- Vivo X200 Pro - a kétszázát!
- Android alkalmazások - szoftver kibeszélő topik
- Google Pixel 8 Pro - mestersége(s) az intelligencia
- Yettel topik
- iPhone topik
- Motorola Edge 60 és Edge 60 Pro - és a vas?
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Brutál akkuval érkeztek az Ulefone X16 modellek
- Betiltották a Pixel 7-et Japánban
- 200 megapixeles zoomkamerát sem kap az S26 Ultra?
-

Mobilarena
OLVASD VÉGIG ALAPOSAN MIELŐTT ÚJ HOZZÁSZÓLÁST ÍRNÁL!!!

Új hozzászólás Aktív témák
-

dezz
nagyúr
válasz
 Jack@l
#10394
üzenetére
Jack@l
#10394
üzenetére
Az egészen más téma. Sokan nem tudják, mi volt ott a háttérben. A 6000-es sorozat felső kategóriás chipjét eredetileg 32nm-re kezdték el tervezni, csakhogy azt később lemondta a TSMC, elég nagy kavarodást okozva ezzel. Állhattak neki áttervezni a chipet 40nm-re. A középkategóriás chipek viszont eredetileg is 40nm-re készültek, így azok addigra már készen álltak a bevetésre. Csakhogy, mivel nem célszerű a középkategóriával indítani egy új sorozatot, mit volt mit tenni, ezzel a chippel hozták ki a 68xx sorozatot... Bár az eredeti konfighoz képest némileg feltupírozva. Így a 67xx sorozat "el is maradt", illetve OEM vonalon ugyanazzal a Juniper chippel hozták ki, mint az 57xx. Aztán, amikor végre elkészült a csúcs chip is, abból lett a 69xx szária. Itt a mese vége, fuss el véle.

ps. és most már alvás!

-
#10393
 TESCO-Zsömle
titán
Jack@l
#10389
TESCO-Zsömle
titán
Jack@l
#10389
TESCO-Zsömle
titán
válasz
Jack@l
#10389
üzenetére
Egyszerű emberek ne akarjanak szakmai témákban megnyilvánulni.
Nekik ott a Máóniká sú (esetünkben, mint műfaji meghatározás), ha elő akarják adni magukat mások előtt...
Az is szerepel azon a szép slide-on, hogy High-Performance Core Roadmap.
Vagyis az adott magok évről évre 10-15%-os teljesítmény-növekedést produkálnak azonos fogyasztás mellett.
-
-

Oliverda
titán
válasz
Jack@l
#10386
üzenetére
Személyeskedtél volna? Én most nem vettem észre.
Azzal van a gond, hogy láthatóan nem tudod miből áll össze az a bizonyos performance per watt. Mindegy, hagyjuk. Majd szólj, ha sikerült értelmezni minden információt ami a slideon van. Momentán nincs energiám most ilyen szintű értetlenkedéseket olvasni. Sorry.
-
válasz
Jack@l
#10363
üzenetére
A ket kocka kozotti kesleltetes nem szamithato kozvetlenul at fps-re, mert az fps a kesleltetesek atlaga. Ha csak egy kiugro kesleltetes van, attol az atlag meg lehet jo. Marpedig az fps 1 masodpercre vetitett atlag.
Ezeknek a kiugro ertekenek az eltunteteseben johet jol a Bull felepitese. Pl. a virusellenorzonek, RSS vagy mail kliensnek van folos eroforras, ha valami idozitett doolog miatt csinalnanak valamit. Az igazsag az, hogy 4 mag felett mar nem nagy a kulonbseg, de kimutathato, X6-al legalabbis ki tudtam merni.
-
#10361
 Lazarus911
aktív tag
Jack@l
#10358
Lazarus911
aktív tag
Jack@l
#10358
Lazarus911
aktív tag
-
válasz
Jack@l
#10357
üzenetére
Az fps elegge tud csalni, mert egy atlag erteket ad vissza. Sokkal pontosabb, hogy a kopek kozott mekkora a kesleltetes es annak mekkora az ingadozasa. A Bull abban jo lehet, hogy ugyan a kesleltetes nem a legalacsonyabb, de az ingadozas az igen, mert mindig van egy mag, ami eppen nincs leterhelve.
-

Abu85
HÁZIGAZDA
válasz
Jack@l
#10337
üzenetére
Asztalra nem hiszem, vagy ha van, akkor kevés (tömörítők esetleg). Ez inkább szerver workload (webszerverek, levelezőrendszerek, adatbázisok vagy alkalmazásszerverek). A teljesítménykritikus alkalmazásokból sok ilyen van. Nem csak fixpontos műveletekkel dolgoznak, de 80-90%-ban igen.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#10272
üzenetére
Elég nagy rá az esély, hogy lesz javítás, csak időbe kerül. Azért az AMD és az MS között eléggé puszipajtás a viszony. A C++ AMP-hez például az AMD készíti a támogatást a nem Windows operációs rendszer esetében. Ez a gyártóknak nagyon nem tetszik, de az MS nem változtat a döntésen. Mondjuk ez a rész nekem sem tetszik. Elég sok dolgot lehet szoftverből befolyásolni, számomra nyilvánvaló, hogy a Linuxhoz készülő C++ AMP fejlesztőkörnyezet nem fog a konkurens hardverekre optimalizálni.
A gyorsulás több helyről is jöhet. Nyilván az AMD számára csak az OS scheduler rész érdekes az FX esetében. Persze a többinek is örül mindenki. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#10269
üzenetére
A Linuxon az AMD már orvosolta a problémát az új kernelt érintő fejlesztésekkel. Windowsba meg nem nyúlhatnak bele, hiszen nem open source. Az MS egyébként a Win 8-ban már szintén okosabb ütemezőt épített. A Bulldozer már a Win 8 Developer Preview verziójától gyorsult emiatt. A Win 7 esetében nyilván kell a patch, de nem olyan könnyű, mert elég komoly frissítésről van szó, hiszen az ütemezést kell átdolgozni. Elég mélyre le kell nyúlni a programkódban.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#10237
üzenetére
Azóta már kiderült pár apróság, ami más megvilágításba helyezheti ezt. A Catalyst 11.4 óta olyan rutinok is vannak a driverben, amik a CPU-ra vonatkoznak. Mivel az AMD platformot kínál (és hozzá platformszintű támogatást), így megtehetik, hogy a saját procijaikhoz extra optimalizálást készítenek egy-egy programra. A CAP profilok adatbázisában is vannak CPU-ra vonatkozó beállítások.
-

stratova
veterán
válasz
Jack@l
#10216
üzenetére
Már többen jeleztük az adott topikban, hogy valószínűleg nem stimmel a kártya. Nem túl nagy a valószínűsége, hogy egy HD 6790 CrossFireX kiköhög 80+ fps-t 2560 x 1600-as felbontáson Dirt 3-ban, amikor ugyanezen a felbontáson egy HD 6870X2 2600K-val karöltve produkál kevesebbet. Reális a HD 6970 CFX lenne, csak gondolom átvették a PH! hírben ezt a bakit.
-
stratova
veterán
válasz
Jack@l
#10200
üzenetére
Erre alapozhatja. A 980X 2600K-hoz viszonyított, játékok alatt mért, teljesítményét figyelembe véve, Bull a kifejezetten sok szálra optimalizáltak alatt nyújt jó (2600K körüli) teljesítményt, másutt 2600K lehet előnyösebb. Nemsoká' elválik mennyire reális ez az elképzelés, de az árazás ilyesmire engedne következtetni.
-
Abu85
HÁZIGAZDA
-
stratova
veterán
De, arra alapoznak. Ezt a persze költőien túlzó 400 W TDP-re írtam. Már az sem rossz, hogy HD 6950 szintű GPU befér majd 100W alá (PowerTune nélkül is); azaz egy nagyobb notebookba (< 300W és < 225W helyett).
A HD7900 viszont új lesz, igaz enni is kér (150-190 W-ról pletykálnak).
Abu: te magad is írtad, hogy továbbviszik a Cayman alapot Szerintem semmi baj nincs azzal, ha egy viszonylag energiahatékony felépítés alacsonyabb csíkszélességen újul meg, felette meg ott lesz az új lapka. Alatta pedig az APU-k Barts-Cayman keverékkel. -
stratova
veterán
Ha minden igaz HD 7850 HD 6950-es, HD 7870 pedig HD 6970-es szintje felett teljesíthet 90 W illetve 120 W-os TDP-vel. Messze van ez még az APU-ba integráltságtól, de szép fogyókúra.
Annak sincs sok értelme, hogy pár notebookgyártó a Sandy Bridge i3 és i5-ök mellé HD 6370-et tesz.
-
Oliverda
titán
Az átlagember meg a Raytracing... Az OpenCL-ről beszéltél miközben a CUDA-ra gondoltál. Előbb szerintem nézz utána pár alapvető dolognak mert itt is nagyon kiütközött, hogy nem igazán vagy tisztában azzal amiről beszélsz. Ugyanez volt a helyzet korábban a magok/modulok történetével, valamint amikor a SuperP alapján szerettél volna az új CPU-k között erősorrendet felállítani. Gondolom ezt is Szirmay javasolta.

-
Oliverda
titán
Megint ott tartunk ahol tegnap. Bizonyos dolgokkal kapcsolatban erős sötétség dereng nálad, ami önmagában még egyáltalán nem is lenne probléma, ha nem próbálnád folyamatosan pont az ellenkezőjét bizonygatni. A HPC-hez pl. hogy jön a Raytrace? Szerintem sehogy.
"Raytrace-es renderelőknél a sok magos processor teljesítménye mondhatni mérési hibányit számít egy erősebb gpu-hoz képest. Magyara lefordítva: heterogén, de minek..."
Ebből pedig szerinted egyenesen következik, hogy egy másik API-val egy bármilyen más felhasználási területen vagy alkalmazásban is ez pontosan így működik.

Egy kicsit sincs igazad mert az eredeti téma az OpenCL volt és nem a CUDA. Ezzel kapcsolatban pedig gyakorlatilag csak olyan dolgokat írtál le amik nem állják meg a helyüket. Egy kalap alá vetted a kettőt ami finoman szólva sem jó húzás. Attól hogy a CUDA-hoz valamennyire értesz, még jól láthatóan nem jelenti azt, hogy az OpenCL-hez is konyítanál valamennyire. Vagy arra már programoztál? Vannak konkrét teszteredményeid? Amennyiben igen akkor ide velük!
Volt itt egy cwn (alias vers) nevű tag. Na ő jutott most eszembe ezekről a hozzászólásokról.
-
Oliverda
titán
Heterogén.
A CUDA és az OpenCL pedig két eléggé különböző API. Legalább most már azt tudjuk, hogy mivel keverted az OpenCL-t.
A CUDA pl. baromira nem heterogén."Olyan programot még nem láttam ami először cpu-ra lett fejlesztve, és azért pakolják át opencl-re hogy azt csak cpu-n futtassák. "
Senki sem mondta, hogy létezik ilyen.
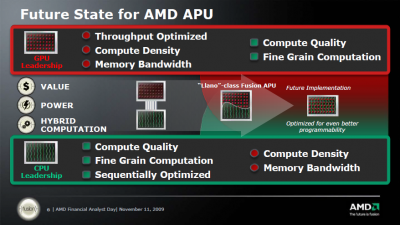
Ezt pedig nézegesd, hátha olyan szerencséd lesz, hogy egyszer csak koppan valami.
akosf: Ugyan kicsit más, de elég ha pl. megnézed AES alatt a VIA Nano-t, meg mondjuk egy alapvetően hasonló számítási teljesítményű AES támogatás nélküli CPU-t. Ott is hasonlóan nagy a különbség.
-
Abu85
HÁZIGAZDA
Ez sajnos nem teljesen van így. Vannak olyan kódok, amik alkalmasabbak a processzorra, mint a mai GPU-kra. Nyilván a GPU-k fejlődésével ez változhat, de jelenleg nem ez a helyzet. Az aktuális GPU architektúrák ebből a szempontból még mindig elég gyengék. A nextgen már erős lesz, persze 20x-ről ott sem lehet beszélni. Max 10x, de a jelenlegi 2-3x-nél ez is jobb.
-
Abu85
HÁZIGAZDA
Az FMA4 utasítás nem csak gyorsít, hanem pontosít is az eredményen, mert egyszer kerekít a Mul-Add kettő kerekítése helyett. Nagyjából hat éve kérik a fejlesztők a támogatást a processzorok oldaláról. A GPU oldaláról a FMA támogatása a DirectX 11-ben került be, de ez nem pont ugyanaz, mint a CPU-s támogatás.
Az OpenCL egy heterogén API a kezdetek óta. Egyébként az FMA4 nincs az OpenCL-hez kötve, csak az OpenCL alatt mutatta be az AMD ezt a funkciót. Gyanítom azért, mert az Intel OCL drivere egy nagy rakás nulla jelenleg, sebességben szerintem nagyon sokat lehet még rajta javítani. Az AMD CPU-s OpenCL driverével az OpenCL alkalmazások jelentősen gyorsabban futnak a Core 2 Quad procimon. Az Intel drivere nagyon lassú.
Elsődlegesen az FMA-t nem a sebességérét kérik a fejlesztők, hanem a pontosságáért. -
Oliverda
titán
"Opencl-re kb 1-1,5 éve hozták be a heterogén cpu támogatást"
Tévedés. Már az első 1.0-s API-ban is benne volt a CPU támogatás mivel ez egy heterogén rendszer. Még hír is volt róla majd három éve.
The language specification describes the syntax and programming interface for writing compute kernels that run on supported accelerators, such as AMD GPUs and multi-core CPUs.
Az általad linkelt anyagból pedig:
Devices
There can be more than a single device on a platform.
The list of device IDs can be queried with clGetDeviceIDs(). You can filter the devices using CPU, GPU and ACCELERATOR flags. -
Oliverda
titán
-
Abu85
HÁZIGAZDA
Én még nem láttam valós idejű, normális ray-tracing-et. Ami valós idejű az elég gyenge, ami pedig nem a sebességre gyúr, ott olyan mindegy, hogy nincs 30 képkockád egy másodpercen belül, vagyis úgy dolgoztatod a PCI Express buszt, ahogy akarod, tök lényegtelen, mert folyamatos sebességed amúgy sincs.
A CPU+GPU feldolgozástól nem is lehet többet várni. Egyszerűen a modell még nem teljesen jó. APU-n akkor kapsz jobb eredményt, ha zero copy-zol, de sokkal jobb teljesítményed akkor sem lesz. Ennél jobb eredményhez architektúra integráció kell, ami a következő lépcső.
Nincs mért eredmény, de itt a Carmack interjú. [link]
-
Abu85
HÁZIGAZDA
Az integráció a fizika törvényei, és a fejlődési irány miatt következik be. Ez elkerülhetetlen. Egy hagyományos PC a CPU->VGA modellel képtelen lesz azt a feladatot ellátni, mint egy nextgen konzol, ami egy lapka, és a CPU illetve IGP rész akkor dolgozhat együtt, amikor akar. Nincs az a busz, ami ezt kiszolgálja. A PCI Express arra jó jelenleg, hogy a CPU-ról egyszer átküld a feladatot a GPU-nak, ami végez a számításokkal és meg a monitorra a kép. Ez egy nagyon kötött irány, minimalizált buszhasználattal. Integrálás mellett akár 6-szor is oda vissza küldheted az adatot, hiszen lesz egy teljesen koherens közös cache, amiben ezt meg lehet oldani, ráadásul ezt elősegíti a közös címtartomány. Ezzel semmi sem tud mit kezdeni. Egy adatküldésre elég egy külső busz késleltetése és kész. Ezért ennyire fix a feldolgozás iránya. Soha nincs adat visszaküldve a CPU-nak további munkára.
Nem kellenek erős IGP-k, csak low-level elérés. Ha azt a szoftveres réteget ki tudod ütni, amit az API eredményez, akkor többszörösére fogod gyorsítani a feldolgozást. Carmack azért mondta régebben, hogy low-level elérés mellett egy Sandy Bridge-el megverné a legerősebb VGA-kat. Nem a GPU-k teljesítményével van baj, azok szépen mennek előre, és lassan 20x gyorsabbak a konzol GPU-knál, de ami büntetést kapja az API-tól az belassítja a feldolgozást. Ezért fogalmazta meg Carmack az aggodalmát a API+driverrel kapcsolatban. Nem a GPU-kkal van a baj, hanem azzal a modellel, amellyel ezek meg vannak hajtva.(#9888) dezz: A jelenlegi grafikus API-k és a szükséges driverek teremtik ezeket a rétegeket. Ez biztosítja a kompatibilitást. Nyilván a kompatibilitás szükséges, de az a bünti, amit ettől kapsz már sok. Megint csak Carmack-re tudok hivatkozni. Ő a Rage alatt PC-n 10000x lassabb texture update-et mért a konzolhoz képest. Ez egyértelmű, hogy a lassú rétegek bűne. A hardver már 20x erősebb, mégis 10000-szeres büntiben vagy egy ilyen kritikus feladatnál. Ez így nem jó. A nextgen konzolokkal ez a modell nem képes majd tartani a lépést, és nem csak grafikailag. Az, hogy mi a megoldás kérdéses, de valamit ki kell találni.
(#9891) akosf: Dirt 3-ban lehetséges is, hiszen az 8 szálat támogat, de a négy szálat támogató Metro 2033-nál kétséges.
-
dezz
nagyúr
Nem tudom, mit értetlenkedsz, amikor korábban is volt már olyan, hogy VGA-limites helyzetben az AMD jópár fps-sel többet hozott. (Konkrétan nem emlékszem, mely procik között volt ez, talán az első Phenom natív 4-magossága mutatta meg itt az előnyét, de sok tesztoldalon kijött. Gondolom, más is emlékszik rá.)
(#9881) Abu85: Ez nem a legjobb megfogalmazás, hogy az API-t kell eldobni, az API (application programming interface, ugye) önmagában nem tehet semmiről, hanem a szoftverszintet a hw-szinttől túlzottan eltávolító, közöttük nem kevés időbe kerülően fordító absztrakciós layereket.
-
#9887
 FireKeeper
nagyúr
Jack@l
#9885
FireKeeper
nagyúr
Jack@l
#9885
-
Abu85
HÁZIGAZDA
A világ lemodellezése nincs API-hoz kötve. Az egy direkten programozott rész. Az API a rajzolási parancsok feldolgozásától él a maga korlátjaival együtt. Lehet a grafikus driverbe tenni segítséget. Az AMD régóta figyel a platformszintű támogatásra.
Ha drasztikusan akarod növelni a teljesítményt akar el kell dobni az API-t, és a konzolhoz hasonlóan direkten kell, low-level szinten programozni. Ilyenkor a memória sem probléma. Egy olyan lassító réteget dobsz ki az API-val, hogy helyenként több tízezerszer gyorsabb lesz a feldolgozás. A probléma viszont a kompatibilitás, amit az API garantálja.
Nincs mit árúba kapcsolni. A next gen konzolok egy lapkából állnak, azokkal az opciókkal, amiket leírtam. Ilyen körülmények között a VGA post-process szintű feladatokra lesznek jók, mert annyira lassú lesz a busz a CPU és a GPU között, hogy nem fogja kibírni a kommunikációs igényeket, amik egy lapkán belül simán megvalósíthatók. Ezért van minden cég hosszútávú terveiben a fúzió. Több problémára is megoldás ez. Integráció mellett pedig nincs mit árúba kapcsolni. Lehet, hogy még lesznek GeForce-ok, vagy Radeonok, de annyira jelentéktelen szinten, hogy az árukapcsolás lényegtelen lesz.
-
Abu85
HÁZIGAZDA
Ezért nem értjük, hogy a Bulldozer alatt a sok rajzolási paranccsal dolgozó programok miért skálázódnak tovább, mint más rendszer alatt. Mert ez kiszivárgott diákon így látható. Ez lehet szoftveres is. Lehet, hogy az AMD a chipsetdriverben mókol valamit.
Ne számításra gondolj. Az API mellett a legnagyobb korlátozó tényező, hogy a rajzolási parancsok nem adhatók át közvetlenül a GPU-nak. Egy komoly szoftveres procedúra kell, amíg a GPU megkapja az utasítást, hogy ezt és ezt rajzolja ki. Az AMD az új platformnál valamit ezen a részen csinálhat, vagy hardverből, vagy szoftverből, de látszik, hogy ha sok a rajzolási parancs, akkor az FX-8150 processzor 2-3%-nál gyorsabb a 980X-nél max grafikán. Ez az ami érdekes. Ilyennek a VGA-limit miatt nem szabadna bekövetkeznie, mégis megtörténik. A rajzolási parancsra azért gondolok, mert ez az egyetlen opció, ami a VGA-limitnél gyorsabb feldolgozást eredményez, hiszen ha gyorsabban van kiadva a parancs, akkor gyorsabban lesz kész a képkocka.Idővel nyilván a heterogén feldolgozás a jövő. Egy-két generáció max, és minden lapkában ott lesz az IGP. Amúgy az hogy az utasításkészlet egyszerűbb nem gond. Pont az a baj a mai prociknál, hogy rengeteg utasítást támogatnak, és ez zabálja az energiát. Durván haladunk a dark silicon fala felé. A Sandy Bridge-E az első többmagos homogén CPU, ami konkrétan bele is ütközik ebbe. Nem kell sokat várni a következő ilyen lapkára sem, és ezért kell irányt váltani a heterogén feldolgozás felé.
A memória nem probléma. Az integráció következő lépcsője, hogy az IGP és a CPU közös címtartományt és teljesen koherens memóriát kapjon. -
Abu85
HÁZIGAZDA
Nem a számításokról van szó, hanem a rajzolási parancsok érvényesítéséről, és kiadásáról. Ehhez nem kell számolni semmit, csak érvényesíteni kell és/vagy ki kell adni, függően az API tulajdonságaitól. Ez az a pont, ami manapság a PC-n nagyon limitálja a rendszer feldolgozását. Ha itt valamennyit tud dobni a proci vagy maga a platform valahogy, akkor az meglátszik a teljesítményen, mert kiütöd a legfőbb korlátozó tényezőt, ami a VGA-limitet okozza. Mindegy, hogy mást mennyi idő alatt számolsz innentől. A működésben vannak kritikus pontok, amiket ha képes vagy valahogy optimalizálni, akkor az előnyt hoz, míg a nem kritikus pontokon lényegében még akkor sem biztos, hogy nő a sebesség, ha optimalizálsz.
(#9871) akosf: Valóban, simán elképzelhető, hogy platformfícsőr, és nem a proci okozza. De ezt nem tudjuk meg, mert 990-es chipsethez nem tudunk Sandy Bridge-et rakni. Az is lehet, hogy szoftveres a rendszer, simán lehet a chipsetdriver része. Az AMD az elmúlt évben nem kevés szakemberrel növelte a szoftveres csapatot, így volt kapacitás ennek a problémának a vizsgálatára. Itt abból indulok ki, hogy az AFDS-en egy előadás volt annak szentelve, hogy a grafikus API-kban hol vannak a gyenge pontok, és azok javításával nagyságrendi gyorsulás érhető el. Gondolom ezt a részt a vállalat nem véletlenül kutatja. Simán lehet már tényleges eredménye, amivel rájöttek, hogy a VGA-limit miképp tolható ki. Szvsz egyhamar nem tudjuk meg a titkot, csak látjuk, hogy a bulldozeres platform egyes játékoknál jobban kezeli a VGA-limitet.
-
Oliverda
titán
Mivel privát üzenetről van szó, így nincs felhatalmazásom arra, hogy ezt megmondjam.
A trollkodást és a felesleges hangulatkeltést ebben a topikban kérlek próbáld redukálni, és ha úgy érzed, hogy konstruktívan nem tudsz hozzászólni az éppen aktuális témához, akkor inkább sehogy ne tedd. Vannak olyan topikok ahol az ilyen stílus még néha belefér (pl.:[link]), de ez pont nem olyan.
A kitiltás pedig olyan, hogy nem tudsz írni. Amennyiben nagyon meg szeretnéd tapasztalni, akkor tudok olyat aki meg tudja neked mutatni.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Oliverda
titán
Nem az eltérő véleménnyel van a gond, hanem azzal hogy nem vagy képes felfogni dolgokat és ennek ellenére egyből a másikat nézed hülyének. Nem ez az első esett itt és nem is velem szemben történt ez meg először. A közelmúltban kaptam olyan privátokat amiben konkrétan azt kérték, hogy tiltsunk ki ebből a topikból. Hálás lehetnél, hogy ez még nem történt meg, de ugye addig jár a korsó...
-
Abu85
HÁZIGAZDA
A korábbi IDF-es DiRT 3-as eredményeknél írtam, hogy az AMD azért csinál VGA-limites szituációkat, mert azt akarják megmutatni, hogy a Bulldozer itt is skálázódik, ellentétben a többi processzorral. Ha a HD 6970 lenne mellette, akkor is ezek az arányok jönnének. Ha kettő HD 6970-et raksz mellé, akkor is. Minden VGA limites szituáció ugyanaz, de a skálázódás más. A Bulldozer felépítése azokban a játékokban, melyek sok rajzolási parancsot adnak ki (párhuzamosan vagy sem), VGA-limites szituáció mellett +2-3%-os előnyt jelent. Ahol kevés a rajzolási parancs, ott ezt a skálázódást nem érzed, vagyis közel azonos az eredmény, hiszen VGA-limited van.
Ha leveszed a beállításokat low-ra 1024x768-ra, akkor pedig az nem fekszik a Bulldozernek, mert arra tervezték, hogy a throughput teljesítménynél legyen erős, de ott ahol a késleltetés fontosabb, az Intel van előrébb. Nyilván, ha játékra veszel gépet, akkor el kell dönteni vásárlás előtt, hogy maxon vagy minimum beállítások mellett akarsz játszani, és aszerint kell procit venni. Ez jövőre még bonyolultabb lesz, mert beesik a képletbe az OpenCL, és az IGP-k teljesítménye. Ezzel még célirányosabban kell vásárolni. -
Oliverda
titán
Te a gyártó által végzett mérésekre szoktál támaszkodni? Mert ha igen akkor ismét csak gratulálni tudok.
Tudod általában a termékeket le szokták tesztelni független oldalak, akik olyan hardverelemeket pakolnak az adott konfigurációba amilyet jónak látnak. Mi pl. legalább egy HD 6970 szintű kártyával fogunk mérni mert az biztosan van.
Én meg egy böszme nagy trollnak látlak mégsem hangoztatom mindenfele.
-
Abu85
HÁZIGAZDA
Miért? A 32 nm-es SHP esetében szerinted nem lesz meg a gyártókapacitás 2012 tavaszára? Addigra működni fog a New York-i gyár is. Drezdában a 45 nm-es node-okat sorra cserélik ki 32 nm-esre. Év végére az összes ki lesz cserélve. 45 nm-es SOI-n úgy sem gyártat majd senki.
Nem azért késik a Bulldozer, mert nincs kész. Az a baj, hogy nincs rá gyártókapacitás, mert a Llano APU-t is ugyanazon a node-on gyártja az AMD. Az meg természetes, hogy a Llano élvez elsőbbséget, hiszen sokkal nagyobb piaci szeletet fed le.
Elstartolhat a Bulldozer akár holnap is, csak akkor sem lesz a boltban. Elég Llano APU-t sem tudnak gyártani, a Bulldozer megjelenése ezen csak rontana. A szerverbe nyilván szállítják a Bulldozert, mert óriási a haszonkulcs, de a desktopra felesleges elvenni a kapacitást a Llano elől. -

atti_2010
nagyúr
Ez nagy tévedés, ha te kapsz a kezedbe egy négyszögletű valamit és azt mondják hogy tedd be a gépbe és mindent 4x sebességgel csinál, fele annyit fogyaszt, 20.000 Ft, téged még érdekel hány magos vagy hány megahertzen megy? Utóbbi lehet hogy hátha meg lehet tuningolni
a felhasználók 96% fogalma sincs a magokról meg a megahertz-ről. -
Oliverda
titán
-
-
#9464
 Plazmacucci
félisten
Jack@l
#9463
Plazmacucci
félisten
Jack@l
#9463
-
#9298
 hugo chávez
aktív tag
Jack@l
#9293
hugo chávez
aktív tag
Jack@l
#9293
hugo chávez
aktív tag
A Bull lebegőpontos egységeinek képességeit a jelenleg rendelkezésre álló információk alapján innen kezdve vesézgettük, különös tekintettel javaslom P.H. hozzászólásait.
-
Oliverda
titán
Az FPU egy külön ütemezővel ellátott, két, egyenként 128 bites FMAC és kettő, egyenként 128 bites SIMD INTeger egységből tevődik össze. Természetükből adódóan bármelyik képes FADD vagy FMUL (összeadás és szorzás) műveletekre. Ennek okán 128 bites SSE műveletekből párhuzamosan kettőt is végre tud hajtani. A 256 bites AVX műveleteket a dekóder két egy-egy 128 bites részre bontja szét, amelyeket a két 128 bites egység összekapcsolásával akár egyidejűleg is elvégezhet.

A két 128 bites FMAC pipeline-on mellett szintén kettő, 128 bites integer SIMD egység is található az FPU klaszterben. Ezek a megnevezésből sejthetően egész számos (összeadás/kivonás, szorzás, AND/OR/XOR/NOT) művelteket hajtanak végre több számon egyszerre (SIMD), azaz ezek az integer MMX (64 bit), SSE2 (128 bit) és AVX (256 bit) utasításokat hajtják végre. Az FPU-t bármelyik mag használhatja, vagy akár a kettő egyszerre is. Több szálon történő 64/128/256 bites végrehajtás esetében arról nincs egyelőre bővebb információ, hogy a pipeline-ok hogyan kerülnek felosztásra; valószínűleg akár egy-egy szál is kisajátíthatja a teljes FPU-t, ha a másik szál nem igényli azt. Versenyhelyzetben 50-50%-os elosztást várhatunk.

Ez a megosztás gyakorlatilag semmilyen hátránnyal nem jár, mivel egy-egy utasítás latency-je (késleltetése) legalább 2 órajel, de jellemzően inkább 4. Magyarul annyi idő múlva kapja meg az egyik mag a következő utasítása az eredmény(eke)t, a köztes időben pedig lehet a másik mag számításait indítani.
-
Abu85
HÁZIGAZDA
Ja értem. Nem volt világos. Ha két részben írsz, akkor mehet közé egy ---- elválasztás. De mindegy.
Amúgy ez általánosan sem biztos, hogy igaz. Vegyük példának, hogy a Havok, amiről tudjuk, hogy általában jól párhuzamosítják SSE2-be van fordítva. Ilyenkor a Sandy Bridge órajelenként 4 darab 128 bites utasítást dolgozhat fel, míg a Bulldozer 8-at. Ez pont a megosztott FPU-nak köszönhető, mivel az nem csak együtt, hanem megfelezve is használható. Az Intel FPU-ja nem osztható fel így.
-
Abu85
HÁZIGAZDA
Nem értem, hogy a Bulldozer megjelenése, hogy jön a hardveres PhysX-es játékokhoz?
Eleve a PhysX a játékokban egy szálra van korlátozva a CPU oldaláról. A Havok már más tészta, mert az 16 szálon is működhet, és általában 4-6-8 szálon működik is a programokban. A PhysX szoftveres korlátozás miatt fut lassan, általában, mert az NVIDIA azt akarja, hogy lassan fusson, így a GPU PhysX biztosan gyorsabb lesz a CPU-s kódnál. -
Abu85
HÁZIGAZDA
Nem hiszem, hogy eltörölnék a 10 magos szerverprocit. Nincs értelme, mert már a tape out kell, hogy abból 2012-ben termék legyen. Most nekikezdeni egy új terméknek, eleve eltolja tape outot, így 2013-ban lesz termék.
Az nem elképzelhetetlen, hogy a Socket AM3+ platformba jön egy új asztali megoldás, a Socket FM2 helyett, de ez a lapka akkor Zambezi update lehet maximum. És ebből is kell a tape out még idén. Ettől függetlenül a Komodo lapkáját nem tudják törölni, mert akkor két évig nem lesz a szerverbe semmi. -
Na ezzel a posztoddal elmondtál mindent magadról és a hozzáértésedről, hozzáállásodról.
Szerintem mindenkinek jobb lenne, ha eltűnnél ebből a topikból, mert tényleg rohadtul nincs szükségünk egy trollra! Ha meg igen, elővesszük Terry Pratchett könyveit és megidézzük Törmelék őrmestert.
Amennyiben nem tudod, ki az a Terry Pratchett, akkor épp itt az ideje elmenni egy könyvesboltba és egy kis irodalmi ismeretet magadra szedni. Addig sem rontod itt a virtuális levegőt.
-
Oliverda
titán
-
-
Oliverda
titán
Olvasd el a cikket mert le van írva minden, és nincs kedvem ismét leírni. Amennyiben nem olvasod el, akkor meg felesleges úgy tenni, mintha tudnád miről beszélsz.
A superpi-vel pedig itt csak kinevetteted magadat ismét. Aki kicsit is jártasabb a dolgokban az tudja, hogy az minden csak nem mérvadó.
-
Oliverda
titán

Szerintem itt csak egy dolog egyértelmű, mégpedig az, hogy csak találgatsz és sosem teszteltél ilyen platformokat, illetve, hogy nem olvastad el a szöveget, csak a táblázatokat meg a grafikonokat nézted.
Amúgy megsúgom, hogy DDR3-1333-mal sem volt mérhetően lassabb a K12, mert a nagyobb sávszélesség ott a GPU-nak kell.
-
atti_2010
nagyúr
A Superpi egy rendkívül "okos" szoftver, a múltkor mértem vele egy 3 magos AMD és egy 2 magos Intel procit, az AMD procit hajtotta 2 maggal 32%-on a harmadik mag meg sem mukkant, az Intelt vitte 2 szálon 67%-on, találjátok ki melyik győzött, a 3 magos proci mérföldekkel gyorsabb játékokban.
-
atti_2010
nagyúr
-
Oliverda
titán
Köszönjük az újabb konstruktív hozzászólást, de ha lehet akkor másokat ne próbálj megvezetni a saját fantazmagóriáddal. Főleg ne itt, ahova érdemi információkért próbálnak betérni az érdeklődők. Előre is köszi!
Amennyiben jót akarsz magadnak, akkor inkább olvasgass kicsit a témában, és akkor talán egyszer feloszlik a köd.

Amúgy no offense Jack@l, de baromira nem látod át azt amiről beszélsz.








 Tulajdonképpen a wattonkénti teljesítmény nő, el nem tudom képzelni hogy mi a bajod ezzel
Tulajdonképpen a wattonkénti teljesítmény nő, el nem tudom képzelni hogy mi a bajod ezzel 
![;]](http://cdn.rios.hu/dl/s/v1.gif)




























Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
Az ide nem illő hozzászólások topikja:[link]
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva.

- Vivo X200 Pro - a kétszázát!
- Nem tudom a dal címét, előadóját
- Luck Dragon: Asszociációs játék. :)
- Xbox Series X|S
- Medence topik
- Android alkalmazások - szoftver kibeszélő topik
- 3D nyomtatás
- Milyen TV-t vegyek?
- Autóápolás, karbantartás, fényezés
- Milyen asztali (teljes vagy fél-) gépet vegyek?
- További aktív témák...

- Telefon felvásárlás!! Samsung Galaxy S23/Samsung Galaxy S23+/Samsung Galaxy S23 Ultra
- OnePlus 13 - Black Eclipse - Használt, karcmentes
- Keresünk dokkolókat
- Samsung Galaxy A04 128GB, Kártyafüggetlen, 1 Év Garanciával
- Bomba ár! Lenovo ThinkPad L480 - i5-8GEN I 8-16GB I 256GB SSD I 14" FHD I HDMI I Cam I W11 I Gari!
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest