- Magisk
- Honor Magic7 Pro - kifinomult, költséges képalkotás
- Samsung Galaxy A56 - megbízható középszerűség
- Vivo X200 Pro - a kétszázát!
- Yettel topik
- Telekom mobilszolgáltatások
- Samsung Galaxy S25 - végre van kicsi!
- Okosóra és okoskiegészítő topik
- Három Redmi 15 érkezett a lengyel piacra
- Android alkalmazások - szoftver kibeszélő topik
Hirdetés
-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#34049
 Petykemano
veterán
gbors
#34048
Petykemano
veterán
gbors
#34048
Petykemano
veterán
The Stilt veled ért egyet:
..Severely ROP and memory starved.
The Vega iGPU inside Raven also has the lowest ROP to CU ratio of all AMD GPUs so far (0.727).
Ever since Hawaii (1.454 ROP U ratio) the GCN GPUs have been held back by the insufficient render backend resources (apparently current GCN cannot support more than 4 RBs per SE). This is the case with all Polaris GPUs and especially with Vega. The performance difference between Vega 64 & 56 at the same frequency is diminising due to the backend starvation (1:1 ROPU in 64, 1.142 in 56).
U ratio) the GCN GPUs have been held back by the insufficient render backend resources (apparently current GCN cannot support more than 4 RBs per SE). This is the case with all Polaris GPUs and especially with Vega. The performance difference between Vega 64 & 56 at the same frequency is diminising due to the backend starvation (1:1 ROPU in 64, 1.142 in 56). -
-

Abu85
HÁZIGAZDA
Kiderült már pár dolog.
A HBCC inkluzív cache mód még nem lesz aktív, de az úgyis fejlesztői kihasználást igényel, tehát kvázi ráér a Far Cry 5-ig.
Az NGG fast pathról utólag kiderült, hogy már ott van a 16.40 óta, viszont per game aktiválású jelenleg, és a fehérlista lényegében kimerül a Wolf 2-ben.A többi dolog mind aktív. A 16.50-es batch nem tartalmaz ezekre vonatkozóan módosítást.
-

#85552128
törölt tag
-

-FreaK-
veterán
Igen, de konkrétan Abu mondta, hogy majd az új, 1.0-ás driverben lesznek aktiválva. Erről most egyelőre szó sincs, és itt van az ellentmondás. De jó oké, legyen, majd meglássuk ha megjelent

(#33993) rupszi: Ezt nem is tudtam, nem semmi

(#33994) Pinky Demon: ez is egy jó példa erre igen, de ez azt az első mondatot inkább nem kommentálom, mert tuti kitiltást kapok..
-

do3om
addikt
Csak nehogy az legyen amikor kijön valami hogy ez sajnos még nem az amire sokan vártak az még készül és igen jó lesz de csak később, és ami megjelent az ezért nem váltotta be a reményeket, de hamarosan aktiválva lesz a xyz funkció meg.... stb és majd...... szokásos bla-bla.
-
#33920
Petykemano
veterán
gbors
#33917
Petykemano
veterán
A FineWine valójában az AMD által folytatott termékstratégia következménye. Még ha az esetleg nem is igaz, hogy az nvidia egy új termékskála bemutatása esetén nem rontja direkt az előző teljesítményét, valamennyire kikerül a fókuszból. Minél régebbi termék, annál inkább. Az AMD viszont nem tud új termékskálát felvonultatni, csupán évente 2 lapkát szokott, a réseket, amit a full és vágott verzió nem fed le, a korábbi szériákból átmentve pótolják.
Mindenre már nem emlékszem, de GCN1-ből a Tahiti (7970, 7950), Pitcairn (78X0) és Cape Verde (77X0) volt.
GCN2-ből jött a hawaii (290/X) és bonaire (260/X), a 270/X és 280/X pozíciókat a Tahiti és a Pitcairn töltötte be, 250/X pedig cape verde
A következő szériában a GCN3-ból a fiji (Fury/X) és tonga érkezett (380/X), ami a Tahiti váltotta, de 360 néven még volt bonaire, 370 néven pedig Pitcairn, tehát a GCN1-et még mindig támogatni kellett. A 390/X szerepet pedig a GCN2 hawaii töltötte be (készlet miatt)A mainstream polaris megjelenésével került ki a képből - szerintem - a pitcairn, a cape verde támogatása. Eddig tartott a finewine. A polaris mellett nem lehetett megszüntetni a hawaii és a fiji támogatását, mert nem nézett volna ki jól, ha a mainstream kártya beelőzi az akkor még nem kicsivel drágábban kapható FuryX-et, vagy 390X-et, ami azért felsőkategória. Ezért finewine.
Lehet arra számítani, hogy ha szélesebb körben terül a Vega, akkor az egyébként is alacsony penetrációval rendelkező fiji és a hawaii (támogatása) is megy a kukába. Ennek azért már vannak jelei.
A polaris is csak addig lesz támogatva, amíg:
- mainstream kártyaként megmarad a P10. Ha vega 11 nem fölé, hanem helyére kerül, és a P10 gyártása véget ér, akkor az egy minusz
- a P11 és P12 lapkák piacon vannak. Szerintem ezt majd csak 7nm-en fogják már cserélni (Én emiatt számítok arra, hogy a polaris finewine lesz)
- az intelnek készített egyedi design széles körben elérhető, kapható és örököl/nyer bármit az AMD polaris támogatásán -
Abu85
HÁZIGAZDA
A növekvő mennyiség ezen csak rontani fog, mert még több memóriával rendelkeznek majd a PC-k, és még többen fogják úgy gondolni, hogy pusztán a rendkívül sok elérhető erőforrás miatt megéri duplikálni az allokációkat, megrövidítve ezzel a WDDM ellenőrzéseit. Utóbbival kevesebb akadásod lesz, és amúgy is tengernyi memóriát vehetsz magadnak.
-
Abu85
HÁZIGAZDA
Nincs szükségszerűen duplikálva, de manapság a meghajtók és a szoftverek is alkalmazzák ezt a trükköt, ugyanis a rendszermemória allokálása nem ingyenes. Ezt az operációs rendszer végzi el, és ahhoz, hogy valamit törölni tudj a VRAM-ból, előbb allokálni kell neki a helyet a rendszermemóriában, hogy oda vissza lehessen másolni a törlés előtt. Ezzel a törlés ellenőrzési idejét hosszabbítod meg, ami már eleve rendkívül hosszadalmas folyamat, és káros, mert a törlés közben semmit sem csinálhat a GPU a manapság kedvelt legacy API-kban. Ezért manapság igen jellemző trükk a duplikálás, elvégre a törlési idő csökkenthető, ami esetenként megment az akadástól. Hogy ideális-e? Nem az. De jelenleg eleve sok memória van a játékosoknak szánt PC-kben, tehát inkább lehet erre építeni, minthogy többször akadjon a program.
-
#45185024
törölt tag
Az a megoldás hogy nem azonos a fogalom AMDnél a ROPot nem úgy kell értelmezni mint "máshol" Matrox stb
csak a név azonos a szerveződése merőben más, Abban egyeznek hogy mindkettőt ROPnak nevezzük.
A "480-nál semmit nem jelentett a Mem húzás" ???Ez így nem igaz, a 480 egy széles skála volt nagyon eltérő memórimosulokkal a 4 GB sokkal lassabb volt de a 8 Gigán belül is jókora eltérések voltak.
Minőségi 480 esetén igenis számított és mindenki ezzel kezdte a húzást. Vegánál is rengeteget jelent a 800 1100 MHZ re emelés. Egyértelműen látszik a sávszélesség limitesség , egyértelmű visszalépés a 4 halomba szervezett HBM-hez képest a 2 halmos de ez pont azt mutatja hogy olcsó Vegát terveztek és nem a TI ellen akarták vinni, Nem hozol ki 4 halmosat 399 dollárból ! Nincs ezen se mit fejtegetni.
Nem csodálkoznék azon se ha a Vega 11 egy egy halmos 4 gigás olcsóbb megoldást tartalmazna majd.
Ha keresitek a Nex. Gen AMD kártyát akkor lehet arra kellene gondolni eddig hogy is volt.
Az alsó kártyák ha nem rebrand akkor mindigis az aktuális kijövő konzolból gyökereztek...
Eleve fura ha valamit Polaraisnak hívunk (konzolban) amikor GCN 5 utasításokat használ meg odagondolunk mellé egy HBM memóriavezérlőt. Ezt Magyarul szerintem Hibridnek kellene hívni és ezt a fogalmat elterjeszteni. -
Kicsit ásogattam még a kérdésben, és feltűnt egy érdekes dolog - a Polaris die shotokon úgy tűnik, mintha a ROP-ok kb. 18-20%-át vinnék el a teljes chipnek, míg a GP104-en 10-12%-át. Azaz a Polaris 32 ROP-ja kb. 1100M tranzisztort visz el, miközben a GP104 64 ROP-ja kb. 800-at - a 16 ROP ára az egyik esetben 550M, a másikban 200M. Ez így leírva elég hihetetlennek tűnik, viszont magyarázná, hogy miért annyira sóher az AMD a backenddel. Kérek másodvéleményeket!
(#33762) s.bala31: hát így.
-
Abu85
HÁZIGAZDA
Nem hiszem. A ROP-ok eltérő képességűek. Azóta már sokat fejlődtek.
Itt nem arról van szó, hogy nem számított volna a több ROP, hanem, hogy többet nyertek volna, ha aktiválják a 384 bites buszt, változatlan a ROP mellett. A probléma ezzel valószínűleg az volt, hogy a 12 GB-os konfiguráció nem tette volna lehetővé a 200-300 dollár közötti árat. A 6 GB-os oké lett volna, de ahhoz 3 GB-os alapverzió kell, és a 3 GB-os GTX 1060-on látszik, hogy mennyire döglött konfiguráció ez. Emiatt maradt a 256 bit és a 4-8 GB-os fedélzeti tár.
-
Abu85
HÁZIGAZDA
Nem az volt a probléma. Nem lett volna gyorsabb. Az AMD mondta régebben egy briefingen, hogy nekik van egy szimulátoruk, amiben tudják a dizájnokat szimulálni, és ez alapján választják meg a konfigurációt. A Polarist a memória-sávszélesség limitálta. Az extra 16 ROP nem sokat ért volna. A 384 bites busszal nyertek volna, és eredetileg ennyi is van a Polaris 10 lapkában, de ezt már nem használták ki.
-
Abu85
HÁZIGAZDA
Az az oka, hogy a szükségesnél nem kerül be több ROP. De ettől a konfiguráció olyan, hogy akármilyen arány is megoldható.
(#33747) Petykemano: A primitive discard accelerator arra jó, hogy a degeneratív háromszögeket még a pipeline elején kivágja. Ezt nem lehet továbbfejleszteni. Egy újabb ilyen egység, de többet, se kevesebbet nem tudna kivágni. Az NGG fast path teljesen másra van. Az a fals pozitív háromszögekről mondja meg, hogy nem látszanak még a pipeline elején.
Occlusion culling eddig is volt. A procimagok csinálták, de a GPU-k ebben is hatékonyak, és az Intel kialakított egy elfogadható algoritmust a GPU-s gyorsításra. Ez nem elég önmagában, így kap az egész egy middleware-t, amit be lehet építeni, és a GPU-s gyorsítást támogató hardvereken GPU-n fut, míg a többin a CPU-n. Ez még a pipeline-ok előtti szakaszra vonatkozó feladat, ilyenkor még se a primitive discard accelerator, se az NGG fast path nem dolgozik. Ezek csak később jönnek, mert alapvetően a kivágási feladatok is olyanok, hogy lesz egy rakás fals pozitív háromszög, amiről csak később derül ki, hogy nem látszik. Nagyon leegyszerűsítve a primitive discard accelerator és az NGG fast path lényegében hamarabb megmondja, hogy mi fog látszani és mi nem.
Az Intelt valószínűleg nem érdekli, hogy az AMD-n működik-e a middleware-jük. Az egész arra alapszik, hogy ez szabványos lesz, így bárki támogathatja, akinek megvan hozzá a hardvere. Az sem biztos, hogy a saját Kaby Lake-G megoldásukon a Radeonon fog futni, lehet, hogy az IGP-re tolják rá.
-
-

Raymond
titán
"Hát az, hogy rakhatnak mellé 48 ROP-ot."
Nem, mert ez:
"Vagy a 256-bit mellé dupláznak, és akkor 64. Kérdés, hogy chipméretben és fogyasztásban melyik a jobb megoldás - egyszerűség terén nyilván a duplázás."
Csak nem mentem ennyire bele, mert a 384bit egyertelmuen a savszel miatt volt ott a listaban
-
Abu85
HÁZIGAZDA
Így viszont rosszul volt feltéve a kérdés. Ilyenkor konkrét dologra kell kérdezni, ami elől nem tud kitérni.
Például: Figyelj már Jensenkém, mi a koncepció arra az esetre, ha az Intel azt mondja a gyártóknak, hogy akkor is meg kell venniük a Kaby Lake-G-t, mint a felsőházi CPU-t, és ki kell fizetni a rajta lévő Radeont, ha utóbbit pont nem akarják rajta használni?
Vagy például: Nem fosik az NV attól, hogy az Intel lecsökkenti a mobil prociknál a tokozásból kivezetett PCI Express csatornák számát, mert nekik úgyis ott van a tokozáson a Radeon? -
-
Abu85
HÁZIGAZDA
A lapkaterület egy kicsit nehéz ügy már, mert óriási különbség van a bérgyártóknál a waferárak között. Régebben nem volt ekkora eltérés, de ma már olyan mérhetetlenül drágán adja a wafert a TSMC, hogy még az NVIDIA is elviszi a lapkák egy részét más bérgyártóhoz. Ilyenre régebben nem nagyon volt példa, de az új árak kikényszerítik.
-
Abu85
HÁZIGAZDA
Nyilván nem, de annyiban jobb, hogy a mostani meghajtó nem februári fordítót használ. Persze még közel sem biztos, hogy minden végleges benne. Az sem biztos, hogy az órajelek azok, mert a tesztdizájn 135 wattos, holott a célzott szint inkább 100 watt környéki. De persze ez termékminta, itt lehet próbálgatni a paraméterezést.
-
Abu85
HÁZIGAZDA
Elég egyszerű. Amelyik lapra címzés van, azt betölti a HBC-be. Ennyi. Igazából messze nem kell 100 MB-okat mozgatni. Ez a nézet azért alakult ki, mert a szoftveres megoldás valóban mozgathat ennyit, de nem azért, mert kell, hanem azért, mert muszáj allokációkat mozgatnia akkor is, ha abból csak 4 vagy 64 kB kell csak. A HBCC viszont lapalapú menedzsment. Ha 4 kB adat kell, akkor csak azt a 4 kB-ot mozgatja. Ez komoly terhelést vesz le a PCI Express buszról is, mivel jellemző a szoftveres modellekre, hogy az ezen keresztül mozgatott adatok 80%-a eleve nem kerül felhasználásra sosem.
A frame akadások egyébként nem magának a törlésnek, és az adatmozgatásnak köszönhetők a szoftveres modellnél. Az okozza őket, hogy a WDDM egy igen masszív ellenőrzési procedúrát hajt végre a tényleges lépések előtt, aminek az idejéig le is áll a munka. Ezt a HBCC úgy kezeli, hogy a driver minden WDDM-es kérésre csípőből hazudik valamit, a HBCC pedig a háttérben dolgozik, ráadásul nem kell leállítani a munkát sem, ha másol. -
Abu85
HÁZIGAZDA
Ez inkább játékspecifikus lesz. Elég rossz a streaming megvalósítása a Shadow of Warban. Aktív HBCC-vel viszont nem kell beszopni a WDDM ellenőrzéseket, ami komolyan csökkentheti a sebességet. Még a beállított mennyiség sem igazán számít, mert a minimum ~12 GB-tal is ugyanúgy javul, mint ~16 GB-tal.
-
Ja, a Hitman meg a Tomb Raider játékoknál elég komoly limitbe futott a 960. A részletekben rejlik az ördög.
GDDR5X az 1060-hoz az hujjajj.
De az ~60% körüli különbség az 1080-hoz képest azért nem valami jó. És az 1070 és 1080 különsége azonos órajelen szintén elég gyér, ~15% körüli. Az 1070 nem véletlen, hogy kapott 7% órajel mínuszt, különben túl közel lennének. Az 1060 viszont ezzel a mínusszal is virgonc tud lenni. A ROP-raszter aránnyal kapcsolatos kiegyensúlyozatlanság érvét nem értem, mivel az RX480 is az lenne 48 ROP-pal, mégis tudna elvileg profitálni belőle. 
-
Valóban.
 Kezdek megtérülni.
Kezdek megtérülni. 
Fiji vs Tongánál ez érdekes, skálázódás vizsgálatára: 380X OC (Fury X / 2 szinte azonos órajelen)
Felbontás: 2160p 1440p 1080p
GM206 vs GM204 : +107%, +98%, +97%
GM204 vs GM200 : +36%, +33%, +27%
Tonga vs Fiji : +87%, +81%, +68%A Maxwell remekül skálázódik a GM206-GM204 viszonylatában, persze 1440p-től felfelé nem nagyon van értelme a számoknak, 4K-ban már biztosan limitál a VRAM mennyisége. A Titan X-nél már kemény limit van. De kb ugyanolyan mértékben nyílik az olló, mint a Tonga vs Fiji esetén. Szóval tényleg nem igazán lehet frontendre következtetni ez alapján, inkább architektúrális limit.
Maradt a ROP.
Ami még érdekes, hogy a Pascal esetén az GP106 már nem teljesen fele az GP104-nek, mivel a ROP-oknak csak a 25%-át vágták le, s ezt nagyon meg is hálálja, még az alacsonyabb magórajellel is. Kár, hogy az AMD nem tudott ilyet bejátszani, mert ugye akkor az RX 480-nak 384 bites busz kellett volna, amivel lőttek volna az olcsóságának.Várjuk a wunderdrivert.
-
Sávszélben meg nem +25%-ot, hanem +110%-ot (!) kapott a 390 a 380X-hoz képest, lehet arra is következtetni, hogy innen jött a plusz profit, ezt még a DCC sem tudja kompenzálni. A Tongánál biztos, hogy nem a setup a gond, pont ezt vezettem le, ebben egyetértünk. A ROP limit a leggyanúsabb a 32-36 CU-nál, mivel kizártam minden mást, de ezt nem tudom igazolni.
A fő kérdés nem a Tonga limitáló tényezője, hanem a Fiji-é. Az egy dupla Tonga, kivéve a setupot, s szerintem pont utóbbi miat nem skálázódik úgy, ahogy kéne. Egy Hawaii-hoz elég a 4 setup, a Tongához overkill, a Fiji-hez viszont kevés. Persze ettől még a Tongából következően a Fiji ROP limitjének is léteznie kell, de ez irreleváns, mivel a Fiji-nek hoznia kéne egy dupla Tonga sebességét még ROP limittel is.
-
Akkor már nézzük ezt a grafikont, amin rajta van a Polaris meg a Pascal is. A P10-nél valamivel javult a nem látható háromszögek eldobása, bár messze nem eleget, s a Vegánál ugye ezt akarják új szintre vinni, amivel a teljes feldolgozás terén spórolni tudnak.
Érdekes a Tahiti és a Tonga viszonya, utóbbi elég overkill frontendet kapott, azaz csak hányja a háromszögeket, de nem tudott egy millimétert sem előrelépni valós teljesítményben. Így a Polarisnak se kéne tudnia teljesen kihasználni ezt a frontendet, leginkább az órajel segít rajta, s értelmes felbontáson nem képes profitálni a több CU-ból a vágott verzióhoz képest, aminél ráadásul még a sávszél is jóval kisebb. Tehát a Polaris alapvetően ROP limitált kell hogy legyen, s ebből következően valószínűleg a Tahiti és a Tonga is.
A Hawaii +37.5% CU-jához van dupla backend, közel gyorsul is a CU-knak megfelelő mértékkel (lásd 280X vs 290X). De nem többet. Tehát akkor mégsincs ROP limit a 32-36 CU-s GPU-knál? Hisz úgy egyértelműen többet kellett volna gyorsulnia a 290X-nek, de PH, TPU, HW.fr tesztek alapján ez nincs így. A 390-et is behozva a játékba a Hawaii ugyan meghálálja a plusz sávszélt, de elég minimális mértékben, szóval ez nem tűnik limitáló tényezőnek.
A Fiji +100% CU-t hoz, ami overkill. A teljesértékű Tongához képest dupla teljesítményt kéne hoznia, de ebből kb 70-80% lett, hiába van körítésnek dupla ROP és orbitális memória sávszél. A vágott verzió azonos órajelen elhanyagolhatóan lassabb, szóval a CU-k nincsenek kihasználva. A frontendet tudom így oknak felhozni, mivel az nem változott a Tonga óta.
Hol a hiba?
-
-

Z10N
veterán
Es mi a helyzet a Vega28/32-vel: 28/32cu, 1024bit, valoszinuleg felezett rop 32. A ujitasoknak sok vagy keves lesz a backend? Ha ugye 1600-n fognak jarni akkor 204,8GB/s. Ennel a 470-nek is tobb all a rendelkezesere.
Nagyon kell majd az a csoda driver, hogy az 570/580-t le tudja valtani teljesitmenyben. Kulonben megint az egekbe emelik az orajelet es a feszultseget. Arban pedig biztos nem lesz $169/199 a hbm2 miatt. (Marad a P10).
-

HSM
félisten
Oké, csak egy pillanatra álljunk meg!
"a Fiji esetében is azt mondták, hogy csutkára vannak hajtva a ROP-ok"Tehát, 64 ROP, 1Ghz órajel, és volt alá 512GB/s sávszélesség, és ezen elvileg csontra ki volt hajtva. A Vega kapásból durván másfélszeres órajelen jár, tehát durván másfélszeres (elméleti) ROP sebesség alá van mindössze 484GB/s. Ez így nem az igazi, erős a gyanúm, hogy itt komoly sávszélesség limit lehet, pláne, hogy ugye a csip többi része is gyorsabb, jobban terheli az adatbuszt. Tehát, ismét oda lyukadtunk ki, hogy nem lenne értelme több ROP-nak, mert az alá kéne a nagyobb sávszélesség. Viszont az okosságokkal így csontra kihajtható lehet a csip, ami gazdasági szempontból nem rossz. Gondolom, nem kicsit dobta volna meg a költségeket, ha több HBM2 kocka kellett volna...
-
Nekem még mindig rohadt furán hangzik a backend a gyengeség annak tudatában, hogy az AMD pedig már GCN4 óta a frontendet heggeszti egyre okosabbra, s azzal akarja elérni a csodát.
Miért nem tettek 64 ROP-ot az RX 480-ba, ha ez ennyire kézenfekvő +20-30% teljesítményért? Mondjuk a kivitelezés az kérdéses, hogy a ROP-ok mit szólnak ahhoz, ha felezett sávszélt kapnak. Egy 512 bites vagy ne adj isten HBM-es Polaris meg nem kicsit verébre ágyú lenne. Ezzel lehet meg is válaszoltam magamnak a kérdést.
S akkor miért nem a ROP-ok okosítására állnak rá? BeleROPpannának?
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
HSM
félisten
"hogy a Vega feature-ök közül egyik sem enyhíti a ROP-okra nehezedő nyomást."
Dehogynem. A Hawaii-hoz képest ott a színtömörítés, ami sávszélességet takarít meg a ROP-oknak, valamint ott a DSBR, ami szintén sávszélességet takarít meg. Plusz elvileg még a HBM pszeudo channel módja sem aktív.
Megnézheted a 290X-->390X sebességviszonyánál, mennyire fontos a ROP-ok alá a megfelelő sávszélesség. A 290X-ek tempóján már csak a ram időzítés javítása is sokat tudott dobni.
A 290X-ek tempóján már csak a ram időzítés javítása is sokat tudott dobni. -
Nekünk tudatos vásárlóknak valóban nem jó, hogy nincs folyamatos előrelépés, de az átlag vásárló nem tendenciák alapján választ. Bár igazából én sem. Én nem tartanám jó vásárnak akkor sem a Vegát, ha folyamatosan javul. Majd ha kész, és egyértelműen lehagyja az 1080-at, akkor mondható el, hogy Vega ajánlott, mint játékos VGA.
A GCN 1-2 esetén ez alapján tényleg van ott ROP limit. De szerintem a közvetlen elődhöz hasonlítva kell keresni a V10 problémájának forrását. A P10 feleannyi ROP-pal és kevesebb CU-val hozza ugyanazt, mint a Hawaii, s a magasabb órajel ezt önmagában nem magyarázza meg. Szóval nem kevés az a ROP.
A V10 pedig már dupla annyi ROP-ot tartalmaz a P10-hez képest, s a CU-k száma is közel ennyivel több, viszont a frontend (látszólag, az inaktív feature-ök miatt) maradt ahogy volt. És a Vega még magasabb órajelt is kapott, mégsem akkora a különbség a P10-hez képest, mint a CU-k száma alapján kéne, főleg úgy tekintve rá, mintha ROP limites lenne, mert akkor a V10-nek legalább a P10 dupláját kéne hogy hozza. Ebből csak arra tudok következtetni, hogy a frontend kevés, s ezen a csodadriver fog javítani.
-
#33215
Petykemano
veterán
gbors
#33210
Petykemano
veterán
A ROP-nak több munkája van a felbontás növekedésével?
Az megfigyelhető volt a Fiji esetén, hogy nagyobb felbontások esetén reletíve jobban teljesített. Ennek okaként NTG azt nevezte meg hogy a frontend gyér és a compute erős. Kisebb és nagyobb felbontás esetén a frontendnek ugyanannyi dolga van, itt főleg a geometriára hegyezte ki a hangsúlyt. Ellenben a képpontok számolásánál nagyobb felbontás esetén már van haszna a több shadernek.
Ha a ROP munkája több magasabb felbontás esetén, akkor nem igazán lehet a ROP a limit, nem? -
HSM
félisten
Durva, hogy tényleg ennyire megfaragták a 390X-et. Mikor leváltottam a 280X-em egy 290-re, inkább tippeltem volna 25%-ra az érzékelhető ugrást....

Mondjuk az is igaz, hogy 7970-est írtál, és azon még lassabb ramok voltak, mint a 280X-en, cserébe még a 290 is lassabb, mint a 390X, érthető a nagyobb űr.
Igen, jó a teszt, akkor nem a setupon múlt. Viszont ami érdekes, néhol a nagyobb sávszél hozott nagyon szépen a Tahitinek, néhol viszont azért az erősebb setup is villantott a Tonga-ban. -
HSM
félisten
"a 390X közel 60%-kal gyorsabb a 7970-nél"
Szerintem ez egy kicit túl idealista szám. Viszont itt a frontend is duplázódott, a praktikus triangle setup amennyire tudom, a Hawaii 4 motorjával kb. a bő másfélszerese a Tahiti kétmotorosának.
Szerintem amúgy a sávszél fogyott el alóluk, azért se lett volna nagy értelme többet belerakni. És én ezért látok fantáziát abban, hogy a DSBR-el egyfajta tile-rendszer felé mozduljanak, amivel sávszélességet lehetne megtakarítani, ami a feltevésem szerint azonnal ROP sebességet hozna. -
Gipsz Jakab nem bizonytalan, csak azt látja, hogy a Vega nem hozza azt amit kéne. Ígyis-úgyis megveszi a zöldet, Ha a pirosak sok kicsit fejlesztenek, az kevés inger sokszor, nem fog eljutni Jakabhoz. De ha egyszerre sokat, akkor tele lesz a net grafikonokkal, s talán eljut Jakabhoz is, hogy csoda történt az AMD-nél. Már ha tényleg lesz csoda.
Ja, hogy a skálázhatóság nem az igazi, s ugyanannyi ROP van a Pitcairnben és a Tahitiben is, s mégse 100% a különbség, ahogy a Hawaii és a Fiji esetében sincs akkora ugrás, mint kéne lennie a teraflopsok* alapján. De ebből nem következik az, hogy a ROP kevés.
* wtf, többesszám többesszáma
-
A kis változások senkit sem érdekelnek. Ha egyszerre jön az egész egy patchként az marketing szempontból sokkal jobb, jóval drasztikusabb a változás.
Nekem bűzlik az vélemény, hogy backend lenne kevés. Oké, hogy régóta ugyanannyi ROP van, de ezek képessége nem azonos, főleg egy NV-hez mérve. Meg hát elég hülyék, ha ezt a limitációt évek alatt nem vették észre, ráadásul most a frontendet erősítik, ami eszerint csak egy pofon a szarnak.
-
#33202
Petykemano
veterán
gbors
#33201
Petykemano
veterán
A polaris a VI-hez képest 7% "Ipc" többlettel bír és ezen kívül a 32 helyett 28 CU 12.5%-kal kevesebb feldolgozót jelent. Aztán hogy ez gond-e egy általában compute nehéz architektúra esetén az kérdéses, mert láttuk, hogy a vega64 se tud többet azonos órajelen, mint a vega56.
Számszerűleg mindenesetre eseket a differenciákat a 20 max 25%-kal magasabb órajel kompenzálhatja csak, ami nem teszi így egyből elavulttá a polarist.
Az amd ilyet nem szokott csinálni. Utoljára a tongával váltotta a tahitit úgy, hogy érzékelhető különbséget nem hozott.
Tehát vagy a csodadriver csoda driver.
Vagy még az lehet, hogy belátták, hogy össességében jobban járnak, ha a régebbi architektúrákat nyugdíjba küldhetik és nem kell egyszerre 3-4 régi és új architektúrát is támogatni a driverben. Ez üdvözlendő. -
-
Omli85
őstag
Igen valahogy így szóval én ezért is nem látom annyira borúsan a dolgot.
Kb 2.5 éve 120K környékén vettem a 390-et most 134K-ba fájta Vega 56 nekem ez a difi belefér egy ilyen mértékű upgrade esetén.Amúgy van itthon DC2 290 is meg DC2 390 is lehet futtatok pár kör összehasonlító tesztet honnét hova fejlődött a dolog
. -

Z_A_P
addikt
De, ahogy lassan az aláírásomba is beletehetem, várjuk az 1.0-s drivert
Nagyon jo lenne majd egy teszt, ahol a mostani 0.x driver inaktiv csoda-feature-kkel, illetve majd osszel (telen?) az 1.0, aktiv csoda-feature-kkel, egymas melle grafikonon, semmi melleduma, csak szamok.
-
Abu85
HÁZIGAZDA
Hát ez jó kérdés, de nyilván lehet annak is oka, hogy a felbontás változásával a minőségi szint is módosult. Például azt korábban mondták, hogy a PUBG Full HD-high szinten már alapból annyira gyorsan fut, hogy a Vega sorozat veri az 1080 Ti-t. De nem ellenőriztem még ezt az állítást. Elképzelhető, hogy bizonyos beállításoknál kap olyan terhelést a memóriabusz a psuedo channel hiányában, hogy a DSBR azokon javít sokat, míg a többin nincs akkora előnye.
-
Abu85
HÁZIGAZDA
Mindenki hibás. Az AMD azért, mert tudták, hogy a packoknak ez lesz a következménye, eleve erre játszottak. A boltok pedig azért, mert nem gondolkodtak előre és belementek a jónak hallatszó üzletbe, amitől most kényszerűen tele kell rendelniük magukat AMD cuccokkal.
Nyilván egyébként megy a mutogatás is. Azért ennyire agresszív a boltok szempontjából a viselkedés, mert valahol ezzel a packos játékkal szerződésszegésbe kényszeríti őket az AMD. Sok boltban van szerződéses raktárarány, és ha folyamatosan Vegákat és Ryzeneket kell rendelni a körforgás fenntartásáért, akkor ez fel fog borulni. Az Intel és az NV pedig nyugodtan mondhatja, hogy nem teljesítitek a raktárarányt, így mostantól teljes áron kaptok GeForce/Core/akármi hardvert. A boltok ezért idegesek és megy a mutogatás/panaszkodás. Én is ideges lennék, ha Intel/NV szerződésem lenne a raktárarányra.
-
#45997568
törölt tag
Megint terelsz. Allitottal valamit amit nem tudsz alatamasztasztani hivatalos forrassal. Ha azzal kezdted volna hogy: szerintem, mas lenne a tortenet, igy szimplan hazugsaggal probaltad elkendozni a valotlan allitasaidat. Ez egy olyan spiral amibol barhogyan probalsz nem fogsz tudni kikerulni. Te is tudod, masok is latjak, ha elvezed, csinald.
-
Abu85
HÁZIGAZDA
A mezítlábas. De azt egy bolt csak úgy tudja érvényesíteni, ha kupon nélkül adja el a terméket. Ezt megteheti akármikor, akár az összes megvásárolt Vega 64-gyel is. Ellenben az AMD felé mindenképpen a Black Pack árat fizetik, és akkor kapják vissza a 100 dolláros különbséget, amikor a következő adat Vegát rendelik. Utóbbi rendelésnél annyiszor -100 dollár az ár, ahány Vega 64-et mezítlábasként adtak el.
Ebben az a csapda, hogy a bolt rá van kényszerítve a folyamatos rendelésekre, a Ryzeneket, a hozzájuk való alaplapokat, és a FreeSync monitorokat is folyamatosan kell kérniük, hogy a Packekhez tudják adni a hardvereket. Aztán, ha ezekből sok lesz, mert sok lesz a szerződés miatt, akkor ahhoz újra Vegákat fognak rendelni, hogy Packként eladhatók legyenek, és kezdődik a kör elölről. Az egész arra szolgál, hogy az AMD pár gyártó közvetett segítségével fogságba ejtse a raktár/(ploc) jelentős részét. Ebben az a nagyon veszélyes, hogy ha nagyon eltolódik a raktárkészlet az AMD irányába a folyamatos utánrendelési kényszerrel, akkor a bolt kevesebb Intel és NVIDIA árút fog rendelni, mert az AMD holmijanak az eladására kell koncentrálniuk. A boltok ma lehet, hogy úgy gondolkodnak, hogy ebből a csapdából ki tudnak szállni veszteség nélkül, vagy legalább elviszik az egész terhet az ünnepi szezonig, és akkor valóban jó esély van erre. De addig is még több hónap van, és a szükségesnél jóval több AMD cucc rendelésére kényszerülnek. Igazából az a furcsa, hogy ebbe a boltok beleálltak, mert ordít az egészről, hogy mire megy ki. Ha én kereskedő lennék, akkor egyetlen Vegát se árulnék kuponnal. Oké egy hétig benne áll a többletpénz, de az AMD úgyis levonja a következő rendelésből, ilyen rövid időt pedig egy normálisan működő bolt meglévő tőkéje bőven fedezni tud. -
#45997568
törölt tag
AMD hivatalos arazasa a hivatalos sajtokozlonyben van, hivatalosan, le is irtak feheren-feketen. En azota sem lattam sehol hogy AMD hivatalosan arat emelt. Raggie cikke is AMD RX-Vegarol szolt nem egy variansrol.
Az hogy az allatasaidat egyesevel tenyekkel megcafolom es ezt probalod megmagyarazni az tobb mint mokas, hazugsagot hazugsaggal kimagyarazni, nice try.
Teritsd a fantazmagoriaidat az iroi muhelyedben vagy hozz AMD hivatalos forrast ahol kijelentik emelik az RX Vegak arat az MSRP-hez kepest. Mivel ez eddig sem sikerult ezutan sem varok mast

-
#45997568
törölt tag
Ugy latom tenyleg gondok vannak arra fele

Jossz azal hogy AMD emeli az arakat, hozol egy nem hivatalos forrast amire en megmutatom az AMD altal kiadott hivatalos arakat. Erre azzal replikazol hogy azok biztos csak a mezitlabas kartyakra vonatkoznak, nem a pack-okra amik dragabbak, ezt is megcafolom, forrassal, neked meg nem sikerult az allitasodat alatamasztani hivatalos forrassal csak a szomagia megy.
Ebbol en azt latom hogy legbol kapott elmeleteket probalsz meg tenykent beallitani, de a tenyek elfogadasa es a hivatalos forrasok mar smafu. Ok, eddig sem volt sok hitel az irasaidban, most eluszott vegleg
Megbocsatok

- 699$-os MSRP kartya (ami ofc afa mentes az USA-ban, leven allamonkent kulonbozo az afa) 681$-ert nem is rossz, meg el is hoztak ingyen, kocsog AMD
(#32913) Abu85: nem olvas cikkeket vagy nem erti, mind1.
-
#32914
 TESCO-Zsömle
titán
gbors
#32909
TESCO-Zsömle
titán
gbors
#32909
TESCO-Zsömle
titán
Én arra próbáltam korábban rávilágítani, hogy itt nincs megbízható forrás. Az összes áremelésről szóló pletyka/állítás kereskedőktől jött. Eddig két forrást szellőztetett meg a sajtó, az egyikk az a Gibbo volt, aki jó pár bullshitet letolt már a csövön, hogy felverje a Vega keresletét, a másik egy olyan bolt számlája, ami hirhedten drágán ad mindent mindenkinek.
Én legalább egy hiteles OCUK/Newegg számlát szeretnék látni, hogy mennyiért kapják darabját, de ilyet nem fogunk, mert nyilván súlyos üzleti titok. Amíg ez nem történik meg, addig minden szentnek maga felé nyúlik a keze, attól, hogy a kereskedők vannak többen még nem biztos, hogy ők mondanak igazat.
És az se növeli a hitelességüket, hogy a nagy bányászlázban szemrebbenés nélkül vágtak rá egy 100-ast a garantáltan MSRP-n vásárolt RX500-asokra...
-
#45997568
törölt tag
Az jo, mert akkor talan leesik hogy megint tevedsz, bar mar lassan nekem kell elnezest kernem emiatt

Ezt irtad:
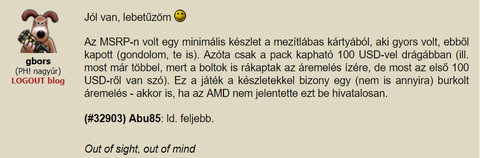
Ez azert hibas mert a rendelesemben nem mezitlabas kartya volt, hanem "pack"

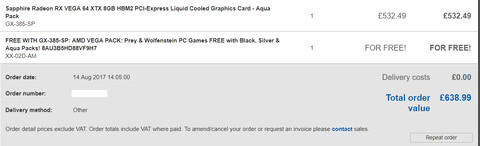
Most hagyok idot hogy betunkent vegig menj rajta, reszemrol elengedtem a temat
ps: ha nagy ritkan tevedek, elismerem, nem ciki
-
#45997568
törölt tag
"Jaja, szokásos, mert most is én böfögtem be valami hülyeséget fél sorban, ahelyett, hogy gondolkodtam volna legalább egy ici-picit" - Ezek szerint ugy nez ki, de ezt nem az en tisztem eldonteni.
A hivatalos AMD press release itt olvashato.
A problemat nem latom, en azon az aron vasaroltam az OCUK-tol a kartyat ami az MSRP-je volt, akkor ki beszel hulyeseget, bocs, bofogott?
Amit linkeltel ott nem latom az AMD "hivatalos" allasfoglalasaban hogy ok azt mondtak: dobjatok ra egy 100-ast, jo lesz az
-
Abu85
HÁZIGAZDA
Ez igazából a packokra vonatkozik. Az AMD-nek ez az állítása konkrétan cáfolja a 600 dolláros árat.
[link] - itt leírtam a lényeget. Egyébként a második bekezdés vége azt is leírja, hogy miképp szállítják a Vegákat. És ez is egy fontos tényező.
A lényeg az, hogy ha valaki kupon nélkül vesz Vegát, akkor az 599-es MSRP-ért vásárolt terméket 499-ért kell odaadni, és a 100 dolláros különbözetet az AMD a következő rendelésnél visszaadja, illetve kvázi kivonja a rendelési árból.
A kereskedők szabadon dönthetnek arról, hogy kuponnal vagy kupon nélkül adják a terméket. De nyilván leginkább kuponnal fogják, mert az AMD mesterségesen arra kényszeríti őket, hogy a rendeléseiket növeljék a cég felé. Ez is ki van fejtve a cikkben, hogy mit használnak ki. -

And01
aktív tag
Ha egy kis létszámú csapatnak olyan munkát adsz,
ami meghaladja a lehetőségeit az valóban vezetési hiba.(#32880) M@trixfan
Tanárom mondta nagyon rég:
A diplomához s..gg kell, nem ész, leül és tanul.Egyébként alapvetően igazad van, viszont elég sok emberrel futottam
össze már, (gondolom nem vagyok vele egyedül) akiknek képességei
finoman szólva is hagynak kívánni való maguk után, de a diplomát megszerezte -

M@trixfan
addikt
Abszolút off, csak mindig jókat röhögök magamban amikor akár az itteni felsőoktatási topikokban fikázzák a gazdasági, memedzsment szakokat. Miközben pedig mennyire nem mindegy ugye
Sokszor olyan téveszméket olvasok esetlegesen profi szakmai emberektől cégek működéséről, vezetésről, hogy csak pislogok... -
And01
aktív tag
Szerintem a legnagyobb baj a szoftveres csapat
alapvetően kislétszámú (költséghatékony) mérete.
Ameddig a régebbi gcn verziókhoz kellett hozni a meghajtót ez jó volt,
sok új dolog nem jött, meghajtó frissítéshez ez is elég volt.
Erre jön a vega jópár olyan dologgal ami eddig nem volt, amihez a nulláról
kell írni a meghajtót, a szoftveres csapat hirtelen kicsi lett a feladathoz,
elmaradnak a munkával.
Ráadásul hirtelen létszámnöveléssel sem lehet megoldani ezt a kérdést,
ugyanis begyakorlott programozókat nem egyszerű találni. -
lehet, hogy van, lehet hogy nincs, egyelőre nem derült ki. legalábbis én nem látom a dirt4 kapcsán, hogy mitől lenne. ugyanis ugyanazzal a feature szettel ment a kártya dirt4 alatt is, mint minden más játék alatt. nem volt aktív olyasmi, ami máshol le lett volna tiltva. sőt, mivel az egész csak fhd alatt ilyen, ahol mértek dirtöt, de fhd-t nem (pcgh), ott ezt szóvá se tették.
hogy melyik voltával fog versenyezni a vega, az meg legyen az amd problémája.
-

stratova
veterán
Én meg a write only mód... Sorry. Szóval, jogos:
Bei den Polygonen fällt im Vergleich zur Fiji-GPU der Fury X ebenfalls auf, dass nur der komplett verworfene Triangle-Strip-Test wesentlich flotter läuft - doch das tat er schon mit Polaris.Annyiból van áthallás a két link között, hogy összességében a geometriai teljesítmény, mint szűk keresztmetszet akkor is csökken, ha eleve figyelmen kívül hagyhat egy jelentős mennyiségű háromszöget (primitive discard) de azáltal is, ha nő a geometriai motor teljesítménye.
Polaris:
Primitive discard
Polaris-based GPUs have 1-4 geometry engines, depending on overall performance targets (e.g. the Radeon™ RX 460 GPU has two, while the Radeon™ RX 480 GPU has four). The screen space is partitioned to load balance between the geometry engines, which can each rasterize a triangle per clock. The Polaris geometry engines use a new filtering algorithm to more efficiently discard primitives. As figure 5 illustrates, it is common that small or very thin triangles do not intersect any pixels on the screen and therefore cannot influence the rendered scene. The new geometry engines will detect such triangles and automatically discard them prior to rasterization, which saves energy by reducing wasted work and freeing up the geometry engines to rasterize triangles which will impact the scene. The new filtering algorithm can improve performance by up to 3.5X (fig. 6), and the benefits are more pronounced in scenes with many polygons.Triangle strip
The Polaris geometry engines are also more flexible than in previous generations. Triangles are commonly organized into lists and strips. A list of N triangles is simply a set of 3N vertices where each set of three vertices represents a triangle. A strip of triangles is a more compact data structure that takes advantage of locality to reduce the number of vertices needed. In a triangle strip, the first triangle takes 3 vertices, and each additional triangle shares two vertices and only needs a single additional vertex – so a strip of N triangles has N+2 vertices. The Polaris geometry engine can handle both lists and strips at full rate, which avoids the overhead of converting triangle strips to lists in software.Vegánál még/már elérhető (6-8), azt nem tördelem be, csak kiragadok belőle pár részletet:
The “Vega” 10 GPU includes four geometry engines which would normally be limited to a maximum throughput of four primitives per clock, but this limit increases to more than 17 primitives per clock when primitive shaders are employed.⁷
Primitive shaders can operate on a variety of different geometric primitives, including individual vertices, polygons, and patch surfaces. When tessellation is enabled, a surface shader is generated to process patches and control points before the surface is tessellated, and the resulting polygons are sent to the primitive shader. In this case, the surface shader combines the vertex shading and hull shading stages of the Direct3D graphics pipeline, while the primitive shader replaces the domain shading and geometry shading stages.
...
Primitive shaders will coexist with the standard hardware geometry pipeline rather than replacing it. In keeping with “Vega’s” new cache hierarchy, the geometry engine can now use the on-chip L2 cache to store vertex parameter data. This arrangement complements the dedicated parameter cache, which has doubled in size relative to the prior-generation “Polaris” architecture. This caching setup makes the system highly tunable and allows the graphics driver to choose the optimal path for any use case. Combined with high-speed HBM2 memory, these improvements help to reduce the potential for memory bandwidth to act as a bottleneck for geometry throughput. -
#32660
TESCO-Zsömle
titán
gbors
#32655
TESCO-Zsömle
titán
-
Abu85
HÁZIGAZDA
De ez hamis ígéret lenne. A Dirt 4 csak egy kellemetlen jelenség miatt fut jól Vegán, és nem azért, mert az AMD direkt gyúrt rá. Az egész megoldás egy korábbi probléma kezelésének mellékterméket. Nem tudja garantálni az AMD, hogy lesz még egy ilyen játék, de még azt sem tudja megígérni, hogy nem lesz.
A primitive shader ezzel szemben egy garantálható dolog.
A setup áteresztőképessége még mindig komoly probléma. Az egy dolog, hogy átnyom egy rakás háromszöget, de a háromszögek fele nem látszik, tehát csak az erőforrást költjük rá. A 17 is igazából egy arányérték. Valójában a hardver nem nyom át ennyit, de a rengeteg kivágással olyan, mintha ennyit nyomna át ... ha nem lenne primitive shader, és megtömnénk a hardvert 20 motorral, és biztosítanánk neki az 5-6 TB/s-os sávszélt.
-
Abu85
HÁZIGAZDA
A Dirt 4-et nem éri meg lobogtatni. Ez csak azért van, mert a régebbi hardverek kifutnak az erőforrásokból. Ugyanígy kifut a Polaris és a Vega is, csak az előbetöltés miatt jóval hamarabb megjön az adat, tehát kevesebb ideig malmozik a multiprocesszor. Szóval itt nem igazán driverből oldja meg ezt a Vega.
A népnek ezt nem lenne érdemes általánosan eladni, mert ezt nem tudja befolyásolni az AMD. Elképzelhető, hogy lesz még ilyen játék, elképzelhető, hogy lesz több is az év végéig, de az AMD tipikusan nem javasolja azokat az übershadereket, amelyek ennyire erőforrás-igényesek. Ezeket az Intel szokta nyomatni.
Sokkal inkább lényeges, hogy ha aktiválják a primitive shadert, akkor a tipikus ~4 tri/clockból ~17 tri/clock lesz. Ez az, amit elmondtak, de végleges teljesítményadatot itt sem mondtak.
-
stratova
veterán
Tényleg nehezen hihető de TPU-n is ez jött le, Guru3D pedig ennyit írt az OC-ról:
We halted testing overclocking until AMD can deliver a final driver where it works properly.
Wildlands-et leszámítva semmi hatása nem volt.
Igaz Vega 56, de Gamernexus tesztjében, ha megnézed a frekvencia diagramot, látható, hogy gyakorlatilag az UV mellett magasabb órajelet ért el a kártya, mint powerlimit +50W beállítással, miközben kevesebbet fogyasztott a kártya.
Itt pedig látszik hogy a venti felcsavarása nélkül a levegős Vega 64 droppolgat. A vizes Vega 64-nek pedig jelenleg ennyi a vége.. pont 1%-ot se nagyon tudtak emelni Wattmanban az órajelen, mert kifagyott.Malibutomi Meglehet. Továbbá, Vega 56 esetében még a HBM OC is hozott a konyhára.
-
HSM
félisten
Az a baj, én még sehol nem látom boltban a Vega-kat, így nem tudok mit mondani az árakról, nincs mit összehasonlítani, így jobb híján az MSRP-t látom.

Nyilván akkor lesz ez tiszta, ha látjuk majd a boltokat, és az árakat.A fogyasztás amúgy powersave módban teljesen korrekt, és a teljesítmény úgy is jó, szval az a +100W azért nem egészen úgy van. [link]
+40-50W viszont már nem a világvége, és itt tenném nagyon gyorsan hozzá, hogy az FE 1080-nál az OC verziók nem csak sebességben, de fogyasztásban is többet kérnek. -
Raymond
titán
" Azt ne felejtsd el, hogy ezek a cikkek nem 15 perc alatt íródtak - valószínűleg a méréseken és a rájuk épülő mondásokon kívül minden megvan már vagy 1 hete."
Ideillik a mai TPU review-bol:
"Two days ago, AMD provided an updated driver for overclocking testing only, which claims to address this, but it came in too late, when I had already left for my summer vacation. "
-
HSM
félisten
A TPU-n egy árba rakták a Vega 64-et a 1080-al, nekem őszintén szólva első blikkre ez teljesen reális, életképes árazás, nekem az eddigi választásaimnál is megért azonos teljesítmény mellett nagyobb fogyasztást, hogy AMD vasam legyen, amit én jövőbiztosabbnak gondoltam, mint a konkurenciáját.
Elég ha az FP16-ra és HBCC-re gondolok. Ha csak ezek hoznak 10-20% előnyt, már verve van a 1080 azonos áron.
A 1070 és Vega 56 árazása esetén is elvileg 350 és 400 dolár az MSRP, szvsz ez is teljesen versenyképes.Tehát a MOSTANI termék a MOSTANI driverével versenyképes a vele MOST egy árban lévő konkurens termékkel a MOSTANI árazásukon. Hol a gond?
Igen, vannak előnyök itt is ott is, de legalább van már választási lehetőség. -
-Solt-
veterán
Így már világos, bár emlékeim szerint az 1070/80/Ti viszonylatában a custom darabok ilyen 4-7% pluszt tudtak a referenciához képest, annyi talán itt is meglesz, bár lehet csak annyi lesz a különbség, hogy hűvösebbek és halkabbak lesznek.
600 USD-s MSRP árral nagyon nem lesz versenyképes... az azt jelentené, hogy a cirka 30-35% plusz teljesítményért csak 25% felárat kéne fizetni, és ott az 1080Ti, de costumok esetében ez lemehet akár 16%-ra is... és akkor még ott az 1080 100 USD-l olcsóbban.
Ennyiért még nekem sem kéne, pedig én nagyon nem szeretném megint az NV kezébe helyezni a pénzemet...
-
-Solt-
veterán
Most ebben a ref kérdésben elvesztettem a fonalat... a ref kártyákban nem igazán szokott tartalék lenni egyik oldalon sem. Vagy mire szeretnél kilyukadni?
Az árazást sem igazán értem... egyrészt a TPU és a Guru is 500 USD-ről ír, másrészt OC.uk-n bruttó 450 Fontért mentek el az első darabok. Kétlem, hogy csak úgy ajándékba adtak 100 USD + ÁFÁ-t a leggyorsabbaknak.
Holtpontra jutottunk ez tény, de egy ennyire szubjektíven megítélhető történetben másra nem is nagyon lehet...
-
nyilván 1080ti átlagot nem fognak belőle csinálni, de azért tartalék még van benne, főleg a fogyasztás terén (lásd még gyári túlfeszelés, hűtés, vrm, és hogy meddig tartja a boost órajelet). ami jó, hogy ebből már lehet custom pcb-set is csinálni. a fijinek is sokkal jobb lett volna a megítélése, ha van belőle néhány jól sikerült custom.
-

gyuszaa
őstag
Ez így van sajnos, majd így rögzül köztudatba. Biztos rajtuk volt a nyomás, sales csapat úgy volt vele, hogy egy komplett terméksála launch legyen egyszerre CPU és VGA vonalon üzleti húzás szempontjából szerintük ez volt mérvadó, gondolom én, de nem nagyon ástam magam bele az eseményekbe, csak spekulálok.
Bár enterprise vonalon ott a comeback Project 47 Epyc és Radeon MI kombóval.
-



 U ratio) the GCN GPUs have been held back by the insufficient render backend resources (apparently current GCN cannot support more than 4 RBs per SE). This is the case with all Polaris GPUs and especially with Vega. The performance difference between Vega 64 & 56 at the same frequency is diminising due to the backend starvation (1:1 ROP
U ratio) the GCN GPUs have been held back by the insufficient render backend resources (apparently current GCN cannot support more than 4 RBs per SE). This is the case with all Polaris GPUs and especially with Vega. The performance difference between Vega 64 & 56 at the same frequency is diminising due to the backend starvation (1:1 ROP
 (röhögjek már egy kicsit mert nem tudom hol kell ezt nézni). Az NV gyorsulni fog, szóval a vega 56 az 1060, a 64 meg 1070 alatt, lesz.
(röhögjek már egy kicsit mert nem tudom hol kell ezt nézni). Az NV gyorsulni fog, szóval a vega 56 az 1060, a 64 meg 1070 alatt, lesz. ![;]](http://cdn.rios.hu/dl/s/v1.gif)




















 Kezdek megtérülni.
Kezdek megtérülni. 



 A 290X-ek tempóján már csak a ram időzítés javítása is sokat tudott dobni.
A 290X-ek tempóján már csak a ram időzítés javítása is sokat tudott dobni. 
















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- NVIDIA GeForce RTX 5080 / 5090 (GB203 / 202)
- Vicces képek
- Milyen billentyűzetet vegyek?
- TCL LCD és LED TV-k
- Magisk
- Milyen egeret válasszak?
- Honor Magic7 Pro - kifinomult, költséges képalkotás
- Forrasztásról mindent az alapoktól!
- A nagy Szóda, Szódakészítés topic - legyen egy kis fröccs is! :-)
- Spórolós topik
- További aktív témák...

- gigabyte 5080 aorus master videokártya
- ZOTAC RTX 3070 8GB GDDR6 Twin Edge OC Eladó!
- Készpénzes / Utalásos Videokártya és Hardver felvásárlás! Személyesen vagy Postával!
- EVGA GeForce RTX 2080 XC GAMING 8GB GDDR6 Videokártya
- Készpénzes / Utalásos Videokártya és Hardver felvásárlás! Személyesen vagy Postával!
- HP 200W (19.5V 10.3A) kis kék, kerek, 4.5x3.0mm töltők + tápkábel, 928429-002
- BESZÁMÍTÁS! ASUS B450M R5 3500X 16GB DDR4 500GB SSD RTX 2060 Super 8GB Zalman N5 Zalmann 600W
- HIBÁTLAN iPhone SE 2022 128GB Midnight -1 ÉV GARANCIA - Kártyafüggetlen, MS2983
- Gamer PC-Számítógép! Csere-Beszámítás! R5 5600X / RTX 3070Ti / 32GB DDR4 / 1TB SSD
- DELL Precision 5540 Workstation i7-9850H Nvidia Quadro T1000 32GB 1000GB 15.6 új akksi 1év garancia
Állásajánlatok

Cég: FOTC
Város: Budapest