Hirdetés
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Samsung Galaxy Z Fold7 - ezt vártuk, de…
- Android alkalmazások - szoftver kibeszélő topik
- Örömhír: nem spórol Európán a OnePlus
- One mobilszolgáltatások
- Samsung Galaxy S25 - végre van kicsi!
- Samsung Galaxy S23 és S23+ - ami belül van, az számít igazán
- Youtube Android alkalmazás alternatívák reklámszűréssel / videók letöltése
- Xiaomi Mi 9 - egy híján
- AGM G3 Pro - ordít róla, hogy szoftverfejlesztők kellenének
Új hozzászólás Aktív témák
-
#3868
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
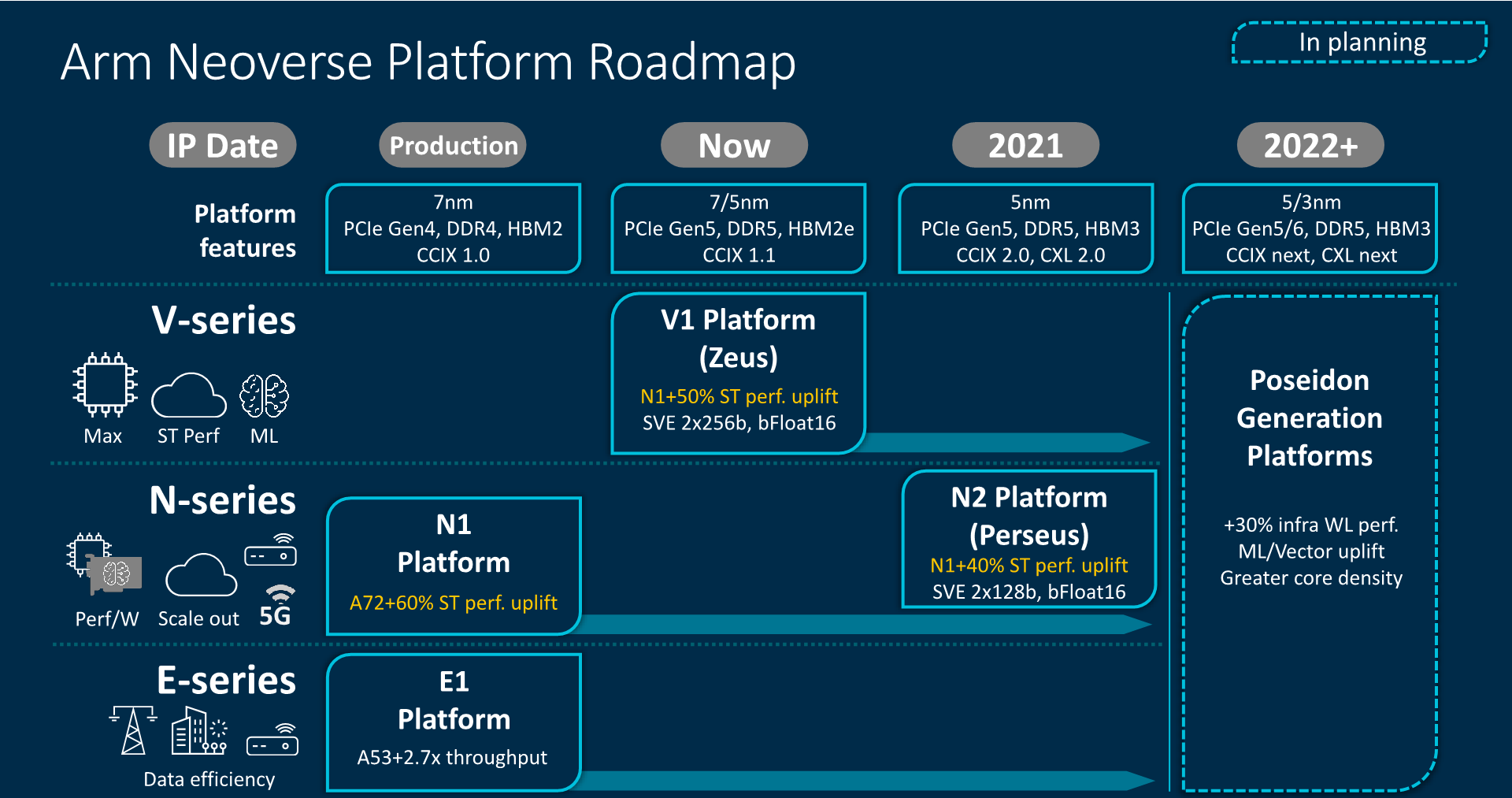
A roadmap nem tudom, mennyire hiteles.
Ez persze ugyanaz, már láttuk.
De a Feltételezett Vermeer és a Renoir - Cézanne vonal egymáshoz képesti elcsúsztatása nem jön ki.
Figyelembe véve, hogy a Renoir közepén van a 2020 és Renoir kár év elején óta van, ezért joggal feltételezhető, hogy a Vermeernek már év közepe óta kéne lennie. -
#3866
Petykemano
veterán
S_x96x_S
#3865
Petykemano
veterán
válasz
 S_x96x_S
#3865
üzenetére
S_x96x_S
#3865
üzenetére
"A DPU is essentially PCIe on one side and Ethernet on the other. "
Én a Mellanox-szal látok hasonlóságot.
[link]Azt gondolom valami ilyesmire az AMD-nek is biztos szüksége lehet.
Ha nem abban a világban élnénk, hogy a cégek elképesztő vagyonokkal rendelkeznek, a versenyhatóságon meg pár yachtozásért kábé minden átmegy, akkor azt is mondanám, hogy lehetne partnerségben is gondolkodni. De úgy tűnik, hogy erős a "piacról való kiszorítás" igénye és ennek nyilván a fentiek miatt egy ellenséges felvásárlás remek eszköze lehet. -
#3859
Petykemano
veterán
S_x96x_S
#3857
Petykemano
veterán
válasz
S_x96x_S
#3857
üzenetére
mármint úgy érted, hogy a zen2 ellen nem csak a szerver környezetben, hanem a desktop zen2 ellen is, ami magasabb órajelen üzemel.
Ebből persze termék idén valószínűleg már nem lesz, csak jövőre, tehát a zen3-mal és a Milannal kell mérkőznie, de szerintem ez nem életbiztosítás.
Ezért mondom, hogy a 15% IPC emelkedés a zen3-tól szerénynek tűnik.
Persze ez itt 7nm továbbra is. 5nm-re váltástól lehet, hogy többet lehet várni, mert emelkedik a tranzisztor büdzsé.
Az Arm az SVE-től is gyorsulhat, gondolom.Kiváncsi vagyok, mit eredményez majd az, hogy azt mondják, a zen2 csupán egy ráncfelvarrása volt az eredeti zennek, viszont a zen3 egy új architektúra. Bár olvastam már olyan véleményeket, hogy végül a zen3 mégse annyira lesz új, csupán egy ráncfelvarrása a zen2-nek és a későbbra halasztott lényegi változások majd az 5nm-en készülő zen4-ben érkeznek meg.
-
#3856
Petykemano
veterán
-
#3846
Petykemano
veterán
S_x96x_S
#3844
Petykemano
veterán
válasz
S_x96x_S
#3844
üzenetére
Nem tudom pontosan milyen az intel oneapi, Mit kínál, vagy mivel hogy kompatibilis. Régen ugye az AMD az opencl-t nyomatta a HSA-hoz. De az opencl azért nyitott, biztos meg lehet oldani benne / vele a kükönböző hardverrel való kompatibilitást.
Nyilván az AMDnek sosem sikerült rávennie a fejlesztőket arra, hogy így fejlesszenek. És erről úgy tűnik, egyelőre le is tettek, különben most is nyomatnák az IGPt mindenhova.
Profi célterületekre gondolom a ROCm van.
A kérdésemmel oda akarok kilyukadni, hogy ez a oneapi olyan keretrendszer, hogy ha elköteleződsz mellette, akkor minden más hardver bukó, vagy azért létezik olyanfajta kompatibilitás, mint az utasótáskészleteknél, hogy lehet hozzá igazodni?
-
#3840
Petykemano
veterán
awexco
#3839
Petykemano
veterán
Frekvenciával is lehet gond.
mindazonáltal elvileg van az AMDnek foglalva 5nm vmikorra, abu szerint custom AMD node.
Ha nem is most, de jövő év első felében arról jönnie kéne vminek.
Nem tudom mi lehet. De vajon van annyi 7nm wafer, amiből ps5, xss, xsx, 2 RDNA2, zen3, cdna - mind kijön?
Mondjuk nem lehet, hogy a Renoir pont azért nem érhető el Nagy mennyiségben? És a Cézanne 5nm? És a Warhol egy beszúrt 5nm zen3, ha már úgyis meg kellett csinálni? -
#3824
Petykemano
veterán
Petykemano
veterán
-
#3823
Petykemano
veterán
Petykemano
veterán
-
#3822
Petykemano
veterán
Petykemano
veterán
Apple A14
+16% vs A13
[link]Ez azért nem behozhatatlan előreképés, vagy legalábbis amivel ne lehetne lépést tartani
-
#3806
Petykemano
veterán
olymind1
#3805
Petykemano
veterán
válasz
 olymind1
#3805
üzenetére
olymind1
#3805
üzenetére
Igen.
Nekem 1700X van (de valójában megbántam, hogy nem 1600X-et vettem anno)
Van a családban egy 3600X is.Azt néztem, hogy cinebench ST-ben 344 vs 501 (+45%), ha erre még rápakolnak 15%-ot, akkor már közel 70%-os gyorsulás jön ki egy szálon. Az azért már szerintem érezhető.
-
#3804
Petykemano
veterán
Petykemano
veterán
Azt mondják az okosok, titkok ismerői, hogy a zen3 előrelépése nem lesz általánosságban jelentős. Egy Cézanne ES vizsgálata alapján ez várhatóan nem lesz elég a Tiger Lake U (8c) lenyomásához.
[link]
(Itt legföljebb az a kérdés merülhet föl, hogy mikor lesz 8 magos tiger lake)A redgamingtech tegnapi videójában (amit kíméletességből nem linkelek), azt mondta belsős infók szerint elégettek a zen3 játékokban nyújtotta teljesítményévél. Tehát itt kifejezetten a játékok volt a hangsúly és a késleltetéseken.
Azt rebesgetik, hogy a rocket lake 5.5GHz-es lesz és ugye Valamit megkap a willow cove magokból. Ez ellen a Vermeer valószínűleg jól fog teljesíteni.
-
#3796
Petykemano
veterán
Petykemano
veterán
TSMC to produce 5nm chips for Intel
[link] -
#3792
Petykemano
veterán
Petykemano
veterán
Google Zork
AMD 3015Ce
2c/4t
Android 9 -
#3791
Petykemano
veterán
Petykemano
veterán
A wccftech Frank Azor mai tweetjéből, ami gyakran tartalmazza a "tomorrow" szót, azt a következtetést vonta le, hogy holnap lesz AMD bejelentés.
""The sun'll come out Tomorrow So ya gotta hang on 'Til tomorrow Come what may Tomorrow, tomorrow! I love ya tomorrow! You're always A day Away!"
[link]"We do encourage everyone to tone down their excitement. AMD has not informed their board partners about the potential unveiling of the new graphics card yet."
[link]Valószínűleg csak egy újabb easter egg.
"Your HP customized order [redacted] contains an AMD processor that has been impacted by the manufacturer. Unfortunately, this means we are not able to complete the build of your computer."
[link]Vajon ez azt jelenti, hogy
- kifogytak
- kiszálltak az AMD notikból?
- EOLt kapott a Renoir? (Mert jön a Cezanne) -
#3789
Petykemano
veterán
S_x96x_S
#3787
Petykemano
veterán
válasz
S_x96x_S
#3787
üzenetére
Az Nvidia által bemutatott technológiák, mint pl az machinery az tűnik igazán korszakváltónak.
Nyilván minden programnak meg kell - ha lehet - találni azt a pontját ahol ML/DL technológiával lehet előrelépni. Nem tudok igazán jó példát mondani. Nemrég jelent meg a gmail szövegkiegészítő, meg a GPT3, IDE-kben is biztos van kódolást segítő előíró.
De nem vagyok biztos abban, hogy ezekhez kell kliensoldali ML kapacitás. A nagy.lehetőség pedig ebben látszik. Pont mint az AMD HSA, csak semmilyen elterjedt kliensoldali szoftver nem csinált olyan nagy párhuzamos számításigényes dolgot.Weben például el tudok képzelni egy olyat, hogy a szar minőségű képet feljavítja a böngésző. Így sávszélességet lehet spórolni.
A DLSS-t miért ne Lehetne youtube videón alkalmazni? -
#3785
Petykemano
veterán
Petykemano
veterán
[konkurencia]
Ez szerintem még csak terv, de impozáns:
Rhea 72 core Arm"Rhea design sports a high-end memory subsystem, with the floor plan labelled as having 4x HBM2E controllers and 4-6 DDR5 controllers. Such a hybrid memory system would allow for extremely high bandwidth to be able to feed such a large number of cores, while still falling back to regular DIMMs to be able to scale in memory capacity."
-
#3783
Petykemano
veterán
Petykemano
veterán
-
#3781
Petykemano
veterán
HSM
#3779
Petykemano
veterán
Pont emiatt érdekes elképzelés.
Azt gondoltam, hogy a zen3 nagy dobása az egységes L3$ lesz 8 magon. Játékok terén nagy dobás.Azért egy 5+5 bedobása a 10 magos intellel szemben elég nagy magabiztosságra vallana.
mondjuk a Rocket lake csak 8 magos lesz
Viszont lehetséges, hogy egy fullos 8 magos lapka drágább (ritkább, Milanhoz kellőbb), mint egy olyan, amin csak 5 mag jó.
4800X vagy akár 4900 is lehet belőle.
-
#3773
Petykemano
veterán
Petykemano
veterán
About Zen 3. Part 1. One of the key features of Zen 3 will be the "Curve Optimizer" , which allows you to configure the boost of the Ryzen processor. In addition, you will be able to customize the frequency for each core without any restrictions.
[link]About Zen 3. Part 2. 10 core's processors - it's real :)
[link]Ez utóbbi egészen furi. 5+5 nyilván. De vajon mi végett?
A Ryzen 7 lenne 10 magos, hogy jobban megkülönböztetődjön a 8 magos cezanne-tól?
Vagy előfordul olyan lapka is, amin egyszerre 3 mag rossz?About Zen 3. Part 3. Infinity Fabric dividers. That is, we can get the memory controller frequency slightly higher in mixed mode. There are a number of mentions of this, but I do not know the mechanism.
[link] -
#3768
Petykemano
veterán
Petykemano
veterán
-
#3767
Petykemano
veterán
S_x96x_S
#3765
Petykemano
veterán
válasz
S_x96x_S
#3765
üzenetére
Hát nem tudom.
Jim Kellert is körüllengi egy ilyen aura. Dolgozik valahol és évekkel azelőtt, hogy a neki tulajdonított munka piacra kerülne és a nagyközönség számára értékelhető lenne, lelép, új kihívásokat keresve.
Persze értem, egy igazán jó high level architectnek, aki nem rejt átgondolatlanságokat a tervbe, nem kell megvárnia, míg a gyalogmérnökök implementálják az elképzelést néhány év alatt.
Ez az aura aztán ad egy áldásos ködöt.
Jim@AMD + zen siker = jim Keller géniusz
Jim@AMD + zen flop = jim már ott se volt, azért jött el mert nem hallgattak rá és meg is lett az eredménye
Ugyanez a teslával és az önvezető ökoszisztémával
Ugyanez az intellel és a következő évek termékeivel
És ugyanez jon masters és a nuvia is.
Ha most ez siker lesz, akkor jon masters érdemeit öregbíti, ha nem, akkor pedig már rég eljöttem onnan.Amúgy igazad van a Nuviával és az nvidiával kapcsolatban.
Ha az nvidiának nem terve lecserélni a malit geforcera, vagyis az összes arm processzort kompatibilissé tenni a geforce IPvel és csak azzal, akkor integrált szerveres ökoszisztéma kínálatához elgendő lenne felvásáolni a Marvellt vagy a Amperet, esetleg a Nuviát.
Ezzel már mondhatná, hogy kell a kimagasló teljesítmény? Persze, tudjuk szállítani x86-hoz is, de ha igazán jót akarsz vedd meg hozzá a szerver procinkat is.Talán az lehet a válasz, ami miatt nem látunk még ilyen törekvéseket a szuperszámítógépeken kívül (threadripper + big igp), amivel abu magyarázta a marvell kiszállását a dobozos szerver proci üzletből: a legnagyobb volumenű szerver eladás még mindig közepes vállalatok vásárlásaiból van és őket nem lehet könnyen rávenni szoftver módosításra.
-
#3763
Petykemano
veterán
Petykemano
veterán
Jon Masters is kiszáll Nuviából.
Nem tudom, neki milyen korábbi érdemei voltak, és Mit tett hozzá a nuviához 10.hónap alatt, de visszamegy a Red Hathez.Ebből még nem merném levonni azt a következtetést, hogy (egyelőre) vége a feltörekvő arm szerver ambícióknak, de ahogy abu is írta, eléggé ez a kép bontakozik ki.
-
#3759
Petykemano
veterán
awexco
#3758
Petykemano
veterán
Nehezen fog kiderülni.
Két dolog szokott lenni:
1) Azzal trükköznek, hogy amikor sebességet mérnek, akkor 15W vs 28W-on mérik. Mert persze ezek gyári értékek, amiket a notebook gyártója állít be.
Aztán az akkumulátor időt már vagy 15W-ra korlátozva mérik, vagy ha mégse, és emiatt leszívja az aksit, akkor azt egy nagyobb akkumulátor beépítésével kompenzálják. Az inteles gép így nehezebb, de gyorsabb, és mivel kap egy minőségibbnek tűnő kialakítást is, ezért összességében megérősnek tűnik a 20% ártöbblet a fapad és lassú AMD-s változattal szemben.Legalábbis én szoktam ilyen értelmezési nehézségekkel küzdeni, amikor notebook teszteket olvasok.
-
#3750
Petykemano
veterán
Cathulhu
#3749
Petykemano
veterán
válasz
 Cathulhu
#3749
üzenetére
Cathulhu
#3749
üzenetére
Miért? A cikkben van racionális indoklás:
ST-ben segít az egy mag számára elérhető dupla L3$. Ebből MT-ben majdhogynem semmilyen előnyt nem jelent ha szálfüggetlen programban teszteltek.
És valószínűleg segíthet az is, hogy magonkénti feszültségszabályozás jöhet. Viszont az összes mag terhelése esetén valószínűleg ez se jelent semmit.Ezek az adatok a Milanra vonatkoznak. Desktopon lehet, tudtak alacsony magszámon turbó frekvenciát is növelni.
Az én várakozásom az általam ismert információk alapján az, hogy a zen3-nak nagyobb lesz az impactja a játékokban, mint a Datacenterben.
-
#3747
Petykemano
veterán
Cathulhu
#3744
Petykemano
veterán
válasz
Cathulhu
#3744
üzenetére
Azt mondod fake?
Én csak arra utaltam, hogy megjelent. Ha tesztelik, néhány hónap múlva piacra kerülhet.
Az "ryzen 5k" következtetés:
Felreppent a pletyka, hogy csak a Renoir lesz 4000, a Vermeer (vagy a tök tudja mi fog megjelenni zen3 magokkal hamarosan) viszont már 5000 lesz. Én azt mondtam, ennek csak akkor látnám értelmét, ha annyira közel van a Cezanne, hogy szinte egyszerre jelenik meg a desktop procikkal. Az lehet tényleg zavaró lenne, ha az ősz folyamán megjelenne a desktop ryzen 4000, és röviddel utána (tehát nem 2021Q1-ben) a Cezanne Ryzen 5000 néven. -
#3743
Petykemano
veterán
Petykemano
veterán
Cezanne
OpenbenchmarkingLehet, hogy ebből tényleg ryzen 5k lesz
-
#3741
Petykemano
veterán
Petykemano
#3734
Petykemano
veterán
válasz
 Petykemano
#3734
üzenetére
Petykemano
#3734
üzenetére
A Marvell elkaszálta a ThunderX3-at, mint általános célú bolti terméket. Semi -custom módban viszik tovább.
Ennek szerintem kell köze legyen a konkurenciához, vagyis például a Milanhoz.
-
#3736
Petykemano
veterán
Cathulhu
#3735
Petykemano
veterán
válasz
Cathulhu
#3735
üzenetére
Azzal egyetértek, hogy önmagában az ISA nem szentgrál.
Olvastam egy olyat is, hogy az x86 és arm IPC nem összehasonlítható, mivel az arm jobban Risc, ezért érthető módon több egyszerűbb.utasítást.tud egy órajelciklus alatt végrehajtani.
Ott látok különbséget, amire és ahogy használják. Ebben talán valóban nem annyira van szerepe az isának, lehet, hogy ha megnyitnák az X86-ot, ugyanezek a szereplők most abban terveznének.
Mire is gondolok?
Abu el szokta mondani, hogy a magas frekvencia elérése tranzisztorokba kerül.
Ebből a szempontból az, hogy az amd ugyanazt a designt,.sőt lapkát használja desktopra és szerverbe, lehet,.hogy hátrányt jelent. Feltételezem, hogy ha egy. Matisse ccd nem kéne 5ghz körüli értéket elérjen, kisebb is lehetne. Nem tudom, ez nincs-e összefüggésben azzal is, hogy az arm szerver üzemi frekvencián alacsonyabb fogyasztással kecsegtet. -
#3734
Petykemano
veterán
Cathulhu
#3732
Petykemano
veterán
válasz
Cathulhu
#3732
üzenetére
két megjegyzés:
1) Természetesen az Arm "lassulása" is érezhető. Legalábbis az utolsó, 5nm-re és nyilván legkorábban jövőre tervezett A78 már nem hozott nagymértékű IPC emeledést. Helyette az X1 hozott, ami az A78-hoz képest viszont nagyobb és energiaigényesebb lesz.2)
A konkrét példák viszont előttünk vannak
az amazon Graviton 2-je A76/Neoverse N1 alapú, az ARM-ról ilyen már tavaly kapható volt. És versenyképes teljesítményt nyújt. (Az összehasonlítás persze még Naples-szel van)
És elvileg lényegesen kevesebbet fogyaszt.Ott van az Apple nagy magja, ami jó, egy kicsit más tészta, mint a szerver, de azonos órajelen 70%-kal jobb eredményt ad specint-ben, mint az intel.
Vannak, amik slide-okon léteznek:
A Marvell bejelentette a 60c/240t ThunderX3, állítólag idén év végén elérhető lesz ()
És a Ampere is bemutatta már a 80c Altra családot szintén év végi elérhetőséget ígérveJó, ezek persze egyrészt majd a Milannal kell versenyezzenek. Abban igazad van, hogy a ThunderX3 96 magja tűnt volna igazán veszélyesnek, de az majd csak 2021-ben debütál.
És akkor ott van a Nuvia, ami szintén egy ígéret, ezért azt most hagyjuk is.
Arról van szó, hogy a Naples => Rome => Milan váltások generációs hozadéka kisebbnek tűnik, mint az Arm-os konkurensek utolsó néhány generációja és az ismert vagy még nem ismert terveik ugyanezekből az időkből.
Charlie (S|A) viszont ezt írja: AMD is going to Celeron Intel’s Xeon margins
Ez viszont azt sejteti, hogy többet kellene hoznia a Milannak, mint 10-20% -
#3731
Petykemano
veterán
S_x96x_S
#3730
Petykemano
veterán
válasz
S_x96x_S
#3730
üzenetére
Ez azért annak függvénye is, hogy áldoztak-e a késleltetésből. Bár gondolom nem lépnék meg ezeket a - lényegében - duplázásokat, ha bukó lenne a késleltetés miatt.
Biztos lesz, ami tudja hasznosítani. Szerintem játékoknál inkább abban az értelemben lesz haszna, hogy ha külön CCX-ben levő CPU magoknak kell kommunikálni, vagy ha egy programszál átdobódik egy másik CPU-ra, ami eddig másik CCX-be landolt, ott gyakorlatilag újra kellett olvasni a memóriából.Szóval én továbbra is számítok a szokásos módszerekkel mért IPC vagy egyszálas teljesítménynövekedés vonatkozásában ahhoz képest további +5-10%, szélsőséges esetben 15%-os többlet javulásra. (Persze fel vagyok készülve a csalódásra)
Abban igazad van, hogy a 4 helyett 8 mag által megosztott, de összességében azonos méretű L3$ a független többszálas teljesítményen kevésbé fog javítani.
mit szólsz a Genoa listájába felkerülő NVDIMM-P-hez?
-
#3729
Petykemano
veterán
Petykemano
veterán
"The slides also list some performance values: These speak of an IPC performance increase of + 15% for integer workloads. For EPYC processors with up to 32 cores, AMD wants to achieve a performance increase of + 20% compared to the Rome processors with Zen 2 cores - the single-treaded performance should also increase by + 20%. For the larger EPYC processors with up to 64 cores, AMD expects a performance increase of around 10 to 15%."
A cikk a 10-20%-os generációs teljesítménynövekedést elismerésre méltónak nevezi. Ha a környezetet nem nézzük, akkor persze ha sok éven át ez hoznák (+ időnként magszámemelés), akkor az egész szép eredmény lenne. De a földből kinövő Arm konkurensek ígéreteihez viszonyítva a 10-20%-os generációs előrelépés olyan szűkösnek tűnik.
"The roadmap now speaks of more than 64 cores for Genoa. It remains with two threads per core, i.e. one SMT2. It remains to be seen whether this will mean a doubling compared to Milan. There is also talk of DDR5, support for Persistent Memory (NVDIMM-P) and PCI-Express 5.0."
-
#3727
Petykemano
veterán
lezso6
#3726
Petykemano
veterán
Senki nem gondolta, hogy a CTR az AVFS-t váltaná ki.
A korrekt válasz az, hogy az AVFS olyan feszültség-frevencia páros beállítását lehetővé tevő algoritmus, ami figyelembe veszi a környezeti hőmérséklet és egyéb szempontokat. De nem feladata és célja az adott kröülmények között beállított frekvenciához a legalacsonyabb stabil feszültség megtalálása.
Anno innen olvastam: [link]
Ha az AVFS levágja, hogy mennyire jó minőségű a chip, akkor azt gondoltam valahogy ezt az alapján teszi, hogy a frekvencia stabilitását figyeli adott feszültség mellett és ha instabil, akkor emeli a feszültséget.
Ha erre képes, arra is képesnek kéne lennie, hogy csökkentse a legalacsonyabb stabil feszültségig. Ezt teszi a CTR is, nem?
És ha jól emlékszem végülis az AMD-nek is van valami Auto UnderVolt megoldása, bár az lehet, hogy csak a GPUknál.
Na de mindegy, ez egy régi vita.
-
#3725
Petykemano
veterán
Yutani
#3723
Petykemano
veterán
igen, de miért?
Abu mindig azt mondja, hogy a hardveres megoldásnál semmi nem gyorsabb és azért rosszak a szoftveres megoldások, mert lassan reagálnak.
Itt az élő példa, hogy lehetne ezt jobban is csinálni. Fura, hogy egy lelkes amatőr 5-10%-ot ki tud hozni a prociból bárki számára egy szoftveres megoldással, de ezt az AMD nem tudja/nem akarja megtenni, miközben van szoftveres megoldása, a Ryzen Master és náluk jobban senki nem érti a hardver működését sem.Az is válasz, hogy másként gondolkodnak. Ha jól emlékszem, a zen3-ban per core alapú feszültségszabályozó van már. Ha eddig ez CCX alapú volt, akkor az hozhat a konyhára.
-
#3722
Petykemano
veterán
Petykemano
veterán
ClockTuner for Ryzen
[link]"The basic idea of this software is an undervolt for each CCX individually. This makes the processor faster and colder. At the same time, all energy-saving technologies remain active. Until CTR came along, this was impossible. Another key feature of this software is smart overclocking."
"The latter pictures show the results that were obtained with CTR. For example, the 3900X was able to increase its performance by almost 7% while reducing power consumption by 9.5%. For 3960X +5% performance and - 4.5% power consumption."
Hosszasan vitáztam abuval már az AVFS-ről és a kérdésem mindig az volt, hogy EZT miért nem tudja megcsinálni. Én értem, hogy a cpu-nak a 60 fokos klímatizálatlan sivatagban is működnie kell és ott valószínűleg ezeket az előnyöket nem lehetne szoftveresen realizálni.
A kérdésem mindig arra irányult, hogy valaminek, ami "Adaptív", nem pont ezt kéne lekezelnie? -
#3719
Petykemano
veterán
Petykemano
veterán
Szerintem.ez.szándékosan szivárgott.ki. vagy minden későbbi még nem biztos. (Raphael... Nav)
-
#3713
Petykemano
veterán
Petykemano
veterán
-
#3712
Petykemano
veterán
Petykemano
#3708
Petykemano
veterán
válasz
Petykemano
#3708
üzenetére
Alibaba azt állítja, a 12nm-es RISC-V procijuk gyorsabb, mint a 2017-es ARM A73
[link] -
#3708
Petykemano
veterán
S_x96x_S
#3707
Petykemano
veterán
válasz
S_x96x_S
#3707
üzenetére
ok, hogy ezek "csak papíron" létező termékek, de durva tempót diktálnak.
Ha az AMD (és persze az intel) csak ilyen évi 10% körüli IPC növekedést, 3-4% frekvencia emelkedést és a kötelező fícsöröket, mint DDR5, PCIe5, ilyen-olyan kompatibilitás és a saját gyorsítóval való együttműködést hozza, akkor szerintem nehezen lesz tartató ez a front.
Arra persze lehet bazírozni, hogy de mi hozzuk a saját gyorsítót, de egyrészt akkor ahhoz el kell hozni az az érát is, másrészt ha az nvidia megveszi az ARM-ot, akkor az armra is lehet natív összekapcsolás. Elég beszédes ilyen szempontból, hogy a Power10-ből hiányzik az NVlink... -
#3704
Petykemano
veterán
Petykemano
veterán
IBM Power10
600mm2
Samsung 7nm
16c SMT8
... -
#3701
Petykemano
veterán
Petykemano
veterán
-
#3695
Petykemano
veterán
Petykemano
veterán
[Leak]
Cezanne
> 8CU 512 Shaders
> 1.85GHz iGPU core clockÚgy tűnik, nem a Cezanne-nal fogják a tiger Lake U IGP-jének támadását kivédeni.
[találgatás]
Vajon lehetséges-e, hogy annyira pro volt az AMD, hogy a 4000G szériát már Cezanne-nal tölti föl és azért kapható korlátozott mennyiségben a Renoir, mert már nem is gyártják?
Vagy éppen ez miatt volt a pletyka, hogy a zen3 5000-es szériával indít?A 4200G-ről sisoft szivárgás 2019 decemberben volt
[link]
A Renoir bejelentés aztán megtörtént januárban a CES-en [link]
Jó, persze asztali verzió ebből aztán csak fél évvel később lett. De 2 hónap legalábbis a bejelentéshez elég lehet -
#3686
Petykemano
veterán
S_x96x_S
#3685
Petykemano
veterán
válasz
S_x96x_S
#3685
üzenetére
Kérdés, vajon mit jelent a high-feature és a low feature cpu?
Az intelnél pont az volt a gond, hogy például az utasításkészlet vonatkozásában különbség volt.a legérdekesebb az első ábra, ami alapján nem pusztán ccx-ben kapcsolódnak. eddig a L2$ privát volt a zen magokban.
Azt gondolom, hogy ahogy abu is elmondta, nagyvonalakban minden node-on választani kell egy fogyasztás, kiterjedés és teljesítmény hármast, amit egy meghatározott célra fejlesztett cpu-nak optimálisnak lehet tekinteni. Ezen belül persze lehet reszelgetni, de a nagyobb teljesítmény nagyobb kiterjedést és fogyasztást eredményez, illetve abba munkát kellhet fekteni, hogy ez ne így történjen. De jellemzően ezt egy kisebb csíkszéleséggel oldják meg inkább.
De azt nem értem, hogy az AMD miért bontaná meg az egész jó, kompakt zen magokat, amelyben az L1$ és a L2$ privát és L3$-en keresztül történik az adatmegosztás, úgy, hogy az L2$ két különböző feldolgozó egységet tápláljon? Ez kicsit olyan, mintha visszaköszönne a buldózer.
Azt gondolnám, ennek akkora lenne értelme, ha nem 1:1, hanem 1:2, vagy akár 1:3 arányban lennének kis és nagy magok. hiszen a kis magok célja az alacsony helyfogyasztás, alacsony fogyasztás és magas throughput.
De milyen összefüggésben lehet ez vajon a pletykált SMT4-gyel? Aminek meg épp az lenne a célja, hogy feldolgozás során keletkező üres buborékokat és másik szál műveleteivel töltse fel?
[találgatás] Létezne, hogy az AMD összerak két különböző fogyasztás-kiterjedés-teljesítmény optimummal rendelkező magot egy backendbe és elétesz egy SMT4-et kezelő frontendet így megoldva, hogy egy mag teljesítményben is ott legyen, energiahatékonyságban is ott legyen és throughputban is?
Mi lenne az előnye azzal szemben, ha különböző clustereket gyártana chiplet formában?
-
#3678
Petykemano
veterán
Yutani
#3677
Petykemano
veterán
Napokban olvastam:
"There is a reason for the name : gamecache"Határozott előrelépés CPU tekintetében a 3400G-hez képest és igp is kicsit többet nyújt.
De feláras. (Mint minden zen apu )
Egy olyan erős gépbe, amibe nem teszel/tehetsz dgpu-t, remek.
De ez még nem az az apu, ami miatt feladnám a dgpu-t, a felár miatt pedig nem biztos, hogy megéri igp.nélküli CPU helyett választani ha nincs konkrét célja a az igp dgpu melletti felhasználásának. -
#3652
Petykemano
veterán
Petykemano
veterán
"00890F80h \ Zen2 \ Mero \ MR-A0 \ 7nm"
[link]
Van Gogh = Mero -
#3645
Petykemano
veterán
Petykemano
veterán
"[RUMOR] AMD is testing a Die which is about 80 mm2 (Zen4?) with TSMC N5. Good yields, ATM. No more info."
[link]Ha jól emlékszem, Abu egy 100mm2-es lapkáról beszélt egy másik topikban.
Mindenesetre az érdekes, ha itt már ES van, a zen3 meg még ki se jött. -
#3643
Petykemano
veterán
Petykemano
veterán
-
#3621
Petykemano
veterán
S_x96x_S
#3620
Petykemano
veterán
válasz
S_x96x_S
#3620
üzenetére
Állítólag Murthy volt az, aki a saját gyártás mellett állt. Távozásával várhatóan minimum nyitnak a külsős gyártó(k) irányába, de esélyes lehet a leválasztás is idővel.
Bár én ebben a leválasztásban nem hiszek. Mármint a tervező és üzletszervező rész számára hasznos lehet ledobni a holt terhet, de a majd Így lesz jó mindenkinek rész mese habbal. A GF-ba kb mindenki betolta a levetett gyártósorait és nem működött.
-
#3599
Petykemano
veterán
S_x96x_S
#3598
Petykemano
veterán
válasz
S_x96x_S
#3598
üzenetére
Vajon miért most akar pénzt látni ebből a softbank?
Annyira jön föl a RISC-V?
Vagy csupán megirígyelte a softbank Azokat a cégeket, amelyek a fed által nyomtatott pénzt nem munkahelyek megőrzésére fordítják (mivelhogy növekvő munkanélküliség, bedőlő ágazatok miatt csökken a kereslet, így rossz befektetés lenne beruházni, vagy termelést felfuttatni, arra meg semmi szükség hogy valaki malmozzon), hanem saját részvényeket vásárolnak. Ezzel látszólag szárnyal a tőzsde, emelkedik a részvényárfolyam, mehetnek a bónuszok, meg hát ha időbeni szállsz ki, realizálhatod a nyereséget.
?
-
#3593
Petykemano
veterán
S_x96x_S
#3592
Petykemano
veterán
válasz
S_x96x_S
#3592
üzenetére
Abunak volt pár hete egy cikke arról, hogy az AMD-nek összefolytak a termékek és abban gondolkodik, hogy egy-egy műsor/rendezvény keretében tudja le a mainstream cpu és gpu és a szerver cpu és gpu rajtokat.
Ennek fényében vajon kapacitás korlátok miatt (chip? vagy doboz?) maradt ki a dobozos Renoir verzió rajtja vagy azért, mert összekötik a Ryzen 4000 többi részének rajtjával?
-
#3569
Petykemano
veterán
Balala2007
#3565
Petykemano
veterán
válasz
 Balala2007
#3565
üzenetére
Balala2007
#3565
üzenetére
Értem
Egy laikussal beszélgetsz
Akkor nem lehetne ez(eket) úgy megcsinálni (reset?) hogy van az
AVX, AVX2, AVX3 - ami utasításkészlet
És tartozik a képlethez még maximális vektorhossz is, ami meg hardveres implementációHa jól értem, az SVE2 esetében is előfordulhat, hogy lesz SVE2.1, SVE2.2
Nyilván ezek azonban mind 128-2048 vektorhosszúságig ugyanúgy jók lesznek.Azt gondolom, hogy a kis és nagymagok közötti szegmentálási lehetőség az ARM-os megoldással (vagyis hogy az utasításkészlet megegyezik a kis és nagy magok között, viszont a feldolgozó szélessége nem) rugalmasabb. Ha az intel nem csinálna hibrid cpu-t, lehet, hogy ez a kérdés fel sem merülne. Hogy látod, lehetne-e, vagy érdemes lenne-e az AVX család következő verzióját már így készíteni?
Vagy lesz egy hátraarc és GPU?
Egy laikussal beszélgetsz
-
#3559
Petykemano
veterán
S_x96x_S
#3557
Petykemano
veterán
válasz
S_x96x_S
#3557
üzenetére
De miért ne lehetne az AVX512-t, vagy későbbieket olyanná "tenni", hogy egy olyan cpu, ami csak AVX-et vagy AVX2-t tud, az azzal a vektormérettel végre tudja hajtani?
Van az AVX, AVX2, AVX256 és AVX512 között más különbség is, mint a vektorhossz?
Afelől nincs kétségem, hogy a jelenlegi AVX512 olyan, hogy erre nem alkalmas (még azt is el tudom képzelni, hogy ebben van némi szándékosság, hiszen az intel az utasításkészletekkel szegmentálta a piacot, lehetett az a policy, hogy ha a legjobb utasításkészlet kell, vedd meg a legdrágább terméket => ez persze meg is világítja a különbséget, hiszen az SVE2-ben ha jól értem az utasításkészlet megegyezik, és a hardver vektorhossz-képességével lehet szegmentálni. Az intel meg ezt összekötötte),
de úgyis nagy a fragmentáció, tehát kiemelkedhetne egy olyan (akár az AMD-től jövő?) ami az Armos irányt viszi és standarddé válik.
-
#3555
Petykemano
veterán
S_x96x_S
#3554
-
#3550
Petykemano
veterán
awexco
#3548
Petykemano
veterán
Hát én úgy gondolom, hogy a magas frekvenciához is elég 1-2 olyan chiplet, ami tud magas frekvenciát.
Amikor 30-60 mag üzemel, ott már szerintem nem megy 4Ghz fölé. Tehát egy 64 magos TR és Epyc között ilyen szempontból szerintem kevés a különbség.De csak azért, mert általában azt látjuk, hogy a 3.5Ghz könnyen elérhető, még nem jelenti azt, hogy minden chiplet keveset fogyaszt 3.5Ghz-en. Tehát az alacsony fogyasztás az epycnél mindenképp szempont, ahol folyamatosan ketyeg.
-
#3545
Petykemano
veterán
S_x96x_S
#3543
Petykemano
veterán
válasz
S_x96x_S
#3543
üzenetére
"... vagy kamu ... vagy sikerült a szivárgást kiküszöbölnie az AMD-nek ..
és ha nincs szivárgás ... minden váratlan és meglepő ..."
Szerintem eddig, 0 eladással kábé semmit nem ronthattak azzal, ha minden piacravezetést hónapokra előre szivárgások és nagy csinnnadratta előzte meg. Most van eladható termék, van miért elvarrni a szivárgásokat, hogy elkerüljék az Osborne-hatást.Ezzel együtt szerintem eltolódás van a zen2 lapkák felhasználásában. Vagy kiszolgálták a megrendelőket (a Google GCP-ben márszinte mindenhol elérhető az N2D), vagy az ügyfelek már megkapták a zen3 mintákat és inkább azzal szemeznek.
(Persze nyilván intelből még így is több fogy.)
De úgy tűnik, hogy az eddigiekhez képest lett fölös kapacitás, amit az eddigi termékek nem fedtek le. mivelhogy most a 8 csatornás TR-t vezetik be a piacra, elég valószínű, hogy ami oda megy, eddig EPYC-ként volt eladva. (lehet akár az IOD is szűk keresztmetszet)A józan ész persze azt mondatja az emberrel, hogy ha az 3000XT és a 8chTR most kerül a piacra, akkor a zen3 még biztos jó messze van. Ha nem jön pár héten belül valami új Rome családba tartozó, akkor logikus lenne feltételezni, hogy ezúttal tényleg a Milan jön ki elsőnek. Úgy, hogy ugye szerver-frekvenciákat árulnak csak el és MT eredményeket - hogy ne nagyon lehessen következtetni a Vermeer teljesítményére - elkerülendő az Osborne-hatást,
-
#3544
Petykemano
veterán
Petykemano
veterán
AMD Pollock
2/4
1.2/2.4Ghz
800Mhz
14nm
4.8WTDP -
#3541
Petykemano
veterán
S_x96x_S
#3539
Petykemano
veterán
-
#3529
Petykemano
veterán
Petykemano
veterán
Ez az XT eresztés elég híg lett.
Computerbase.de-t néztem ott nem játékokban kb 1%, játékokban 3% előrelépés mutatható ki.
Erősen "vedd meg az olcsóbbat" marketing szaga van. Mármint hogy most biztos száz újság leírja ezt, hogy nem érdemes az XT-re áldozni, sokkal jobb ár/érték arányt ad a sima vagy az X. (de senki nem fogja azt mondani, hogy vedd inkább a comet lake-et) -
#3526
Petykemano
veterán
Petykemano
veterán
-
#3515
Petykemano
veterán
Simid
#3514
Petykemano
veterán
Amikor az AMD zen3, később zen4 kapcsán merült föl ez az elképzelés, vagy lehetőség, akkor a szkeptikusok ellenérvelésének oszlopos részét képezte az, hogy hát a programok nem skálázódnak elég jól a szálak számával nemhogy desktopon, de még szerveren se.
Egyébként nem állítom, hogy ebben nem lehet igazság, legalábbis az epyc/2 vs graviton összehasonlításban valóban látszik, hogy sok helyütt nem előny az SMT2 se.Tehát nem azt mondom, hogy lámlám az amd SMT4 ellen érvelőknek mégsincs igaza, csak azt, hogy furcsamód most nem.huhogják, hogy az SMT4 kapitális hiba, vagy legalább felesleges.
Ezzel együtt persze érdekelne is, hogy milyen architekturális különbség állhat a háttérben, ha a nem ellenzésnek nem "márka-politikai" oka van.
-
#3511
Petykemano
veterán
S_x96x_S
#3509
Petykemano
veterán
válasz
S_x96x_S
#3509
üzenetére
azt mondják, hogy a gyorsabb FCLK miatt és a kisebb L3$ miatt kisebbek a késleltetések és emiatt jobbak az eredmények. Logikus lenne azt feltételezni, hogy a magasabb FCLK-t a 7nm teszi lehetővé.
Egyes vélemények szerint
- A Matisse nem skálázódott jól 4.3-4.4Ghz fölött, hiába adtál hozzá százmegahertzeket, nem jött ki belőle arányos teljesítmény, mivel nem minden részegység, pl az FCLK sebessége nem nőtt
- a Matisse 2 nem csak a (nevetségeses mértékben) magasabb órajeleket hozza, hanem a magasabb FCLK-t is. Tehát a tényleges órajelek ugyan nem lesznek lényegesen magasabbak, mint eddig, viszont a tényleges teljesítmény azzal jobban fog skálázódni és emiatt az órajelekből vártnál jobb eredményeket fog hozni. (Meglátjuk.) -
#3496
Petykemano
veterán
S_x96x_S
#3495
Petykemano
veterán
válasz
S_x96x_S
#3495
üzenetére
"SK hynix’s HBM2E supports over 460GB (Gigabyte) per second with 1,024 I/Os (Inputs/Outputs) based on the 3.6Gbps (gigabits-per-second) speed performance per pin. It is the fastest DRAM solution in the industry, being able to transmit 124 FHD (full-HD) movies (3.7GB each) per second. The density is 16GB by vertically stacking eight 16Gb chips through TSV (Through Silicon Via) technology, and it is more than doubled from the previous generation (HBM2)."
1 stack: 16GB, 460GB/sEnnél (és nyilván a telepítésnél) olcsóbb lehet még mindig a 8 (vagy 16db) GDDR6 chip huzalozással együtt 256bit szélességgel?
Pont ekkora sávszélességgel rendelkezik a Navi10

A Renoir 150mm2. És 8CU CPU-val együtt elmegy 1700Mhz-en.
A Navi 12 ~210mm2 két HBM vezérlővel.
A Renoirban és a Navi12-ben is nyilván van egy halom display, meg miegyéb "közös" rész, ami nem a CU
Azzal a sűrűséggel, amivel a Renoir rendelkezik egy Navi12 képességű 8/40 magos APU szerintem valahol 250mm2 körül kihozható lenne. 1 stack HBM2E-vel.
A Navi12 50W TDP. és 1000Mhz.
A Renoir 8 CU-ja tud 1700MHz-et 15W-ból. (35W-ból kijön a 2000MHz is.)
Legyen mondjuk ez az APU 125W-os és akkor még mindig belefér. 1700Mhz-en ketyegve az 5x akkora IGP még mindig csak 75W TDP-t igényelne. Tehát 125W-os TDP keret mellett akár 1800-1900MHz-et is nyaldoshatná.Persze tudom, hogy erre nem nagyon van jelenleg kereslet. Nehéz lenne eladni. Mert ha jól akar keresni az AMD, akkor meg kell kérni az árát. Mennyi egy 8 magos CPU? $300 és mondjuk egy 5700? $300
Jó hogy ezen rajta van már a RAM is, de az 5700-on is rajta van annyiért, tehát azt nem lehet hozzászámolni.
Így legfeljebb $500-ért lehet eladni. Ha ennél többet kérnek, merthogy Small Form Factor, akkor máris nem kavarja fel az állóvizet. Nameg úgyis mobilba menne. -
#3486
Petykemano
veterán
Petykemano
veterán
GF 12LP+
"Driving the enhanced performance of 12LP+ are features including a 20-percent SoC-level logic performance boost over 12LP, and a 10-percent improvement in logic area scaling. These advancements are achieved in 12LP+ through its next-generation standard cell library with performance-driven area optimized components, single Fin cells, a new low-voltage SRAM bitcell, and improved analog layout design rules."powerre nincs százalék. Pedig, ha jól emlékszem, 40%-kal kisebb fogyasztást ígértek.
AMD vajon fogja használni valamire?
-
#3485
Petykemano
veterán
-
#3471
Petykemano
veterán
solfilo
#3469
Petykemano
veterán
válasz
 solfilo
#3469
üzenetére
solfilo
#3469
üzenetére
Próbálom én is értelmezni.... még mindig...
Kevésbé lett volna szemfényvesztés, ha nem nem úgy számolják, hogy "performance gains" / "ETEC efficiency"
A performance nagyjából az, amit az ember gondol. Nagyjából az, hogy mennyivel nőtt a teljesítmény egységnyi TDP-n belül (persze a 15W-os raven kilóg a sorból)
Nem állítom, hogy felhasználói élmény szempontjából az ETEC szám nem érdekes. Az ugye az az energiahatékonyságot adja ki, hogy amikor nem használod, akkor milyen, mennyit bír az aksi, ilyesmi. Ez persze nyilván sokkal inkább egyenesen arányos a gyártástechnológiai előnyökkel.
Szóval számomra igazságosabb lett volna, ha inkább valami átlagot számolnak belőle. És az is meglenne:
5x nagyobb teljesítmény egységnyi TDP-ből, amikor használod
6x kisebb fogyasztás idle, amikor nem használod.
átlag 5.5x nagyobb energiahatékonyságEhelyett van egy hülye nagy szám, ami nem igaz és senki se érti.
-
#3468
Petykemano
veterán
Petykemano
#3368
Petykemano
veterán
válasz
Petykemano
#3368
üzenetére
Tévedtem.
Az AMD a 4800HS-re kihozta, hogy ez már most 31x energiahatékonyabb.
Van egy remek Anandtech elemzés.
De a lényeg, hogy nem úgy számolják a 25x efficiency értéket, hogy a bázishoz képest 25x nagyobb teljesítmény azonos fogyasztás mellett. Hanem ez a 25x a teljesítmény - lényegében bármilyen (legkedvezőbb) TDP mellett és az ehhez a TDP-hez tartozó idle fogyasztás együttes szorzatának optimuma."Overall AMD has achieved a 5.02x performance gain with a 6.33x idle efficiency, which the company is wrapping up into a combined 31.77x performance efficiency metric."
-
#3464
Petykemano
veterán
S_x96x_S
#3462
Petykemano
veterán
válasz
S_x96x_S
#3462
üzenetére
Az intel Végülis jó okkal volt kisgömböc. Olyanokat vásárolt fel, amik a jövőben jelentettek volna komoly konkurenciát. A top500 tagjai nem a cputól vannak ott, hanem a gyorsítóktól. Jól érzékelték, hogy a cpu mindenre jó, de nem elég jó és hogy jönnek majd gpu, fpga, asic kihívók célfeladatokra, amik hatékonyabbak és higy végül a mindent egybeintegrálunk lesz a nyerő.
"ha van egy IKEÁS chiptervezési kisokos - amit az ARM-től lehet licenszelni, akkor mindenképp "
Igen, de a dollárszázmillárdos biznisszel rendelkező Intel mellett az arm sem egy nagy cég.
Igaz, mondjuk, mínimum úgy kéne nézni, hogy Intel vs Qualcomm+arm+tsmc
"de nálam lassan hasonló lesz mint a COVID virus ügye ..
más fórumokon a covid miatt is dünnyögtem - de hogy ekkorára nőtt a virus probléma az engem is meglepett .."
A vírus probléma sztem azért nőhetett ilyen nagyra, mert nem a.vírus az igazán Nagy probléma, hanem már jóideje hitelből létező kapitalizmus a növekvő egyenlőségével. És a technológia nem megmenti az emberiséget. De ez egy más téma. -
#3461
Petykemano
veterán
Petykemano
veterán
Ampere Altra Max
128 mag
2021Elképzelhető, hogy ez magasabb TDP-t is jelent majd, mint 250W.
Namost szerintem egyáltalán nem ér rá az AMD a Milannal 2021-ig. Ha idén kijön a Milan (64c/128t), már annak komoly versenyt jelenthet egy 2021-ben megjelenő 128magos Ampère Altra. Jó, persze az se mindegy, hogy Q1 vagy Q4. De a Genoának is jönnie kell 2021-ben, mármint nem engedheti meg magának a 2022-re csúszást, még akkor sem, ha történetesen 128c/256t konfigurációban jönne.
Egyébként ez ilyen tök fura. Eddig azt gondoltuk, CPU tervezés tök nehéz.
Erre jön egy-két cég és az évtizedes béágyazottsággal bíró intelre rátervez pár tízmillió dollárból. Mármint versenyképes teljesítménnnyel.Ez két dolgot jelenthet azon kívül, hogy az intel fejlődése lelassult és ezért zárkózhatott fel mindenki:
- az Intel és az AMD részben más piacokat szolgál ki, és jóval nehezebb olyan architektúrát készíteni, ami sok helyre jó. Egy adott célra tervezni könnyebb.
- cput.tervezni könnyű. Lényegesen nagyobb nehézség a gyártás, ellátási láncok, és az értélesítés - Amivel ugye az amd is küzd -
#3459
Petykemano
veterán
Petykemano
veterán
Rájár a rúd az x86-ra
Tegnap cikkeztek a Fugakuról, ami egy Arm.procit használó rendszer:
"The new top system, Fugaku, turned in a High Performance Linpack (HPL) result of 415.5 petaflops, besting the now second-place Summit system by a factor of 2.8x. Fugaku, is powered by Fujitsu’s 48-core A64FX SoC, becoming the first number one system on the list to be powered by ARM processors. In single or further reduced precision, which are often used in machine learning and AI applications, Fugaku’s peak performance is over 1,000 petaflops (1 exaflops). The new system is installed at RIKEN Center for Computational Science (R-CCS) in Kobe, Japan."
Peak performance meglépi az 1exaflopot.
Szerintem az A64FX különlegessége nem kifejezetten az Arm utasításkészlet, hanem az a felépítés, hogy HBM eteti a processzort vastag sávszélességgel, ami így egyszerre tud úgy működni, mintha gpu is lenne.Ez kábé ugyanaz az irány, mint az AVX512. Van az armnak is ez a kiterjesztése, az SVE, ami 128-tól 2048bit széles tud lenni.
Oda akarok kilyukadni, hogy szerintem x86 CPU-tól akkor fogunk ilyesmit látni, ha melléteszik a HBM-et. De persze ahhoz olyan CPU felépítés is kell, ami ezzel élni tud. A jelenlegiek nem igazán ilyenek.
Valószínűleg nem véletlenül írt tegnap abu olyanokat:"Ehhez olyan tesztszerverek is készülnek, ahol a processzor mellé be lesz kötve egy gyorsító az Infinity Fabric interfészen keresztül, így gyakorlatilag a két részegység egységes memóriaképet lát majd. Ez tulajdonképpen a 2021-es év vége felé érkező Genoa platform nagy fejlesztése. Az AMD erre a partnerek felé CPU-szerű programozhatóságként utal. Ez effektíve azt jelenti, hogy a rendszert hasonlóan kell majd programozni, mintha csak CPU lenne benne, vagyis az adatmozgásra, illetve a memória kezelésére vonatkozó nem kell beírni semmit, miközben a kód futni fog a gyorsítókon."
[link]
Ez úgy hangzik, mintha végre eljutna a.chipleten keresztül csatlakoztatott CDNA gyorsító (ami már nem IGP, mentes minden grafikától) a kupak alá.A másik merénylet az x86 ellen az Apple műve.
Jó, persze az Apple az egy zárt bioszféra, nem igazán használhatók Apple szoftverek Apple környezeten kívül, vagy Vica versa most se. Nem tudom Mit nyerhetne egy asus vagy Lenovo azzal, hogy arm magos cput pakol a gépeibe - feltéve, hogy nem magának készíti, vagy nem jut hozzá lényegesen olcsóbban. A nagy kérdés, hogy kevesebbet fogyaszt-e egy ugyanolyan gaártástechnológiám készült arm CPU, ha nem jár teljesítménybeli kompromisszumokkal. De presztízs hatása biztosan van/lesz, és bár nem az Apple irányából, de verseny élénkítő hatása mindenképp lehet. -
#3458
Petykemano
veterán
Petykemano
veterán
Nem tudom, hogy egészen új hír-e az nvidia által épített supercomputer, vagy csak a Fugaku által vert hírvihar hordaléka.
De itt egy lista, hogy a top500 supercomputerben hol vannak már AMD zen procik:
#7, Selene, an EPYC 7742 + A100 system for NVIDIA (27.6 PF)
#30, Belenos, an EPYC 7742 system for Meteo France (7.7 PF)
#34, Joliot-Curie Rome, an EPYC 7H12 system for CEA in France (7.0 PF)
#48, Mahti, an EPYC 7H12 system for CSC in Finland (5.4 PF)
#56, Betzy, an EPYC 7742 system for Sigam2 AS in Norway (4.44 PF)
#58, PreE, a Hygon C86 system for Sugon, China (4.32 PF)
#124, Freeman, an EPYC 7542 system for ERDC DSRC (2.5 PF)
#172, Betty, an EPYC 7542 system for the US Army Research Laboratory (2.1 PF)
#268, Cara, an EPYC 7601 system for German Aerospace Center (1.75 PF)
#292, an EPYC 7501 + Vega 20system for Pukou Advanced Computing Center, China (1.66 PF)
#483, Spartan, an EPYC 7H12 system for Atos, France (1.26 PF)
[link]A Selene
-
#3446
Petykemano
veterán
Petykemano
veterán
Ez Nekem tetszetős
[link]
Mármint lehet értelme. Csak kérdés, mi kell ennek kihasználásához.
Nyilván persze nem ez fogja megváltani a világot, de ha mindenütt jelen van, lehet rá építeni.
Nem?Amdnél.készül ilyesmi, vagy hsa?
-
#3442
Petykemano
veterán
Simid
#3441
Petykemano
veterán
Szerintem is idén jön, de végső soron nem mondták ki egyértelműen és később számonkérhetően.
A cikk abból következtet erre, hogy ki és hogy beszélt a zen3-ról. Innen még mindig nyitott egy későbbi magyarázat arra vonatkozólag, hogy igen, hát persze, hogy már akkor is arra gondolt, meg az is, hogy hát GipszJakab általánosságban beszélt a zen3-ról."Doing well, doing great, we love pc gaming"
-
#3440
Petykemano
veterán
Petykemano
veterán
T-bao ryzen minipc
$250-350 rammal és nvme ssd-vel.
Tegyük hozzá, hogy ez a nagyon alacsony ár valószínűleg mindenféle kuponokkal együtt értendő.Gugliban rákeresve magyar forgalmazót nem láttam, másutt forintban 110e-135e között.
-
#3424
Petykemano
veterán
Petykemano
#3413
Petykemano
veterán
válasz
Petykemano
#3413
üzenetére
Addig tekergették a potmétert (a leakeken) a 3000XT-n, hogy végül alig maradt valami
-
#3420
Petykemano
veterán
Petykemano
veterán
-
#3413
Petykemano
veterán
S_x96x_S
#3411
Petykemano
veterán
válasz
S_x96x_S
#3411
üzenetére
Nemrég jelent meg Apisak kezéből egy 3dMark mérés, amely szerint a 3800XT 2.4%-ot hoz a 3800X-re.
Az azért elég sovánka.
Felmerült a kérdés, az AMD miért dobja ki ezeket. És volt találgatás, amely arra célzott, hogy, hogy mert nem kerül semmibe: "A válogatás során több olyan lapka kerül legyártásra már, ami alkalmas lenne 3950X-nek is, viszont 3950X formájában nem tudnának annyit eladni, ezért létrehoztak 3 új kosarat, ahová lehet válogatni új feliratú dobozba kerül és kész.
De hát ez azért elég sovánka.
(Emellett persze ne feledjük el, hogy egyre valószínűbb, hogy az a cél, hogy ne jöjjenek üresen a B550 lapok)
-
#3402
Petykemano
veterán
S_x96x_S
#3401
Petykemano
veterán
válasz
S_x96x_S
#3401
üzenetére
Kényelmes lenne azt mondani, hogy a hősűrűség miatt, de a openbenchmarkingon található részletes adatok alapján többet is fogyasztott.
Hogy miért, azt részletes analízis hiányában csak találgatni lehetne. Ennyire gyenge minőségű selejt, vagy chiplet-Tax.
Ezekre fény derülne, ha összehasonlítanák a nemsokára érkező XT sorozat valamelyikével azonos fekvencián, vagy esetleg ha ugyanezt a tesztet lefuttatnák a Renoir-on majd. -
#3395
Petykemano
veterán
awexco
#3392
-
#3391
Petykemano
veterán
Petykemano
veterán
Azért a 3600XT így már.nem annyira ütős.
-
#3382
Petykemano
veterán
S_x96x_S
#3381
Petykemano
veterán
válasz
S_x96x_S
#3381
üzenetére
Később olvastam a híreket.
Pl a fél év tanácsadást.Találgatnak mindenfélét. Persze ott van, hogy personal reasons, meg hogy szeretne többet lenni a családjával, de hát Raja Koduri is kábé ugyanezeket mondta pár hónappal azelőtt, hogy átnyergelt az intelhez.
Az, hogy 4 emberrel helyettesítik jelentheti azt is, hogy tényleg hírtelen kellett távoznia.
Ami nekem fura, az az, hogy 4 indiainak hangzó nevet soroltak fel. Egészen durva agyelszívás.
Vagy... lehet, Raja építi a birodalmát is kifúrta kellert 😃 -
#3368
Petykemano
veterán
solfilo
#3367
Petykemano
veterán
válasz
solfilo
#3367
üzenetére
Nyugtával dícsérd a napot!
Van az AMD-nek ez a 25x20 vállalása, vagyis hogy 2014-hez képest 2020-ra 25x jobb perf/W értéket érnek el.
A footnotes-ban ez van:
"Based on AMD internal testing as of 8/15/2019.Relative energy efficiency based on a 50:50 weighted average of CPU+GPU performance (variable “C”), as evaluated by Cinebench R15 nT and 3DMark 11 P scores, divided by typical energy usage (variable “E”) as defined by: ETEC (Typical Energy Consumption for notebook computers), Energy Star Program Requirements Rev 6.1 10/2014.
AMD “Kaveri” (2014) represents the baseline of 1.0X for CPU, GPU, and ETEC.
AMD “Carrizo” (2015) efficiency 1.23C/0.35E=3.51X.
AMD “Bristol Ridge” (2016) efficiency 1.36C/0.34E=3.97X.
AMD “Raven Ridge” (2017) efficiency 2.47C/0.44E=5.66X.
AMD “Raven Ridge 2018” efficiency 2.76C/0.26E=9.86X.
AMD “Picasso” (2019) efficiency 2.88C/0.25E=10.88X.Scores in order of Cinebench R15 nT/3DMark 11 P Score:
“Kaveri” 232/2142 (100%),
“Carrizo” 277/2709 (123%),
“Bristol Ridge” 279/3234 (136%),
“Raven Ridge” 667/4425 (247%),
“Raven Ridge 2018” 754/4877 (276%),
“Picasso 2019” 772/5191 (288%).AMD Reference Platform: “Kaveri” AMD FX-7600P, 2x4GB DDR3L-1600, Crucial CT256M4SSD2, Windows 8.1 x64 9600, Graphics Driver 13.350.0.0, 1366x768 / AMD Reference Platform: “Carrizo” AMD FX-8800P, 2x2GB DDR3-1866, Crucial CT256M550SSD1, Windows 10 x64 10586, Graphics Driver 21.19.137.514, 1366x768 / AMD Reference Platform: “Bristol Ridge” AMD FX-9830P, 2x4GB DDR4-2133, Crucial CT256M4SSD2, Windows 10 x64 10586, Graphics Driver 21.19.137.514, 1366x768 / AMD Reference Platform: “Raven Ridge” AMD Ryzen™ 7 2700U, 2x4GB DDR4-2400, Samsung 850 Pro SSD, Windows 10 x64 15254, Graphics Driver: 22.19.655.2, 1920x1080 / AMD Reference Platform: “Raven Ridge 2018” AMD Ryzen™ 7 2800H, 2x8GB DDR4-3200, Samsung VLV2560 SSD, Windows 10 x64 16299, Graphics Driver 23.20.768.0, 1920x1080 / “Picasso 2019” AMD Ryzen™ 7 3750H, 2x4GB DDR4-2400, Samsung 960 PRO SSD (512GB), Windows 10 Pro (17763), Graphics Driver 21.19.137.514, 1920x1080. Results may vary with configuration and driver versions. RVM-108"
2020 van.
Az, hogy nem verik a nyálukat erre a vállalásra három dolgot jelenthet:
a) elfelejtették (Akkor azért leszedték volna a honlapról)
b) nem sikerült
c) Nem a Renoir-ral tervezték elérniA picasso ~11X-es eredményéhez képest azért még mit fejlődni.
A Renoir CB R15 eredménye a 1300-1800 között mozoghat valahol. Majd biztos kiszámítják, hogy 15-35W között hol a legmagasabb a hányados és azt fogják figyelembe venni.
Ha a picasso ~11X-es eredményt ért el és ehhez képest a Renoir CPU része tud 2x jobb lenni (márpedig ott akkor a 3750H-t mérték, ami 35W-os, tehát nyugodtan lehet számolni 1700-zal), akkor a CPU rész pipa.Azt viszont tudjuk, hogy a Renoir GPU nem fejlődött nagy mértékben a PIcasso-hoz képest. Ennek megvan a maga oka, ebbe most ne menjünk bele, a lényeg itt, hogy a vállalás teljesítéséhez valamit a GPU oldalon is fejleszteni kell.
Ha be akarják tartani a vállalást, akkor bizony valahogy még 2020-ban ki kell adni egy olyan apu-t, ami
vagy a számláló GPU részét emeli
és/vagy a számláló CPU részét emeli tovább
vagy a nevezőben található energiahatékonyságot növeli. -
#3364
Petykemano
veterán
Petykemano
veterán
{Találgatás}


Abu említette, hogy az AMD fog kísérletezni a zen3-mal és hogy 8 chiplet helyett 4 chiplet lesz a csomagban HBM-mel.
Ez jelentheti azt is, hogy a HBM-et a az IO lapkához kell csatlakoztatni. mármint GPU-knál eddig ugye ilyet láttunk. Tehát hogy a HBM és a CPU-k is az IO lapka szolgái. Még akkor is, ha esetleg minden chiplet a hozzá legközelebbi HBM-től tudna csak adatot lekérni. (mint ahogy emlékeim szerint ez most is így van, egy CCD nem tud 8 csatornán kereszül adatot lekérdezni, hanem csak a hozzá legközelebbi 2 memóriacsatornán/vezérlőn keresztül.)Ez ugye azt jelentené, hogy egy IO lapka méreténél nagyobb interposer kellene. Az azért biztos elég nagy.
Azon gondolkodtam el, hogy nem lehetne-e ezt úgy megoldani, hogy csak az egymás mellé helyezett chipletekben gondolkoduink, vagyis csak a képen látható ~ 2 CCD méretű interposer kellene a 2 lapka alá. És akkor az abu által mondott kísérlet arról szólna, hogy a az egyik CCD helyére egy HBM-et raknak.
Ebben az esetben nyilván a HBM vezérlőt az interposernek kellene tartalmaznia (active interposer)
És akkor tovább gondolkodtam ezen az aktív interposer dolgon.
Be lehetne-e tenni a CCD-k alá egy olyan aktív interposert, ami gyakorlatilag egy L4$-t tartalmaz?
És 2 CCD-t köt össze. Végülis az Armnál is lehet olyan designt összerakni, hogy vagy van L3$ vagy nincs.Ennek a megoldásnak az lehetne az előnye, hogy akár a Vermeer esetén is használható. Egyrészt remekül kezelné a CCD-k közötti késleltetést, ami most jelen van, másrészt megfelelő méret esetén (ha nagyobb, mint a 2 CCD L3$ összege) akár még a memória elérés átlagos késleltetésén is javíthatna.
És maga az interposer is kicsi.Milan esetén ez persze csak 2-2 csomag késleltetésén javítana, de már az is előrelépés lehetne.
A használata nem kötelező, tehát olcsóbb változatokból és/vagy 1 CCD-s változatokból kihagyható. -
#3363
Petykemano
veterán
Petykemano
#3350
Petykemano
veterán
válasz
Petykemano
#3350
üzenetére
Most van időm erre kommentálni
Szóval az arm filozófiája stabil egyensúlyokon alapszik, vagyis vannak méret és fogyasztásbeli limitek, amiket nem igyekeznek átlépni meghatározott célú designokkal.
Ezt az apple is követi és alkalmaz nagy és kis magokat is.
Egyrészt kérdés, hogy tényleg áttér-e. Minden lehetősége megvan, de ez a minden lehetősége megvan azért lehet egy soha ki nem játszott ütőkártya is. Persze csak ha a fogyasztáson kívül elválasztja valami az Apple jelenlegi mobil lapkáit azoktól, amiket egy komolyabb notebookba vagy Mac proba kell tenni.
De ha tényleg meglépik, minden jel erre utal, akkor azzal új nyomás köszönthet a notebookok piacán...
Hmm, vannak már arm alapon chromebookok. Ezek elsődleges jellegzetessége, hogy kicsit butított.funkcionalitással rendelkeznek,.miközben azt várjuk tőle, hogy legyen olcsóbb.
Ezekben arm procikat használnak. Van ezzel kapcsolatban tapasztalat, hogy ez szuperebb, mint egy notebook?Minenesetre azért egy Apple termék nem biztos, hogy összehasonlítható egy olcsóságra kigyúrt termékkel. Tehát kialakulhat egy nyomás, ha az arm (big.LITTLE) hozza a várt energiahatékonyságot a kismagokkal és a várt teljesítményt a nagymagokkal.
Erre a kihívásra az intel úgy tűnik, az alder- lake-kel fog válaszolni. Ami nagyjából akkor piacra is kerülhet, amikor az Apple hozza az arm alapú macbookokat.
De az Apple nyilván nem fog leállni a fejlesztéssel.
Nekem úgy tűnik, hogy más egyensúlyi pontokkal dolgozik az Apple.
Nekik mindig lesz néhány brutálisan erős magjuk, és több energiahatékony
Az alder lake kis magjai energiahatékonyak, de a nagy magok azért inkább arra vannak optimalizálva, hogy a szerverekben nyújtsanak kiegyensúlyozott teljesítményt. És a frekvenciával játszanak felfelé a maximális teljesítmény érdekében.
Az AMD -nél ugyanez, csak kis magok nélkül.Lesz paradigma váltás a notebookok piacán?
Az x86 tervezők indulnak el a big.LiTTLE irányba?
Vagy a notebookgyártók az arm irányba?

















![;]](http://cdn.rios.hu/dl/s/v1.gif)
Új hozzászólás Aktív témák
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- Samsung Galaxy Z Fold7 - ezt vártuk, de…
- Jövedelem
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- Gyúrósok ide!
- Android alkalmazások - szoftver kibeszélő topik
- Kormányok / autós szimulátorok topikja
- Kuponkunyeráló
- Örömhír: nem spórol Európán a OnePlus
- További aktív témák...

- MSI Katana GF76 - 17.3"FHD 144Hz - i5-11400H - 8GB - 512GB - Win11 - RTX 3050 Ti - MAGYAR
- Bomba ár! Lenovo ThinkPad L460 - Intel 3955U I 8GB I 128GB SSD I 14" FHD I Cam I W10 I Garancia!
- LG 27GR95QE - 27" OLED / QHD 2K / 240Hz & 0.03ms / NVIDIA G-Sync / FreeSync Premium / HDMI 2.1
- ÁRGARANCIA!Épített KomPhone Ryzen 7 5700X3D 32/64GB RAM RTX 5070 12GB GAMER PC termékbeszámítással
- DELL PowerEdge R740 rack szerver - 2xGold 6130 (16c/32t, 2.1/3.7GHz), 64GB RAM, 10Gbit HBA330, áfás
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: ATW Internet Kft.
Város: Budapest