszafelé), akkor az E1xxx-es felvetés jogos is lehet - bár én nem hiszem.
De azt se feledjük, hogy itt (Barcelona-Shanghai esetén) cache-növekedésről is beszélünk, magasabb asszociativitás mellett (meg még esetleges órajel-változásról is).
-
-
P.H.
senior tag
válasz
#95904256
#4895
üzenetére
Azt hiszem, volt erről forrás is, de logikailag is szükségszerű: a fizikai címből eggyel több bitet használnak fel az L3 indexelésére, ekkor kijön 4 MB, és másfélszeresére növelik az asszociativitást, így jön ki a 6 MB.
A K8-as L2 esetén a fizikai címből jövő indexelő bitek számával játszottak (ennek a hibaleírásnak a 6. pontjában konkrétan le is írják ezt), az asszociativitás nem változott 256-512-1024 KB L2 esetén, a Core2-nél viszont fordítva van, azt hiszem: ahogy csökken a családok L2-mérete, annál kisebb az asszociativitás.
-
Balala2007
tag
válasz
#95904256
#4861
üzenetére
Tudtommal van 256 bites HADD az AVX-ben.
VHADDPD (VEX.256 encoded version)
DEST[63:0] <- SRC1[127:64] + SRC1[63:0]
DEST[127:64] <- SRC2[127:64] + SRC2[63:0]
DEST[191:128] <- SRC1[255:192] + SRC1[191:128]
DEST[255:192] <- SRC2[255:192] + SRC2[191:128]VDPPD-bol viszont tenyleg nincs 256 bites
-
Maotun
őstag
válasz
#95904256
#4835
üzenetére
kontrollálhatnánk mint mondjuk a fényt vagy a rádióhullámokat...
Ez a baj velünk emberekkel tudunk olyan ezközt készíteni ami fényt bocsájt ki, vagy rádió hullámot, ettől még nem kontrolláljuk szvsz.
Pl elemlámpa szórt fény , játék a fókusszal, de ha a telep engedi elvilágít 50 méterre pedig én csak 10 méterre szeretném, hogy nem pocsékolja az energiát de ő addig világit ameddig akar szóval nem kontroláljuk és az sem tetszik hogy én csak 50 méterre látok a lámpával de mások ezt 500 méterről látják, ennyit a kontrolról.
gravi kontrolszerűség is van már pl mágnesvasút tudom a gravitációs mező más mint a mágneses mező de majd lesznek antigravi cuccosok is akkor is ugy leszünk ezzel mint az elemlámpával.
Ne haragudj nem kötekedni akartam de világvége hangulatom van jólesik hogy valakinek elmondhatom véleményemet THX -
Maotun
őstag
válasz
#95904256
#4833
üzenetére
Pont ezt akartam javasolni !
Viccen kívűl ha tizedét felfognám annak amiről irtál boldog lennék
azért azt a gravitációt végig gondolom és ha lesz tippem jelentkezek , ki tudja hátha az én fejemre is esik egy alma.. Már támadt is egy érdekes ötletem, az mitől van ,hogy a világon sehol sincs egyenes csak görbe, meg ív? Az alma például egyenesen eset Newton fejére?
Míg tartotta a szára együtt forgott a földel és a tudóssal ... mikor elengedte a szára az almát elindult lefelé és a tudós fejére esett.Miért nem keringenek az almák a föld körül ?Miért esnek le? Le esnek vagy fel esnek ? Mi lenne ha a föld nem forogna, és a magja sem, vagy a magja is egy irányba forogna mint a kérge? A gravitáció lényege a pörgés ha valami nem pörög az esik addig míg megint el nem kezd pörögni.
Nagyon off lett de hirtelen ez jutott eszembe, megyek a linkre megfejtem én azt a gravitációt csak előbb végezném el a nyócat




 Sokat gondolkodtam hogy mi legyen,de nem bírtam már tovább várni a bull-ra,de ami késik, nem múlik ugye
Sokat gondolkodtam hogy mi legyen,de nem bírtam már tovább várni a bull-ra,de ami késik, nem múlik ugye 

















![;]](http://cdn.rios.hu/dl/s/v1.gif) eddig is ez volt
eddig is ez volt , nem ezt mondom(szerintem te vagy az értetlen, és te nem fogod fel)
, nem ezt mondom(szerintem te vagy az értetlen, és te nem fogod fel)




















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.


- ÁRGARANCIA!Épített KomPhone Ryzen 7 7800X3D 32/64GB RAM RX 7800 XT 16GB GAMER PC termékbeszámítással
- Apple iPhone 16 128GB Kártyafüggetlen 1Év Garanciával
- DELL PowerEdge R740 rack szerver - 2xGold 6130 (16c/32t, 2.1/3.7GHz), 64GB RAM, 10Gbit HBA330, áfás
- BESZÁMÍTÁS! Apple MacBook Pro 14 M4 MAX 36GB RAM 1TB SSD garanciával hibátlan működéssel
- Realme C30 32GB, Kártyafüggetlen 1Év Garanciával
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest