Hirdetés
- Samsung Galaxy S25 Ultra - titán keret, acélos teljesítmény
- MIUI / HyperOS topik
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Android alkalmazások - szoftver kibeszélő topik
- Milyen okostelefont vegyek?
- Tényleg nem változik semmit a Samsung Galaxy S26+?
- Google Pixel topik
- Xiaomi 14T Pro - teljes a család?
- Fele annyit ér az iPhone Air, mint amennyibe pár hete került
- Android szakmai topik
Új hozzászólás Aktív témák
-
#7103
 Petykemano
veterán
S_x96x_S
#7102
Petykemano
veterán
S_x96x_S
#7102
Petykemano
veterán
válasz
 S_x96x_S
#7102
üzenetére
S_x96x_S
#7102
üzenetére
Ezt a cikket olvastam, amikor eszembe jutott valami.
A Sunny Cove L3 cache-ről:
"Tiger Lake increases L3 slice size to 3 MB, increasing total L3 size to 24 MB. At the same time, the L3 has been changed to not be inclusive of the L2. With 10 MB of total L2, an inclusive L3 would use over 40 percent of its capacity duplicating L2 contents to maintain cache coherency. Changing to a non-inclusive policy dictates changes to the L3’s cache coherency mechanism. Previously, each L3 line would have core valid bits indicating which core(s) might have that line their private L1 or L2 cache. That reduces snoop traffic on the ring interconnect. Tiger Lake’s non-inclusive L3 has to use a different mechanism, since a line can be in a core’s private caches without being in the L3. There’s likely a set of probe filters alongside the L3, like Skylake-X’s setup.
These changes come at the cost of about 9 cycles of extra L3 latency. Lower clock speed from 10nm process deficiencies make latency even worse, meaning that Tiger Lake relies a lot on its enlarged L2 to maintain performance. Ironically, Tiger Lake’s L2-heavy setup is better for maintaining IPC with increasing clock speed. Intel’s uncore clock (which includes the L3) has struggled to keep pace with core clock ever since later Skylake generations started reaching for 5 GHz and beyond. L3 accesses get more expensive as the gap between uncore and core clock increases, so keeping memory accesses within the full speed L2 helps performance at higher clocks."Én úgy tudom (de ha nem, akkor majd valaki kijavít és abban az esetben elnézést), hogy a Zen esetén az L3$ órajele megegyezik a magórajellel. Legalábbis az, hogy az 5800X3D órajel (pontosabban feszültség) limitációja erre utal. Gondolom azért kell az egész cpu-nak limitáltnak lennie, mert az L3$ nem külön frequency domain.
Ha és amennyiben ez a megállapításom helyes, akkor egyrészt a jövőben az egyre gyakoribb 3D varázslások miatt az ebből fakadó imént említetthez hasonló limitációk elkerülése érdekében talán praktikus lehetne az AMD-nek is meglépni, hogy elválasztja egymástól a core+L1+L2 és az L3 frekvencia tartományokat.
Másrészt az jutott eszembe, hogy mi van, ha ezt a zen4 esetén már meg is lépték és épp azért tud annyira magas frekvenciát elérni, mert a böhöm nagy kiterjedésű L3$-t már nem kell azon a nagyon magas frekvencián járatni. A külön szabályozható L3$ frekvencia abból a szempontból is hasznos, hogy a 3D ráépítmény kevésbé nehezíti meg a hűthetőségét, vagy ha a hőtermelés mégiscsak korlátozást jelentene, akkor külön szabályozható az L3$ frekvenciája, tehát például lehetségessé válik, hogy az L3$ 3D felépítmény nélkül magasabb frekvencián ketyegjen, mint 3D felépítménnyel.
-
#7096
Petykemano
veterán
Petykemano
veterán
Apple M2
25%-kal több tranyó. A gyártástechnológia "2nd Gen 5nm". Nőtt a lapkaméret.
Az Apple architektúra - széles, magasa IPC alacsony frekvencián - szerintem továbbra is példátlan. Az a 18% MT előrelépés a CPU terén tisztességes, de nem megy csoda számba. Tartja a távolságot. -
#7095
Petykemano
veterán
S_x96x_S
#7092
Petykemano
veterán
válasz
S_x96x_S
#7092
üzenetére
impresszív számok.
Ha ez a 15% végleges, akkor kb annyival nőhet a ST teljesítménye, mint a Zen4-nek az AMD saját bevallása szerint.
És nem csak ST-ben lesz erős, hanem Szálfüggetlen MT-ben is - a +8E mag miatt. Kiváncsi vagyok, mennyivel lesz nagyobb a lapka.Nekem úgy tűnik, az Intel - konzumer piacon - kezdi összekaparni magát. Egyrészt hozzák az az ígéretet/tervet, hogy a P magok a ST teljesítmény, az E magok a throughput célt szolgálják.
Kérdés, hogy meg tudják-e oldani, hogy az E magok segítsenek, de legalább ne zavarjanak a szálfüggő alkalmazások esetén.De amit kiemelnék az az, hogy úgy tűnik az intel nagyon gyorsan dolgozik - gyorsabban, mint az AMD. 2021 elején megjelent a Rocket lake, ami lehet, hogy csupán egy többszörös származék volt, de akkor is volt vele munka. És év végén megjelent az Alder Lake is (november)
Bár az intel - ellentétben a titkolózó AMD-vel - jelenleg nyitott könyv módban működik, szeretnek dobálózni az információkkal. A Sapphire Rapids és a Ponte Vecchio is már egy-másfél éve veri le az AMD-t, mint vak a poharat anélkül, hogy ténylegesen megjelent volna. De a kiszivárogtatott eredmény arra utal, hogy azért a Raptor lake is előrehaladott állapotban van. Ha nem is fogja megelőzni a Zen4-et, de azt nem zárnám ki, hogy a Zen4-gyel nagyjából egyidőben jelenjen meg, tehát ilyen szeptember-október táján.
a 10-11 hónapos fejlesztési ciklus durván, de még a 12-13 hónapos is számottevően gyorsabb, mint az AMD-nél tapasztalt 14-15-16-22.Az Alder Lake-ben (és a Raptor Lake-ben, valamint a Zen4-ben is) nekem az elengedett fogyasztás unszimpatikus. De ha az Intel ennyivel gyorsabban lesz képes termékeket megjelentetni (mondjuk 12 havonta 15 hónap helyett) akkor idővel a fogyasztás elengedése nélkül is képes lehet kényelmes előnyt elérni.
-
#7090
Petykemano
veterán
olymind1
#7089
-
#7088
Petykemano
veterán
sb
#7086
Petykemano
veterán
Az általam olvasott magyarázatok alapján nekem így állt össze:
Az egyik magyarázat szerint a Zen4 késett.
Zen: 2017-02
(Zen+: 2018-04) (+14)
Zen2: 2019-07 (+15)
Zen3: 2020-11 (+16)
Zen4: 2022-09 (?) (+22)Ha a Zen+-t rendes generációnak tekintjük, akkor valóban tekinthető késésnek, hiszen akkor év elején, legkésőbb tavasz táján el kellett volna rajtolnia. Mondjuk ha néhány hónappal az Alder Lake után rajtol, és nem a Raptor Lake-kel egyidőben, akkor lehet, hogy másként jön le.
A késedelem oka a szóbeszéd szerint a covid, ami mindent csúsztatott legalább fél évvel.Persze ha a Zen+-t csak filler terméknek tekintjük, akkor meg még úgymond gyorsabban is ment az új node-ra való átállás, mint 14nm-es Zen-ről a 7nm-es Zen2-re. A Zen2 esetén az AMD azzal dicsekedett, hogy tulajdonképpen azért nőtt ilyen nagyot az IPC, mert lehoztak bizonyos fejlesztéseket, amiket eredetileg a Zen3-ban akartak volna megjeleníteni.
A csúszás elméletet alátámasztani látszik az is, hogy a Zen5-öt 2023-as terméknek mondják. Ami megint egy szűkebb, a zen4 feltételezett megjelenési dátumához képest legfeljebb 15 hónapos időablakot jelent.
A második válasz szerint a Zen4-en egy másodlagos csapat dolgozott. Tehát van egy csapat, amelyik az IPC növelésen, új architektúrán dolgozik, egy másik pedig feature-ök hozzáadásán és a gyártástechnolgiai váltásokon. Ezért nincs kifejezetten IPC növelést célzó fejlesztés.
Ha ezt a kettőt így összeteszed, akkor egyébként kijön, hogy a Zen2 esetleg tényleg csak azért hozott nagyobb IPC növekedést, mert lehozták azt a fejlesztést, aminek a Zen3-ban kellett volna megjelennie. Ha nem így tesznek, akkor a Zen2 nem 13-16%-ot hoz, hanem mondjuk 5-8-at. A zen3 pedig nem 19-et, hanem annyival nagyobbat.
Ha ugyanezt nem játszották el a Zen4 és a Zen5 között, akkor máris érthető, hogy a Zen4 miért nem hoz komolyabb IPC növekedést. Nagyjából az lesz érezhető, ami az L2$ dupálzódásból meg a nodeváltás miatt az uncore részek frekvencia emeléséből leesik. (cserébe várhatóan a Zen5 igen komoly IPC előrelépést fog hozni.)
Egy harmadik megfogalmazás szerint, persze ez lehet, hogy csak az előzőek iterálása, az AMD nem csak a gyártástechnológia/architektúra szempontjából tick-tockozik, hanem aszerint (is), hogy fejlesztés célja ST / MT teljtesítmény növelése. A zen3 esetén hangsúlyozták, hogy a cél a ST (Single vagy Low Thread) teljesítmény növelése volt. Egyébként ennek megfelelően - nyilván persze power okokból - a Zen3 MT teljesítménynövekedése alacsonyabb volt, mint a ST.
Ebben a vonatkozásban a 40% egyébként nem rossz. (Bár én az TDP/PPT növelésének nem örülök, kivéve ha ebbe a 170W TDP / 230W PPT keretbe kapok majd egy korrekt és diszkrét összetevőktől olcsóbb APU-t.)
/találgatás/
Szerintem a Zen4 épp a megnövekedett frekvencia miatt remek gaming teljesítménnyel fog rendelkezni. A duplázott L2$ biztosan segít majd sok játéknál, hiszen a játékok nagyon érzékenysek a memóriára. Ahol a V-cache segített, ott a megnövekedett L2$ is segíteni fog - ha másért nem is, akkor azért, mert 4MB/CCX-nyi mértékben tehermentesíti az L3$-t. A frekvencia és a több cache együttesen sok esetben hozni fogja azt, amit a v-cache biztosít.Megkockáztatom - remek meglepetés lenne -, hogy azért ül olyan közel egymáshoz a két CCX, mert a két L3$ szelet össze van kapcsolva, átjárható, együttesen címezhető. Ami olyan, mintha 12/16 magos változatok kaptak volna egy fél v-cache-t a nyakukba.
-
#7087
Petykemano
veterán
Komplikato
#7084
Petykemano
veterán
válasz
 Komplikato
#7084
üzenetére
Komplikato
#7084
üzenetére
> A Gen5 nagyon érzékeny, több rétegű nyák, árnyékolás kellenek, hogy jól működjön.
> Az meg drága.
Drága, mert új, drága, mert elsőre nehéz, drága, amíg általánossá és méretgazdaságossá nem válik az első kísérletezgetéseket követően? Vagy csak simán drága?Azért kérdezem, mert B450-et lehet kapni már mondjuk 30-ért. (persze nem ez a legolcsóbb, de nem is a legdrágább) B550, ami (mármint az ilyen lapok, nem csak a chipset) biztos sok tekintetben jobb és minőségibb, mint a B450 volt, de már inkább 45-50e egy átlagos példány. (Vannak persze ezen a Gen 3-as olcsósított példányok, amikből a feature szempontból egyetlen kézzelfogható előrelépést jelentő Gen4-et kapálták ki.)
És most arról beszélünk, hogy a híresztelések szerint egy döntően Gen4-es (kivéve a Pcie5 x4 storage) B650 alaplap már inkább 70-80eFt lesz.
Én nem mondom, hogy nincs benne újdonság. DDR5/DDR4, PCIe5 vagy PCie4 és értem, hogy ezeknek a kialakítása komplexebb.
És biztos minden más szempontból is minőségibb lesz, mint a B550, pláne mint a B450.De valahogy tökre nem látom magam előtt, ahogy average Joe vesz 100eFt-ért egy új zen4-es cpu-t és mellé egy karcsú és olcsóbb 70eFt-os B650-es alaplapot. Lehet mondani, hogy Average Joe akkor maradjon az A620-as kaptafánál, de ha average Joe akar venni egy új, de olcsóbb GPU-t, akkor kénytelen lesz nem spórolni a PCIe generáción, mert az olcsóbb GPU-ja PCIE5 x4-es csatolóval fog jönni, ami 4GB esetén már problémás lehet.
Ha ezek a költségnövekedések nem csak kezdeti költségek, amiknek fedeznie kell a fejlesztést is, stb akkor nekem ebből a szempontból a PCIe kicsit zsákutcának tűnik. Tehát mondju 2024-ben PCIe6-os alaplapok esetén arról fogunk beszélni, hogy egy nem leggagyibb, korszerű technológiát kínáló alaplap 100eFt?
Ebbe többletbe már lassan bele kéne, hogy férjen inkább olyan integráció, hogy average Joe nem PCie slotba illeszthető GPU-t vesz, hanem egy jó képességű APU-t és a drága DDR5 vagy PCIe5 kapcsolat alaplapi kialakítása rátesznek egy 16GB-os HBM-et, ami akár önmagában is elketyeg, de kapacitás szempontjából meg lehet segíteni valami lassabb de nem fáradó technológával készülő "memóriával" (DDR4? Optane? )
Szóval szerinted ki fog forrni idővel az újabb PCIE generációk technológiája, vagy innentől minden PCIE genváltással 50%-kal drágábbak lesznek az alaplapok?
-
#7069
Petykemano
veterán
hokuszpk
#7068
Petykemano
veterán
válasz
 hokuszpk
#7068
üzenetére
hokuszpk
#7068
üzenetére
A power requirement miatt valószínűleg a B650-nek is jobbnak kell lennie az előző szériánál kialakítás, VRM, hütés, stb szempontból. Persze ki tudja. Lehetnek olyan trükközések, hogy B650-ből nem jön ki a 230W PPT
De valahogy én is kissé irreálisnak érzem 70-110eFT kifizetését egy máskülönben "elmegy" szintű alaplapért. Eltekintve a procitól és a PCIe5-ös NVME csatlakozótól mivel fog ez többet tudni, mint egy 40eFt-os B550?
Tényleg kérdezem. -
#7061
Petykemano
veterán
-
#7060
Petykemano
veterán
Petykemano
veterán
-
#7058
Petykemano
veterán
Petykemano
veterán
Graviton 3 vs Milan vs Ice Lake
Nem tűnik rossznak. Az arm V1 kb ugyanazt az IPC-t hozzá már, mint az x86 magok. Cserébe persze nem ér el akkora frekvenciát, de valószínűleg kevesebbet fogyaszt és valószínűleg kisebb is.
Kiváncsian várom, hogy a néhány hónap múlva rajtoló Genoa és Sapphire rapids új színt hoz-e a versenybe.
-
#7057
Petykemano
veterán
GeryFlash
#7052
Petykemano
veterán
válasz
 GeryFlash
#7052
üzenetére
GeryFlash
#7052
üzenetére
Az AMD úgy tűnik, hogy nem vette be azt a kanyart, amit én gondoltam, hogy az Apple példája alapján be kéne venni. Nevezetesen azt, hogy elindul a széles, de alacsonyabb frekvencián ketyegő irányba.
Ezért nem biztos, hogy hibáztatható most, mert minden jel arra utal, hogy a zen4=zen3+ + 2xL2$ + AVX512 + N5 és ennyi.Egyelőre úgy tűnik, hogy haladnak tovább a magas frekvenciás úton.
Tehát én egész biztos vagyok benne, hogy a perf/W tekintetében az apple továbbra is verhetetlen lesz. Mármint akár az M1 is. Ebben nyilván a tranzisztorszám is egy faktor, ahogy HSM mondja. Nem kizárt, hogy azt is kiszámolják, hogy a rendelkezésükre álló gyártókapacitásból így jön ki több eladható lapka - hiába tudnának másfélszer ekkora lapkából 30%-kal kisebb fogyasztással ugyanilyen teljesítményt kihozni, ezért felárat senjki nem fizetne, viszont kevesebb eladható lapka jönne ki belőle.
Ami az 8N vs N7 viszonyát illeti. Szerintem a Qualcomm 4LPP vs N4 eredménye jól illusztrálja, hogy mi a helyzet.
-
#7050
Petykemano
veterán
paprobert
#7048
Petykemano
veterán
válasz
 paprobert
#7048
üzenetére
paprobert
#7048
üzenetére
A Zen2 esetén mintha lettek volna olyan reportok, hogy tulajdonképpen extrém tuning mellett növelhető a core frekvencia, de az eredmények nem növekedtek lineárisan az órajellel. Emlékeim szerint akkor ennek okát abban határozták meg, hogy a processzor más részei nem tudták követni (pl az FCLK) és hogy emiatt ha a mag bírna is magasabb órajelet, akkor se igazán lenne érdemes kitekerni belőle.
Nem tudom, valami ilyesmi jelenségre gondoltál-e?A Gigabyte leak szerint a processzor más részein is órajelnövekedést intéztek:
[link]
Az FCLK-re pl 2.4Ghz-et írnak. A zen3 kb 1.8-1.9-ig skálázódott. -
#7046
Petykemano
veterán
Petykemano
#7045
Petykemano
veterán
válasz
 Petykemano
#7045
üzenetére
Petykemano
#7045
üzenetére
Lehet, hogy én értettem félre.
A VCZ is azt hangsúlyozza, hogy ez csak elméleti maximum. -
#7045
Petykemano
veterán
Busterftw
#7044
Petykemano
veterán
válasz
 Busterftw
#7044
üzenetére
Busterftw
#7044
üzenetére
Hát ha komolyabb APU-t szeretnének készíteni, annak is mindenképp indokolt.
De a "szenzáció" itt most az, hogy nem csak arról van szó, hogy a platform limitek mik lesznek, hanem hogy a látott eredményeket és frekvenciákat ennek a fogyasztásnak a függvényében kell értelmezni.
Eddig 105W volt a TDP és 142W a PPT.
A bemutató után azt mondták, a PPT volt 170W, vagyis a TDP 125W - ami hát inkább egy szerény "miheztartás végett" jellegű (+20%) kiterjesztése a CPU számára rendelkezésre álló fogyasztásnak és ennek függvényében látott eredmények igencsak megsüvegelendők.
Viszont most úgy tűnik, hogy valójában a TDP 170W, a PPT pedig 230W, ami 60%-os fogyasztásnövekedést jelenthet.
Persze nem mondom, hogy nem indokolt, hiszen a 16 magos zen3 már eléggé limites volt, és az Intel is ezt az utat választja, de én (és a bolygó is) azért sajnálom, hogy azért a néhány százalékért lemondunk az energiahatékonyságról.
(Nem, az nem menti meg a bolygót, ha én majd letekerem a TDP-t) -
#7043
Petykemano
veterán
Petykemano
veterán
"AMD would like to issue a correction to the socket power and TDP limits of the upcoming AMD Socket AM5. AMD Socket AM5 supports up to a 170W TDP with a PPT up to 230W. TDP*1.35 is the standard calculation for TDP v. PPT for AMD sockets in the “Zen” era, and the new 170W TDP group is no exception (170*1.35=229.5).
[link]
Így már értem a sok kondenzátort. -
#7041
Petykemano
veterán
Petykemano
veterán
A RedGamingTech nyilvánosságra hozott CB23 MT pontokat
Persze a számokat ne vegyük biztosra.
Mindenesetre ezeket a növekményeket elég jól magyarázhatja a megemelt PPT keret és persze az energiahatékony magas órajel, amire az AMD utalást tett.
- Érdekes, hogy a 16 magos verziók esetén a növekmény megegyezik azzal, amit az AMD Blender esetén is bemutatott.
- A 16 magos verzió növekménye azért lehet nagyobb, mert a 16 magos zen3 vélhetően limitbe futott. A 5950X és 5900X eredménye közötti különbség kisebb, mint amennyivel több magja van. Zen4 esetén ez a regresszió eltűnik.
- Hasonló különbséget mutat a 6 és 8 magos - ezúttal a 6 magos javára. Itt feltehetően arról lehet szó, hogy a 6 magos Zen3 esetén a jóval alacsonyabb TDP jelenthetett egy korlátot. Az 5800X nagyobb mértékben volt gyorsabb, mint a magok számából eredeztethető. A 6 magos Zen4 feltehetően újra ugyanazzal a TDP-vel kerül forgalomba, mint a 8 magos, így a teljesítménybeli különbség visszaáll a magok számának arányára.Ha CB esetén 2-3%-os IPC növekedésssel számolunk, ahogy az a >15% szám alapján feltételezhető, akkor azt leszámítva kb 40%-kal teljesít jobban a 6 magos Zen4 - más okokra visszavezethetően.
Az 5600X tech jesus videója szerint kb 4.4Ghz-en ketyeg MT workload esetén.
Ha csak frekvenciával akarnánk magyarázni, akkor ahhoz 6.1-6.2Ghz-en kéne mennie a 6 magos Zen4-nek.Ez azért egy picit talán soknak tűnik.
Ha azzal az 5.5Ghz-el számolunk, amit a bemutatóban láttunk, akkor a 4.4-hez képest az 5.5Ghz épp 25%-os többletet jelent. Amennyiben abból indulunk ki, hogy a 6 magos Zen4 5.5 all-core turbót fog tudni, úgy itt is marad ~12% teljesítménynövekedés, amit valami másnak kell magyaráznia.Az jutott eszembe, hogy mi van, ha a megnövekedett L2$ (CB23-ban mérhető ST) IPC-n ugyan nem segít, de az SMT hatékonyságát megdobja?
-
#7040
Petykemano
veterán
S_x96x_S
#7038
Petykemano
veterán
válasz
S_x96x_S
#7038
üzenetére
> Ha a ZEN4 TCO-ja ( teljes bekerülési kültsége ) több mint +60% extra költég
> és a platform csak +30-40% -ot tud adni a ZEN3 -hoz képest,
A zen4 lapkák mérete kicsit kisebb, valamivel több lapka is kijöhet, mint Zen3-ból.
Az N7/N6 olyan brutál drága már nem lehet, ha megengedhetik maguknak a $200-os 5600-at és a kb ebben az árban levő 180mm2-es 5600G-t is.
Az N5 gyártástechnológia sem mai. Elképesztően jó a yield. Még ha $17000-os wafer költséggel számolunk is, akkor sem lehet egy zen4 CCD lapka önköltségi ára $25-nál nagyobb. Számoljunk ugyanennyivel az IOD-ra is.Ezzel együtt valószínűsítem, hogy legjobb esetben is annyi lesz a Zen4, mint a Zen3 induláskor, de inkább megint +$50-100. Ha az Intel versenyképes, akkor annyival drágábban nem is adhatják majd. Viszont őket erősen szorítani fogja a kapacitás. Majd biztosan hivatkoznak az inflációra, de az ár inkább kereslet-szabályozó eszköz lesz.
Szerintem az érezhető drágulás majd inkább az alaplapokat érinti majd. A B550 és a B650 között talán csak a PCIe5 storage lesz a különbség. Meg persze a 170W-os PPT.
+ DDR5 árak.
Talán nem véletlenül mondta Lisa Su is - ismét - hogy az AM4 velünk marad még néhány évig. -
#7039
Petykemano
veterán
Petykemano
veterán




A lapkák közelebb ülnek egymáshoz. Nincs köztük az oválisnak ható széleket adó "ragacs"
Vajon lehet jelentősége?
- egy régóta várt kapcsolat a két chiplet között, összekapcsolható L3$? EFB? -
#7037
Petykemano
veterán
Petykemano
#7035
Petykemano
veterán
válasz
Petykemano
#7035
üzenetére
Elég sok anyag keletkezett a sandbagging témában. Meghallgattam MLiD új Broken Silicon epizódjából azt a részt is, ami a téves IPC jövendölésre vonatkozik.
Bennem egy olyan kép alakult ki azzal kapcsolatban, hogy "honnan jött, hová lett a nagyobb IPC növekedés gondolata?", hogy talán tényleg félreértelmezett eredmények (pl: látok egy teljesítmény növekményt, leosztom a magok számával és feltételezem, hogy mondjuk 8-10%-kal többel nem nőhet a frekvencia, a többinek IPC növekedésnek kell lennie) vagy partikuláris eredmények értelmezése alapján jöhetett (bizonyos tesztek reagálhatnak jól a megnövelt L2$-re és/vagy az AVX512-re)
Tehát a Zen4 tényleg egy Zen3 die-shrink (annak minden előnyével) AVX512 támogatással és (nagy eséllyel az előző miatt ) duplázott L2$-sel új DDR5 platformon.
A >15% ST növekmény a minimum, aminek nagy része a valószínűleg 5.52Ghz-es boost órajelből fakad, ami ha tényleg ennyi lesz, akkor máris 12.5%-ot magyaráz (vs 5950X 4.9Ghz)
Nem elképzelhetetlen, hogy végleges SKU majd 5.6Ghz-es lesz. És az sem elképzelhetetlen, hogy továbbra is lesz PBO és ez brutális feszültség mellett tovább tornázható (Extreme overclocking)A maradékot magyarázhatja IPC növekedés. Mivel az architektúrához nem nyúltak hozzá (lásd Intel, amelyik minden új verziónál növelget ilyen reorder buffereket meg regisztereket) ezért a >15% ST esetében a frekvencia által nem fedezett növekményt - IPC növekedést - a DDR5 nagyobb sávszélessége, valamint a Gigabyte leak-ben szereplő egyéb órajelnövekedések magyarázhatják. Pl FCLK Ez az N6-on készülő IOD előnye lehet.
De lehetnek olyan szoftverek, amelyeknél ennél nagyobb teljesítmény növekedés, sőt akár nagyobb IPC növekedés is lesz mérhető. Biztosan vannak olyanok, amelyek jól reagálnak a L2$ méretnövekedésére és AVX512-t használó szoftverek esetén is biztosan látványosan nagy számokat lehet majd bemutatni. És
Nem is kell messzire menni, mert ott van rögtön az AMD által bemutatott Blender teszt. Ha feltételezzük, hogy bemutatott mérnöki példány 40%-kal gyorsabb, mint az 5950X és előbbi 5.2 all-core frekvencián ment, míg utóbbi mondjuk 4.2-t. Akkor a 40%-os gyorsulásból ~25%-ot magyaráz a magasabb frekvencia, a maradék ~12% viszont úgymond IPC-növekedésből kell eredjen.
Ez máris több, mint a >15% ST számból származtatható 2-3%. Ha valaki az L2$-re és a megnövelt AVX képességekre jobban reagáló programot futtatott, azokból könnyen juthatott arra a következtetésre, hogy itt kéremszépen 20-30%-os előrelépés tapasztalható nem számítva a frekvenciát. -
#7035
Petykemano
veterán
S_x96x_S
#7027
Petykemano
veterán
válasz
S_x96x_S
#7027
üzenetére
> és mi van ha nem létezett?
Lehetséges. AdoredTV is készített egy videó és elővett egy 2 évvel ezelőtti Zen4-ről szóló satát anyagot, ami azt erősíti meg, hogy a Zen4 csak egy zen3(+) die shrink + 1MB L2$ + avx512
Én csak próbáltam összerakni egy olyan koherens történetet, amibe bele lehet illeszteni a zen4-ről IPC-ről szóló történetszálakat. Amik persze vagy valóban valamilyen ES eredmenyéi, vagy annak félreértése, specifikus teszt alapján való félreértelmezése, vagy akár kamu is lehet persze.
Ha 2020-ban AdoredTV ennyire pontos infókat kapott a 2022-es Zen4-ről, akkor akár az is lehet, hogy a Chips&Cheese, MLID, RTG már valójában a nextgenről kapott infókat, anélkül, hogy ők, vagy a szivárogtató tudná, hogy pontosan milyen termékről szól az infó.
Mindenesetre a félreértések elkerülése végett mondom, hogy ez nem a sandbagging vonalon való lovaglás részemről, hanem éppen az, hogy ebben a zen4 termékben nem lesz több, nem érdemes csodára várni.
Érdekes egyébként, hogy Coreteks a gaming területen látja az esetlegesen visszatartott információt, AdoredTV pedig ott, hogy mennyi mag férhet el a lapkán. Szerintem a magszámban nem lesz meglepetés. Viszont akár az L2$, akár a magas all core boost szép eredményeket hozhat játékokban.
A módosítást természetesen én sem utolsó pillanatban gondoltam. Hanem hogy többféle designt is elkészítenek: lehetett egy minimalista és egy, ami komolyabb IPC növekedést is hozna. Aztán valamikor 1-1.5 éve eldönthették, hogy a minimalista designt dobják piacra zen4 néven. Gondolom több részegység fejlesztése párhuzamosan történik különböző kisebb csoportok által. Lehet, hogy az AVX512 hamarabb kész lett.
-
#7028
Petykemano
veterán
S_x96x_S
#7026
Petykemano
veterán
válasz
S_x96x_S
#7026
üzenetére
Tehát:
X670E:
- sok IO (2 chipset)
- garantált GPU & NVME PCIe5
x670:
- sok IO (2 chipset)
- garantált NVME PCIe5 + opcionális GPU PCIe5
B650E:
- kevés IO
- garantált GPU & NVME PCIe5
B650:
- kevés IO
- garantált NVME PCIe5Ez egész korrektnek szegmentálásnak tűnik.
Kivéve azt, hogy az olcsóbb alaplapnál a PCIe generáción spórolnak, az olcsóbb GPU-nál pedig a sávokon. Nem tudnák úgy megoldani valahogy, hogy a PCIe4-es lapok esetén x16 PCIe4 vagy x8 PCIe5 legyen? -
#7024
Petykemano
veterán
S_x96x_S
#7023
Petykemano
veterán
válasz
S_x96x_S
#7023
üzenetére
Egyelőre nem tudni, hogy mennyire lesz probléma.
De sajnos tartok tőle, hogy az AMD azt az utat fogja választani, hogy a B650 lapokból kimarad a PCIE5 a GPU-nak, de az olcsóbb GPU-kba - ha nem is 2022-ben, de 2023-ban - már csak 4x PCIe5 kerül.Megy a spúrkodás az AMD részéről.
Azt gondolják, hogy nem engedhetik meg maguknak, hogy nagyvonalúan bánjanak a szilíciummal. Charlie azt említi, hogy Zen3 helyett Zen2 magok használatával pár centet spórolhattak, de szerintem arról van szó, hogy
- A Mendocino valójában egy kész Van Gogh design, amit portoltak N6-ra, de amúgy nem nyúltak hozzá
- Ha 5-10%-kal kisebb a lapka, mint Zen3-mal lehetne, akkor nem az az $0.5-1 költség számít, hanem hogy annyival többet tudnak eladni.Szerintem nagyjából minden lépésüket ez hatja át.
Megkockáztatok egy elméletet: (Persze lehet, hogy csak annyira fog bejönni, mint a double substrate, de így a fejemben egész kereken áll össze)
Láttuk már az AMD részéről, hogy képesek lehetnek akár több különböző design változatot elkészíteni, kipróbálni. Ha nem a szándékos félrevezetés, akkor ez magyarázhatja a GPU-k terén látható viszonylag nagy szórást mind a specifikációkra, mind a teljesítményre vonatkozóan is. Elképzelhető, hogy az AMD ma már CPU-ból is többféle verziót elkészít, kipróbál. Ez szintén magyarázná a nagy szórást arra nézve, hogy milyen előrelépés várható.
Megfigyeléseim szerint a gyártástechnológiai váltások teszik általában lehetővé azt, hogy komolyabb architekturális kigyúrások (nem átgondolás!) megvalósuljanak. Emiatt volt nem abszurd a Zen4-gyel kapcsolatos IPC-növekmény elvárás.
Azt is láttuk már, hogy az AMD képes CPU feature-öket előrehozni. Nyilván képes lehet elhalasztani is.Szóval mi van, ha az történt, hogy egyrészt a limitált N5 kapacitás miatt, valamint a késve érkező N3 miatt az AMD változtatásokat eszközölt a designban és az útitervben.
Mi van, ha tényleg létezett egy olyan Zen4 változat, ami komoly IPC emelkedést hozott volna. De végül az AMD úgy döntött, hogy az N5 kapacitás szűkössége miatt inkább többet dolgoznak a frekvencián és elengedik azokat az architekturális feature-öket, amik az IPC emelkedést eredményezték volna, de amiknek tranzisztorköltsége van. Így a Zen4 lapka valamivel (mondjuk 10%-kal) kisebb és így többet lehet belőle gyártani, amire a Genoa indulásakor amúgy is nagy szükség van. Az így kialakított Zen4 megkapja azokat az energiatakarékossági fejlesztéseket, amiket a Zen3+, meg persze az AVX512-t és az 1MB-os L2$-t - ami hol hasznos lesz, hol nem.
Ez eredeti Zen5 - új széles architektúra - tervek elhalasztódnak, mivel azok N3-ra készültek volna, ami viszont nem fog időben rendelkezésre állni.
A kettő közé az AMD betol egy N5-ön vagy N4-en végrehajtott architekturális ráncfelvarrást, ami megkapja mindazokat a fejlesztéseket, amik az "eredeti Zen4"-ben a most hiányzó IPC növekedést hozták. Ez ilyen 10-15% lehet, ami ha 1 évvel a Zen4 kiadását követően ki tudják hozni, egész jó generációs előrelépésnek fog hatni. És ez azt is magyarázná, hogy a Zen5 miképp lehet 2023-as termék annak ellenére, hogy az AMD architektúra váltásai között 1.5-2 év szokott eltelni. 2023-ban már talán bővebb lesz a rendelkezésre álló N5/N4 kapacitás, nem kell annyira spúrkodni a lapkamérettel.Hogy ez az elmélet mennyire lehet helytálló, abból derülhet majd ki, hogy a Zen4 után Zen5 néven érkező processzor családja továbbra is 19h vagy sem.
-
#7021
Petykemano
veterán
Petykemano
veterán
GFX1037 =? Mendocino
-
#7020
Petykemano
veterán
poci76
#7019
Petykemano
veterán
Hát nem állítom, hogy a téma szakértője vagyok.
De arra tudnék tippelni, hogy ahogy az L3$ méretének növekedéséből nem profitált semmit a Cinebench, úgy lehet, hogy önmagában az L2$ méretnövekedéséből sem.Van egy C&C cikk a zen2 vs skylake CB R15-ről
Itt a képeken az látszik, hogy a 256KB L2$-hez képest az 512KB hasznos. De lehet, hogy az 512KB feletti rész már nem nagyon ad hozzá.Feltéve persze, hogy minden más változatlan.
A Cypress Cove magok kb 21% ST CB score-t hoztak. Megemelték az L2$-t 512KB-ra de ott azért ezen kívül többminden más is változott [link]
A Golden Cove persze megint emelt az L2$ méretén, de ott is túl sokminden változott ahhoz, hogy a CB score változását hozzá lehessen kötni.De az is lehet, hogy akik korábban IPC számokkal dobálóztak, valójában csak teljesítményeket láttak, amit nem azonos frekvencia mellett mértek és csak feltételezték, hogy a frekvenciát mondjuk fel lehet tolni 8-10%-kal - a többi pedig IPC
De mondjuk mi van, ha ez a ~40% (vs 5950X) all core perf improvement úgy jön ki, hogy a az 5950X nemtom 3.8-4.0Ghz helyett a 5+GHz all-core boost-on ment ami a 170W TDP-be belefér. Akkor máris a frekvencia magyaráz a 40%-ból 25-30%-ot.(És ez még mindig nem feltétlenül zárja ki azt, hogy legyen egy Genoa vs Milan teszt, ami azonos frekvencián és magszám mellett hoz 29%-ot - mert érzékeny az L2$ méretére.)
-
#7018
Petykemano
veterán
poci76
#7003
Petykemano
veterán
Greymon helyesen feltette a kérdést:
A footnote szerint az AMD rendszer valami 204mp alatt, az intel rendszer pedig 297mp alatt végzett. Ez alapján számolták ki a 31%-ot, ami ugye azt jelenti, hogy 31%-kal kevesebb időre volt szüksége.De ha valaki egységnyi távot 206mp alatt, valaki más pedig 297mp alatt teljesít, akkor valójában az, aki az egységnyi távot 206mp alatt futotta le, 297 mp alatt (tehát egységnyi idő alatt) 46%-kal nagyobb távot tenne meg.
Tehát a Zen4 Multithreadben valójában nem 31%-kal, hanem 46%-kal volt gyorsabb.
A tesztek jellemzően valamilyen egységnyi idő alatt elvégzett munkamennyiséget jelenítenek meg egy szám formájában.
Valami , ami 50%-kal gyorsabb, az idő 33%-át takarítja meg.
Ami 100%-kal gyorsabb, az idő 50%-át takarítja meg.Vajon miért a kisebb számot jelentették meg? Ennyire figyelmesek lennének, hogy nem marketing-bullshit számokat tesznek fel a diára, hanem olyat, ami kézzel fogható, még ha kevésbé impozáns is?
A chips&cheese cikkéből:
"From IPC gains over 25%, a total performance gain of 40%, and even possibly (finally) 5GHz all-core thanks to the new (full node) N5 fabrication at TSMC! Now, I can’t say what is true and what is an over-exaggeration, however I was told from a trusted source that a Genoa engineering sample (Zen 4 server chip) was 29% faster than a Milan (Zen 3) chip with the same core config at the same clocks."40% IPC+freq total
Itt tegyük hozzá, hogy a 46% az 12900K-val szemben van, de az 5950X valójában egy pár százalékkal gyorsabb annál. Tehát ha a a C&C a zen3-hoz képesti számokat mondott, akkor a 40% eléggé pontos.A számok persze nyilván nem függetlenek attól, hogy milyen tesztet futtatsz.
-
#7017
Petykemano
veterán
S_x96x_S
#7016
-
#7014
Petykemano
veterán
hokuszpk
#7013
Petykemano
veterán
válasz
hokuszpk
#7013
üzenetére
"perpill jatekokban nemtunik annyira szelesnek az ollo Zen3 vs Alder viszonylatban, mint ami a CineBench pontszamokbol kovetkezne."
Ezt a területet fedi az 5800X3D.
A jóslatom szerint (persze tévedhetek) kicsivel a Raptor Lake megérkezése után a Zen4d (Multithread) és a Zen4-X (gaming) fedheti azokat a lukakat, amiket az üt. -
#7009
Petykemano
veterán
hokuszpk
#7007
Petykemano
veterán
válasz
hokuszpk
#7007
üzenetére
Nem vagyok biztos benne, hogy ez úgy működik, hogy ha magasabb csúcs-frekvenciát elér egy design, akkor ugyanakkora fogyasztás mellett közepes frekvenciaszinten is magasabbat elér.
De akkor is számolni kell azzal, hogy a magas frekvencia alacsonyabb tranzisztorsűrűséggel jár. Nagyobb lesz tőle a lapka, mint lehetne.Most mindenki azon gúnyolódik, vagy kesereg, hogy a Zen4 = Zen3+ @ N5 + AVX512
Ami egyébként nagyvonalakban igaz.
Vajon ha most nem a várakozások letörését, altatást láttunk, akkor mi állhat a háttérben?Induljunk ki a legrosszabb esetből: 10% frekvencia és 5-10% IPC növekedés. Ez még mindig nem annyira rossz abszolút értelemben. Viszont az N5 node-ra való váltástól, annak képességeitől és a zen3-hoz képest eltelt 2 évtől várt előrelépéshez képest marad el. Az intel ha jól emlékszem, azért évente hozta azt a 10-15%-ot a sandy-skylake korszakban.
Ráadásul abból az 5-10%-ból (worst case scenario) is valamennyit magyaráz a DDR5, valamennyit szintén magyarázazhat önmagában a N6-on gyártott IO lapka, ami esetleg magasabb FCLK-t jelent, alacsonyabb késleltetéseket.
Végülis nem zárható ki, hogy az AMD az erőforrásait ebben a körben a gyártástechnológiai váltásra, valamint a platformváltásra fókuszálta és az architektúra csak az AVX512-t kapta meg (és az L2$ duplázás csak ennek része volt, nem pedig valami IPC növelési irány), mint a zen3 továbbfejlesztése (meg esetleg a Zen3+ energiahatékonysági fejlesztéseit)
Ez a gondolkodás tulajdonképpen nem volna idegen az AMD-től. Hiszen a zen2 fókusza is hasonló volt: gyártástechnológia váltás, duplázott FPU. Eredeti tervek szerint a brand new/ground-up Zen3 architektúra nagyobb IPC növekdést hozott volna a Zen2-höz képest, de a Zen2 megkapott valami TAGE predictort, így tehát kiegyenlítettebb lett az IPC növekedés.
A zen3 volt tehát a brand-new/ground-up architektúra, aminek a célja kifejezetten az IPC növelés volt.
és most a Zen4 szintén dupla FPU, gyártástechnológia váltás. Ezúttal azonban nem valami IPC növelő fejlesztés jött be pluszként, hanem a Zen3+ energiahatékonysági fejlesztései.
(Nem mellesleg ugyanúgy magszámot is növel, mint a zen2, de csak a szerverek terén)Aztán majd jön a Zen5, ami megint brand-new/ground up IPC növelés céllal.
Tick-tock.
-
#7005
Petykemano
veterán
Petykemano
veterán
Engem meglep egy picit ez az extrém magas frekvencia. Egyrészt nem gondoltam volna, hogy az N5 ennyivel többre képes - tehát azt hittem, majd kb 5.2 lesz a teteje.
Másrészt azt se gondoltam volna, hogy az AMD IPC-re fog hajtani, nem frekvenciára. Ugyanis ha terveznek egy olyan architektúrát, amivel 5.5Ghz-et el tudnak érni, annak semmi hasznát nem veszik a szerverek terén.Ez a 15% szerintem sandbagging.
Az 5.5Ghz a 4.9-hez képest 10%-kal jobb. Nem tartom valószínűnek, hogy a 2x tranyósűrűséget kínáló gyártástechnológián 2x akkora L2$ mellett csak 5% IPC növekedést sikerült összedobni.Az intel így prezentálta az ADL előrelépését:

Jól látható, hogy a bal szélen vannak tesztek, amik alig néhány százalékos előrelépést mutatnak, vagy akár csökkenést is. Az AMD szerintem a bal szélét adta most meg egy ilyen grafikonnak.Csodára persze nem kell számítani. De egészen biztosan lesznek olyan szoftverek, tesztek, amik kifejezetten jól reagálnak majd az L2$ növekedésére, valamint az FPU duplázására (ezt most én csak feltételezem, hiszen elvileg 1 ciklus alatti AVX512 végrehajtás volt a cél, ami talán azt is megengedi, hogy 1 ciklus alatt kétszer annyi AVX2 utasítást is végre tudjon hajtani)
Szóval a lényeg, hogy biztosan lesznek a jobb szélen is szofverek vagy tesztek, amiknél 30-40-50%-os IPC növekedést is ki lehet majd mutatni.
Az átlag pedig végül lehet 15-20% körül. Az előzetes leakek/bemondások nagyjából ilyen értékekről szóltak.Most már csak az a kérdés, hogy miért akarná az AMD letekerni az elvárásokat?
De szerintem egy egyértelmű. Pár hónapja indították el az olcsósított Zen3-at: el akarják kerülni az osborne hatást.Persze lehet, hogy az AVX512 nem a játékos népnek szól, hanem a szervereknek és a munkaprogramoknak. De hát a játékos népnek ott az 5800X3D. A Zen4 primér targetje szerintem azok, akik máskülönben 5900X-et vagy 5950X-et, vagy ennek megfelelő Intel terméket vennének. Na nekik meg el is juttatták a megfelelő üzenetet a Blenderrel, hogy "hahó, ne vegyél Alder LAke-t, mert néhány hónap múlva +30%"
Mindenki másnak meg ott az 5800X3D.A most látott számokhoz képest az AMD még bármit változtathat.
Merthogy pre-production példány volt. Tehát bármelyik tesztről kiderülhet, hogy korlátozva volt a frekvencia, vagy le volt tiltva a cache fele, vagy nem használt valamilyen utasításkészletet, stb.
A szóbeszéd RPL-B1 steppingról szól, ami ha igaz, akkor lehetett valami komoly oka az újratervezésnek. -
#6998
Petykemano
veterán
S_x96x_S
#6997
Petykemano
veterán
válasz
S_x96x_S
#6997
üzenetére
Igen, teljesen igazad van.
Upto vagy átlagot.szoktak mondani. Mert jobban hangzik. Ez meg from/over. Tehát leggyengébb ST javulás is 15%. Ebből persze lehet, hogy 10%-ot a frekvencia magyaráz.
De hát láttuk, milyen szórása volt a v-cache-nek is. Biztos lesz, ami lényegesen jobban reagál az L2$-re.
Ezen kívül a zen4 célja az avx512 volt. FP végrehajtásban lehet,.hogy nagyon parádés lesz.Ezzel.együtt ahogy várható volt, elindult 15% keveslése.
-
#6996
Petykemano
veterán
Petykemano
veterán
Na megindult a csirip...
"If this tweet gets 1 like we will ... ah nevermind, Ryzen 7000 launches 'this fall' 🙃"
[link]"So Ryzen 7000 has two core chiplets 🤫"
[link]AMD Ryzen 7000 desktop series to offer over 15% single-thread uplift, launch this fall
(Hát az a 15% elmarad a várakozástól... de ez sandbaggingnek tűnik, ha csak ősszel rajtol)

Nincs double substrate.
Csak sok kondenzátor. -
#6989
Petykemano
veterán
Petykemano
veterán
Nem mai hír, de a Benchleaks szerint a Raphael B1-es steppinggel fog megjelenni:
Looks like Raphael got it's production model ID (the previous one was 96), probably stepping RPL-B1. AMD Eng Sample: 100-000000514-03_N AuthenticAMD Family 25 Model 97 Stepping 1 / A60F11
[link] -
#6987
Petykemano
veterán
Petykemano
veterán
"The VRM delivery for X670E/X670 looks insane.
X570 Taichi - 16 Phases
TR40 Taichi - 16 Phases
Z690 Taichi - 20 Phases
X670 Taichi - 26 Phases"
[link]
Ugh... -
#6986
Petykemano
veterán
S_x96x_S
#6985
Petykemano
veterán
válasz
S_x96x_S
#6985
üzenetére
Úgy tűnik AM5 bemutató az lesz.
Hát most akkor lehet tippelni, hogy vajon bejelentik a Raphaelt, mint nagy attrakciót az AM5-höz, vagy csak a Rembrandt-ot.
Szerintem a Rembrandt nem egy olyan nagy wasistdas, hogy érdemes legyen ráépíteni a bemutatót.
Tehát én arra számítok, hogy az AM5 elrajtol most. És elrajtol a Rembrandt is. És akkor van értelme piacra dobni.
De bejelentésre kerül a Raphael is, mint fő attrakció, ami viszont majd csak nyáron válik elérhetővé. -
#6982
Petykemano
veterán
S_x96x_S
#6981
Petykemano
veterán
válasz
S_x96x_S
#6981
üzenetére
Hát akkor legalább az AM5 Rembrandt-ot is be kéne jelenteni hozzá.
Bár Szerintem eléggé csalódást keltő lenne, ha a CES után a Computex is csak a Rembrandtról szólna. Ezért szerintem akkor be kell jelenteni a Zen4-et is. Teaser már volt a CES-en. Tehát legalább néhány SKU-t és teljesítményábrákat kell mutogatniuk, mégha a piaci rajt esetleg csak júliusban lesz is.
május 23. Vagyis 5 és 2+3=5. Mint 5nm.
Minden jel erre mutat. -
#6979
Petykemano
veterán
S_x96x_S
#6978
Petykemano
veterán
válasz
S_x96x_S
#6978
üzenetére
Ehhez a működéshez az applikációnak és/vagy az OS-nek tudnia kell, melyik mag melyik. Az Arm esetén a kis és nagy magok megkülönböztetése feltételezem már egy ideje adottságnak tekinthető.
Másrészt az általad bevágott szövegben kulcsfontosságú kifejezés az, hogy high-priority applications - tehát ezt is tudni kell. Nyilván erre vonatkozólag az Intel azon megközelítése, hogy ami az aktív user fókuszt kapja, az a high-priority - nem jó.Viszont szerintem van itt egy másik probléma is.
Az Arm és az Apple esetében is a kis magok létezésének célja tényleg az, hogy a háttérfolyamatokata lehető legkisebb energiabefektetés mellett elvigyék.
Ennek megfelelően nem is törekednek arra a designokban a kis magok számát szaporítsák.Az Intel esetén viszont a kis magok célja nem ez, hanem a MT teljesítmény növelése alacsonyabb energia és helyigény mellett. Az Alder Lake esetén egyébként ez a "high priority applications" megközelítés még nem szúrt volna szemet. De Mondjuk az már elég hülyén nézne ki, hogy ott van a Raptor Lake.ben 16 E mag, ami mondjuk egy blender renderelésben nem vesz részt.
Mondani nyilván könnyű, de szerintem valahogy úgy kéne kinéznie, hogy a background taszkok mindenképpen az E magra üzemeződnek.
A high-priority taszkok mindent is használhatnak, de affinitással rendelkeznek a nagy magokra. Ez azt jelenti, hogy alacsony szálszám esetén csak a nagy magon fut, nagy szálszám esetén terjed át az E magokra.
A user fókusszal rendelkező program pedig kitúrhat mindent és bármit a P magokról.Ennek egyébként a Zen5+Zen4D esetén is pont így kellene működnie.
-
#6977
Petykemano
veterán
S_x96x_S
#6976
Petykemano
veterán
válasz
S_x96x_S
#6976
üzenetére
> vagyis, hogy 2 -nél több chipetet tud-e kezelni a desktopos io-die
Ezt a kérdést kiküszöbli Zen4+Zen4D, ami 2023Q1-ben gyártható.
> Ami furcsa lesz nekem, hogy míg az AVX-512 támogatást az AMD kiemeli majd ...
AdoredTV utolsó videója szerint a Genoa és a Bergamo is támogatni fogja az AVX512 utasításokat, 256b-es Load/Store műveletekkel, de a tényleges művelet végrehajtás elvileg 512bites lesz.
Az AMD helyében én azt csinálnám, hogy a Zen4D esetén a műveletvégrehajtást is kettévágnám 256bites szeletekre. és akkor kisebb a mag, de az ISA támogatás ugyanaz.> Agner on Aldder Lake
AZ elején említi, hogy azért nehéz tájékozódnia a programnak vagy az operációs rendszernek, mnert a DRM miatt egységesíteni kellett a P és E magok CPUID-jét. Bármilyen hülyén hangzik is, de szerintem ez egy nem várt probléma az Intel részéről, amire csak egy rossz megoldást tudtak adni. Azt gondolom, hogy ha nem CPUID-vel, akkor valamilyen más módon megoldást fognak találni arra, hogy a magok megkülönböztethetők legyenek egymástól.Másrészről a Ryzen és szerintem az Intel cpu-k esetén is valahogy tudatható a rendszerrel, hogy melyik a legjobb és második legjobb mag. Az más kérdés, hogy ezzel aztán mi mit kezd, de nyilván ez a fajta megkülönböztetés szintén kiterjeszthető.
Harmadrészt sajnálatos, hogy Agner Fog irományában egy árva szó nem esik az Arm-ról. Pedig az ARM esetén évek óta létezik a külön clusterba szervezett kis és nagy magok megkülönböztetése, a klaszterezés első generációja a big.LITTLE volt, most tudtommal a DinamIQ néven fut. De még ha feltételezzük is azt, hogy ez annyira egyszerű, mint ahogy az Intel Thread Director csinálja, vagyis hogy a Foreground applikáció fut a nagymagos clusteren és minden más background folyamat a kismagos clusteren, amiről ugye Agner is azt mondja, hogy ez desktop környezetben nem jó megközelítés. Akkor is ma már a nagymagos clusterben is kétféle mag van: a Cortex X1/X2 típusú és a Cortex A78/A710. Ebben az esetben az Arm hogy csinálja? hogy különböztetik meg ezeket a magokat? Teljesen véletlenszerű lenne, hogy a nagymagos clusterben a programszálat az X_ vagy a A7_ típusú mag kezeli?
-
#6975
Petykemano
veterán
poci76
#6973
Petykemano
veterán
Gondolkodtam.
Ismerve az AMD jelenlegi hozzáállását és rendelkezésére álló kapacitásait szerintem a következő fog történni:
A zen4 előbb jön (Q3), mint a Raptor Lake (Q4), ezért nagy biztonsággal pakolhatja ki az AMD a szokásos felhozatalt akár a kurrens zen3 fölé:
Ryzen 9 7950X - 16c: ~$800-900
Ryzen 9 7900X - 12c: ~$550-600
Ryzen 7 7800X - 8c: $400-450
Ryzen 5 7600X - 6c: $300-350
A magasabb árat lehet indokolni a komoly ST teljesítmény növekedéssel - ami persze tulajdonképpen a mérésekben csak beéri a legerősebb Alder LAke-t, de már csupán 30%-os ST teljesítménynövekedéssel élre ugrik a 7950X megelőzve a brutális fogyasztással hajtott 12900KS-t. Másrészt pedig az IGP-vel.
A valóságban persze az árakat inkább a kapacitás korlátokhoz igazítják.Aztán megérkezik a Raptor Lake Q4-ben. Potenciálisan visszaveszi a ST elsőséget és szerintem még akkor is esélyes a MT korona elvételére, ha az AMD kitolna egy all-core 5Ghz-es 16 magos procit. (Most én itt részletes számolásokba nem mentem bele, csak nagyvonalakban vázolom az elképzeléseimet)
AdoredTV leakjei alapján tudjuk, hogy a Bergamo és a GenoaX 2023Q1-ben rajtol. TEhát Q4-ben már gyártani kell a 16 magos Zen4c/Zen4D lapkákat és a 3D tokozást is.
(Nem biztos, hogy a Zen4 esetén ugyanazt a megoldást fogják látni, hogy rátesznek a tetejére egy szint L3$ kiterjesztést. Hiszen láthattuk, hogy ennek pozitív hatása azért eléggé korlátozott néhány professzionális alkalmazásra és a játékokra, tehát érdemes lehet gondolkodni valamilyen megoldáson, hogy más területen is hasznosítható legyenEz azt jelenti, hogy legkésőbb Q1-ben az AMD meg tud jelentetni a Raptor Lake ellen egy olyan terméket, ami a pletykáltaknak megfelelően 24 magos és
- egyrészről egy 8 magos Zen4 lapkából áll. Ezt lehet cizelllálni egy 3D tokozott L3$-sel a Single/low-thread / Gaming teljesítmény maximalizálására
- másrészről egy 16 magos bergamo Zen4c/Zen4d lapkából a MultiThread teljesítmény maximalizálására.Ennek a megközelítésnek az előnye az, hogy nem kell azon gondolkodni, hogy vajon a szubsztráton elfér-e 3CCD és hogy az IOD ki tud-e szoglálni 3 CCD-t. Mert úgy lesz a végén 24 mag, hogy csak 2 CCD van. Mégis a lehetőségekhez képest a ST és a MT is ki van maxolva.
Hátránya persze az, hogy ez egy heterogén architektúra. Legalábbis valamivel heterogénebb, mint az eddigi 2CCD-s modellek. De azért azt ne felejtsük el, hogy egy 2 CCD-s sku esetén a szálkezelőnek eddig is tisztában kellett lennie hogy melyik CCD-n vannak a magasabb frekvenciát elérni képes magok. Persze egy tévedés ebben az esetben legfeljebb 5-10%-os teljesítménykülönbségben, vagy ingadozásban nyilvánult meg. a 3D tokozott L3$-sel rendelkező fullos Zen4 magok és az alacsonyabb órajelre optimalizált Zen4c magok között ennél nyilván lényegesen nagyobb különbség is mutatkozhat.
Amennyiben ezt el akarja kerülni az AMD, akkor a 24 mag összejöhet úgy is, hogy vágott Zen4c magokat tesz a CCD-re. De ebben az esetben a Zen4c CCD gyártását nem tudja olyan mértékben sűrűségre optimalizálni, mert ha ennek kell kiszolgálnia a single/low thread igényeket is, akkor nem engedheti meg magának, hogy csak alacsony órajeleket érjen el. -
#6974
Petykemano
veterán
Petykemano
veterán
Mesa 22.1:
"AMD GFX1036 / GFX1037 support. "
(Raphael IGP) -
#6972
Petykemano
veterán
Petykemano
veterán
Napvilágot láttak a Raptor Lake cache számai.
Itt is az L2$ növekszik, mint a zen4 esetén.
P: 1.25MB => 2MB
E: 2MB => 4 MBMár az Alder Lake esetén felmerült, hogy a $300-os 6+4 magos i5 tulajdonképpen eléggé versenyképes az akkor még jóval drágább 8 magos 5800X-szel. Egyesek szerint a 6P + 8e magos - i5 13600K néven és szegmensben várható - Raptor Lake már nagy valószínűséggel gyorsabb ia lesz, mint a 8 magos Raphael. De minimum legalább ugyanannyira versenyképes. [link]
Bár az AMD árait elsősorban nem a desktop piaci verseny, hanem az ide maradó kapacitás szokta meghatározni, de azért marketing szempontból blama lenne épphogy versenyképes terméket érezhetően drágábban megjelentetni.
Arról már volt szó, hogy a 8P+16E magos Raptor lake ellen lehet, hogy nem lesz elég a 16 magos Raphael. Versenyképes - főleg fogyasztásban - éppenséggel lehet, de az Végülis egy presztízskérdés lehet, hogy átengedi- e az AMD a koronát. Ez indokolhatja a 24 magos sku létét.
Feltételezvén, hogy az Intel tartja a szegmensek árazását, az alsóbb szegmens is nyomás alá kerülhet. Nem biztos, hogy egy $300-os 13600K mellett el.lehet adni új platformban $400-500-ért egy 8 magos Raphaelt.
Eddig nem tartottam valószínűnek, de most lehetségesnek tűnik, hogy a versenyhelyzet tényleg arra késztethezi az AMD-t, hogy fölülre betoljon egy 24 magos SKU-t, ami mindent eggyel letol.
Vagyis vagy a Ryzen 5 7600X lehet egy 8 magos oéldány $300-ért, vagy az 5700X utódaként jön a szintén 8 magos Ryzen 7 7700X, de az is $300-ért.
(Mármint persze az árak attól függnek, hogy a 13600K milyen áron jön. Tehát pl a $350 nyitóár sem zárható ki ) -
#6962
Petykemano
veterán
hokuszpk
#6961
-
#6959
Petykemano
veterán
Petykemano
veterán

-
#6956
Petykemano
veterán
Petykemano
veterán
/Genoa/
- SDCI (Smart Data Cache Injection) Accelerator
- SDXI (Smart Data Acceleration Interface) Accelearator
[link]Más részletek is érdekesek a Dragon Range-ről, Phoenixről, Storm Peak-ről, Bergamoról.
Zen5-ről, TurinrólElég feszes rajt dátumokat jelöl meg - legalábbis 2023-ra nézve.
2023 elején kéne megjelennie a Dragon Range-nek, a Phoenixnek és a Storm Peak-nek is.
Ez talán annyira nem meglelő. Addigra talán az Apple átvonul az N3 node-ra és felszabadul az N5 kapacitás.
De a Bergamo is 2023 során jelenik meg.A Zen5 valószínűleg nem N3, hanem N4P gyártástechnológián készül majd. a 256c/512t sűrűségű Zen5-re épülő Turin szintén 2023 végén kerülne piacra. (valószínűleg sampling to selected customers)
Ha ez igaz, akkor nagyjából ezzel egyidőben tehát 2023 végén, 2024 elején meg kéne jelennie a desktop változatnak is.A jövőben az AMD termékei, amennyiben képes technológiai fölényt szerezni és megtartani, az árak el fognak szállni, mert az AMD a szűkös kapacitásait mindig igyekezni fog a legmagasabb árszegmensben pénzre váltani.
Én azért reménykedem, hogy az alacsonyabb árszegmensekbe majd lecsorog valami, olcsóbb gyártástechnológián készülve.
-
#6953
Petykemano
veterán
Petykemano
veterán
/Zen4 - nem biztos információ/
Megjelent kép egy táblázatról, amelyben a 7950X-et 24/48 magos/szálas prociként említik. Olyan $1000-os áron.
[link] [link]Ennek létezése nem zárható ki.
Ha az AMD tartja magát az IOD felépítésének eddig gyakorlatához, akkor ugye felmerülhetett a kérdés, hogy kvázi 6 db IO lapka van-e összepakolva, amelyben egyenként 2-2 DDR5 csatorna és IFOP van-e, vagy 4db olyan, amiben 3-3?
A kérdést - hogy ezúttal is ugyanazt a megközelítést alkalmazzák-e - persze árnyalja, hogy és akkor a Genoa IO lapkájában van 4/6db olyan IGP, mint a Raphaelben? Vagy akkor az IGP már eleve (3D) tokozva kerülne rá?Egy ilyen termék némileg magyarázná azt is, hová tűntek a HEDT Threadripperek. (nem a PRO) És magyarázná a 170W-os TDP-t is persze.
Szerintem elég kemény lenne. Mármint ebben a kategóriában az AMD eddig is királynak számított. Igaz, hogy a csutkára húzott Alder Lake megszorongatta az 5950X-et. De azért én nem gondolnám, hogy a Raptor lake-be bekerülő +8 E mag annyival megdobná a MT score-t. Kivéve persze ha az E magokon sokat reszeltek és mondjuk átlag feletti IPC emelkedést hoz.
-
#6952
Petykemano
veterán
Petykemano
veterán
"RPL has been produced in small quantities.
PHX is about to begin testing.
Navi3 expects to begin package testing next month."
[link]
Nem tudom, hogy ez melyik termék esetén mennyi időt jelent a rajtig.
De a kis mennyiségben gyártott Raphael alkalmas lehet arra, hogy a Computexen bemutassák. -
#6951
Petykemano
veterán
Petykemano
veterán
-
#6950
Petykemano
veterán
Petykemano
veterán
A RedGamingTech szerint a csúszó és a Intel/Apple által lefoglalt N3 helyett a Zen5 (és az RDNA4) egy custom N4 gyártástechnológán fog érkezni. (N4X - valószínűleg nagyjából ugyanaz, mint amin az nvidia kártyák) [link]
Nem tartom ördögtől valónak a dolgot. A 3D cache hozzáadásával is sikerült - ha nem is általánosságban, de néhány célterületen - igen komoly, generációs előrelépést felmutatni.
Tehát lehet, hogy a Zen5 emiatt esetleg még nem az a Zen5 lesz, amit Zen5.ként vártunk (széles architektúra, nagy L1$) hanem a Zen3-ban debütált, zen4-ben fejlesztett architektúra egy újabb iterációja.
Inteles módon, a bufferek, cache-ek növelésével lehet itt-ott 1-2 százalékot nyerni és ezt az N5=>N4X félgenerációs váltás esetleg meg is engedi.
Mindenesetre amit mondani akarok az az, hogy ha se a node, se az architektúra nem leszegy fullos váltás, a Zen3D példája azt mutatja, hogy attól függetlenül nagyonis lehet akár a packaging vonalon olyan fejlesztést csinálni, ami egy generációváltásnak megfelel.Egyébiránt teszem hozzá a legutóbbi elmélkedésem azt vázoltam, hogy szerintem a Zen5 legfőbb változtatásai teljes mértékben 3D tokozott L3$ és az L2$ szeletek egyesítése. Ehhez lehet, hogy elég az N4X is.
-
#6949
Petykemano
veterán
Petykemano
veterán
Illetve van itt még egy kis finomság a szerverek oldaláról is:
[link]
PEGATRON Lightning
AMD Eng Sample: 100-000000866-01
CPUID: A10F01 (AuthenticAMD)1MB L2 => Zen4
Microsoft Windows Server 2022 Datacenter (64-bit) => Genoa
Elvileg 1.2Ghz-en hoz 464 pontot GB5-ben. Ami a Megosztó szerint 73.1%-kal alacsonyabb, mint az 5800X. Ez az eredmény egyébként annyira nem tűnik acélosnak. Mármint: nem árulkodó, nem lehet belőle semmit kiolvasni. -
#6948
Petykemano
veterán
Petykemano
veterán
Van itt egy új benchmark
Kicsit fura, nem vagyok meggyőződve arról, hogy autentikus és ellenőrizni sincs módom.AMD Eng Sample 100-000000666-20_Y @ 5.21GHz (8 Cores / 16 Threads)
AMD Splinter-RPL (WS22427N BIOS)
AMD GFX1036
AMD Rembrandt Radeon HD Audioaz RPL arra utal, mintha Raphael lenne. A GFX1036 nem tudom milyen designhoz tartozik, csak azt, hogy RDNA2
Viszont az Audio résznél meg Rembrandt-ot ír. De ez lehet amiatt is, hogy megegyezik és a driver így ismeri fel.A 100-000000665-21_N kódnevet korábban valóban Raphaelként azonosították [link]
A Splinter-RPL platform kifejezésre nincs sok találat sem a google-ben, sem a Geekbench keresőjében
A GFX1036-hez március elsején érkezett driver bejegyzés.A GFX1036 és GFX1037 új, eddig meg nem jelent azonosítók.
gfx1030 RDNA 2 Sienna Cichlid/Navi21gfx1031 RDNA 2 Navy Flounder/Navi22gfx1032 RDNA 2 Dimgrey Cavefish/Navi23gfx1033 RDNA 2 VanGogh (APU)gfx1034 RDNA 2 Beige Goby/Navi24gfx1035 RDNA 2 Yellow Carp/Rembrandt (APU)Ha feltételezzük, hogy a GFX1036 a Raphael IGP-je, akkor vajon mi lehet a GFX1037?
(Dragon Range?) -
#6947
Petykemano
veterán
Petykemano
veterán
Viszont ha már itt tartunk a tévedésemet felhasználva had kérdezzek:

A graviton3 esetén az IO lapkák 55micronos microbump-on keresztül csatlakoznak.Vajon az AMD miért nem csinált - legalábbis eddig- ilyet?
Úgy rémlik, mintha a 3D hybrid bond kapcsán emlegették volna, hogy az ő 3D megoldásuk mennyivel sűrűbb, de ilyet meg még nem is haszáltak.
Ez is annyira új lenne? Vagy vajon annyira nincs különbség eközött és a szubsztráton átvezetett IF között teljesítmény/fogyasztás tekintetében?Mármint hogy persze azt értem, hogy ebben a megoldásban nincs SerDes, míg az IF esetén van és ebben az értelemben talán univerzálisabb csatoló. Jól értem?
-
#6946
Petykemano
veterán
S_x96x_S
#6940
Petykemano
veterán
válasz
S_x96x_S
#6940
üzenetére
> és inkább feltételezem, hogy a "Dragon Range" már RDNA3 -as lesz.
Nekem ez most állt össze:
A jelenlegi infómorzsák szerint lesz egy GFX1103 kódszámú RDNA3, ami egy APU [link]Ha a Dragon Range egy a Phonenix-hez hasonló - feltételezve, hogy az egy monolitikus APU - , csak minden szempontból nagyobb, akkor saját kódnevet kellett volna (vagy kellene a későbbiekben), hogy kapjon.
Persze ez nem szünteti meg az összes bizonytalanságot.
Mert azon kívül, amit én mondtam, elméletileg még mindig lehetséges, hogy a Phoenix és a Dragon Range is chiplet alapú APU, ahol az általuk használt IGP rész megegyezik, csak a a CPU más. Viszont ez ellentmond annak az állításnak, miszerint a legalacsonyabb fogyasztású szegmensekbe csak monolitikus felépítésű chip használható.
Vagy még az lehet, hogy egy teljes értékű Phoenis lapkához hozzá lehet kapcsolni még egy zen4 CCD-t.Mindenesetre egyelőre úgy tűnik, hogy a Phoenix-től eltérő másik/nagyobb - monolitikus- RDNA3 APU nincs.
-
#6945
Petykemano
veterán
Devid_81
#6944
-
#6943
Petykemano
veterán
Petykemano
veterán
-
#6939
Petykemano
veterán
S_x96x_S
#6938
Petykemano
veterán
válasz
S_x96x_S
#6938
üzenetére
> induláskor a Raphael -ben mintha még csak egy pici RDNA2-es lenne,
Igen.
> és csak a ~félévvel később érkező "Dragon Range" -re irnak RDNA3-at.Elnézést, lehet, hogy elkerülte a figyelmem.
Arra emlékszem, hogy az ábrán nem szerepel, hogy milyen grafikával érkezik - ezt Ian Cutress a tweetjében ki is emeli: "Process node not mentioned. Graphics not mentioned."Mivel nem találkoztam azzal, hogy a Dragon Range RDNA3 lenne, ezért legalábbis ez alapján nem kizárható, hogy a Dragon Range valójában Raphael-H(X) (tehát chipletes cucc)
Mondom, tehát lehet, hogy elkerülte a figyelmem, ezért kérdezem: honnan jött az az infó, hogy a Dragon Range RDNA3 lenne (és a cpu pedig új zen4 stepping)?
Természetesen ha Abu-nak van igaza és ez inkább egy a Phonenix-hez hasonló annak felturbózott változata, akkor lehet RDNA3. -
#6937
Petykemano
veterán
Petykemano
veterán
bájdövéj arról meg is feledkeztünk, hogy hol meddig tartanak a csíkok.A Raphael 2022 harmadik harmadától indul. Ez azt jelenti, hogy valóban szeptemberben várható a rajt.
Bár az kétségtelenül elég zavaró, hogy eltérő szélességűek az évek.
Elképzelhető, hogy a 2022-es oszlop szélessége az évből hátralevő részt jelenti. A pixelekből számolva kijön, hogy eltelt az év egyharmada és a slide készültekor (május 3) még az év kétharmada van hátra és ezért a 2023-as oszlop másfélszer szélesebb, mint a 2022.
Ha így nézzük, akkor a hátralevő 8 hónap kb kétharmadának kell eltelnie még, míg rajtol a Raphael. Ami inkább október közepe - november eleje rajtot sejtet.A másik kettő 2023 elejétől legalább 2023 végéig ér.
Ez azt is jelentheti - amennyiben nem csak titkolózási céllal húzták ki a Raphael csík 2023 végéig -, hogy 2023-ban nem jön Zen5.
-
#6936
Petykemano
veterán
Petykemano
#6934
Petykemano
veterán
válasz
Petykemano
#6934
üzenetére
Abu szerint külön lapka:
"Az AMD a Dragon Range-et kifejezetten a játékosoknak szánja, és úgy harangozta be, hogy a mobil piacra szánt processzorok tekintetében az eddigi legtöbb mag, szál és gyorsítótár kerül bele. Úgy tudni, hogy a Dragon Range és a Phoenix által használt lapka eltérő, de az építőkövei valószínűleg megegyeznek, csak előbbiben minden fontosabb részegységből több van."
[link] -
#6935
Petykemano
veterán
S_x96x_S
#6933
Petykemano
veterán
válasz
S_x96x_S
#6933
üzenetére
> viszont ha lesz 16 core ( a Dragon Range -ben )
> .. annak már kell 55W+
> .. és pariban lehet az 5950x -el.
Igen, ehhez nem kell más, mint hogy olyan chipletet használjanak, mint az epyc-hez: alacsony fogyasztásút. notebook termék lévén az se feltétlenül baj, ha a boost órajel esetleg 400Mhz-cel alacsonyabb, mint a desktop termék esetén. Másként megfogalmazva, ami egy 65W-os 7950 lehet, mert olyan lapkákból áll, az elmegy 7950HX-ként is 55W-ból. Cserébe ha van V-cache, akkor még arról se kell lemondani mobil környezetben. Talán erre utalt Abu, amikor azt pedzegette, hogy igen, az 5800X3D is tudna menni 35W-ból, de ebből ilyen termék már nem lesz.
Én azt remélem, hogy a kupak alá besúvasztanak az egyik CCD helyére egy RDNA3 chipletet is. Talán annak úgy már lenne megfelelő méretű piaca. Mármint a double subrstrate setup-pal: ami nem megy el FP7-be, azt kiszórják AM5-be. A v-cache (IFC) segítene, hogy a DDR5 sávszél elég legyen egy nagyobb teljesítményre is.
170W TDP meg azért elég sok.
/csuri/ -
#6934
Petykemano
veterán
S_x96x_S
#6933
Petykemano
veterán
válasz
S_x96x_S
#6933
üzenetére
> valami hasonló ..
> ~ új zen4-es stepping + RDNA3Ezt nem értem. Ha a Dragon Range-re írtad, akkor szerintem a Dragon Range mobil tokozású Raphael. Ahogy a Rembrandt meg fog érkezni AM5 tokozásba, úgy a Raphael is a mobilba. (FP7?)
És ezt az teszi lehetővé, hogy (feltehetőleg) az IOD-ban lesz IGP. Ez alkalmassá teszi high-end notebook eszközbe
- olyanba is, ahol a cpu erő számít és nincs is benne dGPU. Ezt a területet A Cézanne és Rembrandt igazából csak alulról kapargatja.
- és olyanba is, amiben nagyonis van dgPU, amit egyrészt ki kell hajtani, másrészt pedig nem kell megkötni üzemidőben azt a kompromisszumot, hogy a játékon kívüli képet is a dGPU adja és szívja az aksit.Emlékszel még arra a kérdésre, hogy miért olyan "egzotikus kialakítású" az AM4 kupakja?
Akkor a - szerintem - legközelebbi tipp az volt, hogy dupla tokozás van a kupak alatt.
double substrate setup~kb így:

Szerintem ez az AM5-ös kupak alatt egy FP7-es szubsztrát van így jön létre ez a két termék egyféle kialakításból. Amit nem tudnak FP7 tokozással eladni, az megy az AM5 szemétledobóba.
-
#6921
Petykemano
veterán
S_x96x_S
#6919
Petykemano
veterán
válasz
S_x96x_S
#6919
üzenetére
A Nuvia ígérete 40-50%-kal magasabb ST teljesítmény volt 33%-os energiafelhasználás mellett.
Az Apple M1 szerintem ebből csak egyszerre egyet teljesít. Tehát vagy harmadakkora fogyasztás mellett hoz ugyanakkora teljesítményt, egyébként meg amennyivel nagyobb IPC-vel rendelkezik, aménnyivel magasabb frekvenciákat elérnek az X86 procik.
Szóval a zen2-höz képest már a zen3 is hozott 15%-ot. Ehhez képest még idén hoz 20-25%-ot a zen4.
Ezzel a 40-50% ST többlet már nem is előny. A fogyasztás persze kérdés.Viszont 2023 végére várjuk a zen5-öt is. Ami jelen ismereteink szerint széles architektúra, nagy L1-L2 cache segítségével +30% IPC és N3 gyártásttechnológia. Ennek fényében az eredeti Nuvia ígéret már egészen konzervatívnak tűnik.
Az még kérdés, hogy idén milyen tervet.virít az arm, akiből jövőre termék lehet.
Az Apple egyértelmű előnyben van. De ennek egy része azért abból fakad, hogy mindénkinél előbb használják a fejlettebb gyártástechnológiát. Amíg ez megmarad, mindig nagy lesz a távolság teljesítményben vagy fogyasztásban. -
#6918
Petykemano
veterán
Petykemano
veterán
/EUV vs DUV/
Nincs különösebben köze az AMD-hez, de nagyon informatív videó: [link]
Mivel tudjuk, hogy az EUV használatában a TSMC élen jár, ez megmagyarázza, hogy miért küszködik a gyártástechnológával az Intel és a Samsung is, és miért dobta el a 7nm-t a GF.
És azt is megmagyarázza, hogy a sok EUV layert használó N5 (és N6) gyártástechnológiák miért hozhatnak kiváló eredményt még az N7-hez képest is. -
#6915
Petykemano
veterán
S_x96x_S
#6912
Petykemano
veterán
válasz
S_x96x_S
#6912
üzenetére
> AM5-re portolni fogják a mostani Ryzen6000-res APU-t,
> csak más tokozás kell neki,
Ez egész biztosan meg fog történni. Ezzel mindenki kalkulál, még Abu is megírta: [link]
A Rembrandt (zen3+@N6) összképét viszont egyfelől rontja a Vermeer-hez képest feleakkora cache (Tehát a frekvencia előny épphogy pariba hozza a Vermeer-rel)
másrészt az AM5 a DDR5 miatt magasabb platform költséggel jár.Amikor én azt mondtam, hogy kihozhatnak egy Zen3-at N6-on, akkor azt a platformköltség figyelembevételével az AM4-hez gondoltam. Egyszerűen azért, mert ha jól tudom, még a Raptor lake sem fog szakítani a DDR4 támogatásával, tehát a alsóbb szegmensek dömpingáras (+alasonyabb platformköltség) intel termékei ellen nem lesz hatásos fegyver, ha az AMD a Rembrandtot kínálja. Persze ez mind azon a feltételezésen alapul, hogy a DDR5 árak a következő negyedévekben még mindig jelentősen meg fogják haladni a DDR4 árakat (Abu erre hivatkozik, hogy miért csak ősszel jelenik meg az AM5 és a Rembrandt)
> És az is lehet, hogy tesznek a zen3+ -os APU-ra egy 3D VCACHE-t,
Ez sokat segítene a játékos felhasználók számára.> Ha nagyon szorítja az Intel az AMD-t,
> akkor a ZEN3(+)-os chipletekből egy új io-die -al
> tud olcsó 12 -16 magos AM5-ös procikat is csinálni.Technikailag ez sem kizárt. De én épp abból indultam ki, hogy a DDR5 magas ára miatt lenne praktikus a olcsóbb szegmenseket még 1 esetleg 2 évig AM4-gyel lefedni és azt a kérdést feszegettem, hogy a már minden szempontból olcsónak számító AM4 foglalatba illő processzorok versenyképességét miképp tudná erre az 1-2 évre még természetesen minimális befektetéssel (!) növelni az AMD. Nemrég egy interjúban Lisa Su is azt mondta, hogy az AM4 még velünk marad 1-2 évig.
Bocsánat, tehát nem egy, hanem két szempontot vettem figyelembe:
- szűkös N5 kapacitás
- drágább DDR5 ramok.Amennyiben csak a szűkös N5 kapacitás áll fenn, akkor igazad lehet, hogy megoldható az alsóbb szegmens lefedése AM5 Rembrandt APU-kal is.
-
#6911
Petykemano
veterán
S_x96x_S
#6910
Petykemano
veterán
válasz
S_x96x_S
#6910
üzenetére
> de azért az Intel dömping-áraival is számolni kell,
> vagyis túl nagyon nem szállhatnak el az árakkal.Én azt gondolom, hogy az AMD első körben legfeljebb ugyanazokat az sku-kat fogja megjeleníteni, mint a zen3 esetén volt. Megkockáztatom, hogy talán még 6 magos se lesz.
Nem biztos, hogy igazam lesz, tévedhetek, de ha az Intel még sokat szerencsétlenkedik a Sapphire rapids-zal, akkor a Genora-ra (épp az általad említettek miatt: +25% IPC ; 5Ghz ; AVX512, a gyorsabb DDR5 memória és a Gen5) még a Milan-nál is nagyobb igény lehet. Tehát szerintem a kapacitás nagyon szűk lesz. Persze az is igaz, hogy elvileg ezúttal az AMD a saját szempontjából cutting-edge gyártástechnológián csak zen4-et és Navi3X-at gyártat (abból is csak a felső osztályt) tehát nem lesz konzol, ami limitálja.Mindenesetre amit mondani akartam, hogy hát ha és amennyiben tényleg szűkös az AMD N5 gyártókapacitása, akkor ezzel (intel dömping ár) nem nagyon fog tudni mit kezdeni egy ideig Zen4 alapon. A zen3-at tudja olcsón kínálni, vagy Zen3D-t tud bevetni, de nekem azért úgy tűnt, hogy ahhoz, hogy a zen3D-nek legyen érezhető hatása, kell valami $700-1000-os gpu is.
Vagy hát azzal lehet még erőlködni, amit Abu írt az 5800X3D-hez, hogy tulajdonképpen a B2 stepping nem csak gyárthatósági szempontokat javított, hanem az AMD áttervezte a lapkát úgy, hogy jelentősen csökkenjen a fogyasztás (vagy legalalábbis az adott frekvenciához szükséges feszültség) Gondolom, hogy ezek ugyanazok az energiahatékonysági fejlesztések, amiket a Rembrandt is megkapott. Erre lehet akár új sku-t kihozni. (Bár Abu azt írta, hogy ilyen nem fog történni)
Vagy amit még lehet az az, hogy kihoznak egy zen3-at N6-on - gyakorlatilag ami a Rembrandt CPU része. Az lehet, hogy elmenne akár 5.2Ghz-ig is. Azért az is lenne 7-8% egy 5800X-hez képest.Ha van elegendő N5 kapacitás, akkor ez persze fölösleges szerencsétlenkedés volna.
-
#6909
Petykemano
veterán
S_x96x_S
#6907
Petykemano
veterán
válasz
S_x96x_S
#6907
üzenetére
Kiemelném:
Az Apacer táblázata szerint a Zen4 desktop 2022 H2-ben rajtol. (Egyébként a Genoa-val együtt)
Ebből persze még nem derül ki, hogy Q3 vagy Q4 - jelenthet akár egy szeptemberi rajtot vagy egy decemberi elérhetőséget is.
Egyrészt a pletykák szerint előbb fog érkezni, mint a Raptor lake, ami inkább Q3-as rajtot sejtet, ezen kívül az RDNA3 tapeout dátumok pedig azt sejtetik, hogy Q4-et inkább az fogja betölteni. Én egy olyan Q3-as rajtot valószínűsítenék (mint a Zen3 esetén is volt), amivel elviszik lehengerlik a benchmarkokat, de a termékeket a korábbiaknál drágábban jelentik be, amivel egyrészről magas árrést söpörnek be, másrészt elfedik, hogy a Genoa-ra szánt kapacitások miatt amúgy se tudnának nagyobb piacot lefedni. Aztán Q4-ben jön a raptor lake, ami nagyjából ugyanazt az utat fogja bejárni a piacon, mint az ADL. -
#6900
Petykemano
veterán
S_x96x_S
#6899
Petykemano
veterán
válasz
S_x96x_S
#6899
üzenetére
Az eddigi ismereteink alapján a dual-chipset csak IO kapacitást ad hozzá.
Vagy az van, hogy az AMD opcionális bővítőkártyák újabb típusával kívánja lefedni a piacot a Xilinx segítségével
Vagy a CXL által ígért szintén bővítőkártyás forradalomra készíti fel a platformot. Itt egy 4x pcie5-re rá lehet már kötni valami RAM bővítményt.
Így vagy úgy, azt hiszem, a Threadripper (nem feltétlenül mint név, hanem a piaci igény, amit az lefedett) az x670-ben él majd tovább. -
#6897
Petykemano
veterán
Petykemano
#6896
Petykemano
veterán
válasz
Petykemano
#6896
üzenetére
Azóta már tisztázták, hogy nem nem lesz Zen4+DDR4
5800X3D Linuxos szemmel: [link]
-
#6896
Petykemano
veterán
S_x96x_S
#6893
Petykemano
veterán
válasz
S_x96x_S
#6893
üzenetére
További érdekesség, hogy a cikkben lamentálnak azon, hogy vajon az AMD az A620-as alaplapokat DDR4-gyel tervezi-e. Ez persze nem biztos, tehát csak mint lehetséges opció merül föl azon cél érdekében, hogy az olcsóbb platform RAM szempontjából is kellően olcsó tudjon lenni.
De ezt vajon hogy oldanák meg? az IO lapka eleve rendelkezne DDR4 támogatással? Vagy az olcsóbb Zen4 termékek kapnának csak DDR4 támogatást? Vagy valamilyen átalakítóval? (ami költség) Igazából csak azért említetem, fel, mert ha már valamilyen módon az A620-as alaplapokkal előállna az, hogy DDR4-es Zen4, akkor ugyanazzal a lendülettel AM4-be is lehetne nyomni.
Ez persze nyilvánvalóan nem fog megtörténni - persze nem valamiféle kompatibilitás miatt, hanem mert szerintem kapacitás okokból az AMD-nek nem lesz célja olcsó Zen4 platformot kínálni. -
#6894
Petykemano
veterán
S_x96x_S
#6893
Petykemano
veterán
válasz
S_x96x_S
#6893
üzenetére
Én úgy értelmeztem, hogy nem a B650 alaplap képessége x8 Pcie4, hanem a chipseté kifelé. Tehát szerintem a videokártya nem lesz mindenképpen x8 Pcie-re korlátozva.
Viszont számomra némi magyarázatra szorul hogy a proci és a chipset között 4x Pcie4 van, de a chipset kifelé 8x-at tud. Ez azt jelenti, hogy mondjuk a chipsetre kötött usb-USB vagy USB-m.2 eszközök közötti adatforgalom nem terheli a procit? -
#6891
Petykemano
veterán
Petykemano
veterán
/Raphael-X, Milan-X/
"n a few months the factory will decide whether Genoa/Raphael 3D will add production lines. In short, the technology is gradually maturing."
[link] -
#6890
Petykemano
veterán
Petykemano
veterán
@S_x96x_S
-
#6889
Petykemano
veterán
Petykemano
veterán
Genoa kémfotó
AMD 4th Gen EPYC - Genoa
(Board)
【The CPU slot is extremely large!】 https://t.co/XBjxtZsnOU -
#6888
Petykemano
veterán
Petykemano
veterán
1.2.0.7 - MSI - hamarosan
[link] -
#6886
Petykemano
veterán
S_x96x_S
#6884
Petykemano
veterán
válasz
S_x96x_S
#6884
üzenetére
A Phoenix vajon chiplet alapú, vagy monolitikus?
Előbbi megmagyarázná, hogy miért nem biztos, hogy RDNA2 vagy RDNA3 és hogy 16 v 24 CU -t tartalmaz. Lényegesen leegyszerűsítené ezeket a kérdéseket. (másokat meg esetleg felvetne)
Bizonyos szempontból egészen egyszerű és logikus lenne, ha a Raphael és a Phoenix ugyanazt a CCD-t használná, csak előbbi egy szerény méretű IOD-dal (kicsi IGP) rendelkezne, utóbbi viszont egy nagyobb IGP-vel és persze IFC-velAz APUk esetén megszokott és fogyasztási szempontból indokoltabb monolitikus design esetén megint nehéz dönteni.
Egyrészről az AMD utóbbi időben generációnként csak egyik részt szokta cserélni.
Renoir: zen=>zen2 CPU + Vega IGP (kakukktojás)
Cézanne: zen2 => zen3 CPU + Vega IGP
Rembrandt: Zen3 CPU + Vega=>RDNA2 IGPA Nextgennek az volna logikus, hogy fognak egy Remrandt designt és kicserélik benne a CPU-t.
Ugyanakkor az azt is jelentené, hogy meg kell tervezni az RDNA2-t N5-re, ami pedig lehet, hogy fölösleges munka ha már egyszer az RDNA3 elkészül N5-re (és mellesleg N6-ra is)Ha tippelnem kéne, én inkább az RDNA3-at mondanám.
-
#6878
Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
válasz
S_x96x_S
#6874
üzenetére
/zen5/
Ha tippelnem kéne, azt mondanám, hogy az Apple-t követik:
privát L1 + L2 és megosztott L3 (zen3)
 ( [link] )
( [link] )Látszik, hogy 32KB-ig 1ns a késleltetés, aztán az L2$ feléig még mindig alacsony, aztán szépen felkúszik 10ns-ra, ami az L3$ közel eső szeletének késleltetése, majd az is feltörik.
Ehhez képest az M1:
A késleltetés 128KB-ig nagyon alacsony és utána 8MB-ig 5ns (noha valójában 12MB az L2$)
Ha ezt meg tudják csinálni, akkor valóban kevesebb szükség lehet L3$-re.
Bár az Apple is alkalmaz L3$-t (System Level Cache néven), de ha jól emlékszem,. akkor azt már nem csak a CPU, hanem az IGP is tudja használni.Ez viszont csak akkor valósítható meg, ha a az L3$-t kompletten kiemelik a CCX-ből, összecsúsztatják az L2$ részeket és végül egységesítik az L2$-t úgy, hogy stacked L3$ rápakolására még mindig lesz lehetőség. Abban az esetben ha az L3$ stacked azzal sincs probléma, hogy a stacked L3$ rész késleltetése picit magasabb.
Ezzel egyébként egy roadmapet is felvázoltunk.
Szerintem nem volt akkora hülyeség a wccf által publikált rajz [link] [link]
Csak nem arra vonatkozik, amire ők gondolták.
Szóval a roadmap szerintem:
- zen4: az új zen3 architektúra finomítása, megnövelt L2$ (aminek hatására kisebb a nyomás az L3$-en), új gyártástechnológia, FPU duplázás
- zen4c/zen4d: L3$ kiemelése (legalább felezése, de inkább kiemelése) a CCX-ből. Az L2$ összecsúsztatása (privát 1MB vagy 2 mag által megosztott?), 3D Stacked L3$, visszaállás 2 CCX / CCD-ra (16 magra egységesített L3$, vagy 2x 3D stacked L3$ lapka )
- zen5: új architektúra: architektúra szélesítése, megnövelt L1$, L3$ kiemelése a CCX-ből, L2$ összecsúsztatása és egységesítése (=> megosztott, 8MB)Azt gondolom, hogy az L3$ kiemelése a designból és az L2$ összecsúsztatása nem egy nagy kunszt, tehát a zen4d/c és a zen5 fejlesztése ebből a szempontból lehetett párhuzamos. A wccf cikk fő mondanivalója ugye az, hogy két zen4 mag fog osztozni 1MB L2$-n. Ebből a szempontból a zen4d/c egy pilot projekt is lehet(ett) a zen5 egységesített L2$-éhez.
Az a kérdés merült föl bennem, hogy azt mondják, hogy nem véletlen, hogy az Apple M1 olyan, amilyen és a zen valamint az intel processzorok is olyanok, amilyenek cache felépítés szempontjából. Konkrétan: az M1 egy konzumer eszköz, ahol jellemző az egy programos használat (nem feltétlenül egyszálas, de hogy a rendszert döntően egy program veszi igénybe egyszerre), amely esetben jól jöhet, hogy megosztott L2$, amin keresztül az egy programhoz tartozó szálak adatot tudnak megosztani egymással. Ehhez képest a szerverek terén inkább jellemző az, hogy egymástól teljesen független programszálak futnak, amiknél meg inkább a privát cache hasznos. Persze elképzelhető, hogy ki lehet kapcsolni a megosztást. Tehát konzumer termékben 8MB L2$ látható, szerver termékben magonként 1MB L2$.
-
#6868
Petykemano
veterán
S_x96x_S
#6866
Petykemano
veterán
válasz
S_x96x_S
#6866
üzenetére
A Zen4 olyan, mint a zen2. Die shrink + core refinement + FPU fejlesztés.
A zen5 viszont ground up New architecture, Amiről mondták is, h szélesedik. A magasabb IPC növekedés nem meglepő.
Ha ez a Zen5 az, amit 2023 végén várunk, akkor az elég jól hangzik, hiszen akár 50%-ot is verhet zen3-ra - ami most válik szélesebb körben (olcsóbban) elérhetővé, másfél év múlva elavult teknős lesz. (Igen, tudom, nem avul el, van aki még P4-gyel nyomul és nem érzi, hogy váltania kéne)A magszám duplázódása ambivalens. Most biztosan úgy gondoljuk, hogy igazából céltalan, bár jól esne, ha egy tierrel lejjebb csúsznának a.magszámok árban.
Viszont mondjuk az, hogy nő a max magszám még nem feltétlenül jár együtt ezzel. Én nem számítanék $300-os 12 magos procira újonnan. Bár már most lehet kapni $400-500-ért 12-16 magosat, de azért ez már 4 éves gyártástechnológia és 2.5 éves termék.
Viszont az Intel várhatóan minden generációval emelni fogja az E magok számát és ezzel lépést kell tartani.
Nagy eséllyel a magasabb magszámot az AMD is a Dense magok.segítségével.fogja elérni.A M1/A14 esetén láttuk, hogy egy széles design mennyivel nagyobb L1$-sel dolgozik. Ez is várható. A kérdés legfeljebb az, h az Apple hogy csinálta, hogy 5x akkora mérettel dolgozik, és még sem szignifikánsan rosszabb a késleltetés. Én továbbra is azt gondolom, hogy a magas frekvencia cél és az amiatti nagy / ritka tranzisztoroknak eredménye a nagy fizikai kiterjedés, és hát mivel a fénysebesség adott, a cache fizikai kiterjedése korlátot jelenthet. Magyarul, ha csökkentjük a frekvencia célt, kisebb kiterjedésű lehet ugyanakkora cache kapacitás és javulhat a késleltetés - az alacsonyabb frekvencia ellenére.
Majd meglátjuk.A unified L2$ viszont teljesen értelmezhetetlen számomra. Egyrészt úgy tudom, hogy a szerver workloadok kifejezetten szeretik a nagy privát L2$-t.
Hogy kell ezt érteni? L2$ szeletek.nincsenek is közel egymáshoz. Ez valami tartalmi egységesítés lenne, hogy tisztában lesz mindegyik mag, hogy melyik mag L2$ szeletében mi van? Vagy valami olyasmi, mint az IBM virtuális L3$-e?
-
#6865
Petykemano
veterán
Petykemano
veterán
Ez Vajon mi lehet?
[GB4 GPU] Unknown CPU
CPU: AMD Eng Sample: 100-000000082-40_40/17_Y (4C 8T)
Min/Max/Avg: 2747/3605/3223 MHz
CPUID: 860F00 (AuthenticAMD)
https://t.co/lTrvHl9SIU -
#6846
Petykemano
veterán
S_x96x_S
#6839
Petykemano
veterán
válasz
S_x96x_S
#6839
üzenetére
A szerver piaci részesedés szerzése biztos nem megy egyről kettőre. Csak.az alapján nem lehet viszonyítani a technológiát.
Csak azt akarom mondani, hogy egyelőre nem tudjuk, hogy az AMD cicózik-e. Az ADL eléggé versenyképes, de nem teljesen egyértelmű, hogy az AMD ezen a piacon teljes gőzzel hajt-e. Ha az AMD ügyes, akkor lépést tud tartani akár gyártástechnilógiai hátrányból is. Azt gondolom, talán a döntő pillanat nem idén fog eljönni (zen4 vs RPL)
-
#6843
Petykemano
veterán
carl18
#6838
Petykemano
veterán
Erős a nyomás az intelt részéről. Azt rebesgetik, hogy a tsmc késett az N3-mal és nagyon megcsúszott az N2-vel és az Intel gyártástechnológiában vissza fogja venni a vezetést 2025.táján.
Mindenesetre én arra számítok, hogy a Zen5 nem az lesz, amit várunk - a szélesítés, hanem csak egy utolsó refinement N4X-en.
Mármint arra gondolok, hogy a zen mindig is egy egyensúlyt jelentett. A zen3 ugyan elvileg egy ground-up új architektúra, de változatlan célokkal, súlyokkal. Ha lesz egy új, szélesebb, alacsonyabb frekvenciát célzó architektúra család, ami máshová helyezi a súlyokat, azt talán érdemes lenne más néven illetni. Nem azt mondom, hogy ez lesz, mert nyilván a marketing érték is egy szempont. És új névvel illetni csak akkor lenne érdemes, ha kifejezetten megkülönböztetni akarnák. -
#6833
Petykemano
veterán
HSM
#6831
Petykemano
veterán
Kompromisszumok és szerény igények mellett biztosan nagyon sok rendszer használható elég sokáig. Hogy ki meddig hajlandó lemenni, egyéni kérdés.
Én csak azt mondtam, hogy ha van $400-500-od és az igényeidet kiszolgálja 6 mag és annál több nem, vagy csak rendkívül ritkán válna hasznodra, akkor jobban jársz, ha ma a $400-500-od felét költöd el arra a hat magra, amire épp szükséged is van és a fennmaradó összeget 2 generációval később költöd el a 2 genérációval újabb 6 magra, mint hogy ma megvegye ebből az összegből a +6 magot (=12) azért, hogy a +6 mag, amihez látszólag jó áron jutott hozzá, majd milyen jól fog jönni 2 generáció múlva.
-
#6817
Petykemano
veterán
carl18
#6816
Petykemano
veterán
Én a helyedben nem élném bele magam ebbe a hosszúéletűségbe. Valószínűleg már egy 12 magos zen4 körbeszaladja majd. Egy jövőre érkező zen4-3D pedig állva hagyja. Aztán jön a zen5, ami pedig ugye a széles architektúra - elvileg.
Nagyon csábító, hogy ennyire jóáras kezd lenni a felső rész is, de csak akkor éri meg elcsábulni, ha azt érzi az ember, hogy tényleg hasznot hajt számára a sok mag, csak eddig drágállotta. Arra nem érdemes építeni szerintem, hogy a sok mag hoz majd időtállóságot. -
#6806
Petykemano
veterán
S_x96x_S
#6803
-
#6793
Petykemano
veterán
Petykemano
veterán
B650?
-
#6792
Petykemano
veterán
S_x96x_S
#6791
Petykemano
veterán
válasz
S_x96x_S
#6791
üzenetére
Nem állítom, hogy nincs benne igazság - valóban felemás.
Mindenesetre fura.
Azt, hogy végül minden hátránya mellett kihozták lehet indokolni azzal, hogy tavaly júniusban bejelentették, megígérték, hogy lesz ilyen.
Nekik azt már legkésőbb tavaly ilyenkor látni kellett, hogy jön az Alder Lake és nekik nem lesz semmijük. Nem tűnik úgy, mint egy nagyhirtelen meghozott döntés.Az más kérdés, hogy viszakozni nem tudtak belőle. De ha itt csak a marketing lett volna a cél, akkor ezt a rajtot - out of stock jelzéssel - megejthették volna hónapokkal ezelőtt. Hiszen a Milan-X-et már egy ideje szállítják. Vagy ha igazából nem szeretnék eladni, akkor árazhatták volna $600-700-ra is.
Én simán el tudom képzelni azt is, mostanra sikerült lefedni a professzionális szerverpiacot, ahol ennek valódi haszna van. Azért egész biztos, hogy ez is egy niche piac. Az árazása arra utal hogy már a B terv pörög: szórjuk ki a gamereknek.
-
#6789
Petykemano
veterán
Petykemano
#6788
Petykemano
veterán
válasz
Petykemano
#6788
üzenetére
Bár Greymon szerint a 3D packaging gyártósorok át lesznek állítva Zen4-re:
"ZEN3D currently has only one production line. ZEN4 will have vcache, and current 3D packaging devices will switch to ZEN4 3D in the future." [link] -
#6788
Petykemano
veterán
Petykemano
veterán
Tesztek a Zen3 szobából:
(abridabri gyűjtése)Linus Tech Tips :
["The Fastest Gaming CPU in the World"]
HW Unboxed :
[Ryzen 7 5800X3D, AMD's Gift To Gamers!]
GNexus :
[AMD Hits Hard: Ryzen 7 5800X3D CPU Review & Benchmarks vs. i9-12900KS]Bennem az olyan érzés alakult ki, hogy ez productivity szempontból még egy 5800X-szel szemben sem kifejezetten ajánlott. Legfeljebb szerényen semleges, tehát nem vesztesz olyan sokat (az 5800X-hez képest, viszont a magasabb magszámúakkal szemben igen). Viszont a játéktesztek során megszégyenítően utasította maga mögé a sor végén kullogó 5950X, 5900X, 5800X procikat.
/spekuláció/
Szóval bennem kifejezetten erősödött az az érzés, hogy ez a processzor egyáltalán nem való azoknak, akik számára a productivity fontos. Viszont a sor végén szomorkásan ott kullogó 5950X, 5900X(, 5800X) vonulatot néhány hónap múlva váltja a Zen4. Az lesz majd az a real-deal, ami azoknak szól, akiknek fontos a productivity (is)
ÉS a mi a lényeg: a budget szegmenst a Zen3 fogja lefedni mégpedig úgy, hogy az igazi búcsúajándék a gamereknek egy 5600X3D lesz. Ha azt feltételezzük, hogy az AMD N5-ös kapacitása limitált lesz, akkor valójában egy 5600X3D lehet az egyetlen más, zsírosabb piacokról kapacicást el nem vonó, komolyabb volumenben bevethető fegyver az AMD kezében, amivel akár most, de különösen a Raptor lake megjelenésével a $200-300-os szegmensben fel tudja venni a versenyt. -
#6787
Petykemano
veterán
Petykemano
veterán
CPUZ (cpu-z) 2.0.1 changelog
- AMD Rembrandt & Raphael (zen4, zen 4) APUs (RDNA2).
[link] -
#6777
Petykemano
veterán
Petykemano
veterán
AMD N7=>N5
Mi magyarázhatja, ha az AMD 2x-es tranzisztorsűrűséget ér el?
"In my mind what is more interesting would be how much tradeoffs AMD would have to make this time, or rather what things they need not have to sacrifice this time.
Even if AMD did not go with a 3 fin design with N7, they made a lot of the cells taller and increased the number of tracks in order to get the needed drive performance for ~5GHz operation. (I think it is 2x poly)
This degraded density, and the taller cells also degrade RC characteristics leading to lower energy efficiency.
Then there are those additional metal layers needed to deliver the signals and power which is necessitated by the high frequency design which also introduced additional RC losses. If I remember well, all the way to 19 metal layers compared to 13-14 for mobile SoCs.
If on their custom N5 they can go with standard 2 fin layout with compact/shorter cells and keeping more or less similar frequency it would already be a big leap. Far higher efficiency than what TSMC is advertising for N7--> N5 transition because basically the N7 customizations AMD made nerfed efficiency in no insignificant amount.The other double whammy is that the taller cells cut density a lot, so if they can stick to a compact 2 fin cell layout on N5 would really boost Xtor density allowing a greater density gain than TSMC's advertised gains for N7-->N5 transition. (In performance optimizations the cells can go almost 30% larger than usual)
This was the reason I found that Zen 4 process reveal from last year's accelerated DC event to be interesting, it indicated that they indeed did not have to sacrifice density and efficiency much and because of reasons above got better gains vs N7 than TSMC's N7-->N5 transition (using mobile as standard)
They will gain base frequency and all core frequency simply due to being more efficient. And the density gain is a wild card, it is very plausible that they literally meant it when they said 2x density gain. which could be up to 60% MTr gain for a Zen 4 CCD with the rumored die sizes. What are they doing with so much more MTr on a arch refresh?"
[link]Azt én is szoktam mondani, hogy a magas frekvencia elérése nincs ingyen és hogy tranzisztorsűrűséget veszít vele egy design. Ez egy eléggé hozzáértőnek tűnő magyarázat a jelenségre.
-
#6776
Petykemano
veterán
Petykemano
#6775
Petykemano
veterán
válasz
Petykemano
#6775
üzenetére
Hát ez egy szerény döntetlen, nincs általános földbedöngölés. Tökre érthető az árcédula. Talán picit még sok is. Pont úgy, ahogy a GN is fanyalgott az 5500/5600/5600X árakon. Too Little, too late.
Illetve úgy fogalmaznék, hogy csak annak nem sok, aki csak cput vált.
Ők is várják az 5600X3D-t.
Én így áraznám :
5600: $179
5600X: $199
5600X3D: $249
5700X: $299
5800X: $329
5800X3D: $399 -
#6775
Petykemano
veterán
Petykemano
veterán
5800X3D review - xanxogaming
Elvileg 14 Lett volna a dátum, nem? -
#6771
Petykemano
veterán
Petykemano
veterán
Meg Greymon szerint a raphael tömeggyártása megindult.
-
#6765
Petykemano
veterán
Petykemano
veterán
/5800X3D/
"AMD R7 5800X3D in Shadow of the Tomb Raider. As for comparison, the 12900KS hits ~200 FPS in this scene and the 12900K ~190 FPS."
[link]Nem tudom, vajon itt a képernyő tetején levő 227-228fps-es avg értéket kell nézni, vagy a képernyő alján levő 290fps-t?














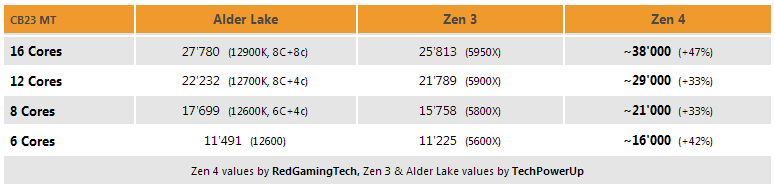




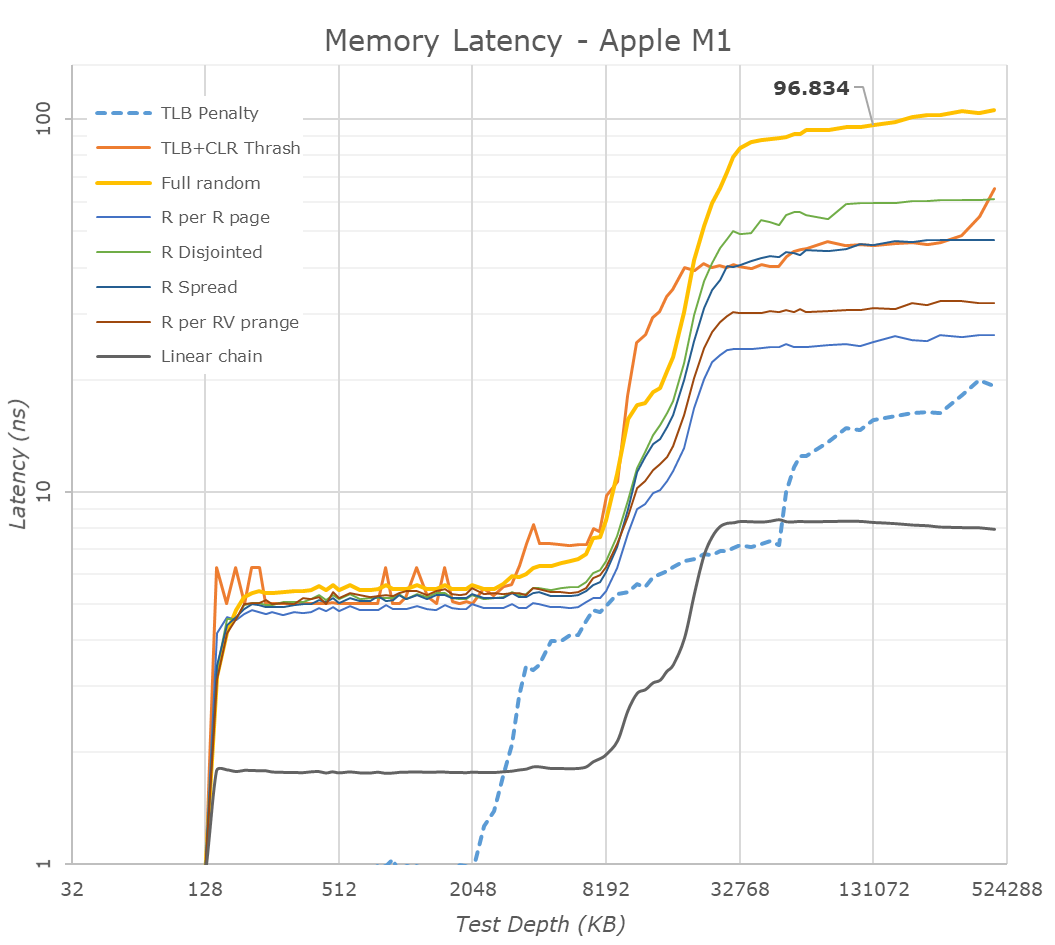


Új hozzászólás Aktív témák

- LG 27GR95QE - 27" OLED / QHD 2K / 240Hz & 0.03ms / NVIDIA G-Sync / FreeSync Premium / HDMI 2.1
- Nuki Smart KeyPad 1 okos zár kiegészítő
- Lenovo L13 Core I3-10110U / 4GB DDR4 zsanér törött laptop
- Dell Latitude 5420 14" Touchscreen i5-1135G7 16GB 256GB 1 év garancia
- LG 27GR95UM - 27" MiniLED - UHD 4K - 160Hz 1ms - NVIDIA G-Sync - FreeSync Premium PRO - HDR 1000
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: ATW Internet Kft.
Város: Budapest