Hirdetés
- „Új mérce az Android világában” – Kezünkben a Vivo X300 és X300 Pro
- Bemutatkozott a Poco X7 és X7 Pro
- Realme 9 Pro+ - szükséges plusz?
- Vivo X200 Pro - a kétszázát!
- Megtartotta Európában a 7500 mAh-t az Oppo
- iPhone topik
- Samsung Galaxy S23 Ultra - non plus ultra
- Samsung Galaxy Watch (Tizen és Wear OS) ingyenes számlapok, kupon kódok
- Fotók, videók mobillal
- Google Pixel topik
Új hozzászólás Aktív témák
-

S_x96x_S
addikt
válasz
 Cathulhu
#5325
üzenetére
Cathulhu
#5325
üzenetére
> SiFive-nak van nem open source ipje?
az én értelmezésem szerint
A RISC-V IP ( referencia design és ISA ) Open Source -os ..de mintha a SiFive -nek egy egyedi Apple Silicon hoz hasonló
megoldása IS lenne
( custom design - ami a publikus "szabad" ISA-t implementálja )
és a legújabb design nem találod meg a repojukban
https://github.com/sifive
( vagy csak én nem találom a "Performance P550 core"-t, mert béna vagyok. )
Vagyis csak egy része open-source-os , pont annyira, hogy a saját ügyfeleik életét megkönnyítsék.
https://github.com/sifive/freedom-e-sdkHa teljesen "szabad licenszű kell " akkor ott van még a Rocket-Chip
https://github.com/chipsalliance/rocket-chip -
S_x96x_S
addikt
válasz
Cathulhu
#5262
üzenetére
> de a v-cache-t is a TSMC fogja gyartani?
igen ; spéci TSMC 7nm -es integráció - TSMC's CoW (Chip-on-Wafer)
Anandtech:"The TSV interface is a direct die-to-die copper interconnect, meaning that AMD is using TSMC’s Chip-on-Wafer technology. " [link]
-->
https://www.tsmc.com/english/dedicatedFoundry/technology/platform_HPC_tech_WLSI
> Az nem mehet 12 nanon a GF-nel?minden lehetséges, de szerintem nem éri meg.
ráadásul úgy, hogy még az idén meg is jelenjen a közös integráció ..és extrém bonyolult lenne.
egyben kellene látnia és kezelnie a rendszernek
a TSMC-s 7nm -es belső L3Cache -t a GF12nm-es ráépülő L3Cache-el.
Mégha együtt is tudna müküdni, még a sebességnek is hasonlónak kell lennie. Ráadásul több pontos - függőleges integrációval
és hogy ez müködjön a két cég mérnökeinek nagyon együtt is kellene dolgoznia, gyártási titkokat kellene megosztani, ...
és ha nem müködik, ki a felelős?
Most a TSMC felel érte .. Ha az AMD erösködik, hogy legyen benne a GF is a buliban .. akkor az AMD lesz a felelős .. a TSMC és a GF egymásra mutogat majd ..
sőt szerintem a TSMC akarja a jövőben az I/O Die-t is gyártani N6-on!
"Zen 4 chips are stated to feature two Zen 4 CCD's based on the TSMC N5 process node and a CIOD (I/O die) based on the TSMC N7 process node however the latest reports suggest that the I/O die has been moved to a 6 nm process node." [link]ráadásul most úgy tünik, hogy a GloFO eléggé
elhanyagolta a fejlesztéseket.
friss hír: Az IBM már perelni akarja.
"WHY IBM IS SUING GLOBALFOUNDRIES OVER CHIP ROADMAP FAILURES"
https://www.nextplatform.com/2021/06/10/why-ibm-is-suing-globalfoundries-over-chip-roadmap-failures/amúgy a cikkben van egy AMD - GF spekuláció is.
"What we don’t know is if AMD decided to jump over 10 nanometer processes to 7 nanometer processes to get an edge on Intel or if it really had no choice to do so because GlobalFoundries was pulling the plug to focus on its dual-prong 7 nanometer effort. We think AMD was hit by the same 10 nanometer surprise that IBM was, but AMD never said anything about that and put the best spin on it. Much as IBM did with the difficulties that GlobalFoundries apparently had bringing 14 nanometer processes and IBM never said much at all about 10 nanometer issues. AMD, of course, used 14 nanometer processes from GlobalFoundries for its first generation “Naples” Epyc 7001 chips and still uses 14 nanometer processes in the I/O and memory hub at the heart of the Rome and Milan server processor packages. The Rome and Milan cores are etched by TSMC in 7 nanometers, and Infinity Fabric links hook hub and the cores together in a single package."
-
S_x96x_S
addikt
válasz
Cathulhu
#5171
üzenetére
ennek az APU-nak elméleti maximuma ~ 2.048 TFLOPs
vagyis elég gyenge a DDR4-es GPU teljesítménye.> Mennyi is az, 1? 1.2? Valahogy úgy.
"With the base model PlayStation 4 being capable of 1.84 TFLOPS and the PS4 Pro being capable of 4.2 TFLOPS, the PS5 is dramatically ahead of both with its recently-revealed capacity for 10.28 TFLOPS " [link]
-
S_x96x_S
addikt
válasz
Cathulhu
#4960
üzenetére
> Az az 1TB/s brutalisan soknak tunik.
és akkor az 1.6TB/s ?

Ez a cél a 72x Arm Neoverse Zeus - magos SiPearl-nél
ami már a TSMC N6-ján készül és 2022Q4-re tervezik kihozni.
https://sipearl.com/index_en.php
" a Rhea SoC could feature up to 96 GB of HBM2E at 1.6TB/s as well as up to 6TB (using 8-Hi 16Gb-based DDR5 stacks) or 12TB (using 16-Hi 16Gb or 8-Hi 32Gb-based stacks) of DDR5 memory using two modules per channel."SiPearl's 72-Core Rhea HPC SoC to Be Made Using TSMC's N6 Node"
https://www.tomshardware.com/news/sipearl-rhea-n6-open-silicon-research ( 2021Feb)
https://www.anandtech.com/show/16072/sipearl-lets-rhea-design-leak-72x-zeus-cores-4x-hbm2e-46-ddr5 ( 2020September8)Igazából az Intel 1TB/s - lehet, hogy kevés is lesz
 ..
..
Főleg ha az AMD az Epyc Zen4- el is hasonlót tervez ( ~ 1.6TB/s ) -
#4962
 Petykemano
veterán
Cathulhu
#4960
Petykemano
veterán
Cathulhu
#4960
Petykemano
veterán
válasz
Cathulhu
#4960
üzenetére
Kezdetben csak 42GB/s, kétirányú volt, 1333Mhz-en: [link]
Azóta ezt sikerült feljebb vinni a Renoir esetén már 2200Mhz-ről beszéltek, ami már majdnem 70GB/s: [link]
Ez persze talán nem teljesen ugyanez, de A Radeon VII esetén arról, hogy 2db egyenként 84GB/s kétirányú link van rajta.
Abu meg 100GB/s-ről beszélt itt: [link]Ezzel az AMD is kísérletezget: [link]
Én sem értem, hogy fogják hasznosítani. Ha mondjuk dupláznák a linkeket, még az is legjobb esetben 150GB/s lenne / CCDEgyébként itt egy mérés: [link]
Azt valaki el tudja nekem magyarázni, hogy hogy lehet, hogy a 8 memóriacsatornából csak 100GB/s jön ki?
Azért van, mert egy mag tényleg csak a hozzá legközelebb eső memóriavezérlőt tudja használni?Na mindegy, attól függetlenül azt akartam mondani, hogy az ábra szerint ilyen 40GB/s érhető el egy magnak. Ha ezt fel tudnák emelni 150GB/s-ra már az is nagy előrelépést jelenthet.
-

hokuszpk
nagyúr
válasz
Cathulhu
#4960
üzenetére
a fabricbol abban a szuperize kompjuterben mar mukodik a 3.0 -s verzio, ha oda jo lesz, akkor az EPYCbe sem lehet olyan rossz. ÉS lehet rosszultudom, de a HBM ugy eri el azt a brutal savszelt, hogy 4096 bites busszal operal, a 8 csatornas DDR5 az meg talan 1024 bitre jon ki ?
-
#4941
Petykemano
veterán
Cathulhu
#4929
Petykemano
veterán
válasz
Cathulhu
#4929
üzenetére
"Hova kapkodjanak most a Zen4-gyel."
Az AT tesztjeiben most és a Milan esetében is jelen volt a 80 magos Ampère altra, és nem is szerepelt rosszul. Pedig az abban levő mag nem kifejezetten friss, az A76 szerver varinsa, azóta meg már van A77 és A78/X1
(Abból persze termék ugyanúgy nem lesz, amíg nem tudJák 5nm-en gyártani.)Szerintem már egy N2-re épülő szerverprocesszor is csúnyán bekavarna nem is beszélve arról a lehetőségről, hogy a Qualcomm által felvásárolt Nuvia épp ide fejlesztett. És akkor még nem is beszéltünk az armot felvásárló nvidiáról.
Sokaknak szimpatikus az SVE is, mert a programkód nem függ a hardverben található feldolgozó szélességétől szemben az AVX/2/512 szerteágazó implementációival.
Azt mondják persze, hogy idővel a CPU jelentősége csökkenni fog és át fog helyeződni a.hangsúly arra, milyen gyorsítókat tudsz mellérakni. De ebben meg az nvidia és az Intel sincs lemaradva.
-
S_x96x_S
addikt
válasz
Cathulhu
#4929
üzenetére
> Hova kapkodjanak most a Zen4-gyel.
elméletileg ~ ősszel jön ( vagy inkább csak bejelentik )
az Alder Lake-et ( ami már Gen5, DDR5 -is tudhat)
és jövőre jöhet a Sapphire Rapidshoz hasonló HEDT cpu - Alder Lake alapokon ( akár HBM + CXL-el )és az Év végén /Jövő év elején az Intelnek ki kell hoznia az első DDR5-ös konfigját .. mert a memóriagyártók nem fognak csak úgy gyártani a raktárnak.
-
S_x96x_S
addikt
válasz
Cathulhu
#4906
üzenetére
> a little endiannak amugy is tobb ertelme van,
> az ARM meg mar vagy 30 eve bi-endian architectura, nem latom itt az apple nagy ujitasat.jó kérdés .. de mintha a kód és az adat endián eltérne.
"Note that ARM does not support big endian code. Code is always little endian - only data accesses can be big endian."Egy emulációnál - az önmagát újrairó trükkös kódoknak - programvédelmeknek is futnia kell.
de egy InfoQ cikk - ezt igy fogalmazta meg:
"One major concern with Rosetta is performance. With the transition from PPC to x86, one factor slowing down Rosetta was the different byte ordering used by the two platforms, with PowerPC being a big-endian architecture, and x86 little-endian. While byte ordering is not a problem for the transition from x86 to ARM, another issue related to memory, namely the memory consistency model total store ordering (TSO), could hamper performance in this case. To prevent this from happening, Apple added support for x86 memory ordering to the M1 CPU, as Robert Graham noted on Twitter."de pontosítsál/cáfoljál .. mert már nagyon megkopott és régi a hexa tudományom.
( ami nagyjából azt jelenti, hogy ARM szinten laikus vagyok ) -
#4907
Maelephant
senior tag
Cathulhu
#4906
-
hokuszpk
nagyúr
válasz
Cathulhu
#4808
üzenetére
ezzel adtak a sz* -nak egy pofornt. még így is megéri.
nomeg ha eddig a Vegara meg mindenre is bányászbiosokat hekkeltek, akkor majd pont erre nem. Egy regi drivertelepitoben modositanak 1-2 szamjegyet, aztan megy majd ez is maxigázzal.
szvsz az lenne a megfejtés, hogy kb. grafkártya árban 1.5-2x bányászteljesítményű vasakat adni nekik, akkor előbb-utóbb azt vennék, mert jobban megéri. Programozhato FPGA vasakat a banyaszpiacra ! -
hokuszpk
nagyúr
válasz
Cathulhu
#4806
üzenetére
lehet nemerimeg aputgyartani, viszont ha nemtudsz az igpmentes procidmellé valami normalis vgatvenni, akkor elobb-utobb eladhatatlanok lesznek az asztali procik.
// nezd milyen f*sza gepem van, csak kepet kellene belole fakasztani !
oke ; dobjukki, vegyunk Intelt, abban legalabb van igp... // -
#4673
Maelephant
senior tag
Cathulhu
#4669
-
S_x96x_S
addikt
válasz
Cathulhu
#4659
üzenetére
> A desktop APUk ... altalaban csak irodai vagy netezos gepekbe mennek
<spekulálok>

akár ... megváltozhat ez is, ha az integrált GPU és a külső Radeon GPU -t együttmüködését mégjobban kigyurják[1]
és tényleg igaz lesz az, hogy az új APUk megközelítik az X-es konfigokat.[2]
VAGYIS ha az 5700G ilyen jó [2] .. akkor milyen lehet majd az 5800G ?szerintem benne van a pakliban ... van rá esély ...
[1]
"AMD Radeon™ Dual Graphics is an innovative technology exclusive to AMD platforms that allows AMD APUs and select AMD Radeon™ discrete GPUs to work together. When combined, the platform delivers stunning quality and performance capabilities that are better than either device alone." [link][2]
AMD Ryzen 7 5700G 8 Core Cezanne APU Performance Leaks Out, Overclocked To 4.75 GHz & Faster Than Ryzen 7 5800X
https://wccftech.com/amd-ryzen-7-5700g-8-core-cezanne-apu-performance-leaks-overclocked-to-4-75-ghz/ -
S_x96x_S
addikt
válasz
Cathulhu
#4653
üzenetére
> Nem nagy érvágás szerintem, aki desktop APUt vesz, annak nem kell a latest and greatest,
Azért a konkurenciától ( = Intel ) is függ ...
Az Intel az új 8 magos prociját - gpu-val ( ~ kvázi APU kategória )
márciusban kezdi nyomniHa az AMD csak a Q2 leges legvégén kezdi kihozni az új deskop APU-kat,
akkor az egy pici előny az Intelnek.
Ha már Április elején - akkor legalább lesz egy kis verseny - ami jót tesz az áraknak is.De hát ez van ... szűk gyártási kapacitás ... és el kell dönteni, hogy melyik ujját harapja meg az AMD .. Ezek a nehéz döntések.
-
#4613
Petykemano
veterán
Cathulhu
#4612
Petykemano
veterán
válasz
Cathulhu
#4612
üzenetére
Elég semmi volt ez a CES keynote megint.
Úgy tűnik, mintha én is, és Lisa Su is izgatottabb lett volna az első zen bejelentésekor, amikor még volt valami a zsákban. Csak én érzem azt, hogy hogy én is és Lisa Su is egyre kevésbé lelkes úgy, hogy szinte semmi nincs a zsákban?
Tényleg olyan volt, mintha úgy állt volna ki, hogy hoznék én nektek mindent, csak semmit nem tudunk legyártani és piacra vinni. Tehát most az a high end notebook Cezanne vajon hány eladást fog produkálni? 100-200e?
-

Busterftw
nagyúr
válasz
Cathulhu
#4607
üzenetére
Csak kozben elkeszult a 10 superfin, ott talan mar megoldottak.
Az Intel szerint az Alder Lake-ben levo Golden Cove 50%-al jobb IPC-ben mint a Skylake, viszont azt nem tudjuk melyik, mert ugye a Comet Lake is Skylake.Aztan hogy ez mire lesz eleg a valosagban, majd kiderul.
Intelnek most az volt a fontos, hogy viszaerjen az AMD melle/fele (ahol tud).Na meg az az atlag 15% IPC is nagyon jol hangzik a generaciok kozott, de ne felejtsuk el, hogy volt honnan novekedni. Most a 4. gen Ryzen hagyta le az Inteleket pl ha jatekot nezzuk, 7nm-en, kb fel evig, ha az Intel Rocket lake leakek igazak.
Az Intelnek a legfontosabb az ido. Addig kell kibirni amig ok is helyrehozzak a gyartasi gondokat. Mar a Rocket lake sem tunik rossznak, az Alder Lake szerintem a Windows-on fog inkabb bukni (big.little miatt).
Az sem garantalt, hogy az AMD tudja evekig tartani a tempot. Mar lattuk, nagyon sok minden valtozhat par ev alatt. -

TRitON
aktív tag
válasz
Cathulhu
#4603
üzenetére
"Ehhez meg Zen4-sem kell, egy Zen3 refresh eleg lesz es honnan fogjak majd tudni onnan tartani a lepest?"
Ez lesz a Warhol.
BTW, rendkívül kíváncsi lennék, hogy egy 5800X-szel szemben (1CCD, vagyis kisebb core to core késleltetés) mit megy ez a processzor, azonos magszámmal. -
-
-
válasz
Cathulhu
#4603
üzenetére
Játékban még léphetnek előre ph írás alapján, csak kell hozzá alacsonyabb csíkszélesség:
"A problémát az adja, hogy a mag dizájnját alapvetően 1,25 MB-os L2 cache-re tervezték, de ennyit a 14 nm-es node-on nem lehetett beépíteni, így kényszerűen be kellett érni az 512 kB-os kapacitással. Úgy tudjuk, hogy ennek csak a játékokban lehet valóban mérhető korlátozó hatása, de a mai, többszálú feldolgozásra tervezett címek esetében ez egészen minimális." -
S_x96x_S
addikt
válasz
Cathulhu
#4552
üzenetére
> FPGA ... szerintem csak a szuperszamitogepek piacan lehet igazan impactja.
Én azért bízom benne, hogy a "jövőben" a szűk keresztmetszeteket
"nagyrészt" át lehet tolni az FPGA-s részre ...A xilinx ilyen példákat emleget:
- LZ4 Compression ( 2X sebesség a CPU -hoz képest )
- Haversine Distance (10x sebesség )
- Regex Overlay ( 18x sebesség )
- ...
De már egy egyszerű adatbázis gyorsítás ( PostgreSQL, REdis, Appache Arrow,... )
is sokat fantáziáját beindithatja,
https://www.xilinx.com/applications/data-center/database-data-analytics.htmlpersze a jövő a CPU + GPU + FPGA fúziója ...
szerintem

-
S_x96x_S
addikt
válasz
Cathulhu
#4527
üzenetére
> Vennem kellene egy ilyet (dolgozni fokent),
> szerintetek majus fele kaphato lesz ertelmes aron?A CES után picivel többet tudunk ...
de elsőként amúgy is a játékos laptopok jönnek. a jó hír.. hogy már párat be is áraztak ..."Acer Nitro 5 with Ryzen 7 5800H and RTX 3080 for 1950 EUR"
https://videocardz.com/newz/acer-nitro-5-notebook-with-ryzen-7-5800h-and-geforce-rtx-3080-listed-for-1950-eur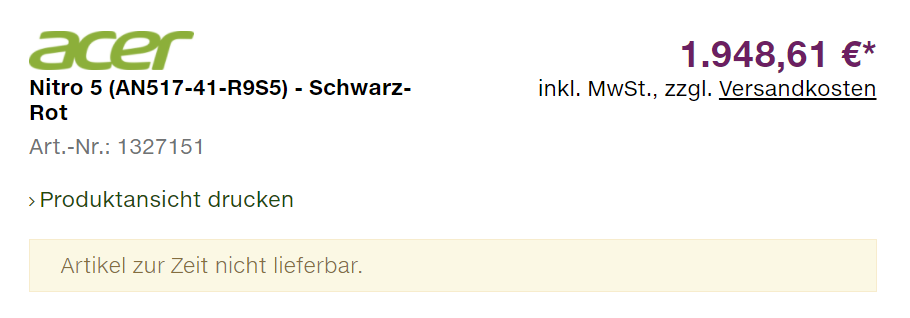
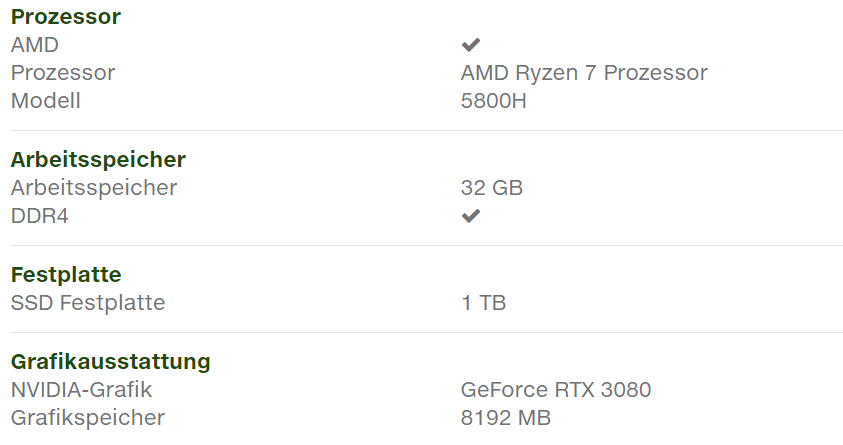
egy másik verzió
Acer Nitro 5 2020 ..
vagyis lesz olcsóbb GPU-val is.
-
-
#4393
Petykemano
veterán
Cathulhu
#4391
Petykemano
veterán
válasz
Cathulhu
#4391
üzenetére
Szerintem az ábra ellenére ez csak egy koncepció, amit bármelyik szinten be lehet vetni.
Azt nem tudom, hogy érdemes-e csak egy közbülső szinten bevetni? Csak L2 esetén, de L1és L3 esetén nem.De a koncepció azért érdekes, mert a késleltetés romlása elkerülhetetlen.
A zen esetén már az L2 esetén látható, hogy a második szelet 256KB késleltetése rosszabb. Ugyanez igaz a legtávolabbi L3 szeletre.A cache kapacitását növelni kell. Eldöntheted:
1) a cache méretét növeled? Ennek valószínűleg lineárishoz közeli lesz tranzisztor- és fogyasztásköltsége és minél nagyobb/távolabbi a cache szelet, annál inkább romlik a késleltetés.
2) beépítesz egy fixfunkciós tömörítő egységet. Ennek is lesz tranzisztorköltsége és fogyasztásköltsége is és bizonyosan rátesz valamekkora késleltetést is.Tehát mindenképpen lesz tranzisztorköltség, fogyasztás és késleltetés. Az a kérdés, hogy vajon melyik megoldással mennyi a nyereség és mennyi a költség?
Az L4$-ről:
Egyetértek. Ugyanakkor most elgondolkodtam.
A zen3 nagy újítása az, hogy 2db 4magos CCX-et egyesített 1db 8magos CCX-ben ezzel megduplázva az 1 mag számára elérhető L3$ méretét és eliminálva azt a kényszert, hogy 1 CCD-n belül elhelyezkedő CCX-ben levő magok az IOD-on, vagy leginkább a memórián keresztül legyenek kénytelenek adatot megosztani. Ez az elmélet.Egyébként az anandtechnek erre vonatkozóan voltak is mérései:
https://www.anandtech.com/show/16214/amd-zen-3-ryzen-deep-dive-review-5950x-5900x-5800x-and-5700x-tested/53950X vs 5950X
Nagyon szépen látszik, hogy már nem csak 4, hanem 8 mag között zöld a késleltetés.
De ami még érdekesebb, a zöld már nem 30ns-ot, hanem 17ns-on jelent két egy CCX-be tartozó mag között. Ez óriási előrelépés!És akkor a kérdés:
Rendben van, hogy ha ez az óriási előrelépést jelentene egy 6-8 magos generációváltás esetében. De Ha a játékokban tapasztalt intelhez képest gyengébb teljesítményt az inter-CCX kommunikáció okozta (ami ugye a 6-8 magos Vermeer lapkákon megszűnik), akkor miért nem tapasztaljuk ugyanezt a teljesítmény-regressziót az 5900X/5950X esetén, ahol továbbra is van CCX-CCX kommunikáció?Ha innen nézem, nem is biztos, hogy olyan sokmindent megoldana egy hatalmas L4$ az IO lapkán
-
#4350
Petykemano
veterán
Cathulhu
#4348
Petykemano
veterán
válasz
Cathulhu
#4348
üzenetére
A ps4 és ps4 pro cpuja 100-130gflops teljesítményt tudott.
Az AT mérései alapján az ps4 megjelenésekor már elterjedtnek mondhat 2500k is legalább másfélszer nagyobb cpu teljesítményt jelentett. Single threadben 2x is
[link]Tehát a ps4 megjelenésekor az elterjedt mainstream cpuk erősebbek voltak, mint a konzol CPU.
Ennek köszönhető az, hogy sok esetben egy mai 4/8 elegendő lehet egy játékra. És ennek köszönhető az is, hogy 8 teljes értékű magnál többet felvonultató CPU esetén nagyítóval kell keresni az előnyöket. Mert 7-8 mag a target.Én azt mondom, hogy 2-3 év múlva a 4/8, a 6/6 esetén biztosan és talán a mai 8/8 és 6/12 magos cpuk esetén is enyhén érezhető lesz, az a fajta lemaradás, amit ma a 2/4, 4/4 cpuknál tapasztalunk.
Azt senki nem mondja, hogy egy 8/16-os, későbbi generációs 8/8, 6/12 ne Lehetne elég a játékra,de ugyanolyan belépőszintnek fog minősülni, mint ma a 4/8.
-
-

paprobert
őstag
válasz
Cathulhu
#4344
üzenetére
#4332 -t olvasd el újra szerintem.
1. helyzet: A legelső játékok, úgy az első 1-2 évben biztos hogy csak az RDNA2-t használják ki teljesen. Azaz az általad is említett GPU limit lesz eleinte konzolon.
2. helyzet: Azonban ne légy naiv, + egykét év eltelik, és vegyes limit irányába fognak haladni a fejlesztők az érkező új motorokkal a konzolon.1. helyzet: RDNA2 a 30fps mérce-> már most van sokkal gyorsabb GPU PC-re, nem lesz túl nagy gond PC-n a grafikával. (a Jaguar szintet már bőven meghaladtuk.) Mindenki boldog.
2. helyzet: Zen2 CPU és RDNA2 GPU is 30fps mérce egyszerre-> gond lesz PC-n a processzorlimittel, hiába lenne erős GPU elérhető, 60 alatt marad az fps számláló, bármilyen GPU-t raksz mellé bármilyen felbontáson. -
paprobert
őstag
válasz
Cathulhu
#4338
üzenetére
A multiplatform játékokat a Jaguar-limit figyelembe vételével tervezték meg eddig. Ezentúl ez egyre többször nem így lesz.
Vizsgáld meg a single- és multicore eredményeket a tesztelt CPU-knál, vesd össze az Athlon 5150-nel, akkor megérted miért futhatnak itt-ott jól a címek.
Nextgen-ben a Zen2 lesz a mérce, az lesz a 30 fps nagyon sok esetben. Call of Duty-ban, ahol a 60 a minimum mindig, ott rendben lesz a PC. Lassabb játékmenetű, 30 fps-re készült, CPU-heavy címeknél viszont esélytelen.
Most nem az alig észrevehető X360 - Jaguar átmenetről van szó, hanem egy közel 10 éves ugrás lesz technológiában.Lesz itt meglepődés, úgy gondolom.
#4339 TESCO-Zsömle
Na igen, de amikor 720p-ben is 30-60 fps között teljesít a géped, az onnantól egy kikerülhetetlen probléma. -
paprobert
őstag
-

BiP
nagyúr
válasz
Cathulhu
#4316
üzenetére
Nem ismerem az AMD erre vonatkozó terveit, de még csak most ugrottak a CCX-enkénti 4-ről 8magra, szóval talán ez jó ideig megmarad, ebből bármit össze lehet legózni, ami desktopra nagyon sokáig elég lesz. Emellett az IPC is ugrott ~20%-ot, szóval ilyen téren sincs gond.
Az 5950x 16mag,32szál desktopra már tényleg olyan, hogy nincs játék, vagy hobbi otthoni felhasználás aminek több kell, talán nem lépnek feljebb egy ideig. Már így is olyan szintet állítottak be ezzel, ami pár éve még HEDT vonalon sem volt. -
#4317
Petykemano
veterán
Cathulhu
#4316
Petykemano
veterán
válasz
Cathulhu
#4316
üzenetére
Lehet, hogy igazad.van, ám abu a nyáron még arról cikkezett, hogy 5 és 3nm-en is dupláz az AMD. De a roadmapek persze változhatnak. A warhol beékelődése például nehezen illeszkedik abba, amit 14-15 hónapos kiadási ciklusok alapján várunk.
Amúgy persze mind a desktop, mind a szerver magszámmal kapcsolatban igazad van, utóbbinál cikk is született arról, hogy inkább az alacsonyabb magszámú termékekre van nagyobb kereslet. A SzerverMérnök szerint azért, mert a cégek a biztonsági parák miatt átálltak 7 helyett 3 éves csereciklusra. 3 évre meg nem éri meg drága, magas magszámú procit venni. Az alacsonyabb magszámú termékeken viszont vékonyabb a marzs, ezért csökkent az Intel marzsa. És ugyanez miatt jön az abu által emlegetett kicsi Epyc.
És ha ez igaz,.akkor valóban lehet vonzóbb egy 24 magos, ami jövőre 15 helyett 25%-kal nagyobb IPCt hoz, mint ha 48 magos lenne, amire a licenc is drágább.
Hát majd meglássuk.
-
#4243
Petykemano
veterán
Cathulhu
#4242
Petykemano
veterán
válasz
Cathulhu
#4242
üzenetére
hát igen, csak azért a Xilinx tulajdonosainak (bárki is volt) el kellett fogadnia az AMD részvényt fizetségként - nyilván abban a reményben tették ezt, hogy az AMD részvény
- magasabb tőkejövedelmet biztosít (függetlenül attól, hogy azt osztalék vagy részvényérték formájában teszi)Igazából azt nem tudom, hogy miért kellett felvásárolni.
- olcsóbb lesz így a wafer?
- ha feltételezzük, hogy a biznissz megy tovább, akkor az egy pontra fókuszálható fejlesztési kapacitás ettől nem lesz több, mert más üzletben utaztak együtt.
- A szinergia magasabb lesz, mintha külön cégként teszik össze amijük van?
- ellenséges kivásárlás megakadályozása?Kiváncsi vagyok, mire fogják használni az FPGA-kat, amihez a felvásárlás szükséges vagy érdemes volt.
-
-

HSM
félisten
válasz
Cathulhu
#4123
üzenetére
Persze, ez abból jön, hogy Intelnél minden magnak tudnia kell az adott esetben igen magas turbó órajelet, AMD-n nem. Erre akartam rávilágítani. Persze, Intelen amikor minden magot jól megterhelnek a maximális turbón, akkor fog fogyasztani, de ez nehezen összehasonlítható a másik oldal "kevésbé szigorú" turbójával.
Egyébként képes rá a 3600-asom, kb. 1,23V-on használom több hónapja allcore 4,2Ghz-en, és nincs vele stabilitási probléma. Ehhez képest gyárilag 1,35V-ok magasságában járt, néha 1,4V felett is, órajelben pedig inkább 4Ghz körül, 4,2-t szinte sosem láttam. Ezért is állt tőle égnek a hajam, sok feszültséggel, melegedéssel és fogyasztással hozott így rosszabb teljesítményt, mint minden magot fixen beállítva 4,2Ghz-re és finoman beállítva hozzá a megfelelő üzemi feszültséget....

-

Yutani
nagyúr
válasz
Cathulhu
#4080
üzenetére
Teljesen igaz. Még ha sz@r is volt a Netburst (az volt), akkor is azt vették a népek (és főképp az OEM-ek), mert Intel (meg az egészséges versenyt lehetetlenné tévő tisztességtelen ajánlataik).
Ugyanakkor az Bulldozer azt adta, amit az áráért el lehetett tőle várni, mégis szar volt. Gyengébb volt egy 8 magos Dózer egy i7-nél? Igen. Sokkal olcsóbb is volt? Igen. Akkor meg? Ja persze, a győztesnek könnyű szurkolni és leszólni a vesztésre állót.
Most meg? Van AMD oldalon régóta jó ajánlat, de sokan hallani sem akarnak róla, csak az Intel, bármi áron!

Szerk: Áttettem OFF-ba.
-
#4079
Petykemano
veterán
Cathulhu
#4078
Petykemano
veterán
válasz
Cathulhu
#4078
üzenetére
De akkor a Bulldozer érában hogy boldogult az Intel? Mindenkinek az 5Ghz-es bulldozert (piledriver) kellett volna venni, hiszen az 5Ghz, nem suta 3.5 meg 3.7Ghz-ek. Veszítenie kellett volna az 5Ghz-től megbabonázott vásárlók miatt.
Azonban mégis mindenki tudta, hogy
AMD => szar magok + 5Ghz => kazán
Intel => elképesztően hatékony magok => teljesítmény, energiahatékonyság
De mondok mást:
Miért nem próbálják meg azt, ami az ARM X1/A78-ban jött, hogy hát van egy alap design, amit még fel lehet turbózni itt-ott?Az intelnek sikerült a Turbo Boost 3 technológiával azt megoldani, hogy minden magról tudja a a rendszer (a szoftver), hogy meddig tud turbózni és a legmagasabb turbóra képes magra osztja a legdurvább ST feladatokat.
"Intel Turbo Boost Max Technology 3.0 is a feature used by some Intel CPUs to improve performance of lightly- or single-threaded applications by pushing those workloads to the processor’s two favored (or fastest) cores. Using both hardware and software, Intel claims Turbo Boost Max Technology 3.0 delivers “more than 15% better single-thread performance.” "
Az AMD eddig csak az L3$ méretével játszott
De miért nem csinálja azt az AMD, hogy minden CCX-be betesz +1 magot, ami mondjuk 32 helyett 64KB L1$, 512KB helyett 2MB L2$ (csak hogy ne szaladjunk egyből messzira) és most hogy már a CCX közös L3$-t használ, akár ezt is rá lehet csatlakoztatni a 32MB megosztott L3$-re.
Valamit csak számít. +15-20% IPC úgy, hogy mondjuk annak az egy szerencsétlen magnak a fogyasztás 2x nagyobb és a mag mérete is 2x nagyobb. Nagyjából ezt látjuk az A78/X1 esetében is.Hiába hogy a szervereknél több a MT workload, Amdahl törvénye ott is él, vannak szűk keresztmetszetek ott is, amit ST erővel lehet legyőzni.
-
S_x96x_S
addikt
válasz
Cathulhu
#3876
üzenetére
> uhhh, egyre pofatlanabb claimekkel jonnek mindenfele bizonyitek nelkul,
persze az apróbetűs részben van a titok ..
A Ryzen 4700U -t benchmarkolták.
https://nuviainc.com/blog/performancedeliveredanewway
amúgy a Dell is a befektetőjük .. https://nuviainc.com/investors"The data shows that both AMD and Intel demonstrate higher peak performance than the ARM CPU but at much higher power. The Ice Lake and Zen 2 curves are neck-in-neck with no clear leader. That higher power can be anywhere between 6x to 11x the power of the ARM core comparing peak to peak operating points; however, the X86 solutions are only 40-50% faster. The design philosophies are also clearly contrasted. The x86 CPU cores are designed to run at very high operating points, and the perf/W curve clearly enters a flatline area where every last bit of performance is extracted, at the expense of disproportionately higher power consumption. In stark contrast, the ARM CPU cores have very steep curves.
Once the Apple A13 and A12Z curves are added, it becomes clear that a well-designed custom ARM CPU can achieve higher performance than even the best x86 designs and at a much lower power. The combination of high performance at low power is the critical characteristic required to achieve leadership in any SoC that is power constrained."
a zen2-nek ( zöld) és a sunnyCove -nak (kék)
mintha hasonló görbéje lenne.A Nuvia arra spekulálhat, hogy egy adott Watt keretbe - több magot és teljesítményt tud belesüríteni. Persze a többi ARM-es chiparchitektúra is erre megy ..
"When measured against current products available in-market in the 1W-4.5W power envelope (per core), the Phoenix CPU core performs up to 2X faster than the competition."
persze a skálázás és valóság már más ..
Amit tudunk, hogy az ARM hosszú távon veszélyes ..
A NUVIA csak ráblöfföl egy picit erre ..
Aztán majd meglátjuk.
( A verseny általában jó; és remélhetőleg az Intelből és az AMD-ből is a legjobbat hozza ki .. ) -
#3750
Petykemano
veterán
Cathulhu
#3749
Petykemano
veterán
válasz
Cathulhu
#3749
üzenetére
Miért? A cikkben van racionális indoklás:
ST-ben segít az egy mag számára elérhető dupla L3$. Ebből MT-ben majdhogynem semmilyen előnyt nem jelent ha szálfüggetlen programban teszteltek.
És valószínűleg segíthet az is, hogy magonkénti feszültségszabályozás jöhet. Viszont az összes mag terhelése esetén valószínűleg ez se jelent semmit.Ezek az adatok a Milanra vonatkoznak. Desktopon lehet, tudtak alacsony magszámon turbó frekvenciát is növelni.
Az én várakozásom az általam ismert információk alapján az, hogy a zen3-nak nagyobb lesz az impactja a játékokban, mint a Datacenterben.
-
#3747
Petykemano
veterán
Cathulhu
#3744
Petykemano
veterán
válasz
Cathulhu
#3744
üzenetére
Azt mondod fake?
Én csak arra utaltam, hogy megjelent. Ha tesztelik, néhány hónap múlva piacra kerülhet.
Az "ryzen 5k" következtetés:
Felreppent a pletyka, hogy csak a Renoir lesz 4000, a Vermeer (vagy a tök tudja mi fog megjelenni zen3 magokkal hamarosan) viszont már 5000 lesz. Én azt mondtam, ennek csak akkor látnám értelmét, ha annyira közel van a Cezanne, hogy szinte egyszerre jelenik meg a desktop procikkal. Az lehet tényleg zavaró lenne, ha az ősz folyamán megjelenne a desktop ryzen 4000, és röviddel utána (tehát nem 2021Q1-ben) a Cezanne Ryzen 5000 néven. -
#3736
Petykemano
veterán
Cathulhu
#3735
Petykemano
veterán
válasz
Cathulhu
#3735
üzenetére
Azzal egyetértek, hogy önmagában az ISA nem szentgrál.
Olvastam egy olyat is, hogy az x86 és arm IPC nem összehasonlítható, mivel az arm jobban Risc, ezért érthető módon több egyszerűbb.utasítást.tud egy órajelciklus alatt végrehajtani.
Ott látok különbséget, amire és ahogy használják. Ebben talán valóban nem annyira van szerepe az isának, lehet, hogy ha megnyitnák az X86-ot, ugyanezek a szereplők most abban terveznének.
Mire is gondolok?
Abu el szokta mondani, hogy a magas frekvencia elérése tranzisztorokba kerül.
Ebből a szempontból az, hogy az amd ugyanazt a designt,.sőt lapkát használja desktopra és szerverbe, lehet,.hogy hátrányt jelent. Feltételezem, hogy ha egy. Matisse ccd nem kéne 5ghz körüli értéket elérjen, kisebb is lehetne. Nem tudom, ez nincs-e összefüggésben azzal is, hogy az arm szerver üzemi frekvencián alacsonyabb fogyasztással kecsegtet. -
#3734
Petykemano
veterán
Cathulhu
#3732
Petykemano
veterán
válasz
Cathulhu
#3732
üzenetére
két megjegyzés:
1) Természetesen az Arm "lassulása" is érezhető. Legalábbis az utolsó, 5nm-re és nyilván legkorábban jövőre tervezett A78 már nem hozott nagymértékű IPC emeledést. Helyette az X1 hozott, ami az A78-hoz képest viszont nagyobb és energiaigényesebb lesz.2)
A konkrét példák viszont előttünk vannak
az amazon Graviton 2-je A76/Neoverse N1 alapú, az ARM-ról ilyen már tavaly kapható volt. És versenyképes teljesítményt nyújt. (Az összehasonlítás persze még Naples-szel van)
És elvileg lényegesen kevesebbet fogyaszt.Ott van az Apple nagy magja, ami jó, egy kicsit más tészta, mint a szerver, de azonos órajelen 70%-kal jobb eredményt ad specint-ben, mint az intel.
Vannak, amik slide-okon léteznek:
A Marvell bejelentette a 60c/240t ThunderX3, állítólag idén év végén elérhető lesz ()
És a Ampere is bemutatta már a 80c Altra családot szintén év végi elérhetőséget ígérveJó, ezek persze egyrészt majd a Milannal kell versenyezzenek. Abban igazad van, hogy a ThunderX3 96 magja tűnt volna igazán veszélyesnek, de az majd csak 2021-ben debütál.
És akkor ott van a Nuvia, ami szintén egy ígéret, ezért azt most hagyjuk is.
Arról van szó, hogy a Naples => Rome => Milan váltások generációs hozadéka kisebbnek tűnik, mint az Arm-os konkurensek utolsó néhány generációja és az ismert vagy még nem ismert terveik ugyanezekből az időkből.
Charlie (S|A) viszont ezt írja: AMD is going to Celeron Intel’s Xeon margins
Ez viszont azt sejteti, hogy többet kellene hoznia a Milannak, mint 10-20% -

awexco
őstag
-

Simid
senior tag
válasz
Cathulhu
#3626
üzenetére
Értem, hogy miért írod azt amit, de ez maximum egy vérszegény B-tervnek jó.
A példádnál maradva, egyrészt még mindig annyi a kereslet a gumikacsákra, hogy egyáltalán nem fáj nekik, hogy diófa asztal az viszont nincs, mindent eladnak, sőt még kevés is a kapacitás. Persze ez hosszú távon nagyon megbosszulhalja magát, de szerintem nincs nagyon választásuk. Gondolj bele, hogy mi lett volna, ha azt csinálják amit írsz és 2 éve kiszervezik. Akkor az elmúlt 2 évben a kiszervezett gyártósorok 100%-kát le is foglalták volna, szóval nem bérgyártóként működtek volna. Vagy nem foglalják le mind, akkor viszont nincsen ekkora bevétel. Speciel ebben egyetértek Abuval, hogy rekord bevétel ide vagy oda, a háttérben már komoly probléma nekik, hogy melyik kezükbe harapjanak.
Az Intel évente több tízmillió CPUt ad el és nincs az a bérgyártó jelenleg aminek kapacitása lenne legyártani ekkora mennyiséget (versenyképes, 5-7-8nm-re gondolok most persze). Vagy kifejlesztik és kiépítik maguknak a gyártósorokat és akkor hülyék lesznek bérgyártásba kiadni vagy gumikacsát árulnak és akkor hosszútávon megszűnnek annak lenni, amik az elmúlt évtizedekben voltak."Az intel 10 es 7 nanoja se lenne rossz, ha nem az egyetlen megrendelojuk az intel lenne, lehetetlen elvarasokkal (10+ magos hatalmas monolitikus designok, 5+ GHz-ekkel)."
Ez csak feltételezés! Mi itt a fórumon sehogy sem fogjuk megfejteni, hogy egy több évtizedes múlttal, komoly szakmai tapasztalattal megáldott és bőséges anyagi forrással rendelkező cég miért nem tudja tartani a lépést. Az hogy mi csak annyit látunk, hogy szar a kihozatal és alacsony az órjel, az lehet hogy csak a jéghegy csúcsa. De igazából ez mindegy is! Ha tényleg diófa asztalt akarnak, akkor ahhoz az kell amiket felsoroltál. Gumikacsát azt tudnak sokan gyártani. -
Simid
senior tag
válasz
Cathulhu
#3622
üzenetére
Dehát most sem az a problémájuk, hogy nincs mit gyártani. A gyárkiszervezésnek szerintem két oka lehet. Vagy nincs elég pénz a fejlesztésre, vagy a kiépített gyártósorokkal nem tudják visszatermelni a költségeket. Az AMD-nél mindkettő fennállt annak idején, Intelnél egyik sem. Az a problémájuk, hogy nincs megfelelő technológiájuk és ezen a kiszervezés/bérgyártás nem fog segíteni.
Olvastam egy összehasonlítást múltkor a különböző félvezetőgyártókról. Az Intel kb 800.000wafer/hó kapacitással rendelkezik (ez szerintem 200mm equivalent). Nem tudom ebből mennyi lehet a 14nm és 10nm együtt, de gondolom több mint a fele és ezen még bővítettek idén. A TSMC teljes 7nm gyártókapacitása 140000wpm, most hogy duplázták 2020 H2-ben. Szóval ha az intel ekkora szereplő akar maradni akkor kell nekik a saját gyár, mert brutális mennyiségben gyártanak most. Ha nem lesz versenyképes technológiájuk, akkor hiába a rekord nyereségek, nem fogják tudni fenntartani a jelenlegi pocíciójukat. -
S_x96x_S
addikt
válasz
Cathulhu
#3597
üzenetére
nézegetve az egy hetes hírt[1] .. úgy néz ki, hogy a SoftBank nagyon pénzt akar csinálni ... és úgy gondolhatja hogy mostanra kell időzíteni
( miután bejelentette az Apple a váltást ? )
Szerintem az Apple lehet az akinek van pénze és fontos lehet még ...
talán fel akarja tornázni az árakat ...A másik lehetőség, hogy kimegy tőzsdére ( IPO ) mint a többi cég.
-----------------------
07.14.2020 ( ~ 1 hete )
"Softbank is said to have been weighing the possibility of holding an initial public offering (IPO) for Arm Holdings, but now there’s said to be at least one company out there that wants to straight-up buy Arm from Softbank."
[1]
https://www.eetimes.com/softbank-said-to-have-a-buyout-offer-for-arm/# -
#3268
Petykemano
veterán
Cathulhu
#3256
Petykemano
veterán
válasz
Cathulhu
#3256
üzenetére
"Apple-lel, Qualcommal amugy se tudna versenyezni az 5 nanos kapacitasert"
2020-ban talán nem is, de 2021-re talán már jutna. Különösen úgy, hogy állítólag saját eljárást kapott az AMD. Nem?TEhát ez a "TSMC's enhanced 5nm process enters mass production in Q4" hír lehet, hogy az ő kizárólagos lapkájukra vonatkozik
" A jomultkor is azt kerdeztem bele a levegobe, hogy miert nem marad 2-3 generaciot egy nodeon, az intelnek is nagyon bejott, maig versenykepes tud marad azon a 14-en, amit mar az egekig optimalizalt. Desktopon nem olyan fontos a fogyasztas mint ultramobil szinten."
Azért a 14nm az intelnek tényleg saját eljárása és tényleg kimaxolta szépen.
2-3 generáció... szerintem az lehet a baj, hogy a desktopon kívül mindkét lényegesebb piacon nagyon számít a fogyasztás és a lapkaterület is. Tehát tök jó lenne, ha 2-3 generáción kereszül tudnák 7nm-en bütykölni és növelgetni a frekvenciát, miközben generációnéknt hoznak 5% IPC-t. A végére ez már biztosan nagyon olcsó lenne, csak épp mobil szegmensben és szervereknél is többet érsz, ha inkább meg tudod felezni a fogyasztást. Ráadás az, hogy trantisztor áldozásával IPC-t is tudsz növelni és a szervereknél esetleg még az is sokat számt, hogy a kupak alá több magot tudsz bezsúfolni.
Ezek a piacok sokkal inkább drive-jai a fejlesztések.De részben egyetértve veled épp ezért mondtam, hogy szerintem a Matisse refresh marad még velünk 1-másfél, esetleg 2 évig is az alsó szegmensben.
-
S_x96x_S
addikt
válasz
Cathulhu
#3261
üzenetére
> most meg a kalapbol elohuznak egy 5 nanos designt a Zen3-hoz?
> Nehezen hiheto szamomra.
szerintem mindenki emésztgeti ...
lehet, hogy tényleg csak kamu ... felhajtani a részvényárakat ..ha viszont az 5nm igaz, akkor azt irják, hogy csak a CES-en januárban jelenik meg ... és akkor nem lesz idén ...
megjegyzés részemről: Pedig Lisa Su megigérte ... hogy idén ..
-
awexco
őstag
válasz
Cathulhu
#3251
üzenetére
Még ha egy nullát levennél akkor is korrekt lenne .
Operating Income 2019 : $631M
Net Income 2019 $341MA kettő közt nem tudom mi lehet a difi . (talán cirka 300 misi hitelt vissza fizettek vagy eszközleírások valaki biztos tudja , hogy könyvelnek usa-ban )
De ha a kissebbik öszeghez viszonyitod a fizetését akkor bármelyik normális gondolkozású embernek égnek áll a haja .
Igen jól látod abból a rengeteg pénzből fejlesztőket lehetne felvenni . Akár új termékeket kifejleszteni új piacokra lépni stb. Durva ... -
#3216
Petykemano
veterán
Cathulhu
#3214
Petykemano
veterán
válasz
Cathulhu
#3214
üzenetére
(A zen csak az AMD életében volt nagy ugrás. De nem különösebben tér el a felépítése a Core architektúrától. mondhatjuk úgy is, hogy eddig minden eddigi ettől eltérő próbálkozás kudarc volt.)
Arra lennék kiváncsi, hogy vajon mennyi tranzisztort és energiát emészt fel az, hogy az AMD/INtel processzorai el tudnak menni ~5Ghz-ig. Mármint ugyanazzal az IPCvel mennyivel lenne kisebb, vagy mennyivel fogyasztana kevesebbet azonos frekvencián, ha mondjuk csak 3.5Ghz-ig tudna elmenni.
Ott és azért érdekes ez, mert a szervereknél, ahol sok a mag és mindet használja egyszerre, kétlem, hogy bármi is tudna ténylegesen 5Ghz-ig turbózni, miközben 63 másik mag ketyeg 3Ghz-en. TEhát egy Rome esetén az architektúrában felesleges feature az, hogy amúgy elvileg el tudna turbózni 5Ghz-ig. Nem is engedik, mert csak értelmetlenül elvenné a power envelope-ot más szálaktól.
Én azt gondolom, hogy fel fogják használni az X1-et mobiltelefonokban is. De mondjuk úgy, hogy csak 1 olyan lesz. 4 A78 és 4 A55.
Azt is gondolom, hogy x86-ból is lehetne, lehetett volna már építeni olyan magot, mint amilyen apple-nek van. De szerveres környezetben nem sok haszna lenne 8-ból 1 olyan magnak, ami mondjuk 50%-kal többre képes egy szálon, miközben 2x annyit fogyaszt.
De mobil és akár desktop szegmensben ennek akár haszna is lehetne.Vajon fognak így elválni a designok?
-
#3170
Petykemano
veterán
Cathulhu
#3168
Petykemano
veterán
válasz
Cathulhu
#3168
üzenetére
Érdekes grafikonok.
Csomó olyan van, ahol valójában az SMT nem hogy nem dob 30-50%-ot, de még ront is.Ezzel együtt érdekes látni, hol tart az ARM.
Talán van még reménye az AMDnek (és az intelnek)A kommentek közt mindkettőre.van válasz:
Sok esetben a HPC/cloud szegmensben olyan alkalmazások futnak, mármint itt a tesztben,.ami nem fér bele.a.cachebe és a memóriasávszél szűk keresztmetszetet jelent. Valóban lehetett azoknak némi igazuk, akik a magok számának duplázása kapcsán felvetették: hogy fogja tudni ezt 8 csatorna etetni.Ez megmagyarázza a Milannál a 32MB+ L3$ jelzést és azokat a spekulációkat is, hogy HBM lehet szükséges. Nem kifejezetten késleltetéscsökkentő, hanem sávszélességnövelő gyorsítótár gyanánt.
A másik dolog a kommentekben az ARM.
Egyik hozzászóló elmondja, hogy az isának kevés köze van az energiahatékonysághoz. Szar vele dolgozni, és szar a sok legacy utasítás, de nem ez a döntő.
Energiahatékonyság jöhet abból, hogy mire van kitalálva egy architektúra.és hát az x86 iránya elég régóta a vastag többszálú adatfeldolgozás. Az armos implementációk pedig eddig nem erre hegyezték ki. De most hogy épülnek a szerverek, majd kiderül, hogy sok adat feldolgozásához sok energiát kell.Itt jön képbe a data locality. Coreteksnek volt egy videója arról, hogy valójában mennyire kevés enegiát igényel az adatfeldolgozás, a számítás az adatmozgatáshoz, memóriából való kiolvasáshoz képest.
De valószínűleg ez inkább ügyes mérnöki megoldás, semmint isa kérdése.Ami mégis döntő lehet, hogy az arm licencelhető. Az x86-ot az AMD és az Intel bütykölgeti.
De arm oldalon saját specifikus célra be tudnak szállni olyan dollárszázmilliárdos cégek,.mint Apple, amazon, Google, facebook, akik sok esetben azt se tudják, hová tegyék a profitot (hogy az adóhatóság ne lássa) -

Tanisz
senior tag
válasz
Cathulhu
#3117
üzenetére
Köszi.
Most vagy én vagyok láma és nem értek valamit, de nem az U-s APU-s notikat várom.
Sima 4800H CPU-val szerelt munkára fogható laposokat. (Dell, HP, Latitude, EliteBook..stb). amik nem gamer laposok, azok már vannak tudom.
Bár jöhetnének ezek az APU-k is 35-45W-on, nyugodtan egy Latitude-ba, az is megfelelne -
#3031
Petykemano
veterán
Cathulhu
#3030
Petykemano
veterán
válasz
Cathulhu
#3030
üzenetére
De ez nem egy hardver, hanem egy storage engine, amit ilyen jellegű hardverekre optimalizáltan terveztek.
Storage Engine a mongodbben pl a wiredTiger. Mysqlben az InnoDB. Ezt a hse-t szerintem wiredTiger helyett használhatod.Ott persze biztosan van kötődése, hogy mi a fenének fejlesztene pont a micron pont egy ilyet, ha nem épp saját hardvereinek eladását próbálja ezzel támogatni, hogy valóban kiaknázható legyen az abban rejlő potenciál.
-
-
-
S_x96x_S
addikt
válasz
Cathulhu
#2868
üzenetére
> valid?
A i7-10710U még csak 14nm,
ezzel nem sok értelme van összehasonlítani.ami érdekes lesz az Inteltől az a "Tiger Lake-U"
ahol a "the single-core score of 1,400 points" kiemelkedő;
https://www.notebookcheck.net/Quad-core-Intel-Tiger-Lake-processor-outscores-AMD-s-Ryzen-9-3950X-in-Geekbench-single-core-test.451119.0.html
főleg amiatt mert a desktop-os Ryzen9 3950X -nek csak 1312 a single score-ja.A "Tiger Lake-U" = 10nm , AVX512. Gen12 max 96 execution units
és ezzel kell az AMD 4000 mobil APU-nak versenyezni. -
S_x96x_S
addikt
válasz
Cathulhu
#2838
üzenetére
hosszú távon jobb a transzparencia;
vagyis minél hamarabb kiderül - annál jobb ( nincs szarabb, mint visszahívni több generációnyi processzort )
-----
közben a reakciók ..."This has, of course, generated plenty of attention, but it is noteworthy that the study's Intel-funded co-authors have also disclosed Intel vulnerabilities in the past (10 on Intel, 3 on ARM, 2 on AMD, 1 on IBM). The lead researcher also responded on Twitter, disclosing that Intel funds some of its students and the university fully discloses the sources of its funding. He also noted that Intel doesn't restrict the universities' academic freedom and independence, and that Intel has funded the program for two years. "
https://www.tomshardware.com/news/new-amd-side-channel-attacks-discovered-impacts-zen-architecturelegalább nem javíthatatlan
"The paper suggests several remediations for the vulnerability through a combined software and hardware approach, but doesn't speculate on the performance hit associated with the suggested fixes. " -
S_x96x_S
addikt
válasz
Cathulhu
#2810
üzenetére
> Egy szo mint szaz, en is orulok a versenynek,
> mint ahogy a Microsoft is, csak a hazugsagot nem toleralom jol
a microsoft cloud-nak kell. ( Azure )
Mivel a rivális piacvezető AWS már bejelentette a saját ARM-es szerverprociját és azt is, hogy jön az idén,
erre valamit a Microsoft Azure-nak is lépnie kell.
és mivel a Cloud-ban könnyű az átállás ( elég csak újrafordítani a kódot )
emiatt 20-30% -os TCO csökkentésért sok mindenre képesek a managerek.szóval a Microsoft Azure(Cloud) kényszerhelyzetben van, kell nekik egy potens ARM-es szerverchip, emiatt is örülnek.
-
#2799
Petykemano
veterán
Cathulhu
#2793
Petykemano
veterán
válasz
Cathulhu
#2793
üzenetére
Érdekes, de a simlisségek ellenére vannak méltató szavak:
Microsoft, Oracle, gigabyte, Lenovo
“We are pleased to see the launch of the Ampere Altra cloud optimized platform that helps bolster our hyperscale datacenter priorities around power efficiency, resiliency, telemetry and security. Ampere’s standards-based approach made it easy for us to bring up our software stack and we are actively evaluating their systems in our labs.”
Dr. Leendert van Doorn, Distinguished Engineer, Microsoft Azure, Microsoft CorpEz alapján lehet, hogy lesz tényleges érdeklődés
-

Devid_81
félisten
válasz
Cathulhu
#2766
üzenetére
(meg mindig kivancsi vagyok ki fogja elnyerni a brit meteorologiai szuperszamitogep ~1 mrd dollaros tenderet)
Mint 9 eve Angliaban elo megmondom neked az idojarast szuperszamitogep nelkul is, esni fog, de neha elal, majd ujra esni fog
![;]](//cdn.rios.hu/dl/s/v1.gif)
Majustol Szeptemberig a valtozas annyi, hogy lesznek naposabb idoszakok is, de amugy esni fog 
-
#2767
Petykemano
veterán
Cathulhu
#2766
Petykemano
veterán
válasz
Cathulhu
#2766
üzenetére
Persze, szép fokozatosan építheti a mindshare-t. Ez volt benne implicit a próbavásárlásos kérdésemben. Fogalmam sincs, az a 80k mag mekkora tétel az azure összkapacitásában, de elképzelhetőnek tartom, hogy ha beválik a próbavásárlás és a következő beruházási körben az AMD még mindig jobb, akkor már nagyobb tételben nyergelnek át.
A google cloudban pl még mindig vannak haswell szerverek. Azt gondolnám, hogy egy epyc mellett azok üzemeltetése már áramfogyasztás tekintetében lényegesen rosszabb lehet, és sűríteni is lehetne, tehát helyfoglalás szempontjából sem ideális.
Oda akarok kilyukadni, hogy ha az erőviszonyok változatlanok maradnak, akkor valóban várható, hogy a Milanból még nagyobb tételeket fognak értékesíteni
-
#2720
Petykemano
veterán
Cathulhu
#2719
Petykemano
veterán
válasz
Cathulhu
#2719
üzenetére
Hogy bánhatja szegény AMD, hogy ehhez nem tud még Arcturust kínálni.
(Bár persze lehet, hogy az Arcturus olyan projekt-termék, amit pont az ilyenekbe próbálnak elsősorban eladni, aztán vagy sikerül vagy nem)Kiváncsi vagyok, hogy ha üzembe áll, vagy legalább elkezd épülni a Frontier, közben, vagy utána lesz-e elmozdulás, vagy továbbra is az nvidia CUDA lesz a nyerő minden ilyen célre.
Tegyük hozzá, hogy a 100db V100 nem egy nagy összeg (~$6000). Nem több, mint $1m.
De 290304 mag, ha 64 magos procikkal számolunk, akkor 4536 és ha a legcsúcsabbat veszik, ami kb $8k, akkor sem jön ki több, mint $35mmondjuk ha a többi alkatrészt is beleszámoljuk, nem tudom, hogy jön ki 3db $71m-ból, de mindegy.
-

joysefke
veterán
válasz
Cathulhu
#2620
üzenetére
Nem értem hogy egyáltalán min vitatkozunk. Azt sem értem, hogy mi a problémád az unrollingra írt két mondatommal.
Ha jobban tudod, hogy mi az unrolling, akkor kérlek írd le, hogy hol a probléma a kijelentésemmel és ne wikipediát idézz, mert én akkor meg a Mestert idézem: https://www.agner.org/optimize/optimizing_cpp.pdf (c.h 12.3)
Tehát még egyszer: A loop unrolling sok minden optimalizációra (lehet) jó, ezek közül az egyik, hogy lehetőséget ad(hat) automatikus vektorizálásra, mivel több (2-4-8-16 attól függően hogy mennyi adatelem fér egy vektorba) skalár adaton végzett ciklustörzset egyesít egy nagyobb ciklustörzzsé, ahol az egy-egy skalár adaton végzett műveletet helyettesíteni lehet nagyobb vektorműveletekkel.
Lehet hogy te arra gondoltál, hogy egy konstans hosszúságú loop
Ahhoz hogy ez a fordító által automatikusan megvalósítható legyen a kódnak egyszerűnek kell lennie: az egymás után következő ciklusok között csak könnyen feloldható függőség lehet. Bonyolult függőségeket és branchelést nem fog tudni magától feloldani/kezelni a fordító.
Attól függetlenül, hogy a compiler bizonyos egyszerű skalár kódrészleteket (pld for ciklussal egyenként végiggyalogolok egy tömb összes elemén és hozzáadok az aktuális elemhez valami konstansot) hatékonyan tud vektorizálni, ennek még zéró köze van egy SIMD- utasításokat használva kézzel optimalizált kódhoz.
Erre mondtam azt, hogy ha Pistike ír mondjuk egyszerű képmanipulációs szoftvert skalár műveletekkel, mondjuk egy Sepia filtert, ami ugye az egyik legegyszerűbb RGB adatokon dolgozó algoritmus, a compiler nem fog tudni a skalár kódból érdemi SIMD kódot generálni.
Az ok pedig annyi, hogy a hatékony SIMD kódhoz elengedhetetlen, hogy a bemeneti és köztes adatok struktúráját hozzáigazítsd a vektoros feldolgozáshoz. Ez nagy munka. Az RGBA adatokat pld transzponálni kell, hogy a bemeneti [RGBARGBARGBARGBA] helyett kapj valami ilyet:
[RRRR] [GGGG] [BBBB] [RRRR] [GGGG] [BBBB] stb stb (az A alapvetően nem kell a szépiához).Aztán ott van a branchelés. Ha a módosított képen valamelyik színkomponens nem 0-255 közé esik, akkor csonkolni kell. Ezt sem fogja tudni érdemben automatikusan skalárról vektorra fordítani a compiler.
stb stb stbAz MKL az intel sajat, zart forrasu kodja, kb termeszetes, hogy bunteti a nem intel procikat
Nem, nem természetes. Itt arról van szó, hogy ha a dispatcher nem intel procit detektál, akkor rá sem engedi az AVX2 kódra, akkor sem, ha a proci egyébként támogatja azt.
Ennyi erővel az intel fgv könyvtárak akár az x86-os kódot is tilthatnák AMD-n.
Egyébként attól, hogy egy kódot AVX2 -t használva írtak meg, az még nem lesz önmagában ideális egyszerre Skylakere és mondjuk ZEN2-re.
Az intel nyilván a saját AVX2-t tudó processzoraira fogja az AVX2 -t használó kódrészletet optimalizálni. Figyelembe veszi az L1/L2 cache méretét asszociativitását, adott SIMD utasításból hányat tud egyszerre végrehajtani a mag és mekkora az utasítás késleltetése stb. A sebességet mérik is, és nyilván úgy csiszolják, hogy a legjobb legyen a saját procijuknak. Tehát az AMD proci itt is hátrányban lenne, de legalább nincsen szándékosan kigáncsolva. (mintha skalár kódot futtatna enyhén szuboptimális vektorkód helyett)Tehát én azt várnám el az ilyen gyártói fgv könyvtáraktól, hogy ha a konkurens processzor tudja a szükséges utasításkészletet, akkor az is fusson rá az optimalizált útvonalra.
A fenti hosszú irományom lényege pedig az, hogy semmilyen compiler nem fog saját kútfőből skalár kódból vektor kódot csinálni eltekintve pár low hanging fruit leszedésétől.
-
joysefke
veterán
válasz
Cathulhu
#2620
üzenetére
Az MKL az intel sajat, zart forrasu kodja, kb termeszetes, hogy bunteti a nem intel procikat, de ennek semmi koze az 512-hoz, hiszen a legtobb intel proci se tamogatja azt.
Pontosan erről beszélek. Amikor vektorkódnál hátrányban van az AMD akkor nem azért van hátrányban mert "csak" AVX2-t támogat és nem AVX512-t mint a legmodernebb szerver/ws intelek, hanem azért, mert az AMD-proci nem fog ráfutni a számára legoptimálisabb kódútra, hanem egy csomó szoftverben skalár kódot fog végrehajtani, pedig futtathatná az AVX2-es kódutat is. ez az igazi hátrány
Ezen a problémán nem egy esetleges AVX512 támogatás fog segíteni, hanem ilyen olyan módon rá kell bírniuk a szoftvergyártókat, hogy gondoskodjanak róla, hogy az AMD is az AVX kódot futtassa, ha ez nem megoldható MKL alapon, akkor más libraryt kell keresni.
Nemelyik fordito kepes skalar kodot automatikusan vektorizalt kodra optimalizalni, es ehhez nincs szukseg a programozonak explicit SIMD kodot irnia, a forditonak kell eleg intelligensnek lennie (es itt megint felmerul az ICC partatlansaga).
A fordító soha nem fog helyetted vektorkódot írni.
Egyszerű for ciklusokat fog automatikusan unrollolni, ha nem érzékel az egymás után következő ciklusok között függőséget/branchelést, illetve egy csomó alap fgv van még vektorizálva (pld egy némely stringművelet).
Egy "skalár megírt Cinebench"-ből semmilyen fordító nem fog CB20-at csinálni...
-
S_x96x_S
addikt
válasz
Cathulhu
#2557
üzenetére
> Arra jutottam ez a VMWare huzas jelenleg
> (es elore lathatolag 1-2 evig biztos) jobban szivatja az intelt
> mint az AMD-tservethehome -os elemzést olvasgatva ... :
szerintem ha az AMD -ha "szemétkedni" akarna,
akkor simán át tudná alakitani a ccx - et úgy, hogy a rendszerből
4c/16thread -nek látszódjék ami amúgy 8c/16t ..
vagy még jobb lenne ha igazából BIOS -ból lehetne állítani ..
Persze erre a VMWare is újból pontosítana a licenszfeltételekon - kizárva a thread-ekkel trükközést.mindenesetre a hasonló eseteknél az AMD a ccx-es architektúrájával gyorsabban és jobban tud reagálni.
--------------------
“We cannot continue pricing on a per-CPU basis, where CPUs could have unlimited core counts.” (Source: VMware)
AMD is Not the Most Impacted by VMware Change
When we think about the impacts of this change, things get interesting. Many have pointed to the 64-core AMD SKUs that now require two 32-core per socket licenses. AMD is undoubtedly impacted. Still, AMD has several 32-core options that can maximize the license better than Intel can. AMD also has options for something like a 4 core per CCD 32 core and 256MB L3 cache part that is clock speed optimized to further press this advantage.
... ( érdemes az egészet átfutni )
Licenseageddon Rages as VMware Overhauls Per-Socket Licensing
https://www.servethehome.com/licenseageddon-rages-as-vmware-overhauls-per-socket-licensing/ -

Cifu
félisten
válasz
Cathulhu
#2553
üzenetére
Csakhogy a futó VM-ek száma rugalmasan változhat és változik az igényeknek megfelelően. Ez a fő probléma a VM alapú licencel, hogy nem lehet korrektül követni. Hogy fogod előre megmondani? Na, eddig max. 120 VM-re volt szükségem, szóval veszek 128 licenszt, és elég lesz. Majd bejön, hogy hopp, hirtelen kéne még 60VM egy projektre, egy hétre, és most indulna. Most mi legyen? Vegyenek egy éves VM licenszeket? Mit csinálunk utána, ha nem kell? Vagy mi a kukutyin legyen? A pénzügynek hogy adjuk be, hogy hirtelen ez van?
A CPU alapú számítás előnye volt, hogy relatíve könnyű számolni vele. Van egy szerverparkunk mondjuk 20db szerverrel, egyenként 2db CPU-val, az összesen 40 licensz. Akkor ennyire kell éves licensz, tessék, itt a számla, utaljátok a pénzt.
VM-ekkel számolni irtó macerás...
-
S_x96x_S
addikt
válasz
Cathulhu
#2528
üzenetére
> $200 Picasso laptop, SSD-vel
The $199 Motile M141 With AMD Ryzen 3 3200U Offers Surprisingly Decent Performance
https://www.phoronix.com/scan.php?page=article&item=ryzen-3200u-motile&num=1"The Motile M141 with Ryzen 3 3200U was just ahead of the Core i7 Haswell and Broadwell laptops tested... Back from when Intel Core i7 CPUs in mobile devices were two cores / four threads, similar to the 3200U. The Core i5 8265U processor meanwhile was just 8% faster than the Ryzen 3 3200U."
-
S_x96x_S
addikt
válasz
Cathulhu
#2517
üzenetére
> Leszedték
Le biza
 ... ;
... ;
még szerencse, hogy néhány képet belinkeltem ..
azok még megvannak ... ( vagy legalábbis nálam látszódnak )Persze nem lehet, tudni, hogy miért szedték le ..
( lehetett benne durva hiba is )
Ha pár héten belül nem kerül vissza, akkor ... így jártunk ... -
#2490
Petykemano
veterán
Cathulhu
#2488
Petykemano
veterán
válasz
Cathulhu
#2488
üzenetére
Lehet, hogy az Intel gyártókapacitása a legnagyobb a világon. 14nm-en, amit az Intel termékeire gyúrtak ki.
De az intelen kívül - jelenleg - ki akarna ezen gyártani? Ez arra lenne elég, hogy az olyan másodvonalbeli szereplőket kiszorítsa a másodvonalbeli piacról, mimt az umc, smic, gf.Azt nem is értem, hogy hogy gondoltad, hogy verseny. Az Intel épp azért választaná le, mert (ha) NEM versenyképes, amit ki tud izzadni magából. Tehát lehet, hogy másodvonalbeli gyártókkal versenyképes lenne, de az Intel az igényeit épphogy a jelenlegi két élvonalbeli gyártóhoz vinné át. Az új gyár nem harmadik lenne az élvonalbeli gyártók körében, hanem negyedik a másodvonalbeliek között.
Maximum olyasmi Lehetne, hogy az Intel direkt a rosszabbik samsunghoz viszi a gyártását, mert olcsóbb és megfinanszírozza így annak versenyképesnek maradását. De ezt eddig egyik cég sem igazán tette meg, mindenkinek a jobb node kell.
A 10nm pedig pontosan olyan rossz volt, hogy tavaly csupán 2magos igp nélküli lapkára futotta. 2020H2 most a ramping up ígéret.
Ha valamivel nem értesz egyet, légyszi mondj példát, mert Szeretném megérteni, hogy hogy gondolod, de így nem tudom elképzelni, hogy ez nem holt teher levetése lenne. A modemek, amiket írtál pont ilyen olcsóbb másodvonalbeli gyártók/nodeok termékei.
-
#2487
Petykemano
veterán
Cathulhu
#2483
Petykemano
veterán
válasz
Cathulhu
#2483
üzenetére
Én nem hiszem, hogy az intel és gyárai különválás mindkét üzletágnak előnyös lenne.
Láttuk, hogy a GF esetén nem volt az. Egyrészt a GF fő partnere megmaradt az AMD. Még az IBM gyártórészlegének beolvasztása után (még az IBM fizetett az átvételért!) sem sikerült az AMD és az IBM mellett más lényeges megrendelőket szerezni. Feltehetőleg a GF még most is abból él, hogy az AMD onnan rendeli a zen1/+ és IO lapkákat.Mi a helyzet az intellel? Iszonyatos gyártókapacitásuk van 14nm-ből. Ez annyira nem rossz, de az intel épp azért fontolgathatja a leválasztást, mert nem elég jó. a 10nm és a 7nm pedig vagy elég jó és akkor nem kell leválasztani, vagy bukás és senki másnak sem lesz elég jó.
A nem cutting edge, azaz nem elég jó node-okból szerintem elég nagy a kínálat, a GF, a Samsung, a TSMC, de az UMC és talán az SMIC is kínál már ilyet. Biztosan sokan átálltak már arra az üzletpolitikára, hogy ezt minél olcsóbban. De még a GF SOI irányának eredményei sem láthatóak. Olcsón nem szupergyors node kell, márpedig az intel 14nm-es gyártástechnológiája az. mármint az intelen kívül kinek kéne még 5Ghz egy amúgy nem elég jó gyártástechnológián?Tehát szerintem az történne, hogy amíg az intel használja ezeket a gyártósorokat, addig életképesnek tűnne, persze a 7 és 10nm-es fejlesztések finanszírozása nyilván megcsappanna, lelassulna. És ahogy az intel kiszáll a 14nm-ből, vagy fölös kapacitások alakulnak ki, amire már az intel is alkudna, hogy legyen olcsóbb, a gyártó cég összeomlana.
-
S_x96x_S
addikt
válasz
Cathulhu
#2483
üzenetére
>Mas: szerintetek van alapja az AMD + Xilinx pletykaknak?
nem tudom, határeset ...
már most is erős partnerkapcsolat van közöttük .. ami mindkét fél számára most is előnnyel jár ..https://www.nextplatform.com/2020/01/16/hpc-in-2020-acquisitions-and-mergers-as-the-new-normal/
"The only problem is that Xilinx’s current market cap of around $25 billion, or about half the current market cap of AMD. And if you’re wondering about AMD’s piggy bank, the chipmaker has $1.2 billion cash on hand as of September 2019. Which means any deal would probably take the form of a merger rather than a straight acquisition. There’s nothing wrong with that, but a merger is a more complex decision and has greater ramifications for both parties. That’s why the rumors of a Xilinx acquisition have tended to center on larger semiconductor manufacturers that might be looking to diversify their offerings, like Broadcom or Qualcomm. Those acquisitions wouldn’t offer the HPC and AI technology synergies that AMD could provide, but they would likely be easier to execute"
-
válasz
Cathulhu
#2483
üzenetére
Az intel bérgyártó képességének is jót tenne ha külsőssé válnának.. Legalábbis az igények kiszolgálása esetében nagyobb eséllyel mennek egy olyan céghez ami a saját termékei értekében nem "einstand" olja a gyártáskapacitást ah hirtelen nagyobb igény lenne rá, és tud gyártani a partner aki időnként azért X mennyiséget berendelne pár éven át az adott technikára megtervezett chipből. Az ilyen esetben felmerülő kártérítés sokszor nem fedezi a tervezett bevételeket, hisz akár egy teljes termékpaletta múlhat egy-egy esetlegesen komolyabb chipen (amit mondjuk nem tudtak szállítani emiatt).
-
S_x96x_S
addikt
válasz
Cathulhu
#2468
üzenetére
>bar ezek szerintem 25W TDP-re vannak konfiguralva 15 helyett,
nézegettem az Intel - leendő 8 magosát .. hogy milyen lesz ..
https://wccftech.com/intel-core-i9-10980hk-8-core-5-ghz-mobility-cpu-benchmarks/
de az meg H-s .. és más a TDP ... emiatt nem fair az összehasonlítás.
"Now, this is not an apple to apple comparison since Ryzen 7 4800U is a 15W-25W chip while the Core i7-10750H is a 45W part so a better comparison would be this versus the Ryzen 7 4800H but we don't have 3DMark Timespy scores for the Ryzen 7 4800H."
mindenesetre H-soknál teljesítményben lesz verseny,
( habár itt még az Intel 14nm-en marad , emiatt hamar eléri a TDP keretet .. )Másrészt lelkiekben kezdek felkészülni a 8 magos Notebookokra ..
már megint cserélnem kell -
S_x96x_S
addikt
válasz
Cathulhu
#2450
üzenetére
> Kerdes a 670 is benne van a dealben
ha tudja a PCIe 4.0 -át és az USB 4.0 -át ( Thunderbolt3-al), akkor szerintem műszaki akadálya nem lehet.
és a digitimes-os cikk szerencsére megemlíti az USB4-et.
"ASMedia has also begun development of a USB 4 controller chip, which is set to be released in 2020, "
-
S_x96x_S
addikt
válasz
Cathulhu
#2427
üzenetére
> mert megint menni fog a hiszti, hogy senki se akar
> majd B550-es lapot venni az uj procihoz.szerintem az új Desktop APU-k -al ( 4400G ) egyidőben jön ki.
és "valami" extra talán lesz bennük, ami miatt rábeszéli magát a kedves vásárló - hogy egymáshoz párosítsa őket ..
( Én speciel egy USB 4.0 -nak örülnék , de erre minimális az eséy )A520 : persze a most megjelenő - "ASRock Jupiter A320" - még a régebbi chipsettel jelenik meg. Remélem annyi előnye lesz,hogy gyorsan lehet a chipsetet updatelni.
-
S_x96x_S
addikt
válasz
Cathulhu
#2428
üzenetére
> Amit viszont elkezdtem kivesezni az a i7-1065G7 vs 4800U
elnézve az új Acer gépeket
https://www.anandtech.com/show/15305/acer-swift-3-either-with-core-i71065g7-or-ryzen-7-4700u-the-laptop-market-just-blew-wide-openAz inteles-ben a (~2/4) mag kompenzálására lesz:
- Thunderbolt 3,
- Wi-Fi 6
- ultra-low power display ???
- CPU extra: Intel® AVX-512 ; DL boostAz AMD proci [2] : cTDP10-25W
Az Intelesre[1] meg: 12-25W adtak meg .. habár az a +2W nem jelent semmit se .. az is lehet, hogy másképp mérik.valószínüleg a Microsoftnak és a Lenovo-nak is lesz Intel-vs-AMD konfigja ..
[1]
https://ark.intel.com/content/www/us/en/ark/products/196597/intel-core-i7-1065g7-processor-8m-cache-up-to-3-90-ghz.html
[2]
https://www.amd.com/en/products/apu/amd-ryzen-7-4800uAmi még érdekes, hogy
az AMD Ryzen™ 7 4800U - re PCI Express® VersionPCIe 3.0 -at irnak.
mobilban még nincs itt a PCIe Gen4. -
#2299
Petykemano
veterán
Cathulhu
#2298
Petykemano
veterán
válasz
Cathulhu
#2298
üzenetére
Valóban izgalmas lesz.
Az Arm procik nemcsak hogy számosságukban sokasodnak, hanem eddig ragyogó előrelépéseket produkáltak évről évre. Persze tegyük hozzá, hogy a bejelentést követően mindig közel egy év kell, hogy abból piaci termék váljon és mindig csak a legújabb gyártástechnológián.A kunpeng ilyen szempontból nem biztos, hogy igazán jó összehasonlítási alapot fog adni, sokkal inkább az amazon 64 magos cucca, ami Neoverse N1-re épül - ha jól tudom, ez az arm utolsó kifejezetten szerverfelhasználást célzó designja.
Ezzel szemben a kunpeng TaiShan v110 magokból áll, ami Cortex A72-re alapulnak. Persze ha megnézzük a speficikációt, biztosan jobban ki vannak tömve cache-sel, tehát nem biztos, hogy az A72 => A73 => A75 => A76 => A77 átmenetek között megadott névleges teljesítménykülönbség irányadó, hiszen az magában foglalja a frekvenciaemelkedést is ahhoz képest, amin az A72 eredetileg ment. Az Arm ezek között mindenesetre ~30%-ot adott meg, az 185%-os előrelépést jelentene. Ha ebből kivonjuk a frekvenciát, meg azt, hogy a TaiShan v110 is jól ki van már tömve cache-sel, akkor is szerintem még jó sok százalék benne marad.
Mindenesetre az biztos, hogy az Arm nagy előrelépései is mindig részben a jobb (sűrűbb) gyártástechnológiából fakadtak. A nagy kérdés az, hogy
- az Arm ezt fenn tudja-e tartani, tehát hogy 5nm-re lépve is hoz-e majd mondjuk egy A78 +30%-ot?
- az X86 tervező cégek fel tudják-e venni a versenyt.Utóbbihoz annyit tennék hozzá, hogy hát azt látjuk, hogy az intel 10nm-re lépve hozott átlag 18% IPC-t (ezt szerverek terén valószínűleg realizálni is tudja majd frekvencia bukó nélkül) és a willow cove is egy kisebb lépés előre, majd a 7nm-en megint nagyobb előrelépés.
Az AMD-ről nem tudunk semmi konkrétumot, de ilyen konkurencia mellett ha a zen3 (és így tovább) csak a korábbi években megszokott 8-10%-os IPC emelkedést hozná, akkor halálra van ítélve. Tehát muszáj az AMD-nek - és az intelnek is - nagyot gurítani.
Összességében én egy elképesztően felgyorsuló cpu piacra számítok a következő 5 évben. 2x-es teljesítménynövekedésre 1 szálon. Tehát míg ma azt gondoljuk, hogy hát egy 2014-ben vásárolt 4/8-as Haswell vagy Skylake egész jól elketyeg, szerintem a ma használt procik 5 év múlva kifejezetten lassúnak fognak számítani.
Természetesen ha készpénznek vesszük, hogy az x86-ot nincs hová fejleszteni, akkor az AMD és az intel vagy kiesik, vagy átállnak más utasításkészletre.
-
válasz
Cathulhu
#2290
üzenetére
mondjuk ez lehetséges, fél év alatt javul a gyártás és/vagy ki lehet válogatni annyi "golden" chipet amire lehet építeni egy külön terméket ... már ha megéri persze... ez szerintem nagyban függene attól, hogy a konkurensek milyen terméke van.. jelenleg nem nagyon kellene törni emiatt magát az amdnek, maximum valami erősebb 8 magos kellene csak ami tud kicsit magasabb órajelet (összességében).. De ezt én nem tudom megállapítani megéri-e egy ilyen "presztízs" terméket készíteni mert játékon kívül mindenben gyorsabb lenne a 12 és 16 magos (amin valószínű a haszon is nagyobb)..



 ..
..


























![;]](http://cdn.rios.hu/dl/s/v1.gif)

 ... ;
... ;
Új hozzászólás Aktív témák
- Milyen billentyűzetet vegyek?
- Kerékpárosok, bringások ide!
- Eredeti játékok OFF topik
- Kinéztél egy RTX 5060 Ti-t? Lehet jobb, ha lecsapsz rá!
- Amlogic S905, S912 processzoros készülékek
- Azonnali processzoros kérdések órája
- gban: Ingyen kellene, de tegnapra
- „Új mérce az Android világában” – Kezünkben a Vivo X300 és X300 Pro
- Most állítólag törölték a korábban pletykált GeForce RTX 50 Super sorozatot
- Házimozi haladó szinten
- További aktív témák...

- BESZÁMÍTÁS! Asus H370 i5 9600K 16GB DDR4 512GB SSD RX 5700XT 8GB Rampage SHIVA CHIEFTEC 700W
- Eladó Samsung Galaxy Tab A9 4/64GB / 12 hó jótállás
- Dell Precision 7560 - Intel Core i9-11950H RTX A4000 32GB 1TB SSD FHD
- Samsung Galaxy A17 5G / 8/256GB / 12Hó Garancia / Kártyafüggetlen / Akku 100%
- DELL Thunderbolt TB16 Dock (ELKELT)
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest