Hirdetés
- Samsung Galaxy Watch7 - kötelező kör
- Hivatalos a OnePlus 13 startdátuma
- Samsung Galaxy A52s 5G - jó S-tehetség
- Kis méret, nagy változás a Motorolánál
- One mobilszolgáltatások
- Samsung Galaxy A54 - türelemjáték
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Fotók, videók mobillal
- Samsung Galaxy S24 - nos, Exynos
- Bloomberg: Az iOS 27 a stabilitásra és az AI-ra fókuszál majd
Új hozzászólás Aktív témák
-

#36531588
törölt tag
válasz
 S_x96x_S
#7889
üzenetére
S_x96x_S
#7889
üzenetére
Vagyis 2x64 mag gyorsabb, mint 2x52.
 Gondolom árban sem ugyanannyi.
Gondolom árban sem ugyanannyi. ![;]](//cdn.rios.hu/dl/s/v1.gif)
Ár/érték? Tudod mindenki a pénztárcájával szavaz!

Xeon - 104 mag 95.014 v-ray pont - 913 pont / mag
Epyc Milan 3DV - 128 mag 102.843 v-ray pont - 803 pont / mag
Ezt akartad mutatni? Már be is érte az intel az epyc-et, nem tartott soká..... -

S_x96x_S
addikt
válasz
S_x96x_S
#7882
üzenetére
Egy picit zavar, hogy egyesek összekötik Robert Hallock távozását és a Zen4 launch-et.
Lehet valami összefüggés?Yuri Bubliy:
https://twitter.com/1usmus/status/1569756160210751488
A few facts about the launch of Zen 4
🔴There are already 9 versions of AGESA
🔴NDA has been shifted two times
🔴CPU and motherboard releases shifted (the first shipments arrived at the warehouse)
🔴Robert Hallock leaves AMD
🔴Enthusiasts are not allowed to test (marketing only) -
#36531588
törölt tag
válasz
S_x96x_S
#7870
üzenetére
"vagyis az x4 és x8 -as sávszálcsökkentett GPU-kat nem lehet elkerülni a jövőben
és ( "aki teheti") annak érdemes a Gen5 felé tendálni."[link] Senkit nem zavar a x8 sőt normális kártyával a x4 sem. Ezért felesleges a gen5 felé tendálni, egyrészt mindenki tudja, hogy csak azért mondod mert az amd lesz gen5-ös, másrészt pont nv-t kell venni amit nem érint a sávszél, mint ahogy az amd sokkal érzékenyebb rá.
Ezt már itt [link] kitárgyaltuk, ennek ellenére máshol kezded újból. Szerinted van ennek értelme, azon kívül hogy csak az látszik, mindenképpen félre akarod tájékoztatni az embereket, hogy amd-t vegyenek? Hitelesség? Mondjuk nálad lassan mindegy.
Megnyugtatásul a gen5 rdna3 és gen5 ssd témáról is lekattanhatsz, mert több helyen több ember elmondta neked, hogy még a gen4 ssd-k sincsenek kihasználva, amiről pedig te álmodsz, az ha sikerül is az amd-nek, még évek múlva is csak lehetőség lesz, nem követelmény, amihez újabb évek kellenek.
Összefoglalva amiért kampányolsz, és szerinted érdemes rdna3-ba ruházni, az még jó esetben is olyan messze van, hogy aki most vesz rdna3-at, már rég elfelejti hogy volt neki. -
#7860
 Petykemano
veterán
S_x96x_S
#7859
Petykemano
veterán
S_x96x_S
#7859
Petykemano
veterán
válasz
S_x96x_S
#7859
üzenetére
Igen, ez jó érv amellett, hogy az Intel komolyan (hamar) gondolja az AVX1024-et.
Náluk mondjuk meg is lesz nemsokára a szükséges háttér. Legalábbis azt mondják, hogy a vektor/mátrix műveletekhez alapvető fontosságú a sávszélesség (lásd még: Fugaku) és ez a HBM-mel szerelt Sapphire rapids esetén meg is lesz.
Nem tudom, hogy mik az AMD tervei ezen a téren. Abu korábban emlegette ezt a HBM-es vonalat, de a jelek szerint elvetették, vagy a 3D stacked V-cache mellett döntöttek. Egyelőre nincs látható jele annak, hogy ezen a vonalon hasonló megoldással kívánnának versenyezni.
Az AMD erre a területre a Mi300-at hozza majd, ami biztosan nagyobb teljesítménnnyel és perf/W mutatóval fog rendelkezni, csak gondolom APU-ra programozni eggyel bonyolultabb, mint AVX512 helyett AVX1024-re.
-
#7857
Petykemano
veterán
S_x96x_S
#7856
Petykemano
veterán
válasz
S_x96x_S
#7856
üzenetére
Szerintem a Zen5 egy from-stratch ground-up new architecture, aminek a fókuszában ismét a ST/IPC növelés lesz. Elképzelhető, hogy ennek részét képezi majd az is, hogy az FPU végrehajtó egységeket 256bitesről 512bitre bővítik. ilyen változtatáshoz biztos hozzá kell nyúlni a regiszterek szélességéhez, meg ilyesmi. Mármint hogy praktikus lehet a L1d duplázását is ide időzíteni. És az, hogy AVX512 műveleteket nem kettő, hanem 1 órajel ciklus alatt végrehajt úgyanúgy eladható IPC növekedésként.
Én arra számítanék, hogy a Zen5 még N4-en készül.
Aztán a Zen6 megy N3E-re, ami a valódi nodeváltás.
Nem tudom, hogy az Intel mennyire gondolja komolyan ezt az AVX1024-et.
- Vajon Mikortól lenne praktikusabb inkább egy IGP-t használni?
- És hogy mekkora igény lehet rá ténylegesen?
- Vagy mekkora nyomás jön ilyen téren az Arm-os konkurencia irányából?Mindenesetre én legkorábban a Zen6 esetén látnám reálisnak. Hasonlóan a Zen4-hez: nodeváltás és utasításbővítés, MT teljesítmény.
-

Alpi.
addikt
válasz
S_x96x_S
#7849
üzenetére
"Akkor én a "B" felé hajlok.
( vagyis 5.0 PCIe és semmi extra és csicsa .. )
megj: én főleg munkára használnám "Na, ezaz ! Pont ezeket az "okosabb" megoldásokat veszik ki a képletből. Akinek kell, úgyis megveszi, náluk meg több pénz landol, mivel top chipset lévén "prémium" sarcot kap.
Máshol is ugyan így megy. Pl. autóknál egy magasabbra pozicionált típust kizárólag a nagyobb hátsó lábtérrel és csomagtartóval nem lehet elindítani. Csomó más ponton el kell választani a kisebb tesóktól. Abba 1,5" -al nagyobb kijelző kell, a tükör emblémát kell vetítsen az aszfaltra, stb. És ezeket sosem szabad a kicsiknek megkapnia azonos generációnál, mert akkor azonnal hasztalan az egész.
(szintén privát vélemény )
) -
#36531588
törölt tag
válasz
S_x96x_S
#7799
üzenetére
Itt úgy látom, csak az x670e lapok támogatják a pcie 5 ssd-t és a gen5 pcie x16-ot, a nem "E" lapoknál csak a pcie x16-on lesz gen5. [link]
"The X670E series will support PCIe Gen5 interface for both PCIe x16 interface (graphics) and M.2 slot (storage). The X670 non-Extreme series only have dedicated Gen5 support for M.2 slot."
Egyébként nem semmi árak. E-s lapok 480-1300 dollárig.
-
#36531588
törölt tag
válasz
S_x96x_S
#7812
üzenetére
"Emiatt nem árt tudni, hogy mi - mire van rákötve ..
ha egy x4 -es chipseten lóg pár M.2-es akkor a szűk keresztmetszet a chipsetre vándorol.
Még két külön - külön használt x4-es M.2 -nél nem lehet annyira észrevenni,
de ha a RAID egyszerre próbálja meghajtani a két M.2-őt .. akkor az galibás"Nem most jöttem a hathúszassal
egy nvme ssd abban a slotban, ami a cpu-hoz van bekötve, 2db nvme ssd pedig egy asus hyper m.2 x16 gen 4 kártyában, így azok is teljes értékű x4 sávszélhez jutnak, a 3090 pedig manuálisan korlátozva x8-ra.Na látod ezért kértem a block diagramot ahhoz a két laphoz, hogy lássak a pályán.

De ez nem csak nálam jelenség, ha utána nézel a weben látod, másnak is ez a tapasztalata az amd raid-el.
-
-
-
#36531588
törölt tag
-
#7769
Petykemano
veterán
S_x96x_S
#7766
Petykemano
veterán
válasz
S_x96x_S
#7766
üzenetére
> a zen4c alacsonyabb freq-n és kisebb cache-el müködik a zen4-hez képest ..
> emiatt itt is vannak optializálási-ütemezési teendők.
A HT óta probémát jelent, hogy a szoftvernek (alkalmazás és/vagy OS) tudnia kell, hogy mely két hardveres szál tartozik egy maghoz és hogy ha egy új programszálat ráütemez egy olyan hardveres szálra, amely magnak a másik hardveres szála már dolgozik valamin, akkor szuboptimális eredményt kap. Nem tudom, hogy hogy csinálják, vagy hogy pontosan mi intézi, de valahogy meg kell oldania, hogy ez ne így történjen, hanem tudja, hogy mely mag programszálai szabadok. Mintha anno a Zennel kapcsolatban lettek is volna ilyen jellegű optimalizációs problémák.
Az első Zen óta problmát jelent - a CCX-ek miatt - a thread locality, vagyis hogy a szoftvernek (alkalmazás és/vagy OS) pontosan tudnia kell, hogy ha egy programszálat átütemez, vagy egy új, de adat szempontjából kapcsolódó programszálat a másik CCX-re ütemet, akkor szuboptimális eredményt kap. Ebből biztosan voltak problémák, amelyeket több-kevesebb sikerrel sikerült orvosolni. Persze nyilván az, hogy két cluster között nincs direkt adatmegosztás, csak a memórián keresztül, az mindig hátrány marad, de az irracionális ütemezést és az ostoba, a CCX-ekre tekintettel nem levő ütemezésből fakadó teljesítményproblémákat szerintem sikerült kiküszöbölni.Az már nagyon régóta úgy van, hogy a legjobb és/vagy a két legjobb, legmagasabb frekvenciát elérni képest mag meg van jelölve. Elvileg ezt az ütemező figyelembe is veszi.
Nyilván persze a P mag és E mag közötti különbség nagyobb annál, mint hogy egyik mag 40-50Mhz-cel többre tud turbózni.
De pl az 5950X esetén a két CCD fogyasztási jellemzői között azért elég számottevő különbség volt, nem tartom elképzelhetetlennek, hogy a két CCD legjobb magjának maximális turbó frekvenciája között akár 200-300MHz is lehet.Jó, ez persze még mindig nem vészesen nagy. Nyilván minél nagyobb a magok közötti különbség, annál nagyobb az impactje az ütemező tévedésének. De valahogy ezeket a különbségeket eddig is kezelte, nem?
-

poci76
aktív tag
válasz
S_x96x_S
#7755
üzenetére
Szerintem nem ilyen egyértelműen billen a mérleg a ZEN4 felé.
A DDR4 támogatás sokaknak számíthat: megtartja a korábbi RAM-ját, így egyáltalán nem kell RAM-ot venni.
- Nem egy "dead platform" ... és zen4/zen5 3D-re lehet upgradelni
Sokan terveznek hosszabb távra, mondjuk 3-5 évre, nekik teljesen érdektelen, hogy lehet-e procit cserélni.- jobb SSD támogatás ( Gen5 )
Nem tudom, hogy ez hány felhasználónak érv. Mikor SSD teszteket néztem, az jött le a számomra, hogy egy SATA SSD és a leggyorsabb NVMe SSD között normál alkalmazásokban nincs érdemi különbség. Úgyhogy, ha két alaplap között csak az lenne a különbség, hogy az egyik PCIe 3-as a másik 5-ös, és más a színük, akkor a szín alapján döntenék.
- 1 hónappal korábbi piacra lépés
Aki tényleg a két platform között mérlegel, és nem muszáj azonnal választania, az ki fogja várni azt az egy hónapot.
Ha csak magamat nézem: ha nulláról kellene egy új gépet építenem, akkor 7950X-et vennék. Ennek oka egyrészt az AMD iránti szimpátiám, másrészt, hogy több generációt tudnék ugyanabba az alaplapba tenni, hogy kevesebbet fogyaszt, hogy ott az AVX512, és nem annyira zavar, hogy biztosan lesz sok gyerekbetegsége az új platformnak. Viszont, mivel ott a sok DDR4 RAM-om, már nem lenne ilyen egyértelmű a dolog (pont emiatt ugrottam bele az Alder Lake-be, meg mert nagyon jó áron volt). (Persze most kényelmes helyzetben vagyok az Alder Lake-kel, mert ha esetleg a csere mellett döntök, akkor sokkal olcsóbb és kockázatmentesebb csak a procit kicserélni egy Raptorra, mint teljes platformot cserélni, és vállalni az ezzel általában együttjáró szívásokat, amiből az Aldernél is volt bőven, és mivel gyakorlatilag egyenértékű a ZEN4 és a Raptor, ez egy viszonylag fájdalommentes lépés, még ha az AVX512-ről le is kell mondanom. Most arra számítok, hogy a ZEN5-nél ugrom vissza AMD-re.)
-
-
#7743
Petykemano
veterán
S_x96x_S
#7740
Petykemano
veterán
válasz
S_x96x_S
#7740
üzenetére
Szögezzük le, hogy a látott W értékek a PPT/PL2-t jelentik.
Ez talán annyiból lehet fontos, hogy ez elvileg nem tartós fogyasztás, hanem a pillanatnyi. a pillanatnyi hő elvezetéséhez pedig inkább a hővezető képesség [W/(mk)] legalább annyira fontos, mint hűtőrendszer TDP minősítése.Mindenesetre szerintem némiképp pontatlan és/vagy félrevezető a számítás.
Egyrészt elsőre jogosnak tűnik, hogy a Zen4 esetén csak a CCD méretét veszik figyelembe, hiszen a hő ott termelődik, és nincs direkt kapcsolatban az IOD-dal. De azért tudjuk, hogy a package power kb 25%-kal magasabb, mint a magokon mérhető fogyasztást - a különbözet legalább részben feltehetőleg az IOD-on keletkezik (memóriavezérlő, infinity izék, stb)
Másrészt noha igaz, hogy az Intel monolitikus lapkája lehetőséget ad a magoknál termelődő hő 2D irányba (a chip többi területére) való terjedésére is, de attól, hogy ez a hőterjedés lehetséges a monolitikusan beépített részek irányba, az korántsem jelenti azt, hogy a lapkaterület teljes része valóban részt vesz a hőleadásban. (lásd: [link] )
Fentiek értelmében szerintem nem lehetetlen, hogy az AMD sorokban a 71mm2-es kiterjedésű lapkákra eső W értékekből el lehet venni 10%-ot.
Míg az MSI által készített hőtérkép alapján az Intel sorokban simán meg lehet felezni a hőleadásban valóban hasznosan résztvevő lapkaterületet. -
#7731
Petykemano
veterán
S_x96x_S
#7729
Petykemano
veterán
válasz
S_x96x_S
#7729
üzenetére
Ezt az XpressConnect Retimer és Switchtec PCIe Switch ábrát én is megtaláltam.
De egyrészt nem tudom pontosan milyen funkciót töltenek be a retimer, switch chipek. mármint utóbbiról van fogalmam - az amd esetén az alaplapi chipset pl egy PCIe switch.Másrészt úgy értelmeztem az ábrát, hogy ez a cég kínál valamilyen olyan retimer/switch chipeket/IP-t, amivel 60ns-ról 10ns-ra csökkenthető a PCIe jeltovábbítás/osztás. Amit ha használsz, jobb lesz.
Itt gyorsan be is fűzöm, hogy hát feltételezem az B650 és X670 esetén talán pont valami ilyesmi a jelentősége az 1 vagy 2 chipsetnek. Hogy mondjuk az X670 esetén azért van két chipset, hogy alacsony legyen a késleltetés, míg a B650 esetében valami "other retimer"-t használtak, ami vagy megfelel a PCIe5 szabványnak, vagy még annak se.
Viszont olyan jellegű összehasonlítást, hogy a fenti PCIe5 minimumnak tekinthető számokhoz képest mit tudott vagy mi volt az elvárás a PCIE4-gyel szemben, olyat nem találtam.
Illetve hát egy-két helyen belefutottam egy 100ns-os értékbe abban a konnotációval, hogy ez a PCIE5 esetén sem változott. -
#7730
Petykemano
veterán
S_x96x_S
#7727
Petykemano
veterán
válasz
S_x96x_S
#7727
üzenetére
Talán furcsa lesz, amit mondok, de fogyasztói szemmel nézve nem biztos, hogy ez jó irány.
Persze sok függ a kondícióktól. Mondom mire gondolok:Van ez a jelenség, tudjátok, amikor úgy emelik a tejföl árát, hogy nem az árat emelik, hanem a tejföl méretét csökkentik.
Jelenleg tudtommal a legtöbb cloud szolgáltató párosával adja a vcore-okat. A GCP-ben nem is nagyon titkolják, hogy 2vcore = 1 core + SMT. Utóbbiről lemondhatsz. Attól még persze olcsóbb nem lesz.
Az új architektúrák jellemzően magasabb IPC-t, nagyobb sávszélességet, esetleg valamivel több cache-t ígérnek, olykor magasabb frekvenciát. De utóbbi nem feltétlenül igaz, az Intel szerverchipjei esetén jellemző volt, hogy bár több mag fért el egy lapkán, de a magok alapfrekvenciája csökkent.
Ugye ez aki szerverben, vagy socketben gondolkodik annak tök jó, mert magasabb lesz a throughput, a Throughput/W és a throughput/socket.
De aki vcore-t bérel, az... háááááááát talán a generációváltással járó IPC és a sávszélesség növekedése hoz annyit, amennyit a frekvencia csökkenése esetleg elvisz.
És akkor itt van ez a Bergamo. Hejjdekirály, 128 mag!!!! uhhhh
Igen, aki socketben gondolkodik, annak tök jó, mert magasabb lesz a throughput, a Throughput/W és a throughput/socket.
De aki vcore-t bérel, annak... hááááááááát
Feleakkora L3$ és 10%-kal alacsonyabb alapfrekvencia. (A Genoához képest)
És ugye SMT is van tehát továbbra is el lehet adni úgy, hogy 2vcore = 1core+SMTHááááááááát ugye ez azt jelenti, hogy akinek Genoa helyett Bergamo jut, az pont semmilyen előrelépést nem fog érezni mondjuk egy Milanhoz képest, miközben a szolgáltató ugyanazt a pénzt szedi be a vcore-ok után, viszont 2x annyit tud belőle értékesíteni.
Persze nyilván sok múlik a kondíciókon. Cloudban nem igazán versenyeznek egymással architektúrák vagy ISA-k. A Cloud szolgáltatók versenyeznek egymással.
Tehát persze el tudnék képzelni olyan konstrukciót, hogy a Bergamo értékesítése már úgy történjen, hogy ugyanazért a pénzért, vagy esetleg picit többért már 4 vcore-t adjanak, vagy esetleg kapásból le is tiltsák az SMT-t és 1vcore=1core legyen. -
#36531588
törölt tag
válasz
S_x96x_S
#7721
üzenetére
csak az RDNA3 lenne az egyetlen "komoly" Gen5-ös videókártya,
( az RTX 40 marad Gen4 -en ; és az ARC csak félkomoly státuszban van még )Az RDNA2 és a RTX 30 pont annyit használ a pcie4-ből, hogy semennyit. Pont ugyan ez lesz az RDNA3-al, szinte biztos hogy semmi különbség nem lesz teljesítményben hogy milyen foglalatban van, sőt még az sem lesz jelentős különbség, hogy x8 vagy x16.
Csak ehhez meg kell várni hogy megjelenjen, és kijöjjenek az első tesztek ezzel kapcsolatban. Addig is folytathatod a mellébeszélést.
-
#7725
Petykemano
veterán
S_x96x_S
#7721
Petykemano
veterán
válasz
S_x96x_S
#7721
üzenetére
> és a Gen5-nek alacsonyabb a latency-je és nagyobb a sávszélessége;
ezt én is így tudtam.
Egyik nap próbáltam méréseket keresni, de valójában nem találtam semmilyen bizonyítékot. A PCIe5 hardveren keresztül működő CXL viszont csökkentheti
[link]Esetleg neked vannak adataid - PCIe4 vs PCIe5 ?
-
#36531588
törölt tag
válasz
S_x96x_S
#7720
üzenetére
"A befektetők is a pénzükkel szavaznak, és jelenleg az AMD már többet ér mint az Intel.
Az AMD piaci tőkeértéke (137,01 milliárd USD) > mint az Intelé (131,06 milliárd USD)"Ez is csak most érdekel, 2 éve még nem példálóztál vele. Elmondom a különbséget, az intel egy stabil vállalat, gyárakkal, állandó teljesítménnyel. Az AMD pedig jelenleg egy feltörekvő cég, így rengeteg spekuláns bele teszi a pénzét, hogy aztán nyereséget realizálva dobja a papírt. Majd meglátod hogy spriccelnek szét, ha lesz egy kedvezőtlenebb negyedéve, amit Lisa be is lengetett az előző eredmények ismertetésekor.
"magamból indulok ki ...
és én figyelembe veszem (beárazom) az opciós lehetőségeket is."Azt látom. De attól még mindig ott járunk, az egyéni prefereciák messze nem tükrözik a nagy átlag viselkedését, valamint te a saját dolgaid alapján általánosítasz, ami így nem valós.
"csak ne vedd személyesre a vitákat ... mert az elrontja mindenki élményét
"Dehogy veszem, csak jót mosolygok azon a vak elfogultságon amit az amd irányába teszel.
-
#7719
Petykemano
veterán
S_x96x_S
#7714
Petykemano
veterán
válasz
S_x96x_S
#7714
üzenetére
"És amúgy is az RDNA3 túl jól sikerült és kell hozzá egy erős proci ami nem fogja vissza."
Tudom, mondtam már pár egzotikus dolgot, aminél az AMD (és a technológia) konzervatívabb volt. De kíváncsi vagyok, mikor viszik egy szinttel feljebb a Smart Access Memory technológiát. "Smart Access Cache." (TM) tehát amikor egy V-cache-sel szerelt CPU és egy Infinity cache-sel szerelt RDNA3 egymás L3$-ében turkál (mintha valamelyik nap az intelnél láttam volna hasonló pletykát) -
#36531588
törölt tag
válasz
S_x96x_S
#7714
üzenetére
Kb ezeket vártam tőled, a valósággal köszönőviszonyban sem levő dolgok. Inkább csak annyi, ne maradjon a raptor a best a zen5-ig.
Ha az RDNA3 úgy sikerül, mint a zen4, vagyis hogy 7nm-ről 5nm-re kellett váltani, hogy egy raptorral szembe tudjon nézni, akkor elég nagy a baj.
Ezzel az upgraddel meg társaival max a fórumozókat hozod lázba, aki most megvesz egy raptort vagy egy zen4-et, 4-5 évre letudja a gépcserét, és az emberek 90% fölötti része ilyen.
-
#7697
Petykemano
veterán
S_x96x_S
#7692
Petykemano
veterán
válasz
S_x96x_S
#7692
üzenetére
Asus B650 lapok [link]
Elnézést, az M.2 oszlopban tudom értelmezni, hogy lesz egy Gen5-ös és egy Gen4-es M.2 slot és azt is értem, hogy ha több van.
De a PCIe oszlopban mit jelent minden sorban mit jelent a PCIeX16_1 meg PCIeX16_2?
Azt, hogy tulajdonképpen két slot lesz, többségében mindkettő Gen4?Ezt egyébként nem úgy szokták csinálni, hogy ha két kártyát teszel a gépbe, akkor fele-fele arányban osztoznak a rendelkezésre álló sávszélességen? Vagyis 2x x8?
És akkor tényleg minden B650 alaplap két darab PCIe x16 slottal lesz ellátva?
Azt meg vajon minek?
Az AMD ezekkel a lapokkal már előre készül a PCIe bővítőkártyák (XDNA, XCL memória, stb) robbanására?További kérdésem, vajon miért nem lehet azt megoldani, hogy van egy slot, ami PCIe4 módban x16, de tudja a PCIe5 módot is, de azt csak x8 sávszélességben?
Ez sokkal barátibb lenne a jövőben a GPU-knál várható spórolási metodikával, ahol is nem a PCIe generációval spórolnak, hanem a sávok számával. És tök jó lenne, ha amikor beteszel az "olcsó" B650-es lapodba egy "olcsó" RX 7600-at (ami legjobb esetben is Pcie5 x8 lesz, de talán csak x4), akkor mondjuk nem a kétféle spórolás metszeteként előálló legrosszabb forgatókönyvet kapod -
#36531588
törölt tag
válasz
S_x96x_S
#7510
üzenetére
""Persze ehhez az kell, hogy ne "clock-down"-os implementáció legyen .."
a ZEN4-ben .."Sikerült, nem clock-down-os lett.
 Cserébe csak AVX-256. Vagyis a teljesítmény ugrott.
Cserébe csak AVX-256. Vagyis a teljesítmény ugrott. Csak próbálok rávilágítani, megint mekkora tévedésben voltál, mikor azt hitted majd az amd mérnökei megoldják amit az intel nem tudott.

De folytassuk:
"Az ügyfelek egy része kipróbálta .. ( pl Maxon ... ) és
úgy ítélte meg, hogy több vele a macera mint a haszon ..
~ főleg a "clock-down" miatt."Na itt nincs clock-down, de a teljesítménye is várhatóan a fele. Akkor szerinted, most mi lesz a csábító, ha kvázi teljesítményben a végeredmény ugyan az, mint az intelnél?
-
#7623
Petykemano
veterán
S_x96x_S
#7616
Petykemano
veterán
válasz
S_x96x_S
#7616
üzenetére
Elolvastam.
Számomra két érdekes pont volt. Az egyik a hatalmas FP kapacitás, ami a GPU-k világába repíti.
Kicsit kapcsolódik ide a múltkori kérdésem, hogy mi végett kell az AVX512 (itt: "AVX1024"), amikor ott vannak a GPU-k. Érteni vélem, hogy a szoftver nem tart ott, hogy egy pcie slotba helyezett gpu esetén a fédélzeti memória korlátos és pcie-keresztül a rendszermemóriából másolni lassít. A Fugaku is hasonló elképzelés mentén készült és... tulajdonképpen a Mi300 is. Azt a kérdést akartam feltenni, hogy ha ez a probléma, hogy. Szoftver cpun fut, de a számítást vektoros egységek végzik a gpun, akkor miért nem úgy közelítik meg a kérdést, hogy egy bazinagy gpu-ba beintegrálnak egy 8 magos CCX-et, azt kész. Ez megtörtént a konzolok esetén is.
De valószínűleg hasonló történik majd a Mi300 esetén is, csak chipleteket fognak összerakni.Egy másik gondolatom.az lett volna, hogy a 64 magos 6-7TFLOPs zen2 esetén egyszerű.szorzásokkal.el lehet jutni a Prodigy teljesítmémyéig (mármint papíron) 256bites vektor egységek helyett 1024b, 64 mag helyett 128 és kb kétszer nagyobb frekvencia.
Nyilván persze nem ennyire egyszerű, hiszen a cikkből is kiderül, hogy ezt tudni kell.etetni.De mivel úgy tűnik Mi300 is majd ennek a kérdésnek a lefedésére érkezhet, félő, hogy a prodigy vagy papír, vagy rétegtermék maradhat. Abban esetleg látnék lehetőséget, hogy európai AI és HPC kezdeményezések erre épüljenek.
-

HSM
félisten
válasz
S_x96x_S
#7620
üzenetére
Én ezek miatt kevésbé aggódom. A PCIe5 az az IOD dolga, ahogy a DDR5 is, illetve DDR5-öt már tudott a Rembrandt is, így aligha hiszem, hogy ezekkel baj legyen. Ezek legfeljebb alaplap/BIOS szinten okozhatnak némi fejfájást, amit remélhetőleg idővel kezelni is tudnak majd, ha esetleg szükségessé válna.
Számomra ami kritikusabb, hogy fog kinézni a fabric, jó lesz-e az új IGP-s IOD, jól sikerül-e maga a CCD.... És reméljük nem találnak rajta valami security lyukat, amire kétszámjegyű százalékú teljesítmény veszik el befoltozni....
-
HSM
félisten
válasz
S_x96x_S
#7617
üzenetére
"de másrészt viszont a túl gyors verseny
a vevőknél néha "pszichológiailag" problémát okoz,"Az én esetemben ezt nyugodtan elvetheted. A véleményem erről, hogy a túl erős verseny miatti szűk határidők miatt nem volt idejük 'befejezni' a csipet, így mobilba CPPC nélkül jött, miközben az asztali verzió (ami egy "rugalmasabb" piac) már tudta ezeket. Ennek a 'befejezetlenségnek' kézzelfogható, érzékelhető, napi szinten előjövő hátrányai vannak. Torony magasan a számomra legidegesítőbb, hogy pl. ha 5-10 másodpercre megállítok egy YT videót, utána már csak késve indul újra, ha folytatni szeretném. Ugyanez egy két generációval korábbi négymagos Intel laptopon semmi problémát nem okoz, abban a pillanatban megy tovább, ahogy megnyomtam a gombot.
Természetesen emiatt nem váltottam vissza azért az előző rendszeremre, de határozottan kellemetlen visszalépés egy optimálisabb esetben több, mint duplaerős processzortól, főleg, hogy a probléma természetéből világosan látszik, hogy maga a vas képes azonnal újraindulni (5 másodpecen belül), csak pihenő módból látványosan túl sok idő, mire magához tér.Egyébként a kékenél is érzékelhető 'némi' versenyhez kapcsolódó túlzott kapkodás, pl. Alder Lake esetén elég 'érdekes' lett, ahogy összedrótozták a két polcon fekvő architektúrájukat (cache-alrendszer/belső fabric), illetve az AVX512 'kényszerű' kiesése (de a nagy magban való jelenléte) is erősen szuboptimális megoldás volt. Az erőszakos, szoftveres/firmware-es utólagos tiltás pedig külön bohózat volt.
Nagyon remélem, hogy a Zen4-nél kiforrott megoldásokat kapunk majd.

-
HSM
félisten
válasz
S_x96x_S
#7614
üzenetére
"és itt a Zen3+ fejlesztés rámutatott .. hogy eddig ez azért problémás és elhanyagolt terület volt."
Voltak azért hiányosságok bőven, pl. a mobil Renoir még a CPPC-t sem tudta (!!!) [link] . Persze, ettől még látom a gyakorlatban, hogy működik így is egészen jól, de azért jobban örültem volna, ha tudja ezt egy 2020-as termék, amikor a konkurencia már 2016-ban kipipálta ezt.Mindenképpen szükség lesz a Zen3+ fejlesztéseire, ha mobilon meg akarják tartani a pozíciójukat a Zen4-el is.
-
#7609
Petykemano
veterán
S_x96x_S
#7608
Petykemano
veterán
válasz
S_x96x_S
#7608
üzenetére
Ez a skálázhatóság nekem leginkább ilyen jól hangzó elmélkedésnek tűnik, amit persze nyilván szükséges és hasznos teljesíteni, de ritkán kerül ténylegesen alkalmazásra - legalábbis abból a perskeptívából nézve, ahogy eddig az AMD csinálta.
Magszám skálázás szerintem nem arra vonatkozik, hogy a chiplettel lehet a magszámot skálázni. A magszám skálázása magára a chipleten belüli magszámra vonatkozik. Ilyet az amd esetén csak elvétve láttunk. Eltérő magszámú chiplet nem is volt, de a CCX-t csökkentett magszámmal be tudták építeni más monolitikus designba.
A core generation scalability nekem megint valami olyasminek tűnik, hogy az eltérő mag-architektúrákat külön-külön is ki lehet cserélni és egy félidős terméket megjelentetni vele. Ezt majd valóban meglátjuk, ha az AMD is elkezdi keverni a magtípusokat.
A node.scalability szerintem nem az, hogy eltérő részegységek különböző gyártástechnológián készülnek,.hanem hogy ugyanaz a design készülhessen más gyártástechnológián. Mondjuk az IOD az asztali processzor esetén elég ha egy prevgen nodeon készül, mobil Cpu esetén ugyanaz legyen cutting edge nodeon.
Ilyet nem láttunk az AMDnél. Pedig lehetett volna, hogy pl az IOD-t és a Zen3-at átdobják N6-ra és kiadnak egy zen3 refresht.Cache scalabilityt is csak akkor láttunk,.amikor a CCX-et bedobják egy APU-ba. Illetve valóban a 3D cache is tekinthető ennek egy fajtájának.
Ennek persze megvan a magyarázata. Az AMD chiplet megközelítésének nem csak az volt, hogy a chiplet legyen kicsi, legyen jó a hibaarány és legyen jó a válogathatóság. Hanem az is, hogy egyetlen designnal fedjenek le több piacot.
Amit én az Intel anyagból kiolvasni vélek az az, hogy ők az "egy design mindenre" elvet elvetve ezt egy új szintre emelnék és ugyanabból a chipletből célpiactól függően eltérő magszámú, magok tekintetében eltérő összeállítású, akár más és más gyártástechnológián készülő és más cache konfigurációval rendelkező chipletet készítenének.
Ennek a megközelítésnek az előnye az, hogy takarékos a tranzisztorral/gyártókapacitással. Viszont biztosan több mérnöki munka megy el arra, hogy a különféle változatokat elkészítsd és persze rendkívül pontosan tudni.kell előre, hogy melyik változatból mennyi kell.
Én egyelőre nem látok tapogatózást ebbe az irányba az AMDnél. De ez változhat, hiszen látjuk,.hogy az AMD is bővítette a designok mennyiségét.
-
#36531588
törölt tag
válasz
S_x96x_S
#7595
üzenetére
Akkor, ha csak ilyet gyártat az amd, akkor lehet, mondom lehet hogy ki tudná szolgálni egy nagy oem igényeit. Szerintem a többi meg elég lesz az intelnek.
Ez a "big problem" is egy bizonyos közönség számára vehető komolyan. Tök jó lesz egyébként ez a cucc, ha mindenki játszani veszi, mert kb ott jön ki a 3DVcache előnye.
Ami ugye, nem túl életszerű. -
#36531588
törölt tag
válasz
S_x96x_S
#7569
üzenetére
"megj: persze nálam inkábba a Workstation-os felhasználás dominál és kevésbé a gaming;
és ott az AVX-512 és az alap Gen5 SSD igencsak előny, főleg akkor ha rendes ECC támogatás is lesz."Akkor, ha jól gondolom intelt használtál eddig ugye?
Vagy csak most azért lesznek ezek fontosak, mert az amd tudja. "Viszont 2-3 éven belül a Gaming-et is eléri az AVX-512 ;
amúgy lefogadom, hogy már idén is látunk 1..n ( amd támogatott ) játékot,
amit avx-512 -re optimalizáltak ( persze multi-arch-os és furnak avx2 -vel is )"Nos oké, meggyőztél. Akkor én ez alapján instant cserélek egy 7900X-re, és két év múlva folytatjuk. Úgy néz ki lesz egy vevőm a 7900X-re, új áron 2-3 év múlva.
Kicsit se zavarjon hogy az intel akkora piaci részesedéssel sem tudta ledugni az avx-et a gaming "torkán" (olyan cuki voltál a ps3 emulátorral
) ami az amd-nek sose várható, meg az se hogy az amd semmit nem tudott "átverekedni" eddig, lásd mantle, trueaudio, HBM ram játékra, ellenben fut az nvidia után, lásd RT, DLSS..... Úgyhogy legalább azt írd oda hogy szerinted, és ne tényként közöld az álmaidat, mert ez így félrevezetés.De megnyugodhatsz, tesztelni már lesz mivel, szóval szemetelhetsz vele a fórumokban. [link]
-
#7551
Petykemano
veterán
S_x96x_S
#7550
Petykemano
veterán
válasz
S_x96x_S
#7550
üzenetére
Ez elég tisztességes előrelépés.
Szerintem kevesebb, mint ami az Apple minden kétséget kizáró legyőzéséhez szükséges lenne - tehát bizonyára továbbra is fogunk hallani "az x86-nak vége" típusú megszólalásokat. (Amik persze lehet, hogy nem teljesen alaptalanok, csak azt kívántam kiemelni, hogy ezt a kérdést a zen4 nem fogja azzal zárni, hogy "ugyan, dehogy")Annyit azért hozzátennék, hogy a VCZ ábráin az 5700X kicsit alul van mérve. Ott CB20 ST 558 érték szerepel, a cpumonkey oldalán viszont 588.
De még úgy is közel 30% tempóelőnyt lehet számítani.Ez ugye egy 7700X chip, Vélhetően nem ennek lesz a legnagyobb órajele. Vajon az AMD a >15%-ot úgy értette volna, hogy a 7600X ST mérésben minimum 15%-kal gyorsabb az 5950X-nél?
MT vonatkozásában a 7900X és 7950X, valamint a 7600X valószínűleg ennél nagyobb előrelépést fog hozni az előző generációhoz képest a kitolt TDP keret miatt.
Úgy tűnik, az IPC vonatkozásában mindenki tévedett, de a Chips&cheese által publikált 29-40%-os értékek elég közel álltak a valósághoz. (Még ha részleteiben lehettek is tévedések)
-

hokuszpk
nagyúr
válasz
S_x96x_S
#7544
üzenetére
"- Density: 2x
- Power efficiency: 2x
- Performance: >1.25x"a háromból kettőt választhat. esetleg egyet mint fő csapásirány + a másik kettőből felet.
Az AMD a "Densityt" tette elsődlegesnek, + egy pici power effiency, + ~1.15x orajel.#7547 : talán a Ryzen izé oc tool "HYDRA" az kb. ugyanaz lehet, mint ez a "Dynamic oc switcher" ; de majd ALPI megszakérti, én a memory saccometer után nem csesztem el az értékes időt 1Usmus újabb vívmányaira.
-
#7546
Petykemano
veterán
S_x96x_S
#7545
-
#7540
Petykemano
veterán
S_x96x_S
#7533
Petykemano
veterán
válasz
S_x96x_S
#7533
üzenetére
Én nem vonnék le ebből a ábrából konklúziót a zen3/3D vs zen4 vonatkozásban semmit.
A0, tesztpéldány, stb okból.
Az 5800X3D célpiaca a gaming volt - ott se profitált belőle minden. a Zen4 fejlesztési célja pedig egyértelműen a MT teljesítmény növelése volt. Nem elképzelhetetlen, hogy lesz néhány olyan játék, ahol az 5800X3D megőriz valamit az előnyéből.Mindenesetre 1usmus szerint hülyeség:
"I will say that this is outright nonsense, because the bottle neck of the Zen 4 is the "width of the conveyor belt," not the cache."
[link]
(conveyor belt = futószalag)Esetleg azt is érdemes lehet megemlíteni, hogy nem törvényszerű, hogy csak az L3$-t lehet 3D (vertikális) irányba bővíteni. Mi van, ha a V-cache Gen2 lényege épp az, hogy nem csak az L3$-t fedi le (a megfogalmazás szándékos) és növeli a kapacitását, hanem az L2$-t is, ami fizikailag is ott van az L3$ mellett?

A harmadik dimenziós kiterjedés-növekedés miatt az L2$ késleltetése sem nőne számottevően, de az L2$ és L3$ méretnövekedése együtt már lehet, hogy magyarázná a 30%-os IPC növekedést és hovatovább talán azt is, hogy miért profitál belőle olyan alkalmazás is, amely a victim cache méretnövekedéséből nem. -
hokuszpk
nagyúr
válasz
S_x96x_S
#7510
üzenetére
clock-down lesz, csak nem ugy, mint az Intelnel, gondolom az AMD belepasszirozta a PB/PBO mukodesi keretei koze, az igazi kerdes az, hogy kb. mennyire all be az orajel, AC terheles eseten, es azon a frekin jon-e belole annyi pluszteljesitmeny, amiert megeri foglalkozni vele.
-
#36531588
törölt tag
válasz
S_x96x_S
#7497
üzenetére
"Én abban reménykedem, hogy kb ~ 1 éven belül kijön az
új Cinebench verzió ... ( R25?? )
amiben az AVX-512 engedélyezve lesz."Az intel 2019-2021 között támogatta desktopon az avx-et. Miért csak most várod a Cinebenchet ami mérni tudja?
Eddig miért nem volt érdekes az avx? -
S_x96x_S
addikt
válasz
S_x96x_S
#7477
üzenetére
státus:
Post by agner » 2022-08-08, 9:13:02
szerencsére az Intel clang fordítóra váltott
ami ingyenes .. és ez már nem hozza etikátlanul hátrányba az AMD procikat ..
https://www.agner.org/forum/viewtopic.php?f=1&t=6#p216agner: """
There is an important update to this story. Intel have switched to a Clang-based compiler that works well with non-Intel microprocessors.
If you download the new Intel "oneAPI" Compiler, you get two versions. A legacy version named "Classic" which is a continuation of the old compiler, and a new "LLVM-based" version which is in fact a forking of the Clang compiler. The classic version is not recommended for new projects and may soon be discontinued.
...
The same article shows benchmarks indicating that Intel's LLVM-based compiler optimizes better than Clang. However, such a difference is not seen in my tests.
My conclusion now is that Intel's LLVM-based compiler may be used for compiling code that can run on all brands of CPUs, but you may as well use the plain Clang compiler which is almost identical and optimizes at least as good.
Intel's SVML library may be used for vector math functions. Other alternatives include the Sleef library and my Vector class library.
Other Intel function libraries should be used with care as long as there is no clear indication from Intel about the CPU dispatching in these libraries. You may do your own tests to see how well they perform on the best AMD processors.
""" -
hokuszpk
nagyúr
válasz
S_x96x_S
#7474
üzenetére
azert ennyire Ferenginek nem nézném az AMD -t, mert akkor olyan optimalizacio kellene, ami Zen4 -en megy, de Intel procin nem. Viszont ezzel kb. az 5xxx szeriat is azonnal herénvernék ; ilyen NV féle város alatt hullámzó tengerhez hasonlót sem láttunk tőlük soha, bár a top Arcnak biztos jót tenne
Inkább a driverben lehet ezt-azt elkövetni, majd aszondják mérj Zen4 + Radeon kombóval...@Albus : lassan az Intel is bérgyártat, legalábbis mostanában ezek az írek terjednek.
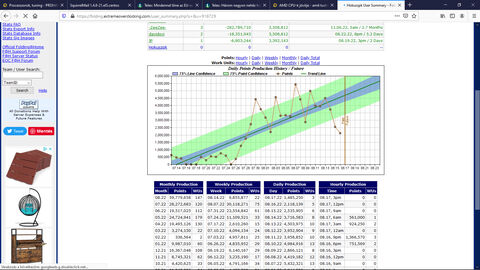
jaigen a driver : a folding & home durvat gyorsult ; még pont nem csúszott ki az extremeoverclocking grafikonból, valamikor Juli 24 után tettem fel az uj drivert, a konfigban annyi változott, hogy az 5700G -t cseréltem 5800X -re, de a másodlagos gépemben ugyanaz a mezei 2700 van. addig az ilyen napi 1M pont már ünnep volt, azóta meg 3M alatt akkor van, ha valamiért le kell állítanom a motyót.
-
#36531588
törölt tag
válasz
S_x96x_S
#7470
üzenetére
Szóval playstation 3 emulátor.
Értem miért nem írtad ki.PC-s játék?
#7471hokuszpk: "a piacvezeto gyarto pont most hoz rá implementációt."
Hahaha. Már az első két szó sem igaz, az amd nem gyárt, nincs hol , csak bérgyártat - mert ugye arra gondoltál. Desktop 20%, amit az amd fel tud mutatni. Ez nem piacvezető 
-
#36531588
törölt tag
-
HSM
félisten
válasz
S_x96x_S
#7444
üzenetére
Az elterjedésnek az sem segített, hogy több Intel CPU-n alapból kellett egy módváltás, hogy használhasd, és amikor használtad az órajel is jelentősen csökkent, így akár lassulhatott is a szoftver az új utasításoktól. Remélem, az új Ryzeneken nem lesznek ilyen problémák.
-
#36531588
törölt tag
válasz
S_x96x_S
#7447
üzenetére
Ha már csúszik, akkor csússzon arra a napra, ez egyértelmű. De a csúszás oka az nem mindegy, főleg hogy komoly oka van/lehet.

Ha már válaszolok, akkor elmondom ezt is, jókat mosolygok az avx-es fejtegetéseden. Főleg az ilyeneken: "játék enginekben is várható." Szerinted az amd a mostani piaci részesedés 20%-val majd megváltja a világot avx fronton, miközben az intel az alder előtt 3 generáción keresztül támogatta az avx-et desktopon, akkor még majd 90%-os részesedéssel?
Mindezt úgy, hogy a dvga piacon is alig alig van meg az amd 20%-a? Se cpu, se gpu oldalon nem tud igazán diktálni.... Értem én hogy nagyon elszaladt az a ló, de azért na.... -
#7439
Petykemano
veterán
S_x96x_S
#7438
Petykemano
veterán
válasz
S_x96x_S
#7438
üzenetére
"In the AVX512 single-threaded benchmark, the Zen 4-based Epyc Genoa part performs roughly in the same league as the Intel Xeon (Golden Cove) Sapphire Rapids-SP parts. We’re looking at 627 points for Zen 4 (2.15 to 3.5GHz) vs 628 for the Golden Cove (1.9 to 3.7GHz) core. In the multi-threaded AVX512 test, the former scores 15,625 points, higher than any other Sapphire Rapids chip on the list."
-
#7436
Petykemano
veterán
S_x96x_S
#7435
Petykemano
veterán
válasz
S_x96x_S
#7435
üzenetére
> vagyis akkor nagy valószínűséggel lesz benne AVX-512
Úgy tudom, hogy a zen4 AVX512 képessége nem valós. Mármint hogy az FPU csak 256bites, csak tudja az utasítást, hasonlóan ahogy a Zen1 is úgy tudta az AVX2-t, hogy valójában csak 128bites FPU csövekkel rendelkezett.
A Bergamo lehet, hogy úgy tudja az AVX512-t, hogy az FPU a Zen1-hez hasonlóan csak 128 bites.
> - szerintem ez már nagyrészt egy következő generációs 3D-s proci lesz .. (pl. Cache csak 3D-ben lesz )
Szerintem is. Kiemelik a lapkából a L3$-t és akkor elfér a lapkában 2db 8 magos "CCX" (ha lehet így még annak nevezni). Csak a csatlakozókat kell meghagyni.
Nem elképzelhetetlen, hogy a 3D tokozott L3$ pedig már 2x8 mag között megosztott/közös.Volt egy ilyen elképzelés a wccf-től, csak ők Zen5-nek nevezték.
[link] -
#36531588
törölt tag
válasz
S_x96x_S
#7425
üzenetére
"Az Intel a 13gen bemutatón nem tud hivatalosan benchmarkolni a zen4-ellen "
Mint ahogy a zen4 sem tud benchmarkolni a 13 gen ellen = az emberek nagy része megvárja a 13 gen megjelenését.
"Az Intel 13gen K-s procik a Z790-el október17-én jelennek meg,
vagyis csak novemberre lesznek "rendes&független" összehasonlító tesztek a Ryzen 7000 és a 12genK között."A 13 gen megy a Z690-el is.
"agyis ellopja a SHOW-t az Intel elől .."
Igen, ilyen cikket már írtak itt. Csak az volt a baj, hogy az amd show-n 30 újságíró volt, az intelén meg 130. De azért volt aki bevállalta a cikket.
-
#7426
Petykemano
veterán
S_x96x_S
#7425
Petykemano
veterán
válasz
S_x96x_S
#7425
üzenetére
A rajt eltolására elég logikusan hangzik az, hogy az Intel ne tudjon 13gen vs zen4 slide-okat mutogatni.
De akkor ez azt is jelenti, hogy számos mérés vonatkozásában a RPL jobb, mint a RPH.
Ez nem biztos, hogy azt jelenti, hogy jobb, de mondjuk CB meg GB5 és UB score-okat lehet mutogatni, hatalmas különbséggel. -
#7418
Petykemano
veterán
S_x96x_S
#7417
Petykemano
veterán
válasz
S_x96x_S
#7417
üzenetére
Szerintem a két képet (comp/decomp) együtt érdemes nézni [link]
Nem tudom, hogy a score a két művelet esetén mennyire összevethető, de az ábra alapján a ryzen az, ami a compression értékhez képest lényegesen nagyobb mértékben nagyobb score-t ér el decompression esetén.Az okot nem tudom. Abu mintha egyszer említette volna.
Az 5800X3D teljesítményéből lehet tudni, hogy nem a L3$ mérete az oka.Mindenesetre ha a blenderben nőtt az AMD-nek az SMT yield, akkor lehet feltételezni, hogy ez itt is számítani fog. Majd meglátjuk.
-
#7399
Petykemano
veterán
S_x96x_S
#7363
Petykemano
veterán
válasz
S_x96x_S
#7363
üzenetére
Abu is lehozta a kanadai webshop árait.
De hát ki tudja mi az igazság. Mert tényleg lehet placeholder. A kanadai cég gondolkodhatott úgy is, hogy a valódi árakat nem ismervén a zen3 induló áraihoz hozzápasszintott egy 10%-os inflációs értéket és kész.Nem tudni, Greymon honnan szerzi az információit. Az is vagy igaz, vagy nem. Az árazás az utolsó pillanatig változhat és nagyon sokminden befolyásolhatja.
Például az, hogy a Zen3 esetén szűk volt a wafer kínálat, hiszen ugyanakkor indult el a nagyon várt és eléggé wafer igényes PS5/XSX, valamint akkor kellett a Navi2X-szel az akkor elindult Ampere-nek is konkurenciát állítani és nem utolsósorban röviddel utána fel is futott fel a bányászat és persze a Zen3/Milan volt az első az Intel-nél tényleg több szempontból (nem csak magszám) jobb szerverprocesszor.
Ezekből legalább a konzolhatás kiesik és a videokártyák volumen szempontjából jelentős része N6-on marad. Tehát elvileg juthat Zen4 gyártásra bőven.
De persze lehetnek más hatások is. (Túl persze azon, hogy az Intel árazására is oda kell figyelni.) Például az, hogy esetleg kezdetben az alaplapok volumene is lehet alacsony, vagy a PCIE5-ös SSD-k kínálata, vagy a DDR5 ramoké. Persze nem feltétlenül kellene az AMD-nek ilyesmikre figyelnie, de mostanában szorosan együttműködik a Hynix-szel és a Phisonnal, az alaplapgyártókkal meg alap.
Tehát az árazásban figyelembe vehet ilyen partneri szempontokat is: elképzelhető, hogy azért nem lesz olcsó kezdetben, mert ha túl sokan rohamozzák meg a boltokat, akkor az alaplap vagy DDR5 memória szűkössége ezekre nézve úgyis árfelhajtó hatású lesz és akkor megint nem náluk csapódik le a mani.Szóval ezzel csak azt akartam mondani, hogy tökre nem lehet biztosra venni semmit.
Ezért készüljünk inkább úgy, hogy a kanadai árak helyesek. Ez következne abból, hogy az AMD sikeres, sikeres termékeket dob piacra, és hogy az általános piaci hangulat az inflációkövető áremelés.
Így remélhetőleg már csak kellemes meglepetés érhet minket. -
#7398
Petykemano
veterán
S_x96x_S
#7397
Petykemano
veterán
válasz
S_x96x_S
#7397
üzenetére
Köszi. Félig-meddig megválaszoltad: az AMX egy konkurens DL/ML kiszolgálási irány.
Azt értem, hogy milyen előnyökkel járhat dGPU-s megoldással összevetve.
De miért AMX és miért nem egy IGP, ami koherens módon látja ugyanazt a memóriaterületet és oneAPI segítségevel sejtésem szerint elrejthető, hogy tulajdonképpen milyen hardverelem hajtja végre a műveletet? -
#7395
Petykemano
veterán
S_x96x_S
#7382
Petykemano
veterán
válasz
S_x96x_S
#7382
üzenetére
Én ezt az AMX-et nem értem.
Miért volna praktikus mátrix.szorzást.CPU-n végrehajtani és ahhoz külön egységeket, de legalábbis utasításokat beépíteni, amikor ezt a területet viszi a legrosszabb esetben is GPU?
Ugyanez a kérdés persze már a vektor utasításokkal felvetődött. És mindig is az volt az álom, hogy a vektor utasításokat az IGP hajtja végre.Szóval vajon miért tolja az Intel az AMX-et, miközben ott vannak a tensor magok (nvidia és google)?
-

carl18
addikt
válasz
S_x96x_S
#7393
üzenetére
"ősszel miért fizetek ki egy valag pénzt ZEN4-re, DDR5-re meg a többi drágaságra.
Szerintem attól függ jelenleg milyen platformon vagy, mire használod a gépet és hány évre tervezel vele. De szerintem azért manapság sokkal lassabban avulnak a gépek mint mondjuk 20 éve.
A Zen 6-ra kíváncsi vagyok, nincsenek még róla ígazán hírek. -
#36531588
törölt tag
válasz
S_x96x_S
#7385
üzenetére
Nem, nem választott, hanem alkalmazkodott a helyzethez, miszerint a chiphiányban elmozdult a drágább szegmens felé, azzal a mennyiséggel amit le tudott gyártatni, és simán el tudta adni "elengedve" azt a piacot, aminek a megerősödését köszönhette. Kicsit máshogy hangzik.
Persze hogy nem kell kiélezni, és persze hogy jó a verseny. És ez mennyivel máshogy hangzik, mint a "Emiatt a Raptor és az Alder nagyon gyorsan elavul" meg az avx512-es hurráoptimizmus, aminek borítékolható a vége.
#7387hokuszpk: Mivel a táblázatot én szedtem ki a cikkből, láttam hogy egyet támogat a zen4 és egyet nem. Pont ezért léptem túl rajta. Azt viszont eldönthetjük végre, hogy az utolsó 3 gen ugyan azt a halmazt támogatja?
-
carl18
addikt
válasz
S_x96x_S
#7385
üzenetére
Igen, erről van szó ha drága lesz a AMD majd a piac eldőnti van-e létjogosultsága. Ha valami drága vagy úgy gondolod nem éri meg az árát nem kell megvenni.
Egy biztos az intel is fog majd árat emelni, de azt nem tudni pontosan milyen mértékű lesz. Lisa Su mamival csináltak valami riportott, ahol azt mondta ők azt akarják az AMD is prémium termék legyen vastag árazással. Innen látszik ők se szeretett szolgálat, és csak azért volt olcsó Zen/Zen+ Mert nekik meg kellet vetniűk újból a lábukat a piacon.
Azért az tegyük hozzá valamilyen szinten az is ígaz, hogy a 7 és 5 nanométeres gyártásnak magasabbak is a költségei.
-
#36531588
törölt tag
válasz
S_x96x_S
#7366
üzenetére
"vagyis sok játékot eleve alapból AVX-512 -re optimalizálnak.
Emiatt a Raptor és az Alder nagyon gyorsan elavul..."Már láttuk mit jelent az hogy évekkel ezelőtt a konzolokba amd került. Semmit. Pedig anno meg lett mondva, hogy namost végeazintelnekmegaznvidiának.
Közbe az nv 80%-os piaci részesedést ért el a dvga-val, pedig mindenki az amd-re optimalizált a konzolok miatt . És letette az RTX-et az asztalra, ami végre hozott valamit látványban hosszú évek helyben toporgása után, miközben az amd tizesével dobálta a kódneveket, amiknek semmi haszna nem volt.És erre az amd fanboyok ennyit tudtak:
- RTX: na nehogy már játék közben valaki észre vegye hogy tükröződik a pocsonya
- DLSS: figyeld már a drótkötél, milyen szarul néz ki
Az amd pedig lohol utána, mind RTX mind FSR vonalon. Az AVX halott, egyébként. Te temetted el Abu-val
, ki ne találd már hogy majd most az amd miatt lesz belőle valami. "Ki tudja milyen secret-handshake van beépítve a lapba, ami miatt az RDNA3 szuper gyors lesz."
Mindenki tudja, semmilyen.
-
hokuszpk
nagyúr
válasz
S_x96x_S
#7368
üzenetére
"ettől függetlenül az Intel bepróbálkozik .. "
akkor a jelenlegi AMD helyében megvonnám a vállam, és hazardiroznek egy picit olyan "nosza gyerunk csináljátok" jelleggel. Szerintem van még egy ütőkártya, ami a kompatibilitás.
Kérdés, hogy az MS/SONY mennyire akar ezzel foglalkozni , de ha joltudom a mostani gen is olyan gpu -t kapott, ami nagymertekben nativan eszi az elődre írt kódokat amitmeg pont azért kértek, hogy induláskor a régi genre írt szoftverek nagyresze fusson.régen is ezt csinálták. ( de az Intel is ) :
11. Amit érdemes eladni, azt érdemes kétszer is eladni.
-
-
#7350
Petykemano
veterán
S_x96x_S
#7349
-
hokuszpk
nagyúr
válasz
S_x96x_S
#7344
üzenetére
az LCLK az izgi, a Biostar lapomban most is van rá opció. Viszont nemigazán jött le, hogy mi az, a legvalószínűbbnek az i/o freki tűnik, ( vannak ilyen megfejtések, hogy "local clock" meg valami, hogyaszondja a pci-express power managentjevel kapcsolatos ; )
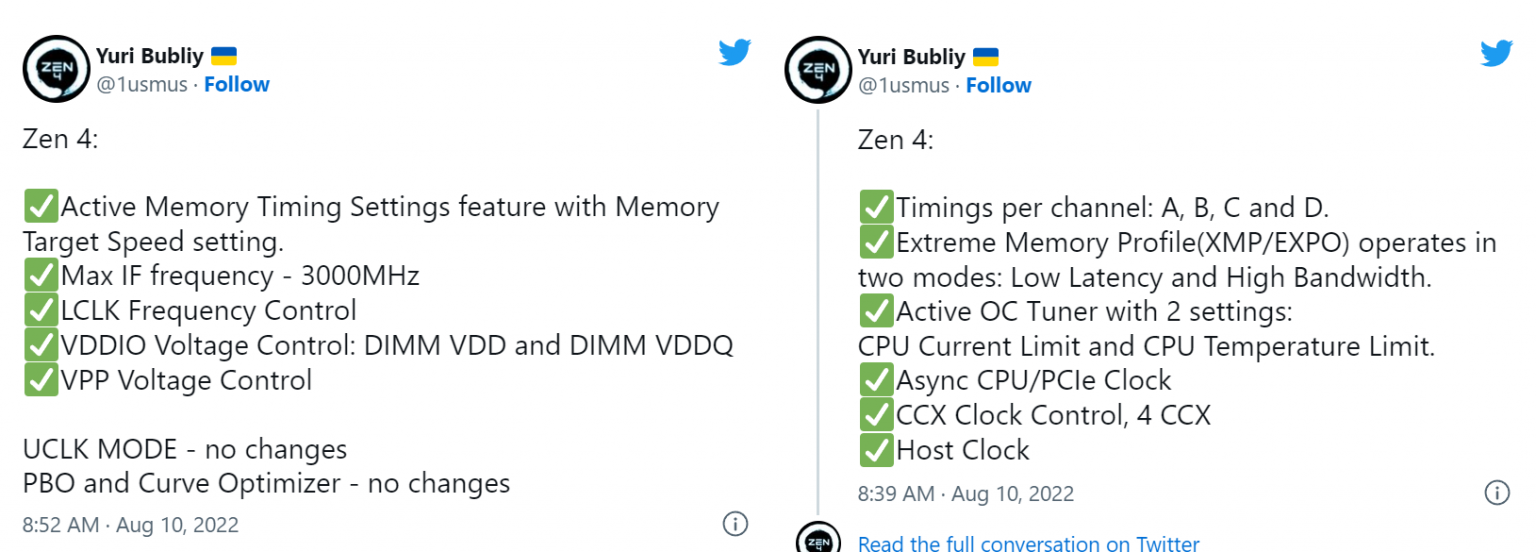
1000 -es értékkel már nem bootol a gép, 800 már majdnem stabil ; 600 -as érték teljesen jó, de ahol találtam erre utalást, ott az van, hogy ennyi az alap. -


 Gondolom árban sem ugyanannyi.
Gondolom árban sem ugyanannyi. ![;]](http://cdn.rios.hu/dl/s/v1.gif)





 )
)












 Cserébe csak AVX-256. Vagyis a teljesítmény ugrott.
Cserébe csak AVX-256. Vagyis a teljesítmény ugrott. 







Új hozzászólás Aktív témák

- Apple iMac 19.2 i5-8500 Radeon Pro 560X 4GB 16GB 256GB SSD 21.5" 4K Retina
- Bomba ár! HP Elitebook 840 G1 - i5-4GEN I 8GB I 500GB + 32SSD I Radeon I 14" FHD I Cam I W10 I Gari!
- Samsung Galaxy A54 5G /8/128GB / Kártyafüggetlen / 12HÓ Garancia /
- Keresek Xbox Series S / Series X / Playstation 5 konzolokat
- Bomba ár! Lenovo ThinkPad T430u - i5-3GEN I 8GB I 500GB I 14" HD I Cam I W10 I Garancia!
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopműhely Bt.
Város: Budapest