Hirdetés
- Félmillió felett a kiszállított Xiaomi autók száma
- QWERTY billentyűzetes, üzenet-fókuszú androidos mobil a Clicks Communicator
- Samsung Galaxy A54 - türelemjáték
- iPhone topik
- Apple iPhone 13 mini - miért nem veszik elegen?
- Milyen okostelefont vegyek?
- A piac legerősebb kameráját ígéri a Xiaomi 17 Ultra
- CES 2026: 4. generációs szemkímélő kijelzővel debütált a TCL NXTPaper 70 Pro
- Samsung Galaxy S21 FE 5G - utóirat
- Snapdragon 8 Gen 5-tel jön a Realme Neo8
Új hozzászólás Aktív témák
-

cousin333
addikt
Azt hiszem a helyes megoldás ez lenne, ami mellesleg megszünteti a félreértéseket is:
if a%2 == 1 is not winningSit(n/a):Egy másik érdekesség számomra ez a két sor:
n,m=map(int,raw_input().split())
arr=map(int,raw_input().split())Nekem valahogy nem a map jut eszembe megoldásként, sokkal inkább a list comprehension, különösen a második sornál:
n, m = (int(i) for i in raw_input().split())
arr = [int(i) for i in raw_input().split()] -
cousin333
addikt
A zárójeles megjegyzésed (szó szerint) adja meg a választ. A Python támogatja az összehasonlítások összefűzését, például ez teljesen rendben van:
if 3 < a < 10:
print('Közötte van')
else:
print('Nincs közötte')A 2.7-es Pythonban így írnak erről: [link]
Tehát ez azonos azzal, hogy 3 < a és a < 10, valamint az egész sor rögtön hamis lesz, ha a%2 egyenlő nullával.Ezek alapján a kérdéses sorod azt jelenti, hogy a%2 egyenlő 1 és 1 nem egyenlő winningSit(n/a). Ha kiteszed a zárójeleket (ahogy írtad), akkor már azt jelenti, amire te gondoltál.
-
#858
cousin333
addikt
Orionhilles
#857
cousin333
addikt
válasz
 Orionhilles
#857
üzenetére
Orionhilles
#857
üzenetére
Javaslom, hogy járd körül egy kicsit a szeletelés témakörét: [link]
Ebben az esetben így néz ki:
lista[-tól:-ig]
Tehát egy tartományt választ ki, nem egy elemet. A 3. elemhez elég csak egy indexet megadni:
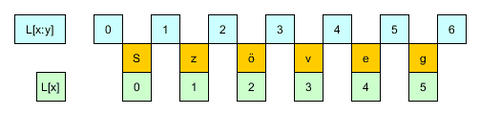
lista[2]Ez valóban a 3. elem lesz, mert a számozás nullától indul. Fentebb listát írtam, de ez ugyanígy működik sztringeken is. Pl.
>>> a = "Szöveg"
>>> a[1:4]
'zöv'Az 1:4 tehát az második elemtől a negyedikig lévőket írja ki. Kicsit fura talán, de az alábbi ábra nekem is segített:
-
#854
cousin333
addikt
Willy_Billy
#853
cousin333
addikt
válasz
 Willy_Billy
#853
üzenetére
Willy_Billy
#853
üzenetére
Az első esetben nyilván az volt a probléma, hogy a szöveget nem tetted idézőjelek közé. Egyébként a "hozzáadás" mást jelent, használd inkább a hozzárendelés vagy értékadás kifejezéseket.
A második eset arra mutat rá, hogy Python 3.x-es verzióját használod, az általad nézegetett példák viszont a 2.x-hez vannak. Nos a
printaz egyik leggyakoribb és leglátványosabb különbség.
-
cousin333
addikt
Egy kicsit zsúfoltan kaotikusnak tűnik ez a kód...

Ha megvan a sor, pl:
sor = "C [29 9 8 16 92 79 1 4 0 0 1 4 0 0 14 5 23 24 ]"akkor egyszerűen strip(), ahol "felsorolod" a mindkét oldalról törlendő karaktereket, valahogy így:
sor.strip('ACGT[] ')Az eredmény:
'21 9 10 29 0 0 31 47 52 25 17 19 7 2 22 45 40 15' -
cousin333
addikt
Valóban, a hivatalos dokumentáció inkább referencia, mintsem olvasmányos segédanyag. Akkor jó, ha már az alapok megvannak (de akkor nagyon
).Én 3 könyvet tudok javasolni, ami megfelel a kitételeknek. Ha elolvasod az első néhány fejezetet, már el tudod dönteni, melyik áll a legközelebb a te stílusodhoz.
Ingyenes, angol nyelvű könyvek Python 3-hoz:
- Dive Into Python (pdf)
- Think Python (pdf)
- Learn Python the Hard Way -
cousin333
addikt
válasz
 Tigerclaw
#834
üzenetére
Tigerclaw
#834
üzenetére
Igen, fel. A megoldás a virtualenv. Az Anaconda csomag - amiből van "mindent bele" és minimalista (aka. Miniconda) minden jelentősebb oprendszerre - elég jól támogatja. Mindegy, hogy a 2.7-et vagy a 3.5-öst teszed fel alapból, könnyen létrehozhatsz egy új környezetet a másik verzióval is. Sőt, még a csomagokat és azok verzióját is megválaszthatod, ha például egy bizonyos feladathoz mindenképpen Numpy 10.1 kell.
Ami az eredeti kérdésedet illeti, nincsen konkrét válaszom, viszont én azt mondanám, hogy 2.7 a legacy projektekhez (pl. kiegészítő modulokhoz), minden máshoz minimum 3.5.
-
cousin333
addikt
válasz
Tigerclaw
#824
üzenetére
Ugye milyen jó?
Kár, hogy sajnos nem teljesen igaz... 
Szóval kicsit utána olvasgattam és az jött le nekem, hogy egyes típusok azért immutable-k, mert csak (nyilván emögött van elgondolás, az immutable objektum kb. olyan, mint valami konstans).. Nézzünk pár példát (az
idfüggvény az adott objektum memóriabeli kezdőcímét adja vissza):>>> a = [1, 2, 3]
>>> id(a)
2238629696072
>>> id(a[0])
1970405872
>>> id(a[1])
1970405904
>>> id(a[2])
1970405936
>>> type(a)
<class 'list'>
>>> type(a[0])
<class 'int'>
>>> b = (1, 2, 3)
>>> id(b)
2238629604520
>>> id(b[0])
1970405872
>>> id(b[1])
1970405904
>>> id(b[2])
1970405936A fenti esetben létrehoztam egy listát (
a) és egy tuple-t (b), mindkettőt ugyanazzal a három elemmel. A címeket kiolvasva a következő megállítások tehetők:- az
aés abkét külön objektum, egymástól viszonylag messze
- mindkettő elemeiint-ek és az elemek ugyanarra a memóriaterületre mutatnak!
- magyarul csak egy darab 1-es van a memóriában, és mind a lista, mind a tuple ugyanarra hivatkozik
- úgy tűnik azintobjektum tárolására 32 bájtot használ a rendszer>>> b[1] = 4
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> a[1] = 4
>>> id(a)
2238629696072
>>> id(a[0])
1970405872
>>> id(a[1])
1970405968
>>> id(a[2])
1970405936
>>> id(b[1])
1970405904
>>> id(b[2])
1970405936Itt azt látjuk, hogy a
bmásodik elemét nem engedi módosítani (hiszen az egy tuple eleme), aza-ét viszont igen, noha mindkettő ugyanarra az elemre mutatott! Ha a lista módosítása után is megnézzük a címeket, akkor azt látjuk, hogy az 1, 2 és 3 a "helyén" maradt, viszont a rendszer létrehozott egy új, 4 értékűint-et és aza[1]már erre hivatkozik.>>> c = "szoveg"
>>> id(c)
2238629677408
>>> for x in c:
... print(id(x))
...
2238534181640
2238539112832
2238534182144
2238538540512
2238534181696
2238538838680A harmadik példa egy
sztringobjektum, aminek az elemei a memóriában nem egymás mellett, hanem elszórtan helyezkednek el. Ellentétben azzal, amit korábban írtam.Python data model: "The value of some objects can change. Objects whose value can change are said to be mutable; objects whose value is unchangeable once they are created are called immutable."
ui: csak nekem tűnik randomnak a Programkód kapcsoló hatása?
-
cousin333
addikt
válasz
Tigerclaw
#820
üzenetére
Nem vagyok expert, de valahogy a következőképpen tudom elképzelni (ez most vélhetően elég pongyola lesz): meg kell különböztetni magát az objektumot és az arra mutató referenciát:
a = 13
b = aA fenti kód esetében a 13 mint egész szám, eltárolódik a memóriába, és erre az a változó hivatkozik. A második sor egy b nevű referenciát hoz létre, ami azonban szintén ugyanarra a 13 objektumra vonatkozik! Ha most az alábbi kódot írod:
a = "szoveg"akkor tulajdonképpen nem az a-t változtatod meg, hanem létrehozol egy "szoveg" tartalmú sztringet és az a ezen túl arra az objektumra fog mutatni. Ha ugyanezt mondjuk a b-vel is eljátszod (ami most még mindig a 13-ra mutat!):
b = 9.817akkor létrejön a 9,817 lebegőpontos szám és a b arra mutat. A 13-ra már nem mutat semmi, azért a szemétgyűjtő (garbage collector) előbb-utóbb összegyűjti ("megsemmisíti").
Tehát amikor a "sztringből egész számot csinálsz", akkor nem magát a sztringet változatod meg, hanem csak a hivatkozásod (változóneved) már egy más memóriaterületen lévő, másik objektumra fog utalni. Ha egy karaktert írnál át akkor viszont ugyanazt az objektumot módosítanád, ami nem lehet, hiszen immutable. "Módosítani" csak úgy tudod, ha létrehozol egy teljesen új sztringet, ami már tartalmazza a kívánt módosítást (pl. "alma" -> "elme") és azt ugyanúgy nevezed el, ahogy a régit hívták. Ekkor az eredeti sztring még ott van, csak már nem kell senkinek és megy a "kukába". Tehát:
a = "alma"
a = "elme"A két sztring objektum teljesen különbözik, az l és az m sem "közös". Csak mindkettőt ugyanúgy hívják, a Python meg "elfelejti" az elsőt és mindig csak az utolsóra emlékszik.
Azon objektumokat, amiket helyben nem, csak másolással és aközbeni módosítással lehet "módosítani" nevezzük immutable-nak.
Ezzel szemben egy Python lista például nem olyan mint pl. a C tömb, ahol azonos típusú elemek vannak egymás után a memóriában. A lista egy viszonylag bonyolult objektum, ami többek között mutatókat tartalmaz az egyes listaelemekre. Ezért tartalmazhat egy lista tetszőleges típusú elemeket, akár listákat is vegyesen. Ebben az esetben egy listaelem módosítása tulajdonképpen az adott elem referenciájának módosítását jelenti (pl. mostantól a
23helyett a "szöveg" sztringre mutat), viszont minden más elemet érintetlenül hagy. Volt erről egy jó kis Youtube videó valahol.Remélem érthető volt valamelyest és nem is írtam totális hülyeségeket.

-
#817
cousin333
addikt
Chesterfield
#815
cousin333
addikt
válasz
 Chesterfield
#815
üzenetére
Chesterfield
#815
üzenetére
3-as Pythonnal próbálkozz és inkább a könyvet cseréld le, mert már elég régi.
Amúgy igen, vannak kisebb-nagyobb változások szép számmal: pl
print. -
#814
cousin333
addikt
concret_hp
#811
cousin333
addikt
válasz
 concret_hp
#811
üzenetére
concret_hp
#811
üzenetére
Tulajdonképpen miben lenne más ezen a téren a "sima" Python kód, mint az iPython szkript? Gondolom utóbbival egy cellában beolvasnád az adatbázist (mivel? Pandas?), a többiben meg mókolnád. Ezt viszont megteheted sima kóddal is: lefuttatod az alap kódot (pl. a beolvasást), majd megkapod a promptot a kísérletezgetéshez.
-
cousin333
addikt
Szia! Sok sikert hozzá!
Az IDLE az alapértelmezett, ám meglehetősen buta Python-szerkesztő. Egyszerűen nem támogatja ezt a funkciót, csak az állapotsávban írja ki. (Természetesen a fájl nézetről beszélünk, a parancssor alapból nem támogatja). Kiindulásnak jó, de ha sorszámozás és/vagy komolyabb funkciók kellenek, akkor érdemes más editor után nézni. Megfelelő lehet a Spyder, a PyCharm Community Edition esetleg az egyszerűbb Ninja IDE (úgy látom, már nem fejlesztik) de pl. az MS Visual Studio is támogatja. Vagy a parancssor számozásához pl. az IPython. Esetleg egy sima szövegszerkesztő, pl. Notepad++, bár azzal nehezebb automatikusan futtatni az elkészült kódot.
A második kérdésedre a válasz a lebegőpontos számábrázolásban keresendő. Egyes számok nem ábrázolhatóak elég pontosan 32 (64) bites változókkal, ezért kapod a pontatlanság. Megoldás lehet, ha kiíratásnál kerekítesz.
-
cousin333
addikt
válasz
 cousin333
#797
üzenetére
cousin333
#797
üzenetére
Ha már a végén a térképet emlegettem: ez azért fontos, mert a "teljes Pythont" úgysem fogod megtanulni, csak azt a részét, amit használni fogsz. Ezért kell azt is látni, hogy milyen globálisan használható funkciók és trükkök vannak, amiket te is felhasználhatsz a saját kódodhoz, programodhoz.
Szerencsére a Python egy jól összerakott nyelv és az efféle alapelvek szépen összekapcsolódnak egy egésszé: Pl. vannak az iterálható elemek (iterable) mint pl. a lista, a set vagy a sztring, meg vannak az iterátorokat "fogyasztó" funkciók, mint a for ciklus a zip, a min... stb. Ezért van az, hogy egy listában végigmehetsz az elemeken, vagy kiírathatod a legnagyobb elemet, és ezért van az is, hogy a for ciklus végigmegy a listán (az elemeken) meg használható a sztringre is (ott a karaktereken megy végig).
Ami még kimaradt az előző felsorolásomból, az az objektum-orientáltság, azon belül is az öröklés (Super considered super!), illetve mondjuk az osztályoknál a "dunder" metódusok:
__init__, __add__, __next__stb. De a @property dekorátor is nagy királyság, egy Java-s ember biztos értékelné őket. Ehhez kapcsolódva még egy zseniális videó az osztályokról: Python's Class Development Toolkit . Ez sokat segíthet kezdőknek is, hogy jobban megértsenek olyan fogalmakat, mint a staticmethod.
. Ez sokat segíthet kezdőknek is, hogy jobban megértsenek olyan fogalmakat, mint a staticmethod. -
cousin333
addikt
Igen, a Python3-ban egyféle int típus van, ami gyakorlatilag tetszőleges méretű számot képes kezelni. Ha pedig szükség van a hosszakra - például egy 16 bájtos összetett struktúrát kell értelmezni -, akkor ott a beépített struct vagy a nagyszerű bitstring modul, amivel használhatsz 23 bites előjel nélküli egész számokat is, ha éppen az kell neked, vagy igazi, egy bites boolean-t (vagy többet). Mindezt kicsi indiánnal vagy naggyal (endianness).
-
cousin333
addikt
A programozási nyelvek (pl. Python) tanulásának egyik nehézsége, hogy már a legelején kompromisszumokat kell kötni: hiszen "minden mindennel összefügg", nem lineáris a folyamat, így nehéz eldönteni, hogy egy adott ismeret megtanulása túl korai-e. Például a típusoknál van egész meg lebegőpontos szám, sztring meg lista. De igazából mindegyik egy osztály, aminek vannak pl. metódusai, amiket szintén nem árt ismerni. A kérdés, hogy mennyire mélyen kell belemenni ennek a magyarázatába mindjárt a legelején.
Véleményem szerint a tanulás során az a fontos, hogy meglegyenek a stabil alapok és fogalmak:
- Python telepítése
- interaktív mód, "fájl-mód" használata
- típusok ismerete, néhány metódussal
- hasznos gyári függvények megismerése (print, type, int, input, range, len, zip)
- utasításszervezés: ciklusok (while, for) és feltételes elágazások (if, else)A fenti ismeretekkel már el lehet boldogulni és hasznos programok készíthetők. Ezek tanulásakor viszont kiemelten fontosnak tartom - különösen a Python esetén -, hogy a helyes használatot sajátítsuk el, mert jobb, ha az elején az ragad meg bennünk. Például korábban linkeltétek ezt a Python programozást tanító oldalt. Már az elejétől egy kicsit ide-oda kapkodónak tűnik, de a fentebb említett okok miatt ez még belefér. Az viszont már nem, hogy pl. a 8. részben - aminek a teljes léte vitatható ebben a formában, mert olyan dolgokat ecsetel, amiket Pythonban nem kell "kézzel" megcsinálni - képes ilyen példaprogramot írni:
def kereses (L, e):
for i in range (len(L)):
if L[i] == e:
return True
return FalseKicsit szégyenlem is, hogy idemásoltam, de mindemellett szeretném hangsúlyozni, hogy a Python nem C! A kód második sora ennek megfelelően egy Python elleni merénylet. A
forciklus ebben a nyelvben az elemeken lépked végig, nem az indexeken. A fenti megoldás rondább - és lassabb! - mint a helyes változat:def kereses(L, e):
for i in L:
if i == e:
return True
return FalseAmi még mindig nem az igazi, hiszen máshogy kell lekódolni azt, hogy egy lista tartalmaz-e egy bizonyos elemet:
e in LJól látható, hogy a fenti kód "némileg" egyszerűbb, mint az eredeti... Aki tehát az alapokat rendesen szeretné elsajátítani, (ismételten) ajánlom neki Raymond Hettinger (Python core-developer) videóját. Angol, de elég a kódot nézni. Felül a rossz, alul a jó.
A másik fontos feladatnak a globális szemlélet elsajátítását tartom. Ez kicsit olyan, mintha távolról néznél egy térképet, hogy lásd, hol vagy körülbelül a térképen. Ezek pl: a "tor"-ok: iterator, generátor, dekorátor, vagy például list comprehension.
-
cousin333
addikt
válasz
 gratzner
#782
üzenetére
gratzner
#782
üzenetére
Nem olyan szörnyű, mint ahogy elsőre hangzik. A Python telepítésen belül a lib mappában vannak az alap Python részét képező modulok py fájlok formájában. Ha ide bemásolod a tiédet, akkor azt is látni fogja. Egy saját modul készítése és "szakszerű" telepítése sem lehet bonyolult, de ilyet még sosem csináltam
-
cousin333
addikt
válasz
 #93284608
#778
üzenetére
#93284608
#778
üzenetére
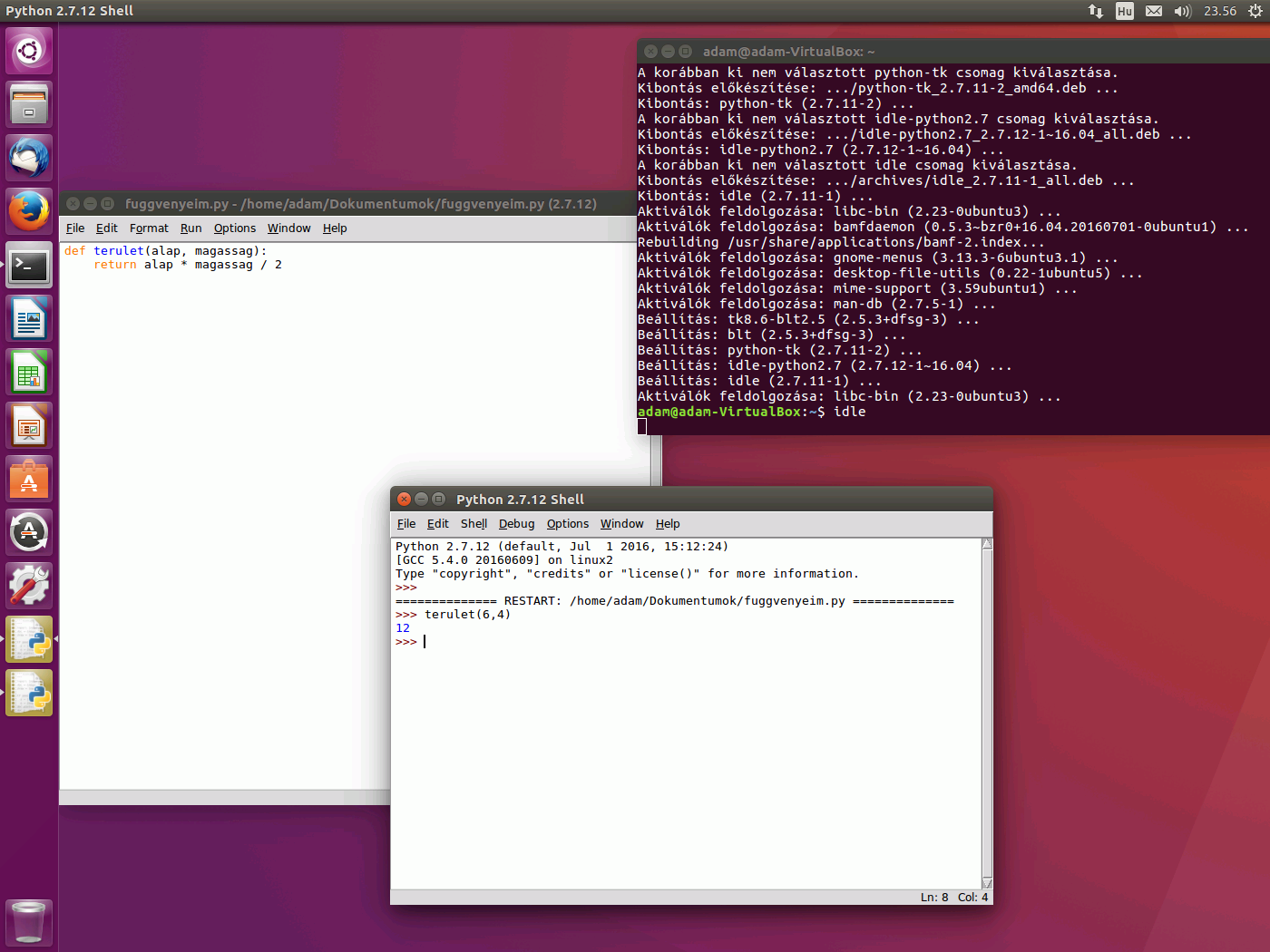
Az is működik, csak nem így. Akkor előbb importálni kell a függvénykönyvtáradat (py fájlodat) a parancssorból, de ehhez a Pythonnak is tudnia kell, hol találja. Pl.:
import enfajlomutána lehet használni a benne levő függvényeket:
x = enfajlom.terulet(6,4)Legegyszerűbb talán úgy elindulni, hogy csinálsz egy fájlt a függvényeidnek, majd ugyanabba a mappába egy másikat, amiből emezt hívogatod és a végén az utóbbi fájlt indítod el.
#780: Amit írsz az csak egy konkrét környezetre (az IDLE-re) igaz. Te meg nem azt használod éppen. Tedd fel:
sudo apt-get install idlemajd ha települt, akkor egyszerűen:
idleAz IDLE az alapértelmezett környezet pl. a Python windowsos telepítése után. Egyszerű, mint a bot, de kezdésnek megfelel.
-
cousin333
addikt
válasz
#93284608
#777
üzenetére
A hozzászólásoknál használd a programkód kapcsolót a forráskód-részletekhez.
Értem én, hogy mit csinálsz, de mondom, hogy nem jó. Olyan, mintha írnál egy füzetbe, majd félreteszed, előveszel egy másik füzetet és csodálkozol, hogy nincs benne amit addig írtál.
Hagyd a fájlt, mindjárt nyisd meg a promptot, és oda írd be (soronként, enterrel):
>>> def terulet (alap, magassag):
... return alap * magassag / 2
...
>>> terulet(6,4)
12
>>>A return kulcsszót ne felejtsd el behúzni (pl. 4 szóközzel), mert azzal kapcsolatos lesz a következő kérdésed.
-
cousin333
addikt
válasz
#93284608
#775
üzenetére
előbb kell a terulet függvény definiálása, csak után hívhatod meg. Tehát:
def terulet (alap, magassag):
return alap * magassag
eredmeny = terulet(4,6)
print eredmenyIlletve most nézem csak, hogy rossz nyomon jársz. Az enter után lefut a kódod, definiálja a terulet függvényt, ... és ennyi. A következő sorban nyitsz egy Python interpretert, ami a nulláról indít, semmit nem tud a fájlról, amit korábban futtattál, így a terulet függvény sem mond neki semmit. Vagy mindkettőt az fájlba írod, vagy mindkettőt az interpreterben. Vegyesen nem megy. A Spyderrel mondjuk mehetne...

-
#774
cousin333
addikt
justmemory
#773
cousin333
addikt
válasz
 justmemory
#773
üzenetére
justmemory
#773
üzenetére
Érdekes teszt lenne pedig, hogy a megadott sor elé (elnevezés, paraméterek zárójelben és kettőspont) miket lehet beírni, hogy helyes Python kódot kapjunk.
Pl.:def
class
whileMind helyes, de persze az első a legvalószínűbb...
-
-
cousin333
addikt
válasz
#93284608
#769
üzenetére
Ezek közül szvsz az utolsó még ér is valamit (bár régóta nem fejlesztik), a többi inkább csak bohóckodásnak tűnik. Akkor inkább már egy szimpla szövegszerkesztő. A komolyabb cuccokhoz persze kell némi ismeretség, de az alapok hamar elsajátíthatók.
Kísérletezni (vagy mondjuk adatelemzésre) jó lehet még az IPython (vagy ahogy most nevezik: Jupyter) Notebook. Böngészőben akár össze-vissza sorrendben futtatható kóddarabokkal. Az általam említett Anacondában ez is benne van. Itt egy kis bemutató video Ubuntuval.
Angollal hogy állsz? Met ha rosszul, akkor nem linkelek angol nyelvű Youtube oktató videókat. Bár néha a puszta kód is magáért beszél....
-
cousin333
addikt
válasz
#93284608
#764
üzenetére
Elvileg szimplán ez kell a parancssorba abban a mappában, ahol a py fájl van:
python haromszogterulet.py
Mondjuk nem tudom, másnak mennyi kedve van parancssorban küzdeni, én feltennék egy IDE-t, igaz, nem olyan kicsik, de van integrált szerkesztőjük, debuggerük, "parancssoruk". A jelöltjeim:
- Spyder (sudo apt-get install spyder), mondjuk sok mindent fel akar tenni
- PyCharm Community Edition - ez se kicsi
- Anaconda: ez egy teljes környezet, sok plusz csomaggal, all-in-one, a Spyder is benne van (vagy csupasz haverja, a Miniconda)Egy pár soros programocskához nyilván mindegyik overkill, de az integrált segítő funkciók (súgó, kiegészítési javaslatok, változók pillanatnyi értékei) miatt nagyon hasznosak. Ráadásul már nem érnek újdonságként, ha egyszer komolyabban elkezdesz Python-ozni...
![;]](//cdn.rios.hu/dl/s/v1.gif)
Persze még mindig ott az IDLE...
-
cousin333
addikt
Igazi fejlődésre már csak a 3-as esetében számíthatsz, így a 3.5-ös verziónál már eléggé kiforrott, szinte minden értelmes modulból van kompatibilis verzió. Szerintem hacsak nincs nyomós indokod a 2.7 mellett (pl. nagy mennyiségű régi kódot kell karbantartani, kiegészíteni), akkor én a 3-ast javasolnám. Pár dolgot pl. rendbe tettek benne (lásd raw_input). Az új print függvény is jobb, bár elsőre kényelmetlenebbnek tűnhet.
Ha az angol a barátod, akkor a könyvekkel sem lesz bajod. Magyarul már neccesebb, de ez szerintem nem lehet valós ok.
-
cousin333
addikt
bemenet = input('kerem adja meg a szavakat vesszovel elvalasztva: ')
lista = bemenet.split(',')
print(lista)A split függvény szétbontja a beérkező sztringet a vesszők mentén, az eredmény meg egy lista lesz. Még esetleg kiegészíthető ezzel:
lista = [i.strip() for i in lista]Ez meg leszedi a lista elemeiről a kezdő és záró szóközöket.
A print nálam miért lett lila

-
cousin333
addikt
Máskor szerintem használd a Programkód formázást. Köszi!
Bevallom nem teljesen világos számomra, hogy mit is szeretnél csinálni. Az egy elemű szótár mondjuk nem néz ki túl jól. Az if-es példádnál az megvan, hogy a szótár értékei függvények is lehetnek? Pl:
def nyomtat(valami):
print(valami)
def osszead(a,b):
print(a+b)
def semmi():
pass
d = {'a': nyomtat, 'b': osszead, 'c': semmi}Ezt futtatva és használva:
>>> d['c']()
>>> d['a']('Minden')
Minden
>>> d['b'](3,6)
9
>>>Lehet persze, hogy esetedben teljesen rossz nyomon járok, de ez az infó még jól jöhet másoknak is
-
#720
cousin333
addikt
DrojDtroll
#719
cousin333
addikt
válasz
 DrojDtroll
#719
üzenetére
DrojDtroll
#719
üzenetére
-
cousin333
addikt
Nem tudom, miféle feladat ez, de így biztos nem fog működni. Az első
forciklus végigiterál a külső szótár kulcsain: "key1" és "key2". Eddig OK. A második ciklus végigmegy a kulcsok által mutatott szótárak értékek"internal_key1" kulcs alatti elemén, ami itt most csak egy 1 elemű lista ("value1"), ez lesz avalue. A baj ott van, hogy, a "key2" szótárában nincs "internal_key1" elem. Ennek úgy lenne értelme, ha mindkettő helyen csak "internal_key" szerepelne, szám nélkül.A
selfmár csak hab a tortán, ennek alapján ez a kód egy osztály része, magában le se fut. Viszont ha egy osztály metódusában van benne, akkor is problematikus, mert a sample_map egy lokális változó lesz, a self.sample_map pedig egy példányváltozó. Tehát ha korábban nem jött létre egy self.sample_map, akkor a program megint csak nem csinál semmit. Illetve de: hibát dob. -
cousin333
addikt
Szebben? Először is úgy, hogy használd a Programkód kapcsolót a hozzászólás szerkesztésénél...
Egyébként pedig azt kell tudni, hogy egy sztring szorzása a sztring ismétlését jelenti:
for i in range(1,8):
print("*" * i)Ha a fentit nem tudod, akkor még mindig jobban jársz egy dupla for ciklussal:
for i in range(1,8):
for j in range(i):
print("*", end="")
print("", end="\n")Természetesen az első módszer a preferált.
-
cousin333
addikt
Én pont fordítva szoktam. Ha szembesülök egy problémával, eszembe jut, hogy hátha van rá beépített vagy 3rd party modul. És általában van is.
Ez mondjuk nem rossz gondolat: ide (vagy akár az 1. hsz-be) ki lehetne posztolni érdekes cikkeket, videókat honlapokat, ahol hasznos tudással lehet bővíteni az ismereteinket. Tehát nem kell minden Python cikk, csak ami tényleg jó és tartalmas. Ugyanezt kiegészíthetnénk modul-ajánlóval is.
-
cousin333
addikt
Én Mercurial-t használok. Folyamatosan fejlesztik, gyors, stabil megbízható és könnyen megtanulható. Van hozzá rendes GUI és Windows támogatás. Ez is elosztott rendszer, a BitBucket kínál hozzá is online repókat, de azt nem használom. A git-et nem ismerem, de kétlem, hogy egyszerűbben használható lenne.
Dokumentálni általában ott a Doxygen, bár Pythonhoz elvileg a Sphinx dukálna, de azt még sosem használtam.
Python tippeket meg a Youtube-on is találsz, van jónéhány PyCon rendezvény, amiben egy-egy modult mutatnak be. A részletekért meg úgyis a dokumentációt kell bújni.
-
#695
cousin333
addikt
DrojDtroll
#694
cousin333
addikt
válasz
DrojDtroll
#694
üzenetére
Típushibára

Kattints rá a linkre (vagy keresd meg a kérdéses fájlok kérdéses sorát), hogy lásd, mit csinál. Én ennyi infóból azt mondanám, hogy a
MediumMotor()osztály példányosításakor lefut az__init__()függvény, ami valamit inicializálna, pl. egy szótár változóból (dictionary) olvasna ki egy elemet, de a szótár helyett egyNone-t kap. Nem lehet, hogy valamilyen paramétert kéne átadni az osztálynak?Mod: a válasz elvileg nem. Én ezt találtam: [link], bár gyanítom, hogy ez a kód nem teljesen ugyanaz a verzió, mint a tied, mert ennek a sornak le se szabadna futnia, max a 334-től kezdve, de szerintem abban sem indokolja semmi ezt a hibát.
-
#693
cousin333
addikt
DrojDtroll
#692
cousin333
addikt
válasz
DrojDtroll
#692
üzenetére
Tehát ha jól értem, egy virtuális környezethez volt fenn a modul (nem használtam még a
virtualenv-et), indításkor viszont a normál környezet futott, ami persze nem látta.Úgy látom reszeltek a programkód beágyazáson. Színes meg minden...
-
#691
cousin333
addikt
DrojDtroll
#683
cousin333
addikt
válasz
DrojDtroll
#683
üzenetére
Ennyi erővel már a konkrét problémát is beírhattad volna ide
Ez olyan "Megkérdezhetem, hogy mennyi az idő? Persze, kérdezd csak meg nyugodtan!" típusú hozzászólás volt.
-
#680
cousin333
addikt
AeSDé Team
#679
cousin333
addikt
válasz
 AeSDé Team
#679
üzenetére
AeSDé Team
#679
üzenetére
Az OpenCV tényleg alkalmasnak látszik a feladatra, én ezzel kezdeném: [link]
Mivel itt arról van szó, hogy a kamera képét képként beolvasod, majd azt elemzed, szerintem nincs különösebb szükség komolyabb támogatásra.
Nem tudom, mit és hogyan akarsz irányítani vele, de egér és billentyűzet automatizált kezelésére egy lehetséges opció a pyAutoGUI.
-
#674
cousin333
addikt
justmemory
#671
cousin333
addikt
válasz
justmemory
#671
üzenetére
Az objektum orientált Python programozáshoz egy remek video:
Python's Class Development Toolkit -
cousin333
addikt
válasz
EQMontoya
#672
üzenetére
Szerintem is talán a legprofibb eszköz Python fejlesztéshez (is), ha nagy projektem lenne, valószínűleg abban nyomnám. Kis projektekhez viszont - épp az autocomplete és a hozzá hasonló funkciók miatt - elég fejnehéznek tűnik. Értsd: túl komplex egy pár soros programhoz (a telepítője 160 MB) és túl sokat molyol a háttérben, amitől kissé darabosnak érződik a számomra.
Aki nem ismerné: PyCharm
-
#670
cousin333
addikt
justmemory
#669
cousin333
addikt
válasz
justmemory
#669
üzenetére
Na igen, a Python más nyelveknél is sokkal háklisabban reagál a vegyesen alkalmazott behúzásokra...
Az általam használt szövegszerkesztők (Notepad++, Spyder, IPython... stb.) szinte mindegyikének van olyan funkciója, hogy a Tab-ot automatikusan a kívánt számú (esetemben 4) szóközre cseréli. A behúzás csökkentése is megoldható Shift + Tab használatával.
Ami a GUI-t illeti: én sem használom a tk-t, sőt, mást se nagyon (kivéve a Jupyter Notebook-ot). Csak azért javasoltam, mert az alapból része a Python telepítésnek és ilyen egyszerűbb feladatra vélhetően ez a legjobb.
Valóban egyszerűbb lehet kiválasztani a fájlt, mint begépelni az egész elérési utat, de a szkriptnyelves és a GUI-s implementálásnál csak egy rosszabb van: a kettő vegyítése - legalábbis ha utóbbit vegyítjük az előbbibe. Egy GUI implementálása más szemléletet igényel, hiszen "folyamat-alapú" működés helyett eseményvezéreltté válik. Nem is beszélve az integráláshoz szükséges, arányaiban sok extra kódról.
Ha pedig GUI, akkor én nem csak a fájl-választót írnám bele, hanem az egészet, a generálás gombtól kezdve a kimeneti címkéig. Úgy legalább megspórolná az eléggé esetleges while ciklust is.
-
#667
cousin333
addikt
justmemory
#666
cousin333
addikt
válasz
justmemory
#666
üzenetére
Az a 12 karakteres behúzás csak engem zavar? Már a 8-at is sokallom, a 2 meg kevés, én a 4-re szavazok. Természetesen szóközzel, nem tabulátorral.
"A fájl mentését én valószínűleg gtk-val oldanám meg"
Amit írsz, az igaz, de egy szkriptnyelvnél a GUI szerintem minimum a második lépés, vagy még későbbi. Akkor is inkább a tk-t próbálnám ilyen egyszerű feladatra, mert az része az alap Python telepítésnek.
"Tennék bele egy olyan apróságot is, hogy az "i" és "n""
Meg a zárójelezés is teljesen felesleges az == után. Kivéve talán ezt az esetet:
if kerdes in ('i', 'n'):
"#!/usr/bin/python - nem feltétlenül szükséges, csak könnyebb futtatni;"
Windows alatt is?
"#-*- coding:Utf-8 -*-; nem tudom, hogy ez utóbbi feltétlenül kell-e"
Python 3 alatt nem kell, az már tudtommal full Unicode, ékezettel, meg amit akarsz.
Még a fájlkezelésnél használnék context managert. Szerintem szebb, elegánsabb, és minden körülmények között automatikusan bezárja a fájlt:
with open(fajlnev, 'w') as f:
f.write(akarmi) -
cousin333
addikt
válasz
#82595328
#654
üzenetére
Na, milyen nagy élet lett itt hirtelen...
A Python 3-ban a print már egy függvény, így ezt is lehet használni:
with open('D:\\teszt.csv', 'w') as f:
for sor in lista:
print(*sor, sep=', ', file=f)Működik
De akkor is a pandas a legegyszerűbb, csak itt a lista egy Pandas.DataFrame objektum:
import pandas as pd
...
lista.to_csv("D:\\teszt.csv", sep=',')ui: Ezt gyorsan felejtsd el...
for i in range(len(lista)):Helyette inkább használd így:
for elem in lista:Vagy ha mindenképpen kell az index is, akkor így:
for i,elem in enumerate(lista): -
#644
cousin333
addikt
justmemory
#642
cousin333
addikt
válasz
justmemory
#642
üzenetére
pip install pandas ???
Talán mehetne, legfeljebb a C-optimalizált részek helyett a Python kód futna. Tehát működne, csak lassabban. Ha viszont nincs dateutils, akkor szerintem nem települ, mert még a 0.12-es verziónak is függősége.
-
cousin333
addikt
válasz
#82595328
#634
üzenetére
Az első pár dologban nem tudok kellően segíteni, de legalább a programot nem is kell lefordítani...
A leírtak alapján továbbra is a pandas modult favorizálnám, mivel nagyon sokrétűen használható. Hogy a példádnál maradjak:
- képes beolvasni a csv és más strukturált fájlokat
- beolvasásnál meg lehet mondani, hogy melyik oszlop(ok) tartalmaznak dátumot (pl. akár akkor is, ha az év, hónap, nap és idő 4 külön oszlopban szerepel)
- a dátum értelmezéséhez megadható saját függvény, de az ésszerűség határain belül képes értelmezni őket. Például az alábbi tesztfájlt gond nélkül beolvassa:
Szam,Datum,Szoveg,Pont
11,2016-01-01,Valami,12
21,2016-03-05,Masik, 23
31,2016-1-5,Harmadik,34
41,2016-feb-8,Negyedik,48
51,2016.08.12,Otodik,56Ehhez csak az alábbi kódot használtam:
import pandas as pd
data = pd.read_table('D:\\pandas_test.txt', sep=',', parse_dates=[1])Az eredmény pedig egy Pandas.DataFrame objektum lesz:
>>> data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 4 columns):
Szam 5 non-null int64
Datum 5 non-null datetime64[ns]
Szoveg 5 non-null object
Pont 5 non-null int64
dtypes: datetime64[ns](1), int64(2), object(1)
memory usage: 240.0+ bytesLátható, hogy a Datum oszlop típusa datetime64. A beolvasott táblázat valahogy így néz ki (A legelső oszlop az index, amit jelen esetben ő maga generált):
>>> print(data)
Szam Datum Szoveg Pont
0 11 2016-01-01 Valami 12
1 21 2016-03-05 Masik 23
2 31 2016-01-05 Harmadik 34
3 41 2016-02-08 Negyedik 48
4 51 2016-08-12 Otodik 56A dt.date függvényednek szükséges formátumot is könnyen előállíthatod:
>>> x = data['Datum']
>>> x.dt.date.values
array([datetime.date(2016, 1, 1), datetime.date(2016, 3, 5),
datetime.date(2016, 1, 5), datetime.date(2016, 2, 8),
datetime.date(2016, 8, 12)], dtype=object)Ezt már megetetheted a függvényeddel. De igazából nem is biztos, hogy kell, hiszen az oszlop már dátum formátumú.
-
cousin333
addikt
válasz
EQMontoya
#632
üzenetére
Melyik Python verzió volt? A 3-asban nyilván iterátort használ, minden ciklusban kér (és kap) pontosan egy új sort, ezáltal kevés memóriát fogyaszt. Akkor tölti be az egészet egyszerre, ha listát készítesz belőle. Viszont a Python for ciklus nem a sebességéről híres, de talán a fájllal könnyebb dolga van, bár az sem fix, hogy összefüggő memóriacímen helyezkedik el.
Én a fájl olvasgatásnál mondjuk a numpy genfromtxt függvényét vetettem össze a pandas from_table függvényével és meglepetésre utóbbi látványosan gyorsabb volt.
-
cousin333
addikt
válasz
#82595328
#629
üzenetére
Már írták, hogyan lehet két with-et egymásba ágyazni, Ettől függetlenül én még nem ijednék meg pár ezer sorocskától, hanem egyben beolvasnám, hacsak nem kvarcórán akarod futtatni...
Már csak azért sem, mert a rengeteg I/O művelet aligha tesz jót a teljesítménynek.Fejlécet tartalmazó, több oszlopos csv fájlra meg javaslom a pandas modult. Van pl. külön egy read_csv függvénye, ami igen gyorsan képes nagy mennyiségű adatot beolvasni és jónéhány trükköt is ismer. Ezt szintén gyorsan képes feldolgozni, soronként, oszloponként vagy elemenként, majd a to_csv függvénnyel kiírathatod. Arra is van lehetőség, hogy kisebb csomagokban (chunk) olvasd és írd a fájlt. Néhány millió sornál már én is elgondolkoznék ezen a megoldáson.
Biztosra veszem, hogy lényegesen gyorsabb lesz, mint a sima open függvény meg a soronkénti iterálás. Ha konkrét teendőt is írsz, akkor talán kódot is tudok adni hozzá.
-
cousin333
addikt
Köszönöm!
Így azért már más a megoldás, hiszen a feladat szerint nem lehet egyszerre beolvasni a teljes fájlt. Ebben az esetben az első 2 példa továbbra is érvényes, a harmadiktól kezdve más megközelítés szükséges. Én összevonnám a feladatokat, hogy a fájlt csak egyszer kelljen megnyitni és iterálni benne. Remélem nem maradt ki semmi, nem futtattam le a kódot:
with open("kiserlet.txt", "r") as f:
fej_db = 0 # Fejek száma
iras_db = 0 # Írások száma
dupla_db = 0 # A pontosan két egymást követő fejek száma
csakfej = 0 # A csak fejekből álló sorozat aktuális hossza
csakfej_max = 0 # A csak fejekből álló sorozat maximális hossza
# A legutóbbi három dobás tárolása
e1, e2, e3 = None, None, None
# Szépen soronként végiglépdelünk a fájlon
for line in f:
line = line.strip('\n')
if line == 'F':
fej_db += 1
# Számolás a 6. feladathoz
csakfej += 1
csakfej_max = max(csakfej_max, csakfej)
if line == 'I':
iras_db += 1
# Számolás a 6. feladathoz
csakfej_max = max(csakfej_max, csakfej)
csakfej = 0
# Számolás az 5. feladathoz
if line == 'I' and e1 == 'F' and e2 == 'F' and e3 == 'I':
dupla_db += 1
# Eltároljuk a legutóbbi dobásokat
e1, e2, e3 = line, e1, e2
# 3. feladat: Az összes dobás száma a fejek és írások összege
ossz_db = fej_db + iras_db
print('A dobások száma: {}'.format(ossz_db))
# 4. feladat
print('A fejek relatív gyakorisága: {:.2%}'.format(fej_db/ossz_db))
# 5.feladat
print('A dupla fejek száma: {}'.format(dupla_db))
# 6. feladat
print('A leghosszabb fej-sorozat: {} dobás'.format(csakfej_max)) -
#626
cousin333
addikt
szaszayanou
#624
cousin333
addikt
válasz
 szaszayanou
#624
üzenetére
szaszayanou
#624
üzenetére
Nem találtam a feladatsort, ezért az általad írtakra hagyatkozom:
Az első feladatban nem zártad be a megnyitott fájlt. Ezt megelőzheted a with használatával, az automatikusan bezárja, és amúgy is a preferált mód. Megnyitjuk a fájlt, egy lépésben beolvassuk és a sortörések (\n) mentén szétszedjük:
with open('D:\\kiserlet.txt', 'r') as f:
kiserlet = f.read().split('\n')A második példában feltétlenül számokat kell beírni? Használhatnád a random könyvtár choice függvényét is, ami egy lista-szerű elemből választ ki egyet találomra. Ez a lista most persze fej vagy írás:
valasztek = ('F', 'I')
tipp = input("Fej (F) vagy írás (I)? ")
if tipp == random.choice(valasztek):
print("Eltaláltad!")
else:
print("Sajnos tévedtél!")A harmadik feladat megoldása jó. Esetleg még így lehetne:
print("A kiserlet {} mintabol allt.".format(len(kiserlet)))
Tekintve, hogy a fenti beolvasás nyomán a kiserlet egy lista, a negyedik feladat megoldásához felesleges a for ciklus, és használhatjuk a sztring formázást is a céljainkhoz.
arany = kiserlet.count("F") / len(kiserlet)
print("A fejek relatív gyakorisága {:.2%}".format(arany))Az utolsó feladat pontos célja nem elég világos számomra, ezért most feltételezem, hogy nem lapolódhatnak át az "FF"-ek, tehát az "FFF" csak egynek számít, az "FFFF" meg kettőnek. Ebben az esetben használhatunk beépített függvényt, de ehhez a listánkból először egy sztringet gyártanunk a join használatával. Így egy lépésből megvan a kívánt szám:
dupla = "".join(kiserlet).count("FF")
print("A két egymást követő fejek száma: {}".format(dupla))Tényleg, mit lehet használni egy ilyen vizsgán?
-
#611
cousin333
addikt
csaszizoltan
#609
cousin333
addikt
válasz
 csaszizoltan
#609
üzenetére
csaszizoltan
#609
üzenetére
Pedig én is azzal kezdtem, igaz, nekem már nem volt újdonság a for ciklus fogalma (bár a Python kicsit máshogy használja).
Vannak "emelkedettebb" részek, de át is lehet őket ugrani. Annyit biztos ér, mint a sulinetes Free Pascal reklám
Nagyobb probléma, hogy öreg, mint az országút, de az alapokhoz meg így is elég.De ha megy az angol, akkor persze több könyv is ajánlható. Viszont nem vagyok kezdő programozó (bár profi sem), így bevallom elég nehéz beleképzelnem magamat az ő helyzetükbe.
-
cousin333
addikt
Egy magyar könyv: [link]
Ha meg megy az angol, akkor jó néhány könyv közül lehet válogatni. Pl. Think Python, Dive Into Python vagy mondjuk a Learning Python, ami elég alapos.
A tipikus programozási struktúrák alapvető megértéséhez ott a Wikipedia: pl. ciklusok.
-
cousin333
addikt
Teljesen igaz, amit írsz, a Python 2-ben a range egy komplett listát hoz létre és azon iterál végig. Ugyanakkor - bár nem szoktam kihangsúlyozni, de - Python 3 párti vagyok (és minden kezdőnek ezt javasolnám), tehát nekem az az alapértelmezett, hacsak nem írom ki, hogy Python 2. Márpedig a Python3 egyik előnye, hogy elhagyták az i-s és x-es hülyeségeket, és az alap kulcsszó már magát az iterátort jelenti. Tehát van a zip a régi izip, és a range a régi xrange helyett. Tisztább, szárazabb, biztonságosabb érzés.
>>> for i in range(5):
... print(i)
...
0
1
2
3
4
>>> for i in xrange(5):
... print(i)
...
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'xrange' is not definedui: Ha valaki a régi megoldásra vágyik, mert sok a RAM-ja, természetesen az is elérhető:
list(range(10))
-
cousin333
addikt
válasz
EQMontoya
#594
üzenetére
Először is, nincs benne ékezet, és ők is magyart használtak a pszeudokódban. Másrészt ez egy magyar fórumon adott segítség, az ilyesmi legyen a vizsgázó baja

Azért kíváncsi vagyok, mit szólnának ehhez, elvégre angolul van
:def isnumber(input_string):
ans = True;
for i in range(len(input_string)):
if ((input_string[i] < '0') or (input_string[i] > '9')):
ans = False;
return ans; -
cousin333
addikt
Igen, ezek is teljesen jó megoldások és átlagosan még gyorsabbak is. De akár bevethetjük a Python egyik fura szintaktikai megoldását, amivel nagyjából a második algoritmusodat kapjuk vissza:
def szam_e(szo):
for betu in szo:
if betu < '0' or betu > '9':
break
else:
return True
return FalseMég jó, hogy a Pythonnál az egyszerűségre törekedtek, és minden problémára lehetőleg csak egy (praktikus) megoldás létezik.
-
cousin333
addikt
Az én is olvastam, hogy érettségi feladat. A pszeudokód fogalma is rendben van, csak fura volt a szintaktikája.
Nyilván hűen követni kell a leírást, de azt kérdezte, hogy én hogyan írnám meg
Ha ezt így érettségin elém adnák, valószínűleg a 2. megoldásomat adnám be. Vagy te máshogy írtad volna? -
cousin333
addikt
válasz
 XP NINJA
#586
üzenetére
XP NINJA
#586
üzenetére
Ez meg milyen leíró nyelv?
Azt kérdezted, én hogyan írnám meg. A válasz: sehogy, mert minek újra feltalálni a kereket, amikor van erre jó kis gyári függvény. Pl:
>>> szo1 = "Valami szöveg 123"
>>> szo1.isdigit()
False
>>> szo2 = "536 25"
>>> szo2.isdigit()
False
>>> szo3 = "53625"
>>> szo3.isdigit()
TrueHa viszont hűek akarunk lenni a példához - a Python nyelv elvárásain belül - akkor ezt írnám:
def szam_e(szo):
valasz = True
for betu in szo:
if betu < '0' or betu > '9':
valasz = False
return valaszA for ciklust mondjuk így is írhatnád:
for betu in szo:
if not '0' < betu < '9':
valasz = FalseVagy esetleg így:
import string
for betu in szo:
if betu not in string.digits:
valasz = FalseUpdate! Egy kis adalék: a saját megoldások futtatási ideje sorrendben 1,41, 1,61 és 1,55 us (mikroszekundum), ellenben a gyári függvénnyel 53,9 ns (nanoszekundum). Utóbbi tehát úgy 26-szor gyorsabb...
-
cousin333
addikt
válasz
XP NINJA
#576
üzenetére
Szintén kerekíteni kell, de azt csak tizedesjegyekre lehet. A megoldás szerintem, ha ideiglenesen megduplázod a számot, tízesekre kerekítesz, majd kettővel osztasz (jobbra shifttel, mert a sima osztásnak nem biztos, hogy egész szám az eredménye). Példa:
In [9]: def kerekit(x):
...: return round(2*x, -1) >> 1
...:
In [10]: for i in range(20):
....: print('{}: {}'.format(i, kerekit(i)))
....:
0: 0
1: 0
2: 0
3: 5
4: 5
5: 5
6: 5
7: 5
8: 10
9: 10
10: 10
11: 10
12: 10
13: 15
14: 15
15: 15
16: 15
17: 15
18: 20
19: 20Jónak tűnik...
-
#572
cousin333
addikt
DrojDtroll
#571
cousin333
addikt
válasz
DrojDtroll
#571
üzenetére
Pont ma néztem meg, hogy milyen lehetőségek vannak (bár elsősorban a kódfuttatás érdekelt). De kb. ennyi.
-
cousin333
addikt
válasz
#82595328
#563
üzenetére
Egyáltalán mivel olvasod be? Kézzel, soronként? A csv modullal vagy valami mással? (melyik Python?)
Én a csv fájlokhoz (is) a pandas nevű modult használom. Jelen esetben talán kicsit túlzás, de amúgy sokrétűen használható. Van neki egy read_csv() metódusa, amiben sok egyéb mellett a kódolást is meg lehet adni.
A jelek szerint a LibreOffice mégiscsak kelet-európai kódolással ment (ahogy tipikusan az Excel is).
-
cousin333
addikt
A Qt egy C++ alapú keretrendszer GUI-k létrehozására. A Designer tudtommal az ő programjuk, így teljesen független a Pythontól.
Az Anaconda alapvetően egy jó disztribúció: tehát Python (2.7 vagy 3.5) + fejlesztőeszközök (pl. IPython, Spyder) + egy tonna külső fejlesztésű modul (numpy, scipy, matplotlib... stb.) vannak benne. Frissíteni, újat telepíteni meg a conda nevű, Linux csomagkezelőhöz hasonló programmal lehet.
Pl. telepítés:
conda install pyvisaMinden csomag frissítése:
conda update --allui: Az Anaconda elég nagy méretű, de van egy ún. Miniconda, ami csak az alapokat tartalmazza és a conda-t az esetleg hiányzó csomagok letöltéséhez.
-
cousin333
addikt
Tehát az első mondatodban QT helyett Tk-t kell érteni?
A helyzet az, hogy a GUI egy olyan téma, amit én is kerülgetek, mint a forró kását. Inkább az egyszerűbb, "szkriptesebb" irányba mentem el, ami az IPython Notebook (újabb nevén Jupyter Notebook) használatát jelenti a klasszikus adatgyűjtés-feldolgozás-ábrázolás-mentés négyes mentén, változó sorrendben.
De terveim közt szerepel "rendes" GUI-k létrehozása is. Eddig arra jutottam, hogy Qt-t használok majd. Létezik hozzá egy Qt Designer nevű program, amivel a klasszikus drag'n'drop-pal tudod megtervezni a felületet (hasonlóan a LabView-höz vagy CVI-hoz). A program kimenete egy ui kiterjesztésű fájl. Ezt a Python programodba az alábbi kóddal - vagy ennek megfelelő módosításával - lehet beilleszteni (itt találtam):
import sys
from PyQt4 import QtGui, uic
class MyWindow(QtGui.QMainWindow):
def __init__(self):
super(MyWindow, self).__init__()
uic.loadUi('mywindow.ui', self)
self.show()
if __name__ == '__main__':
app = QtGui.QApplication(sys.argv)
window = MyWindow()
sys.exit(app.exec_())Innentől az UI elemeit a Python kódból tudod piszkálni. A szokásos csúszkák, gombok, kapcsolók mellett az egyik ilyen lehetséges elem a Matplotlib widget, tehát tulajdonképpen egy grafikon felületet integrálhatsz az UI-ba.
A fenti módszert már kipróbáltam és működött, de élesben még nem használtam. A WinPython nevű Python disztribúcióban minden benne van, de pl a cross-platform Anaconda-ban is szinte minden, a Qt Designer meg egy külön telepíthető program.
Számomra a "végső megoldás" egy olyan program lehetne, amiben a GUI elemek mellett egy nagyobb szövegmezőbe érvényes Python kódot lehet írni és futtatni, ezáltal egyesíthetném a GUI-alapú előre megírt programok előnyeit egy Python-féle szkriptnyelv rugalmasságával.
-
cousin333
addikt
Mint a LabView?
Gondolom a virtuális műszer valami igazinak a leképezése lenne (multiméter, tápegység vezérlés, ilyenek). Nem tudom, meddig jutottál vele és milyen irányból közelítetted meg a témát.
Ami a modulokat illeti: pyvisa, pyserial, numpy, scipy, pandas, ilyesmi. Emellett érdemes megnézni a Qt Designer-t, amivel egyszerűen lehet felületeket kreálni (grafikusan). A WinPython-ban benne van minden.
-
#545
cousin333
addikt
DrojDtroll
#542
cousin333
addikt
válasz
DrojDtroll
#542
üzenetére
Én mondhatni friss szoftver mániás vagyok, ezért nálam a 3-as a nyerő, mert sok mindent rendbe szedtek, ami korábban kicsit szét volt csúszva: pl. range vs xrange, zip vs izip. Valahogy koherensebbnek tűnik az egész. Ma már minden tisztességes modulból találhatsz Python3-as verziót, szóval szerintem ez sem lehet kifogás.
A 2-es viszont kiforrottabb (bár így a 3.5 megjelenése után már ezt sem feltétlenül mondanám) és még mindig elterjedtebb. Ha korábbi kódot kell kiegészíteni, akkor egyértelmű a választás.
Ami nem tetszik annyira a 3-asban, az a sztring-bájt szétválasztás és a print függvény, bár nyilván mindkettőt jó okkal változtatták meg.
-
cousin333
addikt
Milyen témára kéne elsősorban? Azaz mire szeretnéd használni? Léteznek általános célú könyvek, meg specifikusabb tematikájúak is. Attól is függ, milyen stílust szeretsz: ami jó alaposan körbejárja, a témát, vagy ami a második bekezdésben már webszerver kódot közöl.
Előbbire jó példa lehet a Mark Lutz féle Learning Python, ami elég alapos, helyenként talán túlságosan is. Vagy mondjuk a Think Python.
Utóbbiak sokan vannak, előbb szűkíteni kell a kört. Például Think DSP, az A Primer on Scientific Programming with Python vagy a Numerical Methods in Engineering With Python 3 esetleg a Python for Signal Processing. Ezeket kevéssé ismerem, de igényesnek tűnnek.
Mindezek az általános tudást alapozzák meg. Egyébként pedig meg kell ismerkedni a Python ökoszisztémával (pl. Spyder, PyCharm, Jupyter Notebook) és a hasznos modulokkal (pl. Numpy, Scipy, Sympy). Akkor pedig lehet olvasgatni ezek dokumentációját, az általában elég alapos és naprakész.
-
#521
cousin333
addikt
DrojDtroll
#517
cousin333
addikt
válasz
DrojDtroll
#517
üzenetére
Van, több is. Attól is függ, hogyan akarod használni a Python-t.
1. kódszerkesztő (nagyobb programokhoz)
Spyder - talán az egyik legsokoldalúbb, noha nem hibátlan
PyCharm (Community Edition) - talán az egyik legkomolyabb
Ninja IDE - aranyos, de úgy látom, már nem fejlesztik2. interaktív: parancssorból, soroként (mint az IDLE)
Spyder
IPython - A Spyderben is van ilyen interpreter3. kódblokkonként, újra futtathatóan:
IPython Notebook (újabban Jupyter Notebook) - elsősorban kísérletezésre, adatfeldolgozásra, prezentációra. Demo -
#516
cousin333
addikt
DrojDtroll
#515
cousin333
addikt
válasz
DrojDtroll
#515
üzenetére
Nem csak téged. Ezért (sem) használok IDLE-t...
-
cousin333
addikt
válasz
XP NINJA
#512
üzenetére
1. kérdés
A Python lista nem igazán erre való, de van egy elegáns, bár nem triviális megoldás a problémára, ami megvillant valamit a Python tudásából
:szamok = list(range(90)) # A 90 számból álló lista
sor = 6
elem = 15
# tuple-k listája
felosztva = list(zip(*[iter(szamok)] * elem))
# listák listája
felosztva = [list(i) for i in zip(*[iter(szamok)] * elem)]Ha valaki nagyon tömbökkel/mátrixokkal akar szórakozni, akkor mindenképpen a numpy modul ajánlott. Ez a tudományos területen a Python-használat alfája és omegája, viszont nem része az alap Python telepítésnek. Ebben pl. van reshape függvény, ami pont erre való, igaz azt nem listákon, hanem a speciálisabb ndarray tömbökön lehet végrehajtani.
2. kérdés
Erre alapvetően a datetime modul datetime objektuma való, de az dátumot is vár, nem csak órát meg percet. Furcsamód a time objektum nem támogatja a kivonást. Példának ott az #509-es hozzászólásom.
3. kérdés
Ez két lépés. Az első, hogy bizonyos karaktereket le kell cserélni. Ehhez létre kell hozni egy hozzárendelést, ami megmondja, hogy mit mire kell cserélni, majd el kell végezni a cserét. Nem tudom, hogy van-e egyszerűbb módszer.
>>> szoveg = "Árvíztűrő tükörfúrógép"
>>> trans = str.maketrans("áéíöüóőúűÁÉÍÖÜÓŐÚŰ", "aeiouoouuAEIOUOOUU")
>>> szoveg.translate(trans)
'Arvizturo tukorfurogep'Az angol karakterkészlet a string modulban szerepel:
>>> import string
>>> string.ascii_letters
'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'Ebből az eltávolitás valahogy így megy:
>>> szoveg = "Szoveg,-amit meg?:akarunk#szurni"
>>> szurt = [i for i in szoveg if i in string.ascii_letters or i in " "]
>>> szurt = "".join(szurt)
>>> szurt
'Szovegamit megakarunkszurni' -
cousin333
addikt
válasz
#82595328
#508
üzenetére
Használd a hozzászólás-szerkesztőben a Programkód gombot, akkor nem rontja el a formázást (pl. behúzást) a fórummotor.
Igazából nem véletlenül gyanakodtam a for ciklus kapcsán, mert jelen esetben a használata teljesen felesleges, sőt kontraproduktív (lassú). Javasolnám a célra a szorzás műveletet.
import datetime as dt
x = dt.date(2015,12,15)
y= dt.date(2016,2,8)
z = y-x
print(100 * z.days)Vagy még szebben:
print("{} forintot kerestem összesen".format(100 * z.days))
-
cousin333
addikt
válasz
#82595328
#505
üzenetére
A fenti példádhoz miért van szükséged for ciklusra? Amúgy a dátumhoz és azok kezeléséhez jó a datetime modul. Példa a használatára:
>>> import datetime as dt
>>> x = dt.date(2015, 12, 3)
>>> x
datetime.date(2015, 12, 3)
>>> y = dt.date(2016, 1, 12)
>>> y
datetime.date(2016, 1, 12)
>>> z = y-x
>>> z
datetime.timedelta(40)
>>> z.days
40
>>> type(z.days)
<class 'int'> -
-
cousin333
addikt
válasz
XP NINJA
#498
üzenetére
Természetesen nem baj, ha tisztában vagy a kétdimenziós listákkal is, sok feladatnál kellhet ilyesmi. Arra emlékeztetnélek, hogy a Python nyelvben a sztring maga is iterable, azaz indexelhető, kereshető, mintha egy lista lenne. Pl.
>>> a = "Valami"
>>> a[2]
'l'
>>> a[-1]
'i'
>>> a.find('m')
4A lényeg, hogy gyakran feleslegesen bonyolult a sztringet karakterek listájává vagdosni. Ilyen értelemben a fenti példához első ránézésre nem kétdimenziós lista, hanem sztringek egyszerű (soronkénti) listája kell. Valami hasonlóra példa #453-as hozzászólásomban lévő megoldás.
-
cousin333
addikt
válasz
 olivera88
#495
üzenetére
olivera88
#495
üzenetére
Akkor meg. Említettem az URL parser könyvtárat. SZerintem az a legelegánsabb megoldás, de kicsit macerás. A favágó módszer, hogy az URL-t sztringként kezeled és a time modullal állítod elő a mai dátumot. Azaz:
link = "http://dcpc-nwp.meteo.fr/services/PS_GetCache_DCPCPreviNum?token=__5yLVTdr-sGeHoPitnFc7TZ6MhBcJxuSsoZp6y0leVHU__&model=ARPEGE&grid=0.1&package=SP1&time=61H72H&referencetime=2016-01-26T12:00:00Z"
Majd ezzel kell kiegészíteni a korábbi kódot:
import time
links = link.split("=")
t = time.localtime()
fmt = "%Y-%M-%dT12:00:00Z"
links[-1] = time.strftime(fmt, t)
link = "=".join(links)Vagy valami ilyesmi. Ez értelemszerűen csak a dátumot írja át, az órát perce nem.
-
cousin333
addikt
válasz
XP NINJA
#496
üzenetére
Amikor a split-tel felosztottad a sort, és kaptál egy listát, azt ne append-del add hozzá a már meglévő listádhoz, hanem extend-del. Példa a különbségre:
>>> a = [1,2,3]
>>> b = [4,5,6]
>>> a.append(b)
>>> a
[1, 2, 3, [4, 5, 6]]
>>> a = [1,2,3]
>>> a.extend(b)
>>> a
[1, 2, 3, 4, 5, 6] -
-
#488
cousin333
addikt
DrojDtroll
#487
cousin333
addikt
válasz
DrojDtroll
#487
üzenetére
Bevallom, ezen a téren nem vagyok képben, de számomra akkor a fájl alapú megosztás tűnik kézenfekvőnek. Nem használtam ugyan, de én a pickle modul körül nézelődnék.
-
#486
cousin333
addikt
DrojDtroll
#484
cousin333
addikt
válasz
DrojDtroll
#484
üzenetére
Mit csinálnak a szkriptek? Az egyik szkript (vagy egy harmadik) importálja be a másikat. Esetleg egy fájlba összevonni a kettőt.
Vagy valami fájl objektumon keresztül tegye közzé a kérdéses változókat.
-
cousin333
addikt
válasz
#82595328
#468
üzenetére
A return - mint a neve is mutatja - egy függvényhívásból tér vissza egy értékkel. Ahhoz, hogy visszatérhess, előbb értelemszerűen "el kell menni", tehát egy függvényt kell hívni. Abban lehet a return. Az első példádban egy függvényt hoztál létre a def utasítással (vagy mi ennek a szabatos neve) ami visszatér a beírt számmal. Ha meghívod, pontosan ez történik.
A többi példádban nincs függvény, csak egyedi utasítások. Egyszerűen nincs miből visszatérni, így a return értelmetlenné válik és hibát dob.
A return tehát a függvény kimeneti értékével tér vissza, nem pedig egy változó értékével, mint az utolsó példádban. Az az alábbi módon lenne helyes, mert a print függvény maga is visszatér egy konzolra írt üzenettel, ami itt maga az x:
>>> x=1
>>> print (x)
1Mivel ez a konzol, még a print sem kell, ez is működik:
>>> x=1
>>> x
1 -
cousin333
addikt
válasz
#82595328
#466
üzenetére
Nem kell beletenni, működik úgy is, ahogy mondod. De ha változóba rakod, akkor az elveszik, amint kilépsz a függvényből. Kivéve, ha globális változóba teszed, de az meg nem túl elegáns (kivéve talán a mikrokontrollereket). Biztos van itt nálam ideológiailag képzettebb, aki jobban elmagyarázza.
Szóval használnod nem kell, de pont azért találták ki, hogy az értéket visszaadja. Innentől kezdve nincs sok ok, hogy ne használd.
-
cousin333
addikt
válasz
cousin333
#462
üzenetére
Folytatás: a 25-26-os sort meg le kell cserélni erre, és elvileg már működik is:
self.ser = serial.Serial(self.combobox_port.get_active_text())LógaGéza: Korábban amúgy nekem sem ment a listázás, pedig jó lett volna, de akkor nem így próbáltam. Talán ezzel már menni fog.
-
cousin333
addikt
válasz
 LógaGéza
#458
üzenetére
LógaGéza
#458
üzenetére
Itt a PySerial dokumentációja a kérdéses modullal: [link]
Ezek alapján a kód a következő (létezik az, hogy nekem nincs egyetlen COM portom sem? Az Eszközkezelő sem említi őket
Majd holnap én is kipróbálom):# Valahol a kód elején a többi importtal
import serial.tools.list_portsA port lista létrehozása a comports() függvénnyel. Ez egy generátor objektumot hoz létre, amiből a portok így adódnak:
ports = list(serial.tools.list_ports.comports())Ennek a listának az elemei a dokumentáció szerint 3 elemű tuple-k. Ebből nekünk az elsőre van szükségünk (ami igazából a nulladik), azt adjuk be a serial.Serial() objektumnak. Ha csak az első elemek kellenek, akkor a fenti helyett egyszerűen írjuk ezt:
ports = [p[0] for p in serial.tools.list_ports.comports()]Ez elvileg működik, mint írtam, COM port hiányában nem tudom most kipróbálni... De holnap biztos megteszem, mert a téma engem is érdekel.
A kérdéses kódban pedig a 85-87-es sort kell módosítani, imigyen:
for p in serial.tools.list_ports.comports():
print(p)
self.combobox_port.append_text(p[0]) -
cousin333
addikt
válasz
XP NINJA
#459
üzenetére
sonar megoldása jó, de mivel a Pythonban a sztring iterable, egy sima for ciklussal végig lehet menni rajta. Ezért nem hiszem, hogy mindenáron listát kell csinálni belőle.
Ha pedig sztring, akkor a függvények a Python string metódusok.
Pl. sonar példájával élve ez is működik:
>>> s = "python"
>>> s[3]
'h'

















 . Ez sokat segíthet kezdőknek is, hogy jobban megértsenek olyan fogalmakat, mint a staticmethod.
. Ez sokat segíthet kezdőknek is, hogy jobban megértsenek olyan fogalmakat, mint a staticmethod.



![;]](http://cdn.rios.hu/dl/s/v1.gif)



















Új hozzászólás Aktív témák

- Eredeti Lenovo 300W töltők - ADL300SDC3A
- ÚJ MacBook Pro 14" M4 PRO 24GB 512GB Space Black
- Xiaomi Redmi 15 / 6/128GB / Kártyafüggetlen / 12Hó Garancia
- BESZÁMÍTÁS! MSI B450M R5 5600X 16GB DDR4 1TB SSD RX 6800 16GB Zalman S2 TG GIGABYTE 750W
- Azonnali készpénzes nVidia RTX 5000 sorozat videokártya felvásárlás személyesen / csomagküldéssel
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest

Cég: Laptopszaki Kft.
Város: Budapest