Hirdetés
- Jelentősen átalakulhat a Xiaomi 17 Ultra kamerarendszere
- Google Pixel 7a - venni vagy nem venni?
- Honor 200 - kétszázért pont jó lenne
- iPhone topik
- Apple Watch
- Google Pixel topik
- Samsung Galaxy S25 - végre van kicsi!
- Samsung Galaxy S24 - nos, Exynos
- AGM G3 Pro - ordít róla, hogy szoftverfejlesztők kellenének
- „Új mérce az Android világában” – Kezünkben a Vivo X300 és X300 Pro
Új hozzászólás Aktív témák
-
#9161
 Petykemano
veterán
Petykemano
veterán
Petykemano
veterán
A SDXE ~170mm2 méretű. [link]
Ami elég jó ahhoz képest, hogy a Phoenix is 178mm2 azonos gyártástechnilógián. Többre számítottam.
Az IGP a gyakorlatban kb ugyanazt tudja.
Viszont úgy vélem, hogy az NPU fejlettebb lehet és 12 remek ST teljesítménnyel és energiahatékonysággal működő mag van benne. Pusztán a magok száma kezelhető kihívást jelent, hiszen 4 nagy mag beáldozásával (+ néhány milliméter) 8c mag beépíthető.
Ugyanakkor a cache méretben még akkor is lennek különbség. 12 maggal 12x1MB L2$ lenne. Jelenleg 16MB L3$. Ennél épp másfélszer nagyobb cache mennyiséggel rendelkezik az SDXE. Ez különösen amit fájó, ha az eloszlása is más és L1$-ban és L3$-ben bővelkedik.A Zen4 persze döntően csak egy die shrink. A zen3 jó példája annak, mennyivel többet lehet kihozni, ha egy architektúrát kezdetektől az adott gyártástechnológiára terveznek. Én a Zen5 esetén is számítok hasonlóra, vagyis hogy nagyobb lesz, mint a Zen4, de azért nem brutálisan nagyobb. (Mármint egy mag)
Mindenesetre én arra számítok, hogy a Strix inkább 220-230mm2 lesz.
-
#9160
Petykemano
veterán
Petykemano
veterán
Azt valószínűsítem, hogy a Strix pointnál látott 12 mag normál és c magok egyvelegéből fog összeállni.
Viszont azért pár kérdés felmerülhet:
A 12 mag 1db vagy 2db CCX-be lesz szervezve?
Szerintem a c magok azonos frekvencián érdemben nem sokkal energiahatékonyabbak, mint a normál társaik (ha nem számoljuk a kisebb L3$-t) Elsődleges céljuk a MT skálázódás. 15W-os környezetben 2-3 mag igénybevétele után úgyis jelentősen csökken az további igénybe vett magokon az elérhető frekvencia. Ennélfogva 2-3 magon túl megspórolható az arra költött lapkaméret, hogy bármelyik mag az egyszálas csúcsfrekvencia közelében legyen.
Ha két CCX-ből áll, akkor lehet értelmet és érvelést találni a 8+4c, 6+6c és a 4+8c elrendezésben is.
Ha egy CCX-be szervezik - ami a gaming szempontjából mindenképp hasznos volna - akkor viszont a 4+8c-n kívül nem tudom van-e értelme másnak.De vajon hogy tudná az AMD 12 magot 1CCX-be szervezni?
Vajon a hagyományos Zen5 chiplet még hagyományos ringbusszal jönne, de a 16 magos Zen5c és a Strix már az új létra elrendezéssel? -
#9159
Petykemano
veterán
Petykemano
veterán
December 6 - AIMD event
-
#9158
Petykemano
veterán
Petykemano
veterán
Az AMD 2023Q3-as pénzügyi jelentése szerint
- a Turin mintapéldányok már a partnereknél vannak, 2024-ben rajtol
- szállítják a Mi300A-t az El Capitanhoz
- idén $400m, jövőre $2b bevételt várnak a Mi300 AI gyorsítókból
[link] -
#9157
Petykemano
veterán
Petykemano
veterán
MLiD a zen5 apuk előzetes várakozásokhoz képesti csúszását jelentette [link]
Ez elég sajnálatos. Én azért tényleg reméltem, hogy kellő erőforrással fel tudják gyorsítani az apuk kiadását, hogy minél kevesebbet késsen az asztali/szerver változatokhoz képest. Persze lehet, hogy az is később jön, mint reméltük.Elnézve ezt a roadmapet, elég elszomorító. 2024-ben az AMD végig cipeli magával a régi termékeket:
Zen3 alapon N7-es Barcelo - miközben a Vega driver.támogatását már el is akarják hagyni. N6-os Rembrandt. És Phoenix refresh.Nagyon úgy tűnik, hogy az amd vagy képtelen komoly wafermennyiséget lefoglalni, vagy nem mer ebbe befektetni, hanem annyira spúr, hogy a megmaradt kapacitásokat igyekszik felcsipegetni és abból készíteni olcsó portfóliót.
Ez azért probléma, mert a Qualcommnak, Mediateknek általában nem szokott problémát jelenteni nagy volumenű gyártáshoz gyártókapacitás lefoglalása. 2024-ben jön az SDXE és azzal ez a felhozatal nem leysz versenyképes. Nem is beszélve az Apple-ről, persze az más liga.
És értem, hogy az intel is csúszik, de ha.ahhoz igazodnak, akkor csak elősegítik az arm terjedését.Az Apple elvileg 2024-re áttér N3-ra, az N4 kapacitások felszabadulnak.
És az AmD 2025-ben is majd még RDNA3.5-tel és N4-en gyártott termékekkel.akar versengeni? Hááát... vajon miért? Tartok tőle, hogy az nvidia fel fogja mosni a padlót az amdvel az apuk terén is.
-
#9156
Petykemano
veterán
Petykemano
veterán
/konkurencia - Apple M3/
15%-ot mond az Apple CPU teljesítmény növekedés gyanánt az előző generációhoz képest. Ami nem rossz. De a kezdeti kiugráshoz képest szerényebb. Annyira szerény hogy maga az Apple is az M1-hez hasonlítgatja.
Pedig még új gyártástechnológiát is használnak. Ezzel valahol ott lehetnek, mint a QCSDXE. De az ultra valószínűleg nagyon szépen fog teljesíteni, felfelé skálázódni.
-
#9154
Petykemano
veterán
S_x96x_S
#9153
Petykemano
veterán
válasz
 S_x96x_S
#9153
üzenetére
S_x96x_S
#9153
üzenetére
Lehet, hogy így volt, csak az nem.derült ki, hogy a nem válaszban az volt-e, hogy nem tudunk,.vagy az, hogy a jelenlegi architektúránk, a célpiacaink által meghatározott know-how és azboda kijelölt irány nem teszi lehetővé, csak nektek meg nem fogunk külön archutektúrát fejleszteni.
Az atom lehet, hogy arm versenytársnak volt kezelve az intelnél, de szerintem arra azért gondosan ügyeltek, hogy mindig meglegyen a megfelelő rés, ne legyen túl erős.
De... amennyiben létezik valamilyen olyan követelmény a meglevő célpiacokon (pl szerver), ahová a széles architektúra nagy L1$-sel és alacsonyabb célfrekvenciéval nem ideális, a kifejezetten nem szerverbe, hanem alacsony fogyasztású kliensekbe szánt atom esetén az intel igazán megkísérelhette volna a szélesítést, és a nagy cache-t - legkésőbb akkor, amikor ezt az Apple felvetette/kérte.
Ugyanakkor még ebből sem egyértelmű, hogy azért-e, mert lehetetlen, vagy csak mert az intel hibázott.
-
#9152
Petykemano
veterán
S_x96x_S
#9151
Petykemano
veterán
válasz
S_x96x_S
#9151
üzenetére
> Amint tudjuk .. az Apple a saját méréseit vette alapul .. és dobta az Intelt ..
Ezzel arra akarsz utalni, hogy a 2014-es extremetech cikkben arra, hogy az Apple miért nem fogja leváltani az Intelt és az x86-ot azt az érvet hozták fel, hogy a fogyasztásbeli különbségeket elsősorban architekturális különbségek, semmint az ISA-ból fakadó elkerülhetetlen hatékonytalanság magyarázza, és mivel az Apple végül mégiscsak dobta az Intelt, ezért ez az érv eredendően téves? -
#9147
Petykemano
veterán
S_x96x_S
#9146
Petykemano
veterán
válasz
S_x96x_S
#9146
üzenetére
> hogyha az AMD-nek is lesz mobiltelefonba Ryzen chipje,
> vagy az Intel újra nekilódul a mobilpiacnak az X86-al ..
Kétlem, hogy az AMD ilyesmibe vágná a fejszéjét.
A miért kérdés feltevésekor pedig eljutunk ugyanoda, hogy vajon azért-e, mert az AMD képtelen volna erre? vagy mert az x86 alkalmatlan erre?
Vagy csak mert az AMD célpiacain teljesen más szempontok szerint kell terveni a magjukat és teljesen felesleges lenne egy olyan mobil design-t készíteni, ami annyival jobb biztosan nem tudna lenni (már ha egyáltalán jobb tudna lenni), hogy komoly érdeklődést keltsen fel, miközben meg egyébként az ARM processzorhoz szokott mobiltelefon piacon senki nem kiváncsi az x86 processzorra. Az egy évtizedes vállalkozás lenne, miközben az AMD (és az Intel) nem képes befolyásolni a szoftveres ökoszisztémát.Mindazonáltal azzal természetesen egyetértek, hogy kéne bizonyíték.
-
#9145
Petykemano
veterán
Petykemano
veterán
Talán az Qualcomm bemutatójában volt, hogy valami 10-11 cég fog a Snapdragon X Elite-re építve PC-t (vélhetően miniPC-t vagy notebookot) készíteni.
Elgondolkodtam, hogy vajon mi lehet az ARM PC iránti rajongás, rajongva vágyakozás oka.
Elnézést, ezzel persze senkit nem akarok megbántani.
Csak próbálom megérteni a felvillanyozódás okát, amit én magamon nem tapasztalok.Részben persze arról a végéről is meg tudom fogni, hogy eleve nem tanácsos valamiből kimaradni, ami lehet, hogy hatalmas dobás lesz. Mármint az, hogy mit tudnak az x86 alapú processzorok tervezői/gyártói az eléggé kiszámítható piaci irány szerintem és inkább az lehet kérdés hogy arm alapú PC-kből fúvódik-e - valamilyen okból kifolyólag - lufi, vagyis nagy lesz-e a roham az ilyen gépekért.
Nyilván százezrek lesznek kiváncsiak csak mint újdonságra is, de ha a Windows olyan (ISA-agnosztikus), hogy semmilyen hátrányt nem szenvedsz attól, hogy x86 vagy Arm alapú processzort használsz, akkor a kiváncsiságon kívül mi vihet rá valakit (embert vagy céget), hogy inkább Arm alapú processzorral szerelt notebookot vegyen/kínáljon
Az elmúlt néhány évvel ezelőtti általános vélekedéssel ellentétben az szerintem mára kiderült, hogy az x86 ISA miatt nem következett be plafon az elérhető IPC vonatkozásában és valójában csak az Intel lapkaméretre történő optimalizálása miatt tűnt úgy, hogy lelassult a fejlődés. No meg persze a fejlődésnek fontos feltétele a tranzisztorsűrűség növekedése, a fejlettebb gyártástechnológia, amivel szintén megcsúszott az Intel, de ez az Arm esetén is pontosan így van.
Tehát a nyers teljesítmény elvileg nem lehetne meghatározó tényező ebben. Persze mondhatja valaki, hogy "mindig is egy Arm/androidos gépre vágytam, de eddig a telefonom nem volt elég gyors, de már igen", de ez azért nem teljesen az az érvelés, hogy azért válasznom az Arm alapú processzort, mert gyorsabb.Az Apple-re lehetett mondani, hogy gyorsabb volt. De abban azért - legalábbis az első két generációban - benne volt az is, hogy mindenki másnál fejlettebb gyártástechnológiát voltak képesek használni, és annak többletköltségét képesek voltak megfizettetni a vásárlóikkal.
A Qualcomm esetén ez nem biztos, hogy igaz lesz.Az energiahatékonyság egy fontos szempont. De az energiahatékonyság - meggyőződésem szerint - főleg a designból ered, nem az ISA-ból. Az Apple processzora azért képes lényegesen energiahatékonyabb lenni, mint az x86 versenytársak, mert lényegesen alacsonyabb frekvencián üzemel. Alacsony frekvenciájú design. A magas frekvencia elérése is tranzisztorba kerül és arra nem költ, cserébe költ egy csomó tranyót a széles design-ra, sok L1 cache-re.
Biztos nem ennyire egyszerű.
De azt sem hiszem, hogy ha az AMD a Zen processzorcsalád frontendjét lecserélné x86-kompatibilisről Arm-kompatibilisre lényegében minden mást változatlanul hagyva (most azt hagyjuk figyelmen kívül, hogy mondjuk micro-op cache-re nem lenne szükség, tehát lehet, hogy szabadulna fel tranzisztor büdzsé), akkor hirtelen 30-40%-kal javulna az energiahatékonyság zárva az ollót az Apple mag designjával.
Lehet, de én azért nem hiszem, hogy ennyire egyszerű volna. Ha ennyire egyszerű volna, miért ne jelentették volna meg már a saját Arm szerverprocesszorukat rábízva az ügyfélre a választást? Nem tökmindegy nekik, hogy az ügyfél melyiket veszi? Az ügyfél döntse el, hogy neki megéri-e az ISA váltást meglépni, vagy sem.Szóval elképzelhetőnek tartom, hogy a SDXE energiahatékonyságban pöpec lesz és természetesen mind a fogyasztónak, mint az OEM-nek egy fontos szempont az üzemidő, vagy hogy mennyivel lehet csökkenteni a termék költségeit a kisebb akkumulátorral.
Ez egy jó érv lehet majd.Kiváncsi vagyok, hogy felpezsdíti-e majd a versenyt. Az AMD és az Intel aludhatott, ülhettek a babérjaikon mert az ő vásárlóik nem tudtak eddig közvetlenül az Apple-től vásárolni. Ha most a piacra belép a Qualcomm, akkor az sarkallhatja az AMD-t és az Intelt erőfeszítésekre. Ennek szerintem azért látszódnak a jelei:
- az AMD Zen5 APU-k talán minden korábbinál kisebb késlekedéssel érkeznek, minden része megújul és egyre bővül a kínált termékportfólió is.
- az Intel is úgy tűnik, mintha külön név alá szétválasztotta volna a mobil és desktop termékvonalat.Ok.
Ami még számításba jöhet az az ár.
Tartok tőle, hogy Snapdragon processzor legalábbis egyelőre nem lesz majd kapható DIY piacon alaplapba illeszthető tokozással. Később persze lehet, mert miért ne lehetne megtámadni a Workstation piacot is. De ez még inkább a távoli jövő zenéje.Ha viszont a fogyasztó közvetlenül nem látja a SoC árcéduláját, akkor ugye nem is tudhatja, hogy vajon a Qualcomm milyen áron szállítja majd. Nyilván az Arm magos eszközöket annak megfelelően fogják majd árazni, hogy mennyiért tudnál x86 alternatívát venni. Ha egyébként egy ilyen eszközön vastagabb a profit, lehet olcsóbban adni, de ha tényleg annyival jobb az üzemideje, akkor meg felárat is kérhetnek érte.
Ha az eszköz kisebb fogyasztású, akkor kevesebb hűtés is elég lehet neki és kisebb akkumulátor, tehát ha a Qualcomm nem is adja olcsóbban a versenytársaknál, az építési költségen összespórolt összeggel lehet olcsóbb egy ilyen termék. Valamivel olcsóbb.Szóval nagyon kiváncsi vagyok, hogy mi lesz a drive
-
#9139
Petykemano
veterán
Petykemano
#9135
Petykemano
veterán
válasz
 Petykemano
#9135
üzenetére
Petykemano
#9135
üzenetére
én tökre nem voltam vele tisztában:
Úgy tűnik, hogy a Snapdragon 8 és a 8cx különböző termékvonal.
A SD 8 Gen3 valóban Cortex X4 magokkal rendelkezik. Ehhez képest az AT által összehasonlításképp említett Snapdragon 8cx Gen 3 csak Cortex X1 magokat tartalmaz.Nem teljesen értem a lemaradást - hacsak nem szándékos. Mindenesetre a szintén friss SD8cxGEn3 és a most bejelentett Elite közötti nagy különbséget részben magyarázhatja majd.
-
#9137
Petykemano
veterán
Busterftw
#9136
Petykemano
veterán
válasz
 Busterftw
#9136
üzenetére
Busterftw
#9136
üzenetére
Az izgalmas kerdes szerintem inkabb az, hogy ezt a felepitest/teljesitmenyt a Windows (on ARM) hogy fogja kezelni es atadni az alkalmazasoknak.
A felvetésednek két aspektusát is látni vélemAmennyiben úgy érted, hogy a Windows (12?) maga ISA agnosztikus lesz-e (amit én elképzelhetőnek tartok), de hogy milyen módon lesz képes Arm magokon futtatni korábbi x86 alkalmazásokat, akkor igen, az egy remek kérdés. Egyrészt szerintem nem volna elfogadható, ha nem foglalkoznának vele. Úgy értem, hogy a MS felé mindig is elvárás volt, hogy nem szakíthat a múlttal. Másrészt szerintem nem is ez a hozzáállás. a MS eddig is nagyon sokat foglalkozott a Windows-on belüli virtualizációval, aminek végső kifejlete lehet éppen egy olyan layer, amivel szükség esetén elrejtik a hardvert.
Egyrészt hallottam valami olyasmiről, hogy Win11-en már futtathatók Android alkalmazások. Másrészt (elnézést a pongyolaságomért) tudtommal az Android alkalmatzások is valahogy pont így működnek, hogy hogy minden app egy-egy Java-szerű virtualizációs környezetben fut.
Nyilván ebben az a kérdés, hogy ha valami nem natívan fut, akkor mekkora a teljesítményveszteség.Másrészt a kérdésedet esetleg úgy is lehet értelmezni, hogy vajon az eltérő architektúrát hogy fogják tudni kihasználni az alkalmazások. Állítólag legalábbis annak magyarázata, hogy az Intel és az AMD nem hoz radikálisan új architektúrát az, hogy a(z x86) szoftverek a jelenlegi felépítésre vannak optimalizálva.
-
#9135
Petykemano
veterán
S_x96x_S
#9133
Petykemano
veterán
válasz
S_x96x_S
#9133
üzenetére
Vegyünk egy mély levegőt...
Na nézzük, tehát egyszer látunk egy 3200-as GB6 eredményt.
Ezt a chip 4.3Ghz csúcs-frekvenciával hozza.Az Oryon a 2023-as bejelentés ellenére tudtommal egy 2024-es termék, tehát megvásárolni majd csak 2024-ben lehet termék formájában.
Itt írnak a Samsung Galaxy S24-ről, amiben az új (már beépíthető) Qualcomm SD 8 Gen 3-ról, ami már az új Arm Cortex X4-et használja. [link] Egyébként elvileg az is 2024-es termék. Ez lehet, hogy csupán egy backup a Qualcomm részéről, de a két külön termék jelezheti azt is, hogy az Oryon valamilyen oknál fogva, legalábbis az itt bemutatott formájában egyelőre nem célozza a mobil piacot.
Szóval az Arm Cortex X4 elér GB6-ban mintegy 2200 pontot. Ehhez képest tehát az Oryon 45%-kal gyorsabb. Ehhez a 2200 ponthoz elvileg 3.3-3.4Ghz társul.
Az Oryon 4.3Ghz-en megy. A nagyobb teljesítményből máris 26%-ot magyaráz a frekvencia. Ami azt jelenti, hogy az X4-hez képesti többletteljesítményből mindössze 15% köszönhető az új architektúrának.Noha lehet azt mondani, hogy a 15% nem annyira sok, az persze igaz, hogy aki a Cortex X4 és az Oryon között vacilál az nem ezt a 15%-ot látja, hiszen a designnak része a magasabb frekvencia elérésére való képesség. Ennek persze valószínűleg lehet ára a lapka méretében (ahogy ugye az AMD és az Intel is tranzisztorszámban és lapkaméretben fizet a 6Ghz-ért) Ez lehet magyarázata annak, hogy miért a notebook a célpiac.
Ezzel együtt az energiahatékonyság figyelemre méltó.
Itt az Intel chippel való összevetést talán csak annyira érdemes megemlíteni, hogy talán nem véletlen, hogy azzal történt az összehasonlítást. De végülis nem is tudom, hogy a Phoenix hivatalosan elrajtolt-e, bekerült-e valamilyen notebookba, vagy mindent elvittek a kézikonzolos gyártók. Na mindegy. Szóval a raptor lake mobile nem egy kifejezetten energiahatékony termék. Etekintetben sokkal versenyképesebb alternatíva lesz a Meteor lake. Elvileg. 2024-ben. Bár az 50%-kal jobb energiahatékonyság még mindig csak kozmetikázza a 70%-os lemaradást.
Az Apple-lel való összevetés is elég jól mutat. 15%-kal jobb teljesítmény VAGY 30%-kal energiahatékonyabb működés. Tudtommal az M2 is N4-en készült már és az M3 ugyan N3-on készül, de elég kevés fókuszt kapott a CPU és az energiahatékonyság sem javult lényegesen. A Oryon előnye talán csak az Apple bealvásának köszönhető. (Vagy ha másképp fogalmazunk, akkor annak, hogy átmentek oda az Apple mérnökök)
Én úgy látom, hogy nagyon nagy verés most sem fog történni. 10-20%-os teljesítmény és/vagy energiahatékonyságbeli különbségek lehetnek majd. Amire majd mondhatjuk, hogy a verseny jó. Legkevésbé sem hegyezném ki a kérdést az ISA-ra. Ha az x86 hátrányt is jelent valamiben, nem gondolom, hogy akár az AMD, akár az Intel ne tudna ARM alapú processzorok tervezésére átevezni. Az x86 processzorok élveztek eddig és talán élvezhetnek még a jövőben valameddig némi helyzeti előnyt a szoftveres ökoszisztéma miatt, de ennek valószínűleg előbb utóbb vége szakad.
Ami számomra izgalmasabb kérdés, hogy vajon milyen lehet az Oryon magok felépítése. (És hogy vajon a bizonyos értelemben elszigetelt versenytárs Apple helyett ennyire közvetlen versenytárs érkezése rákényszeríti-e az AMD és/vagy az Intelt a magas frekvencia helyett a sűrűbb, és szélesebb design felé fordulásra)
Az egyik slide-on 42MB cache szerepel 12 maghoz.
Úgy vélem, hogy a Nuvia is eredetileg széles magban gondolkodhatott: alacsony frekvencia, sok cache.
Többféle felépítést el lehet gondolni:
1.)
Az intel és AMD magokhoz hasonlóan nagy privát L2$ és egy megosztott L3$.
Mivel eredetileg az Oryon magokat szerverbe szánták, és állítólag a szerver workload-ok szeretik a nagy privát L2-t és nem kifejezetten jól hasznosítják az L3$-t:
- 24MB megosztott L3$-t,
- 12x1MB privát L2$-t
- és magonként 0.5MB L1$-t (valamilyen felosztásban a L1d és L1i között)2.)
Ugyanez kicsit más felosztásban, még "szerveresebben"
- 12MB megosztott L3$-t,
- 12x2MB privát L2$-t
- és magonként 0.5MB L1$-t (valamilyen felosztásban a L1d és L1i között)3)
A blokk diagram persze inkább 3db 4 magos CPU klaszter felépítésre utal, és a blokk diagramon nem utal semmi arra, hogy azokat összekötné valamilyen koherens cache.
- 3x12MB megosztott L2$
- és magonként 0.5MB L1$-t (valamilyen felosztásban a L1d és L1i között)
Ez inkább az Apple megközelítésére hasonlít. Nyilvánvalóan ugyanazokkal a hátrányokkal rendelkezne, mint egy Zen2, vagyis bármilyen koherenciát igénylő alkalmazás, ami az egy klaszterhez tartozó 4 magon túl terjeszkedne, kehegni fog. -
#9132
Petykemano
veterán
-
#9122
Petykemano
veterán
S_x96x_S
#9120
Petykemano
veterán
válasz
S_x96x_S
#9120
üzenetére
Ha ez úgy működne, hogy az x86 és arm frontend csak 5-10% tranzisztortöbbletet jelentene és onnantól bármilyen utasítással megbírkózna, annak cloudban talán lenne értelme, hiszen nem kéne külön arm és x86 infrastruktúrát fenntartani, bármilyen feladatot, vagy legalább VM-et ki lehetne osztani.
De én tartok tőle, hogy bonyolultabb lenne, mint 5-10%. Ráadásul ha versenytárs nem szórakozik ilyennel, annyival gyorsabb vagy olcsóbb is lehet. -
#9117
Petykemano
veterán
Petykemano
#9113
Petykemano
veterán
válasz
Petykemano
#9113
üzenetére
NVIDIA and AMD reportedly working on ARM-based processors for PCs [link]
-
#9113
Petykemano
veterán
Petykemano
veterán
CPU: 12 Oryon high-performance cores
▫️ MEM: LPDDR5X 136GB/s
▫️ GPU: Adreno 4.6 FLOPS, triple 4K support
▫️ NPU: Hexagon 45 TOPS
▫️ NET: 5G/Wi-Fi7
▫️ Integrated Always Sensing ISP
▫️ Claim: up to 2x faster CPU&GPU vs. x86 arch
▫️ GenAI: 13B parameters on device, 30 Token/s 7B LLM
[link] -
#9107
Petykemano
veterán
Petykemano
veterán
RGT szerint Zen5@CB2024
ST: 140
MT: 2400
[link]A számok kerekítettek.
Ez olyan 12-15%-os ST és 10-12% MT teljesítménynövekedést jelent.
Feltehetőleg nem végleges termék/órajel, de már bizonyára közel lehet. -
#9103
Petykemano
veterán
Petykemano
veterán
A napokban megjelent pár dia/roadmap. Inkább megerősítő infókkal, mint újdonságokkal. [link]
Csak azért dobom be, mert furcsállom, hogy a korábbi infókkal ellentétes a ramra vonatkozó rész.
Emlékeim szerint úgy volt eddig, hogy a strix point a hagyományos apu, ami váltja a Phoenix-et és amiből lehet asztali változat is DDR5-tel. És a Strix Halo az, ami biztosan csak notebook vagy minipc OEM, szélesebb LPDDR5X támogatással, ezért asztali változat nem lesz, meg a foglalat is biztos más, nagyobb, amihez nem fognak külön alaplapot gyártani.
Viszont ezen az ábrán meg épp fordítva van.
-
#9096
Petykemano
veterán
S_x96x_S
#9095
Petykemano
veterán
válasz
S_x96x_S
#9095
üzenetére
> Erős külső nyomás van az AMD-n, hogy valamilyen IPC növekedés legyen.
Valóban létezik az AMD irányába egy elvárás (nyomás). De szerintem az nem igaz, hogy ez külső, fogalmatlan személyek a bilibe lógó kezük kisujjából szopták ki.A közösség várakozásait először szerintem Mike Clark gerjesztette fel, aki 2021-ben így kommentálta a Zen5 architecture meetingről kijövet az ott megismerteket:
"Coming out of that meeting, I just wanted to close my eyes, go to sleep, and then wake up and buy this thing."Persze Mike Clark számokat nem mondott. Elképzelhető, hogy akkoriban még nem a Zen4-hez csupán Zen3-höz mérhette. De az hogy így nyilatkozott róla az mégiscsak egy csodálatos megoldásokat és grandiózus eredményt sejtet, amely mérnöki teljesítménytől még ő is elámult.
Lehet, hogy hibázott. De akkor se lehet azt mondani, hogy a Zen5-öt övezi - immáron externalizálódott - elvárások kizárólag a műsorgyártó youtuberek képzelgéseiből, vagy szenzációhajhászásából fakadnak.
-
#9094
Petykemano
veterán
b.
#9093
Petykemano
veterán
> Hol olvastál ilyet hogy "feltehetőleg " és hogy Mlid gyártotta őket?
Úgy fogalmaztál, hogy "a kiszivárgott vagy kreált chartok"
Én ezt úgy értelmeztem, hogy szerinted az MLiD által megjelentett anyag vagy kiszivárgott, vagy - mivel hogy most épp az ő hitelességéről beszélünk - , ő maga kreálta őket.Ha arra gondoltál, hogy az általa megjelentetett anyag valótlan, de nem ő maga, hanem egy harmadik személy készítette szándékos félrevezetés, dezinformáció céljából. Hát az lehetséges. Ha jól emlékszem, AdoredTV is akkor hagyta abba, amikor azt érzékelte, hogy szándékosan dezinformálták. Ez nehéz ügy. Én úgy vélem, hogy a lehetőségeihez mérten igyekszik ügyelni a szavahihetőségére és ennek megfelelően ellenőrizni az információkat. De olyan soha nem lesz, hogy valaki ennyivel a megjelenés előtt biztos információkat jelentessen meg. Ilyen akár több éves roadmapek közreadása és fél évvel a megjelenés előtti adatbányászat szerintem más műfaj.
Én elfogadom, hogy szerinted előbbi kóklerság és abban igazat adok, hogy nem ritka a tévedés. Nem kell mindent bucira levenni. De ebben az epizódban szerintem épphogy nem a 30%-kal való közönség-izgatás, hanem inkább az elvárások hűtése történt.
A kritika megfogalmazásának jobb helye lett volna RDNA3 esetén, ahol valóban nagy melléfogások történtek.
A chips&cheese kritikájára reagálnék még:
Az Intel szerint a Golden Cove a Cypress Cove-hoz képest átlagosan 19% IPC növekedést eredményezett. A C&C szerint az MLiD által megjelentett slide alapján (már amennyiben hihetünk annak) az AMD a Zen5-be nagyjából ugyanazokat a mag méretének növekedését eredményező hatékonytalan és pazarló megoldásokat fogja beépíteni. Azt nem tudom, hogy ez egyébként hitelességet növelő vagy épp csökkentő tényező. Mindenesetre ha valóban csak ez fog történni, akkor számomra nem tűnik irreális elvárásnak a 10-15%, bizonyos esetekben pedig esetleg az ennél is nagyobb mértékű IPC növekdés.@hokuszpk
Én inkább enyhe órajel csökkenésre számítok. -
#9091
Petykemano
veterán
b.
#9090
Petykemano
veterán
Azért nem értelek, mert nem mondtál konkrétumot, csak minősítettél.
Akkor tehát azt állítod - vagy úgy véled, a C&C-re ezt állítja -, hogy a két MLiD által publikált dia, a roadmap és annak részletei, valamint a blokkdiagram hamis és feltehetőleg MLiD gyártotta őket?
"Rombolást" és "hype train"-t említesz. Amit azért nem értek, mert az eddigi - mások által megalapozott* - 25-30%-os ST teljesítménynövekedésre vonatkozó várakozásokhoz képest a 10-15% IPC növekedés megjelentetése a roadmap slide-on kifejezetten a kedélyek és várakozások hűtését szolgálja. Egyes vélemények szerint a AMD épp ezzel a céllal , szándékosan juttathatta el hozzá ezeket az információkat.
Megtennéd, hogy konkrétan megnevezed azokat az ebben a videóban elhangzó információkat , amik szerinted az általam érzékelt hatással szemben szerinted épp ellentétes hatást váltanak ki?
* mások által megalapozott várakozások:
- Jim Keller Tenstorrent videója 25%-os teljesítménynövekedésről számol be, későbbi pontosítás szerint annyit vár/becsül specINT mérésben
- AdoredTV egy Zen5-ről szóló 4-5 hónappal ezelőtti videójában egy kiszivárgottcinebench eredményt elemezve jutott arra a következtetésre, hogy a Genoa-hoz képest 32%-kal nyújthat nagyobb teljesítményt
- A RedGamingTech csatorna 1-2 havonta kiad egy frissített híradást a Zen5-ről szóló várakozásokról. Nem tudom, hol tart most, de ő is 20-30% ST teljesítménynövekedést szokott mondani.
- az AT fórumban egy adhoc_thurston nevű magát beavatottnak előadó fórumozó következtesen 30+% ST teljesítménynövekedésről(Fent nevezett állítások valóságtartalma természetesen megkérdőjelezhető. Azonban szükségtelen, mert ezen állítások hiteltelenítése nem növelné MLiD felelősségét az általad felhozott rombolás vádjában)
-
#9089
Petykemano
veterán
b.
#9088
Petykemano
veterán
Az valóban elmondható, hogy az AMD eddigi látványos húzásai javarészt arról szóltak, hogy néhány módosítással letervezték nagyvonalakban azt a bevált architektúrát, amit az Intel is.
Van persze különbség, hiszen az AMD magjai azért érezhetően kisebbek, az intelnél meg érezhető, hogy nincs igazán új ötlet, csak növelgetik a feldolgozókat, puffereket, regisztereket. Ezzel hízik a mag, de a sebesség (IPC) csupán kisebb mértékben növekszik (diminishing return)A cikk írója egyrészt azt feltételezi, hogy az AMD - az eddigi gyakorlatnak megfelelően - az Intel iránymutatását követve ugyanezeket a lehetőségeket fogja lehívni. Abban bizonyára igaza van, hogy ha egy aechitektúrának csak úgy egyesével elkezded növelgetni a paramétereit, akkor előbb-utóbb eljutsz oda, hogy már hiába növelsz vagy' növelnél bármit, a végeredményre nem lenne.hatással. mert az architektúra nem skálázódik. A gpu-knál ilyenkor szokott jönni egy újratervezés. És hát elvileg a zen5 is egy from-scratch design ígéretét hordozza. Ez alapján egyáltalán nem biztos, hogy ugyanazoknak a paramétereknek a megváltoztatásával ugyanarra az eredményre fognak jutni, mint az Intel.
Másrészt érezni a cikk írójának irányából az MLiD típusú szereplők által végzett tevékenységgel szemben érzett ellenszenv.
Én továbbra is úgy vélem, hogy aki képtelen együtt élni azzal a bizonytalansággal, hogy az általa látott információk lehetnek
- szándékos félrevezetések a forráscégtől
- szándékos félrevezetések konkurens cégtől
- régi, meghaladott információk
- vagy akár a "leaker" is kitalálhatja a műsort persze
... annak nem érdemes ezzel foglalkoznia.Szerintem helyesebb lett volna azt az álláspontot felvenniük, mint maguk a cégek is, hogy pletykákra nem reagálnak.
A rombolást azonban ezúttal nem értem. Ezt esetleg kifejthetnéd, hogy miben látod a zen5-re vonatkozó slide-ok megjelentetését rombolónak és hogy mitől jobb, hogy a C&C kifejezte hitetlenségét, nemtetszését?
-
#9087
Petykemano
veterán
Petykemano
veterán
MLiD által nyilvánosságra hozott Zen5 infók elemzése a Chips&Cheese-től [link]
-
#9081
Petykemano
veterán
hokuszpk
#9080
Petykemano
veterán
válasz
 hokuszpk
#9080
üzenetére
hokuszpk
#9080
üzenetére
Valamivel mérni kell és még azért nem annyira sok natív cross-platform eszköz van, amivel ez megtehető.
Szerintem vitán felül áll az, hogy az Apple chipje jó.
Legfeljebb arról lehet vitatkozni, hogy tényleg jobb-e annyival, mint amennyit a grafikonok mutatnak, de biztosan nem rosszabb, mint az X86-os versenytársak.
És eközben szerintem az is vitán felül áll, hogy a nagyonis versenyképes ST teljesítmény leadása közben azért észrevehetően kevesebbet fogyaszt.mondhatjuk, hogy a különbséget tulajdonképpen az eredményezi, hogy az Apple procija széles feldolgozókkal közepes frekvenciára van tervezve, míg ehhez képest az x86 processzorok hagyományosan vékonyabbak, cserébe magasabb frekvenciával kompenzálják a szűkösséget. A magas frekvenciához pedig magasabb feszültség kell, ami négyzetesen emeli a fogyasztást
MT teljesítményben ennek megfelelően a teljesítmény és hatékonyságbeli különbség már nem látványos, vagy szinte el is tűnik. A lapkaméreten persze továbbra is lehet vitatkozni.
De ezzel megint ott vagyunk, hogy egy mobil 8 magos Zen4 APU-ban - vagy akár CCD-ben is - tulajdonképpen szinte feleslegesen foglal el az összes Zen mag teljes kiterjedést. Persze nyilván nem annyira egyszerű, mert nem lehet tudni előre, hogy a 8 közül melyik lesz az, amelyik majd a kívánt legmagasabb frekvenciát eléri.Azért is ködös számomra, hogy miért a magas frekvenciát választják tervezéskor a széles design helyett, hiszen a processzorok fő felhasználási területe, ahová ténylegesen és igazából készül az a szerver, ahol meg nem szükséges a magas frekvencia.
Valószínű, hogy azért nem annyira egyszerű jó széles architektúrát építeni. Ha elengedik a frekvenciát, akkor azzal sok helyet nyerhetnek (tehát kisebb lehet a lapkaméret), de nem biztos, hogy az ALU-k, FP pipe-ok, és gyorstótárak méretének növelésével együtt magától megérkezik az Apple chipben látható magasabb IPC is.
Engem például meglep, hogy a Zen5-ben, csak az L1d növekszik 48kB-ra 32-ről, miközben az Apple cpu-ban 192kB + 128kB van.
-
#9078
Petykemano
veterán
S_x96x_S
#9077
Petykemano
veterán
válasz
S_x96x_S
#9077
üzenetére
Az jutott még eszembe, hogy AdoredTV szerint az AMD valami létre elrendezésű busszal fogja megoldani a 16 (és később bizonyára a 32) mag egy CCX-be integrálását.
A Strix Halo 16 magjából valamennyi lehet(ne) akár helytakarékos Zen5c mag is.
A PHX2 bizonyítja, hogy akár egy designon belül is lehet alkalmazni a két különböző sűrűségű magot. Persze ott talán több hely van a méretkülönbségekből fakadó többlethely feltöltésére, míg egy CCD elég téglalap alakú.A régi wccf-es ábra [link] is olyasmire utalt, hogy vegyítve vannak a normál és az alacsony frekvenciát bíró magok.
Ha standarddé válik a 16 mag, szerintem azt nem is volna érdemes úgy megvalósítani, hogy 16 normál, nagy kiterjedésű mag. Egészen bizonyos, hogy a 16-ból az utolsó - mondjuk - 8 soha nem fog azon frekvencián üzemelni, amit névleg - turbóval - elérhetne, mert ezt a feladatot a nálánál jobb magok fogják megvalósítani.
Viszont ezzel a gondolattal nem is mennék tovább, mert semmilyen információ nem támasztja alá, hogy a hagyományos magas frekvenciát elérni képes Zen5 CCD és a 16 magos Zen5c CCD mellé az AMD készítene további változatokat.
-
#9076
Petykemano
veterán
Devid_81
#9075
Petykemano
veterán
válasz
 Devid_81
#9075
üzenetére
Devid_81
#9075
üzenetére
> Strix Halo az erdekes lesz
Az eddig látott információk alapján sajnos nekem vannak kétségeim.
A Strix Halo-t az eddigiekben 16 magos konstallációban emlegették. Szerintem a 16 mag sok. Akit egy 40CU-s APU érdekelhet - feltételezve, hogy addig nem dob le az AMD valami ütős szoftveres cuccot, ami a 40CU-t egy diszkrét kártya mellett is hasznossá teszi - annak bőven elég lenne emellé 6-8 mag is.
(Legyen 6 mag + 36CU, 8 mag és 40CU)Szerintem aki 40CU-val beéri, annak nem kell 16 mag, akinek meg kell 16 mag, az nem fogja beérni 40CU-val, hanem kell a diszkrét kártya.
Értem, persze, biztos van egy olyan még ennél is szűkebb réteg, aki renderelni akar 16 magon és elfogadható minőségben játszani is, de utóbbira azért olyan sokat nem költene. De akkor is azt gondolom, hogy ezek kevesebben vannak, mint akiknek egy kompakt játékos minipc-hez 6-8 mag is elegendő.Azt gondolom, hogy talán az lehet az AMD gondolata, hogy a 40CU nagyon sok és sok helyet foglal és ezt azzal próbálják növelni a marzsot, hogy az egyébként mondjuk $350-400-os terméket (merthogy 6-8 magért és egy RX 7600-ért összekötve szerintem ekörül költene egy kompakt miniPC-re vágyó felhasználó) egy plusz chiplettel hirtelen a $700+-os szintre lökik.
Ezt persze meg lehet tenni, de akkor ez a termék nem a mainstream GPU-kat leváltó nép-gamer APU lesz, amire már évek óta áhítozunk, hanem egy alacsony volumenben gyártott termék, ami lényegében nem felhasználói igény kielégítésére, hanem technológiai mutogatásra készítenek: egy halo product.
Persze senki nem mondja, hogy ne lehetne az egyik CCD-t levenni, vagy letiltani. De szerintem hiba volna ebben reménykedni.
A Zen5 még a hagyományos összeköttetéssel és IOD-vel érkezik és elvileg a Zen6-tal fogja az AMD megreformálni a chipletek elrendezését, csatlakoztatását.Számomra az tűnik logikusnak, hogy a Strix Point monolitikus. Erre a napokban érkezett is egy 225mm2-es lapkaméret jóslat/leak.
A 40CU viszont nagyon sok. A közel ugyanekkora mennyiségű feldolgozóval rendelkező Navi33 esetén 32MB infinity cache-t alkalmaznak 128bit GDDR6 mellé. DDR5 mellé valószínűleg ennél lényegesen több kéne. Emiatt szerintem a Strix Halo nem monolitikus, hanem egy olyan kísérleti termék, amiben az AMD beveti a Mi300-ban is használt "base die + compute dies" megközelítést. Ez mondjuk megmagyarázná, hogy miért halo (drága és kis volumen.
-
#9070
Petykemano
veterán
hokuszpk
#9069
Petykemano
veterán
-
#9068
Petykemano
veterán
Petykemano
veterán
Úgy tűnik, az AMD Phoenix érkezik AM5 foglalatba [link]
-
#9065
Petykemano
veterán
Petykemano
veterán
Lisa Su interjú: [link]
-
#9058
Petykemano
veterán
S_x96x_S
#9053
Petykemano
veterán
válasz
S_x96x_S
#9053
üzenetére
"Jön fel mint a talajvíz. "
"és egyre csökken a rés az x86 között."
Szerintem már megérkezett.
Egyrészt a Cortex-X sorozat ott van, ahol lennie kell. Tulajdonképpen az szerverek vonatkozásában is eléggé sok megoldás érhető már el. Az Apple irányt mutatott és bár a Nuviához sok remény fűződik, sajnos egyre több helyről hallani, hogy nem fog egy újabb ugrást jelenteni az Arm életében az X4-hez és az Apple P magokhoz képest.Az Apple P mag valóban kimagasló, viszont azt is látni kell, hogy a Cortex-X sorozat sem ugrál már olyan elképesztő nagyokat. Én nem érzem azt, hogy teljesítményben jön, mint a gyorsvonat és állva hagyja az X86-ot.
Amit az Arm magokról jelenleg el lehet mondani az az, hogy perf/W és talán PPA vonatkozásában valóban előnyben vannak az X86-hoz képest.
De nem vagyok róla meggyőződve, hogy ez az ISA következménye. Sokkal inkább az, hogy az x86 magokat magas frekvenciára tervezik, míg az Arm magokat alacsonyabb frekvnciára és több, de sűrűbb cache-sel. Szerintem is az utóbbi a jobb, láthatjuk a Zen4c-n, hogy mennyivel lehetne összesűríteni a magokat, ha elengedjük a magas frekvenciát.Szóval teljesítményben csodát már nem várnék.
A perf/W nem lebecsülendő és engem is érdekel, hogy vajon mikor fog az Intel és az AMD reagálni erre az aspektusra - ami márpedig a legnagyobb profittal kecsegtető szervereknél és a notebookoknál egy elképesztően fontos szempont.Az adoptáció egy másik kérdés.
Nyilván ha a Windows-t fel tudom telepíteni egy bolti Arm-os notebookra is, és a windows elfejti az egyéb szoftverkompatibilitási problémákat is, akkor a vásárlót elvileg nem kéne érdekelje, hogy mi van a gépben. De ez most is igaz. Az se kéne érdekelje, hogy Intel vagy AMD van és - állítólag - a vásárlók mégis az intel márkanévben bíznak inkább.
Persze az is lehet, hogy ez humbug és ezt csak az OEM-ek mondják. Akkor viszont az fog dönteni, hogy egy arm mag, ami teljesítményben versenyképes és perf/W vonatkozásban előnyben van, vajon olcsóbb is lesz-e annyival, hogy megérje a nyűgöt, vagy ahhoz az hagyományosan lenni szokott a perf/W előnyt megfizettetik a vásárlóval?A lényeg, hogy én itt már tökre ugyanazokat a piaci mechanizmusokat várom, mint ami meghatározza, hogy Intel vagy AMD processzorból mennyi fogy notebookokban.
Tartok tőle, hogy ha áttörés lesz, akkor az inkább annak köszönhető, hogy lesz egy oylan - Arm tervező - szereplő, aki hajlandó és képes alacsonyabb marzzsal és nagy volumenben - annak kockázatával együtt - vállalni a chipgyártást. Azt meg ugye tudjuk, hogy az AMD általában kínosan ügyelt, hogy helyenként megnyert technológiai előnyét inkább marzsnövelésre, mint piaci részesedés növelésére fordította. -
#9047
Petykemano
veterán
Petykemano
veterán
STX
TSMC N4P 225mm²
4c Zen 5 L3: 16 MB L2: 4 MB
8c Zen 5C L3: 16 MB L2: 8 MB
8 WGP RDNA3+
64 AIE tile
DDR5-5600 / LPDDR5X-8533
28-35+ W
[link]Nem kristálytiszta, hogy ez most 2 CCX-et jelent-e, vagy 1CCX-et, amire mind a 12 mag rá van fűzve. És, hogy ez most 1x16MB, vagy 2x16MB L3$-t jelent-e.
Figyelembe véve, hogy mennyit számított ez a Zen2 esetén a játékokban, szerintem 2CCX hiba lenne. Úgy értem, hogy annyit szerintem nem ér meg -15% teljesítményt játékokban +4 MT-ben használható "kis" mag. -
#9043
Petykemano
veterán
Petykemano
veterán
"Zen6 has three CCD types." Kepler_L2
-
#9041
Petykemano
veterán
b.
#9039
Petykemano
veterán
Szerintem egy chipletbe vagy chipbe gyártani x86 és Arm magokat is és annak megfelelően bekapcsolni egyik vagy másik ágat... hátő ha nagyon magas szinten hajtod végre, akkor nagyon pazarló, ha meg úgy csinálod, hogy szinte csak az utasításokat értelmező frontendek kapcsolódnak ki vagy be az meg biztos rendkívül bonyolult.
Én azt gondolnám, hogy ha az AMD szeretne Arm magokkal szerverchipet, vagy APU-t készíteni, akkor azt megtenné, de nem ilyen csalafinta módon.
A Xilinx felvásárlással örököltek Arm designokat és azt nyilatkozták, hogy azokat nem is tervezik x86-ra átkényszeríteni. Úgyhogy ha eddig őrizgettek a fiókban K12 terveket, esetleg a Zen designokat - akár bizonyos késleltetéssel - portolták Arm ISA-ra, hogy mindig relatív friss legyen a fiókban levő Arm design, akkor azokat a Xilinx termékekben vélhetőleg bevetik majd.Mindamellett, hogy az Apple ARM alapon dolgozik és hogy nyilván ha az NVidia megjelentet kliens termékeket (Nvidia Shield notebook, minipc, etc), az is Arm alapon fog létrejönni (ahogy a Shield termékek eddig is) továbbá nyilván minden mobil SoC gyártó törekszik abba az irányba, hogy létrehozzon egy olyan erős SoC-t, ami alkalmas lehet egy notebook igényeit is kiszolgálni.
Ugyanakkor én nem vélem felfedezni egyelőre azt a piaci - szoftveres - nyomást, amiből az következne, hogy az AMD akkor tudná legnagyobb mértékben növelni a notebook piaci részesedését, ha Arm alapú SoC-val rukkolna elő.Mindazonáltal ha valami ilyesmiről lenne szó, akkor azt nem hívnák Nirvana-nak, de legalábbis oda lenne írva, hogy "Arm-based sister design" vagy "Hybrid Arm design"
Szerinted?
-
#9035
Petykemano
veterán
paprobert
#9031
Petykemano
veterán
válasz
 paprobert
#9031
üzenetére
paprobert
#9031
üzenetére
> De akkor 3-4 különböző chiplet lesz tervezve?
Ezt nem tudom. Nem hiszem.
mindazonáltal ugye most is van egy Zen4 és egy Zen4c chiplet.
De a Phoenix2-ben vegyítve vannak a magtípusok.
Ami elég logikus. Szerintem statisztikailag kiszámolható, hogy ha van egy 8 magos CCD, akkor a legmagasabb frekvencia alapján sorban állított magok közül az utolsó 4 lehet, hogy soha nem fog azon a frekvencián üzemelni, amit névlegesen maximálisan el tudna érni, mert ő mindig az 5-8. mag lesz, ami terhelést kap és addigra az első 4 mag már biztosan felvesz akkora áramot, hogy a TDP kereten már osztozni kell.Ahogy mondtam, szerintem a Low power option inkább a dense option továbbfejlesztése.
-
#9027
Petykemano
veterán
S_x96x_S
#9024
Petykemano
veterán
válasz
S_x96x_S
#9024
üzenetére
> A "low power core option" az mégis mi?
A Zen4-nél a Dense option jelenik meg.
A Phoenix 2-ben megjelent a Zen4 és Zen4c mag vegyítve. Ezért valószínűtlen, hogy erről lenne szó.
Annak nem nagyon látnám értelmét, hogy legyen a Zen5 mellett egy dense (ami nem low power) és egy low power (ami nem dense) is. következésképpen én arra gondolok, hogy a dense option-t fejlesztik tovább és immáron nem kizárólag az magra alkalmazott library-t cseréik, hanem bizonyos belső változtatásokat is eszközölnek rajta, (pl felezett L2$), ami már nem csak csökkent frekvencia, hanem architekturális megkülönböztetést igénylő viselkedéssel is jár. -
#9023
Petykemano
veterán
Petykemano
#9021
Petykemano
veterán
válasz
Petykemano
#9021
üzenetére
Fontos adalék lehet az információk értelmezéséhez - és ezt MLiD is elmondja - hogy az általa megszerzett és publikált ábra szerver/EPYC roadmap. El is mondja, hogy az ábrán látható dátumok és határok miért azok, amik és jelölgeti, hogy ahhoz képest mikor voltak a desktop rajtok.
Azt is elmondja az elején, hogy az IPC nem egy egzakt érték, hanem 15-25 alkalmazásban/játékban azonos frekvencia mellett tapasztalt gyorsulások (esetleg lassulások) átlaga. Ez az érték a definícióból fakadóan jelentős mértékben függvénye a beválogatott alkalmazások/játékok listájának.
Azt már korábban is tapasztaltuk, hogy az AMD különböző IPC értéket adott meg a Zen4 esetén a desktop (8%) és a szerver (14%) termékhez. A különbség nagyobbrészt adódhat a tesztelt programcsomag összetételéből, kisebb részben talán abból is, hogy különböző frekvenciamagasságban esetleg eltérő lehet a tapasztalt IPC.
-
#9021
Petykemano
veterán
Petykemano
veterán
Zen5, Zen6 szivárgás [link]
Hát a Zen5-höz tervezett 10-15%-os IPC nagymértékben elmarad a várakozásoktól, főleg amiatt, merthogy ez volt az az architektúra-szélesítés, amitől többet lehetett volna várni.
Ez különösen annak fényében csalódást keltő, de minimum fura, hogy a szélesebb architektúra és a nem nagymértékű gyártástechnológiai előrelépés (N5=>N4P) miatt kisebb mértékű frekvencia regressziót várnak.Persze MLiD elmondja, hogy az ábrán szereplő számok minimumot jelölnek, de azt is, hogy arra azért nem lehet számítani, hogy ennek duplája következzen be.
MLiD szerint:
- a Zen5 rajtolhat 2024 elején
- a Zen6 2025H2-ben fog piacra kerülni.A zen5c-vel nő 16 magra az egy CCX-be tartozó magok száma
A Zen6 ezt követi - tehát itt várható magszám növekedés - és a Zen6c esetén ez megint 32-re nő.A Zen6-tal fog változás érkezni a tokozásban, ami jelentősen növelheti a CCD-k irányába a sávszélességet és csökkentheti a késleltetést.
Elgondolkodtató.
Az AMD tick-tock stratégiája alapján azt, hogy a Zen6 az uncore részen - a magszám növeléssen, a MT teljesítményen, CCD kommunikáción stb - fog jelentős változásokat hozni, eddig is lehetett sejteni.
De én azt reméltem, hogy a Zen5 ezt megelőzően egy nagyobb IPC növekedéssel fog kiemelkedni és a zen3-hoz hasonlóan egy az olcsóbb csomagolás/gyártás miatt egy olcsóbb, de általános célokra remekül használható alternatíva marad évekig.
De ha a Zen5 nem ez lesz, akkor elgondolkodtató, hogy nem lesz-e érdemesebb-e inkább megvárni a Zen6-ot és learatni a magszámnövekedésből fakadó előnyöket (is) -
#9019
Petykemano
veterán
S_x96x_S
#9009
-
#9017
Petykemano
veterán
Petykemano
veterán
HWinfo
"Improved support of AMD Strix and Storm Peak."
Egy korábbi alkalommal amikor a Zen2 "improved support" jelzőt kapott, ahhoz képest 4-5 hónappal később megérkezett a termék(bejelentés). [link]Számomra nehezen hihető, hogy ha a Zen5 2022 októberében "early/preliminary support", majd egy évvel később "improved support" és hogy ez úgy történjen, hogy közben a termék majd csak valamikor 2025-ben jelenjen meg, ahogy azt Abu állította itt
Az persze igaz, hogy a Zen5 legalább 3-4 termékkategóriában jelenik meg - szerver, mobil, desktop, HEDT - és egyáltalán nem szükségszerűen egyszerre.
-
#9012
Petykemano
veterán
kleinguru
#9011
Petykemano
veterán
válasz
 kleinguru
#9011
üzenetére
kleinguru
#9011
üzenetére
> ilyen "alap" dolgot, azért implementálhatnának legalább nem

Szerintem igen.
Szerintem ebben az esetben is az lenne a helyes eljárás - mint a magok számának vonatkozásában - hogy a hardvergyártó odateszi a hardvert, elér vele bizonyos penetrációt és csak utána jön szóba a szoftvernél, hogy akkor vegyük használatba. Lehet, hogy ez is akadályokkal teletűzdelt. De az még ennyire se fog megvalósulni, hogy a szoftver valamiféle/mindenféle gyorsítókra felkészül és aztán várja, hogy mikor kerül alá a megfelelő hardver.Etekintetben az Nvidia nyilván előnyben van, mert az ő hardverét erre kifejezetten használjá és emiatt előrébb jár a CUDA szoftveres támogatása.
A másik nagy szereplő pedig értelemszerűen a MS, akinek lehet, hogy saját elképzelései vannak. Pl: nem fog bekerülni a windows-ba helyi hardveren futtatható AI támogatás, mert a MS szeretné, ha az ő cloud szolgáltatásukat vennéd igénybe, lehetőleg úgy, hogy fizetsz is érte. -
#9010
Petykemano
veterán
S_x96x_S
#9009
Petykemano
veterán
válasz
S_x96x_S
#9009
üzenetére
> in part because Intel has so much unsold inventory of its own comparable processors that buyers want product at the same price.
Ebben azért el van rejtve a sorok közé az, hogy viszket a tenyerük, hogy árat emelhessenek.Egyébiránt az, hogy a desktopon nem fogják nyomni az AI-t...
Ez most jó hír, vagy rossz? Segíts már értelmezni, kérlek..
Ezen gondolkodom...
Mármint ha úgy ítélik meg, hogy a desktop piacon nincs kereslet az AI gyorsítókra, akkor az egyben azt is jelenti, hogy a fókuszt a ST teljesítényről nem fogja elvinni valami olyan feature, aminek csak réteg-haszna van. Tehát továbbra is erőteljesen fogják nyomni az IPC-t és a ST teljesítményt. Ez gondolom azért jónak mondható.
Lehet, hogy itt az volna az elképzelés, hogy desktopon akinek AI kell, annak úgyis nagyteljesítményű AI kell és akkor az majd vesz egy GPU-t? -
#9007
Petykemano
veterán
S_x96x_S
#9006
Petykemano
veterán
válasz
S_x96x_S
#9006
üzenetére
Hát igen, tulajdonképpen az AMD előnyei a TSMC technológiájából származnak, Amivel az AMD talán csak mindenkinél előbb kísérletezget, részt vesz a fejlésztésben, de nem egyáltalán nem biztos, hogy aki később kapcsolódik be, az is ugyanúgy végig fog "szerencsétlenkedni" 3-4 évet.
Ez egy lényeges különbség az AMD és az nvidia között is. Az AMD terméket csinál a kísérletezésből és ezzel sokáig úgy tűnik, hogy 2-3 év előnye van bizonyos teroleteken. Aztán az nvidia kidobja a saját termékét, ami egyből jó és úgy tűnik, az nvidia mennyivel jobb, vagy milyen sokat szeremcsétlenkedett az AMD. Valószínű magyarázat az, hogy addigra beérett a technológia és az nvidia nem adott ki kisérleti terméket.
Persze a 3D v-cache nem tűnik szerencsétlenkedésnek és már két generáció óta biztosít előnyt az amdnek.
Nekünk fogyasztóknak pedig az a jó, ha valami végül standarddé válik monopólium helyett.
-
#9005
Petykemano
veterán
Petykemano
veterán
Az elmúlt napokban az Intel elég sok fejlesztést bemutatott.
Vajon ezek továbbra is csak látványos Vaporware jellegű ígéretek, vagy hamarosan indokolt lesz bemutatni a Zen5-öt (mobil és szerver piacon legalábbis)? -
#8998
Petykemano
veterán
hokuszpk
#8997
Petykemano
veterán
válasz
hokuszpk
#8997
üzenetére
Az a kérdés motoszkál bennem, hogy vajon számít ez?
Ha egy sokmagos asztali gépet MT teljesítményre húzol fel, az papíron jól hangzik, de egyrészt a 300W elég nevetséges. (1-2 generáció múlva ugyanezt fogja hozni egy 15W notebook) másrészt miközben kicsit talán bele is harap a Workstation piacba, desktopon valóban érdemben ki lehet használni?
Igazából ugyanezt gondolnám egy 3CCD-s Ryzenről is. Maximum akkor látnám értelmét, ha igazából a plusz magok (pontosabban a többlet MT teljesítmény) a régi sku-khoz képest grátisz és csuklóból jönnek és nem felárért. A 300W-os fogyasztás viszont némiképp izzadtságszagúvá teszi.
Hasonló helyzetként lehetne emlegetni a Zen1 betörését, hogy hát ott is feleslegesen jöttek a plusz magok. Annyiból látom másnak a helyzetet, hogy akkor azt gondoltuk, hogy a Skylake-en túl generációról generációra már csupán néhány százaléknyi IPC növekedésnek maradt szufla - legalábbis az x86 mikroarchitektúrákban -, így logikus volt azt gondolni, hogy nincs más út, mint növelni a magok számát.
Akkor persze sokan azt gondolták, hogy az Intelnek ott van a fiókban a titkos új architektúra, amivel majd újra megszégyenítő vereséget mér az MT teljesítménnyel bohóckodó AMD-ra, csak eddig cicázott vele. Végül nem lett.
De hát most minden jel arra utal, hogy a Zen5 is komoly ST előrelépést hozhat és 10-15% ST előny a desktop CPU-k terén mindig sokkal meggyőzőbb volt mint 10-15% MT előny - különösen ha annak a fogyasztásban is komoly ára van.
Ennélfogva bár az AMD valóban képes lehetne 3 CCD-t ledobni egy SKU-ba (nyilván lehet, hogy kellene hozzá új IOD és nyilván szükséges lenne hozzá valamilyen nagy frekvenciájú RAM is), de szerintem ez lényegesen kisebb sikerrel kecsegtetne, mint a Zen5.
-
#8993
Petykemano
veterán
Petykemano
veterán
Amikor megjelent az Apple M1 N5-ön gyártva, mindenki megijedt, hogy az arm tarol.
Azóta is persze minden iterációja nagyon remek, de elveszteni látszik - nem feltétlenül az előnyét, de a varázsát.
Az M2-höz N4-en gyártott és és most az A17-ben debütált N3B-n gyártott lapkák egyszálas CPU teljesítménye szinte alig növekedett.Vajon mi lehet az oka?
- az N4 és azt követően az N3B is annyira kis előrelépést biztosító gyártástechnológia, hogy nem fér bele több? Valóban azt tudjuk, hogy az IO és az SRAM skálázódása lényegében megállt, nem véletlen, hogy Nagy erőkkel folyik a fejlesztés a chipletezés irányába.
- ennyire hiányoznak a Nuviát megalapító chiptervezők?
- az Apple fókusza a GPU-n és az NPU-n van, és nemsokára olyan AI funkciókkal fognak előrukkolni, ami teljesen háttérbe szorítja a hagyományos CPU-t. Vajon lehetséges egy algoritmust AI segítségével.értelmeztetni, taníttatni és futtatni gyorsabban, mintha az hagyományos számítóegységeken futna? -
#8992
Petykemano
veterán
Petykemano
veterán
"Chips made for Apple and other TSMC clients in Arizona will still have to be shipped back to Taiwan for advanced packaging, therefore TSMC Arizona does not reduce America’s reliance on Taiwan" [link]
Jár a taps... /facepalm
-
#8990
Petykemano
veterán
Petykemano
veterán
-
#8989
Petykemano
veterán
S_x96x_S
#8986
-
#8985
Petykemano
veterán
hokuszpk
#8984
Petykemano
veterán
válasz
hokuszpk
#8984
üzenetére
Nem.vagy amatőr, nagyonis jól teszed, hogy azt várod.
Elméletben nagyon izgalmas, hogy a CCD-IOD kapcsolat szélessávúvá és - talán - alacsonyabb késleltetésűvé tétele milyen lehetőségeket hordoz magában.
De ha az AMD - ahogy egyes pletykák magyarázzák - az AI kereslet kielégítése érdekében hajlandó volt lemondani az RDNA4 chipletes változatairól, akkor ez a kapacitás-szűkösség érintheti a zen6-ot is. Ami ennek következtében, ha az AI kereslet fennmarad, akkor vagy nem, vagy csak drágábban lesz kapható. Emiatt azt mondják, hogy a zen5 sokáig lesz a zen3-hoz hasonló hosszan támogatott, olcsó változat.
De ez nem is biztos, hogy baj. Szerintem a zen6 alcsonyabb csíkszélességen elsősorban a zen5 fogyasztását fogja korrigálni és a MT teljesítményt fogja emiatt javítani. Viszont nem biztos, hogy ugyanakkora frekvencia ugrásra lehet számítani megint, mint a zen4 esetén.
-
#8983
Petykemano
veterán
Petykemano
veterán
AMD Venice - Zen6 [link]
- 384 mag
- 12-16 ch DDR5
- 2025
- azt mondják, a Zen5 lesz az új core, a zen6 pedig az új uncore, ami teljesen megújítja azt, ahogy a.chipletek kapcsolódnak egymáshoz. Azt mondják, a Mi300 úttörő és bár az RdNA4 chiplet változatait elkaszálták,.a technológiát továbbviszik a többi termékre. Tehát itt is hasonló várható.A roadmapen megjelenik a Mi400A, Mi400X és Mi400C. Utóbbi minden. Bizonnyal a csak CPU chipletekből álló HBM-es szerverchip.
-
#8978
Petykemano
veterán
S_x96x_S
#8977
Petykemano
veterán
válasz
S_x96x_S
#8977
üzenetére
Kicsit igazán lehettek volna bátrabbak, karakánabbak, határozottabbak annak megfogalmazásában, hogy a Zen4 működésében észlelt szűk keresztmetszetek (amik persze nyilván egyensúlyi döntések eredményei) milyen célszerű/praktikus fejlődési irányt jelölnek ki a Zen5 számára.
Nekem az állt össze, hogy bizonyos szélességű backend számára meghatározott mennyiségű cache és buffer elegendő. A cache és buffer méretek növelése - ahogy az az intelnél is látszik - 1-2%-ot számíthat a végső IPC-ben, de ha túllősz a célon, akkor tulajdonképpen pazarlás is lehet.
A zen5 48kB-os L1d engem arra enged következtetni, hogy szélesítették az architektúrát és 6 széles lett a backend.
-
#8972
Petykemano
veterán
Petykemano
veterán
Cisco Silicon One
Ez valami hálózati chip lehet. A név nem új, de lehet, hogy a felépítés, ami eléggé hasonlít a Graviton3-ra, újszerű.Persze ez is egy bizonányára méregdrága hálózati eszköz, aminek az árába belefér az egzotikus csomagolás. De azért remélem, hogy mihamarabb látunk hasonló megoldást az AMD-től is az IOD és más compute lapkák csatlakoztatására.
-
#8969
Petykemano
veterán
Petykemano
veterán
Megérkezett a RISC-V is.
Van egy-két meglepő, jól hangzó állítás
pl:
"Ventana targets 3.6 GHz, but Veyron V1 can clock lower to reduce power consumption. At 2.4 GHz, the core pulls less than 0.9 W of power."Ami azért elég jól hangzik.
Még akár akkor is, ha ez csak a mag.
A GEnoa-t most hagyjuk, mert gondolom, hogy annak azért némieg cél a magasabb frekvencián üzemelés - a Bergamohoz képest. A Bergamonál viszont az energia és területhatékonyság a cél. A 100-as nagyságrendű magoknál persze már a tizedek is számítanak.A másik a terület:


Azért az nem hangzik rosszul, hogy egy Veyron V1 mag még a Bergamonál is 30%-kal kisebb. De ezt nehéz csak a méret alapján megítélni, hiszen nem tudjuk, hogy végülis milyen teljesítményt nyújt. Vagy legalábbis ebből nem derül ki.Viszont az, hogy egy 16 magos cluster kisebb, mint a Bergamo úgy, hogy magonként 2 helyett 3MB L3$ jut rá - mindezt ráadásul úgy, hogy egy mag számára is nem 16MB, hanem 48MB érhető elé, az objektíve jobbnak hangzik. Jó, persze nyilván itt is számít a workload.
Viszont a Bergamo mag Neoverse V2-vel való összevetése is érdekes. A Zen4c esetén az L2$ mérete még így is elég nagy. A Neoverse V2 közel ugyanakkora magterület mellett viszont kétszer akkora L2$-sel rendelkezik.
A Bergamoról már elvileg nem lehet elmondani, hogy jójójó, de lényegesen magasabb frekvenciával amennyivel több helyet foglal, annyival nagyobb is a teljesítménye.
Nekem úgy tűnik, hogy az AMD még a kicsinyített méretű Bergamoval is eléggé le van maradva - azonos csíkszélességen - a Cache sűrűség tekintetében.
Kiváncsi lennék, hogy ez kompetencia kérdése-e, vagyis arról van-e szó, hogy az ARM által tervezett SRAM ennyivel jobb és az AMD képtelen őket utolérni/lemásolni, vagy arról, hogy az AMD egy olyan SRAM designnal rendelkezik, ami a ~6Ghz elérésére is alkalmas. Ezt a designt HD libraryvel ennyire lehet összesűríteni. Ha átterveznék az SRAM designt, akkor képesek lennének elérni az ARM által mutatott sűrűséget, de az a design már mondjuk csak 4GHz elérése lenne alkalmas HP libraryval is. -
#8968
Petykemano
veterán
Petykemano
veterán
Strix Point
 [link]
[link] Több szempontból fura
- továbbra is 2x1MB L2$-t ír az "E" magokhoz. Ami nem valószínű, hiszen eddig arról volt szó, hogy az E magok belső felépítése a L3$-t kivéve megegyezik.
- AMD Strix - Internal GPU - GDDR6?7.61-es HWinfo-val olvasták le, az a legújabb beta.
Gondolom, hogy ezt majd egy frissebb HWinfo korrigálja. -
#8966
Petykemano
veterán
S_x96x_S
#8965
Petykemano
veterán
válasz
S_x96x_S
#8965
üzenetére
> Amúgy nem tünik rossznak a Grace ..
Nem mondtam, hogy rossz lenne. Sőt... ha nem így gondolnám, nem azt kérdeztem volna, hol lehet a szűk keresztmetszet, min kellhet javítani.LPDDR5X vs DDR5
Emlékszem, hogy Abu egyszer erről értekezett, hogy az LPDDR5X egy középút sávszélesség, fogyasztás és ár, nameg persze kapacitás tekintetében a DDR5 és a HBM között és akkor azt hiszem, azt mondta, hogy az LPDDR5X lehetőségét az AMD végülis a kapacitáskorlát miatt vetette el.Az az igazság, hogy ugyanakkor nem hiszem, hogy kizárólag erről lenne szó. Hiszen mennyiből tartana az AMD-nek csak az IOD helyett egy LPDDR5X-eset tervezni és azzal kínálni valami jelzéssel. Pont ez lenne a chipletezés egyik előnye, hogy ezt könnyen megteheted. Viszont szerintem a CCD-IOD kapcsolat sávszélessége (ami most talán valahol a 60-70GB/s-nál járhat [link] egy 7950X esetén, de nem biztos, hogy a Genoa is tud ennyit) sem biztos, hogy érdemben képes lenne a nagyobb sávszélességet a magok felé hasznosítani.
Persze az IOD és a CCD között létezhet dupla infinity fabric kapcsolat is, de azzal meg csökken a magok száma.
Talán ugyanez lehet - részben - a magyarázata annak is, hogy miért nincs L4$. Lehet, hogy kissé csökkenteni lenne képes a késleltetést, de a CCD és IOD között nincs meg az a sávszélesség, hogy valóban azt lehessen érezni, hogy az L4$ hasznos.
Viszont akkor ez azt is jelenti, hogy amíg nem változik meg a CCD-IOD kapcsolat egy aktív interposeres szélessávú megoldásra addig nem valószínű, hogy a memória alrendszerhez hozzányúlnának. Máskülönben meg ott HBM-es használó Mi300
-
#8962
Petykemano
veterán
Petykemano
veterán
@S_x96x_S
Láttam, hogy az Nvidia találgatósban megosztottad az aggályodat, hogy az Nvidia Genoa-t és nem Genoa-X-et használt a teszteléshez.
Csak kiváncsiságból kérdezem, hogy Te tudod-e, hogy pl az OpenFoam hogy működik:
- milyen utasításokat,
- milyen feldolgozókat (FP/INT) használ
- működése közben mekkora az interdependencia és adatmegosztás a szálak között?Azért kérdezem, mert nekem elsőre az jutott eszembe, hogy nem csak a Genoa, de akár a Bergamo is jobb ellenfél lehetett volna. De nem.
A Bergamo (9754) valójában még a Genoa-nál is gyengébb eredményt ad. [link]
Hiba több a mag. Pedig nem valószínű, hogy az OpenFoam szkálázódásával lenne a gond.A Genoa, Genoa-X és Bergamo eredményei között a legszembetűnőbb különbséget talán épp a L3$ mérete adja. De a Genoa és a Genoa-X L3$ mérete közötti nagy különbség ellenére is a teljesítmény differencia csak 14%, ami hasznos (és elképzelhető, hogy per socket gyorsabb is), de nem tűnik elégségesnek a Grace hatékonyság-előnyének behozatalára.
A Grace 72 maghoz 117MB egységes L3$-t kínál. Ami egyébként összességében kevesebb, mint amit egy Genoa összesen tartalmaz (384MB) és nem sokkal több annál sem, mint amit egy Genoa-X CCD birtokol (96MB)
De az mégiscsak egységes, emitt meg hiába van 1GB L3$, egy adattárból akkor is csak 8 mag tud dolgozni.
Persze egyáltalán nem biztos, hogy ez a meghatározó tényező. De akkor mi?Memória sávszélesség? Az mondjuk a Genoa esetén feleakkora
Feldolgozók száma? A Grace-ben 4x128b SVE2 FP feldolgozó van, az nem tűnik többnek, mint a Zen4-é
CPU chipfelépítés?Van itt egy táblázat: [link]
Azért persze van különbség
Míg a Grace mag 64+64KB L1$, addig a Zen4 csak 32+32
De mindkettőben magonként 1MB L2$ van.Régen az AT-en voltak ilyen mérések, amik azt mutatták meg, hogy mennyi energia megy a magokhoz és mennyi a package veszteség. És emlékeim szerint a kép azt mutatta, hogy a Milan esetén elég nagy.
Kiváncsi lennék, a Genoa esetén ez változott-e és hogy mikor terveznek lépéseket tenni ez ellen.
Pl:
- Lecserélni a szubsztráton keresztüli távoli, magas frekvenciás, de szűk sávos kommunikációt valamilyen modern csatlakozóra
- egységes L4$ az IOD-on a memóriasávszélesség kímélésére és CCD-k közötti adatmegosztásra
- CCD-k közötti adatmegosztásra szolgáló L4$ (megosztott L3$)Vagy lehet, hogy nincs ilyen terv, hanem majd a Zen5c-vel rákötnek 16 magot egy egységes L3$-re és akkor ismét kesz valamelyest érzékelhető teljesítményjavulás itt-ott, ahol a teljesítmény függ a szálak kommunikációjától.
Mit gondolsz?
-
#8955
Petykemano
veterán
Petykemano
#8949
Petykemano
veterán
válasz
Petykemano
#8949
üzenetére
7800X3D közel $100-ral akcióban [link]
Vajon ez eseti akció lehet, vagy futnak ki a szerveres megrendelések és halmozódik a készlet és/vagy közeledik a Zen5?
-
#8954
Petykemano
veterán
Petykemano
veterán
(Olrak29 szerint) a desktop Zen5 (Granite Ridge) ugyanazt az IOD-ot fogja használni, mint Zen4-es elődje. [link]
Ami elég fura, mert azt gondoltam volna, hogy ott is indokolt lehet az RDNA3-mal érkezett AI képességek bevezetése.
-
#8953
Petykemano
veterán
-
#8950
Petykemano
veterán
Petykemano
veterán
Nem mai hír... De legyen meg
Június 7-én jelent meg a Benchleaks által ez az azonosító, ami elvileg Zen5 Eng Sample:
100-000001290-11_N -
#8949
Petykemano
veterán
S_x96x_S
#8948
Petykemano
veterán
válasz
S_x96x_S
#8948
üzenetére
A MS Azure-ben június 13-mal vált elérhetővé a Genoa(-X) [link] NEm tudom, hogy hagyományos Genoa volt-e már előtte elérhető.
mindenesetre ha jól értem, akkor az AWS-ben a Genoa most, 2023-08-15 napon vált elérhetővé. [link]
Az a fura, hogy az Oracle is idén júliusban jelentette be az GEnoa-val szerelt E5 elérhetőségét [link]
A GCP-nél még nem találtakoztam sem Genoa, sem Genoa-X, sem Bergamo említésével.Több mint háromnegyed éve jelent meg a a Genoa és persze az asztali Zen4. Máskor is ilyen lassan szokott menni a terjedés, vagy most tényleg nem volt érte akkora kapkodás?
Lehetett valami korlátozó tényező? Pl DDR5 szerver ramok elérhetősége, vagy a új platform (szerver-alaplap) validálása? Vagy csak ennyire limitált mennyiségben tud az AMD Genoa-t szállítani, hogy mondjuk 2-3 havonta tud egy-egy nagyobb ügyfelet kiszolgálni csak?Még a GCP hátra van. De lehet, hogy ők sincsenek messze lemaradva.
És utána vajon mi fog történni? Tavaly tavasszal elég látványosan zuhantak be a zen3 árak - 5600G, 5700G, 5500, 5700X megjelenésével. Vajon ha a nagy cloud szolgáltatókat kiszolgálták, felszabadulnak az chipletek? -
#8943
Petykemano
veterán
Petykemano
veterán
Tachyum Prodigy - 192 mag [link]
Nem találkoztam ugyan még ténylegesen legyártott és használt Tachyum processzorral. (Tartok tőle, hogy ez ez egy olyan EU forrásból finanszírozott projekt, Aminek valójában nincs meg a gyakorlati felhasználásról szóló vége, nincsenek európai tech vállalatok, akikbek szintén támogatást nyújtva elő lehetne segíteni az európai infrastruktúra fejlődését)
Mindenesetre ha nekik sikerült, hamarosan másoknak is mehet (Ampere, Graviton) -
#8939
Petykemano
veterán
S_x96x_S
#8937
-
#8929
Petykemano
veterán
S_x96x_S
#8927
Petykemano
veterán
válasz
S_x96x_S
#8927
üzenetére
Az AMD egy újabb lépést tesz előre a témában a Bergamoval? Vagy a Bergamo 2x8 magos CCX-eket tartalmaz?
A chiplet kommunikáció késleltetésén pedig feltehetően lehetne javítani azzal, ha szubstrát helyett valamilyen modern chip2chip kommunikációt biztosító megoldást használnának. Csak az a kérdés, hogy elfér-e.annyi chiplet az IOD körül. Sztem nem.
Ha valaha látni fogunk valamit, akkor én egy olyan megoldásra számítanék, mint a mi300 esetén, hogy ráültetik a CCD-ket egy base die-ra. Ez a base die lehet egy cache die, ami összefog 2-3 CCD-t és az csatlakozik az IOD-hoz. Vagy lehet eleve az IOD is. Úgy persze addícionális megosztott cache nem lenne. De ezt már több éve várjuk hiába.
-
#8926
Petykemano
veterán
Petykemano
veterán
Zen5 (zen 5) Linux kernel patch [link]
znver5 -
#8923
Petykemano
veterán
S_x96x_S
#8922
Petykemano
veterán
válasz
S_x96x_S
#8922
üzenetére
"APU a gyorsító sávban"
LoL
"az is lehet, hogy a Zen5 -ös APU a gyorsító sávba került.
( valamiért nagy prioritást kapott Lisa Su-tól )"
Kaphatott.
A volumen az OEM-ektől jön. A magas volumenre teríthető R&D-től lehet az R&D vagy a profit magas, vagy az ár versenyképes. Az ok ami miatt a desktop megelőzte mindig az az, hogy az együtt jár a még fontosabb szerver termékkel.Egyébiránt pedig ha az asztali Raptor Lake refresh nem is lesz túl erős, a Meteor Lake érkezik az Inteltől - mobilba. És az sokat javíthat a fogyasztási és teljesítmény értékeken is. Tehát a Zen5 APU megjelenítése emiatt bizonyára elég fontos.
Az is lehet, hogy a PhoenixAPU -val valami gond van
 .. nagyon lassan megy a launch.
.. nagyon lassan megy a launch.
és az AM5 -ös desktop-os Phoenix verzióról kevesebb a pletyka mint a Strix Point -ról.Milyen érdekes meglátás!
Erről volt már szó. Nem úgy van, hogy a Phoenix APU-t az AMD a ROG Ally-ba értékesíti Ryzen Z1 (extreme) néven?
Egy olyat olvastam, hogy 500e-1m között lehet az eladás [link]
Az mondjuk nem olyan hatalmas tétel az évi 150-250m eladott notebookhoz képest. -
#8921
Petykemano
veterán
Petykemano
veterán
Zen5, Zen 5, CPUz, CPU-z, hwinfo, AMD eng sample
Hybrid 12-core config of AMD Ryzen 8000 “Strix Point” APU seemingly confirmed by leaked screenshots


Eredeti forrás: [link]
L1$:
- 4x32 + 4x48
- 8x32 + 8x48Amennyiben a képernyőkép valid, az igazolja a 48Kb-os L1d-re vonatkozó pletykákat.
Zen4 esetén az még 8way, itt már 12wayAmi még nagyon különös az az L2$!
8 magra 2x1M?
Hmm... nem, nem hiszem, hogy az AMD a normál és dense magok között változtatna a cache hierachián - legfeljebb az L3$ méretén. Gyanítom, hogy ez a HWinfo hibája, ami E magnak ismeri fel és az Intel E magjai esetében tényleg úgy van, hogy 4 magos clusterek vannak 1db L2$-re fűzve és csak rosszul ismeri fel.És míg a Zen4 esetén az L2$ is 8 way, addig itt már 16 way.
Azt gondolom, hogy a Zen4 esetén a L2$ méretének növelése valóban csupán azt a célt szolgálhatta, hogy elférjenek benne az AVX512-höz használatos nagyobb hosszúságú adatok és alig járt IPC növekedéssel. Addig az asszociativitás növelése viszont valóban hozzájárulhat ahhoz..A zen4-hez CPUz (CPU-z) 2022 szeptemberben jelent meg [link] De akkor már nem AMD Eng Sample volt a megnevezése.
Zen4-ről nem feltétlenül CPUz, vagy hwinfo jellegű leak pedig január és május között jelent meg. Vagyis 4-8 hónappal a szeptemberi release előtt.Bennem ez azt erősíti, hogy a 2024Q1-es Zen5 rajt sínen van.
-
#8918
Petykemano
veterán
HSM
#8917
Petykemano
veterán
Nem érzem azt, hogy egyik vagy másik cég termékei jobban célpontja lenne ilyen kutatásnak, tehát nem sejtek részrehajlást. Olyan mintha általában ez a kérdés kevesebb nyilvánosságot, vagy kevesebb kutatást kapott volna a Zen előtt.
Persze nem kizárt, hogy arról van szó, hogy a cégek egymás lejáratása érdekében keresztfinanszírozzák egymás biztonsági réseinek felderítését, amit a Zen óta tudnak vagy érdemes megtenni. -
#8915
Petykemano
veterán
S_x96x_S
#8914
-
#8910
Petykemano
veterán
S_x96x_S
#8909
Petykemano
veterán
válasz
S_x96x_S
#8909
üzenetére
Az egy szerver roadmap.Abból is látszik, hogy nem az asztali megjelenést látjuk, hogy a roadmap szerint a Raphael alapú AM5 platform előkészítése 2023 során zajlik és 2023Q4-ben kerül piacra vezetésre - miközben az asztali Zen4 már 2022 év vége óta elérhető.
Nem állítom persze, hogy mindent 1 évvel elcsúsztatva kell értelmezni, csak azt, hogy amit ezen az ábrán látunk az nem az asztali termék megjelenésére vonatkozóan mérvadó.
Abban sem vagyok biztos, hogy vajon ez a roadmap még pontos. A Bergamo emlékeim szerint például 2 hónapja jelent meg, tehát csúszott 2 negyedévet.
Elnézést, persze én is csak ködszurkálok. Meglátjuk majd.
Két dolog miatt hiszek a 2024Q1-es rajtban:
Egyrészt mert az architektúrák közötti intervallumszámítás alapján - figyelembe véve a Zen4 2 negyedéves csúszását - úgy jön ki.
Másrészt szerintem az üdvrivalgás is korai jelenség volna 1 évvel a kiadást megelőzően.De majd meglátjuk.
Szerintem CES-re remek téma lenne. -
#8908
Petykemano
veterán
Petykemano
#8907
Petykemano
veterán
válasz
Petykemano
#8907
üzenetére
Nagyon erősnek tűnik a hype és az elégedettség a zen5 tesztpéldányokkal.
Azt nézegettem, hogy Vajon mikor jelentek meg az első olyan leak-ek, amiket nem Mlid, RGT jelentettek meg, hanem a twitter sejtelmes közönsége is somolyogva lebólogatott. Szerintem nyáron ilyen már biztos történt.
A 2024Q1-es rajt elég valószínű.
Igazából persze a nép annak örülne, ha karácsonyra vihetne haza egyet.A 25% körüli ST teljesítménynövekedés valószínű. Bármi ennél jobb, legyen inkább meglepetés. A raptor lake refresh nem tűnik túl erősnek. Mivel az Intel árat akart volna emelni, ezért az árcsökkentés valószínűtlen, tehát minimum a zen3 borsos árazásához való visszatérés várható. Főleg a kisebb magszámú skuknál.
-
#8907
Petykemano
veterán
Petykemano
veterán
Vector Width
Znver1: AVX2 128 bit
Znver2: AVX2 256 bit
Znver3: AVX2 256 bit
Znver4: AVX512 512 bit
Znver5: AVX512 512 bit*2
[link] -
#8906
Petykemano
veterán
Petykemano
veterán
Zen5 (Zen 5) benchmarks leak - RedGamingTech
CineBench R23 (MT)
16 Core = 49000
12 Core = 36000
8 Core = 23000
6 Core = 17000Igen különös eredmények. A 16 és 12 magos változat rendre 27% és 23%-os előrelépést mutat. A 8 és 6 magos viszont csak 12%-ot. Ez igencsak meglepő. Azt jelenti, hogy a Zen5 tulajdonképpen relatív sokat fogyaszt és a 12-16 magos változatoknál a nagyobb TDP nagyonis ki van használva.
De ugyanakkor az energiaéhség nem meglepő, ha figyelembe vesszük azt, hogy jelenlegi tudásunk szerint a rendkívül Zen5 N4P gyártástechnológián fog készülni. Ennek megfelelően a target - a Zen3-hoz hasonlóan - a ST (+lightly threaded) teljesítmény növelése lehetett, miközben - a Zen3-hoz hasonlóan - a MT teljesítménybeli növekedése korlátozott. Ez majd az N3_ port esetén korrigálódik. A dense és mobil chip azon fog készülni.
A szöveg alapján a R23 ST mérésben 2500-3000 között teljesít. Ami egy elég tág intervallum. És persze ezt a tág meghatározást már akkor is teljesítik, ha a MT értékeknél látott 23-27%-os növekményt teljesítik.
És persze ne vegyük készpénznek a fent látott számokat.
-
#8903
Petykemano
veterán
Petykemano
veterán
Azt pletykálják, hogy a Strix Point 4P+8e összeállítású lesz ,míg a Strix Halo 8P+8P
Bár mintha valahol azt olvastam volna, hogy 8P+8eUtóbbi nem tűnik túl valószínűnek... kivéve, ha strix halo monolitikus lesz.
Jön a PS5 Pro is.Itt gondolkodtam el, hogy vajon mi lesz végül monolitikus és mi lesz chiplet?
A Strix Point persze valószínűleg monolitikus.
A Strix Halo esetén a 8P+8P egészen úgy hangzik mintha chipletes lenne: 2 hagyományos Zen5 chiplet + egy 40CU-t tartalmazó "IO" lapka. Egy 40CU-s IO lapkát nem volna praktikus úgy tervezni, hogy azt akár diszkrét kártya formájában is el lehessen adni? És akkor vajon a PS5 Pro is ilyen felépítést kap, vagy az marad monolitikus? Ha az monolitikus, akkor lehet-e a Strix Halo is monolitikus inkább?
-
#8883
Petykemano
veterán
Petykemano
#8878
Petykemano
veterán
válasz
Petykemano
#8878
üzenetére
Ez max 24GB, 1.2TB/s
24GB szerintem egy gépnek ma már nem számít kifejezetten soknak. Minimumnak talán inkább a 16GB-ot mondanám. Figyelembe véve, hogy a ebből kellene kiszoglálni az IGP-t is, a 24GB indokolt.
Azon gondolkodtam el, hogy vajon minek kellene teljesülnie, vagy milyen akadályok vannak még ma is az előtt, hogy egy HBM-es készülék készüljön.
Az előny ott van:
- 1.2TB/s, ami egy 150W TDP-be beférő közepes GPU-t taralmazó APU-t
- kompakt módon ki tudna szolgálni.Mit jelent a kompakt (a gép méretén kívül)? Azt, hogy az IOD-ból elhagyható lenne
- a RAM vezérlő, az alaplapról a RAM huzalozás
- a PCIe sávok nagyobb része.Hátránya persze ezzel az volna, hogy sem RAM, sem bővítókártyás GPU fogadására nem volna alkalmas. Nem mintha ezt meg tudnád tenni a manapság egyre népszerűbb kézikonzolok esetén.
A RAM bővítés esetleg lehet szempont. Erre a jövőben viszont talán elegendő lehet PCIe sávokat meghagyni és hagyatkozni a CXL-re, amely esetben egy m.2 csatlakozós bővítőkártya (akár DRAM-okkal) csak overflow kezelését célozná.Ma már nem szükségszerű a nagy interposer, meg tudják oldani "hidakkal". Persze annak is nyilván van valamekkora többletköltsége. Az IOD-on lehet picit spórolni.
Vajon még ennél is olcsóbban megvalósítható LPDDR5X és/vagy 3D stacked v-cache?
-
#8878
Petykemano
veterán
Petykemano
veterán
-
#8876
Petykemano
veterán
Petykemano
veterán
A napokban Lisa Su - a média szerint - cáfolta, hogy az AMD lepaktált volna a Samsunggal. Lisa Su arra hivatkozott, hogy a TSMC nagyon fontos partnerük, hiszen a Mi300 ma nem lenne lehetséges a TSMC nélkül.
Mai Xeet:
"AMD will use Samsung GAAFET nodes."
[link]Természetesen a dolog nem arról szól, hogy az AMD teljesen elhagyja a TSMC-t.
Lehet, hogy csupán arról van szó, hogy összetett chipekhez bizonyos chipletek, vagy kisebb monolitikus mobil chipek és/vagy Xilinx termékek készülnek majd a Samsungnál. -
#8875
Petykemano
veterán
-
#8865
Petykemano
veterán
S_x96x_S
#8864
Petykemano
veterán
válasz
S_x96x_S
#8864
üzenetére
Különös.
Nem töketes driverrel ki szokták adni. Vajon ennyire fontos, hogy a Phoenix jó benyomást keltsen, hogy csúszhat is, vagy annyira elvonták a szoftveres tagokat a ROCm-hoz, hogy a gpu drivert már nem volt ki fejlessze (RDNA3 esetén látszólag hiányzik a dual issue támogatása és volt egy féléves.időszak az RDNA3 megjelenését követően, amikor RDNA2-től lefelé nem jött driver update ), hogy egyszerűen nem volt ki beletegye az apu támogatását?
Vagy a hardver volt hibás, ahogy a gpu-ról is beszélték, csak erre rászánták a fél éves respint a korrekció érdekében. -
#8859
Petykemano
veterán
S_x96x_S
#8857
Petykemano
veterán
válasz
S_x96x_S
#8857
üzenetére
> én ezt már nem tartom furcsának.
Nem úgy értettem, hogy az APU notebook vagy desktop változata, hanem hogy a Zen5 APU vagy desktop (vagyis chipletes) változata> És az is lehet, hogy csak konzol csip lesz
> .. és nem is kerül kisker forgalomba még egy jó ideig.
Én is ettől tartok.
Nem mintha egyébként megoldhatatlan lenne.
Különösen abban az esetben, ha esetleg ez a változat már nem is monolitikus. Abban esetben akár megoldható lenne, hogy az IO lapka cserélhető.
Milyen szép is volna, ha cserélhető lenne, hogy LPDDR5X vagy DDR5, de több infinity cache. (akár 3D stackelve) -
#8856
Petykemano
veterán
Petykemano
#8849
Petykemano
veterán
válasz
Petykemano
#8849
üzenetére
Azt hiszem, ez nem mót vég.
A 12-core AMD Ryzen 8050 Zen5 “Strix Point” APU has been spotted
- benchleaks, milkyway, boinc
- AMD Eng Sample: 100-000000994-03_N [Family 26 Model 32 Stepping 0]Korábbi mérnöki példányok felbukkanási ideje alapján tényleg azt lehet jósolni, hogy 7-8 hónap múlva megjelenhet.
Különös, hogy ezúttal az APU változat (mérnöki példánya) látott előbb napvilágot és nem pedig az asztali.Szerintem 4P+8d lehet a hatékony felállás. Azt gondolom, hogy ha már 4 magnál többet kell használni mobil környezetben, akkor ott már nem nagyon lehet korlátozó tényező az, hogy egy d mag esetleg nem megy feljebb 3.5-4Ghz-nél.
mindazonáltal számomra a 40CU-s változat sokkal izgalmasabban hangzik.
Ugyanakkor én korlátozásként (kitolásként) élném meg, ha azt csupán valamilyen előregyártott kompakt egybegépként lehetne megvásárolni. Fájna a szívem, ha a már meglevő kiegészítőimtől (pl CPU hűtő) ezért kéne megválni. -
#8853
Petykemano
veterán
-
#8851
Petykemano
veterán
Valdez
#8850
-
#8849
Petykemano
veterán
Petykemano
veterán
AMD GFX1150/1151, the GPUs for Ryzen 8000 “Strix” series
LLVM Zen5
[link] -
#8847
Petykemano
veterán
Petykemano
veterán
Genoa-X sku-k [link]
-
#8846
Petykemano
veterán
Petykemano
veterán





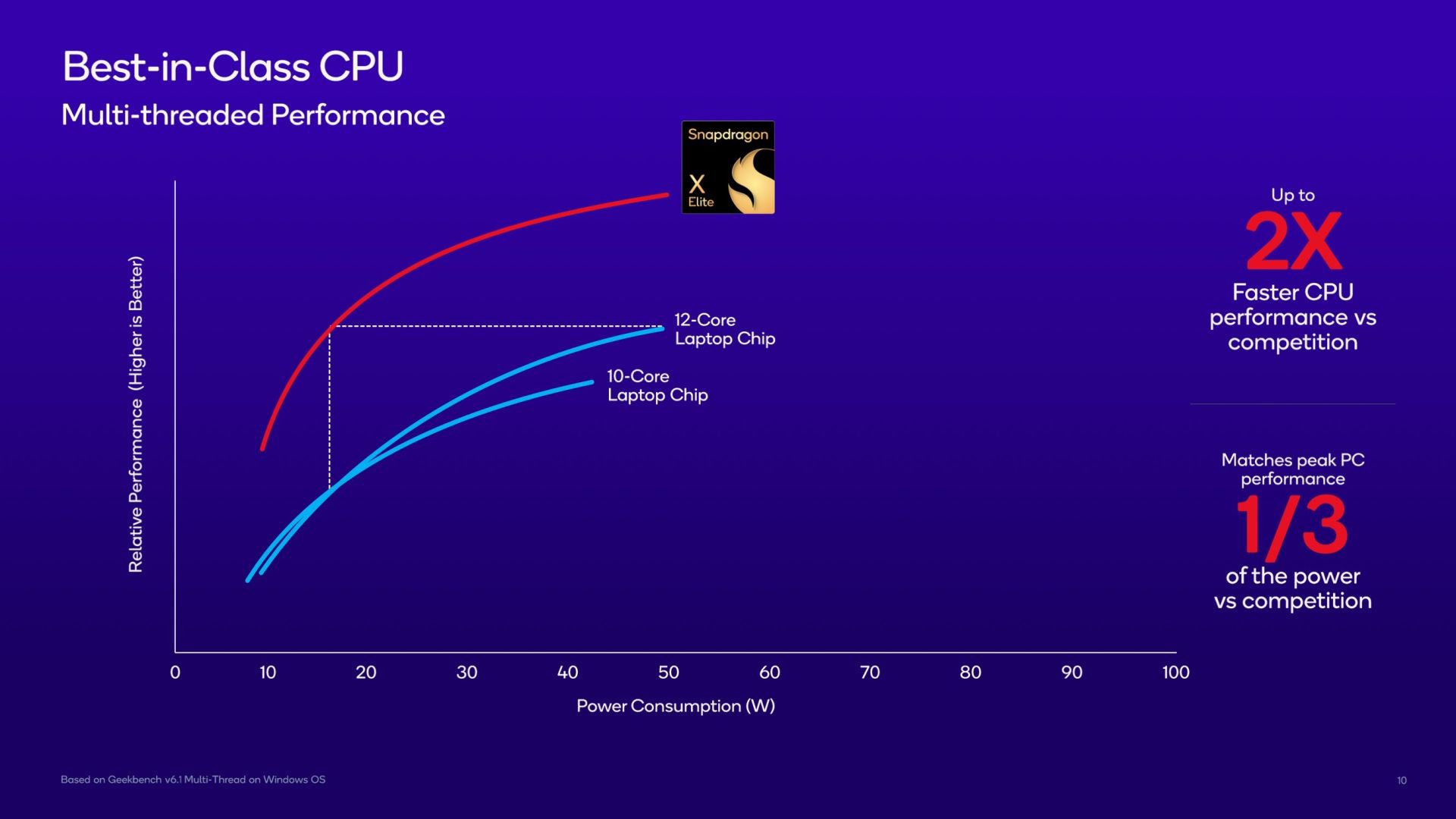






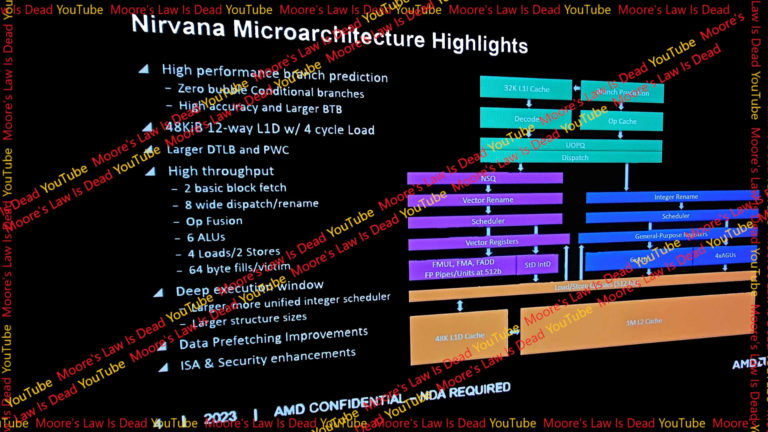
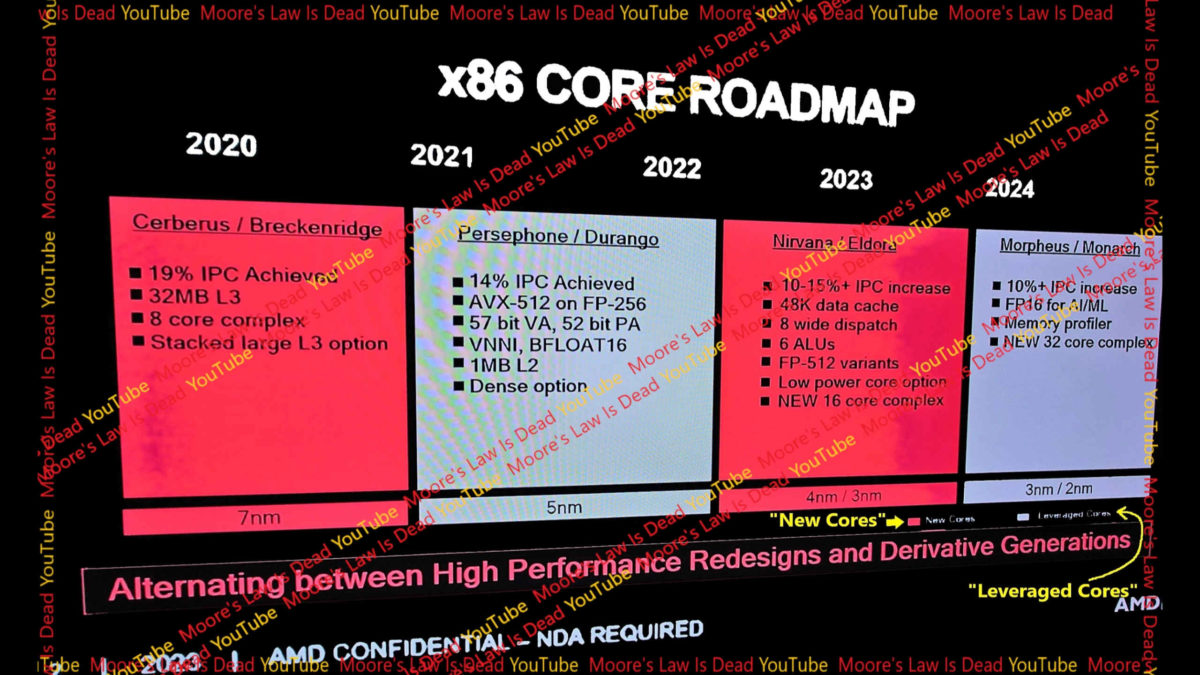





 .. nagyon lassan megy a launch.
.. nagyon lassan megy a launch.

Új hozzászólás Aktív témák
- Autós topik
- Sub-ZeRo: Euro Truck Simulator 2 & American Truck Simulator 1 (esetleg 2 majd, ha lesz) :)
- Jelentősen átalakulhat a Xiaomi 17 Ultra kamerarendszere
- Házimozi belépő szinten
- Luck Dragon: Asszociációs játék. :)
- Milyen széket vegyek?
- Kuponkunyeráló
- Kodi és kiegészítői magyar nyelvű online tartalmakhoz (Linux, Windows)
- OTP Bank topic
- Google Pixel 7a - venni vagy nem venni?
- További aktív témák...

- Hófehér,megkímélt Asus 15,6",Intel(2,4Ghz)akár 1TB SSD,jó akku, nagyon szép
- insta 360 x4 8K bontatlan új + kiegészítők ELADÓ
- Nagyon szép,megkímélt Asus 15,6",Intel(2,58Ghz)akár 1TB SSD,nagyon jó akku
- ASUS ROG STRIX RTX 3070 Ti OC EDITION
- ThinkPad.15,6",FullHD IPS,8.gen.core i5 (8X4,0Ghz)16-32GB RAM,256-512SSD
- GYÖNYÖRŰ iPhone 12 mini 64GB White -1 ÉV GARANCIA - Kártyafüggetlen, MS3849, 100% Akksi
- Telefon felvásárlás!! Apple iPhone SE (2016), Apple iPhone SE2 (2020), Apple iPhone SE3 (2022)
- GYÖNYÖRŰ iPhone 12 Pro Max 128GB Pacific Blue -1 ÉV GARANCIA -Kártyafüggetlen, MS3996, 100% Akkumulá
- Új monitor állvány- elegáns megoldás a dupla A/4-es papírcsomag helyett - csak össze lett szerelve
- Acer Nitro 16 - 16" WQXGA 165Hz - Ryzen 7 8845HS - 16GB - 1TB - Win11 - RTX 4070 - Garancia
Állásajánlatok

Cég: BroadBit Hungary Kft.
Város: Budakeszi

Cég: ATW Internet Kft.
Város: Budapest