-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#35373
 Abu85
HÁZIGAZDA
Petykemano
#35372
Abu85
HÁZIGAZDA
Petykemano
#35372
Abu85
HÁZIGAZDA
válasz
 Petykemano
#35372
üzenetére
Petykemano
#35372
üzenetére
Na most erről már vannak érdekes dolgok a gyártóknál. A Radeon Pro SSG az csak ma egyedi professzionális termék. Hamarosan lejut a koncepció gamingbe is. Persze nem 1 TB-os SSD-vel, de a Samsung simán gyárt majd 128/256 GB-osat, ha erre VGA-k szintjén van igény.
-
#35369
Abu85
HÁZIGAZDA
Petykemano
#35368
Abu85
HÁZIGAZDA
válasz
Petykemano
#35368
üzenetére
Semmit nem kell programozni itt. Az AMD úgy csinálta a saját tesztjeit, hogy fogták magukat, és a 8 GB-os Vega VGA-n letiltottak a 8-ból 6 memórialapkát. Ezzel csináltak mesterségesen egy 2 GB-os VGA-t, majd ráeresztették azt a tartalmat, amihez HBCC nélkül kb. 8 GB kell. Így a HBCC-s 2 GB-os kártya HBCC nélkül nagyon lassú volt (nyilván hiányzott a memó a pazarlás mellett), HBCC-vel pedig hozta a 8 GB-os mód eredményeit, holott csak 2 GB-nyi HBC-je volt. Ezt így lehet bemutatni, mert ma még nincsenek 16-24 GB VRAM-ot igénylő tartalmak. Egyedül a Middle-earth: Shadow of War olyan, hogy 14 GB-nyi VRAM kell neki ideálisan, amit nyilván nem kap meg semmitől, ezért ha ennyit beállítasz HBCC csúszkával minimum, akkor gyorsul a játék 15%-ot.

Ezt egyébként a letölthető motorokkal ki lehet próbálni. Simán tudsz olyat csinálni, hogy csak úgy heccből csinálsz egy demót, ami 20+ GB-nyi VRAM-ot igényel. Ezzel én szórakoztam, amíg itt volt a Vega 56, és egészen 22 GB-ig nem lassult be. Utána kezdte érezni azért a határokat. Ha letiltottam a HBCC-t, akkor sima 8 GB-tal diavetítés volt. Persze sok függ itt a motortól is, azért én eléggé arra építettem, hogy direkt marha sok egyedi tartalom legyen a kijelzőn, ahogy fordulgatok. Minden csempének egyedi 4K-s textúrát adtam, stb. Direkt erre gyúrtam ki, hogy küldje padlóra.
Azt egyébként nehéz megmondani, hogy ennek hol a határa. Elméletben tudom, hogy az AMD 256 TB-ra állította a hard limitet a gaming kártyáknál, és 512 TB a limit a PRO Vega termékeknél, ez egyébként a hardver tényleges elméleti limitje. De, hogy hol a reálisabb határ azt nehéz belőni. Kellene olyan gép, amiben van 128 GB memória, és akkor meg lehetne nézni a 64 GB-os HBCC beállítást, én magamnak 32 GB memóriát tudtam csak kunyerálni.
-
#35366
 Z10N
veterán
Petykemano
#35359
Z10N
veterán
Petykemano
#35359
Z10N
veterán
válasz
Petykemano
#35359
üzenetére
Abbol meg van keszleten?
-
#35363
 Jack@l
veterán
Petykemano
#35362
Jack@l
veterán
Petykemano
#35362
Jack@l
veterán
válasz
Petykemano
#35362
üzenetére
Még mindig nincs kint 4gb-os vega, pedig mennyivel olcsóbb lehetne a gyártás.
Nem azt mondom hogy nem működik, hanem azt hogy bazi lassú realtime grafikához. Cad-ben 10fps-hez talán jó, de azért ott már húzzák a szájukat a mérnökök... -
#35361
Jack@l
veterán
Petykemano
#35358
Jack@l
veterán
válasz
Petykemano
#35358
üzenetére
 ))
))
Ha elég lenne fele vram, már rég azzal tolnák orrba-szájba... Nem véletlen hogy csak szájkarate van róla és ahol lehet 4gb-ra húzzák meg a határt (amd supported) játékokban.
4K full ultra tomb raiderre kíváncsi lennék mit művel hasonló kaliberű kártyán 4gb vs 8gb vrammal. Még senki se akrta ezt a mérést kiposztolni. -
#35343
 Yutani
nagyúr
Petykemano
#35341
Yutani
nagyúr
Petykemano
#35341
válasz
Petykemano
#35341
üzenetére
Ez de fájt!

-
#35335
 #45185024
törölt tag
Petykemano
#35329
#45185024
törölt tag
Petykemano
#35329
#45185024
törölt tag
válasz
Petykemano
#35329
üzenetére
Cáfolat 2. hivatalos
Az első prioritású régiók az APEC* és Latin-Amerika. Ezután az ASRock fokozatosan elindítja az üzleti tevékenységet más régiókban .
A híres latin amerikai piac érted ...ne viccelj gringosz mucsosz 580osz
*APEC= Asia-Pacific Economic Cooperation (ázsiai és a csendes-óceáni térségben létrejött gazdasági és politikai szövetség)
-
#35334
Z10N
veterán
Petykemano
#35333
Z10N
veterán
válasz
Petykemano
#35333
üzenetére
Ok. A lenyeg, hogy vegre van valami. Akkor viszont juniussal bezarolag be kell jelenteniuk.
-
#35332
Z10N
veterán
Petykemano
#35326
Z10N
veterán
válasz
Petykemano
#35326
üzenetére
Lehet ez lesz a pipe-cleaner, belepo vega12 7nm-n. 2,6-3TFLOPS-szal nem is olyan rossz, maximum $99-ert.
Ui: Csak meg osz elott lehessen kapni

-
#35327
#45185024
törölt tag
Petykemano
#35326
#45185024
törölt tag
válasz
Petykemano
#35326
üzenetére
Azt akarod mondani hogy 1980 Mhz a max a Vega 12-nél ? ?
Jobb ha sietnek mert a dream team elemében van !... EZÉRT -
#35318
 Z_A_P
addikt
Petykemano
#35315
Z_A_P
addikt
Petykemano
#35315
Z_A_P
addikt
válasz
Petykemano
#35315
üzenetére
Pedig AMD jovoje ezen mulik, minden az EPYC-re van epitve. Ott van igazan sok $ es %.
-
#35316
 awexco
őstag
Petykemano
#35315
awexco
őstag
Petykemano
#35315
awexco
őstag
válasz
Petykemano
#35315
üzenetére
Mindezt úgy , hogy bizonyos tudásban sokkal jobb mint az intel ....
remélhetőleg 2. szériát jobban viszik majd ... -
#35297
 JordyG
tag
Petykemano
#35296
JordyG
tag
Petykemano
#35296
JordyG
tag
válasz
Petykemano
#35296
üzenetére
Szándékosan nem tettem OFF-ba. S bár ez egy szakmai fórum, azért előfordul, hogy a szakma sem szakmaiasan működik, van, hogy éppen kontárkodva.
Szerintem elég egyértelmű.
 Nem tudtak értelmeset válaszolni, a nem kicsit gyanús vádakra (nem is tudtak, hisz akármit mondanak abból se jönnek ki jól), és elejébe próbáltak menni egy komolyabb vizsgálódásnak. (bár elég egyértelmű volt a szándék, így nem engedném el és folytatni kéne, mert egy büntetés alaposan kijárna) Számukra a történet már lényegtelen, minden márka behódolt, és amit akartak elérték. (Asus, MSI, ..... és tovább) Így erre a programra ilyen formában már nincs szükség!
Nem tudtak értelmeset válaszolni, a nem kicsit gyanús vádakra (nem is tudtak, hisz akármit mondanak abból se jönnek ki jól), és elejébe próbáltak menni egy komolyabb vizsgálódásnak. (bár elég egyértelmű volt a szándék, így nem engedném el és folytatni kéne, mert egy büntetés alaposan kijárna) Számukra a történet már lényegtelen, minden márka behódolt, és amit akartak elérték. (Asus, MSI, ..... és tovább) Így erre a programra ilyen formában már nincs szükség!
Ha nagyon vájogparaszt akarok lenni, akkor azt sem tartom kizártnak, hogy elejétől ez így volt a terv.Az teljesen már mindegy mi lesz ezután, mert ha úgy kell mondani szétverették a márkák házon belüli eddigi rendjét, és mint látható ez nem feltétlen csak az elnevezéseket vonja magával, hanem esetlegesen minőségbeli retardálást, ami mindenképpen szar helyzet. Vajon erre az Asus, MSI és aki már feltárta magát nem fog visszatáncolni (???), így a piacnak mindenképpen ártott.
Már ezért megérdemelnének egy hatalmas pofont.Innentől már senkit nem érdekel, a tudatos vásárlón kívül, hogy bemegy Gyuri a Boltba, és egy ROG Strix-et kérek, fel se tűnik neki, hogy csak NVIDIA GPU-val szerelt van, elkönyveli vagy mert az előző is ezzel a névvel volt (hogy az a legjobb) mert fel sem ötlik benne mert nem lát, hogy AMD GPU-val szerelt is lehetne, és lehetne választása. Mert történni az fog, hogy Asus Arez Strix néven jön AMD, és legyint, hogy ez új ezt nem ismerem és még csak nem is Gémer (elvégre nem ROG) inkább biztosra megyek.
Ennyit számít egy már bejáratott név, kb. mintha eztán Cola név alatt csak Coca lehetne a polcokon és a Pepsi-nek új nevet kéne adni, és lekerülne az olcsó tucat áruhoz.
Ettől, és ezen a ponton sérül a vásárló szabad választásának joga és gyakorlata. Ha felnéz valaki az Asus oldalára, láthatja, hogy az új Arez név kb. úgy lapul ott a semmiben, mintha eddig is ott lett volna, mint valami mostoha gyerek, aki iskolás lett, csak előtte senki nem látta. Ez csak akkor lett volna tiszta, ha bekerül a ROG csoport alá, és ott lesz külön NVIDIA és RADEON külön szál elkülönítve, de a teljes kizárás az olyan mint az ellenfél csapatának legjobb játékosát szándékosan felrúgni így küldve le a pályáról.A Kaby Lake G ott sántít, hogy lényegében egy ideiglenes termék, amíg az Intel nem hozza a saját minden téren házon belüli megoldását. Az ilyen alapokra készült gépek, egyebekre jó eséllyel szabnak majd ők ruhát, elnevezést, ha gémer, ha nem, erősen elkülönítve az egyéb egybe vagy DIY gépektől, kihangsúlyozva.
A probléma persze nyilvánvaló, hogy processzor mellé kerül az eddigiekhez képest erős vga.Csak, hogy érthető legyek, én értem az NVIDIA álláspontját is, hogy megpróbál előre menekülni, mert ha eljön az idő... és mivel mi ezt még nem tudhatjuk jelenleg.. De ha a Navi a Radeon részéről valóban 1080-as teljesítményt tud adni $250 dollárért ahogy egyes információk erre alapoznak (ami még annyira nem is probléma
 ) viszont ezt egy processzor(-ba -ra) is rátudja tenni, na ott kezdtek számukra redőnyt szerelni a lehúzáshoz.
) viszont ezt egy processzor(-ba -ra) is rátudja tenni, na ott kezdtek számukra redőnyt szerelni a lehúzáshoz.
S ugye a jövő ez, az Intel is ezen dolgozik, tehát van két processzor gyártó, és lényegében három gpu. Ebből kettőnek van CPU részlege, a harmadik pedig amennyiben nem talál (VIA ???) partnert, akkor záros idővel megfojtásra kerül.Amit ebből sokan nem értenek, hogy az NV nem belefog lépni egy csapdába, hanem már most megfogta őket a rókacsapda. Nem CPU gyártó, így kiszorulhat jelentős piacról ami ma a gémer szekció, és legjobb esetben csak a felsőkategória marad, mert az alsó, és közép beköltözik a CPU-kba, és marad még a professzionális állomások, és egyéb.
Viszont az életben maradásnak nem ez az útja, amit most látunk, láthattunk. Ez egy veszett vad vagdalózása, és ebből érezhető a baj. Legalább is az NVIDIA számára.De ez is megmutatja, hogy van gatyaféken tartva, a jövő és innováció. Ahogy amíg az Intel sem volt rákényszerítve nem lépet magszámot, és hatalmi játszmában, és a profiért mindenre hajlandó volt.
Az NVIDIA akárhogy is látszik, és éves bevétel rekordokat döntöget, hatalmas bajban van, a már vázoltak miatt.
Jelenleg egy olyan vonaton ül, amin az Intel is, amiről csak nyers erővel lehet őket leszállítani, de a kalauz az állomáson a WC-ben ragadt. Ők meg addig kidobálnak mindenkit a vonatról. (ezt láthattuk a memória piacon is, és ennek is köszönhető a jelenlegi helyzet, és árak - Samsung-Hynix-Micron, és a Kartel -)
De egyszer eljön a következő állomás, ahol a kalauz helyet a rendészet vonul fel a járatra, és lehajigálja a randalírozokat.Mit lehet ilyenkor tenni???
Egy mezei pénzbüntetés, semmit nem ér, ez már az Inteles ügy esetén is kiderült, és sok egyéb területen ahol előkerült a regula, így olyan mód kell ami valóban érzékenyen érinti, ott fogja meg ahol igazán lehet.
Ha én lennék egy bíró egy ilyen ügyben, akkor az ítélet olyan jellegű lenne, ahol a legnagyobb fájdalmat okoznék az adott cégnek. Az éves profitjának 25%-át a konkurenciának kéne utalja 5 évig (már csak a várható bevételkiesés miatt is, és hiába az éves rekordbevétel, ez annál jobban fáj minél nagyobb), és a reklám egyéb kampányaiban ki kéne hangsúlyoznia, hogy van más alternatíva a saját termékén kívül, és, hogy miben más.Az, hogy mi lesz eztán majd kiderül, az biztos, hogy nem lesz jótékony hatással a piacra.
Az NV most egy rossz gyerek volt, aki mindenkit megdobált sárral, amit nehéz lemosni, majd ki jól végezte dolgát elmegy a cukrászdába sütizni és jégkrémezni.
Csak végül nehogy majd a fagyi nyaljon majd vissza. -
#35268
 TTomax
félisten
Petykemano
#35264
TTomax
félisten
Petykemano
#35264
TTomax
félisten
válasz
Petykemano
#35264
üzenetére
Nem,de 5éven belül nem lesz belőle semmi.Majd egyszer ez lesz a jövő,de addig jó néhány dolgot meg kell oldani,először is le kell menni olyan csíkszélességre ahonnan nagyon hosszú idő a továbblépés,aztán meg kell oldani a skálázódás/órajel gondot mert nem éppen errefelé megyünk mostanában,aztán a hűtést is meg kell oldani valahogy,és még sorolhatnám.Szerintem ebből csak akkor lesz valami amikor már nem lesz hova tovább,és akkor sem biztos hogy ebben a formában,mert ami jó egy telefonba az nem biztos hogy jó lesz egy gpunak.Lehet keveset is mondtam az 5 évvel,akár 10 is lehet.
-
#35266
Jack@l
veterán
Petykemano
#35260
Jack@l
veterán
válasz
Petykemano
#35260
üzenetére
Azért kérdeztem hogy teszemazt X tranzisztoros lapkából 4-et tudnak egymásra pakolni. De azt csak 500mhz-es órajelen stabilan, mert benntreked a hő(akár leolvad a két középső mag), akkor annak mi értelme van? Miközben 1 db elketyeg már ma is 1600+mhz-en, de a 2000 se kizárt.
-
#35261
TTomax
félisten
Petykemano
#35260
TTomax
félisten
válasz
Petykemano
#35260
üzenetére
Csakhogy ahhoz olyan design is kell,és nem igazán erre felé mentek eddig.Mert annak nem sok értelme ha 3 egymásra helyezett lapka hozza a két egymás mellé helyezett teljesítményét.Szerintem addig erről kár is álmodozni amíg a csíkszélességet tudják lejjebb vinni,mert túl drága játék lesz ez tömeggyártásba még egy jó hosszú ideig.
-
#35259
Jack@l
veterán
Petykemano
#35257
Jack@l
veterán
válasz
Petykemano
#35257
üzenetére
Mért jó neked 1 ghz alatti gpu?
-
#35258
#45185024
törölt tag
Petykemano
#35257
#45185024
törölt tag
válasz
Petykemano
#35257
üzenetére
"Kell annak a GPU-nak a 3D TSV mint egy falat száraz kenyér."
 Stratova
Stratova 
Ha lenne egyszer usefull topicgazdánk én összegyűjtetném vele a 100 legjobb mondatot a szobáról az infóban, akkor ez biztos benne lenne.
Petyke:
Egyrészt ugye egy 7 nm es Navit véve alapul 150 Watt. ha ezt negyedelet az csak harminc valahány.
Ezt a szintet kellene átvinni egy hűtési megoldással.
végigolvastam Redditen erről folyó diskurzust 3 gondolat ragadta meg a figyelmemet.
Az egyik egy 2010-es tanulmány Integrált folyadékhűtőrendszerek 3-D halmozott TSV modulokhoz
Tehát mondható hogy nem újkeletű a történet és lehet üreges rendszer a megoldás.
Másrészt Stratova-nak mindenben teljesen igaza van, (az általunk ismert technológiai szinten)
Erről pl nem is hallottam hogy a HBM-ek legalsó szintje alacsonyabb órajellel megy a magas hotspot miatt ?
De ahogy az egyik komment rávilágít a 3D GPUkkal a 3D hűtésnek is fejlődnie kell.
Az az elmélet megdőlt hogy csak kis lapkák lesznek vagy így vagy úgy torony / egymás mellé ragasztgatással megoldható , kérdés hogy AMD tudja e csökkenteni a ragasztgatás által fellépő késleltetési időket, vagy egy lehűthető torony terjed el, de ez nem azon múlik hogy meg tudjuk e valósítani hanem hogy melyikből lenne AMDnek helyzeti előnye.
Az APUknak pl van az az átkozott nagy előnye hogy nem hat rá a bányászláz árfelhajtó hatása. -
#35250
#45185024
törölt tag
Petykemano
#35249
#45185024
törölt tag
válasz
Petykemano
#35249
üzenetére
AHA a part mentén az a sok nagy szikla tudod
Hatalmas monumentális GPUkat rakatnak így össze akár egy központi memória köré akár tornyosan felfelé 6-8-10 ezer shaderrel (nem cuda, a cuda az nem shader). -
#35248
#45185024
törölt tag
Petykemano
#35231
#45185024
törölt tag
válasz
Petykemano
#35231
üzenetére
Itt fut zátonyra az egyre kisebb csíkszélességen egyre kissebb GPUk koncepciója.
A TSMC bejelentette az új WoW (Wafer on Wafer ) technológiáját.amin egymásra rakhatja hasonlóan ahhoz, ahogyan a NAND flash memóriák.
Na de olvasgassatok csak Ti Jöhet a Tower Power 

-
#35233
#45185024
törölt tag
Petykemano
#35231
#45185024
törölt tag
válasz
Petykemano
#35231
üzenetére
Hadd kezdődjön kisfiam nyomd a kevlárpáncélos plüssmackódat a mellkasodhoz aztán jöjjenek a támadók mi baj lehet ?
Mérni kell egyet 1000 Mhz es GPUval meg alap HBM-el mert itt nem a húzás számít hanem az összehasonlítás... azt valamit látunk az is infó...
Valami továbbra is mocorog tehát lesz új kiadás csak mi ???
Gamer Nexus újratöltve.Vega 'Refresh -
#35232
 Plasticbomb
addikt
Petykemano
#35231
Plasticbomb
addikt
Petykemano
#35231
Plasticbomb
addikt
válasz
Petykemano
#35231
üzenetére
Nem emelkedik számottevően az FPS ha a HBMet felhúzod 945ről 1100ra, vagy akár 1200ra, szal a fene tudja, ellenben nem vesztesz sok fpst, ha a GPUt gyári helyett bányász módon hagyod, 1GHzen, szal valami biztos nincs egyensúlyban, de hog y mi, azt ki kéne tesztelni rendesen.
Pepee, majd letesztelem, de most gridcoint nyomatok vele ezerrel grcpoolon...
-
#35195
#45185024
törölt tag
Petykemano
#35194
#45185024
törölt tag
válasz
Petykemano
#35194
üzenetére
Hát igen de írja a GPU-t is de az csak a Vega 20 lesz szerverbe szánt árral.
Magyarán Konzolra meg olcsó Navira ne is számítson senki 7 nanón 19 H1-ben. Arra meg nem akarok gondolni hogy az addigi úton említett 9Gbps GDDR5 is kinek lesz jó. Ha NV kijön a GDDR6-al mehet is azzal a lendülettel a bányába, ha addig nem történik valami... -
#35192
Z10N
veterán
Petykemano
#35186
Z10N
veterán
válasz
Petykemano
#35186
üzenetére
Remelem a kukazott Vega28/32-t hozzak vissza ezzel, ha mar a hbm2-re nem telik. Mondjuk eleg oszver lenne, de a semminel jobb. Egy fiokos polaris rev3 mar unalmas lenne, ha csak nem piszok olcson adjak (kezdetben).
-
#35178
 füles_
őstag
Petykemano
#35177
füles_
őstag
Petykemano
#35177
füles_
őstag
válasz
Petykemano
#35177
üzenetére
Ez egy bundle három alkatrésszel.
-
#35172
 velizare
nagyúr
Petykemano
#35170
velizare
nagyúr
Petykemano
#35170
válasz
Petykemano
#35170
üzenetére
volt még ott némi sávszél-optimalizáció is emlékeim szerint, de igen, a piac zabálta miatta.
-
#35168
velizare
nagyúr
Petykemano
#35167
válasz
Petykemano
#35167
üzenetére
pchez képest? keveset fogyasztott. az adreno az armek gpuja.
-
#35164
velizare
nagyúr
Petykemano
#35163
válasz
Petykemano
#35163
üzenetére
felvették már wangot és rayfieldet oda, és a semi-customot is betolták az rtg alá.

-
#35126
Abu85
HÁZIGAZDA
Petykemano
#35124
Abu85
HÁZIGAZDA
válasz
Petykemano
#35124
üzenetére
Ezek nem érdemek. Amikor egy GPU-t terveznek, akkor a gyártók az élettartamot figyelembe véve felvázolják maguknak a potenciális problémákat. Nem olyan dolgokat, hogy ray-tracing, mert az egy eljárás, és önmagában nem probléma.
Mik a következő időszak legnagyobb problémái?
- quadraszter: Nem tudjuk növelni a geometria részletességét, mert a GPU-k négyes pixelblokkokon dolgoznak. Egy újszerű raszterizáció ezt megoldaná, de a kompatibilitás miatt az API-ban kellene megoldani az egészet, vagyis amíg erre nem jön egy új pipeline, addig úgy lehet elérni a geometria részletesség növelését, ha a korábbinál hatékonyabbá teszik a kivágást. A Vega megoldása erre a primitív shader, de igazából kb. hasonlóan jó a compute culling. Ehhez kapcsolódó problémakör a túl sok ismételt vertex shader munka azokon a háromszögeken, amelyek normálvektorai a nézőpont irányvektorával 90 foknál nagyobb szöget zárnak be. Ezt csak a primitív shader tudja kezelni, erre nincs szabványos compute megoldás, de még egy ideig azért lehet élni nélküle, viszont 2018 végén már azért limitáló lehet.
- többletrajzolás: Ez is kb. eléggé para, mivel egy jó minőségű szimulációban ezrével kell leképezni a részecskéket, és bizony egy részecske sokszor nem csak pixelnyi méretű, és ugye ezek a kis mocskok még átfedik is egymást. Erre teljesen hardveres megoldás a Vegában a DSBR draw stream pipeline-ja. A régi hardvereknél kezelési lehetőség lehet a tiled compute kivágás mondjuk Harada2.5-tel, de az optimális a hardveres kezelés.
- memóriaallokáció: Elég sokáig téma volt, hogy bizony a VRAM kezelése borzalmasan nehézkes az új API-kkal, illetve a memóriák drágulnak, tehát nagy butaság lenne a jövőben is brute-force megoldásra építeni. Erre a Vega alternatívája a HBCC. Csak azt az adatot tartsd a GPU mellett, amivel tényleg dolgozik.
- LDS pressure: A teljesen statikus allokációk miatt az egyre komplexebb übershaderek egyszerűen kifutnak az LDS-ből. 32 kB nem elég, így egyre kevesebb wavefront futtatható a CU-n. Erre a Vega megoldása az LDS dinamikus particionálása.
Kb. ezek futottak át a mérnökök agyán, tehát nem létező effekteket vagy eljárásokat elemeznek, hanem csupasz problémákat ezek alatt. A DXR-t speciel eléggé scamnek tartják a fejlesztők a jelenlegi formájában. Erre igazából még az AMD se lő, bár nyilván 2-3 év múlva értelmes dolog lehet belőle, de ma még az is probléma, hogy pár kedvelt adattípust a DXR nem is kezel. Azért itt nincs teljesen hurráoptimizmus, ahogy a hype mutatja, mert azt nehéz megoldani, hogy összerakj 16 ms alatt egy 4K-s képet DXR nélkül. DXR mellett ugyanerre jó ha van 8 ms-od, tehát ha egy játékba ray-tracinget tervezel, akkor bizony a raszterizálást el kell kezdeni butítani, és akkor csak annyit érsz el, hogy harapdálod a kezed, a kérdés, hogy melyiket. -
#35123
Abu85
HÁZIGAZDA
Petykemano
#35122
Abu85
HÁZIGAZDA
válasz
Petykemano
#35122
üzenetére
Minden GCN verzióban változott eddig a buszrendszer. Eltérő sebességű lett, sőt lapkánként sem ugyanaz. Igen a Polaris esetében visszább lett fogva, mert eleve nem volt betervezve nagyméretű lapka belőle. Miért is terveznél hozzá nagy, tranzisztorzabáló buszrendszert? Azért egy méretesebb konfiguráció pusztán a bekötés oldaláról legalább 500-700 millió tranzisztorral dobja meg az igényeket. Ha nem használod ki, akkor értelmetlen ennyi extrát beépíteni egy lapkába.
Feleslegesen találgattok. Ott van az AMD-nek a Radeon GPU profiler eszköze. Fiji, Polaris és Vega mellett minden explicit API-t használó játéknál megnézhető, hogy miképpen van kihasználva a GPU. Abszolút megmutatja a szűk keresztmetszeteket.
-
#35119
Abu85
HÁZIGAZDA
Petykemano
#35118
Abu85
HÁZIGAZDA
válasz
Petykemano
#35118
üzenetére
Ennek semmi köze a driverhez. A compute culling a motorokban szimpla compute shader.
A DSBR az egy driveres dolog. Majdnem mindenre engedélyezve van valamelyik módja.
Ugye primitive shader nem is lesz abban a formában, ahogy elképzelték. Ugyanazt meg tudja oldani a compute shader. A primitive shader innentől kezdve egészen speciális rendszer, elvileg lesz kiterjesztés, de olyan dolgokra fogják csak használni, amit például compute shaderrel képtelenség megoldani. A GPU-driven pipeline pont nem ilyen. Persze a compute megvalósítás nem olyan elegáns, mint a primitive shader, de végeredményben működik, és alig lassabb. Nagy előnye pedig az, hogy szabványos. Ráadásul a sebességbeli hátránya bőven kezelhető aszinkron compute-tal, tehát az ellenérv maximum annyi, hogy tényleg nem elegáns a kód, de eddig mindenki leszarta, hiszen ellátja a feladatát.
Nem játékok támogatják ezt, hanem motorok. Egy korábbi hsz-ben felsoroltam ezeket.
Mi a hosszú? Nem csak az számít, hogy legyen a piacon új hardver, hanem legyen is eladva a felhasználóknál. Azért mondjuk a DXR-nél nem véletlen, hogy az NV csak a Volta architektúráról beszélt, és amikor szóba jött a Pascal, akkor el is hessegették a kérdést. Ezzel szemben az AMD még drivert is fog kínálni a GCN-re, vagyis nem a fallback layerre építenek. De ha az aktuálisan kapható hardvereket nézzük, akkor is látni lehet már, hogy a nemrég kiadott fallback layer alapján egy Vega 10 simán veri a GP102-t DXR-ben, a GTX 1080-hoz képest két és félszer gyorsabb. És ez még csak a pure compute layer.
Ha azt hiszed, hogy a meghajtók írásánál ezek az architektúrák jelentik a nehézséget, akkor eléggé nagyot tévedsz. A legtöbb meghajtó eleve layered, tehát az implementáció oldalán megpróbálják annyira egységesíteni a dizájnt, amennyire csak lehet. Aztán a hardver felé majd egy low-level rétegben kezelik az eltérést. Akár száz architektúrát is tudnak így problémamentesen támogatni, mert a különbségek csak egy rétegen belül nyilvánulnak meg. Azt egyszer megírod és kész. A problémát a hardverek tesztelése jelenti, de az API-kra vonatkozó implementáció szempontjából az architektúraspecifikus rész a kód nagyon kis részét teszi ki. Ez a hagyományos API-knál jelentett problémát, de az explicit API-k esetén eléggé általános kódokat írnak. Sőt, az AMD nem is ír specifikus API implementációkat, hanem egy platformabsztrakciós rétegre húznak fel mindent. Egy külön réteg kezeli csak az explicit API-k különbségeit.
-
#35105
Abu85
HÁZIGAZDA
Petykemano
#35102
Abu85
HÁZIGAZDA
válasz
Petykemano
#35102
üzenetére
Persze, hogy lehetséges. Nem azzal van a baj, hogy nem lehetséges, hanem azzal, hogy nem éri meg.
A Pascalt nem arra tervezték amire a Vegát. Sosem volt cél, hogy működjön olyan terhelés mellett is, amin a Vega még vígan elvan. Ez az élettartam, amit beleterveznek. A megjelenés után kb. két év. Ez különösen látszik a professzionális alkalmazásoknál. A Vega még vígan működik, amikor egy Pascal már rég out of memory-t kiáltott. Ilyen egyébként a Polaris is, az is megáll kb. annál a határnál, ahol a Pascal feladja.
A Polaris belső buszrendszere nagyon eltért attól, amit a Vega használ. Nem tudott skálázódni az SE 12 CU-nál tovább. Hiába építettél volna be többet, azokra nem volt meg a busz sávszélessége. Ez egy fix limit, míg az optimális konfiguráció 9. A Vega esetében lecserélték a belső buszrendszert egy modernebbre, amely busz legalább kétszer gyorsabb is, így teljesen más konfigurációk is elérhetővé váltak. Be tudtak építeni úgy is 16 CU-t, hogy a busz bőven tudja őket etetni. Mehet egyébként még tovább is, bár a fix limitet nem adták meg, állítólag 28 körül van.
Az Intelnél nemrég kiderült, hogy rengeteg Vega részegység nem is volt nekik elérhető. A Semi-Custom üzletág még nem tudta őket beemelni a portfólióba, így abból kellett főzniük, amit az AMD felkínált. Nem kapták meg a hatékonyabb ROP-okat, a DSBR-t, a modernebb belső buszt, még az új nCU-t sem, ahogy a sokkal gyorsabb setup motorok is kimaradtak. Egyedül a HBCC-t tudták beemelni. Minden más Polaris alapú fejlesztés. Tudtommal a Semi-Custom idén még nem tud Vega dizájnt tervezni. De jövőre már igen, de akkor sem a 7 nm-es portot.
-
#35104
Abu85
HÁZIGAZDA
Petykemano
#35101
Abu85
HÁZIGAZDA
válasz
Petykemano
#35101
üzenetére
A compute culling nem közeledik, hanem már itt van! Ezt nem tudják halasztani, mert a poligonok számát ugyan lehet növelni, de beleesnek a hardverek a quadraster problémába, amit egyik API sem kezel. Vagyis ha növeled a poligonok számát, akkor növelni kell a kivágás hatásfokát, különben a hardver egyre több haszontalan munkát végez. Arra meg felesleges tranzisztorokat költeni, hogy egyre több úgy sem látható háromszöget számoljunk. Emiatt állt át minden nagy stúdió GPU-driven pipeline-ra. A jövőben ez természetesen fejlődik, mert például hasznosítható itt a rapid packed math, az aszinkron compute és a shader modell 6.0. Szóval igen, idén már nem csak szimpla compute culling lesz, hanem ennek az optimalizálása.
-
#35103
#45185024
törölt tag
Petykemano
#35102
#45185024
törölt tag
válasz
Petykemano
#35102
üzenetére
Nyugodj meg és egyél egy csokit.
DigitalFoundry végigveszi a pletyiket és a PS5-től egy íven át a Naviig végigbeszéli főleg a teljesítményeket.. Érdemes végignézni pont egy csokievésnyi idő...
Ez nem olyan okosan tudományos mint a Ti beszélgetésetek de egy picit populárisabb -
#35100
Abu85
HÁZIGAZDA
Petykemano
#35099
Abu85
HÁZIGAZDA
válasz
Petykemano
#35099
üzenetére
Ha elméletben összekötnél mondjuk két Vega 10-et, akkor ott a 8 SE már 24 TFLOPS fölötti teljesítményt ad. Ergo ahhoz a számítási teljesítményhez már kell a többlet, de nem kell a 12 TFLOPS-hoz. Ott hibáztok, hogy azt hiszitek, hogy ezek az egységek nem egymáshoz vannak tervezve. Az egész attól függ, hogy a tömbben mennyi multiprocesszor van. Ha csinálsz 4 tömböt tömbönként 16 multiprocesszorral, akkor az a szimuláció alapján optimális lesz. De ha csinálsz 8 tömböt tömbönként 8 multiprocesszorral, akkor valójában tranzisztort fogsz pazarolni. Persze ez csak a Vega dizájnjára érvényes. A régebbi dizájnok más konfigurációban működhetnek jól.
-
#35098
Abu85
HÁZIGAZDA
Petykemano
#35093
Abu85
HÁZIGAZDA
válasz
Petykemano
#35093
üzenetére
Ha arra vonatkozik a kérdés, hogy háromszögek feldolgozása legyen jobb, akkor a motorok fejlődését tekintve inkább TFLOPS-okat rakj bele és ne setup egységeket. A compute culling erősen megváltoztatja a hardverek működését is, ugyanis a játékon belül háromszögekből jóval több lesz, de a GPU oldalán már a pipeline kevésbé lesz terhelve ezektől, mert jó részüket már a pipeline elején kivágja a rendszer. Innentől kezdve a setup terhelése pont, hogy csökken, viszont a multiprocesszorok terhelése nő. Egyre több motor új verziója működik így (idtech, Dunia, Frostbite, Dawn, Glacier, stb.). A több setuppal itt nem érsz el semmit, mert nem ebből lesz kevés, hanem a TFLOPS-okból.
-
#35092
 gbors
nagyúr
Petykemano
#35091
gbors
nagyúr
Petykemano
#35091
válasz
Petykemano
#35091
üzenetére
Ha a 4x16 CU teljesítménye nem hasznosul, akkor ott van valami szűk keresztmetszet. Vagy az SE-k, vagy a ROP-ok, vagy a memória, vagy valami az egész chip infrastruktúrájában.
-
#35090
velizare
nagyúr
Petykemano
#35088
válasz
Petykemano
#35088
üzenetére
te is írtad, hogy egyes teszteken még a 4 se sem skálázódik maradéktalanul.
-
#35089
 Cathulhu
addikt
Petykemano
#35087
Cathulhu
addikt
Petykemano
#35087
Cathulhu
addikt
válasz
Petykemano
#35087
üzenetére
Ne haragudj, de csak arra tudok reagalni amit irsz, arra nem amit gondolsz. Az irasodbol meg eleg osszevissza, meg ha szakmailag elegge rendben is van, de olyan dolgokon lovagolsz, ami ebben a kontextusban ertelmezhetetlen, amikor meg megrpobalod kontextusba helyezni, akkor meginkabb. Tovabbra sem ertem (bar lehet egyedul vagyok ezzel) hogy megis mit akarsz kihozni abbol, hogy a vega 10-ben most van IF vagy sincs.
Egyreszt irrelevans, mert a multi GPU osszekottesre nem alkalmas, masreszt irrelevans mert nincs multi-vega10 (egyreszt marha nagy lenne, draga es kilowattnyi hot termelne), harmadreszt majd lesz vega 20-ban ami meg azert irrelevans, mert semmikepp se befolyasolja az, hogy gamereknek mire van szukseguk, megis belemesz egy bottleneck fejtegetesbe. -
#35086
Cathulhu
addikt
Petykemano
#35083
Cathulhu
addikt
válasz
Petykemano
#35083
üzenetére
"Eddig annyit tudunk, hogy a vega20 szinte majdnem ugyanaz lesz, mint a vega10, csak DP támogatással és kétszeres HBM kapacitással és sávszélességgel (amúgy mi végett? A vega10 talán sávszél limites? Vagy esetleg ez annak beismerése, hogy a vega 10 pixel-engine limites és ahogy gbors is mondta, majdnem jó lenne a dsbr, csak több pixel engne kell hozzá, amihez meg több sávszélessség?)"
Az a baj abbol a feltevesbol indulsz ki, hogy a vega20-at gamer kartyanak szanjak, es ehhez nezed a bottleneckeket. Hivatalosan Instinct lesz, ahol a legevesbe sem szamitanak pl a ropok, de annal inkabb a memoria mennyiseg es savszel.
-
#35085
 leviske
veterán
Petykemano
#35074
leviske
veterán
Petykemano
#35074
leviske
veterán
válasz
Petykemano
#35074
üzenetére
Engem speciel a 1950X meggyőzött a skálázódásról. A DX11 pedig eleve olyan formában kezeli a GPU-t, ahogy azt a driver neki mondja. Amikor adott az egységes memória, akkor elméletileg nem kéne, hogy gond legyen a skálázódással (a késleltetéseken túl, persze).
A tranzisztorpazarlásnál meg figyelembe kell venni, hogy mennyivel drágul egy lapka legyártásának költsége a méretével arányosan. Nem kizárt, hogy az az 50%-os emelés drágábbra jön ki egy monolitikus lapkával megoldva, mint egy 100%-os emelés két kisebb lapkán megoldva. Ezt meglátjuk az év végéig.
MOD: a hosszabb hozzászólásod még nem létezett, mikor elkezdtem írni
-
#35076
Cathulhu
addikt
Petykemano
#35074
Cathulhu
addikt
válasz
Petykemano
#35074
üzenetére
De az IF nincs benne a Vegaban. Csak egy kis resze. Pont az hianyzik ami osszekotne ket vegat. Az majd most kerul bele.
-
#35073
 Carlos Padre
veterán
Petykemano
#35045
Carlos Padre
veterán
Petykemano
#35045
Carlos Padre
veterán
válasz
Petykemano
#35045
üzenetére
Anno volt egy víziója az AMD-nek, miszerint a CPU és GPU részleget összefésülik, mindkettőből a legjobbat hozva ki, de jött ez a Raja és megtorpedózta az egészet. A végeredményt mind látjuk. Most, hogy lelépett úgy látszik visszatérnek az eredeti koncepcióhoz.
-
#35071
Cathulhu
addikt
Petykemano
#35067
Cathulhu
addikt
válasz
Petykemano
#35067
üzenetére
Kozosen IF neven emlegetnek tobb kulonbozo bust, amik mas-mas feladatot latnak el a modulok kozti kommunikacioban. Az a gyanum (de ezt megalapozni nem tudom), hogy ami a jelenlegi veganal van, az csak egy kis resze ennek, es nem a teljes IF ami ket vega kozotti kommunikaciot is lehetove tenne. Abu cikkjebol viszont az jon le, hogy eggyel tovabb lepnek az uj vegaban.
#35070, koszonom, egyre gondoltunk akkor.
-
#35070
Abu85
HÁZIGAZDA
Petykemano
#35065
Abu85
HÁZIGAZDA
válasz
Petykemano
#35065
üzenetére
Csinálhatnak, ez csak döntés kérdése. A Vega esetében a 4 az optimális, mert a 6 tömb aránytalanul sok extra tranzisztorköltség ahhoz képest, ami előnyt ad.
A probléma a jövőben specifikus lesz. A 7 nm-es node-on már jelezték a bérgyártók, hogy a méretes lapkákat igen gazdaságtalan lesz legyártani. Emiatt a mostani tipikus 400-500 mm^2 közötti reális határ inkább 300-350 mm^2 lesz. Nem fognak megérni fölé menni, de az optimális is inkább 200 mm^2. Tehát költségben, 7 nm-es node-on sokkal előnyösebb 4 200 mm^2-es lapkát csinálni és valahogy összekötni, mint egy 700 mm^2-est. Az 5 nm-re még borúsabbak a kilátások. Ott inkább 100 mm^2 tűnik az optimális határnak, de egyelőre erről még kevés a tapasztalatra épülő adat. Ez persze akkora gond így sem lesz, mert mire elérjük az 5 nm-et, addigra 3D-ben is építkezhetünk majd, tehát úgy összeköthetsz mondjuk négy stacket, hogy egy stack kettő vagy akár négy lapkából áll majd, vagyis effektíve 16 lapka lesz összekötve. 5 nm-en túl teljes homály van. Nagyjából abban ért egyet mindenki, hogy a chipletek koncepciója az egyetlen gazdaságilag fenntartható opció.
Erre készül a Vega 20, amibe beépítik a GMI-ket. Onnantól tényleg legó az egész, lásd EPYC.
(#35066) Pinky Demon: Maga az Infinity Fabric már a Vega része, elvégre a Raven Ridge-ben a Zen és a Vega klaszter így van összekötve (részben emiatt olyan veszettül gyors az az IGP), és nyilván a Vega 10-ben is IF van belsőleg. Ami hiányzik az a GMI, vagyis az IF kivezethető memóriakoherens interfésze. Emiatt nem lehet most összekötni két Vegát, de a Vega 20 ebből tartalmaz majd négyet is.
-
#35066
Cathulhu
addikt
Petykemano
#35065
Cathulhu
addikt
válasz
Petykemano
#35065
üzenetére
"Miért nem teszi meg ezt az AMD két Vega lapkával?"
Nem emiatt lesznek az uj vegaban IF busok? Ha 7 nanon merseklodik a fogyasztas es az ar, akkor ugyan meg mindig dragan, de meg lehet csinalni. Lehet nem veltlen az MI a celpiac. Kerdes, hogy ki vesz MI-re AMD-t. -
#35064
Plasticbomb
addikt
Petykemano
#35059
Plasticbomb
addikt
válasz
Petykemano
#35059
üzenetére
köszi, hogy emlékeztettél, el akartam már olvasni gbors cikkét, de elfeledtem, most megtettem. De most végre megyek fürödni, elég jó cikk volt, nem bírtam ott hagyni...
-
#35061
Abu85
HÁZIGAZDA
Petykemano
#35056
Abu85
HÁZIGAZDA
válasz
Petykemano
#35056
üzenetére
Az Infinity Fabric arra van, hogy ezzel ne kelljen törődni. A 4 darab Zeppelin magot használó EPYC is egyetlen 32 magos processzornak látszik az operációs rendszer felé. A kulcs a koherencia.
Egyébként a mai GPU-k belül nem különböznek ettől. Ott is tömbökbe vannak szervezve a multiprocesszorok, és egymás felé eléggé lassú a kommunikáció (30-40 GB/s maximum). De ugye kit érdekel, alig kommunikálnak egymással, a GCN esetében azt is egy 64 kB-os táron keresztül. Az Infinity Fabric-nak elég ezt a tárat szinkronizálnia a lapkák között.
-
#35058
#45185024
törölt tag
Petykemano
#35056
#45185024
törölt tag
válasz
Petykemano
#35056
üzenetére
Jaj Petyke jaj, 19 még messze van. AMD-é 18 ban már itt lesz.
Inkább nézzél 'ménsztrím' videókat:
Facebook sucks Future AMD GPUs could be GREAT! - WAN Show Apr.13 2018 -
#35057
 Televan74
nagyúr
Petykemano
#35056
Televan74
nagyúr
Petykemano
#35056
Televan74
nagyúr
válasz
Petykemano
#35056
üzenetére
Ez attól függ mikor jön a Navi. A Nvidia is a xx60 -at csak 2019 tavaszára dátumozza.Addig csak a xx70/xx80 modellek fognak érkezni ősztől.
Több GPU egyben,ha nincs driver oldali támogatás,akkor csak benchmarkolni lesz jó.
AMD mindig szerette a kihívásokat,különös megoldásokat és erre párszor rá is b@sztak.
-
#35055
#45185024
törölt tag
Petykemano
#35054
#45185024
törölt tag
válasz
Petykemano
#35054
üzenetére
No ha már nem félünk az erős szerverprocis Apuktól amik részegységeit lekapcsolva CPUsan feszt spórolnak meg térjünk át a másik mondandódra az 1080 teljesítményű Navira.
A történetből egy apró dolgot hagytál ki hogy a Fudzillás leaksben van egy ár
Pletyka: Az AMD Navi a GeForce GTX 1080-as szintű teljesítményét kínálja a 250$ -os Budget árszegmensben.
Igen ez szörnyű katasztrófa lenne, ha az 1080 at is ennyiért árulnák
Akkor meg nem ha ezt beteheted egy APUba és mellé tehetsz egy 2700x+40%os CPU-t
Kiállsz a pódiumra és ezt mondod.
Amézing mostantól nem kellenek videókártyák 1080-as (vagy Vega) szintig.
és itt vannak a real 4K konzolok olcsón, ki is akarna ekkor méregdrága videókártyákat venni ?
Kiáll 3 lány miniszoknyában a pódiumra és a középső thay szépségkirálynő szoknyában kb így öltözve
A középsőnél lesz az APU (CPU-GPU) a szélsőknél a fantáziádra bízom mit tokoznak össze (CPU-CPU , GPU-GPU) -
#35046
#45185024
törölt tag
Petykemano
#35045
#45185024
törölt tag
válasz
Petykemano
#35045
üzenetére
De ezt miért érzed bajnak ? Eddig is az volt már az új mantra hogy a GPU elCPUsodik. Nem az a logikus hogy olyan szakember megy át ?
Igazán azt sem értem miért van bajuk az embereknek hogy a Vega Epycet összekötik.
Vega 20 nem gamer, mindenkinek van Vega 10-e aki akart és most Navi várás van. Relax.
"Ez nekem azt jelzi előre, hogy borús évek várnak az AMD kártyákra"
Nekem meg azt jelenti hogy előbb ott foglalkoznak a problémával ahol kilowattokban mérik a spórolásokat, Naviról ettől még semmit nem tudunk, max azt hogy addigra összetokozunk mindent mindennel hozzávetőlegesen rizikómentesen. HBM3 , DualNaviRipper lágyul a szíved rá mi ?
-
#35026
Cathulhu
addikt
Petykemano
#35025
Cathulhu
addikt
válasz
Petykemano
#35025
üzenetére
Mivel a chill mindig is whitelist vagy manapsag blacklist modban mukodik, biztos vagyok benne, hogy a benchmark programok blacklistelve vannak.
-
#35024
Yutani
nagyúr
Petykemano
#35023
válasz
Petykemano
#35023
üzenetére
Szerintem nem esemény, hanem objektum és effekt függő. Ha kevés az ojjektum és az effekt a képernyőn, nem kell akkora póver a megjelenítéshez, így mehet a kártya csillébe.
-
#35021
#45185024
törölt tag
Petykemano
#35018
#45185024
törölt tag
válasz
Petykemano
#35018
üzenetére
Arra mit szólnál ha kiderülne az X-ek drájverébe alapértelmezetten be van kapcsolva a CHILL.
Minden teszter lusta mint az atom és 90% in stockba tesztel nem foglalkozva a kártyák valódi optimalizált teljesítményével.
Jó kis fogyasztás csökkent tesztek születnének -
#35010
 smc
addikt
Petykemano
#35009
smc
addikt
Petykemano
#35009
válasz
Petykemano
#35009
üzenetére
Művelődhetnél kicsit, tele linkelik mindig a topikokat orosz és német oldalakkal, akkor ez a kínai? sem okozhat nehézséget.
-
#34996
Televan74
nagyúr
Petykemano
#34995
Televan74
nagyúr
válasz
Petykemano
#34995
üzenetére
De azért jó duma volt!A GDDR5X meg a GDDR6 szóba került,sőt még egy esetleges +30Mhz is.
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
#34991
 -FreaK-
veterán
Petykemano
#34988
-FreaK-
veterán
Petykemano
#34988
-FreaK-
veterán
válasz
Petykemano
#34988
üzenetére
Nem, lehet hogy tényleg fejlődött, de nem is ez a legjobb szó rá, inkább kiforrott. Ez szerintem +50Mhz, +W nélkül mondjuk. Na nem mintha ez olyan nagy előrelépés lenne
szerk.: ja most látom, hogy valójában akkor egy nagy semmiről van szó -
#34983
leviske
veterán
Petykemano
#34982
leviske
veterán
válasz
Petykemano
#34982
üzenetére
Szerintem pont azért, mert az előző lépésnél is ez volt. A 300-as széria sem úgy sült el, ahogy kellett volna. Ráadásul így a rx500 sorozat eladásait is meghúzhatják ahelyett, hogy ellehetetlenítenék az eladásukat.
A GDDR6-ot én kizárnám, mert ahhoz gondolom komolyabban kellett volna változtatni a lapkákon. Viszont a GDDR5X esélyes lehet.
-
#34981
#45185024
törölt tag
Petykemano
#34980
#45185024
törölt tag
válasz
Petykemano
#34980
üzenetére
Tudjuk hogy mennyire picikre tud az AMD első számot emelni, ha nem tette nekem azt jelenti hogy ez nem gddr6, hanem ez egy második szintű megemelt órajel + gyorsabb gddr5 memória .
Régiek meg lehet kapnak egy EOL-t.
Ki mer merészebbet mondani ? -
#34950
#45185024
törölt tag
Petykemano
#34946
#45185024
törölt tag
válasz
Petykemano
#34946
üzenetére
A Vega 12-vel az van hogy az a kedves fiatalember a Michael Larabel aki egyébként ez: remélem nem teszi túl nagyba ki a képét, naná hogy teszi...
 :
:
Ő idézgeti hogy már benne van a driverekben a Vega 12 , de az nem az Inteles...
Na de hát van az Inteles a Ryzenes meg a Molbil Vega mi más?
Persze az emberek szeretnék a 680-nak hinni...
De most ne zavarj képzeld tesztelem új Vegámat, megőrülsz olyan cukker van rajta piros szivárvány))) -
#34921
Z10N
veterán
Petykemano
#34908
Z10N
veterán
válasz
Petykemano
#34908
üzenetére
Naow Victorious?
-
#34915
#45185024
törölt tag
Petykemano
#34914
#45185024
törölt tag
válasz
Petykemano
#34914
üzenetére
Petyke ma is mesélsz a Jensen Huanggal folytatott tegnapi beszélgetésedről ?
))
Na ki mondja el a legszebb AMD-s locsolóverset ?
-
#34914
 Petykemano
veterán
Petykemano
#34908
Petykemano
veterán
Petykemano
#34908
Petykemano
veterán
válasz
Petykemano
#34908
üzenetére
Ez csak áprilisi tréfa volt
-
#34911
 tailor74
addikt
Petykemano
#34908
tailor74
addikt
Petykemano
#34908
válasz
Petykemano
#34908
üzenetére
Április elsejei pletykának nem rossz.
Meggyőző volt, de a "Titan V-t kétszer kettéhugyozza" résznél elvérzett a hír. -
#34910
#45185024
törölt tag
Petykemano
#34908
#45185024
törölt tag
válasz
Petykemano
#34908
üzenetére
EZ mi ez mi ?
A 7 nm-en nem kétséges hogy megverik a 12 nanós kártyákat.
De nem tenne magának keresztbe a Vega 20nak hogy idő előtt kihozza a Navi-t.
A bányászat meg már beomlóban van csak a használt piacra kell nézni, egy navi sem fog tudni egy ASICcal mit kezdeni.
De milyen új kártyákról is beszéltetek itt amiket öngyi lenne most kiadni ?
Semmi nem akadályozza most a GDDR6 kiadását, hacsak nem maga a GDDR6
ASRock-ot meg én nem értem hogy ilyenkor akar bányászkártyákat kihozni..
ennek semmi értelme hacsak nem tudnak ők is valamit a GDDR6-os kártyákról. -
#34909
 beef
őstag
Petykemano
#34908
beef
őstag
Petykemano
#34908
beef
őstag
válasz
Petykemano
#34908
üzenetére
Mit fogsz te ezért kapni
-
#34902
 Raggie
őstag
Petykemano
#34891
Raggie
őstag
Petykemano
#34891
Raggie
őstag
válasz
Petykemano
#34891
üzenetére
Én ha jól látom, akkor a VEGA-s box fele-harmad akkora, mint a ZOTAC 1080-assal szerelt változatai. Ennek a kialakításnak pont ez az előnye, hogy nem kell nagy hely neki, cserébe egy kis teljesítményt áldoz fel. Ezt szerintem maximálisan teljesíti.
Az már egy következő kérdés, hogy ki az aki ezt értékeli és ki fogja emiatt megvenni.
-
#34899
Jack@l
veterán
Petykemano
#34898
Jack@l
veterán
válasz
Petykemano
#34898
üzenetére
Procierőben, fogyasztásban? Meg eleve ebből nem lesz notebookos példány.
-
#34896
Yutani
nagyúr
Petykemano
#34891
válasz
Petykemano
#34891
üzenetére
FullHD-n bicsaklik még sok esetben, szerintem bandwidth bottleneck van, kevés az egy kocka HBM ilyen tekintetben.
-
#34894
gbors
nagyúr
Petykemano
#34891
válasz
Petykemano
#34891
üzenetére
Sajnos semmit, ez egy NUC teszt, eleve a video teljesitmenye nehezen izolalalhato (kb. feluton 960 es 980 kozott), es ehhez nem tudjuk a tenyleges orajeleket. RX 470nel szemben kellene megnezni.
-
#34893
 Fred23
nagyúr
Petykemano
#34891
Fred23
nagyúr
Petykemano
#34891
válasz
Petykemano
#34891
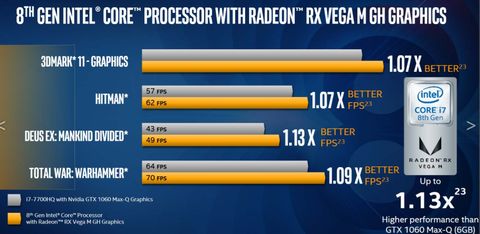
üzenetére
A teljesítménye alatta van a reklámozottnak sokszor.

Ettől függetlenül nekem jobban kéne, mint egy ilyen noti.
-
#34892
Z_A_P
addikt
Petykemano
#34891
Z_A_P
addikt
válasz
Petykemano
#34891
üzenetére
Talan igy nagyobb nyomas lesz a fejlesztokon is hogy VEGA-ra is optimalizaljanak
-
#34861
Jack@l
veterán
Petykemano
#34853
Jack@l
veterán
válasz
Petykemano
#34853
üzenetére
A vega a jelen generáció, az 580-ak évekkel ezelőtti tupírozás/átnevezés.
-
#34857
smc
addikt
Petykemano
#34853
válasz
Petykemano
#34853
üzenetére
És most a bányászok leálltak a felvásárlással?
Csak mert a nagyker amit nézni szoktam egész jól feltankolt most, mondhatni van készletük. Persze az árak továbbra is el vannak szállva.. -
#34803
 TESCO-Zsömle
titán
Petykemano
#34802
TESCO-Zsömle
titán
Petykemano
#34802
TESCO-Zsömle
titán
válasz
Petykemano
#34802
üzenetére
Ami szintén nem egy rossz dolog. A Ryzen kint van, bizonyított, egy hónap és a refresh is kint lesz, az is bizonyít majd. Jó bornak meg nem kell cégér.
VGA-ügyben sincs miről beszélni amíg dúl a kripto-őrület. Hiába lenne jó a Vega is meg az RX580 is az áráért, ha nem lehet kapni. A hiány meg ezt teszi az árakkal. Ezt nem tudod kivédeni, mert nem állhatnak bele a gyárak ebbe a hülyeségbe, különben nagyot bukhatnak. Utólag meg könnyű okosnak lenni...
-
#34788
TESCO-Zsömle
titán
Petykemano
#34787
TESCO-Zsömle
titán
válasz
Petykemano
#34787
üzenetére
Adná az ég...
-
#34770
Cathulhu
addikt
Petykemano
#34769
Cathulhu
addikt
válasz
Petykemano
#34769
üzenetére
Jó lenne tudni az előtte lévő byteok mire vonatkoznak, mert ott van eltérés, így akár még jelenthet mást is mint amit sugall, de ha jót sugall, akkor lehet egy egyszerű átnevezéssel van dolgunk, és az csak egy átnevezett Polaris lenne, azaz mégsem adják az intelnek a latest and greatest?
-
#34753
#45185024
törölt tag
Petykemano
#34752
#45185024
törölt tag
válasz
Petykemano
#34752
üzenetére
A PI Titkai Írta ABU 2018. 04. 18.
Avagy hogyan csökkentsünk Vafer selejtet a moduláris elvekkel.
Jajj bocsássatok meg ezt a kommentet majd csak két hónap múlva fogom leírni -
#34739
Abu85
HÁZIGAZDA
Petykemano
#34738
Abu85
HÁZIGAZDA
válasz
Petykemano
#34738
üzenetére
Nyilván ennél vannak egyszerűbb megoldások is. Megkérdezni egy mérnök kontaktot, vagy jelen esetben megnézni a review guide táblázatát, ami a ROPs sornál 16-ot ír.
Azok más piaci szempontok. A Vega 10 olyanra is jó, amire a Vega IGP és az Intel Vegája nem. Bár alapvetően mindegyik hardver ugyanaz a nyers tudás szempontjából, azért a Vega 10-nek a teljesítménye is megvan a komplex shaderekhez, például a programozható blendinghez is. A többin is futhat a kód, de 10 TFLOPS alatt nem jössz ki jól belőle.
-
#34737
Abu85
HÁZIGAZDA
Petykemano
#34736
Abu85
HÁZIGAZDA
válasz
Petykemano
#34736
üzenetére
Az az ábra már az ACE-eket sem jelzi jól. Mondjuk a Vega 10-nél sem, ennyi mentsége azért van a marketing-teamnek, akik nyilván megfelelő szaktudás nélkül szimpla félreértésből összeollózták.
Valójában a Vega esetében csak a HWS-t kellene jelölni, mert korábban ez már önmagában egy jelzés volt arra, hogy van hozzákötve két-két ACE (lásd Fiji és Hawaii). Viszont a Vegában egy HWS nélküli ACE sincs, nemhogy négy. Eközben command rész a Fiji, a Hawaii és a Vega esetében sokszor ugyanúgy van jelölve, holott a különbség óriási. Ez egy ideje megfigyelhető amúgy, hogy a marketingrészleg nem érti a hardver működését, és eltérő felépítésű hardvereket jelölnek ugyanúgy. -
#34734
 stratova
veterán
Petykemano
#34733
stratova
veterán
Petykemano
#34733
stratova
veterán
válasz
Petykemano
#34733
üzenetére
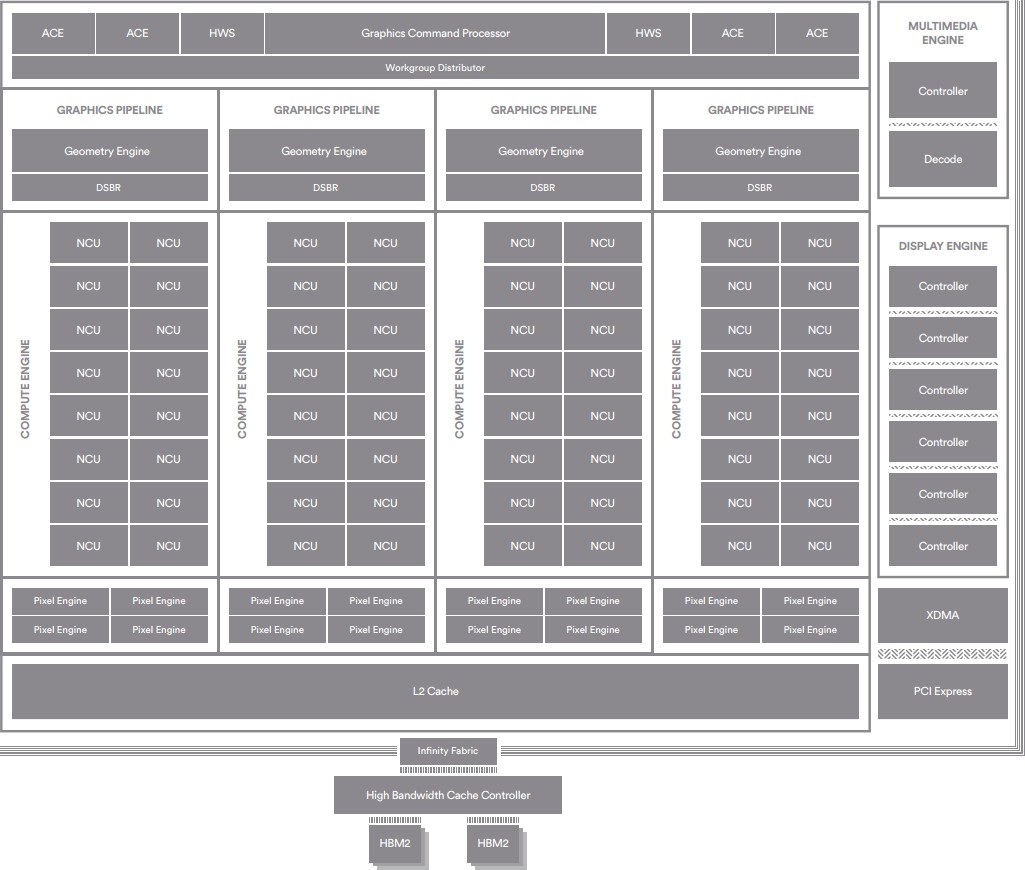
Az a szép hogy senki, csak ha jól látom Polaris óta megváltozott a szervezésük.
Vega:
4 darab ROP blokk kapcsolódik. Ezek a ROP blokkok úgynevezett pixelmotorokat tartalmaznak, egészen pontosan 4-etRaven:
két darab ROP blokk található, amelyek tartalmazzák az úgynevezett pixelmotorokat, mégpedig egyenként kettőt, -
#34732
stratova
veterán
Petykemano
#34730
stratova
veterán
válasz
Petykemano
#34730
üzenetére
Vega10:
2400G IGP

-
#34728
Z10N
veterán
Petykemano
#34709
Z10N
veterán
válasz
Petykemano
#34709
üzenetére
Ez gondolom csak koltoi kerdes volt
-
#34719
 apatyas
Korrektor
Petykemano
#34709
apatyas
Korrektor
Petykemano
#34709
apatyas
Korrektor
válasz
Petykemano
#34709
üzenetére
Sehány, mert a noti bios (uefi akármi) butább mint egy vágódeszka, be se tudod állítani, hogy mit szeretnél beletenni és az mennyin működjön. Pedig nem fájna senkinek.
-
#34714
Abu85
HÁZIGAZDA
Petykemano
#34708
Abu85
HÁZIGAZDA
válasz
Petykemano
#34708
üzenetére
Itt nem a sikerességről van szó. A siker akkor lenne értékes, ha mondjuk az IGP és a pGPU úgy feszülne neki a dGPU-knak, hogy az Intel és az AMD visszafizeti a listaárból ezeknek a költségét, ha az adott OEM nem kapcsolja be őket. De nekik eszük ágában nincs ezt megtenni, tehát innentől kezdve ez nem a sikerért megy, hanem a piacra való rákényszerítésért, függetlenül attól, hogy ki akarja és ki nem.
És azért ne felejtsük el, hogy az Intelt évek óta ismerjük. Egy kis szemétkedésben mindig benne vannak, az FTC pedig nem kényszeríti már őket, hogy rakjanak a procikba 16 PCI Express csatornát. Amint lesz saját pGPU-juk egy koherens interfészen bekötve, simán le lesz korlátozva ez négy PCI Express csatornára, hogy a számukra konkurens terület hátrányból induljon. Nem fogja érdekelni őket, hogy ez kinek tetszik és kinek nem, abból a pozícióból, amiben vannak, ők diktálnak. -
#34710
Yutani
nagyúr
Petykemano
#34708
válasz
Petykemano
#34708
üzenetére
Az IGP már most sikeresebb, mint a diszkrét, egyedül a pGPU-ról nehéz megmondani, milyen sikeres lesz. Az biztos, hogy az IGP mellé nem fog felnőni, ahhoz túl drága és bonyolult.
-
#34672
Abu85
HÁZIGAZDA
Petykemano
#34671
Abu85
HÁZIGAZDA
válasz
Petykemano
#34671
üzenetére
Szerinted az Intel aktuális IGP-i piacképesek? Költői a kérdés, rögtön ugrok egyet: a piac 70%-át birtokolják ezekkel. Szóval alapvetően az OEM nem nézi, hogy mi a piacképes és mi nem. Ha egy kiló pékárút akar, akkor nem vesz egy kiló zsemlét és egy kiló kenyeret is. Ennyire egyszerűen működik, az Intel csupán ezt ismerte fel régebben, és a piac 70%-át be is húzzák vele, annak ellenére, hogy az IGP-ik marhára nem versenyképesek szoftveres és ma már hardveres szinten sem.
Abból a téves feltevésből indulsz ki, hogy az OEM-ek megnézik, hogy mit vásárolnak, de nem. Ha a CPU-val már jár egy célpiacnak megfelelő teljesítményű grafikus vezérlő, akkor meg se nézik, hogy mik a konkurensek ajánlatai, mert úgy sem fogják ezeket alkalmazni. Nincs értelme két hasonló hardvert megfizetni ugyanarra a területre. Ez nem összeesküvés, hanem egy alapvető stratégia. Told az OEM alá csomagban a platformot. Ez a Kaby Lake-G-vel igazán veszélyes lesz a VGA-piacra, mert nagy a pGPU teljesítménye. Az OEM-nek igazából mindegy, hogy ők választják ki a hardvert, vagy az Intel mondja meg, hogy mit használhatnak. Mindkét esetben a pénzüknél és a célzott teljesítménynél vannak. Aki ezzel rosszul jár az az NV és később az AMD, amikor már az Intel sem tőlük fogja rendelni a pGPU-t, de ezt körülbelül az összes OEM leszarja.
Az AMD egyedül az Apple-nél jár jól ezzel, hacsak az Intel nem fogja a Kaby Lake-G-t elrejteni az almások elől. Nehéz lesz, és lehet, hogy nem sikerül. Ha az Apple ezt a platformot akarja, akkor gyakorlatilag az Intel búcsúzhat is a piactól. Már ma olyan szinten GCN-centrikus a Metal 2 API, hogy azzal gyakorlatilag képtelenség versenyeznie az Intelnek és az NV-nek. Számos fontos dolgot, például az argumentum puffert csak emulálva kapnak meg belőle, de nem azért, mert a hardverük amúgy nem lenne jó rá, hanem azért, mert az API oldali megoldás a GCN-re és az Rogue-ra lett írva. Úgy megpakolja így az Apple az Intel és az NV hátizsákját kövekkel, hogy még egy lassabb AMD hardver is kétszer megjárja a hegyet, mire a többiek eljutnak félútig. Innen a hardvert cseszhetik, a verseny ettől már nem fair. -
#34663
Abu85
HÁZIGAZDA
Petykemano
#34659
Abu85
HÁZIGAZDA
válasz
Petykemano
#34659
üzenetére
A VGA-piac alsó szegmensére nem a Kaby Lake-G a veszélyes. Egyáltalán nem veszed észre, hogy mi történik. Az AMD-nek és az Intelnek mindegy, hogy az OEM vesz-e NV GPU a megvásárolt CPU mellé. Az a lényeg, hogy az OEM fizesse ki az IGP-jüket és a pGPU-jukat is. Aztán, ha ezt kifizették, akkor persze letilthatják, és ugyanannyiért vehetnek még egy ugyanolyan erős NV GPU-t is. Érted a problémát? Veszel a boltban 1 kg kenyeret, de inkább nem eszed meg, és veszel mellé 1 kg-nyi zsemlét, amit már megeszel, a kenyeret pedig elrakod dísznek. Szoktál ilyet csinálni?
Az AMD csak a CPU magok egyes részeire használ HDL-t. Az IGP-re pedig már egy ideje csak HPL-t használnak. A mai node-okon már marginális jelentősége van ennek. Régen a 28 nm-es node-on sokat számított.
-
#34661
 lezso6
HÁZIGAZDA
Petykemano
#34659
lezso6
HÁZIGAZDA
Petykemano
#34659
válasz
Petykemano
#34659
üzenetére
A Kaby Lake-G, mint koncepció fogja megenni a GPU piac lényegét, azaz a pGPU. Az AMD is biztos fog gyártani ilyesmit, ami lehetne akár Vega 32 alapú is. Ha már felfelé nem, lefelé skálázás az AMD-nek nagyon jól megy. Ez végülis APU, csak két lapkával és HBC-vel, ami már nem a hagyományos értelemben vett grafikus memória, hanem egy hatékony gyorsítótár.
-
#34660
 solfilo
veterán
Petykemano
#34659
solfilo
veterán
Petykemano
#34659
válasz
Petykemano
#34659
üzenetére
A legolcsóbb zöld VGA, ami eléri, verheti a Ravent, ugye az a GT 1030. A GT 740 és társai majd messziről szagolják a Raven nyomát.
Megfelelő játéknál már aKaveriGodavari is lenyomta!G4560 - 20k
GT 1030 - 23k
Ez a kombó olcsóbb lesz, mint a 2400G, de drágább, mint a 2200G, szóval valós alternatíva lehet a Raven tényleg, procierőben mindkettő elkapja a G4560-at.mod: off
-
#34653
#45185024
törölt tag
Petykemano
#34631
#45185024
törölt tag
válasz
Petykemano
#34631
üzenetére
De tudod ez hogy volt reálisan?
-Lisa asszony mi mit adunk ki Április 12.-én ? és így kezébe nyomott egy cikket
-a ...csába szedd össze a cuccod, messze költözünk) -
#34624
 do3om
addikt
Petykemano
#34622
do3om
addikt
Petykemano
#34622
do3om
addikt
válasz
Petykemano
#34622
üzenetére
Tudom már ez "elavult", szépen megfogalmazva.
Csak azért raktam be mert pont most jön a Navi! ha ránézel.A konkurenciának is volt akkor ilyen, csak ők nem késtek hanem megelőzték a roadmapot
Volta-igaz csak úgy mondanám jelképes vga de ott van, nem marketing volt a roadmap. -
#34623
stratova
veterán
Petykemano
#34622
stratova
veterán
válasz
Petykemano
#34622
üzenetére
Legalább egy évet szoktak hagyni egy-egy terméknek az adott kategóriában. Így szerintem lehet olyan Navi amit bejelentenek még idén, de lesz olyan is ami szinte borítékolhatóan csak jövőre jelenik meg.
-
#34621
do3om
addikt
Petykemano
#34617
do3om
addikt
válasz
Petykemano
#34617
üzenetére

-
#34608
Abu85
HÁZIGAZDA
Petykemano
#34596
Abu85
HÁZIGAZDA
válasz
Petykemano
#34596
üzenetére
Nem így működik. Ma már előre lekötött szerződések vannak. Amelyik stúdiónak szerződése van az egyik céggel, oda se megy a másikhoz. Sőt, ma már igazából a kutatás szintjén is gyártói segítség van. Az adott stúdió megrendel valamit, a partner pedig szállítja a kész kódot. Sokszor ezen nem is módosítanak, vagy akár olyan licenc is lehet, ami eleve kizárja a módosítást.
Azt ma már nagyon kevés stúdió engedheti meg magának, hogy gyakorlatilag önállóan finanszírozzák a PC-s kutatásaikat, teljesen függetlenül mindegyik nagy gyártótól. Ennek egyrészt az az oka, hogy költséges és időigényes, másrészt rengeteg korábban játékfejlesztőknél dolgozó programozót ma már csak a gyártók tudnak megfizetni, lásd Timothy Lottes és Matthäus G. Chajdas. Ráadásul az utóbbi időben rengeteg korábban PC-n dolgozó szakembert felszippantott a Sony. Szóval kb. az Activision és az EA van olyan helyzetben, hogy visszautasíthatja a gyártók segítségét, ők is azért, mert sok kiváló szakembert alkalmaznak, és meg tudják őket fizetni. Az az intő jel, hogy az Ubisoft is kezd elbukni ezen a szinten. A korábbi nagy Bart Wronski, Michal Drobot és Steve McAuley trióból már csak egyedül McAuley dolgozik ott. Ezért is szerződtek le az Intel és az AMD partnerprogramjába.
-
#34599
Jack@l
veterán
Petykemano
#34596
Jack@l
veterán
válasz
Petykemano
#34596
üzenetére
B verzió:
AMD esélyünk sincs beérni a konkurenciát hatékonyságban, találjunk ki valami ficsőröket, amik jól hangzanak de gyakorlati haszna a nullához közelít és adjuk el úgy mintha világmegváltás lenne. Beszéljünk olyan fejlesztőkkel, akikkel gyakorlatilag puszipajtások vagyunk évek óta, hogy mit lehetne beletenni és kommunikáljuk a jónép felé mintha szinte MINDEN játékfejlesztő ezt hiányolná.
Csinnadratta megjelenéskor, nagy füst minimális nyereség a végén az összes szereplőnek.
Lassan már vagy 3-4 generáció óta ez megy, nem csoda hogy megunták a gamerek. -
#34598
 imi123
őstag
Petykemano
#34596
imi123
őstag
Petykemano
#34596
imi123
őstag
válasz
Petykemano
#34596
üzenetére
Sajnos ez az Úttörők sorsa.
Belét kidolgozza és más aratja le a munkája gyümölcsét.
Az értékes mérnöki energiát 5 évvel később jelentkező problémák megoldására összpontosítja holott a jövő évre jelentkezőre már nem tud reagálni.
Kis megfontolt lépésekkel kevésbé lesz sáros az embert mintha hatalmasokat szökell egy pocsolya közepén. -
#34577
Abu85
HÁZIGAZDA
Petykemano
#34575
Abu85
HÁZIGAZDA
válasz
Petykemano
#34575
üzenetére
Nem csak a skálázhatóság a lényeg. Sokan azt hiszik, hogy elég csak a multiprocesszorok számát növelni, de valójában számtalan problémára kell még választ adni. Például ami most a legsürgetőbb az a statikus erőforrás-allokáció elhagyása. Egyszerűen túl pazarló az a modell, amit a GPU-k alkalmazna, hogy a betöltött shadernél előre lefoglalják a szükséges regisztereket és helyi memóriákat. Ez annak ellenére behatárolja a shadereket, hogy elméletben a nyelv nem szab különösebb korlátokat. És a Vegának az LDS dinamikus particionálása, vagy a Volta összevont L1-LDS memóriája csak egy tűzoltás. Egy-két évet nyer vele az AMD és az NV, így a megterhelőbb shadereknél sem omlik majd össze a Vega és a Volta teljesítménye, de magát az alapproblémát nem oldja meg. Innentől már dinamikus erőforrás-allokációban kell gondolkodni. Valszeg ez majd a 7 nm-en jön, mert erre már hardvert kell építeni, ami fogyasztásban is fájni fog, hiszen nem csak annyi lesz a koncepció, hogy "foglald le, ami esetleg kellhet és kész". Sokkal inkább az lesz, hogy "csak azt foglald le, ami valóban kell". Szóval a skálázhatóság a legkisebb gond. Meg ha már itt tartunk, akkor én az AMD helyében írhatóvá tenném a vgpr_base és vgpr_size regisztert a wave-ekből. A Vegát csak ez választja el a GRAMPS-tól.





 ))
))







 Nem tudtak értelmeset válaszolni, a nem kicsit gyanús vádakra (nem is tudtak, hisz akármit mondanak abból se jönnek ki jól), és elejébe próbáltak menni egy komolyabb vizsgálódásnak. (bár elég egyértelmű volt a szándék, így nem engedném el és folytatni kéne, mert egy büntetés alaposan kijárna) Számukra a történet már lényegtelen, minden márka behódolt, és amit akartak elérték. (Asus, MSI, ..... és tovább) Így erre a programra ilyen formában már nincs szükség!
Nem tudtak értelmeset válaszolni, a nem kicsit gyanús vádakra (nem is tudtak, hisz akármit mondanak abból se jönnek ki jól), és elejébe próbáltak menni egy komolyabb vizsgálódásnak. (bár elég egyértelmű volt a szándék, így nem engedném el és folytatni kéne, mert egy büntetés alaposan kijárna) Számukra a történet már lényegtelen, minden márka behódolt, és amit akartak elérték. (Asus, MSI, ..... és tovább) Így erre a programra ilyen formában már nincs szükség! ) viszont ezt egy processzor(-ba -ra) is rátudja tenni, na ott kezdtek számukra redőnyt szerelni a lehúzáshoz.
) viszont ezt egy processzor(-ba -ra) is rátudja tenni, na ott kezdtek számukra redőnyt szerelni a lehúzáshoz.
 Stratova
Stratova 











![;]](http://cdn.rios.hu/dl/s/v1.gif)

 :
:















Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- Honor Magic6 Lite 256GB, Kártyafüggetlen, 1 Év Garanciával
- Bomba ár! Lenovo X1 Yoga 3rd - i5-8GEN I 8GB I 256GB SSD I 14" FHD Touch I W11 I CAM I Garancia!
- Telefon felvásárlás!! iPhone 12 Mini/iPhone 12/iPhone 12 Pro/iPhone 12 Pro Max
- ÁRGARANCIA! Épített KomPhone i5 14600KF 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! MSI B450M R7 5700X 16GB DDR4 512GB SSD RTX 3060 12GB Rampage SHIVA Chieftec 600W
Állásajánlatok

Cég: PC Trade Systems Kft.
Város: Szeged

Cég: Promenade Publishing House Kft.
Város: Budapest