- Android alkalmazások - szoftver kibeszélő topik
- CMF Buds Pro 2 - feltekerheted a hangerőt
- iPhone topik
- Samsung Galaxy Watch7 - kötelező kör
- Megjelent a Poco F7, eurós ára is van már
- Telekom mobilszolgáltatások
- One mobilszolgáltatások
- Vivo X200 Pro - a kétszázát!
- Mobil flották
- Okosóra és okoskiegészítő topik
-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-

füles_
őstag
válasz
 Jack@l
#38342
üzenetére
Jack@l
#38342
üzenetére
250 dollárért, 150W TDP-vel. Ez szerintem nem kicsit lenne versenyképes. 15%-kal erősebb, mint a 2060 és 100 dollárral olcsóbb. 200 dollárért meg 2060 szint 120W TDP-vel. Először hihetetlennek hangzik, főleg a TDP, de a 7nm-től ez már elvárható. Meg az ár sem olyan lehetetlen, Navinál valószínűleg nem lesz RTX tax, mint a Turingnál.
-
füles_
őstag
-

Abu85
HÁZIGAZDA
válasz
Jack@l
#38233
üzenetére
A GPU-knál eleve brutálisan szemetelt az L2 cache. Abból leginkább a ROP-ok profitálnak, de a multiprocesszorok munkáját igazán az LDS segíti. A CPU-nál azért számít igazán a cache, mert ott hardveres szálak futnak, és ott ezeket nem tudod másra cserélni, ha nincs adat, emiatt fontos, hogy a cache-ben ott legyen. A GPU-knál az a trükk, hogy ha nincs adat, akkor félrerakja a hardver a wave-et, és betölt egy másikat. Emiatt tudják a hardverek igen jól áthidalni a tipikus 700-900 ns-os betöltési időket. Egy mai top GPU kezel közel sok száz hardveresen menedzselt wave-et. Az egyik futtatható lesz szinte mindig.
-
válasz
Jack@l
#37780
üzenetére
Valószínűleg nem driver issue, különben nem egy játékot érintene.
Simán lehet, hogy nála sima, mert valami olyan beállítást érint, ami nála ki van kapcsolva, hogy bírja a rendszer az fpst. De ha ezt egy vegán kikapcsolod, akkor 1. rondább mint dx11-en, 2. lesz egy tonna fpsed fölösben, és akár egy 560-570-et is vásárolhattál volna, minek a Vega. Következtetés: DX11
-

HSM
félisten
válasz
Jack@l
#37670
üzenetére
Ha már Steam, bár nem tartom reprezentatívnak, de ránéztem. A felhasználók mindössze 11%-ának van 8GB vagy több videoramja, ami ugye a 1070/1080/Vega/RTX, de ebbe még ugye a régebbi 390-ek, 470/480/570/580-ak egy része is benne van. (2018 októberi adat)
De ha megnézed a 2% feletti elterjedésű kártyákat is azt fogod látni, amit mondtam....
GTX 1060: 14.30%
GTX 1050 Ti: 10.70%
GTX 1050: 6.19%
GTX 750 Ti: 4.33%
GTX 1070: 3.83%
GTX 960: 3.74%
GTX 970: 2.97%
GTX 1080: 2.65%A piac több, mint 30%-a van GTX1050/1060-as kártyákon, amik azért nagyon nem 1080/Vega kategória. Ez amúgy durván a VGA piac fele (Steam alapján, 48%), és ennek a 1070+1080 együtt is csak durván a 13%-a. Az ennél erősebb kategóriából értékelhető elterjedtséggel egyedül a 1080Ti van, 1,5%-al, ami elég harmatos ahhoz képest, amiket itt felsoroltam.
Az AMD statisztikájához szvsz az is erősen hozzátartozik, hogy a kártyáik jó része szvsz továbbra is a bányákban számolgatja a kriptopénzeket....
-

-Solt-
veterán
válasz
Jack@l
#37526
üzenetére
Iróniával szerettem volna érzékeltetni, hogy komolytalan a megjegyzésed. Adott két közel azonos árú termék, az egyik kevesebbet fogyaszt és pár százalékkal jobban húzható, a másik többet fogyaszt*, kevésbé húzható, de alapból pár százalékkal gyorsabb. Ha semmi mást nem nézünk, ez már önmagában versenyhelyzet, és akkor ott van még a FreeSync monitorok jóval kedvezőbb ára, vagy éppen a beharangozott játékok. Erre jöttök azzal, hogy ez így nem versenyképes... Az ilyen megjegyzéseket nem lehet komolyan venni!
Én ebben kategóriában biztos, hogy AMD VGA + FreeSync párost választanék, mivel utóbbi annyit hozzáad a játékélményhez, amennyivel a kisebb fogyasztás + jobb tuning lehetőség nem tud versenyezni.
*100W többletfogyasztás napi 3 óra játék esetén évi ~4000.-Ft pluszköltséget jelent. Ne bohóckodjunk már ezzel...
-
-

sutyi^
senior tag
válasz
Jack@l
#37194
üzenetére
Hát... 299 USD MSRP vagy nettó hülyeség, vagy lényegesen többet tud ez a kártya mint amit eddig láttunk.
Ha csak nem full fat 40CU magasabb órajelekkel és nincs nagyon közel egy GTX 1070-hez alulról, akkor igencsak túl van árazva szerény meglátásom szerint, főleg ha azt nézem hogy normális AIB partner kártyákat lehet lőni 230-250 USD között kint, azokhoz képest 20-30% felár lenne +10-15% plusz sebességért?
-
#37179
 Petykemano
veterán
Jack@l
#37174
Petykemano
veterán
Jack@l
#37174
Petykemano
veterán
válasz
Jack@l
#37174
üzenetére
Az mondjuk Szerintem sandbagging.
De csodát nem kell várni. Még az ngg (& primitive shader) sem gyógyul meg Gfx10 előtt.
Az 1080 szintnél én többet várok, de számomra már meglepetés lenne, ha az 1080ti-nél jobbat hozna.
És persze mindent lehet magyarázni azzal, hogy pro kártya, pro driver -
-

Yany
addikt
-

Callisto
őstag
válasz
Jack@l
#36648
üzenetére
Kommersz kategóriában (értsd gamer) nem nagyon fogod a memsávszélnek előnyét látni szerintem, mert szerintem nem úgy fogják fejleszteni a játékokat, hogy kihasználja (RTX képesség lesz a limit). Hacsak nem lesz konfigurálható a játékokban a minősége.
AMD már jó ideje a professzionális piacot tartja szem előtt és ott ennek van előnye, de lehet tévedek. -

Cathulhu
addikt
válasz
Jack@l
#36648
üzenetére
Tegyuk hozza, hogy HBM ide vagy oda, a (hulye) AMD mindig ugy intezte, hogy veletlenul se profitaljon a nagy savszelbol, mert mindig ugy rakta a stackeket, hogy ne legyen gyorsabb a GDDR-nel... Igy sose fogjuk megtudni, valoban hozott volna-e a HBM barmit is a konyhara amellett, hogy draga...
-
Yany
addikt
válasz
Jack@l
#36567
üzenetére
Márpedig abban Abunak teljesen igaza van, hogy itt almát hasonlítasz körtével. Az itt látható ray/s mértékegység nagyon nem ugyanaz, mint amit a RTX-es demóban realtime látsz. Teljesen más paraméterekkel, algoritumssal és részletességgel történi realtime és render környezetben a raytrace. Gyanítom, hogy a számítás pontossága sem ugyanannyi bites.
-
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#36564
üzenetére
Dolgozz a filmiparban. Ott ez a probléma konkrétan fáj. Láthatod a videóban, hogy meddig tudsz jutni a HBCC nélkül. És akkor ültetheted oda az embereidet, hogy bontsák a tartalmat sok-sok apró szeletre, hogy beférjen. Vagy ha van pénz, akkor venni kell egy CPU-s rendszert, amit meg lehet támogatni több TB memóriával.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#36562
üzenetére
Tudtommal nem 8 MB, de felőlem lehet annyi is, ha ettől megnyugszol, viszont itt az a lényeg, hogy semmi gond nincs a nagy állománnyal sem. Múltkor egy 250 milliárd háromszögből álló adatmennyiséget töltöttek be. [link] - A Vega óta ez mindegy, mert a memóriavezérlő automatikusan kezeli a nagy adatmennyiség problémáját.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#36560
üzenetére
Nem valószínű. 80 GB a modell. Közkincsé szoktak néha tenni dolgokat, de 80 GB-ot hülyeség lenne.
Csak egy sugár az nem egyenlő egy másik sugárral. Baromira nem mindegy ugyanis, hogy a gyorsítóstruktúra belefér-e az L1 cache-be, vagy esetleg talán az L2 cache-be, vagy csak a VRAM-ban. Aztán, ha ezen túljutottunk, akkor az sem mindegy, hogy a modell belefér-e a VRAM-ba.
-
Yany
addikt
válasz
Jack@l
#36556
üzenetére
A mozgatás közben látható szemcsés állapot az, amit az RTX kártyák is előállítanak, csak A Tensor magok faszán kisimítják. Azonban a BF V-ben is látható néhány tükröződésnél, hogy ott "zajos" maradt, valószínűleg technikai oka van, vagy csak még a pre-pre-béta állapot miatt nincs befutva mindenhol ez a fázis. Szóval a tempó nem hasonlítható össze 1:1-be, mert nem tudhatod, hogy pontosan mennyit kellene számolni ahhoz, hogy egy Tensor-hoz hasonló megoldás RTX-hez közeli minőséget eredményezzen. (vagyis, hogy mennyire maradhat még szemcsés a vége ahhoz, hogy kidolgozható legyen a sok hiányzó részlet realtime)
-
-
#36497
 FollowTheORI
nagyúr
Jack@l
#36496
FollowTheORI
nagyúr
Jack@l
#36496
-
#36486
Petykemano
veterán
Jack@l
#36485
Petykemano
veterán
válasz
Jack@l
#36485
üzenetére
Hát én azt gondoltam eleve, hogy a tsmcnél tömegtermelés (amds léptékkel) nem lesz, csupán néhányszázezer lapkára való. Az az Apple igényének töredéke. És a mainstreamebb cpu vagy gpu gyártása továbbra is az olcsóbban, de kicsit szarabbart, es később gyártó GF viszi nagytételben (néhánymillió lapka)
Ez persze most is egy lehet. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#36313
üzenetére
A CPU miatt. A HBM2 memóriabusza a Fenghuangon csak az IGP HUB-jába van bekötve. Ergo a CPU-nak is kell egy saját memória. Nyilván itt a HBM nem opció, mert túl pici a kapacitása. Az, hogy a GDDR5 drága nem igazán számít, mert nem tudsz mit rakni a helyére.
Sose mondtam, hogy a Vega csak HBM-mel működik. Sőt, sokszor ismételtem el, hogy a HBCC nem függ a HBM-től. Azért van HBM2 a Vegán, mert jelenleg ez a létező legjobb memória. Csak nagyon sokan a HBCC-t a HBM-hez kötötték. Eléggé alaptalanul.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35995
üzenetére
Ha ez ennyire egyszerű lenne, de a helyzet az, hogy a Sony és a Microsoft saját IP-ket is fejleszt, míg mondjuk egy rakás OEM nem. Ez a Semi-Custom bája és egyben rákfenéje. Ezek az IP-k a Sony és a Microsoft számára úgy lesznek meg fizikailag, hogy az AMD Semi-Custom részlege elkészíti a logikai dizájnból, méghozzá a megrendelő mérnökeivel közösen, és ez a fizikai dizájn az AMD tervezőkönyvtáraival lesz megalkotva, hogy kompatibilis legyen az AMD saját IP-ivel, a teljes lapkára kialakítva a saját routingot. Ilyen formában például semmit sem tud vele kezdeni mondjuk az Intel, mert más tervezőkönyvtárakat használnak, és már szimpla legózással sem lesz kompatibilis az IP. Ezt újraterveztetni igen nagy költség, főleg amiatt, mert a legalsó szoftveres réteget is újra kell írni a nulláról, és nem egy ilyen IP van a mostani konzolokban, hanem több tucat. Szóval a Sony és a Microsoft számára igen kedvezőtlen bárki máshoz menni a következő generációban, mert mindent, amit az elmúlt nyolc évben megalkottak közel a nulláról újra kell tervezni, míg az AMD-nél maradva egyszerűen le lehet portolni az egészet egy új lapkába, elvégre a Semi-Custom fő célja az egyedi dizájnok kialakítása, vagyis a birtokolt fizikai dizájnokat mindig egymáshoz legózhatóvá tervezik.
Az OEM-eknél azért sokkal könnyebb, mert ők nem adnak semmit egy kész lapkába. A legnagyobb teher a platform leváltásánál a nyomtatott áramköri lap áttervezése, és némi szoftveres probléma, ami aránylag olcsón megoldható. Ilyen szerencséje a Sony-nak és a Microsoftnak nincs. Nekik a beszállító leváltása rendkívül extrém költségekkel járna, annyira komollyal, hogy jobban megéri minden technológiát elengedni, amin az elmúlt évtizedben dolgoztak az AMD-vel. Kérdés persze, hogy erre megvan-e az akarat. Ha mondjuk nem találnak olyan partnert, aki tényleg tud egyedi igényekhez lapkát tervezni, akkor nincs értelme váltani sem. Már csak azért sem, mert az AMD-ben már megbíznak, hogy a titkaikat nem szivárogtatják ki harmadik félnek, ami egy komoly szempont, hiszen mégis dollármilliós nagyságrendű kutatásokat kell megosztani egy konkurenssel.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35993
üzenetére
Teljesen mindegy, hogy mi lesz a konzolokban, SoC vagy nem SoC. Az AMD-n kívül nem kínál senki más olyan üzleti konstrukciót, amit a Sony és a Microsoft keres. Ez a Semi-Custom átka a megrendelők felé. Egy idő után annyira függővé vállnak a kiszolgálótól, hogy nincs hova menni, az AMD-nél van az összes IP-jük fizikai dizájnja, amit ők könnyen be tudnak építeni a saját dizájnjaikba. Nem tudnak mást választani, mert egyrészt egy csomó cég ezeket a dizájnokat be sem építi, még igényre sem, másrészt annyira át kellene alakítani azokat, hogy kompatibilisek legyenek a más partnerek által használt tervezőkönyvtárakkal, hogy arra se pénz, se erőforrás, se akarat. Nyilván az AMD nem fogja odaadni nekik a saját tervezőkönyvtárát, tehát mindent újra kell terveztetni valaki mással.
Ebből a helyzetből csak úgy tud szabadulni a Microsoft és a Sony, ha lemondanak minden olyan fejlesztésükről, amit az elmúlt nyolc évben dolgoztak ki, és akkor tudnak venni egy tömegeknek szánt kész lapkákat másoktól is, ahogy például a Nintendo is tette a Tegra esetében. A gond ezzel annyi, hogy lópikula lesz a teljesítménye, miközben elég sok pénzbe kerül, hiszen nincs egyedi megrendelés, ehhez szabott üzleti feltételekkel. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35858
üzenetére
Nem kell nőnie, mert nincs több erőforrásod a hardver oldalán, de persze nagyon picit nőhet, viszont a mértéke elhanyagolható. Az történik, amit leírtam. Amikor az n képkocka számítása a végéhez közelít, akkor az n+1 elkezdődik. Ezzel lesz átfedés, mivel a feldolgozás egy részében van olyan pillanat, amikor két képkocka számítása zajlik párhuzamosan. Ez teljesen normális, mivel egy grafikus vezérlő heterogén processzornak tekinthető, vagyis amikor az n képkocka már nem terheli a parancsmotorokat, a tesszellátort, stb., akkor az n+1 képkockának eléggé szabad az út, hiszen azok aktuálisan malmozó részegységek. Emiatt az átlapolás a mai driverekben egy abszolút használható stratégia. Az más kérdés, hogy ennek a késleltetésben komoly ára lesz szinkronizálás mellett.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35856
üzenetére
A mai játékokban azért a motion blur faék egyszerűen van megoldva. Az adott pixel végeredménye mindig a környező pixel valamilyen módon számolt súlyozott középértékéből van származtatva. A gyorsulást szimplán skálázhatod a képkockasebességből. A temporális screen space megoldások marhára nem elterjedtek ám. Persze kétségtelenül lehetségesek, csak egyrészt a számítási idő és a memóriaigény tekintetében relatíve költségesek, másrészt az eredményük nem sokkal jobb, így például nem adnak választ azokra a problémákra, hogy mi van azokkal az objektumokkal, amelyek már pont nincsenek rajta a képen. Szóval az egész egy baromi nagy screen space trükközés jelenleg. Úgy tudom egyedül a Nitrous működik másképp, az valóban temporális, ráadásul objektumszintű motion blurt használ, de ott eleve a leképező marhára más a texel shading miatt, tehát egy csomó mai motorra jellemző limitációval nem kell küzdenie. Ha kész egy objektum árnyalása egy viewportból, akkor azt annyiszor használhatod fel, ahányszor akarod, csak extra rajzolási parancs az ára, nem kell másodjára, harmadjára, vagy sokadjára árnyalni, mint az árnyalást és leképezést nem függetlenül elvégző motorok esetében.
Nem kapsz több fps-t a tripla puffereléssel, vagy csak egy nagyon picit. Egyszerűen arról van szó, hogy a késleltetés növelése és a memóriaigény emelése árán biztosíthatod a jobb szinkronizációt tripla pufferelés mellett. De attól, hogy három képkockapuffered van, még a GPU erőforrásai nem nőnek meg, vagyis az éppen számolt képkocka mellett elkezdi számolni az következőt is a GPU, azaz valamekkora mértékben megtörténik a képkockák párhuzamos számítása. De ne úgy képzeld ezt el, hogy egyszerre elkezd két képkockát számolni, és egyszerre el is készülnek azok, hanem amikor az n képkocka számítása a vége felé jár, akkor már elkezdődik az n+1 képkocka számítása, a parancsok parancspufferekből történő behívásával. Ez az oka annak, hogy minél jobban növeled a képkockapufferek számát, annál inkább nő a késleltetés is.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35849
üzenetére
Dehogynem. Úgy hívják, hogy triple buffering. Ilyenkor két back buffer van, és azt párhuzamosan számolja a hardver. Az utófeldolgozás olyan lehet, amilyen az algoritmusa. Egyáltalán nem kötelező hozzá az előző képkocka. Még a régi Xbox 360 esetében számított bevált trükknek, hogy az előző képkockához megmaradt adatokból számoltak bizonyos dolgokat az új képkockánál, de azt is amiatt, hogy a 10 MB eDRAM nem volt elég nagy a bizonyos leképezési eljárások mellett.
-
#35845
Petykemano
veterán
Jack@l
#35844
Petykemano
veterán
válasz
Jack@l
#35844
üzenetére
A Crossfire egy olyan szoftveres megoldás, ahol a két gpuból az egyik a páratlan, másik a páros képkockákat számolta. Amellett, hogy ez némi késleltetést vitt a képmegjelenítésbe, szerintem elsősorban azért nem lett igazán elterjedt, mert kevés szoftver volt erre felkészítve, ami pedig azért volt így, mert a felhasználók igen kis részének volt két kártyája.
Szerintem ugyanez igaz a (heterogén) multiadapterre is: igen kevés felhasználónál volt jelen két gpu. Persze az IGP-re lehetett volna valamit építeni, de valószínűleg nem építettek rá, mert legalább annyira változatos volt a felhozatal, mint a CPU utasításkészletek tekintetében (ahol ugye még csak most kezd kötelező elemmé válni az AVX)


A GPU-k már most is kisebb egységekből állóan működnek. A vega esetén pl 4 Shader Engine-be van szervezve a geometria, a compute, meg a raszter, meg a pixel, stb. Ezeket köti össze az L2, és ezek előtt vannak a HWS, meg az intelligent workload distributor, ami a 4SE közötti terhelést irányítja. Ezt Nerdtechgasm például eleve úgy illusztrálja, hogy a képernyőt 4 felé osztják és a 4 SE a ezeken dolgozik.
Az infinity fabric biztosan lehetővé teszi, hogy különböző részegységek tényleges fizikai helyüktől függetlenül egyben látszódjanak, vagy egynek lássák saját magukat. Ahogy az zen esetén is valójában dedikált L3 van, az IF fabric segítségével az L3-at mindkét CCX egyben látja, egyben címezi. Az persze egy sajnálatos lassító esemény, ha egyik magnak valamiért a másik CCX-hez tartozó L3-ban található adathoz kell nyúlnia (számomra itt csak az nem világos egyébként, hogy hogy lehet, hogy ennek pont ugyanakkora késleltetése van, mintha a memóriához nyúlna) Az ilyen lassít, vagyis rontja a CCX-eken alapuló processzor skálázódását. Ezért az ütemezőnek törekednie kell arra, hogy azonos adatokkal dolgozó programszálak lehetőleg ugyanarra a CCX-re kerüljenek (De ne gondold, hogy az Intel mesh megoldásánál hasonló optimalizálás nem szükséges, mert ugye ott is számít, hogy a négyzetrácsban az egyes magok milyen messze vannak egymástól, ezért nagyonis célszerű az azonos adatokkal dolgozó programszálakat egymáshoz fizikailag közeli magokra osztani)
A multiadapter esetén úgy emlékszem, hogy úgy működtek egy kártyák, hogy az egyik kártya volt a master, a másik a slave. A tesztek azt mutatták, hogy ha az erősebb hardveres frontenddel rendelkező fiji a master (hipervisor?) és a 980Ti a slave, akkor jobb eredményeket értek el, mind fordítva. Ehhez persze még szoftveres támogatás is kellett
A multiGPU-k szent grálja, hogy szoftveres támogatás nélkül egyként látszodjon két gpu úgy, hogy fizikailag különálló hardver-elemek közötti kommonikáció minimális legyen és tűrhető késleltetésű.Az egyben láthatóságra és a tűzhető késleltetésre szerintem az infinity fabric mindenképpen megoldást ad. Innentól már csak a kommunikáció minimalizálására lenne szükség, vagyis hogy a két valójában egymástól távol levő saját, de egyben látott L2$-sel rendelkező egységek minél kevesebbet dolgozzanak egymás térfelére. Ami azt illeti, mivel már most is SE-be szervezve dolgoznak a GPU-k, szerintem ez nagyrészt megoldott. Ha az SE-k olyan sokat kommunikálnának egymással, akkor nem is lehetne ilyen egységekbe szervezni őket. Ezzel együtt persze valószínűleg nem jelentéktelen, különbem abu nem mondaná, hogy 4GMI link szükséges (100GB/s) A tökéletlen kommunikációs elválasztás, vagyis workload distribution, nyilván tökéletlen skálázódást eredményez.
De ezt valahogy megoldották a multiadapter esetén is. És az is valamiféle félig-meddig hardveres megoldás kellett hogy legyen, hiszen ha csak a szoftveren múlt volna, hogy a képernyő két részét más és más kártyákkal számoltatja, akkor nem kellett volna a master-slave felosztás és nem számított volna ebben az erős ütemező.
Ha ez már így ilyen master-slave módon működött, megvan a mód, hogy egyben látszódjon két kártya, akkor az összetevők szerintem megvannak.
-
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35764
üzenetére
Maga a VRAM nincs definiálva a Vega esetében. De ha mindenképpen akarod valahogy ezt definiálni, akkor gyakorlatilag a VRAM megegyezik a beállított caching szegmenssel. Na most ebbe a HBCC működése alapján, kifejezetten a professzionális driverben (mert a sima driver itt is különbözik) beletartozhat a GPU melletti memória, a rendszermemória, a helyi adattároló és a hálózati adattároló. Az egész egy csúszka a szoftverben, amit oda állítasz ahova akarsz, persze az elméleti limitekig bezárólag. Persze az igényelt adat a HBC-n belül lesz. Gyorsítótárazza. Ha nincs direkt támogatás a szoftverben, akkor pedig a HBC+rendszermemória lehet a HBCC szegmens.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35743
üzenetére
Igen. Az a lényeg, hogy maga a Vega, ezen belül is a professzionális verzió 512 TB-ig be tud tölteni bármit. A gamer verzió csak 256 TB-ig, ez egy driveres limit. Na most igazából mindegy, hogy hol van az adat, a HBCC eléri, akár lehet a hálózaton egy NAS-ban is, a HBCC-nek nem számít. Az SSG amiatt gyorsabb, hogy a GPU melletti HBC mellett van még NAND a NYÁK-on, tehát oda tud gyorsítótárazni a rendszer, így a legtöbb adatot hamarabb éri el, és nem kell elnyúlni érte a rendszermemóriáig, a helyi adattárolóig, vagy akár a hálózati adattárolóig. Funkcionálisan viszont az SSG és az SSD nélküli professzionális Vega ugyanarra képes, csak utóbbi lassabban, sokszor jelentősen.
Maximum elkezdte leképezni, és a hiányzó ray-ek adatai nem látszanak a felvételen. De megközelítőleg sem volt kész. Ahhoz több másodperc kell. Ha egy 250 milliárd háromszöges modellt 1 másodpercen belül megoldaná egyetlen mai GPU, akkor az iparág a seggét csapkodná a földhöz örömében, és nem építene senki 100+ processzorból renderfarmokat. Az AMD sem építette volna meg a Project 47-et, hiszen minek is telepítsen bérelhető, petaflopsos szintű erőforrásokat Hollywood mellé, ha egy GPU-val simán megvan a feladat egy másodpercen belül. 7000 dollárt mindenki ki tud fizetni, az még a ZS kategória alatt is vállalható összeg. De sajnos nem, jóval több időbe kerül.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35734
üzenetére
SSG nélkül inkább 5-6 másodpercen belül. Valószínűleg nincs sok tapasztalatod erről, de vizualizációnál beállítod a kamerát, és a rendszer abból a nézőpontból elkezdi a leképezést. Úgy nagyjából 1 másodperc múlva már látsz annyit a jelenetből, hogy kifejezetten az ilyen felvételeken az késznek tűnik, de ettől a hardver dolgozik tovább, és a teljes eredményig azért jó pár másodperc eltelik, csak ilyen távolról, ilyen minőségű videón ez nem látszik. Maga a rendezvény is professzionális közönségnek szólt, ezért nem rágták ezt szájba, mert feltételeztek annyit, hogy a közönségnek azért van egy minimális tapasztalata a tartalomvizualizációról, ergo tudják ezt. Ők sem a sebességet értékelték, mert ahhoz nem ilyen demót szoktak mutatni, ugyanis kérhetsz olyat is, hogy benyomod a jelenetet a programba, és leméred, hogy mennyi időt vesz igénybe egy képkocka elkészítése. De itt nem ezen van a hangsúly, hanem azon, hogy van egy bitang nagy, TB-os szintű adathalmazod, és azt nem kell 100-200-300 darabra bontani, mert a hardver egyben megoldja out of memory hibaüzenet nélkül. Vagy ha az anyagi részét fogjuk meg, akkor nem kell hozzá venni több tucat kétutas EPYC-et, hogy legyen 4 TB-nyi rendszermemóriád betölteni az adatokat. Ergo, ha nem akarsz hatalmas CPU-s renderfarmra költeni, vagy darabolni, akkor most már van alternatíva, igen olcsón is. Ezt akarták megmutatni ezzel. Ezért viccel egyébként a fószer a fehér képernyő láttán, hogy évek óta ezt látja. Persze, Bollywood sem olyan gazdag, hogy CPU-ból csinálják meg ezt, annak komoly fenntartási költségei vannak, így inkább vesznek GPU-s workstationt, szopnak a darabolással, és alapvetően sokkal olcsóbban megvan, csak közben marha sok extra meló is, mert ha nem jól daraboltad ki, akkor fehér képernyőt kapsz nincs több memória üzivel.
-
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35725
üzenetére
Milliárd.
Ez a kétrészes Baahubali filmhez készült tartalom. [link] a trailerben látható is, és a film egy jó része itt játszódik.
Egyébként ez nem az AMD tulajdona, csak megvan nekik, mert Rajanak az indiai cége részt vállalt a film elkészültében, és így birtokában van az adathalmaz. Azért jó ezzel demonstrálni a rendszer képességeit, mert a legtöbb vásárló a közelében sem lesz ennek a terhelésnek, de így megmutatják, hogy ezt is bírja.(#35726) Jack@l: Amíg 512 TB alatt van, addig a HBCC-nek nem jelent problémát a funkcionális kezelése. 512 TB fölött már jönni fog az out of memory. Itt még megjegyezném, hogy a gamingre szánt RX sorozatnál a meghajtóban van egy konfigurált limit, ami 256 TB, de a professzionális modellek a hardver elméleti határáig működnek.
(#35724) Z10N: A Vulkan is kb. ugyanazokkal a limitekkel küzd, mint a DX12. Alig van eltérés ma a két API képességei között, és ez behatárolja azt is, hogy mik a limitációk.
A GMI csak eszköz. Lehetne GenZ is. Ezeknél nem maga a protokoll számít, hanem a memóriakoherencia biztosítása. Van szabványos memóriakoherens interfész a PCI Express helyére, csak túl vízfejű az AMD, az NV és az Intel ahhoz, hogy ne a saját érdekeiket nézzék.
A konzoloknál az ára miatt természetesen eléggé reális opció. Mennyit lehet már spórolni vele ugye. És ahogy láttuk a PS4-nál, marhára számít ám, ha 399-en tud startolni a gép.
És ahogy láttuk a PS4-nál, marhára számít ám, ha 399-en tud startolni a gép. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35722
üzenetére
Itt a Baahubali adathalmaz egyben, ami több TB, pontosan nem tudni, hogy mennyi, viszont annyi hivatalos, hogy ~250 milliárd háromszög. [link] - persze ez a W9100-on ment, az SSG-n gyorsabb lenne, viszont alapvetően mindkettőnek ugyanúgy 512 TB a hardlimitje, csak a sebességen segít az SSG.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35707
üzenetére
A memória az előnye. Amíg a GV100-nál ez fixen 32 GB, tehát ebbe bele kell férni, ha törik, ha szakad, addig a Vega 10 esetében nincs ilyen limit. Illetve nyersen van, 512 TB, de ez aligha megközelíthető. Az a tapasztalat, hogy ~120 GB-os tartalomig bőven jó a sima Vega 10, míg efölött az SSG verzió az ajánlott, mert elkezd érezhetően gyorsabb lenni.
A scene mérete változó. A sima Vega 10 olyan 150 GB-nál kezd nagyon lassulni. Ott fogy el a HBCC tudása. Az SSG verzió 3,5 TB-ig tud hasonlóan működni. Efölött ugyan működik még a leképezés, de már durván visszalassul. Ugyanakkor sok esetében még így is megéri, mert többet nyernek a lassabb vizualizációval, mintha elkezdenének darabolni. Na meg ugye az is lényeges tényező már, hogy a 4 TB memóriát támogató szerverplatformok elég drágább, tehát persze ha kiépítesz egy csomót belőle, akkor előnyben leszel, de az nagyon durván növeli a költségeket. -
Abu85
HÁZIGAZDA
válasz
Jack@l
#35608
üzenetére
A GDDR6 teljesen független ettől. Ezt a Hynix már nagy mennyiségben is tudja gyártani, csak magas az ára. De mivel a bányászat az NV szerint is apadni fog, őszre a GDDR5-ös termelés helyreállhat, így az új gyártósorokat is tudja majd GDDR6-hoz igazítani a Hynix.
Az AMD-nek ez lényegtelen. Nekik egyrészt a Samsung a partnerük, másrészt a Vega 12 és a Vega 20 is HBM2-t használ.
Szerk.: De az AMD-nek már nincs általános reklámszerződése az EA-vel. Innentől kezdve az EA akárkivel tud szerződést kötni, mert nincsenek előre lekötött üzletek. Az A Way Outra az AMD-vel kötöttek, a BF5-re az NV-vel. Nekik ez így megfelel, mert a Seed és a Frostbite Team elég tapasztalt, hogy gyártók nélkül megoldja a problémákat.
Az AMD-nek a legfőbb partnerek a Bethesda/Zenimax lett. Ők vették át az EA helyét. Az NV így szabadon lövöldözhet az EA játékokra. -
-
válasz
Jack@l
#35540
üzenetére
Szerintem ezek az első valóban használható APU-k - pont azért, mert az 1030 teljesítménye körül mozognak. Játékokra koncentrálva továbbra sem nyernek sem ár / teljesítményben, sem fogyasztás / teljesítményben, viszont most már nincsenek is számottevően lemaradva, teljesen reális low end alternatívák.
-
Abu85
HÁZIGAZDA
válasz
Jack@l
#35516
üzenetére
A Vega 20? Az a 7 nm-es Radeon Instinct. Az AMD így hivatkozik arra a termékre, aminek a mintáit a nyáron szállítani fogják a partnereknek. A Vega 20-at nem szokták emlegetni, de ja, a GPU kódneve a Vega 20.
Erre egyébként rengeteg projekt készül. A Radeon Instinct csak az egyik. Később lesz Radeon Pro, sima Radeon, illetve ezzel kezd majd a nagyobb HPC projekt, aminél az EPYC proci mellé ugyanarra a tokozásra kerül maga a GPU. Ezért lesz a Vega 20-on négy GMI is, hogy így össze tudják kötni a CPU-val. Abban kételkedek, hogy ez a fejlesztés első körben a szerverpiacon kívül megjelenik, de később nyilván általános lesz.
-
#35466
Petykemano
veterán
Jack@l
#35464
Petykemano
veterán
válasz
Jack@l
#35464
üzenetére
Amit csinálsz, az szándékos félreértés.
Szerintem senki nem mondta, hogy másfél évvel ezelőtt 140 dollár lett volna a ram.
Másfél évvel ezelőtt, vagy mondjuk úgy, 2017Q1-ben mégvidáman $200-250 körül lehetett kapni ezeket a kártyákat. Aztán Q2-Q3-ben jött a boom. Ezt az árukeresőn vissza lehet követni a grafikonokon. Ez alapján elméletben lehetséges, hogy Q1-ben még "normál" áron, vagyis például $9-ért árulták a GDDR lapkákat, ahogy a GN is állítja, aztán Q2-Q3-ban a megnövekedett kereslet miatt már jóval drágább áron kezdték árulni a ram lapkákat.Tehát az elméletben lehetséges, hogy az akkori $200-os árból $60 volt a RAM, míg most a $300-350-os bolti árból pedig 144. Ez persze még nem jelenti azt, hogy a $18-os modul ár valós, de az a kutyulék, ahogy próbálod lehetetlennek beállítani a dolgokat, az semmiképp se állja meg a helyét.
-
válasz
Jack@l
#35363
üzenetére
AMD már megmutatta, hogy működik real time (Deus Ex demó), én is csináltam tesztet Cryengine-el. Teljesen alaptalan amit állítasz, nincs is rá bizonyítekod. A vega 10 mellé két stack jár, a legkisebb stack pedig 4gb. Ennyi az egész. Kaby Lake G 4-et kapott, mert az egy stacket használ.
-
#35362
Petykemano
veterán
Jack@l
#35361
Petykemano
veterán
válasz
Jack@l
#35361
üzenetére
Én nem vonom kétségbe, hogy a HBCC kiválóan működik.
Hogy például ha 8 helyett csak 4GB lenne a Vega 10 lapka mellett, akkor csak 2-4%-ot csökkenne a teljesítménye, nem 20-at, és 2GB esetén is mondjuk csak 10-12% lenne a veszteség 60% helyett.
Azt se vonom kétségbe, hogy ha neked 8 helyett 24GB adattal kell dolgoznod, akkor ez sokat számít. Azt már igen, hogy a gamer Vega10 a Gk104-gyel szemben 8GB-idö kiazerelésben valaha is kamatoztatni tudná azt, hogy képes lenne 8 helyett 16, 24, 32 stb. GB adattal is dolgozni feltéve persze hogy ennek csak egy kisebb részére van gyakran szükség. Ez persze sose lesz jobb, vagy ugyanolyan jó, mint ha ott lenne a szükséges mennyiségű RAM. Pont az lenne a lényege, hogy minimális teljesítmény beáldozása mellett megspórolható az a mennyiségű RAM. Csakhogy pont ezt nem látjuk a 8 és 16 GB Vega10 esetén.
Erre négy magyarázat lehet:
A) ámít te mondasz, hogy valójában nem működik
B) működik, de a performance target miatt nem volt beáldozható kevés százalék sem.
C) még nem működik tökéletesen
D) minden jó, de csak 4 és 8GB méretben volt kapható a hbm, ennél kisebb használata semmisem lett volna olcsóbb. -
#35293
 Németh Péter
őstag
Jack@l
#35291
Németh Péter
őstag
Jack@l
#35291
válasz
Jack@l
#35291
üzenetére
Kicsit le vagy maradva. A kínai átlagfizetés már elérte, sőt lehagyta a magyart. Jelenleg olyan 250 ezer forint per hó Kínában.
https://www.statista.com/statistics/743522/china-average-yearly-wages/
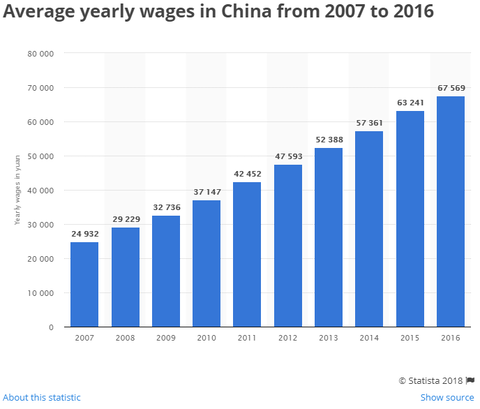
-
#35292
FollowTheORI
nagyúr
Jack@l
#35291
-
#35288
Németh Péter
őstag
Jack@l
#35221
válasz
Jack@l
#35221
üzenetére
Visszatérve a Steam statisztikákra, pár napja kijött az áprilisi statisztika. Ami az érdekes, az az, hogy egy mellékelt tájékoztatóban elismerik, hogy az elmúlt fél évben rossz adatokat közöltek, mert az ázsiai, de főleg a kínai internetkávézók átlagtól eltérően használják a számítógépeiket és emiatt ugyanaz a gép többször lett elszámolva. Emiatt nőtt meg hirtelen a kínai felhasználók száma és ez teljesen eltorzította a statisztikákat. Az e havi jelentés már ezt a hibát korrigálja.
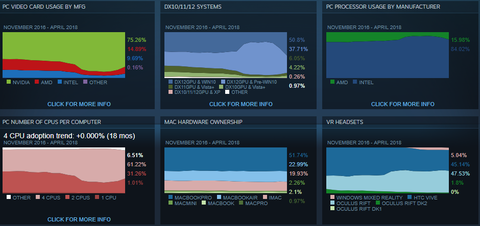
https://store.steampowered.com/hwsurvey
STEAM HARDWARE SURVEY FIX – 5/2/2018
The latest Steam Hardware Survey incorporates a number of fixes that address over counting of cyber cafe customers that occurred during the prior seven months.Historically, the survey used a client-side method to ensure that systems were counted only once per year, in order to provide an accurate picture of the entire Steam user population. It turns out, however, that many cyber cafes manage their hardware in a way that was causing their customers to be over counted.
Around August 2017, we started seeing larger-than-usual movement in certain stats, notably an increase in Windows 7 usage, an increase in quad-core CPU usage, as well as changes in CPU and GPU market share. This period also saw a large increase in the use of Simplified Chinese. All of these coincided with an increase in Steam usage in cyber cafes in Asia, whose customers were being over counted in the survey.
It took us some time to root-cause the problem and deploy a fix, but we are confident that, as of April 2018, the Steam Hardware Survey is no longer over counting users.
-
válasz
Jack@l
#35284
üzenetére
egyenként kisebbek, mint a nagy. ha a nagyban van hiba, akkor kuka az egész, vagy legalábbis értékcsökkent, ha lekapuzható. ha ugyanekkora alapterületre viszont két kisebb chipet is fel lehet gőzölni, és ugyanúgy van egy hiba ezen a területen, akkor még mindig marad egy hibátlan chiped, míg a másik vagy menthető, vagy nem, de legalább 50%nál vagy.
ha egy waferből kijön (ex has számok!!!) 100 nagy, vagy 200 kisebb chiped, és van 10 ilyen hibád, akkor az worst case 10 selejt és 90 ép a nagyból, és ugyanennyi selejt meg 190 ép a kicsiből. viszont a kicsiket összelegózva össze tudsz rakni 95 ép nagyot.
minél több darabból legózod össze a nagy chipeket, annál jobb lesz a kihozatali arányod állandó waferhiba mellett. a négyfelé vágós példádat alapul véve lesz 390 kis chiped, amiből 97 és fél nagy jön ki összerakva.
a wafer hibaarányának romlásával még durvább lesz a különbség a kihozatalt tekintve. -
válasz
Jack@l
#35272
üzenetére
te most tényleg azt kérdezted, hogy miért jobb, amikor ugyanazt, vagy hangyányival jobb teljesítményt kapsz kevesebb pénzért?
azt hogy az uarch ehhez mennyivel bonyolultabb, az pont nem érdekel.@stratova: a t1/t2 becsapós. az amd már jó ideje x2 kártyákat hoz ki az általad t1-nek nevezett rétegre. tavaly decemberben már feltolták az x2es instinct kártyáikat megnevező patcheket a linux kernelbe.
> +6860, 04, Radeon Instinct MI25x2
> +6864, 04, Instinct MI25x2
> +686C, 04, GLXT (Radeon Instinct MI25x2) MxGPU -

stratova
veterán
válasz
Jack@l
#35272
üzenetére
Profi kártyára mehet akár 4 GPU, ami amúgy nem lenne újdonság lásd Tesla M10-et, amihez még TSV sem kellett.
Nálam most csak picit elgurult a gyógyszer és ha már lego, Titan V-hez mértem (ami gamer piacon nem életszerű) ellenben egy 1080Ti-vel vagy legyen Titan XP.
Gamer vonalon Tier2-höz még elég lehet egy átgondoltabb monolitikus GPU 4 SE-vel (az NV 4 GPC-jéhez hasonlóan) jobb órajelekkel és fogyasztással.
Ha AMD-t limitálja a 4SE felépítés akkor Tier1-re legózhatnának. Ehhez alap lehet egy Vega M GH vagy Fenghuang vagy ezeknél magasabb CU számú megoldás. Bár ezzel ráérnek foglalkozni, ha újra emberi árban kell adniuk a gamer VGA-kat úgy rémlik estek már 10-15%-kal.
úgy rémlik estek már 10-15%-kal.De egy Quadro GV100 most is 7000$ felett megy, vagy 8700$-os Tesla V100-hoz mérve (más órajelekkel) duplázott backenddel 7 nm-en, akár össze is jöhet nekik, ahogy NV-nek is nyilván készül többlapkás terve.
Jelenleg AMD legdrágább eredetileg 2200$-os WS kártyája (a 7000->4600$-os Radeon Pro SSG-t nem számítva) 1600$, a közelében sincs ez az ár a csúcs Quadrokénak. De a profi vonal még monolitikus Vega 20-szal frissül (noha szvsz a 32 GB-os verziót sem tudják majd GV100 árszinten adni).
NV-nél a 815mm²-es GPU-val el is érhették, a TSMC gyártási képességeinek határát, így
elvileg 4 lapkás MCM GPU-ban gondolkodnak.
Our evaluation shows that the optimized MCM-GPU achieves 22.8% speedup and 5x inter-GPM bandwidth reduction when compared to the basic MCM-GPU architecture. Most importantly, the optimized MCM-GPU design is 45.5% faster than the largest implementable monolithic GPU, and performs within 10% of a hypothetical (and unbuildable) monolithic GPU. Lastly we show that our optimized MCM-GPU is 26.8% faster than an equally equipped Multi-GPU system with the same total number of SMs and DRAM bandwidth. -
#35270
Petykemano
veterán
Jack@l
#35266
Petykemano
veterán
válasz
Jack@l
#35266
üzenetére
az lehet értelme, ha széltében - akár monolit, akár multi chip - már áthidalhatatlan mértékben nőne a távolság miatti késleltetés. A késleltetés egyik leküzdési módszere a frekvencia emelése, ami viszont ugye feszültségigénnyel és hőtermeléssel jár. Ha a távolság csökkentésével megoldható késleltetés csökkentése, aminek hatására csökkenthető a frekvencia, akkor az jó eredményre is vezethet.
Vagy pl az milyen lenne, ha két réteg közötti harmadik réteg a cache, vagy fordítva: egy lapka körül két lapka csak a cache-t tartalmazza?
Most ezek persze csak ilyen nagyhirtelenséggel kigondolt lehetőségek. Az se biztos, hogy így tud működni.
Nem gondolnám - és ez szól Ttomaxnak is - hogy ez lenne most a szent grál. Csak azt, hogy ha a chipleteket nem csak egymás mellé, hanem fölé is lehet pakolni, akkor az plusz egy strigula lehet a chiplet koncepció érvei mellett a monolitikussal szemben. -
#35267
 Plasticbomb
addikt
Jack@l
#35266
Plasticbomb
addikt
Jack@l
#35266











![;]](http://cdn.rios.hu/dl/s/v1.gif)



 Az a bizonyos DL teszt pedig pontosan az, amivel az NV anno a Tesla V100-at
Az a bizonyos DL teszt pedig pontosan az, amivel az NV anno a Tesla V100-at 
































Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.
- Dune Awakening - Máris túl az 1 millión
- Konzol Screenshot
- Vezetékes FEJhallgatók
- Mesterséges intelligencia topik
- sziku69: Szólánc.
- sziku69: Fűzzük össze a szavakat :)
- Luck Dragon: Asszociációs játék. :)
- Továbbfejlődött a Keychron egéralternatívája a Logitech MX Masterre
- Vicces képek
- Kettő együtt: Radeon RX 9070 és 9070 XT tesztje
- További aktív témák...

- Steam, EA, Ubisoft és GoG játékkulcsok, illetve Game Pass kedvező áron, egyenesen a kiadóktól!
- Telefon felvásárlás!! Apple Watch SE/Apple Watch SE 2 (2022)
- BESZÁMÍTÁS! Sony PlayStation4 PRO 1TB fekete konzol extra játékokkal garanciával hibátlan működéssel
- Több mint 70.000 eladott szoftverlicenc
- AZONNALI SZÁLLÍTÁS Eredeti Microsoft Office 2019 Professional Plus
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest