- Samsung Galaxy A54 - türelemjáték
- Samsung Galaxy Z Fold7 - ezt vártuk, de…
- Honor Magic V5 - méret a kamera mögött
- 165 Hz-es panelt tesztel a OnePlus
- Jimmy Choo felel a Magic V Flip 2 dizájnjáért
- Samsung Galaxy S24 Ultra - ha működik, ne változtass!
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Fenntartható, tartós kiegészítőket mutatott be a Fairphone
- Xiaomi 14T Pro - teljes a család?
- Zeiss triplakamera az új Vivo V60-ban
Hirdetés
Új hozzászólás Aktív témák
-

ukornel
aktív tag
Talán EZ lenne a gigászi "HPC-APU"?
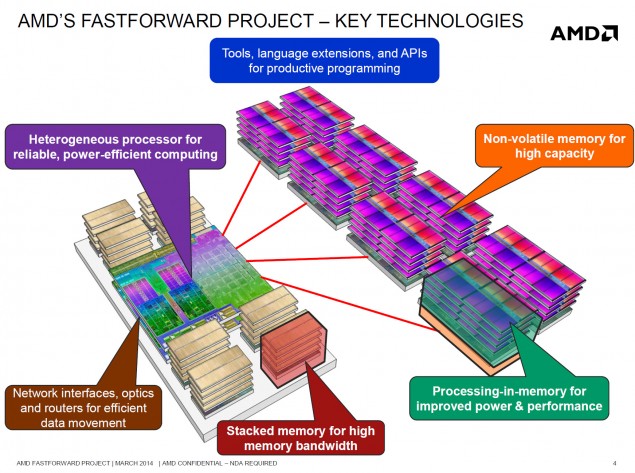
Néhány részlet: 16-core, 32-thread [...] total amount of L2 cache gets to a whopping 8MB, backed by 32MB of L3 cache [...] 16GB of HBM memory with 512GB/s speed packed on the interposer [...] 1/2 rate double precision compute, enhanced ECC and RAS and HSA support [...] 64 PCI express Gen 3 lanes [...] DDR4 memory controllers in 4x72 configuration [...] total capacity of 256GB per channel.Szerk. Most látom, a hír fönt van az iponon is.
-

Fiery
veterán
válasz
 sayinpety
#84
üzenetére
sayinpety
#84
üzenetére
Arra gondolok, hogy a jelenlegi OpenCL implementaciokban az OpenCL kernelt elvileg a Direct3D-n (vagy legalabbis a videodriveren) keresztul lehet futtatni, azaz nem egy sajat kernel drivert hasznal az OpenCL API. A HSA-nal elvileg ezt megoldotta az AMD, persze ez siman lehet, hogy csak AMD-specifikus limitacio volt (ill. nem, mert lehet tudni, hogy a tobbi gyarto is ugyanigy -- ugyanilyen rosszul -- oldotta meg az OpenCL-t).
"Egyfele ILt hasznalnak es fejlesztenek."
Koszi, ez egy fontos info. En csak azzal szembesulok, hogy a folyamatos fejlesztes ellenere me'g mindig eleg sz** a forditojuk

-
Fiery
veterán
Egy Haswell-EP-szeru dual ring-bus-nal nem tul valoszinu, hogy ki kellene sajatitani a teljes buszt 2 mag kozotti szinkronizacio eseten
"A KNL biztos nem snoopingot használ. Egyetlen Xeon Phi-re sem jó ez a megvalósítás"
Megint osszemosod a Knights Cornert es a Knights Landinget, holott mar tobbszor leirtam, hogy nem sok kozuk van egymashoz. De feladom, ha Te szakmailag ugy gondolod, hogy egy kartyara pakolt, dedikalt RAM-mal rendelkezo, nyakatekert Linux implementacioval meghajtott, sajat egyedi utasitaskeszlettel (LRBNI) biro, in-order P54C architektura kore epulo (GP)GPU-t egybemosol egy socketelt CPU-val, ami out-of-order Silvermont architekturara epul, a rendszermemoriat hasznalja, tekintelyes meretu es sebessegu near memory-val rendelkezik, es standard utasitaskeszlet architekturara (x86 + AVX-512) epul, akkor legyen ugy.
"De abban egyébként volt szó róla, hogy az Intel saját mérnökeivel és a többi külsős szakemberrel együtt ajánlották a vezetőségnek, hogy dobják az x86-ot, mert nem fog működni."
Mint ahogy fentebb leirtam, Intel = x86, es aki ilyet ajanl az Intelnek, annak elgurult a gyogyszere.
-

Abu85
HÁZIGAZDA
Az összeköttetés típusa nem annyira lényeges, mert az csak a sebességre van hatással. A buszt így is ki kell sajátítani a szinkronizációra.
A KNL biztos nem snoopingot használ. Egyetlen Xeon Phi-re sem jó ez a megvalósítás. A directory protokollt alkalmazza az Intel bizonyos magszám felett. Ez lassabb, mint a snooping, illetve sokkal több tranyót visz el, de a snooping meg nem skálázódna ennyire sem.Andrew Richards egyszer leírta a sztorit, csak az Intel annyira befenyítette, hogy mindenhonnan letörölték. De abban egyébként volt szó róla, hogy az Intel saját mérnökeivel és a többi külsős szakemberrel együtt ajánlották a vezetőségnek, hogy dobják az x86-ot, mert nem fog működni. A pénzügyi vezetők álláspontja az volt, hogy csinálják meg az eredeti tervet és majd lenyomják a piac torkán.
-
Fiery
veterán
Iszonyatosan leegyszerusited a dolgokat. Nem mennék bele a reszletekbe, de lenne egy fontos kerdesem: milyen osszekottetes van a CPU-tokon belul a magok kozott, es milyen osszekottetes van az alaplapon a CPU-foglalatok kozott? Ugyanaz a 2? Pont-pont mindegyik, vagy ring-bus mindegyik?
Mert ha nem ugyanaz, akkor nem ertem, miert kellene oket egymassal szembeallitani. Raadasul, semmi garancia arra, hogy a snooping es cache koherencia pontosan ugyanugy mukodik a KNL-nel, mint manapsag mondjuk egy Xeon E5-nel. Siman lehet, hogy idovel le kell mondanunk az x86 platformokon (is) a teljes cache koherenciarol, a teljesitmeny novelese erdekeben. Onnantol pedig ertelmet veszti az a nyavalygas, amit csinalsz a core skalazas vs. cache koherencia problema miatt -- ami egyebkent sem feltetlenul okoz olyan oriasi problemat, lasd a fentebb idezett ZLib skalazodasi lista. A Westmere-EX egyszerre sokmagos (socketenkent 10 mag) es 4 socketes, tehat eleg sokretu a snooping, megis tud skalazodni. Es nem 4 vagy 8 magrol beszelunk, ugyebar."Több céget és szakembert bíztak meg. Egyébként minden külsős ugyanazt ajánlotta, még Michael Abrash is."
Es mindegyik cegrol pontosan tudjuk, hogy mit ajanlott? Ezek tok nyilvanosan mentek? Azt is tudjuk, az Intel mernokeinek mi volt az allaspontja? Azt is tudjuk, a felsovezetesnek mi volt az allaspontja? Azt is tudjuk, ahhoz kepest, amit ajanlottak, ill. ahhoz kepest, hogy milyen volt az elozo generacio, pontosan hol is helyezkedik el a KNL? Mert ugye ha azt vesszuk, hogy a javaslat az volt (bar kizart, hogy egyetlen javaslat lett volna), hogy csinaljanak egy klasszikus GPU-t (masoljak le a GCN-t, hiszen mindannyian tudjuk, hogy annal jobb nincs es nem is lesz
![;]](//cdn.rios.hu/dl/s/v1.gif) ); es a Knights Corner-t hagyjak a francba, akkor nem lehet azt mondani, hogy a KNL-nel egyertelmuen erre vagy arra huzott az Intel. Akarhogy probalod beallitani annak, a KNL nem a Knights Corner pepitaban, hanem egy teljesen uj architektura, ami -- ahogy fentebb is irtam -- sokkal jobban hasonlit egy Xeon E5-re (Haswell-EP), mint egy Knights Cornerre. Ennyi erovel a Conroe-t is el lehetett volna asni elore, annak fenyeben, hogy a NetBurst mennyire nem jott ossze -- csak ugye tok mas architektura volt a Conroe, tehat ertelmes ember nem a NetBurst alapjan derivalta le a Conroe potencialis kepessegeit.
); es a Knights Corner-t hagyjak a francba, akkor nem lehet azt mondani, hogy a KNL-nel egyertelmuen erre vagy arra huzott az Intel. Akarhogy probalod beallitani annak, a KNL nem a Knights Corner pepitaban, hanem egy teljesen uj architektura, ami -- ahogy fentebb is irtam -- sokkal jobban hasonlit egy Xeon E5-re (Haswell-EP), mint egy Knights Cornerre. Ennyi erovel a Conroe-t is el lehetett volna asni elore, annak fenyeben, hogy a NetBurst mennyire nem jott ossze -- csak ugye tok mas architektura volt a Conroe, tehat ertelmes ember nem a NetBurst alapjan derivalta le a Conroe potencialis kepessegeit.Azt sem igazan ertem, miert kellene mindenkinek GPU-t keszitenie. Mi van, ha valamilyen problemat, problema kort mas megoldassal is ugyanolyan jol meg lehet oldani? Tudtommal mar manapsag is vannak, akik inkabb egy sokmagos Xeon E5/E7-re szavaznak, Tesla helyett, mert mondjuk a Haswell-EP/EX architektura jobban fekszik az igenyeikhez (pl. ray-tracing).
-
Abu85
HÁZIGAZDA
Li-Shiuan Peh professzornak volt egy előadása, ahol beszélt róla, hogy a cache-koherencia azonos szinten borzalmasan nehéz egy bizonyos magszám felett. A több socket azért működik, mert a cache-koherencia többszintű. Például, ha van négy processzorod, akkor két mag közötti kommunikációra a hardver szintjén kisajátítják a procimagok az összeköttetésre szolgáló buszt. Ezzel 8 mag közötti kommunikáció oldható meg 4 socket esetében egyszerre (socketenként 2-2 mag). De ha ugyanannyi mag csak egy foglalatban, egy processzorban van, akkor már 2 magra korlátozódik a busz kisajátítása. Ez limitálja a rendszert.
(#60) Fiery: Több céget és szakembert bíztak meg. Egyébként minden külsős ugyanazt ajánlotta, még Michael Abrash is. A pénzügyi szakemberek ezzel nem értettek egyet.
-

derive
senior tag
Abban igaza van Fierynak, hogy az OpenMPvel igen komoly fegyvertenyt tudhat maga mogott az Intel. Eleg nepszeru API, mert 1 sorbol megvan a tobbszalusitott program. Igaz nem hatekony de jobb orszagokban egy jo programozo eves bereert veszel meg 40-50 gyorsitot.
-

LordX
veterán
Támogatja, csak ezzel a két apró problémával:
Recommendation: Avoid using Shared Local Memory on the Intel Xeon Phi coprocessor.
We recommend avoiding the use of barriers.
(OpenCL* Design and Programming Guide for the Intel® Xeon Phi™ Coprocessor)
Konkrétan egy redukciót nem csinálsz meg ezek nélkül. (Ja, de, atomics. Ha 240 szál futtat loopban LOCK CMPXCHG utasításokat, az egyszeri viccnek jó..) Nem az OpenCL programozás minősül nehéznek, hanem az olyan OpenCL kód írása, ami ennek a kettőnek megfelel. És bonyolultabb, mint egy hello world.
-
Fiery
veterán
válasz
sayinpety
#72
üzenetére
Azert ennel tobbet is a HSA-hoz szoktak sorolni, legalabbis amikor az AMD-vel beszelsz a HSA-rol. Pl. szerintuk a Direct3D kikerulese (mi is annak a buzzwordje?) is a HSA stack resze. Plusz, en nem vagyok rola meggyozodve, hogy egy zart HSA-nak nincs ertelme. Nincs rola konkret infom, de pl. nem vagyok rola meggyozodve, hogy az Intel csak egyfele IL-t hasznal a CPU-n es a GPU-n. Ha pedig 2 fele IL van, akkor kapasbol kulon OpenCL compiler kell a CPU-hoz es GPU-hoz, mindket lepcsonel. Ezen lehetne egysegesiteni es racionalizalni egy "internal HSA"-val.
-
-
#71
Fiery
veterán
VaniliásRönk
#67
Fiery
veterán
válasz
 VaniliásRönk
#67
üzenetére
VaniliásRönk
#67
üzenetére
Olyan ertelemben nem szabadon lophato, hogy ha valaki pontrol pontra lemasolna az egeszet, az tamadhato lenne. De ha magat az otletet veszed csupan, es minden mast mogeteszel, sajat kutfobol, sajat specifikacioval, adott esetben kiegeszitve es feljavitva is az eredeti koncepciot, akkor senki nem szolhat egy szot sem.
Mondok nehany peldat. A C# es a Java eleg kozel allnak egymashoz, nyilvanvaloan a C#-ot alapvetoen a Javarol mintaztak, de feljavitottak, maskepp neveztek el szinte mindent, es igy nem lehetett a Microsoftot lopassal vadolni. De a koncepcio ugyanaz. Masik pelda: fogod az x86-ot (mondjuk amit most a Broadwell tamogat), lemasolod pontrol pontra, de mas mikrokodot hasznalsz, mashogy hivod az utasitasokat, kihajitod az elavult reszeit, es beraksz nehany ujdonsagot, fejlesztest is. Az Intel egy szot sem szolhat, holott a koncepcio ugyanaz
-
-
#69
 Vladi
nagyúr
Balala2007
#35
Vladi
nagyúr
Balala2007
#35
Vladi
nagyúr
válasz
 Balala2007
#35
üzenetére
Balala2007
#35
üzenetére
az szerintem htop és 240 mag.
-
#65
Fiery
veterán
VaniliásRönk
#63
Fiery
veterán
válasz
VaniliásRönk
#63
üzenetére
En nem tudok rola, hogy a HSA le lenne vedve barmilyen formaban. Ha a DX12-vel "lemasolhatta" a Microsoft a Mantle-t, akkor a HSA miert ne lenne megoldhato nagyon hasonlo formaban, mas neven, mas gyarto altal? Persze szigoruan zart formaban, a la Intel
-
mi két ok miatt szoktunk tanácsadót felkérni. az egyik, hogy a kirúgott felsővezetőket így tartsuk távol az álláspiactól (és a vetélytársaktól), amíg a céget illető naprakész ismereteik elviselehtő kockázati szintre esnek le.
a másik pedig amikor olyan tudást vagyunk kénytelenek importálni, amely nem érhető el a cégen bellül, illetve amelyet nem célszerű/lehetséges hosszabb távon megtartani. -
Fiery
veterán
Hanyszor irjam me'g le, hogy SIMD x86-ot _es_ OpenCL-t is tamogat a KNL? Vagy az OpenCL 2.x is nehezen programozhatonak minosul?
Tovabbmegyek, sejtesem szerint az Intel elobb-utobb le fogja koppintani a HSA-t is, valamilyen formaban. Ha pedig a HSA sem eleg egyszeru, akkor mi lenne az?
-

freeapro
senior tag
Te azt írod, hogy ezen a területen nem számít a könnyű programozhatóság. Ha 10 zseni kódol rá akkor igazad van, ha mégis ipari méretekben kezdenek fejleszteni rá akkor hatalmas probléma lesz. Egyszerűen azért, mert sem a sem a felhasználási terület, sem az alakalmazni kívánt emberek tömege, sem a használt toolok nem teszik lehetővé, hogy ilyen alacsony szintű problémákkal foglalkozz. Pl mert nem assemblerben fognak fejhleszteni, hanem matlabból generálnak kódot.
-
Fiery
veterán
Egyre viccesebb, amiket irsz. Lassuk csak, mi tortent. Az Intel megbizott egy ceget, hogy adjon tanacsokat GPU compiler temaban. Esetleg -- ezt nem tudjuk ugye -- megbizott me'g nehany ceget, plusz vannak ugye sajat mernokei is, akik biztos nem zsenik (szerinted), biztos nem nagy koponyak (szerinted). Mindegyik szakerto/szakember mond valamit, hogy szerintuk mi lenne a jo megoldas. Aztan az Intel ugy dont, hogy marad az egyik megoldasnal a sok kozul, es megkoszoni mindenkinek a munkat, a kulso szakertoket kifizeti, mindenki megy az utjara, mindenki orul. Ezutan az egyik kulso szakerto elkezdi fikazni az Intelt, mert nem az o megoldasat valasztotta a sokfele opcio kozul. Vilagos, csak ez az ember lehet a zseni a sok szakerto kozul
Azert megneznem a CodePlay uzleti eredmenyet, es mondjuk melletennem az Intel uzleti eredmenyenek, es aztan csinaljuk meg ugyanezt 10 ev mulva, amikorra a KNL kapcsan hozott "rossz" dontes csodkozeli allapotba juttatja az Intelt, mikozben a CodePlay tobbtiz milliard dollaros eves forgalmat general 
-
#58
Abu85
HÁZIGAZDA
Balala2007
#56
Abu85
HÁZIGAZDA
válasz
Balala2007
#56
üzenetére
A kulcsszó a socket. Négyutas rendszerben nincs igazán gond. Egy lápkán belül jönnek elő a limitek. Ezek is kezelhetők a gyorsítótárak méretének extrém növelésével, csak ez nem feltétlenül kifizetődő, mert egy újabb ISA-val meg feldolgozókat is építhetsz ugyanarra a területre.
-
Fiery
veterán
Nem igazan ertem, pontosan mi a butasag? Az, hogy egy szuk kor szamara keszul a KNL es az AMD HPC APU? Jelen allas szerint pedig ez a helyzet. Az megint mas kerdes, ha hirtelen elobukkannak olyan uj piacok, ahova jol illeszkedne egy ilyen termek, pl. az emlitett onvezeto jarmuvek, vagy mondjuk VR vagy holografikus megjelenites vagy barmi mas trendi technologia, ami most me'g sci-finek tunik. Mindenesetre, tovabbra sem ertem, miert lenne a gond a KNL programozasa, amikor _egyarant_ tamogat SIMD x86-ot es OpenCL-t is. Ergo egy x86 programozo szamara sem lesz idegen, de egy mostani GPGPU programozo szamara sem. Hol itt a gond?
-
#56
 Balala2007
tag
Abu85
#13
Balala2007
tag
Abu85
#13
Balala2007
tag
szimuláción sem működött több feladatban 20 magnál jobban a skálázódás
Ez az AIDA64 ZLib tesztje egy 4 socketes Westmere-EX-en, 30MB L3-mal. Minden thread 32MB tomorites. En erre ra merem mondani, hogy az x64 legalabb 40 core-ig egesz jol skalazodik.
# 0 Pmask:0x0800000000000000:0000000000000000 T: 1 : 28.572 MiB/sec( 1.00000)
# 1 Pmask:0x0a00000000000000:0000000000000000 T: 2 : 57.136 MiB/sec( 1.99970)
# 2 Pmask:0x0a80000000000000:0000000000000000 T: 3 : 85.613 MiB/sec( 2.99642)
# 3 Pmask:0x0aa0000000000000:0000000000000000 T: 4 : 114.029 MiB/sec( 3.99087)
# 4 Pmask:0x0aa8000000000000:0000000000000000 T: 5 : 142.716 MiB/sec( 4.99490)
# 5 Pmask:0x0aaa000000000000:0000000000000000 T: 6 : 171.148 MiB/sec( 5.98998)
# 6 Pmask:0x0aaa800000000000:0000000000000000 T: 7 : 199.931 MiB/sec( 6.99735)
# 7 Pmask:0x0aaaa00000000000:0000000000000000 T: 8 : 228.132 MiB/sec( 7.98436)
# 8 Pmask:0x0aaaa80000000000:0000000000000000 T: 9 : 256.596 MiB/sec( 8.98057)
# 9 Pmask:0x0aaaaa0000000000:0000000000000000 T: 10 : 285.006 MiB/sec( 9.97489)
# 10 Pmask:0x0800008000000000:0000000000000000 T: 2 : 57.115 MiB/sec( 1.99896)
# 11 Pmask:0x0a0000a000000000:0000000000000000 T: 4 : 114.222 MiB/sec( 3.99764)
# 12 Pmask:0x0a8000a800000000:0000000000000000 T: 6 : 171.293 MiB/sec( 5.99506)
# 13 Pmask:0x0aa000aa00000000:0000000000000000 T: 8 : 228.555 MiB/sec( 7.99927)
# 14 Pmask:0x0aa800aa80000000:0000000000000000 T: 10 : 285.620 MiB/sec( 9.99653)
# 15 Pmask:0x0aaa00aaa0000000:0000000000000000 T: 12 : 341.518 MiB/sec( 11.95272)
# 16 Pmask:0x0aaa80aaa8000000:0000000000000000 T: 14 : 398.875 MiB/sec( 13.96017)
# 17 Pmask:0x0aaaa0aaaa000000:0000000000000000 T: 16 : 455.253 MiB/sec( 15.93333)
# 18 Pmask:0x0aaaa8aaaa800000:0000000000000000 T: 18 : 512.796 MiB/sec( 17.94727)
# 19 Pmask:0x0aaaaaaaaaa00000:0000000000000000 T: 20 : 567.009 MiB/sec( 19.84465)
# 20 Pmask:0x0800008000080000:0000000000000000 T: 3 : 85.326 MiB/sec( 2.98632)
# 21 Pmask:0x0a0000a0000a0000:0000000000000000 T: 6 : 171.413 MiB/sec( 5.99927)
# 22 Pmask:0x0a8000a8000a8000:0000000000000000 T: 9 : 257.052 MiB/sec( 8.99666)
# 23 Pmask:0x0aa000aa000aa000:0000000000000000 T: 12 : 341.985 MiB/sec( 11.96908)
# 24 Pmask:0x0aa800aa800aa800:0000000000000000 T: 15 : 427.328 MiB/sec( 14.95598)
# 25 Pmask:0x0aaa00aaa00aaa00:0000000000000000 T: 18 : 511.770 MiB/sec( 17.91135)
# 26 Pmask:0x0aaa80aaa80aaa80:0000000000000000 T: 21 : 595.182 MiB/sec( 20.83067)
# 27 Pmask:0x0aaaa0aaaa0aaaa0:0000000000000000 T: 24 : 683.108 MiB/sec( 23.90797)
# 28 Pmask:0x0aaaa8aaaa8aaaa8:0000000000000000 T: 27 : 762.421 MiB/sec( 26.68385)
# 29 Pmask:0x0aaaaaaaaaaaaaaa:0000000000000000 T: 30 : 842.788 MiB/sec( 29.49659)
# 30 Pmask:0x0800008000080000:0000000000080000 T: 4 : 113.341 MiB/sec( 3.96681)
# 31 Pmask:0x0a0000a0000a0000:00000000000a0000 T: 8 : 228.124 MiB/sec( 7.98408)
# 32 Pmask:0x0a8000a8000a8000:00000000000a8000 T: 12 : 342.240 MiB/sec( 11.97800)
# 33 Pmask:0x0aa000aa000aa000:00000000000aa000 T: 16 : 456.621 MiB/sec( 15.98119)
# 34 Pmask:0x0aa800aa800aa800:00000000000aa800 T: 20 : 568.893 MiB/sec( 19.91059)
# 35 Pmask:0x0aaa00aaa00aaa00:00000000000aaa00 T: 24 : 681.146 MiB/sec( 23.83932)
# 36 Pmask:0x0aaa80aaa80aaa80:00000000000aaa80 T: 28 : 790.318 MiB/sec( 27.66022)
# 37 Pmask:0x0aaaa0aaaa0aaaa0:00000000000aaaa0 T: 32 : 898.272 MiB/sec( 31.43848)
# 38 Pmask:0x0aaaa8aaaa8aaaa8:00000000000aaaa8 T: 36 : 1009.439 MiB/sec( 35.32917)
# 39 Pmask:0x0aaaaaaaaaaaaaaa:00000000000aaaaa T: 40 : 1112.584 MiB/sec( 38.93913) -
Fiery
veterán
Tok mindegy, mennyire archaikus az x86, az Intel akkor is ragaszkodik hozza. Ezt el kell fogadni, mint tenyt, nem erdemes ez ellen harcolni vagy ezzel a dontessel vitatkozni. Amugy meg, ha megnezed pl. az ultramobil piacot, az x86 kozel sem szerepel annyira rosszul, mint sokan szeretnek hinni
A megoldast arra ertettem, hogy ha nem akar valaki a szalkezelessel foglalkozni, akkor hasznalhat OpenCL-t. Nem hardveres megoldaskent gondoltam ezt, hanem nyilvan szoftvereskent. Es az, hogy mennyire lenyeges vagy sem a hardveres szalkezeles, az majd a gyakorlatban ki fog derulni. De az alapjan, hogy a mostani 2/4/8 utas Xeon E5/E7 prociknal nem hallani, hogy annyira nagy problema lenne a 72+ szal kezelese, nem gondolnam, hogy a KNL-en hirtelen ez most elobukkanna, mint megoldhatatlan problema. Hiszen a KNL vegeredmenyben nem mas, mint egy Xeon E5, csak tobb magja van, nagyobb cache-ei, 4x HTT, es AVX-512-t tamogat. Ezert sem ertem, miert kell allandoan a mostani Xeon Phi-hez hasonlitani. Sokkal-sokkal tobb koze van a Haswell-EP/EX vonalhoz, mint a Knights Corner-hez.
-
Abu85
HÁZIGAZDA
Andrew Richards az iparág egyik legelismertebb koponyája a complier technológiák területén. Ha ő nem képes valamire, akkor nem sokan. Nem véletlenül szerződtette pont őt az Intel anno. Drágán dolgozik, de pontosan tudták, hogy szakmájában ő a legjobb.
Az Intel arra kérte őket, hogy tanáccsal lássák el a mérnökeiket. Ezek a szakemberek pedig megtették a legjobb tudásuk szerint. Az már az Intel saját döntése, hogy nem fogadták meg a tanácsaikat. Nyilván a vezetőség gazdaságilag vizsgálta a kérdést, míg a szakemberek technikailag írták le a helyzetet, hogy egyáltalán az, amit az Intel elgondolt működhet-e. Ők azt mondták, hogy nem, és az eddigi gyakorlati produkcióból is az derült ki, hogy igazuk volt. De nyilván a pénzügyi szakemberek jobbnak látták, ha nem hallgatnak a mérnökökre.
-
freeapro
senior tag
Egy nagyon specialis, nagyon vekony piaci reteg igenyt igyekeznek ezekkel kielegiteni a gyartok. Amikor pedig ennyire specialis termekrol van szo, hidd el, nem lesz problema a programozokkal megiratni a f*sza kodot. Mint ahogy arrol sem lehet sokat hallani, hogy a Tesla kapcsan problema lenne a programozas.
Ez butaság. Csak azért nem látod problémának mert a projektek és fejlesztők köre is igen limitált. Ezek egymást lassító tényezők. Azt kizártnak tartom, hogy az AMD azért lépjen be erre a piacra, hogy egy szűk szegmenst kiszolgáljon. Ezekre a masszívan párhuzamos rendszerek hamarosan nagy mennyiségben lesz szükség (egy területet mondok: önvzető járművek) és akkor ott lesz az igény a könnyű programozhatóságra. Ha erre a piacra a tömegeket tudsz átképezni meglévő rendzserek minimális módosításásval akkor nyertél.
-
Abu85
HÁZIGAZDA
Az x86 alapjait több éve rakták le. Természetes, hogy egy újabb tervezésű ISA jobb lehet nála. Ez egyszerűen csak a fejlődéssel megmagyarázható. Nem véletlenül cserélgetik a gyártók a GPU-architektúrák ISA-ját pár éves ciklusokban. Aki azt hiszi, hogy ez megkerülhető az előbb-utóbb belefut egy óriási falba.
Hogyan oldja meg a hardver? Ezek szerint a KNL csak emulálja az x86-ot? Van benne egy új ISA, amit már skálázásra terveztek hardveres szálkezeléssel és szinkronizálással? Ez nekem új információ.
-
Fiery
veterán
Mar megint jossz a zseni kifejezessel. Mibol szurted le, hogy Andrew Richards zseni? Volt egy olimpia a zseniknek, es ott o elodontos volt? Mibol derivaltad le, hogy epp ra kellene hallgatni, es nem mondjuk arra a par emberre, aki Intel reszvenyt vasarol, es ezzel tamogatja a KNL projektet? Ha a KNL egy borzalmas katasztrofanak nezne ki, akkor szerinted a reszvenyesek/igazgatotanacs nem kezdett volna el morgolodni, hogy miert pont abba a projektbe teszik a penzt az Intelnel, ahelyett, hogy mondjuk felvasarolnak az nVIDIA-t, es igy megszereznek mondjuk a CUDA-t?
Miert pont Andrew Richards a legnagyobb koponya, akinek minden szavat el kellene hinni, es minden joslatat keszpenznek kellene venni?"Ezek az emberek ugyanakkor eltávolodtak az Inteltől, amikor a cég nem fogadta meg a tanácsaikat. [...] Ezért a szerződésüket felbontották."
Aham, tehat bepoccentek, es most fikazzak az Intelt. Tehat amit ok mondanak, az 100%-ig objektiv. Vilagos.
"Ezek közül a legfőbb az volt, hogy dobják az x86-ot, mert nagyon öreg ISA, és nem is tervezték túl skálázódóra a memóriamodelljét."
Tehat tancsoltak valamit az Intelnek, ami nyilvanvaloan hulyeseg, hiszen Intel = x86, ergo sosem fogjak eldobni. Megprobaltak, nem kellett senkinek (Itanium), most miert gondolja barki is azt, hogy az x86 eldobhato? Aki meg ilyeneken gondolkozik (Intel minusz x86), annak en egyetlen szavat sem vennem komolyan, ugyanis eleve komolytalan (szak)emberrol van szo. Ennyi erovel probald meg a Microsoftot lebeszelni a Windowsrol, vagy a VW csoportot probald meg lebeszelni a Golf es Passat markanevekrol
-
Fiery
veterán
A PR katasztrofa akkor alakulna ki, ha az Intel arrol kezdene beszelni, hogy az x86 nem (eleg) jo, es helyette hasznalj valami mast. Nem, ilyen nem fordulhat elo. Az Intel az x86-rol szol, akarcsak a Microsoft a Windowsrol. A Microsoft sem fogja sosem azt mondani, hogy a Windows sz*r, hasznalj helyette mast. Az megint mas kerdes, ha csinalnak egy szuboptimalis (oke, mondjuk ki, sz*r) termeket egy adott koncepciora, majd tobb generacion at foldozgatjak, mig vegul osszeall, es hasznalhato lesz. De me'g ebben az esetben sem lehet azt mondani, hogy hasznalj mast, es nem lehet hatraarcot csinalni. Jo pelda erre a Xeon Phi is, de pl. a Windows is. A Windows Vistanal felresiklott az Microsoft, de nem adta fel, es a Windows 7-re osszerakta a dolgokat, ami megint jo lett. A Windows 8 is felrecsuszott, jott a korrekcio a Windows 8.1-gyel, de me'g mindig nem lett (eleg) jo. Vegul a Windows 10-zel kerulnek a helyere a dolgok (remelhetoleg), _de_ ez nem jelenti azt, hogy a Windows 8.x alapjan elore el lehetne konyvelni f*snak a Windows 10-et. Szerintem varjuk meg mindkettot (KNL, Windows 10), mielott az elozo generacios benazasok okan elore eltemetjuk oket.
"Az Intelnek azt kell megértetnie a programozókkal, hogy amit eddig tapasztaltak a FirePro vagy a Tesla rendszerekről az a Phi esetében nem teljesen igaz."
Mintha el sem olvasnad, amit irok
Direkt leirtam, hogy _semmi_ de semmi bizonyitek arra, hogy a KNL-en fejlesztok mas GPGPU platformokrol erkeznek. Es ha x86-rol erkeznek, akkor mi van? Akkor ki a francot erdekel, hogy mi van a Teslaval? Amugy meg, ennyi erovel en ha x86-on programozok mondjuk Pascalban, akkor elore lelkileg fel kellene keszitenie a Google-nak engem arra, hogy milyen megrazkodtatas lesz az androidos fejlesztes Javaban? Hol nem sz*rja ezt le a Google? Ha programozo vagyok, es nem vagyok teljesen bena, akkor meg fogom tudni tanulni az Android+Javat is, nem kell a kis kezemet fogni. Ne nezd mar teljesen gyamoltalan f*sznak a programozokat Van biztos olyan is, de en szemely szerint nem ismerek olyat, aki ne lenne kepes valamilyen szinten x86 SIMD vagy OpenCL/CUDA programozasra, vagy epp a ketto kozott valtani, ha ugy hozza a sors."Majd megoldja a hardver?"
Ha OpenCL stack lesz a KNL-re (marpedig lesz), akkor igen, a hardver megoldja, ha azt szeretned.
-
Abu85
HÁZIGAZDA
Andrew Richards a CodePlay elnök-vezérigazgatója volt mindig is. Az Intel egy rakás magasan jegyzett és elismert szakmai zsenit felkért a projekthez, akik segítették a munkát. Ezek az emberek ugyanakkor eltávolodtak az Inteltől, amikor a cég nem fogadta meg a tanácsaikat. Ezek közül a legfőbb az volt, hogy dobják az x86-ot, mert nagyon öreg ISA, és nem is tervezték túl skálázódóra a memóriamodelljét. Persze az Intel kifizette a szakértelmüket attól, hogy nem fogadták meg a tanácsaikat, csak ezek az emberek nem akartak úgy a projektben részt venni, hogy tudták, hogy nem fog működni. Ezért a szerződésüket felbontották.
-
Abu85
HÁZIGAZDA
Nem értem a PR katasztrófa részét. Az Intelnek azt kell megértetnie a programozókkal, hogy amit eddig tapasztaltak a FirePro vagy a Tesla rendszerekről az a Phi esetében nem teljesen igaz. Amit az egyetemen tanítanak az a Phi-nél nem teljesen igaz. Egyszerűen csak fel kellene erre hívni a figyelmet, és leírni, hogy mire kell optimalizálni. Nagyon sokszor elhangzik az előadásokon, hogy a mai vektorarchitektúráknál a függőségre nem kell figyelni, mert ez már nem limitálja a feldolgozást, de ez a Phi-re nem igaz. Ugyanígy a szinkronizálás és a szálkezelés. Majd megoldja a hardver? Egy csomó rendszer igen, de nem a Phi. Ha ezekről beszámolnak az pont azt szorgalmazza, hogy a programozó jobban megértse a hardvert.
-
Fiery
veterán
Egyebkent errol az Andrew Richards-rol van szo?
Mert ha igen, akkor eleg fura, hogy nem irta be az elozo munkahelyei koze az Intelt. Vagy az annyira elhanyagolhato ceg, hogy nem erdemes megemliteni sem, mert ugyse ismeri senki?
Vagy nem is dolgozott valojaban a Xeon Phi-n (ahogy irod), hanem a Xeon Phi-vel dolgozott? Vasarolt egyet, kiprobalta, azt mondta, hogy sz*r?
Persze latom en, hogy GPU compilerekkel foglalkozik, de ugye a KNL-en nem kell (ujfajta) compiler, az nem holmi GPGPU, hanem egy sima CPU... Tehat a mostani Xeon Phi sz*r, mert Andrew Richards nem tudott ra GPU compilert irni, ergo a kovetkezo, teljesen mas architekturaju Xeon Phi (azaz a KNL) is az lesz, hiszen ............ <-- es ide jon egy nyakatekert logikai manover, amit kitalaltal? -
Fiery
veterán
"A nehezebb és a szart pedig ne keverjük össze."
Ha az Intel elkezdené azt sujkolni a programozokba, hogy az x86 nem eleg jo a KNL-re valo fejlesztes kapcsan, az lenne az igazi PR katasztrofa. Ok nem a Microsoft, hogy maguk alatt vagjak a fat
A programozok meg hidd el, eleg okosak ahhoz, hogy eldontsek, x86 SIMD-vel akarnak molyolni, vagy OpenCL-lel probalkoznak inkabb. Nagyban fugg ez attol is, mit csinalsz pontosan, mit akarsz elerni, es hogy van-e mar meglevo kodod. Ha mar van mondjuk egy Xeon E5-re fejlesztett x86 kodod, akkor hulye leszel OpenCL-re portolni azt, ha minimalis modositassal a KNL-en is szakitani fog. De persze a masik oldalrol meg ha OpenCL-ben vagy CUDA-ban mar van egy kesz kerneled, akkor meg nem fogsz nekiallni x86-tal szorakozni, ha az OpenCL kod is remekul fut."Tehát ha meg tud írni a programozó két szálra egy 128 bites SSE2 kódot, akkor ebből következik, hogy 288 szálra is tudnia kell 512 bites AVX-et?"
Igy van. Vagy ha nem megy neki, akkor nem eleg jo x86 SIMD programozo az illeto. Ez esetben pedig lehet OpenCL-lel probalkozni.
"Hallgass meg egy pár Andrew Richards előadást. Ő dolgozott a Phi-n és megpróbálta meggyőzni az Intelt, hogy ez a koncepció nagyon nehéz lesz a programozóknak."
Asszem innentol felesleges is tovabb vitazni errol. Te egyetlen ember velemenyebol derivalod le, hogy az egesz KNL koncepcio (ami egyebkent _nem_ azonos a mostani Phi koncepciojaval, csak ezt se igazan vagy kepes megerteni, vagy csak elegansan atleped a kerdest, mint ha nem ez lenne az egyik legfontosabb valtozas) ugy ahogy van, rossz. Tegyel igy, en azt mondom, a piac majd eldonti a kerdest. Ugyanigy, a piac mar sok kerdest eldontott, pl. Seattle, Kaveri GDDR5, Itanium, stb.
-
Abu85
HÁZIGAZDA
Nekem mindegy, hogy az Intel oktat-e belőle vagy sem. Nekik nem lesz jó, ha nem tudják használni a hardvert.
Ki mondta, hogy a SIMD szar? Ez jó, csak nem olyan könnyű, mint a SIMT. És a Xeon Phi kihasználatlanságához nagyban hozzájárul az, hogy a programozók nem tudják hogyan kell programozni. Ez részben az Intel felelőssége, mert a "plusz két sor a meglévő OpenMP kódba és minden fasza lesz" szöveg mellé adhattak volna támpontot is.
Tehát ha meg tud írni a programozó két szálra egy 128 bites SSE2 kódot, akkor ebből következik, hogy 288 szálra is tudnia kell 512 bites AVX-et?
Hallgass meg egy pár Andrew Richards előadást. Ő dolgozott a Phi-n és megpróbálta meggyőzni az Intelt, hogy ez a koncepció nagyon nehéz lesz a programozóknak. -
Fiery
veterán
Tovabbra sem ertem, mi a problemad, es miert kellene az Intelnek barkit is oktatnia a KNL programozasaval kapcsolatban. A SIMD uj dolog? Nem. Az, hogy milyen szeles, masodlagos kerdes, a programozo majd megoldja. Volt eddig is sok szalu konfig? Volt, hogyne lett volna. Aki meg 16 szalra tud kodot irni, az 240-re is tud. Az OpenCL sem egy uj dolog, raadasul egy plusz funkcio, amivel tagulnak a lehetosegek. Az OpenCL kapcsan pont nem az Intelt kellene **szogatni, hiszen az AMD es nVIDIA megoldasaival szemben, a KNL-et lehet direktben is programozni, mindenfele plusz retegek (OpenCL, CUDA) nelkul. Mig ugyanezt az AMD es nVIDIA vonalon nem tul sokan vallaljak be, hiszen baromira nem "coder-friendly" ott a nativ kodolas.
"Az Intelnek arra kellene figyelnie, hogy megértesse a programozókkal, hogy ez nem annyira könnyű, mint a GPGPU paradigmák, amelyeket ráadásul megszokott a piac"
Eloszor is: az Intelnek kellene megertetni a vilaggal, hogy a (SIMD) x86 sz*r? Ennyire hulyenek nezed oket, hogy tökön lovik sajat magukat?
 Es kulonben is, ha lesz OpenCL tamogatas, akkor minden programozo, sajat hataskorben el fogja tudni donteni, hogy mit akar hasznalni. Ha nem tetszik az x86, lehet OpenCL-t hasznalni. Ha nem tetszik az OpenCL, akkor viszont csak a KNL-en tudsz SIMD x86-ot hasznalni, ami viszont sok embernek sokkal ismerosebb, mint a mindenfele GPGPU-s hobortok.
Es kulonben is, ha lesz OpenCL tamogatas, akkor minden programozo, sajat hataskorben el fogja tudni donteni, hogy mit akar hasznalni. Ha nem tetszik az x86, lehet OpenCL-t hasznalni. Ha nem tetszik az OpenCL, akkor viszont csak a KNL-en tudsz SIMD x86-ot hasznalni, ami viszont sok embernek sokkal ismerosebb, mint a mindenfele GPGPU-s hobortok.A megszokott a piacon meg csak nevetni tudok. Miota van x86? Miota van SIMD x86? Miota van OpenCL, amit gyakorlatban is lehet hasznalni? Miota van koherens (SVM) OpenCL? Miota van CUDA? Most akkor melyiket szokta meg tobb programozo? Nem kenyerem a szemelyeskedes, de rajtad qrvara latszodik, hogy nem vagy programozo. Akkora suletlensegeket, amiket irsz, egy programozo sosem irna le. Amivel persze nincs baj, marmint hogy nem vagy programozo, hiszen nem lehet minden informatikaval foglalkozo szakember programozo. De van egy pont, ahol meg kellene allni, es hagyni, hogy a programozok eldontsek maguknak, mi a jo nekik. Es szereny velemenyem szerint a programozok a KNL megjelenese utan nem az x86 miatt fognak eloszor utcara vonulni, kovetelve egy absztrakt GPGPU-s f*szsagot _helyette_. Hangsulyozom: helyette. Mert ugye lehet igy is, ugy is programozni a KNL-et.
-
Abu85
HÁZIGAZDA
Széles SIMD-ek esetében a koncepció ugyanaz. Az AMD és az NV megoldásai esetében annyi a különbség, hogy a programozónak nem kell törődnie a vektorizálással a SIMT modell miatt, míg az Intel koncepciójában ez egy kritikus rész.
Az Intel nem véletlenül hozott OpenCL-t a processzoraihoz. A helyzet az, hogy ezen egyszerűbb programozni széles SIMD-eket, mint vector intrinsics-szel. Nagyon sokan ezért szeretik az OpenCL-t, és nem feltétlenül a GPGPU-s lehetőségek miatt.
Ne gondold, hogy egyszerűbb vector intrinsics-szel 512 bites SIMD-eket kivágni manuális szinkronizálással 280+ szálra. Az Intelnek arra kellene figyelnie, hogy megértesse a programozókkal, hogy ez nem annyira könnyű, mint a GPGPU paradigmák, amelyeket ráadásul megszokott a piac. Ez sokat segítene a KNL helyzetén.
-
Fiery
veterán
Szerintem nem latod a fatol az erdot
Probalod ugy beallitani a Xeon Phi-t meg a KNL-et, mintha az azoknak keszult volna, akik hatalmas spilerek GPGPU temaban, pl. OpenCL vagy CUDA alapokon. Mibol gondolod, hogy ez igy van? Mibol gondolod, hogy pl. a KNL nem azoknak keszul, akik jelenleg tobbszalu SIMD _x86_ kodot keszitenek mondjuk Visual Studioban? Mibol gondolod, hogy tobbsegeben vannak azok, akik OpenCL/CUDA platformokrol erkeznek; azokkal szemben, akik x86 programozassal tengetik az eletuket, es esetleg tobbszalu SIMD kodot is kepesek kesziteni valamilyen eszkozzel?"Az Intelnek el kell magyaráznia a piacnak, hogy a Phi nagyon specifikus rendszer, amit sokkal nehezebb programozni, mint a GPGPU-kat. Ez biztosítaná a Phi jövőjét."
A mostani Xeon Phi-t talan nehezebb programozni, mint az OpenCL ill. CUDA alapu AMD/nVIDIA megoldasokat, de nem igazan ertem, miert lenne olyan nagy varazslat programozni a KNL-et. Mas, ez teny. De ennyi erovel akkor egy 72 szalu (2 utas) Xeon E5-re is ugyanugy nehez programot kesziteni. Vagy ha a hagyomanyos szerver Xeonokkal megbirkoznak a programozok, akkor miert lenne nehezebb boldogulni a Knights Landinggel? Mindketto x86, mindketto sokszalu, mindketto AVXn (n = 1..512
), mindketto rendszermemoriabol dolgozik nagy cache-ekkel. -
Fiery
veterán
Alapvetoen arra gondoltam, hogy ha egyetlen gepben gondolkozol (nem klaszterben), akkor 1 db szerverbe bele tudsz pakolni 4 vagy 8 db dGPU-t is, mig APU-bol csak egyet. Es egy-egy ilyen konfignal nemileg szelesebb tartomanyban tud mozogni a dGPU-k TDP-je, mint az APU-ke. A wattot pedig alapvetoen videokartya vs. APU tokozasra ertettem, tehat egy adott videokartya hany wattbol tud gazdalkodni ill. egy APU. Az reszletkerdes, hogy egy videokartyara 1 vagy 2 db dGPU-t szerelnek, az mar egyeni preferencia kerdese, hogy ki milyet szeretne a szerverbe pakolni. Viszont, APU-bol csak 1 db-ot tudsz hasznalni szerverenkent a megosztott memoria miatt, kiveve persze ha a koherenciarol lemondasz.
-
Abu85
HÁZIGAZDA
Mivel a szálkezelés és a szinkronizáció nem változik, így a programozónak ugyanazt kell csinálnia.
Annyiban igen, hogy az Intel mondta, hogy a meglévő OpenMP kódok használhatók lesznek. Sokan ezért választották ezt a gyorsítót, mert az Intel így promótálta. Aztán amikor kiderült, hogy ez nem igaz, akkor kidobtak egy OpenCL-t rá. A gond az, hogy az OpenCL alatt a legtöbben úgy közelítik meg a Phi-t, mint a FirePro és a Tesla rendszereket. És ez okozza a rossz megítélést. Nyilván másra nehéz gondolnia egy programozónak, minthogy rossz a hardver, ha egy FirePrón és Teslán tökéletesen működő kód Phi-n nem működik.
Az Intelnek el kell magyaráznia a piacnak, hogy a Phi nagyon specifikus rendszer, amit sokkal nehezebb programozni, mint a GPGPU-kat. Ez biztosíthatná a Phi jövőjét. -

lenox
veterán
Hat per gpu nincs kijebb tolva a tdp, nem tudom, az miert lenne erdekes mondas, hogy pl. 100 gpu-nak nagyobb tdp-je van, mint egy apunak, nyilvan a tdp skalazast per chip erdemes nezni. Szamomra mint irtam skalazhatonak tuntek az apuk eddig is tdp-ben, te irtad, hogy de a dgpu-kat jobban/kijebb lehet, de a valosagban meg nem skalazzak oket 250 watt fole.
De ha jo a klaszter, akkor xeonbol is jok lennenek az 1-2 utasak is, tehat az nem az a feladat, amikor specialis megoldas kell.
-
Fiery
veterán
Es szerinted a mostani vagy epp az elozo generacios Xeon Phi-nek mennyi koze van a KNL-hez? Szerinted ugyanugy kell programozni?
Az az Intel sara, hogy valaki epit egy balf*sz modon osszerakott szuperszamitogepet, majd nem tud megfelelo kodot kesziteni hozza? Miert vettek meg, ha nem tudjak kihasznalni? Vagy ha arra gondolsz, hogy az egesz csak egy PR-fogas volt, akkor egyetertek, de akkor meg az Intel csinalta jol, hiszen a sz*rt milyen ugyesen tudta promotalni
Abban egyebkent nem fogunk vitatkozni, hogy technikailag nem jo megoldas a mostani Xeon Phi. De ne vetitsuk le azt elore a KNL-re is, mert az tok mas megkozelites. Nagyjabol annyi koze van egymashoz a 2 termeknek, mint mondjuk egy low-end GCN1 dGPU-nak a Carrizohoz.
A bizalom kerdest meg inkabb ne feszegessuk egy alapvetoen AMD-s hirhez kapcsolodo topikban szerintem

 Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon.
Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon. -
Abu85
HÁZIGAZDA
Ma az ipar arról beszél, hogy 48 000 Xeon Phi-t nem használ a Thiane-2, mert nem tudják befogni. Ez nem az első eset. Az első Knights terméket az Intel ki sem hozta, mert tudták, hogy rossz. A másodikat kihozták, majd mikor kiderült, hogy nem úgy működik ahogy ígérték megdobták a piacot egy OpenCL meghajtóval. Azokat a megrendelőket, akik direkt azért kértek Xeon Phi-t, hogy úgy használják ahogy az Intel ígérte és ne OpenCL-en keresztül. Mennyi bizalom maradt?
Nem az x86 miatt bukdácsol a Xeon Phi vonal, hanem leginkább amiatt, hogy azok a programozási paradigmák, amelyek kialakultak nem működnek rajta. A hardver egyébként működik az Intel assembly példakódjaival.
-
#32
 JColee
őstag
Balala2007
#29
JColee
őstag
Balala2007
#29
JColee
őstag
válasz
Balala2007
#29
üzenetére
Ez mi, htop?
-
Fiery
veterán
"Tesla k80 az ket gpu, nem egy..."
Es? Nem az szamit, hany GPU, hanem hogy hany TFLOPS DP-ben. Amugy meg, ha nem tevedek, a dGPU-knal ennel durvabb TDP-t is ki lehetne tuzni, ha meg tudnak oldani a hoelvezetest -- mig az APU-knal mar a 200-250W is neccesnek hangzik.
"Ahova a 8 socketes xeon e7 keves, ott egy apu nem tudom, mit fog kezdeni, szerintem semmit"
Nem ugyanaz a TDP-osztaly, ahogy irod is. Es ezeket az APU-kat is lehet majd klaszterezni.
-
Fiery
veterán
Hadd kerdezzem mar, ennek, amit irtal, mi a frasz koze van barmihez is? Nehogy mar a Xeon Phi-t hasonlitsuk egy Knights Landinghez vagy az AMD HPC APU-jahoz. Teljesen mas megkozelites, mas utasitaskeszlet, mas architektura, minden **rvara mas. A Xeon Phi valoban korulmenyes, plane ha melleteszel egy Teslat. Onmagaban a Xeon Phi sem egy megoldhatatlan problema, hiszen mar reges-reg kitalaltak az x86 piacon a tobbszalu kodoknal a beallithato CPU maszkot
 Egy 36 magos (2 utas) Xeon E5-nel sem kotelezo mind a 72 threadet kihasznalnia egy x86 szoftvernek, ha gyorsabb kevesebb thread hasznalataval a kod.
Egy 36 magos (2 utas) Xeon E5-nel sem kotelezo mind a 72 threadet kihasznalnia egy x86 szoftvernek, ha gyorsabb kevesebb thread hasznalataval a kod.Egy Knights Landingnel majd a programozok kimérik, hogy mi az optimalis thread leosztas. Legyen ez az o problemajuk, nemtom miert kellene Neked eldonteni helyettuk, hogy jo lesz-e a KNL nekik vagy sem. Az biztos, hogy nem igenyel uj paradigmat, hiszen x86. Ha az Itanium a nem-x86 architektura miatt bukott meg, akkor a KNL-rol elore eldontjuk, hogy pont az x86 miatt fog elbukni?
Amugy meg, remelem szamodra is teljesen vilagos, hogy se a KNL, se az AMD HPC APU-ja nem a mainstream piac szamara keszul. Egy nagyon specialis, nagyon vekony piaci reteg igenyt igyekeznek ezekkel kielegiteni a gyartok. Amikor pedig ennyire specialis termekrol van szo, hidd el, nem lesz problema a programozokkal megiratni a f*sza kodot. Mint ahogy arrol sem lehet sokat hallani, hogy a Tesla kapcsan problema lenne a programozas. Pedig ott masolgatni kell a memoriat, meg kell tanulni a CUDA-t, stb. Megis elboldogulnak vele azok, akinek ez a feladatuk. A CUDA-val szemben viszont az x86 programozok szama igencsak nagysagrendekkel nagyobb, me'g azoke is, akik adott esetben nem teljesen fogalmatlanok a multi-threaded + SIMD programozas kapcsan sem. Lesz, aki kodot gyartson majd a KNL-hez.
Az AMD HPC APU-ja pedig pont ugyanaz pepitaban, mint a Kaveri. Aki most is gyart kodot a Kaverihoz, az imadni fogja az AMD HPC APU-jat is. A gyakorlatban majd kiderul, melyik a tuti megoldas. Siman lehet, hogy a HSA-val parositva nagyon vonzo platform lesz az AMD HPC APU-ja -- de az is lehet, hogy a konkurens x86-os megoldas miatt megsem.
-
#29
Balala2007
tag
Balala2007
tag
Huzzanak bele, a KNL mar itt tart:

Innen van. Zavaros a szoveg, keveri a core-t meg a thread-et, de a kep akkor is erdekes, ha "csak" thread, es nem 240 core hasznalatat mutatja.
-

#06658560
törölt tag
-
lenox
veterán
Tesla k80 az ket gpu, nem egy...
Ahova a 8 socketes xeon e7 keves, ott egy apu nem tudom, mit fog kezdeni, szerintem semmit. Mondjuk olcsobb lesz, annyi elonye lehet, meg kevesebbet fogyaszt, de teljesitmenyben tul sokra nem fogja vinni szerintem, vagy legalabbis akkor azt a feladatot nagyon erre kell kihegyezni, nem tudom, mi lehetne az...
-
Fiery
veterán
1) Near memory-nak eleg a 16 giga, de ez siman meg is valosithato jovore. Marmint, ha az Intel meg tudja csinalni, akkor nyilvan az AMD is meg tudja. Hogy HBM-mel mennyit tudnak pakolni az APU kore, az megint mas kerdes, ez majd kiderul a gyakorlatban. Persze az is lenyeges kerdes, hogy a rendszermemoria fele milyen savszelesseget biztosit az APU: ha mondjuk lenne egy combos 8 csatornas DDR4, akkor eleg lenne kevesebb near memory is.
2) En ugy ertelmezem, hogy a Knights Landing es ez az AMD HPC APU is inkabb specialis feladatkorokre lesz, nem a top500-at ostromolni. Inkabb oda lehetnek ezek jok, ahova a Kaveri lassu, a dGPU nem jo (a memoria masolgatas miatt), es a 4-8 socketes klasszikus x86 (pl. Xeon E7) keves. Ez pedig eleg vekony szelete a piacnak, viszont adott esetben egy nagyon fontos szelete, hiszen a jovo siman lehet, hogy ilyen HPC megoldasokat fog hozni a mainstream piacra is.
3) Tesla K80, ami 300 Watt, ha nem tevedek.
-
Abu85
HÁZIGAZDA
Nagymértékben meghatározza a rendszer működését a szálkezelés. A legfőbb oka annak, hogy a mai gyorsítók hardveres szálkezelést és hardveres szinkronizációt használnak az, hogy a programozó képtelen lenne biztosítani a manuális kezelésüket és szinkronizálásukat. A Xeon Phi esetében is látszik a probléma, mert se OpenMP, se OpenCL alól nem lehet igazán használni.
A Phi egy újszerű paradigmát igényel. Figyelembe kell venni az algoritmust és nem az a jó, ha mindegyik magot befogják, hanem az, ha annyit fognak be, amennyivel gyors lehet. Ha ez csak 10-20 mag akkor annyit, de érdemes limitálást figyelembe venni, mert sokszor ettől gyorsul. Ez az oka annak is, amiért a Xeon Phi az iparág által el van könyvelve szarnak. Pedig nem rossz, csak nagyon speciális programozást igényel. -
lenox
veterán
1. Itt van nalam m6000, k80, w9100, w8100. Nincs rajtuk tobb, mint 16 GB, szoval ha ezekhez eleg, akkor egy apun is eleg lenne. Vagy lehet, hogy az nem jott at, hogy ezt a szokasos sokcsatornas memoria melle kepzelem, nem helyette.
2. Nem tudom, top500-ban nem sok ilyen van, tippem szerint ezzel a top500-nak megfelelo piacra akarnanak menni.
3. Melyik gyorsiton van 250 wattnal nagyobb tdp-ju gpu, amit HPC piacon hasznalnak?
-
Fiery
veterán
Dehogynem a Knights Landing ellenfele. Mindket procit specialis szamitasokra szanjak, mindketto egy dGPU helyet veszi at, mindketto a megosztott memoria koncepciojara epit (bar nem feltetlenul ugyanolyan modon), mindketto tulajdonkeppen egy CPU tokba rakott dGPU, mindkettonel van near memory (tok mindegy, hogy hivjak), de mindketto elsosorban a rendszermemoriaba dolgozik. Ja, es mindketto nagyjabol ugyanolyan TDP-osztalyt celoz. Az, hogy az architektura heterogen vagy homogen, me'g tok ugyanaz a vegcel mindket HPC megoldassal.
"Szerintem az AMD valami gyakorlatban is használható rendszert szeretne, aminek lehetséges a programozása."
((( Kepzelj ide egy big f* facepalmot ))) Mert ugye a Knights Landing-et nem lehet a gyakorlatban programozni. Lassuk csak, irni kell egy 240 szalra skalazott x86 kodot. Jajj, vajon azt hogyan oldja meg a programozo? Az x86 valami tok uj dolog, nem tudom, hogyan fogjak a programozok elsajatitani hirtelen ezt az uj megoldast...
-
Fiery
veterán
1) Dehogy eleg, marmint egyseges rendszer- es videomemorianak. Mar most is 12 meg 16 gigas profi kartyakkal nyomulnak, 2-3 ev mulva mar kozel sem lesz elegendo a 16 giga a HPC piacon. Ne a jatekokbol indulj ki, az semmit nem jelent, hogy egy Radeonon mennyi videomemoria talalhato
2) Nem a dual APU az igazan izgalmas a HPC-piacon, hanem az olyan vadorzo GPU-szerver konfigok, amikben mondjuk van 4 vagy 8 db dual-GPU-s Tesla
Tehat nem az 1 db GPU vs. 2 db GPU az izgalmas kerdes, hanem az 1 db vs. 8/16 db. Az meg mar nagyon nem mindegy. A Knights Landing es ez az AMD HPC APU sem lesz jo mindenre, egy csomo vonalon megmaradnak a Tesla-szeru dGPU-s megoldasok, de sok esetben pedig pont a megosztott memoria miatt nagyon-nagyon jol lehet majd hasznalni ezeket a HPC APU-kat majd. Mint ahogy most is baromi jol lehetne hasznalni a Kaverit bizonyos HPC feladatokra, _ha_ ennel sokkal erosebb lenne az iGPU-ja, es sokkal nagyobb lenne a memoria savszelesseg.3) Tipikusan 200-250 Watt korul erkeznek a HPC APU-k, mig egy dGPU-nal ennel kijjebb is lehet tolni a TDP-t. 50-100 Watt pedig marha sokat szamit.
-
#06658560
törölt tag
Mi az APU lényege? A GPU és CPU rész közötti adatmásolás megúszása. mik a sajátosságai? Olyan feladatra vannak kitalálva, ahol egyszerre kell mindkét rész számítási sajátossága, azonos adatokon. Mik a hátrányai? Adott fogyasztási keret mellett, adott hűtési teljesítmény mellett könnyen bele lehet futni abba az állapotba, hogy egyidejűleg a CPU és GPU részt nem lehet teljes mértékben kihajtani, mert megsülne a rendszer.
A dedikált rendszer hol jó? Ahol kevesebb alkalommal kell adatokat másolni, de olyankor akár nagyobb egységeket is. A CPU és GPU rész külön-külön jobban kihajtható, nem fűtik egymást normálisan felépített rendszer esetén.Hogy egy végeselemes rendszerben írjak példákat: egy öt rúdból álló rácsszerketzet statikus vizsgálatához nagy valószínűséggel egy CPU is pont elég. Egy hatszázmillió csomópontot tartalmazó, nemlineáris, dinamikus, többparaméteres, esetleg nemstaacionárius paraméteres rendszer vizsgálatánál már nagyobb eséllyel megéri csak GPU részt használni, böhöm clusterbe rakva, ahol a CPU részek csakis az adatmásolással foglalkoznak. Itt a kihasználtság inkább olyan, hogy az elemek egy csoportja bekerül egy memória-címtérbe, amik a legszorosabb kapcsolatban vannak egymással, s adott GPU egység az általa számolt csomópontok eredményeit egyben adja tovább, nem egyesével.
A két állapot között pedig van az a terület, ahol az APU-k, a multi GPU-s, multi CPU-s rendszerek megélnek. Itt mindig a feladat dönti el, milyen rendszer a legjobb, mind szoftverarchitektúra, mind hardverarchitektúra szempontjából.#12 lenox: HPC, tehát tuti rohadt kevés lenne a 16 GiB.
#8 Fiery: kieg.: HPC piacon belefér, hogy pontosan definiálják az igényt, s az upgrade lépésekbe belefér a mindent egyben cserélni állapot, kisebb léptékben viszotn a memóriaigény szokott leghamarabb megszaladni, s ott nem is tolerálják a vegyél új CPU+GPU+RAM egységet logikát.
-
Abu85
HÁZIGAZDA
Gondolom nekik lesz tempósabb dedikált gyorsítójuk. Elképzelhető egyébként, itt még mindig elviszi a fogyasztási keret egy részét a procirész.
(#7) Fiery: Ez nem a Knights Landing ellenfele. Az AMD korábban is mondta már, hogy kipróbálták a sokmagos koncepciót. Egyrészt directory protokollt igényel, ami azt eredményezi, hogy a tranzisztorok felét csak a cache-be verik, illetve szimuláción sem működött több feladatban 20 magnál jobban a skálázódás. Ugyanezt egyébként az Intel is folyamatosan elmondja, hogy nem a maximális kihasználásra kell törekedni, hanem az optimálisra, mert a Xeon Phi-vel ma is előfordul, hogy kevesebb aktív mag több sebességet ad. Szerintem az AMD valami gyakorlatban is használható rendszert szeretne, aminek lehetséges a programozása.
-
Fiery
veterán
A dGPU-knak -- jelenleg -- az alabbi elonyei vannak:
1) Nagyon gyors es egyben nagyon sok memoriat is lehet mellé pakolni. A HBM az AMD HPC APU-janak near memory szerepeben fog mukodni (ha jol ertelmezem), ergo nem lesz rengeteg belole, "csupan" 4 vagy 8 (esetleg 16) GB, a tobbi a "lassu" 4+ csatornas DDR4 rendszermemoriabol lesz hasznalva.
2) Tobb GPU-t is telepithetsz egy konfiguracioba
3) Kicsit szelesebb tartomanyban lehet a TDP-t szabalyozni
-
#9
 v_peter2012
csendes tag
v_peter2012
csendes tag
v_peter2012
csendes tag
Én azon lepődtem meg hogy az amd ilyen messzire tervez
-
Fiery
veterán
Az AMD ezt mar a Kaverival is meg akarta csinalni, bar me'g GDDR5 (BGA) alapokon, es az sem sikerult nekik. Az APU igeretes volt, de a PC-piac ellenallt, nem volt gyakorlatilag olyan alaplap gyarto, aki bevallalta volna. A HPC piac van annyira specifikus, hogy ott kevesbe problema, ha egyedi megoldast szallit valaki, de a mainstream piacon nem lehet sajnos egyenieskedni. Amikor a memoria modulra rakott DDR3/DDR4 a divat, akkor nem lehet BGA-val egyenieskedni, es ugyanigy a HBM sem mukodne sajnos rendszermemoriakent

-
Fiery
veterán
Oke, szoval az AMD belengette, hogy csinal konkurenciat a Knights Landing-nek. Eleg furcsa, hogy a hirben egy szo sem esik errol, marmint a tenyrol, hogy ez egyertelmuen a Knights Landing ellenfelenek keszul. Amondo vagyok, hajra AMD, kell a piacnak egy eros konkurencia, es ha a HBM-et bevetik near memory-kent, az egy igen-igen erdekes megoldas lenne.
-
#3
 FollowTheORI
nagyúr
lenox
#1
FollowTheORI
nagyúr
lenox
#1
-
pl. úgy, hogy biztos léteznek olyan feladatok, ahol a APU-ban lévő CPU magok (és a bonyolultabb memóriavezérlő?) feleslegesek, és helyettük okosabb még több feldolgozó egységet a lapkára tenni.
Ezen kívül sima gyorsítóból lehet többet is használni, ha nem érzékeny pont az adatmásolás. -
lenox
veterán
Az utolso bekezdest nem ertem. Ha 300 watt fogyasztassal es tobb gigabytenyi HBM-mel csinal valaki apu-t, annal hogy lesz egy dedikalt gyorsito jobb? Mert jelenleg attol jobbak a dedikalt gyorsitok, hogy nagyobb savszelessegen erik el a sajat memjuket, es nagyobb tdp all rendelkezesukre. Ha ezek a korlatok nincsenek, akkor nem tudom mitol lenne jobb egy ugyanolyan tulajdonsagu hw pcie buszra kotve...








![;]](http://cdn.rios.hu/dl/s/v1.gif) "
"

















 Es kulonben is, ha lesz OpenCL tamogatas, akkor minden programozo, sajat hataskorben el fogja tudni donteni, hogy mit akar hasznalni. Ha nem tetszik az x86, lehet OpenCL-t hasznalni. Ha nem tetszik az OpenCL, akkor viszont csak a KNL-en tudsz SIMD x86-ot hasznalni, ami viszont sok embernek sokkal ismerosebb, mint a mindenfele GPGPU-s hobortok.
Es kulonben is, ha lesz OpenCL tamogatas, akkor minden programozo, sajat hataskorben el fogja tudni donteni, hogy mit akar hasznalni. Ha nem tetszik az x86, lehet OpenCL-t hasznalni. Ha nem tetszik az OpenCL, akkor viszont csak a KNL-en tudsz SIMD x86-ot hasznalni, ami viszont sok embernek sokkal ismerosebb, mint a mindenfele GPGPU-s hobortok.

 Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon.
Teszek helyette inkabb egy meresz joslatot: _szerintem_ soha nem fog elkeszulni ez az AMD HPC APU. Vagy ha el is keszul, pont olyan sokat adnak el belole, mint a legutolso nagy szerver probalkozasbol, lasd Seattle. Az AMD nem ilyen speci cuccokkal kellene, hogy veszodjon.














Új hozzászólás Aktív témák
Hirdetés
- Óra topik
- Milyen légkondit a lakásba?
- Lakáshitel, lakásvásárlás
- Samsung Galaxy A54 - türelemjáték
- Battlefield 6
- Sorozatok
- Wise (ex-TransferWise)
- Épített vízhűtés (nem kompakt) topic
- Telekom otthoni szolgáltatások (TV, internet, telefon)
- AMD Ryzen 9 / 7 / 5 9***(X) "Zen 5" (AM5)
- További aktív témák...

- MSI CreatorPro Z16P RTX A5500 TOUCH! (vapor chamberrel)
- Készpénzes / Utalásos Videokártya és Hardver felvásárlás! Személyesen vagy Postával!
- Gamer PC-Számítógép! Csere-Beszámítás! R5 5600X / RX 7600 / 32GB DDR4 / 1TB M.2 SSD
- PS Plus előfizetések
- Lenovo Thinkpad L14 Gen 4 -14"FHD IPS - i5-1335U - 8GB - 256GB - Win11 - 2 év garancia - MAGYAR
Állásajánlatok

Cég: FOTC
Város: Budapest