Hirdetés
- Külföldi prepaid SIM-ek itthon
- Milyen okostelefont vegyek?
- Kis méret, nagy változás a Motorolánál
- Realme GT 2 - aláírjuk
- iPhone topik
- Xiaomi 15 Ultra - kamera, telefon
- Samsung Galaxy Watch7 - kötelező kör
- Google Pixel topik
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Fotók, videók mobillal
Új hozzászólás Aktív témák
-
#637
 Petykemano
veterán
Petykemano
#636
Petykemano
veterán
Petykemano
#636
Petykemano
veterán
válasz
 Petykemano
#636
üzenetére
Petykemano
#636
üzenetére
Pinky Demon:
"Tovabbra is tartom azt, hogy a sima ryzenek 1 chipletes, max 8 magos integralt I/O-s kiszerelessel jonnek. 2019-ben semmi szukseg es semmi nyomas sincs 8 magnal tobbre asztali gepnel. Akinek tobbre van szuksege, lesz majd TR 16-tol 64 magig. Az kozponti I/O-val jaro extra kesleltetes pont agyonvagna az egyszalas teljesitmenyt, ami itt a legfontosabb (FPS). Es mivel ugy nez ki nem lesz L4 az I/O chipben igy az IF megint a RAM sebesseggel lesz szinkronban ami DDR5 hianyaban ugyanugy vallalhatatlan kesleltetest hozna szerintem, mint a jelenlegi TR-eknel."Hogy miért lenne nem praktikus és illogikus korábbi érák érvelése szerint a külön monolitikus design itt leírtam.
A rome IO chipjében elvileg nincs L4. De ez nem jelenti azt, hogy a ryzen chipekhez ne lehetne olyat készíteni - a drágábbakhoz - amin van. Persze tudom, most úgy fogok dobálózni az IO chipekkel, mintha az ingyen lenne, de a GF14nm-én 8MB L3$ 16mm2 64MB kéne 2 zen2 chiplet mögé, a 128mm2. Ha ehhez hozzáadjuk a IO részeket szerintem 200mm2-ból biztosan kijön. Egy ilyen megoldás $15-ral dobhatná meg a költségeket. De Ne azt nézd, hogy ez abszolút értékben mennyi a megszivárogtatott árakhoz képest. Hanem, hogy ehhez képest mennyivel kerülne többe 7nm-en egy másik chipet tervezni, ami nagyobb is, mint a rome-hoz tartozó zen2 chiplet és a rome-ból hátramaradt hulladékot meg a kukába dobni!
"
Anno bulldozer eraban sem voltak rosszak a dozerek, felso kategoriaban nem versenyeztek, de eros kozepkategoriat megutottek, es mai arakhoz kepest fillerekert lehetett kapni oket. Cserebe hoztak 8 magot 4 helyett, es mire ment vele az AMD? Nem sokra. Most ugyanigy nem latom ertelmet 2019-re a 12-16 magos standard asztali kiszerelesnek. Hasra utok, de ha tudnak kisebb latencyvel mondjuk 10%-ot hozni 1 szalon, az szvsz tobbet jelent egy 8 magos Ryzennel, mint +50% mag. Gamereknel nem fog mindsharet nyerni tobb maggal, ha a legtobb FPS-t a meghatarozo jatekokban intel fog hozni. Jelenleg is aki gamer, az inkabb intelt vesz, hiaba kiegyensulyozottabb valasztas a Ryzen. Tavaly lehetett azt mondani, hogy streamereknek jobb, mert a 8 mag sokkal kiegyensulyozottabb FPS-t hoz mint a 4, de mar az intel sincs lemaradasban itt.Workstation es server piacra ez a strategia tokeletes, epp most veszunk egy 2990WX-et de maris csurog a nyalam, ha bele gondolok mi johet(ne) jovore. Ugyanakkor szerintem nem ez kell ahhoz, hogy az atlag pistit is megnyerjek maguknak, ahhoz az kell, hogy CS:GO-ban, PUBG-ben es Fortniteban is jobb legyen mint az intel, es szerintem az nem fog menni most oszver designnal, mert ahhoz kell az IPC, kell az 5GHz es kelleni fog az alacsony kesleltetes is. Viszont most van szabad 7nm-es kapacitas es forras is vegre, hogy egy kicsit modositott (integralt I/O) lapkat is gyarthassanak.
"Szerintem teljesen más volt az a helyzet, amikor feleolyan erős magokból vehettél 8-at, vagy egységnyi erőt képviselő magokból 4-et. Ehhez képest a Ryzen megjelenésekor úgy dönteni, hogy most veszek 8 magosat, ami magonként 10%-kal gyengébb egy valódi, hosszabb távon gyümölcsöző döntés volt. Nem állítom, hogy ez már beérett, de mivel az intel is elkezdte emelni a magszámot, idővel be fog érni.
Mégegyzer mondom: lehet, hogy a mai intel felhozatallal szemben elégségesnek tűnik, ha ugyanannyi magszámmal rávernek a ma kapható 9900K-ra 10%-ot (mindenféle értelemben) De a ryzen 3000 szerintem nem a 9900K ellen készül, hanem az intel 2019-es felhozala ellen, amiről egyfelől már pletykálják, hogy 10 magos, meg hogy 10nm és minden vonatkozásban előrelépést jelent majd, erősít. Egy 10 magos +50% L1$-t és mindenféle csodákat felvonultató intel újdonság ellen egy 12 magos zen2 szerintem épphogy megütheti +10%-ot.
Abban persze igazad van, hogy ha monolitikus lenne a chip és arra törekednének, hogy minimalizálják a késleltetéseket, akkor akár abból is meglehetne a 8 mag & +10%
Ehhez képest a chiplet, aminek mindenképpen hátránya a lapján kívüli memóriaelérés, a következő előnyökkel kecsegtet:
- nem kell új, nagyobb chipet tervezni 7nm-en. Eddig az AMD mindig megúszósan kezelte a designt, a külön konzumer és pro gpu-ért is hiába könyörgünk.
- Ha egyféle - 8 magos - chipletet használ fel, akkor azok méretüknél fogva rendkívül jól válogathatók
- Ha egyféle - 8 magos - chipletet használ fel, akkor a selejtet fel lehet használni az olcsóbb chipekhez kidobás helyet. Ha két külön design van, akkor egyik selejtjét se nagyon tudod felhasználni.
- Később marha egyszerű lehet a zen2-t átrakni DDR5-ös AM5-re.A video szerint a Ryzen5 és Ryzen7 esetén is 2 zen2 chipletből áll, mindkettőben olyan lapkák, amikben 1 vagy 2 magot le kellett tiltani. Ez tehát abszolút hibás, selejt lapkák felhasználását jelenti. Úgy képzelem, hogy ennek ellenére az 1-1 lapkán üzemelő 4-4 vagy 6-6 mag mellett mind a 32-32MB L3$ aktív lesz. (ilyen ugye a zeppelin lapká felhasználásánál is van, a 4 és 6 magos zeppelin ryzenek rendelkeznek a teljes 16MB L3$-sel)
Ez egy 8 magos selejt chipletből felépűlő proci esetén pont 2x annyi L3$-t jelentene, mint ha monolitikusan készülne maximum 8 maggal. Én azt gondolom, hogy ha a videoban ismertetett felhozatal végül igaznak bizonyul, akkor a Ryzen 5-ök lesznek a legjobb gamer procik. -
#633
 hokuszpk
nagyúr
Petykemano
#632
hokuszpk
nagyúr
Petykemano
#632
hokuszpk
nagyúr
válasz
Petykemano
#632
üzenetére
vannak helyek, ahol a multbol nemlehet megelni. mindenki azzal jott, hogy "de hat az RTXet milyen jol eltalaltak". Hoogyne, hiszen, az NVtol kapták az infot. Most meg elfelejtettek megemliteni, hogy ez is az NVtol jott.
Szoval varjuk meg a mai videot, ha nem az lesz benne, hogy "hat ennek csunyan bedoltunk", akkor felolem vedheted is, ugyse dolok be. -
#630
hokuszpk
nagyúr
Petykemano
#625
hokuszpk
nagyúr
válasz
Petykemano
#625
üzenetére
mar messzirol hápogott.
-
#626
 S_x96x_S
addikt
Petykemano
#625
S_x96x_S
addikt
Petykemano
#625
S_x96x_S
addikt
válasz
Petykemano
#625
üzenetére
>Akkor tisztázódott, kacsa
legalábbis a Koreai kampány - gerilla kampány; valószínüleg megkapják a nyereményt - amikor megjelenik - hogy ez mikor lesz? jó kérdés

Közben AdoredTV újabb videóval készül ( ma-holnap? )
de ettől függetlenül mindenhol megy a ködösítés.Benni330:"Hey AdoredTV, I read in the notebookcheck article saying that Steve from HUB stated that “Ryzen will be nothing like Rome” any comments on that...? Big fan btw."
AdoredTV:"Yeah he's right, it'll be a maximum 16 cores instead of 64 and much higher clock speeds but only dual-channel memory. Quite a difference.
 "
"Benni330:"Hmm.. but it’s a very weird comment, I mean it’s going to be different in terms of memory channels and core clock etc. that’s a given, so saying it’s different in that sense is basically circumventing your main point on the specifications and giving themselves a leeway if they were wrong. Or they are taking a stance that they did get insider information. So it might be an elaborate bluff.
Its very interesting to see such conflicting information lol.
Thx for replying XD"AdoredTV:"I know what he means, it'll all be made clear in tomorrow's video.
" -
#624
S_x96x_S
addikt
Petykemano
#620
S_x96x_S
addikt
válasz
Petykemano
#620
üzenetére
>Május is tavasz
hát igen ...
Januárban kicsi a valószinüsége, hogy meg is vásárolhatóak.inkább a március-április-május a valószínűbb.
piacra dobás előtt 1 hónappal már szivárognak a benchmarkok - de most még semmi; vákum.
majd meglátjuk - a januári bejelentésen.
-
#621
 Simid
senior tag
Petykemano
#620
Simid
senior tag
Petykemano
#620
Simid
senior tag
válasz
Petykemano
#620
üzenetére
Fogalmam sincs, hogyan működik a gyártósorok átállítása egy másik dizájnra, de gondolom nem 2 hét. Arról sincs semmi infonk, hogy egyáltalán a yield, a gyártókapacitás vagy maga a termék véglegesítése (nem tape outra gondolok, hanem sorozatgyártásba kerülő steppingre) a szűk keresztmetszet. Lehet ha a világ összes gyártókapacitása a rendelkezésükre állna akkor sem tudnák előbb kiadni. Na meg ott van a kérdés, hogy egyáltalán ugyanazon a gyártósorokon készülnek-e a mobil lapkák mint a ZEN2.
-
#618
S_x96x_S
addikt
Petykemano
#617
S_x96x_S
addikt
válasz
Petykemano
#617
üzenetére
>Guess Ryzen 3700X & 3600X Cinebench score contest
Remélem nem fake .. kell egy kicsit hütenem magamat... A végén még tiszta Apple-ös hype lesz még itt.
Azt nem értem, hogy miért ér véget a verseny Dec14-én.
- Korábbi bejelentés is lesz ? ( Az Intel -szokásos trolkkodásának a kivédése ? )
- Vagy akkora várható, hogy kiszivárognak az igazi eredmények? ( mert elkezdik teriteni a chipeket? )
Valószinű, hogy az utóbbi.
Csak nem kezdenek el ilyen korán reklámozni valamit ... ( Habár léteznek paper launch-ök )Ha igaz - akkor se tudom, hogy a CES-en bejelentik ( hogy majd a következő félévben )
vagy tényleg 1-2 héten belül kapható is lesz.Közben meg megy a vita, hogy mennyire valószínű AdoredTV állítása.
mindenesetre kiáll a forrásáért - ( A MHz-re garanciát vállal , de az árakra nem, mert azok még változhatnak )
A többi válaszait is érdemes átnézegetni.AdoredTV:"The problem with all these "too good to be true" posts is that AMD is right now analyzing them and coming to the conclusion that a price increase is justified. If I made a mistake in the video it was not pointing that out strongly - prices can change at any time, literally right up to launch and even afterwards.
The specs won't change though and when the 3850X(A) lands at 4.3GHz/5.1GHz everybody will know I was given real information"
-
#615
 lezso6
HÁZIGAZDA
Petykemano
#614
lezso6
HÁZIGAZDA
Petykemano
#614
válasz
Petykemano
#614
üzenetére
Persze, az ördög a részletekben rejlik.
A lényeg a memóriakoherens összeköttetés, ami nem csak lapkán belül működik, azaz hiába több chip, ha az egész egyként működik. Ez a nagy varázslat. -
#613
lezso6
HÁZIGAZDA
Petykemano
#612
válasz
Petykemano
#612
üzenetére
Én a napokban azon agyaltam, hogy az AMD most gyakorlatilag "visszafejlődik". Gondolj bele, az I/O lapka az nem más, mint a northbridge.
 Pontosan ugyanazt csinálja, csak az a különbség, hogy nem egy CPU csatlakozik hozzá HyperTransporton keresztül, hanem több. És egy tokban van. Ez persze nem rossz irány, csak érdekesség.
Pontosan ugyanazt csinálja, csak az a különbség, hogy nem egy CPU csatlakozik hozzá HyperTransporton keresztül, hanem több. És egy tokban van. Ez persze nem rossz irány, csak érdekesség. Innentől kezdve ha lesz desktopon I/O lapka, akkor az APU-t úgy lenne érdemes megoldani, hogy az I/O chip-be van építve az IGP. Ahogy régen az északi hídba tették, csak akkor az alaplapon volt.
-
#609
S_x96x_S
addikt
Petykemano
#608
S_x96x_S
addikt
válasz
Petykemano
#608
üzenetére
> ryzen3, pcie4 @ computex
Az új pcie4.0 -ás GPU-s kártyákhoz kell AM4-es alaplap is. Váható volt.
De ez valószínüleg megnöveli az alaplapok árát is.
Szerintem kb 30% -al drágább lesz az X570 -es alaplap a hasonló X470-es hez képest.Vajon a B550 -re lesz-e pice 4.0 támogatás?
------
Egyéb érdekesség:
- német Mindfactory Novemberi stat: ( 69% AMD - 31% Intel ( darabszámra ))
- AMD Athlon 200GE -et unlockolni lehet az új MSI biossal.
- AMD EPYC CPUs Grab 2 Percent Of 2018 Server Market, 7nm Zen 2 Rome Could Top 5 Percent In 2019
- Gigabyte H261-Z60 Server Review 2U4N AMD EPYC for Dense Compute - vagyis kezd beindulni a szerver támogatás ..
--- itt érdekesség: a CPU0-ra kötött majdnem összes háttértár lehetővé teszi az 1 CPU-s módot is."When it comes down to it, this is the dense platform you want to use. Using today’s AMD EPYC “Naples” gen1 parts, one can handle 256 cores, 512 threads, 8TB of RAM, 24x SATA SSDs, 8x M.2 NVMe SSDs, OCP networking, and still have room for 16x PCIe x16 half-length low profile cards. Intel platforms simply cannot match this. Indeed, we know the next-generation AMD EPYC 2 “Rome” will double this maximum core count so we will be looking at 512 cores and 1024 threads in a single 2U box. The current and next-generation of comparable Intel Xeon Scalable servers will be limited to 224 cores/ 448 threads and cost a lot more to get to that number. If you are looking for cost-effective compute density, the Gigabyte H261-Z60 is available today and has a bright roadmap.
Our biggest points of improvement would be that that the Central Management Controller continues to gain features. This would be an enormous benefit to the unit but it is an option we would love to see as it would be nice to login via a single management interface per chassis. This is still a great feature simply for reducing cabling. The other point of improvement is we want to see NVMe. Gigabyte launched the H261-Z61 variant of this server, which has that functionality built-in. Now the action would simply be to pick that SKU if you want more NVMe.
Overall, these high-density plays are awesome for virtualization clusters. There is a bigger implication though. Since all but one M.2 slot is accessible via CPU0, one can retain virtually all of the functionality using a single AMD EPYC processor. That means a 4x CPU, 128 core/ 256 thread 2U system is extremely affordable and offers a surprising amount of expandability in such a compact form factor."
-
#607
S_x96x_S
addikt
Petykemano
#604
S_x96x_S
addikt
válasz
Petykemano
#604
üzenetére
>"The con: it's too damn slow. It does well on the Phoronix Test Suite.
>It does poorly benchmarking our website fully deployed on it (nginx + php + MediaWikiAzért találtam olyan teszt - amikor a legjobb ár teljesítményt nyújtja az ARM.
( Még az Intel és az AMD ellen is - AWS árakon )Persze a Rust"parallel Mandelbrot" - inkább kivétel, de egy jó fordítóval tényleg ki lehet hozni a maximumot az ARM-ből.
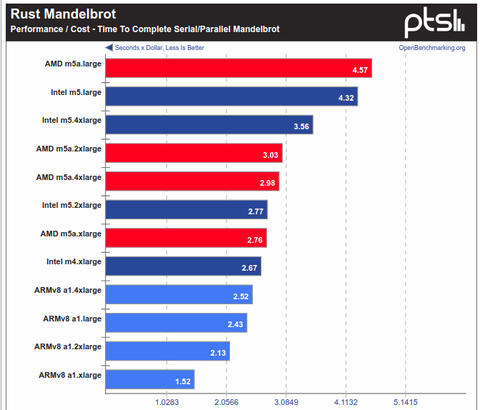
A Rodina v.2.4("OpenMP LavaMD") - tesztben meg az Intel-lel van (ár-teljesítmény) pariban az ARMv8 ,
nem véletlen, hogy az AMD-nak erősítenie kell az AVX2-ön.A PHP/Python -on teszteket meg bukta az ARM.
"The performance of the Graviton processors powering the A1 instances came up well short of the comparable M5 general instance types with either AMD EPYC or Intel Xeon processors. Even with the cheaper pricing, the performance-per-dollar was still generally just on-par with the equivalent or slightly better than the Intel/AMD offerings."
https://www.phoronix.com/scan.php?page=article&item=ec2-graviton-performance&num=5A mostani AWS-es ARM chipek tesztelésre jók - ez lesz a fő piac. A többi területen pedig csak kivételesen rughat labdába ( Mandelbrot
)visszatérve az AMD-re ; azért én látok egy erős fenyegetést az ARM-es vonalról.
jövőre jön ki az ARM Neoverse (Ares 7nm) -en
és
"The Neoverse war plan calls for server processors that will eventually scale up to 128 cores. Our guess is that Arm will use a multichip module approach that leverages the Cortex-A72 blocks to get 48 cores on a die at first, and then puts eight cores on a chiplet or chip block at first with “Ares” in 2019, then twelve cores per chunk with “Zeus” in 2020, and then sixteen with “Poseidon” in 2021, which also switches to 5 nanometer chip etching. Variants used in dataplane applications that have up to 256 cores eventually, which is interesting indeed."szóval nem lesz könnyű éve az AMD-nek jövőre.
Az ARM jön fel mint a talajvíz - és szintén a TSMC-vel gyártat.
https://www.arm.com/company/news/2018/10/announcing-arm-neoverseÉs kis szerencsébel még az Intel is kijöhet 2019 végén a saját 7nm-es termékeivel
"Intel is facilitating a 7-nm fab with EUV in Chandler, Arizona, now, but no production is expected until at least late next year. Even Intel’s current 14-nm yields are “above threshold but vary widely by product,” said Jim McGregor, principal of Tirias Research." (via)szóval nem fogunk unatkozni.
-
#605
 Cathulhu
addikt
Petykemano
#604
Cathulhu
addikt
Petykemano
#604
Cathulhu
addikt
válasz
Petykemano
#604
üzenetére
Ezek ujabb vagy regebbi ARM szerverek?
-
#596
lezso6
HÁZIGAZDA
Petykemano
#593
válasz
Petykemano
#593
üzenetére
Közvetlenül nem biztos, hogy nyomnák az ARM-ot, viszont customként eléggé rizikómentes, folyamatosan tejelő, Lisa Su kompatibilis biznisz lehetne. Ami tapasztalatot összeszednek IF skálázhatóság terén a Zennel, azt a K12-nél is tudják hasznosítani, ami igencsak ütőképes.
-
#594
S_x96x_S
addikt
Petykemano
#593
S_x96x_S
addikt
válasz
Petykemano
#593
üzenetére
>Az szerintem nem lesz, amíg az ARm ökoszisztéma nem gyorsulja le az x86-ot
Eddig a szoftveres támogatás volt a legnagyobb probléma, de ezek egyre inkább megoldódnak.
Hiába volt az ARMv8 -ha nem tudott optimalizált kódot generálni az a fordító. ( llvm, go, gcc )
Az opensource-os package-ket nem tudták kitesztelni, optimalizálni
- de most már egyre több Cloud-ban elérhető ARMv8-as gép
Ennek ellenére még most is előfordul, hogy 1-2 éves stabil linux rendszereket ( ubuntu 18.04 LTS) nem tudsz használni alapból - mert csak az ubuntu 18.10 -esen van lefordítva az adott package. ( ARMv8-ra !!! )
szóval konzervativ cégeknél ez már eleve probléma.
Persze ott vannak a pici málnás gépek, meg a klónjaik - vagyis egyre több fejlesztő tudja elérniMindenesetre ha a Windows-nak elterjed az ARM-es verziója, és lesz Windows server ARM-re is, akkor
az megint egy újabb lendületet ad.Az ARM lassan de biztosan erodálja az AMD64(X86) -os piacot.
megj: A ZEN-1 es szoftveres támogatás se ment olyan könyen, és a laptopokon még mindig kiforratlan.
Az AMD64(X86) - nem tökéletes de legalább kiforott, kevesebb meglepetés éri ott a felhasználót/fejlesztőt.
és ha az AMD olcsón tud ZEN -es csipeket adni, akkor az ARM-es erjeszkedés is lelassul.Mert az AMD versenytársa igazából a feltörekvő ARM (és az IBM-es Power) velük kell árban versenyeznie.
Ha olcsón tud hatékony teljesítményt adni az AMD a ZEN-es architektúrával, akkor ezzel le tudja lassítani az ARM-es szerverpiacot. ( de megállítani nem tudja ) -
#590
lezso6
HÁZIGAZDA
Petykemano
#588
válasz
Petykemano
#588
üzenetére
Hát, ez van, akkor mégis 4+4. Bár igazából mindegy, a késleltetés a millió dolláros kérdés.
-
#572
Cathulhu
addikt
Petykemano
#571
Cathulhu
addikt
válasz
Petykemano
#571
üzenetére
Furcsa amugy, pont az APU piac lenne ami fekszik az AMD-nek, megis ezerrel hanyagolja.
-
#568
lezso6
HÁZIGAZDA
Petykemano
#567
válasz
Petykemano
#567
üzenetére
A Picasso csak egy ráncfelvarrt Raven Ridge lesz. A változás mindössze az energiamenedzsmentet érinti. Ez valamikor jövő év első felében fog érkezni, nagy eséllyel 12 nm-en, Zen+ alapon.
Lásd Raven Ridge, ami sima 14 nm Zen, de a Zen+ energiamenedzsmentjét kapta meg, és az idén februárban jött, pár hónappal a Zen+ magos processzorok előtt. Ez alapján a Picasso is ilyesmi hibrid lesz. Szerintem az IGP 1500 MHz körül fog ketyegni + natív DDR4-3200 támogatás.
-
#557
Cathulhu
addikt
Petykemano
#556
Cathulhu
addikt
válasz
Petykemano
#556
üzenetére
De nem úgy volt, hogy a PCI express marad a chipleteknél?
-
#552
Cathulhu
addikt
Petykemano
#549
Cathulhu
addikt
válasz
Petykemano
#549
üzenetére
Az való igaz, hogy azt mondták az IF órajele azért szinkron a RAMmal, mert egyébként mindenféle cacheket kellene bevetni és ez megbonyolítaná a designt, de ha most lesz egy nagy L4, akkor az IF gyakorlatilag olyan órajelen üzemelhet amilyet csak fizikálisan elbír, a feladata az L3-L4 szinkronizáció lesz, ha jól sejtem. A nagy késleltetés meg részemről csak egy rossz előérzet.
#551 igen emlékszem, jól meg is mosolyogtam, de egyre inkább úgy érzem, hogy nem vicc. Még a végén eljön az Abu által évek óta mondogatott szoftver rendering korszak
-
#550
Petykemano
veterán
Petykemano
#549
Petykemano
veterán
válasz
Petykemano
#549
üzenetére
Ugyanakkor persze annyi különbség van, hogy az SE-k mögötti L2 és HBCC mellett az előttük levő Command processor és Workload distributor is közös. De miért ne lehetne ez az IO chipen?
Fogj meg egy aput, vágd ki belőle a cpu magokat és a CU-kat és kösd hozzá kívülről, skálázd. Voilà.
Ugyanakkor valamiért Dávid Wang mégiscsak azt mondta, ez nem olyan egyszerű nem compute taskok esetén.
(A gput folytassuk a radeon találgatósban) -
#542
lezso6
HÁZIGAZDA
Petykemano
#541
válasz
Petykemano
#541
üzenetére
Szerintem semmilyen strukturális kompaTIBILÁTÁS nem kell, a lényeg a socket. Oprendszer felé úgyis egy processzorként látszik az egész, aztán úgyis kap másik drivert.
Érdekes a rajz, nagyon megy a spekuláció. Ha azt a 128 MB SRAM-ot rá tudta zsúfolni, akkor 512 eDRAM simán elfér, wikichip alapján egy eDRAM cella negyede sincs egy SRAM-énak a Glofo 14 nm-én.
-
#537
Simid
senior tag
Petykemano
#535
Simid
senior tag
válasz
Petykemano
#535
üzenetére
"zennél 2x8MB L3$ van
Egyik CCX-től a másikig elég magas a késleltetés"Igen, ismerem ezt a grafikont. Pont ez az a rész amit nem értek. Ugye van egy 8MB-os rész ami gyorsan elérhető az adott CCX számára. Aztán van egy kevésbé gyorsan elérhető 8MB L3 (kvázi L4). És TR vagy EPYC esetében további 16/48MB L3 (kvázi L5) ami még ennél is lassabban elérhető.
Az Intel esetében az eDRAM a die-on volt, így gyorsan elérhető volt. Ilyen a Rome esetében úgy néz ki nem lesz.Továbbra sem kétlem, hogy egy L4 cache nagyon hasznos lehet szerver környezetben, főleg így, hogy a RAM elérés már minden esetben IF-el összekötött I/O die-on történik. De ez semmit nem fog javítani azon a problémán amit ez a lépcsős grafikon mutat nekünk. Egyszerűen megnövelik annak a cachenek a méretét ami lassan (de a rendszer memóriánál még mindig sokkal gyorsabban) elérhető.
Hogy röviden összefoglaljam, a közeli és gyorsan elérhető L3 hiányát nem lehet pótolni egy távoli és lassan elérhető L4-gyel. Gondolom ezért döntöttek a megnövelt L3 mellett.
"Azért gondoljuk, hogy a CCX-ek közötti elérésben, adattranszferben valahol a memória közrejátszhat, beépülhet, mert az inter-CCX latency általában a mérésekben magasabb, mint a memory latency."
Ez is megvan, de én úgy értelmeztem az előadásból, hogy ez nem fog változni a IF 2.0 esetében sem, csak szélesebb a link. Laikusként nézegetve az IF működését pl ezen leírás alapján nekem az jött le, hogy az SDF bár a mem órajelen üzemel a szinkronizáció miatt, de máskülönben független tőle. Ha ez nem így van és ténylegesen a rendszer memórián keresztül történik a kommunikáció, akkor máris értelmet nyer egy esetleges L4 cache.
-
#531
lezso6
HÁZIGAZDA
Petykemano
#527
válasz
Petykemano
#527
üzenetére
Kiegyenesítettem a perspektívából a legjobban sikerült Rome fotót simára. A nyáklap 58.5 mm × 75.4 mm, szóval pixel-arányból kiszámolható melyik lapka mekkora. Zeppelinre így 220 mm2 jön ki, szóval egész pontos.
Eredmény: egy Zen2 lapka ~75 mm2, az I/O lapka meg ~430 mm2.
Hely szintjén meg lehet spórolni gyakorlatilag elég sok mindent. Csak az Infinity Fabric, PCIE, DDR4 vezérlő szentháromságra van szükség. Előbbi kettő új, így nem tudni mekkora, utóbbi ismert csak, kb 60 mm2 + körítés lenne legalább.
-
#528
Simid
senior tag
Petykemano
#527
Simid
senior tag
válasz
Petykemano
#527
üzenetére
Ennek az eDRAM-nak mi lenne a funkciója amúgy? Értem én, hogy L4 cache, de miért érné meg ez egy CPU-nál? (Laikusként kérdezem, tényleg nem tudom)
A zeppelinhez képest nem csak a redundanciát kell szerintem figyelembe venni, hanem azt is, hogy ez egy jóval bonyolultabb IF, ami már 8 chipet képes összekötni. Gondolom ez nem kis különbség a korábbihoz képest.
-
#526
lezso6
HÁZIGAZDA
Petykemano
#523
válasz
Petykemano
#523
üzenetére
1000 mm2? Wat, mi annyi?
Ha csak cellát számolok, akkor ~75 mm2 512 MB eDRAM GloFo 14 nm-en, ami eléggé apró, a HD SRAM ugyanígy számolva ~350 mm2-re jön ki. De ezt persze valamivel vezérelni is kell meg kérdéses a buszszélesség is.
-
#525
S_x96x_S
addikt
Petykemano
#524
S_x96x_S
addikt
válasz
Petykemano
#524
üzenetére
> Arra gondolsz ..
akár,
de fontos megjegyezni, hoy a memória probémákkat fókuszban tartja az AMD.
és tényleg nem mindegy, hogy egy szállra mekkora memória sávszélesség esik."Over the last decade, we have actually lost major grounds. In other words, the GPU and CPU are increasing in performance at a much faster rate than the memory bandwidth. The inability to feed the processors with data fast enough continues to increase and as the gap widens, memory bandwidth will exceed in severity the other barriers in the future."
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/3/"Full 3D Stacking" - van hosszú távon megcélozva, de rövid távon akár lehet tényleg egy 12/16 csatornás megoldás.
"Su’s ambitious vision didn’t stop with 3D stacking. She proceeded to explain a concept she called “full 3D stacking” whereby AMD would be able to stack the GPU on top of the CPU along with the HBM and NVRAM all together to form a “superchip” of a sort with incredibly high bandwidth and I/O communication between the data, the CPU, and the GPU."
...
"AMD believes that in the future workloads will become increasingly diverse and no one type of design would be able to attack every problem. “In the legacy world, the CPU was the center of everything.” Su said. But in the future heterogeneous architectures will take on a much more prominent role.
Su believes that there is a lot of opportunity in not only maintaining the rate of performance and efficiency but also accelerating the performance curve over the next ten years. “What I would like to say is that there is an opportunity to really bring in all of the conversation around 2.5D integration, 3D integration, multi-chip architectures, memory integration, and different types of memory so that we re-architect the system in a way that each of the components are able to get as efficient as possible.”"
https://fuse.wikichip.org/news/523/iedm-2017-amds-grand-vision-for-the-future-of-hpc/4/
persze ettől nem lettünk okosabbak, de majd megátjuk milyen lesz a végleges Epyc ROME és az utódja.
szóval nem tudok semmit se ..
-
#522
S_x96x_S
addikt
Petykemano
#519
S_x96x_S
addikt
válasz
Petykemano
#519
üzenetére
>Mennyi esélyét látod annak, hogy az amd később, csináljon egy sp3+/sp4 foglalatot,
> ami értelemszerűen még nagyobb , és ami 12ch DDR4 (esetleg már ddr5) Memóriát támogat
>és a lapkán 12 chiplet kapna helyet?jó kérdés - spekulálásra tökéletes.
biztos elemzik az AMD-nél, de óvatosak - kicsi az erőforrásuk és egy ilyennek a bevezetése nem olyan rövid idő. Ha valamelyik partnernek lesz egy ilyen igénye - akkor lesz.
imho: A 12ch DDR4 akkor lesz fontos, hogyha memória sávszél limites lesz az EPYC(2;3;4) - és a DDR5 extrém drága lesz.
Vagyis ez lesz a szűk keresztmetszet.De talán a memória compresszálás valamit segíthet a sávszélességnél is
- és nem véletlenül van ott a Chiphell-es ábrán, ha már titkosítják a memóriát(AES), akor lehet előtte tömöríteni is. ha GPU-knál bejött miért ne lehetne a CPU-knál is ?
https://arxiv.org/pdf/1807.07685.pdfDe az EPYC CPU-nál a HBM bevetése is (elméleti) alternativa.
- "HBM is a new type of CPU/GPU memory (“RAM”) that vertically stacks memory chips, like floors in a skyscraper." https://www.amd.com/en/technologies/hbmnem tudom igazából,
de nem is zárom ki mint elméleti lehetőséget.Én a Deep learning miatt a hibrid HBM+DDR4/5 irányt forsziroznám inkább mnt a 12ch -t:
de 1 év múlva okosabbak leszünk. -
#520
lezso6
HÁZIGAZDA
Petykemano
#515
válasz
Petykemano
#515
üzenetére
Igen, most már világos. Én úgy értettem, hogy külön chip, stb. IF-fel így logikus meg az is, hogy miért ekkora az I/O (~300 mm2).

Számolgattam...
Az Intel 22 nm-en készülő 128 MB eDRAM-ja 84 mm2. Wikichip alapján csak cellákkal számolva 31 mm2 jön ki, ami ugye kevés.
De ha csak az Intel 22 nm és a GloFo 14 nm eDRAM cella méretéből arányosan szorzok, akkor az jön ki, hogy 202 mm2 512 MB eDRAM. Tehát az I/O chip kétharmadát vinné.Azonban nem hiszem, hogy 100 mm2-re ráfér minden I/O. TriTon számai alapján legalább 40 mm2 lenne egy alap uncore kiszerelés a Zeppelinből. Így 160 mm2-re jön ki a tiszta I/O. Emellé 256 MB eDRAM fér a fenti számolás szerint. Hacsaknem a tömbösítések miatt valahogy "megtrükközhető" kisebbre.
SRAM biztos nincs az I/O-ban. Az sokat fogyaszt és 3x akkora.
-
#510
 HSM
félisten
Petykemano
#507
HSM
félisten
Petykemano
#507
HSM
félisten
válasz
Petykemano
#507
üzenetére
"de a másik CCX L3-ból olvasni úgy tűnik nem volt gyors"
Vélhetőleg az nem a másik L3-ból olvasott, viszont ha ott volt a szükséges adat aktuális állapota, akkor azt előbb vissza kellett menteni a rendszermemóriába, hogy utána onnan a másik CCX kiolvashassa.Ez nem nem volt gyors, és lassulást okozhatott, hanem keményen okozott is az erre fel nem készített alkalmazásoknak, lásd pl. az Nv drivert mikor megjelent a Ryzen.
Így viszont egy L4-el lehet csinálni egy viszonylag gyors köztes lépcsőt, amin keresztül a memória kihagyása nélkül, lényegesen gyorsabban lehet adatot cserélgetni a CPU csoportok között.
Amúgy vannak alkalmazások, amik nagyon szerették az L4-et, lásd pl. a PH tesztet: [link], egy esetben még az 5960X-et is odakente!
 [link]
[link](#509) lezso6: Bruteforce avagy sem, én AM4-en is szívesen látnék egy 32-64MB-ot belőle L4-ként, ha marad a több CCX-es felépítés.

-
#509
lezso6
HÁZIGAZDA
Petykemano
#507
válasz
Petykemano
#507
üzenetére
Egyelőre az Infinity Fabric 2-t kéne látni akcióban. Az eDRAM meglehetősen bruteforce megoldás.
-
#503
lezso6
HÁZIGAZDA
Petykemano
#501
válasz
Petykemano
#501
üzenetére
Jó, ez jogos, ott az OEM. De azért ha nem gyárt a procikhoz ott semmit, az jelentős kiesés a GloFo-nak szerintem.
-
#500
lezso6
HÁZIGAZDA
Petykemano
#499
válasz
Petykemano
#499
üzenetére
Szerintem szimplán csak olcsóbb a GloFo. Meg ugye ha az AMD nem gyárt semmit a GloFo-nál, akkor utóbbinak kb lőttek.
-
#497
Cathulhu
addikt
Petykemano
#495
Cathulhu
addikt
válasz
Petykemano
#495
üzenetére
Ez bennem is felvetődött, hatalmas lett az IO chip, sok minden elfér benne, egy L4 meg kifejezetten hasznos lenne.
-
#494
Cathulhu
addikt
Petykemano
#493
Cathulhu
addikt
válasz
Petykemano
#493
üzenetére
Valoszinuleg a gigantikus (Zen1-hez kepest legalabbis) L3 a kulonallo IO-t probalja kompenzalni.
-
#487
 TRitON
aktív tag
Petykemano
#486
TRitON
aktív tag
Petykemano
#486
TRitON
aktív tag
válasz
Petykemano
#486
üzenetére
Én úgy értettem, hogy a tegnap bemutatott CCX chiplet-ekben lévő, az EPYC-ben amúgy letiltott DRAM és I/O vezérlő lesz aktív, így nem kell sehova külön chipet tervezni.
-
#484
Cathulhu
addikt
Petykemano
#450
Cathulhu
addikt
válasz
Petykemano
#450
üzenetére
Kicsit visszatekintve tegnapra:
"Linpack up to 1.21x versus Intel Xeon Scalable 8180 processor and 3.4x versus AMD EPYC 7601
Stream Triad up to 1.83x versus Intel Scalable 8180 processor and 1.3x versus AMD EPYC 7601"Na ma az derult ki, hogy az uj Epyc64C128T elmeleti lebegopontos teljesitmenye 4x-esere nott, illetve hogy c-rayben (szinten elvileg erosen lebegopontos) elveri a dual 8180-at. Ha ez igaz, akkor itt kerem buciraveres esete fog fennallni.
-
#463
S_x96x_S
addikt
Petykemano
#461
S_x96x_S
addikt
válasz
Petykemano
#461
üzenetére
mostani infó
Magyar idő szerint este 6óra. ( 18:00 )
AMD Next Horizon Live Blog: Starts 9am PT / 5pm UTC
https://www.anandtech.com/show/13547/amd-next-horizon-live-blog-starts-9am-pt-5pm-utc -
#462
Cathulhu
addikt
Petykemano
#461
Cathulhu
addikt
válasz
Petykemano
#461
üzenetére
Ugy nez ki lesz live blog
-
#461
Petykemano
veterán
Petykemano
#450
Petykemano
veterán
válasz
Petykemano
#450
üzenetére
-
#454
S_x96x_S
addikt
Petykemano
#450
S_x96x_S
addikt
válasz
Petykemano
#450
üzenetére
>Az intel nem szokott ilyen megelőző csapásokat intézni.
Az AnandTech -esek szerint is szokatlan
"Food for thought... at 11pm PT on a Sunday. Kind of an odd time for this announcement."
https://twitter.com/IanCutress/status/1059340497569832960Az AMD Horizont eventjének nem látom az időpontját. de szerintem késő este / szerda hajnalban lesz valami infó. ( SanFrancisco időzóna )
"AMD's next horizon event is scheduled for Tuesday, November 6, 2018, where we will discuss innovation of AMD products and technology, specifically designed with the datacenter on industry leading 7-nanometer process technology."Várhatóan az AnandTech -en lesz valami ...
https://twitter.com/IanCutress/status/1059186720497852416 -
#453
Cathulhu
addikt
Petykemano
#452
Cathulhu
addikt
válasz
Petykemano
#452
üzenetére
Ez arra jo, hogyha valakit holnap meggyozne mondjuk az Zen2-es Epyc es elgondolkodna a valtason mondvan az intelnek semmije sincs ez ellen, mehessen a marketinges es lebeszelhesse az ingadozot. Aztan az mar kit erdekel, hogy ehhez ugyanugy foglalatvaltas kell mintha epycre allna az ember, vagy hogy ennek a foglalata sem lesz hosszabb eletu mint az SP3.
Arra van barmi esely, hogy AVX512 support jojjon a Zen2-ben? Tudom nagyon retegigeny, de az intel egyetlen megmaradt fegyvere benchmarkokban. -
#451
Cathulhu
addikt
Petykemano
#450
Cathulhu
addikt
válasz
Petykemano
#450
üzenetére
Dehogynem, threadripper 2 előtt chiller? Pont ilyen kétségbeesett volt, csak sajnos működik.
Bízom benne, hogy az Zen2 ezt a borzalmat is alázza.
Azt meg nem is minősíteném, hogyha a xeonhoz képest 20% mindössze az előrelépés, akkor hogy jött ki az Epychez képest 240... Nagy nehezen találtak valószínűleg egyet AVX512 tesztet, innentől kezdve nem támadható a kijelentés... -
#449
S_x96x_S
addikt
Petykemano
#447
S_x96x_S
addikt
válasz
Petykemano
#447
üzenetére
>Már nem büdös a technocol.
ez már presztizsharc ... mindenáron a leggyorsabbnak kell lenni:
“It is our intent and design to deliver performance leadership throughout 2019,” Lisa Spelman , INTEL
itt már a tecnocol is megengedett.de a gazdaságosság már más tészta :
"Intel could meet or beat AMD on performance, slash prices like crazy (with this 48-core Cascade Lake AP part not costing much more than a monolithic top-bin 28-core Skylake part), and still lose out bigtime on performance/watt and cost/performance/watt."
https://twitter.com/NicoleHemsoth/status/1059438873804193793bővebb : "INTEL TO CHALLENGE AMD WITH 48 CORE “CASCADE LAKE” XEON AP"
https://www.nextplatform.com/2018/11/05/intel-to-challenge-amd-with-48-core-cascade-lake-xeon-ap/"We will see what AMD has to say this week out in San Francisco, and then take stab at trying to figure out how it will map to what Intel is doing. We have heard on the rumor mill that Rome Epycs will have 48 cores (as we expected) and only eight memory channels (we were hoping for more, but Rome has to be socket compatible with Naples); others are expecting AMD to crank Rome up to 64 cores in a socket, and still others say Rome is 48 cores and the kicker “Milan” processors will reach up to 64 cores. Intel just forced AMD’s hand into disclosure"
Engem a 12 memóriacsatorna egy kicsit meglepett, de ha nem számítanak a költségek - akkor mindent lehet
-
#444
 solfilo
veterán
Petykemano
#443
solfilo
veterán
Petykemano
#443
válasz
Petykemano
#443
üzenetére
Az is lehet, hogy csak utólag magyarázzák a bizonyítványt.
Athlon 200GE hozza az A10-9800 teljesítményét, miközben 35W vs 65W TDP.
Itt mértek pár játékkal, hol egyik, hol másik a gyorsabb: [link]
Hogy lesz ebből azonos teljesítmény azonos thermal limitnél, ha ekkora fogyasztásdifi mellett is kb egyformán teljesítenek?
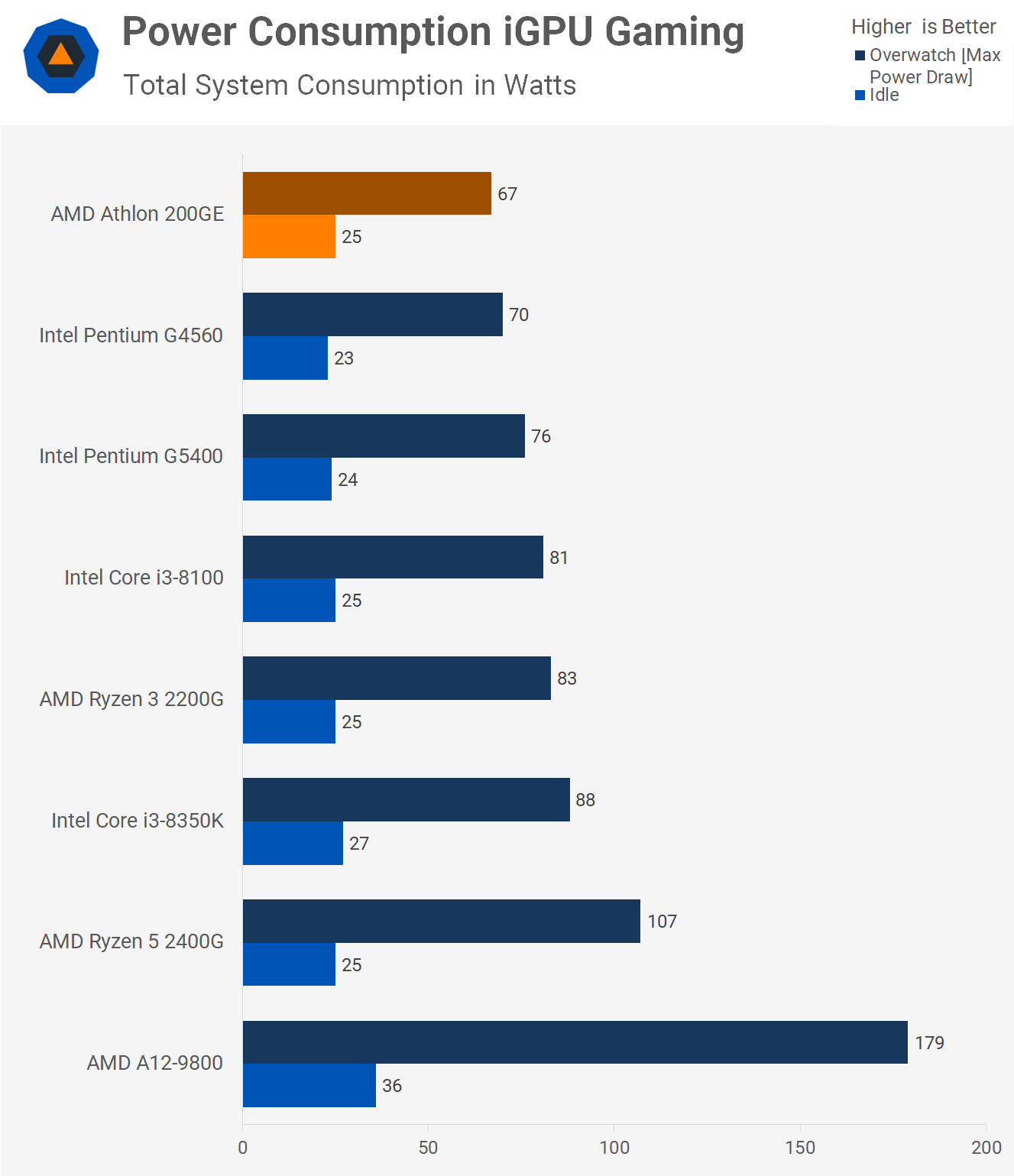
mondjuk ez alapján, hogy "We will continue to maximize the thermals to allow the Bristol Ridge APU to run at maximum speed", elég spórolósra vehették a hűtést.
-
#441
S_x96x_S
addikt
Petykemano
#439
S_x96x_S
addikt
válasz
Petykemano
#439
üzenetére
>Talán így fog mutatni az epyc2 és ryzen3
rengeteg ábrát fabrikált, de ezek csak spekulációk.
"Reminder: These aren't leaks, just my idle speculation. Do what you want with them."
https://twitter.com/chiakokhua/status/1057166488627380224 -
#440
Petykemano
veterán
Petykemano
#439
Petykemano
veterán
válasz
Petykemano
#439
üzenetére
Úgy tűnik, egy CCX 8 mag lesz. 32MB L3$
Kicsit tartok attól, hogy innentől minden cpu lapka mellé kell IO lapka is és innentől minden lapkaközi kommunikáció lapkán kívül történik (core-core, core-ram)es az is igaz, hogy így contol chipből is többet kell majd tervezni.
De az így biztosra vehető, hogy a mainstream LEHET 16 magos. És az is valószínű, hogy a control chiphez fog csatlakozni az igp is nagymértékű flexibilitást biztosítva.ZenX - ezmiez?
-
#436
Cathulhu
addikt
Petykemano
#435
Cathulhu
addikt
válasz
Petykemano
#435
üzenetére
-
#433
 Fiery
veterán
Petykemano
#432
Fiery
veterán
Petykemano
#432
Fiery
veterán
válasz
Petykemano
#432
üzenetére
Bulldozer? Mit kommentaljak egy halott allatorvosi lovon?

-
#427
HSM
félisten
Petykemano
#423
HSM
félisten
válasz
Petykemano
#423
üzenetére
"Akárhogy is, felvetődhet a kérdés, miért hagytak ki egy csak CCX-ek közötti megosztást célzó L4-et a lapkából?"
Ha engem kérdezel, logikus döntés, hiszen az egész dizájn azon nyer nagyon sokat, hogy gyakorlatilag két független CPU-komplexként működik a két CCX. Ugye, ezen nyernek, hogy nem kell állandóan adatot szinkronizálni 8 mag cache-ei között, ami lényegesen komolyabb meló lenne, mint 4-et szinkronban tartani, hanem minden CCX megteszi magán belül, ha pedig adatot kell cserélni, megoldják a memórián keresztül.(#424) S_x96x_S: Tény. Mondjuk ennek a benchnek a hitelességét nálam erősen megkérdőjelezi, hogy a 2600X 6 maggal hozza ugyanazt, mint a 2700X 8-al. Itt nekem valami nem kerek.

-
#425
Cathulhu
addikt
Petykemano
#421
Cathulhu
addikt
válasz
Petykemano
#421
üzenetére
Nem igazan a memoriak orajeletol fugg, pontosabban az I/O bus sebessegen megy, ami viszont egyenesen aranyos a memoriak sebessegevel. Ha igy kozelited meg, akkor viszont teljesen ertheto miert van ez. Azt nem tudom egyaltalan meg lehetne-e valositani ertelmes kereteken belul, hogy ettol elterhessen, talan amihez nem kellene nagy varazslat, hogy annak valami egesz szamu tobbszorosen uzemeljen, de azt az orajelet meg lehet siman nem birna.
-
#422
HSM
félisten
Petykemano
#421
HSM
félisten
válasz
Petykemano
#421
üzenetére
Szerintem logikus döntés, hogy a memóriasebességgel skálázódik a rendszer. Minél gyorsabb a memória, annál több adatot kell elszállítani. Így szerintem egy fix aránnyal összeszinkronizálni is egyszerűbb lehetett a dolgokat. Ettől függetlenül én is fontosnak látnám még javítani ezen interconnectek sebességén.
"Kicsit olyan, mintha a két CCX a memórián keresztül kommunikálna."
Hát, nem lépődnék meg, ha így lenne."csak nem világos, hogy miért a memóriaelérés késleltetése alacsonyabb a szomszédos L3$-nél?"
Gondolom, a szomszédos L3 tartalmát először ki kell írni memóriába, majd onnan betölteni a másik L3, tehát nyilván ez egy memória írással lassabb lesz, mint ha csak egyből a memóriából kéne beolvasni.Vigyázat, nem tudom (ha valaki ismeri az architektúrát javítson ki), ez csak feltételezés.
-
#420
HSM
félisten
Petykemano
#419
HSM
félisten
válasz
Petykemano
#419
üzenetére
A négy lapkás Threadrippereknél van két lapka, aminek nuku memóriája sincs.
A sima kétlapkás Threadrippereknél mindkét lapkának van memóriája, a probléma ugyanakkor ott is jelen van, hiszen ha az adott magnak olyan adat kell, ami a szomszéd csip tárában van, akkor megint a lassú távoli elérés esete fog befigyelni. Ezért találták ki a game módot, ami ha jól emlékszem, komplett lekapcsolja az egyik magot, praktikusan kreálva egy sima AM4-es procit.
"Second, Game Mode disables the cores in one of the silicon dies. This isn’t a full shutdown of the 8-core Zeppelin die, just the cores. The PCIe lanes, the DRAM channels and the various IO are still active, but the cores themselves are power gated such that the system does not use them or migrate threads to them."
Forrás: [link]
Itt szépen le is mérték, gyors DDR4-3200-as memóriákkal: 65ns near memory and 108ns far memory (87ns average). Szóval, a far memory 65ns egész jó (most nem trollkodom, hogy a 8 éves X58 rendszerem vígan befigyel gyors DDR3 ramokkal 50ns alá, vagy mégis?![;]](//cdn.rios.hu/dl/s/v1.gif) ), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
A késleltetés a system agent órajelén múlik, ha minden igaz, ami emlékeim szerint a ram frekvencia felén megy, ezért is fontos Ryzen alá a magas órajelű ram, mert szuperül csökken tőle a rendszer késleltetése.Szóval ez egy jó megoldás, lekapcsolva a fél TR-t megoldani, hogy csak lokális memória elérés legyen, ami gyors, csaképpen ugyanezt olcsóbban is lehet produkálni egy sima AM4-es Ryzennel.
-
#384
S_x96x_S
addikt
Petykemano
#383
S_x96x_S
addikt
válasz
Petykemano
#383
üzenetére
>A 32 magos TR2-re gondoltak, nem az egyébként jó frissítésnek számító 16 magosra.
Szept4 -el kezd Jim Anderson az új helyén, és szerintem az ő döntése, hogy megvárta a TR2 launch-ot.
Valószínüleg aug1-verl értesítette Su-t és az új cégével ( Lattice Semiconductor ) már tavasszal elkezdődtek a puhatolozzó megbeszélések.
Tehát én nem hiszem, hogy a 32magos threadripper miatt kellett mennie.Mivel Jim Anderson CEO - szeretett volna lenni és Lisa Su szénája egyre erősödött - nem sok lehetőséget látott a cégen belül.
Legalábbis ez a hivatalos álláspont.
"An AMD spokesman said that it was always Anderson's career ambition to eventually become a chief executive."A 32magos Threadripper kb +30%-os cpu freq -on üzemel a 32magos Epyc-hez képest
és a tesztek nagy többségénél ez bőven elegendő, hogy leverje az EPYC-et is a tesztekben.
Ezen kivül még olcsóbb is.
Valamit a 32 magos TR az a chip, ami elvette az Inteltől a koronát. A 28magos Inteél demó után nem volt más választása az AMD-nek.
Szóval én inkább azt hiszem ez pozitiv lap lesz az AMD történetében.Sikeresség II.
Az árazás lineáris a magok számával. A 16magos fele annyi mint a 32 magos.
És ha nem kell a piacnak, akkor még mindig csökkenthetnek árat.
Vagyis nincs rossz processzor - csak rosszul árazott proceszor
persze ha kijönnek a 7nm-es EPYC-procik, akkor már más lesz a felállás, de jó árazással akkor sincs gond. -
#382
S_x96x_S
addikt
Petykemano
#379
S_x96x_S
addikt
válasz
Petykemano
#379
üzenetére
>Állítólag a Threadripper 2 miatt kell mennie, merthogy papíron jól mutat, de szűkös a pálya,
>ahol tényleg skálázódik.Szerintem ezt az Intel Fan-ok terjesztik .. A 16 magos - 2950-es elég jó !
de végiggondolva:
Az már az EPYC piaca ... nem hiszem, hogy a saját EPYC piacuk kannibalizálását akarnák.
Meg a mostani Threadripper2 -tőt az X399-es alaplap korlátai fogják vissza. ( pl. memóriacsatorna ) nem sajnálták a magokat.De majd a piac eldönti.
Úgyis jönnek a Gamer EPYC lapok -
#380
S_x96x_S
addikt
Petykemano
#378
S_x96x_S
addikt
válasz
Petykemano
#378
üzenetére
>A legújabb GF hírek szerint....
>A matisse vagy nem 7nm, vagy nem a GF gyártja.vegyes stratégia is lehetséges. az AM4-es ZEN2 magú procik ( ár) alsó szegmensét a GF - a felső ( drágább; > 8 core ) szegmensét a TSMC gyártja.
persze ez felboritja a tisztán 7nm-es next gen roadmap-et.Az Anandtech-es cikkben ezt már így fogalmazták meg:
"Furthermore should AMD decide to start on any new chips that don’t require a bleeding-edge manufacturing process (e.g. a chipset), then GlobalFoundries is still an option."hivatalos AMD reagálás ( befektetőknek )
Anandtech elemzések:
AMD's 7nm CPUs & GPUs To Be Fabbed by TSMC, on Track for 2018 - 2019
https://www.anandtech.com/show/13279/amd-to-fab-7nm-cpus-gpus-at-tsmcGlobalFoundries Stops All 7nm Development: Opts To Focus on Specialized Processes
https://www.anandtech.com/print/13277/globalfoundries-stops-all-7nm-development
" The company will keep working with AMD for many years to come in fabbing current-generation CPUs and GPUs, and then switching exclusively to wafers with embedded APUs/GPUs as well as with first-gen EPYC dies, as these products have very long lifecycles. However, the number of wafers GlobalFoundries processes for AMD will be dropping rapidly starting from 2019. Whether GF will be able to substitute AMD’s orders with orders from enough smaller players to Fab 8 full utilized is something only time will tell." -
#375
Cathulhu
addikt
Petykemano
#374
Cathulhu
addikt
válasz
Petykemano
#374
üzenetére
Se a 2x energiahatekonysagba se az 1.35x-os performance-ba nem illik bele, meg ugy a ketto kozti atmenetbe sem igazan, szerintem. Mindenesetre ha ez lenne a Zen2, az (nem)kicsit csalodast kelto lenne, szerintem
-
#373
Cathulhu
addikt
Petykemano
#372
Cathulhu
addikt
válasz
Petykemano
#372
üzenetére
Mennyire megbizhato az urge? Mert ez inkabb tunik egy Zen++-nak, mint egy Zen2-nek.
"95W 8C/16T 4.2 base/4.5-4.6 Boost?"
mindezt 7 nanon? mondjuk ugy, hogy elegge buzlik -
#356
S_x96x_S
addikt
Petykemano
#352
S_x96x_S
addikt
válasz
Petykemano
#352
üzenetére
>Ez biztos drága,
Nem olcsó , $325 - $450 között lesznek - akár már agusztusban.
""
The Sapphire FS-FP5V will be available later this month. Consumers interested in grabbing one can order it directly through Sapphire's website. Pricing is as follows:
FS-FP5V1807B V1807B 35-54W 52093-00-40G - $450
FS-FP5V1756B V1756B 35-54W 52093-01-40G - $390
FS-FP5V1605B V1605B 12-25W 52093-02-40G - $340
FS-FP5V1202B V1202B 12-25W 52093-03-40G - $325
""
https://www.tomshardware.com/news/sapphire-amd-ryzen-v1000-apu,37408.htmlAz UDO Bolt - 229$ -tól indul - Látja valaki, ami miatt a közel $100 -os felár indokolt?
https://www.kickstarter.com/projects/udoo/udoo-bolt-raising-the-maker-world-to-the-next-leve
-
#355
 -=MrLF=-
senior tag
Petykemano
#354
-=MrLF=-
senior tag
Petykemano
#354
-=MrLF=-
senior tag
válasz
Petykemano
#354
üzenetére
Szerintem ebből nem jön komplett gép, de remélem jön valami egyszerűbb lap azzal hozhatnának ki Barabone csomagot. Négy DP++ kimenettel, meg ECC RAM támogatással ez a fenti lap aranyárban lesz.
-
#353
-=MrLF=-
senior tag
Petykemano
#352
-=MrLF=-
senior tag
válasz
Petykemano
#352
üzenetére
Köszi, itt is írnak róla: [Sapphire Shows Off New 5x5 Ryzen V1000 Platform for Embedded Systems]
Honlapukra is felkerült: [SAPPHIRE FS-FP5V] 147.3mm x 139.7mm (5.8" x 5.5")
[FS-FP5V alaplap kép nagyban]Egyértelműen mini-STX kompatibilis, de valamiért ezt nem írhatják rá.
Jöhetne csomagban házzal táppal mint a [Deskmini]
[Asrock H110M-STX link][H110M-STX alaplap kép nagyban]
Mini-STX Form Factor: 5.5-in x 5.8-in, 14.0 cm x 14.7 cm -
#344
Simid
senior tag
Petykemano
#343
Simid
senior tag
válasz
Petykemano
#343
üzenetére
"Please note that actual wafer starts per month (WSPM) output of a fab depends on multiple factors, including process technologies used. As a result, all the WSPM capacity numbers are relative and may not reflect actual performance. Keep in mind, that as foundries and IDMs increase usage of multi-patterning techniques, their effective WSPM output drops as wafers spend more time in the cleanroom. Hence, to keep the wafer starts per month capacity, chipmakers need to add equipment (which may, or may not, involve physical expansion of the cleanroom space)." by Anandtech
Gondolom ez lehet az oka.
-
#340
Fiery
veterán
Petykemano
#339
Fiery
veterán
válasz
Petykemano
#339
üzenetére
48 vagy 64 mag, majd elvalik, mennyire lesz jo a 7 nano. A HEDT szegmensben nem valoszinu, hogy lesz ertelme 32 mag fole skalazni jovore.
-
#336
Fiery
veterán
Petykemano
#335
Fiery
veterán
válasz
Petykemano
#335
üzenetére
A TDP-t el kell ereszteni TR4-en (TR4+ ?), es akkor mehet a 32 magos Threadripper 4 GHz korul. Az eleg lesz, elegnek kell lennie.
-
#330
S_x96x_S
addikt
Petykemano
#329
S_x96x_S
addikt
válasz
Petykemano
#329
üzenetére
> Persze ha világosan látható több évre előrevegítve, hogy jobb lesz az Arm, aki bátor, ráugrik.
miért jövőidő? valamiben már most jobb.
Anandtech:"From the early server software testing we have done so far, we can only be pleasantly surprised. The performance-per-dollar of the ThunderX2 in both Java Server (SPECJbb) and Big Data processing is – right now – by far the best in the server market. We have to retest AMD's EPYC server CPU and a Gold version of the current generation (Skylake) Xeon to be absolutely sure, but delivering 80-90% of the performance of the 8176 at one fourth of the cost is going to very hard to beat."
persze főleg az EPYC-re veszélyes.
Anandtech:"So all in all, the ThunderX2 is a very potent contender. It might even be more dangerous to AMD's EPYC than to Intel's Skylake Xeon thanks to the fact that both Cavium and AMD are competing for much of the same pool of customers considering switching away from Intel." -
#327
S_x96x_S
addikt
Petykemano
#325
S_x96x_S
addikt
válasz
Petykemano
#325
üzenetére
> És jóhogy ez még mindig 10%-kal van a skylake IPC alatt
a Szerver piac egy külön kategória , lesz még itt meglepetés.
Az új ARM-es cavium-thunderx2 ( 16nm) eléggé bekavar a XEON - EPYC versenynek.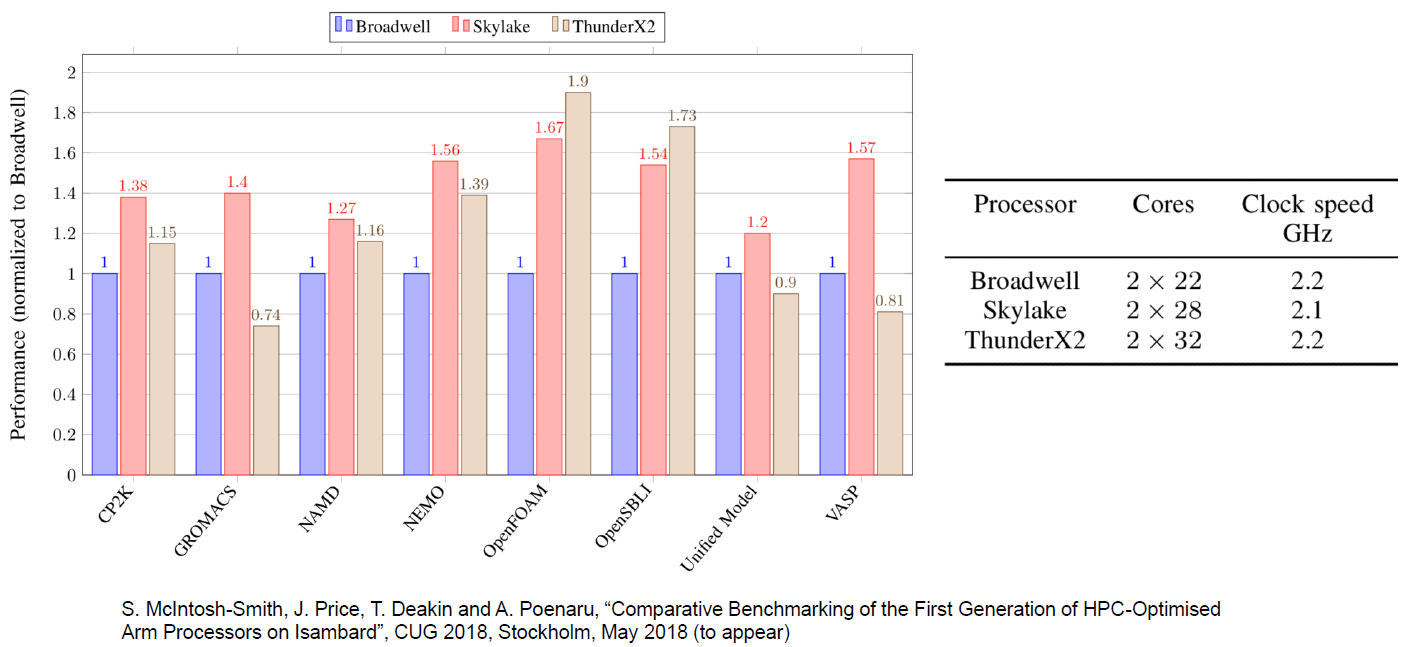
https://www.anandtech.com/print/12694/assessing-cavium-thunderx2-arm-server-realityhosszú távon az áramvonalasabb ARM -é a jövő.
Az X86 -ot újra kellene tervezni. ( Jim Keller vajon csodát tesz ? ) -
#326
HSM
félisten
Petykemano
#325
HSM
félisten
válasz
Petykemano
#325
üzenetére
IPC... Jól látom, hogy két teljesen más utasításkészletű processzornál beszélünk IPC-ről? Illetve szerintem megér egy misét, hogy a Skylake eléggé brutális vektoros illetve lebegőpontos képességekkel rendelkezik (pl. avx2), míg lebegőpontos IPC-ben még a qualcom lassan 2,5 éves házi fejlesztése is elverte (Snapdragon 820-821 Kyro) az A75-öt... [link]
Oké, lehet csodát csinálnak az A76 lebegőpontos teljesítményével, de nem tartom valószínűnek, így viszont azért fenntartásokkal kell szerintem kezelni a kérdést. A Ryzenben pedig ugyanúgy erős lebegőpontos és vektoros egységek vannak, amik szintúgy bőven foglalnak el helyet a lapkában, és nem feltétlenül jelentkeznek markánsan az "általános" IPC-ben.
-
#324
S_x96x_S
addikt
Petykemano
#322
S_x96x_S
addikt
válasz
Petykemano
#322
üzenetére
> Atari VCS bristol Ridge. Kár, ha igaz.
Van más kickstarteres project is
tökéletes mini PC és választni lehet a procit - akár " AMD Ryzen™ Embedded V1605B"UDOO BOLT: Raising the maker world to the next level
Almost twice as fast as the MacBook Pro 13", for VR, AR, and AI projects. The first Maker PC with the AMD Ryzen™ Embedded V1000https://www.kickstarter.com/projects/udoo/udoo-bolt-raising-the-maker-world-to-the-next-leve
-
#323
solfilo
veterán
Petykemano
#322
válasz
Petykemano
#322
üzenetére
Wow, még csak nem is A12.
-
#314
 Yutani
nagyúr
Petykemano
#313
Yutani
nagyúr
Petykemano
#313
Yutani
nagyúr
válasz
Petykemano
#313
üzenetére
Persze én is meglepődtem, de ha fogyasztásban jó, valamint olcsó is, akkor asztali gépbe megfelel.
-
#312
Yutani
nagyúr
Petykemano
#311
Yutani
nagyúr
válasz
Petykemano
#311
üzenetére
Ha nem bonyolult az áramkör és nincs értelme drágább processre átvinni fogyasztás és órajel miatt, akkor miért ne?
-
#300
bpx
őstag
Petykemano
#299
bpx
őstag
válasz
Petykemano
#299
üzenetére
Mit tud az AMD EPYC, amit az Intel Xeon nem, és érdemes lenne emiatt arra váltani?
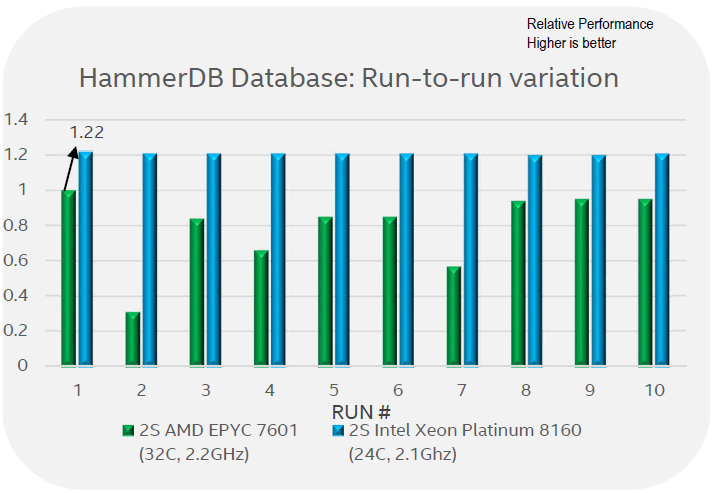
Magasabb órajellel és több core-ral kisebb a teljesítménye. Olyan környezetben, ahol core alapon licencelik a szoftvert, és a CPU ára és licencköltség között akár egy nagyságrendbeli eltérés is lehet.
-
#298
HSM
félisten
Petykemano
#297
HSM
félisten
válasz
Petykemano
#297
üzenetére
A programot optimalizálni kell a HT/SMT működésre, különben kérdéses, mi lesz a végeredmény, pont azon jelenség miatt, hogy erőforrást vehetnek el egymástól a szálak. Sajnos erre az ütemező sem feltétlen tud megoldást, hiszen nem lát bele a programba, melyik szálnak mikor kellene elkészülnie, hogy minek adjon több erőforrást.
Az OS, ütemező optimalizálva van rá, az amit tehet, megteszi, de a program oldaláról sem árt, ha van direkt optimalizálás. -
#296
HSM
félisten
Petykemano
#295
HSM
félisten
válasz
Petykemano
#295
üzenetére
A dolog egyébként logikus. Ha letiltod az SMT-t, akkor rosszul optimalizált programban megszűnhetnek pl. a mikrolaggok, miközben SMT nélkül kevesebb TDP-t használ fel (hiszen lassabban dolgozik, rosszabb a magok kihasználtsága) így marad valami magasabb turbó órajelet elérni (ha a csipben eddig a TDP volt a korlát, nem az elérhető órajel). Ugyanakkor ez max sebtapasznak jó, bugos vagy rosszul optimalizált programokra. Ha a program jól van megírva, SMT-vel lesz gyorsabb hiszen az az egyik leghatékonyabb módja az összteljesítmény javításának.
-
#290
solfilo
veterán
Petykemano
#289
válasz
Petykemano
#289
üzenetére
Ryzen 5 1400-on is vághattak volna, így kb értelmetlen lesz megvenni 2400G mellett.
-
#225
 leviske
veterán
Petykemano
#224
leviske
veterán
Petykemano
#224
leviske
veterán
válasz
Petykemano
#224
üzenetére
Őszintén szólva én konkrétan a HSA kapcsán inkább arra számítok, hogy csendben eltűnik (ahogy Abu is lassacskán elhallgatott a témában). Arra tökéletes volt a projekt, hogy kijelöljön egy fejlesztési irányt, de véleményem szerint a Google és a Microsoft idővel előáll a saját kontrolljukon belül eső variánsaival.
A Microsoft esetében eleve valami ilyesmi formában tudom elképzelni azt, hogy ARM lapkán tudtak futtatni X86-os rendszert. Persze ez még nem heterogén számítás, szimpla X86 emuláció, de azon a szoftveres alapon szvsz megoldható volna ez is. Pláne, hogy a C++AMP is igazából a heterogén irányba tekintget, ha jól tudom. Redmond elég nagy ahhoz, hogy amennyiben átállnának alkalmas területeken a heterogén számítások támogatására, akkor abban kénytelen volna a piac lekövetni, szabvány szinten.
-
#223
leviske
veterán
Petykemano
#222
leviske
veterán
válasz
Petykemano
#222
üzenetére
Amennyiben az i7 5775C eredményeiből indulunk ki, akkor a HBM (és annak mérete) még egy lehetséges evolúciós irány lehet az AMD számára. Ahogy az is, ha sikerülne a HSA-ból végre előnyt is kicsikarni pár alkalmazás alatt az APU-kkal.
Szóval nekik azért nem feltétlen csak az X86-os teljesítmény növelése a lényeg.
-
#220
 derive
senior tag
Petykemano
#213
derive
senior tag
Petykemano
#213
derive
senior tag
válasz
Petykemano
#213
üzenetére
Nem biztos, hogy keszpenznek kell venni, amit a clickbaites oldalak irnak. Valoszinuleg csak a hardveres kompatibilitas szunik meg, ha nagyon kell, tovabbra is tudja majd emulalni a regi utasitasokat. Az AMD mar jopar eve ezt csinalja az x87el es az MMXel. Az intel messze nincs olyan helyzetben, hogy hirtelen eldobja a visszafele kompatibilitast. Azt kijelentheti, hogy a jovoben par nagyon regi utasitas csak szoftveresen lesz megoldva, de ha nagyon erolkodik, meg az MS is otthagyja (mint az IA-64 eseteben).
Jut eszembe, valamit tenyleg ki kell talalnia az Intelnek, mert 2023ban lejar az x86-64 szabadalma es barki epithet kompatibilis procit. Nem veletlen, hogy az ARMok most a 486ig bezarolag emulaljak ax x86ot
-
#214
leviske
veterán
Petykemano
#213
leviske
veterán
válasz
Petykemano
#213
üzenetére
Nem rég mutatott be egy X86-ot szimuláló ARM-es gépet a Microsoft egész egyszerűen azért, mert visszafelé kompatibilitás nélkül nem tudnak érvényesülni a piacon az Android hullámmal szemben. Innentől én annak sok alapját nem látom, hogy a Microsoft ahhoz asszisztálna, hogy saját magát végleg kigolyózza a piacról is.
Az már egy elképzelhető dolog, hogy az Intel bizonyos utasításokat elhagyna és rábízná azok szimulálását a Windows-ra, de a szerver piacon komolyabb tényező Linux-os közösséget is fel kéne ilyesmire készíteni, ahogy az Apple-t is. A teljesen egyedi, Intel-exkluzív ISA-k fókuszba helyezéséhez kellene egy olyan fejlesztői háttér, amire támaszkodhat a cég. Amennyiben ez a Microsoft volna, a Redmondiakat semmi nem akadályozná meg abban, hogy az AMD exkluzív utasításkészleteit is támogassák. Viszont ilyesmi szerintem legkorábban 10 év múlva lehet életképes.
Ráadásul az Intel elég veszélyes vizekre evezne azzal, ha az AMD-t szoftveres oldalról akarná megfogni. Elvégre pont ezen a területen erősödtek az elmúlt 10 évben. A HSA végett a cég valószínűleg hamarabb tudná elérni a fejlesztőket, vagy minimum kierőszakolni a Microsoft-ból, hogy ne hagyják ki Őket sem.
-
#192
leviske
veterán
Petykemano
#191
leviske
veterán
válasz
Petykemano
#191
üzenetére
de, csak az az egyetem dolgozik rajta így gondoltam kapják ők a látogatottságot.
-
#177
Fiery
veterán
Petykemano
#176
Fiery
veterán
válasz
Petykemano
#176
üzenetére
Ez itt erosen offtopic, tekintettel a topic cimere. De annyit azert leirok, hogy semmi ertelme egy relative egyszeru blokkokbol, repetitiv modon felepitett, alacsony orajelre optimalizalt GPU-t osszehasonlitani egy magas orajelre optimalizalt, komplex CPU-val. Talan egy GPU vs. _mobil_ APU osszehasonlitasnak lenne ertelme, ott az orajelek is kozelebb lennenek egymashoz.
-
#175
Fiery
veterán
Petykemano
#174
Fiery
veterán
válasz
Petykemano
#174
üzenetére
Semmi sincs me'g kobe vesve. A borzongatoan alacsony orajeleken mar tullepett a Summit Ridge, ez biztos. En azt varom, hogy a Broadwell-E, legalabbis a 6800K es 6900K elleneben mar lesz eselye a mostani allapot szerint. Ahhoz viszont, hogy a 6700K vagy 7700K ellen legyen municioja a nem masszivan tobbszalu alkalmazasokban/jatekokban/benchmarkokban is, ahhoz nagyon sokat kellene me'g fejlodnie a gyartastechnologianak. Maga a Zen architektura fel van keszitve a magas orajelekre, tehat itt egyertelmuen a Samsung/GF processze a ludas.
-
#173
Fiery
veterán
Petykemano
#172
Fiery
veterán
válasz
Petykemano
#172
üzenetére
Szerintem a tajekozott PC felhasznalo el fogja tudni donteni, hogy melyik benchmarknak higgyen es melyiket ignoralja. A media egyebkent is hetekig (sot, a szerver cuccokkal egyutt honapokig) hangos lesz a Zentol. Nem egy, nem 10, hanem legalabb 100 kulonfele benchmarkot, real-world applikaciot, jatekot, professzionalis szoftvert fognak kiprobalni rajta. Aki egy ekkora valasztekbol sem tudja leszurni, hogy neki szemely szerint jo lesz-e a Zen, azzal nehez jot tenni. Azzal egyetertek, hogy vannak olyan website-ok, vannak olyan reviewerek, vannak olyan benchmarkok, amik nem kedveznek majd a Zennek, mondhatni nem fogjak kimelni az uj termeket. De pont ezert kell mindent elolvasni, nem csak az X.com-ot meg az Y.hu-ot, hanem _mindent_, ami a Zenrol megjelenik majd.
Egyebkent ha engem kerdezel, szerintem nagyon ritka lesz az a szoftver vagy nem szintetikus benchmark, amiben igazan gyengen fog szerepelni a Summit Ridge, amennyiben az orajel nem lesz tul alacsony. Ha az orajel eleri a 3,5-3,7 GHz-et, akkor nem lesz nagy baj. Az AMD pedig nyilvan a piachoz fog igazodni az arazassal: ha a Summit Ridge csucsmodellje pl. a 6800K szintjen lesz a "big picture" alapjan, akkor annal kicsivel olcsobban fog piacra kerulni. En nem feltem innentol az AMD-t: az orajel mar nem annyira tragikus, mint par honapja, az AM4 alaplapok is kezdenek vegre osszeallni, clock-for-clock az eddigi infok alapjan abszolut versenykepes a Zen architektura: innen mar nem lesz nehez a celba beterelni a jarganyt. Aki me'g vacillal, hogy mit vegyen, annak tovabbra is azt mondom: varjon. Erdemes nem elsietni a vasarlast, legalabbis pont most semmikepp.
-
#161
 gabi123
senior tag
Petykemano
#160
gabi123
senior tag
Petykemano
#160
gabi123
senior tag
válasz
Petykemano
#160
üzenetére
Ez nagyon kemény!

-
#153
 lee56
őstag
Petykemano
#149
lee56
őstag
Petykemano
#149
lee56
őstag
válasz
Petykemano
#149
üzenetére
Amúgy van benne valami, de sokkal jobb érvek szerintem, hogy akkor már a ZeN a tervezőasztalok felszínére került és túl nagy meló lett volna (amd-éknek) párhuzamos FX vonal fejlesztése és a zen dizájnolása. Másik érv pedig a szokásos, a fogyaztás, intelhez képest sokkal roszabb fogyasztás/teljesítmény mutatójú szerverprocesszort nem nagyon tudtak volna (és nem is tudtak, ezért kb már nincs is szerverrészesedésük) eladni, még ha adott Xeonnál esetleg olcsóbban is adták volna. Mai világban már szervereknél is spórolnak, go go green van mindenhol. Több támogatást kapnak a szerverparkok is ha kevesebb lesz a CO faktoruk. HSA pedig nem B terv, mivel nem volt más választásuk, az egyetlen terv. Amiközben zent építgették/ik addig amig meg nem jelenik, azzal kell főzni ami van nekik, feljavított FX dizájnos APU, azaz carizzo, plusz háttérben a Visheránál leragadt FX asztali processzorok gyártása, mert az már amúgyis elég olcsó ennyi év után.
Szóval meg tudom érteni miért mentek erre. Csak ezzel egyidejűleg kicsit sajnálom is, mert látszik carrizzonál is azért hogy még elég jó sikereket elérhettek volna a Bulldozer családdal is ha tovább dolgoznak rajta, csak hát tényleg úgy látszik könyebb volt újratervezni az egész arch-it mint foltozgatni a Bullt.
Pedig szerintem sokan vettek volna tovább javított FX-ekből esetleg még kevesebben is rágnak be és váltanak intel platfromra ha nem így alakulnak a dolgok, ki tudja.. -
#141
 Thrawn
félisten
Petykemano
#140
Thrawn
félisten
Petykemano
#140
Thrawn
félisten
válasz
Petykemano
#140
üzenetére
A csíkszélesség ismerete önmagában nem elég ahhoz, hogy megtippeljük hány GHz-es lesz, ez ennél jóval bonyolultabb.
-
#139
Yutani
nagyúr
Petykemano
#138
Yutani
nagyúr
válasz
Petykemano
#138
üzenetére
Az biztos, ha a Zen nem hoz legalább egy Haswell szintet, akkor megyek Intelre.
-
#132
 dezz
nagyúr
Petykemano
#131
dezz
nagyúr
Petykemano
#131
dezz
nagyúr
válasz
Petykemano
#131
üzenetére
A kép hivatalos slite-ról származik (persektíva-korrigáltan), két ismert személyiség (Hans de Vries, Dresdenboy) is hivatalosnak vette és neki is álltak elemezni. Thrawn is érdemesnek találta betenni a másik topikba. Így a cinizmus nem kicsit áll. Felesleges ennyire túlspilázni.
-
#130
dezz
nagyúr
Petykemano
#129
dezz
nagyúr
válasz
Petykemano
#129
üzenetére
Ez pont nem egy kósza pletykán alapuló vad találgatás, hanem odaillő kérdés.
Talán maga a memóriavezérlő. A mellette lévő rész lehet csak a kapcsolódási pontok. Meg kellene nézni pár korábbi die-shotot.
-
#121
solfilo
veterán
Petykemano
#120
válasz
Petykemano
#120
üzenetére
Köszi!
Ha jól látom, akkor 1 szálon elverik a macskákat, gondolom van valami agresszív turbó, több szálon meg a két szálas Stoney nagyjából egyenlő egy 4 szálas Carrizo-L APU-val. Hát kíváncsi leszek, sikerre vezet e ez a váltás.
-
#99
leviske
veterán
Petykemano
#98
leviske
veterán
válasz
Petykemano
#98
üzenetére
Ezen nem módosít az, hogy egy olyan piacra, ahol keveset adnak a SoC-ért, nincs értelme külön lapkát tervezni, ha egy egyszerű letiltással is megoldható.
Ahhoz viszont véleményem szerint sokat kell csökkennie a HBM árának, hogy a vele szerelt Raven benézhessen a mainstream piacra. Ráadásul, ha az Intel a Kaby esetében a Iris-ek árát nem lövi be versenyképesre, akkor az AMD-nek tényleg nem is lesz igazán oka az ilyen cuccait $300 alatt adni a konzumer piacon. Ráadásul a mini PC piac nagy részének bőven elég lehet, amit egy DDR4-es, pár letiltott CU-val rendelkező Raven nyújt majd. Valószínűleg.
Amúgy kizártnak tartom, hogy ne lenne Raven DIY piacon. Egy szóval nem állítottam ilyet. Viszont HBM-es verzió szerintem csak FP5-be és esetleg S4-be jöhet. AM4-be SZERINTEM az egyetlen HBM-es processzor a 2017-18 környékére pletykált FX lehet majd, ami gondolom kap majd 2-4GB HBM-et L4 gyanánt és csók. Ott is kérdés, hogy nem-e jön elő az AM4+.
-
#97
leviske
veterán
Petykemano
#96
leviske
veterán
válasz
Petykemano
#96
üzenetére
A Raven célpiaca első sorban az $1000-3000-os FirePro. Hogy a szűkülő low-end desktop piacra mit dobnak be, gyakorlatilag irreleváns. Azt meg már a másik topikban Oliverdával átdumáltam, hogy engem meglepne, ha jönne HBM-es Raven desktopra. Pont az ára miatt. Viszont mobil vonalon 100%-ig biztosra merem venni, hogy a csúcs processzoraik 4-8 vagy 16GB HBM-el jönnek egybe tokozva.
Azt meg már a Kaveri esetében is le tudták nyelni, hogy benne van a lapkában +1 memvezérlő, valószínűleg a kisebb Raven esetében se okoz majd gondot.
(#95) stratova: A rejtett +2 csatorna tényleg csak az én saram és csak példaként hoztam fel, hogy az AMD-től nem ismeretlen az ilyen sem.
-
#95
 stratova
veterán
Petykemano
#93
stratova
veterán
Petykemano
#93
stratova
veterán
válasz
Petykemano
#93
üzenetére
Az AM4-es 8c/16t ill. esetleg 6c/12t Summit Ridge Intellel szemben nem 4 hanem 2 csatornás memóriavezérlőt kap és ebbe a foglalatba érkezik majd a max 4c/8t + iGPU Raven Ridge.
Szóval a 32 magos szerver kivitel is legfeljebb 8 csatornás, ahogy az egy CERN mérnök prezentációjából is kiderült.
Állítólag minden mag 512 kB L2 cache-t kap és 4 mag (1 core complex) osztozik 8 MB L3-on.
Amikor az ember azt hiszi, hogy a szintén MCM-es G34-es Opteron nagy...
Majd keresni kezdi a legutóbbi 4 lapkás MCM procit.. Szembe jön vele a 2009-es 32 magos Power7

-
#94
leviske
veterán
Petykemano
#91
leviske
veterán
válasz
Petykemano
#91
üzenetére
A Raven egy egészen más dolog. Ott lesz egy kétcsatornás DDR4 vezérlő és jó eséllyel mellette egy HBM vezérlő. Ráadásul úgy megoldva, hogy ezek párhuzamosan tudjanak működni. A Summit esetében viszont én csak a pletykált 2017 végi, HBM-es HEDT/szerver variánstól várnám a HBM vezérlőt a sima CPU-k esetében.
-
#92
stratova
veterán
Petykemano
#91
stratova
veterán
válasz
Petykemano
#91
üzenetére
Vá-vá-várjunk. Capt. Raven és Summit Ridge esetére vedd alapul Vishera (4/8+8MB L3) és Trinity (2/4 nincs L3 de van iGPU) helyzetét, mindkettő 2 csatornás, ennyi. Itt egy csatornás kivitel szerintem már nem lesz Excavator alapú apuból is csak azért van, mert Bristol mellett készült egy Stoney Ridge, ami natív 1 modulos 2 szálas egy csatornás. Ilyen pl. energiatakarékosági vagy/és kis lapkaméret miatti tökmag-dizájn viszont szvsz 14/16 nm-en már nem szükséges, max. kiadnak HT nélküli 2 magosat.
-
#86
leviske
veterán
Petykemano
#84
leviske
veterán
válasz
Petykemano
#84
üzenetére
A 200mm2 alatti méret elég optimistának tűnik. A Skylake GT2-es IGP-vel elvileg 122mm2 és az egy 4 magos cucc, otthoni felhasználásra szabott cache mérettel. A Summit viszont egy 8 magos lapka lesz és a Haswell-E nyomán ehhez illene 20MB körüli L3-t párosítani. Ráadásul a Skylake esetében a lapka integrált FCH-t sem tartalmaz. Tény, hogy eddig nem számoltam a ténnyel, hogy a Skylake tartalmaz egy IGP-t (
), de így is meglepő volna, ha a Summit megállna 150-160mm2 környékén. 150 környékén én inkább a Raven-t várnám, mert a nagyobb lapkaméret még megérheti, ha cserébe egyértelműen vissza tudják évekre venni a koronát.Mivel 22nm-en a Haswell-E 350mm2 volt, szerintem a Summit 200mm2 környékére jöhet (az IGP beleszámolás előtt 240-250 környékére vártam) és esélyes, hogy a Broadwell-E a 10 mag miatt nagyobb lesz. Bár persze még ezekbe is beleszólhat a HDL.
-
#80
stratova
veterán
Petykemano
#77
stratova
veterán
válasz
Petykemano
#77
üzenetére
AMD 10 nm-ig szinte biztosan FinFET Bulk eljáráson marad, így nem kell átültetniük a GPU-khoz használt lib-et sem FDSOI-ra. Jelenleg pedig kb. olyna lapkán van hasznuk, amiben van GPU is, egyedi lapkák konzolba és GPU-k a CPU részleg momentán csak viszi a pénzt.
DX12 alat simán elképzelhető, hogy egy FX-8370 felveszi a versenyt egy alacsonyabb órajelő Skylake i5-tel, bár a dolog pikantériája, hogy ez inkább Nv mellett történik meg:
AotS (legutóbb itt elírtam az értéket):
DX12 GTX 980 Ti
i7-6700K - 99% 54,6 fps
i5-4690K - 100% 54,7 fps
FX-8370 - 89% 48,7 fpsDX12 GTX Fury X
i7-6700K - 100% 67,9 fps
i5-4690K - 97% 66,0 fps
FX-8370 - 76% 51,9 fps -
#73
leviske
veterán
Petykemano
#70
leviske
veterán
válasz
Petykemano
#70
üzenetére
Attól, hogy nem jön 4 magos variáns, még HT nélküli jöhet. Bár kérdés, hogy mennyire lesz problémás a HT, hogy esetleg érdemes legyen egy 8 működőképes maggal rendelkező prociban kikapcsolni.
szerk.: amúgy ez annyira nem meglepő. az új lapok és az új hűtők mind arra engedtek következtetni, hogy a Vishera-t még életben tartja egy darabig a cég.
-
#72
stratova
veterán
Petykemano
#70
stratova
veterán
válasz
Petykemano
#70
üzenetére
Ez azért érthető 2 ill 4 magosnak ott lesz jövőre Raven Ridge. Intel is hasonló 6 ill 8 magos felállásban adta ki a Haswell E alapú HEDT procikat Broadwell E ettől annyiban tér el, hogy ott már elérhető a 10 magos kivitel is.
Éppen DX12 alatt a 4/8-as Visherák egész szépen felzárkóztak, a korábbi harmatos DX11 teljesítményhez képest. Az API vagy/és a WDDM 2.0 gyermekbetegségei ellenére.
(FX-8370 vs i7 6700K)
Hitman: 47-57% -> 83-90%
Rise of Tomb Raider: 76-93 -> 96-98% (bár ez a port nem lett valami fényes)
AtoS: 55-72 -> 89-109% (és az RTS-ek még szépen skálázódnak 4c/8t felett is) -
#71
Yutani
nagyúr
Petykemano
#70
Yutani
nagyúr
válasz
Petykemano
#70
üzenetére
Én is tegnap olvastam az egyik fórumon, hogy 6-8 magos procik jönnek először, aztán ha összegyűlik a sok selejt, jöhetnek a 4 magosak.
Van benne ráció, előbb a jobbakkal kell megjelenni és nagyobb árbevételt elérni. Persze ha rossz a kihozatal, akkor előbb jöhetnek a kisebb verziók.
-
#67
leviske
veterán
Petykemano
#66
leviske
veterán
válasz
Petykemano
#66
üzenetére
Nem is annyira a korábbi tapasztalatok mondatják ezt velem, mintsem inkább az aktuális. Eddig egy alkalom se volt (vagyis én nem tudtam róla), hogy a foglalat/platform akadályozta volna meg a megjelenést. Most meg a lapka gyakorlatilag hónapok óta kész lehet. A polaris amúgy nyár végén jön, nem?
A másik topikban úgy láttam, hogy egyetlen die készül most a Zen-ből minden piacra. Szerveren 8 magnál többet elvileg csak MCM formában fognak nyújtani, desktopon 8magnál kevesebbet meg ugye letiltásokkal. Kockázatos és felesleges lett volna most két lapkán párhuzamsan dolgozni. Ilyesmire még a K10-es időkben se volt keret.
Nem a CMT az egyetlen dolog, amiben meghasonult magával a cég. Gyakorlatilag majdnem minden csak általuk támogatott utasításkészletet kipakoltak az architektúrából és lekövették az Intelt. Az AIDA-nál is úgy számolnak a srácok, hogy a Haswell/Broadwell/Skylake optimalizálások kb lefedik majd a Summit Ridge-et is.
Ez ahhoz képest elég nagy lépés, hogy korábban az AMD még fel is dobta volna a CPU teljesítményt APU-k terén az IGP-ért cserébe. A Raven-is ehhez képest elég CPU túlsúlyosnak ígérkezik az elődjeihez képest. Bár persze előbb derüljön ki az is, hogy mekkora egy Zeppelin mag. Ahhoz a Skylake méretei alatt kéne maradni, hogy a Raven esetében esély legyen legalább az 50/50 felosztásra.
Persze ott a Greenland, szóval nem azt akarom ezzel sem mondani, hogy magából a HSA-ból szerethetett ki a cég, de valószínűleg 2 év alatt sikerült valamennyire helyére tenni a dolgot.





 "
"

 Pontosan ugyanazt csinálja, csak az a különbség, hogy nem egy CPU csatlakozik hozzá HyperTransporton keresztül, hanem több. És egy tokban van. Ez persze nem rossz irány, csak érdekesség.
Pontosan ugyanazt csinálja, csak az a különbség, hogy nem egy CPU csatlakozik hozzá HyperTransporton keresztül, hanem több. És egy tokban van. Ez persze nem rossz irány, csak érdekesség. 










![;]](http://cdn.rios.hu/dl/s/v1.gif) ), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.
), viszont a 108ns a szomszéd csip memóriájáig iszonyat magas. Plusz ha véletlen a másik magnak is kéne onnan adat, akkor 16 mag figyelne ott két csatornán adatot, ami így már szívószálnak is vékonyka.









Új hozzászólás Aktív témák
- Steam, GOG, Epic Store, Humble Store, Xbox PC Game Pass, Origin Access, uPlay+, Apple Arcade felhasználók barátságos izgulós topikja
- Call of Duty: Black Ops 7
- Háztartási gépek
- 5.1, 7.1 és gamer fejhallgatók
- Mibe tegyem a megtakarításaimat?
- PlayStation 5
- World of Tanks - MMO
- TCL LCD és LED TV-k
- Soundbar, soundplate, hangprojektor
- Projektor topic
- További aktív témák...

- iKing.Hu - Nubia Z70 Ultra 5G Black Teljes kijelzős zászlóshajó, AI-erejű teljesítmény
- ÁRGARANCIA! Épített KomPhone Ultra 7 265KF 32/64GB RAM RX 9070 16GB GAMER PC termékbeszámítással
- HP Z8 G4 Workstation (gamer célra is) dupla CPU Xeon Gold 6134
- HIBÁTLAN iPhone 13 mini 256GB Pink -1 ÉV GARANCIA - Kártyafüggetlen, MS3441, 92% Akkumulátor
- Apple iPhone 13 Pro Alpine Green ProMotion 120 Hz, Pro kamerák 128 GB-100%
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest