Hirdetés
- Milyen okostelefont vegyek?
- iOS alkalmazások
- Kicsomagoljuk és bemutatjuk a Poco F8 Ultrát
- Az iPhone Air buktája elkaszálhatta vékonyítási lázat
- iPhone topik
- Redmi Note 12 Pro - nem tolták túl
- Google Pixel topik
- Huawei Watch GT 6 és GT 6 Pro duplateszt
- Samsung Galaxy Watch8 - Classic - Ultra 2025
- Fotók, videók mobillal
Új hozzászólás Aktív témák
-

cucka
addikt
Designer többféle lehet:
Akkor biztos csak nekem nem volt eddig szerencsém a dizájnerekkel.Arra jó az egész, hogy ne legyen a HTML kód phpval teliszórva, illetve fordítva, a php ne legyen htmlel teliszórva.
Tehát a html nincs php-val teleszórva, cserébe tele van szórva sablonkóddal, amihez tartasz egy bonyolult sablonkezelő rendszert csak azért, hogy átfordítsa neked php kódra . Nem azt mondom, hogy szórjuk tele a php-t html kóddal, de az szerintem mindegy, hogy a kiiratásnál php szintaxissal illeszted be a változókat vagy a sablon saját szintaxisával.
. Nem azt mondom, hogy szórjuk tele a php-t html kóddal, de az szerintem mindegy, hogy a kiiratásnál php szintaxissal illeszted be a változókat vagy a sablon saját szintaxisával.A sablon, ha XMl alapú, ha bármi el van romolva , akkor vagy a benne lévő szöveget irja ki, vagy tök üres marad a XML element rész és nem is jelenik meg.
Ez előny és hátrány is egyben. Php hibaüzeneteket egyszerűbb azért debugolniHa igy csinalod es a menu nincs db-ben, akkor hogy rendelsz hozza egy menuponthoz pl 10 cikket???? pl. ha ajanlani akarsz valamit?
A menüpontnak van azonosítója, sorrendje, neve, url-je és tartalma. A tartalom mondja meg, hogy mi kerül oda. A tartalom kiiratásnál megkérdezem a menü objektumtól, hogy az aktuálisan kiválasztott menüpontnak mi a tartalma, ez alapján megkérem a megfelelő objektumot, hogy legyen szíves írja ki magát. Elmondva bonyolultabb, mint megvalósítva. -
cucka
addikt
Miért haszontalan? A designernek elég a html kódhoz érteni.
Az adatot meg megkapja.
Eddigi tapasztalataim:
- a dizájner nem tud html/css kódot írni, vagy tud, de az olyan, hogy inkább megírom én helyette
- nincs dokumentálva az oldal minden egyes eleme 100%-os pontossággal
- a pontatlan doksi és a menet közben történt változások folyamatos programozó-dizájner kommunikációt igényelnek, tesztelésnél várni kell a másikra
- a programozó dizájner kommunikáció több időt vesz el, mint ha a programozó megírja maga a html kódot
- a legfontosabb: a sablon csak szintaktikailag különbözik a php+html kódtól, szemantikailag nem. Tehát behozol egy új absztrakciós szintet a rendszeredbe, ami gyakorlatilag semmi másra nem jó, mint hogy bizonyos fogalmakat átnevezzen.Ez utóbbi a legfontosabb ellenérzésem az egésszel kapcsolatban. Gyakorlatilag mindegy, hogy a <modtagcloud> tag-et cseréled le a print_mod_tag_cloud() függvény visszatérési értékére, vagy direktben írod ki azt. Bevittél a rendszeredbe egy nagy, bonyolult, hibalehetőségeket tartalmazó modult, ami annyit tud, hogy a saját szintaxisát lefordítja php szintaxisra.
Ami még problémás, hogy a sablonozás nem igazán felel meg az oop szemléletnek. Hiába vannak objektumaid, azok nem tudják kiírni magukat, pedig pont ez lenne a lényeg, hogy az alkalmazáslogikában az értelmes dolgokkal foglalkozz és az érdektelen dolgok legyenek megvalósítva az objektumban. Ilyen érdektelen dolog a html kiírás.
Tehát ha van egy menü objektumom, akkor az be tudja tölteni az adatait, el tudja menteni az adatait, lehet menüpontot hozzáadni/törölni és ki tudja írni magát html-ben. Az alkalmazáslogikát tartalmazó file-okban nincs semmi, ami a menü belső reprezentációjával kapcsolatos, mint ahogy a sablon file-okban sem. Igazából tök mindegy, hogy az a menü honnan jön, hány szintes, hogyan van belül reprezentálva, ez nem tartozik sem az alkalmazáslogikára, sem pedig a sablonra. Ettől lesz oop-s .
Ennek tükrében az általad említett tagcloud modul az nem egy 100-200 soros lineáris php szkript, hanem egy osztály. Az osztályt példányosítom, felparaméterezem, majd a sablonban szólok neki, hogy írja ki magát. Az osztály hordozható, általános. Ha valamilyen speckó viselkedésre van szükség, akkor származtatok belőle egy alkalmazásspecifikus osztályt, ahol megvalósítom a változtatásokat. Sőt, az ős osztályom származhat egy lista osztályból, ami valamilyen lista kezelésére alkalmas. A tagcloud osztálynál így csak és kizárólag a kiírást kell megvalósítanom, minden más benne van az ősben.
Amúgy tudom, nem csak ezzel az elképzeléssel lehet jól működő weboldalt gyártani, egyszerűen csak jelezni próbálom, hogy az átlag mvc-jellegű megoldásoknál vannak jobbak is .Menünél nem tartom jó ötletnek , ha a user átír egy filet, nagyon nem, elronthatja satöbbi.
Menüszerkesztésnél a júzer nem tudja, hogy mit ír át. Kap egy felületet színes gombokkal, amivel tudja szerkeszteni a menüjét. Az az én dolgom, hogy a változtatásokat file-ban vagy adatbázisban tárolom. -
cucka
addikt
Azon gondolkodtam a templateengine amit hasznltunk, illetve amit írok anélkül mvc, hogy tudnám jobban mi az mvc, és csak nem is oop.
Egy template engine nagyjából ugyanazt jelenti, mint az mvc view része. Amúgy kevés haszontalanabb dologgal találkoztam eddig, mint a template engine-ek (pl. Smarty). Bár lehet, hogy nem találtam még meg a jó template engine-t.Külön van a megjelenítésért felelős kód, a template-ben csak xml-ek vannak, php nincs, és egyéb dolgokat a php modulok végzik.
Tehát a php és a html közé bevezettetek még egy absztrakciós szintet? Mesélnél erről bővebben, milyen plusz funkcionalitást hordoz?Írnál az mvcről még?
Nagyon sokat nincs mit írni, igazából nagyobb a füstje, mint a lángja. A lényege, hogy külön legyen az adatok reprezentációja és értelmezése (ezek osztályok, segédfüggvények), külön az események kezelése és külön a kiírás. Erre néhány weboldal elkészítése után magadtól is rá tudsz jönni, szóval nem kell túlmisztifikálni, nincs benne semmi extra.
A másik dolog, hogy a szigorúan mvc elgondolás szerintem elég kényelmetlen, fapados, nem eléggé entörprájz, a sokkal magasabb szintű absztrakciót képviselő doboz hierarchia elgondolás közelebb áll hozzám, minél távolabb van a html/css/javascript hármastól, annál jobb . (Valójában keverni szoktam a kettőt, annak függvényében, hogy melyik a hatékonyabb. Például a korábban leírt fa reprezentációm jellemző példa a doboz hierarchiás elképzelésre) -
#3981
cucka
addikt
Sk8erPeter
#3980
cucka
addikt
válasz
 Sk8erPeter
#3980
üzenetére
Sk8erPeter
#3980
üzenetére
Most mit kötekszel? Nem arról volt szó, hogy fingom sincs, mi az a gráf vagy fa, hanem arról, hogy jelen esetben Te hogy oldottad meg a gyakorlatban.
Nem kötekedésként írtam. A fa tárolási eljárásom amúgy teljesen szokványos megoldás, nincs benne semmi hókuszpókusz. Azért kérdeztem, hogy tanították-e, mert általában egyetemeken ilyesmiket meg szoktak mutatni gyakorlati órákon, tehát nem kell mindent az alapoktól magyaráznom .A kérdés oka az volt, hogy először úgy képzeltem, hogy a language táblát is azért kell joinolni, mert mondjuk úgy kérdezel le, hogy "... WHERE language.name='en';", és akkor tényleg kellett volna joinolni, mivel akkor különben honnan szeded a nevet?
Egy lekérdezésnél akkor kell bejoin-olni egy táblát, ha szükséged van valamilyen mezőre belőle. A nyelvek kezelését egy nyelvkezelő osztállyal oldom meg, amely a konstruktorában betölti a rendszerben található összes nyelvet. Ha szükségem van arra, hogy a "hu" nyelvnek mi az azonosítója, akkor megkérdezem a nyelvkezelő objektumtól (és nyilván fordítva is, ha mondjuk a 2-es nyelv szöveges nevére van szükség). Így megspórolom, hogy minden egyes, többnyelvű adatot érintő lekérdezésbe bele kelljen join-olni a nyelv táblát is.Igen, viszont így megnő az esélye annak, hogy elcseszi a fájlt, és ha nem ért a HTML-hez, akkor néz, hogy miért nem működik.
Félreértetted. A felhasználó által szerkesztett menü egy xml-ben van, a felhasználó által szerkesztett szöveges tartalom pedig file-okban. Magát a honlap sablonját nem piszkálhatja, egyszerűen csak kap egy fckEditor-t, ahova beírhatja a szöveges tartalmakat. Így nem tud elrontani semmit.Akkor meg már mondjuk az a kérdés is felmerül, hogy miért is ne használjunk adatbázist a saját életünk megkönnyítésére, és alakítunk ki egy jó admin felületet a megrendelőnek, ahol sokkal szebb felületen tudja szerkesztgetni a menüpontokat és a belső tartalmat.
A most említett file-os megoldásom pontosan ugyanazt tudja, mint ha adatbázisból működne a dolog. A korábban említett, oop-s fa reprezentációm pont ezért hatékony, mert a hozzá tartozó alkalmazáslogika, adminisztrációs felület vagy megjelenítés szempontjából érdektelen, hogy adatbázisban vagy xml-ben tárolod a fát/menüt.A file-ban tárolós megoldás azért hatékony, mert sok ügyfél csak egy pár menüpontból álló szöveges honlapot kér. Ezt megfelelő keretrendszerrel ezt 1-2 nap alatt meg lehet csinálni és csak egy php-s tárhelyre van szükség hozzá. Gyakorlatilag csak a html/css részét kell elkészíteni, a többi már kész van, ezért fontos követelmény a programkódnál az újrafelhasználhatóság.
-
#3977
cucka
addikt
Sk8erPeter
#3971
cucka
addikt
válasz
Sk8erPeter
#3971
üzenetére
Jaaaa, akkor már sejtem a parent_id szerepét. Vagyis ez akkor arra való, hogy adott menüpontnak tetszőleges számú almenüpontja legyen?
Igen. Vagyis tetszőleges elemszámú és mélységű menüt lehet vele reprezentálni.
(Sőt, tulajdonképpen tetszőleges mélységű fát lehet vele reprezentálni, tehát nem csak menüre jó, hanem mondjuk webshop termékkategóriákhoz is). Az iskolában nem tanították, hogy hogyan kell gráfokat és azon belül fákat reprezentálni?Na, ez az MVC-szerkezet egyelőre kicsit magas
Pedig eddig is erről volt szó.
Az M betű a modell, ez az osztályaidat jelenti, amelyek általános feladatokra készültek.
A C betű a controller, ez gyakorlatilag az alkalmazáslogika. Itt példányosítod be az osztályokat, itt kezeled le az eseményeket és itt végzed el azokat a műveleteket, amelyek a html kiíráshoz szükségesek.
A V betű a html sablonokat jelenti. Ezekben már nincs alkalmazáslogika, csak html kiírás.De ettől függetlenül valószínűleg mindenképp joinolni kell a language és menu táblát is, hogy ezek azonosíthatók legyenek.
A menü táblához join-olod a menu_content táblát inkább. A language-et csak akkor, ha muszáj.Akkor már nem lenne esetleg jobb/szebb megoldás egy külön összekapcsoló táblát létrehozni erre a célra?
Nem. A menü és a menü tartalom táblák között 1:n típusú reláció van. Ha n:m reláció lenne, akkor lenne szükség kapcsolótáblára. Ezt sem tanították az iskolában?Tehát ha azt mondod, hogy nem lesz gyorsabb attól, hogy fájlból olvasom ki, akkor mindenképp maradok az adatbázisnál.
A file-os megoldás azért jó, mert tudsz olyan oldalt készíteni, amelynél a megrendelő saját maga szerkeszthetik a menüt és a menüpontok tartalmát, mégsincs hozzá szükség adatbázisra. -
cucka
addikt
Ez a két sor bekerült a httpd.conf-ba?
LoadModule php5_module php/sapi/php5apache2.dll
AddType application/x-httpd-php .php
(vagy valami hasonló, netről másoltam . A loadmodule mondja meg az apache-nak, hogy használja a php modult, az addtype pedig azt, hogy a .php file-okat dobja át a php modulnak)
. A loadmodule mondja meg az apache-nak, hogy használja a php modult, az addtype pedig azt, hogy a .php file-okat dobja át a php modulnak)Másik megoldás, hogy letöltöd és telepíted az appserv nevű cuccot, ami lényegében egy normálisan beállított apache+php-nak felel meg, nincs benne semmilyen "nem szabványos" cucc.
Oop-t pedig érdemes megtanulni, nagy rendszernél esélyed nincs normális megoldásokat készíteni oop nélkül.
-
#3963
cucka
addikt
Sk8erPeter
#3960
cucka
addikt
válasz
Sk8erPeter
#3960
üzenetére
A táblakapcsolásokról a képet, amit betettél, milyen programmal generáltad?
Dbdesigner 4 a program neve, ingyenes és néha kicsit bugos. [link]Hmm, hogy érted, hogy magára mutat? Mármint ezt MySQL-utasítások tekintetében hogy kellene elképzelni?
Ugyanúgy, mint ha egy külső táblára mutatna, semmi különbség nincs. A magára mutat alatt azt értem, hogy egy menüpot szülője szintén egy menüpont, tehát a menü tábla parent_id mezője a menü tábla egy másik sorára mutat, vagy nulla ha nincs szülő.Ez igazából csak egy felsorolás, vagy egyfajta leírás magadnak, hogy mi van benne?
Nem, ez mondja meg, hogy az adott menüponthoz milyen típusú tartalom tartozik. Tehát innen tudja a rendszer, hogy ha ráklikkelsz egy menüpontra, akkor szöveges oldal jön be, fórum oldal, kapcsolatfelvétel űrlap, keresési form, stb. Ez az mvc elgondolásból a c betűt jelenti . Amúgy a menü osztályaim struktúrája pont nem mvc stílus, sokkal inkább a hierarchiában található dobozok elgondolásához áll közel. Ezt a kettőt szeretem keverni Tehát ez mindenféle formázást nélkülöz? Mert én arra gondoltam, hogy magát a honlap tartalmát TinyMCE-vel (vagy más JS-es szövegszerkesztővel) lehetne szerkeszteni, és az kerülne bele az adatbázis megfelelő mezőjébe.
Az adatbázis szinten teljesen mindegy, hogy a szöveges tartalmat hogyan kell értelmezni, ez nem az adatbázis vagy a menü dolga. A menu_content táblában a menüpontok nyelvfüggő paramétereit tárolod, az én példámban egy címet, valamilyen hosszú szöveget és egy url-t (a többnyelvű friendly url-ek miatt). Ezeket a mezőket az aktuális feladat szerint kell megválasztani. (Tehát ha az adott honlapon minden menüponthoz kell egy többnyelvű magyarázó szöveg, akkor az is ide fog kerülni)Ez meg ugye nem túl szép, akkor már jobb lenne, ha tart_id és tartalom elsődleges kulcsok lennének, és akkor aszerint lenne rendezve.
Tényleg nem túl szép. Ha egy többnyelvű honlap adatbázisát készíted, akkor legyen egy language táblád, ahol fel vannak sorolva a nyelvek és a többi tábla oszlopai legyenek függetlenek attól, hogy ennek a language táblának mi a tartalma. (Tehát a struktúrád működjön tetszőleges számú nyelv esetén)Az az "url" mező mire kell? Hogy tudj a címre önhivatkozó linket készíteni?
Hogy a menüponthoz tudjak friendly url-t készíteni. Azért van a menu_content táblában, hogy a friendly url többnyelvű legyen. Ha csak 1 nyelvűre van szükséged, akkor ezt helyezd át a menu táblába.A megoldásod, azonbelül a táblaszerkezet és a fa osztály is nagyon okos és rugalmas megoldás.
Igen, a rugalmasság miatt találtam ki. Meg tök jó szemléltetése annak, hogy mire jó az oop, mivel több, mint a sima procedurális gondolkodás.Mellesleg az is eszembe jutott már, hogy simán csak fájlba kellene menteni a tartalmat, amit a felhasználó szerkeszt - vagyis a fájl tartalmát az admin felületen megnyitni, és bedobni egy textarea-ba majd módosításkor felülírni az eredeti tartalmat
Igen, így is lehet csinálni, teljesen jó megoldás. Bizonyos paranoid és/vagy balf*sz rendszergazdák által üzemeltetett szervereken problémásabb megoldás, továbbá nehezebb backup-olni. Továbbá meg kell oldani azt is, hogy ha egy tartalom megtekintéséhez valamilyen jogosultság szükséges, akkor a tartalom file-t se lehessen kintről elérni. (Nem nehéz, csak oda kell figyelni)mert a tartalom várhatóan elég ritkán fog változni, így valószínűleg gyorsabb lenne a megjelenítés.
Nagyjából ugyanolyan gyors lesz. -
cucka
addikt
válasz
 lamajoe
#3956
üzenetére
lamajoe
#3956
üzenetére
Az érdekelne, hogy ezek mennyire támaszkodnak PHP-re illetve mennyire adatbáziskezelésre?
Nem tudom, hogy egyáltalán php-ban írták-e az említett szoftvereket vagy sem, de az egészen biztos, hogy nem lehet őket megvalósítani szerveroldali programozási nyelv és adatbázisok ismerete nélkül.Csak az érdekelne, hogy mennyire járjam körbe az adatbáziskezelést ha a jövőben ilyet szeretnék csinálni?
Elég komolyan.Érdemes külön könyveket vásárolnom hozzá? Ha igen, milyet?
Passz, gondolom bármilyen könyv megteszi, ami az adott adatbázis szoftverről szól. Webhez mysql-t vagy postgresql-t szokás használni, de azért vannak kivételek.Amúgy szerintem igyekezz kissebb projektekkel foglalkozni. Egy Ikariam színvonalú játék megírásán több profi fejlesztő szokott dolgozni és nem hiszem, hogy bármelyikük rutinfeladatként kirázná a kisujjából.
-
cucka
addikt
válasz
lamajoe
#3954
üzenetére
Nem azért akartam felvenni valakit MSN-re, hogy a mentorom legyen, hanem, hogy 1-2 naponta ha elakadok akkor 2 percet szánjon rám, hogy meg tudja válaszolni a kérdésem.
Beírod ide és megválaszoljuk .Bocs, ha a class nem az aminek írtam, valahogy nem érzem a fontosságát annak, hogy a classt a saját fejemben parancsnak vagy kulcsszónak írom le
Szerintem sem érdekes, hogy a te fejedben minek írod le, viszont ha szeretnél megtanulni php-ban programozni, akkor érdemes tudni, hogy a különféle dolgokat hogyan is hívják pontosan. A különféle dokumentációkban és könyvekben az általánosan elfogadott megnevezésekkel fogsz találkozni.
Amúgy olyan, hogy "parancs" igazából nincs is. Általában kezdők hívnak parancsnak bármit, amit begépelnek és ennek hatására a gép csinál valamit, de ezeknek mind van rendes nevük (definíció, deklaráció, függvényhívás, stb.). Például a class az egy kulcsszó, amivel a nyelv egy funkcióját tudod használni, jelen esetben osztályokat tudsz vele definiálni. A kulcsszavak foglalt szóként viselkednek, tehát nem tudsz "class" nevű konstanst, függvényt vagy osztályt létrehozni, viszont változónevet igen. -
#3952
cucka
addikt
Sk8erPeter
#3947
cucka
addikt
válasz
Sk8erPeter
#3947
üzenetére
Mivel lenne olyan max. 6 menüpont, így nem tudom, érdemes-e egyáltalán azonosítószámot rendelni az egyes menüpontokhoz, vagy elég lenne, ha mondjuk lenne két összetartozó elsődleges kulcs, mondjuk PRIMARY KEY (oldal_rovid_neve, nyelv), vagy ez már gagyibb megoldás?
Amiről te beszélsz, azt kompozit kulcsnak hívjuk és jelen esetben igen, gagyibb lenne.Ha normálisan szeretnéd megcsinálni, akkor valamilyen újrafelhasználható megoldásban gondolkozz. Például itt egy táblaszerkezet olyan esetre, amikor 1 menü van az oldalon:
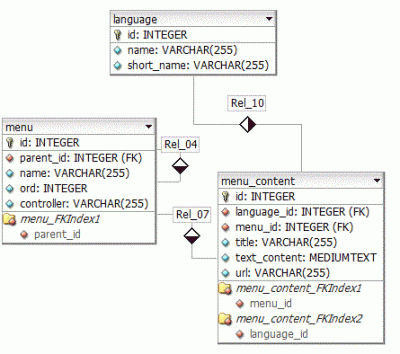
Van egy menü tábla, ahol a menüpontok vannak. A parent_id mező a menü táblában saját magára mutat, így tudsz tetszőleges mélységű menüt létrehozni. A controller mezőben azt tárolom, hogy a menüponthoz milyen tartalom tartozik. (Pl. sima szöveges oldal, kezdőlap, fórum, stb., amire szükség van). A menu_content táblában a menüponthoz tartozó szöveges tartalom található. Nyilván, ha a menüpont nem egyszerű szöveges tartalom, akkor a mezők lehetnek üresek (de pl. a címre szükség van). Ide kerülhet bármi, ami a menüpont függvényében változik az oldalon és nyelvfüggő (pl. fejléc cím, meta tag-ek, utolsó módosítás, vagy amit csak akarsz).Amúgy a menü kérdését én úgy oldottam meg, hogy írtam egy általános fa osztályt, aminek van hozzáadás, törlés művelete, le lehet kérdezni a fa csúcsainak tartalmát, stb.
Írtam hozzá egy serializer interface-t, aminek az a szerepe, hogy feltöltse a fát adatokkal és elmentse a változtatásokat. Írtam még hozzá egy visualizer interfészt, aminek a szerepe, hogy a fából html-t gyártson. Ezáltal van egy olyan fa struktúrám, amit bármire fel lehet használni, a tartalmát tetszőleges helyről tudja beszedni és ugyanoda el is tudja menteni saját magát és tetszőleges módon lehet kiiratni. (A serializer és visualizer osztályokat kell ehhez cserélgetni). Ebből a fából származtattam egy menü osztályt, aminek egyetlen plusz funkciója van, az aktuális url-ből meg tudja mondani, hogy mely menüpont van kiválasztva. Kb. ennyi, ezzel a struktúrával viszonylag egyszerűen bármilyen fa adatstruktúrát könnyen lehet kezelni. (pl. menü, webshop kategóriák, könyvtárstruktúra, stb.). -
cucka
addikt
válasz
lamajoe
#3950
üzenetére
Valaki tudna írni egy gyors összefoglalót, hogy mit is kéne tudnom az objektumokról?
Hát a szintaxis magyarázata is legalább 1 fejezet egy könyvben, általában az objektumorientált programozásról pedig rengeteg könyvet írtak. Ne várd el, hogy egy hozzászólásban elmagyarázza neked bárki az egészet. Szerintem vegyél egy könyvet, ahol részletesen le van írva és ha van konkrét kérdésed, akkor arra minden bizonnyal válaszolni fog itt valaki. Még annyit, hogy ha a procedurális programozással nem vagy tisztában (alapvető vezérlési szerkezetek, függvények, stb.), akkor nem érdemes belekezdeni az oop-be.Addig meg van, hogy a class paranccsal hozunk létre egy osztálysablont.
A class egy foglalt szó, nem pedig parancs, és osztályok megadásához lehet használni. A sablon mást jelent. (Php-ben amúgy nincsenek sablonok).Azt olvastam, hogy a var kulcsszóval az osztály összes többi eleméhez hozzárendelhetjük alapértelmezett értékét a változónak.
Nem.
Az osztály képzeld el, mint egy változó típust. Az osztálynak lehetnek adattagjai (vagyis változók) és metódusai (pl. függvények). Arra jó az egész, hogy a logikailag összetartozó adatokat és függvényeket egy helyen tárold. Ezeket adod meg a class kulcsszó után. Ha használni szeretnéd, az osztályt példányosítani kell, erre jó a new kulcsszó, ilyenkor az osztályodból egy konkrét objektum példány lesz.Annak is nagyon örülnék ha valaki felvenne MSN-re, vagy írna PM-et, hogy tudjunk kommunikálni, mert biztos, hogy el fogok még akadni.
Nézd, nem akarlak megbántani, de szerintem senkitől ne várd el, hogy pusztán jófejségből sok-sok órán keresztül megtanítja neked azt, amit bármelyik korszerű php könyvben le van írva. -
cucka
addikt
válasz
 brunzwik
#3932
üzenetére
brunzwik
#3932
üzenetére
Jól illesztetted be és nem ismeri, ez látszik az oldalad html kódjában is. (Pusztán annyi van, hogy figyelmen kívül veszi azt az indexét a tömbnek).
Amúgy nem ismerem ezt a portálrendszert, tehát fogalmam sincs, hogy hol kell átírni. Azt kéne megtalálni, hogy hol lesz ebből a menü tömbből html, onnantól egyszerű a helyzet.
-
cucka
addikt
válasz
brunzwik
#3929
üzenetére
Az a baj, hogy amikor a portál rendszered kiírja a menüt, akkor nem állít be target-et a linkeknek, tehát azok a saját frame-ben nyílnak meg. A menü linkekhez egy target="_top" paramétert be kéne valahogy illeszteni a portál által gyártott html-be.
1. megoldás: a portál rendszer ismeri a target paramétert, az általad beillesztett kódba kell egy ilyen sor és kész vagy.
2. megoldás: a portál rendszer nem ismeri ezt a paramétert, a menü kiíró részt át kell írd, vagy esetleg beállítod, hogy a menü minden egyes linkjére ott legyen a target="_top" . (Ez utóbbi nem fogja elrontani az oldalt, klikkelésnél újra fog töltődni a felső banner és ennyi) -
-
cucka
addikt
-
cucka
addikt
válasz
 PazsitZ
#3903
üzenetére
PazsitZ
#3903
üzenetére
Még korábban én is barkácsoltam ilyen rövidítő kódot, de nem olyan egyszerű (még az enyém sincs kész csak félig-meddig ), mondjuk nálam az is szempont, hogy a szövegben lévő tag-ek is érvényesek maradjanak.
Pedig ez nem túl bonyolult feladat, a lényege, hogy szét kell bontani szavakra a szöveget. Kétfajta szó lesz benne: html tag-ek és sima szavak. Ezután végigmész a szavakon és a következő algoritmust használod (kell hozzá egy verem és fontos a sorrend):
- Ha az aktuális szó nem html tag, akkor kiírod az output-ra és növeled a kiírt karakterek/szavak számát.
- Ha az aktuális szó nyitó és záró tag egyben, akkor kiírod az output-ra. (Például ilyen a <br />, aminek nincs záró tag-je, mert már le van zárva).
- Ha az aktuális szó html nyitó tag, akkor kiírod az output-ra és a html tag-et lerakod a verembe. (tehát csak magát a tag-et, az attribútumokat nem). Példa egy veremre: {'span', 'a', 'div'}
- ha az aktuális szó egy html lezáró tag (pl. </div>), akkor kiírod az output-ra és a veremből addig dobálod ki a tag-eket, amíg ki nem dobtad az aktuális html lezáró tag párját.Az iterációnak akkor van vége, ha elfogytak a szavak, vagy a kiírt karakterek/szavak száma elérte az előre meghatározott limitet. Ezután a veremben maradt elemeket kidobálod és mindegyikre kiírod a hozzá tartozó lezáró html tag-et. (Tehát ha a verem tetején egy div tag van, akkor azt fogod kiírni, hogy </div>, ezután pedig kiszeded a veremből.
Az algoritmus pár lényeges tulajdonsága:
- Megőrzi a html tag-eket.
- Csak a képernyőn látható betűket/szavakat számolja, a html tag-eket nem.
- Ha a szövegedben vannak lezáratlan tag-ek, akkor is működik. Ha a szövegben olyan lezáró tag van, aminek nincs nyitó párja, akkor nem működik helyesen, de kiegészíthető, hogy erre az esetre is jó legyen.
- Az algoritmus kimenetében nem lesznek lezáratlan html tag-ek.
- Bizonyos tag-eket a böngészők automatikusan lezárnak (pl. br, hr), ezek felismerésével ki kell egészíteni az algoritmust. -
cucka
addikt
Attól függ, hogy mennyi memória van a gépben, mennyire sokan használják egyszerre a php-s szolgáltatásodat illetve hogy milyen egyéb programok futnak a gépen.
Ez a limit egyébként 1 php szál maximális memóriáját jelenti, tehát
- A php annyi memóriát foglal le a scriptednek, amennyire szüksége van. A maximális korlátot azért találták ki, hogy ha egy szerveren több php-s szoftvert is telepítettek, akkor egyik se tudja megenni a szerver memóriáját. (Pl. hosting szolgáltatónál nem fog előfordulni az, hogy egy rosszul megírt kód beakasztja a teljes szervert)
- Miután lefut a script, a php felszabadítja a neki lefoglalt memóriát.
- Ha a php szoftverednek 32 mega memóriára van szüksége, akkor állítsd be úgy. Annyit érdemes beállítani limitnek, ami biztosítja, hogy a futtatott php szoftverek ne fogyjanak ki a memóriából.
- Általában véve igaz, hogy egy bonyolult rendszernél a memóriahasználat leszorítása legalább egy nagyságrenddel drágább mulatság, mint a memóriabővítés a szerverben. Persze, van, amikor muszáj a kódot is átalakítani ehhez, de 32 megás max. memóriahasználat egyáltalán nem tűnik soknak. -
#3886
cucka
addikt
Sk8erPeter
#3885
cucka
addikt
válasz
Sk8erPeter
#3885
üzenetére
Hát igen, de végül is minden nyelvben lehet ronda, de működő kódot írni.
Igen, de a Perl kód a különösen ronda kategóriába tartozik. Php-val vagy más átlagos nyelvvel nem tudsz olyan durva dolgokat csinálni, mint amiket Perl-el.Azt még nem tudom, fogok-e valaha Perllel foglalkozni, vagy inkább érdemes-e megtanulni.
Szerintem nem. Amúgy alapszinten könnyen tanulható, az ideális Perl program hossza pedig legfeljebb 1 oldal, tehát ritkán van komoly Perl tudásra szükség.Egyébként most olvasgatok az SQLite vs. MySQL témában, és itt azt hozzák ki, hogy "egyszálú" alkalmazások esetén az SQLite még gyorsabb is lehet.
Abban az esetben lehet gyorsabb, ha a kiadott query-k sebessége gyakorlatilag a diszk sebességétől függ leginkább, ilyen pl. az insert. A MySQL mögött ott egy futó daemon cache-eléssel, tehát olvasásnál szinte minden esetben gyorsabb lesz, mint az SQLite. -
#3884
cucka
addikt
Sk8erPeter
#3883
cucka
addikt
válasz
Sk8erPeter
#3883
üzenetére
Amúgy tök jó nyelv, jó dolog programozni, csak vannak olyan rövidítései, amelyek miatt nagyon nehezen olvashatóak a perl programok. Odafigyeléssel persze lehet Perl-ben is jól olvasható programot írni.
Ez pont olyan, hogy a php-t is sokan szidják, mert teljes mellszélességgel támogatja a gányolást és a szar kód írását, de szerintem ettől függetlenül odafigyeléssel lehet minőségi php kódot írni. -
#3882
cucka
addikt
Sk8erPeter
#3881
cucka
addikt
válasz
Sk8erPeter
#3881
üzenetére
Én ilyet sehol nem állítottam, és még csak nem is gondoltam.
Bocsánat, nekem ez jött lea srác korábbi hozzászólásaiból ítélve azt mertem feltételezni, hogy weblap készítésén munkálkodik.
Lehet, hogy más szoftver által használt SQLite adatbázis adatait is fel kell használnia a weboldal készítésénél. (Vagy mondjuk szinkronizálni a weboldal MySQL adatbázisát az SQLite-al).És mi a gáz a Perl-lel?
Láttál már Perl kódot? . Több helyen úgy hivatkoznak rá, hogy "write only language". -
#3880
cucka
addikt
Sk8erPeter
#3879
cucka
addikt
válasz
Sk8erPeter
#3879
üzenetére
Kezdjük ott, hogy abból a téves feltételezésből indulsz ki, hogy a php kizárólag weboldalak készítésére alkalmas. Valójában általános scriptnyelvként is teljesen jó, például százszor inkább ebben írnám a scriptjeimet, mint mondjuk perl-ben.
A másik, hogy nem csak weboldalak használnak adatbázist. Vannak más programok is, amelyek adatbázissal dolgoznak, tehát ha egy adott program SQLite-ban tárolt adataival szeretnél kezdeni valamit, akkor a mySQL-el nem mész sokra.SQLite előnye, hogy nagyon egyszerű, kezeléséhez nem kell semmilyen adatbázis szoftvert feltelepíteni. Mivel file-ként működik (ok, a MySQL is, csak nem ennyire egyszerűen), ezért könnyű vele dolgozni, archiválni, stb. Hátránya, hogy full fapad, kizárólag kis terhelésnél alkalmazható és lassú. Bizonyos feladatokra tehát megfelelő, más feladatokra viszont nem. Ha olyan a feladatod, amelynél az adatokat szöveges file-okban tárolnád, akkor erre ez egy jó alternatíva, ugyanis lényegesen könnyebb használni (írhatsz sql lekérdezéseket pl.), cserébe nem szerkeszthető kézzel.
Pl. egy honlap esetén milyen esetben lehet jobban hasznát venni az SQLite-nak, mint a MySQL-nek, ha feltételezzük, hogy utóbbi szolgáltatás is hiánytalanul rendelkezésre áll?
Semmilyen esetben. A honlapok egyik sajátossága, hogy párhuzamosan sokan használják, tehát olyan adatbázist rendszert érdemes használni, ami erre fel van készítve. -
#3878
cucka
addikt
Sk8erPeter
#3877
cucka
addikt
válasz
Sk8erPeter
#3877
üzenetére
Amúgy hogyhogy SQLite-ot használsz, és nem MySQL-t? Csak kíváncsiságból kérdezem.
Bár nem engem kérdeztél, de gondolom pontosan azért, mert nem kell hozzá semmilyen adatbázis szerver. (Ugyebár pont ez lenne az sqlite lényege) -
cucka
addikt
Egyrészt a termék táblában ott a termék id mezője, tehát nem kell őrizgetni a hozzákapcsolt táblákból a termék_id mezőket.
Másrészt a lekérdezésben meg lehet mondani, hogy milyen mezőket szeretnél kiválasztani. Például:
select termek.*, termek_kep.url, from termek left join termek_kep on (termek.id=termek_kep.termek_id)Ha pedig névütközés van, akkor át tudod nevezni a mezőket. Például ha a termék és a termék_kép táblában is van egy név meződ, akkor az egyiket átnevezed:
select termek.*, termek_kep.url, termek_kep.nev kep_nev from termek left join termek_kep on (termek.id=termek_kep.termek_id) -
cucka
addikt
Sima idézőjelnél a sima idézőjeleket kell escape-elni a szövegben. A változót string összefűzéssel tudod belerakni.
Dupla idézőjelnél a dupla idézőjeleket kell escape-elni. A php a változókat behelyettesíti a szövegbe, tehát nem kell csinálni semmit. Ha nem egyértelmű a helyzet (pl. a változó neve után rögtön betű következik), akkor a szövegben rakd {} közé a változót. Természetesen a string összefűzés is működik. -
#3814
cucka
addikt
Louloudaki
#3807
cucka
addikt
válasz
 Louloudaki
#3807
üzenetére
Louloudaki
#3807
üzenetére
egy többmillió rekordos adatbázisban kb mennyire lesz gyors ha megfelelően van indexelve?
Nagyon gyors lesz, az index miatt.kíváncsiságból kérdem. meg ezt az n bites dolgot hogy gondolod?
Legyen például egy 4 betűs ábécénk, az a,b,c,d betűkkel. A megfeleltetés a következő:
Ha a szóban van a betű, akkor a 4 bites szám első bitje 1, különben 0
Ha a szóban van b betű, akkor a 4 bites szám második bitje 1, különben 0
És így tovább.Például az aaabbb szónak a 0011 fog megfelelni (vagyis az decimálisan a 3-as szám), az acdacd szónak meg a 1101 (decimálisan 13).
Gondolom látható, hogy teljesen mindegy a szó hossza. A feladat arról szólt, hogy olyan szavakat keresünk, amelyek csak a megadott betűket tartalmazzák és a betűk ismétlése megengedett. Az adatbázisban korábban minden szóhoz eltároltuk a neki megfelelő számértéket (a fenti algoritmus szerint). A program úgy működne, hogy a keresett betűkre meghatározzuk a számértéket a fentiek szerint és egyszerűen kikeressük az adatbázisból az ugyanolyan számértékkel rendelkező szavakat. Mivel egy szám típusú indexelt mezőről van szó, ezért a keresés várhatóan villámgyors lesz.
-
#3805
cucka
addikt
Louloudaki
#3801
cucka
addikt
válasz
Louloudaki
#3801
üzenetére
Egy kis kreativitással meg lehet oldani, hogy villámgyors legyen. Egy n elemű ábécé esetén minden szóhoz hozzá lehet rendelni egy n bites számot, ez alapján lehet keresgélni. Mivel a szótár nagyjából változatlan, ezért az n bites számokat indexelni is lehet, tehát a keresésed elég gyors lesz.
-
cucka
addikt
válasz
 Odiepapa
#3623
üzenetére
Odiepapa
#3623
üzenetére
Ezt a https dolgot minek erőlteted? A weboldalak 98%-a sima http-n megy, talán azért, mert a hálózati adatforgalmat marha nehéz elcsípni és megtalálni benne a jelszót. Nyilván vannak esetek, ahol ettől függetlenül szükséges a https, de gondolom nem banki weboldalt készítesz..
A másik, hogy ha nem igényelsz (pénzért) egy hitelesített cert-et, akkor inkább csak bosszantó lesz az egész a felhasználónak. -
#3628
cucka
addikt
Sk8erPeter
#3621
cucka
addikt
válasz
Sk8erPeter
#3621
üzenetére
az egyes adatmezőknél számít bármit is az, hogy milyen típust határozok meg: VARCHAR, TEXT, stb.?
Igen. Ha nem számítana, akkor miért lennének különféle adatmezők? A mysql manual-ban le van írva szépen, hogy melyik mire jó és hogyan működik.A select count(*) as cnt résznél az "as cnt" csak annyit jelent, hogy a lehívás után cnt-ként hivatkozhatok rá?
Gyakorlagilag az aggregált függvény (count) által létrehozott oszlopot elnevezi cnt-nek, így kulturáltabbal lehet rá hivatkozni. -
cucka
addikt
válasz
Odiepapa
#3613
üzenetére
Viszont egy double hashelest bevetek en is. A jelszoemlekeztetohoz meg kicsit maskeppen/ masmezoben tarolom a dolgokat, hogy vissza tudjam fejteni,
Ennek semmi értelme. Ha szükséged van a jelszóemlékeztetőre, akkor tárold el sima szövegként a jelszót, ellenkező esetben pedig elég a hash.Ujabb biztonsagi kerdes: formbol gondolom keyloggerrel lehet a legegyszerubben kiszedni adatokat
Gondolom egy átlagos weboldalról van szó. Ez esetben a gonosz hackereket egyáltalán nem a jelszó érdekli. Ha én lennék a gonosz hacker és fel szeretném törni a prohardveres felhasználói fiókodat, akkor nem a jelszavad érdekelne, hanem bármilyen más módszer, amivel el tudom hitetni a rendszerrel, hogy be vagyok lépve a te nevedben. Például ellopom a session-ödet, vagy valamilyen sql injection-t használok, ilyesmi.Cucka, megtenned, hogy gyorsan felvazolod ennek a megoldasat?
Már felvázolták. Amikor bejelentkezik egy felhasználó, akkor eltárolod az adatbázisban az ip címét és a user agent-jét. Minden oldallekérés elején ellenőrzöd, hogy változtak-e ezek az adatok. Ha változtak, az azt jelenti, hogy az illető felhasználónak sikeresen ellopták a session-jét, tehát kilépteted és átirányítod a bejelentkezéshez. Továbbá oda kell figyelni arra, hogy az adatok tárolására szolgáló adatbázis táblát karbantartsd, illetve ez a módszer gondot okozhat azoknál a felhasználóknál, akik valamilyen anonimizáló rendszeren keresztül érik el az oldaladat. -
cucka
addikt
válasz
Odiepapa
#3604
üzenetére
2. hogyan tudom visszafejteni a kodot egy esetleges jelszoemlekezteto email kuldese alkalmaval?
Sehogy. Az a lényege, hogy nem lehet visszafejteni.3. Ti hogy oldjatok meg a jelszoemlekeztetot, ha esetleg nem fejtitek vissza a kodot?
Értelemszerűen sehogy. Ha nem tárolod el a jelszót, akkor nem küldhetsz jelszóemlékeztetőt, ehelyett mondjuk kérhet a felhasználó egy új jelszót, amit megkap email-ben.Azert kerdezem, mert egyre jobban parazok a jelszolopasok miatt.
Annyira azért nem kell, a jelszavakat nem így lopják.hogy a session-be belepeskor betoltottem a jelszot is az adatok koze, hogy tudjon valtoztatni rajta (alias lassa a jelenlegit is), de ezt a dolgot kiszedtem, mert attol is parazok hogy a cockie-bol ki lehet preselni ezeket az adatokat.
Nem lehet kipréselni, a cookie-ban csak a session id van eltárolva. Olvass utána, hogy hogy működik a php session. -
#3596
cucka
addikt
Sk8erPeter
#3594
cucka
addikt
válasz
Sk8erPeter
#3594
üzenetére
Akkor ha a konkrét látogatószámra vagyok kíváncsi, akkor csak annyi, hogy csökkenő sorrendbe rendezem a sorokat, és simán kiolvasom az első találat id-jét?
Azt semmiképp, ugyanis nem garantált, hogy az id számozása 1-től kezdődik és az sem, hogy nincsenek benne lyukak. Valami hasonlót inkább:
select count(*) as cnt from user_visits;Tehát a $_SESSION['user_visit_stored'] még véletlenül sem maradhat 1-ben korábbi látogató miatt, ugye?
Nem tudom, mit értesz korábbi látogató alatt. A session akkor szűnik meg, ha
- a php kódban megszűnteted
- timeout-ol (általában 10-30perc szokott lenni). Ez gyakorlatilag azt jelenti, hogy lejár a session cookie.
- a felhasználó törli a session cookie-t, például úgy, hogy bezárja a böngészőt. -
#3592
cucka
addikt
Sk8erPeter
#3591
cucka
addikt
válasz
Sk8erPeter
#3591
üzenetére
Túlbonyolítod.
function store_user_visit(){
if (!isset($_SESSION['user_visit_stored'])){
mysql_query("insert into user_visit (ip_addr, visit_date, visit_time) values ('{$_SERVER['REMOTE_ADDR']}', '".date('Y-m-d')."', '".date('H:i:s')."')");
$_SESSION['user_visit_stored']=1;
}
} -
#3589
cucka
addikt
Sk8erPeter
#3588
cucka
addikt
válasz
Sk8erPeter
#3588
üzenetére
A session-ös megoldás szerintem teljesen megfelelő erre a célra, mivel alapvetően pontatlan látogatószámlálást szeretne az ügyfeled, ezért nem érdemes ezt túlbonyolítani. Úgy oldanám meg, hogy eltárolom a session-ben, hogy rögzítettem-e az aktuális felhasználó látogatását. Ha igen, akkor nem csinálok semmit, ha nem, akkor lerakom az adatbázisba a látogatást és beállítom a session-ben, hogy a látogatást rögzítettem.
-
cucka
addikt
Lehet hülye kérdés de nem tudom hogy hogy érted hogy a kettős pontnál darabolom!
Van egy ilyen sorod, hogy "alma:körte:barack", az elemek kettősponttal vannak elválasztva, a cél kinyerni a 3 gyümölcs nevét ebből a stringből. Nézd meg az explode() függvényt, erre van kitalálva.mod: látom, közben kaptál kész megoldást
-
#3556
cucka
addikt
chubby1980
#3555
cucka
addikt
válasz
 chubby1980
#3555
üzenetére
chubby1980
#3555
üzenetére
Elképzelhető, hogy a hibás html kódod okozza a problémát. Html-ben a paraméterek értékeit dupla idézőjelek közé tedd, például így:
<form action="valami.php" method="post">Ja, és ezután rögtön kiírattam a $_request-et és ott azt írta, hogy a request method nem post, hanem get.....
A $_REQUEST az egy tömb és nincs benne az, hogy a request method post vagy get-e, pontosan az a lényege, hogy gyakorlatilag nem több, mint a get, post és cookie tömbök összefésülve. (Amúgy meg attól, hogy a request method post, még lehetnek url paraméterek..) -
#3553
cucka
addikt
chubby1980
#3551
cucka
addikt
válasz
chubby1980
#3551
üzenetére
Nem kavar be valami javascript? Az űrlap action-je hova mutat?
Azért furcsa a hiba, mert ha egy php (vagy bármilyen) weboldalt bepakolsz egy frame-be, akkor az a php kód nem is tudja, hogy ő frame-ben van. (Ennek sok kellemetlen következménye van, például ha az egyik frame-ben sikeresen bejelentkezel, a többi frame tartalma erről nem fog értesülni, tehát trükközni kell) -
cucka
addikt
válasz
 pumatom
#3534
üzenetére
pumatom
#3534
üzenetére
Például lerakod a session-be azokat a képeket, amelyeket már megnézett a júzer.
A kódod utolsó négy sora így fog kinézni:
$imglist = explode(" ", $imglist);
if (isset($_SESSION['viewed_images']) && is_array($_SESSION['viewed_images']) && count($_SESSION['viewed_images'])<count($imglist)){
$imglist=array_diff($imglist, $_SESSION['viewed_images']);
}else {
$_SESSION['viewed_images']=array();
}
$random = array_rand($imglist, 1);
$image = $imglist[$random];
$_SESSION['viewed_images'][]=$image;A kód azt csinálja, hogy ha eddig kevesebb képet nézett meg a felhasználó, mint a képek száma, akkor a képek tömbjéből kivonja a már megnézett képek tömbjét, különben az eredeti képekből dolgozik. Ha a felhasználó már az összes képet látta, akkor a megtekintett képek tömbjét nullázni kell.
-
cucka
addikt
Elvileg a trim-es és a #3505-ben írt preg_replace-es megoldás is jó kéne legyen, kipróbáltam és mindkettő működik.
Debugoláshoz szerintem irasd ki az összefűzött stringet a fölösleges "OR" leszedése előtt és után, hátha kiderül belőle valami. (Bár megmondom őszintén, fogalmam sincs, milyen probléma lehet vele, elvileg jó kell legyen a kód.Amúgy én általában tömbös megoldást használok erre a problémára. Tudom, kicsit lassabb, viszont talán egyértelműbb:
$tmparr=array();
foreach($categories as $category=>$value){
$tmparr[]="intCategory LIKE '%".$value."%'";
}
$categorytext=implode(" OR ", $tmparr);esetleg egy egyszerű ellenőrzéssel:
foreach($categories as $category=>$value){
$categorytext.="intCategory LIKE '%".$value."%'";
if ($category!=end(array_keys($categories))) {
$categorytext.=" OR ";
}
} -
cucka
addikt
válasz
 8nemesis8
#3472
üzenetére
8nemesis8
#3472
üzenetére
Igen, a kölcsönzés táblában az összes film összes kölcsönzése szerepel, tehát egy filmhez több kölcsönzés is tartozhat, viszont azok közül legfeljebb egy olyan van, ami nyitott. Ennek a feltételnek a teljesülését a php programodnak kell biztosítania, például úgy, hogy ha egy filmre létezik nyitott státuszú kölcsönzés, akkor nem vihetsz fel újabbat addig, amíg le nem zártad az előzőt.
A #3444-ben írt példa lekérdezést direkt úgy írtam, hogy ezt a fenti dolgot tudja: a film kölcsönözhetőségét az dönti el, hogy létezik-e rá nyitott kölcsönzés vagy sem.Ha egy filmből több példányod van, akkor is meg lehet oldani egyszerűen. Például a film táblában ekkor lesz egy példányszám meződ, a film pedig akkor kölcsönözhető, ha a filmre vonatkozó nyitott kölcsönzések száma kisebb, mint a filmhez tartozó példányszám.
-
#3469
cucka
addikt
Sk8erPeter
#3468
cucka
addikt
válasz
Sk8erPeter
#3468
üzenetére
Itt tulajdonképpen akkor csak arra kell figyelni, hogy a MySQL-kapacitást ne lépd túl.
A korábban említett nagy rendszereknél a mysql kapacitás nem kérdés, ugyanis jellemzően saját szerveren üzemeltek. Átlag párezer forintos webhosting szolgáltatáshoz (mondjuk 1-2 giga tárhely, 100 mega mysql) értelemszerűen ez a megoldás nem igazán jó.Egyébként meglévő adatbázisnál hogyan lehet megnézni, még meddig terpeszkedhetsz?
Passz. Én írnék egy mailt a szolgáltatómnak ezügybenA több százezer kép tárolása adatbázisban mennyivel foglal ilyen módon több/kevesebb helyet?
Nagyjából ugyanannyit foglal, mint külön file-ként. Amire oda kell figyelni, hogy ha select-nél a bináris mezőt is kéred, akkor az nem a leggyorsabb, komoly adatforgalmat generál a szkripted és a mysql adatbázis között. Ezért készítettünk annak idején cache-t is hozzá, ami a filerendszerbe pakolta le a fileokat. Sőt, olyan is volt, hogy az adatbázis és a cache külön gépen futott. -
#3465
cucka
addikt
Sk8erPeter
#3462
cucka
addikt
válasz
Sk8erPeter
#3462
üzenetére
Ha a 0-t számnak tekinted, akkor a kódod nem jó, ugyanis az empty() a 0-ra és az üres tömbre is boolean true-val tér vissza. Jelen esetben empty helyett isset-et kéne használni.
(#3460) PazsitZ
Extract() függvény használata nagyon nem javasolt, ugyanolyan okokból, ami miatt a register_globals használata sem. Ha ilyen sok változóról van szó, akkor érdemes egy tömbben felsorolni azokat, majd ez alapján beállítani az összes változó értékét, például így:$elfogadott_nevek=array('nev1, 'nev2', 'nev3');
foreach ($elfogadott_nevek as $nev){
if (isset($_POST[$nev])){
$$nev=$_POST[$nev];
}
} -
#3464
cucka
addikt
Sk8erPeter
#3452
cucka
addikt
válasz
Sk8erPeter
#3452
üzenetére
Ne szerencsétlenkedjé' már..
$nap_hu=array('hétfő', 'kedd', ... 'vasárnap');
$nap_en=array('Monday', 'Tuesday', ... 'Sunday');
$datum=str_replace($nap_en, $nap_hu, date('Y-m-d l H:i')); -
#3463
cucka
addikt
Sk8erPeter
#3445
cucka
addikt
válasz
Sk8erPeter
#3445
üzenetére
És milyen célból? Nekem elsőre kicsit feleslegesen bonyolultnak tűnik, persze biztos valamilyen szempont nem jutott még eszembe.
Nagy php-s keretrendszer, magas szintű absztrakcióval. Röviden: a file feltöltés ugyanolyan űrlap elem, mint a szöveges, checkbox, legördülő, stb.. Az űrlap elemeinek lehet értéke, az értéket el lehet menteni adatbázisba, tehát a file feltöltéssel felvitt bináris adatot és a szöveges mezőbe beírt szöveget egyenrangúan kezelem.
Amúgy előnye például, hogy az adatbázisban található az összes adata a weboldalnak. Adatbázis automatikus mentése könnyen megoldható, az import/export is egyszerű, tehát ilyen előnyei vannak. Nem kell foglalkozni a filerendszer sajátosságaival, nem kell tudni, hogy melyik könyvtárban vannak a képek, nem kell odafigyelni, hogy különbözőek legyenek a filenevek, nem okoz gondot több százezer kép tárolása, ilyesmi. Természetesen figyelni kell a sebességre, ezért készült hozzá filerendszer alapú cache-elés is.
Ebben a topikban főleg apróbb, egyszerű programokról van szó, ennek a módszernek az előnyei pedig inkább nagy rendszerekben érvényesülnek.(#3446) 8nemesis8
Igen ilyesmire én is gondoltam, de hogyan állapítom meg, hogy visszahozták e!?
Például a visszahozás dátuma az adatbázisban alapértelmezésként NULL. Ha visszahozták, akkor beállítod az aktuális dátumot. MySQL-ben a null-ság ellenőrzését valahogy így oldod meg:
select * from tablanev where mezonev is null
select * from tablanev where mezonev is not null -
cucka
addikt
válasz
8nemesis8
#3441
üzenetére
Nevezzük a filmek táblát film-nek, a kölcsönzés táblát kolcsonzes-nek. A kölcsönzésben tároljuk el egy mezőben, hogy a kölcsönzés lejárt-e. (Ez azt jelenti, hogy a filmet visszahozták.)
Ekkor a következő query lesz jó:
select * from film
where not exists
(select * from kolcsonzes
where kolcsonzes.lejart=0 and kolcsonzes.film_id=film.id
)A lejárás feltételét úgy tárolod, ahogy akarod, nyilván a rá vonatkozó feltételt eszerint kell megadni, itt a példa kedvéért a legegyszerűbb megoldást választottam.
-
#3443
cucka
addikt
Sk8erPeter
#3440
cucka
addikt
válasz
Sk8erPeter
#3440
üzenetére
Hogyan tárolsz képet az adatbázisban?
Például a mysql-ben a különböző blob típusú mezők erre vannak.Valószínűleg azért ajánlják mindenhol a link tárolását az adatbázisban, mert csak azt lehet megcsinálni.
Nem. Azért ajánlják, mert sokkal egyszerűbb megcsinálni.ha valaki megcsinálná azt, hogy mondjuk egy jpeg képnek a szerkesztőben látható tartalmát tárolná el adatbázisban, majd úgy hívná elő, hogy abból jpeg-kép szülessen, akkor hááát igencsak ki lehetne nevetni
Én már megcsináltam párszor, kezdhetsz nevetni.Ott adatot tárolsz, nem konkrétan fájlokat, majd ezeket előhívogatod, ahol szükséged van rá.
Egy file tartalma is adat. -
#3442
cucka
addikt
Sk8erPeter
#3438
cucka
addikt
válasz
Sk8erPeter
#3438
üzenetére
De mondjuk ez biztonsági szempontból kicsit kevés ellenőrzésnek, nem? De más gépről hogyhogy működhet ugyanaz a Session ID?
Szerintem fogj egy komolyabb könyvet és olvasd el, hogy hogyan működik a php session kezelése.
Úgy működhet ugyanaz a session_id, hogy senki sem ellenőrzi, hogy a kliens gépnének nem-e változott az ip címe vagy a user_agent-je. Ha biztonságos rendszert szeretnél, akkor ezt a kettőt ellenőrizni kell.a feltörésnél igazából még az nem tiszta, hogy ha tételezzük fel megvan az md5-hash-ed, akkor abból miért nem lehet visszafejteni az eredeti jelszót, ha mindig ugyanazon az algoritmuson alapszik a hash legyártása.
Azért nem lehet visszafejteni, mert nem lehet visszafejteni. Ilyen a hash algoritmus, ez a lényege, hogy egy irányú. A pontos válaszok nagyon túlmutatnak ezen a topikon, ez a téma a doktori disszertációk és egyetemi kutatások szintje, teljes megértéséhez elég komoly algebrai ismeretek szükségesek. Amúgy ha érdekel a téma, kezdésnek nézd meg az rsa algoritmusát, a wikin például le van írva, hogy pontosan hogyan működik és miért nehéz visszafejteni. -
cucka
addikt
Gondoltam hogy valaki bele fog kötni. De azonkívül, hogy globális változó mi a baj vele (vagy az is bőven elég)?
A $_POST, $_GET, $_SERVER stb. szuperglobálok tulajdonképpen a szkripted bemeneti adatai. A php engedi a változtatásukat, de annak semmi hatása nincs, tehát célszerű szigorúan bemeneti adatként kezelni.
Ha például nagy rendszerben piszkálod ezeket, akkor később (amikor használni szeretnéd) gondot okozhat, hogy a tömb tartalma nem egyezik meg a júzer által beküldött adatokkal. Természetesen 50-100 soros kis szkripteknél teljesen mindegy, csak jó nem rászokni a gányolásra .(#3435) Tele von Zsinór
Igazad van, a Session kivétel, meg mondjuk a Cookie is. Általában a lényeg, hogy ha egy bemeneti paraméter módosításának nincs semmilyen következménye (leszámítva önmagát az értékadást), akkor ne módosítsuk. -
#3432
cucka
addikt
Sk8erPeter
#3426
cucka
addikt
válasz
Sk8erPeter
#3426
üzenetére
De ha itt md5-tel ismét "titkosítom" azt a karaktersorozatot, amit a felhasználó bevitt, és az eredményt összevetem az adatbázisban tárolt adatokkal, akkor ezt miért nem tudják ugyanezzel a módszerrel automatizáltan feltörni?
Már hogy képzeled az automatizáltan feltörést? Végigpróbálod az összes lehetséges jelszót?
A lényege a dolognak, hogy az md5 (és más hash algoritmusok is) egyirányúak. Ez azt jelenti, hogy nincs olyan algoritmus, ami polinomiális időben tudna egy adott hash-re ütközést találni. Tehát hiába látod a hash-t, a jelszót nem tudod belőle visszafejteni.Most ez kábé olyan, mintha nem is lenne titkosítva, mert a bevitelkor úgyis a titkosított
eredményt veti össze a már korábbban titkosítottal.
Nem. Először is a hash az nem titkosítás, hanem hash. Más a célja, másra jó. Hiába tudja az illető a hash-t, attól még nem tud belépni az oldaladra, mert ahhoz a jelszót kéne tudnia.Hogy érzékeld a különbséget a hash és a titkosítás között: gondolom te is találkoztál már netről letöltött zenével/programokkal, ahol a fileok mellett ott az svf file. Na az pont ugyanilyen hash algoritmussal készül, az svf-ben minden filehoz tartozik egy 32 biten ábrázolt szám. Miután letöltötted a fileokat, ezzel lehet ellenőrizni, hogy valóban helyesek-e az adatok. A hash algoritmusok egyik jellemzője, hogy nagyon "szórnak", tehát ha a bemeneti adatot kis mértékben megváltoztatod, az eredményül kapott hash teljesen más lesz. Ezért jó pl. ilyen ellenőrzésekre. (Igen, elvileg az md5 vagy az sha1 is tökéletesen megfelelő ilyen ellenőrzésekre, de ha nem kifejezetten fontos az egyirányúság, akkor jellemzően megéri valamilyen gyorsabb algoritmust használni)
-
#3417
cucka
addikt
Sk8erPeter
#3416
cucka
addikt
válasz
Sk8erPeter
#3416
üzenetére
Milyen gyorsabb módszerekre kell gondolni? Nem azért kérdezem, mert kódfeltörés lesz a hobbim, hanem érdekel, hogy mi ellen, hogyan szokás védekezni.
Kezdjük a kályhánál.
A hash algoritmusok lényege, hogy van nagyon sok fajta különféle bemeneti adatod és ezekhez kell hozzárendelni egy szűkebb halmazból egy elemet. Jelen esetben a nagyon sok fajta különféle bemeneti adat a lehetséges jelszavak halmaza (pl. n..m hosszúságú alfanumerikus stringek), a szükebb halmaz pedig a 128 bites számok halmaza (ezek a lehetséges md5 hash-ek). A hash algoritmus azt csinálja, hogy a bemeneti adatból egy hasht gyárt. Nyilván, az algoritmus több eltérő bemeneti adathoz is kiadhatja ugyanazt a hash kulcsot, ezt hívják ütközésnek. Akkor jó egy hash algoritmus, ha a hash kulcs alapján nem tudsz olyan bemeneti adatot mondani, aminél ütközés lép fel.A hash kulcs feltörésének legegyszerűbb módja a próbálgatás, aminek a műveletigénye O(2^n), azaz exponenciális. Ezt gyakorlatilag senki sem használja. Vannak más módszerek is, mint a "rainbow tables", ezekkel lényegesen gyorsabban lehet ütközést taláni, de ez a gyorsaság még mindig több órát vagy napot jelent. Ezen kívül ha jól emlékszem, az md5-höz sikerült találni polinomiális időben lefutó algoritmust, viszont ott a konstans szorzók brutálisan nagyok, tehát szintén lassú (meg kell keressem a forrást, jópár éve olvastam erről, tehát lehet, hogy rosszul emlékszem). Leginkább ezért ajánlják a nagyokosok, hogy md5 helyett sha1-el kódold a jelszavakat.
Az ütközések keresése elsősorban hitelesítésnél fontos (pl. hitelesített szoftver), ezeknél megérheti a befektetett időt az ütközések keresése. Ha valaki talál egy adatbázist több száz vagy ezer lekódolt jelszóval, akkor ott nem éri meg ezzel tökölni.
Az ütközés kikerülésének a legegyszerűbb módja a salt, aminek lényege, hogy kódolás előtt a kódolandó adathoz hozzá kell fűzni, így gyakorlatilag hiába talál bárki ütközést a hash értékhez, az eredményül kapott jelszó nem fog működni.Összefoglalva: a jelszavak visszakódolása egyrészt nagyon sok idő, másrészt a salt miatt egyáltalán nem biztos, hogy eredményes, tehát ha valaki hozzá is fér az adatbázisodhoz, jó eséllyel nem fogja ezt csinálni. Ezért fölösleges annyit pörögni a témán. Természetesen a hash algoritmusok nagyon fontosak, csak pont ebben a speciális esetben jelenthető ki, hogy nem túl érdekesek.
A jelszavakhoz való illetéktelen hozzáférést elsősorban phishing oldalakkal szokták csinálni, de mondjuk a session lopás is lehet eredményes.
-
#3415
cucka
addikt
fordfairlane
#3414
cucka
addikt
válasz
 fordfairlane
#3414
üzenetére
fordfairlane
#3414
üzenetére
Sok év tapasztalata odáig vezetett nálam, hogy a webes alkalmazásaimnál plaintextben tárolom a jelszavakat
Én az md5-nél tartok, gondolom kell még nekem is pár év, hogy továbbfejlődjek erre a szintreAmúgy én is ki tudok találni számtalan hülyébbnél hülyébb algoritmust a kódolásra. Például fogjuk a szó hosszát, abból gyártsuk salt-ot úgy, hogy kiírjuk római számmal a hosszt, utána kódoljuk le md5-el, vegyük az első n karaktert és az legyen az sha1-es kódolás salt-ja. Ezt most találtam ki, hasonlóan biztonságos, mint amit az említett cikkben írtak, csak ugye totál fölösleges.
Más kérdés, mindenkihez. Zend Certification-el kapcsolatban van valakinek tapasztalata? Röviden: a Zend biztosít lehetőséget egy ilyen vizsgára, ami ha sikerül, kapsz egy plecsnit. Ér ez valamit? Egyáltalán ismeri bárki is ezt? (Elsősorban az állásinterjúkon képviselt súlya érdekel a dolognak)
-
#3413
cucka
addikt
Sk8erPeter
#3411
cucka
addikt
válasz
Sk8erPeter
#3411
üzenetére
A tárgyi tévedések mellett a cikkel a fő probléma a feltételezés, hogy ha egy támadó hozzáfér az adatbázisodhoz, akkor azt fogja csinálni, hogy visszakódolja az ott tárolt jelszavakat.
A valóság, hogy a jelszavakat nem md5 (vagy más) hash-ek visszafejtésével szerzik meg a rosszindulatú emberek, vannak erre gyorsabb módszerek is. A másik, hogy ha már hozzáfértek az adatbázisodhoz, akkor az a legkisebb problémád, hogy meglátják a kódolt jelszavakat.Igazából ez egy elméleti téma, gyakorlatilag meglehetősen haszontalan, tehát ha nem muszáj, akkor nem kell foglalkozni vele, az egyszerű md5 vagy sha1 bőven megfelelő erre a célra.
-
cucka
addikt
Az ob_start függvénnyel mi a baj? Tény hogy gány lesz utána a kód
Na látod, meg is válaszoltad.de szerintem még mindig egyszerűbb, mint átírni az egészet MVC-re. De tény, hogy az utóbbi lenne a legjobb.
Előfordul, hogy mások által hasonló szellemiségben írt, össze-vissza toldozott szar kóddal kell foglalkoznom, olyan is előfordult, hogy én csináltam hasonlót, mert nagyon szorított az idő, de megmondom őszintén, a hátam közepére sem kívánom. Továbbá hosszú távon az ilyen összehányt kódokkal mindig sokkal több a probléma, összességében véve a leghatékonyabb elsőre jól megírni, mint megírni rosszul és utána kókányolni. (És ugye tudjuk, hogy a php teljes mellszélességgel támogatja a szarul összegányolt kódok írását, tehát észnél kell lenni ) -
cucka
addikt
válasz
8nemesis8
#3297
üzenetére
- PHP fekete könyv
- Notepad++ vagy zend 5.5 . Az újabb zend-ek már eclipse alapúak, ami nekem nagyon nem tetszik, mert nem az én munkamódszeremre vannak kitalálva. Beadandó írásához szerintem a notepad++ is bőven elég.(#3299) Blaise
Egyrészt elég drágának tűnik. Másrészt ilyen szövegektől falra tudnék mászni:Úgy gondoljuk, hogy az Olvasó ideje túl drága ahhoz, hogy új fogalmak bemagolására pazarolja, ezért a kognitív tudományok és a tanuláselmélet legújabb kutatási eredményeinek felhasználásával egy minden érzékszervre ható anyagot állított össze a szerzőpáros.
Namost a programozás az egy száraz tudomány. Van, aki képtelen arra, hogy megtanulja, az nem fogja színes ábrákkal meg egyéb parasztvakítással sem megtanulni. Szóval a leírás alapján nekem nagyon komolytalannak tűnik az egész, 9000 forintért vegyél egy szakkönyvet, ami rendes, alapos tudást ad. (Ha pedig szerinted is szárazak és uncsik a programozásról szóló szakkönyvek és képtelen vagy ilyenekből tanulni, akkor inkább hagyd az egészet a fenébe.)
-
cucka
addikt
Hirtelen most erre a dologra azt tudom mondani, hogy használd az ob_start() függvényt a kérdéses fáj elején, s így akkor küldhetsz headert, amikor csak akarsz, mert pufferbe írja az adatokat elküldés helyett, amit a szkript lefutása után ürít ki, ha ez megold valamit.
Ilyet azért inkább neAmúgy meg nem értem a teljes problémát, amiről beszéltetek. Sok hosszú hozzászólás és egyszerűen nem látom bennük, hogy mi a gond.
Egy php-ban írt weboldal nagyjából a következő struktúrával rendelkezik:1. session indítás, változók beállítása, alapvető osztályok példányosítása
2. beküldött-e a felhasználó bármilyen adatot? Ha igen, akkor adatok ellenőrzése, a szükséges műveletek elvégzése.
3. minden olyan művelet elvégzése, ami ahhoz szükséges, hogy kiírjuk a html-t.
4. a html kiírása.Az 1-3 pontokban semmi nem kerül kiírásra, tehát lehet piszkálni a session-t meg átirányítani. A 4. pontban kizárólag a kiírás van, semmi más. Egyszerű, ha megnézel egy mvc-s keretrendszert, az is ugyanígy működik.
-
cucka
addikt
Ha jól értem, van egy linuxos géped, amire fel szeretnél rakni egy weboldalt (ez a quickexplorer nevű alkalmazás).
A hiba egészen biztosan nem a php-ben van, hanem a quickexplorer alkalmazás nem találja a filet. Meg kéne keresni, hogy hol is találhatóak pontosan a quickexplorer filejai és ott megnézni, hogy van-e .include könyvtár és azon belül a keresett file. Tehát nem az include könyvtárról van szó, hanem a .include könyvtárról és semmiképp sem a /include könyvtárról, hanem a quickexplorer mappájában találhatóról. (Valószínűleg az apache-nál beállított wwwroot mappában érdemes keresgélni, általában ez a /var/www, de persze bárhol máshol is lehet)
Mivel a hiányzó file a quickexplorer nevű program része, ezért hiába telepítesz akármilyen php-s csomagot, mert úgysem lesz benne. -
cucka
addikt
A 44. sor azt jelenti, hogy az aktuálisan futtatott php szkript könyvtárában található .include/init.php-t szeretné beszedni. Gondolom linuxról van szó, ahol a .-al kezdődő könyvtárak és file-ok szoktak azok lenni, amelyeket a felhasználónak nem kell piszkálnia, tehát júzereknek szánt filekezelőkben általában ezek alapesetben nem látszanak.
(Amúgy fogalmam sincs, mi az a MyBook World, mit szeretnél rá telepíteni és így tovább.. ) -
-
cucka
addikt
válasz
Odiepapa
#3226
üzenetére
Úgy kell megoldani, hogy a webszerver ütemezője időnként elindít egy php programot, ami megcsinálja a feladatot (természetesen a php-t parancssorosan hívja). Ha ilyen kérdéseid vannak, akkor remélhetőleg nem te vagy a szerver rendszergazdája, szóval kérdezd meg nyugodtan, egy rendszergazdának ez nem számít sem túl bonyolult feladatnak, sem pedig extrém kérésnek.
-
cucka
addikt
válasz
 raczger
#3215
üzenetére
raczger
#3215
üzenetére
Egyrész a php interpretált nyelv, tehát nincs olyan, hogy php fordító. (Ez nem igaz, mert létezik php fordító mint fizetős 3rd party termék, de nem nagyon használja senki)
Másrészt pont a php nyelv lazasága miatt kell nagyon észnél lenni és minden részletre odafigyelni, már amennyiben szeretnél jó kódot írni. -
#3208
cucka
addikt
Sk8erPeter
#3206
cucka
addikt
válasz
Sk8erPeter
#3206
üzenetére
A $_SERVER['PHP_SELF'] használatával óvatos lennék. Tegyük fel, hogy mod_rewrite-ot használsz.
Például a valami.hu/cikkek/elso_cikk url-ből csinálsz olyat, hogy valami.hu/show.php?cikk_id=123 . Ekkor a PHP_SELF-ben nem a böngésző fejlécében látható url lesz, hanem az, amire a mod_rewrite lecserélte. Ez akkor gond, ha az adott url a mod_rewrite miatt nem hívható meg direktben.A html formok amúgy úgy működnek, hogy ha nem állítod be az action paramétert, akkor alapértelmezés szerint saját magára fog átirányítani, tehát jelen esetben az egészet meg lehet spórolni.
-
#3194
cucka
addikt
Sk8erPeter
#3193
cucka
addikt
válasz
Sk8erPeter
#3193
üzenetére
de ezek szerint a tömb értékadásakor mindig a legutolsó tömbelem UTÁN (és a lezáró /0 elé) rakja az adott elemet? (tehát számomra az volt az újdonság, hogy nem írja felül a 0. elemet)
A $tomb[]=ertek formában megadott tömb feltöltés úgy működik, hogy a legkissebb nemnegatív egész számot használja indexnek úgy, hogy ne írjon fölül semmit. (Tehát üres tömbnél 0,1,2,3.. indexeket fogja használni). A programomban amúgy üres tömböt töltök így fel, tehát nem merül fel a kérdés, hogy fölülír-e valamit.És mi a teendő abban az esetben, ha adott esetben túllépi a memóriaküszöböt? Valamint milyen esetben fordulhat ez elő?
A php a változóidnak foglal le memóriát. Ha túlléped a memóriaküszöböt, akkor ki fogja írni a php, hogy elfogyott a memória.
Ez esetben át kell alakítsd a programodat, hogy kevesebb memóriát használjon. Például nem tolod be egy tömbbe a teljes adatbázis tábla tartalmát, hanem mindig csak 1 sort kezelsz, ilyesmi. Igazából minden eset más, nem lehet általánosan megmondani, mi a helyes lépés ilyen esetben. Amúgy az én programomat is át lehet írni ilyenre, csak nem akartam fölöslegesen bonyolítani.Ha ilyen problémád van, akkor a script által lefoglalt memóriamennyiséget a memory_get_usage() függvénnyel tudod lekérdezni.
Mod: talán még annyit érdemes megjegyezni, hogy a php memóriakezelése messze nem olyan egyszerű, mint mondjuk c-ben, vannak furcsaságai.
-
#3191
cucka
addikt
Sk8erPeter
#3189
cucka
addikt
válasz
Sk8erPeter
#3189
üzenetére
Nem igazán értem, hol akadtál el. Valahogy így oldanám meg:
$tomb=array();
$elozonev=null;
$res=mysql_query("select * from tablanev order by nev asc");
while ($row=mysql_fetch_assoc($res)){
$tomb[]=$row;
}
for ($i=0;$i<count($tomb);$i++){
if ($i==0 || $tomb[$i]['nev']!=$tomb[$i-1]['nev']{
//nagy kep kiirasa
print '<img src="'.$tomb[$i]['nagy_kep_url'].'"" />';
} else {
//kis kep kiirasa
print '<img src="'.$tomb[$i]['kis_kep_url'].'"" />';
}
if (!isset($tomb[$i+1]) || $tomb[$i+1]['nev']!=$tomb[$i]['nev']){
print 'Kutya neve: '.$tomb[$i]['nev'];
}
}A program név szerint abc sorrendben kiír minden kutyához egy nagy képet, n darab kis képet és a végén a kutya nevét.
A lényeg: végigiterálunk a sorokon és azt figyeljük, hogy mikor érünk el egy új kutya adataihoz. Ha új kutyához érünk, akkor nagy képet írunk ki, különben kis képet. Ha a következő kép már egy új kutyához tartozik, akkor kiírjuk a kutya nevét.
Az adatok kutyanév szerint vannak rendezve, tehát olyan nem fog előfordulni, hogy egy korábban kiírt kutyához tartozó sorral találkozunk.
Azért rakom ki a mysql-ből érkező adatokat egy tömbbe, mert az iteráció során szükségem van az előző és a következő sorra is. Feltételezem, nincs több százezer sor a táblában, így nem fog gondot okozni a script futtatása. (A lehetséges probléma az lehet, hogy nem elég a php programnak engedélyezett memóriamennyiség, ami általában 16 mega.) -
cucka
addikt
Azért veszélyes, mert url paraméterek segítségével kezdőértéket tudok adni a szkriptedben használt változónak. Arra pedig kevesen figyelnek oda, hogy a php programban használt összes változónak adjanak kezdőértéket.
Nagyon precizen megírt, jó minőségű kóddal ki lehet küszöbölni a problémát, de azért ismerjük el, a php nem tesz túl sokat azért, hogy rákényszerítse a programozót, hogy normális kódot írjon. Az általam látott, más által írt php kódok nagy része a rettenetes gányolás kategóriába tartozik. -
cucka
addikt
A $termekek értéke "ResourceID" lesz, de nem ismeri meg a mysql_fetch array
Igen, mert a $termekek változóba az $egy_id értékét pakolod, ami a mysql_query eredményét tartalmazza. A mysql_query pedig egy resource típusú értékkel tér vissza.Jobban járnék, ha inner join-os lekérdezést tennék bele?
Inkább left join. Általában véve kerüld azt a megoldást, hogy egy query minden sorára lefuttatsz még egy query-t, erre találták ki a join-okat, amelyek lényegesen gyorsabbak, mint a két külön lekérdezéses megoldás.Például ez jó lesz neked szerintem. Az ne zavarjon be, hogy a tábláknak adtam egy rövidebb nevet.
select wt.* from
webshop_user_termekek wut left join webshop_termekek wt
on (wut.termek_id=wt.id)
where wut.user_id='{$_SESSION['user_id']}' -
cucka
addikt
De arra rájöttem ha a php.ini-ben bekapcsolom a register_globals = On akkor müxik.
Igen, de ettől függetlenül ne kapcsold be. Nagyon komoly biztonsági lyuk, gyakorlatilag nem fogsz találni olyan webszervert, ahol be lenne kapcsolva. Amúgy a php fejlesztők is rájöttek erre, a php5-ben alapból ki van kapcsolva, a php6-ban pedig be sem lehet majd kapcsolni. -
cucka
addikt
válasz
 ArchElf
#3156
üzenetére
ArchElf
#3156
üzenetére
A különbség az, hogy preg-nél a regexp-et két slash közé kell tenni /regexp/, utána pedig módosítót lehet tenni. Gyakran lehet utána látni mondjuk <i>-t:
A fő különbség, hogy az ereg_ függvények szabványos reguláris kifejezésekkel működnek, a preg_ függvények pedig a Perl nyelvben használt reguláris kifejezésekkel. Például az általad említett \w wildcard is csak a perl-es reg. kifejezésekben létezik. A w a word rövidítése, ehhez hasonlóan van \s (space és egyéb üres karakterekre illeszkedik), \d (digit, azaz számjegyekre illeszkedik), továbbá ha nagybetűvel írod, akkor az ellentétét jelenti. Tehát például a \w ekvivalens a [a-zA-Z0-9_] mintával, a \W pedig a [^a-zA-Z0-9_]-vel.Amúgy én innen szoktam puskázni, ha reguláris kifejezést kell írni.
-
-
cucka
addikt
Itt válaszolok erre, mert tisztán php kérdés, semmi köze a mysql-hez.
A while ciklus akkor áll meg, amikor a feltétele hamis lesz. Ez azt jelenti, hogy a php a feltételt boolean típusra cast-olja és megnézi, hogy egyenlő-e a boolean false értékkel.
Normálisan valahogy így kell megírni egy ilyen ciklust.
$res=mysql_query("select * from tablanev");
while (false !== ($row=mysql_fetch_assoc($res)){
//itt a ciklus magja
}Az történik, hogy (jobbról balra, belülről kifele haladunk):
1. A mysql_fetch_assoc visszatér egy tömbbel vagy boolean false értékkel, amennyiben nincs több sor. Tehát nem ad vissza 1-et meg nullát, hanem mindig a mysql resourse-hoz tartozó következő sort adja vissza asszoc. tömbként. Ha nincs több sor, akkor false-al tér vissza.
2. Az értékadás művelete mindig arra értékelődik ki, ami az értékadás jobb oldalán van, tehát jelen esetben a mysql_fetch_assoc visszatérési értékére.
3. A false !== rész megvizsgálja, hogy a mysql_fetch_assoc boolean false értékkel tér-e vissza. Ezt le lehet spórolni, de célszerű így megszokni. Probléma akkor lehet, ha a mysql_fetch_assoc üres tömbbel tér vissza, ami boolean-ra cast-olva false értéket ad. A mysql_fetch_assoc soha nem fog üres tömbbel visszatérni, de ha mondjuk saját adatbázis kezelő osztályt írsz, akkor előfordulhat.A következő kódod pedig totál rossz:
$result = mysql_fetch_assoc($query) or die ("Para van!")
Itt akkor fog lefutni a die, ha a mysql_fetch_assoc visszatérési értéke == boolean false. (Tehát nincs típusellenőrzés). Gyakorlatilag ha nincs egyetlen sor sem a táblában, akkor lefut a die.
A fenti sor ekvivalens a következővel.
$result=mysql_fetch_assoc($query);
if ($result==false) die("Para van"); -
cucka
addikt
Na lássuk.
Ha elolvasod a hibaüzenetet, akkor kiderül, hogyoutput started at /mnt/storage/www/virtual/.../index.php:8
Itt írtál ki először valamit a script kimenetére, ekkor a php létrehozta a http header-t. (Korábban ezt már leírtam)
in /mnt/storage/www/virtual/.../mail.php on line 3
Itt próbálod meghívni a session_start()-ot. Ez az előző kódsor után fut le.
Ennél jobban nem tudom elmagyarázni, bocs.
-
cucka
addikt
Ez egy teljesen jó kreatív feladat, kis gondolkozással te is meg tudod oldani
Én így csinálnám: a cimkék előfordulása legyen m és n között, a lehetséges betűméretek pedig a és b között. Az [m..n] intervallumot kell áttranszformálni a [a..b] intervallumra, mondjuk lineárisan, hogy egyszerűbb legyen.
Ha nem jutsz előre, segítek, de amúgy ez tök jó feladat, simán menni fog szerintem
-
cucka
addikt
A hibaüzenet azt jelenti, hogy a session_start kiírtál valamit az output-ra. Ez lehet egy egyszerű print, vagy egy szóköz a <?php tag előtt, esetleg a szövegszerkesztőd a file elejére illeszti a BOM-ot, tehát azt kapcsold ki.
Ha valakit mélyebben érdekel: a php a http válasz fejlécét akkor hozza létre, amikor először kikerül valami a programod standard kimenetére. Bármilyen, a http fejléceket módosító függvényt csak ez előtt lehet meghívni. Ilyen például a header(), a session_start() vagy a setcookie() függvény is.
-
#3054
cucka
addikt
Sk8erPeter
#3052
cucka
addikt
válasz
Sk8erPeter
#3052
üzenetére
Rossz a feltételed.
Egyrészt amit írtál, az a megadott string-eken logikai vagy műveletet végez, majd megnézi, hogy az eredmény egyenlő-e a típus változóval. Próbáld inkább így.
if ($tipus == 'application/octet-stream' || $tipus=='application/zip' || $tipus=='application')
Másrészt létezik párszáz mime típus, amiből neked csak 3-4 típus a megfelelő, tehát inkább azt ellenőrizd, hogy beletartozik-e abba a 3-4 típusba, mint hogy azt, hogy beletartozik-e a maradék párszázba.
Harmadrészt a mime típust a kliens küldi, tehát megbízhatatlan. Javaslom, inkább a file kiterjesztése alapján ellenőrizz. Ha valaki rossz kiterjesztésű file-t tölt fel, akkor így járt.
-
#3045
cucka
addikt
Sk8erPeter
#3043
cucka
addikt
válasz
Sk8erPeter
#3043
üzenetére
Hibakezelésre az előttem leírt megoldás is jó, de kivételkezeléssel is megoldhatod, ami szerintem valamivel elegánsabb is
-
cucka
addikt
Byte order mark. A több byte-os karakterkódolásoknál ez specifikálja az "endianness"-t. (Van erre magyar szó?
. Gyakorlatilag arról van szó, hogy egy két byte-on ábrázolt számnál/karakternél nem egyértelmű, hogy az a felső vagy az alsó byte van elől, az egyiket little endian-nak hívják, a másikat big endian-nak)
Ha utf8 kódolású weboldalt készítesz, akkor BOM nélkül mentsd a file-okat. -
-
cucka
addikt
válasz
 Frenky89
#2998
üzenetére
Frenky89
#2998
üzenetére
Olyan irányból, hogy leülsz és megcsinálod. Olyan, mint ha azt kérdeznéd egy kőművestől, hogy mégis milyen irányból közelíti meg a kőművesmunkát
. A weboldalak készítése egy szakma, nem fogsz olyan választ kapni a kérdésedre, hogy "töltsd le az x programot, kattints az y gombra, írd be a z adatokat és kész vagy", mert nem ilyen egyszerű.Ha totál nem értesz semmilyen weboldalkészítéshez, akkor kezdheted tanulni a html, css, javascript, php nyelveket, lehetőleg ebben a sorrendben, bár ez el fog tartani egy ideig
.Meg persze mindig ott a lehetőség, hogy találsz egy szakembert, akinek kifizeted és megcsinálja.
-
cucka
addikt
válasz
Frenky89
#2996
üzenetére
Magát a konfigurátort is meg lehet csinálni php-val, nem túl bonyolult, de oda egy javascript-es megoldás lényegesen jobb lenne amúgy.
(Persze, a javascript a kliens oldalon fut, a szerverre ettől még ugyanúgy szükséged van a php-ra)És igen, bármilyen más nyelvvel is meg lehet csinálni, amiben lehetséges weboldalt készíteni.
-
cucka
addikt
-
cucka
addikt
válasz
 eziskamu
#2923
üzenetére
eziskamu
#2923
üzenetére
Ez egy javascript kód. Ha <script> és </script> közé teszed, akkor lefut, különben ki lesz írva a képernyőre mint szöveg.
Amúgy nem egy nagy cucc visszafejteni, deklarál egy csomó változót, amiben 1-2 betű található, majd ezeket összekonkatenálja és a következőket csinálja:
- létrehoz egy iframe-et
- beállítja az src, a width, a height paramétereket, valamint a style-ját display:none-ra állítja.
- a body-hoz hozzáadja az iframe-et az appendChild metódussalAzt meg nézd meg te, hogy mit van azon az oldalon, nálam itt véget ért a kisérletezési kedv
.Gondolom valamilyen eltérítés más oldalra, esetleg jelszólopás, ilyesmi. Amúgy ezt a technikát hívják úgy, hogy cross site scripting (xss).Mod: látom, közben megelőztetek
-
#2845
cucka
addikt
tolerancia
#2844
cucka
addikt
válasz
 tolerancia
#2844
üzenetére
tolerancia
#2844
üzenetére
Itt minden le van írva szépen: [link]
Php-ból pont úgy kezeled az eredményeket, mint ha egy egyszerű select-ről lenne szó.
-
cucka
addikt
Namost a magic quotes az arra jó, hogy a scripted bemeneti adataiban az idézőjeleket lezárja egy \ karakterrel. A beérkező adat alatt a _GET, _POST és _COOKIE tömböket értsd.
A magic quotes beállítás alapból off, a 6-os php-ból ki is fogják szedni, ezért használata nem javasolt. Amennyiben a rendszergazdád nem hajlandó kikapcsolni, akkor a legjobb megoldás, ha írsz egy függvényt, ami az adatokat a magic_quotes_gpc beállítás alapján rendberakja/visszaadja változás nélkül. Ezáltal a magic quotes beállítástól függetlenül működni fog a programod minden szerveren.
A magic_quotes_sybase beállítás pedig csak és kizárólag sybase adatbázis esetén él, gyanítom, hogy nem olyat használsz . -
cucka
addikt
válasz
 Orb1337
#2821
üzenetére
Orb1337
#2821
üzenetére
Ha egyelőre újdonság neked a php és a mysql, akkor javaslom, hogy az Ajax-ot, meg az Ajax-os js keretrendszereket egyelőre hanyagold.
Az Ajax egy sor ergonómiai problémát is felvet, nem véletlen, hogy a legtöbb profi weboldal nem használ Ajaxot a tartalom újratöltésére. -
cucka
addikt
Igazából az a hiba, hogy nem arra használod az osztályodat, amire való.
Az osztály változóit csak deklarálni kell, alapértelmezett értéket a konstruktorban kapjanak. Az osztály változóinak megadásakor lehetőleg mellőzd a var kulcsszót, helyette specifikáld az adott változó láthatóságát, vagyis hogy public, protected vagy private típusú-e az a változó.
A var kulcsszó a php4 teljesen elb*szott oop részének a maradványa, akár el is hagyhatod. Ha nem specifikálod a láthatóságot, akkor az alapértelmezés szerint public lesz.Itt egy példa, hogy kb. hogyan képzeld el..
class imageUpload{
private $id;
public $basedir;
public $maxuploadsize;
public function __construct($p_id, $p_basedir=null){
$this->id=$p_id;
if ($p_basedir) $this->basedir=$p_basedir; else $this->basedir=$this->id;
$this->maxuploadsize=10;
}
} -
#2775
cucka
addikt
Louloudaki
#2774
cucka
addikt
válasz
Louloudaki
#2774
üzenetére
Korábban ideírtam egy függvényt, valami hasonlóval tudod megoldani a problémát, mert pl. a latin1-es kalapos ű-t semmi nem fogja neked automatikusa utf8-as rendes ű-re konvertálni.
(Nyilván, amit beírtam, az utf8->latin1 konverzió, neked a fordítottja kell) -
#2766
cucka
addikt
Louloudaki
#2765
cucka
addikt
válasz
Louloudaki
#2765
üzenetére
Sem iconv-al, sem mb_convert_encoding-al, sem pedig utf8_decode-al nem fogja helyesen kezelni a magyar ékezetes betűket.
Itt egy példa, ami utf8-as szöveget alakít át iso-8859-1 kódolásra. A kód az ű betűből kalapos ü-t csinál, mert jobbat nem tudunk ebben a karakterkódolásban, de ez alapján el lehet indulni. A lényeg, hogy a problémás karaktereket kicseréljük valamire, utána használjuk a php beépített függvényeit (itt utf8_decode-ot, de iconv is jó neked), utána a lecserélt karaktereket ismét lecseréljük az új kódolású megfelelőikre.
function my_utf8_decode($p_str){
$str=str_replace(array('ő','ű','Ő','Ű'), array('&o";', '&u";', '&O";', '&U";'), $p_str);
$str=utf8_decode($str);
$str=str_replace(array('&o";', '&u";', '&O";', '&U";'), array(chr(0xf5), chr(0xfb), chr(0xd4), chr(0xdb)), $str);
return $str;
}Ami még fontos, hogy az excel csv export-jának karakterkódolása változó lehet, tehát gyakorlatilag nem lehet hozzá normális feldolgozó programot készíteni.

 . Nem azt mondom, hogy szórjuk tele a php-t html kóddal, de az szerintem mindegy, hogy a kiiratásnál php szintaxissal illeszted be a változókat vagy a sablon saját szintaxisával.
. Nem azt mondom, hogy szórjuk tele a php-t html kóddal, de az szerintem mindegy, hogy a kiiratásnál php szintaxissal illeszted be a változókat vagy a sablon saját szintaxisával.
 . A loadmodule mondja meg az apache-nak, hogy használja a php modult, az addtype pedig azt, hogy a .php file-okat dobja át a php modulnak)
. A loadmodule mondja meg az apache-nak, hogy használja a php modult, az addtype pedig azt, hogy a .php file-okat dobja át a php modulnak)



























Új hozzászólás Aktív témák
- PlayStation 5
- Linux Mint
- Soundbar, soundplate, hangprojektor
- Pendrive irás-olvasás sebesség
- Audi, Cupra, Seat, Skoda, Volkswagen topik
- One otthoni szolgáltatások (TV, internet, telefon)
- Pánik a memóriapiacon
- World of Warships
- Elektromos autók - motorok
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- További aktív témák...

- HP Zbook 15 G6, I7-9850H CPU, 32GB,1024GB SSD, Nvidia Quadro T2000, 15.6" FHD IPS, WIN11 Pro
- Újszerű Lenovo Ideapad Gaming 3 15ACH6 eladó!
- Acer 15.6",FullHD,core i3 8145U(4x3,9Ghz)MX230 2/4GB DDR5VGA,8-20GB RAM,SSD,szép állapot,Win.11
- Eladó NAS HDD - WD Red 8TB 3.5" 5400rpm 256MB SATA3 (WD80EFAX)
- 2év Garancia,Lenovo Slim 3,i5 12450H(12x4,4Ghz)15,6"FullHD IPS,Magyar vil.bill,8-16GBDDR5 RAM,512SSD
- BESZÁMÍTÁS! MSI B450M R5 5600X 32GB DDR4 512GB SSD RTX 4060 TI 16GB ZALMAN Z1 Plus A-Data 650W
- Apple iPhone 16 Pro 128GB,Újszerű,Dobozával,12 hónap garanciával
- LG 25GR75FG - E-Sport Monitor - FHD 360Hz 1ms - NVIDIA Reflex + G-sync - AMD FreeSync - HDR 400
- Bomba ár! HP ProBook 440 G5 - i5-8GEN I 8GB I 256GB SSD I HDMI I 14" FHD I Cam I W11 I Garancia!
- ÁRGARANCIA!Épített KomPhone i5 12400F 16/32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi