- Google Pixel topik
- One mobilszolgáltatások
- Erős hardverrel érkezik a Honor 10 000 mAh-s mobilja
- iPhone topik
- Fenntartható, tartós kiegészítőket mutatott be a Fairphone
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Telekom mobilszolgáltatások
- Zeiss triplakamera az új Vivo V60-ban
- Samsung Galaxy S24+ - a személyi asszisztens
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
Hirdetés
-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
válasz
 bjasq99
#71011
üzenetére
bjasq99
#71011
üzenetére
Erre lenne jó az, ha akár kicsit gyengébb,de eltérő node-on gyártják a gamer kártyákat és akkor nem kell egyik kezükbe sem harapni. A csúcs node pedig mehet AI / robotika iparba.
Szerintem az Intellel ha összejön a 18A az Nvidiának a gamer kártyákra az AMD is elkezd ilyesmiben gondolkodni.
Plusz most kellene lépni MCM irányába, mert a több kisebb GPU összekötözése egyértelműen előnyös a gyengébb gyártások kihozatalának, mint a hatalmas monoliktikus GPU-k, miközben teljesítményt is lehet nyerni vele.
Szerintem mindkettőt meglépik a zöldek,utána a 3D stackek is leszivárognak a gamer szegmensbe közben a fotonikus gyártás is megérkezik. [link]
Nagyjából ez lesz szerintem az elkövetkező 3-5 generáció forgatókönyve.
Az AMD is visszatér ebbe az irányba szerintem. -

bjasq99
tag
válasz
bjasq99
#70755
üzenetére
Szóval ahogy ígértem egy szerintem lehetséges helyzet amikor a dinamikus allokáció elhasal és végtelen ciklusba kerül.
Alap helyzet: Több wave is nagy regiszter mennyiséget akarna foglalni, de az egyiknek már nem jut elég.
Következmény: A wave leáll addig ameddig nem szabadul fel számára elég regiszter.
2. Feltétel a végtelen ciklushoz: Képzeljük el hogy a megállított wave ben fel kellene oldani egy lockot (vagyis egy memória címet visszaadni a közösbe, hogy ne csak az az egy wave használhassa), miközben a futó wavekben fut egy ciklus ami azt ellenőrzi hogy fel van e oldva már a lock. Az ilyen esetben a nem futó wavenek kellene feloldania a lockot, de mivel nem fut így nem tudja, ezért a másik wavek nem tudnak előre haladni a végrehajtással és így regisztert sem tudnak visszaadni, ami miatt nem fog tudni futni a nem futó wave... és így tovább, létrehozva a végtelen ciklust. -
bjasq99
tag
válasz
bjasq99
#70754
üzenetére
Szóval az általam már boncolgatott helyzetben amikor a szálak max regiszter terhelése egybe esik és együtt több regisztert foglalnának mint amennyi hardveresen van, akkor ez deadlockhoz is vezethet. Én elöször azt írtam hogy ilyen esetben nyilván meg kell állitani egy wavet, de a deadlock is logikus leírom miért. Azt azonban nem tudom hogy ilyen helyzetben mindig deadlock lesz a vége mert túl sok az allokálni kívánt regiszter vagy csak bizonyos helyzetekben mint pl amit a következő hozzászolásomban leírok.
-
#70751
 bitblueduck
senior tag
bjasq99
#70746
bitblueduck
senior tag
bjasq99
#70746
-
bjasq99
tag
válasz
bjasq99
#70745
üzenetére
Vagyis összefoglalva: csak compute shaderekben, egy workgroupban nem lehet mixelni a dinamikusan nem dinamikusan allokáló threadeket, nem mehet le 0 nagyságúra egy thread regisztere, és nem is terjeszkedhet a teljes regiszter állományra, és csak wave 32 ben működik. Szóval vannak azért megkötések a használatára.
-

paprobert
őstag
válasz
bjasq99
#70251
üzenetére
Teljesen jól értelmezed. A throughput és a kihasználtság csökken, elkerülhetetlenül, amint elkezdődik az erőforrás shuffling.
Cserébe a choke pointok csökkennek, ha egy wave valami oknál fogva kétszer akkora regiszterterületre szeretne terpeszkedni, és a további konkurens feldolgozás függött ennek az eredményétől.
Más értelmezésben:
A jövő regisztermennyiségével dolgozhat az adott shader a ma hardverén. Vagy kevesebb HW-es regisztermennyiség is elég lehet ugyanolyan branchelés mellett.Vagyis nincs ingyen ebéd, az univerzalitása viszont nő a hardvernek.
-
paprobert
őstag
válasz
bjasq99
#70243
üzenetére
A compiler által előállított kód hint-eli a parancsmotort az allokációról. Én egyedül így tudom elképzelni.
így is sokkal nagyobb mint a geforcoké és nyilván azért a fejlesztők nem hagyják megdögölni a geforce implementációját, (hisz övék a piac)
A fejlesztők kényelmét (is) szolgálja, indirekten a szoftver-kompatibilitást növelheti, és az AMD driver költségeiből faraghat. Ebből a szempontból nyerő fejlesztés, de valóban, ettől még nem a farok fogja a kutyát csóválni.
-
paprobert
őstag
válasz
bjasq99
#70232
üzenetére
Csak tippelek, de szerintem van egy hardveres QoS modul, ami kiegyensúlyozza a dolgot, valószínűleg a parancsmotorban.
Ez nekem egy lassan beérő fejlesztésnek tűnik amúgy.
Mikrobenchmarkban lehet villogni vele, hogy kétszámjegyű az előrelépés XY együttállása esetén, de valójában ez egy csendben, háttérben dolgozó funkció, ami a nagy képet nézve nem állítja a feje tetejére a papírformát. -

hokuszpk
nagyúr
válasz
bjasq99
#67550
üzenetére
"Tegnap pl egy multi platformos cpu cache latency tesztelőt írtam ami órajel ciklusban méri ki a cacheid és ramod latencyét. "
az enyemet ugyan nem !
- mert nemkülted át
itt az ideje, hogy ennyi tapasztalattal megmutasd szerencsetlen hwfejlesztőknek, mire vágyik az igaz cuda/opencl programozó !
![;]](//cdn.rios.hu/dl/s/v1.gif)
** de amugy csak kitört a hétvége, és a mai nap után ennek épp nagyon örülök.
-
bjasq99
tag
válasz
bjasq99
#67545
üzenetére
Akár a cpuk úgy a gpuk regiszter területeik több portot szolgálnak ki. A tensor core egy ilyen port része ami a regiszter területből kapja az adatokat feldolgozásra. Másik portokon helyezkednek el "cuda" magok amik ugyanazt a portot érik el. Egy órajel ciklusban elméletben több különböző portra adható ki munka ( ha van elég operandus) , de egy porton belül lévő egységeknek nem lehet egyszerre munkát kiadni ( ez a port konfliktus ). Más kérdés hogy úgy tudom hogy egy ilyen sm negyednek ( az sm negyedének külön ütemezői vannak ) csak egy dispatch unitja van szóval nem tud két utasítást elkezdeni 1 órajelben egy ilyen negyed, szóval az nvidia nem dual issue hardver. A tensor core így tud párhuzamosan futni: a dispatch unit az első órajel ciklusba kiadja a munkát a az egyik cuda mag portnak ami egy 16 széles simd -t tartalmaz , de egy warp 32 elemből áll szóval a comit hoz 2 órajel ciklus kell. És itt jön az hogy a masodik órajelciklusban a dispatch unit már szabad, így ő már ki tud egy másik végrehajtandó utasítást adni egy másik portnak egy másik warpból , pl egy tensor portnak vagy egy másik cuda portnak.
És akkor így a két operáció párhuzamosan fut.
Ezért fölösleges dual issue nak és co issue nak nevezni az Nvidia hardverét mert különböző warpokból egymás után kerülnek ki a párhuzamosan futó micro op -k. -

Abu85
HÁZIGAZDA
válasz
bjasq99
#67531
üzenetére
Az más. A CDNA-ban tényleg van erre dedikálva részegység, ami csak és kizárólag erre jó. Az RDNA3-ban viszont úgy van, hogy van egy alap SIMD, és van egy Matrix Unitos SIMD. Ebből jön ugye a dual issue. Tehát ha van AI feladat, akkor a Matrix Unit le van foglalva, ha viszont nincs AI feladat, akkor mehet a dual issue. Ezt persze bonyolítja a variálható wave-méret, de alapvetően a SIMD32-es működés ilyen.
#67532 Raymond : A GPU-k ma statikus erőforrás-allokációt használnak. Előre betöltik a teljes shadert úgy, hogy x számú wave-et futtatnak majd a multiprocesszoron. Ezzel tudják átlapolni a memóriaelérést. Ha a teljes regiszterterületet megkapja a SIMD az NV dizájnján, akkor elég sok wave futhat, de ha más részegység is aktív, például a Tensor, akkor nyilván az is tárolni fogja a regiszterben az adatokat, tehát a SIMD-nek kevesebb terület jut. Ezáltal ugyanazt a shadert kevesebb wave-en tudja futtatni. Ettől még egyébként lehet elég sok wave a memóriaelérés átlapolására, de lehet, hogy nem elég, és akkor jelentősen romlik a sebesség. Ez a tényező a SIMT elvű GPU-k alapvető működéséből ered.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#67527
üzenetére
Igazából lehet használni a fő ALU-t Tensor mellett is, csak a gond az, hogy ugyanaz marad a regiszterterület. Ha a fő ALU egy olyan shadert futtat, ami teszem azt 10 wave-vel tud menni, akkor ha a Tensor aktív lesz, akkor ez a szám csökkenhet mondjuk 3 wave-re. És ez már elég lesz arra, hogy ne működjön hatékonyan a hardver. Tehát elméletben működhet a shader és a tensor együtt, csak azt fogja elérni a fejlesztő vele, hogy nem lesz elég adat a feldolgozáshoz, így nem lapolható át jól a memóriaelérés késleltetése. Emiatt nem szokták együtt működtetni a tensort és a fő ALU-kat. Nagyon sokszor hasznosabb, ha csak az egyik aktív, mert még két multiprocesszort bevetve is gyorsabb lesz a feldolgozás a nagyobb wave-szám miatt.
#67528 bjasq99 : Az RDNA3-nál lényeges, mert ott a SIMD-nek és az Matrix Untinak külön regiszterterülete van. Tehát ott a két egység úgy tud működni egymás mellett, hogy nem zavarják egymást. Az NV-nél ez annyiban más, hogy közös a regiszterterület, tehát ha együtt dolgozik a tensor és a SIMD, akkor nagyon lassítják egymást.
-

Raymond
titán
válasz
bjasq99
#67522
üzenetére
De erted hogy a 7900XTX-nel az a 123 mindent csinal, nem ugyanaz mintha kulon egysegek lennenek erre. Kontextvaltas stb. Az FSR-nalis lathatod hogy tobb teljesitmeny veszik a Radeon kartyakon ha bekapcsolod az FSR-t mint a GF-en ha bekapcsolod a DLSS-t mindezt ugy hogy joval rosszabb minoseget produkal. Ahhoz hogy ugyanazt a minoseget produkalja mint a DLSS3 (nem is a DLSS4) vagy az uj FSR4 amit lattunk az alltalanos magokon ahhoz te menyi sebessegbazuhanast lennel hajlando vallalni? Mert itt nagyon hamar a ketjegyu szamok birodalmaban talanad magad.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#67525
üzenetére
Igen, de valószínűleg itt az a kérdés, hogy honnan jön az x TFLOPS. Viszont jelenleg igazából mindegy, mert mindegyik architektúrában közös regiszterterületen osztoznak a feldolgozók, akkor is, ha különállók. Tehát együtt nem igazán tudnak működni. Mellesleg az egész kérdés irreleváns, mert az AMD-nek is van az RDNA 3-ban AI-ra szánt feldolgozója, csak ők Matrix Unitnak hívják.
-
válasz
bjasq99
#67519
üzenetére
TensorRT Model Optimizer akár 2/3 ad sebeséggel gyorsabb FP4 támogatással. és az nem mindegy hogy natívban mekkora számítási teljesítményt kapsz.Ez egy dedikált hardverelem amin erre van optimalizálva a végrehajtás sebessége.
Ugyan ez volt az RTX voice-nél is hogy akár 15 % teljesítmény vesztéssel járt más architektúrán miközben a Ampere ugyan azt a sebességet hozta. -
Raymond
titán
válasz
bjasq99
#67509
üzenetére
"Pontosan ismerem az architektúrákat,"
De nem ugy nez ki, mert a ket ertek teljesen mast takar a ket kartyanal. A Radeon eseteben a "shared core"-ok FP16 teljesitmenye, tehta ez a max amit a kartya kipresel magabol. Ez a 2080Ti-nal kb. 26, az amit te irtal hogy 113 az a tensor magokon futo FP16 szamitasok pluszba.
-

Micsurin
nagyúr
válasz
bjasq99
#67503
üzenetére
Még mindig nem akarod érteni
Elvégezheted köztes layerrel az ML számítást, de marhára nem lesz ugyan az a végrehajtási időd mint dedikált ML magokkal.Nem mindegy milyen futószalagon akarok milyen számítást végig küldeni. Konkrétan NINCS az AMD-nek még mindig 1:1 hasonló teljesítményű hardveres válasza az NVIDIA megoldására. Az újakkal már lehet majd okoskodni, de még mindig nem fognak ott tartani architektúra fejlettségben.
Az RDNA3-at meg full felesleges felemlegetni ebben a kérdésben...amit max lenne értelme az CDNA a Matrix magokkal, de az ismét egy másik kérdés. -
Abu85
HÁZIGAZDA
válasz
bjasq99
#67476
üzenetére
Fut egy ilyen projekt. Csúcskategóriában nem lenne vállalhatatlan. Ott adhatod a cuccot 1000 dollárért, és a képszámításhoz használt puffereket több TB/s-mal lehetne elérni. Akár teljes BVH-t bele lehetne menteni. Ez a mostani VRAM-ig menetelős módszernél nagyságrendekkel gyorsabb. Gondolom itt arról van szó, hogy most tesztelik. Megéri beletervezni a mostani lapkába teszt szintjén, mert alapvetően csak 1-2 mm^2-nyi pluszt jelent. Ha jól sikerül, ki is adhatják, de valószínűleg olyan lesz, mint az 5800X3D. Első körben ilyen nulladik generációs próbálkozás.
-

Jacek
veterán
válasz
bjasq99
#67470
üzenetére
Elviekben nemnazert dobjak a felso hazat mert a kovetkezo genben ujra egyesul a ket arhitektura? Es nem.akartak eroforrast erre pazarekolni?
Valami jon van ujdonsag kuss a kovetkezo genig
Elore vetitem nem vagyok csodavaro, de ami most kijott az NV-tol az is egy siralom volgye....Pl en a 4090 annyira meg tudtam huzni hogy 100%-ot utott az elozo 3090-re szintetikus benchekben.
Kivancsian varom most ez megvalosul e Szerintem a 4080S sem lesz meg duplan pl. Timespyban.. Ennyit a fejlodesrol.. -
Abu85
HÁZIGAZDA
válasz
bjasq99
#67470
üzenetére
A középre persze, hogy nem reális. A 3D V-Cache nem annyira olcsó. Meg korábban nem volt realitás, mert felülre kellett helyezni, de a mostani megoldás alulra megy. És nyilván egy ilyen GPU-s rendszerrel a cél az lehet, hogy a képszámításhoz használt pufferek ne a memóriába kerüljenek, hanem a cache-re.
-
hokuszpk
nagyúr
válasz
bjasq99
#67434
üzenetére
errefelé szilikont a cicibe teszünk, és nem lehet elég nagy
szvsz nemkell a cache lapkat 4nm -en gyartani, eleg hozza a 6nm node is annak talán már csökkent az ára. A 2.5D tokozás az még lehet drága, nemtom mennyire bővítette fel a TSMC ezt a tevékenységet.
no mind1, amint beiktatták Trumpot, mi is meglassuk, hogy baziL3cache * 8 vagy koherenciamatek esetleg mindketto. -
bjasq99
tag
válasz
bjasq99
#67427
üzenetére
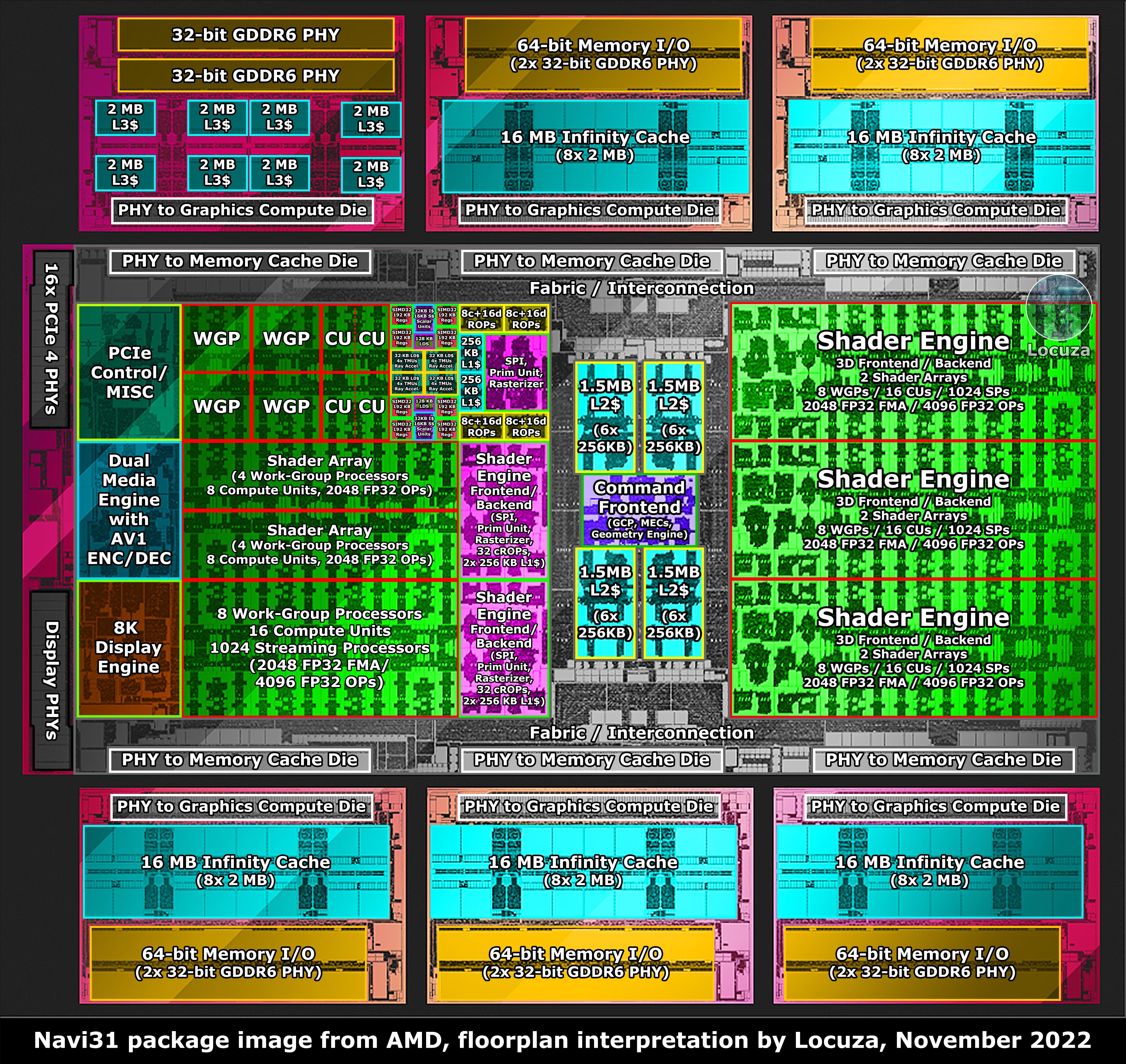
Igaz a 7xxx szériában az io die -ok -ra került a cache, de az sem x3d cache. És egyáltalán nem olcsó megoldás az ilyen nagy szávsélességet biztositó tokozás megoldása. Valamint az IO die -okat sem lenne gazdaságos megduplázni, lásd ezt a képet az rx 7900 xtx ről és gondolj bele hogy nézne ki ha 2x akkora lenne az a hat io die.
.jpg)
-
hokuszpk
nagyúr
válasz
bjasq99
#67424
üzenetére
"Mekkora hely maradna a többi egységnek? "
tokmindegy, az L3 cacherol beszélünk, AMD "infinity cache", ami egy külön csak cachet tartalmazó lapka és ujabban ( Zen5 óta ) a compute lapka alá heggesztenek. ( x3d ismerős ? ) Már a Radeon 6xxx -is megkapta, de sajnos a legnagyobb ( 6900XT ) is csak 128MB -t.
-
hokuszpk
nagyúr
válasz
bjasq99
#67401
üzenetére
ezeket már nagyjából összeszedtem, pár éve volt egy cpu cache thread, ahol kiokosítottak
ott még volt valami olyan is, hogy a cache meretet el kell osztani a cache line meretevel, es akkor ugye kijon, hogy a cacheba hány line fér. Aztán a fizikai memoria meretet elosztjuk a cache lineok szamossagaval, es nagyjabol az igy kijovo memoriablokkmerethez lesz rendelve egy cache line. Aztán a srácok még ezt is elkezdték tovább bonyolítani
no mindegy, március 31 -ig ki fog derülni, hogy mit talált ki az AMD ; addig leteszem a dollárt a bazinagy cache * 8 mellé, mert abba 8x annyi adat fér, mint a simán csak bazinagyba. -
hokuszpk
nagyúr
válasz
bjasq99
#67377
üzenetére
én ebben annyira nemvagyok szaki, szóval csak az alantas paraszti logika marad ; de
"Elöször is nem csak az számít, hogy mennyi a hit/miss arány, hanem a cache teljesítménye,"
szvsz a "cache teljesitmenye" az pont a hit/miss aranyon dol el. ha mondjuk 10/20 hit/miss aranyt sikerul 10/10 -re szoritani, az jelentosen javithatja a teljesitmenyt. Nekem itt falun ez jon ki. Lehet magasabb szintu matematikaval be lehet bizonyitani, hogy nem ; de nem volt olyan tanarom, aki addig a szintig elmagyarazta volna.
" Ha két eltérő compute uniton futó szál is, ugyanahhoz a memória területhez nyúl, akkor duplikálva lesznek az adatok( mindkét privát cacheben benne lesz) "
tokmindegy ; az a lenyeg, hogy a bazinagy L3 -ban legyen benne, akkor mindket privat cache onnan nyalhatja fel, nem az lesz, hogy eloszor a lassu memoriabol kell behozni.
Persze valamikor be kell hozni, meg ugye kerdes, hogy az L3 az AMDnel szokasos "L2-bol kieso" adatokat fog tartalmazni, vagy megis csinaltak valami fejlettebb elobetoltest, ami még dobhat rajta picit. Az egesznek az a lenyege, hogy minel kevesebbszer kell a memoriahoz fordulni.
Ami meg a "ket szal egy cu -n futhatna" -t illeti, az inkabb utemezesi kerdes, ha az ütemezo felismeri, hogy rokonok, es ugy intezi, hogy lehetoleg 1 cu -ra keruljenek, az jo ; ha meg nem, akkoris segithet rajtuk a magasabb L3 hit.
röviden : szvsz mint mindenhol, itt is igaz, hogy altalaban a legegyszerubb megoldas adja a legjobb eredmenyt, amit aztan +3-5-10% teljesitmenyert el lehet kezdeni bonyolitani, de perpill a leggyorsabban megoldhato megfejtes az L3 meretenek novelese... -

HSM
félisten
válasz
bjasq99
#60343
üzenetére
GPU cache-ről beszél a dia, nem IC-ről, vagy legalábbis nem egyértelmű.
Egyébként tisztában vagyok a cache rendszerek működésével, de szerintem az is nyilvánvaló, hogy ha ennyire jól cache-elhő lenne egy GPU, akkor nem kellene alá TB/s nagyságrendű memória sávszélesség... Sajnos nem vagyok kellően naprakész GPU-architektúrákból, pontosan milyen adatokért nyúlkál a különböző cache-ekbe, melyik részegység mekkora méretű adatokon dolgozik, azok mennyire cache-elhetőek, de biztos vagyok benne, hogy ez egy komplex és messzire vezető témakör.
Azért mindenesetre felraktam ezt a profilert, ha lesz kis időm belekukkantok majd mivel szorgoskodik a 6800XT-m.
 Szerintem van még itten felfedezni-való.
Szerintem van még itten felfedezni-való. 
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60343
üzenetére
Ennél egy kicsit bonyolultabb. Például az AMD specifikusan ment bizonyos adatokat. Az L0 elsődleges feladata a textúrázók és az RT egységek kiszolgálása, és emiatt elég jó lesz a hit rate, mert jellemzően jól cache-selhető koherens adatelérésekről van szó. Az L1 cache már jóval univerzálisabb, az már számos olyan munkafolyamatra is vonatkozik, ami nem jól cache-selhető. Ezen túlmenően sok adat közvetlenül az L2-be lesz kiírva a multiprocesszorból. Tehát az L1 cache rossz hit rate-je attól van, hogy olyan adatok kerülnek bele a mögötte lévő memóriákból beolvasva, amivel nem mindig lehet jó hit rate-et elérni.
Az L2-nél sok múlik azon, hogy az AMD mennyire épít az IC-re. Mert amíg régebben muszáj volt ebből kiszolgálni a ROP-ot, addig manapság már építhetnek arra, hogy van egy védőhálójuk, ami ugyis felfogja a szükséges gyorsítótársorok egy részét, tehát nem muszáj az L2 cache nagy részét rosszul cache-elhető ROP műveletekre használni.
-
HSM
félisten
válasz
bjasq99
#60317
üzenetére
Érdekes cikk volt, köszi a hivatkozást.

#60322 Raymond : Pedig az AMD által közzétett adatok is őt támasztják alá: 10MB nagyságrendű cache-nél alig van hit-rate [link] . Persze, jó lenne látni, pontosan milyen helyzetekről is van szó, de a footnote kb. csak annyit mond, hogy a modelljeik alapján.
#60332 Petykemano : Alakul, ahogy várható volt. Kezdenek szimpatikus ársávba kerülni az AIB kártyák.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60317
üzenetére
Mert csak kiemel hívásokat, de nem csak ennyi a grafikai feldolgozás. Az L2 legnagyobb terhelői a ROP-ok, mert azok az L2 kliensei a modern GPU-dizájnokban (a Maxwell és a Vega óta). A legnagyobb L2 terhelés is innen érkezik, hiszen messze ezek mennek a legnagyobb adamennyiségért a memóriába. Az persze tök jó, hogy a kb. 8 kB-os memóriaigényű shaderek jó hitet érnek el az L2-ben, de a ROP-ok már nagyon nem, és ezek felelnek az L2 adatmásolások legalább 98%-áért. Ezért épített az AMD Infinity Cache-t a lapkákba akár 100 MB-ot, mert az egyszámjegyű megabájtos L2-t teljesen kiheréli a ROP. Alig van cache hit benne a lapok cseréjével. De ez így normális, egyszerűen túl sok adat mozog túl aprócska gyorsítótárban.
#60318 b. : Az Infinity Cache csak egy védőháló, ami felfogja a kidobott L2 lapokat, amelyek kellhetnek még a ROP-nak. Ezt nem lehet program oldaláról befolyásolni, így értelmetlen lenne láthatóvá tenni. De van egy kulcs hozzá, ami megmutatja, csak ahhoz nem elég developer módba kapcsolni a drivert. Szükséges a support mód is, azt meg csak a kiemelt fejlesztők kapják meg.
#60320 b. : A CPU-limiten az tudna javítani, ha nem emulálná a bindlesst az NV driver. Ez egy szoftveres probléma, nem hardveres. Amikor kidobják az összes hardver támogatását az Ampere-ig, akkor át tudják írni a drivert bindlessre, de ehhez előbb meg kell szüntetni a Maxwell, a Pascal és a Turing terméktámogatását.
-

PuMbA
titán
válasz
bjasq99
#60317
üzenetére
Ez az oldal nagyon baró, mert sok NVIDIA infó is van az AMD mellett és így van architektúra összehasonítás
"AMD and Nvidia thus make different tradeoffs to reach the same performance level. A chiplet setup helps AMD use less die area in a leading process node than Nvidia, by putting their cache and memory controllers on separate 6 nm dies. In exchange, AMD has to pay for a more expensive packaging solution, because plain on-package traces would do poorly at handling the high bandwidth requirements of a GPU.
Nvidia puts everything on a single larger die on a cutting edge 4 nm node. That leaves the 4080 with less VRAM bandwidth and less cache than the 7900 XTX. Their transistor density is technically lower than AMD’s, but that’s because Nvidia’s higher SM count means they have more control logic compared to register files and FMA units. Fewer execution units per SM means Ada Lovelace will have an easier time keeping those execution units fed. Nvidia also has an advantage with their simpler cache hierarchy, which still provides a decent amount of caching capacity."
-
válasz
bjasq99
#60317
üzenetére
ah ez egy remek cikk ,nagyon köszi!
Igazi kincs ez az oldal, végre!
Nagyon érdekes hogy a CPU nál a a találati arány az L0+ L1 esetén kifejezetten magas, ,GPU nál extra alacsony 25 % körüli és az L2 ben pedig több mint 90 % ra emelkedik, ... tehát pont a nagy L2 az ami a hitrate javarészét lehozza.
ami még nagyon érdekes hogy nehezményezi a cikkiről hogy a magasztalt AMD a profilozó nem enged betekintést az Infinity cache működésébe, nem tudnak kiolvasni belőle adatokat. -
válasz
bjasq99
#60184
üzenetére
pedig szerintem erre ott a válasz amit írtál:
"Azt ne mond, hogy egy általános eljárás jobb lehet minőségre!"
Szerintem az a válasz ,amit leírtam, hogy igen jobb.
Elvi síkon persze hogy az lenne ha jó ha mindenki magának készítené el a tökéletes felskálázást és azt ráadásul tökéletesen végezné el,( itt és eddig van igazság abban amit te írsz) de nincsenek egyforma képességű és mennyiségű fejlesztők, szakember, tudás, pénzösszeg és infrasktruktúra és egyforma/ megfelelő hardverek egy neurális háló tréningeléséhez minden stúdiónál és nem tudja mindenki kihozni a maximumot egy egy eljárásból , grafikai motorból, még elvileg sem, nem hogy gyakorlatilag. -
bjasq99
tag
válasz
bjasq99
#60182
üzenetére
Az egész onnan indult, hogy mitől jó egy feature, kell hozzá e a támogatottság.
Na ez attól függ, hogy hogyan definiáljuk a feature jóságát.
Én úgy definiálom, hogy ha elméletben mindent megtesznek a feature kihasználása érdekében, akkor az sokat ad a felhasználónak.
Ezért mondom, hogy az Fsr újítása is csak innovatív mert lehet nem fogják soha kihasználni a tudását. Ezért írtam, hogy a feltételes időben a dlss 1 jóságát is, ott sem támogatták elággé.
Te szávaidból kivéve pedig valahogy úgy definiálod a feature jóságát, hogy számításba veszed a fejlesztési költséget, és a terjeszthetőséget.
Ezen definíció esetében nyilván a támogatottság nem a jó feature feltétele, hanem következménye. -
válasz
bjasq99
#60182
üzenetére
Érthető amit írsz,de Hiába gondolkodsz elvi síkon ,ez ma már életképtelen.
Nézz körül melyik kiadónak és játékgyártónak van ma ideje elkészíteni egy hibátlan és bugmentes játékot , mert én ilyennel utoljára Nintendon találkoztam, de pc-n ?
Ha ez a fejlesztőkre lenne bízva, soha nem kapnál értelmes minőséget egy felskálázási megoldásból, sőt több lenne a rossz minőség cserébe egy-kettő -talán néhány esetben jobb FSR vagy DLSS játékért. Ebben biztos vagyok, főleg, hogy a mostani eljárások általánosan már jó minőségűek.
Olyan megoldás kell szerintem egy játékkészítőnek, ami gyors , olcsó, és viszonylag/ általánosan jó minőségű. Nem pedig olyan ,ami drága, sok munkát és időt igényel és jó minőségű.
Ráadásul ez utóbbi megint azt eredményezné, hogy egyes gyártók kártyáin jól futna míg másokon nem lenne elérhető vagy bugos lenne.
Így az van, hogy hiába hívják DLSS-nek vagy FSR-nek vagy XeSS-nek minimális fejlesztői munkával megkapja az egész piac abban a játékban.( állítólag 1 nap alatt átültethető egy
temporális kód a másik gyártói megoldásra, tréningelés és varázslat nélkül) -
válasz
bjasq99
#60180
üzenetére
Erről szól a DLSS 2.0 és 2.1. és ide csatlakozott be a z FSR 2.0 a temporális oldalon mert az FSR 1.0 már életképtelen lett minőségben a DLSS 2.0 val szemben..
Tovább kellett lépniük egy általánosan jobb megoldásra, mert a DLSS 1.0 drága volt és az mellett hiába tréningelted volna 100 évig ,se lett volna jobb, mert például a vékony vonalakat , tárgyakat nem tudta kezelni megfelelően. -
válasz
bjasq99
#60178
üzenetére
Az nvidia szálította nekik a neurális hálót NGX modulban.igényelhettek/ vehettek gépidőt, annak tréningezéséhez vagy kaptak ingyen,ha támogatott /szponzorált cím volt.
A trénigeléstől függetlenül DLSS1 technikai korlátait ennyit tettek lehetővé, ezért léptek tovább róla.Egyértelműen tartalmazhatnak, számomra a következtetés véleményes megint én nem az AMD FSR -jére tettem véleményt, hanem az nem okozott meglepetést a kommentben hogy Nvidia és Intel lemaradásba került ezzel szemben és dogozniuk kell a lemaradáson...
megint.. -
válasz
bjasq99
#60173
üzenetére
Nem attól függ szerintem egy feature minősége, hogy mennyire támogatott. ( A vulkan akkor nem is létezhetne Dx 12-vel szemben mégis több szempontból jobb.)
Ez a "normálisan" kifejezést nem értem ide vonatkoztatva. . A DLSS1 technikai korlátai ennyit tettek lehetővé ez nem azt jelenti hogy nem foglalkoztak vele a "gyártók" .( itt nem tudom kikre gondolsz ez alatt.) -
#60170
 Petykemano
veterán
bjasq99
#60166
Petykemano
veterán
bjasq99
#60166
Petykemano
veterán
válasz
bjasq99
#60166
üzenetére
Igen.
Nekem az eddigiekből az jött le, hogy az Nvidia előnye...
... olyan, Orbán narratívaképzése, hogy mindig van valami valóságalapja, csak sokszor valami egészen elképesztőt és mégis rendkívül meggyőzőt kreál belőle, amiért igazán lelkesedni lehet...
... Illúzió, varázslat.Annyival nem tart előrébb, annyival nem jobb, nem annyival van több vagy kevesebb hiba, stb mint amennyinek látszik. A megítétélésben eső hatalmas differenciát az amúgy nem túl széles különbségekre épülő sales/marketing sikerek láttatják hatalmasnak.
Na és ha már úgyis ez az út, akkor miért ne lehetne egy FSR-ops értéket megdobó fixfunkciós hardvert/fpga-t beépíteni? Nem azért, mert az feltétlenül szükséges, hanem csak hogy legyenek szép számok (meg persze eredmények), amire lehet veretni.
-
bjasq99
tag
válasz
bjasq99
#60163
üzenetére
Az Nvdiára is értve az előzőket. Mert az, hogy egy ennyire gyártóspecifikus algoritmust megoldjuk a compute unitokba integrált tensor core -okkal az szerinem sokkal pazarlóbb mintha a gpu ban lenne egy külön részegység amely a mostani tansor core -k feladatát látják el.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60155
üzenetére
Teljesen valid a felvetés, és egyébként már most is lehet ilyet csinálni, az FSR2 ugyanis etethető extra adatokkal, ami pont azokra a helyzetekre van, ahol ezek a felskálázók csődött mondanak az általános jellegük miatt.
[link] - az UE4-re ez bővebben ki van fejtve.
Valószínűleg idővel elmegy mindegyik felskálázó abba az irányba, amerre ment az FSR2, hogy extra adatokkal javítható a működés. És akkor az általános rendszer specifikusan konfigurálhatóvá válik. Az AMD itt előreszaladt, mert az irány egyértelmű, bizonyos helyzetekre sosem fognak tudni reagálni az általános megoldások, így ezekre külön kerülőutak kellenek.
-
válasz
bjasq99
#60146
üzenetére
alapjába véve a DLSS és az FSR új verziója "kompatibilis" egymással. Minimális munka működésre bírni az egyik eljárást ha benne van a másik.
AMD is hozza a frame generálást,(Fluid Motion Frames néven) nem lennék meglepve ha az is így működne. Amúgy az RX sorozaton már most is aktiválható a frame generation az Nvidia által és Intelen is megy.[link]
Így szinte a játékfejlesztőknek érdektelen lenne ebbe plusz munkát befektetni ekkora hardveres lefedettségnél és sokszínűségnél, ha a hardvergyártóknál működik az átjárhatóság és a megfelelő hardverekre megoldják ők.
Valószínűleg pont a hardveres diverzitás az oka, hogy ezt nem lehetne megfelelően megoldani engine szintjén. -
válasz
bjasq99
#60122
üzenetére
Az OEM vasarlo sok minden, csak eppen nem fanatikus, messze nem melyed bele annyira, a szo amit keresel, az a korai benyomasok alapjan reszrehajlo/komformista a folytatolagos vasarlasai soran, de ez is kisebb szelete.
Az OEM (magan, nem ceges) vasarlo leginkabb max budget orientalt.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#60137
üzenetére
A PC-s DXR-ben nyilván nem egyszerű, mert az API úgy működik, hogy a TLAS és a BLAS-ok közötti kapcsolatok fixen meg vannak határozva a gyorsítóstruktúra kiépítésekor. Tehát menet közben nem lehet eldönteni, hogy mi történjen, ha az adott sugár belép az egyes boxokba. Ehhez programozhatóság kell per-objektum szinten, de ezt maga az API nem támogatja. Viszont technikailag nem nehéz, mert a Microsoft DXR-nek az Xbox Series verziója meg már támogatja ma is. Tehát a kód létezik, csak nincs megegyezés a PC-ben róla, ami valószínűleg abból ered, hogy a PC-s DXR-hez használt egyedi BVH adatstruktúra-formátumot a tulajdonosa nem akarja megnyitni, enélkül pedig programozhatóság sem lesz. Ezért csinálja most azt az AMD, hogy akkor áthozzák PC-be az Xbox nyílt egyedi BVH adatstruktúra-formátumát, és akkor a DXR-rel meg topogjon egy helyben a Microsoft ameddig akar.
#60138 Yany :
- Az RT-t a Microsoft hozta el a DXR-ben.
- Valójában az RT PC-s megvalósításban hígfos, és mindaddig az lesz, amíg nem lesz programozhatóság a TLAS és a BLAS-ok között. Csak olvasd el egy elismert fejlesztő véleményét a témában: [link] - nem úgy írja le, mintha egy működő valami lenne. Az, hogy a user nem ért hozzá az rendben van, de vannak akik érteken hozzá és leírják, hogy nem jó. Máig nincs reakció a felvetett tényezőkre. Illetve az NV tervezett az Adába olyan újításokat, amik ezeket megkerülik, de itt az lesz a probléma, hogy egy generációig működő fejlesztésekről van szó, tehát x játékot mondjuk megírnak Adára, és a next-genen már fos lesz a sebesség, mert nincs rászabva a kód a friss architektúrára. Tehát minden egyes játékhoz kell tartani egy VGA-t abból a generációból, amire ki van alakítva a kerülőút. Tényleg ezt akarjuk? Nem lenne jó mondjuk szimplán per-objektum leprogramozni a problémára a megoldást traversal shaderrel? Persze tudom, jobb a gyártóknak, ha mindig új GPU-t veszel, csak hangosan gondolkodom ezzel az ördögtől való programozhatósággal.
- A DLSS1-et hozták akkor, és mindenki mondta, hogy fos. -
Abu85
HÁZIGAZDA
válasz
bjasq99
#60133
üzenetére
Az RT jelenleg alig működik, mert maga az API holt szar. Az Ada esetében az NV pont azért vezette be a két újítást (OMME, DMME), hogy reagáljanak a holt szar API-ra, de ez csak Ada GPU-kon működik, vagyis mindenki, aki már vett eddig RT hardvert, dobhatja ki a kukába, mert iszonyatosan lassú lesz a compute shader emuláció. Ez csak bajt fog hozni az egész rendszer fejére, mert innentől kezdve minden generációban kerülőutazni kell az API-nak a masszív hiányosságait, vagyis minden generációban megvásárolt hardver mehet a kukába, mert megváltozott a kerülőút.
Ezért pofázom egy ideje, hogy ezt a gondot programozhatóság nélkül nem oldjuk meg, mert minden generációban új hardvert kell venni az új kerülőkhöz, amivel az API-t "gyógyítjuk". Erről szerinted hány vásárló tud, hogy a rendszer jelenleg csak egy generációig kínál kompatibilitást? -

Busterftw
nagyúr
válasz
bjasq99
#60122
üzenetére
Az OEM vasarlasokat az is befolyasolja, hogy az Nvidia nagyobb keszlettel es valasztekkal van jelen a piacon, tobbfele verzioban/kiepitesben, tobb markaval dolgoznak.
Nagyon sokaig az a problema a mai napig, hogy hiaba volt egy kompetetiv AMD mobil CPU "bejelentve", aztan honapokig nem volt elerheto, utana meg vadaszni kellett az azzal szerelt laptopokat.
Desktopon AMD kartyaval szerelt rendszereknel szinten problema, hogy az AMD nem gyartat eleget, meg most sem, pedig nincs kapacitas gond. (es nincs love gond)Az AMD odamegy a Dell/Corsair/random prebuilt gyartohoz, hogy figyi itt az uj Radeon, tudok szallitani 50k/ev, a Dell kirohogi, mert mondjuk evi 5 millio "gamer" PC megy el.
-

Yany
addikt
válasz
bjasq99
#60118
üzenetére
Az AMD a legtöbb újkori feature-jét az NV után dobta be, hiába free formában, az innovatőr szerepet egymás után bukja el. Ahol viríthatott volna egy brutálisat, a low-level API-k frontján, azt a ziccert iszonyatosan kihagyta. A "minőségi" brandet is folyamatosan alulbecsüli és el is bukja, illetve a "professzionális" attitűd sincs a hétköznapi emberek tudatában (Quadro, Tesla, ugye, NVENC, stb). Szinte minden fronton, ami nem price/perf mutató, abban az NV előrébb van. És a kartell gyanú folyton folyvást csilingel a fülemben, mert a hajlandóság sem mutatkozik, miközben árban sem igazi a verseny. Minden oldalról ordít, hogy az AMD nem, vagy alig akar ezen változtatni, pedig nem hülyék ülnek ott sem a tervezőasztal/szervező/marketinges/egyéb management osztályokon. Ha mi látjuk, nekik is kell látniuk, és igen, ezek már nyilvánvaló, nem pedig véleményes különbségek az NV javára.
Erre a látszat-versenyre innen belföldről egy másik témában is tudnék erős analógiát, de nem akarom ennyire eloffolni a dolgot.
-
#60123
Petykemano
veterán
bjasq99
#60122
Petykemano
veterán
válasz
bjasq99
#60122
üzenetére
> Igen az Oem vásárlók nagy része valószínűleg valamilyen mértékben fanatikus
Én erről nem vagyok ennyire meggyőződve.
Elképzelni is inkább az ellenkezőjét tudnám: a prebuilt gép / notebook vásárlók többsége szerintem inkább felületes ismeretekkel rendelkezik, azok a hírek érik el, amik az origón és az indexen megjelennek. Olyan benyomásaik vannak az Nvidia és AMD kártyákról, mint ami alapján az emberek mosószert, vagy hűtőmárkát választanak. "Legyen jó" és élnek a feltételezéssel, hogy ha már valaki veszi a fáradtságot, hogy jó drágán összerakja neki, akkor nem fogja a rosszabbat választani.Vajon hány ember veszi figyelembe az 1-2 évente megjelenő mosószer-teszt eredményét ahelyett, hogy az megszokott, reklámokban gyakran látott, megbízhatónak gondolt márkát emelné le a polcról?
-
#60107
Petykemano
veterán
bjasq99
#60104
Petykemano
veterán
válasz
bjasq99
#60104
üzenetére
Első reakcióm:
De akkor tényleg ennyire nem lehet semmit se tenni? Tényleg ennyire rugalmatlan, merev a piac, ennyire erős a brand-hűség? Tényleg ennyire széleskörben ismertek és nélkülözhetetlenek az Nvidia ismertebb és elvileg jobb szoftveres feature-jei?Nem mondom, hogy nem.
És bizonyára nem egyösszetevős kérdés. Mármint lehet, hogy csak egy hibátlan driver, vagy jobb szoftveres környezet, vagy egyértelműen gyorsabb és energiahatékonyabb sem törné meg az Nvidia brand-értékét.Aztán eszembe jutott, hogy a mindfactory adatai alapján azért általában az AMD és Nvidia piaci részesedése nem annyira szélsőséges, mint a JPR jelentésből ki szokott tűnni. Persze ez csupán egyetlen bolt egy országban, de legalábbis ott nem úgy tűnik, hogy a olyan elsöprő mindshare-rel rendelkezne az Nvidia, hogy az AMD szinte csak a futottak még kategóriában van. (legalábbis persze eladási darabszám alapján)
Nem lehet, hogy arról van szó, hogy a kártyák teljesítménye, teljesmény/W, teljesítmény/ár mutatója, szoftveres környezete, driverhibák, királytermék, vagy bármi, ami brand-hűséget, mindshare-t okoz, amihez az Nvidia kártya vásárlás motiváltságát tulajdonítjuk, valójában nagyonis meg tudja mozgatni az ilyen dolgok iránt érdeklődő közönséget, és egy árverseny meg tudja dobni az eladásokat, de ez a közönség a DIY piacon vásárol és a DIY piac az összeladásokat tekintve kisebbség. Tehát egy jó akcióval hiába fordítana az AMD a DIY piacon akár 20-30-40%-ot is, ez a változás az összeladásokban csupán 4-5%-nyi elmozdulást jelentene, mert a volumen az OEM-ek prebuilt desktop és notebook gépeiben keletkezik.
Persze a jobb termék, jobb teljestmény, jobb perf/W mutató, meg az ár itt is számít, de talán egész más módszerekkel lehet meggyőzni egy végfelhasználót, mint egy OEM partnert. ÉS persze kétségtelen, hogy a márka-hűség nyomhatja az OEM-et is: "a vevőink ilyen vagy olyan processzorral vagy videokártyával szerelt gépet keresnek", de azért a benchmarkon kívül mégiscsak megjelenhetnek más szempontok is.
A jó mutatók megléte alap, de például bejöhet olyan szempont is, hogy tud-e az adott gyártó az igényelt volumenben szállítani.
Ezt a szcenáriót látszik igazolni az is, hogy Abu a részesedés 8%-ra esésést azzal magyarázta, hogy az AMD felhagyott a Polaris12 forgalmazásával.
MLiD a tegnapi videóban említette, hogy pl a professzionális kártyáit az Nvidia is csak Retail-ben adja $7000-ért, nagy tételben vásárolva $3000-4000-ért megkapható.
Nyilván hasonló kedvezményrendszer konzumer videokártyák vonatkozásában is van OEM-ek irányába.Az általam felvázolt szceniárió hibája az, hogy ha a DIY piac valóban annyira kicsi, hogy az ottani versengés csak elhanyagolható százalékban befolyásolná a teljes piaci részesedést (és persze volument), akkor annak is igaznak kéne lennie, hogy ha az AMD vagy az Nvidia ott mondana le kártyánként $50-100-ról, annak is elhanyagolható bevételkiesést kellene jelentenie. Tehát akkor miért ne lehetne versengeni?
Erre nehéz nem azt gondolni, hogy azért, mert az OEM eladások nagy volument jelentenek ugyan, de a nagy megrendelésért folytatott nagy verseny alacsony haszonkulcsot eredményez, míg a "békés" DIY piacon az alacsony volumenre elképesztően magas hasznot pakolnak. -
#60106
 Alogonomus
őstag
bjasq99
#60104
Alogonomus
őstag
bjasq99
#60104
Alogonomus
őstag
válasz
bjasq99
#60104
üzenetére
Az AMD fókusza az elmúlt években sokkal inkább a megrogyó Intel piaci pozícióinak átvételére irányult (Ryzen, EPYC), miközben az Nvidia professzionális termékeinek is konkurenciát készítettek az Instinct termékvonallal. Azért ezekre fókuszált az AMD, mert ezekkel lehet a legnagyobb egységnyi hasznot kitermelni, és az AMD gyártási kapacitása még mindig bőven elmarad az Inteléhez képest.
Szerintem az AMD a gaming GPU szektorra most csak annyi energiát fordít, amivel teljesíti az általad is leírtakat. "Az Amd -nek elég a mostani ár is, hogy megadja vásárlói számára a lelki nyugalmat a price/performance körében."
Valószínűleg nincs komoly különbség a fanatikus Nvidia és fanatikus AMD hívők száma között. Mind a két csoport nagyjából a vásárlók 15%-át teheti ki, vagyis a vásárlók 70%-a megfelelő ajánlattal meggyőzhető. $900-os 7900 XTX és $750-os 7900 XT bevetésével az elkötelezetlen 70% túlnyomó része valószínűleg az AMD felé mozdult volna el, de ezzel az AMD kevesebb hasznot tudott volna megtermelni a korlátozott gyártási kapacitásával, mint amennyit ugyanazzal a gyártási kapacitással megtermel az EPYC/Threadripper/Instinct vonalon, ahol igazából legfeljebb az Instinct nincs generációs előnyben a konkurencia termékeihez képest.
A gaming GPU szektorban elérhető nyereségarány sehol sincs a szerverek területén elérhető nyereségarányhoz képest, és az AMD haszonmaximalizál.Közben persze az AMD nem hanyagolta el a gaming területét sem, de inkább a konzolokon keresztül ügyködött, aminek a hatékonyságára a legtökéletesebb példa valószínűleg az új 9-es IW engine, illetve az UE 5, amik már egyértelműen az AMD kártyáknak fekszenek jobban. A kérdés már csak az, hogy az AMD, vagy az Nvidia tudja majd hatékonyabban orientálni a játékfejlesztőket egy bizonyos játékmotor irányába.
Szóval extrém mértékben erős price/performance high-end gaming kártyára szerintem nem számíthatunk az AMD részéről a közeljövőben, mert az RDNA kártyák csak a CPU-k, alaplapi chipsetek és CDNA termékek, valamint a konzolok APU egységei után megmaradó gyártási kapacitás terhére készülnek. -
#59867
Petykemano
veterán
bjasq99
#59845
Petykemano
veterán
válasz
bjasq99
#59845
üzenetére
Ez egyébként szerintem is érdekes kérdés.
Elvileg az N5 előnye sűrűség kéne hogy legyen. A lapka nagy része N5-on készült elég magas, megsüvegelendő tranzisztorsűrűséggel.Túl a L0 regiszter méretkülönbségén....
Locuza rajzainak tanúsága szerint az infinity interconnect kapcsolatonként az MCD-ből és a GCD-ből mindössze 6-6mm2, összesen 36mm2. Mondjuk összességében nem kevés. Nem csak lapkaméretben, hanem biztos tranzisztorszámban is. A TPU szerint átlag 111.0M / mm² a tranzisztorsűrűség, ha ezzel számolunk, akkor ez is lehet 3-4mrd tranyó.
Az MCD-ken nem csak L3$ és GDDR vezérlő van, hanem TSV is, hogy fogadni legyen képes a 3D a v-cache-t. Abu szerint azt elkaszálták, de attól még foglalja a helyet és a tranyókat. A kiterjedése úgy sacc/kb lehet akkora, mint az interconnect PHY. Azt persze nem tudom, hogy az ott mennyi tranyót jelent.
Azt sem tartom lehetetlennek, hogy az MCD esetén annyira nem törekedtek a helytakarékosságra, hiszen ott azt is figyelembe kell venni, hogy méret szerint passzoljon a V-cache-hez. Tehát nem kizárt, hogy van ott némi "structural silicon" is.
Számomra a GCD-n elég soknak tűnik a szürke terület, ami "Fabric/Interconnection" néven szerepel. Nem vagyok szakértő, de kissé pazarlónak tűnik. Olyna mintha nagyon sok területet (és tranzisztort?) emésztene fel a széleken elhelyezett memóriavezérlőktől központi parancsprocesszorig és L2$-ig a huzalozás. Nekem úgy tűnik, mintha az Nvidiánál kevesebb ilyen szürkével jelölt csupán adatszállításra használt, de legalábbis másnak nem azonosított részegység lenne. A különbség magyarázata lehet valami olyasmi, hogy az AMD esetén a széleken levő L3$ és a központban levő (jó messze) L2 között lényegesen nagyobb sávszélesség van, mint az Nvidia esetén a széleken levő GDDR6 vezérlő és a központban levő nagy L2$ között.Elképzelhető, hogy a Navi33 esetén, mivel jóval kevesebb a GDDR kapcsolat, azért hatékonyabb elrendezést tudnak használni és ott is kevesebb az "huzal".
(Nem emlékszem, mi a szakkifejezés rá, de egy videoban láttam, hogy a 3D stacking azért is fontos előrelépés, mert mivel a tranzisztorsűrűség épp a jellemzően a lapkán belül levő részegységek esetén skálázódik és a lapka szélein levő adatkapcsolatra szolgáló (PHY-k) meg nem, ezért egy idő után egyre inkább szűkösebbé válnak a lapkák szélei és egyre több lehet a holt terhet jelentő huzalozás "befelé"Ami még számíthat az az, hogy a Navi33 esetén biztos nem lesz 16x PCIe PHY. a 200mm2-be bizonyára csak 4x fért el és valószínűleg a Media engine sem dual.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#59796
üzenetére
A szemetelést csak koherenciamotorok oldhatják meg, és olyanra még nem nagyon dolgoznak a hardverek. Az Imagination Wizard dizájnja volt ilyen több éve, de olyan tranzisztortöbblettel jár, hogy már az Imagination is kidobta a rendszert, mert jelenleg bőven olcsóbb szoftveresen ügyködni a koherenciáért.
#59797 bjasq99 : A fixfunkciós bejárás igazából csak amiatt jelent orbitális korlátozást, hogy a BVH geometriája nem streamelhető. Ez konkrétan azt jelenti, hogy a sugár kilövésének pillanatában be kell állítani a LOD szintet, és az később nem módosítható, akkor sem, ha csak egy pixelt foglal el a kijelzőn a több millió háromszögből álló objektum. A jelenlegi PC-s RT API-k kötelezővé teszik a több millió háromszög leszámolását RT-ben egy szem pixelnyi információért is. Ezen a problémán segítenek a programozhatóság azzal, hogy a sugár kilövésekor csak egy kezdeti LOD szint lenne, de az később módosulhatna akkor, ha a sugár átlép egy másik AABB dobozba, vagyis streamelhetővé válik a BVH geometriája. Nem mellesleg a nem látható objektumok is kivághatók lennének. Ma még ez sincs. Ha egy objektum nem is látszik, mondjuk eltakarja teljesen egy fal, akkor is muszáj RT-ben leszámolni, mert az API nem ad lehetőséget a kivágására a programozhatóság hiányában. És akkor még nem beszéltünk arról, hogy ez mekkora többletigényt jelent a VRAM tekintetében.
Ha csak ezt a problémát megoldaná az ipar, akkor brutálisat gyorsulna a rendszer PC-n, mert egy csomó, amúgy teljesen felesleges számítás, aminek úgy sem lesz látható eredménye, eltűnne.#59800 Yutani : Igazából tuningprogramokat a jövőben is lehet fejleszteni, csak nem az ADL, hanem az ADLX SDK-val. [link] - Az RDNA 3 már nem támogatja az ADL-t. Az át lett rakva legacy-ba. Az ADLX annyiban más, hogy újraírták a nagy részét, és ezzel reagáltak arra a sokat kritizált tényezőre, hogy a régi ADL-nél driver főverziókhoz kötött a működés. Vagyis bármikor jöhetett egy olyan driver, ami a 3rd party tuningprogramot működésképtelenné tette. Az ADLX ezt módosította úgy, hogy ha egyszer meg van írva a program, akkor az oda-vissza kompatibilis marad a driverekkel. Tehát a program kiadása előtt és után megjelentekkel is működni fog a rendszer.
Erre a gyártók is átírják a tuningprogramjaikat, és természetesen a MorePowerTool is átírható. Már csak azért is lényeges ezt meglépniük, mert a régi ADL-től idővel elvágja a drivert az AMD, ugyanis nagyon sok panaszt okozott az minden oldalról, hogy jött egy driver, és nem működött tovább a rendszer, amíg nem frissítették a driverhez a 3rd party tuningprogramot. Ezért hozták az oda-vissza kompatibilitást, hogy ilyen többet nem fordulhasson elő, de ahhoz át kell állni ADLX-re a 3rd party tuningprogramon belül.
-
Abu85
HÁZIGAZDA
válasz
bjasq99
#59793
üzenetére
Nem. A sugárkövetésre valójában nagyon szarok a hardveres megvalósítások. Azért szenved ez a terület, mert egy csomó dolog nem programozható a futószalagon, így nem lehet optimalizálni, hogy gyorsan fusson.
A DXR ugyanazon a fejlődésen fog átesni, mint anno a hardver T&L. Először fixfunkciós volt, aztán jötte a programozhatóság. Sőt, Xbox Series S/X konzolon már át is esett ezen az elmúlt évben.
#59794 Petykemano : Azért van így felosztva a lapka chipletben, hogy elég legyen az 5,3 TB/s.
-
HSM
félisten
válasz
bjasq99
#59759
üzenetére
"de adott termékek esetén nem ez kell hogy meghatározza döntéseinket hanem a nyújtott szolgáltatás"
Az egyik nagy probléma ezzel, hogy ha most veszel egy VGA-t, akkor annak csak a múltbeli játékok teljesítményéről, és a jelenleg elérhető szolgáltatásaival fogsz tudni tapasztalatokat szerezni. Nem tudhatjuk pl., hogy az Nv beharangozott RT-s fejlesztései mennyire fognak bejönni [link] ahogy az AMD-é sem [link] . Ugyanakkor arról lehet némi fogalmunk, hogy melyik mennyire széleskörűen alkalmazható, gondolok pl. az Nv-féle újítások egy részének szoftver oldali támogatás-igényére. Ugyanakkor vélhetőleg ha ma veszel egy 1-2000 $/€ értékű VGA-t, akkor az elkövetkező években megjelenő címekhez is veszed, nem csak az aktuálisan elérhetőkhöz... Ezt pedig a technikai leírásoknak kellene bizonyítania, hogy jó helyre teszed a pénzed, és nem lesz egy év múlva papírnehezék a kártya.Egyébként egyik implementációval sem vagyok maradéktalanul elégedett. Az Nv-é szvsz túl kötött, az AMD-é nem mindig elég gyors.
-
bjasq99
tag
válasz
bjasq99
#59759
üzenetére
Akit érdekel annak kicsit még jobban kifejtve nézeteimet:
Tudok mondani olyan részleteket amik alapján tényleg az amd hardverek a fejlettebbek, de ugyanakkor tudok ennyi dolgot mondani ami miatt a Geforce -ok lehetnek a jobbak és persze végtelen számú info van amit egyikünk sem fog megtudni. Ezen sok érv és ellenérv tömkelegéből sosem fogjuk tudni kibogozni, hogy akár adott folyamatra melyik hardver a jobb elméletben. Az a fő mit látunk gyakorlatban. Azt inkább le se írom mindenki megtudja ítélni saját magának, hogy ki mit lát az Amd és az Nvidia termékeiben úgymond szolgáltatásaiban.








![;]](http://cdn.rios.hu/dl/s/v1.gif)

 Azonban köszönöm a választ!
Azonban köszönöm a választ! 



















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- Bomba ár! HP Zbook 15 G5 - i7-8750H I 32GB I 512SSD I Nvidia P2000 4GB I FHD I Cam I W11 I Gari!
- Playstation Dualsense PS5 kontrollerek
- BESZÁMÍTÁS! AOC 24B1XHS 60Hz FHD IPS 7ms monitor garanciával hibátlan működéssel
- Eladó SAMSUNG Odyssey G3 LS24AG320NRXEN 24'' Sík FullHD 165 Hz 16:9 FreeSync VA LED Gamer monitor
- Új és újszerű 13"-14" Gamer, ultrabook, üzleti készülékek nagyon kedvező alkalmi áron Garanciával!
Állásajánlatok

Cég: FOTC
Város: Budapest