Hirdetés
- One mobilszolgáltatások
- Kezünkben a OnePlus 15 és az Oppo Find X9-ek
- Samsung Galaxy S21 és S21+ - húszra akartak lapot húzni
- Netfone
- Milyen okostelefont vegyek?
- Android alkalmazások - szoftver kibeszélő topik
- Honor Magic6 Pro - kör közepén számok
- Örömhír: nem spórol Európán a OnePlus
- Honor Magic5 Pro - kamerák bűvöletében
- iPhone topik
Új hozzászólás Aktív témák
-
#5902
 Petykemano
veterán
S_x96x_S
#5901
Petykemano
veterán
S_x96x_S
#5901
Petykemano
veterán
válasz
 S_x96x_S
#5901
üzenetére
S_x96x_S
#5901
üzenetére
Tulajdonképpen akkor csak akkor előnyös, amikor a 2 csatornával több magot szeretnél kiszolgálni. Tehát mondjuk lehet, hogy productivityben az 5950X megköszönné. De egy 5600X esetén nem tapasztalnál különbséget. Kivéve persze ha a magasabb késleltetés miatt még lassabb is.
A gyengébb késleltetést pedig végső soron nagyobb L2$/L3$ mérettel kell kompenzálni.Ezzel együtt a DDR5 átmenet meg fog történni. Lehet, hogy rosszabb, de a növekvő density miatt majd mindenki kénytelen lesz majd elgondolkodni, hogy 32GB DDR4-et vagy 64GB DDR5-öt vesz-e ugyanannyiért. Persze nem most.
-
válasz
S_x96x_S
#5892
üzenetére
Igazán megmondhatnák már, mi a módszertana az overall share számításának, 2021 Q2-bn is magasabb volt az overall, mint a részek együttese.
2021Q2
overall: 22,5%
desktop: 17,1%
mobility: 20%
server: 9,5%
viaHogy jön ebből ki a 22,5%?
Most is gyanítom ugyanez lesz, minden részhalmaz alatta lesz a 24,6%-nak. -
#5872
Petykemano
veterán
S_x96x_S
#5871
Petykemano
veterán
válasz
S_x96x_S
#5871
üzenetére
Ha Ezek az árak stabilizálódnának, azért az nem volt túl örömteli.
Tegyük mellé a 6 magos ryzenek eredményeit is
5600G: ~4000
5600X: ~4400Mikor utoljára néztem, az 5600G 95-100eFt, az 5600X pedig 98-100eFt körül volt.
Ha így nézzük, akkor az 5600G-hez képest 50%-kal jobb MT pont 35-40%-kal drágábban.
Az 5600X-hez képest 35-40%-kal több MT pont 20-25%-kal drágábban.Ami hát persze még mindig előrelépés, de azért nem annyira fényes. Ha a tendencia - hogy a teljesítménynövekedéssel 10%-kal lemaradva lépést tart az áremelkedés is - folytatódik, akkor a processzorok magszám-forradalma elmarad, hamarosan újra 2-4 magos gépekben fogunk majd gondolkodni.
-
válasz
S_x96x_S
#5861
üzenetére
AMD oldalán is fent van, linkelem, hátha van más is, mint az anand cikkben.
Taps a szövegírónak:
The year-over-year and quarter-over-quarter increases were primarily driven by a richer mix of EPYC™, Ryzen™ and Radeon™ processor sales.Ezt nagyon szomorúan olvasom 2400G tulajként.

AMD partnered with Microsoft to bring powerful, reliable computing to users with Windows 11, powered by Ryzen processors and Radeon graphics. Through this collaboration, more than 175 AMD CPUs are now compatible with Windows 11 operating systems to drive ultimate PC and gaming experiences. -

S_x96x_S
addikt
válasz
S_x96x_S
#5861
üzenetére
"""
$AMD does what you'd expect and smashes Q3. Highlights:-Rev +54%; GM +70%; GM percent +450 bps-Opinc +111%-NI +137%-DC market doubles (Epyc + Instinct)-CCG +44%; CPU/GPU ASP increase-EESC +69%; Epyc and semi-customIsn't growth mode fun?
https://twitter.com/PatrickMoorhead/status/1453103230330736641
-

HSM
félisten
válasz
S_x96x_S
#5845
üzenetére
"és az AMD eddig is egy picit rugalmasabb volt"
Önállósodásra ez a fajta "semi-custom" szvsz egyáltalán nem megfelelő, amit az AMD kínál. Ez más, mint mikor kapsz egy licenszt és tervezhetsz sajátot.Megnéztem mit mond erről a wikipedia: "Partly. For some advanced features, x86 may require license from Intel; x86-64 may require an additional license from AMD. The 80486 processor has been on the market for more than 30 years[1] and so cannot be subject to patent claims. The pre-586 subset of the x86 architecture is therefore fully open." [link]

Én erről a témáról azt gondolom, nem feltétlen az utasításkészlet, amin állni vagy bukni fog a dolog. Persze, egy jól megtervezett ISA azért előny lehet. Illetve kritikus fontosságú a szoftveres oldal, az x86 jelenlegi legerősebb oldala szvsz ez, az elérhető szoftveres infrastruktúra és kompatibilitás.

-

Busterftw
nagyúr
válasz
S_x96x_S
#5845
üzenetére
"X86-64 vonal az már szinte duopólium .. ( Intel + AMD )
habár az Intel tele van most igéretekkel ."
Ugye most lesz Intel bergyartas es arrol is beszeltek, hogy akar sajat designt is lehet licenszelni.
Ezzel nem lesz automatikusan elerheto "barki" szamara a X86-64?
Vagy legalabb a x86. -
#5842
Petykemano
veterán
S_x96x_S
#5841
-
#5840
Petykemano
veterán
S_x96x_S
#5839
Petykemano
veterán
válasz
S_x96x_S
#5839
üzenetére
( mindenki ~ akinek van rá erőforrása)
Valaha volt nemzetállami szabályozás - amely értelemszerűen kifelé vámhatárokat, befelé pedig fogyasztóvédelmi és versenyjogi szabályok érvényesítését jelentett. Persze egyrészt ezek a cégek túlnőttek a nemzetállami határokon, másrészt (bár lehet, hogy részben emiatt) sajnos ezekben a modern időkben nemzeti hatóságok felügyelete alatti szinten ritka a verseny, nemzetek vagy inkább most már kontinensnyi tömbök legfeljebb egymással versengenek. A nemzeti bajnokok korát éljük.
Az intel is állami tízmilliárdokból fejleszt, de talán a Samsung is, és az EU is tízmilliárdokkal igyekszik idecsábítani a chipgyártókat.
Ezzel csak azt akarom mondani, hogy pénze bárkinek lehet, akinek van egy pénz kibocsátására nemzeti bankja és/vagy a hátát tartó (=adófizetők pénzét osztogató) állama.
Ezzel együtt tényleg érdekes.
Most vagy az van, hogy szoftverszolgáltatók halálra keresték magukat az elmúlt években sokkal többet keresve egy felhasználón és és így hiába a többéves szakértelem, lényegesen kisebb kasszából tudnak fejleszteni a hardvergyártók.
Vagy ennyire könnyű Arm alapon fejleszteni, hogy a bolondnak is megéri.
Vagy azért lesz ezekből a projektekből pár, amit majd szép csendben elengednek. Volt pár arm szerverchip fejlesztő az elmúlt években és úgy igazán senki nem harapott rá egyikre sem. Az Ampere is küszködik. És azt persze mindenki elmondja, hogy az általános felépítés nem jó mindenhová, de én itt ebben a cikkben nem olvastam semmit, hogy mi lesz az az különleges dolog, amit nem találtak meg a piacon. Ami leginkább arra utal, hogy inkább arról lehet szó, hogy azt gondolják, hogy 50-100 millió dollárból ők is össze tudnak legózni egy Arm procit, ami lényegesen kevesebb, mint kifizetni 500-1000 milliót kész chipekre. -
#5828
Petykemano
veterán
S_x96x_S
#5823
Petykemano
veterán
válasz
S_x96x_S
#5823
üzenetére
Hát igen...
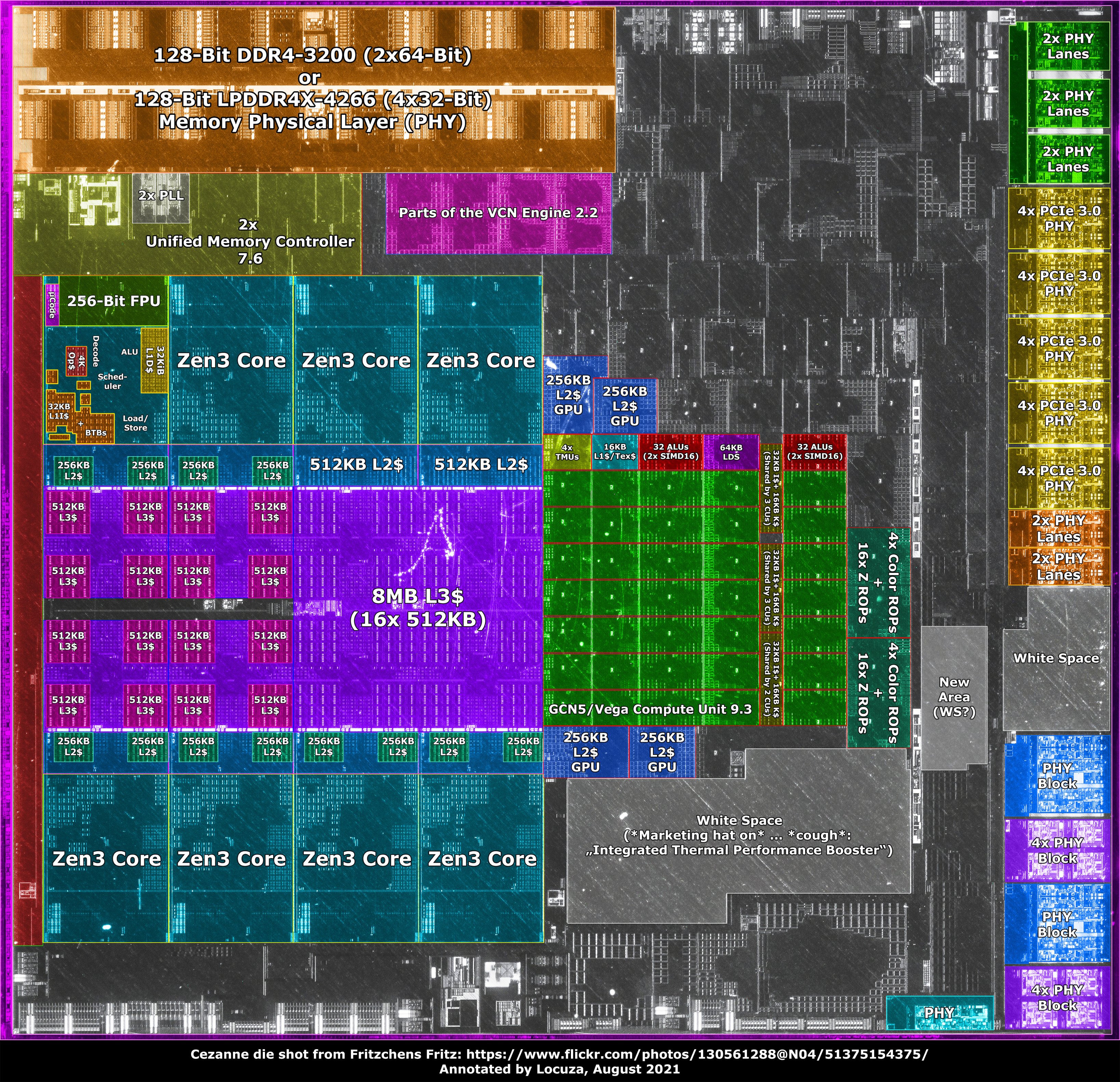
Bár nem mondanám, hogy az AMD mostanában olyan nagy szekértolója lett volna az APUknak. Kivéve persze a semi-customot. De asztali/notebook piacon úgy tűnik nem látta eladhatónak/kifizetődőnek a komolyabb apuk bevetésének. A Renoir és a Cezanne legalábbis elég vékony apuk voltak. Munkagépekbe való, ami képet ad dGPU nélkül, vagy gamer notiba dGPU mellé tarcsiba. De nem célozták az önálló nagyteljesítményű APU... hát talán mondjuk úgy fogalmát. Hogy piaca van-e, azt szerintem most fog majd kiderülni az Apple jóvoltából.Azt nem tudom, hogy a CPU részen bütyköltek-e valamit, ezért azt most skippelem. Nekem úgy tűnik, hogy nem igazán, mármint persze azon kívül, hogy 4 helyett 8 performance mag van. Ez magyarázza, hogy hogy jön ki a ~2x akkora CPU teljesítmény ~2x akkora fogyasztásból. Persze a hasonló fogyasztású konkurenciához képest az előny impozáns.
A legimpozánsabb talán a görbék meredeksége - hogy az Apple mennyire a meredek részen skáláztatja.Ami az IGP részt illeti. Hát igen....
M1 PRO
256bit LPDDR5 = 200GB/s (32GB)M1 MAX
512bit LPDDR5 = 400GB/s (64GB)... ezek azok a sávszélességek, amikre mindig is gondoltunk, hogy illene, meg kéne, ha nem csak prüntyögőnek szánják.
De nézzük a másik oldalát is:
az M1 120mm2.
A képen 120px * 120px, az M1 Maxra pedig 220x240-et mértem azaz az M1 MAX egy ~440mm2-es lapka.
Ráadásul ez 5nm-en!Ez elég brutális, olyan, mintha az AMD hozzácsomagolna a 6800XT-hez egy CCD-t is!
(Nem is számolva azzal, hogy a Apple lapkái általában azonos gyártástechnológián is sűrűbbek, mint az AMD-i)Ezzel nyilvánvalóan lőttek a Apple megrendelésére gyártott AMD GPU-knak is.
De elnézve ezeket a perf/W grafikonokat még inkább kiváncsi vagyok, az Apple sikeresebben veszi-e majd fel a küzdelmet a bányászokkal, mint az Nvidia, vagy ő maga fogja kínálni a Store-ból némi jutalékért cserébe?
A jó hír az, hogy talán nemsokára lesz 7nm-es GPU a boltokban. -
HSM
félisten
válasz
S_x96x_S
#5825
üzenetére
"Az 5nm sokat számít."
Igen.
Illetve arra akartam célozni, hogy tényleg durva nagy szám, amiből az is következik, hogy így "könnyű" 70%-al megverni a konkurenciát perf/watt, ráadásul +2 maggal, jelentsen bármit is a különösebb konkrétumokat nélkülöző ábra.
És még csak nem is egy takarékosra hangolt aktuális Ryzent, hanem egy 45W-os Core i7-11800H-t szerepeltettek ellene, amiről nekem nem épp az ideális perf/watt jut eszembe... -
#5819
Petykemano
veterán
S_x96x_S
#5817
Petykemano
veterán
válasz
S_x96x_S
#5817
üzenetére
> addig most az Intel az AlderLake-el
> a mobil-desktop vonalat kezdi összevonni.
> és a desktop architektúrát egyszerűen le tudja vinni mobilra.
Ez elég régóta így volt. Kivéve persze, hogy a chip mobilra (15-45W) volt tervezve és azt árulták desktopban is elengedve a fogyasztást.
A 10nm miatt vált némileg ketté a mobil portfólió ami által lettek olyan 10nm-es termékek, amik nem jelentek meg a desktop kínálatban.> míg az AMD a Desktop-Workstation-Server vonalat helyezte közös alapra ( közös chiplet )
> és az APU külön került kezelésreA jelenlegi konszenzus az, hogy a chiplet késleltetésben és fogyasztásban (idle) némileg hátrányban van a monolitikus designokhoz képest, de rendesen skálázni csak chiplettel lehet. (Kivéve Arm)
A nagy bravúr az lenne, ha az AMD megoldaná, hogy ugyanazt a chipletet használja mobilban, desktopon és szerverben anélkül, hogy csorbát szenvedne a chiplet miatt a fogyasztás. Ez azért a szervereknél is fontos tényező.> A mobil erőltetett menet gyökere szerintem az Apple-től kapott fricska volt.
Az intel az Apple-től több fricskát is kapott. Egyrészt perf, másrész perf/W téren.
Szerintem az Intel célja a hybrid architektúrával kettős. Egyrészt a kis magok jók lehetnek arra is, hogy javítsák a standby vagy idle üzemidőt. Másrészt viszont elég biztosnak látszik, hogy a throughput teljesítményt kis magokkal fogja megoldani. -
#5813
Petykemano
veterán
S_x96x_S
#5812
Petykemano
veterán
válasz
S_x96x_S
#5812
üzenetére
Szegények kénytelenek lesznek a Raptor Lake ellen virítani valamit.
Ez szerintem egy sima asztali zen4 lesz, amit jól leválogatnak alacsony szivárgásra és kiadják 35-45W-os vonalon. Kétségtelen, hogy nem ideális, a chipletnek lehet némi többletfogyasztása, de talán versenyképes megoldás és jobb, mintha széttárnák a kezüket, hogy ott a 8 magos Rembrandt, vagy fél év múlva a (valószínűleg szintén) 8 magos Phoenix.
-
#5799
Petykemano
veterán
S_x96x_S
#5206
Petykemano
veterán
válasz
S_x96x_S
#5206
üzenetére
Zen3d, v-cache
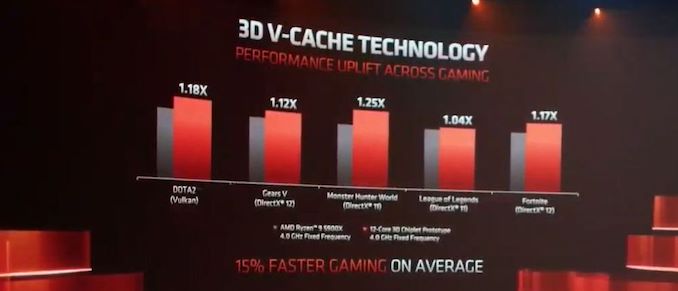
Azon gondolkodom, hogy Vajon lehetett-e csalafintaság abban, hogy 4GHz-es modellt teszteltek.
- vajon ez egy underpromise-overdeliver szituáció lesz, mert a frekvenciát is növelik majd?
- vagy épp ellenkezőleg, a v-cache fogyasztása és egyéb időzítési okokból az elérhető frekvencia romlik majd?
- csupán arról van szó, hogy az ES-t szokásos módon egy alacsonyabb frekvencián tesztelték és kész. -
HSM
félisten
válasz
S_x96x_S
#5788
üzenetére
A legérdekesebb: "If rumors surrounding the late-October/early-November launch dates of 12th Gen Intel Core "Alder Lake" processors are true, then the situation with these patches will have a direct impact on AMD. Processor reviewers will be compelled to use Windows 11 for their Core "Alder Lake" testing, as the new operating system supposedly has greater awareness of the heterogeneous core design."
Majd lehet nézni a review-ok kisbetűs részeit, fenn voltak-e AMD-n a megfelelő patchek (ha addig valóban a helyükre kerülnek egyáltalán a dolgok)....
-
#5784
Petykemano
veterán
S_x96x_S
#5783
Petykemano
veterán
válasz
S_x96x_S
#5783
üzenetére
Hát ez egy ilyen kétoldalú valami - Pat Gelsinger interjúja.
Ha egyik oldalról nézem, akkor "a kutya ugat, karaván halad". Technikai szemmel nézve egyelőre nem látszik az intel visszatérése. Szerintem
Ha a másik oldalról nézzük, akkor meg szintén a "kutya ugat, a karaván halad", csak épp a kutya itt az AMD és úgy kell érteni, hogy valójában az Intel sosem veszítette el az elsőséget. Ami volumen meg cégkapcsolatok tekintetében nagyon is igaz, tehát ha lerak valamit, ami csak annyira jó, hogy már befogott orral el lehet fogadni, mert a korábbiakhoz képest előrelépés, már az záruló ajtókat jelenthet az AMD-nek és nyíló pénztárcákat az Intelnek. -
#5782
Petykemano
veterán
S_x96x_S
#5780
Petykemano
veterán
válasz
S_x96x_S
#5780
üzenetére
> A Gen5 jó hír
Ne vedd tutira. Az első gondolatom nekem is az volt és a VCZ is ezzel a kétkedéssel folytatta, hogy RH nem mondta, hogy a Raphael rendelkezni fog PCIe5 támogatással, csak azt, hogy az AM5. Olyat meg már láttunk, hogy az AM4 rendelkezik PCIe4 támogatással, se ez nem kötelezi PCIe4 támogatásra sem az összes ezzel a foglalattal kompatibilis processzort, de még azonos generációhoz tartozó chipsetet se.> elég erős hatást kelthet a piacon.
Ez erősen ár függvénye. Ha $200-ért ledobják, akkor az tényleg elég jó. $250-ért már picit meh - Az én standardjaimmal mérve: mivelhogy úgy csak 5%-kal jobb, mint az 5600X, aminek eleve $250-nak kellett volna lennie és tulajdonképpen már most is $250-ért megy.Nekem egyébként a RH interjú egy picit ilyen neszesemmifogdmegjól érzetet keltő volt. Megerősítették, amit eddig is tudtunk - tőlük. Hiszen eredetileg is úgy volt, hogy idén év végén kerül tömeggyártásba a V-cache és sejthető volt, hogy abból jövő év elején lesz termék. Azt is tudtuk, hogy Rembrandt jön. De persze lehet, hogy az ilyen hivatalos beszélgetések visszhangja messzebbre elér azoknál, mint akik kifejezetten hegyezik a fülüket.
-
HSM
félisten
-
HSM
félisten
válasz
S_x96x_S
#5760
üzenetére
Az impulzus vásárlónak szvsz édesmindegy az is, hány magos. Neki megtetszett az a szép zöld pici gép a kirakatban, megveszi, kész.

Szvsz nagyobb baj, hogy a technikai hátterűeknek is egyre nehezebb eligazodni, mert egyre kevesebb a pontos, technikai specifikáció.

Én pl. elég durván meglepődtem, mikor kiderült, hogy a 4650U-s Renoir CPU-m nem támogatja a CPPC-t és a magonkéti feszültség szabályozást, csak az asztali és "Lucienne" átmatricázott kiadásai.
 Ettől persze nem lett kevésbé jó CPU, de a felfedezés eléggé váratlanul ért "CPU-érdeklődőként" is.
Ettől persze nem lett kevésbé jó CPU, de a felfedezés eléggé váratlanul ért "CPU-érdeklődőként" is. -
HSM
félisten
válasz
S_x96x_S
#5758
üzenetére
Ezt a marketinget már eljátszották a négymagos "Pentium" atomokkal, amiket egy picit drágább nem-atom alapú kétmagos Celeron is körberöhögött.
Ilyen szempontból a 2 > 4 néha mégis igaz.De szerintem ilyen árkategóriájú gépet, mint egy ilyen Alder/Zen már többségében nem olyanok vesznek, akik nem néznek utána. Ott pedig igen hamar ki fog derülni, kinek milyen kártyái vannak.
Az energiatakarékossághoz szerintem hozzátehet majd az új GPU, és a modernebb gyártástechnológia is, mégha ez csak egy half-node is.
No, és persze a pontos konfigurációt, vezérlő szoftvert is lehet mindig kicsit csiszolgatni. -
HSM
félisten
válasz
S_x96x_S
#5756
üzenetére
Volt róla szó, hogy ez lesz a "standard" mobilos lapka (BGA Type3 [link] ).
Ami nekem újdonság, hogy ezt már 12W-tól be lehet vetni.Én amúgy erre a szegmensre vagyok a leginkább kíváncsi, mit tudnak ebből a konstrukcióból kihozni, akkus üzemidő kontra sebesség az ultrahordozható kategóriában (~12-25W). Ebben egyébként az AMD jelenlegi nyolcmagosa erős terhelés mellett igen jó, de folyamatos alacsony terhelésen szvsz nem a leghatékonyabb.
-
#5750
Petykemano
veterán
S_x96x_S
#5749
Petykemano
veterán
válasz
S_x96x_S
#5749
üzenetére
Amikor ilyen "dinnye" jellegű dolgokkal jött az AMD, akkor lesajnálást kapott, meg persze a fogadtatás is az volt, hogy már semmire sem socketenként, hanem magonként, esetleg 32 magonként kell licence-t fizetni - és hogy ehhez képest a CPU ára nem olyan sokat nyom a latba.
Jól értem egyébként a benchmarkot, hogy 2P konfigurációban a 2x128 magos Ampere Altra max hozta a 2 x 64C/128T Milan-t?
az N2 és V1 IPC növekedése eléggé hívogató volt. Abból vajon mikor készül Ampere?
-
#5734
Petykemano
veterán
S_x96x_S
#5731
Petykemano
veterán
válasz
S_x96x_S
#5731
üzenetére
> de ott van még a fapados szerver/consumer szegmens is
> ahol az Intel elég erős versenytársat indit.
> és ez teljesen (~tudatosan) el lett hagyagolva.
Egész pontosan mikre gondolsz itt, mint fapados szerver/consumer szegmens?
A Ryzenre, vagy a TR-re? vagy az embeddedre?Megelőlegzem, hogy a Ryzenre gondoltál, mint consumer szegmens.
Viszont én továbbra is azt gondolom, hogy a Ryzen vonalon meg fog jelenni a V-cache.
Az ADL elég jónak tűnik és bár a L3$ méretkülönbség miatt jelentékeny lesz a különbség az 12900K és az 12600K között, azért az eddig ismert előzetes számok alapján arra lehet számítani, hogy újra kedvelt versenyző lesz az intel a konzumer piacon.
Az AMD pedig a V-cache-t először gaming témakörben demózta.> vagyis ha a ZEN4 alapból pariban lesz a ZEN3D -el;
Én arra számítok, hogy a Zen3D / MilanX olyan területekre megy majd, ahol van haszna a megnövekedett L3$ méretnek. Az AMD bemutatója alapján a gamingben van haszna. És azt gondolnám, hogy más memóriaintenzív alkalmazások esetén is, mint pl adatbázisok. (Ha nincs szerencsénk, akkor még az is lehet, hogy valami coint remekül fog bányászni)A Zen4 IPC-ben szerintem meg fogja előzni a zen3D-t:
"Zen 3+ looks to be a small IPC gain on base Zen 3, having been told “It’s more than Zen+ was [over Zen 1] but not much” which I interpret to mean around a 4 to 7% IPC gain along with customary clock gains moving to the smaller N6 node from TSMC. N6 is a variant of N7 using 5 layers of EUV and is not a true “new node”, more of a refinement. However, the most interesting thing to me is that Zen 3+ on desktop may be the first AM5 CPU. I was told that the IO die for Zen 3+ desktop is using “Not quite [the same] IOD as Zen 4 but uses Zen 4 IP” which I take to mean that it will be using DDR5 and it will be on the same node as Zen 4’s IOD. That’s all I have on Zen 3+, so now on to Zen 4.Zen 4 is what a lot of people are waiting for, and, if the info I have is accurate, that wait will prove to be even more worth it. It is important to note that the one common thread in all Zen 4 chatter I have heard is resounding positivity. From IPC gains over 25%, a total performance gain of 40%, and even possibly (finally) 5GHz all-core thanks to the new (full node) N5 fabrication at TSMC! Now, I can’t say what is true and what is an over-exaggeration, however I was told from a trusted source that a Genoa engineering sample (Zen 4 server chip) was 29% faster than a Milan (Zen 3) chip with the same core config at the same clocks. Factor this in with what I have heard about the possible clock gains that N5 will enable over N7 and Zen 4 sounds like it is going to be a monster of a CPU."
[link]
Tehát a két termék simán elfér egymás mellett/alatt/fölött úgy, hogy zen4 általános felhasználásban fog nagyobb mértékű előrelépést jelenteni.Azt beszélik, hogy "N5 on N5" 3d stacking eljárás 2022Q4-ben lesz kész. Tehát gondolom 2023 elején várható majda Zen4.
#5732 Devid_81
> Lesz Zen3D meg XT is?
Én se tudtam.
Azt csiripelik, hogy már a Zen2 esetén megjelenő XT-t is V-cache-sel tervezték eredetileg, de az nem készült el vagy nem lett jó, vagy tudja a pék, ezért csak minimális frekvencia emelés lett belőle.
Némileg persze ellentmond ennek, ha most meg külön számoljuk a Zen3D-t és az XT-t. De még az is lehet, hogy ugyanaz. Vagy az is lehet, hogy mégiscsak lesz zen3+/Warhol.
Könnyen lehet, hogy nincs igazam, ebben nem vagyok eltökélt, semmi bizonyíték nincs rá, de azért nem engedem el, mert kapacitás okokból érdeke az AMD-nek kisajtolni a maximumot a N7/N6 gyártósorokból. Tehát ha a sima, olcsón gyártható zen3-at (értsd: v-cache nélkülit) át tudja tenni N6-ra és kicsit megpiszkálva zen3+ magokkal az előbb említett 3-7% IPC növekedést és hasonló mértékű frekvencia emelkedést el tud érni, akkor az lehet, hogy még épp versenyképes az ADL-kel és még további két évig árulható budget optionként. -

hokuszpk
nagyúr
válasz
S_x96x_S
#5720
üzenetére
"Mig az X86-64 - jól megvan a 64biten."
azert az a neve, ha 128 bites lenne, akkor betippelnem, hogy x86-128 -nak neveztek volna el
azert perpill aztmondanam egyelore tenyleg semmi szukseg a 128 bitre, pl. a 64 bites cimterbol is csak 40-48 bitet hasznalnak, utobbi valami szereny 256Tib memoria cimzesere alkalmas, annyi memoria talan még in-memory adatbazisokhoz is megfelel.** nemreg egy projektben kertem 3x20TB diszkteruletet, mert az adatgyujtokbol jovo cucc feldolgozasa utan 1-2 even belul kb. akkorara fog noni az adatbazis, azt is lealkudtak 3x15TB -re, pedig elegge nagy es jolmeno cegnel tortent.
-
#5706
Petykemano
veterán
S_x96x_S
#5704
Petykemano
veterán
válasz
S_x96x_S
#5704
üzenetére
a 35., 34., 33. heti eladásokban sem szerepelt az 5600G jobban a 6. helynél.
Ami egyfelől lehetne meglepő, hiszen elvileg a alacsonyabb az msrp-je, mint az 5600X-nek. Viszont valójában az 5600X ára is lecsökkent kb oda, ahol az 5600G van.Feltehetőleg olyanok vásárolják az 5600X-et, akiknek már van GPU-ja és ezért nem szükségszerű a GPU vásárlása is, és ennek megfelelően IGP-re se feltétlenül van szükségük.
upgrade, ahogy mondod. -
#5702
Petykemano
veterán
S_x96x_S
#5697
Petykemano
veterán
válasz
S_x96x_S
#5697
üzenetére
Ugyanez audio-vizuális formában
Talán én nem olvastam elég figyelmesen az AT cikk végét, ezért engem most meglepetésként ért, hogy nagyjából ugyanazt mondta az interposeres megoldásra, mint amit én.
Hogy van egy interposer, azon rajta van 3 CCD. Az így kialakított szigeteket nem 1-1-1, hanem 3 IF link köti össze az IOD-dal és az interposeren keresztül nem csak az azonos lapkához tartozó magok, hanem a CCD-k közötti kommunikáció is természetesen gyors. -
#5698
Petykemano
veterán
S_x96x_S
#5697
Petykemano
veterán
válasz
S_x96x_S
#5697
üzenetére
Nekem az első kérdésem az volt, hogy tulajdonképpen miért kellene az AMD-nek növelnie a CCX-ben a magszámot?
A cikkben arra tesznek utalást, hogy jelenleg úgy jön ki a 64 mag, hogy a 8 magos gyűrűs vagy legalábbis gyűrű alapú topológiát használó (szerintem a bemutatottak közül a Twisted Hypercube az esélyes) CCX-ek vannak felfűzve egy újabb gyűrű, vagy gyűrű alapú topológiát követő IO lapkán belüli kommunikációs körre.
A cikk gondolom azt fejtegeti, hogy hogy hát a CCX-en belül megnövelni a magok számát nehézkes gyűrű topológiát használva - ugye ezzel küzdött az intel is a Comet Lake esetén.
És hát a külső gyűrűnél is ugyanazok a problémák jelentkezhetnek, ha az ottani 8 megállót kellene bővíteni.Szerintem a témában nagyon tanulságos AdoredTV egy 3 évvel ezelőtti videója:
https://www.youtube.com/watch?v=G3kGSbWFig4
már akkor arról beszélt, hogy a kisebb magszámú lapkákban gyártott CCX-eket aktív interposerrel kellene összekötni.Szerintem az AMD azt fogja majd csinálni - nagyjából ezt említik egyébként a mai cikk végén is. De abban nem vagyok biztos, hogy az AMD fogja növelni a magok számát a CCX-ben.
Teszemhozzá, azt nem tudom, hogy a Bergamo (Genoa+) esetén miként oldották meg a 96 magot...
Amit most mondok, az nem arra válasz, hanem az eredeti, az AT által feszegetett kérdésre.
Szerintem az AMD azt fogja csinálni (és mégegyszer mondom, ez nem a Bergamo), hogy meghagyja a 8 magos CCX-eket és ráteszi őket egy aktív interposerre. Így az egy interposeren helyet kapó processzorok közötti késleltetésnek le kellene csökkenie.
Az aktív interposer egyrészt összekötné szintén valamilyen gyűrű topológiával a rajta levő mondjuk 3-4 CCD-t, de ha lehetséges, akkor át lehetne építeni abba az Infinity Fabric-ot, ami szintén nem kevés hely és biztos nagyon rosszul skálázódik

Ilyetén módon a jelenlegi 8x8 helyett egy 8x(3-4)x8 topológia alakulna ki.
Az interposerre rá is lehetne tenni HBM-et, amit mondjuk 3 CCX együtt használ. -
HSM
félisten
válasz
S_x96x_S
#5692
üzenetére
"- és az NVMe protocol overheadje ( a PCIe felett ) lehet."
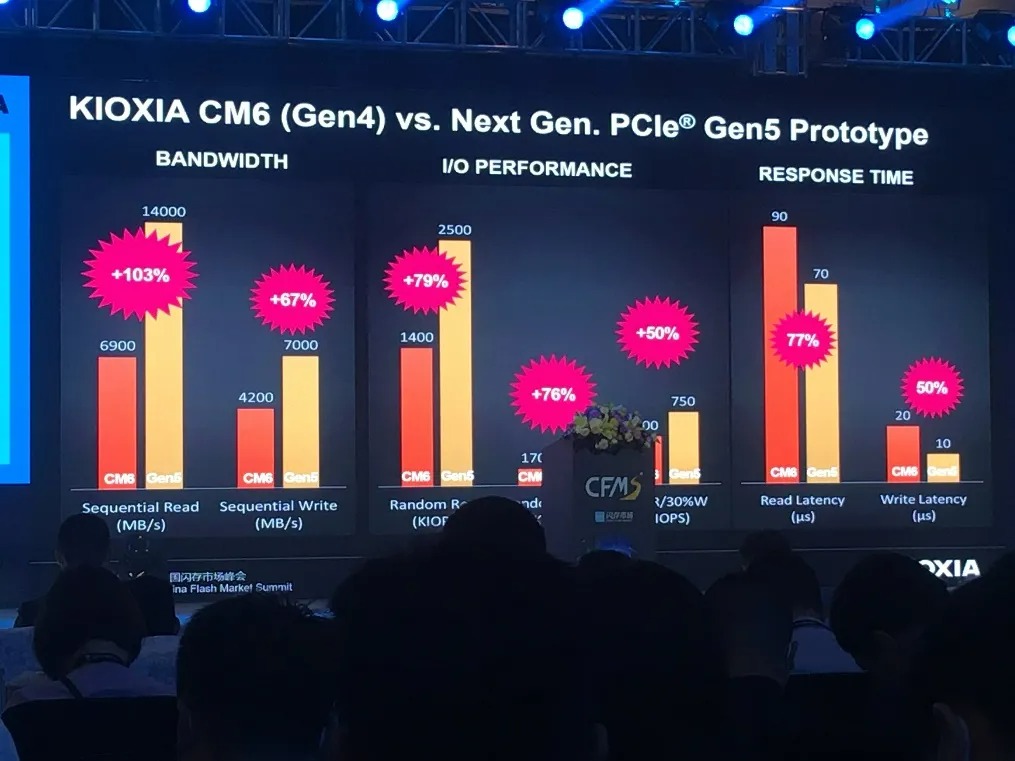
Ez egy érdekes kérdés, ezt most akkor hardware vagy software kategóriába soroljuk."ettől függetlenül az ábra arra jó, hogy jelezze, hogy mennyi optimalizálandó van még a rendszerben"
Az én véleményem szerint az ábra félrevezető lehet, ugyanis nagyvonalúan eltekint attól, hogy az a vastag "software latency" bizony hasznos és szükséges szolgáltatásokat nyújt a rendszernek.Valamint attól is eltekint, hogy a "hagyományos" NAND alapú tárolók sem véletlen lettek ilyenek, évek óta a tárterületre eső költségek durva optimalizálása folyt, főleg consumer oldalon. Én már a (2bit
) MLC-nél fogtam a fejem, TLC-nél (3bit MLC) már nagyon, erre már jönnek a hírek a PLC (5bit MLC) NAND-okról is.... [link]
Pedig már a Z-NAND is jól mutatta, milyen brutális gyorsulás lehetséges már a meglévő infrastuktúrán is csupán azzal, hogy nem a tárterületre és olcsóságra van az egész optimalizálva.A DDR "halálát" én annyiból nem tartom realitásnak, hogy nem véletlen használunk olyanokat, a bővíthetőség fontos opció a legtöbb szegmensben. Persze, egy CPU mellé integrált HBM, mint nagyméretű gyorsítótár nagyon hasznos újítás lehet, de emellett komoly korlátja is lenne a fejleszthetőségnek, ha nem lenne mellé még valami.
Persze, idővel igen hasznosak lehetnek ezek a CXL kütyük, ugyanakkor technikailag szerintem nem reális, hogy az alacsony késleltetés a DDR busz késleltetésének szintjére csökkenjen, pont az univerzalitás/kompatibilitás miatti "vastagabb" hardware/software stack miatt.#5694 Petykemano : Önmagában szerintem kevés lesz a sávszélességben utolérni.
-
HSM
félisten
válasz
S_x96x_S
#5690
üzenetére
Az ábra alapján a szoftver késleltetése a leginkább számottevő, így szemre kb a fele a 10µs késleltetésnek, ami nagyon sok. Ennek semmi köze a PCIe-hez. A PCIe ~1µs-je persze egy számottevő faktor, de szvsz nem ezen fog elúszni még a nextgen megoldások tempója sem.

Hogy a maradék 4µs hardware latency mire megy el az ábrán, az nekem nem világos.Azon meg nincs mit csodálkozni, hogy ha gyakorlatilag DDR memóriaként, a tárolási rendszer "szoftveres" oldalát teljesen kihagyva/megkerülve gyorsabb, főleg hogy ott már csak 64B-ot néztek, míg a többinél 4kB-ot. Viszont így nyilván a szoftveres tárolórendszer szolgáltatásainak is búcsút lehet inteni.
Az sajnos nem derült ki a cikk utáni kisbetűs részekből sem, hogy az "Idle" itt pontosan mit is jelent, pl. egy mélyalvásból ébresztett PCIe nyilván lényegesen magasabb latency-t fog produkálni, mint egy épp használatban lévő, vagy kevésbé energiatakarékos módban lévő PCIe.
-
HSM
félisten
válasz
S_x96x_S
#5685
üzenetére
"A mostani PCIe -nél már maga a PCIe a szük keresztmetszet."
A PCIe késleltetése rendszerenként eltérő lehet, de amiket találtam méréseket, alapvetően szűk 1µs nagyságrendű értékekről beszélünk, lásd pl [link] .
Ehhez képest egy átlag NAND olvasási késleltetése nagyságrendekkel magasabb, lásd pl. [link] (~50µs) , de még a kifejezetten latency-re kigyúrt Z-NAND is többszörös késleltetésű (a cikkben 3µs).
Meg lehet nézni a teszteket is, a Z-NAND-os SSD elég szépen lesöpörte a hagyományos NAND-os konkurenciát, hiába ugyanúgy PCIe-es."És a Gen4-nek ugyanolyan sz*r a latency-je mint a Gen3-nak"
Ezzel sem értek egyet. Kellőképpen meg vagyok róla győződve, hogy pl. egy 1GB-os állomány lényegesen hamarabb (azaz alacsonyabb késleltetéssel) fog azonos szélességű 4.0-s PCIe-en átcsorogni, mint 3.0-on.![;]](//cdn.rios.hu/dl/s/v1.gif)
Itt azért azt hozzátenném, hogy a késleltetés megítélése (alacsony, magas, stb) erősen függ attól, milyen felhasználáshoz. Hagyományos NAND alapú tárolók mellé úgy tűnik bőven elég gyors, de mondjuk egy dedikált VGA memóriájának rendszerbe bekötéséhez fájóan lassúnak tűnik."A NAND mellé sokszor tesznek be DRAM cache-t ; Én amúgy nem vennék "DRAM-less SSD" ."
Én sem vennék (és nem is vettem soha). De a cache az SSD esetén úgy tudom nagyrészt az írási műveletek és a "cellatérkép" gyorsítótárazására használatos, tehát ugyanúgy ott tartunk, hogy a NAND késleltetése a szűk keresztmetszet így is. -
HSM
félisten
válasz
S_x96x_S
#5677
üzenetére
"virtuális valóság kütyüknek ( headset) és játékoknak azért nem árt a latency."
Így igaz. Ugyanakor nem vagyok meggyőződve róla, hogy a PCIe latency okozna ott gondot, és nem egyéb szűk keresztmetszetek, pl. CPU/GPU. Ilyen szempontból én nem vagyok optimista az Alder Lake-el, több ponton is előjöhetnek problémák. Pl. a 4 kis mag csak egy "ring állomás", valamint az átütemezés késleltetése a kis nagy magok között. A késleltetés minimalizálására éppen az architektúra kiszámíthatósága lenne a legfontosabb és specifikus optimalizálás."Az egységes memóriát használó újgenerációs konzolokról áthozott játékoknak - is jót tehet a Gen5-ös latency csökkentés."
Tehetne, de nem fog. Mert nem fogják áthozni, mert a játékmenetet érintő dolgoknak skálázódnia kell, hiszen nem rakhatják túl magasra a minimum gépigényt, mert az eladásokból élnek. Ezeket a dolgokat eddig is emiatt átírták/kukázták PC portnál."amikor már van Nvme SSD-ből és GPU -ból
is CXL/Gen5-ös választék."
Itt azért a NAND-ok késleltetése is okozhat még némi fejfájást, elvileg a mostani PCIe-nél is az a szűk keresztmetszet. -
#5680
Petykemano
veterán
S_x96x_S
#5679
Petykemano
veterán
válasz
S_x96x_S
#5679
üzenetére
Elég érdekes koncepció.
A zenről az elején azt feltételeztük,.hogy a CCX-ek között van infinity fabric kapcsolat. És hogy azon keresztül legalább olvasásra megosztott a CCX-ek L3$-e. Nem állítom, hogy nem lehetett az AMDnek erre vonatkozólag terve, de mérések nem igazolták vissza, hogy ez létezik, vagy hogy ha létezik, akkor.lenne érdemi hatása.A cikkből kiderül, hogy ha nem egy Next level cache,.akkor egy low latency high bandwidth interconnectnek kell lennie, ami összeköti a magokat. Meg is említik, hogy a lapkán belüli magok között van ilyen és a magok közötti L2$-hez való hozzáférés +12ns késleltetést ad hozzá.
Késleltetést persze nyilván ugyanúgy hozzáad egy valódi L3$-ben való turkálás. A különbség ha jól értem annyi, hogy az L3$ vezérlő nem egy neki dedikált tárterületben turkál, hanem a magok amúgy privát L2$ tárterületében.
Ügyes, valóban újszerű megközelítés - különösen az AMD "szilíciumpazarló" v-cache megközelítéséhez képest.
Kíváncsi vagyok, viszont fogjuk-e látni valahol másutt.Azért biztos lehetnek hátrányai is. Az impresszív számok egyszálas terhelés során érvényesek. De amikor az összes mag fullra van terhelve, akkor mindenkinek van 32MB L2$, de senkinek nincs L3$.
Persze ezzel biztos kalkuláltak.
Azért a 256MB cache lényegesen több 8 magra, mint amennyivel egy 8 magos zen3 CCD rendelkezik. Még. Ha majd az is kap 4 layer L3$-t akkor már igazán érdekes lesz összehasonlítani. -
HSM
félisten
válasz
S_x96x_S
#5672
üzenetére
Én a CXL-ben és PCIe5-ben rövid távon nem nagyon látok fantáziát.
Az összes játék ma úgy van megírva, hogy még véletlen se legyen érzékeny a latency-re, hiszen időtlen idők óta magas. Mielőtt az alacsony latency-re épülő bármi megjelenhet, azelőtt kellene alá felhasználói bázis valamint rengeteg fejlesztés. Ez minimum évek. Mire ezeknek jelentőségük lesz, szvsz már rég kidobtuk az összes AL vagy Zen4 CPU-t. -
-
hokuszpk
nagyúr
válasz
S_x96x_S
#5646
üzenetére
kihagytad azt a kombot, hogy az I/O die tetejere teszik a VCache -t
"Intel Core i9-12900K is 12% faster than Ryzen 9 5950X in single-core and 3% faster in multi-core tests"
az jo, mert akkor csak 100-200 Mhz -t kell tolni az 5950X -en, hogy multiban visszavegye a vezetest, nyolc mag feletti procit meg azert valoszinuleg nem a single core teljesitmeny miatt veszi az emberfia.
-
#5648
Petykemano
veterán
S_x96x_S
#5646
Petykemano
veterán
válasz
S_x96x_S
#5646
üzenetére
> vagy most még csak vegyes konstrukció lesz.
> pl. a 8 magos chipletből csak 4 magot tunningolnak fel,A jelenlegi CCX-ek közösen/megosztottan érik el és használják a L3$-t.
Az én értelmezésem szerint a V-cache nem L4$ lesz, hanem az L3$ kibővítése.
De sehogyse értem, hogy miképp lenne megvalósítható, hogy 8-ból 4 mag látja csak a kibővített - v-cache - területet.Azt esetleg el tudom képzelni, hogy egy 2CCD-s kialakításban csak az egyik kap v-cache-t. Ez mondjuk a 2 CCD-s Ryzenek esetén talán kevésbé lenne látványos/jelentős lépés, de ha egy Threadripper épülne fel úgy, hogy 4-ből csak 1 kap tornyot az már eléggé a big.LITTLE irányába hatna. És nyilván ahogy mondod, szükség is lenne a megfelelő megkülönböztetésre.
Ilyenkor az emberek mindig megijednek, hogy na itt ette meg a fene, de hát valahogy eddig is kitalálta a hardver és az ütemező együtt, hogy melyik az a mag, amelyik a legmagasabb frekvenciára tud boostolni és hogy oda akkor mit érdemes ütemezni a maximális teljesítmény elérése érdekében.
Ezzel együtt én valószínűbbnek tartok egy v-cache méreten alapuló szegmentációt. egy CCD felett 64 v 32
-
HSM
félisten
válasz
S_x96x_S
#5646
üzenetére
"vagy az új 6950X - nél csak az egyik chiplet lesz 3DVcache tunningolt."
Ennek mutatták be először a prototípusát. [link]Érdekes gondolat egyébként, a big-little első megközelítésének is megfelelne.
Az ütemező miatt túlzottan nem aggódnék, a CPPC-ből konfigurálható mag-preferencia eddig is adott volt, és a Ryzeneknél eddig is voltak erősebb és gyengébb magok, hiszen nem egyforma volt a magok maximális BOOST órajele, tehát simán SMU-ból is kezelhetőnek tűnik a dolog ahogy jelenleg is. -
#5635
Petykemano
veterán
S_x96x_S
#5633
Petykemano
veterán
válasz
S_x96x_S
#5633
üzenetére
> de főleg a core alapján licenszelt szoftvereknél lehet ez hátrány.
> valami árazással ki kell egyensúlyozni.Nem tudom, hogy a sapphire rapids esetén az AVX512 használata jár-e még órajelcsökkentéssel. De ha esetleg az AMD megoldotta - ahogy az AVX2 esetén is tette - hogy órajelcsökkenés nélkül tudja a mag használni, akkor már az is kompenzálhatja azt, hogy kevesebb az 512b feldolgozó.
> #5634 HSM
> Pedig ez tűnik a legjobb megoldásnak.
> A kis mag utasítás szinten kompatibilis az AVX512-vel is, csak csiga lassú,
> ha tempó is kell, majd átrakja az ütemező a nagyobb magokra.Szerintem azért nem így lesz (kis mag érti az AVX512 utasítást, de vékony feldolgozókkal rendelkezik és egy AVX512 utasítást több órajelciklus alatt tud csak végrehajtani), mert az Intel számára az E mag nem Low Power, amely esetén kényszerből, de minél olcsóbban megvalósítják a utasítás-parítást. Az E magokat az intel throughputra akarja használni.
Nem tudom megmondani, hogy mi az ideális, de azt feltételezem, hogy nem a minimum. Nyilván attól is függ, hogy milyen a kód, amit futtatni kell.
Jelenleg a Gracemont magok AVX2-ot tudnak, elvileg 256b feldolgozókkal -
#5631
Petykemano
veterán
S_x96x_S
#5628
Petykemano
veterán
válasz
S_x96x_S
#5628
üzenetére
Az N2 sok szempontól vastagabbnak tűnik, mint a zen3, más szempontból viszont nem. [link]
És mégis nagyon pici.Mondjuk nehéz összehasonlítani.
7nm-en 1.1-1.4mm2 az N1 [link]
Ehhez képest a zen3 brutálisan nagy, több mint 3mm2 [link]
(A számok csak a core részeket tartalmazzák)
Persze az IPC-je is másfélszeres és nyilván az elérhető frekvenciában is jelentős különbség van [link]az N2 kiterjedése 5nm-en nem változott az N1-hez képest.
Elvileg egyébként a zen4 lapkaméret is csökkent. Ha jól emlékszem olyan 70mm2 - annak ellenére, hogy az L2 a duplájára nőtt és az AVX512 is eléggé helyigényes - azt mondják 0.5mm2 a core részből csak az.> És szerintem min +10% IPC csak össze tudnak kaparni
> Elég nagy változás önmagában
> az AVX-512 kielégítő implementálása.Nem kívántam lekicsinyleni. Csupán megállapítottam, hogy ha volt egy design goal listájuk a zen4-re vonatkozóan, akkor annak első helyén az AVX512 implementálása lehetett. Emellett persze nyilván dolgoznak,csiszolnak-reszelnek más részegységeket is és ha valamilyen fejlesztés elkészül, akkor az bekerülhet a release-be. (ahogy anno a zen2-be is bekerült valami Tage branch predictort, amit eredetileg a zen3-ba terveztek)
Szerintem 10%-nál több lesz az IPC növekedés - a szokásos módon ahol az L2$ számít, ott nagyobb.
> Akkor a ZEN4-ben fele annyi lesz.
De dupla annyi mag.Lehet, hogy innen érdemes ágaztatni.
A zen5 újdonsága lehet, hogy az lesz, hogy a backend szélesedik. -
#5627
Petykemano
veterán
S_x96x_S
#5625
Petykemano
veterán
válasz
S_x96x_S
#5625
üzenetére
Ahogy a Ch&Ch elemzésben is írták, a zen4 fundamentálisan nem különbözik a zen3-tól. AZ AVX512 utasításcsalád és a 256bit helyett 512bites feldolgozók persze a vektor egységen nagy előrelépésnek számít, de más vonatkozásban inkább csak csiszolgatás-reszelgetés.
A viszonylag jelentősnek mondható L2$ méretnövekedését is e kettő kategóriába sorolnám. Úgy értem, hogy el tudom képzelni, hogy ezzel a cél nem az IPC gyorsítás volt - Na nem mintha nem nőne tőle az IPC -, hanem elsősorban a duplázódó adatméretek tették indokolttá.
Példaként a Golden Cove magokat szokták felhozni, reszelgetés (+10%) helyett elég komoly (+50+%) méretnövekedésen esnek át bizonyos alegységek, mint pl a reorder buffer. De ahogy a múltkor is mondtam, ha a zenből e nélkül is lehet IPC növekedést elérni az jó jel, mert arra enged következtetni, hogy van még benne tartalék.
Engem amúgy meglepett, hogy az L1$-t egyáltalán nem növelték. Én arra számítottam, hogy 48kB-ra nő az is.
-
#5624
Petykemano
veterán
S_x96x_S
#5623
Petykemano
veterán
válasz
S_x96x_S
#5623
üzenetére
> persze a jövőben - az AMD-nek is meg kell oldania - az AVX-512 - Big-Little architektúrát
> ( remélhetőleg nem kiherélten - mint az Intel Alder Lake )Nekem nem lenne bajom azzal, ha csak a kompatibilitás végett úgy oldanák meg ,hogy 128 bites feldolgozók vannak a kis magokban és 4 órajelciklus alatt hajt végre egy AVX512-es utasítást.
De szerintem nem ez lesz. -

awexco
őstag
válasz
S_x96x_S
#5615
üzenetére
Intelnek ha a gyártásra elköltött durva pénzösszegekből profitot is akar látni és képesek lesznek élvonalbeli gyártás technológiával előrukkolni akkor át kell magához csábítani az AMD-t . Apple az már sokkal keményebb dió mert ott lehet valami durva háttéralku , hogy a legfejlettebb gyártósorok nagyon nagy részét csak ő kaphassa .
-
#5609
 TESCO-Zsömle
titán
S_x96x_S
#5608
TESCO-Zsömle
titán
S_x96x_S
#5608
TESCO-Zsömle
titán
válasz
S_x96x_S
#5608
üzenetére
Értam, amit mondasz, csak nem az én kérdésemre ad választ. A DirectStorage nem a PCIe3 és PCIe4/5 közötti késleltetés-különbség miatt működik, hanem mert az adatfolyam útjából kivágják a CPU-t.
A koherens multi-GPU-t meg már lobogtatják egy ideje, kezdve a Lucid Hydra-val, ahol konkrétan eltérő gyártókat/architektúrákat is lehetett vegyíteni, csa kaztán mégse...
Ne érts félre, örülnék, ha lenne a dologból bármi is, csak ugye anno, mikor bejött a 3D, mint olyan, lobogtatták, hogy a multi-GPU rendszerek milyen jók lesznek, mert beteszel két egyforma GPU-t és az egyik az egyik szemet, a másik a másik szemet számolja... Aztán ugyanezt belengették, mikor az Oculus megjelent, hogy majd a VR milyen jó lesz, mert nem kell egy GPU-nak számolnia az irdatlan FPS-t és felbontást, mehet a két szem képe két külön GPU-ra... Azóta már a multi-GPU is -kvázi- megszűnt, az említett megoldásokból pedig soha nem lett semmi.
-
#5607
TESCO-Zsömle
titán
S_x96x_S
#5605
TESCO-Zsömle
titán
válasz
S_x96x_S
#5605
üzenetére
"Workstation kategória,
Videó szerkesztés
Kiterjesztett valóság ; Spéci alacsony latenciájú 3D szemüvegek
AI ;
Adatfeldolgozás"
Tipikus dolgok, amiket 8-12 óra szalag/üzletkötés után csinálni szeretnek az emberek, mint kikapcsolódás. De most komolyan, mennyit nyersz késleltetésben PCIe3-hoz képest nem munka-célú felhasználás alatt?
Optane persze hogy érezhető, azt írtam én is, mert számottevően jobban skálázódik, mint a NAND. Ez azért érezhető különbség:
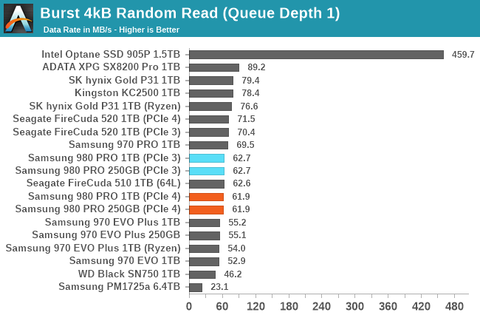
De mikor megnéze legy új PCIe4-es NVME tesztet, ahol játékok betöltése, alkalmazások indítása közt van 1mp szünet, ott megvakarod a fejed, hogy akkor azért most le akarsz-e szurkolni annyi pénzt.
-
#5606
Petykemano
veterán
S_x96x_S
#5602
Petykemano
veterán
válasz
S_x96x_S
#5602
üzenetére
Én is azt néztem a táblázatban, hogy azokban a számokban, amiknek sokan az M1 magas IPC-jét tulajdonítják, a zen3 alacsony értékekkel rendelkezik. Persze nem mindenben.
De az a ROB pl alacsony a Sunny/Willow Cove magokhoz képest.
Ez szerintem azért jó, mert van még hová növekedni.
Persze nyilván minden egyes duplázás megtérülése IPC-ben csökkenő mértékű és külön-külön minden elhanyagolható mértékű.
Mindenesetre én is arra számítok, hogy a jövőben ezeknek az értékeknek a növekedését fogjuk látni.
Ja igen, azt elfelejtettem mondani - a másik threadben - hogy az intel IPC növekedése nagyjából a sandy bridge-től a skylake-ig azért volt szerény - összehasonlítva azzal, hogy most néhány év leforgása alatt duplázást terveznek - mert akkoriban az intel - konkurencia hiányában - a lapkaméret csökkentésére is koncentrált. (=> gyártási volumen ^^ és profit ^^)
Ami a Gracemontot illeti...
Szintén a táblázatban azt írják, hogy 2.5-ös az IPC szintje, ami kb annyi, mint a skylake és igazából csak 20%-kal (~1 generáció) van lemaradva a zen3 mögött. Nyilván nem volna jó, ha csak ebből állna egy cpu, de azért kis prüntyögőnek sem mondható.Ilyen magokból lesz 4db egy nagy mag helyén. A maximális frekvencia pedig kb 1Ghz-cel lesz lemaradva. Én arra számítok, hogy 2 Gracemont mag teljesítmény nagyjából 1 Cove mag 2 szálas teljesítményével fog felérni, viszont 4 Gracemont mag fogy annyit fogyasztani, mint 1 cove mag.
Most sokan morognak amiatt, hogy az AVX512 támogatás kikerült az Alder Lake-ből.
Fenti ábrából számomra nem derül ki, hogy a Gracemont hány és milyen méretű FPU porttal, vagy pipe-pal rendelkezik. (Egy helyet találtam, ahol azt írták, hogy a gracemont fpu port size 256b) Ha jól tudom a Zen eredetileg 4x128b volt, amivel tudott AVX2-es utasításokat végrehajtani úgy, hogy két portot összeolvasztott. Aztán ez a zen2-ben bővült 4x256b-re.
Korábban pedig beszéltünk arról, hogy az Arm SVE esetén is megoldható az, hogy egy hosszabb vektorutasítást rövidebb feldolgozóval több órajelciklus alatt hajtson végre.Remélem, hogy a raptor lake-ben megoldják, hogy AVX512 visszajöjjön
1) vagy úgy, hogy összeolvasztással, vagy több órajelciklus alatt történő végrehajtással.
De szimpatikus lenne egy olyan megközelítés, mint a zené, hogy 4x128bit a feldolgozó képessége, amivel lightweight taskokat gyorsan tud kiszolgálni, de kompatibilis tudna maradni akár AVX512 utasításokkal egy órajelciklus alatt is.2) Nem tudom, emlékszel, hogy az új Low-power Arm magoknál a "Compex" kifejezésre
[link]
Lényegében az amd bulldozer köszönt vissza: megosztott, összeolvasztható FPU
Na ez még elég ütős lenne -
#5591
Petykemano
veterán
S_x96x_S
#5588
Petykemano
veterán
válasz
S_x96x_S
#5588
üzenetére
> azért a 8C+16c is necces lehet 2 csatornás DDR5 mellett ..
> de a "40 (8C+32c)" ( Arrow Lake ) -et már végképp nem értem."2016-ban 4 mag volt a desktop maximuma 2ch mellett, és 6-8-10 magot kaptál 4 csatornával. Pedig szerintem már az is DDR4 volt akkor.
Jóllehet csak 2400. Ennek ma leginkább másfélszerese a széleskörben elterjedt, ugyanakkor 2 csatornával már 16 magot is elérhetsz.A magyarázat szerintem ott keresendő, hogy mennyi L3$ volt a 4 magos skylakeben és mennyi a 16 magos ryzenben.
-
#5582
Petykemano
veterán
S_x96x_S
#5579
Petykemano
veterán
válasz
S_x96x_S
#5579
üzenetére
> a desktopon
> a jövő "kövér - szteroidos - kigyúrt magoké"
> lásd Apple M1 ; AVX-512 / AMX
Igen, ebben egészen biztos vagyok én is. Jim Keller is mondta az Intel designokról, hogy hízni fognak. És abban is biztos vagyok, hogy a szteroridos magok hízását szeretnék a big.LITTLE koncepcióval ellensúlyozni - Multithread felhasználáshoz tényleg nem kell minden magnak gyorsnak és kövérnek lennie.De szerintem csak a desktopon lehet sikere/helye a big.LITTLE-nek, vagyis annak, hogy a fürge, de optimális hely és energiahatékonyságú magok mellett vannak kövér, szteridos magok is. Egyrészt a cloud gamingben szerintem lehet szerepe a desktophoz hasonló -- big.LITTLE - felépítésű, de szerver minőségű processzoroknak. másrészt pont azokban a szegmensekben, amikről Abu mesélt, hogy <32 mag az igény, ott is lehet nagyon hasznos, hogy egy hosszantartó/main processre erős mag jut, míg a kisebb, jobban szálasítható folyamatokat elviszik a kismagok.
> Az AMD előreszaladt egy kicsit a sok*sovány mag irányába,
> ami a szerveres/cloud szinten jó ..
> de a desktop-on a szoftveres integráció le van maradva.
> emiatt nem éri meg mindenáron tovább növelni.
Nem tudom, hogy az AMD magjait illik-e soványnak nevezni. Talán az Apple M1 magjainak árnyékában lehet - ha majd kiderül, hogy mennyi lesz egy zen4 5nm-en.
De soknak sok.Természetesen nem állítom, hogy ha a mai árszínvonalon lehetne egy tierrel magasabb cpu-t (ez általában +2 magot magasabb szinten +4 magot jelent) kapni, akkor azt holnap már ki is lehetne használni.
Ahhoz, hogy a többmagos kompatibilitás kiáradjon, valakinek meg kell tennie az első lépést.
Vagy a hardvergyártó kínál - eleinte persze kihasználatlan - többletmagokat a vásárlónak és a többletmagokat látva követi a szoftver, vagy a szoftvert készítik el előre úgy, hogy 1-2-4 magnál jobban skálázódjon, hogy majd sok évvel később széleskörben elérhetővé váljanak azok a hardverek, amelyeken ez a skálázódás meg tud történni.szerintem az első megközelítés működik, mert a több magot ki lehet írni, az lehet egy selling point az emberek mohóságára bazírozva.
> De az egy memória-csatornára eső CPU számot nem lehet büntetlenül növelni
> .. a szük keresztmetszet átmegy a memória elérésre.
> .. és a magszám növelésének haszna elolvad
> a ZEN4/Epyc -nél a 96 mag / 12 mem csatorna = 8
> A ZEN3/AM4 -nél 16 mag / 2 mem csatorna = 8
> vagyis most a 8core/1memCsatorna
> a mágikus szám, amit nehéz átlépni.
> Vagyis a magszámok növelése nem lineáris
> .. a memória csatorna visszafogja.Ezt a problémát szerintem mindig is a cache-sel oldották meg.
Itt van egy érdekes ábra arról, hogy időben állandó a bandwidth / core: [link]Tehát két szempontból is érdekes a 8c/1ch
Egyrészt mert zen4 esetében már elvileg nem DDR4, hanem DDR5 lesz.
Másrészt meg a 3D stacking miatt épp a cache méretek áttörésének küszöbén lehetünk - a növekvő cache méretek pedig csökkenthetik a rendszermemóriára nehezedő terhet.
Vagy lényegesen magasabb - egyszálas - teljesítményt tehetnek lehetővé.Apopó, ha már itt tartunk. Megintcsak megjegyezném.
Ezek az információk nyilván a Gigabyte-tól származnak. De összességében nem fura, hogy mennyi infó érkezik a zen4-ről mostanság és mennyire semmi a zen3D-ről? -
S_x96x_S
addikt
válasz
S_x96x_S
#5556
üzenetére
egyesek szerint az Intel -csak 2023 -ban fér hozzá a TSMC 3nm -hez.
és nem fogja beelőzni az AMD-t> Intel Grabs Majority of TSMC’s 3nm
Apple to be TMSC’s Only 3nm Client in 2022, Followed by AMD &NVIDIA; No 3nm Chips for Intel Till 2023 [Report]
https://www.hardwaretimes.com/apple-to-be-tmscs-only-3nm-client-in-2022-followed-by-amd-no-3nm-chips-for-intel-till-2023-report/
(digitimes-ra hivatkozik forrásként ) -
HSM
félisten
válasz
S_x96x_S
#5558
üzenetére
"... és 2-3-5 év múlva képesek az M1/2/3/4 -et is lekörözni - innovációban;"
Ez még mindig nem biztos, hogy elég ellensúlyozni a hátrányt, hogy nem saját kezükben a platform. Az M1 jó teljesítménye szvsz inkább eladni volt szükséges, a gyártó számára szvsz a legnagyobb előny a teljes kontroll a hardveres rész felett.#5561 Petykemano : Azt ne felejtsük el, hogy ezek erősen optimalizált blokkok. Hiába "férne el" mondjuk +2 CU, ha mondjuk a kevésbé optimális vezetékelés miatt buknának csomót az órajelen. Nem bolondok tervezik a chipet, ha reális alternatíva lett volna jobban kihasználni a drága és korlátozottan elérhető wafert, megtették volna.
-
#5561
Petykemano
veterán
S_x96x_S
#5555
Petykemano
veterán
válasz
S_x96x_S
#5555
üzenetére
ITt van már annotáció is:
[link]"AMD didn't utilized the area which became free because of it, there is quite a lot of white space. Without the apparently empty spaces, Cezanne would be only 9% larger and not 16%."
"Moreover, simply based on the area, it would have been possible to fit 3 additional GCN5 compute units (11 in total, as on Raven Ridge) while pushing everything else down. 4-8x PCIe3 PHYs could also been added. But obviously, this ignores power limits, extra work, etc."
-
#5559
Petykemano
veterán
S_x96x_S
#5558
Petykemano
veterán
válasz
S_x96x_S
#5558
üzenetére
> ... és 2-3-5 év múlva képesek az M1/2/3/4 -et is lekörözni - innovációban;
Azért ez jelenleg elég merész gondolat.
Nem azért, merthogy azt gondolnám, az intelnél butább emberek ülnek, hanem mert
- az Apple-nek a bőre alatt is pénz van.
- az x86 (legalábbis azok a magok, amiket ma látunk) jelenleg azért úgy tűnik, nincs annyira közel az M1-hez. -
hokuszpk
nagyúr
válasz
S_x96x_S
#5556
üzenetére
ilyen gyorsan adaptalni tudjak az Intel designt a TSMC technologiara ?
de ha friss fejlesztes, akkoris kapkodosnak tunik.
+Vicces, hogy a TSMC fejleszteseit az Intel finanszirozza, megsem az a celjuk, hogy beszallnak a bergyartasba es visszaveszik a vezetest a technologiaban ? -
#5538
Petykemano
veterán
S_x96x_S
#5537
Petykemano
veterán
válasz
S_x96x_S
#5537
üzenetére
Szerintem legalább kétféle válogatási szempont (minőségi jellemző) létezik.
1.) Fogyasszon alapfrekvencián (3-4ghz) minél kevesebbet minden mag használata mellett
2.) Tudjon elérni minél magasabb frekvenciát legalább néhány magon.A kettő szerintem nem feltétlenül esik egybe, vagyis nem biztos, hogy alapjáraton az a lapka fogyaszt keveset, ami egyébként 1-2 maggal magas frekvencia elérésére képes.
A 64 magos epycekhez biztosan Azokat válogatják,.amik rendkívül.jó fogyasztási mutatókkal rendelkeznek'
A 12-16 magos ryzenekhez pedig valószínűleg Azokat, amik nagyon magas frekvenciát el tudnak érni.De az pl már megállapításra került, hogy a 16 magos ryzen esetén csak az egyik lapka jó minőségű max frekvencia szempontból, a másik tök "átlagos"
-
#5533
Petykemano
veterán
S_x96x_S
#5532
Petykemano
veterán
válasz
S_x96x_S
#5532
üzenetére
> Vajon mit jelenthet a "ZEN4D" -ből a "D" ?
> Persze ha a ZEN3 3D-V-cache - ZEN3D -nek nevezik majd összel, akkor
> közelebb leszünk a megfejtéshez.
Én úgy emléskszem, hogy az AMD nem nevezte a V-cache-sel elláttott zen3-at zen3D-nek, hanem ezt a kivejezést a rajongótábor aggatta rá.
Ami inkább az AMD-hez (vagy AMD-hez közeli szivárogtatókhoz) kötődik, az inkább a "Milan-X" kifejezés, aminek szerintem szintén egy nem AMD, hanem közönség általi mutációja a Vermeer-X.Az elnevezés kérdése érdekes.
Nagyjából tudható - csak mindig megfeledkezünk róla - hogy a fejlesztések nagy része, irányában és mértékében a szerverpiacnak és a notebookok piacának szól. A PR és a marketing viszont a nagyon lelkes "gamer" rajongótábornak.
A V-cache-ről is lehet sejteni, hogy elsősorban nem a játékosoknak készült, hanem a memóriaintenzív HPC alkalmazások alá. Persze akár szerver, akár desktop szegmensben is egy remek húzás lehet a V-cache-sel szerelt "olcsó" DDR4-es platformmal menni a drága DDR5-ös ellenfelekkel szemben. Tehát mégegyszer: a Milan-X szerintem érhet el komoly sikereket azzal, hogy olcsóbb DDR4-gyel ér el jó eredményeket.A desktopra mindig a nyesedék és hulladék érkezik. Nem mondom, hogy a szemét, de a termelés gyengébbik része.
Ha meg tudják oldani, akkor nem csak mag szám, hanem V-cache méret vonatkozásában is lesz szegmentáció.
Mondjuk:6600: szokásos6600X: szokásos6600XT: V-cache6800: szokásos (OEM only)6800X: szokásos6800XT: v-cache6900: szokásos, (OEM only)6900X: szokásos,6900XT: v-cache6950X: szokásos,6950XT: v-cachePersze azt sem szabad kihagyni a számításból, hogy a Daytona biosban már láttuk, hogy az AMD elvileg nem csak 1 layer v-cache-sel készül, hanem upto 4. Tehát nem csak olyanfajta szegmentáció lehetséges, hogy van-e layer, vagy nincs, hanem hogy mennyi működőképes/aktív.
Pl:
6600 : cache nélkül6600X: cache nélkül6600XT: 1 layer6800: cache nélkül (OEM only)6800X: 1 layer6800XT: 2 layer6900: cache nélkül (OEM only)6900X: 1 layer6900XT: 2 layer6950X: 1 layer6950XT: 3 layerA desktop elnevezéssel kapcsolatban abban egészen biztosak lehetünk, hogy valami olyan lesz, ami hangzatos és lelkesítő a nyesedéket megkapó gamer közösség számára. Ezt olyan elnevezésekkel érik el, amivel elhitetik, hogy mintha a fejlesztés nekik készült volna. Mint pl a gaming cache.
Frame Rate Stabilizer Buffer
Gaming Cache Cube (that improves your gaming experience with a new dimension)
3D Game Cache -
#5528
Petykemano
veterán
S_x96x_S
#5527
Petykemano
veterán
válasz
S_x96x_S
#5527
üzenetére
Szerintem a uop (L0).cache megjelenése tette lehetővé az L1$ méretének csökkentését és a cél szerintem épp a késleltetés caökkentése lehetett.
Én a zen4 esetén... hmm elgondolkodtató. Max.egy szolid emelést tartok valószínűnek (48KB) L1$ terén. És 1MB-os L2-t.
Aztán a komoly áttervezés - Almásra - majd inkább a zen5. Azt gyanítom, nem véletlen, hogy a zen5 mellett jelenik meg a "zen4D"*, ami azt sejteti, hogy lesz egy zen vonal a zen4-ből, ami a jelenlegi egyensúlyi pont optimalizációja, és ágazik egy nagyobb mag.
* elvileg Abban a környezetben a zen4d nem a v-cache -sel szerelt változatot jelentette
-
#5523
Petykemano
veterán
S_x96x_S
#5519
Petykemano
veterán
válasz
S_x96x_S
#5519
üzenetére
Szerintem Amikor tranzisztorsűrűségről beszélünk, az fizikai kiterjedést is jelent és cache esetén szerintem ennek nagyonis van hatása a késleltetéssel. Vagyis amikor növelsz egy cache-t, akkor szerintem a fizikai kiterjedése hozzájárul ahhoz, hogy mekkora a késleltetés. Nagyobb sűrűség mellett a fizikai kiterjedés kisebb, tehát csökkenhet a késleltetés.
Az Apple cache-e egyébként nemcsak nagy kapacitású, hanem ráadásul fizikailag kicsi is.
Azt nem tudjuk, hogy forradalmi cache design vagy csupán a 5nm sűrűsége tette lehetőve.
Mindenesetre én arra számítok, hogy növekedni fog legalább az L2, de talán az L1 is és az 5nm miatt nem fog nőni a késleltetés.
A 3d cache épp azért lesz forradalmi, mert úgy tudod növelni a cache kapacitását, hogy a fizikai kiterjedés nagyon minimálisan nő.
-
#5514
Petykemano
veterán
S_x96x_S
#4912
Petykemano
veterán
-
#5511
Petykemano
veterán
S_x96x_S
#5510
Petykemano
veterán
válasz
S_x96x_S
#5510
üzenetére
De fura, hogy a 3600X-et beköltöztették az "others" kategóriába. Tavaly november-december környékén az csúcsosodott - drága lett az 5600X, ezért mindenki gyorsan lecsapott a 3600X-re.
> nagyon hiányzik az "olcsó" kategória ..
IgenÉrdekelne egy hasonló kimutatás GPU-k terén.
Nyilván a mindfactory nem reprezentatív, de azért érdekes lenne látni, hogy darabra ugyanannyit vásárolnak az emberek, csak drágábban, vagy a drágulással az eladási volumen is letört? - CPU-knál ez látszik.És ha az eladott volumen GPU-k terén is kisebb, mint 1 éve, akkor vajon hová, vagy milyen ellátásái láncon keresztül történik az értékesítés? Mert az Nvidia és az AMD bevételei nem csökkentek.
-
#5503
Petykemano
veterán
S_x96x_S
#5502
Petykemano
veterán
válasz
S_x96x_S
#5502
üzenetére
>> Brecken Ridge
>érdekes mintha a festők és a földrajzi helyek??
>váltakoznának a jövőben ..
>lehet, hogy valami tick-tock szerüség?Azt mondák már a múltkor is, hogy van a CCD-nek is saját kódneve: [link]
> Amúgy a 3DStack főleg a gyártástechnológiáról szól. És lehet, hogy ezután sokkal nagyobb
> változtatásokat is beleraknak - ami már megérdemel egy külön elnevezést ?Arra gondolsz, hogy az AMD fejlesztései (sem) node-agnisztikusak, tehát hogy van egy rahedli fejlesztésük tervezés szintjén készen, de az implementáláshoz (ahhoz, hogy megérje), szükséges a nagyobb tranzisztorsűrűség (Hasonló okokból láttunk az Intelnél is megtorpanást, amit végül a Rocket Lake formájában igyekeztek oldani) és aztán miután lementek 5nm-re utána egy ideig gyorsabban tudnak új designokat kiadni?
-
válasz
S_x96x_S
#5478
üzenetére
Bevallom Intelre és Nvidiára gondoltam, nem nagyon lehet megmondani a szervezeti felépítés miatt, mennyi profit jön prociból, konzolchipek is bonyolítják a helyzetet.

Arra nagyon kíváncsi lennék, mennyit nőttek a szerver proci eladások, mekkora nyereséget hoztak, tehát hogy mi a szerkezete az enterprise, embedded, semi custom szegmensnek. Ha abból indulok ki, hogy a konzolchipeken nem nagyon változik a marzs, de legalább is gondolom nem nő, és ennek a szegmensnek jobban nőtt a profitja, mint az árbevétele, akkor gondolom a nagyobb profittal kecsegtető szerverprocik húzhatták a nyereséget itt, csak ez nem igazán van kihangsúlyozva se a dián, se a szöveges értékelésnél.
-
-
#5474
Petykemano
veterán
S_x96x_S
#5473
Petykemano
veterán
válasz
S_x96x_S
#5473
üzenetére
Ez nagyon kemény.
És az is,.hogy még egy ilyen szép számokat tartalmazó grafikont is kozmetikáznak: 2x nagyobb érték 3x hosszabb csík.Ú és a margó is nőtt. Ezt a céget megviselte a covid...
"AMD began initial shipments of their first CDNA 2 architecture-based Instinct accelerators in Q2"
Kár, h nem derül ki, hogy ryzen v gpu mennyi,.és hogy a az epyc vagy konzol mennyi -
#5449
Petykemano
veterán
S_x96x_S
#5448
Petykemano
veterán
válasz
S_x96x_S
#5448
üzenetére
> inkább január az AlderLake-el
Szerinted az Alder Lake csak akkor fog megjelenni?
Nyár közepe van. A mostani AL hírek alapján (Qualicifation Sample), meg hogy kínában már lehet venni a mintákat feketepiacon, azt gondolnám, hogy ez ősszel - legalábbis papír formában - elrajtol.
Az várakozásom/elképzelésem ez és hogy erre az AMD némi árcsökkentéssel, vagy XT verziók kiadásával (és árcsökkentéssel) válaszol még a 5k sorozatban. Amire majd finnyázunk, hogy hát ez kevés, de legalább jó áron van. A v-cache verziót 6k szériának mondják.(Persze én is csak találgatok)
-
#5443
Petykemano
veterán
S_x96x_S
#5441
Petykemano
veterán
válasz
S_x96x_S
#5441
üzenetére
Tehát azt mondod, hogy egy 1060 vagy AMD oldalról egy RX 470-580 középkategóriának számít. (Nem kérdőjelezem meg)
Az AMD tavaly(előtt) hozta a navi 14-gyel, ami 22CU, az RX 580 szintjét. Ez volt 1800Mhz körül.
Az RDNA2-ra épülő és 2500Mhz körül járó 6700XT ennek 232%-át tudja.
Vagyis RDNA2 alapon, ami 2500Mhz körül ketyeg, erre a teljesítményre már akár 16-18CU is képes lehet.
A 32CU-s Navi23 (RX 6600/XT) 32MB oo$-sel rendelkezik és 128bit G6-tal (~250GB/s)Ezt most csak azért mondom, mert hogy amikor azt mondom, hogy szerintem a DDR4/5 lassúságát (a 128bit G6-hoz képest) feleannyi (16-20) CU-hoz szerintem elfedheti ugyanaz a 32MB oo$.
(A Rembrandt, ami elvileg oo$ nélkül jön DDR5-re elvileg 12CU-val fog rendelkezni.)
Sajnos az árak alapján egy ilyen kártya (én kb ide várom a Navi24-et) nem vált belépőszintű, tehát ilyen $100-120 környékivé, legalábbis az utóbbi időben. De amúgy én ezt a szintet ma már inkább belépőszintnek tekintetném, nem középkategóriának.
-

Yutani
nagyúr
válasz
S_x96x_S
#5441
üzenetére
Ha megnézek egy TPU tesztet, ahol a 3090 a csúcs, akkor a középkategória az 5700XT / RTX 3060. Mert ezek fele olyan gyorsak (4k), mint a 3090. Ez a középkategória közepe szerintem. Azon lehet lamentálni, hogy hol kezdődik a kategória (2060/5600XT?), és hol van vége (6700XT/3060Ti?).
Ha így, akkor a felső kategória az ősi 2080Ti-vel kezdődik, az also kategória az 1660 Ti-től lefelé az 5500XT/1650S-ig tart, ami alatt a belépő szint van a még kapható 4-5-6 éves matuzsálemekkel (GT 1030, RX 560). A Polaris 20/30-at (RX 570/580/590) hova soroljuk? Én az alsó kategória aljára tenném, ezek még mindig nem belépőszintú kártyák. Szerintem.
-
#5440
Petykemano
veterán
S_x96x_S
#5438
Petykemano
veterán
válasz
S_x96x_S
#5438
üzenetére
Mi számít manapság ""középkategóriának"?
Kezd olyan lenni a kérdés, mint Magyarországon (és nyilván más kelet-európai országban is ) a középosztály kérdése.
- van egyszer egy képünk arról, hogy hogy él, mit csinál, hogy gondolkodik egy középosztálybeli
- és van az, hogy statisztikai számítás alapján ki tartozik a középső tizedekbe.
És hát a probléma az, hogy a statisztika alapján vett középosztály itt valójában nem engedheti meg magának a ideálkép szerinti középosztálybeli létformát, életvitelt, gondolkodást.Tehát mondjuk az $500-os 6700XT a középkategória teteje és a remélhetőleg $300-os 6600 az alja?
Az a $300-os kártya, amire a kolléga a másik topikban azt mondta, hogy így néz ki a $100-150-os rx 460-a.Na de mindegy.
-
#5435
Petykemano
veterán
S_x96x_S
#5434
Petykemano
veterán
válasz
S_x96x_S
#5434
üzenetére
> de azért teljesítményre az nem sokat dob ..
Ezt nem teljesen értem.
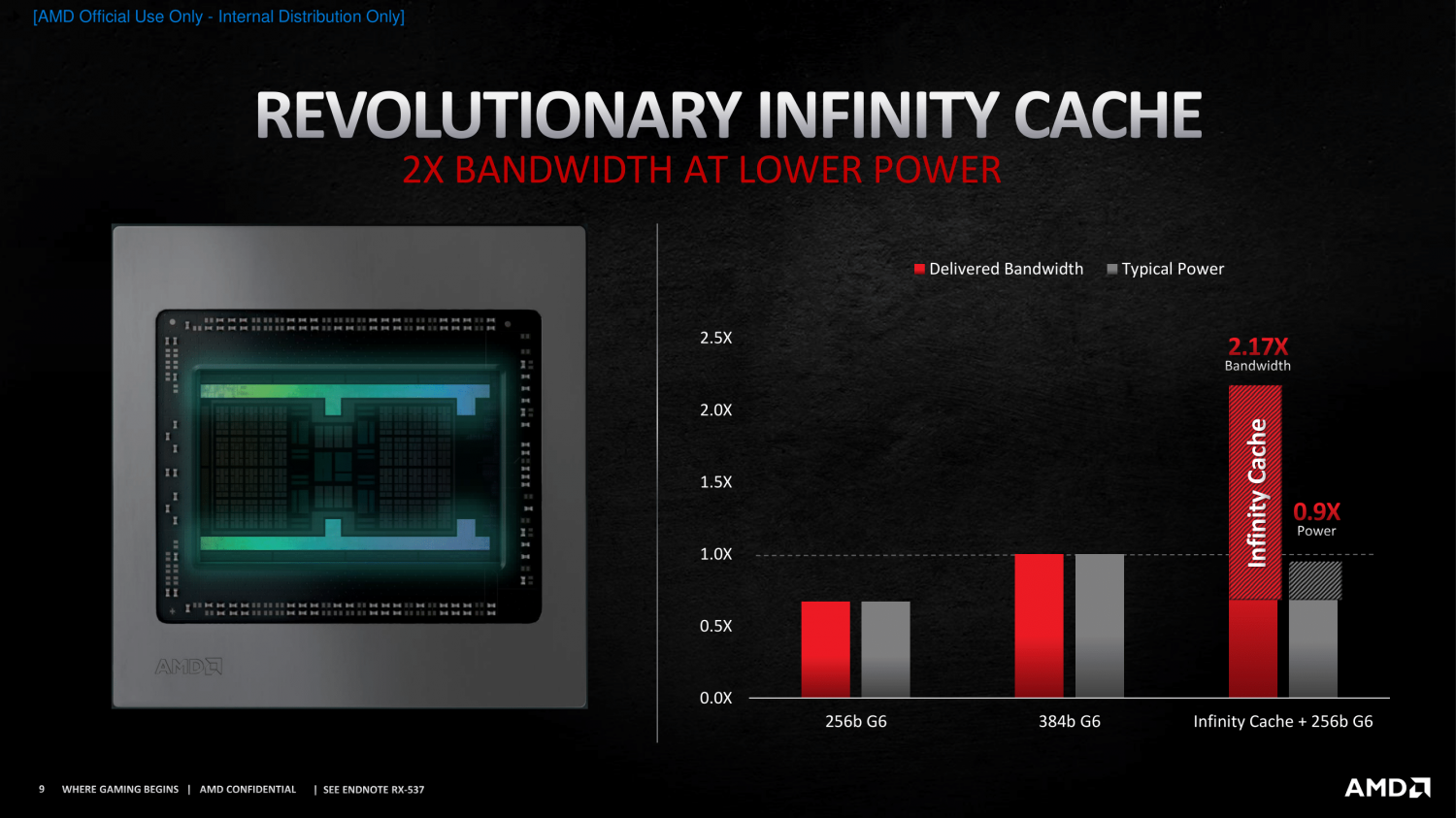
Az AMD amikor bemutatta az infinity Cache, akkor egy olyan slide-ot mutogatott, hogy a 256b GDDR6-höz képest több mint 3x, a 384b GDDR6-höz képest pedig 2.17x nagyobb sávszélességet tudnak elérni a 384b GDDR6-nál kevesebb energiahasználat mellett 128MB oo$ segítségével.256b GDDR6 kb 500GB/s, tehát 128MB oo$-sel együtt a sávszélesség 1.6TB/s lehet
Ha azt feltételezzük, hogy negyedennyi cache csak negyedennyi sávszélességetjelent és a biztonság kedvéért előtte kivonjuk belőle a GDDR6 sávszélességét, akkor is legalább 250-300GB/s-mál járhatunk.Ha azt gondoljuk, hogy 32MB oo$ ki szolgálni 32 CU-t 128bit GDDR6-tal (~250GB/s) 1080p-re, akkor én azért azt gondolnám, hogy ugyanúgy 32MB-nak elegendőnek kellene lennie 16-24CU kiszolgálására 2 csatornás DDR5 (~80GB/s) mellett.
Ez egy érdekes twitter thread a témában:
[link]
Effektív BW számítás:
[link]Ezért mondom én a 32MB-ot. 32MB-tal biztosan megvan a 300-500GB/s gyakorlatilag bármilyen memóriarendszer mellett ( [link] )
Bár a navi 24-re történetesen 16MB-ot mondanak/jósolnak. Szerintem az azért kevés.És hát 32MB oo$ mérete kb 23mm2, ami nem kibírhatatlan méret
[link]
cserébe semmilyen más költség nincs. Se packaging (LSI/interposer), se memória (HBM)Ez nagyjából ugyanaz a vita, amit a zen4 + HBM kapcsán lefolytattunk.
Azt természetesen nem zárnám ki, hogy bizonyos termékekben lehet létjogosultsága. Akár úgy is, hogy egy viszonylag pici cache nem ér semmit (lásd bányászat), akár abból a szempontból is, hogy belefér a költségbe.De ha csak a low-end grafikát nézzük, akkor költséghatékonyabb és kielégítő megoldásnak gondolnám, a oo$-t a HBM-nél.



 Valahogy igy nem?
Valahogy igy nem?

![;]](http://cdn.rios.hu/dl/s/v1.gif)




























Új hozzászólás Aktív témák
- One mobilszolgáltatások
- A Cherry többé nem gyárt kapcsolókat
- Kezünkben a OnePlus 15 és az Oppo Find X9-ek
- Feketelista, avagy a rossz boltok topicja
- Intel Core Ultra 3, Core Ultra 5, Ultra 7, Ultra 9 "Arrow Lake" LGA 1851
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Milyen TV-t vegyek?
- Háztartási gépek
- Path of Exile (ARPG)
- Brogyi: CTEK akkumulátor töltő és másolatai
- További aktív témák...

- Microsoft Surface Prémium minőségi Érintős Laptop Ultrabook 13,5"-65% Ryzen 5 16/256 Tűéles Retina
- Eladó Konfig Ryzen 7 3800X 16GB DDR4 1TB SSD RTX3060 12GB!
- Microsoft Surface Prémium minőségi Érintős Laptop Ultrabook 13,5"-65% i7-1185G7 16/512 Tűéles Retina
- Samsung Galaxy Z Fold7 Dual SIM 256GB 12GB RAM 5G (Jet Black) Fekete, gyári független. BONTATLAN!
- LEGJOBB ÁR AKCIÓ! Samsung Galaxy Z Fold7 256GB 12GB RAM, gyári független. 2 hetes, hibátlan!
- GYÖNYÖRŰ iPhone 15 Pro Max 512GB Black Titanium -1 ÉV GARANCIA - Kártyafüggetlen, MS3867, 100% Akksi
- Xiaomi Redmi Note 14 Pro / 8/256GB / Káértyafüggetlen / 12Hó Garancia
- Apple iPhone 16 Pro 256GB, Kártyafüggetlen, 1 Év Garanciával
- Nvidia Quadro P4000 // Nvidia Quadro P5000 --- Budapest MPL Foxpost
- Lenovo X13 Thinkpad Gen2 WUXGA IPS i5-1145G7 16GB RAM 256GB SSD Intel Iris XE Win11 Pro Garancia
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: ATW Internet Kft.
Város: Budapest