- Yettel topik
- Légies iPhone halvány színei
- Motorola Edge 60 és Edge 60 Pro - és a vas?
- Samsung Galaxy S23 Ultra - non plus ultra
- Itt az igazság a Samsung állítólagos Android Auto alternatívájáról
- Eurós árlista a Google Pixel 10 telefonokhoz
- Vékonyabb lett, jobb kamerát kapott, de az akku maradt a régi: itt a Fold7
- Xiaomi 13 Pro - szerencsés szám
- Változó design, tekerhető lünetta: megjött a Galaxy Watch8 és a Classic
- Apple Watch
Új hozzászólás Aktív témák
-
-

Abu85
HÁZIGAZDA
Volta alatt már ki van bővítve. A Telsa V100 multiprocesszoraiban van egy-egy címfordító egység, ami képes direkten elérni a Power9 CPU-k laptábláját. De PC-ben ehhez olyan címfordító egység kell, ami az x86/AMD64 ISA-ban meghatározott memóriamodellhez igazodik, ez pedig pont annyira licencköteles, mint a Power9 ISA esetében. Csak amíg az IBM-nél ott az OpenPower konzorcium, addig a PC-nél nincs semmi, vagyis meg kell győzni az Intelt és az AMD-t, hogy licencelje nekik az x86-ot és az AMD64-et. Az AMD megoldása például pont a Power9 ISA memóriamodelljét nem támogatja. Így pont annyira nem ér semmit IBM host proci mellett, mint amennyire az NV megoldása nem ér semmit x86/AMD64-es host proci mellett.
A Pascal által alkalmazott CUDA-s megoldást meg lehet őrizni, csak azzal semmire nem mennek a DirectX, Vulkan, OpenCL és OpenGL API-kra írt programokban.
Egyébként nem tudom miért tartod balfasznak az NV-t a több memória miatt. Ez is csak egy kezelési módja az alapproblémának. Nincs leírva a hírben, hogy ez rossz lenne. -

Resike
tag
Akkor rohadtul nem értem az egész cikket, a nVidiának már van rá megoldása, igaz hogy jelenleg csak CUDA alatt, de valószínűleg a Volta alatt ez már ki lesz bővítve. Mégis az AMD van piedesztálra emelve egy olyan funkcióért amit még csak fejleszt, és az nVidia a balfasz hogy több VRAM-ot mer rakni a kártyáira.
És mindez olyan két termékből lett lekövetkeztetve amiről még hiteles hírmorzsák sincsenek... Még jó hogy csak a tények alapján írunk cikkeket.
-
Abu85
HÁZIGAZDA
Igazából az NV beszélt először magáról az alapproblémáról még az előző évtizedben. Az alapvető kutatások valószínűleg elkezdődtek már úgy 2007 környékén. És ez mindkét gyártóra igaz lehetett, hiszen a Vega és a Volta támogat eszközszintű, lapalapú memóriamenedzsmentet a kompatibilis host processzorok és host interfészek mellett.
A korábbi megoldások zárt API-khoz voltak kötve, tehát az elterjedt API-kkal üzemképtelenek voltak. De hardveres támogatás mellett már az API is lényegtelen, egyedül a beépített technológia hardveres követelményeit kell teljesíteni a működéshez. -
Abu85
HÁZIGAZDA
A Pascal működése az NV-nél nagyon titok. Nem igazán reagálnak egyetlen hardverre irányuló kérdésre sem. Arra vonatkozóan általánosan semmit sem lehet mondani. Legjobb esetben is csak következtetni lehet a Maxwellből, hogy talán ugyanúgy működik, de semmi garancia erre.
[link] - itt említettem, hogy a Pascalnak van hasonló API szintű megoldása a CUDA-ra. De más API-val ez nem üzemképes. A Volta helyezi ezt eszközszintre, ahogy a Vega tette az AMD-nél, de a host processzor architektúrájához kötött a működés. A Vega esetében x86/AMD64 a követelmény, míg a Volta esetében Power9. Amúgy egyébként nagyon hasonló a két megoldás, leszámítva a host processzorra és az interfészre vonatkozó igényeket.
-
Resike
tag
Az lehet hogy a Maxwell sorozat így működött, specifikusan a 970 biztosan. De mivel a Pascal rendelkezik HRD támogatással, nincs az az Isten hogy csak felezett sávval el tudná látni a HRD képek feldolgozását úgy hogy pont ugyanannyi ROP egység van a 1000-es kártyákon mint a 900-as elődeiken.
Amúgy amióta én megvettem a jelenlegi kártyámat annyira nem követtem az új VGA ficsőröket, de itt van egy közel 1.5 éves cikk a CUDA 8-ról ami már érinti a Pascal szériát:
https://devblogs.nvidia.com/parallelforall/cuda-8-features-revealed/
"Memory page faulting support in GP100 is a crucial new feature that provides more seamless Unified Memory functionality. Combined with the system-wide virtual address space, page faulting provides several benefits. First, page faulting means that the CUDA system software doesn’t need to synchronize all managed memory allocations to the GPU before each kernel launch. If a kernel running on the GPU accesses a page that is not resident in its memory, it faults, allowing the page to be automatically migrated to the GPU memory on-demand. Alternatively, the page may be mapped into the GPU address space for access over the PCIe or NVLink interconnects (mapping on access can sometimes be faster than migration). Note that Unified Memory is system-wide: GPUs (and CPUs) can fault on and migrate memory pages either from CPU memory or from the memory of other GPUs in the system.
With the new page fault mechanism, global data coherency is guaranteed with Unified Memory. This means that with GP100, the CPUs and GPUs can access Unified Memory allocations simultaneously. This was illegal on Kepler and Maxwell GPUs, because coherence could not be guaranteed if the CPU accessed a Unified Memory allocation while a GPU kernel was active. Note, as with any parallel application, developers need to ensure correct synchronization to avoid data hazards between processors."
Valahogy ismerősen hangzanak az itt leírtak...
-
Abu85
HÁZIGAZDA
Csak ez nem bug, hanem fícsör. A lényeg a tranyóspórolás a multiprocesszorok és a ROP blokkok összekötésénél. Az így nyert helyet másra lehet költeni. Legacy grafikus API-kban jelenthet problémát, de a meghajtóval ezek jól kezelhetők. Az explicit API-kban ez nem kezelhető, itt elképzelhető a sebességvesztés.
-
Abu85
HÁZIGAZDA
Ehhez semmi közük a programozóknak. Az explicit cache mód egy meghajtó szintjén kezelhető funkció. A program fejlesztőjének ezzel semmi dolga nincs.
Az implicit cache mód, amit a program fejlesztőjének kell engedélyezni, mivel szükséges hozzá egy előzetes inicializálás a program indításakor. Itt a programfejlesztő természetesen választhat, hogy rábízza magát a hardverre egy pár soros kóddal, vagy ír egy nagy architektúraspecifikus optimalizálást a Vegára, ami még nem is biztos, hogy gyorsabb lesz az implicit cache módnál. Minden fejlesztő maga eldöntheti, hogy mennyi erőforrást fektet bele. A legtöbben valószínűleg az implicit cache módot fogják választani, mert az sokkal gyorsabban megvan, és az erőforrásukat olyan hardverek optimalizálására fordíthatják, amelyeknek nincsenek eszközszintű menedzseléssel dolgozó hardveres adottságai.Nem tudom, hogy melyik fejlesztő számára realitás egy Vega-specifikus menedzsmentet optimalizálni, amikor a hardver meg tudja oldani ezt magától. Csak az idejüket rabolná le egy szoftveres optimalizálás, mert a user bármikor kiütheti a meghajtóban a HBCC szegmens aktiválásával. Viszont elköltöttek rá teszem azt jó két hetet, így a többi hardverre való optimalizálásra ennyivel kevesebb idő maradt, ezeknek pedig már számít, hogy mit csinál a fejlesztő. Ezt a legtöbben mérlegelni fogják és tök logikus döntés a hardverre bízni a feladatot, mint erőforrást ölni az optimalizálásába.
(#190) namaste: Egy olyan gyártóról beszélünk, amelyik a hardvereit még abszolút minimális szinten sem dokumentálja. A legtöbb fejlesztő abból él, hogy a Twitteren hallotta, hogy valaki egy sarkon kihallgatta az NV mérnökeit, hogy xy textúraformátumnál mekkora a mintavételezési sebesség az egyes szűrési típusokhoz. Merthogy az NV ezt hivatalosan aztán nem mondja el, bármennyire is fontos kérdésről van szó. Én is abból élek, amit az NDA-s briefingeken elmond az NV. Azt, hogy te ezt elhiszed-e a te egyéni döntésed, engem nem különösebben érdekel.
-

sakal83
addikt
"Viszont ehhez előre definiálni kell bizonyos paramétereket, hogy a HBCC lapalapú vezérlése az adott memóriaszegmensre működjön"
Bocsánat de ez megint a kabitas jövőben való kimagyarazasanak lehetősége...
Nagyon profi politikus marketing jogi szöveg.
Majd a programozók azert az 1%os vga lefedettsegert megcsinálják ugye?
Pont ez a szöveg volt a mantle VR DX12 es társai a részedről amikből nem lett semmi az általános gyakorlatban...
-
Abu85
HÁZIGAZDA
Kedvező hatással van rá, hiszen maga a menedzselés lapszinten történik, ami lényegesen kisebb adatok mozgatását jelenti a rendszermemória és a GPU lokális memóriája között. Mindemellett a WDDM kellemetlenségei HBCC-vel nem is léteznek. A meghajtó a WDDM egyes parancsait automatikusan kezeli. Például explicit cache módban a WDDM adhat utasítást az allokáció törlésére, de arra vonatkozóan a rendszer nem fog lefuttatni egy ellenőrzést. A meghajtó visszahazudja, hogy kell az allokáció, méghozzá anélkül, processzoridőt vett volna igénybe. Persze a valóságban lehet, hogy nem kell, de hát arról a hardver majd az eszközszinten dönt.
Az eszközszintű működés miatt van, hogy HBCC mellett folyékonyabban futhat ugyanaz a program. [link] - itt egy példa. A felső sarokban láthatod, hogy a frame time grafikonon kisebbek a tüskék aktív HBCC-vel.
Az AMD is a szűk frame time-ot hangsúlyozta, mint aktuálisan tényleg tapasztalható előnyt.A töltőképernyő azért nem sokat ér. Maximum ad egy alapot az indításhoz, de rengeteg folyamat valós időben történik már. Ez igazából nagyon logikus. Amit nem látsz, annak nem kell a memóriában lennie. De lehet, hogy pár másodperc múlva látni fogod, így akkor majd be kell tölteni. A mai rendszerek egyáltalán nem töltenek be előre mindent a videomemóriába. Az az erőforrás nagymértékű pazarlása lenne.
-
Resike
tag
Igen mindez így nagyon szép leírva, de mégis milyen hatással lesz ez az input lagra és a frametime-re amikor valaminek már ott kéne lennie a VRAM-ban de még nincs ott és be kell húzni oda? És mekkora erőforrás használatra és extra időre kell gondolni amikor erről az extra virtuális memóriakezelésről beszélünk?
Ugyanis a töltő képernyőknek pont ez a feladata hogy ne kelljen 3 fps-el ülnöd a scene előtt amikor épp egy új zónát töltesz be.
-
#186
Resike
tag
->Raizen<-
#174
Resike
tag
válasz
 ->Raizen<-
#174
üzenetére
->Raizen<-
#174
üzenetére
Mert melyik lesz a gyorsabb: megjeleníteni valamit amit már ott van a memóriában vagy azt amit még be is kell húzni oda előtte?
-
válasz
 Dilikutya
#183
üzenetére
Dilikutya
#183
üzenetére
ha jól tudom , a saját Athlon procijukat vették alapul, hogy az AThlon Xp 2500 olyan teljesítményt nyújt, mint a sima Athlon menne 2500 Mhz-n. De mivel akkoriban az Athlon és a Pentium szinte egy szinten mozgott, azért lett ez a bevett tévhit a köztudatba. Akkoriban ez eléggé félreérthető volt amúgy...
-

Dilikutya
félisten
Az Athlon XP-nél nem azt írták a dobozra, melyik Intel processzorral van párban az adott modell. A modellszám, 1800+, 2000+, 2500+ stb. az 1 GHz-es Athlon-hoz viszonyította a CPU-t. Ez egy népszerű tévhit, hogy az Intelnek bármi köze van ehhez. Ha az Intelhez viszonyított sebességet akartad belőni, a modellszámnál 100-200-300 MHz-el lassabb Pentium-hoz állt közelebb, ami az árat figyelembe véve még mindig nem volt rossz. Később már nehezebb volt viszonyítani, mivel a modellszámozás túlhaladt a 4000-en, de az Intel CPU-k órajele 3400 MHz-nél tetőzött akkoriban.
-
Abu85
HÁZIGAZDA
Nem. A ROP blokkok azok teljesen a partíciókhoz tartoznak, és a multiprocesszorokhoz nem tartozik partíció. Az történik, hogy a multiprocesszorok nem minden ROP blokkal vannak teljes sebességgel összekapcsolva. Emiatt bizonyos partíciók címzése hátrányosabb, mint más partícióké. A dolog igazából nagy problémát addig nem jelent, amíg van elég warp átlapolni az adatelérést, de vannak bizonyos szituációk, amikor nincs elég warp, és akkor a meghajtó manuálisan trükközik. Erre van egy felépített rutin a driverben, így a problémás alkalmazásokban a sebességért cserébe több memória kerül felhasználásra. Végeredményben ez hasznosabb megoldás, mert kevesebb tranyót igényel maga a lapka, és a problémás szituációkat a meghajtó oldalán le lehet kezelni, és ennek a hátránya csupán a nagyobb memóriaigény.
-
#180
 Steve_Brown
senior tag
Steve_Brown
senior tag
Steve_Brown
senior tag
Ki gondolta volna, hogy egyszer az AMD fog valamit megoldani ésszel és az nVidia meg erővel.


-
Abu85
HÁZIGAZDA
Itt már a memóriába betöltött adatokról van szó. A PCI Express már nem játszik. Az a probléma, hogy a VRAM is partíciókra van osztva, és nem minden partíció érhető el ugyanolyan sebességgel a GPU belüli blokkoknak. Egy ideje ezzel spórolnak tranzisztort a crossbart használó gyártók, mert maga a probléma kezelhető azzal, hogy a sűrűn használt allokációkat többször berakják a különálló partíciókba, így mindegyik GPU-s belső blokknak lesz egy gyors elérése ugyanahhoz adathoz. Tehát tranyót spórolsz vele, miközben extra memóriával fizetve nem lassulsz semmit. Jelen formában kedvezőbb többletmemóriával fizetni, mint többlettranzisztorral hozni ugyanazt a teljesítményt.
-
Ennek az oka, hogy a crossbar a mai rendszerekben keresztbe csak felezett sávszélességű, vagyis kétszer gyorsabban tölthető be a GPU-ba az adat, ha nincs keresztcímzés.
Ezt fejtsd ki egy kicsit bővebben, mert alapvetően ellentmond az interleavingnek, ill. az is meglepne, ha PCIE-buszról jövő adat nem 32-biten menne le a kontrollerek felé.
-
Abu85
HÁZIGAZDA
Ha eszközszintű megoldást akarnak, akkor ahhoz kell a licenc. Ha API szintűt, akkor arra már most ott van a Pascalban a megoldás, ami csak a CUDA mellett működik. A Volta is azért ment tovább az eszközszint felé a Power architektúra támogatásával, mert nincs igazán köztes megoldás erre a problémára. Az egyik lehetséges alternatíva az lenne, ha a Microsoft és a Khronos kiegészítené a DirectX és a Vulkan API-t, de annyira át kellene ezeket alakítani, hogy egyhamar ezzel nem végeznének. Hosszabb távon persze mindenképpen érdemes majd bevállalni egy átalakítást.
-
Abu85
HÁZIGAZDA
Alapvetően igen, csak az eszközszinten oldja meg. Nyilván az AMD nem talált fel semmilyen spanyolviaszt, csak egy évtizedek óta bevált módszert terjeszt ki a GPU-ra. Megtehetik, mert a hardveres igénye lényegében kimerül egy multiprocesszorokba szerelt AMD64-es címfordítóban.
(#171) Kristof93: A megatextúrát, illetve virtuális textúrázást használja még az id, csak nem úgy, ahogy az id tech 5-ben. Programfüggő, hogy miképp valósul meg, de a Doom 16k x 8k-s textúrákat helyez el a memóriában, amelyek 128 x 128-as lapokra vannak felosztva. Ezek lesznek feltehetően szükségesek képszámításhoz, és ha valami új kell, akkor a motor tud 128 x 128-as lapokat cserélni, mivel ehhez van szabva a fix méretű allokáció, ezzel a töredezettség is jól kezelhető. Nagyon hasonló megvalósítást alkalmaz a Frostbite is a terepre.
-
Abu85
HÁZIGAZDA
A HBCC-nek nem számítanak ezek. Ez a rendszer teljesen az eszközszinten működik. Immunis bármilyen eszközszint feletti programozói ténykedésre, legyen annak hatása jó vagy rossz.
Pedig gyakori trükk, hogy egy sűrűn használt allokáció többször is bekerül. Ennek az oka, hogy a crossbar a mai rendszerekben keresztbe csak felezett sávszélességű, vagyis kétszer gyorsabban tölthető be a GPU-ba az adat, ha nincs keresztcímzés. Emiatt a meghajtó nagyon sűrűn fordul ahhoz a trükkhöz, hogy a sűrűn használt adatokat duplikálja a VRAM-on belül, méghozzá úgy, hogy csatornánként egy partícióban ott legyen.
A színtömörítés manapság teljesen általános technológia.
Messze nem ugyanerről van szó, de ha eddig nem sikerült megértened, akkor ezután sem fog sikerülni.

-
Amiről beszélsz (texture atlas) ma a kivétel, nem a szabály. Teljesen vállra fektetné a streaming rendszert ha minden random objektumot összevissza nagy textúrákba összezsúfolnánk, és a vram igény is masszívan megnőne. (pedig már így is problémás pc-n, a sok 1-2-3 gigás kártyával.) Nem beszélve arról, hogy mekkora fejfájás lenne ezt menedzselni fejlesztés közben. Az ikonok (és pl apróbb növényzet) speciális eset, ezek mindig be vannak töltve, és egyszerre jelennek meg.
-
Resike
tag
válasz
 Kristof93
#171
üzenetére
Kristof93
#171
üzenetére
Ez rohadtul nem a MegaTexture technológia hanem ésszerű spórolás. Ha egy textúrának az egyik részét nem használják akkor oda még be lehet szúrni egy vagy több másikat és virtuálisan felosztani azt annak szub-koordinátái szerint.
De a legtöbb egybetartozó textúrát már alapból így rajzolják meg, ha kell 16 ikon akkor nem fogsz 16 külön textúrát csinálni, hanem létrehozol egy nagyobbat és felosztod, és ezzel még azt is eliminálod hogy egy objektum textúrái nem egyszerre töltődnek be vagy jelennek meg.
És még miért csinálják mindezt a memóriaspórolás és a fregmentációkezelés mellett? Hogy ne kelljen load on demand szerint kismillió kis textúrát töltögetni.
-
-
Azt azért tegyük hozzá, hogy a HBCC gyakorlatilag az oprendszerek jól bevált memória-menedzsmentjét (lapkezelés) másolja. Csak itt swap és RAM helyett RAM és VRAM között megy a dolog. Pont azok a problémák merültek fel most a VRAM kezelését illetően, mint ami anno a RAM kapcsán 30 évvel ezelőtt az x86-os PC-knél. Ugye a lapozófájlról van szó, ami a Windows 3.0 óta létezik, s ennek célja az, hogy a RAM hatékonyabb használatával kevesebb RAM-mal is biztosítható legyen ugyanaz az élmény.
Csak persze a lapozófájl (főleg HDD esetén) az egy bűnlassú valami a RAM-hoz képest, míg a VRAM és RAM között nincs ekkora nagy különbség. Illetve a HBCC egy hardveres valami, nem szoftveres.
-
Resike
tag
Nem kell direkten optimalizálni? Az elmúlt 20 évben a fejlesztők 99%-ban a kis textúrákat egyetlen egy nagy fájlba töltik be és azon belül virtuálisan bontják azt kisebb részekre hogy ne kelljen lapozgatni jobbra-balra és memóriakezelő se duguljon be a reserve-commit hívásoktól.
És nem olyan nincsen hogy egy fájlt kétszer raknak be a VRAM-ba, egyszer betöltik és utána csak a hivatkozások mutatnak ugyanarra a memóriarészre, így lesz egy nagy textúrából több kicsit.
A nvidiát meg lehet bashelni de ők legalább tömörítik a memóriában az egyszínű pixeleket, és mindezt úgy hogy nem a többi komponenstől szívnak el erőforrást mindeközben.
Az meg a legviccesebb az egészben hogy miután a 970 hogy le lett húzva a lassabb elérésű memórialapkái miatt, erre most az AMD eladja kvázi ugyanezt feature-ként ami még sokkal lassabban is fog működni, valamint extra terhelést dob a rendszer többi részére, csak azért hogy lespúrkodjanak pár extra gigabájtot.
-
Mi ez a sok értetlenkedés? Azt a 8gb-ot triviális megtölteni egy teszt erejéig. Ezt valószínűleg az AMD meg is csinálta. Én is kipróbáltam cryengineben kíváncsiságból (igaz 8k*6k felbontással sok textúra helyett) és nagyon jól működik a hbcc. Pár év alatt nem változnak annyit a motorok, hogy ezt ne lehessen tesztelni.
-
#165
 b.
félisten
->Raizen<-
#162
b.
félisten
->Raizen<-
#162
válasz
->Raizen<-
#162
üzenetére
Konkrétan a a 2 GB / frame többszörösére értettem.( 6-8 GB/ frame). Attól, hogy radeon kártyák kijönnek ilyen felállással, attól még a PC piac nem fog átfordulni, a konzolok meg máshogy kezelik ezt a dolgot. 4 K ra alkalmas kártyákon azért nem 4 GB van, hanem 8 ,vagy több jelenleg is.4 GB már valóban néhol szűkös lehet,( pl Rx 480- 580) ha a GPU elég erős FHD-n ,de nem jellemzően.
-
#164
 ->Raizen<-
veterán
Abu85
#160
->Raizen<-
veterán
Abu85
#160
-
ezek a számok még évekig nem fognak beköszönni, nem akarlak megsérteni, de ez megint egyfajta megmagyarázása a bizonyítványnak és pánik keltés. A jelenben és még 2-3-4 évig nem fog gondot okozni, ebben szinte biztos vagyok.Ettől még ez lehet jó megoldás , nem vitatom, csak egyenlőre ebből hasznot csak az AMD élvez, senki más.
-
#160
Abu85
HÁZIGAZDA
->Raizen<-
#152
Abu85
HÁZIGAZDA
válasz
->Raizen<-
#152
üzenetére
Nekik nem kedvez, mert pont ugyanannyira lényeges a rendszermemória HBCC-vel, mint HBCC nélkül. Az allokációk ugyanúgy ott lesznek mindkét megoldással a rendszermemóriában. Tehát a rendszermemória terhelése nem fog lényegesen változni HBCC-vel vagy HBCC nélkül.
De akkor induljunk ki egy gyakorlati példából. Van egy játék, ami a képkockák számításához tegyük fel, hogy 7-8 GB adatot igényel. Ez már eleve egy olyan tényező, ami ma még felfoghatatlannal tűnik, mert a tipikus adatigénye a játékoknak 2 GB körüli, de nyilván eljön ez az idő is. Talán nem is olyan sokára. Itt már ezek a játékok minimum 32 GB-nyi rendszermemóriát fognak igényelni, mert rengeteg adatot streamelnek. Tehát van mondjuk egy 32 GB-os géped, amiben van egy Vega 8 GB lokális memóriával.
A program igényel magának úgy kb. 5-7 GB CPU által elérhető területet, és úgy 18-20 GB CPU+GPU által elérhetőt területet. Az összes memóriaigény így 27 GB körül lesz, de ugye a dual channel miatt a hardverben muszáj 32 GB-ra ugrani, mert az a következő kétcsatornás lépcső.
A lényeg itt a 16-18 GB-nyi, GPU és CPU által is elérhető terület, ugyanis onnan kerülnek az allokációk a GPU lokális memóriájába. Ha HBCC-d van, akkor beállítasz a meghajtóban egy ideális HBCC szegmenst, és akkor a kijelölésre kerül a Windows számára, hogy hova kell helyeznie fizikailag a CPU+GPU által elérhető adatokat. Innentől kezdve az OS oda helyezi, és ebből 7-8 GB-nyi 4 kB-os lap átkerül a lokális memóriába, és ennek a menedzselése zajlik folyamatosan és hardveresen. Jobb esetben a program elvégzi az inicializálást maga, és akkor inkluzív cache módban fut az alkalmazás, ilyenkor még a meghajtót sem kell megnyitni.
Ha nincs HBCC-d, akkor egy kicsit problémásabb a helyzet, mert ugyanúgy szükséged van arra a 7-8 GB-nyi 4 kB-os lap, de ezeket nem tudod csak úgy betölteni. Ilyenkor a konkrét allokációk kerülnek betöltésre, és itt bele kell számolni, hogy egy allokációnak esetleg csak a 30-70%-a szükséges. Ilyenkor viszont be kell tölteni a teljes allokációt a 70-30%-nyi szükségtelen adattal együtt. És itt még számolni kell a különböző hardveres problémákkal, mint a csatornák keresztbe címzése, vagyis az az ideális, ha egy allokációt akár többször is elhelyezel a VRAM-ban, ugyanis ezzel a módszerrel lesz a feldolgozás a leggyorsabb. Ezt nagyrészt a programozó (program vagy driver) határozza majd meg, mivel teljesen szoftveresen menedzselt rendszerről van szó. Emiatt itt általánosítani nagyon nehéz, már csak azért is, mert a gyakorlatban tipikusan az a jellemző, hogy a program feltölti a VRAM-ot, amíg csak lehet, és amikor betelt, akkor kezdi a probléma menedzselését. Ez nem szerencsés több dolog miatt sem, például a WDDM-nek sem ideális ez a forma, de a rengeteg nehezítő körülményt beszámítva ez tűnik mégis a leginkább működő megoldásnak. Mondjuk úgy, hogy a jobb alternatívák implementálása sokkal nehezebb, és emiatt erre nem feltétlenül éri meg pénzt áldozni. Persze vannak kivételek, például a Sniper Elite 4 motorja akkor is szokott törlést kérni, amikor a terhelés egy rövid időre alacsonyabb lesz, illetve ilyenkor valós időben defragmentál is, hogy egymásra tolja a VRAM-ban található allokációkat, ezzel is helyet nyerve. Mert ugye az sem mindegy, hogy az allokációk mennyire töredezettek. Simán van olyan, hogy a memóriában van még 400-500 MB szabad hely, de esetlegesen nem tudod felhasználni, mert az nem egybefüggően van meg, hanem szétszórtan, így hiába férne be például egy 100 MB-os allokáció 4-szer is, akkor sincs 100 MB-nyi egybefüggő allokálható terület neki. A Rebellion szerencséje, hogy független stúdióként nem mondja meg egy kiadó, hogy a hatékony memóriamenedzsmentre nem ad pénzt, hiszen a játék ugyanúgy eladható a sokkal olcsóbb és bénább megoldás mellett is. Tehát végeredményben hiába kér a program csak 7-8 GB-nyi 4 kB-os lapot, azzal neked hardveres szinten legalább ~16 GB-nyi VRAM-mal kell fizetni. De ha a tipikus optimalizálási modellt nézzük, vagyis a betelik aztán majd menedzseljük koncepciót, akkor már ~24 GB-nyi VRAM kell. És a programnak nem lesz kisebb memóriaigénye a rendszermemória oldalán, ugyanúgy ajánlott lesz hozzá a 32 GB, mert a PC az nem csak egy hardver, itt nem tudsz egyetlen egy memóriakonfigurációra rátervezni mindent. Itt van egy rakás hardver, egy rakás memóriakonfigurációval, vagyis a program igényeit is teljesen általánosra kell szabni, annak érdekében, hogy valamilyen beállítással minél több memóriakonfiguráció mellett működjön. Emiatt van az, hogy amíg régebben a rendszermemória kapacitására vonatkozó igény jóval nagyobb volt, mint a VRAM-ra, addig ma már szinte ugyanannyi VRAM kell, mint rendszermemória. A programok komplexebbek és a bevált menedzsmentrendszerek hatásfoka drámai mértékben romlik. -
Én is ezt tartom valószínűnek, Volta néven szerintem nem lesz gamer GPU. Ampere elméletileg ugye 2018 ban fog bemutatkozni, valószínűleg első konkrétumok Drive Px ben jönnek róla.
Ezt a Vram dolgot nagyon fenntartásokkal kell kezelni mindkét oldalról,ugye pont az Új Assasinban történ lassulás a bekapcsolt HBCC miatt és ez nem is igazán használta ki , csak a felületét karcolta a dolognak. Később persze driver szinten jött rá megoldás. Mint írtam x86 Licensz nélkül is dobhat NV fejlettebb memóriakezelés megoldást, azért a világ egyik legjobb IT csapata van most ott és pénzben sincs hiány. Ez nem hinném, hogy hasonlóan fog működni, mint anno az Athlon xp időkben mikor azt írták a CPU ra melyik Intel procival van egy szinten, nem a valós órajelet.
Nekem tökéletesen megfelel, ha a valódi gyors DDR6 vagy 5 Vram fizikailag rajt van a kártyán és a GPU dolgozhat vele..
persze a fogyasztáson majd így biztos jól fog mutatni AMD nél a dolog, ezzel a húzással máris lefaragtak 20 % ot kb a csúcskártyájuknál, mert nem lesz rajt 16 GB HBM, de az ára szerintem benne lesz
-
#158
->Raizen<-
veterán
lezso6
#157
-
Hát a bruteforce megoldás az nem jó. De az NV mást nem is tehet. Csak erre érdemes felkészülni, hogy a több RAM nem feltétlenül több, mivel nincs kihaszálva. Tehát a jövőben valószínűleg az lesz, hogy pl 8 GB AMD VRAM = 16-24 GB NVIDIA VRAM.
Ez a vallásos analógia nálam vicc kategória. Én alapvetően jó indulattal állok hozzá az elmélethez, de ha vásárlásról van szó, akkor a gyakorlat alapján fogok dönteni.
De most a Volta is különösen tetszik, hogy egyszerű, külön Tensor, FP64, FP32 és INT feldolgozókat használnak, kíváncsi vagyok hogy ha a konzumer részleg Ampere lesz, akkor ez mit jelent. Szerintem az lesz, hogy a konzumer kártyákban csak FP32 feldolgozó lesz, ami ugye dupla FP16-ra lesz képes, s ezt végre engedélyezni fogják konzumer szinten is. Azaz a V100-hoz képest az egész GPU tök más feldolgozókat és ütemezést fog használni, innen jön a másik név.
-
Köszi az érthető megfogalmazást, így azért kicsit jobban átlátható a dolog. Probléma megint az,hogy már a cím is megint kétértelműen fogalmaz , és negatívumként kezeli szinte, ha egy kártyán sok ram van.
a HBCC megoldás lehet , hogy jó lesz és működni fog, de attól az, hogy egy kártyán sok Vram van már lassan negatívnak hat. Azért ne essünk át a ló másik oldalára, ez a "hitetlenek "( én is ide tartozom) egyik problémája többek között .Ráadásul az NV új gamer generációjáról Kb semmit nem tudunk. -
válasz
 GodGamer5
#151
üzenetére
GodGamer5
#151
üzenetére
Konzoloknál nincs (értelmetlen) HBCC, mivel egy koherens memória van.
Hitetetleneknek: (
)Ez a HBCC sokak számára olyan, mint az NVIDIA TurboCache vagy annak ATI megfelelője, a HyperMemory. De nagyon nem ugyanaz.

A TurboCache célja a költségkímélés volt. Tesco gazdaságos memória méret és sávszél (tehát nem turbo), ami kb arra volt elég, hogy a framebuffert tartalmazza, tehát az adatok a rendszermemóriában voltak, és ez ugye a PCIE-n keresztül ment át a GPU-ba. Rettenet rossz valami, nem csoda, hogy csak a kisebb GPU-knál terjedt el, mert ott nem volt akkora a büntetés.
A HBCC nagyon más, mégpedig azért, mert itt tényleg gyors a cache, és nem csak a framebuffer fér bele. Továbbá nem az a célja, hogy több memóriát emuláljon a GPU mellé, hanem hogy minél kevesebb felesleges adat legyen a VRAM-ban. Hisz a jelenlegi probléma az, hogy alkalmazástól függően csak 30-60%-a van kihasználva a VRAM-nak. Nem kell a HBCC miatt több sima RAM, mivel HBCC nélkül az adatok ugyanúgy benne vannak a rendszermemóriában is, a HBCC csak azt menedzseli, hogy a RAM és a VRAM között minél kevesebb másolás legyen.
-
#154
b.
félisten
szmörlock007
#153
válasz
 szmörlock007
#153
üzenetére
szmörlock007
#153
üzenetére
Hello.
Ezzel tisztában vagyok, de biztos vagyok benne, hogy ha akarnak, fejlesztenek más megoldást a Vram kezelési problémákra, amihez nem kell licencsz. Én úgy gondolom,hogy lehetséges még több megoldás, ami a hatékonyságot növeli, nem pedig a hozzáadott mennyiséggel orvosolja a problémát. ha esetleg mindkettő jelen lesz ( nagy mennyiségű Vram+ és azok hatékonyabb kihasználása) az szerintem a legideálisabb megoldás.
-
Jack@l
veterán
Az összes hívőnek lassan mondom, és nyugodtan lehet hivatkozni eme téveszmémre az elkövetkezendő pár évben:
Irtó lassú lesz a cucc, amikor már valóban szükség is lesz a ramban tárolt adatokra masszívan. Amikor már kell +4-8gb vram, úgy fog öszecsuklani a hókuszpókusz az mint igp 4k-n... (persze olyan demózáskor, ahol belefér az aktuális scene 1,5 gigába, de 4 gigának mondjuk ott nincs gond) -
Abu85
HÁZIGAZDA
Ha 20 GB VRAM kell, akkor HBCC nélkül is le lesz foglalva a rendszermemóriában az ehhez szükséges allokációk. A rendszermemóriában nem lesz semmivel sem több adat aktív vagy inaktív HBCC-vel. A különbség annyi lesz, hogy a menedzselés HBCC-vel a lapokra történik, míg anélkül az allokációkra. De mondjuk ha nyersen 20 GB lokális memória kell, akkor ahhoz nem árt majd minimum 64 GB-os VGA-t vásárolni a hagyományos modell tipikus hatásfokát is figyelembe véve, és azért rendszermemóriából sem árt majd ekkor már 128 GB közelében lenni. Ilyen környezetben 8 GB HBC már valószínűleg kevés lesz, mert a rendszer azért csodát nem tud tenni. Ez is ki tud fogyni az erőforrásból, csak jóval később.
-

Tigerclaw
nagyúr
válasz
GodGamer5
#144
üzenetére
Azért nem hiszem, hogy olyan gyorsan nőni fog a VRAM igény. Még ha 1-2 csúcskártyára felkerül parasztvakításnak valami 10+ GB VRAM, nem lesz játék ami igényelje, vagy csak 1-1.
Jövőre is elég lesz a legtöbb játékhoz a 4-6GB, ha nem akar valaki 4k-s felbontással játszani. A casual playereknek meg a 2GB is. Én jövőre is 2GB-os GTX-950 -el fogok játszani FHD-ben és egyik játék sem reklamált még nálam a VRAM mérete miatt. Szóval erősen függ, hogy melyik játékkal, milyen felbontással, milyen textúra méretekkel játszol.
-
#143
Tigerclaw
nagyúr
->Raizen<-
#142
Tigerclaw
nagyúr
válasz
->Raizen<-
#142
üzenetére
Ha a HBCC képes mindig a VRAM-ban tartani, időben odamásolni a GPU által igényelt adatokat, akkor nem lesz különbség.
-
#142
->Raizen<-
veterán
gbors
#140
-
Abu85
HÁZIGAZDA
Ha tipikusan a fejlesztő oldaláról nézed, akkor a HBCC amire nem kell direkten optimalizálni, mert az az eszközszinten valósul meg, operációs rendszer alatti absztrakcióval. A hagyományos menedzsment viszonylag magasan, a program vagy a kernel meghajtó szintjén dolgozik, tehát az operációs rendszer felett. Ennek a működéséhez erőforrást kell befektetnie a programozóknak. Ha nincs pénz optimalizálni, akkor azzal pont a HBCC jár jól, mert az eleve teljesen függetlenített a programkódtól. De amúgy muszáj, hogy legyen pénz a memóriamenedzsment optimalizálására, főleg úgy, hogy az explicit API-k hatékony működéséhez ez egy alapvető elvárás. Akinek nincs pénze rá, nos ne írjon programot.
Egyébként persze a fejlesztők számára sokkal egyszerűbb lenne, ha mindenhol HBCC lenne, és akkor nem nyomná a vállukat a memória szoftveres menedzsmentje, ami egy komoly teher a PC-n, ahol van egy rakás eltérő memóriával rendelkező hardver. Egyszerűen hagyhatnák, hogy a HBCC oldja meg hardveresen, és kész, munka letudva. Ilyen viszont belátható időn belül nem lesz. Nem elég az, hogy az egyik gyártó megoldja ezt a problémát. Mindenkinek meg kell oldania, és még akkor is ott vannak a legacy hardverek. A dolognak viszont nincs jelentősége, mert a fejlesztő írhat akármilyen szoftveres menedzsmentet, mert a HBCC annak minden hatását képes eliminálni. Tehát az az ideális, ha a HBCC-s hardverekről tudomást sem vesznek. Ezek működnek maguktól is. Ha nagyon akarnak támogatást rá, akkor engedélyezik az inkluzív cache módot, és ennyi. Ez is csak inicializálásra vonatkozó kódot igényel.(#140) gbors: Természetesen, de attól, hogy előre ki van jelölve a szegmens, még a CPU használhatja azt akármire. Ezért van az, hogy egy CPU-t használó alkalmazás nem omlik össze, ha futtatás közben aktiválod a HBCC-t. Ami az aktív HBCC szegmens mellett egyedül kikötés, hogy a CPU+GPU területnek a kijelölt szegmensbe kell esnie. Az nem számít, hogy más adat is van ott, elfér.
-
-
válasz
Dilikutya
#124
üzenetére
"
AZ, hogy erőből rátolunk 16GB+ "Ezt úgy írod mintha ez a megoldás rosszabb lenne. Biztos vagyok benne, hogy jobb lesz, mint az AMD féle megoldás. Ezzel szemben az árról felesleges előre félni, mert én biztos vagyok benne, hogy AMD től sem fogod majd 15y euroval olcsóbban kapni a teljesítményt , mert nincs rajt 12-16 Gb memória.
Ez puszta elfogultság kérdése, ahogy látod, szerinted NV megint zöld gyíkemberekell erőből megoldja, míg AMD milyen okos és ügyes dolgot talált ki. Józan paraszti ésszel te is megértheted, hogy attól, hogy ez a megoldás vagy működni fog, vagy nem, a dedikált és gyors Vramnál jobb megtoldás nincs egy fejlesztő számára, ebben biztos vagyok.Mindenre van pénz, csak optimalizálni nincs.
NV. ezt jól tudja, reálisan gondolkodik. -
Abu85
HÁZIGAZDA
Minden ismert róla csak el kell olvasni.
Mivel a HBCC eszközszintű menedzsment, így az API mindegy számára. A működése jóval az API absztrakciós szintje alatt valósul meg. Ez az oka annak, hogy a HBCC-s működését nem hátráltatja a rosszul megírt programkód, mert a menedzsment függetlenített a programtól.
(#123) do3om: Ez nem pont a sávszéllel gazdálkodik. Van hatása rá (lásd, amit írt Gbors), de közvetlenül nem ez a célja. A HBCC alapvető feladata, hogy a lokális memóriába kerülő lapok mindegyike igényelt legyen, amivel a memóriában lévő adatok 100%-a hasznos adat lesz. A korábbi modellben nem lapalapú a menedzsment, így az allokációkat másolgatásával rengeteg olyan adat került be a lokális memóriába, amelyekre nem volt szüksége a GPU-nak, de a menedzsment nem volt elég alacsony szintű ahhoz, hogy ezt a problémát meg lehessen oldani. A lapalapú megoldásokhoz mindenképpen hardveres háttér szükséges, míg az allokációk menedzseléséhez elég a szoftveres.
Ez egész alapjára gondolj úgy, mint a CPU-k gyorsítótárára. A koncepcionális alap nagyon hasonló. Alapvetően itt is érvényes a lokalitási elv, csak a feldolgozás mérete miatt jóval nagyobb határok mellett. De ezért van a hardveren GB-os és nem MB-os "gyorsítótár".(#125) gbors: A HBCC szegmensre nem érdemes úgy tekinteni, hogy extra memóriát igényel a rendszermemória oldalán. Ez gyakori tévedés. Induljunk ki az alapértelmezett Vega 10 minimumból. Az 8 GB a kártyán és 4 GB a rendszermemóriában egy 8 GB-os RAM-konfigurációval. Ilyenkor exkluzív cache mód mellett az történik, hogy a meghajtó az operációs rendszert tájékoztatja, hogy a memória felét befogta HBCC szegmensnek. Erről az operációs rendszer tudomást szerez és kap rá egy címtartományt x-től y-ig, ami pont a memória fele. Ezzel lesz 4 GB-nyi rendszermemória azoknak az adatoknak, amelyeket csak a CPU láthat, viszont a játékok igényelni fognak egy olyan szeletet is a rendszermemóriából, amelyet a CPU és a GPU egyaránt elérhet. A HBCC szegmensnél a kijelölt 4 GB használható erre a célra, míg HBCC szegmens nélkül akárhol lehet ez a tartomány. Végeredményben viszont nem lesz több rendszermemória felhasználva, csupán a CPU+GPU által elérhető terület van előre meghatározva a HBCC szegmensnél. Erre viszont HBCC szegmens nélkül is szükség van, csak nem lesz előre meghatározott fizikai címtartomány hozzá. Az adatok viszont akkor is ott lesznek a memóriában. Ha bekapcsolod a HBCC-t a driverben, akkor ugyanúgy megmarad a 8 GB-nyi rendszermemóriád. Még úgy is aktiválni lehet, hogy például egy 7 GB-ot lezabáló CPU-s program éppen fut. Elsötétül a képernyő, visszajön, és fut tovább a program. Egyedül a GPU-t inicializáló programokat kell kilőni, mert a HBCC aktiválásához újra be kell tölteni a drivert, így ezeket a programokat a rendszer lelövi. Gyakorlatilag egy TDR-rel kiszállnak.
(#129) LionW: Eléggé esélyes igen. A hardver szintjén ez a megoldás nem drága, szóval nincs értelme kihagyni a kis VGA-kból, amelyek a legtöbbet profitálnak belőle.
-
Tigerclaw
nagyúr
Jellemzően a VRAM drágább és az extra DRAM univerzálisan használható, szóval elméletben ez a HBCC kedvezhet a vásárlóknak. Ráadásul manapság sok gépben már eleve "túl sok" RAM van kihasználatlanul, főleg egy gamer konfigban, szóval van miből lecsípni bővítés nélkül is.
Gyakorlatban persze majd kiderül, hogy megáll-e az AMD a HBCC-s kártyáinál a memória növelésével. Ha pár éven belül tovább nő a jelenleg sem kevés 8GB VRAM ezeken, akkor sok értelme nem volt kifejleszteni és azzal növelni a kártya gyártási költségeit.
Amúgy a nem HBMx memóriás AMD kártyákon is várható a HBCC chip megjelenése, vagy ez csak a felső kategória kiváltsága lesz?
btw. úgy olvastam, hogy már a Dell is bejelentett egy Raven Ridge-es notit és egész jók a teszt eredmények. A single channel memóriás notik gpu eredményei a várakozásnak megfelelően nem túl jók...nem is értem, hogy gondolták a gyártók, hogy ennyire visszalépnek az időben. Az AMD meg szerződésbe foglalhatta volna az OEM-ekkel, hogy hulladék körítéssel ne gyártsanak notit az új APU-ra, mert az csak rontja a hírét.
-
válasz
Dilikutya
#126
üzenetére
nem veszed meg a sok GDDR-t fölöslegesen
Ebben van egy implicit feltételezés, ami szerintem nem állja meg a helyét - attól, hogy 16GB-tal kevesebb gDDR5/5x/6/whaterver lesz a kártyán, még nem fogsz annyival kevesebbet fizetni érte. Könnyen lehet, hogy szinte semmivel nem lesz olcsóbb, miközben vásárlóként mellé kell tedd a +8GB (de könnyen lehet, hogy +16GB) rendszermemóriát, amiért ki kell csengetned jelen áron 80-100 (ill. 150-200) EUR-t.
Én amúgy a kezdeti erős szkepticizmusom után nagyon pozitívan látom a HBCC-t, viszont ez megint egy olyan feature, amitől direktben a gyártónak lesz jobb. A gyártó aztán eldöntheti, hogy ebből a jóságból mennyit juttat vissza a vásárlónak - annak jelen pillanatban nem látom a gazdasági realitását, hogy ebből széles rétegek jobban jöjjenek ki. Ha valakinek amúgy is 32GB van a gépben (munka), akkor az win, és biztos lehet még pár sarokesetet összeszedni. De a többségnek ez extra költség lesz.
-
#132
 TESCO-Zsömle
titán
Dilikutya
#126
TESCO-Zsömle
titán
Dilikutya
#126
TESCO-Zsömle
titán
válasz
Dilikutya
#126
üzenetére
Azt azért halkan jegyezzük meg, hogy a kóródutyi egy ősöreg motorral operál, ami elég jól fut régi vasakon, cserébe a grafika bánja, míg a Battlefrot 2 és a Battlefield 1 alatt Frostbite dorombol, ami az EA talán egyetlen "értelmes" alkotása és egyben évek óta az aktuálisan elérhető legjobb grafikus motor a piacon. Nem véletlen, hogy nem lehet licenszelni. Cserébe a Fifától az NFS-ig mindent arra írnak.
-
#131
->Raizen<-
veterán
->Raizen<-
veterán
Ja es kevesebb a program oldali osszeomlas eselye mert az allokacio pontosabb.
-
#130
->Raizen<-
veterán
Jack@l
#122
->Raizen<-
veterán
Hbcc nem a teljesitmeny novelesere lett kifejlesztve hanem arra, hogy a v-ram ki legyen hasznalva, es a mikro akadasok durva kihagyasok mellozve legyenek a korabbi modellek miatt.
Most csak olyan adatok kerulnek a v-ramba ami feltetlenul szukseges, nem csak savszel kimelo a dolog , hanem kevesebb adat mozgatasa is hozza a kivant eredmenyt.
Kerdeztem nv-rol vegara atallo usereket es valoban nem tapasztalnak akadasokat. Demozta az amd 2 gb os vegaval az uj deus ex-et max grafikaval. Es nem akadozott a jatek egyaltalan. Utobbi evek leghasznosabb technologiai ujitasa amit driverbol kell csak bekapcsolni, kiveszed a dobozbol es mukodik mindenhol dolog. -
Dilikutya
félisten
Az ugye megvan, hogy a 4K felsőkategóriás felbontás, oda komolyabb GPU sem árthat?
Mire gondolsz, hogy "BF1-et okosba meghúzták 4 giga vramra ultrán"? Tehát akkor az szar, mert top grafikás játékként nem kell alá egy szerverfarm, és csalás van benne? Véletlenül sem jól megírt játék (vonatkoztassunk el, milyen a sztori, milyen a multi)? -
-
Dilikutya
félisten
De így nem kell mind a 16 GB VRAM-nak 7000+ (GDDR6-nál ki tudja mennyi) MHz-es GDDR5-nek lennie, ami feltételezem, nem olcsóbb, mint most a DDR4.
Meg ez dinamikus, így van alapból gyors GDDR memóriád, és ha kell, használsz a RAM-ból, és nem veszed meg a sok GDDR-t fölöslegesen.
Nálam a Battlefield 1 a 2 GB-os RX550-en simán hozta ultrán a 30+ fps-t, ergo hiába voltak 3, 4, 6, 8, 12 GB-os kártyák, 1080p-re ide már ez is játszható szintet hoz, inkább gyorsabb GPU számítana. Talán a 4 GB picit gyorsíthatna, mivel ugye így is hozzányúl a RAM-hoz is a videókártya.
A Battlefront II béta is vajsimán futott, igaz, az csak high-on, ultra presettel már nem mozdult 20 fölé, de itt is sokat dobott volna egy jobb GPU, 4 GB VRAM meg untig elég. A 4K felbontás meg most a felső kategória, oda mehet a 8 GB-os videókártya.
Ahogy nézem, a Call of Duty WWII sem igényel űrtechnológiát. Az Assassin's Creed szériában meg feature a magas gépigény, bár tudjuk jól, hogy nem a realisztikus grafika miatt. -
" simán bekapcsolnak vele valami sávszélességgel való gazdálkodást ettől jön a kis gyorsulás"
Végső soron igen, hiszen az on-demand paging eleve takarékosabb a sávszélességgel. Nincs semmi parasztvakítás, ez egy kellemes mellékhatás.
Az, hogy mennyire fog vagy nem fog kifutni egy 8GB-os kártya a memóriából, az leginkább 2 dologtól függ:
- Mennyi a memóriaigénye egy frame-nek
- Mennyi a delta a memóriatartalomban 2 frame közöttPCIE 3.0-n 16GB/sec megy át, tehát 60FPS-t feltételezve, frame-enként cca. 250MB adat cserélhető ki. Ez azért elég soknak tűnik - ha magához a frame-hez nem kell több, mint néhány GB (és azért az elég durván hangzik), akkor könnyen lehet, hogy a paginges módszer tényleg megoldja a problémát, és bír versenyezni sokkal nagyobb tényleges memóriával. Persze, annak a memóriának fizikailag azért ott kell lenni a gépben., szóval tök jó, hogy az AMD megspórolja (magának), viszont a usernek potenciálisan külön meg kell vennie.
No meg ehhez egy csomó extra munka és finomhangolás kell, míg ha ráb****ák a 24GB memóriát a kártyára, akkor elfér minden.
-
Dilikutya
félisten
Az átbaszás az, amikor a Call of Duty Ghosts nem indult el 4 GB memóriával megjelenéskor. Meg amikor a Crysis 2 láthatatlan, takarásban meg felszín alatt lévő felületeket számolt. Bármiféle optimalizációt én nem neveznék átbaszásnak. Az, hogy erőből rátolunk 16+ GB memóriát a kártyára, hogy nesze paraszt, vakujjá, az átbaszás. Igaz, hogy a memória drága, de nem baj, nem kell optimalizálni. Azt pedig, hogy ténylegesen mennyi kell, mennyi nem kell, nem tudhatjuk. Meggyőződésem, hogy kevesebb erőforrással is menne minden úgy, ahogy most. A közelmúltban írta valaki valamelyik játéknál, hogy a béta még elindult neki, a végleges már nem valami CPU által támogatandó feature miatt. Azt ugye senki sem hiszi el, hogy a béta után ilyen dolgokat fejlesztenek bele.
-

do3om
addikt
Tudom hogy már működik de valahogy úgy képzelem hogy simán bekapcsolnak vele valami sávszélességgel való gazdálkodást ettől jön a kis gyorsulás (párásztávakitás effekt)
A ramból kifutás még nem annyira kivitelezhető de talán majd eljön pár éhesebb játékkal. Ha ez megvan én semmi csodát nem várok amikor elfogy akkor vége, basztathatja majd a lassú rendszermemóriát azt már nem fogja megmenteni. Esetleg amikor kéri hogy mennyi ramod van arra jó lesz hogy átbassza a programot aztán vagy belefér és megy így is vagy belassul, akad, jőnek a különféle anomáliák. Arra már volt példa hogy a program kérte a ramot átbaszás után meg mégis ment kevesebbel is, tehát csak marketingfogás volt, de ahol tényleg kell ott a semmiből nem ugrik a karira extra ram.
Na de majd kiderül. -
Jack@l
veterán
Ilyen ábrákat és magyarázatot én is generálok 2 perc alatt, kb semmit nem mondtál el a konkrét működéséről
Ahogyan azt is elfelejted boncolgatni, miért 0 előnye van dx12 alatt, esetleg 2% 1-2 optimális esetben dx11 alatt. (olyan játákoknál melyek hajszálra 4 giga vramra vannak belőve fullhd-ben)
Kéne majd egy sok játékból álló teszt a hbc varázslatra itt a ph-n is, mikor kijönnek a 16-24 gigás kártyák. -
Abu85
HÁZIGAZDA
válasz
 Tigerclaw
#119
üzenetére
Tigerclaw
#119
üzenetére
Az AMD olyan keveset tesz majd rá, amennyire csak lehet, mert szoftverben található csúszkával te állítod be a kívánt kapacitást. Én úgy gondolom, hogy a tipikus VRAM target negyedével fognak dolgozni. Legalábbis láttuk, hogy a 8 GB-ot igénylő Deus Ex tökéletesen elvolt 2 GB-tal is exkluzív cache módban. Elképzelhető persze, hogy 1 GB-tal is ellett volna, de erre gyakorlati példa nem volt. Az AMD ezt jobban lemérte már magának, én csak a bemutatott gyakorlati példákból tudok kiindulni, mert olyan meghajtónk nincs, ami korlátozza a HBM2-hoz való hozzáférést.
-
Tigerclaw
nagyúr
Szerinted be merik majd vállalni az AMD-nél, hogy ne tegyenek ők is több memóriát a videokártyákra, követve az Nvidia-t? A 8GB-os VEGA kártyák nem erre utalnak. Azt kétlem, hogy csak azért tettek rá ennyit, hogy időt álló megoldás legyen. (ráadásul talán a legdrágább memóriát használták, aminek az ára jól jött volna árrésnek)
-
Abu85
HÁZIGAZDA
válasz
 janeszgol
#116
üzenetére
janeszgol
#116
üzenetére
A programozásnak ehhez igazából nem sok köze lesz. A HBCC eszközszintű megoldás. Alapvetően az inkluzív cache mód támogatása is csak egy inicializálás, de a program nem menedzsel semmit, csak megengedi a hardvernek a menedzselést.
A HBCC akármilyen módban egy out-of-box hardveres technológia, és direkt program oldali kezelést nem igényel.
Az alapkoncepciója nem sokban különbözik a cache-ektől a processzorban. A gyorsítótárak használatához sem kell direkt támogatás. -
Abu85
HÁZIGAZDA
Olvasd el hogyan működik. A későbbi hsz-ekben ezt kitárgyaltuk.
Egyébként ez semmiképpen sem tipp. Ez a rendszer már létezik. Már ma így működik. Semmi olyat nem írtam le ebben a topikban, ami ma ne így működne a gyakorlatban.
Egyedül az inkluzív cache módra nincs gyakorlati példa, de azt nem is igazán tárgyaltuk, mivel az egészet csak az exkluzív cache mód alapján vizsgáltuk.
Az inkluzív cache mód az elméletben annyiban különbözik, hogy nincs HBCC szegmens. Ez a kép szemlélteti a két megoldás különbségét:
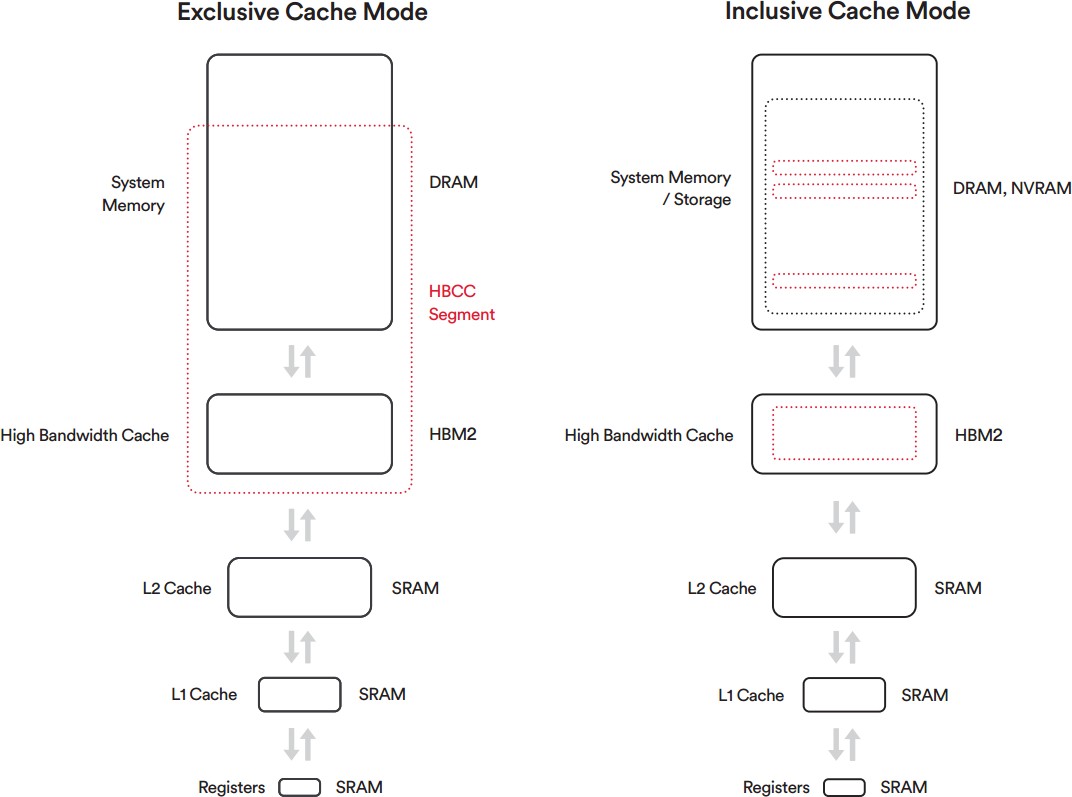
Az inkluzív cache mód aktiválását a program oldaláról kell kérni, míg az exkluzív cache mód driveresen aktiválható.
-
do3om
addikt
Ez az egész annyira a szokásos mesédnek tűnik......csak azért teszek ide hozzászólást hogy visszakeressem amikor magyarázod mért nem jött be amit itt leírsz.
Ha valami nincs az nem is lesz vagy neked nem tűnik fel? Rendszettmemóriát használni oda ahova kicsit komolyabb lérés kell...... valahogy nem tudom egyeztetni a két dolgot.
Amúgy a Furynál is volt már a beetető szöveg hogy ez HÁBÉJEM ebből a 4gb is elég! Vagy elfelejtettétek? Ez ugyan az a helyzet.
Ha vga-ra ram kell? Rá kell rakni. Ennyi.Na majd jövőre linkelem, szórakoztató leszel (ismét)
![;]](//cdn.rios.hu/dl/s/v1.gif)
-
Abu85
HÁZIGAZDA
Bekapcsolható. Beállíthatod akármikor. Mi is aktív HBCC-vel tesztelünk.
Alapértelmezett lesz, amikor megszűnik a Windows 7 support, vagy amikor kettéválasztják a Win 7 és Win 10 csomag tesztelését.
(#111) janeszgol: Nem adja oda. A Win csinálja tovább, amit csinálni kell, csak jelezve van neki, hogy a fizikai címtartományon belül hova rakja a CPU+GPU által is elérhető adatokat. Ha azok ott vannak, akkor a HBCC már az operációs rendszer beavatkozása nélkül is képes dolgozni. Az exkluzív cache módnak lényegében ennyi az igénye.
-

janeszgol
félisten
En ugy tudom elkepzelni, hogy vagy fixen odaadja a win a hbcc-nek az adott memoriat es annak menedzsmentjet, de csak azet, a tobbit tovabbra is az oprendszer kezeli (mivel o az isten) vagy dinamikusan tekint a Win is erre, de ezt meg nem hiszem.
Kivancsi vagyok te hogy latod. Koszi. -
#109
->Raizen<-
veterán
UnknownNoob
#105
->Raizen<-
veterán
válasz
 UnknownNoob
#105
üzenetére
UnknownNoob
#105
üzenetére
Alljunk meg egy szora nem az amd hibaja a vega? Megis kik fejlesztettek ki es dobtak piacra? Megsugom, az amd. En a vega 64 et ekezem javareszt, de a vega 56 a sweet spot jo teljesitmeny fogy arannyal alulfeszelve es huzva. Wolfiba bizonyitott meg par low level jatekba , en se vennek mast vegan kivul hbcc miatt. Ha megtehetnem. Menjetek tecoba jo kis akciok vannak durvan jo kis tv-k pl.
-
-
#105
 UnknownNoob
tag
->Raizen<-
#25
UnknownNoob
tag
->Raizen<-
#25
UnknownNoob
tag
válasz
->Raizen<-
#25
üzenetére
"Lathattuk mennyit er a hbm a vegan. Rohadt sokat fogyaszt a hw egy 1080 hoz kepest."
A Vega fail nagyrészt nem az AMD hibája. Memória és a gyártástechnológia sem felelt meg a beharangozott specifikációnak, amdéék viszont arra tervezték a vegát. A tervezettnél alacsonyabb órajeleket is csak egekbe szökött feszültségek mellett tudták megtartani.
Jól demonstrálja a helyzetet, hogy van néhány golden sample aminél ha leveszed a feszültséget és felviszed az órajelet, akkor még magasabb wattonkénti teljesítményt kapsz, mint a zöldeknél.
Jövőre jön a Vega 20, várhatóan addigra megoldódnak a problémák és verni fogja a Vega a Pascalt. A probléma az, hogy jelenleg nem tudnak eleget gyártani és azzal is csak a baj van ami kijön a gyárból, jövőre pedig jön a Volta.
Mindenesetre a technológia egyáltalán nem gagyi. Intelék sem véletlen akarnak Vegát és nem pedig Pascalt a nagy teljesítményű, de kis fogyasztású CPU+GPU akármicsodáikba.
-

reds.hu
csendes tag
válasz
Dilikutya
#102
üzenetére
Nekem 1999ben egy 4.3Gb seagate ketyegett, szòval a te 20asod az tènyleg nagy volt akkor.
A tèmàhoz annyit, hogy èn sokallom az esetleges 24Gb ramot mèg a csùcskàrtyàkra is. Szerintem max 16 lesz az de az biztos hogy nyugodt lelkiàllapotban kell majd lenni amikor az àrcèdula felèlè fordul a tekintetünk.













































![;]](http://cdn.rios.hu/dl/s/v1.gif)

 A képen felül szerepel a bővítőmodul, de nekem nincs hozzá. Egyben video és hang kártya, és interface az akkori SEGA controllerhez, plusz a hagyományos joystick port.
A képen felül szerepel a bővítőmodul, de nekem nincs hozzá. Egyben video és hang kártya, és interface az akkori SEGA controllerhez, plusz a hagyományos joystick port.










Új hozzászólás Aktív témák
Hirdetés

- Amlogic S905, S912 processzoros készülékek
- BestBuy ruhás topik
- BestBuy topik
- TCL LCD és LED TV-k
- War Thunder - MMO Combat Game
- Majdnem mindenki a TSMC 2 nm-es node-jára vágyik, de van egy nagy probléma vele
- Gitáros topic
- Óra topik
- gban: Ingyen kellene, de tegnapra
- Multimédiás / PC-s hangfalszettek (2.0, 2.1, 5.1)
- További aktív témák...

- Samsung Galaxy S23 128GB, Kártyafüggetlen, 1 Év Garanciával
- Dixit 4 Eredet (bontatlan, fóliás kártyacsomag)
- Tablet felvásárlás!! Apple iPad, iPad Mini, iPad Air, iPad Pro
- Új, verhetetlen alaplap sok extrával!
- LG 27GS60QC-B - 27" Ívelt - 2560x1440 - 180Hz 1ms - AMD FreeSync - Bontatlan - 2 Év Gyári Garancia
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest