Hirdetés
- Redmi Note 14 Pro+ 5G - a tizenhármas átka
- Redmi Note 13 Pro 5G - nem százas, kétszázas!
- Redmi Note 14 5G - jól sikerült az alapmodell
- MIUI / HyperOS topik
- A Sony is belépett a 200 megapixeles klubba
- One mobilszolgáltatások
- Azonnali mobilos kérdések órája
- iPhone topik
- Google Pixel topik
- Milyen okostelefont vegyek?
Új hozzászólás Aktív témák
-
#8445
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
A Wccf szerint a Zen4X3D eredetileg tervezett dátumai: [link]
Announcement - Jan 23
On-Shelf - Feb 23 -
#8444
Petykemano
veterán
Petykemano
veterán
Azt mondják, például Magxarországon például azért is meglehetősen magas az infláció (túl persze a ismert külső és belső tényezőkön), mert az áremelkesések közepette a legkönnyebb árat emelni - akkor is, ha az egyébként nem indokolt költségoldalról, mert nem tűnik fel.
"TSMC To Increase Wafer Prices By 6% In 2022 In Order To Avoid Revenue Hit From Order Cutback & Amidst Rising Inflation"
A TSMC bevételei 15%-kal csökkennek a visszamondott / csökkenő megrendelések miatt és ahelyett, hogy csökkenne az ár, növelik. Nyilván azért (abban a reményben), mert most inflációs környezetben mindenki hajlandóbb felháborodás helyett benyelni. -
#8435
Petykemano
veterán
Petykemano
veterán
"But then look at what we’re doing with the Instinct MI250, is called elevated fan out bridge. So it’s a very, very effective lateral conductivity. In the future, you can combine that type of lateral conductivity with the hybrid bonding we did with the vertical cache, and this allows us to get much more effective heterogeneous computing – CPUs with the accelerators. But it does come at the cost of a longer cycle time, and certainly higher packaging costs than what we’ve had in our organic substrates. So you have to use it very judiciously."
[link]
Ez vajon egy SoIC-H használatára tett utalás? -
#8434
Petykemano
veterán
Petykemano
veterán
Ez kemény
Az SRAM nem skálázódik tovább N5-ről lefelé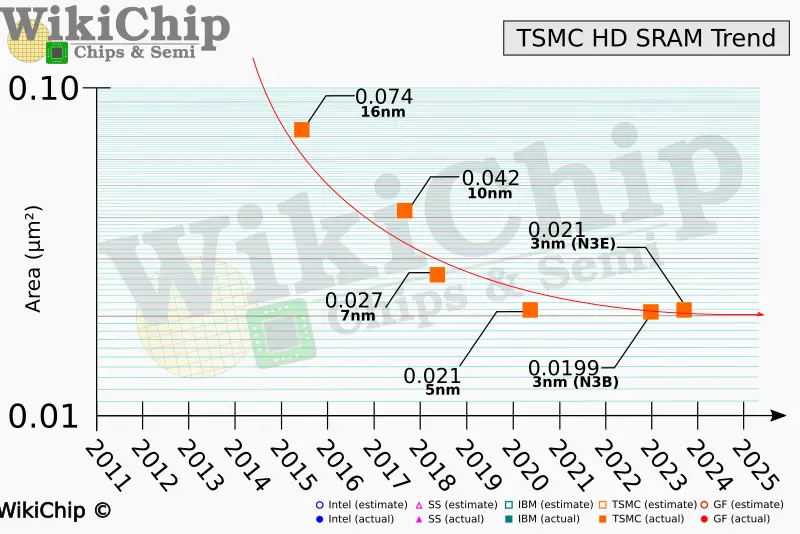
Úgy tűnik, az AMD épp időben - egy lépéssel a vége előtt - Indult el a chipletezés útján.
És úgy tűnik, nagyon nem volt alaptalan az az ábra, ami a CPU-ból kiemelt L3$-t jósolta.
Sokat lehet majd megtakarítani azzal, hogy sz SRAM N4/N5 lapkán marad majd, miközben a feldolgozók N3-ra mennek. -
#8423
Petykemano
veterán
Petykemano
veterán
.
-
#8418
Petykemano
veterán
Devid_81
#8417
Petykemano
veterán
válasz
 Devid_81
#8417
üzenetére
Devid_81
#8417
üzenetére
Szerintem...
A Meteor Lake lesz erre a válasz, ami igazán számít és ahol igazán számít.
Tudjuk, hogy a nagy sales nem a DIY piacon történik.
Ennek megfelelően a Dragon Range (ami a Twitteres források szerint a Raphaelhez hasonló képességekkel fog rendelkezni) lehet az igazi gyomros az intelnek. Főleg ha lesz mondjuk 7950HX3D is.Na erre nem tud megfelelő válasz lenni a Raptor Lake. Az intel fogyasztás mindegy alapon úgy szokott győzni, hogy jobban skálázódik. De egy 45-55W-os környezetben szerintem elvérezne.
Na, de a lényeg, hogy itt veszi fel a kesztyűt a meteor lake. Ami új gyártástechnológia, emlegetmek valami L4$-t is és valószínűnek tartom, hogy lentről felfelé fognak építkezni, mint a Tiger lake esetén.
Elméletileg a Meteor lake már tile based, tehát ez a felépítkezés remélhetőleg nem fog évekig tartani.
És szerintem ez fél év múlva meg fog érkezni.
Desktopon eleinte nem lesz versenyképes, de a cél mobile first.
-
#8412
Petykemano
veterán
Petykemano
veterán
"
They shared 3 exclusive Zen 4 3D info.
1) Three Ryzen 7000X3D model is confirmed. 16/12/8C. But about 8C model, it isn't determined model name whether7700X3D or 7800X3D
2) Unlike Zen 3 3D, clock speed will be same or at least almost same.
3) It is expect Jan 23. So CES."
[link] -
#8411
Petykemano
veterán
S_x96x_S
#8410
Petykemano
veterán
válasz
 S_x96x_S
#8410
üzenetére
S_x96x_S
#8410
üzenetére
Ez elég érdekes.
Látszólag a GPU és a CPU is chipletből áll.
Gondolom, hogy a HBM megosztott memória.
Vajon ez azt jelenti, hogy a CPU és a GPU saját is saját memóriavezérlővel rendelkezik, amelyhez csatlakoztatható HBM?
vagy
Lehet egy aktív interposer, ami tartalmazza a memóriavezérlőket és az infinity cache-t (L4$), és az tudja fogadni a HBM-et és a CCD-t, GCD-t is? NA ez lenne igazán ütős!Látszólag a GPU és a CPU is chipletből áll.
Vajon az ide készített építőelemek milyen mértékben lehetnek újrahasznosítva?
Vajon lesz rokonság, CDNA3 big APU és a mobil apu-k között? -
#8406
Petykemano
veterán
awexco
#8405
Petykemano
veterán
Szerintem a DDR5 önmagában nem. Az apuk jellemzően most sincsenek eleresztve sávszélességgel, teljesítményük nagyon érzékeny volt mindig is a DDR4 frekvenciára.
Ehhez képest rövidtávon 1.5, hosszabb távon 2x teljesítményt tesz lehetővé a DDR5Ami igazán nagy lépést jelenthet szerintem, az az infinify cache
-
#8404
Petykemano
veterán
Petykemano
#8402
Petykemano
veterán
válasz
 Petykemano
#8402
üzenetére
Petykemano
#8402
üzenetére
A kolléga szerint tehát
6WGP
PHX ~ RX570Szerinte a Dragon Range CPU irányú kitekintés
"PHX and Dragon overlap core count.
Difference is cache IO max power max core count iGPU performance.
1 WGP RDNA2 vs 6 WGP RDNA3."Ja és Desktopon 2023H2 elérhetőséggel, amikor az A620 lapok is érkeznek.
Ennek megítélése kettős.
Egyrészt persze az apu dinamikusan erősödik, ez tök jó, már eléri a 6 évvel ezelőtti mainstream teljesítményt.
Másrészről viszont ez az RX.6500XT (navi24) teljesítménye. Azt most épp $100-ért próbálják elsózni. Ez a 6WGP ahhoz nyilvánvalóan kevés, hogy ezzel váltsák ki az ~$300-os kártyákat.Valószínűleg nem véletlen, hogy abu azt mondta, a navi33 áll a navi 22-21 helyébe és a navi23 is még marad.
Az a kérdés, hogy vajon lesz-e meglepetés.
- egy nagy apu formájában
- navi34 formájában, ami a navi23-at váltja. -
#8402
Petykemano
veterán
S_x96x_S
#8400
Petykemano
veterán
válasz
S_x96x_S
#8400
üzenetére
Szerintem annyira nem meglepő, hogy amikor gyakorlatilag 2016 óta nem változott a $100-500 szegmensben a kártyák perf/$ mutatója, hogy
- az emberek némiképp elfordulnak a GPU-któl
- olyan eszközök felé, amelyek relatív olcsón, kompakt módon kínálnak jó teljesítményt és élményt
Ide sorolnám a MS/Sony konzol mellett az elmúlt évek kézikonzol slágerét (Aya Neo, meg Steam deck) - szerintem azok bevételei is a semi-customhoz mennek.Ez különösen igaz az elmúlt 2 év kripto-boom korszakára.
Persze lehet, hogy már nem lesz visszatérés az épített gépekhez.
- Akár amiatt, mert az emberek megszokják a kompakt konzolok által nyújtott kényelmet és a hátuk közepére sem kívánják a PC-t
- Akár amiatt, mert a gyártói lánc gondolja úgy, hogy visszamenni alacsonyabb marzsokkal a $100-500 dolláros szegmensbe versengeni, ott új értéket teremteni (újra ide idézném, hogy 2016 óta alig emelkedett itt a perf/$) túl kevés pénz, túl sok munka és persze kicsi piac és már nem hajolnak le érteSzerintem az AMD a PC piacon is még sokakat meg tudna venni egy PS5/Xbox kapacitású nagy APU-val, ha azért nem prémiumot akarna felszámolni a kompaktság miatt, hanem nagyjából abban az árban adná, mint ahogy a Sony és MS számára.
Most tényleg, egy 200-300mm2-es GPU lapka mellé mekkora költséget jelent odatenni egy 70-80mm2-es CCD-t? Tehát adnak jelenleg N7-en gyártott 180mm2-es Cézanne-t kb $140-ért, meg adnak egy N7-en gyártott 230mm2-es Navi23-at GDDR6 ramokkal PCB-vel hűtővel együtt kb $220-ért, amin még AiB partner költsége és haszna is rajta van.
Azt akarom mondani, hogy összesen 300-400mm2-es (last gen node-on gyártott) APU-kat (ebbe már beleértve a DDR lassúságot kompenzáló 64MB-os V-cache-t/infinity cache-t is) lehetne adni akár $300-ért is.
Abu persze évek óta mondja, hogy ez az AMD terve, de ez még eddig nem jött el.
-
#8398
Petykemano
veterán
hokuszpk
#8397
Petykemano
veterán
válasz
 hokuszpk
#8397
üzenetére
hokuszpk
#8397
üzenetére
Szerintem ez egy mítosz.
Iparági modell - de nem gyakorlat
Ha nincs semmid és nekiállsz egy teljesen új chip teljesen új node-ra való fejlesztésének és mást nem is csinálsz, akkor talán tényleg annyi.Ennek a folyamatnak része lehet akár több teszt jellegű tape-out is.
De variánsokat tervezni meglevő blokkokoat újrahasznosítani mutálni valószínűleg néhány, vagy komolyabb átalaktás esetén néhány tíz misiből már megvan.
Abu nemrég mondta, hogy a >$100 GPU szegmens, hová évek óta tervezik az új GPU-kat csupán néhány milliárd dollár negyedévente. Szerintem nem terveznének 4-5 chipet, ha mindnek az elkészítése külön-külön többszázmillió dolláros tétel lenne.
-
#8392
Petykemano
veterán
Petykemano
veterán
- A költségek emelkedése, jujujujj...
- egyre drágább az új node-ok fejlesztése....
- az olcsó chipek korának vége
- azért drága, mert drága gyártani.Eközben a TSMC-nél:

[link]A többi képen látható, hogy az Intel, AMD és Nvidia profitja "eltűnt"
Az ábra alapján okkal feltételezhető, hogy az emelkedő gyártási költségek tehát nem a gyártási/fejlesztési költség tényleges költségének emelkedése miatt nőtt olyan mértékben, hanem a chipszektorban tapasztalható boom miatt beszűkült a chipgyártó kapacitás lehetőséget adott a TSMC-nek (és nyilván más gyártóknak is) áraik emelésére.Van hová csökkennie a gyártási költségeknek (az AMD, Nvidia és esetleg Intel szemszögéből nézve) Ha az AMD, NVidia és más chiptervezők nem tudják eladni a TSMC által kért gyártási árak mellett portékájukat, akkor nem fognak megrendelést intézni, előbb-utóbb a TSMC is kifogy a megrendelésekből és kénytelen lehet árat csökkenteni - vagyis engedni elég vaskos profitjából.
-
#8390
Petykemano
veterán
hokuszpk
#8389
Petykemano
veterán
válasz
hokuszpk
#8389
üzenetére
Ezzel valóban megoldanád az energiahatékonyságot.
De PPA-ra (Power-Performance-Area) optimalizálnak. Egyrészt annak a magnak, amelyik csak max 4Ghz-ig megy el nem is kell olyan nagynak lenni, lehet sűrűbb. Azon kívül lecsippentenek az egyébként legtöbb helyet elnyelő L3$-ből is. Ezzel szerintem a helyigényt közel megfelezhetik.LEgalábbis az eddig ismert infók alapján a Zen4c nagyjából ez.
(Ami egyébként fura, merthogy nagyjából ezt a mobil lapkáknál eddig is megtették és nem illették külön processzormag névvel. Tehát biztos van valami más is még a kalapban) -
#8388
Petykemano
veterán
S_x96x_S
#8386
Petykemano
veterán
válasz
S_x96x_S
#8386
üzenetére
fura, miért hívják Phoenix 2-nek? Azért elég sokmindenben különbözik.
Nem mendocino, hanem Van Gogh.
Valószínűleg ennek megfelelően rengeteg handheld konzolban fogják felhasználni. De megkockáztatom, akár tabletbe is alkalmas lehetne. Gépjárművak entertainment rendszerébe biztos bekerül.Most már csak az a kérdés, hogy akkor ehhez képest mi a Dragon Range?
-
#8385
Petykemano
veterán
Petykemano
veterán
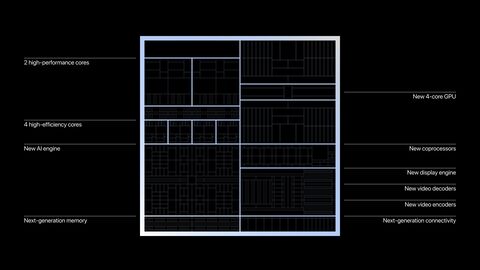
PHX2:
2c Zen 4 (4MB L3, 2MB L2)
4c Zen 4C (2MB L3, 4MB L2)
2 WGP RDNA3 (GC 11.0.4)
LPDDR5X
[link]"can say AVX512 remain. Zen 4 cores clock high. Zen 4C not as high.
It good overall balance. Very competitive with Intel 2+8.
Better than M1 single core, close to desktop."Phoenix 2
Nem tudom, miért "2" - másutt azt mondták, ez egy kisebb verzió. Mendocino méret.
Mindenesetre éles váltás a heterogenitás irányba. Nem csak a magok, hanem a gyorsítók miatt is. Az AI Engine jó Nagy.Persze feltéve, higy az ábra tényleg az amdhez tartozik
-
#8379
Petykemano
veterán
awexco
#8377
Petykemano
veterán
Ez probléma lenne?
Tényleg kérdezem, nem cinizmus.Eddig úgy volt, hogy az A320 alaplap tulajdonképp simán elvitte akár az 5950X-et is.
Probléma lenne, ha egy A620-as alaplap be tudná fogadni a 7950X-et is, de csak mondjuk 95W-os TDP-re korlátozva - forszolt ECO mode. Ez valószínűleg csak a MT teljesítményből venne el.Szerintem ez nem dealbreaker, nem átverés. Nyilván az alaplapra nagy betűkkel rá kéne írni, hogy max 95W TDP. De ha mondjuk attól tényleg olcsóbb a lap azoknak, akiknek nem is feltétlenül van szükségük akkora MT teljesíményre, akkor miért ne?
------------------------------------------------------------------------------------------------------------------------------------------------
Persze tudom, hogy a mostani newegg-es és amazonos árak nem hivatalos árcsökkentésből fakadnak, csak valami kampány, de azokhoz képest a nem-X-es verziókhoz beharangozott ár megintcsak magas.
-
#8374
Petykemano
veterán
Petykemano
veterán
"Achilles heel of #AMD Zen4: the COMPRESS* instructions with memory destination not just ~2-7x times slower than on #Intel Coves, but only the zero mask is optimized somewhat. Thanks for drawing my attention to this, @Mysticial!"
[link] -
#8366
Petykemano
veterán
S_x96x_S
#8364
Petykemano
veterán
válasz
S_x96x_S
#8364
üzenetére
2. Én érteni vélem. Szerintem létezik a trend, hogy a világ a _aaS irányba halad. (Elnézést, nem tudok objektív lenni) De nem arról.van szó, hogy mert úgy olcsóbb (tartok tőle, hogy sokszor épphogy inkább drágább) hanem mert hosszútávon biztosabb jövedelmét jelent.
Egy szolgáltatás kisebb pénz. Míg egy Nagy beruházást recesszió esetén elhalaszthatsz, addig mondjuk a tévé párezres előfizetést csak akkor fogod lemondani, ha tényleg nagy bajban vagy.
Azt akarom ezzel mondani, hogy én tartok.tőle, hogy ezzel nem olcsóbb lesz a hardver, hanem drágább.
Persze Érdekes koncepció, hogy veszel egy Intel processzort és sok esetben akkor is teljes értékű szilíciumot kapsz, ha vágott terméket veszel. És ha fizetsz, felszabadíthatod a működő magokat. Vagy a másik végletbe elvive kapsz egy szilíciumot. (Ingyen? Vagy valami kisebb összegért) és annyi magért fizetsz, amennyire szükséged van.
A szubjektív rész:
Szerintem a világ nem áll készen erre. Az emberek, lélekben. Ahhoz, hogy ne legyen semmijük, mindent csak béreljenek.
Persze tök jól hangzik, hogy egy 120eFt-os mosógépet, ami elketyeg 5 évet ne kelljen megvenni, hanem elég legyen havi 2000Ft-os áron bérelni és az már legyen a gyártó problémája, ha elromlik: akkor jöjjön és javítsa vagy cserélje.
Ezek a háztartási gépek azért ilyen "olcsók" mert sorozatgyártják őket nagy volumenben és kompakt egységekből teszik össze, ami nehezíti az olcsó javíthatóságot. Valamint az anyaghasználat is a tervezett elavulás intézményét szolgálja.
Tartós, javítható gépektől persze megmenekülhetne a bolygó. Csakhogy a tartósság és javóthatóság érdekében való konstrukció és a sorozatgyártás volumenének letekerése okozhatja azt, hogy a gép előállítása máris nem 120e, hanem 2-3x annyiba kerül a gép, ami drágítja a bérlést és a lassuló világgazdaság munkahelyek megszűnését is eredményezné.Bár az lenne, hogy a technológiai fejlődés mellett egyre több időnk jut egymásra. Milyen szép világ lenne, ha a gépek nem a GDP növekedést, hanem az embert szolgálnák és egyre több gép szolgálata mellett egyre kényelmesebben és egyre biztosabban meg lehetne élni.
De én nem ezt látom, hanem azt hogy a nagy cégek és gazdag emberek mindent felfalnak és mindenki mást elnyomnak, kisemmiznek. Biztosan kényelmesebb és könnyebb az élet mosógéppel, mosogatógéppel, stb, ennek ellenére az élet nem lett nyugisabb. 50-60 éve még úgy gondolták, hogy amilyen mértékben emelkedik a gépesítettség, mára elég lesz mindenkinek heti 8-16 órát dolgozni. Ehhez képest mi van? Brutális kizsákmányolás, akarom mondani rugalmas munkaerőpiac.
Ettől függetlenül szerintem meg fog valósulni.
-
#8363
Petykemano
veterán
Petykemano
veterán
Azta, ezek elképesztően informatív ábrák:
[link](Ha jól értem, akkor azért ezek nem eladási statisztikák, hanem "Channel supply volume", tehát hogy miből milyen mennyiség volt elérhető.)
-
#8358
Petykemano
veterán
#36531588
#8356
Petykemano
veterán
válasz
 #36531588
#8356
üzenetére
#36531588
#8356
üzenetére
"Nem, még véletlenül sem ezt teszem, hanem elhamarkodott és valótlan kijelentéseket cáfolok meg. Pl: "> a célfüggvény itt == max(profit) azt még hozzá kell tennem, hogy fenntarthatóan .. hosszú távon .."
Ahogy láthatjuk, pont az ellenkezője történik, így helytelen dolgot cáfoltam meg az adatok alapján. Nem is értem miért az ellenkezőjét látod? Kamuzok, pontosan értem.![;]](//cdn.rios.hu/dl/s/v1.gif) "
"
Hmm... (Ahogy Geralt mondaná)
A "profitmaximalizálás" és a "profitnövelés" nem ugyanaz. Nem lehet, hogy a félreértések oka ennek a két fogalomnak az összemosódása?Egy változó piaci környezetben egy árcsökkentés lehet profitmaximalizálási folyamat része, miközben a profit (vagy a profitráta) éppenséggel csökken. A profitmaximalizálás folyamata alatt végrehajtott árcsökkentés célja épp az, hogy kedvezőbb árral - kisebb profit mellett - jobban menjen a termék, míg egy konkurens árcsökkentés nélküli szcenárióban még annyira sem fogy és bár lehet, hogy az egyes eladott termékeken az árrés magasabb, de a profit összege végül kisebb lehet.
"Az látszik, hogy ezen az áron már "kell" a termék, és elkezdték venni. Pedig még tele a raktárak
az am4-el...."
Szerintem az történik, hogy a világ - ide értve az AMD-t, az Intelt és a TSMC-t is - reagál a háborús szankciós inflációs recessziós keresletcsökkenésre.
Végső soron a TSMC-nek is lehet egy MAX(profit) függvénye, ami ha kapacitás szabadul fel, akkor árcsökkentésre kényszeríti. a Hard limit ott nyilván az, hogy a wafer feldolgozást - legalábbis a régebbi gyártástechnológiákon, amik már bőven visszatermelték a fejlesztési költségeket - nem adhatja olcsóbban, mint az számára megjelenő amúgy jelenleg magas energiaköltségek. (többek között persze, nyilván, csak példaként mondtam egy tételt, ami bizonyára magas egy pár évvel ezelőtti helyzethez képest)Az AM4 procik ára is folyamatosan csökken. 75eFt egy 5600X és 60e egy 5600G - miközben fél éve amikor én vettem, azt gondoltam, hogy 72eFt-nál olcsóbb tuti nem lesz.
Tehát lehet, hogy nem arról van szó, hogy kifogyott az AM4 készlet, hanem csak arról, hogy az egész product stack ára megy le.
-
#8353
Petykemano
veterán
#36531588
#8352
Petykemano
veterán
válasz
#36531588
#8352
üzenetére
Azért kérdezi, mert AMD grafikonokat idézel be és vonsz le belőlük a cég termékeivel és azok versenyképességével és megítélésével kapcsolatos végletes konklúziókat anélkül, hogy az adatokat más hasonló cégekével összevetve kiszűrnéd a szezonális hatásokat, piaci trendeket.
-
#8345
Petykemano
veterán
#36531588
#8343
Petykemano
veterán
válasz
#36531588
#8343
üzenetére
> Már csak az a kérdés miért csökkentik akkor az am5 árát.
Szerintem nyugodtan kijelenthetjük, hogy az AM5 iránti kereslet valóban nem túl magas. Azt nem tudjuk, hogy vajon ez szándékos/tervezett volt-e az AMD részéről vagy sem
Lehetett tervezett azért, mert kellett a CCD készlet a Genoa felé, vagy mert sok volt a bennragadt AM4 készlet.A nem tervezett/szándékos "sikertelenség" is legalább két okból következhetett be:
Lehetett amiatt, mert az Intel jobb terméket rakott le az asztalra, de lehetett csupán azért is, mert a világ megy bele a recesszióba.Ezért a 2022 második felétől kezdődő AMD-s pénzügyi adatokhoz légyszíves mindig mellékeld az Intelét és az Nvidiáét is, hogy ki tudjuk szűrni a "szezonális" hatást.
A célfüggvény pedig valóban létezhet. Nem állítom, hogy könnyű kiszámítani, de modellezni éppenséggel lehet. A cél a profitmaximalizálás, ahhoz pedig tartozik egy minden bizonnyal időben és volumentől függően változó előállítási költség és persze egy vélelmezett kereslet.
Nyilván ha túl magas árat szabsz meg, akkor termékenként magas lesz az árrésed, de nem fogják venni a termékedet (esetleg a konkurenciáét fogják venni) Minél inkább túlárazott a termék, annál nagyobb az árrés, de annál kisebb a kereslet.
Nyilván ha túl alacsony árat szabsz meg, akkor termékenként alacsonyabb lesz az árrés, de vinni fogják. Minél alacsonyabb az ár, annál nagyobb lehet a kereslet (persze nem feltétlenül lineáris az összefüggés, lévén, hogy a cpu csak egy része a platformköltségnek) de annál kisebb az árrés egy terméken is. Nyilván hard limitként mindig megjelenik, hogy mekkora gyártókapacitással rendelkezel.
Ennek a leegyszerűsített függvénynek valahol lehet egy olyan pontja, ahol a árrés és a volumen szorzata mint profit a legnagyobb.
Ahogy fentebb mondtam, az árcsökkentésnek lehet magyarázata:
- hogy elkalkulálták a kompetitív helyzetet
- hogy elkalkulálták a recessziós környezetet
- hogy sikerült az előállítási költséget csökkenteni és/vagy nagyobb kapacitáshoz hozzáférniValószínűleg mindegyik esetben árrésről kell lemondani annak érdekében, hogy a növekvő eladási volumennel érje el a profit a maximumot, amit adott lehetőségek között ki lehet hozni.
Tartok tőle, hogy a gúnyolódó/cinikus, egyoldalú megnyilvánulásaiddal, amivel a többi fórumozó elfogultságára igyekszel rámutatni (és amivel egyébként AMD vs antiAMD hangulatúvá teszed a találgatós topicot) egyúttal saját magad kényszeríted bele a többi fórumozót az erőteljes pro-AMD álláspontba
-
#8330
Petykemano
veterán
#36531588
#8329
Petykemano
veterán
válasz
#36531588
#8329
üzenetére
Nem tudhatjuk, hogy milyen mélyről indul az árcsökkenés.
Abu $35000/wafer árról írt az N5 kapcsán. mások ennél jóval kisebb költségről tudnak.
Lehetséges, hogy a korábban lefoglalt kapacitások ténylyeg annyira drágák voltak. De több megrendelés visszamondásáról is hírt adtak a TSMC-nél. Ha a TSMC-nél is szorul a hurok, jöhetnek új egyezségek: légyszi vegyetek több wafert, mi meg olcsóbban adjuk.A Ryzen árai szerintem pont nem költségalapúak. Hiszen még az abu által bemondott wafer árak alapján is a lapka költsége nem lehet nagyobb $100-nál 2CCD esetén.
Tehát sokkal meghatározóbb lehet a kapacitás.
Ha az AMD kapott plusz kapacitást, akkor adhatja olcsóbban is - hogy jobban fogyjon.De a többlet kapacitás jöhet onnan is, hogy a Genoa-t nem viszik.
Vagy persze akár az alaplapgyártók is kérhették.
-
#8300
Petykemano
veterán
Petykemano
veterán
AMD Ryzen 9 7845HX
Dragon Range?Eredeti forrás: [link]
A nagy kérdés persze az, hogy van-e ebben valami különlegesség, vagy csak simán annyira jó a fogyasztása a Raphael-nek, hogy a 55W-ba is belefér?
-
#8299
Petykemano
veterán
S_x96x_S
#8298
Petykemano
veterán
válasz
S_x96x_S
#8298
üzenetére
Biztosan lesz SPR is, hiszen azért versenyképes.
Nem kizárt, hogy a SPR-HBM megtalálja a helyét a szuperszámítógépek között is.De mivel a fejlődés nagyon látványos, ezért 2023 folyamán is biztosan folytatódni fog az AMD térnyerése (Itt újra hangsúlyozom, hogy nem a SPR ellenében, hanem a korábban szinte 100%-ban Intel szuperszámítógépek kárára)
A Genoa és a Bergamo valószínűleg ott is finom falat.De különösen érdekes lesz a Mi300.
Úgy képzelem, hogy a Mi300 is az általam már csak "Infinity Interconnect"-nek becézett csatolót fogja használni ahhoz, hogy a CDNA és Zen magokat összekapcsolni egy közös HBM memóriát használva.
-
#8296
Petykemano
veterán
Csokissütis
#8295
Petykemano
veterán
válasz
 Csokissütis
#8295
üzenetére
Csokissütis
#8295
üzenetére
A Zen3 (ide értve az asztalit és a szervert is) és az RDNA2 is ugyanazon év végefelé indult ugyanazon a gyártástechnológián készülvén, mint a konzolok. Persze, hogy dönteni kellett arról, hogy az ennyi termék számára szűkös kapacitást hová allokálják. Nem azt mondtam, hogy ilyen allokációs döntés nem létezik, hanem arra próbáltam célozni, hogy annak kell, hogy legyenek más jelei is a piaci részesedésen kívül, ha a piaci részesedésben történő változás ilyen döntésnek következménye.
Olyanok, amiket Te magad mondtál, hogy alig pár darab radeon kártya volt, illetve hogy a Ryzen 5000 alulról túlárazva érkezett, ami arra utal, hogy nyilván az eladási volumenen akartak spórolni."három és fél százalék szerver részesedésért beáldozott majd kilenc százalék mobilt és hat százalék desktopot" => ha ezt a két értéket így szembe állítjuk (amiről nem is tudjuk, hogy ugyanakkora volument jelent-e), akkor azzal azt sugallod, hogy az AMD egyik negyedévről a másikra kivont egy meghatározott volument a két "beáldozott" szegmensről, ahol vagy hiánynak, vagy áremelkedésnek kellett volna történnie. De nem történt olyan, mint ami a zen3/rdna2/konzol rajt során volt tapasztalható. Sőt, azidőtájt mentek le a Zen3 procik árai.
Nem tudom, mi történt, de szerintem a számokból nem lehet kiolvasni hogy az AMD kapacitás-allokációs tevékenység által szándékosan áldozott be itt százalékokat hogy más szegmensben nyerjen párat.
-
#8294
Petykemano
veterán
Csokissütis
#8293
Petykemano
veterán
válasz
Csokissütis
#8293
üzenetére
Én nehezen hinném, hogy ez valóban így működne, hogy itt elengedem, ott megfogom. Ha hiány alakulna ki, akkor szerintem a DIY lenne az első, ami kiszárad, ilyet meg nem tapasztaltunk. Sőt!
Inkább valami olyasmi állhat a változás háttérben, hogy egyik vagy másik OEM tendert az Intel nyerte el az Alder Lake-kel. Ennek lehetett az az oka, hogy az ADL tavasz táján relatíve új termék volt, a Zen3 meg már kifutó. Megkockáztatom, hogy esetleg az ADL bizonyos szempontbok szerintr tényleg jobb, mint a Zen3 apu. Lehet, hogy emiatt nagyobb csinnadrattát is kapott, mint az elég halkan futó Ice Lake (4, illetve 8 magos)
És tényleg simán benne van az is, hogy az AMD nem tudott eleget gyártani és amíg a Zen3 egy elég jó ajánlat volt az Intellel szemben, addig az OEM gyártók hajlandók voltak két forrásból is építkezni, de az ADL érkeztével azt mondták, hogy köszi, egyelőre elég volt. (Talán ilyesmire utal az is, hogy milyen mélyre sülledt a Cézanne lapkák ára)A Zen4 elég hatékony alacsony frekvencián, a Raptor Lake új gyártástechnológia hiányában viszont ezen a téren valószínűleg nem igazán tudott javítani. Így nem elképzelhetetlen 2023Q1-Q2 táján egy visszakapaszkodás az AMD részéről. Erre különösen ráerősíthet, ha kiadnak egy H szériás modellt v-cache-sel, mert akkor az egész biztos vinni fogja a gamer notik királya címet.
Ez a királyság a Meteor Lake érkezéséig tarthat.
-------------------------------------------------------------------------------------------------------------------------------------------------
De ha már itt tartunk:
Az AMD szerintem tudja, hogy a notebook piacon IGP-vel nem lehet nyerni. Különböző szegmenseken eltérő számítási kapacitás szükséges, de önmagában a fixfunkciós részek elég sok helyet foglalnak el. Ha az AMD számára probléma (márpedig mindig is problémát jelentett) a kapacitás szűkössége egyes OEM megrendelések elnyerésében, akkor elemi érdeke ennek a szűkösségnek a kiküszöbölése.Az IGP ebből kifolyólag - legyen az akármekkora - egy teher az APU-kra nézve.
Ha az AMD le tudná választani egy APU esetén az IGP-t egy külön lapkába, akkor az sokkal nagyobb volumenben való gyárthatóságot tenne lehetővé (és még talán olcsóbb is lenne)De álljunk csak meg egy pillanatra. Ez valójában már most is így van! Hiszen a Raphael IOD tartalmaz IGP-t.
Az egyetlen "szépséghibája" ennek a megoldásnak az, hogy az egymástól távol levő chipletek közötti kommunikációt szubsztráton kereszüli vezetékezéssel megoldó Infinity Fabric SerDes energiaigénye elég magas: <2pJ/bitA Navi31 esetén a szóbeszéd úgy tartja, hogy az organikus interposeren keresztül megvalósított kommunikáció (GLink 2.3LL) mindösze 0.27pJ/bit energiaigénnyel rendelkezik.
Az már szerintem elegendő ahhoz, hogy mobil chipben is működjön a chipletezés és a szóbeszéd szerint az organikus interposer lényegesen olcsóbb - itt ráadásul mindössze 200-300mm2-es darabról lehet szó - az IGP-t tartalmazó IOD méretétől függően.
Felvetődhet, hogy ha ez ennyivel jobb, akkor miért nem használja ezt a módszert az AMD a szerver chipeknél, ahol szintén sokat számít a fogyasztás. Nos, szerintem azért, mert túl sok a chiplet a szerver lapkáknál.
De mit is mondott Abu?
"És akkor ezek csak a tervezett dizájnok, de már működik egy olyan prototípus dizájn is, ami a Navi 31 mellé hat helyett négy memóriablokk chipletet rak, a két üres helyre pedig Zen 4 chiplet megy összesen 16 maggal, és ezek is megbolondíthatók 3D V-Cache-sel. Ebből állítólag lesz Radeon Pro verzió a professzionális piacnak." [link]Na most két eset lehetséges:
a) Vagy a jelenlegi CCD képes nem csak SerDes-en keresztül csatlakozni, hanem az interposeren kereszüli csatlakozásra.
Ez azért tűnik valószínűlenebbnek, mert a Zen4 CCD-n nem látszik, hogy lenne ehhez szükséges csatlakozás. Ugyan nem 1, hanem 2 GMI-t tartalmaz.
- Vagy az AMD készít a Zen4 CCX-ből egy mobil variánst - ahogy eddig is. Felezett L3$, sűrűbb library => kisebb lapka. És abban 2GMI helyett 1 másféle PHY, ami csak 3mm2 [link]Mindebből az a kép áll össze, hogy
- az AMD készt egy mobil Zen4 chipletet GMI helyett az NAvi31 MCD-GCD csatlakozó PHY-jét tartalmazza
- Ezt a mobil zen4 chipletet fogja használni az AMD az Abu által írt "kísérleti jelleggel"
- Ezt a mobil zen4 chipletet fogja használni az AMD az APU-k esetén is
- Ebből és az Abu által írtakból kifolyólag a mobil lapka is megbolondítható 3D V-cache-sel.További spekulációk:
Nincs egységes álláspont arra vonatkozólag, hogy pontosan mi lesz a Dragon Range. Többen 16 magos mobil Zen4-et remélnek. Abu viszont jellemzően nagyobb IGP-vel szokta jellemezni.
Abba most éppen ezért nem is mennék bele, hogy minek mi a neve.
De a fentiekből összerakható mindkettő.1) Phoenix Point
Lehet, hogy oka van annak, hogy nem látott még napvilágot a Zen4 IOD-ról lőtt fotó. Elképzelhető, hogy az az IOD már eleve tartalmazza a Navi31-ben is megtalálható PHY-ket 1 vagy 2 mobil Zen4 CCD csatlakoztatásához.
Ebből remekül összeállna 6,8,12,16 magos munkára használható vagy high-end gamer notebook2) Dragon Range
Adná magát, hogy a hasonlóan eleve N6-on készülő Navi33 is tartalmazhatna egy ilyen csatolót, amihez csak hozzá lehet kötni egy Zen4 mobil chipletet ész kész. De ez több szempontból nem megfelelő. Egyrészt mert a Navi33 minden bizonnyal GDDR6 vezérlővel rendelkezik, másrészt pedig bizonyára nem rendelkezik azokkal a vezérlőkkel (USB, PCIe, stb), amiket egy IOD-tól várunk.
Tehát inkább az tűnik valószínűnek, hogy az AMD készít N6-on egy 150-180mm2-es IOD-t, ami a Zen4 IOD egyfajta mutációja, csak a benne található IGP RDNA2 helyett egy nagyobb RDNA3 -
#8289
Petykemano
veterán
Petykemano
veterán
Van itt egy érdekes eszmecsere arról, hogy L3$ bővítés és a HBM milyen mértékben csereszabatos. [link]
Azt mondja David Kanter és Satoshi Matuoka a Fugaku főmérnöke, hogy vannak bizonyos egyébként 32-64GB Vrammal rendelkező GPU-kra tervezet feladatok, amelyek.kifejezetten jó, ha 32-96GB HBM van CPU fedélzetén. Tehát valami olyasmi lehet a HBM-es CPU célja, hogy egy számítási feladatot ne kelljen Gpura offloadolni. Azt mondják, hogy a 32-96GB tipikusan elég, de az adat rosszul cachelhető, ezért ezekre a.számításokra az 1-2GB-os L3$ nem tudja kiváltani a HBM-et. (Bár anélkül biztos még annál is rosszabb lenne)
Egy lelkes AMD-beavatott szerint a Mi300 lesz az AMD HBM-es CPU megoldása. Bár az elvileg APU, Amiről eddig nem tudjuk, hogy a CPU miképp csatlakoztatható. Bár abu azt.mondta, navi31-ből is készülhet olyan változat, ahol 1-2 MCD helyére CCD-t ültetnek.
-
#8284
Petykemano
veterán
S_x96x_S
#8283
Petykemano
veterán
válasz
S_x96x_S
#8283
üzenetére
Mondtam, hogy lesz majd valaki aki majd jól megmagyarázza, hogy miért jogosak, de legalábbis érthetőek a magasan megszabott árak. Ez az Nvidia termékeinek generációról generációra történő áremelései esetén is kivétel nélkül megtörténik. Aztán ugyanezek az emberek elismeréssel tapsolnak a profit rekordokhoz és emelkedő margókhoz, hogy és nem veszik észre, hogy az ő ingyen végzett rajongói marketing tevékenységük hozzájárult ahhoz, hogy a cég ennyire sikeres legyen
Természetesen technikai értelemben lehet igazság a felszabadult N6/N7 készletekben. Abu szerint már csak $5000 egy N6 wafer.
Arra akartam csak felhívni a figyelmet, hogy a 3D stacking most már nem kísérleti, egy egész generáció lefutott vele és már arra is futja - nem csak költség, hanem volumen alapon is - , hogy $329-ért adják.
Ezzel együtt biztosan drága lesz az elején.
Részben azért, mert a volument elviszi a prioritást élvező szerver
Másrészt pedig azért, mert a terméket minden bizonnyal nem költség alapon fogják pozícionálni. Ahogy a $329-es 5800X3D egészen biztosan most sem költség alapon pozicionált ár, hanem kompetitív környezet alapján: A valamivel olcsóbb 13600K-val ez a versenyképes ajánlat. Szóval én nem zárnám ki, hogy mondjuk fél év múlva esetleg még olcsóbb legyen.A Zen3 idején is jelentek meg lamentáló cikkek, hogy hát ez van, az olcsó processzorok kora lejárt, $300 alatt nem lehet chipletes processzort gyártani. És most mi van? Pontosan annyiba kerül egy 5600, mint egy 180mm2-es Cézanne 5600G (forintban), amit ha dollárra átszámítok, akkor legjobb esetben is $130-150 jön ki.
Persze, persze ez pontosan annak eredménye, hogy a volument nem viszi el más piac meg hogy a TSMC gyártási kapacitását sem viszi el más cég és olcsóbb lett a gyártás. De hát akkor azok a cikkek/kijelentések, amelyek sommásan megállapították, hogy $300 az alsó határ azok egyszerűen tévedtek, vagy felültek a céges marketinganyagoknak. Merthogy nyilván amikor az AMD reprezentív beszélget Abuval meg Ian Cutressel, akkor arról fogja megpróbálni meggyőzni, hogy ezek az árak, nem érdemes jobb árakban reménykedni. Jensen úgy fogalmazott az olcsó GPU a múlté. Lehet, hogy most igaz, de nézzük majd meg fél vagy egy év múlva, fognak-e újra mindenféle játékokat csatolni, csak vedd már meg azt a redvás GPU-t.
Ezzel csak arra akartam felhívni a figyelmet, hogy lehet, hogy aki azt hirdeti, hogy a drága örökké drága marad, az hamis proféta, vagy céges érdekeket igyekszik képviselni. Hisz nekik az a jó, ha most veszed és ennyirét.
Eközben a Zen3 és a Zen3D teljesen jó példák arra, hogy miképp eshet egy termék ára egy év alatt, vagy amikor kifutó szériává válik. Ebben egyébként nem lenne semmi meglepő - mindig is ez történt -, ha nem lettek volna olyan állítások a termék életciklusának közepén, hogy ennél olcsóbb soha nem is lesz. -
#8282
Petykemano
veterán
Busterftw
#8280
Petykemano
veterán
válasz
 Busterftw
#8280
üzenetére
Busterftw
#8280
üzenetére
Igen, de az ADL már Q1-től jó ajánlat volt, nem? Mitöbb, nyár végefelé nyílt meg az AM teljes vonalra a zen3 frissítési lehetőség és akkor lett olcsóbb is.
Egyszer sem volt hiány. Persze ez csak a DIY piac. De azt gondolnám, hogy ha hiány lett volna, ez szárad ki először.
Lehet, hogy Q2-ben egy one time felugrás volt a frissítés okán?
Vagy lehet, hogy Q3-ban érkeztek meg az OEMek ADL ajánlatai a piacra?
Na mindegy. Lehet, hogy ez közrejátszik abban, hogy most tényleg nagyon diszkont áron árulják ki a bennragadt készletet.
Apropó, erről jut eszembe.
Az AMD biztos jó drágán fogja majd kínálni a 7000X3D-t. Már előre hallom, ahogy valaki mondja: drága a gyártás. De ne felejtsük majd el, hogy az 5800X3D-t $329-ért már. -
#8275
Petykemano
veterán
S_x96x_S
#8274
Petykemano
veterán
válasz
S_x96x_S
#8274
üzenetére
Hát én is attól tartok, hogy olyan lesz ez a nagy spórolás, mint az otthoni bio-alma: a bio alma termesztője ugyanis nem csak a vegyszer költségét spórolja meg, hanem még a vévőtől is többet kér a vegyszert nem tartalmazó áruért.
Tehát az szuper lesz, hogy ők leakasztanak - persze hosszútávon - egy valag pénzt azzal, hogy a cucc energia és helytakarékos, veled felárat fizettetnek a karbonsemlegességért.
Na mindegy.
SPR
Ha igazad van, akkor Intel nagy bajban van, de legalábbis érthető a 700-800mm2-es monolitikus lapka.
Ugyanis az alap SPR lapkákat 10 (2+2+3+3) EMIB köti össze.
A HBM változat esetén +4 EMIB és +4 HBM ad hozzá költséget. Ami szerintem párszáz dollárnál nem lehet nagyobb, hiszen Vega 4 HBM-es Vega termék ment már $700-ért. Mivel DDR5 mindkettő tud, ezért gondolom, higy a HBM vezérlő is mindkettőben benne van, csak nem használják.Fura ez. Az AMD organikus interposerrel 6 interconnectet használ és abu szerint az előállítási költsége $630.
Vagy az EMIB ennnyire drága, vagy az skuk árát nem a költség határozza meg. -
#8273
Petykemano
veterán
S_x96x_S
#8272
Petykemano
veterán
válasz
S_x96x_S
#8272
üzenetére
Arra leszek kíváncsi, hogy hogyan árazzák be a cloud szolgáktatók. Melyiket hogy?
Egy 64 magos Milanhoz képest a SPR szerintem valamennyire érezhető teljesítménybeli előrelépést jelenthet, Aminek persze TDP-ben is meg kell fizetni az árát. Tehát én arra számítanék, hogy az SPR-t úgy fogják majd pozícionálni, hogy maximális teljesítmény kicsit drágábban, mint az eddigiek.De a Genoa is erősebb azért a Milan-nál még ha nem is számottevően. Cserébe másfélszer több fér el. Míg az előző igaz volt a Rome->Milan váltásra is, addig utóbbi nem. Egységnyi magot lehetne olcsóbban kínálni.
Viszont mindkettő új DDR5 platform, ezért esélyes, hogy hiába a megtakarítás a fő üzenet, tartok tőle, hogy a bekerülési költség magasabb, mint ami a CPU árából fakad, amit az AMD mutogatott.
> relative drága lesz ..
Valószínűleg drágább lehet, mint a még mindig szubsztráton keresztül kommunikáló Genoa. Ki is emelték, hogy a gmi3 <2pJ/bit. Gondolom a következő lépés valami olyasmi lehet, az RDNA3-hoz hasonlóan körbeveszik a CCD-kel az IOD-t. Az elég olcsó lehet. Vagy hogy felfűzik a CCD-ket valami bridgere.
Én utóbbit tartom valószínűbbnek.Node visszatérve. Én nem gondolnám, hogy a SPR a HBM-től drágulna nagyon.
De abban igazad van, hogy ez csak ott segít, ahol a Nagy sávszél szempont.Szerintem ezt nem lehet helyettesíteni CXL memóriával. Utóbbi csak relatív alacsony késleltetés és sávszélesség mellett jelent nagy kapacitású bővítési lehetőséget.
Bár MLID szerint az AmD roadmapjén is szerepel HBM-es bővítmény. De nehéz ügy. Nem elég az IOD-hez kapcsolni, mert azzal nem lesz meg a HBM által kínált High Bandwidth elérhető a CCD számára. Ahhoz vagy közvetlenül a CCD-hez kéne kapcsolni (az intelnél.így van), vagy előtte meg kéne teremteni rDNA3-nál a GCD és MCD közötti 800GB/s kapcsolatot.
A legegyszerűbb nyilván az L3$ további bővítése a stackek.számával.
Szerintem még mindig lenne értelme egy L4$ bevezetésének. Ami persze méret (késleltetés) okoknál fogva csak kvadránsonként teremtene kapcsolatot a CCD-k között.
Ezt lehetne aktív interposer formájában alul, vagy az IOD-re stackelve lehetne megvalósítani.
Ha a 36mm2-be befér 64MB, akkor ~400m nagyságú lapka 640MB L4$-t jelentene stackenként. Az IBM csinált ilyesmit, csak 2D. -
#8269
Petykemano
veterán
S_x96x_S
#8266
Petykemano
veterán
-
#8262
Petykemano
veterán
Petykemano
veterán
Az előadásnak inkább kisebb súlyú témája a teljesítménybeli előrelépés.
A compute density és energy efficiency sokkal hangsúlyosabb.Vajon annak az oka, hogy a selling point nem a teljesítménybeli előrelépés, hanem a megtakarítás, inkább az lehet, hogy az érkező Sapphire Rapids-zal szemben nem mertek a tejlesítményelőnyre apellálni, vagy mert tényleg meghatározó szempont most a szerver piacon is az áramszámlák csökkentése, a gépek hely és áramfogyasztásának csökkentése?
-
#8255
Petykemano
veterán
S_x96x_S
#8254
Petykemano
veterán
válasz
S_x96x_S
#8254
üzenetére
Zen4 IPC Uplift
Desktop: 13%
Server: 14%
[link]
Persze a jóég tudja, hogy a különbség valamilyen bug javításából fakad-e, vagy esetleg abból, hogy a Zen4 valamely része nem skálázódik a frekvenciával, vagy valamilyen memóriasávszélesség? Vagy esetleg eltérő szoftverkosár? -
#8253
Petykemano
veterán
S_x96x_S
#8251
Petykemano
veterán
válasz
S_x96x_S
#8251
üzenetére
Ha jól emlékszem, MLID szerint a Genoa és a SPR 1P is 2022Q4-ben megjelenik
2023Q1 a SPR-HBM - amit tegnap az Intel tulajdonképpen bejelentett.
És a Genoa-X majd csak 2023H2Persze a megjelenés jelentése gyakran változhat bejelentéstől a tényleges piaci elérésig amiatt, hogy a egész más ütemben juthat el ugyanaz a termék a hypervisorokhoz és a DIY-szerver piacra.
Számomra pl fura, hogy a Raphael-X-et CES bejelentéssel relatív hamar, 2023Q1-ben várjuk (és persze nem kizárt, hogy csalódni fogunk), miközben MLiD szerint a a Genoa-X csak 2023 végén jelenik meg.
Most ez vagy azt jelenti, hogy a CES-en a Raphael-X egy a 2021-es előzetes V-cache demóhoz hasonló esemény lesz, amihez képest az, hogy termék legyen még nagyon messze van, vagy azt, hogy a Genoa-X-re olyan hatalmas az igény, hogy valaki (pl MS) mondjuk minimum fél éves exkluzivitást / készletet (fel)vásárolt.Ha hihetünk AdoredTV slide-jainak, akkor ez az esemény ma kizárólag Genoa lesz, a Bergamo és a Genoa-X aszerint fél évvel van lemaradva.
-
#8236
Petykemano
veterán
Csokissütis
#8234
Petykemano
veterán
válasz
Csokissütis
#8234
üzenetére
a PCIE fejlesztésének primér oka egyértelműen szerver. Ott rendkívül fontos, hogy a bővítőkártyák - amelybe most már beletartoznak GPU gyorsítón kívül majd a memóriabővítőkártyák, valamint a storage minél gyorsabb (sávszélesség) legyen.
A DPU-k biztosan sokat segítenek. Úgy képzelem, hogy az egyolyan kártya, amibe belefugják a hálókábelt és az szolgálja ki fizikailag a gépben levő háttértárról a tartalmat. Nyilván PCIE-n keresztül.
Szerintem a CXL sem a játékhoz kell, hanem hogy a GPU vagy más gyorsító közvetlenül az SSD-ről tudjon adatot beolvasni a ML tanításhoz.Ezzel együtt azért érthető, hogy igyekeznek ezeknek az ipari megoldásoknak hasznát venni konzumer piacon is. Nyilván részben a költségek terítésének szándékával.
Én továbbra sem hibáztatnám S_x96x_S-t. Minden jel arra mutatott, hogy az AMD igenis össze akarja rakni az első full PCIE5 konfigot. Az egész AM5 mizéria, hogy melyik chipset mit tud, dual chipset, és hogy miért olyan drága akörül forgott, hogy legyen olyan platform (értelemszerűen nem mind), ahol PCIE5 összeköttetés van a storage és a GPU között.
A szekunder cél a költségcsökkentés a konzumer termékeknél. Minél magasabb a PCIE5 gen, annál kevesebb lane-t kell beépíteni.
(Én egyébként nem zárnám ki, hogy a Navi31 hardveresen valójában tudja a PCIE5-öt, csak lekorlátozták PCIE4-re - a fogyasztás csökkentése érdekében.)
Ne tegyünk már úgy, mintha egy találgatós szoba 100%-os megbízhatóságú és objektív információforrás lenne!
Azt javaslom, hogy ha képzelgésektől, lelkes wishful thinkingtől és elfogultságtól mentes, kizárólag szakavatott hozzáértők által verifikált objektív tényekről szeretnél - a hivatalos bejelentés előtt - megbízhatóan tájékozódni, akkor fáradj át a hivatalos "AMD mélyvíz" topikba, ahol pont az általad igényelt szabályok érvényesek.
-
#8228
Petykemano
veterán
Petykemano
veterán
/Konkurencia - Qualcomm - Nuvia/
"Qualcomm's working on a 2024 desktop chip codename "Hamoa" with up to 12 (8P+4E) in-house cores (based on the Nuvia Phoenix design), similar mem/cache config as M1, explicit support for dGPUs and performance that is "extremely promising", according to my sources."
[link]
2024-ben az Apple már valószínűleg 1 éve N3-on fogja gyártatni az M3-at. (Igaz, persze az M2 nem volt nagy előrelépés)És addigra várhatóan megérkezik a Zen5 is már.
De az lehet, hogy jót tesz a versenynek, ha előkerül egy teljesítményben M1-gyel és az x86 cpukkal versenyképes nem zárt Arm versenytárs. -
#8227
Petykemano
veterán
Petykemano
veterán
Ryzen 5 7600 ( [link] )
Hű, az a 3.8Ghz elég sovány.
-
#8223
Petykemano
veterán
S_x96x_S
#8217
Petykemano
veterán
válasz
S_x96x_S
#8217
üzenetére
Nekem ez tetszik:
> Majd ma kiderül, de minek is addig várni...
> Az RDNA 3 a chiplet tekintetében a memóriát és az Infinity Cache-t választotta le.
> Tehát lesz egy nagy GPU, és mellé Infinity Fabric interfészen keresztül kapcsolódik
> pár kisebb lapka, ami a 64 bitnyi IO-t, a memóriavezérlőt, és némi Infinity Cache-t tartalmaz.Azért ezt is elég bátor volt, nem? NDA...
"A Dragon Range-ből már van olyan prototípus, ami ezt a kis memória chipletet felhasználja, így az IGP mellé lesz kötve némi Infinity Cache. Plusz, ha ez nem elég, akkor a Zen 4 3D V-Cache lapkája úgy van kifejlesztve, hogy a Zen 4 chiplet mellett jó az előbb említett memóriachipletre is. Ki vannak alakítva ugyanúgy a bekötéshez szükséges csatolók. Szóval, ha nagyon muszáj, akkor ezt is rá lehet még legózni. Aki megelégszik mondjuk egy Radeon RX 6600-as szinttel, annak a Dragon Range olcsó alternatíva lehet."
Elég érdekes
Ebből két dolog következik:
1.) a Dragon Range is info_OS alapon fog chipleteket összekötni
2.) Ha a ZEn4 3D v-cache rámegy az MCD-re, akkor valójában a Navi31 IC bővítménye nem 96MB=>192MB lehet, hanem 96MB=>480MB (vagy 32MB-os v-cache esetén 288MB)
Eddig azt gondoltam, hogy MCD-ket fognak egymásra stackelni, de miért használnák azt, ha az csak sram lapka is rámegy?viszont az MCD felhasználás módja nem világos. a Dragon Range (és a phoenix) apu is úgy készülne, hogy a memóriavezérlő + IC le van választva és ugyanazt az MCD-t használja?
-
#8214
Petykemano
veterán
Petykemano
veterán
chips & cheese presents:
AMD’s Zen 4 Part 1: Frontend and Execution EngineA lényeg: a Zen4 esetén is itt-ott kitömködték a buffereket, puffereket, tuningolták a regisztereket - ahogy az Intel architektúrák esetén szokták.
Érdekes, hogy az Intel jellemzően generációról generációra szélesítette a backendet is és az Arrow lake esetén állítólag már 8 széles lesz.
Erről persze még nem volt szó a Zen4-es cikkben.Mindent összevetve a Zen4 még mindig egy relatív "kicsi" architektúra az Intel nagy magjaihoz képest.
Tehát külön érdekes, hogy vajon a Zen5 mit fog ledobni.
Én arra számítok, hogy valamiféle hasonló mag-egyesítés/duplázás jön - annak kvázi mintájára, ahogy bizonyos szemszögből nézve a Zen backendje is a bulldozer modzl int backend összeolvasztásaként felfogható. Persze nem az, de a lényeg, hogy van tapasztalat Mike Clark esetében arról, hogy hogyan jusson el A-ból B-be.
-
#8213
Petykemano
veterán
Petykemano
veterán
A Radeon találgatósban Abu bedobott két számot
Szerinte egy N5 wafer $35000 és egy N6 wafer pedig ennek 1/7-e, vagyis $5000Ez alapján a caly Die Per wafer calculator segítségével 0.07d/mm2 hibasűrűséggel számolva kb 800db többé-kevésbé jó CCD jön ki.
Ez Abu számai alapján ~$44IOD-ra kb ~420 jön ki, ami így darabja $12
-
#8210
Petykemano
veterán
Petykemano
veterán
AM5/Zen4 vs RPL költségelemzés.
Nem olvastam, de esetleg érdekes lehet. -
#8209
Petykemano
veterán
Petykemano
veterán
Egyébként állítólag hivatalosan is $329 lett az 5800X3D
(Kár, hogy pont most ilyen erős a dollár és ratyi a forint.) -
#8208
Petykemano
veterán
-
#8193
Petykemano
veterán
hokuszpk
#8191
Petykemano
veterán
válasz
hokuszpk
#8191
üzenetére
Az az érzésem, hogy az általad hozott use case egy jó példa arra, amikor eleve kifejezetten célszerű és hasznos magas magszámú processzort venni, amire már most is jó megoldás egy 64 magos Milan és annál jobb lehet a 96 magos Genoa, vagy 128 magos Bergamo.
De közben meg valakik valamilyen célból nagy számban veszik a <=40 magos Intel szerver procikat.
Fogalmam sincs, hogy az általad említett use case tipikus PHP.felhasználásnak minősül-e azok körében,.akik szervereket vesznek. Lehet, hogy nem jó példát hoztam. A felhősödés, virtualizáció nyilvánvaló trend, biztos, hiogy egyre kevesebben vásárolnak saját célra hardvert és egyre gyakoribb az erőforrásmegosztás a költségtakarékosság és/vagy magasabb fokú biztonság/redundancia céljából.
De valakik veszik az Intel szervereket és ha nem valami megrögzött brand-hűség miatt, és mivel tudtommal a 4-8 utas szerverek annyira nem gyakoriak, ezért azt gondolnám, hogy ennek.magyarázata talán az lehet, hogy nincs is szükségük annyi magra, mint amennyi már most is kínálnak a csúcs szerver processzorok.
-
#8190
Petykemano
veterán
hokuszpk
#8189
Petykemano
veterán
válasz
hokuszpk
#8189
üzenetére
Én nem teszteltem a vhostonként külön fpm környezetet. De dockeres tapasztalataim alapján így ilyen szétbontásnak a memória footprintje nagyobb. Persze ha lecsökkented a spare workerek számát, akkor eltüntetheted ezt a memória footprintet.
Viszont a biztonsági szempontot félretéve azonos request szám esetén mi alapján gondolod, hogy a multi-fpm-es megoldás számára előnyösebb a több, de valamivel gyengébb mag? Hol keletkezik az overhead?
Én a PHP-t egyébként csak a phoronix PHPbenmark 0.8.1 eredményei alapján emlíettem meg.
-
#8188
Petykemano
veterán
S_x96x_S
#8187
Petykemano
veterán
válasz
S_x96x_S
#8187
üzenetére
Csak egy tipp részemről:
Szerintem a Genoa nem lesz átütő siker a szerverpiacon - annak ellenére, hogy elvileg mindennel rendelkezik, ami elvárható. Több mag,, jobb TCO, stb.
Nem lesz rossz, csak nem fogja nagymértékben tovább húzni a részesedést.Azt gondolnánk,.hogy talán az ár, és hogy az intelt alacsonyabb magszámú rendszereket olcsóbban ad. És hogy majd a Siena és a Zen4c magok - olcsó szerverplatform - megoldják. De szerintem ebben a vonatkozásban - homogén Z4c formában - ez sem lesz lesz olyan siker, ami továbbdobná az AMD részesedését.
Azonban szerintem ennek magyarázata nem annyira az árban keresemdő, hanem meglepő módon a ST teljesítményben és /vagy olyan széles körben használt szoftverekben amelyeknek az intel platform valamiért jobban kedvez. Pl php, Python, mysql
Amikor a régi "rosszul.megírt" szoftveredről van szó, aminél a ST teljesítmény számít abban, higy egy kérést mihamarabb kiszolgáljon, akkor lehet, hogy kevésbé izgat fel a magszám.
Azok, akik eddig nem.rohantak 64 magos procit venni, nem fognak ráugrani a 96 magosra se. Jó lesz nekik a 40-60 magos Intel, ha annak ST teljesítménye bizonyos szoftverekben 20%-kal nagyobb.
Ezért én látom esélyét annak, hogy a Genoa előzése ellenére a SPR-zal az Intel lelassíthatja,.vagy megállíthatja az AMD térnyerését.
-
#8186
Petykemano
veterán
#36531588
#8169
-
#8165
Petykemano
veterán
#36531588
#8163
Petykemano
veterán
válasz
#36531588
#8163
üzenetére
Az grafikon adatforrásként az AMD és Intel pénzügyi jelentést jelöli meg. Nem fekszem és ébredek ezekkel, de úgy rémlik nincs megkülönböztetve adatközpont, mint hyperscaler, valamint szerver. Lehet, hogy tévedek.
De ha nem, akkor a grafikonon ábrázolt értékek az összes szerver és más adatközponti termék árbevételének egymáshoz viszonyított arányát tartalmazza.Ez csak árbevétel. De és nem is mondtam, hogy más.
Az intel kisebb magszámú szerverekből darabra többet ad el, de alacsonyabb áron. Az AMD drága csúcstermékként értékesíti amije van. Lehet, hogy nem is tudna darabra annyit előállítani, mint az intel.
Mindettől függetlenül, ha ezekben az értékekben benne van a sapphire rapids, akkor félő, hogy nem húzta ki a lefelé ívelő trendből. Az.Intel adatközponti profitja eltűnt, nincs hová hátrálni, nem tud tovább árat csökkenteni. -
#8161
Petykemano
veterán
Petykemano
veterán
https://twitter.com/BitsAndChipsEng/status/1586756720432500741?t=YtF2tloflvC5TA1kZPbv-A&s=19 [link]
Állítólag az adatok szerint 2024-ben az x86 szerverek eladásásában érték.szerint átveszi az AMD a vezetést.
A trend egyértelmű.
Ha Albusnak igaza van, és ebben már a Sapphire rapids is benne van, mert már értékesítik, akkor nagy bajban vannak.
Szerintem még nem, s akkor még van remény a trendfordításra. -
#8157
Petykemano
veterán
Yutani
#8156
Petykemano
veterán
Igen, ez egy érdekes kérdés.
Én nem látom okát, hogy miért ne lehetne aszimmetrikus.Ugyanakkor MLiD épp ma osztott meg egy videót a Siena platformról és a Zen4c-ről.
Szerintem érdekes.Elmondja például azt, hogy a Siena méret szempontból 4CCD-re van tervezve.
Elmondása szerint a Zen4c:
- felezett L3$
- alacsonyabb Fmax (2-3.5Ghz) mellett nagyobb tranzisztorsűrűség => kisebb CCX
- 1CCD 2 CCX-et tartalmaz - ahogy a Zen-Zen2 idején
- összességében a Zen4c szélesebb CCD-vel fog rendelkezni, mint a Zen4Fentiekből fakadóan a Zen4c miközben a maximális frekvenciája azon a rendkívül energiahatékony szinten marad, aminél magasabbra szerver proceszorok (és U szériás notebook procik multiban) amúgy se nagyon szoktak menni, aközben az L3$ méretétől eltekintve IPC-ben kb 10%-kal elmaradtva, kb az U szériás APU-któl megszokott eredményt fog tudni hozni.
Három szempontból fontos ez
1) egyrészt a 2. pont - nagyobb tranzisztorsűrűség, kisebb lapkaméret, cserébe alacsonyabb frekvencia - igazolja azt a hipotézisemet, miszerint az AMD és az Intel is nem csak fogyasztással, hanem lapkamérettel is fizet az 5+Ghz-es procikért. Tehát valóban ez lehet az oka, amiért az AMD nem érte el az N7-en a TSMC névleges tranzisztorsűrűségét, míg a 3Ghz körül csúcsosodó Apple M1 igen.2) Másrészt az aszimmetrikus CCD-hez kapcsolódóan megemlíteném, hogy érdekes - számomra furcsa - módon MLID nem említett hibrid megoldást. Még akkor sem említette meg, amikor a Raphael jöt szóba. Pedig szerintem a ST / LT eredmények megtartása érdekében úgy lenne értelme, ha minden SKU-n 1 CCD a "nagy" magos változat maradna. (Különösen akkor, ha V-cache- csak erre lehet tenni, mert a Zen4c-ből helytakarékosság érdekében kimarad a TSV)
És ez hasonló kérdés, mint az ugyanolyan, de eltérő számú magokból álló CCD-k használata.
Egy 6+4 magos 7800X változat jó előjel lenne arra, lehet Zen4+Zen4c hibrid összetételű SKU is.3) Figyelembe véve, hogy mennyire hasonlít a Zen4c felépítése egy Zen2 lapkára, nem lepődnék meg, ha a jövőben valójában a Zen4c válna úgymond a következő generáció alapjává.
a 2X16mb L3$-t újra egyesíthetik. Lehet, hogy 2MB L2$ mellett az minimál, de nem kevés.
Vagy akár ki is emelhetik, hogy honnantól kezdve L3$ csak V-cache formában kerül rá. A 16 mag közötti megosztást persze attól még meg kell oldani. De ha 3D irányban a 32MB-nál már lényegesen nagyobb méretét tudsz ráépíteni, akkor nem biztos, hogy érdemes még küzdeni azzal hogy legyen embedded L3$. -
#8153
Petykemano
veterán
Petykemano
veterán
Megjelentek infók egy 4 magos 7300X-ről és egy 10 magos 7800X-ről. [link]
A zen3-hoz képest elég hamar. Mindkettő arról árulkodik, hogy vagy sok a hibás / fogyasztási elvárásokat meg nem ütő chip, vagy elég olcsó ahhoz, hogy amúgy hibátlan chipek vágásával mesterségesen szegmentáljanak.
A 4 magos változat valahol érthető.
Valószínűleg akármilyen olcsó lenne egy 6 magos, akkor is lenne igény "anyu" gépébe egy 20%-kal olcsóbbra, mert ő csak netezik. Megkockáztatom, ez lehet, hogy nem is a 7300X vásárló felől jön, hanem OEM, nomeg fanless minipc építő partnerek felől.
De a 10 magos (5+5 vagy 6+4, esetleg 8+2?) már meglehetősen szokatlan.
Számomra a >legésszerűbb< magyarázat az volna, tényleg sok a selejt, amit 4 magra kénytelenek korlátozni, ezért olyan sku-kat dobnak be, amikben ezt fel tudják használni.
De ez a 7800X 2 CCD-vel mindenképpen áldozata lesz azoknak az eseteknek,.amikor a 2 CCD hátrány (capframeX mérései a 7950X-szel) vagyis egyáltalán nem biztos, hogy a több mag ellenére előnyös lesz gaming szempontból a 7700X-hez képest.
Viszont multiban meg épp csak annyit ad hozzá, hogy a tesztekben versenyképes legyen a 13600K-val.De ez egyúttal azt is jelenti, hogy nem igazán lehet drágábban eladni, mint most a 7700X-et.
Ebben a 10 magos sku-ban érzek némi izzadságszagot.
Annál inkább fura, ha arra gondolunk, hogy innentől egy 5800X3D már nem lehet 8 magos.
-
#8152
Petykemano
veterán
Petykemano
veterán
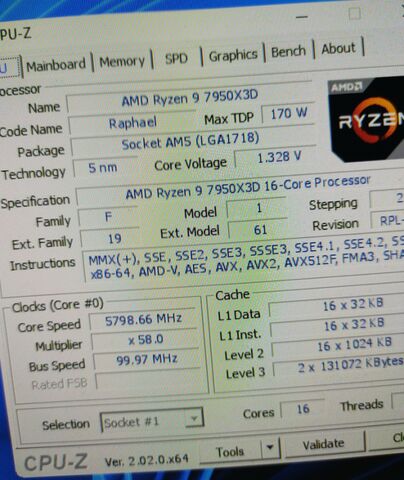
7950x3d
128MB*2
5.7GHz
[link]Vajon valódi?
Vajon helyesen olvassa ki a szoftver?Érdekes, hogy nem 2x(32+64), hanem 2x(32+96)
Ez nagyon hasonlóra emlékeztet, mint ami a GPU-k esetén az infinity cache-nél is történt. Ott is mintha csökkent volna a cache mérete az előző generációshoz képest. Persze az sem nyilvános még, csak pletyka. Mindenesetre ott egy MCD elvileg 16MB-ot fog tartalmazni és egy rápakolható stack +16MB-ot fog biztosítani.Vajon mi történhetett?
Ez N5-ön készülő lapka lenne, amivel a CCD L3$ méretének megfelelő területen már 96MB is elfér?
Vagy 2x 48MB layer lenne N6-on gyártva és csökkentették a lapka kiterjedését, hogy illeszkedjen a kisebb N5-ön gyárott CCD L3$ méretéhez?
Vagy 2x 64MB layer lenne N6-on gyártva, csak vágott?
Vagy 3x 32MB layer?
Vagy 6x 16MB, hogy közösen legyen gyártható?Mindenesetre az ábra alapján tűnik, hogy sajnos a 3D stacked V-cache lapka L2$ bővítést nem tartalmaz.
-
#8148
Petykemano
veterán
Petykemano
#8135
Petykemano
veterán
válasz
Petykemano
#8135
üzenetére
Halványan magasabb a multi eredménye, mint egy 7600X-nek.
A 7700X pedig kb 20%-kal tud többet ennél multiban.
Összességében inkább a 7600X-hez áll közelebb.
Bőven elmarad a 13600K-tól.Viszont a jövőben 13600-ként árult 12600K-val versenyképes - vagy gyorsabb lehet annál.
Én továbbra is azt gondolom, hogy ha ez forgalomba kerül, akkor nem nagyon lehet többet kérni érte, mint most 7600X-ért.
-
#8147
Petykemano
veterán
S_x96x_S
#8145
Petykemano
veterán
válasz
S_x96x_S
#8145
üzenetére
- SDCI (Smart Data Cache Injection).
- és a SDXI (Smart Data Acceleration Interface)
Szerintem igen.
Smart Data Cache Injection
Ez úgy hangzik, mintha a Smart Memory Access-hez hasonló cucc lenne, csak nem központi memória - GPU memória közötti adatcsere/előkészítés, hanem hogy pl a CPU közvetlenül a GPU cache-be (infinity cache) tol be valamilyen adatot és vica-versa.Tehát ez úgy hangzik, mint egy olyan feature, amivel esetleg ki lehet aknázni az AMD-AMD párosításban rejlő lehetőségeket.
Smart Data Acceleration Interface
SDXI - Ez meg úgy hangzik, mintha valami köze lenne az fpga-khoz, amit ugye XDNA-nak kereszteltek el. Lenne abban is ráció, hogy ne csak a CPU-GPU-k, hanem a CPU-FPGA között is legyen hasonló trükközés. -
#8146
Petykemano
veterán
Petykemano
veterán
"mivel az AMD arról tájékoztatta partnereit, hogy az elmúlt hónapok során nagymértékben javult a gyárthatóság, így a lehető legtöbb piacon bevetik.
[...]
és egynél több modell kapja majd meg az extra gyorsítótárat, de a legolcsóbb processzorokig
még mindig nem jut le, ennek úgy néz ki, hogy az aktuális generációban sincs itt az ideje."
Pedig már épp kezdtem reménykedni, hogy kiadják az 5600X3D-t a népnek. De ez alapján valószínűsíthető, hogy még 7600X3D sem lesz.
Egyelőre."váratlan adat ugyanakkor, hogy a technológia 2023-ban eljut a Radeon grafikus vezérlőkre is. Úgy tudjuk, hogy a novemberben bemutatkozó Navi dizájnok egyik chipletjét úgy tervezték meg, hogy arra direkten ráhelyezhető a processzorba szánt chipletekhez készített új 3D V-Cache lapka. Ezzel valószínűleg az Infinity Cache kapacitása növelhető meg jelentős mértékben."
[link]
>> MCD on TSMC N6, ~37.5 mm² [link] -
#8144
Petykemano
veterán
Petykemano
veterán
Genoa hivatalos bemutató: November 10
-
#8141
Petykemano
veterán
Petykemano
veterán
Raptor Lake rajthét - MF adatok:
Érdekes, hogy nem törte meg egyáltalán az AM4 elsőségét.
Részletes adatok: [link]
(TechEpiphany gyűjtéséből)Mivel a Raptor Lake igen komoly kihívást intézett minden szempontból az AMD felé, én ennél picit nagyobb hatásra számítottam
Persze az kétségtelen, hogy
- ez csupán egy bolt.
- ország és ország között komoly eltérések lehetnek
- a Raptor Lake lehet, hogy jobban kezdett, vagy jobban is fog alakulni, mint a Zen4
- készletről árulva az AM4/ADL ára sokkal kedvezőbb lehet, mint az emelkedett értékű dollárért újonnan vásárolt termékek.
- a végső eladási szám bizonyára nem a DIY piacon, hanem az OEM-eknél fog eldőlni.Az jutott eszembe, hogy egyébként a következő hónapokban milyen sok eszköz áll még az AMD rendelkezésére.
- az előbbiekben emlegetett $69-os előállítási ár megengedi, hogy alacsonyabb áron (is) forgalomba hozzanak terméket. Ez csak annak függvénye, hogy van-e elég kapacitások. Ha többet adnak el, akkor ugyanis a fix költségek (tervezés, stb) több darabszámra terül, tehát egy példányra számolva még alacsonyabb is lesz.
- A CES-re pletykálják az X3D változat megjelenését. Ami - ha hihetünk MLID pletykáinak - valamivel jobb előrelépést fog biztosítani, mint a 5800X3D volt az 5800X-hez képest. De talán az ott látott átlagos +15% is elég lehet ahhoz, hogy visszavegye az AMD az elsőséget gaming területen.
Persze ne bízzuk el magunkat túlságosan! Ha a technológia ugyanaz, akkor a megemelt L2$ méret miatt csökkenhet a nyomás az L3$-en és emiatt elképzelhető, hogy esetleg a 3x nagyobb L3$ IPC-re gyakorolt hatása kisebb lesz.- De ezzel nagyjából egyidőben várható a Zen4c bejelentése/megjelenése is. Ez persze szintén nem új információ. Csak kontextusba helyezem:
Ha az AMD megcsinálja a Zen4X3D + Zen4c hybrid SKU-t, akkor minden szempontból visszaveheti az elsőséget.A 7800X(3D) minden bizonnyal 1 CCD + v-cache lesz
De ezen kívül csinálhat:
- 2x6 magos CCD v-cache-sel (vs 13900K gaming & professional)
- 2x8 magos CCD v-cache-sel (vs 13700K gaming & professional)
(- 1x6 magos CCD v-cache-sel (vs 13600K gaming))
- 1x8 magos CCD + 1x16magos CCD (vs 13900K multi)
- 1x6 magos CCD + 1x12magos CCD (vs 13700K multi)
- 1x8 magos CCD V-cache-sel + 1x16magos CCD (vs 13900K ultimate)
- 1x6 magos CCD V-cache-sel + 1x12magos CCD (vs 13700K ultimate)Bizonyára nem soroltam felaz összes lehetséges kombinációt
És bizonyára még az általam felsoroltak sem mind valósulnak majd meg.De azért itt még - elvileg a közeljövőben - elég komoly (szerintem gaming és multi terén akár 20-30%-os) teljesítménynövekedés jöhet. Lehet, hogy az AMD azért sem izgatja magát különösebben, mert ezek lesznek majd a valódi teherhordó termékek, míg a most megjelent SKU-k csupán egy alapot jelentenek.
-
#8135
Petykemano
veterán
S_x96x_S
#8134
Petykemano
veterán
válasz
S_x96x_S
#8134
üzenetére
> 7700 - OEM only
Ez sajnos lehetséges.
A zen3 esetén is volt 5800, ami nagyjából az 5700X OEM only megfelelője volt.
Az biztos, hogy az oemeknek nem kell a 105W-os cucc.
És az eddigi felhozatalban nem volt 65W-os.Ez a $69 szerintem jó hír. Ez csak az anyagköltség. De azért így is 6-8-szoros margóval dolgoznak, abba kell beleférnie a működési költségeknek.
És ez mehet még lejjebb idővel.
Ahogy a szorzó is. 2 év múlva lehet akár $150-ért is adni majd.
Nem is beszélve arról, hogy az X3D hozzáadott költsége ez alapján nem kéne, hogy kb $30-nál több legyen. -
#8132
Petykemano
veterán
Petykemano
veterán
Úgy tűnik, tévedtem.
Úgy tűnik, az AMD mégiscsak reagál a kihívásra egy sajátos, arcvesztés nélküli módon:
Ryzen 7 7700 @65WEz a gyakorlatban egy olyan sku, amivel csökkenti az árat a gaming piacon és nyilván meg se próbál versengeni ott, ahol esélytelen - multithreadben.
Az ára persze nagy kérdés.
Bizonyára azért alacsonyabbak lesznek a frekvenciák. Főleg multiban.
Szerintem ezt kb a 7600X árban kéne adni. De akkor ugye a 7600x azonnal el is avul.De legalább el lehet adni 7600-ként.
-
#8123
Petykemano
veterán
#36531588
#8119
Petykemano
veterán
válasz
#36531588
#8119
üzenetére
> Nagy változást nem is várnék,
Az az igazság, hogy én se.
Az AM4 továbbra is nagy népszerűségnek örvend a MF eladásaiban.A Zen4 elég jól sikerült ha csak a teljesítménybeli előrelépést nézzük, de emelte a fogyasztást, és a platformköltséggel együtt meglehetősen drága.
A Raptor Lake is hozta, ami elvárható volt. A szokásos módon az Intelnek sikerült érezhetően emelni a teljesítményt, viszont mivel ez nem párosult gyártástechnológia váltással vagy más (3D) áttöréssel, ezért ez meg is látszik a fogyasztáson.Ennek ellenére valószínűleg meglesz a közönsége, de én azt látom, hogy egyik sem jelent - az árazást és az fogyasztást is figyelembe véve - a piac számára diszruptív előrelépést.
Akinek mondjuk 12900K-ja van, ahhoz képest olyan nagy előrelépést nem jelent az 13900K. Ha kell a +40-50% MT teljesítmény, akkor persze lehet cserélni, de azt gondolnám, hogy ez egy lecsengő lelkesedés. Az 13600K remek mainstream CPU-nak tűnik, de ehhez jobbára igényli a DDR5-öt és amennyivel jobb az 12600K-hoz képest, annyival talán drágább is. Nem kizárt, hogy ez az 5800X3D-re is igaz. Nem is beszélve arról, hogy ahhoz, hogy egy lényegesen olcsóbb processzorhoz képest kimutatható legyen a különbség egy
$1000-os ($700-os) GPU-t is mellé kell tenni.Biztosan lehet találni pro-kontra érveket, de most is az az érzésem, hogy lehet kedvenc szín szerint választani, nem igazán lehet most szín alapján mellényúlni. Viszont összességében a Raptor Lake is "meh" érzetet kelt, mint a Zen4 is.
Szóval én is azt gondolom, hogy nem fogja egyik napról a másikra felforgatni MF számait.
Volt szó arról, hogy az Intel végül valamivel alacsonyabb árakon hozta ki a Raptor Lake-t a vártnál. Felvetődött, hogy vajon mikor fogja az AMD csökkenteni az árait.
Szerintem az AMD nem fog árat csökkenteni a Raptor Lake érkezése miatt, csak majd akkor, amikor kiadja az Zen4 X3D-t.
-
#8117
Petykemano
veterán
Petykemano
veterán
Megjelentek a tesztek az 13900K-ról.
Nagyjából az lett, amit vártam.
Megcsinálták, hogy gyorsabb legyen, de ennek ára van a fogyasztásban.Viszont az 13600K + DDR4 jó versenytársa lehet az 5800X3D-nek.
-
#8115
Petykemano
veterán
S_x96x_S
#8114
Petykemano
veterán
válasz
S_x96x_S
#8114
üzenetére
Oké,
de akkor miért?
Azért a DDR5 szabvány nem tegnap lett kész.
Tavaly óta kapható Alder Lake, amihez ténylegesen fel is használható.
Korábban volt szó arról, hogy valamilyen frekvencia szabályozó chip átkerül az alaplapról a DDR5 modulra és (gondolom mivel így modulonként kell egy, nem alaplaponként ezért) hiány alakult ki abból. De a chiphiány lassan megszűnik, olyannyira, hogy már mindenki bejelentette, hogy visszafogja a termelés.Azt el tudnám hinni, hogy a DDR5 előállítási költsége annyival magasabb a DDR4-hez képest, hogy a konzumer piacra nem szállítanak, de milyen gyártási nehézség állhat amögött, hogy a szerverekbe sem jut?
-
#8113
Petykemano
veterán
S_x96x_S
#8111
Petykemano
veterán
válasz
S_x96x_S
#8111
üzenetére
> de az már az AMD sara, hogy ezt benézte ...
> és nem kalkulált látható "B" tervvel
egyrészt - szerintem az általad említett DDR5 hiány épp amiatt lehet, mert minden adatközpont/szolgáltató gőzerővel telepíti a Genoa (esetleg SPR) szervereket.Tehát az egyik B terv az AMD-nél lehet pont a Genoa.
Másrészt - a Mindfactory számai arról tanúskodnak, hogy mindig is az AM4 volt a B terv.
Persze ez a zen4-en, mint generáción lehet, hogy nem segít.Abban lehet reménykedni, hogy ha sokan mondanak vissza megrendeléseket, akkor idővel a TSMC is kénytelen lesz árat csökkenteni, visszavezetni a mennyiségi kedvezményeket. Persze nyilván a TSMC-nek mindegy, hogy állnak a gyártósorok, vagy mennek, ha mindenképpen ki van fizetve 1-2 évre előre.
Persze a következő néhány negyedév rázós lesz a konzumer piacon.
-
#8109
Petykemano
veterán
Petykemano
veterán
Nemrégiben a PCIe5 nagy vitákat kavart itt.
És az is meglepetést okozott, hogy az AM5 rajtjával nagyjából egyidőben megjelent Samsung 990 PRO SSD csak Pcie4 interfésszel jött ki.Az eddig bejelentett PCIe5 SSD-k nagyrészt azt domborították, hogy 10-11-14GB/s átviteli sebességet is tudnak (szemben a PCie4 7GB/s-os korlátjával)
Érdemes vetni egy pillantást erre a képre:
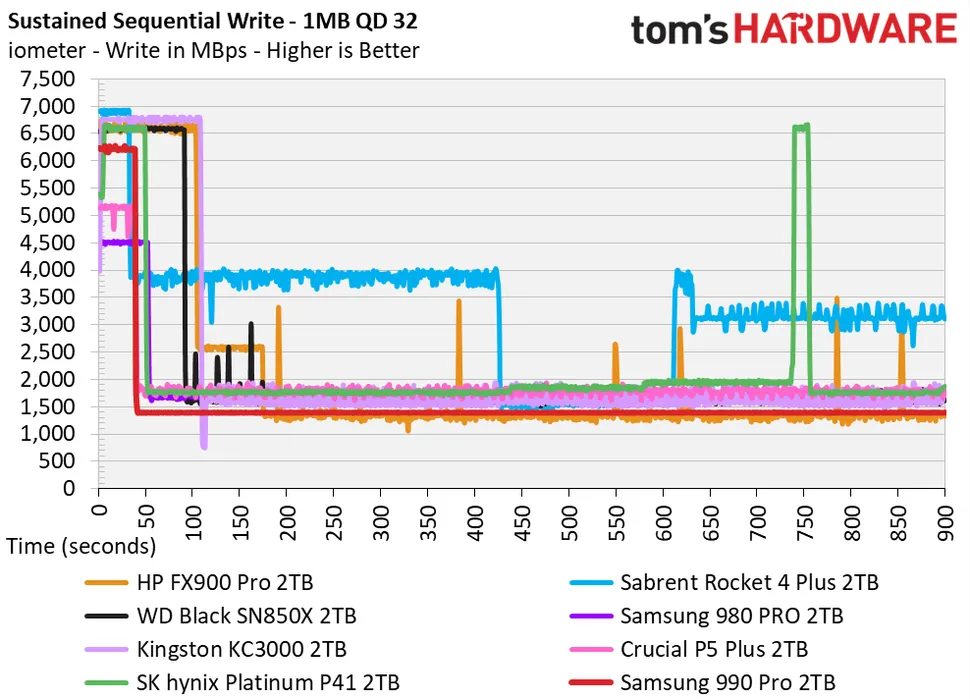
A ábra azt mutatja, hogy az egyes SSD-k milyen hosszan képesek egy meghatározott írási sebességet tartani szekvenciális írás esetén.
Ezzel legkevésbé sem a samsung gyártmányát kívánnám minősíteni, vagy hasonlítgatni más márkákhoz.
Csak arra kívánok rámutatni, hogy a névleges átviteli sebesség, amit a kirakatba tesznek, az valami hasonló, mint a CPU-k esetén a turbó órajel.
Nyilván az, hogy meddig bírja az valamilyen Cache függvénye. Nyilván minden gyártó úgy választja meg, amilyen adatmennyiség szekvenciális írását életszerűnek gondol. Ettől nem lesz sem jó, sem rossz. PCIe5 csatoló használata esetén minden más változatlanul hagyása mellett azt látnánk, hogy a pillanatnyi áteresztő képesség magasabb, de időben hamarabb zuhan be.
Talán csak annyi a tanulsága, hogy aki tényleg hatalmas file-okkal dolgozik, annak tényleg érdemes lehet ezt figyelembe venni.
-
#8107
Petykemano
veterán
Petykemano
veterán
AMD vs Intel adatközpont - számok
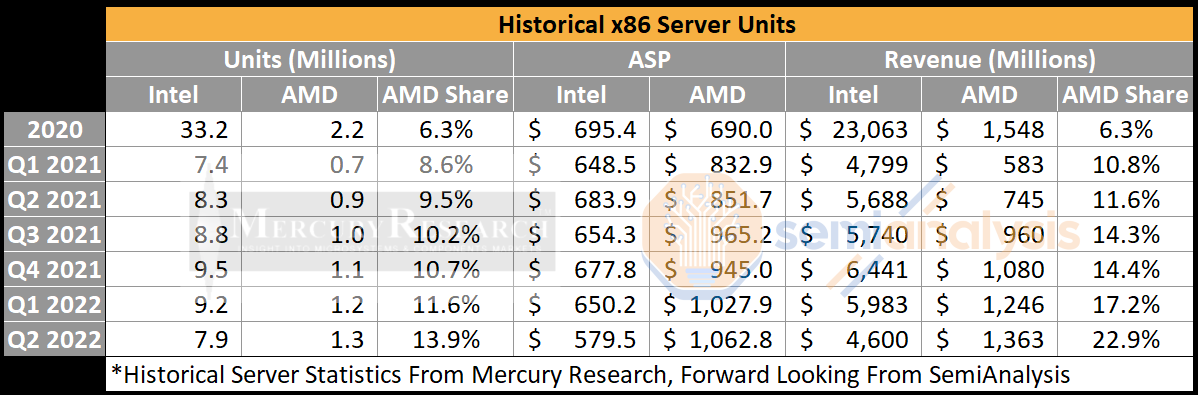
[link]A cikk tartalmaz egy TCO számítást is.
Sajnos Intel oldalon csak ősrégi Skylake/Cascade lake szerepel. De feltételezésem szerint azért, mert más nem is nagyon elérhető. Persze tudom, hogy az Ice Lake létezik, legalábbis úgy tudom, hogy az Intel árulja, még ha esetleg a DIY piacon nem is, épp ezért sajnálom, hogy még csak becslés formájában sem szerepel.Mindenesetre az a gyanúm, hogy a Genoa a nagy cloud szolgáltatóknál hamarabb, de legalább egyidőben lesz elérhető a Sapphire Rapids-zal.
Mit gondoltok (ilyen energiaárak mellett) mikor fognak elkezdeni kikopni a cloud/VM szolgáltatók gépparkjából a Skylake, vagy még régebbi gépek?
-
#8101
Petykemano
veterán
b.
#8100
Petykemano
veterán
Ez a jelenség új? Mármint hogy az 5950X esetén másként volt?
Mi lehet az oka?
Ha tippelnem kéne, én arra tippelnék, hogy a játékok (ide értve az nvidia driver overhead-jét) elkezdtek túlterjeszkedni 8 magon és a másik CCD-re ütemezett szálak esetén ugyanaz a jelenség áll fenn, mint a 4 magos CCX-ek között volt.Kíváncsi lennék, ez minden játék és minden gpu esetén így van-e?
-
#8099
Petykemano
veterán
Petykemano
veterán
-
#8098
Petykemano
veterán
#36531588
#8096
Petykemano
veterán
-
#8097
Petykemano
veterán
#36531588
#8096
Petykemano
veterán
válasz
#36531588
#8096
üzenetére
"Azon meg marhául el kéne gondolkodnod, hogy a microsoft az amd apu-ra épülő konzoljaival miért az nvidiával kézenfogva hozta a directstorage 1.1-et PC-re"
Szerintem ez egy nagyobb jelentőségű kérdés, mint amilyennek gondolod, mint ami miatt szerintem feltetted.
Az első gondolatom az volt, hogy nyilvánvalóan azért, mert a PC piacon az nvidia a piacvezető.
Ugyanakkor ettől függetlenül nem megszokott jelenség ez. A DirectX12 például AMD által inspirált valami.Persze azon kívül, hogy a MS a következő konzolt Nvidia hardverrel csináltatná, más magyarázat is lehet. Például az, hogy a Sonyhoz hasonlóan az Xboxban már eleve van dedikált hardver, nem szorulnak rá arra, hogy a GPU-t használják ilyen célra, ezért a PC a következő piac, ahol az AMD nem szempont. De nem csak a PC, hanem a MS mellett legjelentősebb jelenléttel az game streaming piacon is az nvidia rendelkezik szerintem.
-
#8095
Petykemano
veterán
#36531588
#8091
Petykemano
veterán
válasz
#36531588
#8091
üzenetére
GPU decompression isn’t new. The main problem has been storage, where the SSD couldn’t feed the GPU enough data in time to decompress it (which is why it went through the CPU first).
DirectStorage, with a supported SSD, eliminates that bottleneck.Smart Access Storage looks to further improve that system. AMD’s Robert Hallock explained the key difference to us: “Because we own both the CPU and the GPU endpoints, we do not need to go to main memory like DirectStorage does.”
Instead of using the system RAM, Smart Access Storage provides a direct connection from the SSD to the graphics card, further improving loading times.
Sajnos nem tudom, hogy a kiemelt mondat pontosan mit fed. A megfejtéshez nyilván tudni kéne, hogy a DS mit matat a rendszermemóriában.
Mindenesetre a leírás alapján úgy tűnik, Smart Access Storage = DirectStorage + Smart Access Memory.
-
#8077
Petykemano
veterán
S_x96x_S
#8075
Petykemano
veterán
válasz
S_x96x_S
#8075
üzenetére
Az AM5-ben az 5 a DDR5-höz kötődik, nem a PCIe generációhoz. Úgyhogy nem zárható ki.
Ugyanakkor szerintem örülhet a piac, ha 2025-re a PCIe5 elkezd elterjedté válni a mainstreamben.
Még ma is árulnak PCie3-as alaplapokat és procikat. Az alaplapok alja még csak most lesz PCIE4.ETtől függetlenül persze a CPU és a GPU megkaphatja hasonló nyökögések mellett, mint a PCIe4 esetén is volt.
- kivezetjük-e vagy nem
- az alaplapoknál nem terjed
- apuk még lemaradnak
- de az új mainstream gpu-t viszont x2 PCie6 csatolóval adjuk. -
#8069
Petykemano
veterán
#36531588
#8068
Petykemano
veterán
válasz
#36531588
#8068
üzenetére
> A dollár ára ugyan úgy befolyásolja az am4 cuccokat is.
> Persze amíg készletről árulnak, és nem új beszerzés jön, addig az am4 előnyben lehet.
Én tavasszal vettem egy 5600G-t 73eFt-ért azt gondolván, hogy ennél lejjebb már biztosan nem megy. 1-2 hónappal később már 69eFt is meg lehetett kapni más üzletekben. Azóta nagyon sokat romlott a forint a dollárhoz képest, de ez az ár nem változott. Valószínűleg készletről árulnak, ahogy mondod, és ezért az AM4 árakra egyelőre nem gyakorolt még érezhető hatást a usd/eur változás sem.A recessziós várakozás megnyilvánulhat abban is, hogy most nem veszek egy új drága gépet, hanem inkább beérem a még mindig olcsóbban kapható előző generációs készülékkel is.
Így vagy úgy, de nem kell az AM5 - ebben nincs vita.
-
#8066
Petykemano
veterán
Petykemano
veterán
Nem kezdtek kiemelkedően, de második hétre bezuhantak az AM5 eladások a Mindfactory-n
850 => 250Ahogy azt már korábban is mondtam, szerintem ezt csak részben magyarázza az egyébként valóban platform költség. De szerintem jelentős mértékben hozzájárul a recessziós várakozás és a dollár minden más devizához képest történő erősödése, ami rontja az USA export pozícióit.
-
#8063
Petykemano
veterán
awexco
#8062
Petykemano
veterán
Én matematikai alapon határoznám meg
Most konkrét számok nélkül. Ahol a görbére fektetett érintő dőlésszöge x° alá esik, annál nem lehet nagyobb PPT-t megadni, mert ott az elhasznált energia már túlságosan kis mértékben hasznosul és az már (túlzott/indokolatlan) környezetszennyezésnek minősül.Egyébiránt az is érdekes, hogy 40W alatt az Alder Lake fogyasztási előnye azért kitapintható.
Kiváncsi vagyok hogy csinálnak ebből mobil lapkát (Dragon Range)
Letekernek pár frekvenciát és az elegendő? Vagy bevetnek valami új packaging technológiát?
Vagy a mobil ebben az esetben 45-55W TDP-t fog jelenteni és el kell majd fogadni, hogy a 25000-30000 pontot elérő mobil (gamer/workstation) chip esetén a standby fogyasztás némiképp magas? -
#8061
Petykemano
veterán
Petykemano
veterán
-
#8059
Petykemano
veterán
b.
#8058
Petykemano
veterán
Az általad linkelt cikkből:
"While it’s said that Frontier is showing impressive runs on some codes, we also hear the Slingshot interconnect, tasked with tying the mammoth HPE cluster together, is proving troublesome. Where, specifically, the fabric problems may lie is unclear, but there is speculation it’s related to integrating the HPE Cray-based Slingshot with the AMD EPYC CPUs and Radeon Instinct GPUs that will power Frontier. It’s possible DOE has decided to delay announcing it has stood up the country’s first exascale system until the rumored interconnect issues are resolved."
Tehát azt mondod, hogy az Oak Ridge-nél mindenki kínosan ügyel, nehogy valami a brandnak ártó terhelő jellegű kijelentést tegyenek a CPU és a GPU beszállítóról, de az interconnect szállítóját nyugodtan lehet negatív színben feltüntetni, sőt lehet, hogy van egy nagy összekacsintás is, hogy inkább ők vigyék el a balhét, nehogy véletlen árnyék vetüljön az AMD-re?
Szerintem két eset lehetséges:
Mivel a viszonylag kisméretű Komondoron kívül nincs másik olyan slingshot-11 a listában, ami ne AMD+AMD lenne. Mivel a kisebb méretű slingshot-11+AMD+AMD rendszerek esetén nem jelentettek problémát, ezért feltételezhező, hogy nem valamilyen olyan hibáról lehet szó, amit azt AMD en bloc elrontott. Még kiderülhet, de jelen állás szerint nem ilyesmiről van szó.Az egyik lehetőség tehát az, hogy vagy a slingshot-11 nem képes megküzdeni ezzel a 60 millió alkatrésszel (ez persze nyilván nem mind compute node, de most fejből nem tudom, hány cPU és GPU van benne)
Vagy a másik lehetőség az az, hogy az AMD hardver nem képes 60 milliós méretben skálázódni.Most csak tippelek, de ugye itt valami infinity architecture van már, tehát biztos kommunikálnak egymással a GPU-k és a CPU-k. Lehet, hogy ilyen kommunikáció más rendszerben, ami nem AMD infinity architecture nincs. És lehet, hogy a node-ok egymással való kommunikációja kevés node esetén nem jelent nagy terhet a hálózatra, de ekkora méretben, ennyi node esetén, mint a Frontier már túlterheli a Slingshot-11 interconnect-et.
-
#8056
Petykemano
veterán
#36531588
#8055
Petykemano
veterán
válasz
#36531588
#8055
üzenetére
Tényleg nem szoktak ilyen hírek jönni olyan gépekről, amikben Nvidia GPU-k vannak.
Mivel a nyilatkozatot nem az AMD tette közzé, ezért szerintem nincs okunk azt feltételezni, hogy pontosan az állítások ellentéte lenne igaz.
"nem (kizárólag) az AMD hardverrel van gond" => "az AMD hardverrel van A gond"
"hasonló nehézségek elő szoktak fordulni a hardver összerakása és a tényleges használatbavétel között" => "ez nem szokványos jelenség, nagy a baj, amiért az AMD hardver felelős"Persze nem bíznám el magam, kiderülhet, hogy valami súlyos hiba van a rendszerben, ami miatt soha nem fog működni.
Úgy emlékszem hogy a Tianhe-2 esetén is rengeteg probléma volt - a Xeon Phi - gyorsítókártyákkal, amiket először cserélni próbáltak egy újabbra, de ha jól tudom, akkor azok használatát végül el is engedték.
Bizakodásra ad okot, hogy más AMD+AMD Mi250X rendszerek esetén még nem jelentettek hasonló problémát.
-
#8053
Petykemano
veterán
#36531588
#8052
Petykemano
veterán
válasz
#36531588
#8052
üzenetére
Azt is írják, hogy a hibáknak természetesen részét képezik az AMD által szállított hardverek is, ahogy a Slingshot is, nem arról van szó, hogy az AMD kifejezetten alkalmatlan hardvert szállított volna. Hasonló hangolási nehézségek minden nagyméretű szuperszámítógép rendszer telepítésénél jelentkeznek. [link]
De persze lehet, hogy ez csupán céges maszlag az arcvesztés elkerülése érdekében és az üzembe állás el fog húzódni, mint azAurorarétestészta.
Tudtommal nagyon régóta ez az első olyan szuperszámítógép, amelyben AMD gyorsítókat használnak. (Ez persze nem igaz, mert a 478. helyen van egy Sugon nevű gép, amiben kivételesen Vega 20 van) Minden más projektet döntően az Nvidia szokott vinni, úgyhogy annyira nem meglepő, hogy felmerülhet némi tapasztalatlanság.A slingshot11-et se gyakran látom a listán még AMD-AMD rendszereken kívül.
Eddig a magyar Komondor használja Nvidia gyorstóval.Egyébként érdekes, hogy a top10-ben van 2 másik kisebb AMD-AMD rendszer (a finn Lumi és a francia Adastra). Kiváncsi lennék, hogy azok is érintettek-e.
-
#8050
Petykemano
veterán
Petykemano
veterán
TSMC SoIC-H - Avagy AMD 2D Stacking
Mint ismeretes az AMD a V-cache alap lapkára való ráillesztéséhez a TSMC SoIC technológáját használta. Nem állítom, hogy én annyira szuperül eligazodom a CoWoS, LSI, SoiC és hasonló elnevezések között, mindig utána kell néznem hogy mit írtak a szakértők.
Mindenesetre a V-cache és a SoiC lényege az volt, hogy bump-ok (érintkezők?) helyett hybrid bonding (forrasztás?) alkalmaztak és (bár most nem teljesen egyértelmű, hogy ennek következtében-e, mindenesetre) lényegesen nagyobb kapcsolati sűrűséget (interconnect) értek el (a bump/microbump technológiház képest, amit nem tudom mikor és hol használtak valaha is)
Mindenesetre hát itt ugye írják, hogy ez SoIC
Itt van egy ábra, hogy mit tud a SoIC:
Ebből a v-cache szerintem a (b) változatot valósította meg.Na most a napokban felröppent a hír, hogy a TSMC demózta a SoIC-H nevű technológát.
két paywalled cikk: [link] [link]
Ezeket magam sem olvastam.
Én innen inspirálódtam:"TSMC is talking about things to come, and one of the biggest ones may be newly demonstrated SoIC-H. Where H stands for Horizontal.
It is an interposer(ish) type of thing, where the dies are attached not by using bumps / micro-bumps but by "stacking" the dies on the interposer using hybrid bond connection.
Using hybrid bond connection, the number of interconnects can grow by order of magnitude, most of the latency is squeezed out, clock speeds, bandwidth increased, power overhead drastically cut.End of SerDes. EFB / EMIB, classic interposer leapfrogged."
Nem tudom.... Mondom, én annyira nem vagyok PRO ezekben kifejezésekben, de hát szerintem ennek a SoIC-nak a lényege az, hogy nincs interposer. Mivel SoIC-nak nevezik, ezért a fenti ábrán a SoIC-H-t a (c) változatként azonosítottam be és ott nem jelez a 2 dimenziós módon egymás mellé helyezett lapkák alá egy a kapcsolatot (huzalozást) megvalósító interposer lapkát, hanem mintha a két lapka horizontálisan kialakított módon kapcsolódna egymáshoz, ami pedig kifejezetten egybecseng a tárgyalt új technológia nevével.
De persze lehet, hogy rosszul értelmezem.Az valóban elég valószínű, hogy az AMD ezt fogja használni arra, hogy chipeket egymás mellé tegyen és összekössön. Hol lehet ennek jelentősége? Hát talán már az RDNA3-ban vagy lehet, hogy így lesz chiplet-based a Phoenix point. Vagy akár a Dragon Range működése is erre alapozódhat. Ez persze részemről wishful thinking. Elképzelhető, hogy még nem eszik ennyire forrón a kását.
Én két dologra tudok gondolni, hogy ez miben új, mi lehet a jelentősége.
1) Amennyiben a valóban nem kell interposer a két egymás mellé helyezett lapka alá még olyan kisebb sem, mint az EMIB vagy EFB esetén használatos, akkor technológia lényege, jelentősége az lehet, hogy olcsóbban megvalósítható, mint az EMIB, EFB vagy más interposeres megoldások.2) Amennyiben tévedek az interposerrel kapcsolatban, akkor pedig arról lehet szó, hogy az eddig használt interposeres technológiák csak a bump/microbump használata mellett lehetséges interconnect sűrűséget tették lehetővé ,ami elegendő volt ahhoz, hogy mondjuk egy HBM memóriát rákapcsoli a processzorra széles busszal, de kevés volt ahhoz, hogy a compute lapkát elemeire bontsd és monolitikus chiphez fogható szélesssávú kapcsolatot létesíts közöttük.
Magyarul, hogy ennek jelentősége csupán az, hogy jelentősen emelkedik a kapcsolati sűrűség.Viszont az a helyzet, hogy ez azért nem valószínű, merthogy az AMD már a CDNA2 esetén bemutatott EFB esetén is azzal kérkedett, hogy a MicroBump 3D-hez képest 15x nagyobb az interconnect density , mint ahogy a V-cache esetén 15x nagyobb connection density-t emlegetett . A hybrid bonding által biztosított lényegesen nagyobb kapcsolati sűrűséget egy kisebb interposer technológiával megvalósító technológának tehát már van neve: EFB. Nem valószínű, hogy most újra elneveznék máshogy, ahogy az sem, hogy visszatérnének a nagy interposer használatához.
Következésképpen csak az lehet, hogy a technológia interposer használata nélkül teszi lehetővé egymás mellé helyezett lapkák (2D) csatlakoztatását a nagy kapcsolati sűrűséget biztosító hybrid bonding segítségével.
Jön az AMD Tile-ing.
szerk:
Esetleg még lehetséges 3)-ik eset az, hogy az interposer lapka nem alul van, hanem a 2 egymás mellé helyezett chipet egy felülről rájuk helyezett lapka hidalja össze. Az ábrából ilyesmi nem következik. Hasonlót mintha Coreteks pedzegetett volna az RDNA3-hoz.Kicsit fura egyébként.
Azt gondoltam volna, hogy bármilyen horizontális összekapcsolás előtt fog megvalósulni az, hogy az IOD lesz az interposer és arra 3D stackelik a CCD-ket. és így felejtődik el a SerDespl így:
[*Vcache*][*Vcache*][*Vcache*]
[==CCD==][==CCD==][==CCD==]
[¤¤¤¤¤¤¤¤ L4$ ¤¤¤¤¤¤¤¤]
[######### IOD ##########] -
#8049
Petykemano
veterán
Petykemano
veterán
Az AMD 2022Q3-as előrejelzését $6.7B-ról $5.6-ra módosította.
[link]A Client group bevétele esett. Érdekes módon a gaming szinten maradt. Tudomásom szerint a client a CPU/apu árusításával foglalkozik. A gaminghez tartozik az RDNA és a console semi /custom. [link]
Ez ugye a július-augusztus-szeptember időszak.
Ekkor már jelentős kedvezményekkel adták a Zen3-at és bár az időszak végén rajtolt el a zen4 így szerintem esélye sem lett volna érdemben befolyásolni. A hiányzó $1b-t nem varrnám kizárólag az eladásokat tekintve gyenge zen4 rajt nyakába.Az utolsó három hónapot feszültebb várakozás, visszafogott vásárlás jellemezhette a processzorok terén. A romló eredményekhez hozzájárulhatott a dollár folyamatos erősödése is.
-
#8048
Petykemano
veterán
Petykemano
veterán
Mindig vannak alternatív megközelítések, amelyek sokkal nagyobb teljesítményt ígérnek a piacon levő szereplőkhöz képest. Ilyen volt a Biren BR100 is, és a Tachyum is elég régóta van jelen tervekkel, és a dokumentációkkal, ígéretekkel.
Vannak kétségeim most is, hogy mennyire lesz ez sikeres a piacon.
Viszont az nem elképzelhetetlen, hogy az Európai Unió a chiptervezés terén önálló lábra állás elérése érdekében ilyen európai kezdeményezéseket felkarol.
Hajrá szomszédok! -
#8044
Petykemano
veterán
Petykemano
veterán
Zen5
A minap olvastam egy érdekes fejtegetést.
Az AMD tick-tock megközelítéssel kb 3-4 évente dob le egy friss ground-up architektúrát. És ezeknél a célként megjelölt IPC növekedés jellemzően 40%excavator => zen1
A publikusan megcélzott 40%-ot sikerült túl is szárnyalni, 52% lett
zen1 => zen3
A zen2 esetén 15%, a zen3 esetén 19%-os (átlag) IPC növekedést találtam.
Nem tudom, hogy a zen2 esetén a 15%-ot a Zenhez, vagy a Zen+-hoz mérték-e.
Mindenesetre ez együtt kb 37%-os IPC növekedést jelent.zen3 => zen5
Az eddigiek alapján feltételezzük, hogy a cél itt is a 40% lehet.
Hivatalos adatok szerint a Zen4 átlagos IPC növekménye a zen3-höz képest 13% volt.
Ebből kiszámolható, hogy a Zen5 IPC növekedése - matek alapon - olyan 24%-ra várható.Persze ez más tényezőktől is függ.
1) gyártástechnológia
Nem mindegy, hogy a Zen5 végül N3-on valósul-e, meg vagy N4-en. (és a Zen5 (Zen5+) mobil lesz az N3 pipecleaner)
A Zentől egyszer volt egy gyártástechnológia váltás (Zen2) és ahhoz képest azonos gyártástechnológán megvalósított Zen3 hozta a 36-37%-os IPC növekedést. Tehát a két ground-up architektúra között (nem számolva persze a 10nm-rel) 1 gyártástechnológiai ugrás volt.
Ha ezt a trendet követi a Zen5 és N4-en érkezik, akkor a Zen3 és a Zen5 között nagyjából azonos gyártástechnológiai távolság lehet és nem nagyon várható a 40%-os célszám túlszárnyalása.
Ellenben ha a Zen5 N3-on valósul meg, ott rendelkezésre állhat olyan extra tranzisztorbüdzsé, amivel a végeredmény 40% fölé mehet.2) packaging technológia
Az idén bemutatott L3$ bővítményként bevezetett X3D technológia relatív szűk alkalmazási körben, de ott jelentékeny mértékben növelte az IPC-t (néhány alkalmazás, játékok)
Ha módot találnak arra, hogy a technológia szélesebb körben járuljon hozzá az alkalmazások gyorsulásához és a Zen5-öt már eleve gyárilag 3D tokozásos technológiával való gyártásra tervezik (tehát hogy a bővített cache - legalább valamilyen mértékig - szériatartozék nem opcionális megoldás), akkor az szintén adhat egy lökést, hogy túl lehessen szárnyalni a 40%-os célértéket.
Pl: többrétegű 3D tokozott L1$, ami nem ad hozzá késleltetést, de mondjuk 2-3-4x nagyobb kapacitást biztosít. Ez önmagában lehet, hogy nem sokat segítene (az AMD ábráin is láthatjuk, hogy az átlagos IPC növekedéshez csekély mértékben járult hozzá a duplázott L2$ ) De ha eköré tervezed a processzort, pl növeled a feldolgozók számát, akkor már kiaknázhatóvá válik. Akár egy olyan szcenáriót is el tudok képzelni, hogy a feldolgozók számának és a cache növelésének ütemével a branch predictor és más ST teljesítményt befolyásoló részegységek nem tudnak egyből lépést tartani, de megfelelő rétegzettségű cache bővítmény mellett megnyitja az utat az SMT yield növeléséhez. (SMT4) -
#8043
Petykemano
veterán
Petykemano
veterán
Nem tudom, mikor volt utoljára téma.
bennem az maradt meg, hogy Abu azt írta, az AMD szigorúan előírta, hogy az összes alaplap esetén PCIE5 legyen a storage
A hír nem annyira új, már vagy három hetes: a B650 esetén a PCIe5 storage opcionális.Egyébként olvastam másutt is elképedt hozzászólásokat, hogy a hasonló képességű (DDR5, PCIE5) intel alaplapok 30%-kal olcsóbbak és hogy ez hogy lehet.
(Nyilván úgy lehet, hogy most sápot szednek az early adoptereken)
-
#8037
Petykemano
veterán
S_x96x_S
#8036
Petykemano
veterán
válasz
S_x96x_S
#8036
üzenetére
Szerintem ennek a hőfoknak nincs különösebb jelentősége.
Amúgy nyilván van. Biztosan igaz, hogy minél magasabb a hőfok, annál nagyobb feszültség kell a frekvencia tartásához, ami hozzájárul a fogyasztáshoz és persze a további hőtermeléshez.
Ez alapján persze szerintem is jó lenne, ha nem lenne olyan magas.De ha az AMD szerint ez elfogadható érték és egyébként a mérések alapján a magas hőfokból fakadóan nem throttlingol és nem ég le, a megfelelő hűtőeszközzel hűthető, akkor nincs sok értelme hasonlítgatni.
Másként fogalmazom meg:
Fizikusok bújócskáznak. Einstein a hunyó, úgyhogy eltakarja a szemét és elkezd visszaszámolni 50-től.
A fizikusok meg elbújnak. Egyedül Newton nem talál egyetlen szabad helyet sem, így leül a földre és rajzol maga köré egy 1x1 méteres négyzetet.
Einstein persze azonnal megtalálja:
- Megvagy,Newton!
- Nem, nem, drága barátom, tévedsz! Én egy Newton vagyok egy négyzetméteren, úgyhogy tulajdonképpen Pascalt fogtad meg...Lehet, hogy ez a 95-100° mérhető hőmérséklet egy kisebb területen keletkezik a zen4 esetén, mint a 10°-kal alacsonyabb hőmérséklet akár a Zen3 akár más konkurens Intel processzorok esetén. Ami azt jelenti, hogy amennyiben a kisebb terület felől a hűtő felé a hőátadás/hőszórás (heat spreader) elég jó, akkor a leadott hőmennyiség akár kevesebb is lehet.
Egyébként lehet, hogy a vastagabbnak látszó kupakot valójában nem az AM4 hűtőkkel való kompatibilitás indokolja, hanem épp a megfelelő hőszórás, hogy a CCD-n keletkező hőt az erre a célra megfelelően kialakított forrasztott IHS már önmagában eléggé jól szétszórja arra a felületre, amelyen a hűtőbordával érintkezik.
-
#8032
Petykemano
veterán
Petykemano
veterán
HWinfo - upcoming changes
- Added early support of some AMD Zen5 families.Szerencsére van már egy gyűjtésem [link]
- zen említése először 2015 október 14-én (added preliminary recognition)
=> 2017 márciusi rajt (+17 hónap)
- zen második említése 2016 július 6 (Enhanced preliminary support)
=> 2017 márciusi rajt (+8 hónap)- zen2 említése először 2019 április 3-án (Improved support)
=> 2019 júliusi rajt (+4 hónap)
- zen3 először 2020 május 13-án kerül említésre (Enhanced monitoring)
=> 2020 novemberi rajt (+6 hónap)- zen4 először 2021 július 6-án kerül említésre (Enhanced early support)
=> 2022 szeptemberi rajt (+14 hónap)Az eddig látott megfogalmazások és a szóhasználathoz kapcsolódó az említés és a megjelenés közötti jellemző időeltérés alapján arra tippelnék, hogy valóban olyan ~15-18 hónapra lehetünk a Zen5 kiadásától.
Persze ezzel nem mondok újat, csak megerősítem az eddigi vélekedést.








![;]](http://cdn.rios.hu/dl/s/v1.gif) "
"








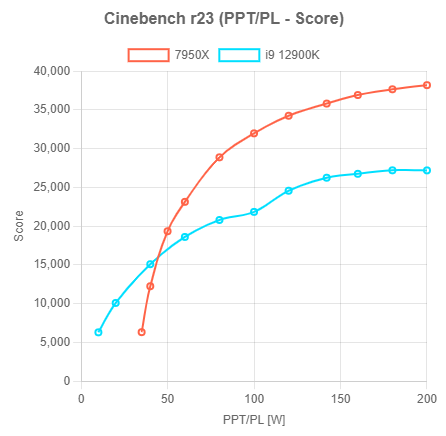
Új hozzászólás Aktív témák
- Kivégezheti a kisebb VGA-gyártókat az NVIDIA döntése
- Redmi Note 14 Pro+ 5G - a tizenhármas átka
- Redmi Note 13 Pro 5G - nem százas, kétszázas!
- Redmi Note 14 5G - jól sikerült az alapmodell
- MIUI / HyperOS topik
- A fociról könnyedén, egy baráti társaságban
- Magga: PLEX: multimédia az egész lakásban
- Mozilla Firefox
- Formula-1
- Kuponkunyeráló
- További aktív témák...

- Raktáron, PlayStation 4 Slim 500GB, gyönyörű szép állapotban, 6 hó garanciával, üzletből!
- AMD RYZEN 7 9800X3D/RTX 5080/32GB DDR5/1TB NVMe/1200W
- Intel i9-14900K/RTX 5080/32GB DDR5/1TB NVMe/1200W
- AMD RYZEN 7 7800X3D/RX 9070 XT 16GB/32GB RAM/1TB NVMe/750W
- AMD RYZEN 7 7800X3D/RTX 5080 16GB/32GB DDR5/1TB NVMe
- ÚJ! AKRacing Arctica gamer szék
- OnePlus 13 Gyors teljesítmény és modern dizájn Midnight Ocean 16/512 GB
- LG 27GS95QE - 27" OLED / QHD 2K / 240Hz & 0.03ms / 1000 Nits / NVIDIA G-Sync / AMD FreeSync
- Azonnali készpénzes Apple Macbook Air felvásárlás személyesen / csomagküldéssel korrekt áron
- LED Happy Birthday felirat USB áramforrás / 12 hó jótállás
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: Laptopműhely Bt.
Város: Budapest