Hirdetés
Új hozzászólás Aktív témák
-
#5378
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
Itt egy másik érdekes kép az eladott PC példányszámokról:
[link]Ha jól értem, akkor a 2020 februári előrejelzés és a 2021 februári előrejelzés között évi 100millió gép különbség van. Nyilván az előrejelzés tényadatokra épül, de arra nem vállalkoznék ez alapján, hogy megmondjam, 2020 és 2021 eddigi hónapjaiban mennyivel volt magasabb tényleges eladásszám / kereslet az előző évekhez képest.
-
#5377
Petykemano
veterán
Petykemano
#5375
Petykemano
veterán
válasz
 Petykemano
#5375
üzenetére
Petykemano
#5375
üzenetére
ITt egy érdekes kép ehhez:
[link]
Az intel processzorok arányával együtt nőtt a korábban csökkenőben levő GTX 1060 is.
Úgy tűnik, talán tényleg csak internetkávézók nyitottak újra. -
#5375
Petykemano
veterán
S_x96x_S
#5373
Petykemano
veterán
válasz
 S_x96x_S
#5373
üzenetére
S_x96x_S
#5373
üzenetére
Én nem vonnék le messzemenő következtetéseket.
Az ilyen hirtelen ugrások általában nem valamilyen cpu piaci mozgás következményei.
Lehet, hogy elindult egy új játék, ami KÍnában népszerű
Lehet, hogy újranyitottak az internet kávézók, amik eddig "a covid miatt" zárva tartottak.
Lehet, hogy a lezárt bányászat miatt a gépeken adtak túl, és azok valami olcsó intel procik voltak.
Lehet, hogy a lezárt bányászat miatt a gépekből új internetkávézók nyíltak.Egyébként egy 4 magos GF12-es zen3 még talán engem is érdekelne. Bár az valószínűleg valami forrasztott cucc lenne, nem AM4.
-
#5356
Petykemano
veterán
S_x96x_S
#5354
Petykemano
veterán
válasz
S_x96x_S
#5354
üzenetére
Az apple egy kuriózum
Az már inkább érdekes, hogy a hagyományos arm miképp engedheti meg magának, hogy eldobjon régi fícsöröket, és az x86 meg miért nem.Azt gondolom, ez abdisztribúciós csatornán múlik.
Az android fő csatornája a play store volt. Nagyon ritkán forgott kézen apk. Vagyis végfelhasználó ritkán szembesült azzal, hogy a régi verzója nem megy.
Ehhez képest x86-on elég gyakori lehetett a nyafogás.De azért szerintem már így is vannak régi dolgok, amik nem működnek. Dosos játékok. Azokhoz már egy ideje dosbox kell.
A Windows 11 nem kompatibilis már az első generációs ryzenekkel sem. Talán lassan itt is elindul az elengeDés.
Bár jim Keller azt mondta, kezdetben azért gondolták, hogy a risc jobb, mert a cisc prociknak kellett egy nagy rom és ha az ahhoz szükséges tranzistorokat inkább számításra használjuk... de ma meg már olyan pici az a rom, hogy szabadszemmel alig kivehető.
-
#5352
Petykemano
veterán
S_x96x_S
#5350
Petykemano
veterán
válasz
S_x96x_S
#5350
üzenetére
Bocs, nem tudtam befejezni...
Az amazon egyben a legesélyesebb és a legkevésbé esélyes is. Valahogy összerakták a gravitont. Biztosan készül már a graviton 3 is a V1 v N2 magokra építve.
Annál persze a zen2+50% biztosan jobb. Ha jól emlékszem, akkor már a A77 elérte a x86 magok IPC-jét, csak nem éri el az 5GHz-et. Szerverben viszont épp azért versenyképes, mert ott minden 3-3.5GHz-et megy.
Ehhez képest az M1 alacsonyabb frekvencián versenyképes az 5GHz-es x86 magokkal.
Ez a zen2+50% elég jól.hangzik ma. De 2023-ban?
Azért számoljunk.
Zen2-höz képest a zen3 +15%. Jövő évben kijön a zen4, ami remélhetőleg rátesz a zen3-ra 15-20%-ot. És ott van még a v-cache is, ami itt-ott szintén jelenthet 15%-ot.
Tehát a peak performance előrelépés éppenséggel x86 oldalról is meglehet.
Viszont a fogyasztás egy érdekes kérdés.
A gyári Arm magok esetén szerintem nem igazán tapasztalható az, hogy lényegsen jobb fogyasztással rendelkezne az arm. Az M1 viszont igen erős. Nyilván mert annyival alacsonyabb frekvencián hozza.
Nyilván a Nuvia is széles designnel oldja meg.Szóval az a kérdés, hogy a TSMC 5nm-e vajon milyen előrelépést hozhat, illetve hogy nem viszi-e el a töbv tranzisztor.
Abu valahol mintha említette volna, hogy legnagyobb jelentősége annak van, hogy full EUV.A verseny mindenképpen örömteli.
Közben az Intel sem tétlenkedik. Elsők között lesznek megrendelői a TSMC 3nm-nek. Az szerintem 2023.
Amúgy ha már itt tartunk, meglepne, ha a nuvia chipeket 2023-ban nem 3nm-en gyártanák. És akkor az már lehet, hogy meg is magyarázza a fogyasztást. Persze én arra számítok, hogy az x86 magok picit mindig többet fognak.fogyasztani, mint az arm magok. -
#5347
Petykemano
veterán
Petykemano
veterán
AMD Daytona vs Gigabyte
MilanEddig ez elerülte a figyelmemet. Az AT újratesztelte a Milan-t egy másik alaplapban (GB) és eltűnt a korábban tapasztalt magasabb Idle power
-
#5344
Petykemano
veterán
Petykemano
veterán
Backporting - erre vártunk.
Monet
4 magos pici apu.
Zen3 magokkal
GF 12LP+ gyártástechnológán készítve./pletyka/
-
#5342
Petykemano
veterán
Petykemano
veterán
MLiD videója szerint a 128 magos zen4 kódneve: Bergamo
[link]Hozzáteszem: a videóban többször hangsúlyozza, hogy ez nem 100%.
Csak azért jegyzetelem le, hogy legyen nyoma, ha kódnevekre keresnénk.Elég valószínű, hogy a 128 magos zen4 létezik.
Persze lehet az AMD részéről csupán egy backup plan, ha az egyik Arm gyártó (esetleg az intel) előállna valami ütős termékkel.
Ebből a szempontból az intel nem tűnik versenytársnak (mármint minden szempontból). Az AdoredTV által bemutatott Sapphire rapids infók alapján az 56 mag elég nagy lapkákból áll össze (~1500mm2) annak ellenére, hogy már 10nm-es. Viszont a fentebb említett speckó utasításokkal (AMX, AVX512, stb) bizonyos specializált részterületeken előremutató lehet és persze ugye az is igaz lehet továbbra is, amit Abu mondott, hogy az eladási volumen nagy része alacsonyabb magszámú termékekből áll.Szóval lehet, hogy csak backup plan az AMD részéről egy potenciális ARM versenytárssal szemben. De az is lehet, hogy végül lesz belőle termék.
Említésre került, hogy a 128 mag cloud szolgáltatóknak menne.
Az nem teljesen világos, hogy csak a magok száma miatt miért kéne külön platformot csinálni? Tehát valami trükközés a magszámon kívül kell legyen még. Még annak se feltétlenül kellene különálló platformot jelentenie, ha - a GCP-ben elhelyezett Milanhoz hasonlóan - le van tiltva az SMT.
Például:
- más az IOD, több memóriacsatornát tud kezelni.
- Esetleg tartalmaz valamilyen olyan módosítást, ami SMT nélkül mégiscsak magasabb egyszálas teljesítményt ad.
- v-cache
- LSI (~EMIB) használata (Nyilván minél több a mag, annál több a inter-chiplet kommunikáció is, amiben éppenséggel gyengélkedik már a Milan is)
- HBM2 (hát talán ez a legkevésbé valószínű)Lehetne olyan prózai is az ok, hogy a 96 mag elfér ugyanakkora helyen, mint az eddigi kialakítások, de a 128 mag már nem.
Mindenesetre az sajnálatos kicsit, hogy az Executablefix által renderelt képek alapján nem látszik változás arra vonatkozóan, hogy miként huzalozzák össze a chipleteket (LSI) Ami arra utal, hogy az egzotikus AM5 kupak alatt sincs semmi érdekes.
-
#5333
Petykemano
veterán
Petykemano
veterán
16GB DDR5
Elég szellős.
Tudom, persze az elején mindig nagyon drága, de erre nagyon hamar fel fog szerintem kerülni egy másik 4-es pakk és ha két modult veszel, akkor az már 64GB.
A kép alapján úgy tűnik, rá fog férni - még mindig egy oldalra - annak kétszerese is a felső sorban. 2 modullal az már 128GBVan egy olyan érzésem, hogy a memória kapacitás jelentősen meg fog nőni a következő néhány évben.
2-3 év múlva lehet, hogy már 64GB-os gépeket fogunk venni (vagy csak nézni) -
#5328
Petykemano
veterán
S_x96x_S
#5326
Petykemano
veterán
-
#5323
Petykemano
veterán
Petykemano
veterán
-
#5316
Petykemano
veterán
Petykemano
veterán
AMD Ryzen Embedded - V3000
Zen 3 (6 nm) - FP7r2
- up to 8 Cores / 16 Threads
- 20x PCIe 4.0 lanes (8x dGPU)
- 4x DDR5-4800 (ECC)
- two 10G ethernet PHYs
- 2x USB 4.0
- 15-30 W and 35-54 W models
- up to 12 CUs (RDNA2)(~Rembrandt)
[link] -
#5315
Petykemano
veterán
paprobert
#5314
Petykemano
veterán
válasz
 paprobert
#5314
üzenetére
paprobert
#5314
üzenetére
"Csak arra utalok, hogy az AMD akkor fogja használni a TSMC polcról levehető, pénzbe kerülő technológiáját, ha kikerülhetetlen falba ütközik a további skálázásban a saját rendelkezésre álló eszközeivel."
Értem és ezzel egyet is értek. Én magam is felvetettem azt a kérdést, hogy tök jó, hogy nagyon magas sávszélesség állna rendelkezésre a CCD és az IOD között és az L4$ is papíron jól hangzik, de vajon ténylegesen mennyit profitálna belőle a cpu?Szerintem egyébként az energiafogyasztás terén szorít a cipő.
Egyrészt a 2pJ/bit sok, ehhez képest kísérleti jelleggel votl már 0.56pJ/W is TSMC+ARm alapon
Másrészt a milan Epyc Idle fogyasztása 100-110W. [link]De ha ezt megoldja csak az IOD alacsonyabb csíkszélessége és/vagy a nagyobb L3$, az is jó lehet.
-
#5313
Petykemano
veterán
paprobert
#5311
Petykemano
veterán
válasz
paprobert
#5311
üzenetére
"Az IF törvényszerűen követi az egységnyi idő alatt egy vezetéken átküldhető adatmennyiség rekordját, tisztes távolságból. Ha ebben fejlődés van, minden interconnect képes gyorsulni."
Nem teljesen értem ezt a megjegyzést. De ez nem biztos, hogy Te hibád, lehet, hogy én vagyok alul- vagy félretájékozott. Távol van tőlem, hogy magamat ezeknek a technológiáknak a beható ismerőjének tüntessem fel, épp csak morzsákat csipegetek.Tudomásom szerint az Infinity Fabric egy linkje egy 32bit széles busz viszonylag magas frekvencián. Tehát persze, ahogy ezt a frekvenciát tudják növelni, úgy nőhet a sávszélesség is és persze a magas frekvencia biztosan segít a viszonylag nagy távolságban levő chipek közötti késleltetés letornászásában.
Ez a megoldás költséghatékony, mivel nincs gigantikus interposer.
Viszont - tudomásom szerint a magas frekvencia miatt - az adattovábbítás költsége (áramfelvétel és hő) magas (2pJ/bit)Felfogásom szerint a régi jó interposer azt tette lehetővé, hogy
- vékony busz helyett széles buszt lehessen használni, ami adja a sávszélességet
- magas helyett alacsony frekvencián lehessen használni, ami jelentősen csökkenti az energiaigényt
- a chipek egymáshoz közel való ültetése pedig javít a késleltetésenUgyanezt teszi lehetővé az EMIB és az LSI is, úgy, hogy nem teszi szükségessé a 1000mm2-es interposer használatát egy EPYC esetén.
"Szerintem az AMD meg akarja úszni hogy TSMC-only technológiára építse fel az egész portfólióját, annak ellenére hogy egyébként szimbiózisban vannak jelenleg. A 3D cache egy viszonylag kockázatmentes projekt ehhez képest. Az új foglalattal lesz új tracing topológia is, azaz ha nagyobb sávszélességgel terveznek, a lehetőség meglesz a kiépítésére házon belül is."
Nem tudom, ezt ma még meg lehet úszni?
A célt érteni vélem, hogy ne legyen teljes függőség. De ezzel arra utalsz, hogy az AMD nem fogja használni a TSMC packaging technológiát, hanem sajátot fejleszt? -
#5310
Petykemano
veterán
Petykemano
veterán
érdekes olvasmány arról, hogy miért döntött az AMD interposer helyett az IFOP megoldás mellett
Talán azt is magyarázza kicsit, hogy miért nincs L4$ és az AMD miért inkább az L3$-t növelgeti. az IFOP késleltetése viszonylag magas és linkenként csak 55GB/s a sávszélessége. Azt gyanítom, hogy nagyon kevés hatása lett volna, ha erre az alapra építenek rá egy az IOD-ban található L4$-t. Nem lett volna elég alacsony a késleltetés és a sávszélesség is szűk lett volna.
Olvastam a hétvégén egy cikket az EMIB-ről is. Az tulajdonképpen egy embedded interposer, ami a chipek széleit köti össze, ellentétben a hagyományos interposerrel, amire az összes lapkát rá kell ültetni - és emiatt az EPYC-nél túlságosan nagy interposert kellett volna alkalmazni.
Én azt gondolom, hogy 1000mm2-es interposert ezután se fognak használni.
Szerintem a következő lépcső a TSMC LSI nevezetű technológiájáa, ami megfelel az intel EMIB-nek.Az IFOP megoldás késleltetése és energiafogyasztása magas. A megnövelt méretű L3$ célja éppenséggel lehet az, hogy minél kevesebb adatot kell mozgatni az IFOP-on (CCD<->IOD<->DDR) keresztül.
Az LSI használata csökkentené a késleltetést és lehetővé tenné a CCD és az IOD közötti szélessávú kapcsolatot. Nem tudom mennyit, de olyasfélét, mint amit egy HBM igényel. (Természetesen az LSI használata lehetővé tenné azt is, hogy a CCD-k egyenként HBM-et kapjanak)
Azt viszont nem tudom, hogy ilyen szélessávú hidak használata - azon kívül, hogy lehetővé tenne egy L4$ kialakítását az IOD táján - vajon mire adna lehetőséget, vajon mit lehetne kezdeni vele?
Az AVX-ről (AVX512-ről) mondják, hogy nagyon cache és memóriaintenzív. Ami nem meglepő, hiszen sok adaton elvégzett vektorművelet. Ez valószínűleg egy dimenzióval fokozódik, ha mátrixműveletekről is beszélünk.
Lehetséges volna, hogy a zen4-be kerüli AVX512 támogatás magával hozza a IFOP cseréjét LSI-re?
-
#5307
Petykemano
veterán
S_x96x_S
#5306
Petykemano
veterán
válasz
S_x96x_S
#5306
üzenetére
Figyelemre méltó ugrás a notebookok terén - még ha ez csupán benchmarkokat jelent is, akkor is arra utal, hogy több az AMD noti, többet tesztelnek, talán több van a polcokon is és többen veszik meg kipróbálni, hogy milyen. A benchmarkból persze mindenképp csak az enthusiast réteg látszik.
-
#5302
Petykemano
veterán
S_x96x_S
#5297
Petykemano
veterán
válasz
S_x96x_S
#5297
üzenetére
Kétféle véleményt láttam megjelenni:
1) "Báháháhá, az SMT letiltásával nyert egyszálas teljesítmény x86 utolsó halálhörgés kísérte próbálkozása, mielőtt az Arm végleg letaszítaná a trónról egyszálas teljesítményben különösen ha figyelembe vesszük a perf/W mutatót is."
2) Az elmúlt években a legnagyobb igyekezet ellenére is több SMT-vel kapcsolatba hozható sebezhetőség felbukkant. A szálak között megoszott erőforrások, cache-ek, bufferek, stb olyan sebezhetőséget rejtenek - most vagy akár a jövőben -, hogy bölcsebb és biztonságosabb már élből tiltani virtualizált környezetben, ahol nem biztosítható, hogy ugyanaz a mag biztosan ne kerülhessen kiosztásra két különböző szervezet vagy projekt számáraÉrdekes egyébként a megoldás.
a GCP-ben vCPU-t bérelsz, ami gyakorlatilag ez hardveres szálat jelent.
Állítólag az Amazonnál hardveres magot bérelsz, az SMT-t ingyen adják. -
#5301
Petykemano
veterán
S_x96x_S
#5299
Petykemano
veterán
válasz
S_x96x_S
#5299
üzenetére
aZ x86 dekóder limitációról:
"For a while we thought variable-length instructions were really hard to decode. But we keep figuring out how to do that. You basically predict where all the instructions are in tables, and once you have good predictors, you can predict that stuff well enough. So fixed-length instructions seem really nice when you're building little baby computers, but if you're building a really big computer, to predict or to figure out where all the instructions are, it isn't dominating the die. So it doesn't matter that much."
-
#5295
Petykemano
veterán
Petykemano
#5288
Petykemano
veterán
válasz
Petykemano
#5288
üzenetére
big.LITTLE híradó
Hát tiszta hülyék vagyunk! Csodáljuk itt az ARM SVE2-t, hogy hűűű, meg háá, milyen jó, hogy az utasításhossza független a hardver feldolgozó-hosszától.
De hát ez eddig is létezett az x86-ban is.Emlékszünk?
"A Jaguar ennek támogatását egy 128 bites FADD és egy szintén 128 bites FMUL egység segítségével oldja meg, vagyis a 256 bites AVX utasításokat két 128 bites részre osztva hajtja végre a rendszer, tehát gyorsnak nem nevezhető, de egy alacsony fogyasztású processzormag esetében ez is jóval több a vártnál. Természetesen a 128-128 bites FADD és FMUL egység a 128 bites SSE utasításokra pozitív hatással lesz, hiszen azokat a Bobcattel ellentétben a Jaguar már nem osztja két részre."
[link]
Tehát a Jaguar képes volt 256bites AVX utasítások végrehajtására, csak 2 órajelciklusra volt hozzá szüksége.
Aztán nem is olyan rég:"The key highlight improvement for floating point performance is full AVX2 support. AMD has increased the execution unit width from 128-bit to 256-bit, allowing for single-cycle AVX2 calculations, rather than cracking the calculation into two instructions and two cycles. This is enhanced by giving 256-bit loads and stores, so the FMA units can be continuously fed."
[link]
Tehát a Zen is 4db 128 bites FP feldolgozóval rendelkezett, amiket össze tudott vonni 1db 256 bites AVX2 utasítás egy ciklusban történő végrehajtására. Akkoriban még volt is szó arról, hogy ennek annyi előnye van az akkor már 256bit hosszú FPU-val rendelkező skylake-kel szemben, hogy akár két különböző 128bites utasítást is végre tud hajtani 1 órajelciklus alatt.Tehát valójában biztos megvalósítható lenne az, hogy
a) 4db 256bites fpu feldolgozó helyett 8 db 128 bites legyen és ezeket vonja össze. a zen1 => zen2 váltás esetén azonban 4db 128bites feldolgozó helyett 8db 128bites feldolgozó használata biztosan bonyolultabb és nehezebb lett volna, mint 4db 256 bites feldolgozó arról nem is beszélve, hogy nem is biztos, hogy ki lehetett volna használni. De ez most mindegy is
b) Az AMD valószínűleg most is képes lenne 4db 256bites feldolgozót összevonva egy órajelciklus alatt végrehajtani 512bites AVX-512 utasításokat.
Vagy akár arra is képes lehetne, hogy összevonás nélkül, 2 órajelciklus alatt hajtsa végre.
(Más kérdés, hogy ennek van-e értelme)Mindenesetre az látszik, hogy akár x86 alapon is megvalósítható lenne az, hogy a kismag csak 2db 128bites FPU-t kap és ennek ellenére feature-kompatibilis marad AVX512 tekintetében az akár 4db 512bit hosszú FPU-val rendelkező nagy maggal. Csak ugyanazt az utasítást lényegesen lassabban képes végrehajtani.
"The current rumored specs for Big.Little appear more or less like this in my opinion:
Small Zen4 cores with 128-bit SIMD and big Zen5 cores with 512-bit SIMD.
Zen4 4-track on 3nm => lower leakage, same frequency capability (smaller FPU requires less current)
Zen5 5-track on 3nm => higher leakage, higher current capability (to feed larger FPU), thus higher frequency support at low/mid SIMD capability.8 Zen5 cores(Big core CCX), 4 Zen4 cores(Small core CCX) => similar strategy as Apple."
[link] -
#5294
Petykemano
veterán
S_x96x_S
#5291
-
#5290
Petykemano
veterán
Petykemano
veterán
AM5 @ 2022Q2
Hát ez elég érdekes lenne.
(Nem is sorolom a kérdéseket és lehetőségeket.) -
#5289
Petykemano
veterán
Petykemano
veterán
Erről nem is volt szó
Arm A510 - Merged Core Architecture: The Complex
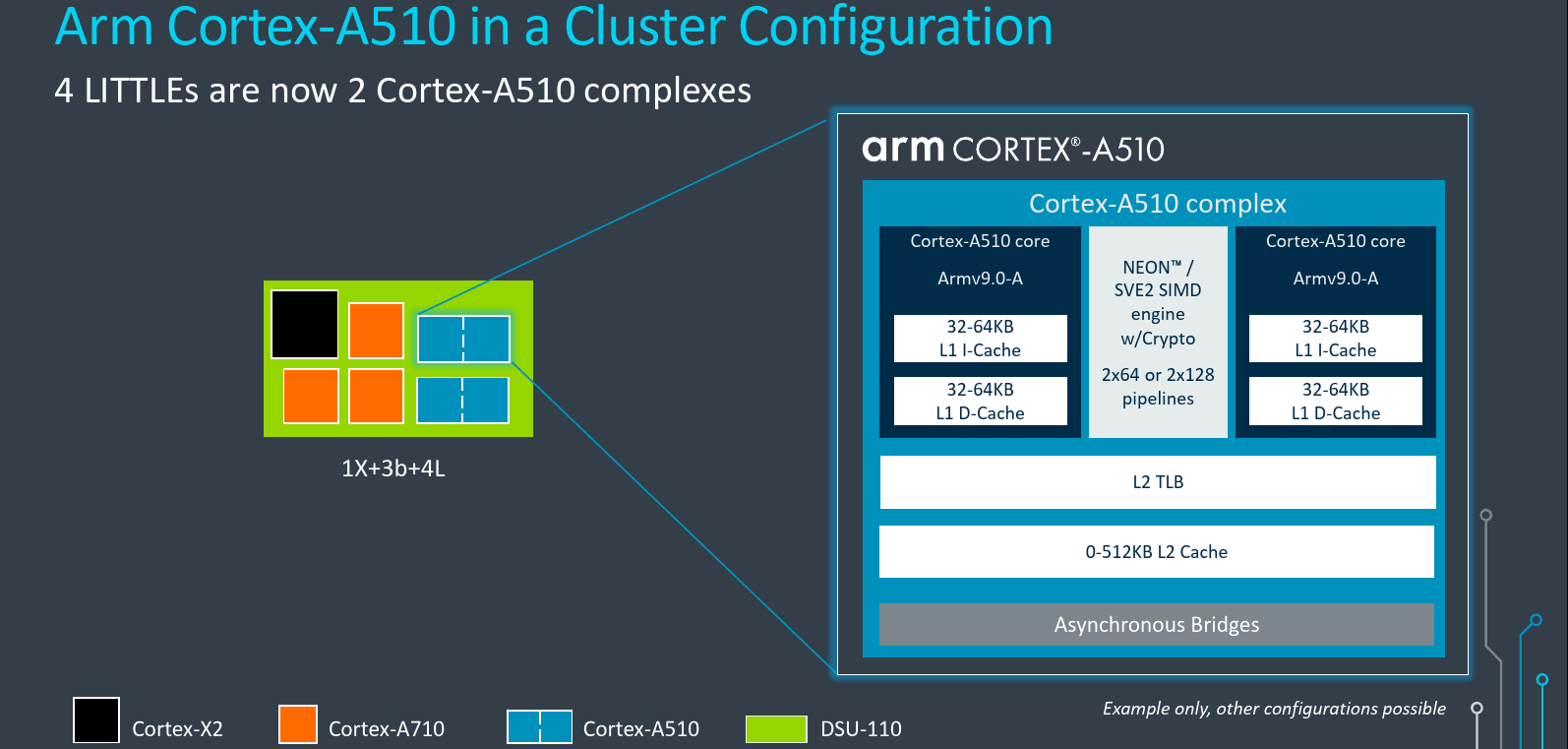
Soha nem gondoltam volna, hogy a bulldozer-féle megközelítés (CMT) még vissza fog köszönni valaha.
Persze ez sem teljesen olyan, mert nem osztoznak a frontenden. A bulldozer olyan, mintha egy 2 szálat kezelni képes SMT-s zen mag az integer erőforrásokat mindenképpen statikusan partícionálva érte volna csak el.
Itt viszont csak az SIMD egységeken osztoznak.Mindenesetre azért érdekes.
-
#5288
Petykemano
veterán
Petykemano
veterán
(Ha jól értem)
Az AMD olyan szabadalmakat jelentetett meg, amely a kis és nagy magok közötti váltást Hardveresen, az OS vagy az App tudta nélkül valósítja meg.
[link]"TL;DR;
With these patents AMD is solving two things, which is a very ingenious approach
1. big.LITTLE architecture that is virtually indistinguishable to the OS scheduler with thread migration done in HW (in contrast to ARM approach)
Using perf monitor to migrate CPU registers, thread state and execution to big core in HW itself without OS knowledge https://www.freepatentsonline.com/y2021/0173715.html Issue here is that only the big or small core is available at any time not both, but not really an issue on desktop if you already have 16 cores to begin with 2. Big and small cores have different levels of ISA support (i.e the small cores cannot support AVX for example and the big cores can). ( in contrast to Intel ADL approach )
Using illegal opcode exception in small core to seamlessly migrate the thread state and execution to big core without OS knowledge https://www.freepatentsonline.com/10698472.html "Nekem egy kicsit fura. Olyan, mintha az AMD több big.LITTLE projektet is futtatna egyszerre.
Legutóbbi ábrán inkább úgy tűnt, mintha lenne big cluster + LITTLE cluster és a fabrichoz kapcsolódnak.Ez a megfogalmazás, hogy a programszál költöztetése úgy történik meg, hogy valójában a kis és nagy mag nem elérhető egyszerre, ez sokkal inkább arra emlékeztet, ami ezt megelőzően "low-feature / high feature core" címszóval jelent meg. De egyébként ez utóbbi tulajdonképpen miben különbözik attól, mintha mondjuk egy mag áramtalanítaná az AVX512 vagy egyéb részeit (regisztereket, cache-t, ALU-kat stb), amit épp nem használ?
Egy ilyen megközelítés a fogyasztáson valószínűleg segít, de a tranzisztorigénye a "kis mag" működésnek nem kisebb.van ellenérv is:
"This sounds terrible from the OS kernel point of view. The physical CPU suddenly getting faster or slower without OS intervention is exactly what you don't want to do. This already happens with hardware-controlled turbo, but this will make this even more complicated (previously you could figure out performance by comparing clock speed, now you have no idea how the little core stacks against the big core)."
"It seems like you are possibly massively over-estimating the amount of floating point used in a JavaScript execution thread vs. the amount of all integer used in actually displaying the GUI. The amount of work to display the GUI is often huge compared to what is actually running in the GUI. Also, I don’t know if anyone is talking about having a core with absolutely no FP resources. If you have a separate small core with a scalar FP unit or even just a small narrow 128-bit unit, that could be used to handle any floating point instructions. Technically they could emulate any vector instructions with a scalar unit; it would just be slow. You could actually emulate floating point units with integer units, but that would be excruciatingly slow.
[...]
Perhaps we are going excavator style with multiple small cores sharing the vector execution resources. It could have a small scalar FPU that handles everything except actual vectorized instructions such that the big vector units stay powered down. Intel has certainly had power issues with processors supporting AVX512, so it would make sense to handle very light loads with a small unit, even if it takes multiple clocks, instead of taking the time to wake up the big unit."
Ez is érdekes ehhez. De ebből nekem nem igazán jön ki a "zen 5 + Zen4D" -
#5285
Petykemano
veterán
carl18
#5283
Petykemano
veterán
Egyetértek a számításaiddal. Nekem is kábé ez a várakozásom.
Viszont ez az épphogy 9000 score azt jelenti, hogy talán elérik a 3950X-et és az 5900X-et, de az 5950X-nek nincs mitől tartania - ahogy HSM fogalmazott.
Ezért mondtam, hogy valójában keveslem a kis magok számát. Az alder-lake-ből pont az a 8 mag fog hiányozni, amit a raptor lake hoz, hogy megfoghassa MT-ben a max 16 magos zen3-akat. De az alder lake fókusza valószínűleg inkább mobil volt.
Az Alder Lake-kel kb együtt az AMD-től is várunk egy termékrajtot. A worst case scenario az, hogy lesz pár V-cache-sel ellátott sku és nem is tudjuk, hogy hogy reagál a megnövekedett L3$-re.
A best case scenario pedig az, hogy 6nm-es gyártástechnológián készül valami, ami így pár száz mhz-cel magasabb frekvenciát kap és az FCLK is hasonlóképp növekszik, esetleg az IOD is megújul és még v-cache-t is kap (a top SKU) Tehát nincs kizárva, hogy az AMD már 12000 táján landoljon.Aztán jön a raptor lake, ami zárja ezt a különbséget, viszont addigra az AMD már megteheti, hogy 24 magos designokat dobjon piacra.
-
#5281
Petykemano
veterán
carl18
#5280
Petykemano
veterán
A kis magok előnye az, hogy
- 4 atom mag kb ugyanakkora helyet foglal, mint 1 Cove mag.
- Eközben ez a 4 atom mag kb kétszer akkora teljesítményt ad le multithread felhasználás esetén, mint 1 Cove mag
- miközben nemom kb feleannyit fogyaszt.Az alder lake szerintem egyértelműen mobil fókusszal érkezik. A 8 kis mag inkább értelmezhető Low-Power célokra, semminthogy érdemi segítséget nyújtson a nagy magok mellett a MT teljesítmény növelésében. Éppen ezért nagy valószínűséggel a kis magokat nem nagyon fogják használni desktop környezetben. Mobilon meg ne számoljál AVX512-t.
Ettől függetlenül biztos lesz átfedés, de nem fog nagy hangsúlyt kapni az, hogy az energiahatékony magok mennyivel megdobják desktop környezetben a MT teljesítményt.A Raptor lake esetén már inkább beszélhetünk ilyen célról. A 16 magot épp ezért én még keveslem. 32 mag esetén elmondhatánk: ugyanannyi helyet foglal, mint másik Cove mag foglalna, de MT teljesítmény szempontjából 16 Cove magot helyettesít, miközben 8 Cove magánál is kevesebbet fogyaszt.
Ezzel mondjuk már fel tudnák venni a versenyt egy akár 24 magos Ryzennel is (most az IPC különbségektől tekintsünk el), amely esetén a 8 fölötti magok szintén csak a MT teljesítményhez adnak hozzá. -
#5277
Petykemano
veterán
S_x96x_S
#5276
Petykemano
veterán
válasz
S_x96x_S
#5276
üzenetére
> szerintem a 3rd gen IA már a PCIe5.0 -re épül
> ( ~4.5 bandwith növekedés erre utal ; 0.5 -öt a latency csökkenésnek tudom be .. )
> Viszont valami ok miatt az AMD - nem PCIe5.0 -nak hivja.
> lásd az oszlopok elnevezését.
> Gen3->Gen4-> 3rdGen Infinity Architekture
Abu Trento és egyéb AMD titkos kódnevek kapcsán valami olyasmit mondott, hogy lesz olyan változat, amiben az AMD azt mondja, hogy toll a fületekbe, ebben nem lesz PCIe csatoló, hanem mindent Infinity Fabric köt össze.Szerintem az Infinity Architecture ezt az elképzelést használja.
Ez persze nem jelenti azt, hogy ne lenne PCIe5 is az asztalon. De én azt valószínűsítem, hogy a Frontier szuperszámítógépben nem lesz.Azt nem tudom megmondani, hogy a "3rd gen IF" milyen viszonyban van a PCIe5-höz és a CXL-hez képest. Mármint azon kívül, hogy értelemszerűen nem kompatibilis. De hogy milyen előnyt jelenthet PCIE5/CXL-hez képest, az előttem nem ismeretes. Azt sem tudom, hogy az IF működik fizikai PCIE4 csatlakozáson keresztül. Talán ennek első szárnybontogatása volna a "Smart Access Memory"?
-
#5275
Petykemano
veterán
Petykemano
#5123
Petykemano
veterán
válasz
Petykemano
#5123
üzenetére
Egy pár hete AdoredTV bedobta, hogy lesz 128 magos zen4/Genoa
Felrobbant az internet, fel is került AdoredTV leak listájába élből "false" státuszban
most:
"Wow, ZEN4 is really more than 96 cores.I was skeptical when I first saw this news in Chiphell. Now I can also confirm that ZEN4 is up to 128 cores."
[link]Mások szerint lehet, hogy létezik 128 magos zen4, de az továbbra sem Genoa.
-
#5271
Petykemano
veterán
Petykemano
veterán
-
#5269
Petykemano
veterán
S_x96x_S
#5268
Petykemano
veterán
válasz
S_x96x_S
#5268
üzenetére
Én is olvastam olyan véleményt, hogy 256MB V-cache mellett (ez egyébként akár 3-4TB/s sávszélesség is lehet) nem.biztos, hogy szükséges/érdemes még a HBM is, pláne úgy, hogy közben épp érkezik a DDR5 is.
Nem hülyéség, csak megúszható.
Nem tudom, hogy egyébként költség terén ez mekkora tétel lenne. Korábbról úgy tudjuk, hogy az interposer illetve az arra való chip ültetgetés drága mulatság.
Az AMDnek brutális nagy interposerre lenne szüksége jelenleg.Én ezt csak az Intel féle tile megoldásban látom megvalósíthatónak. De tegyük össze, amit az AMD RDNA3-ról tudunk és a raphaelről.sejtünk:
Szerintem ez úgy tudna megvalósulni, hogy az AMD készít egy olyan lego elemet, ami egy interposerre tett 1-2-3 chiplet + IOD + HBM3. (Ezt akár külön is lehet árulni a desktop piacon. hBM-mel és anélkül, vagy' akár úgy is, hogy a chipletek valamelyike RDNA)
És ilyen legoelemeket rak egymás mellé két sorba úgy, felfűzi őket egy hosszanti irányban elhelyezett Infinity Cache chipletre (ahogy azt az RDNa3 esetén spekulálták)Ez az újrahasznosíthatóság szempontjából jól.hangzik, de amúgy elég fura, hogy egy HBM valójában közelebb van, mint a kapcsolódásért felelős Infinity cache.
Végülis ha a IOD zsugorodik 6nm-re, akkor eljéozelhető, hogy nem szükséges olyan hatalmas interposer, ha csak a HBM kerül rá, a chipletek nem.
Mindenesetre az intelnek azért ebben van előnye. Ha rápakolnak HBM-et a processzorra, akkor már nyugodtan mondhatják, hogy a DDR slotokba mehet csak optane. Az AMD-től eddig nem láttunk eltérő memóriarendszerek menedzselésére vonatkozó működést.
-
#5264
Petykemano
veterán
awexco
#5261
Petykemano
veterán
Itt volt, hogy az "AMD lelassult" [link]
De ez nyilván csak egy percepció.A zen4 megjelenése szerintem az 5nm elérhetőségének függvénye.
/// Figyelem, wishful thinking következik ///
//////////////////////////////////////////////////////////////A magam részéről elégedett lennék az AMD által végrehajtott ütemmel, ha 2021Q4-2020Q1-ben ha az alsóbb szegmensben kapható termékek árai visszamennének. Tehát mondjuk a 6 magos nem $299 lenne, hanem visszamenne $249-re. (Ez mondjuk már majdnem teljesül az 5600G-vel) és ha a nem emelkedő árszínvonal mellett minden szegmenst ellátnák v-cache-sel. Tehát a 6 magos is kapna csak legfeljebb kevesebbet.
(Én erre azért látnék némi esélyt, mert valószínűleg az Alder Lake is minden szegmensben meg fog jelenni) -
#5253
Petykemano
veterán
Petykemano
veterán
Egy pár hete jelent meg Executablefix rendere a Raphael nevű processzorról.
Akkor az első ami feltűnt nekem az az volt, hogy kicsit mintha magas lenne, magasabb, mint szokott. Ezt talán kevesen említették. Sokkal nagyobb figyelem övezte a kupak megszokottól eltérő formáját, a "lábait" és a "lábak" között elhelyezkedő kondenzátorokat
Összehasonlításképp itt egy kép egy kupaktalanított chipletes ryzenről:

Akkor nem értettem, hogy ennek mi lehet a jelentősége annak, hogy a lábak között kondenzátorok vannak, vagy hogy látszanak. Nem néztem össze.milyen magyarázatai lehetnek?
- Megmondom őszintén nem értek hozzá, de azért nem zárom ki. Volt szó arról, hogy AM5-be kerülő Raphael 120W, de lehet akár 170W-os megoldás is. Tehát nem zárható ki, hogy ilyen áramfelvételhez szimplán több kondenzátorra van szükség.
-Nem emlékszem, hogy találkoztam volna olyan infóval, hogy az AM5 fizikai kiterjedése hogyan viszonyul az AM4-hez. Arról viszont volt hír, hogy a chipgyártásban nem csak chiphiány van, hanem substrate hiány is. (Ha jól tudom a subsrate az a zöld felületű sárga lapka, amin a chipek elhelyezkednek és aminek érintkezők vannak az alján) Tehát az sem kizárt, hogy az AMD szimplán csak egy az AM4-nél kisebb AM5-öt ad ki, hogy takarékoskodjon a substrate összetevővel, ne az legyen a szűk keresztmetszet.
Elnézést, közben előkerült: [link]
Ez alapján az AM5 fizikailag ugyanakkora, mint az AM4 40x40-es.
- Felmerült egy olyan gondolat is, hogy azért volt szükség egy picit a szélhez közelebb elhelyezni a kondenzátorokat, mert a kupak alatt kellett a hely egy nagyobb interposernek
[link]Érdekes elképzelés. Az biztos, hogy az IF relatív sokat fogyaszt és lehetne harapni - főleg a szerver termékek esetén - a fogyasztáson, ha egy energiahatékonyabb módját használnák az adatkommunikációnak.
Persze nyilván ezt az AMD eddig költség okokból nem tette meg eddig. -
#5252
Petykemano
veterán
Petykemano
#5249
Petykemano
veterán
válasz
Petykemano
#5249
üzenetére
[link] a videó az Intel alder lake és raptor lake termékeiről szól, de említésre kerül az amd is, hogy milyen lehetőségei vannak.
Szokás azt mondani, "Intel is coming Back, but AMD isn't slowing down either"
De nekem most mégis egy lassulás érzésem van az amdvel kapcsolatban. Persze lehet, hogy megcsalnak az érzékeim. Hisz a zen után se 15 hónappal jött a zen2. Talán épphogy a viszonylag gyors zen2->zen3 váltás volt egyedi.
Na mindenesetre oda akarok kilyukadni, hogy a 2022 végén érkező zen4 szerintem egy nyitott ablak az intelnek, hogy felzárkózzon. -
#5249
Petykemano
veterán
S_x96x_S
#5246
Petykemano
veterán
válasz
S_x96x_S
#5246
üzenetére
Szerintem Arne Verheyde ugyanaz az személy, mint Twitteren witeken, aki eléggé elfogult az intel irányában.
Nem állítom, hogy nincs igazság a felsorolt pontokban.
-
#5247
Petykemano
veterán
S_x96x_S
#5243
Petykemano
veterán
válasz
S_x96x_S
#5243
üzenetére
A hősűrűség (thermal density) eddig is fokozódó problémát jelentett.
A hősűrűség azért jelent problémát, mert magas hőmérsékleten ugyannak a frekvenciának a tartásához magasabb feszültségre van szükség, ami növeli a hőtermelést.
Nem állítom, hogy a 14nm-es zen1 frekvencia skálázódása emiatt állt meg, de amikor a 12nm-re váltottak, akkor a hírekben arra hivatkoztak a fizikai kiterjedés megtartásával kapcsolatban, hogy így több a "hely" a hőt termelő tranzisztorok között és könnyebben hűl
Valamint a zen2 esetén is szó volt róla, hogy nagyon szép és szuper, hogy milyen sűrű a 7nm-es gyártástechnológia, de az intel abból a szempontból könnyebb helyzetben van, hogy a lapkái 2x akkora kiterjedésűek, és ennélfogva engedheti meg magának a ~2x akkora fogyasztást. másként megfogalmazva: a hősűrűség miatt az AMD ha akarná se tudná növelni a fogyasztást.Szerintem a 3D technológia terjedésével ez a probléma fokozódni fog. A rétegződéssel - gondolom valamelyest növekedni fog a lapkák magassága (Az ExecutableFix által megosztott/renderelt Raphael kupak például kifejezetten magasnak tűnik) A legalsó réteg biztosan távolabb kerül a hőelvezetést szolgáló hűtött felső felülettől. Tehát szerintem egyre kevésbé lesz megengedhető, hogy neked valahol a szilícium téglatestedben - főleg alul - legyen valami nagy hőkoncentrációt okozó részegységed.
Vannak elképzelések a 3D stacked chipek Z irányú hűtésére, de azért annál szerintem lényegesen egyszerűbb, ha a hőtermelést a frekvencia csökkentésével oldják meg. a chipek ma már tele vannak hőérzékelőkkel, tehát nem gondolom, hogy bármikor is alattomosan ki tudna alakulni valami hőtermelő központ, ami leégeti a chipet.
A másik fontos szempont ami megjelenik, hogy ha valahol nagy hő képződik, akkor oda a szükséges kakaót is el kell juttatni.Számomra minden szempontból előnyösebbnek tűnik az alacsonyabb feszültség és a frekvencia és a 3D stacking által kínált cache és feldolgozó szélesítési lehetőség.
Az Apple a példa rá, hogy ebben a vonatkozásban jelenleg az Arm tűnik előnyösebb pozícióban levőnek. És arról pedig volt már szó, hogy az x86 esetén az instruction decoder szélessége tűnik jelentős korlátozó tényezőnek a feldolgozók szélesítése kapcsán.
-
#5242
Petykemano
veterán
Petykemano
veterán
Érdekes olvasmány:
[link]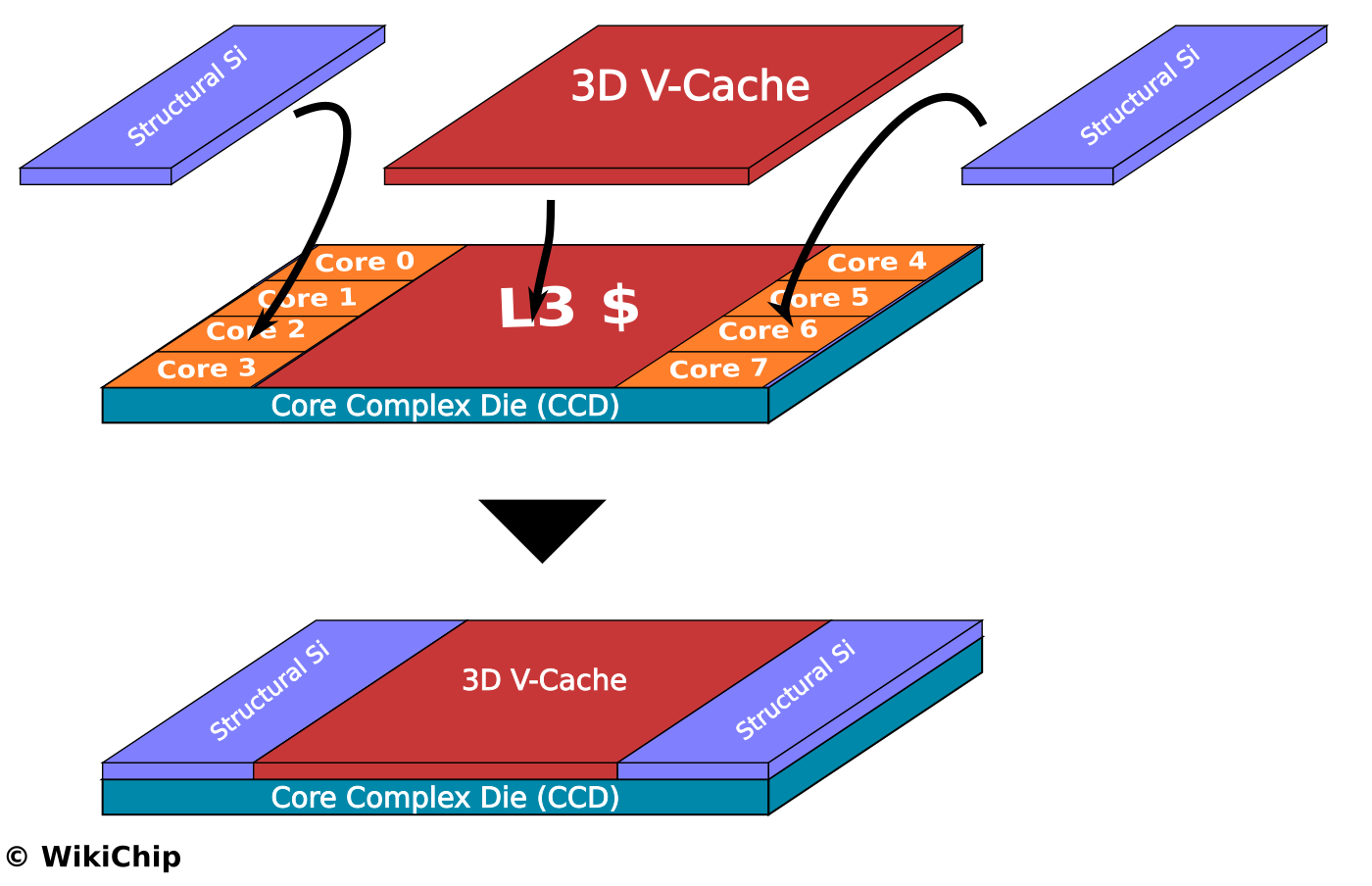
Azon gondolkodtam el, hogy vajon fogják-e lehetne-e valahogy a Structural Si elemeket hasznosítani."Schor speculates that the dummy dies may include thick copper traces to aid heat transfer. However, why not put all that copper to use? I see an opportunity to put fat vector engines in these dies. Instead of squeezing 512-bit wide SIMD units and data paths into the core below to support AVX-512, instead put (perhaps even wider) vector units in the dies above."
[link]
Az első reakció nyilván az: Hát az lehetetlen (és egyébként szentségtörés is volna), hiszen a hő a CCD-ben a logikai részeken keletkezik, amit a Structural Si fed, aminek épp az a célja, ahogy elvezesse az alul képződött hőt, nem pedig, hogy maga is hőt termeljen.De ezen az első felhorgadáson lépjünk túl.
Tényleg mi lenne, ha skálázható lenne egy chiplet. És ebben a skálázhatóságban a L3$ csak az első lépés. A structural Si minden rétege tartalmazhatna L2$-t, vagy akár L1$-t. Vagy ha már AVX, akkor lehetne úgy is, hogy minden egyes réteg tartalmaz egy AVX512 feldolgozót. Ha 4 magas a felépítmény, akkor 4xAVX512 pipeline van, ha nincs felépítmény, akkor meg egy se.
a processzor lelke persze továbbra is a CCD-ben maradna, csak az egyes részegységek elhelyezése/kiterjesztése/skálázása 3D irányban történne, ráadásul opcionálisan. -
#5236
Petykemano
veterán
awexco
#5234
Petykemano
veterán
V-cache alsó házba túl drága
Ez is egy érdekes kérdés egyébként, hogy valójában kit mit gondol alsó háznak?
Nyilvánvalóan nincs egyértelmű meghatározá. Amit látunk az régóta az, hogy az alsó-felső ház
- elsősorban feldolgozószámot jelent. Ez akár 50-100-150%-os különbség is lehet.
- kisebb részben tierenként pár százalékot jelentő eltérő maximális frekvenciát
- és az Intel sokáig láttunk kihagyott/letiltott utasításkészletetA mobil procik egyre inkább fejlődnek. Beérik, vagy beérték a desktop számítógépeket.
Legalábbis abban az értelemben, amire az átlag felhasználó használni akarja. VAnnak, akik arra készülnek, hogy kidobják a(z akármilyen kis) dobozos számítógép gondolatát és csak leteszik a telefont a monitor és a billentyűzet mellé és úgy használják. Persze AAA játékra nyilván nem megfelelő, de számlát befizetni, internetezni, excel táblázgatni kicsi helyett nagy kijelzőn és kicsi billentyűzet helyett emberi klaviatúrán elegendő.Van egy megfigyelés, amely szerint
- a mobil az új desktop
- a desktop az új workstationAz Apple-t hagyjuk, mert bár az M1 kimagasló teljesítényt nyújt, de a 300+eFt-os Mac mini semmiképp nem tartozik az alsó házba. De mondjuk mi van, ha jövőre a Qualcomm beforgatja a Nuvia fejlesztését egy az X2-nél 30-40%-kal gyorsabb processzormagba. Abból már lehetne csinálni - az Apple-nél - olcsóbb 4+4 magos miniPC-ket.
Biztos vannak páran, akiknek nem feltétlenül szükséges 16-24 mag, hanem kicsi, de fürge cpu-t szeretnének. És akkor az AMD azt fogja mondani, hogy ezekkel a 12-16 magos felsőházunk tud versenyképes lenni.
Vagy ott van pl a friss 4 magos Tiger Lake az inteltől, ami GB5-ben 1700 pontot ér el. Ehhez képest az 5600U csak valami 1300, az 5600G meg csak 1500 körül mozog.
Szóval ilyen kemény verseny mellett tényleg lehet azt mondani, hogy az alsó-felső ház nem csak magszámot jelent, hanem az egyszálas teljesítmény erőteljesebb differenciálását is?
-
#5233
Petykemano
veterán
S_x96x_S
#4995
Petykemano
veterán
válasz
S_x96x_S
#4995
üzenetére
zen4 IPC
Sokmindent lehetett eddig olvasni
- volt ez a zen2 =>zen4 +45%
- volt zen3 => zen4 +29% (Milan => Genoe)
- MLiD utolsó videójában zen3 => zen4-re 20+%-ról írtDe az AMD jól megkavarta ezeket információkat.
Mi a zen3? plain zen3, vagy zen3D?
Mi a zen4? plain zen4, vagy a zen4-et már v-cache-sel együtt kell érteni? (Ami még nem jelenti azt, hogy minden sku-n lesz v-cache, de hát ugye "upto*" )És hol jön képbe a Rembrandtnál szereplő zen3+?
"AMD Ryzen 6000 Warhol could hit 5 GHz with 9-12% gains over Zen 3"
Ezeket 9-12%-os értékeket magyarázná, ha a v-cache-re vonatkozna. Bár ha frekvencia növekményt is nézzük, akkor a 9-12% meg elég konzervatív. (Bár lehet, hogy az AMD is azt a pár játékot emelte ki, ahol van létjogosultsága a V-cachen-nek)
Már olyat is olvastam, hogy a v-cache-nek semmi köze a Warholhoz. De olyat is, hogy a Warhol nem a B2-es stepping. Az is lehet, hogy mégis, de az is lehet, hogy az AMD csinált egy B2-es steppinget, ami képes a v-cache felépítmény fogadására, de a végleges termék a Warhol lesz 6nm-en gyártva és a 9-12% úgy jön össze - v-cache nélkül - hogy picit emelkedik a mag frekvencia és picit emelkedik a FCLK is.
Én még titkon reménykedem az új IOD-ben. Van egy olyan elméletem is, hogy a B2 stepping lesz a warhol végül, de 6nm-es IOD kapDe a lényeg, hogy innentől bármilyen hírt nehéz lesz értelmezni.
-
#5227
Petykemano
veterán
Petykemano
veterán
AMD ZEN4 and RDNA3 architectures both rumored to launch in Q4 2022
[link]Ebből elég nagy blama/zúgolódás (=> idővel térvesztés) lesz. Szerintem.
... amennyiben az AMD a Vermeer-X-et (Zen3 refresh) nem úgy fogja bevezetni, hogy minden chiplet kap egy v-cache-t, hanem csak a 12,16, esetleg a legerősebb 8 magos kapja meg és az is komoly áremelkedéssel.Gondolhatnánk, hogy tök jogos az áremelés, meg hogy csak a drágább modellek kapják meg, mert hát drága technológia. Persze, érthető.
Akár nevethetnénk is, hogy ugyan minek kéne erőlködni, az intel sehol sincs, a Vermeer-X bőven elég lesz az Alder Lake ellen (a lényeg úgyis az, hogy chartokon folyó versenyt ki nyeri )
Ahogy az is lehetséges, hogy az AMD az 5nm-hez előbb ha akarna se férne hozzá.
És persze az is érthető, hogy minek gyártsanak jobb terméket, ha még abból se tudnak eleget gyártani, amijük most kapható.De közben Apple oldalról érkezik az M1X meg az M2.
Ha az Apple hoz 10-15% generációs növekményt, akkor azzal még mindig megőrzi az előnyét és ha 4+4 helyett komolyabb konfigurációt hoz, az nagyon el fogja halványítani az AMD erőfeszítéseit. Mindezt ráadásul úgy, hogy lényegesen kisebb TDP-ből kijön.
Mondjuk egy 16+4-es konfigurációban (az apple kis magjai emlékeim szerint nem efficiency, hanem Low Power magok) még az sem feltétlenül biztos, hogy az AMD marad a desktop környezet megkérdőjelezhetetlen királya.A Nuvia a saját csodáját 2023-ra ígérte. A Qualcomm felvásárlással esetleg felgyorsulhatott annyira, hogy 2022-ben ledobjanak valamit, ami emlékeztet az M1-re.
Valahogy azt érzem, hogy ebből az lesz, hogy az AMD küszködik itt a kapacitásokkal, meg az intellel való küzdelemben és az ARM-os megoldások a külső íven fogják előzni mindkettejüket.
-
#5222
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 3 6100 [link]
4 mag
5ghz
Nem valami magas eredmény értékek...
Könnyen lehet, hogy fake -
#5215
Petykemano
veterán
Petykemano
#5211
Petykemano
veterán
válasz
Petykemano
#5211
üzenetére
"In fact, the AM5 schedule is inconsistent with the V-Cache Zen3. This is one of the reasons why AM5 will only appear on ZEN4."
[link] -
#5213
Petykemano
veterán
Petykemano
veterán
Megszakítjuk adásunkat...
IDT => Intel FRED vs AMD SEE
Linux szerint "és"
[link]Kiváncsi vagyok, hogy lesz-e a jövőben valamilyen közös megoldás például a mostanában sokat emlegetett utasítás-hossz problémára, ami szakértők szerint egy objektív akadálya a mag szélesítésének.
-
#5211
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
Feb 2022
a dátum - noha későbbi, mint amit én reméltem - nem irreális,.sőt.
A Vermeer megjelenéséhez képest 15 hónap - a szokásos termék-megjelenés-intervallum.
Lisa Su azt mondta a kísérleti zen3V-re, hogy év végén kerül gyártásba. Onnan még biztosan pár hónap, mire termék lesz.De vajon milyen termék?
Szerverbe nagyonis lenne értelme, ott bármilyen formában megfizettethető. =>Milan-X (Talán nem is nagyon lenne szükség v-cache nélküli termékre.)Viszont abból lenne értelme vajon új szériát csinálni, ha egyébként csak a legdrágább 8-12-16 magos darabokra kerül rá? Na nem mintha sok 8 magosnál kisébb zen3 létezne a piacon. Viszont egy olyan új széria, ami nagyobb drágulást hoz - mert a texhnológia drága - mint amennyi előnyt biztosít, az megint fölháborodást fog kelteni. Persze tudom, így is el fog fogyni.
Na de mindegy, nem is ide akartam kifuttatni, hanem az időzítésekhez. Ha ez az AMD 2022Q1-2023Q2-ig tartó terméke (ide értve a Vermeer-X és Milan-X is) akkor miért mondta Lisa Su, hogy eltökéltek az 5nm-es termékek 2022-ben való megjelentetését illetően?
Persze sokminden lehetséges. Pl:
- 2022 hosszú, a zen4 indulhat akár 2022Q4-ben is és még akkor is 2022. Azt gondolnám, hogy ez talán inkább a DDR5 és az 5nm elérhetőségétől függ, mint attól, hogy kész van-e. A Milan-X a meglevő alaplapokba akkor is remek drop-in-replacement lenne, ha egyébként egyszerre jelenne meg a Genoaval.
- én továbbra is azt remélem, hogy a 7nm-es (AM4) termékek olcsóbb változatként még pár évig a piacon maradnak. Ennek némileg ellentmond az, hogy a zen4-ről meg épp azt rebesgetik, mégsem emel magszámot.
- egy kísérleti terméket láttunk. A végleges 2022-ben megjelenő megoldás épülhet éppenséggel már zen4-re - újabb meglepetést okozva. Nem jött megerősítés arra vonatkozólag, hogy ez volna a Warhol
(Én erre látok legkevesebb esélyt) -
#5210
Petykemano
veterán
S_x96x_S
#5206
Petykemano
veterán
válasz
S_x96x_S
#5206
üzenetére
Jól értem, hogy a 36mm2 = 64MB és ez egy réteg?
Tehát nem 2x36mm2.Vajon.... mi érné meg jobban?
- hasonló rétegeket az L2$ és L1$ fölé építeni?
- a jelenlegi L3$ helyén az L2$ méretét növelni (hogy a V-cache továbbra is cache fölött legyen) és az L3$-t pedig kompletten kiszervezni többrétegű V-cache-be? -
#5204
Petykemano
veterán
S_x96x_S
#5201
Petykemano
veterán
válasz
S_x96x_S
#5201
üzenetére
Agner:
"A serious bottleneck is a decoding rate of 4 instructions or 16 bytes per clock. To compensate for this, the Zen 3 has a micro-op cache with 4096 entries after the decoder.
The increased throughput in terms of instructions per clock may be difficult to utilize if the software has long dependency chains (where each calculation must wait for the result of the preceding one). It is now more important than ever to avoid long dependency chains.
The bottleneck in the decoder appears to be difficult to overcome. This is a consequence of the messy x86 code structure where instructions can have any length from 1 to 15 bytes, and it is complicated to determine the length of each instruction. Intel processors have the same bottleneck and the same decoding rate. The programmer must make sure the critical part of a program fits into this micro-op cache if you want to get the maximum throughput. It is important to avoid loop unrolling where possible in order to economize the use of the micro-op cache. (The Clang compiler often makes excessive loop unrolling)"
[link]Az AT fórumon két elképzelés (patent) is fölmerült.
Én nem értek hozzá, nem tudom megmondani, hogy melyik mennyire jó vagy nem jóVirtualuizált uop cache [link]
A másik pedig a Tremont féle dual-decoder út [link]Persze lehet, hogy mindkettő módszer együttes használata adja a legjobb eredményt - és a legtöbb tranzisztor és fogyasztástöbbletet az Armhoz képest, ahol ilyen trükkökre nincs szükség.
Mindenesetre úgy tűnik ez alapján, hogy egyelőre hard Wall nincs, csak ha fejlődni szeretnének, akkor arra az Armhoz képest több tranzisztort és fogyasztást kell áldozni.
Egyelőre mindenki azt mondja, hogy az IPC szignifikáns növelésének legkézenfekvőbb módja a mag szélesítése lenne [link] aminek az x86 esetén az a korlátja, hogy a decoder nem tudják 4(-5)-nél szélesebbre venni.
Valószínűleg enélkül is lehet IPC-t növelni - valahogy úgy, ahogy az intel teszi, hogy a bufferek, regiszterek és cache-ek 25-50%-os növelése itt-ott ad 1-2%-os gyorsulást, ami végülis kiadhat egy valamirevaló 15%-os előrelépést egy generációban. De ez nem az a fajta ugrás, amit az igen vékony bulldozer magról az akkori értelemben széles ryzen magokra ugrás hozott és amivel utol lehetne érni az Apple M1-et.Úgy tűnik, hogy ennek az akadálynak az elhárítása a következő pár év nagy kihívása és beszédtémája lesz.
-
#5198
Petykemano
veterán
HSM
#5195
Petykemano
veterán
"Ez teljesen jogos.
 Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Tudom, értem, hogy értetted. Architektúra tervezés nem sok ment bele.
Noha elismerem, hogy ez a 12-15% elmehet egy generációs fejlődésnek, de ugyanakkor meg nem értem, hogy a zen3 és a zen4 között nem csupán a szokásosnál valamivel hosszabb (mondjuk 18 hónap), hanem gyakorlatilag a sokásos generációs idő kétszerese fog eltelni (2x15 hónap), akkor nem értem, mit kotlanak azon ennyit, vagy úgy is megfogalmazhatnám, hogy akkor a zen4-nek tényleg nagyon jónak kell lennie. -
#5197
Petykemano
veterán
awexco
#5194
Petykemano
veterán
De a chipletezés előnye elvileg az, hogy válogathatsz, közös gyártósoron készül a szerver és desktop és a gyengét kiszórják a desktopra.
Ha a 3DX technológia csak a szervert célozza, akkor az azt jelenti, hogy előbb ki kell válogatni a szerver piacra szánt hagyományos zen3 lapkákat és azokat kell alávetni a 3D tokozás eljárásnak.
Anno Abu azt mondta, hogy a HBM azért szar ügy, mert ha bármi nem sikerül a tokozás során, akkor dobhatod ki az egészet - az amúgy jó lapkát is.Meg miért Egy 5900X-szel demózták volna, ha egyébként pont az nem célpiac?
mit szólsz ahhoz a lehetőséghez, hogy minden zen3 lapka megkapja a 3d felépítményt, és a desktop azt kapja meg, amelyen nem működik jól?
Fogalmam sincs egyébként melyik megközelítés lehet előnyösebb.
mondanám, hogy ez a 3D tokozás elvileg elkerülhetetlen. De ugyanezt gondoltuk a HBM-ről is és végül az prémium maradt. -
#5196
Petykemano
veterán
S_x96x_S
#5192
Petykemano
veterán
válasz
S_x96x_S
#5192
üzenetére
- az új cache jó dolog, és 7nm-en .. ( nem 5nm! )
- "Feb 2022 launch" -re jósolja a következő AMD cpu generációt.
(feltételezem, hogy valami belsős infó alapján, Ian Cutress a kevésbé blöffölös fajta elemzők közé tartozik)
Elég érdekes felvetés. 2022-re tényleg zen4-et "ígértek". Persze nem kell minden szegmensben elindulnia. Viszont ha ez a Vermeer-X/Milan-X még csak 2022 elején rajtol, akkor hogy lesz ebből még abban az évben zen4?Szerver szinten egy Milan-X is szép előrelépést jelentene mindenképp.
On the performance, we’ve seen L3 cache depth improve gaming performance, both for discrete and integrated gaming. However, increased L3 cache depth doesn’t do much else for performance. This was best exemplified in our review of Intel’s Broadwell processors, with 128 MB of L4 cache (~77 mm2 on Intel 22nm), wherein the extra cache only improved gaming and compression/decompression tests. It will be interesting to see how AMD markets the technology beyond gaming.
Nem nevezném L4$-nek. Én azt olvastam róla, hogy tényleg 3D kiterjesztése a L3$-nek, vagyis nem egy újabb szint, csak a L3$ címzésének egy új dimenzió. Ezzel érdemben valószínűleg nem csökken a késleltetés sem - pont az új dimenzió miatt.
A Lisa SU által említett 2TB/s úgy jön ki, hogy 3x akkora az egész L3 komplexum sávszélessége.Ezzel együtt nyilván nem fog mindent gyorsítani.
-
#5193
Petykemano
veterán
HSM
#5191
Petykemano
veterán
"egy generációnyi fejlődés, a gyártó szempontjából igen "olcsón"."
A kritikusok azt fogalmazták meg, hogy épphogy nem olcsó, merthogy 60%-kal több 7nm-es lapkaterületre van szükség.
Ha a hasznos lapka 6mm x 6mm és ebből kell két réteg a 64MB-hoz, akkor valójában majdhogynem 2x annyi tranzisztort emészt fel.Ian Cutress kérdése valahol jogos: ennyivel több lapkaterület ilyen mértékű gyorsuláshoz vajon tényleg megéri ebben a kapacitáshiányos időkben?
Vajon ez az SRAM HBM innentől kezdve szériafelszereltséggé válik az AMD-nél?
Ugye itt már a lapkamagasság sem mindegy így. Tehát ha nem így gurul le minden CCD - 2 magas SRAM HBM-mel -, akkor még azt is előre el kell dönteni, hogy mire tesznek és mire nem.Vagy vajon vegyíthető-e az új és a régi lapka? Vagy konfigurálható-e úgy, hogy egyik CCD-n aktív a 3DX a másik CCD-n meg nem (mert mondjuk hibás)
-
#5186
Petykemano
veterán
Petykemano
#5184
Petykemano
veterán
válasz
Petykemano
#5184
üzenetére
max 4 stack
[link]
Biosban (talán nem fake) -
#5185
Petykemano
veterán
Petykemano
#5176
Petykemano
veterán
válasz
Petykemano
#5176
üzenetére
Gondolkodom... ezen az 5600G-n, meg a Vermeer-X-en.
Ha létezik és tényleg lesz desktop modell. Bár miért ne lenne, ha pont azon mutatták be.Ez a Vermeer-X - mivel lényegében az alap nem változik - gondolom AM4-be jön.
- Zárójelben: vajon a B2 stepping ehhez kellett?
Szóval ez még mindig AM4-be jön.
Az én B350-es lapomba már a zen3 sem ment bele. Tehát nekem fejlesztés szempontjából érdektelen, hogy ez AM4-be jön.
Ha az AMD kegyes, akkor annak jól jöhet, akinek minimum 400-as szériája van, rosszabb esetben már csak 500-asba megy bele.De vajon érdemes-e még idén év végén egy B550 lapot venni Vermeer-X-szel? Akkor már a küszöbön lesz a DDR5. És a DDR5 nem is szávszélesség szempontjából, hanem kapacitás szempontjából érdekes.
Azt hiszem, maradok az eredeti tervemnél.
Ha jók a számok, a B450-es lapba veszek egy 5600X-et vagy 6600X-et.
És abból a 3600X-re cserélem az 1700X-et. -
#5184
Petykemano
veterán
Petykemano
veterán
Megint e14x
"AMD can stack up to 8 V-Cache stacks of 32MB on top of eachother. It is possible to disable parts of the stack or disable it alltogether in the bios 🤝"
[link]Már másutt is olvastam, hogy SRAM HBM-ként hivatkoztak rá.
256MB/CCD - Impozáns. Persze IPC szempontjából eléggé diminishing returns.
-
#5183
Petykemano
veterán
Petykemano
veterán
- 6 x 6 mm (36 mm²)
- CCD itsel is 80,7 mm²
- IOD is 125 mm²
[link] -
#5182
Petykemano
veterán
HSM
#5179
Petykemano
veterán
> Gondolom itt nem kell versenyeznie/osztoznia az elkészült lapkáknak a legnagyobb profitú
> szerver termékekkel. Valamint feltételezhetően a gyártása is egyszerűbb (olcsóbb?), hogy
> egy helyen gyártják, egy csippel.Biztos több hónapra előre el kell döntenie az AMD-nek, hogy melyik lapkából mennyi gyártását indítja el - már csak azért is, mert míg wafertől eljut valami a chip formáig, az a gyártási folyamat is több hét, vagy 1-2 hónap is lehet.
Ennek ellenére szerintem az, amit mondasz, hogy az elkészült lapkák nagyobb profitú szerver termékekkel kell versenyeznie, az csak rövidtávú, mondjuk 1-2 negyedéven belüli árfelhajtást, vagy hiányt okozna. Arra gondolok, hogy a végső korlátot a rendelkezésre álló wafer jelenti és nem hiszem, hogy ha sokat tudna az AMD keresni szervertermékeken, akkor ne forgatná át a wafer felhasználást arra - olcsó apuk helyett.
A gyártás/csomagolás költségével kapcsolatban igazad lehet. Valószínűleg a monolitikus lapka elkészítésére vonatkozó kapacitás, gyakorlat nagyobb lehet.
Még az jutott eszembe: lehetséges, hogy ennyire sok volna a túl sokat fogyasztó CEzanne? Merthogy ez elvileg ugyanaz a lapka, ami az U szériát is kiszolgálja.
> Pedig ez nagyjából megfelel a várhatónak. Nem véletlen rakott pl. az Intel is inkább kicsit
> kevesebb, de gyorsabb elérésű gyorsítótárakat a kliens CPU-ira. És pont ugyanezért nem
> gyorsult óriásit az 5000-es Zen sem, pedig praktikusan duplázták a "hasznos" L3 méretet.Igen, igen, tökre reális. Ha megkérdezed, én se vártam volna mást. De az embert mégis arculcsapja a valóság.
-
#5176
Petykemano
veterán
Petykemano
veterán
Azt kell mondjam, hogy ez volt az elmúlt 2 év legizgalmasabb-legmozgalmasabb AMD előadása.
Az elmúlt években a ces, computex és egyéb elöadások során az idő 80-85%-át elvitte az eredmények felsorolása, és partnerekkel egymás vállának veregetése. (Én értem, hogy marketing szempontból a jó referencia elképesztően fontos, csak épp borzalmasan unalmas)
Ezúttal végre az idő nagyobbik részében termékbemutató volt.
A $259-os 5600G szerintem is kifejezetten jó.
Nem tudom, mennyivel lehet lassabb , mint az 5600X - feltételezem 5-10%. De azért ez egy 170mm2-es lapka. Kicsit talán érthetetlen is, miért ennyire olcsó. Most vagy az van, hogy (főképp) az AMD IOD-CCD csomagoló kapacitása korlátos, vagy végre tényleg van 7nm kapacitás. Akkor viszont a Vermeer árának is némileg csökkennie kéne, vagy megjelennie az 5600Nak is.Egyébként most már 105eFt a 5600X is. Szerintem ez már csak kábé $250 valós árat jelent.
Eléggé csalogató ez a 5600G számomra. De ehhez nekem új alaplap kéne. Akkor viszont vajon meg tudnám-e várni, míg elérhető a DDR5? 1.5-2 év.
Most már viszont tudjuk, mi a Warhol - ami még érdekes, és csodálom is, hogy még nem került be ide -:
3D stacked L3$
32 MB helyett 96MB / CCDKicsit csalódást keltő, hogy 3x annyi L3$ csak 12-15% IPC növekedést hoz. Ugyanakkor ez valójában tényleg kitesz egy generációt. És elegendő az Alder Lake ellen is.
Az AMD húzása meglepő, vártuk, de nem ennyire korán, senki nem gondolta, hogy a zen3+-ban ledobja az AMD.
De azt kell mondjam, a felhasználás módja várható volt.Az időzítés viszont érdekes. Idén év vége. Én arra számítottam, hogy idén nyár végén dob Valamit az amd, hogy aztán 2022 tavasz végén- nyár elején érkezzen a zen4. Ha ez idén év végén érkezik, akkor zen4 DT valószínűleg tényleg inkább 2022Q3-Q4.
Vajon erről szól a Milan-X is? Vagy ez a verzió szerverben nem lesz használva? Mert ha a Milan-X ilyen lapkákból áll, akkor a Genoa sem valószínű, hogy megérkezzen 2022Q1-Q2 táján.
Egyéblént ez a Warhol - a jónak ígérkező teljesítmény ellenére - eléggé megúszós generáció tervezés szempontjából. A zen3 designhoz tényleg nem kell hozzányúlni.
Ez a technológia az apuk esetén különösen érdekes, illetve a gpuk esetén, ahol az Infinity Cachet teljesen a felső fedélzetre lehet helyezni - eléggé nagy méretben.
Mondjuk egy 250mm-es apura ráfér 128MB IC, ami valószínűleg bőven elégségesse teszi a DDR4/5 sávszélességet. -
#5168
Petykemano
veterán
Petykemano
veterán
> Added LHR variants of NVIDIA GeForce RTX 3080, 3070 and 3060 Ti.
> Fixed reporting of memory clock and some other parameters on Rocket Lake 6c/4c.
> Enhanced early support of some Zen4-based systems.
> Added workaround for systems with stuck SMBus causing large delays.Egyrészt érdekes, hogy megjelent a felsorolásban. De ami különösen érdekes az az, hogy Enhanced. Tehát az early support nem most jelent meg először a szoftverben.
Ez azért eléggé megkérdőjelezi azokat a vélekedéseket, hogy a zen4 még nem design-ready.
A HWinfo version history nem következetes. Keverednek a számozások és a kódnevek.
- zen említése először 2015 október 14-én => 2017 márciusi rajt (+17 hónap)
Viszont az első bejegyzés added, a zen4-hez kapcsolódó viszont enhanced.
Van egy "Enhanced preliminary AMD Zen support." sor is 2016 július 6-án => 2016 márciusi rajt (+11 hónap)
- zen2 említése először 2019 április 3-án => 2019 júliusi rajt (+4 hónap)
- zen3 először 2020 május 13-án kerül említésre => 2020 novemberi rajt (+6 hónap)Nem gondolnám, hogy idén lesz bármilyen zen4 termék, de ez alapján merném feltételezni, hogy esetleg a CES-en bejelentik.
Merész azt feltételezni, hogy az AMD a zen4-et a DDR5 köré építette?
Szerintem a DDR5 rajtja a vártnál jobban halad. Egyre-másra jelentik be a memória modul gyártók, hogy Q3-ban lesz DDR5 termék [link]
Persze nyilván először drága lesz meg minden. De ha az intel is eköré építette az Alder Lake-et, akkor van motiváció az átállásra.Szóval ha az AMD a zen4-et a DDR5 köré építette, és tényleg gyorsabb az átállás, akkor az megmagyarázná, hogy miért van/lesz/volt/lett volna/nem lesz/stb a Warhol.
-
#5167
Petykemano
veterán
Petykemano
veterán
-
#5164
Petykemano
veterán
carl18
#5163
Petykemano
veterán
> Elég csak megnézni az intel pár éve mennyiért adta a
> 16/18 magos hardvereket. Ha az AMD nem fogja
> közre nem nagyon csökkentettek volna ők árat.Az érdem elvitathatatlan, de meddig lesz még az akkor kb 10 éve monopolhelyzetben levő Intel árazása a referencia?
> Viszont a jelenlegi korona vírusos helyzet és a TSMC
> készlet hiány is rájátszik a pocsék árazásra amin az
> AMD is emelt mert valszeg tudták így se tudnak
> eleget gyártani.Egész pontosan Mit értünk ma is vírushelyzet alatt?
Az emberek dolgoznak. Ha nem dolgoznának, az AMD és az nvidia és partnereik bevételei nem döntenének rekordokat.
Még mindig tart a home Office vagy az otthon dekkolás miatti keresleti boom?
Vagy a digitális szolgáltatások terhelésnövekedése?
Mitől tart még a chiphiány?MLiD utolsó DG2 videójában azt állította, hogy nem is a chip, hanem a szubstrát hiány okozza.
-
#5159
Petykemano
veterán
S_x96x_S
#5157
Petykemano
veterán
válasz
S_x96x_S
#5157
üzenetére
Unalomig lehet magyarázni az okokat - amit mint figyelmes olvasó persze értek is, de azért az nem változtat azon a tényen, hogy akkor a top 6 magos $249 volt, most meg $299.
A zen1-gyel megjelenő magasabb magszámú széria nem trendszerűen állította be azt, hogy a core/$ szám növekedjen, hanem két lépésben (zen1, zen2) egy alacsonyabb ársávba sorolta be. Legalábbis ha igaznak bizonyulnak MLiD pletykái, hogy a zen4 esetén is megmaradnak a core/$ vonalak - erre pedig legnagyobb esély akkor van, ha tényleg nem indul 24 magos.
Mindez persze valóban azt jelenti: a verseny (vagy annak hiánya) és a kapacitások foglyai vagyunk.
> igazából Lisa Su
Nem tudom jobban kitenni az idézőjelet -
#5154
Petykemano
veterán
awexco
#5151
Petykemano
veterán
Egyébként értem én az okokat...
A minimum +20% teljesítmény generációnként azért elég jó, elég kielégítő.
Egyrészt egyénileg is. Gondolom kevesen vásárolnak generációról generációra. Ha több generációt kihagysz, azért az már nagyon jelentős különbség. 50-100%
Összességében pedig hát ugye mindent IS elad az AMD. Semmivel nem tudna többet eladni, ha azonos áron magasabb magszámmal csalogatná a vevőket.A játékok terén is igaz, hogy egy nextgen CPU többet ér, mint a jelenlegiből 2x annyi magos. És azon kívül, hogy a játékok mennyit kívannak, persze én se tudnák átlagfelhasználói indokot mondani, miért lenne szükséges vagy indokolt, vagy legalább csak előnyös a a magszám emelése.
Szóval értem. Csak hát akkor is bosszantó, hogy abu magdömpiget "ígér", aztán eltelik pár negyedév és elmarad.
-
#5150
Petykemano
veterán
S_x96x_S
#5149
Petykemano
veterán
válasz
S_x96x_S
#5149
üzenetére
A 16 magra gondolsz?
Elég vicces... egy fél éve még attól harsogott a média, hogy a 8/16 magos konzol proci és az ssd vezérlő brutális terhelést fog róni a procikra.
Abu nemrég azt mondta, at FSR nagyobb terhelést dog róni a procikra.Az AMD meg nem akar több magot adni.
Megy a szerecsenmosdatás. Jójójó, a 8 magos kezdés tényleg nagyszerű volt, letörte a 6+ magos procik árát. De hát ugyanoda tartunk vissza. Jójójó, aztán letörte a 12-16 magosokat is
De a 6 magos procik az 1600/X megjelenése óta nem lettek olcsóbbak, sőt, drágultak is.:
-
#5144
Petykemano
veterán
TESCO-Zsömle
#5143
Petykemano
veterán
válasz
 TESCO-Zsömle
#5143
üzenetére
TESCO-Zsömle
#5143
üzenetére
2xIGP - ez lehetne ugye 12, vagy akár 16CU is per CCD, azaz 24 vagy 32.
Az MCM Navi 31 esetén a jelenlegi pletykák arról szólnak, hogy a lapkákat egy közös LastLevelCache-re (Infinity Cache) fűzik föl, más elgondolások szerint a két lapka közé tesznek cache-t, ami megítélésem szerint a másik lapkán levő memóriavezérlő által kezelt memóriatartalom elérését gyorsítja.
A cache tehát mindenképp a memóriatartalom elérésének gyorsítását szolgálja.Azt gondolnám, hogy egy ilyen APU-ra szereplhető IGP chipletről a memóriavezérlőt ugyanúgy kihagynák, mint a CPU CCD-k esetén.
Ha már létezik (létezni fog) ilyen technológia, hogy különálló cache lapka gyorsít két másik közötti kommunikációt akkor ennek bevetése itt is praktikus lehet. Megfelelő mennyiségű Infinity cache használata kiválthatja a HBM szükségességét.[IGP CCD]-[IC]-[IO]<->DDR5
Ha jól emlékszem, abu a navi 23-ra ilyen 65W-okat mondott.
De nincsenek illúzióim egy ilyen apu HBM-mel vagy anélkül olyan áron kerülne forgalomba, ami semmiképp se tudna alternatívát jelenteni azok számára, akik amúgy $300 alatti videokártyát vásároltak volna. Az ilyen elképzelésekkel az szokott történni, hogy tök jó lenne egy ilyen desktopos alternatíva, de a desktop/minipc piac túl kicsi, prémium notebookokba talán mehetne, de nagy kereslet arra sincs, és egyébként is egyben hűteni egy ilyen aput nehezebb, mint ha két külön eszköz lenne.
-
#5138
Petykemano
veterán
Petykemano
veterán
Strix Point: Zen5+Zen4D
[link] [link]megj: nem lepődnék meg, ha a zen4 és a zen5 között azért lenne még valami töltelék és eltelne ~3 év
vö:
zen: 2017 március
zen+ (azonos node): 2018 április (+13)
zen2 (új node): 2019 július (+15)
zen3 (azonos node): 2020 november (+16) -
#5137
Petykemano
veterán
S_x96x_S
#5135
Petykemano
veterán
válasz
S_x96x_S
#5135
üzenetére
> technikailag kivitelezhető ..
> de Cloud-ban szerintem nem sok értelmét látom..
De hát ezt csinálja az Arm.
A V1 némileg magasabb egyszálas teljesítményre képes és 96 magos processzort lehet vele készíteni (referencia design) az N2 pedig az alacsonyabb egy és magasabb többszálas teljesítményre éleződik ki és 128 magos processzort lehet belőle csinálni.Ennek se látod értelmét?
Nem feltétlenül kellene vegyíteni a különböző lapkákat - cloudban. Sőt, ott lehet, hogy kifejezetten igény lenne arra, hogy eltérő árazással mérhessék a különböző típusú magokat.
Ugyanakkor - szerintem - a játékokon kívül más szoftvereknél is beüthet az Amdahl törvény - vagyis lehet, hogy nagyon hatékonyan tudja kiszórni szálakra a feladatokat, de lehet egy-egy olyan process, aminél az egyszálas teljesítmény limitáláltsága kihat az egész rendszer teljesítményére.
Ez persze már az ütemezés kérdése - ahogy mondod is. Az operációs rendszernek tisztában kell lennie azzal, hogy vannak olyan magok, amelyek más teljesítménnyel bírnak, mint a többi és azt is meg kell fontolnia, hogy egy szálat érdemes-e oda helyezni - vagyis hogy nem okoz-e azzal nagyobb lassulást, hogy ha egy másik CPU clusterbe helyezett programszál miatt megnövekszik a kommunikációs késleltetés.
Ez a probléma újra és újra visszaköszön, amit azért nem teljesen értek, mert az Intel Turbo boost 3 (vagy melyik) arról szól, hogy van 1-2 mag, amelyik magasabb frekvencia elérésére képes, mint a többi és a legdurvább programszálat oda ütemezi.
És a 2+1 chipletes zen2 és zen3 termékek is úgy működnek - ez a 3950X esetén elég világosan látszott - hogy az egyik CCD jobb minőségű és magasabb frekvencia elérésére képes "golden sample" és mellette van egy átlagos, gyengébb. Tehát az ütemezőnek már ebben az esetben is kutya kötelessége volt megtalálni, hogy ne akármelyik magon, hanem a legerősebbe(ke)n futtassa a programszálakat, amennyiben a program nem terhel minden szálat. Azt gondolnám, hogy itt nem megfelelő egy roundrobin száldobálás, hanem nagyonis tisztában kell lennie az ütemezőnek, hogy melyik cpu száltól milyen teljesítményre számíthat.
Azt mondod, hogy ez valójában nem így van, ez csupán szemfényvesztés, hogy papíron leírható legyen a magasabb frekvencia és az ütemezés szub-optimális működését meg elfedi a "mérési hiba"?
> akkor már inkább egy CCD-n belül kellene.
> - 8 core / CCD - amiből 2core extra (duplás) és 6 egyszerű.
> persze ez se ideális ..
> de legalább 1 chiplet-ből megoldható ..
> míg a tied 2 különböző CCD
Abból a szempontból igazad van, hogy egy ilyen esetben kevesebbet kellene "gondolkodnia" az ütemezőnek, hogy mi lesz a késleltetéssel, mert minden clusteren belül lenne "erős" mag, csak azzal kéne pluszban foglalkozni, hogy azokat a szálakat, amelyeket eddig is valamilyen megfontolásból egy clusterbe rakott, azok közül a legnagyobb igényűt a legerősebb magra tegye. "Csak azzal" - nyilván ez nem egyszerűViszont így nem lenne válogatási lehetőség, hogy melyikből mennyit kérek.
-
#5134
Petykemano
veterán
S_x96x_S
#5133
Petykemano
veterán
válasz
S_x96x_S
#5133
üzenetére
Ez már nagyon vagdalkozás részemről, de..
Azt nem tartom valószínűnek, hogy a zen4 CCD magszáma 8-ról 6-ra essen.
De azért amit mondasz,.szöget ütött a fejembe. Az A78 és az X1 lényegében feldolgozók számában és cache méretben különböznek egymástól.
Mennyire lenne bonyi csinálni
- egy zen4 heavy magot, ami 2 x AVX512, meg több cache stb. De csak 6 mag van a CCD-ben.
Célkeresztben a maximális teljesítmény.
- és egy zen4 light magot, ami utasítások terén ugyanazt tudja, csak kevesebb feldolgozó, kevesebb cache. Cserébe 8 mag / CCD. Célkeresztben a perf/W.Ennek már ugyan sok köze nincs ahhoz, hogy 3 CCD esetén -2 mag, de a Genoa 96 és 128 magos változatára magyarázat lenne. És lényegében ugyanezt látjuk az arm V1 és N2 esetében is.
-
#5131
Petykemano
veterán
S_x96x_S
#5128
Petykemano
veterán
válasz
S_x96x_S
#5128
üzenetére
> a mostani 2*8=16 power core - hoz képest
> nem valami nagy előrelépés.
Igen.
Most van ez hype a Milan-X-ről, amiről csak azt lehet tudni, hogy valami 3d stacked cucc (3DX) de azzal kapcsolatban, hogy pontosan mi van egymásra pakolva, csak találgatás zajlik.
Elég valószínű, hogy csupán arról van szó, hogy HBM lesz a zen3-as chipletek mellett használva, amire az elmúlt 1 év hírei alapján számítani is lehetett. De van aki felvetette, hogy vajon CCD-k vannak-e egymásra pakolva?- egyébként megmagyarázná, hogy hogy lenne 128 magos Genoa.
Mindenesetre ezen kezdtem gondolkodni, hogy vajon lehetséges-e, hogy ha már ekörül ekkora hype van, hogy a 2CCD az valójában 2x2 CCD, tehát a normál 24-32 magos és a 3 CCD az 3x2 CCD, de itt már max 7 mag / CCD - és akkor ezzel kijönne 42.
De ennek semmi értelme nem lenne.
Nem így ismerjük az új AMD-t.
Viszont értelmet nyerne a 170W-os TDP keret> meg, ha én tervezném, akkor csak 1 energiahatékony CCD-t
> raknék bele .. nem kettőt ..Miért?
Az energiahatékony az nem low power. Energiahatékony az az, hogy 3.5Ghz-en, amit 24-32 mag használata közben valószínűleg elérhet, a kevesebbet fogyaszt, mint a performance típusú.Abu mondta, hogy lesz RDNA és CCD lapkák cserélhetők lesznek.
A raphael esetén én arra számítok, hogy - és most maradjunk a leakben említett 3 CCD-nél - lesz
3 CCD
2 CCD + 1 IGP
1 CCD + 1 IGP
adabszurdum lehetséges volna 1 CCD + 2 IGP is, ami impozáns lenne, csak megint a memória sávszélesség jelentene probémát -
#5125
Petykemano
veterán
S_x96x_S
#5124
Petykemano
veterán
válasz
S_x96x_S
#5124
üzenetére
"persze most még ~90% -10% lehet az X86 - ARM megoszlás,
de 4-8 év múlva az ARM feljöhet 30 - 40% -ra is ."
Ezt nem vonom kétségbe, de ez csaknem az egyik évről a másikra ugrik meg. Nagyjából mindem évben történik beruházás a legújabb szerverekből. (Persze nem minden telephelyen az igaz.)
Ráadásul most elég nagy ugrások is vannak már generációról generációra -
#5123
Petykemano
veterán
Petykemano
veterán
"AM5 can get 3 CCDs. But each CCDs will lose 2 cores. This explains the increased TDP(170W) + increased number of pins. Also CCD#1 is designed to get maximum frequency. Other CCDs - maximum energy efficiency. Be skeptical of this information."
[link]Ennek a "3 CCD esetén -2 mag / CCD"-nek sok értelme nem lenne, hacsaknem arról van szó, hogy egy CCD nem 8 magos. De erre eddig semmi nem utalt.
De az érdekes info, hogy
CCD#1 => max frequency
CCD#X => max efficiency
Ezt nyilván eddig is így csinálták - csak válogatással.Eközben: AdoredTV emelte a tétet: Genoa náluk már 128 magos
[link]Mások szerint az nem a Genoa.
-
#5120
Petykemano
veterán
S_x96x_S
#5117
Petykemano
veterán
válasz
S_x96x_S
#5117
üzenetére
Ezt a vitát egyszer már lejátszottuk.
Én valahogy nem tudom elképzelni hogy erre - hogy csak egyszer kelljen megvenni a procit,de a kupak alatt kétféle maximálisan profi rendszer legyen, amik között reboottal lehessen váltani - nem tudom ki akarna. Én nem gondolom, hogy ennyire bénakacsák lennének a cloud szolgáltatók, hogy annyira ne legyen elképzelésük, hogy milyen ISA-ra lesz igény 2-5 év múlva, hogy nekik egyenlő mértékben kéne különböző ISA-kból számítási kapacitásra beruházni, mert ki tudja, mit hoz a jövő. Szerintem ők ezt nem annyira lereagálni, mint inkább költség alapon irányítani szeretnék.Annak esetleg látnám értelmét, hogy olyan heterogén architektúra, amiben egyszerre van jelen az x86 és az arm processzor, mindkettő aktív, de persze csak az egyiket használja a host rendszer, a másik lehetőséggel csak tisztában van és ennek megfelelően tud rajta virtuális futtatási környezetet (VM-et) futtatni.
Ha jól emlékszem, az intelnek volt PCIe slotba dugható compute cardja
[link]Ha így nézzük, akkor a gpu is egy hasonló. Egy saját ISA-val rendelkező rendszer, amin ezért sajátos módon, sajátos kódot lehet futtatni. Tehát egy x86-os host rendszerbe dugott Arm kártyán miért ne lehetne Arm kódot futtatni? vagy fordítva.
Azt gondolnám, hogy ennek neked otthon, aki esetleg nem engedhetsz meg magadnak két számítógépet, még lenne értelme. De egy nagy cloud szolgáltató miért járna jobban?
Az persze hatalmas húzás lenne az AMD-től, ha kiderülne, hogy az architektúráit mindig is úgy készítette el, hogy ugyanabból a zen-ből létezett egy olyan változat is, ami nem x86, hanem Arm ISA frontenddel rendelkezik. De ha ilyennel rendelkezik, akkor szerintem azzal már előálllt volna, ha úgy gondolná, hogy előnyös a szerverpiacot két irányból támadni. Ha viszont visszatartja azért, hogy majd a megfelelő pillanatban rántsa elő, amikor az Arm adoptációja már erre készen áll, akkor az valójában azt jelenti, hogy valaki ezt az utat - az AMD x86-os törekvései ellenére - kijárta, kitörte, ha ennél nem jobbal áll elő az AMD, akkor ezen a piacon is elvesztette a versenyt, ha viszont jobbal rendelkezik, akkor minek várt vele?
-
#5111
Petykemano
veterán
S_x96x_S
#5110
Petykemano
veterán
válasz
S_x96x_S
#5110
üzenetére
Én ebből csak azt olvasom ki, hogy nek zárkóznak el az arm elől. (Semi custom?) Még akár azt is,.hogy xilinx területre nem próbálnák beerőltetni az x86-ot, csak mert ők most abban érzik.nyeregben magukat, ha egyébként annak ott nincs se hagyománya, se igénye.
De azt nem látom, hogy ez már egy komplett armos átállásra való felkészítés lenne. Mármint ez megtörténhet, de azt nem látom.ebből, hogy ennek az AMD úttörője lenne. Viszont ha úgy alakulnak az ügyféligények, akkor kiszolgálják.
5-10 éves távlatban szerintem az lehet meghatározó, hogy mennyivel.egyszerűbb armra programozni. Ebben számíthat az is, hogy önmagában arm, vs önmagában x86, és az is, hogy ugyanezek heterogén computinggal.
Ez viszont lehet, hogy már oneAPI vs CUDA vs ROCm terület. -
#5108
Petykemano
veterán
Petykemano
veterán
/konkurencia/
A510, A710, X2
35% vs A55
10% vs A78
16% vs X1Eltekintve az évek óta meg nem újított kismagtól, ez a 10-16% perf uplift azért már nem annyira impozáns, mint a korábbi generációnkénti 20-30% volt.
-
#5107
Petykemano
veterán
Petykemano
veterán
Milan-X
az új kódneve annak, amiről már egy éve is szóltak a hírek ( [link], [link] és abu negyedévente
ír róla: [link] , [link] )
Szóval de most már tényleg!Azt eddig is tudni véltük, hogy a Frontierbe ez mehet. Ugyanez korábban Trento néven futhatott.
Raphael
"- AM5 socket
- DDR5 (no DDR4)
- 28 PCIe 4.0 lanes (+4 compared to Zen 3)
- 120W TDP (170W possible as well )"
Úgy tűnik az AMD megy az intel után a TDP emelésével kapcsolatban. Nehéz volna hibáztatni -
#5106
Petykemano
veterán
Petykemano
veterán
"Strix point adopts the hybrid architecture of zen5+zen4 and introduces a new cache. The desktop version does not know if this mode will be adopted, but it is certain that the same 3nm will be used."
[link]Ugye nyilván meg lehetne toldani, zen2 és zen3 lapkák összetokozását is - hasonló korlátozások mellett, ami a Lakefield-et is érinti. Értelme nem lenne, mert ugyanazon koncepció és ugyanazon gyártástechnológia mentén készülnek.
Kifejezetten izgalmas lenne egy olyan tick-tock mód elindulása, amely esetén minden második új verzió gyártástechnológiai váltást, alacsonyabb fogyasztást, több cache-t, nagyobb IPC-t, stb eredményezne, de nem hozna új tudást és így korlátozások nélkül összetokozható lenne az előző verzióval. Mondjuk képzeljük el azt, hogy készülhetne egy 5nm-es cache-sel jobban kitömött zen3 tudású lapka, ami ezáltal hoz 15-20% IPC növekedést és összetokozható 1-2 7nm-es zen3 lapkával.
Persze tudjuk, hogy a zen4 nem ilyen.
Azt is tudni véljük, hogy az AMD big.LITTLE koncepciója nem különálló magok fejlesztéséről, hanem magon belüli elkülönülésről szólt.Az Intel viszont egyértelműen a különálló magok irányába indult, ahol a nagy magok célja az egyszálas teljesítmény, a kis magoké pedig vagy a sokszálas, vagy az alacsony energiaigényű feladatok vitele. A kétféle mag tudásának összehangolása még feladat, de a koncepció szerintem érthető.
Ha a zen5 nem a zen4 utódja, hanem inkább csak annak kitömött nagytesója, vagy egy bifurkációs pont, ahol elválik egy kis és nagy mag vonal, miért hívná azt továbbra is zen-nek?
-
#5098
Petykemano
veterán
S_x96x_S
#5097
Petykemano
veterán
válasz
S_x96x_S
#5097
üzenetére
Szerintem ez csak a CPU és a chipset közötti kommunikációt jelenti.
A pcie4 megjelenésekor volt szó arról, hogy régebbi alaplapba teszed az új pcie4 procit, akkor engedélyezik-e az amd és az alaplapgyártók (nyilván BIOS frissítés kellhet), hogy azok a sávok,.amiket a proci kezel pcie 4 sebességgel működjenek. Végül döntés alapján ez nem valósult meg, de Végülis a nextgen budget alaplapok így működtek.Bár lehet, hogy ugyanezt mondtad, csak nem "A"-s procikra, hanem "A"-s alaplapokra gondoltál.
-
#5084
Petykemano
veterán
Petykemano
veterán
Ampere Altra Max
- 128 mag
- saját fejlesztésű mag N1 helyett
- 1.5-1.6x nagyobb teljesítmény a Rome-hoz képest.A szám elég impozáns.
És ez még mindig 7nm!Eddig az AMD azzal ekézhette az intelt, hogy náluk sokkal több magot kaphatsz egy socketbe, ugyanazzal a TDP-vel, stb. Ezt aztán azzal hárították, hogy igen keveseknek kell sok mag, mert a licencelés már sehol sem socket alapon, hanem mag alapon megy.
Most az AMD is ebbe a helyzetbe kerül
Időközben persze az AMD-nél már a Milan a kurrens termék, de az legkevesebbet épp a multithread teljesítményen hozott. -
#5075
Petykemano
veterán
S_x96x_S
#5074
Petykemano
veterán
válasz
S_x96x_S
#5074
üzenetére
Ez úgy hangzik, mintha cserélnék az IO lapkát TSMC-nél gyártottra, de az nem feltétlenül jelent előrelépést semmiben.
Egyébként az is előrelépésnek számít manapság, ha ugyanazt lehet megkapni, de nagyobb mennyiségben tudják előállítani (most itt nem a chipletre gondolok, hanem a packagingre) és így olcsóbban hozzáférhető. -
#5073
Petykemano
veterán
hokuszpk
#5072
Petykemano
veterán
válasz
 hokuszpk
#5072
üzenetére
hokuszpk
#5072
üzenetére
Ha ez arra a költői kérdésre válasz, hogy "mi a fenének csinálnának...?"
Akkor: jójó, de hát ez egy kifutó széria (zen3) és 7nm-es lapkát tervezni $300m és a 7nm-es lapkák kapacitása amúgy is szűkös.
Egyébként technikailag egyetértek azzal amit mondtál, csak próbálom ellenérvelni abból a megközelítésből, hogy papíron sokminden jól és logikusan hangzik, amit összetalálgatunk, de a cégek gyakran nem találják az elképzeléseinket üzletileg megtérülőnek.Egyébként a Vegeta nevű Twitter felhasználó többször említette, hogy innovatív megoldás.
Túl azon, hogy esetleg egy új, alacsonyabb csíkszélességgel rendelkező node-on készülhet az IO lapka, esetleg még az egybetokozás módja is számíthat.Korábbi mérések azt mutatták ki, hogy az AMD MCM IF megoldása valami 2pJ/bit energiát igényel adatmozgatásokhoz, ehhez képest valami A76-okkal készített Cowos megoldás csak valami 0.5pJ/bit energiát.
Nemrégiben arról is szó volt, hogy a TSMC-nek is van hasonló megoldása, mint az Intel EMIB
Tehát az említett innovatív megoldásnak - túl a TSMC lapkján - talán egy ilyesfajta új tokozási megoldás, ami szintén csökkentheti az adatkommunikáció energiaigényét, de továbbmegyek:
megteremtheti az L4$ lehetőségét is.
Eddig gyakran ábrándoztunk azon, hogy milyen jó lenne, ha az IOD tartalmazna egy L4$-t. Ennek lehet, hogy az az akadálya, hogy a IOD-on levő L4$ hatékony használatához egy CCD és az IOD között vastag sávszélességű és alacsony energiaigényű kommunikációs lehetőséget kell tudni biztosítani.Ha megnézel egy AIDA tesztet, akkor a L3$ 400-500GB/s sávszélességet biztosít, a memória ennek kb tizedét.
Egyébként nem gondolom, hogy a közeljövőben látnánk L4$-t az IOD-ban, csak azt fejtegettem, hogy valami újfajta tokozás, ami kiszélesítheti a kapcsolatot a CCD és IOD között ahhoz mindenképpen feltétel lenne.
De azt se felejtsük el, hogy érkezik a Frontier is. Az elvileg olyan EPYC lesz, amihez mellétokoznak HBM2-t. Nem feltétlenül gondolnám, hogy erről lenne szó a B2 stepping esetén, de abból a HBM2-n kívül esetleg lecsuroghat valami.
-
#5071
Petykemano
veterán
Yutani
#5068
Petykemano
veterán
Már két generáció óta készítenek 7nm-en uncore-t (Renoir, Cezanne). Szerintem logikus lenne kiemelni a Cezanne-ból "és kész is"
Persze felmerülhet a kérdés: mi a fenének csinálnának az AM4-hez és régi zen3-ashoz való IO lapkát, amikor a zen4-hez majd úgyis új IO lapka kell (PCIe5, DDR5) Ez a kritika jogos. Ennek nyilván csak akkor van értelme, ha tényleg még 1-2 évig megmarad a 7nm-es zen3.
Sokminden történhet.
Az is, hogy a GF-nál gyártott IO lapkákkal szerelt változatokat kivezetik, mert a több forrásból származó lapkák összerakása extra költség. De az is, hogy mindkét változat piacon marad más árszegmensek lefedésére.a 7nm-es IO lapka persze részemről nem bizonyosság, csak wishful thinking. Kevésbé lenne logikus a TSMC-nél 12nm-re áttervezni (10nm nem is tudom, hogy létezik-e még egyáltalán)
-
#5066
Petykemano
veterán
Petykemano
veterán
Érdekes a kontraszt.
Abu szerint idén nem lesz már semmilyen nagy durranás az AMD részéről. [link]
Warhol nem lesz, de ledobják az B2-es Vermeer-t és leteszik az asztalra Cezanne-t.
Aztán a Rembrandt (zen3+ @ 6nm) és a Raphael (zen4 @ 5nm) már 2022 és AM5Ehhez képest egy tag magabiztosan hangoztatja, hogy lesz egy új cpu (nem apu) az idei év második felében [link] ami nagyon erős lesz gaming terén, még az érkező Alder Lake-nél is erősebb [link]
Az én tippem (továbbra is) az, hogy a zen3+-os CCD-ket elkaszálták - ez lett volna a Warhol. Talán nem véletlen, hogy nemrég jelentették be, hogy a GF-zal lazítják a viszonyt. Talán ez a B2-es stepping egy új IO, TSMC-nél készülő IO lapkával készül, ami magasabb FLCK elérését teszi lehetővé.
Korábban volt szó arról, hogy azzal csökkenthetük a packaging költségek, ha a chipletek egy helyen készülnek, nem kell szállítani, stb Ha minden alkatrész a TSMC-nél készül, akkor egy ilyen váltás még abba a képbe is beleillik, hogy a 7nm-es zen3-ak gyártása budget vonalon hosszabb távon megmarad.
-
#5065
Petykemano
veterán
Petykemano
veterán
"B2 Stepping for Vermeer?! 😮
100-000000059-60_50/34_Y
3.4 GHz (up to 5 GHz)
Stepping: B2
Cores: 16100-000000065-06_46/37_Y
3.7 GHz (up to 4.6 GHz)
Stepping: B2
Cores: 6"
[link]Talán ez lesz az XT
(De a 6 magosnál nem látok különbséget.) -
#5061
Petykemano
veterán
hokuszpk
#5060
Petykemano
veterán
válasz
hokuszpk
#5060
üzenetére
szerintem viabilis lenne. (Nem feltétlenül csak a bányászat céljára és nem is csak a bányászat miatt magasra szökött árak miatt - tehát azért az elég nevetséges, hogy 250e-be kerül egy RX 580. De létezik a ócskarégideolcsó fogalma. Csak régen ezt átnevezéssel oldották meg. Lásd ezeket az R3 250, meg hasonlókat, amikat ezért szerintem OEM gépekbe csak képadási céllal időnként vettek )
De mások azt mondják, hogy bár a lapka talán olcsóbb lenne, de minden más vonatkozásban (gddr6, szubsztrát, összeszerelési és csomagolási kapacitás, stb) kapacitásokat vonna el olyan termékektől, amelyeken nagyobb a haszon.
Egyébként nem tudom gyártják-e még.
-
#5058
Petykemano
veterán
S_x96x_S
#5057
Petykemano
veterán
válasz
S_x96x_S
#5057
üzenetére
3 év leforgása alatt $1.6b = évi $500m, vagyis negyedévente kb $130m
Ez szerintem már elég kis tétel az AMD jelenlegi negyedéves jelentéseiben, ennek kb 10x-esét elkölti a TSMC-nél.
Ez egyébként havi $45m
Mondjuk ha a 12/14nm-es waferekre költi, ami mondjuk waferenként $3000 (?) az havi 15000 wafer. Ez szerintem nem olyan vészesen sok, mérettől függően 2-4 millió lapkát jelent.Ebből kell kiszolgálniuk a Rome és Milan termékek IO lapkáját, ha cserélni kell, és ha megtarjták budget katerógiára a 7nm-es gyártást (Vermeer), akkor ott is keletkezik igény.
Azt mondják egyébként, hogy kevésbé cutting-edge igényű FPGA-kat gyárthatnak még ott.
Meg hát ugye az örökéletű Polarist.Egyébként a GF-nak előbb-utóbb biztos elkészül a frissített 12nm-e, ami papíron sokat javít a fogyasztáson.
Az persze igaz, hogy ezek a mai gondolataink erről. És a kérdés úgy hangzott, hogy 2024-ig mit fognak kezdeni ezekkel a waferekkel. De úgy is nézhetjük, hogy chiphiány van. Egy rosszabb gyártástechnológián elkészített lapka bizonyos szempontból még mindigjobb, mint egy nem elkészített lapka.
-
#5054
Petykemano
veterán
S_x96x_S
#5053
Petykemano
veterán
válasz
S_x96x_S
#5053
üzenetére
S=Silent
Abu előrejelzései alapján várható volt az emelkedés, hiszen alacsony magszámú szerverek terén most vették át a vezetést és - abu szerint - az eladások nagy része még mindig ez a terület.
Ebből a szempontból még az Ice lake bezavarhat. De biztosan egyre többen bátorodnak fel. -
#5049
Petykemano
veterán
Petykemano
veterán
Roppant érdekes.
Branch prediktor tesztelés az egyes cpuk esetén és annak mérése, hogy milyen késleltetést eredményez az esetleges tévedés.
Elég beszédes. -
#5048
Petykemano
veterán
S_x96x_S
#5044
Petykemano
veterán
válasz
S_x96x_S
#5044
üzenetére
"We're very excited about our next generation which is our 5nm roadmap, we're committed to have that in the market in 2022 "
Lisa Su - [link]Eddig is úgy volt, hogy 5nm 2022-ben lesz csak, de korábban azt reméltük, hogy mondjuk 2022Q1-ben érkezhet a zen4 és a zen3+ vagy Warhol, vagy akármi, az csak valami szolid refresh, egy filler a valamivel hosszabb zen3-zen4 várakozási időszakban.
Aztán jött a hír, hogy a Warholt elkaszálták - és vele együtt felcsillant a remény, hogy talán csak nem azért, mert a vártnál előbb jön a zen4?
De Lisa Su tisztázta: nem, nem jön 2021Q4-ben zen4.
(noha ugye azt is mondta, hogy zen4 ES példányokat már szállítanak kiválasztott partnerek számára) -
#5047
Petykemano
veterán
-
#5046
Petykemano
veterán
S_x96x_S
#5044
Petykemano
veterán
válasz
S_x96x_S
#5044
üzenetére
Szerintem az 5nm-es gyártókapacitás eleinte (még ha nem is vagyunk már az 5nm-es gyártás elején, sőt, jövőre "elavulttá" válik), szűkös lesz.
Rémlik, mintha egyszer abu is említette volna, hogy a zen4-et az AMD szerverbe hozza először.
Önmagában ez nem volna meglepő dolog. Se ez, se az, hogy a DDR5 és a CCD fejlesztése sokáig tart. Az tűnik egymásnak ellentmondó hírnek, hogy
- egyszer kilövik a filler Warholt, ami alapján azt feltételezné az ember, hogy akkor biztos a zen4 hamarabb jön, vagy valami
- ugyanakkor meg nem, dehogyis, sőt.De ahogy tanult kolléga megállapította a Radeon találgatósban: mindegy, hogy milyen architektúra és milyen gyártástechnológán nem érhető el emberi áron.
-
#5045
Petykemano
veterán
paprobert
#5043
-
#5037
Petykemano
veterán
Petykemano
#5023
Petykemano
veterán
válasz
Petykemano
#5023
üzenetére
Hát ez eléggé lelombozó.
Az ember azt remélné, hogy ha már a Warhol körül forró a talaj (nem lesz, vagy valójában csak frekvenciaemelés lesz, stb), akkor legalább azért inogna meg, mert a zen4 (a vártnál) hamar(abb) jön.
Érdekes, hogy az előző heti kavarás után a Videocardz táblázataiban továbbra is szerepel a Warhol és továbbra is 6nm zen3+-ként. De Ha ez a zen4-re vonatkozó 2022Q4-es infó helyes, akkor persze érthető, valamibe kapaszkodni kell. Nehéz volna elhinni, hogy az AMD ezúttal még egy zenX+-szal sem erőltetné meg magát, arról nem is beszélve, hogy közben az intel támad az Alderlake-kel.
Ki tud eligazni ezeken a (dez)információkon?
-
#5023
Petykemano
veterán
S_x96x_S
#5020
Petykemano
veterán
válasz
S_x96x_S
#5020
üzenetére
Az MLiD videóban az egyik "forrás" azt állította - és én úgy értettem, hogy az egész műsor végülis erre futott ki - hogy Ő ugyan zen3+-ról nem hallott, de a Warhol egy valós kódnév, létező projekt.
Ez persze még nem jelenti azt, hogy
1) Az elhangzottak igazak. Azt például egyszerűen nem hiszem el - ugyanabból a videóból - hogy a 4700S az nem PS5 vagy xbox selejt, hanem egy Subor Z+-hoz hasonló "semi-custom" fejlesztés újrahasznosítása.
A kódnévről más leakerek viszont nem is hallottak.2) és azt sem feltétlenül jelenti, hogy a Warhol - amennyiben tényleg létezik - az, aminek eddig gondoltuk.
A 7nm megtartása mainstream/budget vonalra szerintem továbbra értelmes, logikus döntés lenne. Az 5nm-es gyártás biztos drágább és biztos van annak jobb helye is. Arról nem is beszélve, hogy abu mindig azt mondja, hogy a szerverpiacon sok évre előre kell vállalni azt, hogy adott lapkát fogják gyártani.
Ha nincs Zen3+, egy esetleges Warhol szempontjából akkor is szóbajöhető node a 6nm. Csak nem a compute lapkáknak, hanem az IO lapkáknak. Ha jól tudom, a zen4-et már 6nm-en készülő IO lapkákkal fogják párosítani. De máskülönben a 6nm-es Rembrandtban is 6nm-es lesz az uncore. Azt láttuk, hogy a 14nm-es IO lapka már elég sokat eszik és bizonyára limitációt jelent a FCLK szempontjából is. Logikus lenne, ha a zen3 6nm-es IO lapkával élne tovább.
Ezzel persze nem azt akarom mondani, hogy szerintem biztosan megvalósul. Éppenséggel kaphatott kaszát mondjuk amiatt, hogy a 6nm-es Rembrandtra kell a gyártókapacitás.
-
#5008
Petykemano
veterán
Petykemano
#5007
Petykemano
veterán
válasz
Petykemano
#5007
üzenetére
Mindkettő HPC szegmens, szerverek, cloud, de
V1 => Single Thread fókusz. Ezt az x86-tal mag alapon hasonlítják
N2 => MultiThread fókusz. Ezt az X86-tal szál alapon hasonlítják
A hangsúly persze mindig a perf/W-on van."In fact, in an ISO-process comparison, the Neoverse V1 is about 1.7x the area and 0.7x-1x the power efficiency of the Noeverse N1. The V1 maintains the same frequency as the N1 therefore all of its performance improvements comes entirely from its ~1.5x IPC uplift and the new ISA extensions."
A képek alapján ( [link] , [link] ) úgy tűnik, hogy az IPC növekedés nagy része jellegében hasonló megoldásból fakad, mint az Apple M1 esetén: felvastagított bufferek, meg szélesebb decoder. (Ezzel nyilván nem kívánnám azt sugallni, hogy semmi más teendő nincs, mint megnövelni a buffereket.)
V1: átlag 48% IPC növekedés
N2: átlag 32%-os IPC növekedés
A Neoverse N1-et az Arm 2019 februárban indította útjára.
Kicsivel több, mint 2 év telt el a következő verzióig. És ez átlag 30-50%-os IPC növekedést hozott. Ezek - a számok - persze már 5nm-re vannak kalibrálva. Tehát mondhatjuk, hogy az Arm bölcsen használta fel a többet tranzisztorokat.Nem önmagában az IPC növekedés tűnik figyelemre méltónak. Mert erre mondhatjuk, hogy az AMD is szokott generációnként 15-20% IPC növekedést hozni, ami két generáció alatt szintén 40%-ot jelent.
Viszont úgy tűnik, hogy az Arm-nél ez a 40+% valamivel mintha gyorsabban jönne össze (2 év 2 hónap vs 2 év 6 hónap)
Hanem az is figyelemreméltó, hogy a 30-50%-os IPC növekedés mellett még a magok számát is sikerült derakasan növelni
Ami még igazán érdekes lesz, hogy mindezt milyen fogyasztás mellett hozza.A magszám növekedést persze az AMD is hozni fogja a zen4/Genoa-val. De ebből szerintem idén már lesz graviton platform az AWS-ben. És azzal szemben a Milan ki fog kapni.
Szóval az AMD felkötheti a gatyát.
-
#5007
Petykemano
veterán
Petykemano
veterán

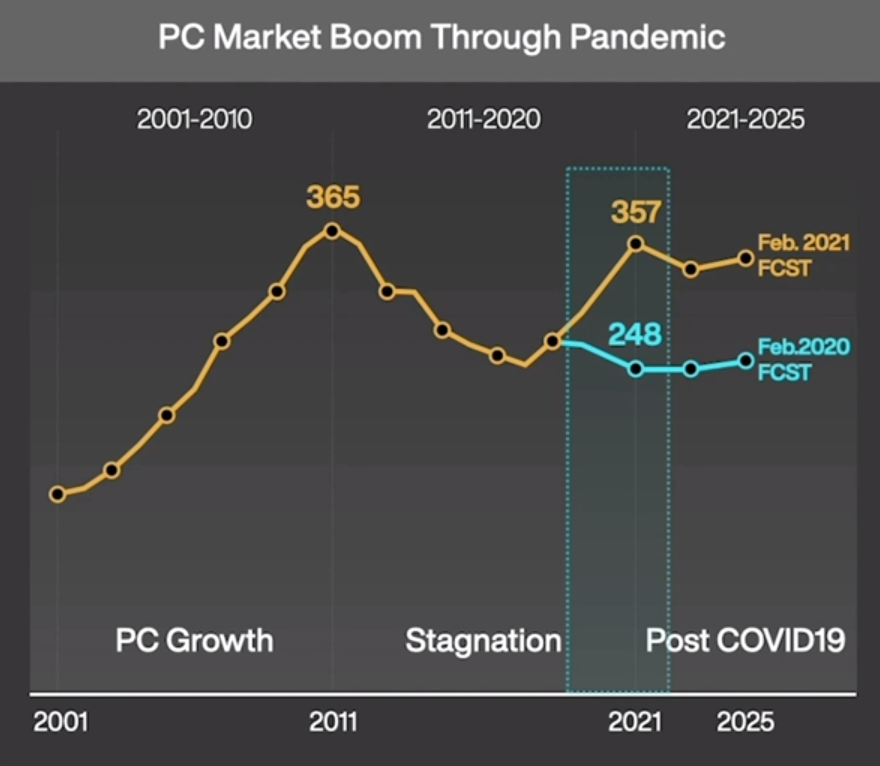




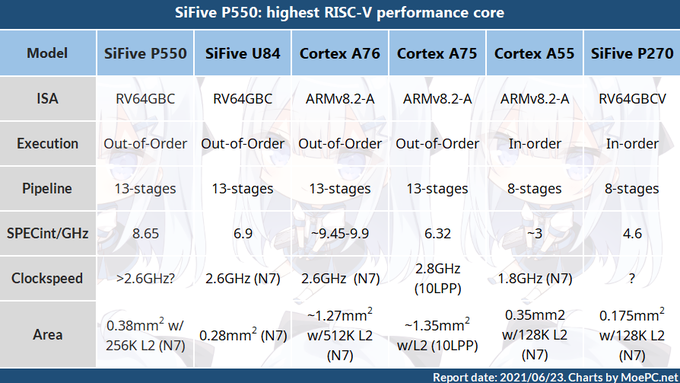






 Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."


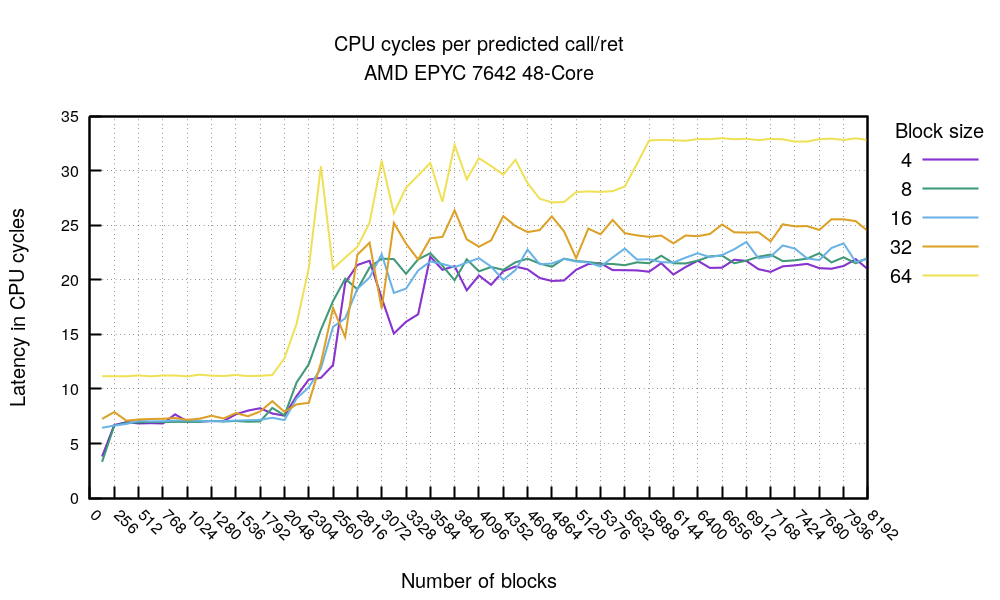
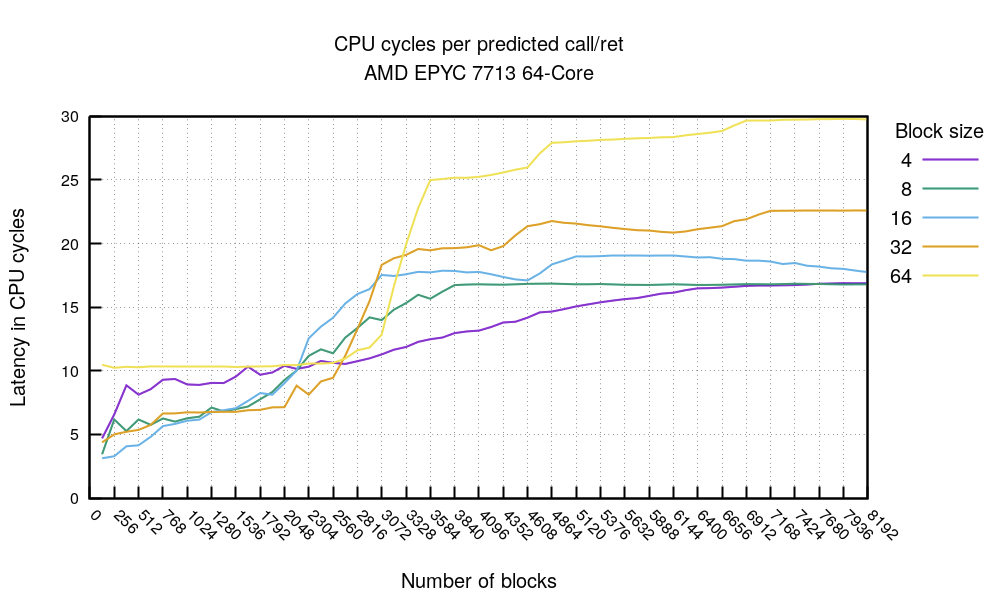
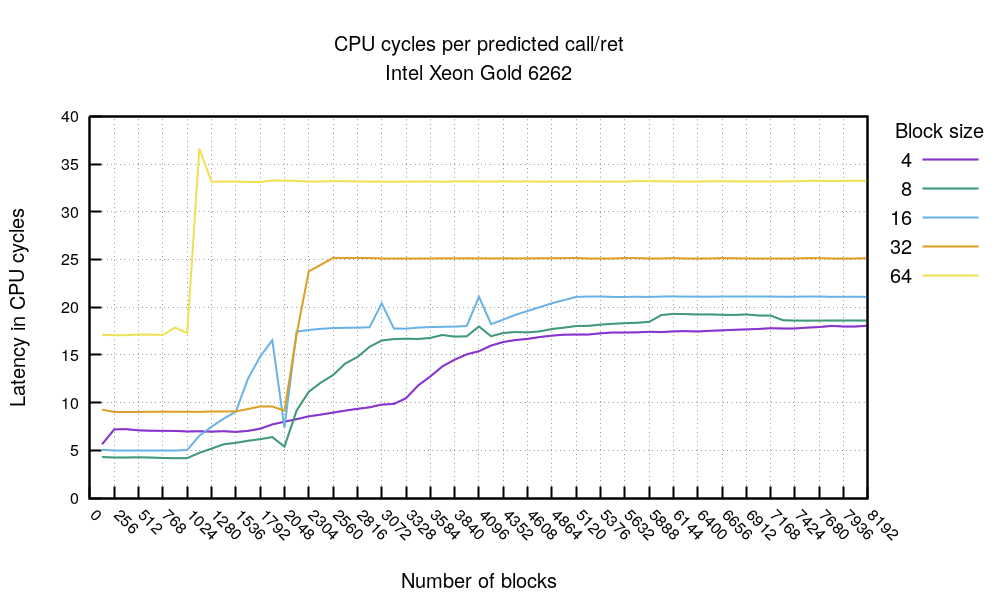
Új hozzászólás Aktív témák

- Samsung DLP projektor, The Freestyle SP-LSP3B
- Samsung Galaxy S10 128GB, Kártyafüggetlen, 1 Év Garanciával
- Targus DOCK423A - USB-C Dual HDMI 4K HUB - 2 x HDMI (120Hz)
- BESZÁMÍTÁS! MSI H310M i5 9500 16GB DDR4 120GB SSD 2TB HDD RTX 2060 Super 8GB ÚJ Zalman T4 Plus 600W
- Bontatlan, Sony PS5 PRO Pro 2TB, lemez mentes verzió
Állásajánlatok

Cég: Laptopműhely Bt.
Város: Budapest

Cég: ATW Internet Kft.
Város: Budapest