-

Mobilarena
A legtöbb kérdésre (igen, talán arra is amit éppen feltenni készülsz) már jó eséllyel megtalálható a válasz valahol a topikban. Mielőtt írnál, lapozz vagy tekerj kicsit visszább, és/vagy használd bátran a keresőt a kérdésed kulcsszavaival!

Új hozzászólás Aktív témák
-
#19099
 Oliverda
titán
Petykemano
#19095
Oliverda
titán
Petykemano
#19095
Oliverda
titán
válasz
 Petykemano
#19095
üzenetére
Petykemano
#19095
üzenetére
Nyilván nem azért tette fel az NV, hogy végül a GDDR5 effektív órajelein hajtsák.
KAMELOT: VR developereknek szánják
-

robertosz91
tag
válasz
Petykemano
#18407
üzenetére
Az tényleg nem lenne rossz.
Televan:
Hát a ház az pofás, az árazás lehet, hogy pofátlan
-
#18261
 gbors
nagyúr
Petykemano
#18259
gbors
nagyúr
Petykemano
#18259
válasz
Petykemano
#18259
üzenetére
Sorry, no cigar

Mondjuk olyan tuti nem lesz - ha így akarnak egy lyukat betömni, akkor tényleg átnevezik és rátesznek duplaannyi memóriát. Max. addig marad ilyen, amíg ki nem jön a teljes 400-as széria.
-
#18260
 #45185024
törölt tag
Petykemano
#18259
#45185024
törölt tag
Petykemano
#18259
#45185024
törölt tag
válasz
Petykemano
#18259
üzenetére
Az már pezsgős

-
#18143
 Z10N
veterán
Petykemano
#18128
Z10N
veterán
Petykemano
#18128
Z10N
veterán
válasz
Petykemano
#18128
üzenetére
A cim megteveszto! A datumokat es a darabszamokat megnezted? Ezek valoszinuleg ES kartyak voltak.
C981: "Polaris", 2db, 47578 INR (~207k), 2015-dec-28
C980: "Polaris", 2db, 40790 INR (~177,5k), 2016-jan-8
C924: "Polaris", 8db, 18263 INR (~79,5k), 2015-aug-13
C913: "Polaris", 30 db, 15182 INR (~66k), 2016-jan-6
C888: Fury X2, 8db, 124696 INR (~542,5k), 2015-nov-26
C880: Fury X, 10db, 78299 INR (~340,5k), 2015-jun-26Az indiai rupia most 4,35 HUF.
A Pascalnak is van egy shipping logja. Szerintem ez a PX2.
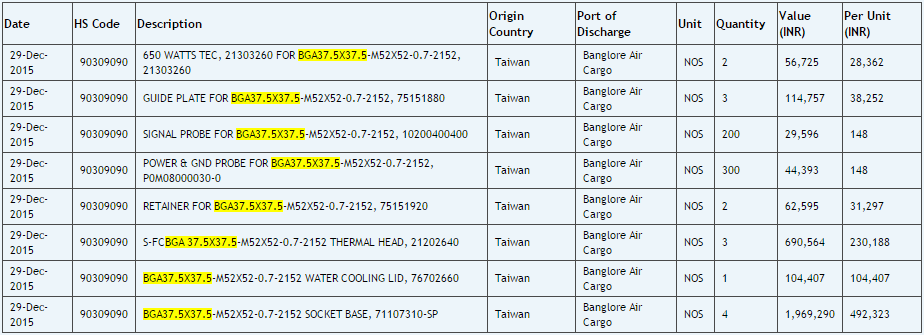
Tovabbi infok a Polaris-rol es a Pascal-rol.
Ui: Valoszinuleg a C924 volt demozva korabban a CES-n. Erre utal az augusztusi ES szallitmany. A C913 darabszambol pedig arra lehet kovetkeztetni, hogy Roll-Out elott van. Ez egybe is vag, hogy jon a low-end.
-
#18131
 Malibutomi
nagyúr
Petykemano
#18128
Malibutomi
nagyúr
Petykemano
#18128
Malibutomi
nagyúr
válasz
Petykemano
#18128
üzenetére
Ugy tunik nem tokolnek sokaig.
-
#18130
 füles_
őstag
Petykemano
#18128
füles_
őstag
Petykemano
#18128
füles_
őstag
válasz
Petykemano
#18128
üzenetére
Asszem lassan elkezdem hirdetni a 280X-szet

-
#18129
 solfilo
veterán
Petykemano
#18128
solfilo
veterán
Petykemano
#18128
válasz
Petykemano
#18128
üzenetére

-
#17722
 rocket
nagyúr
Petykemano
#17719
rocket
nagyúr
Petykemano
#17719
rocket
nagyúr
válasz
Petykemano
#17719
üzenetére
Nem tartom valoszinunek, mivel a GTX970/980 es a Fiji PRO/XT utodja nagy esellyel ugyanarra a GPU-ra fog epulni, igy felesleges lenne vacakolni a GTX970 es a Fiji PRO utodjanal masik Interposerrel a HBM1 miatt.
Kisebb kartyaknal meg joval egyszerubb es olcsobb lesz a GDDR5/GDDR5X vonalon maradni.Mivel egyelore a Micron fogja csak gyartani a GDDR5X memoriat, kerdeses kifogjak-e tudni szolgalni az igenyeket.
Nagy az esely lesznek kenyszeru (nem igy tervezett) megoldasok GDDR5-el a highend VGA-k alatt, vagy par egy ideig alacsony darabszamu (amivel a keresletet nem fogjak tudni kielegiteni) termek GDDR5X memoriaval. -
#17618
 Abu85
HÁZIGAZDA
Petykemano
#17609
Abu85
HÁZIGAZDA
Petykemano
#17609
Abu85
HÁZIGAZDA
válasz
Petykemano
#17609
üzenetére
Az alsó szegmensben az IGP-k megették a morzsákat is, szóval oda IGP-s frissítés jön. A középkategóriától fog megtörténni a váltás.
A váltás szempontjából a kockázatokat kell mérlegelni. A HBM2-re való áttérés kockázat az AMD-nek, az NV-nek pedig pláne az nulla tapasztalattal. Tehát azt kell eldönteniük, hogy ha mégsem sikerül valamelyik komponens miatt a váltás, akkor hány termék csúszása vállalható be. Nyilván a felsőházban nincs sok választás, oda muszáj bevállalni, de alatta elképzelhető, hogy a biztonságosabb utakat választja mindkét cég. 2017-re tolni több 2016-os fejlesztést nem túl kedvező döntés, egy csúcskategóriás holmi még belefér. -
#17610
 Televan74
nagyúr
Petykemano
#17609
Televan74
nagyúr
Petykemano
#17609
Televan74
nagyúr
válasz
Petykemano
#17609
üzenetére
Én remélem hogy a top kategórián kívül is kapunk valami vérfrissítést. Jó lenne már az AMD -től is,hogy ne csak átnevezések legyenek az alacsonyabb kategóriában.A következő kártyámra 150.000-160.000 Ft -ot szánok,szeretnék AMD -t de ha nem dob valami újat a top 200.000+ kategórián kívül,akkor könnyen előfordulhat hogy az Nvidia kártyái közül választok magamnak.
-
#17538
#45185024
törölt tag
Petykemano
#17537
#45185024
törölt tag
válasz
Petykemano
#17537
üzenetére
ilyet hogy "Rendben meggyőztél" PH fórumon még nem olvastam
le is fagyott tőle a fórum...
a"mivan mivan mivan" sokkal gyakoribb
Szerintem a 6 Giga sokkal optimálisabb mint a 390 390X-eken lévő 8G .
Mire egy ilyen középkategóriás kártya megéli hogy 8 giga legyen a határ már teljesítményben rég elfogyott.
Sokkal optimálisabb a 6 giga és emiatt az ára lehet olcsóbb amitől jobb vétel.
Én tartom azt az álláspontomat hogy ha lesz egy jól meghúzott 380x, az VR-re optimálisabb mint a 390 390x esek. Crossfire-be meg egyenesn tökéletes.
Tehát elmondható Full hd ra veszel most egyet és a VR érkezésekor majd mégegyet fél egy év múlva és ott is jó leszel. Ez a legpénzbarátabb megoldás mind közül. -
#17535
 HSM
félisten
Petykemano
#17534
HSM
félisten
Petykemano
#17534
HSM
félisten
válasz
Petykemano
#17534
üzenetére
Másként. Már a régi Tahiti-nél is volt jópár játék, ami profitált a nagyobb sávszélességből.
Pl. Sniper Elite 3, évekkel korábbanról: [link]
A Tahiti LE az az 1536 shaderes, 256 bites butított Tahiti volt. Jól látható, hogy még a jóval alacsonyabb órajelen járó 7950 is rávert bő 6%-ot. A Tahiti LE 1200/1500Mhz-en is csak 44,4FPS-ig jutott. Szóval ebből én azt szűrtem le, hogy jelentős mértékben visszafogta a 256bit.
Jól látható, hogy még a jóval alacsonyabb órajelen járó 7950 is rávert bő 6%-ot. A Tahiti LE 1200/1500Mhz-en is csak 44,4FPS-ig jutott. Szóval ebből én azt szűrtem le, hogy jelentős mértékben visszafogta a 256bit. 
Pedig ez csak egy erősen megvágott Tahiti volt.A 285-nél is ez volt a benyomásom. Volt, ahol a 280X-et is utolérte, de volt, ahol a 280-at sem sikerült neki. A PH tesztben is ez látható. [link].
-
#17533
HSM
félisten
Petykemano
#17532
HSM
félisten
válasz
Petykemano
#17532
üzenetére
Ez nagyon szép és jó, nagy kár, hogy egy (valós) jelenetszámítás marhára nem csak compressed (framebuffer color!!!!) data-ból áll.
Szval slideware-nek jó, de a valós helyzetet nagyon nem tükrözi. A PH cikkben sem viccből írnak 20-25%-ot átlagosan valódi szituációkra. AZ Nv is ennyit írt a sajt color compressionjára.Szerk.: Mondjuk nekem a 3DMark Firestrike per GB/s is kicsit fura ott alul.
-
#17371
 Jack@l
veterán
Petykemano
#17358
Jack@l
veterán
Petykemano
#17358
Jack@l
veterán
válasz
Petykemano
#17358
üzenetére
Engem szintén az érdekelne mi van ha több que van 128-nál, mert nv-nél látszik az ugrás szint, kb lineáris. De amd-nél 128-ig tök statikus a késleltetés(nála ott a határ).
De teljesen mindegy, mert tényleg nem látom hogy masszív grrafika mellett hogy lehet annyi szabad unitot(cu) befogni párhuzamos feldolgozásra. Ha csak 50-et lehet, ahhoz max 50 que kell...
Nyilván ezt oxideék is tudták, nem véletlenül pakoltak bele annyit amennyinél már nv-n rosszabbul fut. Ezért kérte a cég őket, hogy akkor tegyék át soros feldolgozásra.
Lehet az egész benchmark a fury-kra lett kihegyezve, nagy szívás lesz a nano-kon is ha így marad, mert ott fele annyi ACE van mint a fullosban. -
#17368
gbors
nagyúr
Petykemano
#17358
válasz
Petykemano
#17358
üzenetére
Újra leírom: az aszinkron compute akkor gyorsít, ha vannak kihasználatlan ALU kapacitások a rendszerben. Innentől kezdve az első compute queue-nak van esélye jelentős gyorsulást hozni, a második még lehet, hogy hoz valamit, aztán onnantól kezdve már nagyjából mindegy. Biztos lehet speciális eseteket kreálni, ahol több compute queue-val jobb lesz a teljesítmény, de nekem elég értelmetlennek tűnik.
-
#17360
 Laja333
őstag
Petykemano
#17358
Laja333
őstag
Petykemano
#17358
Laja333
őstag
válasz
Petykemano
#17358
üzenetére
Meg először jó lenne egy olyan bench, ami tényleg képes releváns eredményt mutatni. Ennél a grafikonosnál is megjegyezték, hogy a GCN is "sorosan" futott csak.
"In fact, a post points out that due to the workload (1 large enqueue operation) the GCN benches are actually running "serial" too (which could explain the strange ~40-50ms overhead on GCN for pure compute)."
[link] -
#17359
 Ren Hoek
veterán
Petykemano
#17358
Ren Hoek
veterán
Petykemano
#17358
Ren Hoek
veterán
válasz
Petykemano
#17358
üzenetére
Amíg ki nem derül mi van a Maxwell2 belsejében igazából, addig nincs értelme erről beszélni. Lehetetlen válaszolni. Teljesen más a két arch. Lehet hiteles az a grafikon, de lehet hogy valós helyzetben semmit sem fog érni hány queue van.
Első körben az nV nyilatkozatot kéne megvárni, aztán egy nagyobb 10 játékból álló mintán megfuttatni a dolgot. Ez még nagyon messze van.
Az az egy biztos, hogy a fejlesztőkre nehéz idők várnak optimalizálás és kompromisszumkötés terén, ha az NV tényleg susmákolt az Async-el. -
#16788
 Gilthanas
aktív tag
Petykemano
#16787
Gilthanas
aktív tag
Petykemano
#16787
Gilthanas
aktív tag
válasz
Petykemano
#16787
üzenetére
Óvakodnék az AMD védelmétől (a hdmi 2.0 hiánya mély haragvást keltett bennem a FuryX-el), de bízom benne, hogy professzionális szakemberek, megfelelő piackutatás után, rendes stratégiai tervezést követően döntenek a kártyák fejlesztéséről és azok kihozataláról, piaci integrációjáról, pozicionálásáról.. Legalább is muszáj hinnem ebben.
-
#16735
HSM
félisten
Petykemano
#16734
HSM
félisten
válasz
Petykemano
#16734
üzenetére
A 128 nem opció, nem fért volna el HBM-el. HBM nélkül meg a fogyasztás lett volna csúfos. Szerintem okos kártya lett. A drivert mondjuk összerakhatták volna a startra szerintem is.
Tesztelési célokra bőven elég lett volna a Tonga vagy a Hawaii, ezért kár lett volna Fiji-t alkotni. Ami el lett szúrva viszont nagyon, hogy nem sürgették meg hozzá az átírt drivert.

-
#16696
#45185024
törölt tag
Petykemano
#16695
#45185024
törölt tag
válasz
Petykemano
#16695
üzenetére
És az általad irt finFET hány nm t jelent
 /ha nem 20/
/ha nem 20/ -
#16445
Abu85
HÁZIGAZDA
Petykemano
#16443
Abu85
HÁZIGAZDA
válasz
Petykemano
#16443
üzenetére
A cél valószínűleg kattintások gyűjtése, vagy esetleg kis manipuláció, hogy shortolni lehessen, de ez nagyon nehéz.
(#16444) geresics: A 380 általánosan erősebb hardver. A 2 GB sok játéknak elég és elég lesz FullHD-re.
-
#16269
 MiklosSaS
nagyúr
Petykemano
#16264
MiklosSaS
nagyúr
Petykemano
#16264
MiklosSaS
nagyúr
válasz
Petykemano
#16264
üzenetére
Ertem, felreolvastam akkor
-
#16244
MiklosSaS
nagyúr
Petykemano
#16243
MiklosSaS
nagyúr
válasz
Petykemano
#16243
üzenetére
Milyen 7-8 eves lemaradasa van az NV-nek? Az AMD-nek az utolso utos kartyaja az a 5-os szeria volt. A 7-es jo volt de nem annyira hogy elajuljanak tole.A 2XX az fail volt, most a Fiji az eleg gyengen sikerult.
Nem is tudom minek vartak vele ennyit?Szerintem semmilyen lemaradasban nem szenved az NV, vagyis a tesztek szerint....jah, hogy lehet meselni...azt mar megszoktuk az ilyen: ha, majd, jovore, ket ev mulva, majd, stb... Ezeket mar nagyon unom!
-
#16172
Abu85
HÁZIGAZDA
Petykemano
#16156
Abu85
HÁZIGAZDA
válasz
Petykemano
#16156
üzenetére
Nem lehet még beszélni mindenről. Csak a hardvert leplezte le az AMD azt, hogy mit hoznak még a hardverhez nem. De annyit elárulhatok, hogy nem véletlen, hogy júliusban lesz elérhető a sima Fury. Ezzel az a terv, hogy a Windows 10-hez legyen közel a start, hogy ott is le legyen mérve a teljesítmény a 15.200-as csomaggal, amiből egyébként amúgy is kapott a 15.15-os driver a tesztek előtt frissítést. Bár valószínűleg sokan már nem telepítették fel.
A Nano sem véletlenül jön később, hogy nagyobb legyen a fókusz a DX12-vel.Nagyon egyszerű dolog történt amúgy. Az Intel és az NV ugyanúgy látta cirka 7-8 évvel korábban, hogy az API-k a PC-n korlátozók. Rengeteg limittel, és jó lenne, ha ez megváltozna, de nem hittek benne, hogy egy ilyen váltást a PC-n át lehet nyomni egyáltalán. A célja mindig az volt, hogy biztosítsanak egy egyszerűnek tűnő felületet, és a komoly problémát okozó tényezőkkel a háttérben dolgozhat az API és a kernel driver. Ha pedig ez a cél, akkor ehhez kell tervezni a hardvert. Az AMD úgy gondolta 7-8 évvel korábban, hogy egy életük egy haláluk át kell nyomni a változást. És a potenciális változáshoz tervezték a hardvert, gondolva arra, hogy hagyományos szinten hátrányban lesznek, de ha sikerül letolni az ipar torkán a low-level irányt, akkor már a konkurensek lesznek hátrányban. Most történik a váltópont, mert nem kis meglepetésre egyébként, de átnyomták az irányt.
Többek között a DX12 az AMD-nek nagyon fontos, mert rengeteg olyan dolgot megváltoztat, amely most számukra hátrányos a DX11-ben. Például ma a bekötési modell váltása a legfontosabb és nem véletlen, hogy erről beszélnek a legtöbbet. Ma ez úgy néz ki, hogy a CPU beköt egy puffert az API-val és a kernel driverrel, amelynek az eredménye egy adat lesz a hardver számára. Ezt a driver szimplán elküldi a hardvernek mint erőforrás leírót. Ezt persze minden hardver máshogy csinálja, mert implementálás szintjén lehetnek különbséget, itt arról beszélhetünk, hogy a bekötés hol valósul meg a multiprocesszoron belül, például a legtöbb mai modern GPU-ban a textúra-mintavételezőben történik mindez, de itt is számolni kell azzal, hogy tömbösítve történik a bekötés, vagy különállóan. A GCN viszont teljesen egyedi. Ennek az architektúrának nincs szüksége erre a procedúrára. Egyszerűen a shaderbe bele lehet írni memória elérést és kész, a skalár egység elvégzi a bekötést. A hátránya, hogy ma egyik szabvány API sem működik így, tehát ezt le kell "emulálni" a kompatibilitást egy olyan hardverrel, amit nem hagyományosan terveztek. Az új API-k azonban így működnek, és fordul a kocka, vagyis a többi architektúrának kell "leemulálni" a kompatibilitást.
Ugyanilyen probléma a queuing. Egy mai API DX11/OpenGL úgy működik, hogy van a hardver felé egy parancslista, és abba lesz betöltve minden, majd a hardver szépen egyesével lekéri a feladatokat, és azokat sorban végre is hajtja. Ma több modern GPU-t erre terveztek. Egy mérnöki csapat felteszi a kezét, hogy tudunk mi hardvert tervezni, de miért is költsük tranzisztorokat a párhuzamos feladatfuttatás kigyúrására, ha a pipeline-ok úgyis sorban jönnek? És ez egy érthető döntés a maga szintjén. Valószínűleg senki sem vonja kétségbe az Intel és az NV vezetőségében, hogy a mérnökeik képesek lennének egy alternatív GCN-t tervezni, csak nem ezt kérték tőlük. Az AMD viszont úgy gondolta, hogy egy ilyen reformot is átnyomnak, mert azért masszívan párhuzamosításra tervezett rendszer a GPU, hogy olyan programok is fussanak rajta. Megtervezték a GCN-t stateless compute-ra, megpakolták regiszterekkel, gyorsítótárakkal, és igen ebből ma egyetlen szabványos API-n sem lehet kihozni semmit, de mit ad az úr a DirectX 12 queuing modellje copy/compute/graphics halmazba van szervezve, így a hardver tetszőleges számú compute és copy parancslistát kezelhet, és ezekről párhuzamosan kérhet le feladatokat, ha persze van rajtuk betölthető. Ezzel lehetőség adódik, hogy a feltöltés és a compute minden más feladattal párhuzamosan végrehajtható legyen, vagyis megszűnt a soros feldolgozásra kényszerítő modell. Itt megint fordul a kocka és a hátrányból előny lesz. És ezekről egyébként fognak beszélni H2-ben, csak megvárják a játékokat, hogy megmutathassák, hogy ez mit is jelent. A 3DMark API Overheadben már láthatjátok egyébként, hogy mi történik az architektúrák hatékonyságával a DX11-DX12 váltásnál. -
#16157
 Yllgrim
őstag
Petykemano
#16156
Yllgrim
őstag
Petykemano
#16156
Yllgrim
őstag
válasz
Petykemano
#16156
üzenetére
Sztem teszteket csinalnak meg gondolom dolgozik meg nem mindegy, majd ha lesz ugyis ir
-
#16043
#16729600
törölt tag
Petykemano
#16041
#16729600
törölt tag
válasz
Petykemano
#16041
üzenetére
Ez a stratégia, ami kevésbé előremutató, jövőálló termékeket vonultat föl, piacképesebbnek tűnik.
Egyáltalán egy ilyen avulási mértékkel bíró DVGA piacon van bármi létjogosultsága a jövőállóságnak,mint fogalmi kategóriának? Nem hinném.

-
#14880
Abu85
HÁZIGAZDA
Petykemano
#14860
Abu85
HÁZIGAZDA
válasz
Petykemano
#14860
üzenetére
Ezt most is megtehetik. Megjelenik a Win10, kiadják rá a drivert és beszámolnak a gyorsulásokról.
Az egyértelműen hülyeség, hogy ugyanarra az architektúrára két drivert csináljanak.Hogy lesz eladás? Miből gondolod, hogy a GeForce Titan tulajokat nem zavarja, hogy a GTX 960 veri az ezer dolcsis jövőbiztos cuccukat. Vagy a GTX 680 tulajok látva a HD 7970 teljesítményét nem gondolkodtak el azon, hogy nem-e jobban jártak volna a Radeonnal.
-
#13841
Abu85
HÁZIGAZDA
Petykemano
#13834
Abu85
HÁZIGAZDA
válasz
Petykemano
#13834
üzenetére
Lesznek ilyesmi bejelentések. Nagyon leegyszerűsítve az AMD megmutatja, hogy mit akar kezdeni a PC-vel.
(#13836) Komplikato: Nem tudom, hogy a Square Enix hol akarja bemutatni a világnak, de elvileg kint lesz a PC-s port.
(#13840) daveoff: Igen a Battlefront az egyik húzócím a Fijihez.


















 Jól látható, hogy még a jóval alacsonyabb órajelen járó 7950 is rávert bő 6%-ot. A Tahiti LE 1200/1500Mhz-en is csak 44,4FPS-ig jutott. Szóval ebből én azt szűrtem le, hogy jelentős mértékben visszafogta a 256bit.
Jól látható, hogy még a jóval alacsonyabb órajelen járó 7950 is rávert bő 6%-ot. A Tahiti LE 1200/1500Mhz-en is csak 44,4FPS-ig jutott. Szóval ebből én azt szűrtem le, hogy jelentős mértékben visszafogta a 256bit. 





 /ha nem 20/
/ha nem 20/


Új hozzászólás Aktív témák
Hirdetés
A topikban az OFF és minden egyéb, nem a témához kapcsolódó hozzászólás gyártása TILOS!
MIELŐTT LINKELNÉL VAGY KÉRDEZNÉL, MINDIG OLVASS KICSIT VISSZA!!
A topik témája:
Az AMD éppen érkező, vagy jövőbeni új grafikus processzorainak kivesézése, lehetőleg minél inkább szakmai keretek között maradva. Architektúra, esélylatolgatás, érdekességek, spekulációk, stb.

- ÁRGARANCIA!Épített KomPhone i7 14700KF 32/64GB RAM RX 9070 XT 16GB GAMER PC termékbeszámítással
- DOKKOLÓ BAZÁR! Lenovo, HP, DELL és egyéb más dokkolók (TELJES SZETTEK)
- 1-12 részletre.Új noblechairs EPIC műbőr FEKETE - FEKETE. 2 év garancia!
- Bomba ár! Lenovo X1 Yoga 1st - i7-6G I 8GB I 256SSD I 14" WQHD I HDMI I W10 I CAM I Garancia!
- ÖRÖK GARANCIÁVAL - OLCSÓ, LEGÁLIS SZOFTVEREK 0-24 KÉZBESÍTÉSSEL - Windows - Office - LicencAruhaz.hu
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: CAMERA-PRO Hungary Kft
Város: Budapest