- Samsung Galaxy Watch7 - kötelező kör
- Milyen okostelefont vegyek?
- Na! Ez egy JÓ utólagos autós fejegység - Minix CP89-HD
- Szerkesztett és makrofotók mobillal
- 8300 mAh, maradhat?
- Android szakmai topik
- QWERTY billentyűzet és másodlagos kijelző is lesz a Titan 2-ben
- Samsung Galaxy A36 5G - a középső testvér
- Feljutott a G96 a Moto széria csúcsára
- Samsung Galaxy S23 Ultra - non plus ultra
Új hozzászólás Aktív témák
-

julius666
addikt
Már leírták előttem, de kb. lövésed sincs a videó dekódoláshoz (meg úgy ámblokk kicsit underage megmondóember szaga van a kommentednek).
Mondjuk annyiban egyetértek, ez az új API átlagos végfelhasználói szempontból különösebb megváltást nem fog hozni. Windowson hardveres gyorsítás eddig is megvolt DXVA-val, az értelmesebb post-process effektek nagy részét shaderekkel meg tudták oldani (a Linuxos oldalt annyira nem ismerem ott pontosan mit és mivel lehet, de ezekre ott is van mód).
Illetve a videó tömörítést magát én sem forszíroznám a GPU-n, a jelenlegi megoldások rettentően ratyik és a jelenlegi hardverfelépítés mellett jelentősen jobbra nem is nagyon van kilátás. Esetleg egy megfelelő minőségű, az egyes lépésekhez fix funkciókkal rendelkező dedikált egység (lásd dekódolás) lehetne előrelépés (az Intel ugye ezzel próbálkozott is a Sandyban, bár az is elég ratyi lett minőségben, illetve túl "merev", nem lehet belepiszkálni eléggé a működésébe).
Ellenben mégiscsak nagy szó hogy végre valaki végre egy komolyabb platformfüggetlen API-t akar csinálni egy ilyen széttöredezett piacon (ahány platform kb. annyiféle API).
-

eziskamu
addikt
Lehet, épp rosz börben volt Kirk kapitány.

De legalább többet javított, mint rontott. Már az is nagy szó az ilyen felskálázásnál.
Tényleg vajon a fekete fehér filmek színezését meg tudnák oldani GPU-val valós időben? Mondjuk lehet fel kellene paraméterezni, vagy valahogy betanítani, hogy valószerű eredmény szülessen. -

devast
addikt
Okkulj.
Pár vélemény nálam:
a, A hardveres chroma upsampling-nek (radeon 4850-emen) kritikán aluli a minősége pl...
b, Ha beledöglök, akkor sem tudtam elérni, hogy ycbcr 4:2:0 -ba maradjon a jel végig a feldolgozó csatornán. Ergo, a videó ugye olyan, ha a kimenetet is olyanra állítom, akkor valahol a driverben történik egy ycbcr => rgb => ycbcr átalakítás, ami megint csak rontja a minőséget. Így inkább limited rgb kimenetet használok...
De ez már nagyon off... -
Ki tudnád fejteni bővebben, hogy mit jelent az említett szoftverek "képminőség felskálázása"?
Nem ismerem a két említett progit, de kiváncsi vagyok, miben nyújtanak többet egy mezei lejátszónál.
A dekódolás minősége a jobb?
Vagy utómunka által válik jobbá? Ez esetben az új API nem azt eredményezi, hogy ugyanez lehetővé válik pl. linuxon is?Köszi!
-

Abu85
HÁZIGAZDA
Például én nem mondanék le a Cyberlink és az ArcSoft szoftverek képminőség felskálázásáról, túl szép lesz a videó minősége. Ezek csak Winen érhetőek el.
XBMC meg van winre is. Linuxon választani kell, míg winen bármit megkaphatsz. Ez önmagában borzalmas előny. Nem véletlenül van lemaradva a Linux. Utóbbi rendszernek is vannak számottevő előnyei, de otthonra, multimédiára nem kérdés, hogy melyikkel jársz jobban, vagy melyik rendszer kínál több szolgáltatást/lehetőséget ... akár programot.
-
Abu85
HÁZIGAZDA
Médiaboxoknál lehetséges, de a HTPC-knél már valós előny a Win7. A GPGPU az MS rendszerén gyorsabban fejlődik. Ez nem a Linuxnak kedvez.
A HPC-ben teljesen esélytelenek. A Fermi ellen még kereshetnek valamit, de a Kepler és a Knights Corner ellen már semmi esélye sem lesz az SI generációnak. Az AMD-nek implementálni kellene a virtuális memória támogatást, a szálakat meg kellene különböztetni prioritás szerint. Ezek a funkciók viszik a tranyót és abszolút nem illenek bele egy gémer rendszerbe, márpedig az AMD eldöntötte, hogy ők a gémer közösséget szeretnék kiszolgálni. Éppen ezért a Tesla ellen nem sok esély van. Persze a Radeonok esetében egyre nagyobb lesz az előny, hiszen az NV is döntött és inkább a HPC-t választják. Konkrétan sikeresen felosztották maguk között a piacot, mindenki happy, csak majd a userek nem lesznek azok (illetve már most sem azok, mivel a HD 4000-GF 200 esetében komoly árverseny volt, de a két cég eltérő irányba tart, így mostanában az AMD szabja az árakat, az NV pedig igyekszik ezt követni az óriáslapkákkal).
Az AMD-nek alapvetően nem érdekes a Linux. Túl kevés embert lehet nyerni. Odaadják az open driver lehetőségét, ami a heavyuser közösség számára fontos, és az NV nem adja meg, és ennyi szerintük elég egyelőre. Majd a közösség csinál a termékekhez drivert.Persze nyilván jó lenne az AMD-nek a HPC piac is, de jelenleg teljesen más hardver kell oda, mint ami jó PC-s VGA-nak. Mindenki megpróbálja a lehető legtöbb területet lefedni, de a hardvert akkor is priorizálni kell, és el kell döntened, hogy melyik terület fontosabb számodra. Ez akkor lett volna érdekes, hogy ha az AMD is a HPC-t választja, így lényegében az NV-vel egy irányba tartanának, tehát a PC-s GPU esetében mindkét cégnek meg kell küzdeni azokkal a hátrányokkal, amelyeket egy HPC-be fejlesztett architektúra okoz. Pl.: nagy lapkaméret illetve nagyon gyenge skálázhatóság vagy úgymond butíthatóság. Ezekből az AMD nem kért, míg az NV igen. A Fermin lathatóak ezek a jegyek. A legnagyobb chip például óriási. Ráadásul az NV azt a shader szervezést nem is alkalmazza az olcsóbb termékeken, mert nagyon nem hatékony egy játékra. A GF1x4/1x6/1x8 már más multiprocesszorokat használ. Persze a skálázhatóság általános probléma. Ezt látható a GF1x6 és 1x8 esetében. Egyszerűen ezek a lapkák a saját kategóriájukban nagyméretűek, így versenyképtelenek. Az új GeForce GTX 550 Ti egy elég jelentős példa erre, nem is kapott szép értékeléséket. Persze lehet mondani, hogy nem 150 dollárért, hanem 120-ért jó lenne, na de itt jön képbe az előállítási költség, ami a nagy lapkaméretből, és a széles buszból jön, vagyis rosszul lehet a rendszert skálázni.
A Tegra az egy olyan terület, ahova az Androidhoz illő rendszerrel kell nevezni. Az Android fejlesztése nem acélos x86-ra. Megoldható, de állandó késésben van. A Windows 7 meg elég fos érintőképernyős kütyübe. A másik gond, hogy a Brazos platform is túl sokat fogyaszt (5 watt a tabletverzió TDP-je), ez eleve kizáró tényező. Senkit sem érdekel, hogy a Fusion IGP tízszer gyorsabb bármilyen mobil megoldásnál, ha nem fogyaszt a lapka 3 watt alatt, akkor nem kell a holmi. Majd a Wichita lesz oda jó jövőre, ami többnyire egy Ontario 28 nm-en (nem túl jelentős változásokkal). De az Android ott is gond. A Win8 persze megoldás.
-

dabadab
titán
A hagyományos desktopokon tényleg nincs túl sok Linux, viszont HTPC-knél, mediaboxoknál, renderfarmoknál meg úgy általában HPC-nél viszont nagyon ott van és az AMD ezeken a területeken is érdekelt (mondjuk nem vagyok annyira képben, hogy mennyire akar meg fog versenyezni a Teslával meg a Tegrával), ráadásul az Nvidiának azért valahogy sikerült normális drivert faragnia Linuxra is.
-
hát... ne haragudj, de ennek nagy részét nem tudom értelmezni...
"A probléma szerintem nem ezeknek a technológiáknak, inkább az egész GPU alapú filmgyorsításnak a létjogosultságát kérdőjelezi meg. Tényleg szűkség van rá, és tényleg működik a gyakorlatban?"
A VGA alapú dekódolásnak nem az a lényege, hogy kikerüljük vagy csökkentsük a memóriaírást (azt végképp nem értem, a te elképzelésedben hol szerepel a memória, ha már az első mondatban azon akadtál meg, hogy oda kerül a megjelenítendő anyag), hanem az, hogy az iDCT és a MoComp, deblock vagyis az alapvető műveletek ne egy általános egység kezében legyenek (CPU), hanem egy erre dedikált eszköznél, ami ezáltal hatékonyabban végzi el ezeket a számításokat. Az off-host folyamatoknak nem a megváltás a célja, hanem például a fogyasztás vagy gyengébb hardver esetében optimálisabb hardverkihasználás.
"A probléma ezzel az, hogy minden egyes videótömörítésre külön meg kell ezt csinálni. 2 hét múlva kijött egy új verzió? Hát szar ügy, mehet vissza a 100ezres videókártya a dobozba, meg a tervezőasztalra, hogy kicseréljenek benne 100 tranyót. Tényleg szűkséges ezeket a GPU-ba integrálni? Vagy a CPU-ba? Nem az."
Itt most akkor mi a konkrét javaslatod, ha nem az, hogy hardveres dekódolás legyen megvalósítva? Tudom, szoftveres, ezt már kifejtetted, de amióta van UVD, azon inkrementális fejlesztéseket végeznek (és nem azért, mert a H.264 gyökeresen megváltozott). Nem tartom életszerűnek, amit leírtál. Jól működő rendszerekről van szó. (bár ha a VPD-t vesszük alapul, akkor a szoftveres igényeid is ki vannak elégítve
 )
)""Egy számítógép esetében ennek nincs létjogosultsága. Hisz ilyen technológiák léteznek már 10 éve. Azóta se használja őket senki. Meg ezután sem fogja. Persze az ipar nem először gondolkodik, aztán cselekszik.""
"Hát gyorsítsunk vele videódekódolást. Azt már most mondom, hogy nem fogsz. Ugyanis vagy tranyó szinten beteszik az adott videóformátum dekódolását, és akkor fogsz. Azt az egyet. Vagy egy grafikus kártyára épített streaming műveletekre kihegyezett egységre épített általános célú végrehajtó egységekre épített általános célú interfészemuláción keresztül leprogramozótt dekóderrel fogsz egy papíron x000 gigaflops teljesítményű valamivel dekódolni egy framet - a gyakorlatban, mint láthatjuk, max olyan sebességgel, mint egy Pentium2-n alulról, vagy olyan kinézettel mint egy 15 éves mpeg dekódoló kártyán."
Innen átmentem read-only mdba, mert meggyőződést érzek csak, de szakmai érveket nem a kommentben. Plusz tárgyi tévedésekkel is tele van tűzdelve. Nekem valamiféle rizsának tűnik az egész minden konkrétumot nélkülözve. Ne haragudj, vagy nem tudod elmondani, amit akarsz vagy nem tudom.
-

dezz
nagyúr
Huh, ember! Itt nagyon-nagyon türelmesek veled, de én nem kertelek: ebből a postból tökéletesen lejött, hogy bár alapvetően nem vagy teljesen hülye a számtechhez, de a GPU-s videodekódolás témakérében totálisan járatlan vagy! Úgy is mondhatnám, nagyon le vagy maradva ebben.
Az alábbi videotömörítési formátumok dekódolása már vagy 5 éve hw-esen támogatott az összes ATI/AMD, Nvidia (és többé-kevésbé Intel) GPU-ban:
- Mpeg-2
- Mpeg-4/Part 10 (H.264/AVC)
- VC-1
- Újabban: DivX/Xvid, MVC (Blu-ray 3D)Már vagy 3 éve a dekódolás összes lépése hw-esen megy (VLC/CAVLC/CABAC, frequency transform, pixel prediction and inloop deblocking) és csak az opcionális post-processing (denoising, de-interlacing, scaling/resizing) megy shaderekkel.
Bőszen tanulmányozd: UVD, PureVideo
Minimális fogyasztással megy a dolog akár többtíz Mbps-es HD-s anyagokkal, minimális prociterheléssel. Nem lehetetlen persze "kicselezni" a hw-t, azaz úgy enkódolni, hogy ne tudja rendesen dekódolni, de ma már eléggé odafigyelnek az enkódolók erre, főleg a HD-s anyagoknál. Nem csak a GPU-k miatt, hanem a teljesítményigényesebb eljárások esetén ugyancsak hw-es dekóderekkel dolgozó asztali lejátszók miatt is.
A cikket sem olvastad igazán figyelmesen, mert az új API-ban sem a dekódolást akarják a shaderekre bízni, hanem ugyanúgy a post-processinget.
És, hogy mi az egésznek az értelme?
- Nem csak 3-4 GPU-s gyorsítású dekóder lesz.
- Több nem-DXVA alapú lejátszóban jelenik meg a GPU-s gyorsítás támogatása, dekód és post-processing szinten is.
- A meglévő és újfajta post-process eljárások OpenCL-re ültetése, a CPU felszabadításával, kisebb fogyasztás mellett nagyobb teljesítmény igénybevételének lehetőségével.
- Mindezt nyílt szabvány alapon. -
-

GerykO
aktív tag
Én igazából arra gondoltam, hogy bizonyos feladatokra idővel kiválik egy célhardver az általános célú végrehajtókból, majd ha teljesítményt tekintve már nincs rá szükség, akkor ismét visszaköltözik az általános végrehajtóba, és ez periodikusan ismétlődik.
Igazából szebben is meg lehetne fogalmazni, de szerintem a lényeg így is érthető.
De példának ott az FPU, a memóriavezérlő... -
GerykO
aktív tag
Tyű micsoda magas labdák repkednek itt.

Igazából, ha csak hámozott lufi lenne ez az AMD részéről, akkor vajon mégis mitől lenne ilyen sikeres a Fusion (persze eddig csak a Brazos, meg az Ontario van csak a piacon)?
Persze én csak mint laikus szemlélő nézem. Bár igazából minden része teljesen világos volt amit feldobtatok -ezek szerint nem kopott meg a fősulis tudásom -, és mindben van is igazság. De nekem is az AMD terve a legjobb rövid távra, és gondolom hosszú távon, mire a szoftverek is fel lesznek készülve a fúzióra, addigra fognak jobban összekuszált architektúrával előállni. Bár már a CPU-k is ötvözik a CISC, és RISC rendszerek előnyeit, ha ebbe még belevegyítik a GPU-k szintén vegyes architektúráját, egy elég kusza dolog fog kisülni belőle. Arról nem is beszélve, hogy a cache kezelés is elég zagyvává válik -erre egy példa az AMD demóvideójában lévő multitaskolás alatt jött elő az SB prociból.Ezzel az egésszel csak annyira akarok rávilágítani, hogy egyelőre nem érdemes pálcát törni egyik architektúra mellett sem, mert szerintem csak a "sötétben tapogatóznak" -persze azért pozitív irányba fejlődtek az architektúrák-, hogy melyik is a legjobb irány. Látszik, hogy teljesen másik szemszögből keresik a megoldást ugyanarra a problémára.
A Llano megjelenése után már legalább össze lehet majd vetni őket. Aztán, hogy mire állnak majd rá a programozók, az egyszerűbb programozásra (AMD), vagy a bonyolultabb mellett maradnak(Intel) -valószínű a sok pénzmag megéri a túlórát.
Neumann vajon hogy a fenébe látta ezt előre?

-

zsolt501
nagyúr
Az intel részéről bizony a szoftver fejlesztés kissé nehézkes ők inkább a hardver fronton érvényesülnek, ezért én az intel részéről biztosra veszem a támogatást főleg mivel ingyenes a szoftver, és általában ami ingyenes az általában ezeknél a cégeknél fontos dolog.
-
#51
Abu85
HÁZIGAZDA
Meteorhead
#50
Abu85
HÁZIGAZDA
válasz
 Meteorhead
#50
üzenetére
Meteorhead
#50
üzenetére
Azért a kevés OpenCL alkalmazásban az AMD is vastagon benne van. Számukra a nagyobbik Fusion számít, és a programokat is nyári megjelenésre tervezik, hogy az APU nagyobbat üssön. Ha nem számítana a Llano rajtja, akkor több OpenCL program lenne. ... Ez az üzlet.

-
#50
 Meteorhead
aktív tag
leviske
#49
Meteorhead
aktív tag
leviske
#49
Meteorhead
aktív tag
NV nincs olyan helyzetben, hogy diktáljon?!?!
 Ez nagyon tetszik! Bár igazad lenne... NV még mindig a CUDA-val nyert előnyét lovagolja meg és szándékosan hanyagolja el OCL 1.1 driver kiadását. Olyannyira diktál, hogy a többség OCL 1.0-val foglalkozik, mert NV még csak azt támogatja. 6 hónapja nem képesek egy új drivert kiadni ami vinné. Gusztustalan és szánalmas. (Én ezért utálom NV-t, mert rengeteg ilyen húzásuk van) Persze mindenki védi a piaci pozícióját, de amikor valaki ennyire látványosan lehetetleníti el a gyártó-független szabvány terjedését, akkor azért felforr a vérem. Senkinek sem fájna, ha tényleg OCL-en keresztül mérlegre lehetne tenni a kártyákat. NV kártyák nagyon jók és a GPGPU szegmensben bármikor megállják a helyüket, bármilyen API-n keresztül is éri el őket az ember.
Ez nagyon tetszik! Bár igazad lenne... NV még mindig a CUDA-val nyert előnyét lovagolja meg és szándékosan hanyagolja el OCL 1.1 driver kiadását. Olyannyira diktál, hogy a többség OCL 1.0-val foglalkozik, mert NV még csak azt támogatja. 6 hónapja nem képesek egy új drivert kiadni ami vinné. Gusztustalan és szánalmas. (Én ezért utálom NV-t, mert rengeteg ilyen húzásuk van) Persze mindenki védi a piaci pozícióját, de amikor valaki ennyire látványosan lehetetleníti el a gyártó-független szabvány terjedését, akkor azért felforr a vérem. Senkinek sem fájna, ha tényleg OCL-en keresztül mérlegre lehetne tenni a kártyákat. NV kártyák nagyon jók és a GPGPU szegmensben bármikor megállják a helyüket, bármilyen API-n keresztül is éri el őket az ember.Én személy szerint AMD párti vagyok, de ez hosszú és kitartó (ön)lejáratókampányába került Intelnek és NV-nek is. AMD azért nyomatja OCL-t annyira, mert neki nincs más. Intel is azért kapaszkodik mert neki sincs más, de neki is van miért csinálni. OCL-en keresztül lehet majd Knights Corner kártyákat értelmesen programozni. Nekem nem fáj, hogy csak a HPC szegmensben fognak játszani, mert én HPC programokat írok.
És léteznek olyan alkalmazások, ahol a shaderek túl fájdalmasak és lenne létjogosultsága Intelnek is. -

leviske
veterán
válasz
 djculture
#10
üzenetére
djculture
#10
üzenetére
Ha jól rémlik, akkor azért az Intel mostanság elég sok mindenben hagyatkozott az AMD-re, ha OpenCL-ről volt szó. Ennek pedig a fő oka, hogy Ők nem foglalkoznak komolyabban a témával, az AMD meg legalább csinálja.
Az nVIDIA meg jelenleg nincs olyan helyzetben, hogy diktáljon a piacnak, szóval a driver támogatás szerintem a részükről is meglesz.
-
#48
Abu85
HÁZIGAZDA
Meteorhead
#47
Abu85
HÁZIGAZDA
válasz
Meteorhead
#47
üzenetére
32 magos volt az a Larrabee, amit már elkészítettek, de elkaszáltak (ez volt elvileg a tervezés szerinti második generáció, és az első, amiből tényleges hardver lett). Van is kártya, csak nem adják ki. Andrew Richards volt, az aki a leírta a fejlesztéssel kapcsolatos érzéseit. [link] Ebből csináltam anno egy hírt. Sajnos az eredeti írást az Intel levetette, de a lényeget kiemeltem.
Már készül az új verzió, ami majd jövőre jelenik meg. Ebből is csak HPC-be lesz termék. Persze sok esélyt nem jósolok neki a Kepler ellen.Az amin az Intel dolgozik koncepció, az a Larrabee-vel lett volna alkalmazható. Amíg opció volt a projekt, addig ez volt a terv. [link] Azt nem tudom, hogy mostanra mi változott.
-
#47
Meteorhead
aktív tag
Pikari
#34
Meteorhead
aktív tag
Igazad van Pikari, ez nem egy rossz elrendezés, és az Intel Larrabee chipje (amiből volt alaplapra gyógyított variáns) az pontosan ezt csinálta. A koncepció (annak aki nem tudná) az volt, hogy sokkal egyszerűbb x86 magokat csinálni, de sokkal többet (16 azt hiszem). A magok pedig teljesen szabadon számolhattak x86 binárist vagy DX9 API-n keresztül grafikát. A probléma csak ott volt, amikor grafikát kellett számolni. Ugyanis xar volt. Kicsi, kevés, keskeny, sovány, vékony.
A probléma a bonyolultságában rejlik, és nem az elrendezésnek, hanem az x86-nak. Itt nem architektúrális bonyolultságról van szó, ez ARM-mal és semmi mással sem lehetne kivitelezhető ilyen formában, mégpedig a végrehajtóegység bonyolultsága miatt. Egy x86 mag ha meglát egy sinust, kiszámolja, ha meglát egy if()-et, talán át is tudja ugorni anélkül hogy kiértékelné a belsejét (kód előre olvasás). Egy shader ha sinust lát, egy szorzás 137-szeres műveletigényével ki is számolja (dupla pontosságról már nem is beszélek), ha if()-et lát... akkor megáll a világ.
Amire szerintem Pikari gondol az mostanság van készülőben, csak nem verik nagydobra. AMD-nek vannak népbutító marketing videói, mennyivel jobb Llano játékban mint Sandy Bridge ha közben excel számol háttérben és filmet nézel. (Fixed funkciós egységek fitogtatása) Mindez azért van, mert Sandy Bridge IGP-je osztozik a CPU cache-ével (amit az excel rendszeresen kipurgál, ezért megy xarul a játék). MERTHOGY Intel arra utazik, hogy olyan C compilert írjon, ami magától felismeri a vektorosítható műveleteket és azokat minden programozói kijelentés nélkül az IGP-n hajtsa végre. Ez már egy igazi összeolvadása a két egységnek.
Látható, hogy minden csak stratégia kérdése, nem biztos, hogy az erős integráció járható út (Larrabee), lehet hogy a picit herélt mód (Sandy Bridge) lesz a járható, vagy a jó API-kon keresztüli megoldások (Fusion). Én személy szerint az utolsó mellett tenném le a voksomat, de ez ízlés kérdése.
A fixed function videodekódoló egységek pedig igenis jó dolgok, bármit is mond bárki. Nem cserélődnek olyan gyorsan a közkedvelt codec-ek, hogy ne működne a dolog.
-
#45
eziskamu
addikt
errorcode06
#44
eziskamu
addikt
válasz
 errorcode06
#44
üzenetére
errorcode06
#44
üzenetére
Volt már, csak megszüntették
-
#43
eziskamu
addikt
errorcode06
#41
eziskamu
addikt
válasz
errorcode06
#41
üzenetére
Szerintem csak simán időben jutottak nethez és nem (csak
![;]](//cdn.rios.hu/dl/s/v1.gif) ) lenge lányokat nézegettek.
) lenge lányokat nézegettek. -
Abu85
HÁZIGAZDA
Ha gyorsabb memóriát akarsz, akkor azt jelenleg a csatornák növelésével érheted el. Ezt meg kell fizetni a lábak számában. Nyilván a több lábat pedig mi fizetjük majd a kasszánál.
Mindenki elkezdte a GPU-t és a CPU-t egybepakolni. Lassan minden versenyző vállalat realizálja, hogy a heterogén éra elkerülhetetlen, ugyanis a CPU-magok számát nem tudod növelni a végtelenségig. Meg lesz az a határ, ami az egymagos rendszerek karrierjének véget vetett. Nagyon közel járunk a kritikus fogyasztási határ, vagyis olyan útra kell lépni, amivel a vég elnapolható. Ezért pakolják a cégek a CPU-t és a GPU-t össze. A késleltetésre érzékeny szálak a CPU-n lesznek futtatva, míg a párhuzamos végrehajtás esetében ki lehet használni a GPU masszív számítási teljesítményét.
Nyilván a következő lépcsőfok a még szorosabb integráció, de egyelőre erre nincs lehetőség. Majd 2013 környékén. Akkor lehet gondolkodni a memória-sávszélesség problémáján is.
A jelenlegi technikák mellett egy Cellhez hasonló megoldást tudsz kihozni. Ez persze nem olyan rossz, de vannak gyengéi, ami a PC-n alkalmatlanná tenné a rendszert. -
eziskamu
addikt
Esetleg elő kéne venni a Transmeta Crueso-t, csinálni belőle egy százmagosat spéci memvezérlővel, és alapból x86-os morph progit feltölteni, de esetleg szoftveresen lehessen változtatni "magonlént", hogy adott mag x86-os vagy valami más üzemmódban működjön? Vagy ez is hülye ötlet?
-

Pikari
veterán
Igen, de az több ponton is gázos, és sajnos nagyon lényeges pontokban. Egyrészt ha PCI-E-re ülteted, akkor ugyanazok a problémák lesznek rá érvényesek mint amit az előbb már elmondtam. Ha alaplapra ülteted (amit az egyik módosított változatával TALÁN meg lehet csinálni állítólag) akkor viszont csak 4 magot látsz, speciális SDK kell ahhoz hogy a többivel is tudj kezdeni valamit, tehát az egész arhitektúra a rendszer szempontjából nem monolitikus, így nem csoda hogy bukás lett a dologból.
-
Pikari
veterán
Nem kell egy láb sem. Szerintem nem kell külön chipset. Nem kell külön GPU. Nem kell külön speckó memóriavezérlő sem. Néhány külső perifériákkal való kapcsolattartást meg egy külső HUB-ba át lehetne szervezni (pl sata, ide, usb). Szóval nem kell elbonyolítani úgy ahogy a mostani tradícionális x86 ki van alakítva, a lényeg úgyis a bináris kompatibilitás, formailag, arhitektúrálisan nem kell kompatibilisnek maradni. Szépen, egyszerűen egy tömb, és akkor kaptunk egy GPU-hoz hasonló valamit, csak épp x86 támogatással. És akkor amit elvesztessz adón, megspóroltad a vámon. Van már hasonló elgondolás alapján született hardver, ami persze nem pont ilyen, mert ennyire nem merészkedtek messzire, de pl érdemes nézelődni a DPM/Vortex86 irányába, meg látható hogy a GPU-t az AMD és az Intel is elkezdte egybepakolni. De ez ami most van náluk, az nem az, amit elmondtam, mert kvázi külön van a gpu a cputól, ha a cpu alrendszere lenne a gpu, akkor lehetne elindulni ezen az úton.
-
Abu85
HÁZIGAZDA
Ha a jövőben megjelenő Atom nem gyúr rá a multimédiára, akkor az óriási fail az Intelnek, mert a Brazos fényévekkel az aktuális platformjuk előtt jár. Nem azt mondom, hogy verjék meg az AMD-t itt, de illene egy minimális szintet hozni.
Jó. Azt úgy lehet kivitelezni, hogy négycsatornás memóriavezérlőt építesz a CPU-ba. Ez kb. 1500+ láb. Belevéve a routing bonyolultságát cirka hatszorosára nőne a belépőszintű, és háromszorosára a középkategóriás termékek előállítási költsége.
Amit mondasz az mind kivitelezhető, ha a termékek fogyasztói árát megtöbbszörözik. Ja és el lehet felejteni a mobil forradalmat is. -
Pikari
veterán
Az Intel Atomon, a beléjük előszeretettel beépített GMA-kon, és a jövőben megjelenő hasonló kaliberű hardvereken hosszú távon ez az új SDK nem fog segíteni, de érzésem szerint rövid távon sem nagyon.
Szerintem az lenne mindenki számára egyértelmű win, ha a processzor memóriasávszélességét megötszöröznék, saját magába integrált GPU-t kapna mint ahogy elmondtam, meg 8 magot... Mindegyik kapna néhány gpuban megszokott utasítást egy új instruction set keretein belül, és akkor hirtelen azt vennénk észre hogy mindenféle kő alól, meg mocsaras helyekről előbújt furcsa nevű használhatatlan API nélkül is működne minden negyed akkora költségvetésből, normálisan
-
Abu85
HÁZIGAZDA
Érdemes megnézni a gyakorlati példákért a Brazos tesztet. [link] Ott a videólejátszás táblázata, ahol le van vezetve, hogy négy videó lejátszása milyen minőségű. A két legmegterhelőbb videó akad az Atomon, míg a Brazos mindkettőt zsírul viszi. Az Atom + Ion páros gyomrát egyedül a Killa sample fogja meg.
Na most a gyakorlat világosan mutatja, hogy GPU-s gyorsítás nélkül egy Atom mellett meg vagy lőve. Alapvetően a Brazos processzormagjai mellett is meg lennél, ha nem lenne mellette egy UVD 3.0-s motorral szerelt IGP. Ez önmagában megalapozza a GPU-s gyorsítás létjogosultságát. Az AMD csak annyit szeretne, ha ez az élmény egy korszerű API mellett még jobb lenne. A többiek ehhez csatlakozhatnak.Amúgy a shaderekkel nem videokódolást gyorsítasz, hanem post process szűrést. A dekódolásra ott az UVD motor.
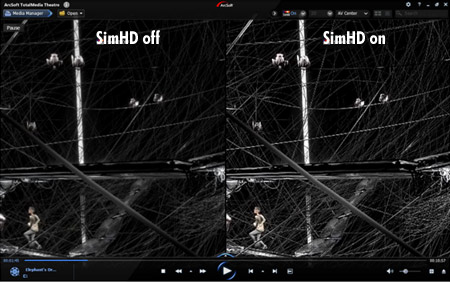
A post process szűrést ellenőriztük a TMT5 szoftverrel, ahol OpenCL-ből alkalmaztunk HD felskálázást. Az OVD-vel ezt a fejlesztő a lejátszóba integrálhatja magába a futószalagba. Ez egyértelműen win számodra, mert javul a videó minősége. Ráadásul Open az egész, vagyis bárki támogathatja. -
Pikari
veterán
Szerintem szemléljük inkább egyben.
Van egy számítógép, amin valaki szeretne nézni egy nagy felbontású videót.
Oké. Stimmel. Beleraksz egy DVD-t, és megnézed. Vagy ott a film a vinyón. Vagy internetről nézed. A téma szempontjából végülis teljesen lényegtelen: a kicsomagolatlan videó először is a rendszermemóriába kerül. Innen, ha azt akarjuk, hogy kép legyen, mindenképpen át kell adni a videókártyának valahogy. Ez mindenképpen meg fog történni legalább egyszer, hiszen más különben nem lenne kép.
A probléma szerintem nem ezeknek a technológiáknak, inkább az egész GPU alapú filmgyorsításnak a létjogosultságát kérdőjelezi meg. Tényleg szűkség van rá, és tényleg működik a gyakorlatban? Ha a videókártyán akarod dekódolni a filmet shaderekkel, akkor először is a nyers, dekódolatlan adatot oda kell adnod. Egy dekódolandó frame függhet az előző frametől, tele van furcsa tömörítési eljárásokkal, amik gyakran még csak nem is párhuzamosíthatók normálisan, tehát shaderekkel ezek dekódolását NEM LEHET normálisan leemulálni. Kivételt képeznek ez alól azok a dekóderek és videótömörítési eljárások, amiket direkt ennek a figyelembe vételével fejlesztettek ki. Ilyen csak papíron létezik. A többit úgy lehet GPU-n dekódolni, hogy hardveres dekódert építenek be tranyó szinten. Ami persze gyorsabb, mintha gpgpuval próbálnák meg kiszmolni a frameket. A probléma ezzel az, hogy minden egyes videótömörítésre külön meg kell ezt csinálni. 2 hét múlva kijött egy új verzió? Hát szar ügy, mehet vissza a 100ezres videókártya a dobozba, meg a tervezőasztalra, hogy kicseréljenek benne 100 tranyót. Tényleg szűkséges ezeket a GPU-ba integrálni? Vagy a CPU-ba? Nem az. Egy asztali dvd lejátszó esetében még van értelme, hiszen az célhardver. Egy számítógép esetében ennek nincs létjogosultsága. Hisz ilyen technológiák léteznek már 10 éve. Azóta se használja őket senki. Meg ezután sem fogja. Persze az ipar nem először gondolkodik, aztán cselekszik. Az ipar az menő ficsőrök köré épül. Például ott vannak a shaderek. Hogy csillog tőle krájzisban a víz! De rohadt menő! Hát gyorsítsunk vele videódekódolást. Azt már most mondom, hogy nem fogsz. Ugyanis vagy tranyó szinten beteszik az adott videóformátum dekódolását, és akkor fogsz. Azt az egyet. Vagy egy grafikus kártyára épített streaming műveletekre kihegyezett egységre épített általános célú végrehajtó egységekre épített általános célú interfészemuláción keresztül leprogramozótt dekóderrel fogsz egy papíron x000 gigaflops teljesítményű valamivel dekódolni egy framet - a gyakorlatban, mint láthatjuk, max olyan sebességgel, mint egy Pentium2-n alulról, vagy olyan kinézettel mint egy 15 éves mpeg dekódoló kártyán. Az egészet kiheréli a lowend gpukon csüngű, GeForce3-mat alulról szagoló 32 és 64 bites 286 szintű bonyolultsággal megtervezett memóriavezérlő, hogy még véletlenül se tudd normális sebességgel kicsomagolni a nagy felbontású videót. Elvégre egy 8 gigabájt/sec-es memóriatransferrel rendelkező integrált kacaton ne akarjon senki egy 4x4096x2048x3as (24 bites) planet valós időben updatelni úgy, hogy közben az egészen még egy dekódert is futtat. Találtak már fel ilyen általános célú kütyüt, aminek az a dolga hogy bármilyen cuccot meg lehessen írni rá. Úgy hívják hogy CPU. Van is belőle vagy 4. Persze a memóriasávszélessége ennek is takony. És azért nem lehet a feladatot tőle hatákonyan átvenni ilyen más cuccra felhegesztett általános célú hardverekkel, mert a vinyó, a hálókártya, a cdmeghajtó, az végső soron a CPU-ra, illetve hát na, a chipsetre van rákötözve, hiába építünk a GPU-ba mindenféle hangzatos nevű technikát, max dísznek lesz jó. Minden erre épített további technológia már csak légvár. A megoldás az, ha a GPU-t a CPU-ba költöztetjük - és akkor a GPUból ledegradálódik egy textúracímzőre, egy speckó interruptra amivel a cpura fallbackel shaderek gyanánt, meg egy hardveres videódekóderre, amit lehet ideig-óráig használni, aztán meg senkit nem fog érdekelni mert lesz helyette 10 másik. Vannak is ilyenek, dvd játékosokban is ez van. Csak egy olyan chip 2 ezer ft és 5Wot fogyaszt. Egy olyan GPU ami ezt meg tudja csinálni, 100 ezer ft, és 100w-ot fogyaszt. Innentől kezdve nekem már csak egy kérdésem van: noooormális? Én az AMD helyében nem mertem volna odaírni az OpenCL-hez a nevem. De mostmár mindegy, így jártak. Viseljék el.
-
Abu85
HÁZIGAZDA
Ez is univerzális, ráadásul nyílt. Pont azért lett meghúzva a képesség ilyen alacsony szinten, hogy a lehető legtöbb hardver támogassa, és a Khronos mielőbb fel tudja venni szabványba.
Ha meg nem támogatják a konkurensek, akkor az Intel és az NV magával szúr ki, mert ezzel az API-val teljesen hardveres futószalag építhető, mindenféle CPU-s bottleneck nélkül. Nyilván program is készül rá a Fusion Fund keretein belül. Az NV és az Intel vagy kínál hozzá drivert, vagy nézi, ahogy az AMD rendszerei több funkciót és jobb feldolgozást kínálnak az adott programok alatt. Igazából az AMD-nek rövidtávon mindkét opció jó. Hosszútávon a legjobb, ha felvetetik az OVD-t szabványba a Khronosszal.Sejtettük, hogy Linuxra nem a DXVA lett megnyitva.
-
#26
 O_L_I
őstag
Meteorhead
#21
O_L_I
őstag
Meteorhead
#21
O_L_I
őstag
válasz
Meteorhead
#21
üzenetére
Pont erre a frame beillesző eljárásra gondoltam mikor a megfingatásról beszéltem
Ez a Spalsh PRO-ban tök jól működik de eszi is a procit rendesen. -
Abu85
HÁZIGAZDA
Nem éppen. Például a DirectCompute alatt eleve a shader modell 5 az ami értékelhető teljesítményt tesz lehetővé. A DXVA viszont nem támogatja a DirectCompute felületet. A legjobb shader modellből ezzel helyből kizártad magad. Persze a DXVA-t tovább lehet fejleszteni, hiszen az MS bármikor megteheti, csak addig amíg ez nem történik meg lenyeled a korlátokat, vagy váltasz egy másik API-ra, ami rugalmasabb. Pl.: a hírben szereplő.
-
Abu85
HÁZIGAZDA
Ezen nem kell csodálkozni. DXVA-hoz az NV és az AMD a CL to D3D10 interop kiterjesztést használhatja. De azon belül is eléggé szenvedés a program megírása. Addig nehéz programot kérni, amíg egy értékelhető felület nem kerül le az asztalra.
A D3D és az OpenGL nem a legjobb felület post processingre. Az OpenCL és a DirectCompute képességei messze meghaladják a korlátozott shader modellek képességeit.
-
#21
Meteorhead
aktív tag
Pikari
#8
Meteorhead
aktív tag
Nem kifejezetten szeretem, amikor a fórumozó népek összefognak és szétszedik az egyetlen más állásponton lévőt, úgyhogy maradok a kultúr véleménynyilvánításnál.
Pikari, ugyan még nem írtam videotömörítést OpenCL-ben, de a legeslegelső OCL béta SDK óta nyúzom az APIt (szinte főállásban) és határozott véleményem, hogy ez nem bonbonos doboz. Ha megnézed 1.1.7-es VLC GPU gyorsított codecjét, akkor látni fogod, hogy egy vicc. (1.1.8-ra csináltak valamit, de még mindig nem az igazi)
Adat GPU-ra >> decode >> adat vissza CPU-ra >> post-process >> vissza GPU-ra >> display
Ugyan GPU accel, de szaggat mint atom, rosszabb mint a sima CPU-s ami tökéletesen működik a 8GB-ba tömörített HD-knál, csak a 25GB+ videok fekszik meg a gyomrát mezei masinákon.
Az értelme ennek az egésznek, hogy egy egységes felület adódik az ilyen problémák nagyon szép és frappáns kiküszöbölésére. Az ember streameli adatot GPU-ra, UVD egyszerű preprocess formában dekódolja az adatot, OCL kernel postprocess javításokat használ rajta és küldi OGL-nek megjeleníteni. Nagyon szép moduláriás és robusztus rendszer.
Hogy mire jó a frappáns elrendezés? Ezzel lehet igazi varázslatot csinálni. Gondolom mindenki látott már 100+Hz TV-n frame beillesztő eljárást, és hogy mennyivel simább lesz tőle a videó. Az ilyen szép strukturált programokkal lehet ilyet csinálni gépen is tv nélkül. UVD dekódol képet küldi OCL-nek, OCL vár még egy frame-re, amikor másodikat kapja interpolál egy kockát a kettő közé (ami számításigényes buli ha szépen akarod megcsinálni), postprocess az első és az interpolált képre és mehet OGL-nek megjelenítésre, már nem 29.7 hanem 59.7 fps streamként.
Ettől a felhasználó már hanyatt esne. Hadd ne folytassam, hogy az encode és transcode variációkkal miket lehet még csinálni, de hidd el hogy az ilyen dolgokért nagyon sokan ölni tudnának (köztük én is). És szeretném kihangsúlyozni, hogy AMD nem olyan mint buzi Intel vagy NV, hogy ahol tudják kiszorítják a konkurenseket, hanem nyílt szabványba invitálja a népeket.
Remélem sikerült megvilágítani Pikari és a kétkedők számára hogy miért jó ez.
-
O_L_I
őstag
Na tisztázzunk valamit mert új vagy itt.
A Troll és a pesszimista szakértő között annyi a különbség hogy a szakértő megmagyarázza hogy miért szar a bizonyos dolog a troll meg csak leírja hogy szar és ezt az álláspontját bármiféle érvelés nélkül a végletekig védi.
A bonbonos hasonlatból nem jön ám le hogy te melyik kategóriába tartozol.
Tehát nem besértődni kell hanem akkor mond el hogy ez szerinted miért nem ér semmit. -
devast
addikt
Én spec pikari-nak adok igazat.
Mutassatok nekem, 1 akármilyen video decodert/encodert ami opencl-t használ. Másrészt a postprocessing-et eddig is d3d/opengl -ben végezte minden jobb dekóder.
ps: linux alatt is nemrég nyitotta meg az ati a dxva interfészét. Mondanom sem kell, az is mint halottnak a csók. -
Abu85
HÁZIGAZDA
Ez a OpenVideo Decode API olyan, mint a DXVA (Windows), vagy a VDPAU (Linux).
Az AMD megoldásának annyi az előnye, hogy az OpenCL-re könnyen megoszthatók a pufferek. A DXVA esetében ez a rész borzalmasan nehézkes, és alapvetően korlátozott is.
Lényegében aki GPGPU-s szűrőket akar futtatni a lejátszójában, annak jelenleg az OpenVideo Decode API a legkényelmesebb megoldás. Emellett még nincs konkretizálva, de az AMD már mondta, hogy tárgyalnak az OVD Khronos specifikációba való felvételéről. Innen eredhet az első verzió úgymond korlátozása is, hogy a lehető legtöbb hardver támogassa. -
#16
 TTomax
félisten
Ł-IceRocK-Ł
#15
TTomax
félisten
Ł-IceRocK-Ł
#15
TTomax
félisten
válasz
 Ł-IceRocK-Ł
#15
üzenetére
Ł-IceRocK-Ł
#15
üzenetére
Pedig nem irt ám hülyeséget...
-
Pikari
veterán
O_L_I: én a szoftveres megoldások híve vagyok. Persze kipróbáltam az OpenCL-t is, szeretek haladni a korral. És a cikkben szereplő dolog annyit ér, mint akna által levitt lábra a papírzsebkendő. A DMA meg mindkét esetben ugyanúgy fogja fingatni az eljárást. This should do the trick.
Ł-IceRocK-Ł:
Végülis igazad van. Azt hiszem, többet ilyen témában nem szólok hozzá. Most no offense, nem beszólás, de felesleges olyanoknak osztanom az észt, akik szó nélkül bekajálnak bármilyen magyarra fordított marketingbullshitet ami mellett ott figyel mondjuk egy AMD logó. Mivel ezekkel az arhitektúrákkal kapcsolatban nagy pénzek forognak, amiben én személyesen is érdekelt vagyok, jobb ha megtartom magamnak a titkokat.
-
O_L_I
őstag
Pikari: Megfogtál valóban nem programoztam OpenCL-ben.
Ami számomra lejött mint újdonság és extra haszon az az utófeldolgozás hardveres gyorsítása Mert jelen pillanatban hiába van hardveres dekódolás a filmen ha bármilyen post process effektet bekapcsolok akár Splash PRO-ban akár PDVD-ben azok azonnal a procit fingatják ráadásul egy HD anyagnál nem is kicsit.
-
#11
 Ł-IceRocK-Ł
veterán
Ł-IceRocK-Ł
veterán
Ł-IceRocK-Ł
veterán
Az amd tényleg nem ül a sejhaján, toják az ipart, ami nagyon hejes. Várom az új katalistot, hogy valójában kiderüljön mi merre hány méter.
Pikari: ha így folytatod te sem leszel hosszú életű itt. személyes véleményem szerint.
-
Pikari
veterán
Erről haverom anyja jut eszembe. Kiment a piacra, és vett egy bazinagy bombont. Akkora volt a csomag mint két laptop. Hogy örült. Csak 300 ft! Szinte ingyen van! Hazament, kibontotta, és volt benne 5 db bombon. Négy a sarkakban, egy db középen.
Használhatatlan semmi, díszes csomagolásban.


















 Az ffmpeg és az XBMC elsődleges platformja is a Linux, ezek után nem nagyon látom, hogy mit jelentene a gyakorlatban az, hogy a Win7-nek előnye van.
Az ffmpeg és az XBMC elsődleges platformja is a Linux, ezek után nem nagyon látom, hogy mit jelentene a gyakorlatban az, hogy a Win7-nek előnye van.








 , de egy sokkal régebbi cikkben olvastam, és ráadásul valamelyik külföldi oldalon.
, de egy sokkal régebbi cikkben olvastam, és ráadásul valamelyik külföldi oldalon.  De attól független alátámasztja a mondanivalóm, annak ellenére, hogy más ember mondta.
De attól független alátámasztja a mondanivalóm, annak ellenére, hogy más ember mondta. 












![;]](http://cdn.rios.hu/dl/s/v1.gif) ) lenge lányokat nézegettek.
) lenge lányokat nézegettek.













Új hozzászólás Aktív témák
Hirdetés

- LG 40WP95XP-W - 40" NANO IPS - 5120x2160 5K - 72Hz 5ms - TB 4.0 - HDR - AMD FreeSync
- Xiaomi Redmi Note 10 Pro 128GB, Kártyafüggetlen, 1 Év Garanciával
- Apple iPhone 13 . 128GB , Kártyafüggetlen , 100% akku
- Nike Airmax 720 43-as sneaker eladó
- BESZÁMÍTÁS! ASUS Z390 i5 9500 16GB DDR4 512GB SSD RTX 2060 Super 8GB Rampage SHIVA Thermaltake 500W
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest