Hirdetés
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Bemutatkozott a Poco X7 és X7 Pro
- Ultra jó ajánlattal lépheti át a Vivo a 7000 mAh-t
- iPhone topik
- Karácsonyi telefonajánló 2025
- Fotók, videók mobillal
- Google Pixel topik
- Apple Watch Sport - ez is csak egy okosóra
- Google Pixel 10 Pro XL – tíz kicsi Pixel
Új hozzászólás Aktív témák
-
#7295
 Petykemano
veterán
S_x96x_S
#7289
Petykemano
veterán
S_x96x_S
#7289
Petykemano
veterán
válasz
 S_x96x_S
#7289
üzenetére
S_x96x_S
#7289
üzenetére
A L2$ mérete bizonyos benchmarkok esetén már korábban is jelentett problémát. Amikor a Zen1 megjelent 512Kb L2$-sel, akkor is volt valami benchmark, amiben kiugró eredményt ért, mert belefért az L2$-be az egész feladat.
Külön-külön sem az 1MB L2$-nek, sem az AVX512-nek nem szabadna ilyen kiugrást eredményeznie. Előbbi ugyanis az Alder Lake esetén okozott volna hasonló ugrást, utóbbi pedig a Rocket lake esetén.
Azt tudnám elképzelni, hogy a megnövekedett L2$ és az AVX512 teszt együttállása okozza. Mondjuk hogy az 1MB L2$-be már pont belefér az AVX512-es teszt. Hiszen az 1MB L2$-t az AVX512-képes Rocket lake hiányolta, míg a 1.25MB L2$-sel rendelkező ADL pedig AVX512-t nem tud.
De ez is sántít, mert az ADL megjelenésekor még az E magok letiltásával vissza lehetett nyerni a P magok AVX512 képességét. Kizártnak tartom, hogy soha senki ne futtatta volna le a UB tesztet E magok nélkül - és akkor ki kellett volna jönnie hasonló "anomáliának", aminek hasonló marketing hírverést kellett volna okoznia, hogy "Hahó, tiltsd le az E magokat, mert nyersz vele +20% ST teljesítményt az UB szerint "
Ezúttal az UB nem adott magyarázatot az anomáliára. Ez alapján sajnos arra kell következtessek, hogy az UB processzorgyártó/család alapján más és más teszteket futtat és a más tesztek eredményét közli néhány pontszámba gyúrva, vagy ha a futtatott teszt ugyanaz, akkor processzorgyártó/család alapján a kapott eredményeket máshogy pontozza vagy máshogy súlyozza.
Létezne, hogy az UB úgy működik, hogy van egy elvárt végeredmény és úgy alakítják ki a mintavételezési algoritmust, hogy pont az jöjjön ki?
-

#36531588
törölt tag
válasz
S_x96x_S
#7289
üzenetére
"Neked mi a véleményed a fenti Intel 11gen vs. 12gen -es okoskodásomról?"
Nagyon nehéz megmondani innen kívülről, mi történt náluk. Ha az avx 512 VNNI kavart be, elképzelhető hogy észre vették az eredményeken és nem engedték ki az intel 11 gennél az eredményeket, és korrigáltak. Ezért nem volt anomália, és ezért nem esett vissza a 12. gen a 11 genhez képest.
Az amd-nél pedig most ezt nem vették észre. Véleményem szerint.Nem biztos kapunk erre választ a későbbiekben, de rendkívül érdekes a téma egyébként.
#7291S_x96x_S
Ha ez így van, az nagyon nagy probléma az intelnél. Bár azt írja a cikk, hogy bizonyos partnerek megkapják a terv szerint 2022-ben, de akkor is. -
#7293
Petykemano
veterán
S_x96x_S
#7291
Petykemano
veterán
válasz
S_x96x_S
#7291
üzenetére
Nagyon kemény.
Az Intelnek szinte semmi nem jön össze. Bár nem feltétlenül gondolnám, hogy kizárólag arról lenne szó, hogy "elhagyta őket a szerencse". A régi nevén 10nm-es gyártástechnológia csúszása nagyon betett nekik. Világos, hogy mindennek az alapja ez. De kellett 2-3 év, mire felocsúdtak a meglepődöttségből. De a gyártástechnológia (régi 10nm) és a chiplet technológia terén is nagyon bátor, nagyon ugrásszerű előrelépéseket terveztek. A gyakorló lépések kihagyásával lólépéssel akarták előzni a konkurenciát. És ez nem jött össze.Az Intel7 eredileg elég nagy tranzisztorsűrűség-emelkedést ígért, Kobalt használatával és EUV nélkül. Őszintén szólva nem is csodálkozom, hogy nem sikerült. Reméljük, hogy az Intel4 esetén már egy iteratívabb megközelítést alkalmaztak.
De ugyanez figyelhető meg a chiplet technológia terén. A TSMC eddig mindössze két olyan designt csinált, amiben a chipletek egymás felé fordítva szélessávú kapcsolattal rendelkeznek (Apple M1 Ultra és AMD Mi 250) Ezeket is idén. Az Intel pedig úgy gondolta, hogy ő majd mindenki előtt összerakja a a 4 ilyen kapcsolattal bíró Sapphire Rapidst, nem is beszélve a Ponte Vecchioról.
Én legalábbis más különösebb okát nem látom a késlekedésnek, hiszen a SPR nagyjából ugyanazokat a magokat használja, mint az Alder Lake és a rács-szerkezetű busz sem új.
Az AMD megközelítése ezúttal jobbnak bizonyult. Bevállalták a Naples-nél azt, hogy a lapkák közötti késleltetés borzalmas lesz. De végülis hibátlanul működött. És a 3D tokozás tekintetében is csak egy cache bővítést tudtak kipréselni magukból. De végülis működött.
A lesajnáló hangnem annak szól, hogy persze ezek az apró, de sikeres lépések, ha az Intelnek összejön a high-bandwidth kapcsolat, akkor bátortalan tötymörgésnek hatnának.(Arra alapozom a gondolatot, hogy a client-computing szekció az egész jól halad, nincsenek csúszások, mert nem használnak kiforratlan chiplet technológiát.)
-
#7292
 TESCO-Zsömle
titán
S_x96x_S
#7291
TESCO-Zsömle
titán
S_x96x_S
#7291
-
#7277
Petykemano
veterán
S_x96x_S
#7275
Petykemano
veterán
válasz
S_x96x_S
#7275
üzenetére
Jól értem, hogy a UB azzal vádolja az AMD-t, hogy direkt tették nyilvánossá az egyébként tudottan "mérési hiba" miatt irreálisam kiemelkedő eredményt, hogy learassák a vírusként terjédő marketing hype előnyeit, ahelyett hogy csendben szóltak volna nekik, hogy valami nem stimmel?
-
#36531588
törölt tag
válasz
S_x96x_S
#7264
üzenetére
Ez egész biztosan nem igaz. Az 5950X msrp-je is 799 dollár. Azóta a tsmc árat emelt, ez azt jelentené az amd enged a profitból.
Ha tényleg ennyi, akkor viszont a visszaeső eladások miatt vágtak az áron. Kíváncsi leszek az amd 2022 Q2-re, az intelé elég szarul fest.
Az kiderült már hogy mennyi a tdp?
-
#7265
TESCO-Zsömle
titán
S_x96x_S
#7264
-
#7262
Petykemano
veterán
S_x96x_S
#7261
Petykemano
veterán
válasz
S_x96x_S
#7261
üzenetére
Állítólag a UB már le is tekerte AzokNak a részértékeknek a súlyát, amik a kiemelkedő zen4 eredményeket produkálták. Persze értem én, hogy real world benchmarks, de....
Most akkor az összes procit újra kellene mérni? Vagy csak a háttérben újrakalkulálták az egészet? Mi változhatott a zen4-ben,.ami ilyen változást eredményezhet, de nem valós? az L2$ nem lehet, mert abból az intelnél is 1.25-2MB van már.
Vagy processzorcsaládonként külön pontozási profil lenne? Ezért jelentett kilövést az 1MB L2$ az amdnél és nem az intelnél? -
#7226
Petykemano
veterán
S_x96x_S
#7224
Petykemano
veterán
válasz
S_x96x_S
#7224
üzenetére
az AMD elég sok nevezéktani következetlenséget elkövetett. Nehéz megtalálni a logikát, mert egyáltalán nem arról van szó, hogy arra törekednének, hogy egy generációban mondjuk a processzormagok homogének legyenek - hacsak nem tekintjük a Zen3+-t egy önálló processzorgenerációnak.
Régen ugye egy generációval le voltak maradva az APU-k. Tehát lehetett tudni, hogy x-es generációban x-1-es cpu architektúra van. Ez egészen a 4000-es Renoirig így volt.
Akkor az AMD dönthetett volna úgy, hogy a 4000-es széria megtartja. Elindulhatott volna a zen3 4000-esként. De valószínűleg mivel a Zen3 a Renoirhoz képest elég későn rajtol és mert az APU-k kezdtek felzárkózni - hamar jött a Cézanne - ezért az 5000-es széria megkezdése mellett döntött.
Ez lehetett volna egy ilyen kiegyenlítő esemény is, hogy jó, akkor innentől adott szérián belül az APU-k ugyanazt az architektúrát használják mint a DT/S processzorok.Szerintem egyébként ilyen szempontból hiba volt a Rembrandt-ot 6000-esként elindítani. VAn különbség a Renoirhoz képest, mert az konkrétan javított a processzor architektúrán a 3000-es nevezéktant addigra elfoglaló Picasso-hoz képest.
De a Rembrandt CPU tekintetében alig különbözik a Cézanne-tól. De valahol érthető, hogy mivel már az összes hely 5980HK-ig foglalt volt, már nem nagyon lehetett tovább fokozni.Viszont nagyjából ugyanaz a helyzet lehet, mint a Zen3 esetén volt. 6000-esként már nem lehet elindítani a Zen4-et, mert a küszöbön van a sokkal jobb procival bíró Zen4 apu is.
Szerintem lehet arra számítani, hogy lesz majd egy szintén foghíjas 8000-es széria is.
Mondjuk egy nagyobb APU Zen4 alapon, vagy esetleg csinálnak egy 8+16 magos Zen4 változatot.Nem tudom, mi a jobb: az ilyen ugra-bugrálás, vagy az, ha egy sorozatszám alá tömnek be több különböző generációs terméket. Mellesleg ilyen is volt.
-
#7217
Petykemano
veterán
S_x96x_S
#7215
Petykemano
veterán
válasz
S_x96x_S
#7215
üzenetére
> vagyis a "végitélethez"
![;]](//cdn.rios.hu/dl/s/v1.gif) várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..
várjuk meg a ZEN4-es DDR5-ös "hivatalos" eredményeket is ..
> És a 5950X - még ddr4! vagyis ez így nem fair
Bocsánat, de én nem mondtam, hogy az AMD dicsősége múlna el, vagy hogy a Zen4 ne lehetne nagyonis versenyképes. Ha ezt lehetett belőle kiolvasni, akkor elnézést a félreérthetőségért.Én csak arra utaltam, hogy a (2019!-es) hiper-szuper csúcs MT ász 5950X-et az idén érkező középkategóriás(nak nevezett, az árát majd meglátjuk) lapka eléri.
Ez akkor is így van, ha egyébként az már DDR5. Persze, ez is előny. Elképzelhető, hogy ugyanez a beérés meg fog történni a versenyképes árazású Zen4 processzor esetén is.
-

HSM
félisten
válasz
S_x96x_S
#7199
üzenetére
"szinte mindenki elkezd hirtelen TCO-t számolni .."
A TCO tekintetében ami nem volt eddig túl erős, az a több CCD-s verziók alacsony terheléses fogyasztása. Bár a másik oldalon meg elhasználták ugyanezt szemöldökráncolós órajelkergetésre... [link]
Ezen lenne még mit faragni, főleg, amikor az ember azt látja, egy nagyságrendileg tokkal-vonóval 15W-os notebook-chip is már remekül elboldogul akár komolyabb feladatokkal is, nem is lassan....
Energiahatékonyságban amúgy az eddigi 7nm Zenek is büntettek, ha kikapcsoltad a szintén túltolt BOOST-jukat, lásd pl.: [link] .
-
#7184
Petykemano
veterán
S_x96x_S
#7183
Petykemano
veterán
válasz
S_x96x_S
#7183
üzenetére
> - not support Infinity Cache (large L3 cache)
Egyrészt kár.
Másrészt viszont azt gondolnám, hogy amennyi CU lehet benne, annak valószínűleg nem indokolt.
De azt gondolnám, hogy ha már az RDNA3 úgyis fel lesz szeletelve, akkor egy lépéssel közelebb kerülünk egy olyan nagytesóhoz, ami esetleg már chiplet formában kapja a GCD-t és 3D tokozva az infinity cache-t. (Nem gondolnám, hogy a Phoenix point ilyen lesz.) -
#7177
Petykemano
veterán
S_x96x_S
#7176
Petykemano
veterán
válasz
S_x96x_S
#7176
üzenetére
Elég komoly....
Nagy Márton recessziót vár év végére
Az amd és az nvidia tsmc gyártókapacitást mond vissza.
A kriptopiac bedőlni látszikEközben:
Genoa lineup -
#7168
Petykemano
veterán
S_x96x_S
#7167
Petykemano
veterán
válasz
S_x96x_S
#7167
üzenetére
Nem teljesen értem.
Nyilván nem vagyok tisztában minden sku teljesítményével.Ebben a tesztben a specint2017 perlbench esetén 7 körül megy az M1 és a mobil zen3 is. Elnézést, most én csak megemlítettem az első csíkot.
Ebben a tesztben az M1 ugyanúgy 7+ ebben a tesztben az X2 pedig nem éri el az 5-t.
Az ADL a zen3-nál elvileg valamivel jobb teszteredményeket ér el. Hogy lesz az X2-nél 11%-kal gyorsabb X3 hirtelen 34%-kal gyorsabb az X2-nél 40%-kal gyorsabb zen3-nál is gyorsabb ADL-nél?
-

carl18
addikt
válasz
S_x96x_S
#7131
üzenetére
Még ha Zen 4-es is lesz a 7600X akkor se fog többet érni mint 300 dollár,már az intel is versenybe van és ha túlárazák akkor nem lesz rá kereslet.
Idén rajtol a Raptor lake is, és nem hiszem hogy drágáb lesz mint a konkurencia 13600k.Én mondjuk az R5 3600-ról nem tervezek még váltani, talán 2024-2025 táján fogja meg igazán lecserélni.

-
#7145
Petykemano
veterán
S_x96x_S
#7144
Petykemano
veterán
válasz
S_x96x_S
#7144
üzenetére
Én nem vagyok ebben 100%-ig biztos.
Lisa Su a FAD-on valóban kiemelte, hogy a fő szerver vonalon megmaradnak ugyan X86 vonalon, de fognak ARM processzorokat is tervezni, mivel a Xilinx és a Pensando standalone termékek Arm processzorokkal készültek eddig és azt nem tervezik lecserélni.Bár most a cikkekben úgy jelenik meg, hogy a K12 projektet Jim Keller távozása után lőtték le, a távozásakor voltak arról pletykák, hogy valójában ugye nem ő volt a chief architect a zen fölött, hanem ha nem is tervezője, de szívügye a K12 volt és távozása épp annak köszönhető, hogy azt lestoppolták.
Lisa Su megjegyzése épp elegendő felületet adhat egy ilyen esetben Jim Keller számára, hogy odaszúrjon, hogy "na látjátok, milyen jól jönne most". Ez nem sértettség, legfeljebb afféle szakmai hiúság: "végül nekem lett igazam"Persze nem tudhatjuk, hogy lett-e volna az AMD-nek erőforrása a hasonlóságok ellenére két külön processzor családot fejleszteni. A cikkek is említik, hogy bár lehet, hogy ma jól jönne egy K12 (mai állapotban), de nem biztos, hogy ugyanazokat a kiváló termékeket látnánk ma, ha az AMD-nek meg kell osztania a figyelmét és erőforrásait.
Viszont azt látjuk, hogy az AMD portfóliója növekszik. És itt most nem a Xilinx és Pensando termékekre gondolok, hanem az X86 processzorcsaládokra. Zen3 esetén készült már V-cache-es változat, Zen4-ből már lesz v-cache és egy dense változat is. APU-kból is most már megengedhetik maguknak, hogy ne egy jack-of-all-trades típusú termékkel fedjék le a piacot, hanem legyen egy elfogadható CPU és GPU teljesítménnnyel rendelkező standalone mainstream APU (Phoenix Point) és legyen egy kifejezetten CPU teljesítményre gyúró, de képet adó - akár standalone munkagép, akár dGPU mellé szerelhető high end APU*.
Számos oldalágon történő projektről hallottunk, ezekből egy végül el is készült, a Mendocino.
Tehát azért az AMD-nek érezhetően több kapacitása lett kísérletezgetni.
Ha Jim Kellernek igaza van és az Arm és X86 processzorok tényleg nem különböznek olyan nagy mértékben, és egy kész zen core designban szinte csak a frontendet kell lecserélni, akkor szerintem is láthatunk majd saját ARM processzort az AMD-től.Végülis a Xilinx-nél és a Pensandonál eddig is megvolt a know-how és a talent, hogy gyári Arm magokat beépítsenek. az AMD cpu design team-nek tényleg csak a CPU magot kell megterveznie (átterveznie) nem az egész SoC-t.
De vajon mit nyerne vele?
Nem arról van szó, hogy ha valaki tervez az ARM processzort, akkor az hirtelen 50-100%-kal jobb IPC-t vagy hatékonyságot ér el. Még kevésbé gondolnám, hogy ha a Zen processzorcsaládot terveznék át, akkor azt hirtelen nagymértékben megtáltosodna IPC vagy hatékonyság tekintetében. Itt eddig egyedül az Apple tudott valamit varázsolni és a Nuvia ígérte ugyanazt. Az AMD-nek (és az Intelnek) ugyan nem IPC, hanem frekvencia irányba van nagymértékű tervezési tapasztalata. Ha viszont az AMD úgy kezd el ARM processzor architektúrát fejleszteni, hogy az széles és alacsony frekvenciát ér el, akkor viszont nem kifejezetten jól lehet a két processzorcsalád között technológát megosztani. Bár én szívesen látnám, ha az AMD követné az Apple-t a széles és alacsony frekvenciát elérő architektúra irányába **
Az AMD kifejezte, hogy a hagyományos szerver termékek tekintetében maradnak x86 vonalon.
Vajon a Xilinx és Pensando termékek esetén mit nyernének, ha az azokban dolgozó Arm magok mondjuk 30-40%-kal magasabb teljesítményre lennének képesek - persze fogyasztás árán.* Az a vélekedésem, hogy Raphael egy dupla szubtsztrátú Dragon Range, nem jött be, de jelen információk szerint a legesélyesebb az, hogy valójában ugyanabból az építőkockákból fog épülni.
** Már nem emlékszem, melyik videoban hallottam vagy cikkben olvastam, hogy magas frekvenciát elérni mindig helytakarékosabb, mint magas IPC-t és hogy az Intel és az AMD designjai azért célozzák inkább a magas frekvenciát, mert a rendelkezésükre álló kapacitás a kiszolgálandó piachoz képest nagyon korlátos. Magyarán így tudnak többet eladni.
Abból nekik kevés előnyük származna, ha a termékeik ugyanezt a teljesítményt tudnák hozni, de csak 30%-kal kevesebbet tudnak belőle értékesíteni a kapacitások miatt, miközben mondjuk 50% áramköltséget spórolnak a vevőnek. -
#7133
Petykemano
veterán
S_x96x_S
#7131
Petykemano
veterán
válasz
S_x96x_S
#7131
üzenetére
Elnéztem volna?
Az alsó két sorra (7800X, 7600X) meg mertem volna esküdni, hogy $550 és $450 a felette levő kettőre nem emlékeztem, de hogy a legalsóban $450 volt az tuti.
De mondjuk nem a tweetet olvastam, hanem csak az értesítőt. Bár úgy tudom, tweetet nem lehet módosítani, legalábbis ingyenes fiókkal nem.
A wccf által felvázolt árakban már semmi kiugró nincs - se pozitív, se negatív irányba. -
#7123
Petykemano
veterán
S_x96x_S
#7121
Petykemano
veterán
válasz
S_x96x_S
#7121
üzenetére
nem számolgattam, de mintha tényleg egyre hosszabb lenne a nyíl, vagyis mintha tényleg egyre több időt venne igénybe az TSMC-nek is egy új gyártástechnológia piacra dobása.
Az meg aztán teljesen szokatlan, hogy előre ismertetik a különféle változatokat.
Emlékeim szerint az N6, később az N4 még egy-egy később ismertetett leágazás volt, de az különféle utógatokról általában csak véletlenül szereztünk tudomást, mert Abu elkotyogta. Lehet, hogy nem volt titok, de nem is volt nagy dobra verve.
Az N3 esetén az alváltozatok viszont szokatlan nyíltsággal lettek már előre bejelentve
Úgy tűnik, tényleg vége a Finfetnek. Mindenesetre én arra számítok, hogy az N3 már nem lesz zökkenőmentes.Szerencsére persze a épp jókor jött megmentésüknkre a chiplet-technológia. Lehet mindent a megfelelő gyártástechnológiai válozaton gyártani. Végülis lehet, hogy csak ez a magyarázat a 3 különböző változatra...
-
#7122
Petykemano
veterán
S_x96x_S
#7120
Petykemano
veterán
válasz
S_x96x_S
#7120
üzenetére
> - 4nm? ( a videocardz ebbe sorolta )
Elvileg úgy van, hogy a Raphael és Raphael-X N5
Az APU pedig N4
A Zen4c-ben nem vagyok biztos. De ha tippelnem kéne, szerintem az is N4> hogy az AMD próbálja az alsóbb szegmenseket is becélozni
Ha figyelembe vesszük, hogy a Rembrandt már 210mm2 N6-on!, egy ilyen 110-150mm2-es cuccnak azért már nem nagyon szabadna olyan nagyon drágának lennie csak azért, mert N5.
Persze ez a jövő évi kínálat már, és mivel N5, lehet, hogy az árakat nem az gyártási költség határozza meg, hanem a wafer kínálat.Egyébként igen, én is azt gondolom, hogy nagyon népszerű lesz.
Egyben azt is jelenti, hogy miközben persze szélsebesen nő az az egyszálas teljesítmény, csúszunk vissza a 8 magból a 4 magba (mainstream) -
#7118
Petykemano
veterán
S_x96x_S
#7113
Petykemano
veterán
válasz
S_x96x_S
#7113
üzenetére
Ami ebből fontos az szerintem az, hogy a Zen5 tehát 2024-ben érkezik csak.
Amennyiben a Zen4 tényleg megjelenik szeptemberben, úgy a Zen5 2024-es megjelenése legjobb esetben is 16 hónapos intervallumot jelent a két termék között.Ez már nem hangzik annyira jól, mint a 2023 végi megjelenés - ha közben az Intel tartani tudja az 1 éves release ciklusokat.
Az okokról érdemes lehet találgatni. Az N3 késése óta latolgatjuk, hogy vajon késik-e vele a Zen5, vagy megoldják valahogy N4X-en. Nem mondom, hogy ez azt jelenti, hogy akkora Zen5 biztosan N3-on készül, mert könnyen lehet, hogy az N4 kapacitásokból meg az Nvidia miatt szorultak ki.
Mindenesetre ezzel kapcsolatan érdemes egy pillantást vetni az ábrára. Nyilvánvaló, hogy a gyártástechnológia számok csak a CCD-re vonatkoznak, de legalábbis nem tartalmazzák az IOD-t, ami a Zen4 esetén N6-on készül, ami viszont nincs feltüntetve.
Ebből én arra következtetnék, hogy a Zen4 N5, Zen4+V-cache N5 és a Zen4c pedig N4
És elképzelhető, hogy ha az alapvető felépítésen nem változtatnak, vagyis nem bontják tovább a chipletet, akkor a Zen5 és Zen5 v-cache N4-en készül, a Zen5c pedig N3-on.További érdekes kérdés, hogy vajon van-e jelentősége annak, hogy a Zen3 esetén "3D V-cache"-t tüntetnek föl, a többi esetében csak simán "v-cache". Az vajon nem 3D lenne? Fura lenne, mert a V-cache-ben a V-ről eddig azt gondoltam, hogy a Vertical-t jelenti.
Persze eközben 16+ hónap közben az AMD ledobja a Zen4 + V-cache és Zen4c termékeket is.
Ezek lehet, hogy elegendőek lehetnek az elvileg 2023-as Meteor Lake ellen. -

hokuszpk
nagyúr
válasz
S_x96x_S
#7115
üzenetére
valahogy nem jon ki a matek, gyarilag a legerosebb Zen3 4.9 -ig megy, ha 5.5 freki teteje, akkor az >10%, erre jon 8% ipc , szóval 20% st. uplift korul jön ki.
* mondjuk az Alder szintetikus tesztekben mutatott egyszalu teljesitmenyet igy sem fogja meg, de ha ez jatekokban valos fpsekre fordul le, akkor jo lesz.
-
#7103
Petykemano
veterán
S_x96x_S
#7102
Petykemano
veterán
válasz
S_x96x_S
#7102
üzenetére
Ezt a cikket olvastam, amikor eszembe jutott valami.
A Sunny Cove L3 cache-ről:
"Tiger Lake increases L3 slice size to 3 MB, increasing total L3 size to 24 MB. At the same time, the L3 has been changed to not be inclusive of the L2. With 10 MB of total L2, an inclusive L3 would use over 40 percent of its capacity duplicating L2 contents to maintain cache coherency. Changing to a non-inclusive policy dictates changes to the L3’s cache coherency mechanism. Previously, each L3 line would have core valid bits indicating which core(s) might have that line their private L1 or L2 cache. That reduces snoop traffic on the ring interconnect. Tiger Lake’s non-inclusive L3 has to use a different mechanism, since a line can be in a core’s private caches without being in the L3. There’s likely a set of probe filters alongside the L3, like Skylake-X’s setup.
These changes come at the cost of about 9 cycles of extra L3 latency. Lower clock speed from 10nm process deficiencies make latency even worse, meaning that Tiger Lake relies a lot on its enlarged L2 to maintain performance. Ironically, Tiger Lake’s L2-heavy setup is better for maintaining IPC with increasing clock speed. Intel’s uncore clock (which includes the L3) has struggled to keep pace with core clock ever since later Skylake generations started reaching for 5 GHz and beyond. L3 accesses get more expensive as the gap between uncore and core clock increases, so keeping memory accesses within the full speed L2 helps performance at higher clocks."Én úgy tudom (de ha nem, akkor majd valaki kijavít és abban az esetben elnézést), hogy a Zen esetén az L3$ órajele megegyezik a magórajellel. Legalábbis az, hogy az 5800X3D órajel (pontosabban feszültség) limitációja erre utal. Gondolom azért kell az egész cpu-nak limitáltnak lennie, mert az L3$ nem külön frequency domain.
Ha és amennyiben ez a megállapításom helyes, akkor egyrészt a jövőben az egyre gyakoribb 3D varázslások miatt az ebből fakadó imént említetthez hasonló limitációk elkerülése érdekében talán praktikus lehetne az AMD-nek is meglépni, hogy elválasztja egymástól a core+L1+L2 és az L3 frekvencia tartományokat.
Másrészt az jutott eszembe, hogy mi van, ha ezt a zen4 esetén már meg is lépték és épp azért tud annyira magas frekvenciát elérni, mert a böhöm nagy kiterjedésű L3$-t már nem kell azon a nagyon magas frekvencián járatni. A külön szabályozható L3$ frekvencia abból a szempontból is hasznos, hogy a 3D ráépítmény kevésbé nehezíti meg a hűthetőségét, vagy ha a hőtermelés mégiscsak korlátozást jelentene, akkor külön szabályozható az L3$ frekvenciája, tehát például lehetségessé válik, hogy az L3$ 3D felépítmény nélkül magasabb frekvencián ketyegjen, mint 3D felépítménnyel.
-

sb
veterán
válasz
S_x96x_S
#7097
üzenetére
Az Intelnél fura a hatékonyság. Elsőre a magas TDP-vel brillíroztak, 10-12 magot lehozva notiba, 6-8 ellen nyert helyzet volt magas TDP-n. Nem is a klasszikus 35-45W H osztályban, hanem még magasabb, 65-80W-os Turbokkal és/vagy felhúzott TDP-kkel.
Kevés maggal nyilván nem lehet behozni ezt.Aztán végiggondolva az lenne normális, hogy lentebb is jó lesz a hatásfok, mert ott meg ha kevés a TDP akkor megint a több mag/alacsonyabb freki(fesz) a jobb felállás. Ehhez képest elég gyér ez a pontszám. Persze itt kérdés a valós egymáshoz képesti TDP is. 28W-on behozza az Intel is szvsz a lemaradást. De ezzel együtt is furcsa nekem. Annyira ott sem rossz a hatékonyság. Desktopon is inkább csak a magas frekik rondítanak bele a dologba. Visszafogva a P és E magok is elég hatékonynak tűntek.
Talán az lehet még mögötte, hogy az AMD minél lentebb megyünk, annál jobb lesz a hatékonyság. Ha a "gyárit" be is lehet fogni, azon felül aligha.
A másik topicban méregettem párat, épp az M1 kapcsán. Bedobom ide, ha már aktuális.
- core power értékek
- CB R23 MT pontszámok
- vegyesen noti silent/normal/perf profilok (ahol a TDP mellett Turbo is van, de a kiírt értékek egy egy CB futtatás core power átlagai), ill. van ami Ryzen Controllerrel belőtt TDP, Turbo nélkül, fix fogyasztásra.5500U 5600U
38W - 8900
35W - 8800
26W 7400 8250
22.7W 7150 7950
16,7W 6500 7200
12.7W 5950 6800
9.7W - 5900Ezek mellé vannak elvileg ilyen M1 értékek:
- M1 Pro: 12400, 30W
- M1: 7760, 10W
Az alsóbb régiókban nincsenek nagyon messze és nyilván a 8 magos AMD-k ennél jobbak, 10 maggal pedig még hatékonyabbak lennének. -
#7095
Petykemano
veterán
S_x96x_S
#7092
Petykemano
veterán
válasz
S_x96x_S
#7092
üzenetére
impresszív számok.
Ha ez a 15% végleges, akkor kb annyival nőhet a ST teljesítménye, mint a Zen4-nek az AMD saját bevallása szerint.
És nem csak ST-ben lesz erős, hanem Szálfüggetlen MT-ben is - a +8E mag miatt. Kiváncsi vagyok, mennyivel lesz nagyobb a lapka.Nekem úgy tűnik, az Intel - konzumer piacon - kezdi összekaparni magát. Egyrészt hozzák az az ígéretet/tervet, hogy a P magok a ST teljesítmény, az E magok a throughput célt szolgálják.
Kérdés, hogy meg tudják-e oldani, hogy az E magok segítsenek, de legalább ne zavarjanak a szálfüggő alkalmazások esetén.De amit kiemelnék az az, hogy úgy tűnik az intel nagyon gyorsan dolgozik - gyorsabban, mint az AMD. 2021 elején megjelent a Rocket lake, ami lehet, hogy csupán egy többszörös származék volt, de akkor is volt vele munka. És év végén megjelent az Alder Lake is (november)
Bár az intel - ellentétben a titkolózó AMD-vel - jelenleg nyitott könyv módban működik, szeretnek dobálózni az információkkal. A Sapphire Rapids és a Ponte Vecchio is már egy-másfél éve veri le az AMD-t, mint vak a poharat anélkül, hogy ténylegesen megjelent volna. De a kiszivárogtatott eredmény arra utal, hogy azért a Raptor lake is előrehaladott állapotban van. Ha nem is fogja megelőzni a Zen4-et, de azt nem zárnám ki, hogy a Zen4-gyel nagyjából egyidőben jelenjen meg, tehát ilyen szeptember-október táján.
a 10-11 hónapos fejlesztési ciklus durván, de még a 12-13 hónapos is számottevően gyorsabb, mint az AMD-nél tapasztalt 14-15-16-22.Az Alder Lake-ben (és a Raptor Lake-ben, valamint a Zen4-ben is) nekem az elengedett fogyasztás unszimpatikus. De ha az Intel ennyivel gyorsabban lesz képes termékeket megjelentetni (mondjuk 12 havonta 15 hónap helyett) akkor idővel a fogyasztás elengedése nélkül is képes lehet kényelmes előnyt elérni.
-

Alpi.
addikt
válasz
S_x96x_S
#7079
üzenetére
Cpu, nem Gpu. Egyébként be lehet dugni a vga csatit is abba (a 6 pinest legalábbis tuti), egy nagy gond van, hogy pont fordítva vannak a +12V és a föld pinek.

Egyébként ez benne van a top 3 ökörségbe nálam... Ha már adott megannyi kombináció a sarok letöréses kulccsal, ki volt az az állat, aki úgy találta ki, hogy belemenjen a vga tápcsati a CPU Eps csatiba.... Ráadásul fordított kiosztással... Még ha egyezne, azt mondom, ok, de így... -
#7040
Petykemano
veterán
S_x96x_S
#7038
Petykemano
veterán
válasz
S_x96x_S
#7038
üzenetére
> Ha a ZEN4 TCO-ja ( teljes bekerülési kültsége ) több mint +60% extra költég
> és a platform csak +30-40% -ot tud adni a ZEN3 -hoz képest,
A zen4 lapkák mérete kicsit kisebb, valamivel több lapka is kijöhet, mint Zen3-ból.
Az N7/N6 olyan brutál drága már nem lehet, ha megengedhetik maguknak a $200-os 5600-at és a kb ebben az árban levő 180mm2-es 5600G-t is.
Az N5 gyártástechnológia sem mai. Elképesztően jó a yield. Még ha $17000-os wafer költséggel számolunk is, akkor sem lehet egy zen4 CCD lapka önköltségi ára $25-nál nagyobb. Számoljunk ugyanennyivel az IOD-ra is.Ezzel együtt valószínűsítem, hogy legjobb esetben is annyi lesz a Zen4, mint a Zen3 induláskor, de inkább megint +$50-100. Ha az Intel versenyképes, akkor annyival drágábban nem is adhatják majd. Viszont őket erősen szorítani fogja a kapacitás. Majd biztosan hivatkoznak az inflációra, de az ár inkább kereslet-szabályozó eszköz lesz.
Szerintem az érezhető drágulás majd inkább az alaplapokat érinti majd. A B550 és a B650 között talán csak a PCIe5 storage lesz a különbség. Meg persze a 170W-os PPT.
+ DDR5 árak.
Talán nem véletlenül mondta Lisa Su is - ismét - hogy az AM4 velünk marad még néhány évig. -
#7035
Petykemano
veterán
S_x96x_S
#7027
Petykemano
veterán
válasz
S_x96x_S
#7027
üzenetére
> és mi van ha nem létezett?
Lehetséges. AdoredTV is készített egy videó és elővett egy 2 évvel ezelőtti Zen4-ről szóló satát anyagot, ami azt erősíti meg, hogy a Zen4 csak egy zen3(+) die shrink + 1MB L2$ + avx512
Én csak próbáltam összerakni egy olyan koherens történetet, amibe bele lehet illeszteni a zen4-ről IPC-ről szóló történetszálakat. Amik persze vagy valóban valamilyen ES eredmenyéi, vagy annak félreértése, specifikus teszt alapján való félreértelmezése, vagy akár kamu is lehet persze.
Ha 2020-ban AdoredTV ennyire pontos infókat kapott a 2022-es Zen4-ről, akkor akár az is lehet, hogy a Chips&Cheese, MLID, RTG már valójában a nextgenről kapott infókat, anélkül, hogy ők, vagy a szivárogtató tudná, hogy pontosan milyen termékről szól az infó.
Mindenesetre a félreértések elkerülése végett mondom, hogy ez nem a sandbagging vonalon való lovaglás részemről, hanem éppen az, hogy ebben a zen4 termékben nem lesz több, nem érdemes csodára várni.
Érdekes egyébként, hogy Coreteks a gaming területen látja az esetlegesen visszatartott információt, AdoredTV pedig ott, hogy mennyi mag férhet el a lapkán. Szerintem a magszámban nem lesz meglepetés. Viszont akár az L2$, akár a magas all core boost szép eredményeket hozhat játékokban.
A módosítást természetesen én sem utolsó pillanatban gondoltam. Hanem hogy többféle designt is elkészítenek: lehetett egy minimalista és egy, ami komolyabb IPC növekedést is hozna. Aztán valamikor 1-1.5 éve eldönthették, hogy a minimalista designt dobják piacra zen4 néven. Gondolom több részegység fejlesztése párhuzamosan történik különböző kisebb csoportok által. Lehet, hogy az AVX512 hamarabb kész lett.
-
#7028
Petykemano
veterán
S_x96x_S
#7026
Petykemano
veterán
válasz
S_x96x_S
#7026
üzenetére
Tehát:
X670E:
- sok IO (2 chipset)
- garantált GPU & NVME PCIe5
x670:
- sok IO (2 chipset)
- garantált NVME PCIe5 + opcionális GPU PCIe5
B650E:
- kevés IO
- garantált GPU & NVME PCIe5
B650:
- kevés IO
- garantált NVME PCIe5Ez egész korrektnek szegmentálásnak tűnik.
Kivéve azt, hogy az olcsóbb alaplapnál a PCIe generáción spórolnak, az olcsóbb GPU-nál pedig a sávokon. Nem tudnák úgy megoldani valahogy, hogy a PCIe4-es lapok esetén x16 PCIe4 vagy x8 PCIe5 legyen? -
HSM
félisten
válasz
S_x96x_S
#7022
üzenetére
Köszi a linket, érdekes volt.

#7024 Petykemano : Az elméleted támasztja alá az is, hogy ha jól emlékszem, az eredeti, Warhol/Zen3+ magoknál is előkerült ilyen pletyka, hogy azért került törlésre, mert "jól haladtak" a Zen4-el.
Lehet, hogy az eredeti Warholt/Zen3+ rakták át AM5/5nm-re, a "valódi" Zen4 meg majd jön egy következő generációval? A SA-s kalkulációk alapján kb. ez a félgenerációs IPC + egy generációs gyártástechnológiai előrelépés látszik....
A SA-s kalkulációk alapján kb. ez a félgenerációs IPC + egy generációs gyártástechnológiai előrelépés látszik....
Feltételezhetően ezt így "eladni" is könnyebb lenne, hogy előbb készült el aWarholkhm Raphael, mint kihozni még egy generációt AM4-re, és égni, hogy hát hogy ennyit meg annyit késik a nagyágyú... A lapgyártók is gondolom már tűkön ülve várták, mikor lehet ellőni a rajtot az újdonságoknak. -
#7024
Petykemano
veterán
S_x96x_S
#7023
Petykemano
veterán
válasz
S_x96x_S
#7023
üzenetére
Egyelőre nem tudni, hogy mennyire lesz probléma.
De sajnos tartok tőle, hogy az AMD azt az utat fogja választani, hogy a B650 lapokból kimarad a PCIE5 a GPU-nak, de az olcsóbb GPU-kba - ha nem is 2022-ben, de 2023-ban - már csak 4x PCIe5 kerül.Megy a spúrkodás az AMD részéről.
Azt gondolják, hogy nem engedhetik meg maguknak, hogy nagyvonalúan bánjanak a szilíciummal. Charlie azt említi, hogy Zen3 helyett Zen2 magok használatával pár centet spórolhattak, de szerintem arról van szó, hogy
- A Mendocino valójában egy kész Van Gogh design, amit portoltak N6-ra, de amúgy nem nyúltak hozzá
- Ha 5-10%-kal kisebb a lapka, mint Zen3-mal lehetne, akkor nem az az $0.5-1 költség számít, hanem hogy annyival többet tudnak eladni.Szerintem nagyjából minden lépésüket ez hatja át.
Megkockáztatok egy elméletet: (Persze lehet, hogy csak annyira fog bejönni, mint a double substrate, de így a fejemben egész kereken áll össze)
Láttuk már az AMD részéről, hogy képesek lehetnek akár több különböző design változatot elkészíteni, kipróbálni. Ha nem a szándékos félrevezetés, akkor ez magyarázhatja a GPU-k terén látható viszonylag nagy szórást mind a specifikációkra, mind a teljesítményre vonatkozóan is. Elképzelhető, hogy az AMD ma már CPU-ból is többféle verziót elkészít, kipróbál. Ez szintén magyarázná a nagy szórást arra nézve, hogy milyen előrelépés várható.
Megfigyeléseim szerint a gyártástechnológiai váltások teszik általában lehetővé azt, hogy komolyabb architekturális kigyúrások (nem átgondolás!) megvalósuljanak. Emiatt volt nem abszurd a Zen4-gyel kapcsolatos IPC-növekmény elvárás.
Azt is láttuk már, hogy az AMD képes CPU feature-öket előrehozni. Nyilván képes lehet elhalasztani is.Szóval mi van, ha az történt, hogy egyrészt a limitált N5 kapacitás miatt, valamint a késve érkező N3 miatt az AMD változtatásokat eszközölt a designban és az útitervben.
Mi van, ha tényleg létezett egy olyan Zen4 változat, ami komoly IPC emelkedést hozott volna. De végül az AMD úgy döntött, hogy az N5 kapacitás szűkössége miatt inkább többet dolgoznak a frekvencián és elengedik azokat az architekturális feature-öket, amik az IPC emelkedést eredményezték volna, de amiknek tranzisztorköltsége van. Így a Zen4 lapka valamivel (mondjuk 10%-kal) kisebb és így többet lehet belőle gyártani, amire a Genoa indulásakor amúgy is nagy szükség van. Az így kialakított Zen4 megkapja azokat az energiatakarékossági fejlesztéseket, amiket a Zen3+, meg persze az AVX512-t és az 1MB-os L2$-t - ami hol hasznos lesz, hol nem.
Ez eredeti Zen5 - új széles architektúra - tervek elhalasztódnak, mivel azok N3-ra készültek volna, ami viszont nem fog időben rendelkezésre állni.
A kettő közé az AMD betol egy N5-ön vagy N4-en végrehajtott architekturális ráncfelvarrást, ami megkapja mindazokat a fejlesztéseket, amik az "eredeti Zen4"-ben a most hiányzó IPC növekedést hozták. Ez ilyen 10-15% lehet, ami ha 1 évvel a Zen4 kiadását követően ki tudják hozni, egész jó generációs előrelépésnek fog hatni. És ez azt is magyarázná, hogy a Zen5 miképp lehet 2023-as termék annak ellenére, hogy az AMD architektúra váltásai között 1.5-2 év szokott eltelni. 2023-ban már talán bővebb lesz a rendelkezésre álló N5/N4 kapacitás, nem kell annyira spúrkodni a lapkamérettel.Hogy ez az elmélet mennyire lehet helytálló, abból derülhet majd ki, hogy a Zen4 után Zen5 néven érkező processzor családja továbbra is 19h vagy sem.
-
#7017
Petykemano
veterán
S_x96x_S
#7016
-
#6998
Petykemano
veterán
S_x96x_S
#6997
Petykemano
veterán
válasz
S_x96x_S
#6997
üzenetére
Igen, teljesen igazad van.
Upto vagy átlagot.szoktak mondani. Mert jobban hangzik. Ez meg from/over. Tehát leggyengébb ST javulás is 15%. Ebből persze lehet, hogy 10%-ot a frekvencia magyaráz.
De hát láttuk, milyen szórása volt a v-cache-nek is. Biztos lesz, ami lényegesen jobban reagál az L2$-re.
Ezen kívül a zen4 célja az avx512 volt. FP végrehajtásban lehet,.hogy nagyon parádés lesz.Ezzel.együtt ahogy várható volt, elindult 15% keveslése.
-
HSM
félisten
válasz
S_x96x_S
#6976
üzenetére
Teljes mértékben egyetértek vele.

Nem véletlen írtam már januárban: "a skálázódási probléma megoldási kényszerének áthárítására a szoftverekre, szoftverfejlesztőkre" [link] .
Illetve: "...a hardveresek átdobták a problémát a szoftvereseknek, amiből ritkán szoktak jó dolgok kisülni" [link] (Itt írtam az ARM megoldásáról is.)
De 2021 közepéről is érdekes az utolsó bekezdés innen: [link] ."persze ezzel majd az AMD-nak is meg kell küzdenie majd"
Úgyérted a szoftverfejlesztőknek, akiknek +1 speciális architektúrára kell majd optimalizálni?
Egyébként szerintem lehet(ne) ezt okosan csinálni, hogy kellőképpen hasonlóak legyenek a magok ahhoz, hogy ne legyen ennyire kényes kérdés, mi, hova ütemeződik. Tehát a jó irány szerintem az lenne, ha azonos módon kellene optimalizálni a magokra, elég lenne az, hogy a magasabb prioritású feladatok a gyorsabb, az alacsonyabbak a lassabb magokon futnának és a szoftverfejlesztőnek nem kellene másra már figyelnie.#6977 Petykemano: Ha jól tudom, ARM alatt az EAS rendszer segít be [link] . (Itt is ír pár dolgot, ami talán hasznos [link] .)
De ez nem teljesen ugyanaz a probléma, hiszen mobilon a prioritás az energiatakarékosság, míg az Alder esetében amarketingkhm,innováció,akarom mondani "throughput". Tehát röviden papíron az ARM azt csinálja, hogy arra a magra igyekeznek rakni a feladatokat, ami a leghatékonyabban el tudja végezni azokat. Abba most ne menjünk bele, hogy ez a rendszer sem olyan szép a gyakorlatban, mint így leírva....
#6980 S_x96x_S: "az ütemezés - szerencsére szoftveres, amin könnyű változtatni."
Az Alder problémájának azt a részét nem fogja az ütemező megoldani, hogy a szoftveredet mire optimalizáld, pl. van-e HT vagy nincs, vagy befékezi-e a buszt a kis mag vagy sem....
A Zen5-féle megoldásnál majd meglátjuk, hogyan sikerül összerakni a rendszert, lesznek-e hasonló gubancok vagy sem.#6986 Petykemano: Csak a Rembrandt nem hinném, hogy "elvinne" a lábán egy platform startot.
 Az még AM4-nél is csak egy erős középkategória lenne. Kéne mellé még valami, ami kicsit nagyobbat szól.
Az még AM4-nél is csak egy erős középkategória lenne. Kéne mellé még valami, ami kicsit nagyobbat szól. #6993 Pakmara: Pl. gyártási/tervezési költség optimalizálása. Az olcsóbb termékbe elég kevesebb periféria vezérlő/PCIe sáv, a drágábba viszont több kell, így pedig egy lapkával megoldják mindkét igény lefedését. Mint a processzoroknál, 8 magig 1 CCD-t, 8-16 között kettőt raknak rá.
-
#6986
Petykemano
veterán
S_x96x_S
#6985
Petykemano
veterán
válasz
S_x96x_S
#6985
üzenetére
Úgy tűnik AM5 bemutató az lesz.
Hát most akkor lehet tippelni, hogy vajon bejelentik a Raphaelt, mint nagy attrakciót az AM5-höz, vagy csak a Rembrandt-ot.
Szerintem a Rembrandt nem egy olyan nagy wasistdas, hogy érdemes legyen ráépíteni a bemutatót.
Tehát én arra számítok, hogy az AM5 elrajtol most. És elrajtol a Rembrandt is. És akkor van értelme piacra dobni.
De bejelentésre kerül a Raphael is, mint fő attrakció, ami viszont majd csak nyáron válik elérhetővé. -

poci76
aktív tag
válasz
S_x96x_S
#6976
üzenetére
Tapasztalatom szerint korántsem ennyire problémás az E és P magok ütemezése. A P magon két szál fut, így az egy szálra jutó számítási teljesítmény nincs messze egy E magra jutó számítási teljesítménytől, így minden optimalizálás nélkül is egész jól ki lehet használni a processzort. Nekem nagy meglepetést okozott a 12900K a 10850K után, mert nem számítottam túl nagy sebességnövekedésre.
Egy szimuláció, amivel nézni szoktam, hogy milyen gyors a proci, a következő futási időket produkálta. A szimulátor nincs optimalizálva heterogén magokra (annál is inkább, mert 2017-es):
Ryzen 3 1200 => 119.753 seconds
Ryzen 7 1800X => 77.733 seconds +54%
Threadripper 1920X => 53.300 seconds +46%
Core i9 10850K => 49.072 seconds +9%
Core i9 12900K => 28.737 seconds +65% -
#6982
Petykemano
veterán
S_x96x_S
#6981
Petykemano
veterán
válasz
S_x96x_S
#6981
üzenetére
Hát akkor legalább az AM5 Rembrandt-ot is be kéne jelenteni hozzá.
Bár Szerintem eléggé csalódást keltő lenne, ha a CES után a Computex is csak a Rembrandtról szólna. Ezért szerintem akkor be kell jelenteni a Zen4-et is. Teaser már volt a CES-en. Tehát legalább néhány SKU-t és teljesítményábrákat kell mutogatniuk, mégha a piaci rajt esetleg csak júliusban lesz is.
május 23. Vagyis 5 és 2+3=5. Mint 5nm.
Minden jel erre mutat. -
#6979
Petykemano
veterán
S_x96x_S
#6978
Petykemano
veterán
válasz
S_x96x_S
#6978
üzenetére
Ehhez a működéshez az applikációnak és/vagy az OS-nek tudnia kell, melyik mag melyik. Az Arm esetén a kis és nagy magok megkülönböztetése feltételezem már egy ideje adottságnak tekinthető.
Másrészt az általad bevágott szövegben kulcsfontosságú kifejezés az, hogy high-priority applications - tehát ezt is tudni kell. Nyilván erre vonatkozólag az Intel azon megközelítése, hogy ami az aktív user fókuszt kapja, az a high-priority - nem jó.Viszont szerintem van itt egy másik probléma is.
Az Arm és az Apple esetében is a kis magok létezésének célja tényleg az, hogy a háttérfolyamatokata lehető legkisebb energiabefektetés mellett elvigyék.
Ennek megfelelően nem is törekednek arra a designokban a kis magok számát szaporítsák.Az Intel esetén viszont a kis magok célja nem ez, hanem a MT teljesítmény növelése alacsonyabb energia és helyigény mellett. Az Alder Lake esetén egyébként ez a "high priority applications" megközelítés még nem szúrt volna szemet. De Mondjuk az már elég hülyén nézne ki, hogy ott van a Raptor Lake.ben 16 E mag, ami mondjuk egy blender renderelésben nem vesz részt.
Mondani nyilván könnyű, de szerintem valahogy úgy kéne kinéznie, hogy a background taszkok mindenképpen az E magra üzemeződnek.
A high-priority taszkok mindent is használhatnak, de affinitással rendelkeznek a nagy magokra. Ez azt jelenti, hogy alacsony szálszám esetén csak a nagy magon fut, nagy szálszám esetén terjed át az E magokra.
A user fókusszal rendelkező program pedig kitúrhat mindent és bármit a P magokról.Ennek egyébként a Zen5+Zen4D esetén is pont így kellene működnie.
-
#6977
Petykemano
veterán
S_x96x_S
#6976
Petykemano
veterán
válasz
S_x96x_S
#6976
üzenetére
> vagyis, hogy 2 -nél több chipetet tud-e kezelni a desktopos io-die
Ezt a kérdést kiküszöbli Zen4+Zen4D, ami 2023Q1-ben gyártható.
> Ami furcsa lesz nekem, hogy míg az AVX-512 támogatást az AMD kiemeli majd ...
AdoredTV utolsó videója szerint a Genoa és a Bergamo is támogatni fogja az AVX512 utasításokat, 256b-es Load/Store műveletekkel, de a tényleges művelet végrehajtás elvileg 512bites lesz.
Az AMD helyében én azt csinálnám, hogy a Zen4D esetén a műveletvégrehajtást is kettévágnám 256bites szeletekre. és akkor kisebb a mag, de az ISA támogatás ugyanaz.> Agner on Aldder Lake
AZ elején említi, hogy azért nehéz tájékozódnia a programnak vagy az operációs rendszernek, mnert a DRM miatt egységesíteni kellett a P és E magok CPUID-jét. Bármilyen hülyén hangzik is, de szerintem ez egy nem várt probléma az Intel részéről, amire csak egy rossz megoldást tudtak adni. Azt gondolom, hogy ha nem CPUID-vel, akkor valamilyen más módon megoldást fognak találni arra, hogy a magok megkülönböztethetők legyenek egymástól.Másrészről a Ryzen és szerintem az Intel cpu-k esetén is valahogy tudatható a rendszerrel, hogy melyik a legjobb és második legjobb mag. Az más kérdés, hogy ezzel aztán mi mit kezd, de nyilván ez a fajta megkülönböztetés szintén kiterjeszthető.
Harmadrészt sajnálatos, hogy Agner Fog irományában egy árva szó nem esik az Arm-ról. Pedig az ARM esetén évek óta létezik a külön clusterba szervezett kis és nagy magok megkülönböztetése, a klaszterezés első generációja a big.LITTLE volt, most tudtommal a DinamIQ néven fut. De még ha feltételezzük is azt, hogy ez annyira egyszerű, mint ahogy az Intel Thread Director csinálja, vagyis hogy a Foreground applikáció fut a nagymagos clusteren és minden más background folyamat a kismagos clusteren, amiről ugye Agner is azt mondja, hogy ez desktop környezetben nem jó megközelítés. Akkor is ma már a nagymagos clusterben is kétféle mag van: a Cortex X1/X2 típusú és a Cortex A78/A710. Ebben az esetben az Arm hogy csinálja? hogy különböztetik meg ezeket a magokat? Teljesen véletlenszerű lenne, hogy a nagymagos clusterben a programszálat az X_ vagy a A7_ típusú mag kezeli?
-
#6946
Petykemano
veterán
S_x96x_S
#6940
Petykemano
veterán
válasz
S_x96x_S
#6940
üzenetére
> és inkább feltételezem, hogy a "Dragon Range" már RDNA3 -as lesz.
Nekem ez most állt össze:
A jelenlegi infómorzsák szerint lesz egy GFX1103 kódszámú RDNA3, ami egy APU [link]Ha a Dragon Range egy a Phonenix-hez hasonló - feltételezve, hogy az egy monolitikus APU - , csak minden szempontból nagyobb, akkor saját kódnevet kellett volna (vagy kellene a későbbiekben), hogy kapjon.
Persze ez nem szünteti meg az összes bizonytalanságot.
Mert azon kívül, amit én mondtam, elméletileg még mindig lehetséges, hogy a Phoenix és a Dragon Range is chiplet alapú APU, ahol az általuk használt IGP rész megegyezik, csak a a CPU más. Viszont ez ellentmond annak az állításnak, miszerint a legalacsonyabb fogyasztású szegmensekbe csak monolitikus felépítésű chip használható.
Vagy még az lehet, hogy egy teljes értékű Phoenis lapkához hozzá lehet kapcsolni még egy zen4 CCD-t.Mindenesetre egyelőre úgy tűnik, hogy a Phoenix-től eltérő másik/nagyobb - monolitikus- RDNA3 APU nincs.
-
#6939
Petykemano
veterán
S_x96x_S
#6938
Petykemano
veterán
válasz
S_x96x_S
#6938
üzenetére
> induláskor a Raphael -ben mintha még csak egy pici RDNA2-es lenne,
Igen.
> és csak a ~félévvel később érkező "Dragon Range" -re irnak RDNA3-at.Elnézést, lehet, hogy elkerülte a figyelmem.
Arra emlékszem, hogy az ábrán nem szerepel, hogy milyen grafikával érkezik - ezt Ian Cutress a tweetjében ki is emeli: "Process node not mentioned. Graphics not mentioned."Mivel nem találkoztam azzal, hogy a Dragon Range RDNA3 lenne, ezért legalábbis ez alapján nem kizárható, hogy a Dragon Range valójában Raphael-H(X) (tehát chipletes cucc)
Mondom, tehát lehet, hogy elkerülte a figyelmem, ezért kérdezem: honnan jött az az infó, hogy a Dragon Range RDNA3 lenne (és a cpu pedig új zen4 stepping)?
Természetesen ha Abu-nak van igaza és ez inkább egy a Phonenix-hez hasonló annak felturbózott változata, akkor lehet RDNA3. -
#6935
Petykemano
veterán
S_x96x_S
#6933
Petykemano
veterán
válasz
S_x96x_S
#6933
üzenetére
> viszont ha lesz 16 core ( a Dragon Range -ben )
> .. annak már kell 55W+
> .. és pariban lehet az 5950x -el.
Igen, ehhez nem kell más, mint hogy olyan chipletet használjanak, mint az epyc-hez: alacsony fogyasztásút. notebook termék lévén az se feltétlenül baj, ha a boost órajel esetleg 400Mhz-cel alacsonyabb, mint a desktop termék esetén. Másként megfogalmazva, ami egy 65W-os 7950 lehet, mert olyan lapkákból áll, az elmegy 7950HX-ként is 55W-ból. Cserébe ha van V-cache, akkor még arról se kell lemondani mobil környezetben. Talán erre utalt Abu, amikor azt pedzegette, hogy igen, az 5800X3D is tudna menni 35W-ból, de ebből ilyen termék már nem lesz.
Én azt remélem, hogy a kupak alá besúvasztanak az egyik CCD helyére egy RDNA3 chipletet is. Talán annak úgy már lenne megfelelő méretű piaca. Mármint a double subrstrate setup-pal: ami nem megy el FP7-be, azt kiszórják AM5-be. A v-cache (IFC) segítene, hogy a DDR5 sávszél elég legyen egy nagyobb teljesítményre is.
170W TDP meg azért elég sok.
/csuri/ -
#6934
Petykemano
veterán
S_x96x_S
#6933
Petykemano
veterán
válasz
S_x96x_S
#6933
üzenetére
> valami hasonló ..
> ~ új zen4-es stepping + RDNA3Ezt nem értem. Ha a Dragon Range-re írtad, akkor szerintem a Dragon Range mobil tokozású Raphael. Ahogy a Rembrandt meg fog érkezni AM5 tokozásba, úgy a Raphael is a mobilba. (FP7?)
És ezt az teszi lehetővé, hogy (feltehetőleg) az IOD-ban lesz IGP. Ez alkalmassá teszi high-end notebook eszközbe
- olyanba is, ahol a cpu erő számít és nincs is benne dGPU. Ezt a területet A Cézanne és Rembrandt igazából csak alulról kapargatja.
- és olyanba is, amiben nagyonis van dgPU, amit egyrészt ki kell hajtani, másrészt pedig nem kell megkötni üzemidőben azt a kompromisszumot, hogy a játékon kívüli képet is a dGPU adja és szívja az aksit.Emlékszel még arra a kérdésre, hogy miért olyan "egzotikus kialakítású" az AM4 kupakja?
Akkor a - szerintem - legközelebbi tipp az volt, hogy dupla tokozás van a kupak alatt.
double substrate setup~kb így:

Szerintem ez az AM5-ös kupak alatt egy FP7-es szubsztrát van így jön létre ez a két termék egyféle kialakításból. Amit nem tudnak FP7 tokozással eladni, az megy az AM5 szemétledobóba.
-
-
#6921
Petykemano
veterán
S_x96x_S
#6919
Petykemano
veterán
válasz
S_x96x_S
#6919
üzenetére
A Nuvia ígérete 40-50%-kal magasabb ST teljesítmény volt 33%-os energiafelhasználás mellett.
Az Apple M1 szerintem ebből csak egyszerre egyet teljesít. Tehát vagy harmadakkora fogyasztás mellett hoz ugyanakkora teljesítményt, egyébként meg amennyivel nagyobb IPC-vel rendelkezik, aménnyivel magasabb frekvenciákat elérnek az X86 procik.
Szóval a zen2-höz képest már a zen3 is hozott 15%-ot. Ehhez képest még idén hoz 20-25%-ot a zen4.
Ezzel a 40-50% ST többlet már nem is előny. A fogyasztás persze kérdés.Viszont 2023 végére várjuk a zen5-öt is. Ami jelen ismereteink szerint széles architektúra, nagy L1-L2 cache segítségével +30% IPC és N3 gyártásttechnológia. Ennek fényében az eredeti Nuvia ígéret már egészen konzervatívnak tűnik.
Az még kérdés, hogy idén milyen tervet.virít az arm, akiből jövőre termék lehet.
Az Apple egyértelmű előnyben van. De ennek egy része azért abból fakad, hogy mindénkinél előbb használják a fejlettebb gyártástechnológiát. Amíg ez megmarad, mindig nagy lesz a távolság teljesítményben vagy fogyasztásban. -
#6915
Petykemano
veterán
S_x96x_S
#6912
Petykemano
veterán
válasz
S_x96x_S
#6912
üzenetére
> AM5-re portolni fogják a mostani Ryzen6000-res APU-t,
> csak más tokozás kell neki,
Ez egész biztosan meg fog történni. Ezzel mindenki kalkulál, még Abu is megírta: [link]
A Rembrandt (zen3+@N6) összképét viszont egyfelől rontja a Vermeer-hez képest feleakkora cache (Tehát a frekvencia előny épphogy pariba hozza a Vermeer-rel)
másrészt az AM5 a DDR5 miatt magasabb platform költséggel jár.Amikor én azt mondtam, hogy kihozhatnak egy Zen3-at N6-on, akkor azt a platformköltség figyelembevételével az AM4-hez gondoltam. Egyszerűen azért, mert ha jól tudom, még a Raptor lake sem fog szakítani a DDR4 támogatásával, tehát a alsóbb szegmensek dömpingáras (+alasonyabb platformköltség) intel termékei ellen nem lesz hatásos fegyver, ha az AMD a Rembrandtot kínálja. Persze ez mind azon a feltételezésen alapul, hogy a DDR5 árak a következő negyedévekben még mindig jelentősen meg fogják haladni a DDR4 árakat (Abu erre hivatkozik, hogy miért csak ősszel jelenik meg az AM5 és a Rembrandt)
> És az is lehet, hogy tesznek a zen3+ -os APU-ra egy 3D VCACHE-t,
Ez sokat segítene a játékos felhasználók számára.> Ha nagyon szorítja az Intel az AMD-t,
> akkor a ZEN3(+)-os chipletekből egy új io-die -al
> tud olcsó 12 -16 magos AM5-ös procikat is csinálni.Technikailag ez sem kizárt. De én épp abból indultam ki, hogy a DDR5 magas ára miatt lenne praktikus a olcsóbb szegmenseket még 1 esetleg 2 évig AM4-gyel lefedni és azt a kérdést feszegettem, hogy a már minden szempontból olcsónak számító AM4 foglalatba illő processzorok versenyképességét miképp tudná erre az 1-2 évre még természetesen minimális befektetéssel (!) növelni az AMD. Nemrég egy interjúban Lisa Su is azt mondta, hogy az AM4 még velünk marad 1-2 évig.
Bocsánat, tehát nem egy, hanem két szempontot vettem figyelembe:
- szűkös N5 kapacitás
- drágább DDR5 ramok.Amennyiben csak a szűkös N5 kapacitás áll fenn, akkor igazad lehet, hogy megoldható az alsóbb szegmens lefedése AM5 Rembrandt APU-kal is.
-
#6911
Petykemano
veterán
S_x96x_S
#6910
Petykemano
veterán
válasz
S_x96x_S
#6910
üzenetére
> de azért az Intel dömping-áraival is számolni kell,
> vagyis túl nagyon nem szállhatnak el az árakkal.Én azt gondolom, hogy az AMD első körben legfeljebb ugyanazokat az sku-kat fogja megjeleníteni, mint a zen3 esetén volt. Megkockáztatom, hogy talán még 6 magos se lesz.
Nem biztos, hogy igazam lesz, tévedhetek, de ha az Intel még sokat szerencsétlenkedik a Sapphire rapids-zal, akkor a Genora-ra (épp az általad említettek miatt: +25% IPC ; 5Ghz ; AVX512, a gyorsabb DDR5 memória és a Gen5) még a Milan-nál is nagyobb igény lehet. Tehát szerintem a kapacitás nagyon szűk lesz. Persze az is igaz, hogy elvileg ezúttal az AMD a saját szempontjából cutting-edge gyártástechnológián csak zen4-et és Navi3X-at gyártat (abból is csak a felső osztályt) tehát nem lesz konzol, ami limitálja.Mindenesetre amit mondani akartam, hogy hát ha és amennyiben tényleg szűkös az AMD N5 gyártókapacitása, akkor ezzel (intel dömping ár) nem nagyon fog tudni mit kezdeni egy ideig Zen4 alapon. A zen3-at tudja olcsón kínálni, vagy Zen3D-t tud bevetni, de nekem azért úgy tűnt, hogy ahhoz, hogy a zen3D-nek legyen érezhető hatása, kell valami $700-1000-os gpu is.
Vagy hát azzal lehet még erőlködni, amit Abu írt az 5800X3D-hez, hogy tulajdonképpen a B2 stepping nem csak gyárthatósági szempontokat javított, hanem az AMD áttervezte a lapkát úgy, hogy jelentősen csökkenjen a fogyasztás (vagy legalalábbis az adott frekvenciához szükséges feszültség) Gondolom, hogy ezek ugyanazok az energiahatékonysági fejlesztések, amiket a Rembrandt is megkapott. Erre lehet akár új sku-t kihozni. (Bár Abu azt írta, hogy ilyen nem fog történni)
Vagy amit még lehet az az, hogy kihoznak egy zen3-at N6-on - gyakorlatilag ami a Rembrandt CPU része. Az lehet, hogy elmenne akár 5.2Ghz-ig is. Azért az is lenne 7-8% egy 5800X-hez képest.Ha van elegendő N5 kapacitás, akkor ez persze fölösleges szerencsétlenkedés volna.
-
#6909
Petykemano
veterán
S_x96x_S
#6907
Petykemano
veterán
válasz
S_x96x_S
#6907
üzenetére
Kiemelném:
Az Apacer táblázata szerint a Zen4 desktop 2022 H2-ben rajtol. (Egyébként a Genoa-val együtt)
Ebből persze még nem derül ki, hogy Q3 vagy Q4 - jelenthet akár egy szeptemberi rajtot vagy egy decemberi elérhetőséget is.
Egyrészt a pletykák szerint előbb fog érkezni, mint a Raptor lake, ami inkább Q3-as rajtot sejtet, ezen kívül az RDNA3 tapeout dátumok pedig azt sejtetik, hogy Q4-et inkább az fogja betölteni. Én egy olyan Q3-as rajtot valószínűsítenék (mint a Zen3 esetén is volt), amivel elviszik lehengerlik a benchmarkokat, de a termékeket a korábbiaknál drágábban jelentik be, amivel egyrészről magas árrést söpörnek be, másrészt elfedik, hogy a Genoa-ra szánt kapacitások miatt amúgy se tudnának nagyobb piacot lefedni. Aztán Q4-ben jön a raptor lake, ami nagyjából ugyanazt az utat fogja bejárni a piacon, mint az ADL. -
#6900
Petykemano
veterán
S_x96x_S
#6899
Petykemano
veterán
válasz
S_x96x_S
#6899
üzenetére
Az eddigi ismereteink alapján a dual-chipset csak IO kapacitást ad hozzá.
Vagy az van, hogy az AMD opcionális bővítőkártyák újabb típusával kívánja lefedni a piacot a Xilinx segítségével
Vagy a CXL által ígért szintén bővítőkártyás forradalomra készíti fel a platformot. Itt egy 4x pcie5-re rá lehet már kötni valami RAM bővítményt.
Így vagy úgy, azt hiszem, a Threadripper (nem feltétlenül mint név, hanem a piaci igény, amit az lefedett) az x670-ben él majd tovább. -
#6896
Petykemano
veterán
S_x96x_S
#6893
Petykemano
veterán
válasz
S_x96x_S
#6893
üzenetére
További érdekesség, hogy a cikkben lamentálnak azon, hogy vajon az AMD az A620-as alaplapokat DDR4-gyel tervezi-e. Ez persze nem biztos, tehát csak mint lehetséges opció merül föl azon cél érdekében, hogy az olcsóbb platform RAM szempontjából is kellően olcsó tudjon lenni.
De ezt vajon hogy oldanák meg? az IO lapka eleve rendelkezne DDR4 támogatással? Vagy az olcsóbb Zen4 termékek kapnának csak DDR4 támogatást? Vagy valamilyen átalakítóval? (ami költség) Igazából csak azért említetem, fel, mert ha már valamilyen módon az A620-as alaplapokkal előállna az, hogy DDR4-es Zen4, akkor ugyanazzal a lendülettel AM4-be is lehetne nyomni.
Ez persze nyilvánvalóan nem fog megtörténni - persze nem valamiféle kompatibilitás miatt, hanem mert szerintem kapacitás okokból az AMD-nek nem lesz célja olcsó Zen4 platformot kínálni. -
#6894
Petykemano
veterán
S_x96x_S
#6893
Petykemano
veterán
válasz
S_x96x_S
#6893
üzenetére
Én úgy értelmeztem, hogy nem a B650 alaplap képessége x8 Pcie4, hanem a chipseté kifelé. Tehát szerintem a videokártya nem lesz mindenképpen x8 Pcie-re korlátozva.
Viszont számomra némi magyarázatra szorul hogy a proci és a chipset között 4x Pcie4 van, de a chipset kifelé 8x-at tud. Ez azt jelenti, hogy mondjuk a chipsetre kötött usb-USB vagy USB-m.2 eszközök közötti adatforgalom nem terheli a procit? -
#6886
Petykemano
veterán
S_x96x_S
#6884
Petykemano
veterán
válasz
S_x96x_S
#6884
üzenetére
A Phoenix vajon chiplet alapú, vagy monolitikus?
Előbbi megmagyarázná, hogy miért nem biztos, hogy RDNA2 vagy RDNA3 és hogy 16 v 24 CU -t tartalmaz. Lényegesen leegyszerűsítené ezeket a kérdéseket. (másokat meg esetleg felvetne)
Bizonyos szempontból egészen egyszerű és logikus lenne, ha a Raphael és a Phoenix ugyanazt a CCD-t használná, csak előbbi egy szerény méretű IOD-dal (kicsi IGP) rendelkezne, utóbbi viszont egy nagyobb IGP-vel és persze IFC-velAz APUk esetén megszokott és fogyasztási szempontból indokoltabb monolitikus design esetén megint nehéz dönteni.
Egyrészről az AMD utóbbi időben generációnként csak egyik részt szokta cserélni.
Renoir: zen=>zen2 CPU + Vega IGP (kakukktojás)
Cézanne: zen2 => zen3 CPU + Vega IGP
Rembrandt: Zen3 CPU + Vega=>RDNA2 IGPA Nextgennek az volna logikus, hogy fognak egy Remrandt designt és kicserélik benne a CPU-t.
Ugyanakkor az azt is jelentené, hogy meg kell tervezni az RDNA2-t N5-re, ami pedig lehet, hogy fölösleges munka ha már egyszer az RDNA3 elkészül N5-re (és mellesleg N6-ra is)Ha tippelnem kéne, én inkább az RDNA3-at mondanám.
-
#6879
 Németh Péter
őstag
S_x96x_S
#6873
Németh Péter
őstag
S_x96x_S
#6873
-
#6878
Petykemano
veterán
S_x96x_S
#6874
Petykemano
veterán
válasz
S_x96x_S
#6874
üzenetére
/zen5/
Ha tippelnem kéne, azt mondanám, hogy az Apple-t követik:
privát L1 + L2 és megosztott L3 (zen3)
 ( [link] )
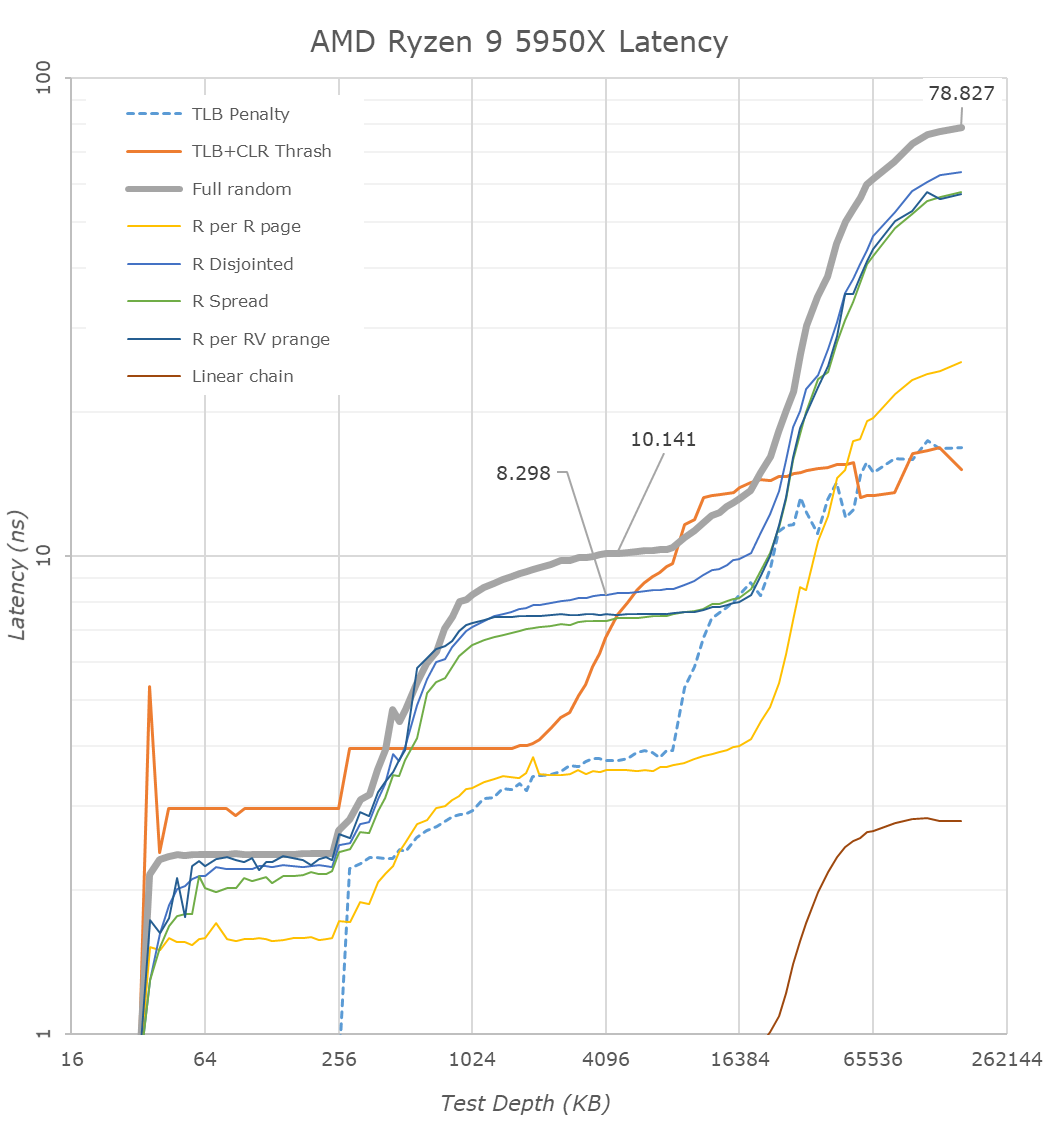
( [link] )Látszik, hogy 32KB-ig 1ns a késleltetés, aztán az L2$ feléig még mindig alacsony, aztán szépen felkúszik 10ns-ra, ami az L3$ közel eső szeletének késleltetése, majd az is feltörik.
Ehhez képest az M1:
A késleltetés 128KB-ig nagyon alacsony és utána 8MB-ig 5ns (noha valójában 12MB az L2$)
Ha ezt meg tudják csinálni, akkor valóban kevesebb szükség lehet L3$-re.
Bár az Apple is alkalmaz L3$-t (System Level Cache néven), de ha jól emlékszem,. akkor azt már nem csak a CPU, hanem az IGP is tudja használni.Ez viszont csak akkor valósítható meg, ha a az L3$-t kompletten kiemelik a CCX-ből, összecsúsztatják az L2$ részeket és végül egységesítik az L2$-t úgy, hogy stacked L3$ rápakolására még mindig lesz lehetőség. Abban az esetben ha az L3$ stacked azzal sincs probléma, hogy a stacked L3$ rész késleltetése picit magasabb.
Ezzel egyébként egy roadmapet is felvázoltunk.
Szerintem nem volt akkora hülyeség a wccf által publikált rajz [link] [link]
Csak nem arra vonatkozik, amire ők gondolták.
Szóval a roadmap szerintem:
- zen4: az új zen3 architektúra finomítása, megnövelt L2$ (aminek hatására kisebb a nyomás az L3$-en), új gyártástechnológia, FPU duplázás
- zen4c/zen4d: L3$ kiemelése (legalább felezése, de inkább kiemelése) a CCX-ből. Az L2$ összecsúsztatása (privát 1MB vagy 2 mag által megosztott?), 3D Stacked L3$, visszaállás 2 CCX / CCD-ra (16 magra egységesített L3$, vagy 2x 3D stacked L3$ lapka )
- zen5: új architektúra: architektúra szélesítése, megnövelt L1$, L3$ kiemelése a CCX-ből, L2$ összecsúsztatása és egységesítése (=> megosztott, 8MB)Azt gondolom, hogy az L3$ kiemelése a designból és az L2$ összecsúsztatása nem egy nagy kunszt, tehát a zen4d/c és a zen5 fejlesztése ebből a szempontból lehetett párhuzamos. A wccf cikk fő mondanivalója ugye az, hogy két zen4 mag fog osztozni 1MB L2$-n. Ebből a szempontból a zen4d/c egy pilot projekt is lehet(ett) a zen5 egységesített L2$-éhez.
Az a kérdés merült föl bennem, hogy azt mondják, hogy nem véletlen, hogy az Apple M1 olyan, amilyen és a zen valamint az intel processzorok is olyanok, amilyenek cache felépítés szempontjából. Konkrétan: az M1 egy konzumer eszköz, ahol jellemző az egy programos használat (nem feltétlenül egyszálas, de hogy a rendszert döntően egy program veszi igénybe egyszerre), amely esetben jól jöhet, hogy megosztott L2$, amin keresztül az egy programhoz tartozó szálak adatot tudnak megosztani egymással. Ehhez képest a szerverek terén inkább jellemző az, hogy egymástól teljesen független programszálak futnak, amiknél meg inkább a privát cache hasznos. Persze elképzelhető, hogy ki lehet kapcsolni a megosztást. Tehát konzumer termékben 8MB L2$ látható, szerver termékben magonként 1MB L2$.
-
#6869
Németh Péter
őstag
S_x96x_S
#6821
válasz
S_x96x_S
#6821
üzenetére
Én is elgondolkoztam egy 5950X-es új gépen.
Ki is néztem ezt a gépet: https://www.youtube.com/watch?v=vAIzTq9t_a8Azt jól értem, hogy az új AMD processzor generációnál a léghűtés kiesik a magasabb fogyasztás miatt? Szerintem az egy fontos szempontos az otthoni felhasználásnál. Az mennyire jelezhető előre, hogy a ZEN4 mennyivel több hőt fog majd termelni?
A legnagyobb általam ismert léghűtésnek a Noctua NH-D15-nek a TDP-je 220W ha jól értem. Az sem világos, ha csökkentik a csíkszélességet, akkor nem kéne csökkenni a fogyasztásnak is? Miért az a trend a GPU-nál is, meg CPU-nál is, hogy egyre többet fogyasztanak? Lassan 1 kW-os tápegységek kellenek a gépekenek.
pl. a gép Inteles testvére, a 12900K-ra építő konfigot már eleve vizessel rakta össze, tizen valahány ventillátorral: https://www.youtube.com/watch?v=wCxA4hFNfjw
-
#6868
Petykemano
veterán
S_x96x_S
#6866
Petykemano
veterán
válasz
S_x96x_S
#6866
üzenetére
A Zen4 olyan, mint a zen2. Die shrink + core refinement + FPU fejlesztés.
A zen5 viszont ground up New architecture, Amiről mondták is, h szélesedik. A magasabb IPC növekedés nem meglepő.
Ha ez a Zen5 az, amit 2023 végén várunk, akkor az elég jól hangzik, hiszen akár 50%-ot is verhet zen3-ra - ami most válik szélesebb körben (olcsóbban) elérhetővé, másfél év múlva elavult teknős lesz. (Igen, tudom, nem avul el, van aki még P4-gyel nyomul és nem érzi, hogy váltania kéne)A magszám duplázódása ambivalens. Most biztosan úgy gondoljuk, hogy igazából céltalan, bár jól esne, ha egy tierrel lejjebb csúsznának a.magszámok árban.
Viszont mondjuk az, hogy nő a max magszám még nem feltétlenül jár együtt ezzel. Én nem számítanék $300-os 12 magos procira újonnan. Bár már most lehet kapni $400-500-ért 12-16 magosat, de azért ez már 4 éves gyártástechnológia és 2.5 éves termék.
Viszont az Intel várhatóan minden generációval emelni fogja az E magok számát és ezzel lépést kell tartani.
Nagy eséllyel a magasabb magszámot az AMD is a Dense magok.segítségével.fogja elérni.A M1/A14 esetén láttuk, hogy egy széles design mennyivel nagyobb L1$-sel dolgozik. Ez is várható. A kérdés legfeljebb az, h az Apple hogy csinálta, hogy 5x akkora mérettel dolgozik, és még sem szignifikánsan rosszabb a késleltetés. Én továbbra is azt gondolom, hogy a magas frekvencia cél és az amiatti nagy / ritka tranzisztoroknak eredménye a nagy fizikai kiterjedés, és hát mivel a fénysebesség adott, a cache fizikai kiterjedése korlátot jelenthet. Magyarul, ha csökkentjük a frekvencia célt, kisebb kiterjedésű lehet ugyanakkora cache kapacitás és javulhat a késleltetés - az alacsonyabb frekvencia ellenére.
Majd meglátjuk.A unified L2$ viszont teljesen értelmezhetetlen számomra. Egyrészt úgy tudom, hogy a szerver workloadok kifejezetten szeretik a nagy privát L2$-t.
Hogy kell ezt érteni? L2$ szeletek.nincsenek is közel egymáshoz. Ez valami tartalmi egységesítés lenne, hogy tisztában lesz mindegyik mag, hogy melyik mag L2$ szeletében mi van? Vagy valami olyasmi, mint az IBM virtuális L3$-e?
-
carl18
addikt
válasz
S_x96x_S
#6845
üzenetére
Igen, én is azon csodálkoztam az AMD csak a Zen 5-ig van betáblázva. Lehet nem véletlen tartják titokban, így nagyon meglepetést tudnak okozni az intelnek.
Az elmúlt évek AMD Lépései által egy biztos most nem lesz könnyű őket úgy lenyomni mint 2010 előtt.Mivel az intel is felfedte és betáblázta a Roadmapját 2025-2026-ig így az AMD is tudja mire készülhet. És nyilván azokhoz fogja az adott generációt igazitani.
Egyenlőre egy biztos az AMD a Meteor Lake ellen még biztosan versenyképes marad. Talán 2025-ben veheti át egy kicsit az intel a vezetést.
A Verseny mindig jó, nem lesz unalmas a most következő időszak. Legalább az intel is felébredt az 5 éves álmából

-
HSM
félisten











![;]](http://cdn.rios.hu/dl/s/v1.gif)
















 Az még AM4-nél is csak egy erős középkategória lenne. Kéne mellé még valami, ami kicsit nagyobbat szól.
Az még AM4-nél is csak egy erős középkategória lenne. Kéne mellé még valami, ami kicsit nagyobbat szól. 








Új hozzászólás Aktív témák
- AMD K6-III, és minden ami RETRO - Oldschool tuning
- Autós topik
- Samsung Galaxy Tab tablet topik
- Kerékpárosok, bringások ide!
- Xiaomi 15T - reakció nélkül nincs egyensúly
- Minecraft
- Motorola Edge 50 Neo - az egyensúly gyengesége
- alza vélemények - tapasztalatok
- Projektor topic
- Kertészet, mezőgazdaság topik
- További aktív témák...

- SZÉP! HP EliteBook 850 G8 Fémházas Tartós Laptop 15,6" -65% i7-1185G7 32/512 Iris Xe FHD
- Corsair Vengeance 64GB (2x32GB) DDR5 6000MT/s CL40 XMP black kit - ÚJ, bontatlan, garis - ELADÓ!
- Garanciával, Számlával! Logitech G29 Driving Force Racing Wheel
- Asztali PC , i5 8400 , RTX 2060 , 16GB DDR4 , 512GB NVME
- Felkonfig
- Gamer egerek és billentyűzetek kitűnő árakon!
- Samsung Galaxy A23 5G 128GB, Kártyafüggetlen, 1 Év Garanciával
- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max
- BESZÁMÍTÁS! LENOVO Ideapad Gaming 3 notebook - R5 5600H 16GB DDR4 256GB +1TB SSD nVidia GTX 1650 4GB
- Vállalom Xiaomi Okoskamerák szoftveres javíttását
Állásajánlatok

Cég: ATW Internet Kft.
Város: Budapest

Cég: BroadBit Hungary Kft.
Város: Budakeszi