Hirdetés
- iPhone topik
- Okosóra és okoskiegészítő topik
- Google Pixel topik
- Yettel topik
- One mobilszolgáltatások
- Megtartotta Európában a 7500 mAh-t az Oppo
- Apple iPhone 12 és 12 Pro duplateszt
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Motorola Edge 70 - többért kevesebbet
- Szívós, szép és kitartó az új OnePlus óra
Új hozzászólás Aktív témák
-

hokuszpk
nagyúr
" a legtöbb Cezanne lapka bőven megfelel a drágább 5700G-nek vagy valamilyen mobil nyolcmagosnak is, és azokat is viszik, mint a cukrot."
az mar akciozas, hogy az Amazonon $283 az 5700G ?
** beneztem, fontban 283. oke, akcio lefujva
-
#6333
 Petykemano
veterán
HSM
#6329
Petykemano
veterán
HSM
#6329
Petykemano
veterán
"Ilyen nagy volumenű, agresszívan árazott terméknél minden apróság számít..."
MLiD BOM listája szerint a 6500XT-hez használt ~140mm2-es lapka gyártási költsége $18
Nem tiszta nekem, hogy ez hogy jött ki. Ha $10000-t elosztok legjobb esetben is 400 jó lapkával, akkor is $25 jön ki nekem. Persze $7000-os wafer megmunkálási költséggel kijön a $18. + az AMD margója.
Mindegy. Szóval szilícium szempontjából itt néhány dolláros költségkülönbözetről beszélünk.2019-hez képest persze biztosan sokminden drágult a megnövekedett igények és a felborult logisztika miatt.
Ami a chiplet és a monolitikus designban közös az a szilícium, legalább az, hogy kell hozzá ugyanakkora szubsztrát, és hogy el kell juttatni a célpiacra.
Ami külünbség lehet, hogy a chiplethez kellhet speciális szubsztrát, összeszerelés, több logisztika. Ha ez lenne olyan mértékben drágább, mint 2019-ban, amit az AT sugall, akkor azt kéne látnunk, hogy a 150-180mm2-es N7 lapkákkal az AMD le tud menni arra az árszintre, ahová az intel i3-ak.De mégse ezt látjuk, hanem azt, hogy a 5600G megáll $239-nél. És egyelőre nem úgy tűnik, hogy az AMD a konkurencia láttán ijedten árat csökkentett volna. Pedig hát hiába lehetséges, hogy az intel i3-ai valóban olyan mértékben hibás példányok, hogy vágni kényszerülnek (tehát nem tökéletesen működőképes chipekből létrehozott mesterséges szegmentáció), akkor sem kényszerülne az 5600G alá ajánlani.
Szóval én nem értem. Nem állítom, hogy az AMD ugyanolyan költségszint mellett gyártat, szállt, stb, mint 2019-ben és közben halálra keresi magát.
Lehetséges volna, hogy ennyit számít logisztikában az, hogy az Intel gyárai az USA-ban (is) vannak, míg az AMD távol-keletről, ráadásul pont Taiwanról, a a kínai befolyási övezet terjeszkedésének határáról és célpontjáról dolgozik?
-

carl18
addikt
Nyilván átlag gépbe mindenki jobban örülne csak nagy magoknak!

32 kis mag helyet jöhetnek magába 16 nagy mag és akkor mindenki boldog lenne. De úgy látszik az intel a kis magokat akarja erőltetni, a renderelés alatt biztos lesz értelme úgy hogy a játék teljesítmény is megmarad jó teljesítményen.
Talán az intel is tudja 8/16 szál egyenlőre elég minden játéknak, a Kis magok háttérfeladatoknak és renderelni kiegészítésként meg bőven jó.
Nyilván ez dobja meg a Cinebench számokat is intel háza táján.
Hát majd meglátjuk mit hozz a jövő, de legalább elindult a fejlődés.
-
carl18
addikt
A 13. generáció raptor lake már 8 nagy 16 kis maggal fog piacra kerülni.
De úgy olvastam az intel 8 nagy 32 kis magig nővekedni fog az évek folyamán.
Azért kíváncsi lennék egy ilyen 40 magos"Hibrid" szörny cpu-ra.
A energia hatákony magok szerintem sokkal gazdaságosabban gyárthatóak. Kevesebb helyen elférne, én például belépő szintre el tudok képzelni egy 8 magos "E-Core Celeront. De ez még a távoli jövő zenéje, túl távoli.
Azért én elismertem a 12. generáció valóban nagy fejlődés volt, de akkár hogy is a Zen 3 lassan másfél éves. A Zen 4 ha valóban fejlődik 30-40%-ot meg fogja tudni verni a 12.-13. generációt is ha minden jól megy.
Meg arra leszek kíváncsi az AMD hol fogja kimaxolni Mainstream fronton a magok számát.
A Zen 4 utodja már hasonló hibrid kialakításban fog megjeleni mint a intel. Szóval a Big.Little a jövő, csak az intel hamarabb kezdte.
Az alkalmazáson meg szép úgy is elkezdenek majd rájuk is portolni. -
hokuszpk
nagyúr
szerintem ha a 3800XT csont nelkul elketyeg ( marpedig ezt elsokezbol tudom igazolni ), akkor a sokat finomitott 5xxx -nek is el kellene mennie siman. PCIe4 -et tiltsak be, oszt haddszoljon.
"Terjeszd be a JEDEC-nek, hogy követeljék meg a DDR5 memóriák DDR4 foglalattal való kompatibilitását. "
oszt minek ? chipletes idoket elunk ; tessenek hozzapasszintani a regebbi proci ddr4 i/o lapkajat, es kesz is
nyilvan nem ennyire egyszeru, de lehet jobb megoldas, mint az Asus DDR4 to DDR5 konvertere. -

S_x96x_S
addikt
>> "és frekvencia regresszió ott már túl nagy lett volna"
> Szvsz ennyire nem fogyaszt sokat egy gyorsítótár.jó kérdés ..
az én megértésem (~spekulációm) szerint -
ez alapján:
https://www.anandtech.com/show/16725/amd-demonstrates-stacked-vcache-technology-2-tbsec-for-15-gaming ( May 31, 2021 )valamennyivel biztosan többet fogyaszt,
-mivel a technológiából eredően egymásra vannak pakolva ..
és így a hőtermelés elvezetése nem olyan egyszerű.
-És még ha le is van kapcsolva[1] .. fizikiailag az is akadályozza (~rontja) a hő elvezetését - az alsó rétegből[2]
-nem egy sikban van az extra cache .. hanem valami felett [3]
és ugyanakkora alapterületen több hő keletkezik.
- És a nagyobb (>200x ) interconnect density [4] - hőelvezetési problémához vezet.
- és ez még csak 2 réteg. [5][1] "The V-Cache is address striped with the normal L3 and can be powered down when not in use. The V-Cache sits on the same power plane as the regular L3."
[2] "The other element is thermals – usually you want the logic on the top die to manage the thermals better as it is close to the heatspreader/heatsink, but moving logic further away from the substrate means that power has to be transported up to the top die. Intel is hoping to mix microbumps and TSVs in upcoming technologies, and TSMC has a similar roadmap for the future for its customers."
[3]

[4] "this packaging enables a >200x interconnect density"[5] "Starting with the technology, this is clearly TSMC’s SoIC Chip-on-Wafer in action, albeit with only two layers. TSMC has demonstrated twelve layers, however those were non-active layers.
The problem with stacking silicon is going to be in the activity,
and subsequently thermals .
We’ve seen with other TSV stacked hardware, like HBM, that SRAM/memory/cache is the perfect vehicle for this as it doesn’t add that much to the thermal requirements of the processor. The downside is that the cache you stack on top is little more than just cache." -

Ueda
senior tag
Szvsz ennyire nem fogyaszt sokat egy gyorsítótár.
Nem tudom ... nekem ilyen tapasztlatom van :
Engemet meglepett (helyesebben mondva zavart) a megnövekedett hőtermelés és fogyasztás, amikor Q8200 -ről Q9650 -re váltottam. Azt gondoltam, hogy a kisebb teljesítményű modellek eleve a rosszabb csipekből kerülnek ki. Ehhez képest a Q8200 jégcsap volt a Q9650 -hez képest. 4 MB vs 12 MB L2 cache. Szerintem az optimális a 8 MB L2 volt, ami a Q6600 -ban volt.
-
carl18
addikt
Igen, még várok de az Alder Lake-S i3-12100F már felröppent csere lehetőségnek.
Sajnos kell a B660 alaplap, mert a H610 nem támogatja majd a Dual Channelt.
#6193
Petykemano
Szerintem nyilván az is elkaszálta a Zen 3+ fejlesztési lehetőségét hogy hatalmas a készlet hiány. Most mindegy mit dobnak piacra úgy se lehet semmit kapni elérhető áron.
Vagy a Zen 4 fejlődése olyan hatalmas hogy már nem érte meg a Warholba fektetni.
A pletykák szerint azonos órajelen 29%-os IPC emelkedést hozhat a Zen 4 a. Ez elég brutális, még a Zen 3 mellet is, és 40%-os gyorsulást könyvelhet el az órajel emelkedés mellet is.
+ még a Zen 4 is kaphat 3D V-Cachet-t ami még brutálisabb gyorsulást könyvelhet el.Abban biztos vagyok az Alder Lake-S nagyon ki fog kapni a Zen 4 megjelenéne után.
Az AMD se engedi le a védelmet, fejleszt gőzerővel és biztos sok ember álla fog le esni. Talán a Zen 4 Cinebench R20 alatt 800-880 pont között hozhat 1 magon. A 30-40% gyorsulást valahova ide vezethet.
LGA 1700/AM5
Én is a kettő között örlödök, de szerintem jobban megéri kivárnom az AM5-öt.
Intelnél azért jelentősen túlárazottak az alaplapok, + az AMD oldalán egy platform jelentősen tovább marad életben. így a jövőre nézve sokkal nagyobb lehetőség van még idővel processzort váltani. -
#6193
Petykemano
veterán
HSM
#6191
Petykemano
veterán
5800X3D
Olvastam olyan véleményt, hogy nem csak kirakat termék, azért lett 12-16 magos verzió is, mert az 5900X és és 5950X is azonos TDP-vel jön és frekvencia regresszió ott már túl nagy lett volna, vagy túl nagy vágás lett volna.
Ugyanakkor ha ez így van, akkor igazán kiadhatták volna 6 magos verzióként is. Az 5600X ha jól emlékszem csak 65W TDP-s, tehát ott bőven lett volna tér a fogyasztás kárára megtartani a frekvenciát.Nem zárom ki ennek a magyarázatnak a lehetőségét, de valószínűbb, hogy csak egy kirakattermék és a 6000-es desktop széria Warholostul, mindenesetül tényleg el lett kaszálva.
De én nem hiszem, hogy itt valamilyen stratégiai kérdésről lenne szó ( [link] ), hogy mérnöki időt spóroljanak a zen4 javára. A Zen4 eléggé készen levőnek tűnik, ha már most 5Ghz-en pörög. Mármint: amikor elkaszálták a Warholt, meg N6-ot, meg zen3+-t (desktopra) ez a döntés akkor született meg. Akkor azt gondoltuk, többen mondták, hogy a döntés a 2021 computexre sikeresen összerakott Zen3D javára történt. De történhetett a Zen4 javára is.
Hogy ez mennyire igaz, ezt majd az dönti el, hogy a 2022H2 során pontosan mikor rajtol a Zen4.
Ha az történik, hogy a computexen (ami ugye nem 2022H2) bejelentik és júliusban kapható, akkor arról lehet azt feltételezni, hogy itt tényleg jól mentek a dolgok, gyorsabban ment a fejlesztés, előbb kaptak gyártókapacitást, stb és sikerült pár hónappal előre hozni a tervezetthez képest, ezért elkaszálták a köztes áthidaló terméket (a Warholt). De ha úgy jelentik be ,mint a zen3-at, hogy októberi bejelentés, november-decemberi elérhetőség, hááát arra ezért nehéz lenne azt mondani, hogy itt egy stratégiai előrehozatal történt. Azt leginkább azzal tudnám illetni, hogy kissé megcsúsztak, megborult a "flawless execution"Persze a desktop piac nem prioritás, úgyhogy nem fognak könnycseppet ejteni.
Abban egészen biztosak lehetünk, hogy 5Ghz-es zen4 mellett a mintákat már biztosan szállítják. A 2022H2 pedig nyilván attól függően jelent július-augusztus vagy november-december, hogy milyen lesz a kereslet a Genoa-ra (Biztosan jó nagy) és milyen lesz a selejtarány (mivel az N5 nem új - az Apple 2020 óta gyártat rajta - ezért elég valószínű, hogy már nagyon jó a kihozatal)Szóval a Zen4 jó ütemű fejlesztése lehet, hogy kiütötte a Warholt - és hát mivel 5Ghz-en ketyeg ez kétségbevonhatatlan. De hogy a malacoknak a Zen3D-ből is csak egy sku jut annak szerintem a Milan/Milan-X-re való kereslet lehet inkább az oka
Barcelo
A Lucienne-ről az AT-en meg biztosan más helyen is részletes ismertető jelent meg, hogy végülis ezzel fejezték be a Renoir-t. Ugyanakkor nem érzem azt, hogy maga a termék olyan nagy port kavart volna. -
S_x96x_S
addikt
> hiszen az ütemező már generációk óta tudja kezelni
> a preferált magokat.Azért ez nem olyan egyszerű.
az operációs rendszer (Linux/Win) még a legegyszerűbb ..
de az csak az egyik része;pl.
- A GoLang ütemezőnek is ismerni kell ezt ..
- vagy az LLVM/Gcc - optimalizált kód generálása ..
// disclaimer: én adatfeldolgozással foglalkozom ; és mindenféle kódokat irogatok .. nálam nem mindig szimmetrikus a thread-ek terhelése. vagyis az átlaghoz képest - túlérzékeny vagyok ebben a témában.
//túl-egyszerűsítve:
Ha vegyesen lesznek a ZEN3 + ZEN3D magok,
akkor ezáltal itt is lesz egy "erős" és egy "még erősebb" mag,
és akkor hasonló szívás is elképzelhető mint az ARM/AlderLake-nél.
vagyis a Big-Little ütemezési probléma.Ami még lényeges, hogy a teszteknél Win11 -et használt
az AMD - aminek nyáron jön ki az újabb verziója.
és akkor ott vagyunk a "Thread Director" problémánál; ami elméletben egyszerű .. de a gyakorlatban még mindig reszelik és csiszolják.Persze a jövőben
a ZEN4 és ZEN4D is hasonlóan eltér - teljesítményben
de itt is az a kérdés, hogy ezeket mennyire akarják vegyesen használni
az életciklus elején. ( a problémát úgyis meg kell oldani, kérdés, hogy mikor .. és érdemes-e várni az Intelre, hogy a Windows és a Linux -ban a kódok 90%-át megirja .. ) -
#6170
Petykemano
veterán
HSM
#6165
Petykemano
veterán
Nem mondom, hogy rossz.
A "takarékos" és "erős" jelen ismereteink szerint annyit jelent csak, hogy milyen frekvencia/fogyasztás engedélyezett számára. Persze elképzelhető, hogy azok a processzormagok sűrűbb libraryt használnak, hogy valamivel kisebb helyet foglaljanak. De az valószínűtlen, hogy más architekturális különbség lenne. -
-
#6132
Petykemano
veterán
HSM
#6125
Petykemano
veterán
"Ezt viszont határozottan nem gondolom problémának..."
2021-ben én sem gondoltam volna problémának, egy 2022-es terméknél viszont szerintem már az lehet. Persze: nincs rossz termék, csak rossz ár.A zen3-nál a legnagyobb dobás valóban az volt, hogy egyesítették az L3$-t, de azért nem merült ki ebben. "Általános" értelemben is hozott kb 15% IPC növekedést és az egyesített L3$ lefaragta azt a kb 15%-os hátrányt, ami CB MT eredményekhez képest a játékokban jelentkezett a két különálló CCX miatt.
Ha a zen2-t a zen3-hoz mérjük, akkor az a 15%-os különbség lehet, hogy tényleg papír jellegűnek tűnik. Ezért is mondtam, hogy 2021-ben korrekt termék lett volna, de 2022-ben már potenciálisan Raptor cove és zen4 magokhoz fogják méricskélni (nem is beszélve az ARM magokról) - még akkor is, ha a mobil zen4 APU-re még bő 1 évet várni kell.
De abban igazad van, hogy a zen3 nincs ingyen. a Renoirhoz képest a Cezanne 20%-kal nagyobb lapkával készül - még ha ebben benne is van némi IGP-t ért fejlesztés is.
Szerintem sajnos nehéz jó kicsi APU-t készíteni. Vannak részegységek, amik rosszul skálázódnak, vagy nem is skálázhatók a lapka képességeivel. Nézd meg a GPU-kat. a Navi 23 szinte minden lényeges számadatban duplája a Navi 24-nek, ennek ellenére csak másfélszer nagyobb (picit több, mint másfélszer, de a NAvi24 N6-on készül a friss pletykák szerint)
Ugyanez valószínűleg érvényes az APU-kra is. Hiába vágnád ki a CPU és GPU magok felét, akkor se kapnál feleakkora lapkát. A kapacitások csökkentésével sehogy se lehet pici és olcsó tömegterméket készíteni. Erre a célra én a Monet fejleszést a GF 12++++-on (ami közel 7nm-es fogyasztást kínál, alacsonyabb tranzisztorsűrűséggel) alkalmasabbnak látom. (Persze még arról is kiderülhet, hogy kacsa, vagy semi-custom.)
A Van Gogh esetén valószínűleg arról lehet szó, ahogy mondod is, hogy handheld gamer eszköznek ahhoz az RDNA2 WGP számhoz 4db zen2 CPU mag is elég és így érdemes is inkább a hellyel spórolni.
-
carl18
addikt
"erősen "budget" opció volt" Hát nyilván 2X áron el is várható tőle hogy lesőpörje.
Igazság szerint a Ryzen 3600 ára is elégé elszált, jelenleg 90E forintotba fáj és ennyit már egyáltalában nem ér meg a szemembe.
Még úgy hogy AMD Tulaj vagyok is azt mondom a 10100F az áráért erősen ajánlott, és ennyi pénzért nincs jobb.30-34E forint egy Ryzen 1200AF ilyen árkategóriába határozottan többet nyújt az intel.
54-65E Forint egy Ryzen 1600AF, ennyiért van 10400F ami megint jobb vétel.Sajnos a chiphiány az AMD áraira erősen kihatással van, egyenlőre a piaci helyzet árak és teljesítmény szempontjából az intel malmára hajtja a vízet.
-
#6124
Petykemano
veterán
HSM
#6121
Petykemano
veterán
Egyébként van még egy érdekes fejlesztésük, a Van Gogh, arra is azért kíváncsi lennék, pl. mekkora fizikai méretből sikerült kihozni (4mag Zen2 + RDNA GPU, Steam Deck). Bár vélhetőleg az sem egy ideális olcsón gyártható tömegtermék alap.
Azt mondják, hogy a Steam Deck (Van Gogh) eléggé megkésett. Steam Deck formában persze lehet, hogy nem vállalhatatlan, de a zen4 rajtjának küszöbén egy Zen2-es CPU-val szerelt APU kissé elavultnak tűnik. Ha a hibás PS5/Xbox chipekre gondolunk, akkor valószínűleg meg fog jelenni a piacon valamilyen formában, de azt nem hiszem, hogy a Steam Deck igényen túl gyártanák és értékesítenék.A korábbi (Kaveri&co) tapasztalatok legalábbis azt mutatják, hogy lehet akár 2-3x erősebb is az IGP, döntően akkor is a CPU ereje határozza mag az eladhatóságot.
-
carl18
addikt
Igen, az intel megteheti hogy gyárt olcsón Core i3-at. De a fogyasztok nagy része azt veszi ami árban is elérhető. Tegnap néztem havernek processzor hogy mit kap manapság olcsón elérhető árban. i3-10100F 27-30E között kapható, és átlag embernek jelenleg ez ami megfizethető és jól teljesít.
Zen 3 12 NM
Igen nyilván valamennyi órajelet be kéne áldozni, de szerintem 3800-4000 mhz elérhető lenne minden magon. És szerintem az emberen nagy része megvenné, mert lehet 400-500 mhz-es kevesebbet megy mint a 5600X de ha tudja hogy féláron megapja akkor mondhatni jobb vétel volna.
Bár keresgéltem, de nem találtam ilyen információkat hogy a piros oldal tervezne hasonlokat... Szóval szerintem nem dobnak piacra ilyen backportot.
Talán ha az intel valóban nagy piaci részt vesz el tőlük akkár talán feljőhet mint opció.Hát majd meglátjuk, egyenlőre a 3D V-Cache ami az AMD különlegesége lesz.
A 12-16 magos processzorok biztos megkapják ezt, a kisebbekből talán kimarad 6/8mag.
Januárba bejelentés, már nem kell sokat várni és kiderül nekik mi a tervük. -
carl18
addikt
Hát azért nekik is be kéne látni hogy az átlag embernek is vásárolni kell Zen 3-at.
Nyilván a 12400F egy visszafogott órajejű, de már egy 11400F is oda tudott verni néha egy 5600X-nek.
AMD Ryzen 5 5600X vs Intel Core i5-11400 — Test in 10 Games! [1080p, 1440p]Nyilván az extra profitot nem akarják bukni, de ha az intel ilyen áron tarolni előbb utobb valamit lépniűk kell. Hát majd meglátjuk mit dobnak ki, már nem kell sokat várni.
1 hét is fény derül az AMD terveire, aztán eldől még is mit lehet venni.
Például lassan nekem is csere érett lesz a Ryzen 5 1600, és kéne egy méltó utod ami nem kerül 3X annyiba. -
S_x96x_S
addikt
> profitráta
Szerintem a dolgozói és a tulajdonosi érdek is belejátszott.
Rengeteg (~hűséges) dolgozó kitartott az AMD -ben
és húzta az igát a legnehezebb időszakokban is.
Lisa Su megemelt részvényopciója már ismert,
és valószínüleg a többi fontos dolgozó is kapott opciókat,
és hogy ezek valamit érjenek is, kell bevétel és profit is!
( mert ha nem, akkor elmennek máshová .. )És nem tudnak mindenkit boldoggá tenni, ( mert nincs kapacitás )
ezért kemény döntéseket kell meghozni.Míg az AM4 platform rekord időt ért meg ..( kényszerűségből is )
és a chipsetek 2-3 CPU generációt is kiszolgáltak ..
de ez az Alaplapgyártóknak már kevésbé volt ideális - mert ők is az eladásokból élnek.
Szóval több különböző (külső) dolgot (érdeket) kell összehangolni
egy jó stratégiához.- alaplapgyártók érdekei
- dolgozók érdekei
- tulajdonosok érdekei
- az ügyfelek érdekei -
S_x96x_S
addikt
>>"te meg egy 2 és 6 magos példát hozol."
>Gondoltam így is átmegy a mondanivalóm.több mondanivaló is volt ..
pl ilyet is irtam feljebb, ezt is vedd figyelembe:
"én durván 1-2GB RAM/thread -el számolnék .."
E küszöb érték alatt már fontos a memória növelésére is figyelni.
amúgy:
az Autodesk - Arnold: nál kifejeztetten ugyanezt a heurisztikát
(ökölszabályt) emlitik:
"If you know you’ll be using your CPU for rendering, another rule of thumb is installing 1 to 2 GB of RAM per thread of your CPU.
For example, if you have a Ryzen 9 5950X (offering 32 threads), you’d want to have 32-64 GB of RAM."
https://www.cgdirector.com/how-much-ram-do-you-need/Amúgy szerencsés is vagy mert a régi és új géped is megfelel ennek.
mostani géped: 20GB/12t ~1.6GB/thread
régebbi géped: 20GB/4t ~5.0GB/threadSzerintem a minimum 1Gb/thread teljesen racionális elvárás - ideális minimumnak a következő pár évre.
Ha -e felett vagy akkor az jó,
de ez alá bemenni kockázatos. ( ~ érhetnek kényelmetlenségek )
2c/4t > min 4GB RAM
4c/8t > min 8GB RAM
6c/12t > min 12GB RAM
12c/24t > min 24GB RAM
16c/32t > min 32GB RAM
32c/64t > min 64GB RAM
vagyis lényegében ez az ideális (~kényelmes) minimum
persze a Windows és más szoftverek igényei ezt is felülirhatják.Ennek az a lényege a háttérben,
hogy ne a memória legyen a szűk keresztmetszet.Ha te még erre is ráteszel a "kényelmed" miatt ( 6c/12t -> 20 GB RAM )
akkor nálad nagyon ritkán lesz ez a terület a szűk keresztmetszet.
-
S_x96x_S
addikt
>> "ahol a 4 csatornás memória - 32 mag felett már
>> eléggé visszafogja a teljesítményt."
> Anandék tesztje épp az ellenkező konklúzióra jutott:értelmezés kérdése;
ahol a szűk keresztmetszet a memória sávszél, ott számít.
ezt irják:
" (c) TR Pro thrashed Threadripper due to memory bandwidth availability. That last point, (c), only really kicks in for the 32c and 64c processors it should be noted. "> A saját példám alapján a korábbi kétmagos laptopomon is nagyjából
> 20GB kellett a kényelmes munkavégzésemhez, a mostani 6-magoson
> is éppen ennyi kell. Pedig a heurisztikád egészen mást mondana erre.Nálam ez a "megszokott" ami nem egyenlő az "optimális"-al.
átfedés lehet, de nem ugyanaz a fogalom.Amúgy valószínüleg erős 16 maggal és 64 GB memóriával
még kényelmesebb lenne ( Gen4-es SSD-vel alatta )Vagy egy ZEN5-ös procival és Gen5-ös NVMe SSD-vel meg még "kényelmesebb".
de amúgy is pontosítottam feljebb
ezt irtam: "De általában a 16,32,64,128,256 magra elég jól működik a heurisztikám." te meg egy 2 és 6 magos példát hozol. -
S_x96x_S
addikt
én a másik oldaláról nézem a problémát.
> Ezért rossz heurisztika, mert nem lesz igaz.
ez bonyolultabb.
itt mindig az a kérdés, hogy milyen irányba tévedünk (fölé vagy alá) - és ott mi a tévedés ára (költsége).pl. 2 ősember beszélget a dzsungel mellett - mikor megzörren a bokor.
Az egyik a heurisztikája alapján azt mondja, fussunk - hátha egy oroszlán vagy egy tigris.
A másik viszont a racionalitás híve - és jelzi, hogy statisztikailag 99.9%-ban nem oroszlán vagy tigris ..
viszont ha ez 1000x megtörténik, akkor a racionális ősemberek előbb-utóbb kipusztulnak, és nem lesznek utódai ..
mert van akkora esély, hogy biztosan belefut egy oroszlánba.Ebben a példában a tévedés ára nagyon nagy.
És az, hogy mi az "igaz" .. az evolúció dönti el a túléléssel.
Ami segíti a túlélést az lesz az "igaz";
még akkor is, ha 99.9%-ban tévedés.másik példa:
Egy (fiktiv) csóró ismerös felhív és jelzi, hogy kapott ajándékba egy procit és egy alaplapot, mekkora memóriát vegyen bele?
És ha azt mondjuk reflexből - a te heurisztikád alapján - hogy 8GB vagy ha van pénze akkor 16GB;
és utána panaszkodik, hogy az ajándékba kapott 64 magos threadripper a 8GB memórával használhatatlan, mert egyes programoknak a memóriaigénye is megnövekedett ..
akkor itt a tévedésnek nem nagy ára van .. irány a bolt és kell még +3 db 8GB memória stick
De általában a 16,32,64,128,256 magra elég jól működik a heurisztikám.
Több mag -> több memória kell. ( általában )De a sáv-széleséggel is összefügg.
lásd Threadripperek példája .. -
ahol a 4 csatornás memória - 32 mag felett már eléggé visszafogja a teljesítményt.A ZEN4-es architektúránál is észrevehető,
hogy az +1 CCD => +1 memória csatorna elvet követik.
Vagyis max 12 CCD -hez már > 12 memória csatornával terveznek.
> Rengeteg program nem is skálázódik akármeddig,
> elindít max mondjuk 8 szálat és nem is tud többet.más a nézőpontunk és az időbeli perspektívánk
egyik se helytelen, csak más.
Talán te valószínűleg nem telepítesz fel új programokat, beéred a régi 5-10 éve megjelent játékokkal, felhasználói programokkal a következő 5 évben is,
De ha valaki a következő 1-2-3 évben megjelenő programokat is - "élvezhető" szinten használni szeretné,
akkor nem árt a ráhagyás a tervezésben ---> vagyis a fölé tervezés.
Legalább annyira, hogy a bővíthetőséget is végig kell gondolni.
( vagy a bővíthetőség költségét ) -
S_x96x_S
addikt
> Dupla annyi maghoz/threadhez - dupla annyi memória kell."
> Ez egy rossz heurisztika,azért heurisztika .. mert olyan leegyszerűsített gondolkodási szabály,
ami a legtöbb esetben beválik és jó eredményt ad,
anélkül is, hogy több napot eltesztelgenénk ..és a heurisztika egy leegyszerűsítés .. nem kell 100%-ban működjön
Amúgy nem alapozhatsz arra, hogy minden program annyira optimalizálva lesz mint a Cinebench R23.
és itt nem az a lényeg, hogy 100 programból találsz egyet,
ami kivétel a szabályra ...
Mert attól még a 100 program "jelentős" részére ugyanúgy igaz marad az állításom.És amúgy is jobban jársz, hogyha ráhagyással tervezel, mintha szűken.
-
S_x96x_S
addikt
> a user gépében ott a 128GB ram, még semmi értelme nem lesz,
> nem lehet majd kihasználni.Ez már a "státusz" szimbólum és a "luxus" területe ..
mint a sport luxusautó .. Ha valakinek egy "valag pénze" van - el tudja költeni.Amúgy mert pl. ez[1] a 2millás konfig 64GB RAM-al furcsán is nézne ki; [1] "Gamer PC - AMD Ryzen 9 5900X 4,8 GHz processzor, NVIDIA GeForce RTX 3090 24 GB, 128 GB RAM DDR4 memória, 2000 GB SSD "
---
amúgy ha nincs más ..
majd a windows vagy a böngésző kihasználja - memória cache-nek.-------------
én jelenleg egy mostani beruházásnál egy alapgépnél:
- notebooknál - 16GB RAM ( iGpu igénnyel )
- asztali gépnél - 32 GB RAM -al ( iGpu igénnyel )
számolnék.A probléma, hogy míg az asztali gép memóriáját jellemzően még lehet bővíteni ( kivéve az új AppleMac )
a notebooknál a bővítési lehetőség lassan már luxus lesz
mert egyre inkább integrálnak mindent. -
S_x96x_S
addikt
add2 ..
> a 4GB-ról 8GB-ra bővítés is azért olyan durva előrelépés,
heurisztika:
Dupla annyi maghoz/threadhez - dupla annyi memória kell.vagyis a memória és a CPU magok száma erőssen összefügg ( korrellál) és a cpu magok száma ... csak nő .. és nő ..
én durván 1-2GB RAM/thread -el számolnék ..(csak a CPU-ra!)
amiből lehet érzékelni a trendet.
( amúgy szerveren én 4GB/thread -el számolok )tegyük fel, hogy most az i5/Ryzen5 az "arany középút" ..
És az i5 jelenleg: 12thread -16 thread -ig terjed ( Alder Lake )
(pl. Core i5-12600K: 10 cores/16 threads )És jövőre az Intel a RaptorLake-el tovább emeli a magszámot.
a felső kategórai 16c/24t -ről 24c/32t -re megy fel, a középkategória is tolódik .. És a MeteorLake-en megint várható növekedés.Vagyis "igény" lesz majd a memóriára ..
Kérdés, hogy fizetőképes kereslet is lesz-e ..Én nem aggódnék a memóriagyártók helyében ..
-
S_x96x_S
addikt
> A 32GB már ennyit szvsz nem fog hozni az átlag usernek még évekig.
ha van fizetőképes kereslet .. akkor lesz rá kínálat.
És ne becsüld le a memóriagyártók piszkos trükkjeit ...
amikor extrém memóriaigényes játék fejlesztéseket szponzorálnak.amúgy nincs értelme "átlag" userben gondolkodni.
Ez olyan mint az orvostudományban az átlag-beteg.
( akinek 1 heréje és 1 melle van )>Tehát az én meggyőződésem, hogy attól, hogy az átlag gépbe könnyű
> lesz 32GB ramot rakni, nem fogja maga mögött vonni az igények gyors
> emelkedését.ne az utolsó 10 év alapján projektálj
főleg mert az Intel miatt egy helyben topogott a pc ipar ..
és nagy előrelépés nem volt.és a következező pár évben az Apple határozza meg nemcsak a software, hanem a hw trendeket is.
és ők elég feszített tempót diktálnak ..Szerintem a Gen5/CXL5 ; az ARM térnyerése miatti verseny és a XILINX beintegrálása miatt a következő 10 év hullámvasút lesz ..
Aki megint egy 10 éves langyosvizes ciklusra tervez,
az koppani fog.> de legrosszabb esetben is 32GB még nagyon sokáig
> overkill lesz szerintem a "mainstream" usernek otthonra.egyes "mainstream" repülőgépszimulátorosoknak
már most kevés lehet.Microsoft Flight Simulator
- minimum gépigény : 8GB RAM + (+2GB VRAM ) ~ 10GB
- ajánlott gépigény: 16GB RAM + (+4GB VRAM) ~ 20 GB
- ideális gépigény: 32GB RAM + (+8GB VRAM) ~ 40 GBpersze ez egy leegyszerűsítés .. mivel egyesek szerint ..
csúcs GPU-hoz.. akár 64GB memória is elkell
64GB RAM + 24GB VRAM ~ 88GB RAM
"""
The 3090 ships with 24GB VRAM and if you fill it with buffer data or textures, you’ll certainly also duplicate a large amount of the VRAM buffers in RAM, and there you are: with 32GB RAM you probably really don’t have enough room to fit both the buffer data copy in RAM and the game working set!
Conclusion: everyone with a 3090 might really benefit from 64GB and this might even be the minimum recommended amount of RAM to use with a 3090.
""" -
#6052
Petykemano
veterán
HSM
#6048
Petykemano
veterán
Hát ha cinikus akarnék lenni, azt idézném, hogy a "640KB-nak bárkinek elégnek kell lennie" mondás tapasztalata. Tényszerűen, vagy kőbe vésve semmi, ez csak az én elgondolásom.
Én egyébként nem arról beszéltem, hogy mennyi most az egy desktop gépbe betömhető RAM maximális mennyisége, hanem hogy mennyi - értelemszerűen az újonnan üzembe helyezett gépek - módusz RAM kapacitása. A mainstream "végfelhasználói" programok fejlesztése során feltételezésem szerint a különböző RAM kapacitások penetrációját talán figyelembe veszik. Ha azt látom, hogy emelkedik a magasabb RAM kapacitás penetrációja, akkor lehet spórolni azon fejlesztési időt, hogy beférjek-e valamekkora ram kapacitásba, vagy lehet kényelmesebben terpeszkedni, hogy gyorsabb legyen a szoftverem.
Nyilván ez nem feltétlenül azt jelenti, hogy egyetlen mainstream "végfelhasználói" program többet igényelne 16GB ramnál, hanem azt, hogy ha nyitva van neked kétféle böngészőt, 20-25 füllel, meg még szövegszerkesztő, excel 2-3 táblával, stb, akkor ezek elférnek-e kényelmesen, vagy elkezd swappelni a rendszer.
De természetesen semmilyen törvény vagy szabály nem írja elő, hogy mondjuk 2022 július 17-től kezdve a 16GB már nem lesz elég. Nyilván van aki ma is 8GB vagy akár 4GB-tal használ valamilyen gépet. Lehet, hogy még büszke is. Szerintem ma már a 8GB éppenhogy csak elég (kevés), könnyen, gyorsan elfogy és aztán jön a swappelés, amivel együtt lehet élni, meg persze be lehet csukogatni a füleket, tehát lehet odafigyelni, csak kevésbé komfortos és azt gondolom, hogy ha DDR5-tel megugrik az újonnan üzembe helyezett gépek RAM kapacitása, akkor ez rövidesen (2-3 év leforgása) meg fog történni a 16GB-tal is.
#6051 S_x96x_S
Jó, persze a felhasználás nem mindegy. Ha csak arra kell egy noti, hogy befizesd rajta a számláidat, vagy elolvasd rajta a népszabadságot, akkor lehet, hogy egy 10 éves 4GB-os gép is elég.Én direkt nem akartam játékokat példaként hozni, egyrészt mert halvány fogalmam sincs, hogy milyen játéknak milyen RAM igénye van, másrészt mert arra könnyen rá lehet fogni, hogy az nem mainstream felhasználás.
-
S_x96x_S
addikt
>> 16GB-os gépek nagyon hamar korosodnak majd."
> Most is alig van mainstream "végfelhasználói" program, ami 16GB-nál többet kér,nem lehet tudni, hogy milyen gyors lesz a váltás ..
valamint mindenkinek mást jelent a "korosodás";
valaki csak 1-2 évre vesz gépet, valaki meg 8-10 évre szeretné ..de szerintem már APU-ban kell gondolkodni.
és a GPU + CPU összesített - közös memória felhasználás a lényeges.A PS5-ben jelenleg is 16GB -os egységes memória van,
ha azokat a játékokat elkezdik átportolni PC-re,
akkor azoknak kb >=20GB gép kell ..
( mert a Windows11 extra 4GB-ját ( ~ overheadjét) is hozzá kell számítani )Persze a Gen5 - CXL.mem korszakban - már lesz szabványos memória növelési lehetőség
és valamikor ez is lejön consumer szintre.A nyomás szerintem a mobiltelefonok felől jön ..
Jelenleg is lehet venni már egy "egyszerű" - 12GB RAM -os mobiltelefont ~ 150e Ft -ért
és persze már 16GB RAM-os telefon kapható. ~ 290e FT
( 8 magos Qualcomm Snapdragon 888+ 5G processzor, 16 GB RAM, 512 GB belső tárhely )És 2-4 év múlva a Qualcomm megcsinálja az új Nuvia magokkal a zsebben hordható - telefon+ pc kombót - 32GB RAM-al
amit csak dokkolsz otthon vagy a munkahelyen.
És a CXL-nek hála .. a dokkoló a CPU magokat és memóriát is megduplázza ..Szóval 6-7 év múlva már kevés lehet a mostani 16GB ram ..
-
S_x96x_S
addikt
> Az összehasonlítás szvsz több sebből is vérzik.
Ha lehagyjuk az NUVIA-s állítását
(ami mögött amúgy az Apple ex tervezője van)attól még igaz:
"Az ARM eredményei minden ponton energiatakarékosabbak/nagyobb teljesítményűek, mint bármi, ami x86-on elérhető, ...."és mert a Graviton3-as történet mögött is ez van - energihatékonyság.
> valós, megvehető termékekkel...
ez cloud .. bérelhető és tesztelhető termékekről van szó.
Az alkalmazások fele ~ ARM-es szerverprocin is elfut. -
S_x96x_S
addikt
>> "de nem olyan egyszerű a lefelé skálázás"
>Ugyanúgy, ahogyan a felfelé skálázás sem.
>Minden rendszernek megvan az optimális mérete, ahol jól működik.A lefelé skálázás alatt
~ "az egyre kevesebb watt-ból - egyre több teljesítményt kihozni"
értem.A Nuvia például azzal az igérettel adta el magát
( persze ezt még bizonyítani kell ... ),
hogy kombinálni tudja a mobilchipek energihatékonyságát a szerverek teljesítményével..
Vagyis jobb és energiahatékonyabb szerver csipet csinál mint a többiek mobil procijai! ( AMD, Intel, Apple )deepl fordítva:
"Az ARM eredményei minden ponton energiatakarékosabbak/nagyobb teljesítményűek, mint bármi, ami x86-on elérhető, még akkor is, ha a felső határon az Apple és az Intel majdnem azonos teljesítményt nyújt ..."és a Cloud -ban az energihatékonyság zsebre megy.
100.000 CPU -nál már ~0.5% -os energihatékonyság több millió $-os éves költségmegtakaritás, amiért érdemes lehajolni.
De egy kis cég, akinek 10 szervere van - ez elenyésző költség.
Veszi a konfekciós szervereket - átalakítás nélkül.
Vagyis a Cloud és a HPC piac egész más optimalizációs problémát igényel az AMD és az Intel részéről.-------------
According to NUVIA’s numbers, this is where the current market stands with respect to Geekbench 5. At every point, ARM’s results are more power efficient/higher performant than anything available on x86, even though at the high end Apple and Intel are almost equal on performance (for 4x the power on Intel).
NUVIA notes that power of the x86 cores can vary, from 3W to 20W per core depending on the workload, however in the sub 5W bracket, nothing from x86 can come close to the power efficiency of high-performance Arm designs. This is where Phoenix comes in.
...
"NUVIA’s claim is that the Phoenix core is set to offer from +50% to +100% peak performance of the other cores, either for the same power as other Arm cores or for a third of the power of x86 cores. NUVIA’s wording for this graph includes the phrase ‘we have left the upper part of the curve out to fully disclose at a later date’, indicating that they likely intend for Phoenix cores to go beyond 5W per core."
https://www.anandtech.com/show/15967/nuvia-phoenix-targets-50-st-performance-over-zen-2-for-only-33-power"Compared to AMD's Ryzen 4700U, the company says it can achieve a 40 to 50 percent higher IPC with only 33 percent of the power consumption." [1]
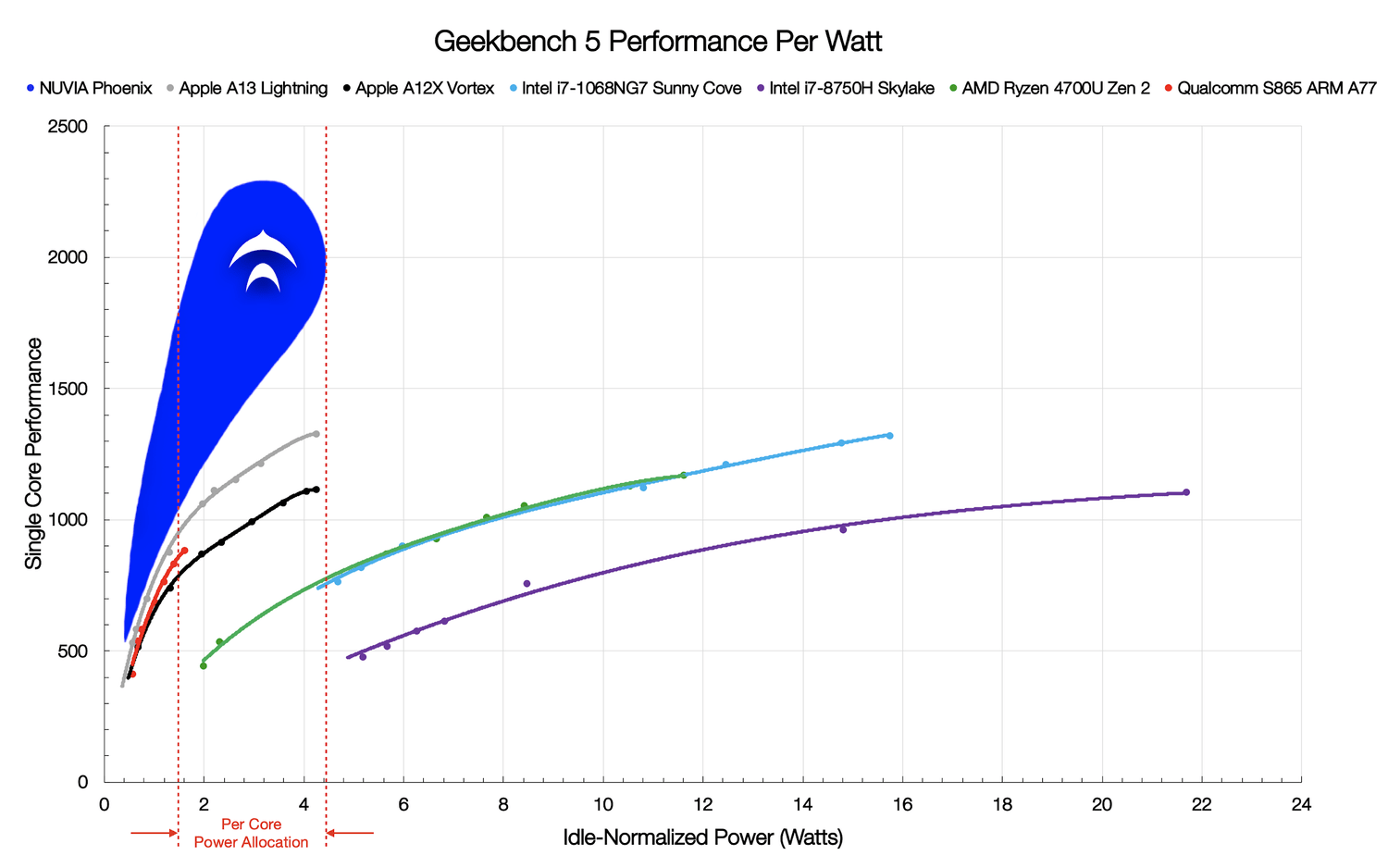
-
#6021
Petykemano
veterán
HSM
#6020
Petykemano
veterán
"A mobilban, főleg az alacsony fogyasztású régióban kritikus a fogyasztás, ahhoz pedig hogy az minél alacsonyabb lehessen fontos a komponenseket minél közelebb és szorosabban integrálni egymáshoz."
Nem akarnám azt sugallni, hogy szerintem lesz chipletes mobil az AMD-től. Csak kérdezem.Ennél:

Ez:

Lényegesen közelebb és szorosabbIlyen "mozaikszerű" módszerrel el tudnád képzelni, hogy mobil célra már közel annyira megfelelhet, mintha monolitikus lenne?
-
S_x96x_S
addikt
>> and clock speeds being pushed too far"
> Ez egyébként erősen paraméterezés kérdése is.
> Hülye példa, de talán szemléletes, hogy notebookokban
> ugyanaz a Cezanne APU konfigurálható 10-től akár 60W-ig is.ez igaz,
de nem olyan egyszerű a lefelé skálázás
és több év kell neki.
Kérdés, hogy mennyire várnak a nagy ügyfelek.Amúgy eddig chipletes mobil proci se nagyon volt;
és ez csak majd a ZEN4-től várható.
Valószínüleg az i/o die-t karcsúsították fogyasztás szempontjából is.Az ARM-nak nagy előnye; hogy alulról felfelé skálázódik
és a fogyasztás kiemelten fontos volt ( telefonok )
És ebben van már több mint 10 éves fókusza, gyakorlata, tapasztalata.És a gyártási technológiára való optimalizálás is fontos
pl.
az Apple (A*)(M1) procik már-már sok-sok éve
főleg a TSMC -re vannak optimalizálva.
és az új TMSC gyártósorok kezdetben nem is birják a ~4ghz feletti freq-kat, de a 3Ghz -et általában tudják.
Emiatt az Apple egyre inkább szélesíti a magjait, hogy egy szálon - alacsony freq-n is jó teljesítményt adjon.
( Az Apple M1 notebook- on hűtés sincs )az X86 hozzá van kötve a magasabb FREQ-hoz.
és az Inteles 14+++++++++++++ -ra való beragadás
is részben ezzel magyarázható.
Mert ha a gyártástechnológia csak 2Ghz-et enged, akkor ennek megfelelő magok kellenek. -
S_x96x_S
addikt
> Nekem elég durva pazarlásnak tűnik ...
> ... meghódítani egy olcsó, négymagos tömegtermék piacot.azért várjuk ki a végét és ne éljük bele túlságosan magunkat.
Lehet, hogy ez csak egy 3-4 évvel ezelőtti OEM-es rendelés teljesítése.
és az AMD legyártja azt a 10e db-ot ( mert erre a szerződés kötelezi)
és utána lezárja a témát.
"AMD's Ryzen 5000 Barcelo APUs Surface In HP's New Laptops"
https://www.tomshardware.com/news/amds-ryzen-5000-barcelo-apus-surface-in-hps-new-laptopsamúgy a zsíros EPYC eladásokhoz képest
- szinte minden más pazarlás .. -
S_x96x_S
addikt
> Alapvetően egyébként én is szoftverfejlesztői szemmel nézem
> a dolgokat, de tény, hogy nem adatfeldolgozási területről.alapvetően I/O mániás vagyok .. és adatokat dolgozok fel ..
de újabban rámjött a CPU optimalizálhatnék is..
és mivel linuxra tudok fordítani ..
tesztelgetem a fordítókat ..
hamarosan jönnek a "x86-64-v3" -ra optimalizált ( ~AVX2) binárisok ..
de az "x86-64-v4" se elképzelhetetlen
https://www.phoronix.com/scan.php?page=news_item&px=LLVM-Clang-12-Microarch-LevelsSzóval szerintem az AVX-512/AMX -nek lehet jövője ..és még a BOLT van a bakkancslistámon.
"BOLT is designed to work with large and complex applications/services. BOLT is already in use for large, production workloads within Facebook for squeezing out greater performance. In a 2019 paper they reported a 7% performance speed-up for their data-center applications on top of the gains already achieved by feedback-directed optimizations (FDO) and LTO. In some cases can even speed up binaries by ~20% or up to 50% if not using FDO/LTO." -
S_x96x_S
addikt
>> "A korai Inteles AVX-512 implementációknál - annyira átmelegedett a chip;
> Ennek nincs köze a csip "átmelegedéséhez"Elnézést, hogyha nem pontosan fogalmaztam volna;
A throttling - nálam a melegedés szinonímája.
Vagy legalábbis a kettő erősen összefügg;Lemire megfogalmazása remélem elég pontos:
https://lemire.me/blog/2018/09/07/avx-512-when-and-how-to-use-these-new-instructions/
"Intel’s new processors have AVX-512 instructions. These instructions are capable of operating on large 512-bit registers. They have the potential of speeding up some applications because they can “crunch” more data per instruction.However, some of these instructions use a lot of power and generate a lot of heat. To keep power usage within bounds, Intel reduces the frequency of the cores dynamically. This frequency reduction (throttling) happens in any case when the processor uses too much power or becomes too hot. However, there are also deterministic frequency reductions based specifically on which instructions you use and on how many cores are active (downclocking). Indeed, when any 512-bit instruction is used, there is a moderate reduction in speed, and if a core uses the heaviest of these instructions in a sustained way, the core may run much slower. Furthermore, the slowdown is usually worse when more cores use these new instructions. In the worst case, you might be running at half the advertised frequency and thus your whole application could run slower. On this basis, some engineers have recommended that we disable AVX-512 instructions default on our servers.
...
"Lemire elég sokat publikál az AVX-512 optimalizációról.
https://lemire.me/blog/?s=avx-512
A régebbi hardvereken - 15%-20%-os teljesítmény csökkenést is kimért - legroszabb esetben. Az újaknál már csak 3%-körül.
A Golden Cove esetében meg még jobb lehet a helyzet.Úgy általában - manapság tényleg kevés praktikus haszna van az AVX-512 -nek; De ha a ZEN4 -ben és a mobile procikban is általános lesz az AVX-512 ; akkor egyre több alkalmazás fogja kihasználni.
-- AMX ..Mivel az új M1-ben is van ( nem dokumentált ) AMX processzor
Elég nagy lesz a nyomás az X86 -alapú processzorok felé is.
Vagyis X86 alapon azzal főzünk ami van; AVX-512 és AMX .. még
ha nem is tökéletes ..# AMX: Apple Matrix coprocessor## This is an undocumented arm64 ISA extension present on the Apple M1. These# instructions have been reversed from Accelerate (vImage, libBLAS, libBNNS,# libvDSP and libLAPACK all use them), and by experimenting with their# behaviour on the M1. Apple has not published a compiler, assembler, or# disassembler, but by callling into the public Accelerate framework# APIs you can get the performance benefits (fast multiplication of big# matrices). This is separate from the Apple Neural Engine.## Warning: This is a work in progress, some of this is going to be incorrect.## This may actually be very similar to Intel Advanced Matrix Extension (AMX),# making the name collision even more confusing, but it's not a bad place to# look for some idea of what's probably going on.
https://gist.github.com/dougallj/7a75a3be1ec69ca550e7c36dc75e0d6fengem inkább fejlesztői oldalról érdekelnek az adatfeldolgozási trendek - és nem felhasználói oldalról. Szóval más lehet a nézőpontom.
-
S_x96x_S
addikt
>>"és persze az x86-ot akarják lecserélni"
> Mivel ahhoz tudtommal nem egyszerű licenszhez jutni,
> így nagyon más opció nem marad annak, aki függetlenedni szeretne.tényleg nincs túl sok opció.
- X86-64 vonal az már szinte duopólium .. ( Intel + AMD )
habár az Intel tele van most igéretekkel ..
és az AMD eddig is egy picit rugalmasabb volt
( de az AMD-nek ott van a kapacitáskorlátja - mind gyártás mind
mérnöki szinten )szóval nem lehet X86 szinten megjósolni a jövőt
- ARM vonalon viszont sok (kész és félkész)
alternativa lesz a jövőben( feltéve ha az nVidia is így gondolja )- és ott van a RISC-V mint szerver chipként
( mert az nVidia ARM-es átvétele miatt sok cég
tartalék tervként tekint a RISC-V -re )privát vélemény:
- Az X86-64 utasításrendszere elég régi konstrukció..
valószínüleg az Intel és az AMD képes
még új lendületet belevarázsolni ... de ez már egyre nehezebb ..
drasztikus és merész megújjítás kellene
és hozzá kellene nyúlni az alapokhoz.- és az ARM-ből bármi lehet .. eléggé stratégiai inflexiós görbén van.
Ha az nVidia jól nyúl hozzá -
akkor akár 10 év múlva lekörözheti az X86-64-et
A másik véglet, pedig, hogy - megdöglesztheti és zárttá teheti.
( vagy sokkal nehézkesebbé )- A RISC-V meg a másik sötét ló ..
szinte minden AI -chip alapja
később akár domináns is lehet.
de akár még az első helyre is befuthat - 20 éves távlatban.szóval ki tudja ...
-
#5835
Petykemano
veterán
HSM
#5832
Petykemano
veterán
Valóban, a tényleges gépekben nagyobb a TdP keret, mint amit az intel ajánl. Ez megmagyarázza, hogy miért nyúlik el hosszan jobbra a grafikonon, de mondjuk azt is, hogy miért lapos.
Én a real life benchmarkokat néztem az 5800h és 11800h vonatkozásában, ami eléggé kiegyenlítettnek mutatkozott. Amit te mutatsz, ott a Cézanne valóban jobb. Egyetértek, inkább azt kellett volna összehasonlítási alapul megjelölni.
Bár attól még a különbség látványos maradt volna.
A 2x5800U felvetésed egyrészről jogos. Beszélik is, hogy az M1X valójában kétszer több tranzisztort tartalmaz, mint a bignavi. Egy bignavi mellé még két Cézanne is elférne.
Persze az Apple CPU ST teljesítménye még akkor is kiemelkedő lenne. És nem tudom, hogy a bignavi beférne-e 80-100-W-ba (a legnagyobb macbook most 140W)
Illetve hogy a fogyasztási különbségből mennyit magyaráz az 5nm.Az is különbség, hogy az Apple-nek milyen a piaca. Nem mondom, hogy milyen piacra termel, mert lényegesen nagyobb mértékben tudja azt befolyásolni, mint az amd.
Egy ilyen macbook pro $6000
Ha létrejönne egy 16 magos mobil bignavi (HBM2e-vel hajtva) notebook $5000-ért, azt hányan vennék meg?
Azt mondják, hogy az AMD legtöbb eladása nem ezen az árszinten van, ezért nem is próbálkozik ilyen big apu történettel. -
#5831
Petykemano
veterán
HSM
#5827
Petykemano
veterán
"És még csak nem is egy takarékosra hangolt aktuális Ryzent, hanem egy 45W-os Core i7-11800H-t szerepeltettek ellene, amiről nekem nem épp az ideális perf/watt jut eszembe..."
Ezt az okfejtést én is elkezdtem...
De valójában a 11800H egy 8 magos 10nm-es Tiger lake. Az 5800H-val nagyjából pariban (https://youtu.be/ot9z0N2z67I?t=832)
A magas fogyasztás irányába elnyújtott ábratalán inkább furcsa, merthogy ennek a procinak nem szabadna 45W (TDP) felett üzemelnie.Az Apple magok tényleg jók az 5nm hozzátesz, de szerintem azért nem ennyit.
Az Intel és az AMD designja viszonylag szűk (persze ezeket régen szélesnek gondoltuk, de az M1-hez képest szűk), ezért a teljesítmény növelése érdekében a frekvenciát növelték, ami viszont a feszültséggel négyzetesen magasabb fogyasztást eredményez, valamint ritkásan kénytelenek rakni a tranzisztorokata túlzott hősűrűség kialakulása ellen. Ugye ezt láttuk az intel 14nm esetén is. Ment fel a frekvencia, az intel pedig elkezdte nem publikálni a tranzisztorsűrűség értéket - feltehetőleg mert az csökkent.
Az apple alacsony frekvencián működő széles designt alkotott, ami által alacsony a feszültség és a fogyasztás, cserébe sűrűbben is tudják rakni a tranyókat.
A bravúr a széles design.
Ez nagyjából ugyanaz a szituáció, mint 10 évvel ezelőtt a Bulldozer és az intel Core architektúrája esetén
- talán azzal a különbséggel, hogy az AMD akkor nem iteratív módon vezette be magát egy zsákutcába, hanem tényleg a nagyon magas frekvencia és a kicsi de fürge feldolgozók voltak a cél. Míg most az intel és az AMD által alkalmazott - egyébként egymásra valószínűleg nagyon hasonlító - felépítés egy lépésről lépésre legjobbnak, ideálisnak gondolt fejlesztés eredménye.Ettől függetlenül a feladat szerintem ugyanaz, mint az AMD esetén volt a Ryzennel.
Aki először megcsinálja azt a a magot, ami mondjuk csak 4Ghz-ig teker ki, de 60-70%-kal magasabb IPC-vel rendelkezik, az nagyot nyer a szerverpiacon is.Az elmúlt 1 évben, amióta az M1 megjelent, számos pro és kontra érvelés is volt arról, hogy az x86 objektív akadálya-e egy szélesebb design megalkotásának. Jim Keller szerint nem.
-
#5829
Petykemano
veterán
HSM
#5822
Petykemano
veterán
"De azt gyanítom, ezt ésszerűbb/gazdaságosabb a mostani értelemben integrált APU-s megoldással megoldani, amibe így egyéb optimalizálások is kerülhetnek, mint pl. felezett L3."
Lehet, én nem mondom nem. Az eredeti kérdés az volt, hogy hogy oldja meg az AMD azt, hogy 8 magnál több legyen - mert a verseny diktálja - és ne kelljen ezért sem külön designnal, sem a chiplet többletfogyasztásával fizetni."aha, jelenleg 23W 6/12 Renoir felhasználó vagyok.
Jó dolog, ha kicsi és könnyű lehet az ember relatív erős munkaállomása, és nem merül le csak attól, ha ránézek."
Jó hát azért a 6/12 még látótávolságon belül van az azt megelőzően standard 4/8-tól.
A kérdés úgy hangzott: minek a 4/8 helyett 8/16. Úgyse futtathatsz rajta olyasmit, ami nagyon , meg hosszan megterhelő, mert akkor pillanatok alatt lemerül.
Én most nem tudnék neked olyan programot vagy eszközt mondani, amit így már lehetővé tett, bár pár élménybeszámolót már én is olvastam, hogy milyen kellemes volt, hogy elindítottam a 8 magos ryzen U-n valamit és milyen gyors volt (MT), és fel se melegedett."Ha én ezzel így célszemélynek számítok, jelenleg sokkal esélyesebbnek látom majd fejlesztésre valamely U-kategóriás 8/16-os Cezanne-t a későbbiekben, mint egy Aldert."
Szerintem az Alder-lake ebből a szempontból nem lesz még átütő erejű. a 8 kismag (2 nagy mag helyén 4 nagy mag MT teljesítményét adva) még nem fog olyan nagyot dobbantani. Bár lehet, hogy a belépő szinten (2C+8c) már fogja éreztetni a hatását (mondjuk a 4/8-as Monet-val szemben)
-
#5821
Petykemano
veterán
HSM
#5820
Petykemano
veterán
> Igazából nem vált az külön
Nem terv vagy szándék szerint vált külön, hanem kényszerből, persze. Az eredeti elképzelés inkább lehetett a nemrégiben desktopon megjelent 8 magos Tiger lake (11900KB) De a Tiger Lake kábé annyira halvány (nem úgy értve, hogy gyenge, hanem hogy marketing szempontból nem átütő erejű, nem meghatározó jelentőséget kapó) volt, mint a Broadwell.
> Ilyen bravúr szvsz nem reális.
Pont azért lenne bravúr, nem?
Azt tudjuk, hogy az IF viszonylag sokat fogyaszt, amit azzal lehetne csökkenteni, ha valami TSV-s megoldást használnának. Viszont cserébe olcsó.
Félreértés ne essék, nem állítom, hogy ez mindenképp meg fog történni.
Vagy ha valamikor igen, akkor nem annak kedvéért, hogy 35-45W-os notebookok magszámban versenyezhessenek.> Nem értem egyébként, mire erőltetik ennyire ezt a "modern standby"-nevű dolgot
Nekem egyetlen notebookom sincs és soha nem is volt, ezért nem tapasztaltam. Viszont filmekben szoktam látni, hogy sokszor úgy használják a notebookot is, mint a telefont. Nem kapcsolják ki, hanem csak úgy otthagyják, és az az elvárás, hogy olyan gyorsan térjen magához, mint egy telefon. Annak is van egy romantikája, hogy csinálsz valamit, félúton összecsukod és amikor legközelebb kinyitod, akkor nem bootol, meg töltődik, hanem pontosan ugyanazt a képernyőt látod.> Ez az, amire a gyakorlatban nagyon kíváncsi leszek, hogyan és mennyire fog működni,
Az számomra is kérdés, hogy pontosan mik lesznek a felhasználási területek. De erre nagyjából ugyanaz lehet a válasz, mint arra a kérdésre, hogy tavaly kinek kellhetett egy 8/16 magos 15-35W-os Renoir.
A pollack szabály alapján az előny megmutatkozhat magasabb throughput teljesítményben, vagy kisebb lapkában. Feltéve, hogy a szálkezelés az interdependens szálak esetén megfelelő. -

Z_A_P
addikt
Hat en semmilyen user feladatot nem igazan tudok elkepzelni a gyenge magokra, mert mi ertelme lenne valamit lassabban elvegezni?
Azonban annak lehet ertelme, hogy pl a wifi/lan driver, sata, bt, usb, stb cuccok mehetnek a lassabb procin. Viszont ezek mennyi fogyasztanak? 0.1% cpu ido?
Ahogy irod, az eszebe ne jusson senki ms/intel/stb cegnek hogy bongeszo/word/stb-t raraknak a gyengebb magra. Ne fejlodjunk mar vissza. -
S_x96x_S
addikt
> De szerintem ilyen árkategóriájú gépet, mint egy ilyen Alder/Zen már
> többségében nem olyanok vesznek, akik nem néznek utána.a világ tele van impulzív-vásárlókkal ...
Ha csak 20-40% ;
akkor már megérte az intelnek a trükközést
( lásd "Intel 7" ; "Intel 4" ... )a verseny jó ... ( persze lehetőleg ne a marketinges rész domináljon)
-
S_x96x_S
addikt
> Ebben egyébként az AMD jelenlegi nyolcmagosa
> erős terhelés mellett igen jó,
> de folyamatos alacsony terhelésen szvsz nem a leghatékonyabb.Az AMD Rembrandt ( 6000U | 6000H )- ot már gyártják..
vagyis a kocka el van vetve ..Talán egy picivel hatékonyabb lesz mint a mostani
ZEN3+ ; 6nm ; Navi2De a magszámot nehéz feltupirozni :-)
Az egyszeri laptopvásárló ha laptopot kell venni a gyerkőcnek, akkor bemegy az "áruházba"
és eldönti, hogy 14magos vagy 8magos laptopot vegyen.a marketinges matek egyszerű: 14 több mint 8.
-
S_x96x_S
addikt
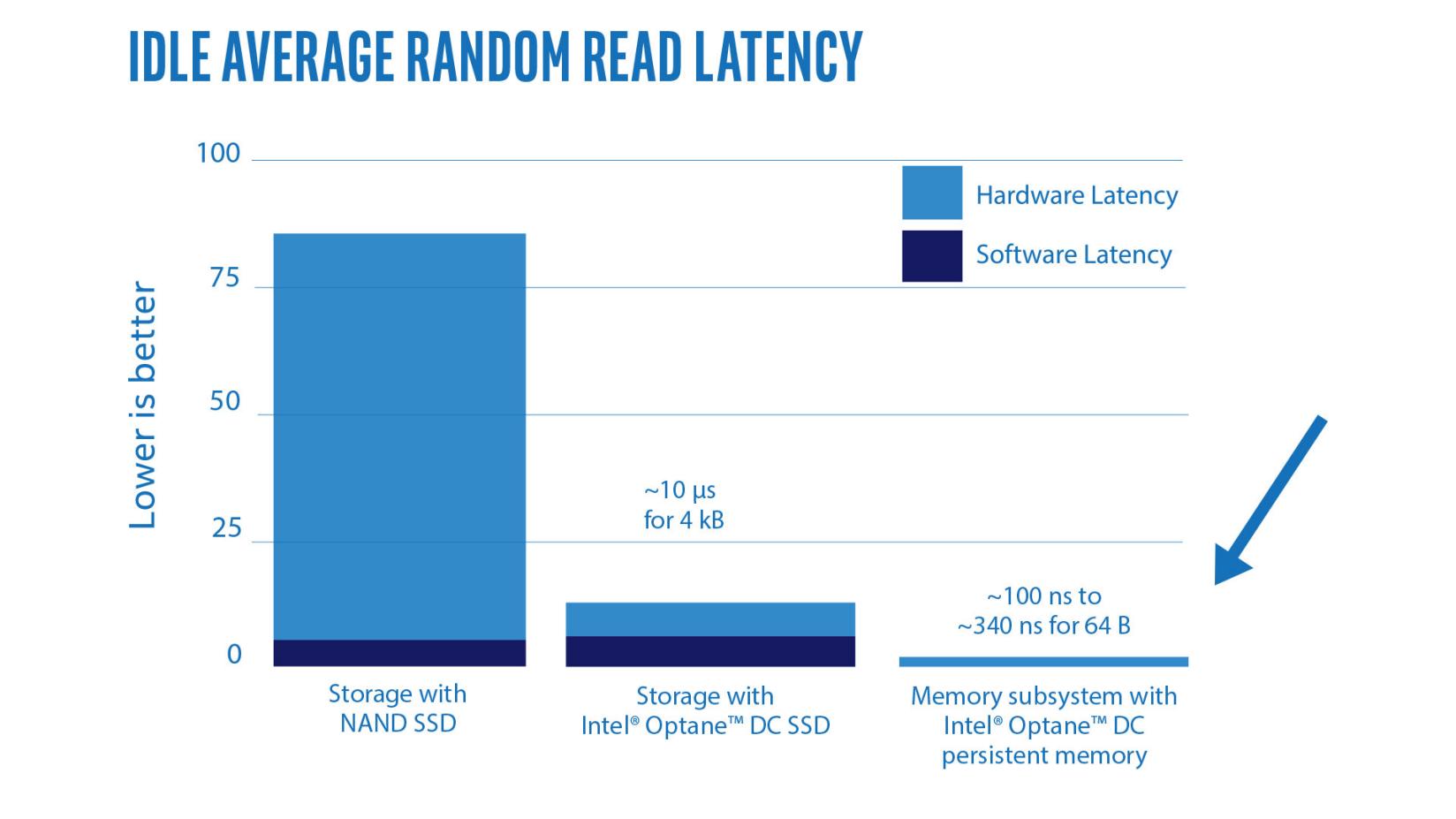
> Hogy a maradék 4µs hardware latency mire megy el
> az ábrán, az nekem nem világos.valószínüleg a
- PCIe 3.0 ( csak nemrég jelent meg a Gen4 -es Optane SSD )
- és az NVMe protocol overheadje ( a PCIe felett ) lehet.de még ha nem is tökéletes - de ettől függetlenül az ábra arra jó,
hogy jelezze, hogy mennyi optimalizálandó
van még a rendszerben,-----------------
Roland Dreier, a senior staff engineer at Google, has tweeted that “HBM is not a good match for CXL, since even future CXL at gen6 x8 speeds tops out at 100 GB/sec, while HBM2E already goes from 300+ GB/sec to TB/sec speeds.” He suggests the industry could “build CXL “memory drives” from normal DRAM.”
Dreier says: “You could imagine a future memory hierarchy where CPUs have HBM in-package and another tier of CXL-attached RAM, and DDR buses go away. (Intel is already talking about Sapphire Rapids SKUs with HBM, although obviously they still have DDR5 channels.)”
He also sees scope for 3D XPoint with CXL: “a 3DXP drive with a 50 GB/sec low-latency byte-addressable CXL.mem interface seems like a killer product that gives new capabilities without forcing awkward compromises.”
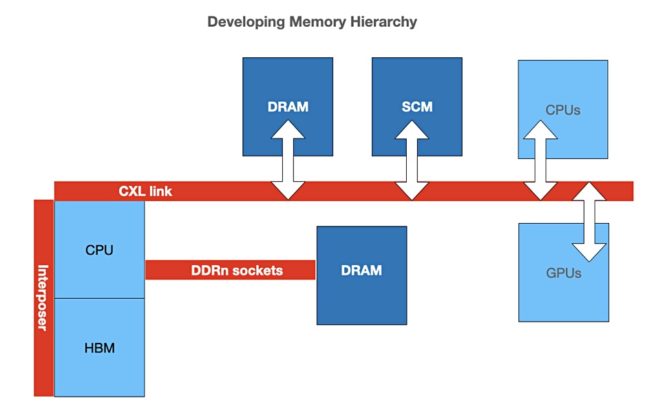
https://blocksandfiles.com/2021/03/25/cxl-and-the-developing-memory-hierarchy/ -
S_x96x_S
addikt
pontosítás:
"A mostani PCIe <alapú csúcs memória technológiáknál> már maga a PCIe a szűk keresztmetszet." <a DDR interfészhez képest - az Intel marketing-anyaga alapján>az Optane .. 3D XPoint - ami PCM - nem sima NAND
Az overhead a grafikon a 2. és 3. oszlop aalapján értelmezhető,
( hogy mit mértek ki, ugyanazzal az 3D XPoint -al.)
Ami tudok még, hogy a Gen5-nél a jitter és más latency csökkentő dolgot elég szigorúra vettek a hitelesítésnél - nem engedik a lazaságot mint a Gen4-nél.itt kell lennie - egy kék szinű ábrának.
-
S_x96x_S
addikt
nagyrésszel egyetértek ... de ezzel nem:
>> "amikor már van Nvme SSD-ből és GPU -ból is CXL/Gen5-ös választék."
> Itt azért a NAND-ok késleltetése is okozhat
> még némi fejfájást, elvileg a mostani PCIe-nél
> is az a szűk keresztmetszet.A mostani PCIe -nél már maga a PCIe a szük keresztmetszet.
És a Gen4-nek ugyanolyan szar a latency-je mint a Gen3-nak; nem nyultak hozzá. Csak majd a Gen5-ben gyurnak rá a CXL miatt.1.)
A NAND mellé sokszor tesznek be DRAM cache-t ;
Én amúgy nem vennék "DRAM-less SSD" .
2.)
A DDR (optane memory; Optane DIMMS ) protokollos csatlakozónak
sokkal kisebb az "összes" overheadje (software+hardware latency)
mint a PCIe-nek. ( remélem az ábra jól látható )
"Intel® Optane™ DC persistent memory can be accessed directly from applications without involving the operating system storage stack, so the software overhead is removed. With persistent memory, idle average read latency drops to between 100 and 340 nanoseconds (ns).5 Consider this low latency in terms of the bandwidth-delay product mentioned earlier. Because latency is low, this memory can be accessed with a small unit size, a single cache line, and still provide its full bandwidth. Intel® Optane™ DC persistent memory is therefore a cache line-accessible, high performance, persistent store—a truly unique new resource."
( Link )
3.) Mindenki a CXL.mem -re készül.
( Kioxia XL-FLASH; Samsung Z-NAND; Micron ; ... )Sok esetben az Intel az Optane Memory-val elég jól tudja kompenzálni a többi hátrányát. ( globális optimum vs. lokális optimum )
-
S_x96x_S
addikt
> Én a CXL-ben és PCIe5-ben rövid távon nem nagyon látok fantáziát.
II.
azért vettem az üzenetet ..Amit én inkább úgy fordítanék le, hogy nem biztos, hogy rögtön az elején az Alder-Lake-S -be - csak emiatt - érdemes lenne beleugrani.
( Legalábbis nem biztos hogy ellensúlyozza az extra magas fogyasztást és az új Gen5-ös kütyük relative extra magas árú belépési küszöbét )De 1 év múlva , ~2022 végén már szerintem teljesen átbillen
a CXL/Gen5 irányába a felső-középkategóriás
és a prémiumos desktop piac is.És akkor már az AMD is kijön a ZEN4-el
és az Intel is a javított Alder-Lake utóddal.és a CXL lesz a kulcstechnológia - ami a forradalmat hajtja ..
-
S_x96x_S
addikt
> Az összes játék ma úgy van megírva, hogy még véletlen se legyen
> érzékeny a latency-re, hiszen időtlen idők óta magas.ha úgy fogalmazol, hogy a játékok nagy többsége - akkor azzal nincs gondom és egyetértek - de ha ragaszkodsz az "összes" == 100% -hoz,
akkor csak felmerülnek bennem a kivételek![;]](//cdn.rios.hu/dl/s/v1.gif)
1.)
A komolyabb élvezhető - virtuális valóság kütyüknek ( headset) és játékoknak azért nem árt a latency.
Én az Intel helyében - ilyen demókkal is készülnék.
"Latency impact on Quality of Experience in a virtual reality simulator for remote control of machines"2.)
Az egységes memóriát használó
újgenerációs konzolokról áthozott játékoknak - is jót tehet a Gen5-ös latency csökkentés. ( a game cache-ek csak korlátozottan segítenek )
A CXL pedig direkt a CPU-GPU kapcsolatra van kigyurva.3.)
GDDR6 Memory On The Leading Edge
Ultra-low latency and AI/ML inferencing team up to power cloud gaming and other new applications.
https://semiengineering.com/gddr6-memory-on-the-leading-edge/de majd a tesztekben meglátjuk
Persze korrekt teszteket csak 2022(Q1-Q2)-ben láthatunk,
amikor már van Nvme SSD-ből és GPU -ból
is CXL/Gen5-ös választék.> Az összes játék ma úgy van megírva
2022Q1-ben már nem csak
a ."... 2020...2021"-ben megjelent játékokkal akarnak játszani.és már most is jó pár "Inteles marketing pénzzel" kitömött
játékstudió - tunningolja az új játékokat az Alder-Lake-S -- Arc -- Gen5 / CXL -re.
"papiron" és a marketing anyagokban biztos jól fog mutatni,
de lehet, hogy a valóságban is.De amint látszik - extrém módon - pozitivan elfogult vagyuk a Gen5/CXL felé .. forradalmat fog okozni - nem csak a szerver - de a PC/Gaming szinten is.
-
-
S_x96x_S
addikt
> SEV ; Ez eléggé súlyosnak hangzik.
úgy általánossában - azért dolgoznak rajta ... pl. az IBM is.
( persze - nem biztos, hogy ez a "folt" gyógyír .. az előzőleg jelentett problémára"
https://lore.kernel.org/lkml/20210809190157.279332-1-dovmurik@linux.ibm.com/
"
AMD Secure Encrypted Virtualization does allow guest VM owners to inject "secrets" into the virtual machines without the host or hypervisor being able to read those secrets. At present though the Linux kernel doesn't allow accessing of these secrets from within guest virtual machines.
Thanks to IBM engineers, support for accessing the confidential computing secret areas within AMD SEV guests is coming in the form of the new "sev_secret" kernel module. The sev_secret module handles copying of the secrets fron the EFI memory to kernel-reserved memory and then allows exposing those secrets within the VM via SecurityFS.
One of the example use-cases for this secret injection usage to VMs is for having guest VMs perform operations on encrypted files and the decryption key being passed to the VM using this mechanism. In doing so, the host/hypervisor doesn't have access to said key and with SEV the guest's memory is also encrypted."
https://www.phoronix.com/scan.php?page=news_item&px=Linux-AMD-sev_secret -
#5542
Petykemano
veterán
HSM
#5540
Petykemano
veterán
"De valamit kezdeni kell azokkal is, amik se különösebben magas órajelet, se különösebben jó fogyasztást nem hoznak.
 Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
Én ezeket gondolnám ideálisnak pl. az 5900X-ek második CCD-jének elszórni. TDP tartalék van bőven, két mag kikapcsolható, és kb. csak a base clock van, mint kötelező specifikáció, amit a nem túl szoros TDP-n belül hozni kell."
Természetetesen, pontosan.
De lehet, hogy az 5950X második lapkája is is ilyen átlagos / semmilyen kiemelkedő jó karakterisztikával nem rendelkező. Sőt, szerintem az 5600X és akár az 5800X is ilyen lapkákat kaphat, ahol szintén van bőven TDP keret és nem is feltétlenül kell a legkiemelkedőbb frekvencia-képesség.
A 6 magos lapkák többsége szerintem nem azért 6 magos, mert hibás, hanem mert 8 magosként túl sokat fogyasztana.Erre mondtam, hogy a desktopra a nyesedék/hulladék/forgács jut. Nem abban az értelemben, hogy amúgy a szemétbe kerülne, de ha ezeket az átlagos / semmilyen kiemelkedően jó karakterisztikával nem rendelkező lapkákat nem tudnák ilyen helyen ellőni, akkor ugye kénytelenek lennének vagy kidobni, vagy az epycekben felhasználni, ami mondjuk magasabb TDP-t, vagy 1-200mhz-cel alacsonyabb frekvenciát eredményezne az SKU-kban.
Ezzel nincs baj, nem azt mondom, hogy a desktopra kellene a legjobb lapkákat felhasználni.
Csak azt, hogy hát pont így - nyesedék/hulladék/forgács - formájában jutnak el a fejlesztések is a desktopra, amit lelkesítő marketingszövegekkel adnak el az itteni közönségnek.Ugyanezen logika mentén gondolom azt, hogy lesz majd V-cache-sel szerelt forgács is, amit majd úgy adnak el a desktop piacon, hogy "gyerekek, ez csakis nektek készült, játékra"
-
S_x96x_S
addikt
> Az 5900/5950x-eken azért ad mozgásteret, hogy elég,
> ha egy chiplet egy magja tudja a magas BOOST órajelet.Az Epyc 7763 ( 64-core )
- Base freq 2450
- Turbo freq: 3500Az 5950X megfelelője ( magszám alapján )
az EPYC 73F3 (16c/32t) F-series ; F= ‘fast’ processors ( $3521 )
base freq :3500
turbo freq :4000mindenesetre a 16 magos ZEN3-as turbók listája:
EPYC 7313P: Turbo: 3.70EPYC 7343 : Turbo: 3.90EPYC 73F3 : Turbo: 4.00TR 3955WX : Turbo: 4.30R 3950X : Turbo: 4.70a "nyesedék és hulladék" chipleteket - simán el tudják a szerveres piacon is sózni.
főleg, hogy az EPYC procikat nem is lehet overlockolni. -
#5472
Petykemano
veterán
HSM
#5464
Petykemano
veterán
Abu a v-cache-ről:
"Kódolási feladatokban már számottevő előnye van, 15-40%-os gyorsulás is realizálható a gyakorlatban, és hasonló módon tündököl a rendszer a modernebb játékokban. Úgy tudjuk, hogy a 3D V-Cache a frissebb címekben 15-25% közötti, gyakorlatban is kimérhető előrelépést biztosíthat, sőt, az Unreal Engine 5-ben akár 30-40%-nyi extra teljesítményt is érhet."
"Az asztali termékek tekintetében csak olyan területre hoznak friss processzorokat, ahol az extra gyorsítótárnak valóban haszna van, így az erre építő Ryzenek kizárólag a játékosokat célozzák majd. Sajnos ezeknek valószínűleg az árát is meg fogják kérni."
[link]Ez alapján azt tippelném, hogy Threadripperből nem lesz v-cache verzió,
legalábbis zen3-ból nem,
legalábbis egyelőre nem, merthogy a Threadripper egyre jobban csúszik.A szövegezés - miszerint új verzió csak ott lesz, ahol a v-cache-nek értelme van - arra utal, hogy a döntő újítás mégiscsak a v-cache és nem lesz zen3+/Warhol jellegű ráncfelvarrás, új IOD. (Persze 100-200Mhz többlet nem kizárt)
Úgy értem, hogy a megfogalmazás nem azt mondja, hogy a v-cache-t csak ott vetik be, ahol értelme van, hanem hanem hogy új processzort oda hoznak.Viszont ha ez tényleg a játékosok a célpiac, akkor ha Neked van igazad és csak az eleve drágább 12-16 magos példányokra teszik rá, akkor az PR-nak természetesen kiváló, mert biztosan minden reviewer lecseréli az addig tesztelésre használt 5950X-et, de a gyakorlatban szemfényvesztés, mert 12-16 magosokat leginkább az veszi, aki valamilyen munka jellegű célra is használja, de kevésbé az átlag gamer.
Ezzel együtt nem mondom, hogy ne történhetne meg, sőt.
-
#5462
Petykemano
veterán
HSM
#5461
Petykemano
veterán
> És ezen szvsz nem fog javítani a V-cache egy cseppet sem.
Ok, értem.
De ha a v-cache hatása ennyire csak egy niche szoftver-szegmenst érint és a költsége viszont ehhez képest nagy, akkor az inkább kéne, hogy egy olyan új termékkategóriát jelentsen, ahol az előny kihasználható, és annyira nagy is, hogy hajlandóak a magasabb költséget kifizetni.De ha - költség és a niche hatás miatt - nem cél, hogy mainstream legyen, akkor az az AMD-nek is némiképp problémát jelent.
Eddig kényelmesen szórták ugyanazt a CCD-t minden piacra.Lehet, hogy igazad van és tényleg csak a drágább modelleken vetik be.
Pl: 6900X(V) és 6950X(V)
És akkor a 6 magos lapkák is megjelennek a mainstream vonalon. -

poci76
aktív tag
Ha az X-es modellek kapnak +100MHz-et, akkor meg is van a kis növekedés, ez még egy sima új steppingből is kijöhet. Az árazás is érdekes lehet. Pl. akar-e esetleg az Intel kicsit kellemetlenkedni, és alacsonyabban húzza meg az árakat, vagy beárazza az Alder Lake-et az AMD-hez.
-
#5459
Petykemano
veterán
HSM
#5458
Petykemano
veterán
A pletykák szerint [link] a 6+4 magos Alder Lake (12600K) ST kb 10%-kal lesz lassabb, mint az 12900K.
Persze sok a kérdőjel. Lehet, hogy a 12900K valójában csak golden sample, amiből kb annyit válogatnak le, amennyit el kell küldeni a reviewereknek.Mindenesetre nem tűnik úgy, hogy az 12900K-hoz képest az Intel középkategóriája (bár manapság ez már felső-közép), az 12600K a megszokott differenciától nagyobb mértékben lenne lassabb. Ez a pletykák szerint akár 750 pontot is jelenthet a CB20ST mérésben az 12600K-nak
Ha az így van, akkor az AMD sem igazán engedheti meg magának azt, hogy a középkategóriája nagyon lemaradjon. Az 5600X jelenleg 600 körüli eredményt produkál.
Ha ezen tényleg csak annyit javítanak, hogy reszelnek picit az órajelen, akkor 650-660-ra felmehet, de azért ez még kevéske.Persze sok a kérdőjel. Mert ha az Intel az 12900K-t $750-ra árazza mondván, hogy annyit megér az, mint az 5950X, akkor persze mindennek az ára mehet feljebb és lehet az 12600K is $400-450, ami alá elfér (sőt, még kedvezőnek is tűnhet) $300-ért egy 10%-kal lassabb 6 magos az AMD-től.
Viszont ebben az esetben az AMD-nek is egy $100-ral nagyobb kerettel gondolkodhat azon, hogy akar-e v-cache-sel szerelt 6 magost.Én egyébként tartok tőle, hogy ez fog történni.
-
#5457
Petykemano
veterán
HSM
#5451
Petykemano
veterán
Mindennel.egyetértek azon kívül, hogy olcsóbb termékekre nem fogják elsütni.
4 magos persze már nem lesz. Arra ott a picasso+++, vagy vangogh selejt, később a pletykált Monet.
De szerintem hatmagoson még lehet. $300-ba azért már csak bele kéne férjen +10$ költség. A 3d.stacking akkor lesz olcsó, ha nagy a volumen.
Nyilván ennek is lehet selejtje. Ha az igp nélküli ps5 lapkákat eladják...(Ugyanakkor az ember hiába gondolja azt, hogy valami kevés, annál több kéne gyakorlat sokszor azt igazolja, hogy annál kevesebb fog csak jönni.)
-
-
#5423
Petykemano
veterán
HSM
#5421
Petykemano
veterán
"Szerintem a véletlennek ehhez semmi köze. Azt gondolom, óriásit kaszálnak azzal, hogy a saját chipjükre zárták be a rendszerüket, és nem kell másoknak fizetniük a CPU-ért.
Így ebben a piaci helyzetben nem csoda, hogy minden pénzt megér nekik, hogy egy ideig előnyben legyen gyártástechnológiailag is, ezzel is erősítve a képet, hogy megéri váltani az új rendszerre a régiekről."Talán nem volt szerencsés szóválasztás a "véletlen"
Átfogalmazom.
Az csupán egyedi felállás (kemény munkát követő "rámosolygó szerencse"), hogy az Apple finanszírozza a TSMC új gyártástechnológiát és még így is nyereséges.
Ezzel azt akartam mondani, hogy ha a Intel nem tolja bele hasonlóképp ugyanazt az összeget a fejlesztésbe, akkor le fog maradni. Ha nem tudja, az persze érthető, de ha csupán azért nem teszi meg, hogy a saját számai - ideig-óráig - fényesebbnek tűnjenek, akkor az hosszútávon káros lehet saját magára nézve.
Szóval a lényeg ez: az Apple helyzete egyedi, nem biztos, hogy az Intel is megengedheti magának azt, hogy behúzza a nagy profitokat, miközben elengedi a gyárai kezét, hogy majd oldja meg az új fejlesztések finanszírozását ahogy tudja, de ne az én profitomból. -
S_x96x_S
addikt
> > a heterogén ( CPU + GPU ( + FPGA )) programozásé a jövő"
> Ezt nyomták a Caveri APU-nál is ezer éve... [link]
> Aztán a forradalom valamiért mégis elmaradt,
> pedig a hardver azóta is adott (lenne) hozzá.Az átállás folyamatban -és csendben zajlik ..
csak még nem annyira látható
az extrém módon fregmentált X86-os consumer piacon.
Még az X86 CPU feature Leveleket is most próbálják szoftveresen szabványosítani .De:
- Konzol szinten ez már a mainstream, a forradalmon már túl vagyunk..
- persze az OpenCL még a gyerekbetegségeit nyögi, de alternativa
- az Intel OneAPI meg még teljesen új ..Mindeközben az Apple tudatosan építi a saját heterogén homokozóját ..
amiben a szoftvert és a hardvert ( NPU, GPU, CPU ) - eléggé össze-optimalizálja. -

Busterftw
nagyúr
-

HSM
félisten
És még egy gondolat, hogy persze borítékolható, hogy majd jönnek a "cherry picked" mérési eredmények azon néhány szoftverből, amik gond nélkül skálázódnak akárhány, akármilyen magokra is, mint pl. a Cinebench... Aztán meg lehet vakarózni, hogy bizonyos alkalmazásokban meg miért nem köszön vissza a várt eredmény... Ahogy az első három generációs Ryzenek is meglepően erős Cinebench versenyzők voltak, miközben azért néhol nem teljesítettek ilyen szépen a konkurenseikhez képest.
#5390 Busterftw : "meglevo OS-ra jott a mas felepites."
Éppen ezaz, nem jött másféle felépítés. Ilyen rendszerek a win10 megjelenése előtt már legalább 5-6 évvel is léteztek, lásd Core2 Quad és kétprocesszoros munkaállomások."Intel biztos odatette magat a Microsoftnal, hogy alljanak ra a temara."
A probléma, hogy nem lehet minden erőből megoldani. Biztos lesz pár szoftver, ami bemutatóra majd jól leoptimalizálnak, de egyébként ez nem fog jól működni automatikusan csak úgy magától, erőből. Ehhez a szoftvereket is finomhangolni kellene. Ráadásul az optimum változhat, hogy mennyire az energiatakarékos és mennyire a gyors működés a preferencia."Sok licensz az."
Nekik mindegy. Így is úgy is elkel a licensz a gépen.
-
Busterftw
nagyúr
Azert Windows 10 es Ryzen eseteben mas volt a helyzet, mert ott meglevo OS-ra jott a mas felepites.
Itt viszont a Microsoft mar ugy fejleszthette a Windows 11-et, hogy hybrid felepites tamogatva legyen indulaskor.
Persze nem mondom, hogy nem lesznek gondok, csak mas a ket eset szerintem.
Intel biztos odatette magat a Microsoftnal, hogy alljanak ra a temara. A Microsoftnak sem mindegy, mert a laptopok 80%-a Intellel kel el. Sok licensz az. -
#5387
Petykemano
veterán
HSM
#5386
Petykemano
veterán
"Szerintem annak még épp van/lenne értelme felhasználói oldalról, hogy 6 helyett 8 magot kapj ugyanannyiért."
Úgy értettem, hogy ha ez így lenne, akkor a növekvő felhasználói értéknek mindenki örülne, de persze a mindennapokban kevés hasznát látná. Tehát a több mag (6-=>8) nem kell úgy, mint egy falat kenyér, mint régen (1=>2, 2=>4)Én arra számítottam, hogy a zen4-gyel majd magszámot emelnek és szépen csúszik le a stack. $200 alá a 6 mag, $200-300 közé a 8 mag, $300-400 közé a 12 mag.
Azt, hogy nem éri meg úgy értettem, hogy egy felhasználónak nem biztos, hogy megér $50-100-t 6 helyett 8 magot venni. A mai 8 magos ugyanolyan elavult lesz 3 év (2 generáció) múlva mint a valamivel olcsóbb 6 magos.
Legalábbis én ezt látom, szerintem nincs lényeges különbség egy 1600X és egy 1800X között. Mindkettőt kenterbe veri egy 5600X.Az üzleti részét értem.
Azt is, hogy az árakat leginkább az befolyásolja, hogy mennyire megy el amit gyártanak azon az áron, amin kínálják. És ebben értelemszerűen a TSMC és más beszállítók árai és keresleti-kínálati viszonyai meghatározók.Azt mondják, a Monet is azért készül, mert "túl jó" a kihozatal. Nem éri meg 4 magosként eladni a lapkákat, ami működnek 6 v 8 magosként is és eladhatók is akként, annyiért.
Akkor lesz változás az árazásban, ha olyan híreket hallunk, hogy túltermelés van a félvezetőpiacon és a TSMC leállít vagy elhalaszt valamilyen gyárépítést és Abu azt írja majd: "hiába szeretné az Apple jövőre a legújabb -1nm-es gyártástechnológián kihozni új processzorát. Lehet, hogy az Apple bele is tolná a fejlesztéshez szükséges pénzt, de utána a TSMC nem tudná megtölteni a gyárakat rendeléssel. Mindenki igyekszik maradni a magas volumennel rendelkező, olcsóbban gyártó és olcsóbban tervezhető gyártósorokon."
"Esetleg az Alder Lake hozhat a maga módján 6+ magot olcsón, de a kis magos megoldásnak is meglesznek szerintem a maga buktatói, szoftveres oldalról a sok kis mag érzékenyebb lehet a programok skálázódási korlátaira, mint ugyanannyi, vagy akár kevesebb nagy."
Ezért fejleszttette az Intel a Windows 11-et, nem? -
-
carl18
addikt
Hát ezt még a jövő zenéje! Hogy mit tud vagy mit nem tud még azt nem lehet eldőnteni, viszont ha jön a nagy magok IPC emelkedése és a kismagok is tudnak számítani 3 ghz környékén azért nem olyan lehetetlen hogy beérjék a jövőben a több magos 5950X-et!
A fő problémára mire jön a meteor lake-S már 2023-at írunk, és addig már piacon a Zen 4 is. (Sőt talán Zen 5 is)

Itt azzal a gond hogy a Zen 3 már létező processzor, de az intel fejlesztései nagy ígéretek amikből nem tudni lesz-e valójában valami.
Mert azt bevett szokás intelnél a 30% ipc emelkedés gyakorlatban csak 15% amit még órajel csökkenés is kövez.Azért a Rocket Lake-S most jött idén év elején és hát egyáltalán nem nevezném konkurenciának. Mert árazást nézve prémium a 11900K de natív teljesítmény /harci erő szinten elégé elmarad egy 5900X/5950X mellet.
-

paprobert
őstag
Abban a termékszegmensben, ahol az egyre jobb termékek már 200-300 dollárokkal lépkednek felfele árban, kigazdálkodják valahogy.
Nyilván azért csinálják, mert megéri csinálni.Egyébként lassan vége a kapacitáshiánynak.
CPU-ból már túltermelés van, és amint az eladatlan termékeken realizálódó kieső profit egyenlőséget tesz a GPU részleg eddigi 30%-os dollár/mm2 hendikepje között a CPU-hoz viszonyítva, a GPU termelés is helyre fog állni.
Gyakorlatilag mindegy lesz anyagilag, hogy melyiket gyártja majd az AMD. -
#5198
Petykemano
veterán
HSM
#5195
Petykemano
veterán
"Ez teljesen jogos.
 Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Tudom, értem, hogy értetted. Architektúra tervezés nem sok ment bele.
Noha elismerem, hogy ez a 12-15% elmehet egy generációs fejlődésnek, de ugyanakkor meg nem értem, hogy a zen3 és a zen4 között nem csupán a szokásosnál valamivel hosszabb (mondjuk 18 hónap), hanem gyakorlatilag a sokásos generációs idő kétszerese fog eltelni (2x15 hónap), akkor nem értem, mit kotlanak azon ennyit, vagy úgy is megfogalmazhatnám, hogy akkor a zen4-nek tényleg nagyon jónak kell lennie. -
#5193
Petykemano
veterán
HSM
#5191
Petykemano
veterán
"egy generációnyi fejlődés, a gyártó szempontjából igen "olcsón"."
A kritikusok azt fogalmazták meg, hogy épphogy nem olcsó, merthogy 60%-kal több 7nm-es lapkaterületre van szükség.
Ha a hasznos lapka 6mm x 6mm és ebből kell két réteg a 64MB-hoz, akkor valójában majdhogynem 2x annyi tranzisztort emészt fel.Ian Cutress kérdése valahol jogos: ennyivel több lapkaterület ilyen mértékű gyorsuláshoz vajon tényleg megéri ebben a kapacitáshiányos időkben?
Vajon ez az SRAM HBM innentől kezdve szériafelszereltséggé válik az AMD-nél?
Ugye itt már a lapkamagasság sem mindegy így. Tehát ha nem így gurul le minden CCD - 2 magas SRAM HBM-mel -, akkor még azt is előre el kell dönteni, hogy mire tesznek és mire nem.Vagy vajon vegyíthető-e az új és a régi lapka? Vagy konfigurálható-e úgy, hogy egyik CCD-n aktív a 3DX a másik CCD-n meg nem (mert mondjuk hibás)
-
hokuszpk
nagyúr
"Egyébként azt gondolom, ez leginkább memória sávszélesség hiányos helyzetekben segíthet igen sokat, azaz szerverekben és a magas magszámú modelleken, asztaliaknál pl. 5900, 5950."
nomeg az integralt gpunak. Lassan tényleg eljön az ideje elfelejteni a böhöm vgakat, tessenek odakomponalni a cpu melle egy tisztesseges gput, ebbol a stacked csodabol 8 reteget es ha belefer, plusz egy ampulla HBM -et is
azon filoztam, hogy hiaba segit az ipc novekedest, az asztali cpufrekinek viszont oda fog vagni vagy azert, mert elmelegszik az egesz motyo vagy azert, mert nem birja tartani 1:1 -ben.
szerverben az "energiahatekony" kombokhoz viszont kivalo. -
#5182
Petykemano
veterán
HSM
#5179
Petykemano
veterán
> Gondolom itt nem kell versenyeznie/osztoznia az elkészült lapkáknak a legnagyobb profitú
> szerver termékekkel. Valamint feltételezhetően a gyártása is egyszerűbb (olcsóbb?), hogy
> egy helyen gyártják, egy csippel.Biztos több hónapra előre el kell döntenie az AMD-nek, hogy melyik lapkából mennyi gyártását indítja el - már csak azért is, mert míg wafertől eljut valami a chip formáig, az a gyártási folyamat is több hét, vagy 1-2 hónap is lehet.
Ennek ellenére szerintem az, amit mondasz, hogy az elkészült lapkák nagyobb profitú szerver termékekkel kell versenyeznie, az csak rövidtávú, mondjuk 1-2 negyedéven belüli árfelhajtást, vagy hiányt okozna. Arra gondolok, hogy a végső korlátot a rendelkezésre álló wafer jelenti és nem hiszem, hogy ha sokat tudna az AMD keresni szervertermékeken, akkor ne forgatná át a wafer felhasználást arra - olcsó apuk helyett.
A gyártás/csomagolás költségével kapcsolatban igazad lehet. Valószínűleg a monolitikus lapka elkészítésére vonatkozó kapacitás, gyakorlat nagyobb lehet.
Még az jutott eszembe: lehetséges, hogy ennyire sok volna a túl sokat fogyasztó CEzanne? Merthogy ez elvileg ugyanaz a lapka, ami az U szériát is kiszolgálja.
> Pedig ez nagyjából megfelel a várhatónak. Nem véletlen rakott pl. az Intel is inkább kicsit
> kevesebb, de gyorsabb elérésű gyorsítótárakat a kliens CPU-ira. És pont ugyanezért nem
> gyorsult óriásit az 5000-es Zen sem, pedig praktikusan duplázták a "hasznos" L3 méretet.Igen, igen, tökre reális. Ha megkérdezed, én se vártam volna mást. De az embert mégis arculcsapja a valóság.
-
S_x96x_S
addikt
> lehetőleg CXL-es PCIe5-el.
ajajj .... tényleg kelleni fog az a PCIe 5.0 ...
Marvell Announces First PCIe 5.0 NVMe SSD Controllers: Up To 14 GB/s
"These new SSD controllers roughly double the performance available from PCIe 4.0 SSDs, meaning sequential read throughput hits 14 GB/s and random read performance of around 2M IOPS. To reach this level of performance while staying within the power and thermal limits of common enterprise SSD form factors, Marvell has had to improve power efficiency by 40% over their previous generation SSD controllers."
-
S_x96x_S
addikt
> 1 év szerintem nagyon optimista...
lehetséges
ezen nem veszünk össze ..Az AMD nincs könnyű helyzetben ezen a téren. és a pici R&D költségből se túl sok jut erre.
Az Intel is megfontoltabb már .. pl. a ClearLinux támogatását visszavették.
És a ClearLinux Desktop vonalat beszüntették .ettől még tény, hogy a leggyorsabb linux AMD ZEN3-ra is
az Intel támogatott ClearLinux
Phoronix 2020Dec: The Fastest Linux OS For AMD Ryzen Zen 3? It's Still Intel Clear Linux
"If taking the geometric mean of all 107 tests, Clear Linux was about 15% faster than the other Linux distributions tested in their out-of-the-box / stock configuration for this comparison atop the AMD Ryzen 9 5900X. This doesn't come at all surprising to us given the past successes we have seen with AMD CPUs on Clear Linux, but just fun to see it still being in good shape for Zen 3 and after Clear Linux has been divesting their desktop interests. Fedora Workstation 33 meanwhile was in last place for the geometric mean average."Ez az X86 kompatibilitás paradoxona - előnye ..
ZEN3 cpu-n használhatod az Intel által fejlesztett ClearLinux -ot -
hokuszpk
nagyúr
az egy Inteles dia. Amivel amúgy semmi probláma, csak ezesetben az elmélet és a gyakorlat között az a különbség, hogy nemveszi figyelembe a létező szoftvereket és a szoftverfejlesztők lustaságát. Pont mint az AMD a mindeféle csodafeaturéival, amire kellett volna a szoftveres optimalizacio. Az Atom is mennyire bejött ugye.
Csak most épp ottartunk, hogy elfogyott az "erőböl oldjuk meg" jatekter. ( Mondjuk a legujabb NV nextgen pletykak ellentmondanak ennek )
szvsz három év múlva térjünk vissza ide -
#4475
Petykemano
veterán
HSM
#4474
Petykemano
veterán
Hát ezért írtam, hogy a zen3 a cache miatt is lényegesen jobb lesz CPU-ban. Viszont waferben sokat nem nyernek.
A fogyasztást sem tartom valószínűnek. Ott van az 5700U és 5800U. mindkettő 10-25W.
Azt esetleg elképzelhetőnek tartom, hogy az 10-25 típusú Cezanne ugyan lehetséges, de ritkább, nehezebb elérni. Feltéve, hogy a lista teljes, az alapján 35-45W-os változatból nem lesz Lucienne -
S_x96x_S
addikt
> "vagyis a komplexitáson többet veszít az X86-64-ISA - mint amennyit nyer a "tömörségével"
> Ehhez azért komolyabb analízis lenne szerintem szükséges.rengeteg (performance per Watt) teszt van, ami a risc-es ARM-nek kedvez.
a nuvia például ontja magából a méréseket ( gondolom a befektetők miatt is )
de azért érdemes átfutni https://nuviainc.com/blog> ugyanazt a munkát egy RISC architektúra több utasításból végzi el,
lásd (performance per Watt)
> Csupán arra akartam ráirányítani a figyelmet, hogy óriási előnynek tűnhet,
> hogy több a dekóder, de többre is van szükség,
> mert ugyanazt a munkát egy RISC architektúra több utasításból végzi el,
> tehát nem megalapozott az órajelenként dekódolt utasításokból
> és órajelből kiindulni, mert más az utasítás architektúra.jelenleg (már régóta) legeslegbelül az Inteles és az ZEN procik is RISC-esek ..
az X86-64-ISA -t átforditják mikrokódokra ..
10 évvel ezelőtt az AMD - ennek kb 10% overheaded-et tulajdonított .."Az Atom mikroarchitektúra minden szempontból ellentéte az Intel 1995-ben a Pentium Próval megkezdett stratégiájának, miszerint az x86(/x64)-es programok végrehajtásának legcélravezetőbb módja azok egyszerű, RISC műveletekké bontása és ezek out-of-order végrehajtása. " ( 2011 - prohardver )
https://www.anandtech.com/show/8776/arm-challinging-intel-in-the-server-market-an-overview/12
2014: "The RISC vs. CISC discussion is never ending. It started as soon as the first RISC CPUs entered the market in the mid eighties. Just six years ago ( ~2008 ), Anand reported that AMD's CTO, Fred Weber was claiming:Fred said that the overhead of maintaining x86 compatibility was negligible, at the time around 10% of the die was the x86 decoder and that percentage would only shrink over time.
Just like Intel today, AMD claimed that the overhead of the complex x86 ISA was dwindling fast as the transistor budget grew exponentially with Moore's law. But the thing to remember is that high ranking managers will always make statements that fit their current strategy and vision. Most of the time there is some truth in it, but the subtleties and nuances of the story are the first victims in press releases and statements.
Now in 2014, it is good to put an end to all this discussion: the ISA is not a game changer, but it matters! AMD is now in a very good position to judge as it will develop x86 and ARM CPUs by the same team, lead by the same CPU architecture veteran. We listened carefully to what Jim Keller, the head of the AMD CPU architect team, had to say in the 4th minute of this YouTube video:
"The big fundamental thing is that ARMv8 ISA has more registers (32), a three operand ISA, and spends less transistors on decoding and dealing with the complexities of x86. That allows us to spend more transistors on performance... ARM gives us some inherent architectural efficiency."
You can debate until you drop, but there is no denying that the x86 ISA requires more pipeline stages and thus transistors to decode than any decent RISC ISA. As x86 instructions are variable length, fetching instructions is less efficient and requires more transistors. The instruction cache is also larger as you need to store pre-decode information. The back-end might deal with RISC-like micro-ops but as the end result must adhere to rules of the x86 ISA, thus transistors are spent on exception handling and condition codes.
It's true that the percentage of transistors spent on decoding has dwindled over the years. But the number of cores has increased significantly. As a result, the x86 tax is not imaginary.
"persze 10 év múlva még okosabbak leszünk









![;]](http://cdn.rios.hu/dl/s/v1.gif)







 Ez elvileg 48 GPU-magból, asztali Alderre még ennél is kevesebbet, 32-t mondanak.
Ez elvileg 48 GPU-magból, asztali Alderre még ennél is kevesebbet, 32-t mondanak.








 Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."
Gyártani nem feltétlenül nagyon olcsó. Viszont mint fejlesztés, egy új csip tervezési, majd gyártás beindítási óriási költségéhez képest itt gyakorlatilag kész elemekből volt építkezve. Így értettem az "olcsót"."Új hozzászólás Aktív témák
- 2,5 gigabittel hasítanak a belépőszinten az új Asustor NAS-ok
- Luck Dragon: Asszociációs játék. :)
- iPhone topik
- GoodSpeed: Nem vénnek való vidék - Berettyóújfalu
- ThinkPad (NEM IdeaPad)
- Nintendo Switch 2
- Feltörték a regisztrációmat vagy elvesztettem a belépési emailcímet, 2FA-t
- Kormányok / autós szimulátorok topikja
- Egyéni arckép 2. lépés: ARCKÉPSZERKESZTŐ
- AMD Navi Radeon™ RX 9xxx sorozat
- További aktív témák...

- Eladó iPad Pro 11" (2022) 128 GB + Apple Pencil!
- Galaxy S23+ 8/512 GB eladó
- Üzletből, garanciával, MSI Creator Z16 A12UET-039IT intel Core i7-12700H/16GB RAM/1TB SSD/RTX3060
- Denon AVR X2100W Magnat Vector 77 5.1 hangfalakkal
- Üzletből, garanciával, Új Lenovo ThinkPad X1 Carbon Gen 12 Ultra 7 155u/32GBRAM/1TB SSD/OLED kijelző
- HIBÁTLAN iPhone 12 mini 64GB Purple -1 ÉV GARANCIA - Kártyafüggetlen, MS3481, 100% Akksi
- ÁRGARANCIA!Épített KomPhone i5 12400F 16/32/64GB RAM RTX 3060 12GB GAMER PC termékbeszámítással
- BESZÁMÍTÁS! MSI B450M R5 5600X 32GB DDR4 1TB SSD RTX 4070 12GB Rampage SHIVA Cooler Master 750W
- X670 DDR5 alaplapok kedvező áron garanciával!
- Apple iPhone 12 64GB, Kártyafüggetlen, 1 Év Garanciával
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest