- Megtartotta Európában a 7500 mAh-t az Oppo
- Android alkalmazások - szoftver kibeszélő topik
- Folytatást kap a legjobb méretű hajlítható
- Samsung Galaxy A54 - türelemjáték
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Okosóra és okoskiegészítő topik
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- Minden a BlackBerry telefonokról és rendszerről
- Google Pixel topik
- Ismét az Apple veheti át a piacvezető pozíciót
Új hozzászólás Aktív témák
-

carl18
addikt
válasz
 paprobert
#2796
üzenetére
paprobert
#2796
üzenetére
Igen, ahogy mondod ez ketyeg és egyszer megadja magát.
Én arra lennék kíváncsi valaki vesz egy ilyen raptor lake-t, 3 év garancia ami jár neki.
Szóval 3 év alatt ha többet terheli renderel megadja magát 2-3 darab és mi lesz ha egy idő után a cég ráun és talál kiskaput ne kelljen a garanciát érvényesiteni.
Azért egy idő után ez nekik minusz/bukás.
Most a Arrow Lake a intel nagy esélye, esetleg a Nova Lake lenne a nagy platform váltás.
8P mag 32E meg de a Nova lake esetén jöhet az virutális mag így a 8P mag ismét 16 szálas lehet. Eddig azt hittem 16P mag 32E core a Nova lake és az igazán jó vétel lett volna. Aztán a AMD is játszhat ilyenekkel, hogy 16 Core Zen6+32Core Zen5C.
Intelnek erre tuti nem lenne válasza.
-

hokuszpk
nagyúr
válasz
paprobert
#2775
üzenetére
"Az átlagkésleltetés csökken szál áthelyezéskor, igen."
azért erre kiváncsi lennék ; szoftveres szempontból ez ha jólemléxem úgy néz ki, hogy van egy utasítás, ami elmenti a cpu állapotot ( -> memoria ) majd amikor ujra ütemezi az ütemező, akkor van rá másik utasítás, ami visszatölti. Tehát az egyik magon mentjük, a másikon visszatöltjük ; ezt csak úgy lehetne gyorsítani, ha a hwbe valahogy beledrótozzák az ütemezést. ( mint az AMD vgaknal az a HAGS vagymi. )
-
#2771
 Petykemano
veterán
paprobert
#2770
Petykemano
veterán
paprobert
#2770
-
#2758
Petykemano
veterán
paprobert
#2757
Petykemano
veterán
válasz
paprobert
#2757
üzenetére
Tartok tőle, hogy a különbség nem csak abból fakad-e, hogy a Meteor Lake esetén csak 8 csomópont van. Ha jól emlékszem 8-nál több csomópont már korábban sem eredményezett optimális késleltetést. (Comet Lake)
Nekem a kezdetektől az a véleményem, hogy az Intel E mag nem a standby mód alacsony fogyasztását célozza,.hanem mainstream magot akarnak belőle csinálni.
Megnéznem a Meteor lake-et 6:8 helyett 4:16 felosztásban is.
Mindazonáltal ott.van a rentable units is, ami hozhat még érdekességeket. -
#2750
Petykemano
veterán
paprobert
#2749
-
#2723
Petykemano
veterán
paprobert
#2722
Petykemano
veterán
válasz
paprobert
#2722
üzenetére
Nem teljesen bulldozer/modul.
Pontosabban a bulldozer modul megvalósítása csak részlegesen felelt meg annak, amit most elvileg az Inteltől pletykálnak.A modulok esetén a frontend és tulajdonképpen a FP számítóegység volt közös, vagy részben közösen használható. De az Integer számítókapacitás teljesen partícionált volt, nem tudta a modul a benne rejlő INT számítókapacitást egy szál futtatásának szolgálatába állítani még részlegesen sem.
Őszintén szólva, ha erre képes lett volna, ebbéli felépítését tekintve nem tudom ténylegesen mi különböztette volna meg a Zen magoktól. (Nyilván a késleltetések és a cache felépítés még nagyon sokat hozzátesznek.)
Anno az Intel megvette a Soft Machines, akik a VISC ígéretével házaltak. Ez nagyjából arról szól, hogy egy a fizikai magok fölé létrehoz egy virtuális réteget és egy programszálat futtat több egyébként különálló mag erőforrásain. [link]
Elképzelhető, hogy ezt építi be az Intel.
De hogy őszinte legyek nem teljesen világos számomra, hogy mi különbözteti meg a hagyományos SMT-t, amit ugye úgy képzelünk el, hogy egy frontend képes két programszálat futtatni a mag erőforrásain, amit ebben az esetben partícionál a szálak között és azt, hogy képzeletben két mag erőforrásait összevonjuk egy szál kiszolgálásához.
Persze nyilvánvaló különbség, hogy azt gondoljuk, hogy egy mag erőforrásai az általa kiszolgálni képes szálak között eleve megosztott, míg ha úgy gondolkodunk, hogy magokat vonunk össze, azt úgy képzeljük, hogy a magok erőforrásai alapból statikusan partícionáltak.Ugyanakkor az SMT/HT esetén sem minden oszlik el a kiszolgált szálak között statikusan:
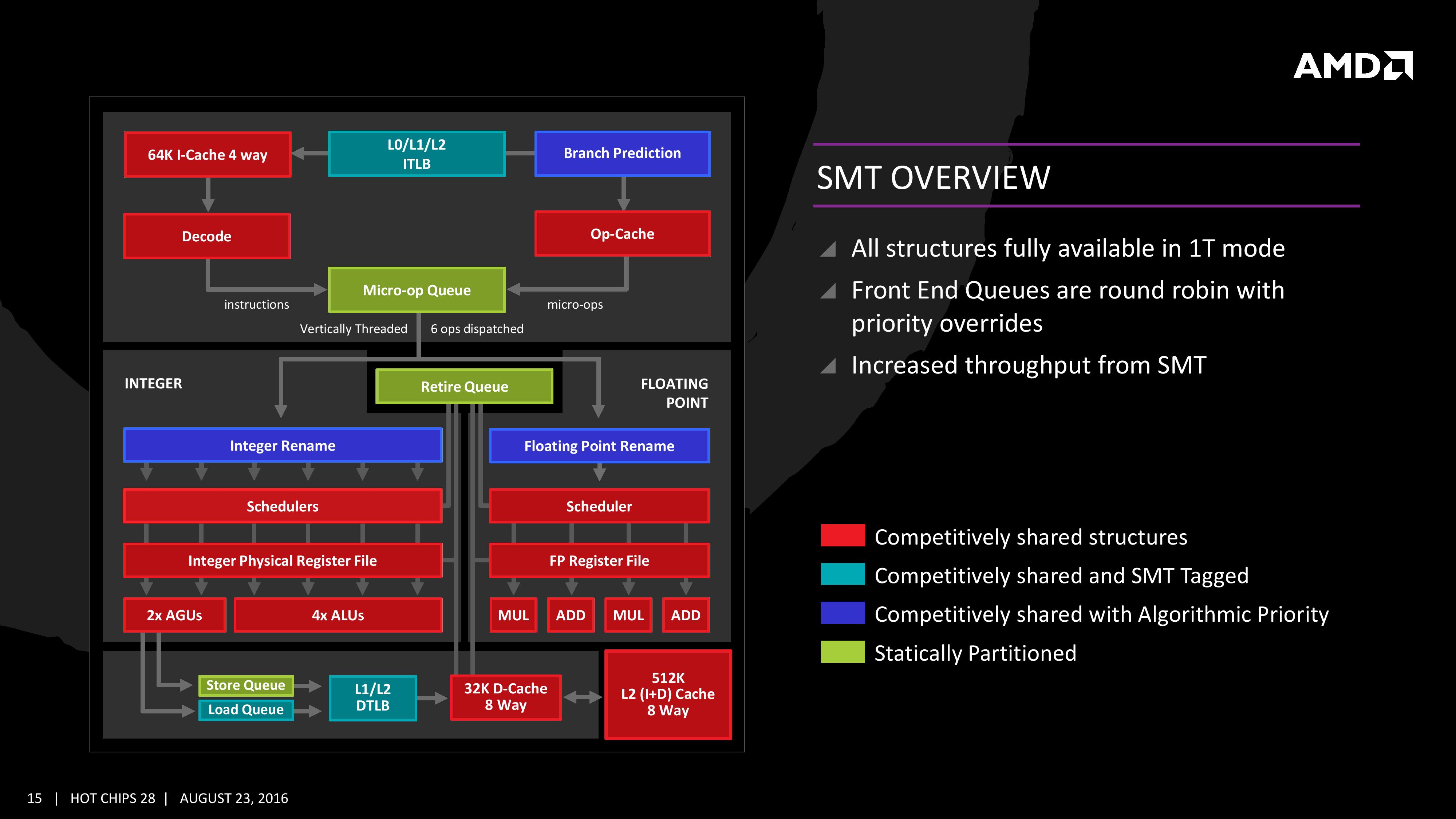
Az Intel már egy ideje szélesítgeti a magokat.
Nem ástam bele magam, de ha nem a Soft Machines-től felvásárolt megoldásról van szó, akkor szerintem csak arról, hogy tovább szélesítik a magot és igyekeznek a szálak közötti erőforrás-partícionálást még dinamikusabbá tenni. -
#2714
Petykemano
veterán
paprobert
#2713
Petykemano
veterán
válasz
paprobert
#2713
üzenetére
""On MTL, GT can no longer allocate on LLC - only the CPU can. This, along with addition of support for ADM/L4 cache calls a MOCS/PAT table update.""
Számomra most nem egyértelmű, hogy mi használhatja majd az L4$-t és mit nevez LLC-nek (Last Level Cache)
De ha tippelnem kéne, vagy tippet kéne adnom, akkor én azt csinálnám, hogy szétválasztanám a P és E magok L3$ szeleteit, külön CCX-be szervezve őket. Persze a P magok esetén hasznos a minél nagyobb L3$, de biztosan számít a gyűrűn levő megállók száma is és az E magok leválasztásával biztosan lehet nyerni késleltetést, miközben amúgy sincs semmilyen gyakorlati haszna, ha a P magról egy folyamat E magra pattan át.
Viszont hogy mégse legyen akkora penalty amiatt, hogy ilyen esetben mégiscsak a memóriához kell fordulni, ezért hasznos az L4$ bevezése.
Az egyes mag komplexumok szétválasztása lehetővé teszi azt is, hogy további késleltetési büntetés nélkül tudják növelni az E magok számát.












Új hozzászólás Aktív témák

- GeForce GTX 1650 SUPER (OEM HP) -
- Lenovo ThinkPad T14S Gen1 Intel i5-10310U Refurbished - Garancia
- Bomba ár! HP ProBook 440 G5 - i5-8GEN I 8GB I 256GB SSD I HDMI I 14" FHD I Cam I W11 I Garancia!
- Xiaomi 11T 128GB, Kártyafüggetlen, 1 Év Garanciával
- GYÖNYÖRŰ iPhone 12 Pro 128GB Graphite-1 ÉV GARANCIA - Kártyafüggetlen, MS3669, 100% Akksi
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: ATW Internet Kft.
Város: Budapest