- Android alkalmazások - szoftver kibeszélő topik
- Profi EKG-s óra lett a Watch Fitből
- Honor 400 Pro - gép a képben
- Samsung Galaxy S21 és S21+ - húszra akartak lapot húzni
- Honor Magic7 Pro - kifinomult, költséges képalkotás
- Samsung Galaxy A54 - türelemjáték
- Milyen okostelefont vegyek?
- Telekom mobilszolgáltatások
- Apple iPhone 16 Pro - rutinvizsga
- India felől közelít egy 7550 mAh-s Redmi
Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
Az összeköttetés típusa nem annyira lényeges, mert az csak a sebességre van hatással. A buszt így is ki kell sajátítani a szinkronizációra.
A KNL biztos nem snoopingot használ. Egyetlen Xeon Phi-re sem jó ez a megvalósítás. A directory protokollt alkalmazza az Intel bizonyos magszám felett. Ez lassabb, mint a snooping, illetve sokkal több tranyót visz el, de a snooping meg nem skálázódna ennyire sem.Andrew Richards egyszer leírta a sztorit, csak az Intel annyira befenyítette, hogy mindenhonnan letörölték. De abban egyébként volt szó róla, hogy az Intel saját mérnökeivel és a többi külsős szakemberrel együtt ajánlották a vezetőségnek, hogy dobják az x86-ot, mert nem fog működni. A pénzügyi vezetők álláspontja az volt, hogy csinálják meg az eredeti tervet és majd lenyomják a piac torkán.
-
Abu85
HÁZIGAZDA
Li-Shiuan Peh professzornak volt egy előadása, ahol beszélt róla, hogy a cache-koherencia azonos szinten borzalmasan nehéz egy bizonyos magszám felett. A több socket azért működik, mert a cache-koherencia többszintű. Például, ha van négy processzorod, akkor két mag közötti kommunikációra a hardver szintjén kisajátítják a procimagok az összeköttetésre szolgáló buszt. Ezzel 8 mag közötti kommunikáció oldható meg 4 socket esetében egyszerre (socketenként 2-2 mag). De ha ugyanannyi mag csak egy foglalatban, egy processzorban van, akkor már 2 magra korlátozódik a busz kisajátítása. Ez limitálja a rendszert.
(#60) Fiery: Több céget és szakembert bíztak meg. Egyébként minden külsős ugyanazt ajánlotta, még Michael Abrash is. A pénzügyi szakemberek ezzel nem értettek egyet.
-

LordX
veterán
Támogatja, csak ezzel a két apró problémával:
Recommendation: Avoid using Shared Local Memory on the Intel Xeon Phi coprocessor.
We recommend avoiding the use of barriers.
(OpenCL* Design and Programming Guide for the Intel® Xeon Phi™ Coprocessor)
Konkrétan egy redukciót nem csinálsz meg ezek nélkül. (Ja, de, atomics. Ha 240 szál futtat loopban LOCK CMPXCHG utasításokat, az egyszeri viccnek jó..) Nem az OpenCL programozás minősül nehéznek, hanem az olyan OpenCL kód írása, ami ennek a kettőnek megfelel. És bonyolultabb, mint egy hello world.
-
-
mi két ok miatt szoktunk tanácsadót felkérni. az egyik, hogy a kirúgott felsővezetőket így tartsuk távol az álláspiactól (és a vetélytársaktól), amíg a céget illető naprakész ismereteik elviselehtő kockázati szintre esnek le.
a másik pedig amikor olyan tudást vagyunk kénytelenek importálni, amely nem érhető el a cégen bellül, illetve amelyet nem célszerű/lehetséges hosszabb távon megtartani. -

freeapro
senior tag
Te azt írod, hogy ezen a területen nem számít a könnyű programozhatóság. Ha 10 zseni kódol rá akkor igazad van, ha mégis ipari méretekben kezdenek fejleszteni rá akkor hatalmas probléma lesz. Egyszerűen azért, mert sem a sem a felhasználási terület, sem az alakalmazni kívánt emberek tömege, sem a használt toolok nem teszik lehetővé, hogy ilyen alacsony szintű problémákkal foglalkozz. Pl mert nem assemblerben fognak fejhleszteni, hanem matlabból generálnak kódot.
-
Abu85
HÁZIGAZDA
Andrew Richards az iparág egyik legelismertebb koponyája a complier technológiák területén. Ha ő nem képes valamire, akkor nem sokan. Nem véletlenül szerződtette pont őt az Intel anno. Drágán dolgozik, de pontosan tudták, hogy szakmájában ő a legjobb.
Az Intel arra kérte őket, hogy tanáccsal lássák el a mérnökeiket. Ezek a szakemberek pedig megtették a legjobb tudásuk szerint. Az már az Intel saját döntése, hogy nem fogadták meg a tanácsaikat. Nyilván a vezetőség gazdaságilag vizsgálta a kérdést, míg a szakemberek technikailag írták le a helyzetet, hogy egyáltalán az, amit az Intel elgondolt működhet-e. Ők azt mondták, hogy nem, és az eddigi gyakorlati produkcióból is az derült ki, hogy igazuk volt. De nyilván a pénzügyi szakemberek jobbnak látták, ha nem hallgatnak a mérnökökre.
-
freeapro
senior tag
Egy nagyon specialis, nagyon vekony piaci reteg igenyt igyekeznek ezekkel kielegiteni a gyartok. Amikor pedig ennyire specialis termekrol van szo, hidd el, nem lesz problema a programozokkal megiratni a f*sza kodot. Mint ahogy arrol sem lehet sokat hallani, hogy a Tesla kapcsan problema lenne a programozas.
Ez butaság. Csak azért nem látod problémának mert a projektek és fejlesztők köre is igen limitált. Ezek egymást lassító tényezők. Azt kizártnak tartom, hogy az AMD azért lépjen be erre a piacra, hogy egy szűk szegmenst kiszolgáljon. Ezekre a masszívan párhuzamos rendszerek hamarosan nagy mennyiségben lesz szükség (egy területet mondok: önvzető járművek) és akkor ott lesz az igény a könnyű programozhatóságra. Ha erre a piacra a tömegeket tudsz átképezni meglévő rendzserek minimális módosításásval akkor nyertél.
-
Abu85
HÁZIGAZDA
Az x86 alapjait több éve rakták le. Természetes, hogy egy újabb tervezésű ISA jobb lehet nála. Ez egyszerűen csak a fejlődéssel megmagyarázható. Nem véletlenül cserélgetik a gyártók a GPU-architektúrák ISA-ját pár éves ciklusokban. Aki azt hiszi, hogy ez megkerülhető az előbb-utóbb belefut egy óriási falba.
Hogyan oldja meg a hardver? Ezek szerint a KNL csak emulálja az x86-ot? Van benne egy új ISA, amit már skálázásra terveztek hardveres szálkezeléssel és szinkronizálással? Ez nekem új információ.
-
Abu85
HÁZIGAZDA
Andrew Richards a CodePlay elnök-vezérigazgatója volt mindig is. Az Intel egy rakás magasan jegyzett és elismert szakmai zsenit felkért a projekthez, akik segítették a munkát. Ezek az emberek ugyanakkor eltávolodtak az Inteltől, amikor a cég nem fogadta meg a tanácsaikat. Ezek közül a legfőbb az volt, hogy dobják az x86-ot, mert nagyon öreg ISA, és nem is tervezték túl skálázódóra a memóriamodelljét. Persze az Intel kifizette a szakértelmüket attól, hogy nem fogadták meg a tanácsaikat, csak ezek az emberek nem akartak úgy a projektben részt venni, hogy tudták, hogy nem fog működni. Ezért a szerződésüket felbontották.
-
Abu85
HÁZIGAZDA
Nem értem a PR katasztrófa részét. Az Intelnek azt kell megértetnie a programozókkal, hogy amit eddig tapasztaltak a FirePro vagy a Tesla rendszerekről az a Phi esetében nem teljesen igaz. Amit az egyetemen tanítanak az a Phi-nél nem teljesen igaz. Egyszerűen csak fel kellene erre hívni a figyelmet, és leírni, hogy mire kell optimalizálni. Nagyon sokszor elhangzik az előadásokon, hogy a mai vektorarchitektúráknál a függőségre nem kell figyelni, mert ez már nem limitálja a feldolgozást, de ez a Phi-re nem igaz. Ugyanígy a szinkronizálás és a szálkezelés. Majd megoldja a hardver? Egy csomó rendszer igen, de nem a Phi. Ha ezekről beszámolnak az pont azt szorgalmazza, hogy a programozó jobban megértse a hardvert.
-
Abu85
HÁZIGAZDA
Nekem mindegy, hogy az Intel oktat-e belőle vagy sem. Nekik nem lesz jó, ha nem tudják használni a hardvert.
Ki mondta, hogy a SIMD szar? Ez jó, csak nem olyan könnyű, mint a SIMT. És a Xeon Phi kihasználatlanságához nagyban hozzájárul az, hogy a programozók nem tudják hogyan kell programozni. Ez részben az Intel felelőssége, mert a "plusz két sor a meglévő OpenMP kódba és minden fasza lesz" szöveg mellé adhattak volna támpontot is.
Tehát ha meg tud írni a programozó két szálra egy 128 bites SSE2 kódot, akkor ebből következik, hogy 288 szálra is tudnia kell 512 bites AVX-et?
Hallgass meg egy pár Andrew Richards előadást. Ő dolgozott a Phi-n és megpróbálta meggyőzni az Intelt, hogy ez a koncepció nagyon nehéz lesz a programozóknak. -
Abu85
HÁZIGAZDA
Széles SIMD-ek esetében a koncepció ugyanaz. Az AMD és az NV megoldásai esetében annyi a különbség, hogy a programozónak nem kell törődnie a vektorizálással a SIMT modell miatt, míg az Intel koncepciójában ez egy kritikus rész.
Az Intel nem véletlenül hozott OpenCL-t a processzoraihoz. A helyzet az, hogy ezen egyszerűbb programozni széles SIMD-eket, mint vector intrinsics-szel. Nagyon sokan ezért szeretik az OpenCL-t, és nem feltétlenül a GPGPU-s lehetőségek miatt.
Ne gondold, hogy egyszerűbb vector intrinsics-szel 512 bites SIMD-eket kivágni manuális szinkronizálással 280+ szálra. Az Intelnek arra kellene figyelnie, hogy megértesse a programozókkal, hogy ez nem annyira könnyű, mint a GPGPU paradigmák, amelyeket ráadásul megszokott a piac. Ez sokat segítene a KNL helyzetén.
-
Abu85
HÁZIGAZDA
Mivel a szálkezelés és a szinkronizáció nem változik, így a programozónak ugyanazt kell csinálnia.
Annyiban igen, hogy az Intel mondta, hogy a meglévő OpenMP kódok használhatók lesznek. Sokan ezért választották ezt a gyorsítót, mert az Intel így promótálta. Aztán amikor kiderült, hogy ez nem igaz, akkor kidobtak egy OpenCL-t rá. A gond az, hogy az OpenCL alatt a legtöbben úgy közelítik meg a Phi-t, mint a FirePro és a Tesla rendszereket. És ez okozza a rossz megítélést. Nyilván másra nehéz gondolnia egy programozónak, minthogy rossz a hardver, ha egy FirePrón és Teslán tökéletesen működő kód Phi-n nem működik.
Az Intelnek el kell magyaráznia a piacnak, hogy a Phi nagyon specifikus rendszer, amit sokkal nehezebb programozni, mint a GPGPU-kat. Ez biztosíthatná a Phi jövőjét. -

lenox
veterán
Hat per gpu nincs kijebb tolva a tdp, nem tudom, az miert lenne erdekes mondas, hogy pl. 100 gpu-nak nagyobb tdp-je van, mint egy apunak, nyilvan a tdp skalazast per chip erdemes nezni. Szamomra mint irtam skalazhatonak tuntek az apuk eddig is tdp-ben, te irtad, hogy de a dgpu-kat jobban/kijebb lehet, de a valosagban meg nem skalazzak oket 250 watt fole.
De ha jo a klaszter, akkor xeonbol is jok lennenek az 1-2 utasak is, tehat az nem az a feladat, amikor specialis megoldas kell.
-
Abu85
HÁZIGAZDA
Ma az ipar arról beszél, hogy 48 000 Xeon Phi-t nem használ a Thiane-2, mert nem tudják befogni. Ez nem az első eset. Az első Knights terméket az Intel ki sem hozta, mert tudták, hogy rossz. A másodikat kihozták, majd mikor kiderült, hogy nem úgy működik ahogy ígérték megdobták a piacot egy OpenCL meghajtóval. Azokat a megrendelőket, akik direkt azért kértek Xeon Phi-t, hogy úgy használják ahogy az Intel ígérte és ne OpenCL-en keresztül. Mennyi bizalom maradt?
Nem az x86 miatt bukdácsol a Xeon Phi vonal, hanem leginkább amiatt, hogy azok a programozási paradigmák, amelyek kialakultak nem működnek rajta. A hardver egyébként működik az Intel assembly példakódjaival.
-
lenox
veterán
Tesla k80 az ket gpu, nem egy...
Ahova a 8 socketes xeon e7 keves, ott egy apu nem tudom, mit fog kezdeni, szerintem semmit. Mondjuk olcsobb lesz, annyi elonye lehet, meg kevesebbet fogyaszt, de teljesitmenyben tul sokra nem fogja vinni szerintem, vagy legalabbis akkor azt a feladatot nagyon erre kell kihegyezni, nem tudom, mi lehetne az...
-
Abu85
HÁZIGAZDA
Nagymértékben meghatározza a rendszer működését a szálkezelés. A legfőbb oka annak, hogy a mai gyorsítók hardveres szálkezelést és hardveres szinkronizációt használnak az, hogy a programozó képtelen lenne biztosítani a manuális kezelésüket és szinkronizálásukat. A Xeon Phi esetében is látszik a probléma, mert se OpenMP, se OpenCL alól nem lehet igazán használni.
A Phi egy újszerű paradigmát igényel. Figyelembe kell venni az algoritmust és nem az a jó, ha mindegyik magot befogják, hanem az, ha annyit fognak be, amennyivel gyors lehet. Ha ez csak 10-20 mag akkor annyit, de érdemes limitálást figyelembe venni, mert sokszor ettől gyorsul. Ez az oka annak is, amiért a Xeon Phi az iparág által el van könyvelve szarnak. Pedig nem rossz, csak nagyon speciális programozást igényel. -
lenox
veterán
1. Itt van nalam m6000, k80, w9100, w8100. Nincs rajtuk tobb, mint 16 GB, szoval ha ezekhez eleg, akkor egy apun is eleg lenne. Vagy lehet, hogy az nem jott at, hogy ezt a szokasos sokcsatornas memoria melle kepzelem, nem helyette.
2. Nem tudom, top500-ban nem sok ilyen van, tippem szerint ezzel a top500-nak megfelelo piacra akarnanak menni.
3. Melyik gyorsiton van 250 wattnal nagyobb tdp-ju gpu, amit HPC piacon hasznalnak?



![;]](http://cdn.rios.hu/dl/s/v1.gif) "
"








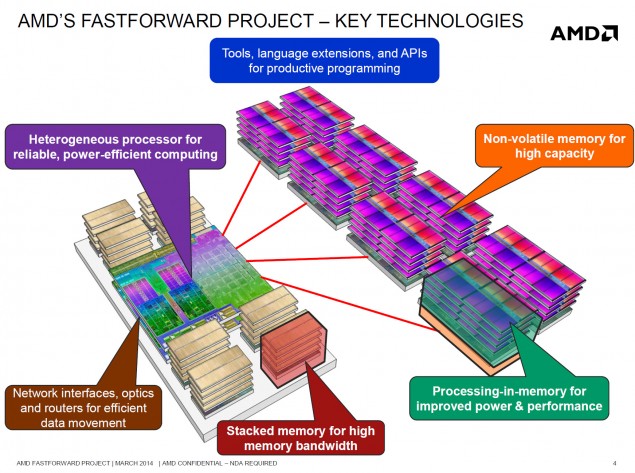
 .
.Új hozzászólás Aktív témák
Hirdetés

- ViewSonic VG700b monitor 17" 1280 1024 DSUB, DVI, beépített hangszórókkal
- Telefon felvásárlás!! iPhone 13 Mini/iPhone 13/iPhone 13 Pro/iPhone 13 Pro Max
- Csere-Beszámítás! Intel Core I9 14900KS 24Mag-32Szál processzor!
- Telefon felvásárlás!! iPhone 12 Mini/iPhone 12/iPhone 12 Pro/iPhone 12 Pro Max
- ÁRGARANCIA! Épített KomPhone i5 12400F 16/32/64GB RAM RTX 5060 8GB GAMER PC termékbeszámítással
Állásajánlatok

Cég: CAMERA-PRO Hungary Kft
Város: Budapest

Cég: Promenade Publishing House Kft.
Város: Budapest