- Samsung Galaxy S25 - végre van kicsi!
- One mobilszolgáltatások
- Nem nyílnak a Foldok?
- Amazfit Active 2 NFC - jó kör
- Xiaomi 15 - kicsi telefon nagy energiával
- Változó design, tekerhető lünetta: megjött a Galaxy Watch8 és a Classic
- Android alkalmazások - szoftver kibeszélő topik
- Google Pixel topik
- Telekom mobilszolgáltatások
- Okosóra és okoskiegészítő topik
Új hozzászólás Aktív témák
-

Abu85
HÁZIGAZDA
Az AFR az csak teljes képernyős módban működik. Más lehetőséged nincs AFR szinten. A programnak kell szétosztania a feladatot. Ezt a szoftver készítőjén múlik.
(#35) Nikk: Ez a különbség a játékra vs. professzionális szintre tervezett architektúra között.
(#33) TTomax: picsába tényleg, de a kép az jó.

-
-

Nikk
senior tag
Jó de ha driverre tudnak csak hagyatkozni a path tracerek írói, hogyan lehetségez az, hogy a felsklálázódás közel lineáris, több kártya használata esetén anélkül, hogy bucket rendert használnának? Valami mégis csak lehetővé kell, hogy tegye... És itt most nem a professzionális kártyákról van szó, hanem mezei geforce-okról...
-
Abu85
HÁZIGAZDA
A specifikus optimalizáció a skálázódás miatt kell. Egy nagyobb clusternél ezt elvégzik. Itt nincs rá lehetőség. Biztos mindent megtesz a fejlesztő, de aránytalanul sok munka minden rendszerre kitesztelni mindent.
Biztos működik híd nélkül is. A híd használatára csak a drivernek van jóga, és mivel nincs AFR feldolgozás, így ezzel nem él a driver. -
Nikk
senior tag
Már amennyire specifikus. Gyakorlatilag bármely OpenCL támogatású kártyával működnek, melyek eleget tesznek a minimum OpenCL szabványnak... Ezek meg HD5XXX-től felfelé + illetve nVidia karik, melyek CUDA magosak... De amúgy egyébként az is CF illetve SLI, csak nem a klasszikus értelemben véve... =) (attól függ, hogy CF/SLI híd nélkül is működnek-e, ezt viszont tényleg nem tudom... =))
-
Nikk
senior tag
-
Nikk
senior tag
A path tracingnek illetve a mostani kártyáknak igencsak elég a teljesítménye arra, hogy töredékére csökkentsenek renderidőket. Nyilván nem fogunk folyamatos képet kapni, de jelenleg nem is ez a cél, hanem az, hogy tört részre csökkenjen a renderidő.
Amúgy egyébként tessék megnézni a profi alkalmazásokat, ahol sok-sok kártya, de nem feltétlen kell, hogy optikai kapcsolat legyen köztük, elég QuadSLI példának okáért, képesek arra, hogy pixeleket osszanak szét egymás közt. Nyilván a számítási kapacitás, egy pixelre vonatkozóan, nem lesz valami hatalmas, de a több szálúsítás miatt, már édes mindegy, hogy 1 pixelt 0,1, vagy 0,15 másodper alatt számol ki a gép, mivel a képek általában nem úgy néznek ki, hogy az egyik kártya csak többszörös mélységű objektumokat számol (üveg) a másik meg egyszerű műanyagot, aminek nincs mélysége. Nyilván ekkor jelentkezne ez az eset, ami megbonthatná ezt a folyamatot, de a programok írói ezekre is gondolnak. Amúgy egyébként ez az eset eleve kizárt, tehát nagy valószínűséggel nem is gondolnak ilyesmire.
A régebbi renderelők bucket renderelési eljárásai a PathTracing területén igencsak háttérbe szorultak, ugyanis LightCache-t használnak. Ilyen esetben nincs szükség bucket-re, ugyanis egy pixel egy bucket. Azt, hogy melyik kártya számolja illetve, hogy melyik szál kapja meg a számolandó pixelt, az a puszta véletlentől függ...
Bizonyos szempontból ez a program kicsit fals, mivel ez szétbontja a rendert bucket-okra, holott az alapját a Bi-Directional típusú LightCahce adja, ami elve pixelenként számol. Minden pixelre egyre és egyre több mintát számol, így kifinomodik a kép. Még akkor is ha ennél a programnál ezt momentán nem látjuk.
Érdemes megnézni pár ilyen programot:
VRay RT 2.0
Octane Renderer
Arion (habár ez hibrid CPU + GPU)
Talán még a Maxwell renderer is, habár erről nem tudom, hogy CPU vagy GPU. Vele még nem foglalkoztam annyit... -
Abu85
HÁZIGAZDA
A CF és az SLI eleve nem fut ablakban. Ha ablakban megy valami, akkor az úgy működik, hogy az egyik kártya számolja az ablak tartalmát, amit egy első kártya kitesz a többi tartalom mellett. Ha van harmadik és negyedik kari, akkor ők malmozni fognak.
OpenCL esetében a feladatot tudod szétosztani, de a programtól függ, hogy ez mennyire hatékony. A professzionális szinten jóval profibb programok vannak. Ott ez alapkövetelmény, hiszen egy GPU-val is másodpercekig tart a számítás. Ezért nincs az asztali szinten jelentősége a PathTracingnek. Cirka 7 év mire meg lesz a számítási kapacitás ehhez.
-
Nikk
senior tag
Nagyon tévedsz... A skálázódása SLI és XFire alatt közel lineáris... No és ugyan ez jellemzi az összes ilyesféle programot. Pláne, ha PathTracingre épül... Mind kihasználja és nem csak 2-3 VGA, ha kell akkor annál jócskán többet is, elég ha csak a Profi kártyákra gondolunk. Optikai szálon kötik össze a karikat és úgy dolgoznak együtt...
-
#21
Abu85
HÁZIGAZDA
Whit3Rav3n
#20
Abu85
HÁZIGAZDA
válasz
 Whit3Rav3n
#20
üzenetére
Whit3Rav3n
#20
üzenetére
A számításokat szétoszthatja, de nem nyersz vele sokat. Ez a része a dolognak még gyerekcipőben jár.
-
#15
 TTomax
félisten
Whit3Rav3n
#14
TTomax
félisten
Whit3Rav3n
#14
TTomax
félisten
válasz
Whit3Rav3n
#14
üzenetére
Nem olyan rossz ez azért... milyen órajeleken ment?Gondolom 6970-re modolt 50-es igaz?
-
#14
 Whit3Rav3n
senior tag
Whit3Rav3n
senior tag
Whit3Rav3n
senior tag
Az új ati sem valami gyors ebben a tesztben de mindegy mert én úgysem használok openCL alkalmazásokat.
-
Nikk
senior tag
A-a... Ne keverd... =) Nem CUDA... OpenCL... =) Amúgy ATi kártyák is tudnak nyomatni pontokat... ugyan 3x 4x lassabban, de összemérni jó. Pláne azért is, mert előbb utóbb kiderül róla, hogy ott is ráturbóznak majd a normális OpenCL használatra... =) (Halkan súgom meg, hogy Barts és BartsXT-vel még nem készítettek tesztet, tehát ha valakinek van, akkor lesse meg... Kíváncsian várjuk mi történik... =))
-
Nikk
senior tag
-
Nikk
senior tag
A tesztelés metódusa:
Mivel még nem láttam OpenCL alapú benchmark topic-ot és mivel egyre nagyobb a térnyerése az efféle programoknak, továbbá a GPGPU számítások a videó kódolásban, konvertálásban, renderelésben és a nagymértékben többszálúsított MultiThread technológiákban, időszerűnek hatott, hogy nyissak egy topic-ot a GPGPU-k erejének, OpenCL-en futtatott eredményeinek összemérésére.
A program, amely alapvetően nagy mértékben képes hagyatkozni ezen technológiákra, nem más mint a renderelés.
Akiket érdekel a renderelés. némi infó:
A renderelés anyagok és fényforrások élethű fizikai szimulációja 3D-s modellek virtuális fényforrások és anyagok létrehozásával. A renderelőmotor az úgynevezett PathTracing eljárást használja, amely a matematikai QuasiMonteCarlo elvre és az úgynevezett Renderelési egyenletre hagyatkozik. Más néven Brute Force eljárás, ami hazai nyelven "nyers erő"-t jelent.
A sok blablát picit leegyszerűsítve: A program gyakorlatilag a fény útját számolja ki adott pixelekre, melyek a kamerába vetülnek adott az tulajdonságú 3D-s modelljeinkről.
Az eljárás egyik legnagyobb előnye, hogy nagyon minimális a processzorhasználat így a GPGPU-k valódi OpenCL teljesítményét méri, ergo NEM processzorfüggő.
A program amit a benchmark-hoz használni fogunk: RatGPU
Több féle verzió is rendelkezésre áll a teszteléshez, operációs rendszerektől függően. Mindenki a sajátjához valót szedje le.
A program telepítése:
nVidia és ATI kártyákhoz célszerű leszedni a legfrissebb driver-ket, akkor nem lehet gond a benchmark-al. nVidia kártya esetén csak a driver-re van szükség, az elég a program futtatásához.
ATI kártyával rendelkezőknek pedig le kell tölteni az OpenCL SDK-t, INNEN, továbbá a legfrissebb driver erősen javasolt a használathoz.
FIGYELEM!!!
ATI HD4XXX sorozat nem támogatott, ugyanis nem állnak rendelkezésre a megfelelő OpenCL utasítások, így őket sajnos mellőznünk szükséges.
A teszt futtatása:
Ha kész vagyunk, semmi különös semmi dolgunk nincs már, mint elindítani a programot és a bal felső sarokban található Benchmark gombra kattintani.
A renderelés elindul: jobb alul látszik, ahogy számol a kártya. Valószínűleg a hangján is hallani fogjuk a gépnek, hogy erőlködik veszettül. Az egér ilyenkor belassulhat, lehetőleg ne is nyomkodjuk, a teszt kártyától függően gyorsabban lassabban lefut. (nVidia esetén gyorsabb, ATi-nál lassabban) Ezen nem kell meglepődni. Az ATi kártyája gamer architektúrán, míg nVidia kártyái kicsit professzionálisabb alapokon nyugszanak.
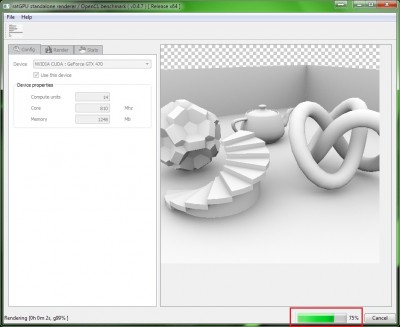
A teszt lefutása után:
Megkapjuk a végeredményt másodpercben. A szokásostól eltérően, itt a kisebb eredmény a jobb, vagyis a pontszám a képekhez szükséges időt jelzi. Íme:
A link validálást is lehetővé tesz, csak szimplán másoljuk be a böngészőablakba és kész is vagyunk...
Ha bármilyen kérdés merül fel, csak tessék kérdezni, illetve végig lehet böngészni még EZT a fórumot, a program alakulásával kapcsolatban...
Jó Benchmark-olást... =)




 Nem volt túl nagy sikere..
Nem volt túl nagy sikere..









![;]](http://cdn.rios.hu/dl/s/v1.gif)
























Új hozzászólás Aktív témák
Hirdetés

- ZOTAC RTX 3090 Ti AMP Extreme Holo
- Nvidia RTX 4070 Gainward ghost Video Kártya
- 4090 BESZAMITAS!! Gainward Phantom RTX 5090 32GB (Bontatlan, Garancia)
- ZOTAC GAMING GeForce RTX 3090 Trinity OC 24GB GDDR6X (6 Hónap Garancia)
- Újszerű - ASUS ROG Strix Geforce GTX 1660 Super Advanced Edition 6GB GDDR6 192bit VGA videókártya
Állásajánlatok

Cég: PCMENTOR SZERVIZ KFT.
Város: Budapest