- Android alkalmazások - szoftver kibeszélő topik
- Bemutatkozott a Poco X7 és X7 Pro
- Milyen okostelefont vegyek?
- Magisk
- Garmin Forerunner 970 - fogd a pénzt, és fuss!
- Kicsomagolták a Vivo X Fold 5-öt (videó és fotók)
- One mobilszolgáltatások
- Samsung Galaxy A35 5G - fordulópont
- Apple iPhone 15 Pro Max - Attack on Titan
- iPhone topik
-

Mobilarena
AMD FX processzorok topikja
- AM3+ tokozás
- Nyolc, hat, vagy négy mag
- DDR3-1866 RAM támogatás
- Szorzózármentes modellek

Új hozzászólás Aktív témák
-
válasz
 #95904256
#1656
üzenetére
#95904256
#1656
üzenetére
Ez esete valogatja tema. Ha ket mag hasznalt egy modulban, akkor az jobban csokkenti a teljesitmenyt, mint a turbo. De ha a TDP-be belefer egy brutalis turbo (mondjuk 3.6-rol 4.2-re huzza fel magat) akkor akar jobb is lehet egy mag. De ilyen lepteku turbo nincs. Szoval en amondo vagyok, hogy szet kell dobni amennyire lehet.
Csak ugye ez a 2 modulos 4100-on igen nehez 4 szal eseten.

Az lenne azigazi, ha mar lennenk normalis BIOS-ok, ahol mindent (TDP, turbo, azok beavatkozasi pontjai...) lehetne allitani.
-
válasz
#95904256
#1630
üzenetére
Van olyan lap, az enyem is tudja.
A fogyasztasnak az a jo, ha keves modult hasznalsz, mert a tobbi aludhat. Ha szetszorod a modulok kozott a terhelest, akkor viszont a sebesseg javul. Erdekes, hogy a linux kernel forditas 4 maggal optimalizalatlan kernel eseten is jobb, mint letiltott magokkal, vagy modulokkal.
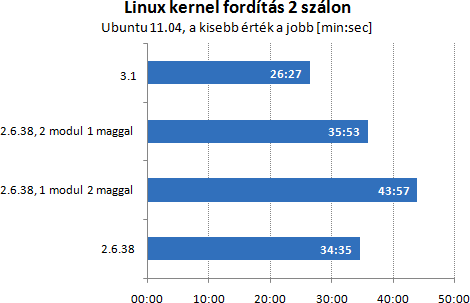
A 3.1-es kernelben levo patch nem csak a szalak utemezesere figyel, hanem a cache kezelesre is tartalmaz javitast: [link] Az utemezes javitasa, ugyan csodat nem tud tenni, mert ott a frontend limitacioja, de a skalazodasban erezheto ekkora javulast hoz (normalizalt a grafikon):

-
#1632
 ricshard444
veterán
#95904256
#1630
ricshard444
veterán
#95904256
#1630
-

Oliverda
titán
válasz
#95904256
#1115
üzenetére
Őszintén szólva se időm se kedvem ehhez. Pusztán arra szerettem volna rámutatni, hogy a valós alkalmazások között nem lehet olyat találni, ahol tükröződne a SuperPI által kirajzolt nagy előny. Vagy ha véletlenül ismersz ilyen hasznos alkalmazást, akkor megírhatnád, mivel én még nem találkoztam hasonlóval.
-
Oliverda
titán
-

Jack@l
veterán
-
Jack@l
veterán
válasz
#95904256
#871
üzenetére
Ja, hogy azt mondod odapakolni neki 8 csomagot, és ha van szabad mag, ő maga pakolgatja be feldolgoztatni? (én meg rá akartam küldeni a 8-at egyszerre, és amikor végez, végez
) Másik topicban már felvetettem, mi lenne ha egy apache webserver benchmark-al megnéznénk mennyi az annyi.
UI: Számelméletet meg ne is emlegesd...
-
Jack@l
veterán
válasz
#95904256
#863
üzenetére
Nem ismerem konkrétan, de ez nem valami biológia seti?
Mondjuk a szálindítások helyett kb olyan jó lehet a 8 egyszálas alkalmazás is, de azt meg nemtom hogy lehetne összemérni egy nem nyolcmagoson is, mert ott meg akkor egyfolytába váltogatja az aktív processeket az ütemező, ami igencsak szép overhead... -
Oliverda
titán
válasz
#95904256
#836
üzenetére
Egyik sem használ ki 8 szálat. A WinRAR nagyjából hármat, a 7-Zip pedig érdekesen működik, mert a tömörítés elején még elég erősen használja a szálakat, de a végére "belustul".
Jack@l: Pedig WinRAR-ban erősebb mint 7-Zip-ben. Persze nem a benchmarkban, hanem valós tömörítésben.
-

P.H.
senior tag
válasz
#95904256
#796
üzenetére
Azt azért ne felejtsd el, hogy ütemezési egyszerűsítések is okozhatják ezt: ha pl. FMA 6 órajeles, egy FADD vagy egy FMUL pedig 4 órajeles lefutású lenne, akkor az FMA indítása után 2 órajellel nem indíthatsz egy FADD egy FMUL műveletet ugyanarra a portra, mivel az azonos órajelben nem írhat ki két végeredményt. Egyszerűbb (kevesebb tranzisztort igényel) az ütemező, ha a lehető legtöbb FMAC-utasítás azonos (5) órajel idejű (az 1 órajeles port-to-port forwarding onnantól mindegy).
Ezt az Intel egy idő (részben 45 nm Core2, teljesen Nehalem) óta erősen figyelembe veszi: egy portra lehetőleg nem ütemez egyaránt hosszabb és rövidebb lefutású műveleteket, illetve Sandy Bridge óta a sima INT, a 64/128 bites SIMD INT és a 128 bites SIMD FP eredmények nem ütköznek azonos órajelben sem, mivel külön-külön result bus-t adtak nekik.
-

dezz
nagyúr
válasz
#95904256
#695
üzenetére
Részben a turbó, részben az azonos adatokon dolgozó threadek párosítása. Az előbbi akár 16+%-ot is hozhat, utóbbi előnye (nem kimondottan erre optimalizált kód esetén) ennek töredéke. Így nyilvánvalóan mindkettőről szó van, de a turbó a fontosabb.
Nem tudom, meddig fogunk még lamentálni ilyen magától értetődő dolgokon?
(#704) darky@: Aki sokat warezol, transzkodólgat és nem 1024x768-ban játszik, annak nem lesz rossz az FX...
-
dezz
nagyúr
válasz
#95904256
#646
üzenetére
Nézd csak ezt a részt: "Valamelyik tesztben van erről egy rész, hogy hány %-ot nyerhetne a BD a megfelelő ütemezéssel." No és mivel is nyerhetne a legtöbbet? Hát a turbóval... Nem én tehetek róla, hogy számodra nem egyértelmű, ami más számára az.
"Másfelől, mint ahogy írtad a megfelelő párosítás még akár HT-nak is kedvezhet."
Kötve hiszem, hogy annyit, mint 6-800 MHz órajelmelekedés.
(#650) Hakuoro: Nocsak, nocsak... Ennyit nem szabadna javulnia a single threadnek per module... Valaki azt vetette fel, hogy a nemrég felfedezett L1I trashing kiiktatása miatt lehet... És/vagy nem kapcsolta ki az illető a turbót, így minden 2. int xluster kiiktatása miatt feljebb mehetett az all-cores turbó.
(#652) sasa134: Még kiderülhet, hogy csak ezzel a verzióval (Zambezi) van valami komoly probléma, nem a teljes mikroarchitektrával. Illetve, hogy részben a gyártástechnológián múlik a dolog. Egyesek szerint sokat fog csökkenni a fogyasztás, ahogy javul a gyártástechnológia. Ezzel együtt az órajel is növekedhet.
(#658): Mainstreamre ott van a Llano.
(#657) subaruwrc: Elmagyaráznád, mi a fene értelme van SuperPI alapján hasonlítgatni, amikor az egy totál elavult és eleve Intelre optimalizált "teszt"? A 3D11 is gyanús az utóbbit illetően.
(#668) subaruwrc: Mikor volt IMC limitált?
(#680): Nem mondom, hogy nem egy érdekesség a geekeknek a C2C, de hogy csak amiatt lenne érdemes elolvasni...

-
Oliverda
titán
válasz
#95904256
#646
üzenetére
"Ennyi erővel arról is lehetne teszt, hogy mennyit nyerhetne a HT a megfelelő ütemezéssel."
Mennyit nyer. A Windows 7 feladatütemezője már HT optimalizálást is kapott. Mivel a Vista elvileg ezt nem tartalmazza, így a két OS segítéségével elvileg ki lehetne mérni a különbséget.
-
dezz
nagyúr
válasz
#95904256
#623
üzenetére
A HT és az CMT közötti különbség leginkább a turbó miatt fontos, az ütemezés szempontjából. Eléggé nyilvánvaló, nem? (A megfelelő párosítás HT-nál sem mellékes.) Senki sem akar hülyének beállítani, de ha netalántán magadból csinálnál azt, arról nem tehetek. Mellesleg szerintem senki sem hiszi azt, hogy emiatt hülye vagy.
-
dezz
nagyúr
válasz
#95904256
#509
üzenetére
Néha nem árt pár másodpercnyi gondolkodás.

(#511) Jim-Y: Nem sokkal egyszerűbb megnézni a teszteket, mint olyan bugyuta válaszokat indukálni, mint pl. (#514) Jack@l? Egyébként feladatfüggő, néhol az X4 980-nál is jobb, néhol meg jóval lassabb.
(#523) TheChos3nOne "Előtte se tudtak cpu szinten sokat felmutatni
 "
"Ezzel csak kinyilvánítottad a tudatlanságodat... K8 vs. P4? K8 X2 vs. P-D? x86-64? (Az AMD dolgozta ki.) Első IMC x86 vonalon? Koherens HyperTransport alapú multiprocessing (aminek az Intel féle QPI szinte 1:1 másolata), ami sokkal jobban skálázódott, mint az Intel FSB alapú megoldásai?
-
-
#483
 FireKeeper
nagyúr
#95904256
#479
FireKeeper
nagyúr
#95904256
#479
-
dezz
nagyúr
válasz
#95904256
#447
üzenetére
A HT-nál sokkal jobban zavarják egymást a szálak egy magon belül, amit az a kis turbó még kompenzálni sem nagyon tud, nem hogy többet számítana. A BD-nél kicsit más a helyzet.
(#448): Ezért:
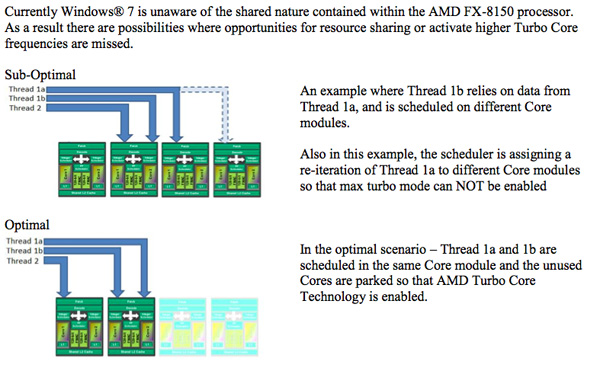
Itt (+ köv. oldal) pedig azt elemzik, mennyit számít az ütemezés.
(#451) Abu85: "Ha mindegyik erőforrás aktívan használatban van, akkor mindegy, mert a turbó nem létezik."
Akkor sem teljesen mindegy, hogy az azonos adatokon (már ami a L2-be fér) dolgozó szál-párok egy modulra kerülnek-e.
(A BD-n all-cores-on-nál is van turbó, a TDP határain belül. Nem tudom, ezt mennyire hagyták érvényesülni a teszteknél.)
-

Abu85
HÁZIGAZDA
válasz
#95904256
#448
üzenetére
A Max Turbo miatt. Egyes feladatokhoz elég lenne, ha a proci fele működne, ami két modul mínusz, és rögtön +600 MHz órajel. Ez a mostani ütemező miatt sokszor nem teljesül. Lényegében itt lenne az egész OS ütemezésnek előnye. Ha mindegyik erőforrás aktívan használatban van, akkor mindegy, mert a turbó nem létezik.
-
válasz
#95904256
#21
üzenetére
szerintem gáz, hogy egy Deneb (ami csak jóindulattal volt pariban a core2duo/quad-okkal) gyorsabb nála. Több éves architektúra. Legalább ugyanazt a szintet illett volna hozni.
Az AVX és társai jó dolgok, de egyelőre kevés az alkalmazás ami ki is használja a feature-ket.




![;]](http://cdn.rios.hu/dl/s/v1.gif)



















 "
"

Új hozzászólás Aktív témák
Hirdetés
A nem témába vágó beszélgetésekhez keressétek fel a (nemcsak) FX-tulajdonosok bazi nagy OFFolós topicját, vagy az AMD offtopikot!
- EA Sports WRC '23
- AMD vs. INTEL vs. NVIDIA
- E-roller topik
- Spórolós topik
- Motorolaj, hajtóműolaj, hűtőfolyadék, adalékok és szűrők topikja
- Így nézz tévét 2025-ben: új ajánlások, régi szabályok
- Android alkalmazások - szoftver kibeszélő topik
- Bemutatkozott a Poco X7 és X7 Pro
- Autós topik
- Linux kezdőknek
- További aktív témák...

- Dell Latitude 8-11. gen i5, i7, 2-in-1 szinte minden típus csalódásmentes, jó ár, garancia
- Telefon felvásárlás!! Samsung Galaxy A14/Samsung Galaxy A34/Samsung Galaxy A54
- LG 55G4 - 55" OLED evo - 4K 144Hz & 0.1ms - MLA Plus - 3000 Nits - NVIDIA G-Sync - FreeSync Premium
- 127 - Lenovo Legion Pro 7 (16IRX9H) - Intel Core i9-14900HX, RTX 4080 (ELKELT)
- Csere-Beszámítás! AMD Ryzen 7 9800X3D Processzor!
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: PC Trade Systems Kft.
Város: Szeged