- Nem növel telepméretet a Galaxy S26 Ultra
- iPhone topik
- Google Pixel topik
- Motorola Edge 50 Neo - az egyensúly gyengesége
- Apple Watch Sport - ez is csak egy okosóra
- Milyen okostelefont vegyek?
- Samsung Galaxy A55 - új év, régi stratégia
- MIUI / HyperOS topik
- Samsung Galaxy Watch7 - kötelező kör
- Xiaomi 14 - párátlanul jó lehetne
Új hozzászólás Aktív témák
-

5leteseN
senior tag
válasz
 S_x96x_S
#2207
üzenetére
S_x96x_S
#2207
üzenetére
A RTX 2080Ti/22GB 5-600$,
- a "gyári", használt "Etalon" (RTX 3090/24GB) 6-700$ az eBay-en,
- az RTX 4090/48GB 2.500-3.000$ Kínából, megbízható kereskedőtől(a magasabb ár körül), de
akár Moszkvából is![;]](//cdn.rios.hu/dl/s/v1.gif) ,
,
- az RTX 4090/96GB pedig 6-7.000$, szintén Kínából.
Sima LEGO-zott, és szépen-csomagolt AI-hardver már nem elég, mióta Kína is beszállt az üzletbe!
-
5leteseN
senior tag
Ernie egész jól, kevés hibával tud magyarul, és az általánosságokkal próbálgatott esetekben nálam jó volt!
Mielőtt egy reménybeli feltaláló elkezdené találmányai finomítására használni: Természetesen jelent Pártunk és Államunknak(Kína), viszont a magyar jogi kérdések jó eséllyel kívül esnek az érdeklődési körén!
...egyébként: Az amcsi AI/MI-k is jelentenek, természetesen a saját-Gazdának!
"Szép Új Világ..."
Ezek tudatában is lehet velük előnyt kovácsolni.
Jelenleg még nem tud keresni a neten, a "Search" az csak a saját doksikban való keresést jelenti!
Abból viszont jóóó sokat lehet csatolni, és a megadott max. méret körülire vagdosva egy csomó törvénykönyv is belefér szerintem!
-
5leteseN
senior tag
Ha szimpla keresés, matek, fizika, statisztika, "egzakt-tudományos" terület, akkor -saját tapasztalat szerint szerint- jobb ha a "Temperature" fedőnevű érték (magyarul inkább "Kreatívitás") le van tekerve 0,2-0,4 közé. Különben a valós eredmények, hasznos válasz helyett jön hülye ötletek alapján a teljesen elszállt bla-bla-bla szöveggekkel, +alig releváns infók.
-
5leteseN
senior tag
Szép összefoglalás volt!
Köszönet!

Androidos ChatGPT-ről: az ingyenes viszonylag jó, nekem nem lassul, de nem is kódolás. Technikai/technológiai dolgaim szoktak lenni, lehet, hogy már rám is állt az Echelon(utódja).
+ 
Mi a módja/"ára" ennek a szerintem lelkes-amatőr szinten jó kezdetnek:
- az elején azzal indítok, hogy közlöm vele, hogy milyen téma-terület,
- és + a : 'Rövid válaszokat kérek!" megy a végére.
- amikor elfelejtem ez utóbbit, 3-5-szörös méretű, azonos információ tartalmú válaszokat kapok, + az 50-250 karakteres felesleges udvariaskodást.
ez utóbbit, 3-5-szörös méretű, azonos információ tartalmú válaszokat kapok, + az 50-250 karakteres felesleges udvariaskodást. 
- mostanában már nem várom ki amíg ilyenkor amíg lelassul, törlöm-újrakezdem a nem-elfelejtett "Rövid válaszokat kérek!" mondattal zárva az első bejelentkezésem.
- Nekem, ezekre a trükkök a nem túl speckó(de elég mélyen belekérdezős) témáimra jó szok' lenni.
- Amikor elfogyott az ingyenes ChatGPT, akkor meg megvárom azt a kb 5-? órát, amire újra munkaképes.Kicsit komolyabb alapszinten nekem még ennyi elég.
Ha-amikor több kell majd, azt már fizesse majd a cég akinek a munkáján dolgozom.
-
5leteseN
senior tag
válasz
 freeapro
#2077
üzenetére
freeapro
#2077
üzenetére
Példák(Gemma3 12B/27B-Q3-4):
Négy-öt sokszögű síkidomból összerakható alaprajz alapterületének és légköbméterének a számítása: Ok.
Nem programozok, elég speckó, abban az online szolgáltatók profi szinten jobbak is.
Technológiai kérdések(titkos ): OK
A Haiku-teszt: Nem ment. Nem meglepő.
Egyéb "ismerkedések", tesztkérdések magyarul: OK. Szerintem. -
5leteseN
senior tag
válasz
freeapro
#2073
üzenetére
Nekem (elméletileg) elég 2x2080Ti/22GB=44GB VRAM is, de ezek a x4/x8 GPU-s infók maradtak meg emlékeimben a korábbi kereséseimből.
Nálam még mindig a GEMMA3-ak a nyerők,
teljesen szabadon használhatóak,
viszonylag jól törik a magyart,
és mellékletekkel is tudnak dolgozni....de ez az én egyéni véleményem, az én nem szakterület specifikus igényeim alapján.
-
5leteseN
senior tag
válasz
 sanya1111
#2070
üzenetére
sanya1111
#2070
üzenetére
Szia!
Ha van egy átlagos(de inkább jobb) PC, akkor egy Q4-Q5-Q6-os kvantálású 32Gb-os modell fog futni egy 3090Ti- 24GB VRAM-ján.
Melyik modell(ek) jók a kinézett feladatra?
Az említett RTX 3090 24GB VRAM-jába a 32B-s modelleknek is van beleférős változata(szerintem).
eBay/RTX 3090: 600€-850€-ig kb.
Szerintem ebben a VRAM méretben a VGA-GPU-k még gyorsabbak az 'Almáknál".
Igazán csak a nagyobb méretű modelleknél van gond(32GB modellméret felett)a fogyasztóknak szánt VGA/GPU-k használata esetén, mert itt már elfogy a VRAM, és 32GB RAM(és felett) már az Apple is a GPU-s nagyok isarany-gyémánt-áron adják a teljesítményüket.
Ha saját vas kell mindenféleképpen, akkor 32-64GB-os saját GPU kell, amik 1000$-tól indulnak, felső határ ebben is a csillagos ég. -
5leteseN
senior tag
OpenRouter:
Ha nem programozás, hanem általános, de komolyabb kérdéseim vannak, akkor nálam a DeepSeek 0324 egész jó, magyarul
 !
!
Mióta az első kérdés után oda írom, hogy"Rövid, lényegre törő válaszokat kérek ezentúl!", azóta kb 3x több potya-kérdésem lehet! ezekkel szoktam kísérletezgetni mielőtt elkezdem apasztani a kreditjeimet.
Sajnos az OpenRouteren keresztül nem tudja az összes funkciót mindegyik modell: a ki-/bemeneti állományokkal, netes kereséssel voltak ilyen tapasztalataim 1-2 hete.
Azóta nem néztem. Lehet, hogy változott(remélem javult).. -
5leteseN
senior tag
válasz
 DarkByte
#2028
üzenetére
DarkByte
#2028
üzenetére
Publikus infó(beleegyezel, mint mindenki használat előtt), hogy a bevitt információid felhasználják a további tréningre, tanulásra, +az angol apróbetűs rész rejtelmi, hogy még mire.
Lásd a Microsoft, Apple, ... kiderült adatkezelési botrányai, amikből az ügyvédek elvitték a 60-80%-ot a többi maradt a pár-ezer összegereblyézett károsultnak a "csoportos kereset"-ből, meg a sok-millió teljesen kimaradt károsult.Sok más cégnél-modellnél is így van: "Szép új Világ!"

Egyébként tényleg egész jó, csak zárt modell, +szinte biztos ötlet-/infó-gyűjtő és -lenyúló funkcióval!
Lásd: Echelon!
...de ez már nem ide tartozik. -
5leteseN
senior tag
válasz
 Mp3Pintyo
#2006
üzenetére
Mp3Pintyo
#2006
üzenetére
A Gemma-3/27B-nek van jól használható modellje, ami a(z egyszer majd csak elkészülő) 22GB-os 2080Ti-men jól tud futni?
A rohanó AI-MI világban kicsit ragaszkodom a Gemma-3-hoz, mert viszonylag jól tud magyarul.Egyébként: Sok videód (és más Yt-videók alapján) Q5-Q6-ig van értelme letölteni, a Q8-asok már nálam "szét-kreatívkodják" az eredményt(emléxem: nálad is a tesztben).
-
-
-
5leteseN
senior tag
válasz
Mp3Pintyo
#1932
üzenetére
Negyed-annyiért a "csak" 85-95%-át tudó bővíthető kínai-tajvani verzió lesz, a szokásos 3-4 hónap múlva.
A nagyok elviszik az extra-profitos részt, azok pedig aki nekik egyébként is gyártják, azok meg a következő "munkásabb" piaci szakasz nyereségét.
Ez utóbbi piaci-versenyezős szakasz jó pillanatait-jókor elkapva lehet, tudunk majd nagyon jól járni.Tapasztalatom, nagyvonalakban.+ : Az ehhez a döntéshez szükséges (egyébként gyakorlatilag bárki számára kis kitartással megszerezhető) szakmai tudással, és gyorsan mozdítható €-$-Ł-okkal.
Ennél bővebben már nem tartozik a témához.
-
5leteseN
senior tag
Programozási feladatoknál is él a "Hőmérséklet" fedőnevű beállítási lehetőség(ami "Kreativitás" mértékét állítja be)?
Azért érdeklődöm, mert ilyen feladatnál pont hátrány(Gondolom én) a felesleges kreativitás, hiszen a programozási szabályokat is felülír(hat)ja, ami egyenesen vezet szintaktikai hibákhoz.
Ezt a "Hőmérsékletet" le szoktátok ilyenkor húzni alacsony(mennyire alacsony) értékre?
...mint említettem: HA van ilyenkor ez a lehetőség! -
5leteseN
senior tag
válasz
freeapro
#1899
üzenetére
Az jó!
Most nemtom' megnézni, mert a a második nV-s VGA-m nem fér be tőle 2 slotra lévő VGA aljzatba a felette lévő 2,5-slot-os 2080Ti túlméretes hűtése miatt.
Körbenézek valami gyorsabb és sok-VRAM-os de csak egy-slot-os nV ügyében. Kicsi az esély, ezek Quadro-k szoktak lenni, civilek ilyet ritkán vesznek a 3-4-szeres áruk miatt.
-
5leteseN
senior tag
válasz
 5leteseN
#1891
üzenetére
5leteseN
#1891
üzenetére
Most vettem észre, hogy a csatolt képen csak egy 3090 van, tehát annál a konfignál nincs mit összeadni.
Mintha írtad is volna, hogy egy korábbi állapot volt a két VGA-s összeállítás.Most már nem tudod ezt a két-VGA-s esetet megnézni az LLM betöltődéssel(hogy az összevont méretű VRAM műxik-e)?
-
5leteseN
senior tag
válasz
freeapro
#1889
üzenetére
1,
2, Azt esetleg meg tudnád nézni, hogy az összegzett VRAM mérethez illeszkedő méretű LLM-et csak a VRAM-okba tölti, vagy használja a rendszer RAM-ot is(kár lenne).
Ez utóbbinál ugyanis "bekapcsol" a rendszer RAM sebességéhez tartozó "csiga-biga üzemmód", amit a visszaeső token/mp számból lehet észrevenni(+a hosszabb "kávé-szünetből"). -
5leteseN
senior tag
válasz
freeapro
#1884
üzenetére

freeapro : "LM Studio egy gépben több VGA-t is tud kezelni észrevehető sebességcsökkenés nélkül. (3070+1080ti -t teszteltem)"Ez sem rossz! Ez igazán akkor lenne főnyeremény, ha összeadja a VRAM-okat!
Összeadta?
Az sem lenne rossz, ha a két LLM-es üzemmód(Spekulatív dekódolás, EBBEN a videóban ) esetén az egyik VGA-n (a kissebben) futna kis LLM, a másikon a nagy.
...vagy csak álmodozom? -
5leteseN
senior tag
válasz
Mp3Pintyo
#1878
üzenetére
Tehát ha van két(akár nem azonos típusú)2080Ti 22GB-osom, akkor 44GB méretnek látja a program?

"Annyi" a gond csak(ha jól értem), hogy ebben az esetben a két 2080ti közötti sebesség lesz a szűk keresztmetszet(igen, tudom: botlenek
), de kétszeres méretű LLM-ekkel tudok dolgozni, az egy 2080Ti-nél valamivel( még nem tudni mennyivel ) lassabban?Ha ezt kb jól láttam, akkor már csak az lenne a hab a tortán (de dúsan
), ha a Windows-os Linux-on(WSL 1-2 ?) is futna ez az exo...! LM Studio-t is kérek...
PLs-pls.. -
5leteseN
senior tag
A Qwen2.5 14B Coder LLM állítólag egész jó a programozás területén. Nem tudom, hogy ezen belül hol-miben.
Ez a tudás összemérhető a "Nagyok" on-line gépeivel?
Saját gépen is futtatható, 12-16GB VRAM-os VGA már elég a magasabb szinthez: LM Studio, gondolom máson is(Olama, ...). -
5leteseN
senior tag
Erősen javasolt egy 8GB(+os még inkább) VRAM-os VGA beszerzése, mert CPU-s üzemmódban hamar ideges leszel a sok várakozás alatt elfogyasztott sok kávéktól (is)!
Számokban(LM Studio, a magasabb érték a jobb):
- CPU: 6-7 token/mp, /
- AMD VGA(Vega56=>64, tuningolt): 22-30 token/mp /
- nVidia(2080Ti alap beállítások): 45-58 token/mp. / AI-MI-t CPUval az
LM Studio-n(LLM-chat),
a Krita-n(kép, video-animáció, ez utóbbihoz brutál PC-VGA kell),
és mintha a Fooocus...is tudná az előzőek három üzemmódját(CPU-s, VGA-s: AMD/nVidia).
-
5leteseN
senior tag
válasz
5leteseN
#1826
üzenetére
A 3090 vs. P40 Yt-videó alól egy hozzászólás (gép fordítással):
@FromDesertTown 1 nappal ezelőtt :
" K80 cards are interesting old monsters - only $50 for a 24GB GPU (used). Sure, it's so old that it only supports up to CUDA 11.4 v4, so you're out of luck trying to run most models, and the technical specs are very lackluster other than the high VRAM, but it's sure to tempt some folks!""A K80 kártyák érdekes régi szörnyek - mindössze 50 dollár egy 24 GB-os GPU-ért (használt). Persze, olyan régi, hogy csak a CUDA 11.4 v4-ig támogatja, így nincs szerencséje a legtöbb modell futtatásával, és a műszaki specifikációk nagyon halványak a magas VRAM-on kívül, de néhány embert biztosan csábít!"

-
5leteseN
senior tag
válasz
 tothd1989
#1825
üzenetére
tothd1989
#1825
üzenetére
Én inkább egy nVidia TESLA P40-et javaslok, az "igazi" 24GB VRAM, nem a kérdéses 2x12GB. Ilyen "magában", PCIe=>EPS adapterrel(eBay: 200$ körül):

...asztali gépbe előkészítve(a +blower hűtővel, kompletten+, kb. 30€/$):

Korábban ide is linkeltünk egész korrekt értékelést a P40-ről, abból kb összegezve: szövegesekhez még jó, több P40-nel tanítani is, kép-videó generálásra már saját használatra is gyengusz, de belépőnek elmegy.
Saját kiegészítés: Kétséges, hogy jól(kb null-szaldós egyenleggel) lehet kiszállni majd belőle.Ilyen:

..is viszonylag megfizethetően kiépíthető(3x200$/€, + az alapgép), de igazán csak szöveges (chat) AI-MI-re, tanításra lesz jó, a kép-videó generáló szoftverekkel eléggé "várakozós".
AI-S induló start-up-nak, tanításra, LoRA, RAG kipróbálásra elég, kis anyagi kockázattal.A Yt-on szerintem pikk-pakk kidobja a P40 összehasonlítós videókat, köztük azt a szerintünk is elég-jó szakmait, amit már linkeltünk is.
Egy a sok közül, ami az etalonnak számító 3090-el hasonlítja össze(nem néztem meg, nemtom' milyen szintű értékelés):
ITT(Yt) .A végére: kis eBay-es "lesben állással" 50-100€ között komplett szervert(HP/DELL) is el lehet csípni hozzá 60(nekem sikerült 128GB) RAM-mal.
A két asztali gépes +hűtő egység-csomag(kb 2x30€) többe kerül!
...kis szerencsével! -
5leteseN
senior tag
válasz
tothd1989
#1818
üzenetére
A TESLA K80 2x12GB!! Gyanús, hogy egyben nem tudja 24GN-ként használni. A rajta használt Kelpler-GPU-t a mostani AI-MI szoftverek egyre jelentősebb része nem támogatja. Ez a folyamat csak rosszabb lesz.
Poénnak jó, jelentős napi gyakorlati használat szempontjából zsákutca.
Ahogy lassan a TESLA P4, P40 és AMD MI25ők is: elfogy alóluk a szoftver támogatás(CUDA, ROCm, ...).Ha nem szerverbe rakod, akkor még +venti-adapter és blower-venti is kell ám hozzá: +25-40€ összesen, kb!
Ismerős a helyzet P40 tulajdonoskén!
-
5leteseN
senior tag
válasz
5leteseN
#1803
üzenetére
Az előzőekhez tartozik a Thunderbolt-5 10GBps-os valósnak becsült sebességéhez képest, hogy a jelenleg többségi használatú alaplapokban a DDR4-ek 35-60GBps közötti sebességűek, kétcsatornás üzemmódban(tipikus-általános, megfizethető-kategóriás asztali-PC).
A DDR5-ösök ezt tudják duplázni 50-120GBp közé.
A Ph-Fórumos DDR5-legjobbra(házi-rekordra) én kb 150GBps-ra emlékszem, V.I.P-RAM-mal, vízhűtéssel, tuning-alaplappal, és természetesen ezek árával +a saját tesztelő-beállító munka.
A Thunderbolt-5 esetén az ezzel összehasonlítható érték ugye az azonos mértékegységbe konvertált 10GBps, és a x4-5-6-ős összeaddó érték az almás kütyük esetében(az első TH-5 100%, a többi x0,7 kb).Így összehasonlítható értékekkel kerek a "történet".
-
5leteseN
senior tag
válasz
S_x96x_S
#1800
üzenetére
Igen,
ez volt az az adat, amire említettem is, hogy nem 100%, hogy jól emlékszem.Ez már egy szép érték, ehhez jön szűk keresztmetszetként a gépek közötti Thunderbolt 5-ös 120Gbps-ából a kb (általam becsült ! )valósnak tippelt és konvertált 10GBps x 4-5-6(Tb-5).
...ha kell majd egyáltalán egy M3 Ultra felhasználónak, mert ugye az 512GB-ba már minden "civilnek" szánt LLM bele fog férni aki rászánja az x-millió(mennyi is ) HUF-ot/€-t/$-t...A piaci-keresleti mérleg serpenyőjében ott leszünk még sokáig majd az ehhez képest sokszor több millióan a korábbi(tipikusan 8-16GB között VRAM-mal szerelt) VGA-kal .
Ezek miatt a piaci arányok miatt nem aggódok azon, hogy nem lesznek rövid időn belül az általam említetthez hasonló további megosztott szoftverek illetve általános+célterület LLM párosítások. A mostani (valóban megdöbbentően eredményes ) Instruct-modelles szoftver alkalmazás mutatja az ebben rejlő lehetőségeket.Józan fejlesztő csoportok (szerintem) szntén eljutottak eddig a lehetőségig, és (úgy gondolom, hogy) már dolgoznak erre a logikusnak tűnő szoftver-válaszon.
...megemlítettem, mint egy (nekem logikus)lehetőség a naponta felbukkanó újak között!Megtaláltam közben: az 512GB RAM-os Ultra M3 4,5millió HUF.
-
5leteseN
senior tag
válasz
S_x96x_S
#1796
üzenetére
A más IT technológiák hasonló párhuzamos működése alapján, ezeket az adatokat:

...figyelembe véve, én úgy tippelem, hogy a (kb csak) laboros körülmények(között lehetséges) 120Gbps-os sebességéből a valóságban 100Gbps lesz.
A szintén IT-technológiák párhuzamosításából átemelve a gyakorlati tapasztalatokat (Pl CPU-k, és sok más terület...), az első almás-kütyü RAM-sebessége(ha jól emlékszem 250GBps körüli). A "Fő-gépet" teljes (250GBps-os) teljesítménnyel számolnám, de a többit kb. 0,7-es szorzóval.
Ez alapján (szerintem):
1, Az öt Tb5-ös rendszer adatátviteli sebessége "összesítve" kb (250GBps+(4x10GBps x 0,7)=320-350GBps.
2, A négy TB 5-ösé pedig a "százassal" csökkentett: 280-300GBps.
(Nem véletlen lett a B vastagbetűs: a bit/s-t "áttettem" kb Byte/s-be.)
Ha jól tudtam az fő-(almás-)gépben meglévő RAM-sebességet, akkor ennyire tippelem a valós számokat. Ha nem akkor ezzel a jó értékkel behelyettesítve érvényes.Magánvélemény:
1, Nem estem hasra! Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB ) VRAM-ja van, a 3090-eknek pedig "csak" 24GB.
Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB ) VRAM-ja van, a 3090-eknek pedig "csak" 24GB.2, Ez a leírtak alapján megtett saját becslés. Tévedhetek is.
3, Érdekel majd a tényleges (teszt-)érték: pár hónap!!
Ilyen értékekre lehet hogy nem lesz teszt, de a gépek közötti teljesítmény különbségből megállapítható lesz, hogy a kettő kiépítés(öt Tb 5-ös vs. négy Tb 5-ös) közötti különbség ennyi lesz-e?
Szerintem a szoftveres feladatmegosztás és csak ezek eredményeinek mozgatása sokkal többet hozna a konyhára!
A valós élet példájából "pont most" :
A kis(04-1,5GB-os) előkészítő LLM 30-80%-kal növeli a hozzá jól illeszkedő nagy(kb 6-20+ GB-os) LLM hatékonyságát.
Az pedig egy sokkal kisebb programozási feladat(szerintem már dolgoznak rajta), hogy a kis LLM egy "kis" VRAM-os/kis teljesítményű kártyái is igénybe vehessen, mert egy PCIe3-4-5(SLI-Crossfire) elég a két(több) kártya közötti kommunikációra, hiszen ekkor "csak" az előzetes eredményeket kell továbbítani.Az AI-MI-re vágyó átlagos(fizetőképességű) felhasználók széép-nagy tömege miatt lesz ilyen irány is!
Még mindig: szerintem, de !Széljegyzet: remélem, hogy jól értelmeztem az idézett képen lévő Gbps-t: "Gigabit per secundum"!
-
5leteseN
senior tag
válasz
S_x96x_S
#1792
üzenetére
Gyanítom, hogy a szűk keresztmetszet a két almás-kütyü közötti sávszélesség lesz!
Az mennyi is(elméletileg-papíron)?Jut eszembe: Az egy almás-kütyün belüli sávszélességet/sebességet lehet, hogy írtátok már, de nem emlékszem.
Az elég jó volt egy VGA-hoz képest?
Az alakuló (külföldi)közmegítélés szerint a 3090 kb az etalon.Széljegyzetbe: egyre gyakrabban röppen fel hír a 48GB-os 3090(Ti ?)-ről.
-
-
5leteseN
senior tag
válasz
Mp3Pintyo
#1776
üzenetére
Annyiban pontosítok, hogy a letöltéskor zölden kiemeli az LM Studio az általa a a VRAM-ba betölthető méretűnek gondolt állományokat. Ezek minden esetben 6,5 GB alatt vannak, pedig a VRAM ugyebár 11 GB a 2080Ti-nél. Ezt ki is írja a megfelelő helyen, tehát tudja a program.
Lehet, hogy ez a program egy kisebb hibája. Kinek mi a gyakorlaban a tapasztalata?
Például: egy 10GB-os LLM mekkora VRAM-ot igényel összesen? ...mert ugye gondolom, hogy a VGA-ban történő műveletekre is igényelnek ezekre plusszban még valamennyi memóriát. -
5leteseN
senior tag
Azt a Puli-s csapat helyében én megnézném, hogy egy magyar-angol fordítót is tartalmazó rész bele lehet-e tenni egy "Instruktor" LLM-be.
Egy ilyennel minden, az Instruktort használó LLM egy-csapásra megtanulna magyarul.
Egyszer kellene egy alapot megcsinálni, valamelyik már meglévő PULI-... erre a feladatra optimalizálásával és "kicsinyítésével".A nagyokat megcsinálnák helyettünk, és ezen keresztül mégis tudnánk a "pöttöm 15 milliónkkal" is használni!
-
5leteseN
senior tag
válasz
S_x96x_S
#1728
üzenetére

S_x96x_S
addikt:
"ouch ... A 96GB RTX 4090 - valószínüleg fake
"384 bit = 24 VRAM Chip w. clamshell = 4GB(32Gb) density per chip. I think it is fake. Afaik, there is no 32Gb density chip one."
https://x.com/harukaze5719/status/1893959550346108975"Ez is jó lenne "holnap":
Reddit
Technical-Titlez
• 1y ago
3090Ti has 24GB using 8 IC's. 3090 has 24GB using 16 IC's. Certainly seems possible to mod a 3090 to 48GB using the same VRAM IC's from a 3090Ti.
-
5leteseN
senior tag
válasz
 consono
#1757
üzenetére
consono
#1757
üzenetére
A Discord-ba "Általános "(Mp3Pintyo-) betettem a CPU:VEGA56(tuningolt:+15%):2080Ti
...token/mp-ket egy régebbi LLM-től és egy DeepSeek Qwen2.5-től is. Utóbbi nyert...
A Qwen2.5 kicsi-párját még nem volt időm megkeresni a spekulatívhoz. Még min 30% javulás lenne szerintem.
-
5leteseN
senior tag
válasz
Mp3Pintyo
#1723
üzenetére
Biztos van ilyen is. Lesz is.
Én azt látom, hogy olyan gyors a fejlesztés, hogy, hogy aki a (még sokáig jelentős mennyiségű) nVidia 2000-es felhasználókat nem veszi figyelembe, az gyorsan kiszorul a többi univerzálisabb, felhasználó-érzékenyebb AI-szoftver miatt, amik ezt a jelentős létszámú réteget is el szeretnék érni.
Kb órák alatt jönnek ki az újabb verziók, amik pár száz visszajelzés miatt módosulnak. Ha valamelyik szoftver "kell" és kimaradtam belőle a 2080 miatt, bizony én is "dobok" 1-2-3 e-mailt! Mindezen véleményem mellett jelenleg az átlag felhasználói rétegnek a 3090(Ti) az Etalon. Indokoltan!
Ezért van viszont egy (szerintem, jelentősen) túlárazott helyzetben a 3090 és a Ti, amire pedig nekem van "válaszom"! -
5leteseN
senior tag
válasz
tothd1989
#1722
üzenetére
A piac ennyire árazza be: kb 300€. Kis "lesben állással" én általában elcsípek jelentősen jobb vételeket. Ezt bárki megteheti.
Most még annyi 5letet bele vittem, hogy nem az 500$-os 22GB-os 2080Ti-t vettem meg, hanem egy 11GB-osat alig több, mint fél-áron. Már úton van.
Egy "szomszéd" cég ár alatt megcsinálja a 22GB-ra bővítést, némi ismeretséggel "alátámasztva".
Azon is gondolkozom, hogy a korábbi saját tudásomat felfrissítem erről a hw javítás-építés területről...Összeadva a két előnyt, nekem biztos megéri. Akinek szintén van ilyen tudásból-ismeretségből átkonvertálható árelőnye. annak is, bőven.
Aki meg nem szán 8-900€-t egy 3090-re, annak is....szerintem.
-
5leteseN
senior tag
Kis érdekesség az AI-MI hardver oldaláról: Megérintett ez a "RTX 2080Ti/22GB VRAM" téma. Kíváncsiságból bejelöltem az eBay-en pár 2080Ti-t(11GB-osakat). Az elmúlt pár órában egymás után jöttek az eBay értesítések, hogy mind a fél-tucat 300€ körüli 2080Ti elkelt!
Még jó, hogy pár napja megvettem magamnak egy 11GB-osat, amit egy kinézett, közeli cég átépít nekem 22GB-osra, ééés: "AI-boldogságosság"!

Ha esetleg valaki tud a 2080Ti-hez "tuti" VRAM beszerzési forrást, szivesen fogadom az infót.
-
5leteseN
senior tag
válasz
5leteseN
#1710
üzenetére
Minden rosszban van valami jó: Kb. negyedáron megcsíptem egy "majdnem-3090"-et!
Ha valaki bomba-(fél-)áron szeretne RTX 3090 tudást(AI-MI-re) akkor jelenleg ez az egyik jó választás(a nem túl sokból)
Összehasonlítás a korábbi kedvencemmel(RTX 4070Ti 16GB VRAM) és a szinte Etalon-nal(RTX 3090 24GB VRAM): ITT
ITT pedig, ha durván adod elő(gondolkodom rajta ):
3090 vs. 2x2080Ti 22GB !
Figyelem: Ez utóbbi teszt "csak" játék összehasonlítás, SLI-s 2080Ti-kel, nem AI-MI teljesítményeket vet össze! A játék teljesítmény (még) nem vehető át 1-az-1-be AI-MI-k esetére, mert a jelenlegi AI-MI-k (még csak !! ) egy VGA-t tudnak használni!
Szerintem(is) kb fél-, más-fél-év múlva jönnek ki ezek a- AI-MI szoftver megoldások. Én készülök! -
5leteseN
senior tag
A hazai másfél milliárdos piaccal is "kihúznák", de lesz az a duplája is(ha csak a fizetőképességet számolom) a "maradék" 6-7 milliárdból!
Túl tekintve a száraz technológián: Ha úgy magamban minden a helyére teszek, akkor (sajnos ismét) igaz a klasszikus: "Az idő nem nekünk dolgozik!"
Ismét a vesztes oldalon vagyunk!
-
5leteseN
senior tag
...és egy "fekete ló" a lopakodó pályán:
Reports Suggest DeepSeek Running Inference on Huawei Ascend 910C AI GPUs(TechPowerUp)Az nVidia részvényeket nem kell sokáig tartogatni! Hamar jöhet egy újabb bezuhanás egy kínai meglepi-bejelentés után!
Ezúttal mondjuk a hardver oldalon, "a változatosság kedvéért"! -
5leteseN
senior tag
válasz
DarkByte
#1656
üzenetére
Igen, az MI25 éppen hogy csak kicsúszott a W-L-es ROCm támogatásból, Linux alatt az MI50 talán benne marad majd a továbbiakban.
Az MI25-eim pedig valószínűleg (BIOS-)"átvillannak" és újjászületnek WX9100-ként, a 3D/CAD(esetleg "filmvágósok") megfizethető örömeként.
...ha sietek! Átállok és is a "zöld-oldalra"!
Nincs időm kivárni, amíg az AMD 1-2 évtized alatt behozza a CUDA-ban tárgyiasult lemaradását GPU architektúrában és szoftverben.. -
5leteseN
senior tag
válasz
Mp3Pintyo
#1654
üzenetére
Hááát, ezek azok amiknél eddig mindig kiderült, hogy mindent is eladtak, attól függetlenül, hogy minden tikosságosságot (is) megígértek? Kb a ".. zúgy hajjak, meg ha eee-mondom bárkinekis!" szintjén vannak!
..de csak, magunk közt, ne mondjuk el senkinek ezt az eddig, utólag közel 100%-ban bejött igazságot.
Pont a múlt hetek egyikén fizetett közel 100 millát ($) a Microsoft egy USA pertársaságnak(abból is kb 70%-ban az ügyvédeknek), hogy ne érdeklődjenek tovább a lehallgatott és eladott infóik után!
A véleményem, röviden-velősen: " " -
5leteseN
senior tag
válasz
DarkByte
#1651
üzenetére
 : "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
: "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
..."Erre várok már kb egy éve("pár" AMD MI25-tel)!
-
5leteseN
senior tag
válasz
5leteseN
#1644
üzenetére
A kérdésem: A 2080-nak felépítéséből adódóan van alapvető hátránya az AI-MI szoftverek Windows-os futtatásánál a 3090, 4000-es, 5000-es sorozathoz képest, ami miatt hosszú távú hobbi alkalmazásra nem ajánlott?
..vagy csak a teljesítményhez képest fajlagosan egyre magasabb fogyasztás a hátránya a modernebb nV-s GPU?-khoz képest
-
5leteseN
senior tag
válasz
 moseras
#1642
üzenetére
moseras
#1642
üzenetére
...csak azért merült fel bennem a kérdés, mert a 2000+ $-s Jetson tudja azt kb, mint max (2x)350$-s 2080Ti, amiből kettő rutinszerűen összerakható.
Az is tény, hogy a Jetson (papiron) ezt 60W-ból tudja, a kb két generációval korábbi 2x2082Ti-s változat meg összesen kb 600W-ból.Persze lehet van más oka is.
AI-MI-re most minden pénz megvan, ez e különbség nem oszt, nem szoroz.
Ez a terület most kb az új "NASA Holdra-szállás", presztízs szempontból.
A többi szempontot kívülállóként meg sem tudjuk ítélni! .
. -
5leteseN
senior tag
válasz
tothd1989
#1638
üzenetére
Mint szintén szerver újrahasznosító tag(ML350p G8, +egyebek...), örülök az ebből a szempontból is gyarapodó csapatnak.
Windows alatt az AMD-k mostoha-gyerekek
, tom', nekem is azok vannak.
Az én MI25-ösöeim a Linux-os ROCm alól is éppen kicsúsztak , talán néhány hónapon belül hozzá hekkeli valaki.A szervert igazán egy reiser-rel kivezetett és kb 4x4-esen elosztott kűlső kiegészítéssel lehet kihasználni, az így megteremtett több VGA-t virtuálisan egyesítve és utána "vmi"(W10-11, Linux,...) alatt futtatva a 2-3-4VGAx0,85(kb az "összehangolási veszteségeket megadó
szorzóosztó") szeres AI-MI teljesítménytSzóval: "Üdv a fedélzeten!"
. -
5leteseN
senior tag
válasz
 Zizi123
#1612
üzenetére
Zizi123
#1612
üzenetére
Én a cég részére történő (kb felesleges ? : lehet, hogy már van egy előre meghozott döntés, szóval ezen)keresés közben összeszednék a helyedben annyi infót a lehetséges költséghatékony hw/sw megoldásokról amennyit lehet! Ha ezt némi otthoni érdeklődéssel, "munkával" kiegészíted, akkor jól megbecsülhetően a kb 1, azaz egy hét intenzív és célirányos munkáddal (a Net-en) nagyon-nagyon jól eladható, friss-naprakész tudásod lesz!
Ebből a tudásból meg akár jobb állásod, saját céged?
...de: ahogy látod!
-
5leteseN
senior tag
válasz
Zizi123
#1610
üzenetére
Én is azt javasolnám, hogy(ha vannak ilyen variációk), akkor a tervezett 2-3-4 hardvert futtatnám szolgáltatónál, és ezt megmutatnám döntés előtt!
És én nem terveznék a 600GB-os LLM-mel: Mp3pintyó videója mutatta, hogy a legnagyobb teljesített a leggyengébben.
Szerintem heteken belül kijon egy felezett és jobb teljesítményű modell.
Egy LLM-hez összerakott, rugalmatlan, nehezen bővíthető és változtatható "vas" a legnagyobb bukta egy ilyen gyors fejlődés alatt álló területen!
A jó megoldás egy kisebb LLM, +szakterületes-RAG/-LoRA kiegészítés a megoldás.
Ehhez sejthető feladathoz a Watt-égető CPU-s megoldások durva pénzkidobás. Vásárláskor is, üzemeltetéskor is.
Az azonos fejlettségi szintű, azonos-elégséges memóriás rendszerek összevetésében a GPU-s megoldások 6-20-szoros teljesítményt tudnak, kb 50-100% Watt-ból.Több szempontos gyors összevetés.
-
5leteseN
senior tag
válasz
consono
#1606
üzenetére
Jogos, én is a linkeltnél egyel magasabb generációra utaltam, a P40-kkel, amik azért négyen már 96GB-al szállnak be a "buliba".
Ezt pedig azért gondoltam elégnek, mert korábban ZiZi említette a kisebb(vmi 400GB) körüli, egy számmal kisebb LLM-et is.
Ez kb a 4-5-ös kvantálással már szerintem belefér.
Most hirtelen nem találom ez mekkora lenne.
Mekkora?Szerintem egyébként gőzerővel készül a kisebb kínai LLM-is!
Mire megépül a rendszer, addigra ki fog jönni!
Pezsgő? -
5leteseN
senior tag
válasz
Zizi123
#1603
üzenetére
Én a helyedben(ha lennék) egy olyan "átlagos", AMD-CPU-s szervert raknék össze, ami sok-csatornás DDR5 RAM-ot használ, és minél több VGA-ja van a későbbi (több-VGA-s
) fejleszthetőség lehetőségét megteremtve.
Ha egy CPU-val nem elég=>megfizethető összegű CPU "miatt" maradt és a +1 "átlagos" szerver CPU-val lesz egy immár duál rendszered, aminél, ha jól vetted a RAM-okat, akkor nem kell további, csak átcsoportosítasz!
Ha ez sem elég, akkor én vennék a már 250$ körüli-"filléres" TESLA P40-eket, amiket egymással össze lehet kötni: 24GB/db!
A számítási teljesítményük grafikás AI-MI-hez már nem elég, de linkeltem ide a forrást, ahol "azt dobta a Gép" az egyik értelmes elemzőnek, hogy szöveges LLM-ekhez belépő szintre elég!
Az Egy P40! ...a 24GB-tal!
Neked meg lesz egy szervered legkevesebb 4 VGA hellyel!
...és(szerintem) a 3-4 TESLA P40, az összegzett 3-4x24GB-jával szöveges LLM-hez már bőven elég, és szerintem a 3-4x250W-ból bőven leveri a keretedből megfizethető csak dupla-Th-tripper-es rendszereket is.
kb ezért, még mindig: A rendszer-RAM-ok (GPU-VRAM-okhoz képest)viszonylagosan lassú sebessége miatt az átlagos AMD-CPU-kat sem fogja a lehetséges maximumra kihajtani.
Az elavultnak tűnő P40-ekkel épített rendszer szerintem bőven veri a csúcs-AMD-s duál szervert is, és a CPU-ár különbözetből bőven ki is jön a P4q "farm"! A "belépős" P40-ekhez: Szerintem fél-egy éven belül legrosszabb esetben féláron eladható, és 2-3-4 szintén összeköthető nVidia-s 4000-es RTX-re lehet váltani, kb bőven megtripázva a GPU számítási szintet, alig kevesebb RAM-okból(24GB helyett "csak" 16GB-ok/darab=>4x16GB=64GB).
Így szerintem jól skálázható egyre feljebb a rendszer, lesz pénz a következő szinthez, és teljesen költséghatékony kb minden szintnél!
A magam egyéni-hobbi szintjén én is ilyet tervezek-csinálok!
-
5leteseN
senior tag
válasz
Zizi123
#1591
üzenetére
... és arról sem szabad elfeledkezned, hogy a két CPU dupla RAM-sebességet tesz lehetővé!
Ez pedig nagyon kell a CPU-knak AZ AI-MI-ben. Ezért tippeltem azt, hogy a két gyengébb CPU az összességében kb dupla memória teljesítménnyel (szerintem) jobb AI-MI teljesítményt hoz, mint az egy(de feleslegesen erősebb)CPU, mert a felezett adatmozgatások miatt nem tudja kihasználni az emiatt felesleges számítási kapacitását.
A RAM-sebesség többet számít, mint a CPU számítási teljesítmény!Nem pontosak az idézett számok, de íme egy VGA RAM(DDR5, DDR6. ...) sebesség és teljesítmény táblázat:

Én az E5-2680 V4-es XEON-ból 4-csatornásan, 2.400MHz-en, alig tudok kifacsarni egy kicsit 41.000 MBps RAM-teljesítmény, ami a fenti táblázathoz átváltva és felkerekítve is csak 42GBps!
Két csatornával a fele a memória teljesítmény és mint írtam, 30-50-??kal kevesebb volt a CPU-s AI-MI teljesítmény!A fenti XEON CPU-m az INTEL laborban tud max 77BGps-ot.
A már elég lepukkant, és MI-re csak belépő szinten alkalmaz RADEON VEGA 56(=>64) VGA-m(jobb alsó sarok: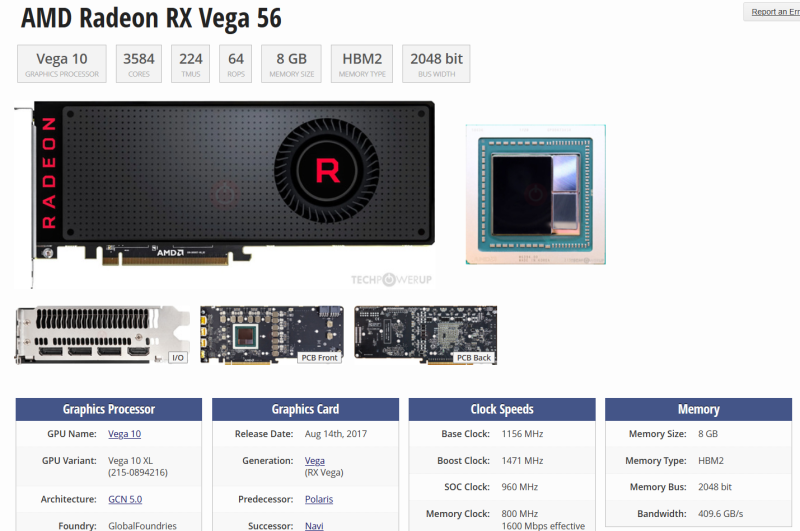
...tud kb 410GBps-ot! Opszi...
A RAM-Témában most írta az egyik tag, hogy a csúcs Ryen-je a csúcs DDR5 RAM-okkal tud 2-csatornásan 150GBps-ot."Jó" feladatot kaptál!
-
5leteseN
senior tag
válasz
Zizi123
#1588
üzenetére
Pont az AI-MI-re nem tudom a választ az 1-CPU kontra 2-CPU kérdésben, de CAD-CAM feladatoknál 1-2 éve az E5-26xx-sorozatoknál tartósan, átlagban a duál processzoros munkaállomás csak 1,4-1,7-es teljesítményt tudott az azonos, de csak 1-CPU-s összeállításhoz képest.
Ez itt most más terület, mert az adatmozgatás is nagyon sokat számít, és dupla CPU dupla memória-sebességet jelent. Nem CPU-k számítása főleg a szűk keresztmetszet az AI-MI-ben(ha jól látom), hanem jóval ennek a számolási szűk keresztmetszetnek a belépése előtt már a RAM-ok miatt satu-fék van.Ezeket az infókat összeadva Én egy "nem-csúcs-processzoros, két-CPU-s" rendszert raknák össze, a lehetséges leggyorsabb RAM-okkal, lehetséges legtöbb memória-csatornás üzemmódot használva.
A neten nézelődve, és korábbi ismereteimet összerakva dobja ezt a "Gép"! Érdekelne majd egy teszt!
Jut eszembe a végére: E5-2680V4 XEON, 64GB DDR4 RAM/4-csatornás üzemmódban a Geekbench 6. az AI teszt alatt 5.200 körüli pontot hozott!
Ugyanez a gép, de csak 32GB RAM/2-csatornás üzemmódban alig több, mint 4000 pontot.
Ez saját mérés volt, nem egy "hallottam, vkitől, aki hallotta..." infó!Azt viszont nem tudom, (mert erre nem mértem akkor), hogy a különbséget befolyásolta-e, hogy az egyik esetben 64GB volt az azonos MHz-es RAM(de 4-csatornán), míg a másik esetben csak 32GB(két csatornán).
"Sorry!"

-
5leteseN
senior tag
válasz
S_x96x_S
#1582
üzenetére
Nekem ey>
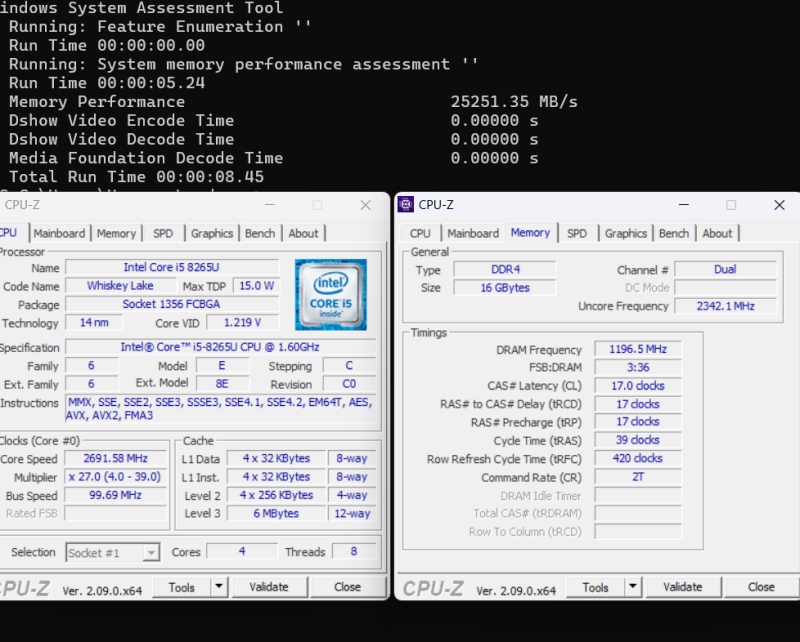
...a laposom(DELL Latitude 3500, DDR4/2400MHz, két-csatornás RAM) ennyit tud a "winsat mem" parancsra: 25.521MBps.
Nálad mennyi RAM, hány csatornán megy, hogy megvan a kb 4 token/s?Lehet, hogy lemérem én is W11-alatt(a tied Linux-os).
Milyen llama és melyik LLM?
...csak hogy ugyanazok legyenek, a jó összehasonlítás alapjaként!
Érdekel, hogy vajon mennyi lesz a különbség és kinek a javára:
L : W ? -
5leteseN
senior tag
Lehet, hogy gyorsan le kellene tölteni a Huginface-ről amíg-lehet/amíg-hagyják DeepSeek és a Qwen LLM-eket, "de-gyorsan"?
Óvatosan a mesterséges intelligenciával, új szabályozás érkezett, és nagy büntetések jönnek(Index)
Egy Tik Tok kizárására emlékeztető forgatókönyvet látok a háttérben, az üzlet-rontó "kici-kínai" megoldással szemben, ismét.
Elvégre: MekkelMenteniA Világot/-demokráciát/...
-
5leteseN
senior tag
A Megszólított által készített vió alapján telepítettem a Faster-Whisper-t, ami bő egy éve is egész jól végezte a dolgát angolról(szinte bármiről) magyarra. Azóta az újabb verzoókat is gyűrőm, mikor szükség van rá, jobbak lettek.
Saját tapasztalat alapján javaslom a Faster-Whisper-t
Gyorsan egyszerűen telepíthető(volt, amikor kb fél éve felraktam az aktuális verziót, nem hiszem, hogy rosszabb lenne, +remélem ). -
5leteseN
senior tag
Nálam is a telefonon a ChatGPT a nyerő. A többi az elsö válasz után elveszi a kedvem a folytatástól. Már csak kéthetente nézek rájuk, hónapok óta sokkal bénábbak, mint a ChatGPT.
Nagyon spec témákat nem kérdezek, de általában jól nyomja. összefüggő szövegeket is jól fogalmaz, angolul is magyarul is. A fordításokban sokkal jobb mint a többi fordító program.
...nálam-nekem. -
5leteseN
senior tag
A legutóbbi videóban említett " Self-hosted AI starter kit, módosított: https://github.com/coleam00/ai-agents... " AMD VGA-n tud futni?
-
#1453
5leteseN
senior tag
hiperFizikus
#1452
5leteseN
senior tag
válasz
 hiperFizikus
#1452
üzenetére
hiperFizikus
#1452
üzenetére
...háát, egyik Bádogember verzió sincs meg és akkor még az esti sörök számával exponenciálisan növekvő 5tletes változatok fel sem merültek!
Szóval kell(ene) az a saját-gépes AI!
-
5leteseN
senior tag
Én ezt úgy próbálnám megoldani, hogy az általános AI-MI-t kiegészítem.
Először egy szakmai tudással kiegészített LoRA tűnt jó megoldásnak, majd a RAG (szinten a szükséges szakmai tudás-kupaccal feltöltve) tűnt még jobbnak.
Sajnos ezek annyira újak( mint az egész AI-MI terület), hogy nincsenek közkézen az ehhez szükséges "Tools"-ok és oktató anyagok, pedig rengeteg órát keresgélem ezeket. -
5leteseN
senior tag
Ha valami olyasmire gondolsz(ami nekem is vágyam lenne), hogy: tudja megoldani azt a problémát, hogy egy pörgős Suzuki motorhoz rakjon egy áttételt, ami leviszi motor kedvező fordulatszám tartományát 2500 körülire és tegyen az ide csatlakozó propellerhez egy állásszög vezérlő lehetőséget is, és mindez bírja ki, a motor max teljesítményét(+50% biztonsági tartalék), akkor (szerintem) ez az a VALÓBAN használható tudásszint, amit soha nem fognak kiadni a "Nagyok" kezükből(ingyen)!
...cserébe kapjuk folyamatosan a parasztvakítást!
Valami nevedből következtethető kapcsolódó példát hoztam(talán sikerült).
A leírt példával próbáltam jelezni, hogy értem a problémát!
Értem? -
5leteseN
senior tag
válasz
Mp3Pintyo
#1274
üzenetére
"...
ApplicationsGraphRAG: running Microsoft's
GraphRAGusing local LLM withipex-llm
RAGFlow: runningRAGFlow(an open-source RAG engine) withipex-llm
LangChain-Chatchat: runningLangChain-Chatchat(Knowledge Base QA using RAG pipeline) withipex-llm
Coding copilot: runningContinue(coding copilot in VSCode) withipex-llm
Open WebUI: runningOpen WebUIwithipex-llm
PrivateGPT: runningPrivateGPTto interact with documents withipex-llm
Dify platform: runningipex-llminDify(production-ready LLM app development platform)
..." -
#1078
5leteseN
senior tag
lockdown90
#1075
5leteseN
senior tag
válasz
 lockdown90
#1075
üzenetére
lockdown90
#1075
üzenetére
Több AMD:
* 1db VEGA56=>64-esre "villantva"(BIOS-flash),
* 2db MI50=>Radeon VII-re, vagy Pro VII-re villantva(ahogy éppen kell-akarom),
* 3db MI25=>WX9100-ra villantva. -
5leteseN
senior tag
-
5leteseN
senior tag
válasz
S_x96x_S
#1070
üzenetére
"A CPU-nak: max 40 PCIe 3.0 sávja van. ..."
A sok (főleg megfizethetőség)szempontból versenytárs Ryzen-eknek meg a fele se. Van a Ryzen-nek 2-csatornás RAM-üzemmódja, amivel valóban lehet arany-árony a gyorsabb DDR5-RAM sebességet letenni az asztalra a jelen esetben 5GBps körüli négy-csatornás DDR3-as helyett, majd megduplázva az említett aranyárat lesz is
felenegyede RAM, mint ez esetben a "kis-öregnek"(2011-3): 128GB. Nekem még ott van a "kis-öreges vas"(2011-3) esetében a tarsolyban a RAM-disk-es futtatás is!
Linux-nál lazán megy(toram ).
Az alapra írják egyébként, hogy 2x16sávos VGA és 1x4sávos VGA van rajta, teljes(16 sávos aljzattal mindegyik)."...Vagyis modern GPU-t nem tudsz kihajtani vele..."
Miért nem?Ha drága az alap rendszer akkor tudok venni bele kezdetnek egy 3090-et, vagy 4060Ti 16GB-ot.
Ezek az AI programon többségénél az AI szoftvet(és modell/LLM/*.safetensor) betöltés után szinte csak a GPU-n dolgoznak. A PCIe3.0-ból 4 csatorna is elég a jelenlegi szoftverek esetén.Ha "fejhető" átlag-felhasználók többségének ez-ilyen VGA-ja van(lesz) akkor ezen a szoftver irányon nem is fognak tudni(akarni) változtatni a kereslet-kínálat törvénye alapján.
"...és egy modern SSD-vel se tudod etetni a GPU-t."
Miért nem tudom? Van 2 PCIe3.0-s SSD-m, szofveres RAID0 alá teszem őket!
Nicsak: Megvan a PCIe4.0-ás sebessége , és szerintem 2x1TB Gen3-as SSD olcsóbb, mint egy 2TB-os Gen4-es.A PCIe5.0-ás ellen valóban maradna a RAID0-ás (kétszeres PCIe3.0=) PCIe4.0-ás sebesség, de ez már olyan, mint amikor a(z ironikus) Playboy-karikatúrában a azon vitáznak ketten , hogy a Ferrari a tulajdonosnak jobb, vagy a Bugatti gazdinak, miközben órák óta ülnek a városi dugóban!
Igen, a PCIe5.0-s SSD sebességét ezzel a 2011-3-as alaplappal nem lehet elérni(csak a PCIe4.0-ásét), de a kettő közötti különbség a gyakorlatban jelentéktelen, viszont az ármegtakarításból a GPU-ra fordítható összeglátványosan megnő, és egy fél-professzionális AI-vas teljesítménye lesz kiépíthető így! ...gondolom(és csinálom) én!
-
5leteseN
senior tag
Elvesztem az AI/MI futtatáshoz ideális, és ár-érték arányban jó(kiemelkedő) "vasak" keresésében(és találásában) az AliExpress-en: rám rúgta az ajtót egy ajánlat, amiben három-VGA-s, 2011-3-as alaplapot adnak, E5-2666v3 CPU-val(bőven elég lesz 5 évig az AI/MI-s VG-ak alá), és döbbenetes (4x32GB=)128GB DDR3 RAM-ot adnak vele. Ez mind kerül kb 120€-ba adó nélkül. Mivel ez nem reklám(hanem ismeret, annak aki "vasat" szeretne), a pontos linket nem írom be(a helyi szabályokat tiszteletben tartva), de döbbenetesen jó ajánlatnak tűnik alapgépnek. Bár a RAM "csak" DDR3-as, de mivel négy-csatornás, ezért közel olyan teljesítményt tud, mint a legdrágább DDR4-ek, amik megfizethető áron vehető alaplapokban csak két-csatornás RAM üzemmódot tudnak, szinte mindig csak: egy VGA-val, csak dulpa-RAM lehetőséggel, kevesebb max-RAM-mal, stb...
Ez azoknak szólt főleg(gondolom én), akik átlag áron nagyon jót akarnak, közben készülve a multi-GPU-s időkre!
-
5leteseN
senior tag
válasz
 gabranek
#1052
üzenetére
gabranek
#1052
üzenetére
Nekem teljesen "PíSzí" promt-ok alatt is 5-6 egy-képes generálásból egy kép homályos, egy paca csak. Nem értettem miért, de akkor most már megvan.
Az az érdekes eredmény tűnt még fel, hogy a CPU-s(E5-2673v3) generálás nem többszörös idejű a VEGA
5664(re BIOS-villantott) eredményéhez képest az Advanced módban, ahol természetesen minden más beállítás azonos volt! Ma estefelé újra rá is nézek a programra.
Az eddig kedvenc Foocus-nál szerintem is sokkal gyorsabb, de az Amuse-tól a "sima" üzemmódban sokszor csak a klasszikus Rejtő képregények stílusa jön.
A sokkal több lépés nálam sem javított, hanem ront!Nem rossz, de remélem gyorsan jönnek frissítések és javítások!
-
5leteseN
senior tag
válasz
Mp3Pintyo
#1046
üzenetére
Gyűrjük egymást keményen az AMD-s AI-újdonsággal(Amuse).
Még ismerkedünk, van jó is rossz is, viszont erősen jobb, mint az eddigi kb semmi !
Mivel az eddigi semmi/alig-valami( a CUDA-hoz képest) nagggyon-qrva gáz (szerintem) az AMD-nek. Úgy sejtem, hogy jönnek majd ezerrel az újabb fejlesztések is rá.
Szerintem a ROCm "faragása" is megy közben ezerrel a háttérben!Köszönet!
-
5leteseN
senior tag
Számomra király hírek jöttek a Discord-csatornádra, már töltöm is a Yt-os Amuse ismertető videó alatti linkről a Amuse-t
Kb az AI-s AMD-sek előre hozott Karácsonyi Ajándéka(Amuse) jött meg!
Kösz-kösz! -
5leteseN
senior tag
válasz
5leteseN
#1032
üzenetére
Miután feltöltöttem új X99-es "barátom" DDR3-as RAM helyeit, gondoltam, megnézem, mi a helyzet a Piacon, és "leültem"!
Ezért: 128GB RAM(4x32GB) 60€ körül DDR3-ból és 70€ körül DDR4-ből. Ráadásul az eBay-es rápillantás után nem győzöm elzavarni őket(Kösz, nem kérek árleszállításost sem, stb...), mert még mindig van egy csomó RAM-om a polcon.
Úgy hogy lazán megéri X99-re alapozott alap-rendszert összerakni(ha valakinek nincs erre a célra korábbi PC-je), mert harmad áron kijön, mint az asztali elemekből összerakott új Ryzen+DDR5 rendszer, annál ugyan 20-30%-kal kisebb CPU-RAM sebességgel, DE cserébe 2-3-szeres RAM-mérettel!
A RAM-ok esetében nem is biztos a sebesség-lemaradás, mert a szokásos Ryzen-ek csak 2-csatornás módban dolgoznak a gyorsabb DDR5-ös RAM-okkal, míg az ebben az üzemmódban nem sokkal lassabb DDR4-ek a szerverprocesszorokkal négy-csatornás üzemmódban "tolják", ősszességében tehát gyorsabbak!
Ott van még (a rövidesen learatható bónuszként) a több VGA-s üzemmód lehetősége is az X99-es platform mellett.Érdekességként:
- kínai X99-es alaplap 8xRAM, 3xVGA: 70€ körül
- Ryzen 3600X szintű CPU: 20-30€
- 128GB DDR4 RAM: 70€
- Bónusz: 2-3(-4+ +20-40€-ért) VGA használat lehetősége!!!
- kétCPU-s alaplap ártöbblete: 30-40+ €.Az nem szabad elfelejteni, hogy VGA-k 5-10(akár-15)-ször hatékonyabbak(RTX 3090), tehát egy dupla-CPU-s (csak-CPU-val dolgozó) AI-PC kb egy gyenge nVidia VGA tudását közelíti, 3-szoros fogyasztással!
A CPU-s rendszer előnye viszont, hogy a csillagászati árú(3090, és 4000-es nV-sorozat) tagjai is csak 16-24GB VRAM-mal rendelkeznek, tehát például egy 40GB-os Flux ugyan úgy CPU-rendszer-RAM összeállítást fog használni(ha van elég a drága asztali RAM-ból) kb dupla sebességgel, mint egy csak CPU+RAM-os X99-es PC.Minden jónak tűnő hír ellenére: Csak CPU-val tartósan nem éri meg AI területen ismerkedni, de (szerintem ! ) jó, és sokkal megfizethetőbb kiegészítője egy X99-es (sok-RAM-os, +sok-VGA-s) gép, mint egy ide(AI) nem optimális jelenlegi (tipikus)új asztali-PC!
Ha már a Flux.1 Image Generator szóba került: ITT lehet online próbálgatni, e-mail-es regisztrálás után.
"Nem rossz, nem rossz..." -
5leteseN
senior tag
Kellemes meglepetésként tegnap megjött az AI-s szupergépem(remélhetőleg az lesz
) alaplapja Kínából. Elsőre indítva bejött a BIOS-t követő menü, majd lazán betöltötte sokat látott WinToGo(Windows10-es) rendszeremet: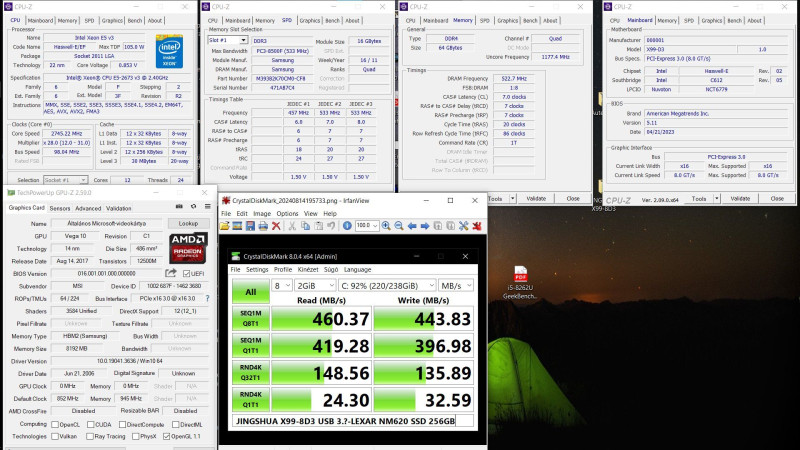
Az USB-s LEXAR(NM620) még kicsit jobban is megy, mit a hasonló korú Latitude 3500-ben, de még a családtag(szintén DELL) T8510-nél is gyorsabb kicsivel(pedig asszem ugyan az az Intel 612-es rendszer-chip alatt megy mindkettő).
Az is kijött, ami miatt az AI-ra jobbnak tartom, mint az eGPU-s laposokatt: a kb 50% órajellel lassabb DDR3-8500-as, 16GBos modulok négycsatornás üzemmódban gyorsabbak a DRR4-es SO-DIMM-eknél, mert bizony azok csak két-csatornás RAM-üzemmódban mennek a Latitude 3500-ban.
Számokban:
- Latitude 3500, DDR4-2400, két-csatornás üzemmód:26.000MBps körüli értékek,
- az X99-8D3 alaplap, DDR3-8500, négycsatornás üzemmód:
28.000MBps körüli értékek.
Elméletileg a DDR3-as RAM-jaim közel 30%-kal húzhatóak lesznek, megbízható működéssel, kis melegedés és +3-5W fogyasztás árán!
Nem viszem OFF-ba a témát, ennyi (mint "cél-hardver"
) szerintem belefér.
Zárásként a lényeg: Mindhárom VGA aljzat rendben van!
Mentem, építem a LEXAR NM 620 512GB-ra az AI-s Windows 11-emet. -
5leteseN
senior tag
válasz
 #79563158
#1029
üzenetére
#79563158
#1029
üzenetére
Én 20+ éve IT-felhasználó vagyok és és csak érdeklődés szinten(szerintem az átlagnál komolyabban) foglalkozom biztonságtechnikával. Ennek ellenére eléggé biztonságban érezném magam valami kényes témában utazó kkv-ként, ha a kényes időpontokban egy páncélból elővett SSD-ről futtatnám az AI-programomat a lehúzott-kikapcsolt vezetékes és Wi-Fi hálózatos kapcsolattal(vagyis így ugyebár azok nélkül) dolgozó PC-n.
Mindezt tenném azután kb, hogy a BIOS-vírusokat is ellenőriztem például egy live-Linux-os írtóval(egyszerírt-lezárt CD-DVD), és az SSD-n lévő eszközzel is.
Szerintem akár egy Op-rendszer indítás előtti BIOS-reset is segítheti még a biztonságom "illúzióját"!Ha pedig a misztikum világáig fokoznánk a dolgot, akkor elmerülhetünk a CPU-mikrokódok "egy-pöttyet" konteós világában is!
Ha ezeknél a korábban említett segédeszközöknél is betartottam a képzeletbeli kkv IT-szakembereként a biztonsági előírásokat, akkor jó eséllyel maradna az emberi-tényező kihasználása, mert mint tudjuk a klasszikusból: "Van az a pénz amitől korpásodni fog a haj!"
Kis poénnal vittem színt a szakmai hsz-be, és a jóval korábbi (BIOS-os ?!? )Stuxnet-es olvasmányaimból is tanultam, és annak az orosz gázvezeték-robbanásnak a "fatális véletlene" is szolgált tanulságokkal!
Ennél jobban nem akarok belemenni ebbe az OFF-os kitérőbe.
Érdekes lenne egyébként erről a kérdésről megkérdezni az AI-kat! -
5leteseN
senior tag
válasz
#79563158
#1027
üzenetére
Akkor szinte mindenben egyetértünk:
 Nem tartom valószínünek, hogy backdoor lenne benne(BIOS)
Nem tartom valószínünek, hogy backdoor lenne benne(BIOS)
Más formában, ugyanezt írtam!  ...(mondjuk azt sem, hogy a szakmai berkek megtalálnák a backdoort),
...(mondjuk azt sem, hogy a szakmai berkek megtalálnák a backdoort),
Miért is nem? ...de ha van benne, akkor nem csak akkor jelent problémát amikor érzékeny feladatokon dolgozol, hanem amikor hálózatra van kötve.
...de ha van benne, akkor nem csak akkor jelent problémát amikor érzékeny feladatokon dolgozol, hanem amikor hálózatra van kötve.
Írtam a megoldást! Annál jobb "Tűzfal" nincs!  Ha a belső hálózatodon van egy backdoorozott gép, akkor gyakorlatilag a teljes hálózatod úgy kell kezelni, mintha direktben internetre lenne kötve, mivel a fertözött hostról bármilyen eszközödet tudják támadni.
Ha a belső hálózatodon van egy backdoorozott gép, akkor gyakorlatilag a teljes hálózatod úgy kell kezelni, mintha direktben internetre lenne kötve, mivel a fertözött hostról bármilyen eszközödet tudják támadni.
Egyéni felhasználót írtam: Magamat!
Ha kellene(nekem, egyénként, egyáltalán) az említett biztonsági szint, akkor a kényes (AI-)időpontokban leválasztom a gépet. Én nem feltétlenül mernék ilyet használni szigorú hálózati szegmentáció nélkül, még akkor se ha van lokális IPS/IDS/tüzfal, mindig minden eszköz azonnal patchelve és hardenelve van, nincs gyenge jelszó, stb. De ugye mindenkinek más a kockázat éhsége.
Én nem feltétlenül mernék ilyet használni szigorú hálózati szegmentáció nélkül, még akkor se ha van lokális IPS/IDS/tüzfal, mindig minden eszköz azonnal patchelve és hardenelve van, nincs gyenge jelszó, stb. De ugye mindenkinek más a kockázat éhsége. 
Magad is írod a jó megoldást!
...gondolom én, még mindig, elég határozottan: A leggyengébb láncszem még mindig az Ember! -
5leteseN
senior tag
Maradjon kettőnk között
: Mikor a Szíriuszra küldött, gyík-embereknek címzett rádió-üzenet AI-s visszafejtését elindítom majd, úgy tippelem, hogy kihúzom majd a hálózati kábelt(és kikapcsolom a Wi-Fi-t is), bárki alaplapját is fogom használni! Komolyabban: Értem a problémát, és (naív-optimista módon) kezelhetőnek tartom.
-
#1020
5leteseN
senior tag
lockdown90
#1018
5leteseN
senior tag
válasz
lockdown90
#1018
üzenetére
Én is hallottam ilyen(a közlő által nem bizonyított) híreket. Nem tudom a választ. Ha találsz valami nemzetközi hírt erről, szerintem szivesen látjuk azt. Mind-e mellet az én becsléseim szerint az AI terület száguldási ütemét látva bármilyen "vas" 3-5 éves élettartamban utazik. Ez alapján pedig ha mégis ilyen "ezer évre" tervezett szerver csipeket (újra-)használnak, akkor erre a további 3-5 évre én személy szerint akkor sem nem aggódom.
Ezen meggyőződésem ellenére sem vagyok (elvakult) hívő, nem erőltetem senkire a dolgot, vannak alternatívák erre, a nem sokkal többek-jobbak, újak, sok év garanciával, olyan 10(+)-szeres áron.Érdekes lenne nekem is egy ilyen AI-területre összerakott "neves cél-hardver" kontra "kínai-vas" összehasonlítás!
-
5leteseN
senior tag
Részben akár jogos is lehet az aggodalom(mint minden más gyártónál is
). Részemről az AI-t off-line(netről lekapcsolva) futtatnám, ha olyan érzékeny területen dolgoznék vele és a probléma megoldva! Érdekessége a kérdésnek(és a válasznak), hogy az eddigi hírek szerint (ahogy én látom) az alaplap BIOS-a gyakorlatig nyilvános, visszafejtett, és jó eséllyel napokon belül futótűz szerűen terjedne a szakmai berkekben, ha mégis kínai hátsókapu lenne benne.
Az pedig alig 1000(+)% , hogy a nagynevű konkurenciák "objektív" háttéremberei is beszállnának a rémhír-terjesztős "buliba". Én ezek miatt gyakorlatilag kizártnak tartom. Ígéretet is teszek egy azonnali értesítésről, ha ilyet hallok, főleg mint aktuális felhasználó!


![;]](http://cdn.rios.hu/dl/s/v1.gif) ,
,







 ez utóbbit, 3-5-szörös méretű, azonos információ tartalmú válaszokat kapok, + az 50-250 karakteres felesleges udvariaskodást.
ez utóbbit, 3-5-szörös méretű, azonos információ tartalmú válaszokat kapok, + az 50-250 karakteres felesleges udvariaskodást. 

















 Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB
Ez kb a jelenlegi 2080Ti-m sebessége(616GBps), alatti bőven, egyetlen (de nagy)előnye az almás konfignak(a meglévő brutálka hype-presztízs mellett), hogy a 2080Ti-nek csak 22(-44GB  : "Nagyon "kicsi" magyar adatkészleten történt a tanítás."
: "Nagyon "kicsi" magyar adatkészleten történt a tanítás."


 : "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
: "...Várnám hogy az LLM szoftvereken túl kicsit több támogatottság jelenjen meg a multi-gpu felállások kezelésére. Otthoni használatra igazán nagy VRAM-os kártyát nem nagyon fogunk kapni mostanság, több esély lenne összefogni több "kisebbet" és felosztani közöttük a munkákat valahogy.
 .
.






 : "...A 3090, ha jól emlékszem valahol 280 környéke."
: "...A 3090, ha jól emlékszem valahol 280 környéke."






 Nem tartom valószínünek, hogy backdoor lenne benne(BIOS)
Nem tartom valószínünek, hogy backdoor lenne benne(BIOS) ...(mondjuk azt sem, hogy a szakmai berkek megtalálnák a backdoort),
...(mondjuk azt sem, hogy a szakmai berkek megtalálnák a backdoort), ...de ha van benne, akkor nem csak akkor jelent problémát amikor érzékeny feladatokon dolgozol, hanem amikor hálózatra van kötve.
...de ha van benne, akkor nem csak akkor jelent problémát amikor érzékeny feladatokon dolgozol, hanem amikor hálózatra van kötve. Ha a belső hálózatodon van egy backdoorozott gép, akkor gyakorlatilag a teljes hálózatod úgy kell kezelni, mintha direktben internetre lenne kötve, mivel a fertözött hostról bármilyen eszközödet tudják támadni.
Ha a belső hálózatodon van egy backdoorozott gép, akkor gyakorlatilag a teljes hálózatod úgy kell kezelni, mintha direktben internetre lenne kötve, mivel a fertözött hostról bármilyen eszközödet tudják támadni. Én nem feltétlenül mernék ilyet használni szigorú hálózati szegmentáció nélkül, még akkor se ha van lokális IPS/IDS/tüzfal, mindig minden eszköz azonnal patchelve és hardenelve van, nincs gyenge jelszó, stb. De ugye mindenkinek más a kockázat éhsége.
Én nem feltétlenül mernék ilyet használni szigorú hálózati szegmentáció nélkül, még akkor se ha van lokális IPS/IDS/tüzfal, mindig minden eszköz azonnal patchelve és hardenelve van, nincs gyenge jelszó, stb. De ugye mindenkinek más a kockázat éhsége. 

Új hozzászólás Aktív témák
Hirdetés

- Bomba ár! Dell Precision M6600 i7-2720QM I 8GB I 500SSHD I 17,3" FHD I Quadro I Cam I W10 I Gari!
- BESZÁMÍTÁS! GigabyteA620M R5 7500F 32GB DDR5 500GB SSD RX6700XT 12GB Bitfenix Nova Mesh Enermax 750W
- ÚJ HP EliteBook 840 G8 - 14"FHD IPS - i5-1145G7 - 32GB - 512GB SSD - Win10 - 6 hónap Garancia
- AKCIÓ! HP USB C G5 Essential (5TW10AA) dokkoló hibátlan működéssel garanciával
- Bomba ár! Fujitsu LifeBook U7310 - i5-10GEN I 16GB I 256SSD I 13,3" FHD I HDMI I Cam I W11 I Gari!
Állásajánlatok

Cég: Promenade Publishing House Kft.
Város: Budapest

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest